
H3DGE: UM GERADOR DE IMAGENS 3D EM HARDWARE · Trabalho de formatura apresentado à Escola...
90
JEFFERSON CHAVES FERREIRA JOÃO PAULO CONDÉ OLIVEIRA PRADO H3DGE: UM GERADOR DE IMAGENS 3D EM HARDWARE Trabalho de formatura apresentado à Escola Politécnica da Universidade de São Paulo como requisito para a conclusão do curso de graduação em Engenharia Elétrica com Ênfase em Computação, junto ao Departamento de Engenharia de Computação e Sistemas Digitais (PCS). São Paulo 2011
Transcript of H3DGE: UM GERADOR DE IMAGENS 3D EM HARDWARE · Trabalho de formatura apresentado à Escola...

JEFFERSON CHAVES FERREIRAJOÃO PAULO CONDÉ OLIVEIRA PRADO
H3DGE: UM GERADOR DE IMAGENS 3D EMHARDWARE
Trabalho de formatura apresentado à Escola
Politécnica da Universidade de São Paulo
como requisito para a conclusão do curso de
graduação em Engenharia Elétrica com Ênfase
em Computação, junto ao Departamento de
Engenharia de Computação e Sistemas Digitais
(PCS).
São Paulo2011

JEFFERSON CHAVES FERREIRAJOÃO PAULO CONDÉ OLIVEIRA PRADO
H3DGE: UM GERADOR DE IMAGENS 3D EMHARDWARE
Trabalho de formatura apresentado à Escola
Politécnica da Universidade de São Paulo
como requisito para a conclusão do curso de
graduação em Engenharia Elétrica com Ênfase
em Computação, junto ao Departamento de
Engenharia de Computação e Sistemas Digitais
(PCS).
Área de Concentração:Sistemas Digitais
Orientador:Profa Dra Cíntia Borges Margi
Co-orientador:Pedro Maat Costa Massolino
São Paulo2011

À minha mãe, que sempre acreditouem mim.Jefferson
Aos meus pais e irmãos, que têm mesuportado e dado suporte desde muitoantes do início deste trabalho.João Paulo

AGRADECIMENTOS
Em primeiro lugar, agradecemos à nossa orientadora, Profa Cíntia BorgesMargi, que nos auxiliou e nos acompanhou nas diversas etapas deste trabalho.
Agradecemos também ao nosso co-orientador, Pedro Maat Costa Masso-lino, que nos forneceu auxílio técnico e valiosos conselhos.
Aos membros do Security and EMBedded systems EngineerIng group(SEMBEI), por terem nos acolhido durante os últimos seis meses e ao La-borátório de Arquitetura e Redes de Computadores (LARC) o qual dispôs osmeios técnicos, as ferramentas e toda a estrutura necessária ao desenvolvi-mento deste projeto.
Enfim, à Escola Politécnica da Universidade de São Paulo e à Télécom Pa-risTech, que nos propiciaram seis anos de aprendizado e crescimento dentroda fascinante ciência do engenho humano.

RESUMO
O ray tracing é um algoritmo capaz de gerar imagens 3D a partir de umacena predeterminada. Seu princípio consiste na geração de raios de luz apartir de uma posição da tela e no rastreamento de seus percursos rumo àsfontes luminosas. A partir dos cálculos de interseção com os objetos da cenae por meio da modelagem dos fenômenos ópticos, é possível obter a cor emformato RGB do ponto em questão.
Embora a complexidade computacional do algoritmo seja alta, o ray tracingé interessante para gerar imagens realistas e com alto nível de detalhe para amodelagem de projetos 3D ou mesmo para os jogos eletrônicos, produzindosaídas superiores às fornecidas pelos algoritmos de renderização usuais.
Este trabalho apresenta uma proposta de arquitetura em hardware para oemprego do ray tracing na geração dessas imagens. A combinação de umaarquitetura dedicada com o emprego de cálculos em ponto fixo e com a inde-xação espacial permite executar o algoritmo com uma performance superiore com menos recursos que os necessários para uma implementação equiva-lente em software. Isso é de grande relevância no contexto da intensificaçãodo emprego da modelagem 3D e dos sistemas embarcados no mundo da tec-nologia da informação.

ABSTRACT
Ray tracing is an algorithm to generate 3D images from a scene. It is basedon the generation of light rays from a given position and on tracing their pathsuntil they hit one of the light sources. Given a scene definition, it is possibleto obtain the RGB color of the current position by carrying out intersectioncalculations and modeling the optical phenomena between the light ray andthe scene objects.
Although the computational complexity of the algorithm is high, ray tracingis an interesting choice for high detail 3D image generation for project designor electronic games, yielding outputs of superior quality when compared withthose from usual rendering algorithms.
This work presents a hardware architecture proposal for the generationof those images using the ray tracing algorithm. The combination of a de-dicated architecture, fixed-point calculations and spatial indexing allows for ahigh-performance ray tracing execution, taking up less resources than thoseneeded for an equivalent software implementation. Due to the intensificationof 3D modeling and embedded systems employment in the IT world, this ap-proach becomes specially relevant.

RÉSUMÉ
Le lancer de rayon est un algorithme capable de générer des images 3D àpartir d’une scène prédéterminé. Il s’agit principalement de générer des rayonsde lumière d’une position sur l’écran et de suivre ses parcours vers les sourceslumineuses. Avec les calculs d’intersection et l’application des modèles desphénomènes optiques, il est possible trouver le couleur en format RGB à cepoint-là.
Bien que la complexité computationnelle de l’algorithme soit élevée, le lan-cer de rayon est intéressant pour générer des images réalistes, avec un niveaude détaille appréciable pour la modélisation de projets 3D ou même pour lesjeux vidéo, fournissant des sorties de meilleure qualité que les algorithmes derendérisation usuels.
Ce travail présente une proposition d’architecture matérielle pour l’emploidu lancer de rayon dans la génération de ces images. La combinaison d’unearchitecture dédiée avec l’emploi de calculs en point fixe et l’indexation spa-tiale permet d’exécuter le lancer de rayon avec une performance supérieureet moins de ressources qu’une implémentation logicielle. Cela est très rélé-vant dans le cadre de l’intensification de l’emploi de la modélisation 3D et dessystèmes embarqués dans le monde de la technologie de l’information.

LISTA DE ILUSTRAÇÕES
1 Exemplo de imagem sintetizada utilizando ray tracing. Extraído
de (OYONALE, 2009). . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Comparação entre imagens sintetizadas por rasterização e por
ray tracing. Extraído de (HOWARD, 2007). . . . . . . . . . . . . . 17
3 Interseção raio - plano . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Reflexão de um raio incidente ~I = − ~Iop . . . . . . . . . . . . . . 24
5 Reflexão acompanhada de refração de um raio incidente ~i -
adaptado de (GREVE, 2007) . . . . . . . . . . . . . . . . . . . . . 25
6 Funcionamento do algoritmo de ray tracing. . . . . . . . . . . . . 30
7 Uma árvore k-d bidimensional. Nós internos são nomeados de
acordo com os planos divisores e nós folha são nomeados de
acordo com a região que delimitam no espaço. À direita está
a árvore k-d que representa a divisão espacial especificada à
esquerda. Extraído de: (FOLEY; SUGERMAN, 2005). . . . . . . . . 32
8 Divisão do espaço por mediana espacial. . . . . . . . . . . . . . 33
9 Divisão do espaço por mediana de objetos. . . . . . . . . . . . . 34
10 Divisão do espaço por um modelo de custos. . . . . . . . . . . . 34
11 O valor de uma função de custo para quatro objetos (duas di-
mensões). As posições limites dos objetos possuem grande
influência na seleção do ponto de divisão com o custo mínimo.
Extraído de (HAVRAN, 2000). . . . . . . . . . . . . . . . . . . . . 35

12 Metodologia de projeto empregada. Adaptado de (ERBAS, 2006). 40
13 Passos para o projeto da plataforma de arquitetura. Adaptado
de (CHU, 2006) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
14 O ambiente de desenvolvimento do modelo de aplicação. . . . . 44
15 Arquitetura da linguagem SystemC. Adaptado de (GROTKER, 2002) 45
16 Plataforma de desenvolvimento ML507 da Xilinx . . . . . . . . . 47
17 O ambiente de desenvolvimento e de simulação em SystemVe-
rilog do modelo de arquitetura. . . . . . . . . . . . . . . . . . . . 49
18 O ambiente de síntese . . . . . . . . . . . . . . . . . . . . . . . . 50
19 Interface do ISE Design Suite, software utilizado para o posicio-
namento e interligação de células. . . . . . . . . . . . . . . . . . 50
20 Fluxograma do particionamento em hardware e software do ray-
tracer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
21 Arquitetura simplificada do sistema h3dge . . . . . . . . . . . . . 53
22 Arquitetura do coprocessador . . . . . . . . . . . . . . . . . . . . 59
23 Fluxo de dados do módulo de interseção de um raio com um
triângulo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
24 Estrutura interna do bloco de processamento das FPGAs Virtex-
5. Extraído de (XILINX, 2010a). . . . . . . . . . . . . . . . . . . . 61
25 Arquitetura do bus PLB v4.6. Extraído de (XILINX, 2010b). . . . . 63
26 O poliedro, uma das figuras geradas pelo algoritmo de ray tra-
cing utilizado no h3dge. Nota-se os efeitos de transparência
causados pela refração dos raios de luz. . . . . . . . . . . . . . . 70

27 Stanford bunny, uma das figuras geradas pelo algoritmo de ray
tracing utilizado no h3dge: visão frontal. . . . . . . . . . . . . . . 70
28 Stanford bunny, uma das figuras geradas pelo algoritmo de ray
tracing utilizado no h3dge: visão traseira. . . . . . . . . . . . . . 71
29 Influência da árvore k-d no desempenho . . . . . . . . . . . . . . 72

LISTA DE TABELAS
1 Organização de um pixel na memória. Adaptado de (XILINX, 2009). 64
2 Influência da árvore k-d no desempenho . . . . . . . . . . . . . . 72
3 Ocupação da FPGA para o sistema-base . . . . . . . . . . . . . 73
4 Desempenho do algoritmo de ray tracing em software no sis-
tema base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5 Ocupação da FPGA para o módulo de interseção . . . . . . . . 75
6 Dimensionamento da memória do coprocessador . . . . . . . . . 84
7 Dimensionamento da memória DDR2 necessária para a aloca-
ção de uma árvore k -d de 70000 triângulos . . . . . . . . . . . . 87

LISTA DE ABREVIATURAS E SIGLAS
API Application Programming Interface
CAS Column Address Strobe
DDR Double Data Rate
DMA Direct Memory Access
DVI Digital Video Interface
FIFO First in First out
FPGA Field-Programmable Gate Array
FPU Floating Point Unit
GCC GNU Compiller Collection
HDL Hardware Description Language
IP Intellectual Property
JTAG Joint Test Action Group
LED Light-Emitting Diode
LUT Look-up Table
PLB Processor Local Bus
RAM Random Access Memory
RGB Red, Green and Blue
RISC Reduced Instruction Set Computing
RS-232 Recommended Standard 232

RTL Register Transfer Level
SAH Surface Area Heuristic
SoC System-on-Chip
SODIMM Small Outline Dual In-line Memory Module
SRAM Static Random Access Memory
TFT Thin Film Transistor
ULA Unidade lógica e aritmética
USP Universidade de São Paulo
VGA Video Graphics Array
VHDL VHSIC Hardware Description Language
VHSIC Very High Speed Integrated Circuits
XPS Xilinx Platform Studio

SUMÁRIO
1 Introdução 15
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.2 Trabalhos existentes . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.3 Apresentação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.4 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.5 Organização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2 Princípios Teóricos 20
2.1 Princípios Matemáticos . . . . . . . . . . . . . . . . . . . . . . . 20
2.1.1 Cálculo de raiz quadrada . . . . . . . . . . . . . . . . . . 20
2.1.2 Interseção de raio com plano . . . . . . . . . . . . . . . . 21
2.1.3 Interseção de raio com triângulo . . . . . . . . . . . . . . 22
2.2 Princípios Físicos . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.1 Reflexão de um raio incidente . . . . . . . . . . . . . . . . 24
2.2.2 Cálculo da refração e da transmissão de um raio incidente 25
2.2.3 Modelo para a luminosidade . . . . . . . . . . . . . . . . 27
3 Técnicas 29
3.1 Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.1.1 Visão Geral . . . . . . . . . . . . . . . . . . . . . . . . . . 29

3.1.2 Hipóteses simplificadoras . . . . . . . . . . . . . . . . . . 31
3.1.3 Otimização com uma árvore k-d . . . . . . . . . . . . . . 31
3.1.4 Configuração das entradas e saídas . . . . . . . . . . . . 38
3.2 Desenvolvimento . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.2.1 Metodologia de projeto . . . . . . . . . . . . . . . . . . . 39
3.2.2 Recursos Utilizados . . . . . . . . . . . . . . . . . . . . . 44
3.2.2.1 Ferramentas de desenvolvimento para os mo-
delos de aplicação . . . . . . . . . . . . . . . . . 44
3.2.2.2 Plataforma de desenvolvimento . . . . . . . . . 46
3.2.2.3 Ferramentas de desenvolvimento para os mo-
delos de arquitetura . . . . . . . . . . . . . . . . 46
3.2.3 Particionamento em hardware e software . . . . . . . . . 51
3.2.4 Especificação e dimensionamento da arquitetura . . . . . 53
3.2.4.1 Visão geral . . . . . . . . . . . . . . . . . . . . . 53
3.2.4.2 Processador . . . . . . . . . . . . . . . . . . . . 54
3.2.4.3 Coprocessador . . . . . . . . . . . . . . . . . . . 56
3.2.4.4 Vias de dados . . . . . . . . . . . . . . . . . . . 61
3.2.4.5 Controlador de vídeo . . . . . . . . . . . . . . . 64
3.2.4.6 Dimensionamento da memória DDR2 externa . 65
3.2.4.7 Considerações a respeito do número de copro-
cessadores em paralelo . . . . . . . . . . . . . . 66
4 Resultados 69

4.1 Imagens geradas . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.2 Melhoria de desempenho causada pelo uso de uma árvore k -d . 71
4.3 Resultados do sistema sintetizado em hardware . . . . . . . . . 73
4.3.1 Sistema base . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.3.2 Coprocessador . . . . . . . . . . . . . . . . . . . . . . . . 74
5 Conclusões 76
5.1 Objetivos alcançados . . . . . . . . . . . . . . . . . . . . . . . . 76
5.2 Dificuldades encontradas . . . . . . . . . . . . . . . . . . . . . . 77
5.3 Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.4 Trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.5 Considerações finais . . . . . . . . . . . . . . . . . . . . . . . . . 80
Referências 81
Apêndice A -- Estimativas para o coprocessador 84
Apêndice B -- Estimativas para a árvore k-d 87

15
1 INTRODUÇÃO
A computação gráfica é a área de estudo a qual engloba o processamento
de imagens focando na síntese digital e na manipulação de informações ge-
ométricas e de conteúdo visual. Sua área de aplicação é diversa e engloba
a área artística, a área de design de produto, os jogos eletrônicos, as anima-
ções de cinema, a engenharia (sobretudo na simulação de eventos físicos e
químicos de materiais envolvidos nos projetos em desenvolvimento) e a me-
dicina. Dessa forma, há uma demanda crescente por meios que possibilitem
a elaboração de elementos visuais com alto nível de detalhe para atender os
requisitos destes vários setores profissionais.
As plataformas computacionais contemporâneas possuem alta capaci-
dade de processamento e conseguem sintetizar imagens realistas com re-
lativa facilidade, contudo tais plataformas muitas vezes não executam os algo-
ritmos de geração de imagens realistas com a desenvoltura almejada. Dessa
forma, o projeto de arquiteturas dedicadas combinadas com algoritmos otimi-
zados de geração de imagens tem sido visto como uma potencial alternativa
a este problema e são um campo de intensa pesquisa.
Este trabalho trata deste assunto e, para atender tais requisitos, combina
um algoritmo com o qual é possível gerar imagens com um alto nível de deta-
lhe com a elaboração de uma arquitetura dedicada em hardware. Além disso,
tal arquitetura também é acompanhada de métodos otimizados de busca e

16
acesso aos dados.
1.1 Motivação
Ray tracing é uma técnica utilizada em computação gráfica para sintetizar
imagens 3-D com alto grau de realismo. O método consiste em rastrear a partir
de uma cena pré-definida todos os fenômenos ópticos (reflexões e refrações)
a que são submetidos os raios de luz que chegam ao observador. A figura 1
apresenta um exemplo de imagem gerada por esse algoritmo.
Figura 1 – Exemplo de imagem sintetizada utilizando ray tracing. Extraído de (OYONALE,2009).
Embora o princípio subjacente não seja sofisticado, os resultados obtidos
por ray tracing são visualmente impressionantes e superiores quando com-
parados a imagens geradas por outros algoritmos, como a renderização por
rasterização (STRATTON, 2008), conforme ilustrado na figura 2. Contudo, o ray
tracing apresenta um alto custo computacional1, sendo indicado para situa-1Em uma implementação simples do algoritmo de ray tracing, para cada raio de luz lançado
é necessário executar uma verificação de interseção para cada primitiva da cena. Comopara cada pixel é lançado pelo menos um raio, a complexidade computacional do algoritmo

17
ções onde o tempo de geração das imagens não é crítico (como fotografias
sintetizadas ou efeitos especiais para filmes e programas de TV); o uso dessa
técnica em video games, por exemplo, é inviável no estado atual da tecnologia.
Figura 2 – Comparação entre imagens sintetizadas por rasterização e por ray tracing.Extraído de (HOWARD, 2007).
1.2 Trabalhos existentes
Existem no mercado diversas soluções em software que implementam a
renderização por ray tracing, tais como POV-Ray e mental ray. No entanto,
realizações em hardware são raras e na maior parte experimentais ((WOOP;
SCHMITTLER; SLUSALLEK, 2005), (HANIKA, 2007)). Recentemente, a empresa
coreana Siliconarts anunciou o lançamento do primeiro core IP para ray tra-
cing (SILICONARTS, 2011), o que pode significar o começo da entrada dessa
tecnologia no mercado de consumo em massa.
Vários centros de pesquisa ao redor do mundo ((HANIKA, 2007) e (PUR-
é O(p · n · r), onde p é o número de pixels da imagem; n, a quantidade de primitivas; e r, onúmero máximo de reflexões e refrações rastreadas pelo sistema.

18
CELL et al., 2002)) trabalham com o objetivo de produzir um protótipo para o
uso do ray tracing em tempo real com a finalidade de abrir as portas para o
uso desta tecnologia. Entretanto, nenhum desses trabalhos implementa uma
arquitetura completa para a execução do ray tracing em FPGAs; é nessa linha
de investigação que se insere o projeto h3dge.
1.3 Apresentação
O objetivo deste trabalho é propor e descrever um raytracer em hardware.
O projeto consiste na definição de uma cena composta de objetos modelados
por um número de triângulos por meio dos quais pode-se obter facilmente a
maioria das figuras em 3D.
Os parâmetros de entrada são compostos por uma lista de triângulos
acompanhados de suas coordenadas no espaço e das propriedades dos ma-
teriais que os compõem (transparente, opaco, translúcido) e por um número
de luzes acompanhadas de suas propriedades (posição no espaço e cor). A
partir destas entradas, o hardware emprega o algoritmo de ray tracing e gera
a imagem em 3D com os efeitos ópticos implementados.
1.4 Objetivos
O objetivo principal deste projeto é propor, implementar e testar uma ar-
quitetura para um raytracer em hardware.
Além disso, devem-se destacar objetivos secundários para a realização de
tal tarefa como:
• Desenvolver um módulo de interface de vídeo;

19
• Desenvolver um módulo para tratar os dados de entrada por meio de
uma porta serial;
• Desenvolver um módulo no qual serão definidos os fenômenos ópticos
do projeto, ou seja, as reflexões e refrações.
1.5 Organização
O restante deste documento está organizado da seguinte forma:
• No capítulo 2 são apresentados os conceitos teóricos essenciais ao en-
tendimento deste projeto, oriundos da Matemática e da Física;
• Em seguida, o capítulo 3 é o cerne do trabalho, apresentando toda a
metodologia e as técnicas utilizadas para implementar o raytracer ;
• O capítulo 4 apresenta os resultados obtidos por meio da aplicação dos
conceitos abordados no capítulo anterior;
• Enfim, as conclusões fecham o documento, com um olhar global sobre
os objetivos alcançados e as possibilidades futuras.

20
2 PRINCÍPIOS TEÓRICOS
Este capítulo trata das abordagens matemáticas para a realização dos
cálculos envolvidos no projeto. Há a seção de princípios matemáticos na qual
se discute os algoritmos utilizados no cálculo de raiz quadrada, na interseção
de um raio de luz com um plano e na interseção de um raio de luz com um
triângulo.
Após a seção de princípios matemáticos, a seção de princípios físicos dis-
cute as abordagens utilizadas para a modelagem dos fenômenos ópticos de
reflexão e refração e no cálculo da intensidade luminosa de um ponto obser-
vado.
2.1 Princípios Matemáticos
2.1.1 Cálculo de raiz quadrada
O emprego da operação de raiz quadrada é muito frequente na computa-
ção gráfica. Apesar de ser uma operação relativamente complexa, ela deve
ser empregada em fórmulas matemáticas (como, por exemplo, na refração) e
em frequentes operações de normalização de vetores. Neste trabalho optou-
se pelo emprego de um algoritmo que utilize operações matemáticas simples,
como deslocamentos e adições, e que já fosse implementado em hardware.
Por isso utilizou-se o Non-Restoring Algorithm já sintetizado em FPGA e des-

21
crito em (PIROMSOPA; APORNTEWAN; CHOGSATITVATAA, 2001). Dado um radi-
cando não negativo de 32 bits D[31 : 0], sua raiz quadrada é dada por Q[15 : 0]
e o resto R[16 : 0] é dado por R = D−Q2. O algoritmo 1 descreve o processo
de obtenção da raiz quadrada.
D[31 : 0] unsigned integerQ[15 : 0] unsigned integer {resultado}R[16 : 0] unsigned integer {resto}R← 0Q← 0for i = 15→ 0 do
if R ≥ 0 thenR← (R << 2)or(D >> (i+ i)and(3))R← R− ((Q << 2)or(1)
elseR← (R << 2)or(D >> (i+ i)and(3))R← R− ((Q << 2)or(3))
end ifif R ≥ 0 thenQ← (Q << 1)or(1)
elseQ← (Q << 1)or(0)
end ifi← i− 1
end forAlgoritmo 1 – Cálculo de raiz quadrada
2.1.2 Interseção de raio com plano
Em 3D, uma reta é paralela a um plano π, ou o intercepta em um ponto
individual, ou está totalmente incluída no plano. Seja a reta L dada pela equa-
ção paramétrica: P (s) = P0+s(P1−P0) = P +s.~u e o plano π dado pelo ponto
V0 e seu vetor normal ~n.
É necessário verificar se L é paralela ao plano π testando se ~n.~u = 0, o
que significa que a direção do vetor ~u da reta é perpendicular ao plano normal
~n. Se esse produto escalar é de fato nulo, então ou L e π são paralelos e não
se interceptam, ou L está totalmente no plano π. Para verificar se L ∈ π, basta

22
testar se um ponto de L (por exemplo. P0) está contido em π.
Figura 3 – Interseção raio - plano
Se a reta e o plano não são paralelos, então L e π se interceptam em um
ponto único P (sI) que é calculado (veja figura 3) a seguir.
No ponto de interseção o vetor P (s) − V0 = ~w + s.~u, onde ~w = P0 − V0, é
equivalente à condição: ~n.(~w+ s.~u) = 0. Por meio de manipulações é possível
obter:
sI =−~n.~w~n.~u
=~n(V0 − P0)
~n(P1 − P0)(2.1)
2.1.3 Interseção de raio com triângulo
O método de cálculo de interseção de raio com triângulo escolhido é o
de Möller e Trumbore (MÖLLER; TRUMBORE, 1997) que utiliza as coordenadas
baricêntricas com o propósito de escolher o ponto de interseção. Um ponto
T (u, v) de um triângulo é exprimido em coordenadas baricêntricas da seguinte
forma:
T (u, v) = (1− u− v).V0 + u.V1 + v.V2 (2.2)

23
onde
(u, v) são as coordenadas baricêntricas e
V0, V1 e V2 são os vértices do triângulo.
Para serem válidos, u e v devem atender às seguintes condições:
u ≥ 0, v ≥ 0, u+ v ≤ 1
Calcular a interseção entre o raio R(t) = O + t. ~D (O é o ponto de origem
e ~D é a direção e o sentido) e o triângulo, T (u, v), é equivalente à R(t) =
T (u, v). A partir da igualdade anterior e da representação em coordenadas
baricêntricas é possível obter:
O + t. ~D = (1− u− v).V0 + u.V1 + v.V2 (2.3)
Com algumas manipulações é possível expressar a representação como
um produto de vetores da seguinte forma:
(− ~D V1 − V0 V2 − V0
).
t
u
v
= O − V0 (2.4)
Nomeando ~E1 = V1 − V0, ~E2 = V2 − V0 e ~T = O − V0 a solução para a
equação anterior, aplicando a Regra de Cramer, é a seguinte:
t
u
v
=1
(( ~D × ~E2). ~E1).
((~T × ~E1). ~E2)
(( ~D × ~E2). ~T )
((~T × ~E1). ~D)
(2.5)
A partir da resolução do sistema anterior e se u e v atendem às condições

24
anteriores conclui-se que o ponto pertence ao triângulo e que t é o coeficiente
do vetor de direção.
2.2 Princípios Físicos
2.2.1 Reflexão de um raio incidente
A figura 4 ilustra a reflexão de um raio sobre um objeto.
Figura 4 – Reflexão de um raio incidente ~I = − ~Iop
Seja ~Iop o vetor oposto à direção de um raio incidente em um objeto, ~N é
a normal a este raio e ~V é o vetor do raio refletido pelo objeto. Cabe ressaltar
que ~Iop e ~N são vetores unitários. O raio refletido é calculado da seguinte
forma:
~V = ~N.( ~Iop. ~N) + ~a (2.6)
e
~Iop + ~a = ~N(Iop. ~N) (2.7)

25
logo:
~V = 2 ~N( ~Iop. ~N)− ~Iop (2.8)
Por meio da substituição de Iop por I, é possível obter:
~V = ~I − 2 ~N(~I. ~N) (2.9)
2.2.2 Cálculo da refração e da transmissão de um raio inci-dente
A figura 5 ilustra a situação na qual um raio de luz, cuja direção e sentido
são indicados pelo vetor i, é refletido e refratado nas direções e sentidos do
vetores r e t respectivamente. Um ângulo θv é o ângulo compreendido entre
o vetor v e a normal n. Com base nesta nomenclatura, o raio refratado é
calculado a seguir.
Figura 5 – Reflexão acompanhada de refração de um raio incidente~i - adaptado de (GREVE,2007)
A refração de um raio ocorre quando um raio incidente cruza uma super-
fície que delimita dois materiais com índices de refração diferentes n2 e n1 e

26
n2
n1≤ 1. Os ângulos de incidência, reflexão e refração são respectivamente θi,
θr e θt e, como os vetores de~i, ~r e ~t são unitários, é possível escrever:
sen(θv) =| ~vh|~|v|
= |~vh| (2.10)
cos(θv) =| ~vv|~|v|
= |~vv| (2.11)
ou
cos(θv) = ±~v.~n (2.12)
A partir da lei de Snell-Déscartes n1senθi = n2senθt e da equação anterior,
é possível escrever:
|~th| =n1
n2
|~ih| (2.13)
Como ~ih e ~th são paralelos e apontam na mesma direção:
~th =n1
n2
(~i− proj~n(~i)) =n1
n2
(~i− (~i.~n)~n) (2.14)
A partir de ~th + ~tv = ~t e do teorema de Pitágoras obtém-se a seguinte
equação:
t =n1
n2
~i−(n1
n2
(~i.~n) +√
1− |th|2)~n =
n1
n2
i−(n1
n2
(~i.~n) +√1− sen2θt
)~n (2.15)
Novamente empregando-se a lei de Snell:

27
~t =n1
n2
~i−
n1
n2
(~i.~n) +
√1−
(n1
n2
)2
(1− cos2θi)
~n⇔
~t =n1
n2
~i−
n1
n2
(~i.~n) +
√1−
(n1
n2
)2
(1− (~i.~n)2)
~n (2.16)
Vale a pena ressaltar que a equação anterior é valida se a condição(n1
n2
)2(1−(~i.~n)2) ≤ 1 for verdadeira. Caso tal condição não se satisfaça, tem-se
o fenômeno de reflexão total e não há raio refratado.
2.2.3 Modelo para a luminosidade
Após os cálculos dos vetores dos raios refletidos e refratados, inicia-se o
cálculo da intensidade luminosa para o pixel. Para tal cálculo o modelo de
iluminação de Whitted (WHITTED, 1980) é utilizado. Ele faz o relacionamento
da reflexão especular, da transmissão, da reflexão difusa e da iluminação glo-
bal com a intensidade total da luz em um ponto preciso por meio da seguinte
fórmula:
I = Ia + kd +
j=ls∑j=1
( ~N. ~Lj) + ksS + ktT (2.17)
Onde:
I: intensidade total
Ia: reflexão devido à luz ambiente
kd: coeficiente de reflexão difusa
N : normal unitária da superfície
Lj: vetor em direção a j-ésima fonte luminosa

28
ks: coeficiente de reflexão especular
S: intensidade da luz na direção do raio refletido
kt: coeficiente de transmissão
T : a intensidade da luz na direção do raio refratado

29
3 TÉCNICAS
Este capítulo aborda o algoritmo empregado e especifica todos os deta-
lhes técnicos envolvidos no desenvolvimento do raytracer em hardware. A
primeira seção aborda o princípio do ray tracing, as hipóteses simplificadoras
e o formato das entradas nas quais o projeto foi especificado.
A segunda seção aborda o desenvolvimento do projeto. Inicialmente são
descritos detalhes sobre o projeto em hardware, após isso inicia-se uma visão
geral das ferramentas e linguagens empregadas.
Na terceira seção documenta-se o processo de desenvolvimento e espe-
cificação da arquitetura do projeto e tem-se as primeiras estimativas sobre os
recursos que serão utilizados.
A quarta seção discute o particionamento entre hardware e software do
projeto e documenta detalhes sobre estas duas partes do desenvolvimento.
3.1 Algoritmo
3.1.1 Visão Geral
Após a descrição dos cálculos empregados no ray tracing, esta seção
apresenta o algoritmo implementado.
O princípio de funcionamento do algoritmo é bastante simples: define-se

30
uma janela de observação sobre a qual a imagem será projetada e posiciona-
se o observador a uma certa distância. Em seguida, para cada pixel da janela
um raio é lançado a partir do observador; calculam-se as interseções desse
raio com os objetos da cena, e para cada interseção são determinados os
raios derivados (refletidos, refratados, etc), que são por sua vez rastreados da
mesma forma, como ilustrado na figura 6. Enfim, a cor do pixel é determinada
pela composição das contribuições dos raios calculados, calculadas a partir
das características do material interceptado (cor, coeficientes de reflexão e
transmissão, etc) e da cor da fonte de luz.
Fonte de luz
Objeto da cena
ImagemObservador
Figura 6 – Funcionamento do algoritmo de ray tracing.
As primeiras soluções para ray tracing usaram lógica de ponto flutuante,
a qual requer mais superfície de hardware para sua realização, contudo a
utilização de lógica de ponto fixo permite a elaboração de soluções mais efi-
cientes e robustas (HANIKA, 2007). Com o objetivo de produzir uma solução
robusta, neste trabalho os cálculos serão feitos empregando-se uma lógica de
ponto fixo com possíveis enquadramentos (mudanças de escala) em cálculos
intermediários.
Além disso, no lugar de algoritmos recursivos (tipicamente utilizados na

31
construção de árvores) serão utilizados algoritmos iterativos para que a des-
crição implementada seja sintetizável em hardware.
3.1.2 Hipóteses simplificadoras
Em uma primeira abordagem, utilizar-se-ão algumas hipóteses simplifica-
doras na implementação do algoritmo de ray tracing:
• Todos os raios partirão paralelos ao plano de projeção. Tal simplificação
permite a obtenção de imagens sem implementar um modelo de câmera;
• Apenas os fenômenos de reflexão e refração serão considerados. Efei-
tos ópticos mais complexos não serão implementados;
• Cada raio partindo do plano de projeção só poderá receber até cinco
reflexões/refrações. Essa medida é essencial para limitar os recursos
utilizados.
3.1.3 Otimização com uma árvore k-d
Segundo (HAVRAN, 2000) existem diversas maneiras para se otimizar um
algoritmo de ray tracing. Entre os algoritmos mais comuns, o algoritmo de
otimização por árvore k-d revelou-se estatisticamente mais eficiente, isto é,
tal algoritmo encontra mais rapidamente o triângulo que um determinado raio
de luz intercepta. A abordagem detalhada destes algoritmos não faz parte
deste trabalho e recomenda-se a leitura de (HAVRAN, 2000) para um maior
aprofundamento em algoritmos de ray tracing.
No ray tracing, a imagem 3D é gerada a partir da verificação da busca
dos raios de luz incidentes, refletidos e refratados no conjunto de triângulos
da cena. Contudo, o processo de verificação tende a ser bem custoso se

32
o algoritmo percorrer a lista inteira de triângulos toda vez que a busca de
interseção do raio for necessária. Para evitar isto, utiliza-se um processo de
indexação espacial por meio de árvores k-d, que organiza os dados com o
objetivo de percorrer um número mínimo de triângulos e verificar a ocorrência
da interseção destes triângulos com um raio.
As árvores k-d são árvores binárias nas quais cada nó contém um ponto
em dimensão k. Cada nó não-terminal representa uma divisão do espaço por
um plano, e o caminho percorrido desde a raiz até um nó terminal descreve a
região do espaço determinada por ele delimitada. O nó terminal ainda arma-
zena referências para todos os triângulos contidos em sua região espacial. A
figura 7 mostra um exemplo de uma árvore k-d.
Figura 7 – Uma árvore k-d bidimensional. Nós internos são nomeados de acordo com osplanos divisores e nós folha são nomeados de acordo com a região que delimitam noespaço. À direita está a árvore k-d que representa a divisão espacial especificada à
esquerda. Extraído de: (FOLEY; SUGERMAN, 2005).
As divisões do espaço são sempre feitas por meio de planos paralelos aos
eixos coordenados, o que simplifica a geração dos filhos esquerdo e direito
de um nó. Por exemplo: se um nó N é dividido pelo plano x = x0, todos os
triângulos cujas coordenadas em x de, pelo menos, um de seus vértices sejam
menores do que x0 estarão referenciados em, pelo menos, um nó terminal
acessível pelo filho da esquerda; o raciocínio é análogo para o filho da direita.
Se um triângulo possuir vértices tanto à “esquerda” de x0 (com coordenada
x menor que x0) quanto à “direita”, ele será referenciado por nós terminais

33
acessíveis pelos dois filhos de N .
Durante a construção de uma árvore k-d, é necessário encontrar um crité-
rio que consiga resolver o problema de dividir um nó em duas sub-regiões do
espaço. Como o problema de divisão de planos na árvore k-d é relacionado
com os eixos que delimitam o espaço para que seja possível encontrar um
determinado triângulo mais rapidamente, seria vantajoso encontrar um mé-
todo que relacionasse os triângulos e sua posição no espaço com a posição
na qual um eixo será dividido. O eixo a ser dividido é o eixo que menos res-
tringe o número de triângulos dentro dele, pois a distância entre a coordenada
máxima e a coordenada mínima aceita é a maior entre os eixos de uma deter-
minada subdivisão espacial. Há vários métodos (HAVRAN, 2000) com os quais
é possível obter uma orientação de como dividir o espaço:
• mediana espacial - na construção da árvore, o plano de divisão sempre
divide o eixo com o maior intervalo no ponto médio da região delimitada
pelo eixo. Esta abordagem balanceia o espaço em cada lado do plano
de divisão;
Figura 8 – Divisão do espaço por mediana espacial.
• mediana de objetos - a coordenada do eixo de maior intervalo é dividida
de tal forma que o número de triângulos seja o mesmo em ambos os
lados das novas sub-regiões do espaço;

34
Figura 9 – Divisão do espaço por mediana de objetos.
• modelo de custos - consiste em determinar uma lista de possíveis posi-
ções candidatas para a divisão de um eixo e escolher aquela que possui
o menor custo de divisão. Isto pode ser feito por meio de probabilidade
geométrica.
Custo
Posição do plano divisor
Figura 10 – Divisão do espaço por um modelo de custos.
Segundo (HAVRAN, 2000), o modelo de custos é que possui melhor de-
sempenho entre os três supracitados e que será empregado neste trabalho.
O modelo de custos a partir da área superficial corresponde ao cálculo de
uma função heurística de custo para todas as possíveis posições do plano de
divisão e a seleção da posição que fornece o custo mais baixo. As posições
possíveis são limitadas pelas coordenadas no eixo no qual será feita a divisão
de cada vértice de todos os triângulos contidos em uma subdivisão do espaço.
Esse modelo, ilustrado pela figura 11, é denominado heurística de área super-

35
ficial (cuja sigla em inglês é SAH — Surface Area Heuristic), e a fórmula para
seu cálculo é a seguinte:
C =1
SA(Ncurr)[SA(LCNcurr)(Trigleft+Trigboth)+SA(RCNcurr)(Trigright+Trigboth)]
(3.1)
onde:
SA(Ncurr) área do nó atual
SA(LCNcurr) área do candidato a filho esquerdo do nó atual
SA(RCNcurr) área do candidato a filho direito do nó atual
Trigleft número de triângulos à esquerda do valor candidato a divisão
Trigright número de triângulos à direita do valor candidato a divisão
Trigboth número de triângulos que pertencem aos dois lados da possível di-
visão
Figura 11 – O valor de uma função de custo para quatro objetos (duas dimensões). Asposições limites dos objetos possuem grande influência na seleção do ponto de divisão com
o custo mínimo. Extraído de (HAVRAN, 2000).
O critério de parada das divisões dos eixos no modelo de heurística de
área superficial ocorre quando o menor custo de divisão de um eixo é maior

36
ou igual ao custo de divisão do nó pai da árvore ou quando a profundidade má-
xima é atingida. O algoritmo 2 descreve a construção da árvore k-d utilizando
o modelo de heurística de área superficial.
o algoritmo inicia com o tratamento da raiz a qual possui custo de divisão∞
while existirem nós a serem tratados and a profundidade máxima não foratingida do
dividir o eixo do espaço indexável que possui o maior tamanhocalcular o custo de todas as possíveis posições de corteescolher a posição de menor custoif custo for menor que o custo da divisão do nó-pai then
executar a divisãocriar dois novos nós para armazenar os triângulos compreendidos naparte esquerda e na parte direita da divisãoadicionar os nós criados ao fim da lista de nós a serem tratados
end iftratar próximo nó
end whileAlgoritmo 2 – Construção da árvore k-d
Após a construção da árvore k-d é necessário o uso de um algoritmo para
percorrê-la a fim de encontrar o triângulo que intercepta um determinado raio
de luz. Dado um raio de luz r, deve-se encontrar a interseção mais próxima
com o espaço indexável (isto é, o espaço que será subdivido dentro de uma
árvore k-d). Para isto foram utilizado os cálculos descritos na seção 2.1.2.
Uma vez que a primeira interseção é encontrada deve-se procurar o nó folha
da árvore-k-d no qual a interseção está contida. Esse processo é detalhado
no algoritmo 3.
Uma vez encontrado o nó-folha, deve-se testar cada triângulo referenciado
por ele (o conjunto destes triângulos é chamado pacote de triângulos). Uma
vez que a interseção é encontrada, calcula-se o raio refletido (seção 2.2.1) e,
se houver, o raio refratado (seção 2.2.2). Após isso, é necessário encontrar o
próximo pacote de triângulos para cada novo raio gerado, usando novamente
o algoritmo 3.

37
parâmetros:ray o raio de luz atualcurrentNode o nó sendo atravessado por ray atualmenteif ainda não foi calculado o primeiro nó atravessado thenpoint← ponto em que o raio entra no espaço indexadoif raio não intercepta o espaço indexado then
return nó nulo (não existe próximo nó)end ifnode← raiz da árvore k-d
elsepoint← ponto em que o raio deixa o nó atualnode← currentNodewhile node não é estritamente maior em todas as dimensões (x, y, z) quecurrentNode do
if node é a raiz thenreturn nó nulo (não existe próximo nó)
elsenode← pai de node
end ifend while
end ifwhile node não é um nó-folha dosplitAxis← eixo de divisão de nodesplitCoord← coordenada na qual splitAxis foi divididoif point[splitAxis] = splitCoord then
if rayDirection[splitAxis] > 0 thennode← filho direito de node
elsenode← filho esquerdo de node
end ifelse if point[splitAxis] > splitCoord thennode← filho direito de node
elsenode← filho esquerdo de node
end ifend whilereturn node
Algoritmo 3 – Busca de um próximo nó na árvore k-d

38
3.1.4 Configuração das entradas e saídas
Há dois arquivos responsáveis pelos parâmetros de entrada do h3dge. O
primeiro é um arquivo .dscx cuja estrutura é a seguinte :
• Primeira linha: a palavra "DSCX";
• Segunda Linha: width e height, a largura e a altura da janela de obser-
vação;
• Terceira linha: nMats, nMedia e nLights, o número de materiais presen-
tes na cena seguido pelo número de meios ópticos e de fontes lumino-
sas;
• nMats linhas seguintes: os materiais cujos atributos são especificados
na ordem: cor vermelha, cor verde, cor azul, coeficiente de reflexão,
coeficiente de transmissão;
• nMedia linhas seguintes: os meios ópticos presentes na cena, caracte-
rizados pelo seu índice de refração;
• nLights linhas seguintes: as fontes luminosas cujos atributos são espe-
cificados na ordem: coordenadas x, y e z; e intensidade da cor vermelha,
azul e verde;
• Linha seguinte: nTrigs, o número de triângulos;
• nTrigs linhas seguintes: o material de cada triângulo, seguido pelos nú-
meros identificadores dos dois meios ópticos por ele separados.
A cena que será processada é formada por triângulos e é armazenada em
um arquivo .off cuja estrutura é a seguinte :
• Primeira linha: a palavra "OFF";

39
• Segunda linha: nPoints, a quantidade de pontos; nTrigs, a de triângu-
los; e um zero;
• nPoints linhas seguintes: os pontos dos vértices dos triângulos;
• nTrigs linhas seguintes: o número de vértices de polígonos (sempre
igual a 3, pois a cena é composta sempre por triângulos) e o número
identificador dos pontos que compõem cada vértice.
Tais informações podem ser obtidas por meio de arquivos de formato pa-
dronizado, tais como os arquivos .off (Object File Format, definido em (SHI-
LANE et al., 2004)), utilizados para representar a geometria de um modelo com
base em polígonos.
A saída do algoritmo é uma sequência de valores RGB correspondentes a
cada um dos pixels da imagem calculada.
3.2 Desenvolvimento
3.2.1 Metodologia de projeto
Os modelos clássicos de projeto em hardware e software tipicamente co-
meçam de uma mesma especificação de sistema que é gradualmente refinada
e sintetizada em uma arquitetura a qual é composta por componentes progra-
máveis ou dedicados. Contudo a grande desvantagem desta abordagem é o
fato de ser necessário um particionamento prematuro entre o que irá ser pro-
gramado em hardware e software. Desta forma separa-se, desde o início da
concepção do projeto, o que será desenvolvido em software e em hardware e,
a partir desta separação, inicia-se o desenvolvimento do projeto. A parte em
software é feita geralmente usando uma linguagem de programação de alto
desempenho (linguagem C, por exemplo); a parte em hardware, por sua vez,

40
é feita utilizando-se simuladores de linguagens de descrição de hardware de
baixo nível como o VHDL ou o Verilog.
A grande desvantagem dessa metodologia é o risco do aumento de com-
plexidade do projeto resultante de um dimensionamento equivocado da di-
visão entre software e hardware. Por isso, para a execução deste trabalho
procurou-se adotar uma nova metodologia (ERBAS, 2006) na qual procura-se
melhorar o projeto do circuito por meio da eliminação da decisão prematura
do particionamento. A figura 12 ilustra esta metodologia em forma de Y a qual
reconhece uma clara separação entre um modelo de aplicação, um modelo de
arquitetura e um passo explícito para o mapeamento no qual se correlacionam
os dois modelos.
Figura 12 – Metodologia de projeto empregada. Adaptado de (ERBAS, 2006).
O modelo de aplicação descreve o comportamento funcional de uma apli-
cação independentemente de especificações arquiteturais como o particiona-
mento ou de características do desenvolvimento temporal do sistema. O mo-
delo de arquitetura define os recursos da arquitetura e captura suas caracte-
rísticas temporais sendo capaz de avaliar a desenvoltura para a execução das
arquiteturas em hardware e software. Logo ao invés de utilizar a abordagem

41
clássica na qual a simulação do hardware e do software são vistas como par-
tes cooperantes, a metodologia em Y distingue as simulações de aplicação
e arquitetura sendo que a última envolve aspectos das partes programáveis
como também das partes dedicadas.
O esquema geral de desenvolvimento é dado pela figura 12. O conjunto de
modelos de aplicação no canto superior direito da figura conduz o projeto da
arquitetura. O primeiro passo do projetista é estudar estas aplicações, fazer
alguns cálculos iniciais e propor uma plataforma candidata para o desenvol-
vimento da arquitetura. Os números resultantes podem inspirar o projetista a
melhorar a arquitetura, reestruturar a aplicação ou mudar o mapeamento. As
possíveis ações do projetista são ilustradas por meio das nuvens de cor cinza
na figura 12.
O desacoplamento dos modelos de arquitetura e aplicação permite utilizar
um mesmo modelo de aplicação para exercitar diferentes particionamentos
entre hardware e software e mapeá-los em um conjunto de modelos de arqui-
tetura. Esta capacidade demostra a eficiência do desacoplamento por meio
do reuso de ambas as partes do modelo.
Após encontrar uma alternativa que atenda aos requisitos do projeto, é
necessária a transição para a abordagens de baixo nível visando à síntese do
circuito. Para isto recorre-se a modelos Register Transfer Level (RTL) sinteti-
záveis com os quais é possível obter modelos mais precisos e que atendam
aos requisitos de projeto. Para tal tarefa é necessário um conjunto de ambi-
entes de desenvolvimento nos quais existam diferentes níveis de abstração
para um mesmo projeto. Assim enquanto modelos executáveis abstratos de
aplicação exploram eficientemente as abordagens de projeto, modelos mais
detalhados agregam mais detalhes de desenvolvimento e consequentemente
trazem uma maior precisão e permitem um projeto eficiente em hardware.

42
O fluxo de desenvolvimento da plataforma de arquitetura (parte esquerda
da metodologia em Y da figura 12) começa com uma descrição RTL do cir-
cuito. Tal descrição pode ser acompanhada por um conjunto de detalhes
específicos de execução da plataforma de desenvolvimento. Um arquivo se-
parado conhecido como testbench (bancada de testes) provê uma bancada
virtual para a simulação e verificação do circuito. Ela incorpora o código para
gerar os estímulos de entrada e monitorar as respostas de saída. Uma vez
que estes arquivos são criados, o circuito pode ser construído e verificado
de uma maneira eficiente. Os passos do desenvolvimento da plataforma de
arquitetura, segundo (CHU, 2006), são descritos abaixo:
• Desenvolver o arquivo de projeto da arquitetura e a bancada de testes;
• Utilizar o arquivo de projeto da arquitetura como a descrição do circuito
e executar a simulação para verificar se as funções do projeto funcionam
de maneira adequada;
• Executar a síntese do circuito;
• Utilizar o arquivo netlist de saída do sintetizador, que especifica as ins-
tâncias e as interconexões das diversas células do projeto, como descri-
ção do circuito e realizar uma simulação e análise de tempo para verificar
a regularidade da síntese e checar se o tempo de execução é adequado;
• Executar o place-and-route (posicionamento e interligação de células);
• Anotar as informações precisas de tempo para o netlist, realizar a simu-
lação e análise de tempo para verificar a correção do place-and-route e
verificar se o circuito atende as restrições de tempo;
• Gerar o arquivo de configuração e programar a plataforma de desenvol-
vimento;

43
• Verificar o funcionamento da parte física.
O fluxo descrito acima representa um processo ideal, pois assume que a
descrição do projeto inicial siga a especificação funcional e atenda as restri-
ções de tempo. Na realidade, o fluxo de desenvolvimento pode acarretar em
várias iterações para corrigir os erros funcionais ou problemas de tempo. É
possível que haja necessidade de rever os arquivos de projeto de arquitetura
originais para ajustar parâmetros da síntese e no place-and-route. A figura 13
ilustra todos os passos descritos acima.
Figura 13 – Passos para o projeto da plataforma de arquitetura. Adaptado de (CHU, 2006)

44
3.2.2 Recursos Utilizados
Esta seção descreve todas as ferramentas e recursos utilizados no pro-
cesso de desenvolvimento do raytracer segundo a metodologia descrita na
seção 3.2.1 .
3.2.2.1 Ferramentas de desenvolvimento para os modelos de aplicação
Neste trabalho para a execução dos modelos de aplicação foi utilizada
a interface Eclipse CDT configurada para executar a biblioteca SystemC. A
figura 14 mostra o ambiente de desenvolvimento do modelo de aplicação.
Figura 14 – O ambiente de desenvolvimento do modelo de aplicação.
Um dos objetivos principais da linguagem SystemC é possibilitar a mode-
lagem de sistemas em um nível de abstração acima das descrições RTL, in-
cluindo sistemas que podem ser desenvolvidos em hardware, software ou uma
combinação dessas abordagens. A camada de base do SystemC proporciona
um kernel de simulação orientado a eventos. Com ele é possível realizar ope-
rações com eventos e processá-las de maneira abstrata, sem conhecer o que
os eventos realmente representam ou o que os processos fazem. Isto é bem

45
interessante para proporcionar uma linguagem de projeto de sistemas diante
de uma ampla variedade de modelos de computação e comunicação.
Outros elementos do SystemC incluem módulos e portas para representar
informações estruturais, interfaces e canais que podem ser utilizados em abs-
trações para a comunicação. O kernel e estes elementos abstratos compõem
a linguagem núcleo. No topo desta linguagem é possível adicionar modelos
mais específicos de computação, bibliotecas e metodologias de projetos que
são úteis para o projeto de sistemas.
Figura 15 – Arquitetura da linguagem SystemC. Adaptado de (GROTKER, 2002)
A figura 15 expõe as diferentes camadas do systemC. A camada de base
mostra que SystemC é construída inteiramente em C++. Isto significa que um
programa escrito em SystemC pode ser executado por meio de um compila-
dor C++. Junto com a linguagem de núcleo, há os tipos de dados que são
úteis para a modelagem de hardware e para certos tipos de programação em
software (como os tipos em ponto fixo). Os canais primários da camada su-
perior incluem modelos que são amplamente utilizados como sinais, timers
e buffers FIFO. As camadas do topo não fazem parte do SystemC padrão,
contudo pode-se escolher usá-los ou mesmo desenvolver componentes para

46
novos modelos computacionais.
3.2.2.2 Plataforma de desenvolvimento
Para o desenvolvimento da arquitetura foi utilizada a plataforma de desen-
volvimento ML507 (figura 16), da Xilinx. Essa placa é construída ao redor da
FPGA Virtex-5 XC5VFX70T e possui uma série de periféricos, dentre os quais
destacam-se (XILINX, 2011b):
• Memória DDR2 SODIMM de 256 MB;
• Memória flash de 32 MB;
• SRAM de 9 MB com barramento de dados de 32 bits e 4 bits de paridade;
• Saída de vídeo DVI, e adaptador para VGA incluso;
• Conector DB9 para porta serial RS232;
• Interface JTAG;
• LEDs, botões e switches para debug.
A Xilinx também fornece as ferramentas de software para utilização da
placa, notadamente o Embedded Development Kit, parte da suíte de desen-
volvimento ISE, que contém diversos IPs para a utilização dos periféricos dis-
poníveis.
3.2.2.3 Ferramentas de desenvolvimento para os modelos de arquite-tura
A linguagem SystemVerilog foi utilizada para o desenvolvimento dos mo-
delos de arquitetura (notadamente o coprocessador) e seu uso justifica-se em
sua praticidade. Trata-se de uma extensão da linguagem Verilog a qual busca

47
Figura 16 – Plataforma de desenvolvimento ML507 da Xilinx
maior produtividade no projeto de grandes chips com um elevado número de
portas e de IPs. Uma grande vantagem desta linguagem é seu maior grau de
abstração que permite uma transição mais suave na concepção dos modelos
de arquitetura a partir dos modelos de aplicação.
SystemVerilog (SYSTEMVERILOG, 2011) é capaz de suportar a modelagem
e verificação no nível de abstração de transação. Ela permite a invocação
direta de funções em C/C++ e é a primeira linguagem baseada em Verilog que
permite uma cossimulação eficiente entre blocos em SystemC. Isto é muito
interessante para estabelecer ligações entre o design em uma abstração de
sistema para uma implementação em hardware.
A linguagem também é dotada de um conjunto de extensões que atendem
requisitos avançados de projeto. Alguns exemplos são a modelagem de inter-
faces que permitem maior produtividade no desenvolvimento de projetos nos
quais o uso dos barramentos é intensivo; o fim das restrições no número de
conexões nas portas dos módulos, permitindo qualquer tipo de dado em cada
lado da porta; tipos de dados estendidos que permitem modelagem similar

48
aos tipos de dados do C (estruturas, por exemplo) e melhorias na proteção
das IPs. As melhorias no suporte a verificação dos módulos são bastantes
significativas. Novas metodologias permitem o aumento da precisão nos tes-
tes, simplificam as bancadas e facilitam o reúso de código, diminuindo drasti-
camente o tempo dispendido na eliminação de erros.
SystemVerilog também possui novas características para suportar mode-
los de hardware e bancadas de testes que utilizam técnicas de orientação a
objeto que são inteiramente reutilizáveis. A combinação de um método de
interface em SystemVerilog com as técnicas de criação de uma bancada de
testes orientada a objeto permite o desenvolvimento simplificado de metodo-
logias de testes baseadas em requisitos exigentes de projeto.
Para a descrição dos modelos de arquitetura em SystemVerilog e a sua
posterior simulação e verificação utiliza-se a ferramenta ActiveHDL. A ferra-
menta possui um ambiente gráfico para o desenvolvimento em HDLs permi-
tindo testes integrados de diversos módulos com uma relativa flexibilidade. Ela
suporta FPGAs dos principais fabricantes, incluindo a plataforma Xilinx que é
empregada neste trabalho (ALDEC, 2011). A figura 17 ilustra a interface do
ActiveHDL.
Após a especificação de todos os módulos do coprocessador utilizando
SystemVerilog, incia-se o processo de síntese. Neste passo, as representa-
ções e descrições dos módulos são convertidas em representações geométri-
cas as quais serão dispostas fisicamente dentro da FPGA. Na síntese leva-se
em conta as propriedades da plataforma de desenvolvimento utilizada, as cé-
lulas padrão, as regras de disposição das células e suas limitações temporais
e é o primeiro passo da transformação de uma descrição em hardware de
nível abstrato em um dispositivo físico. Todas as informações, regras e limita-
ções da FPGA na qual uma descrição em hardware será sintetizada estão em

49
Figura 17 – O ambiente de desenvolvimento e de simulação em SystemVerilog do modelo dearquitetura.
bibliotecas disponibilizadas pelo fabricante.
Para a síntese a ferramenta Synplify Premier with Design Planner é em-
pregada. Segundo (SYNOPSYS, 2011) tal ferramenta é o ambiente de verifi-
cação e desenvolvimento em FPGAs mais produtivo no meio industrial. Além
disso, inclui um conjunto de ferramentas de síntese compreensivo, de alta ve-
locidade, com correlação temporal precisa, previsão de consumo e tecnologia
de otimização. A figura 18 ilustra a interface do Synplify Premier.
Após a síntese é necessário executar o posicionamento e interligação de
células. No projeto de hardware usando FPGA, esta etapa geralmente não é
feita por uma pessoa pois geralmente usa-se uma ferramenta disponibilizada
pelo fabricante da FPGA ou outro fabricante de software. A necessidade de
um software é estimulada pela complexidade interna de uma FPGA e pelas
características do projeto a ser inserido neste dispositivo. O primeiro passo, o
posicionamento, envolve decidir em quais partes da FPGA que serão coloca-
dos os subcomponentes eletrônicos e dispositivos lógicos. Após isso, segue-
se a fase de interligação (roteamento) na qual é decidido a maneira como

50
Figura 18 – O ambiente de síntese
todos estes dispositivos serão interligados, levando-se em conta as regras e
as limitações do dispositivo em geral especificadas no software responsável
por esta etapa. Neste projeto o posicionamento e interligação de células foi
feito por meio do ISE Design Suite disponível para a plataforma de desenvol-
vimento da Xilinx empregada na síntese dos modelos de arquitetura (seção
3.2.4). A figura 19 ilustra a interface do ISE Design Suite da Xilinx.
Figura 19 – Interface do ISE Design Suite, software utilizado para o posicionamento einterligação de células.

51
3.2.3 Particionamento em hardware e software
O particionamento entre hardware e software levou em conta a frequência
das operações que ocorrem no processo de geração de uma imagem em 3D.
O processo inicia-se com a leitura dos arquivos de entrada especificados na
seção 3.1.4 a partir de um disco rígido de um PC e o envio destes dados para
a plataforma de desenvolvimento ML507 por meio da porta serial. Estes dados
são armazenados na memória DDR2. Após a transferência dos dados, incia-
se o trabalho do processador, responsável pela execução de um software que
indexará os triângulos enviados pela porta serial por meio da construção de
uma árvore k -d.
Após a construção da árvore k -d, inicia-se o trabalho dos coprocessado-
res, descritos em hardware, os quais executam o algoritmo de ray tracing,
calculando as reflexões e refrações dos raios de luz no conjunto de triângulos.
A partir destas reflexões e refrações, pode-se calcular a intensidade luminosa
(seção 2.2.3) em um ponto da janela de observação (seção 3.1.1), o que tam-
bém é feito em hardware. No fim de todo o processo, utilizando a interface
disponível na plataforma de desenvolvimento ML507, é possível exibir a ima-
gem 3D gerada pelo algoritmo.
Para cada imagem gerada, é necessária a construção de uma árvore de
indexação espacial antes da execução do algoritmo de ray tracing. Dessa
forma não haverá sobrecarga de nenhum barramento presente o que viabiliza
tal divisão. A divisão permitirá uma implementação mais facilitada sem pre-
judicar as vantagens de se possuir um hardware dedicado para a execução
do algoritmo de ray tracing, justificando sua construção por meio do software.
Além disso, poupa-se superfície em hardware a qual pode ser usada para es-
pecificar outros fenômenos ópticos, por exemplo. A lista a seguir e a figura 20

52
resumem o particionamento em hardware e software de todas as atividades
envolvidas na geração de uma imagem em 3D usando ray tracing:
• Entrada e construção da árvore de indexação espacial - software;
• Interseção, reflexões e refrações - hardware;
• Cálculo da intensidade luminosa - hardware;
• Saída dos dados - hardware (utilizando recursos disponíveis na plata-
forma embarcada).
Figura 20 – Fluxograma do particionamento em hardware e software do raytracer
Uma vez o sistema base definido, foi possível a adaptação dos modelos
de aplicação para seu uso como software embarcado. Tal implementação
iniciou-se com a adaptação do port do sistema operacional FreeRTOS para a
versão 13.1 da ferramenta de desenvolvimento da Xilinx, que modificava em

53
alguns pontos a API utilizada. Após modificações nas camadas de abstra-
ção do hardware, o sistema pôde ser executado com sucesso na FPGA. Em
seguida, tendo em vista o particionamento software/hardware, modificou-se o
software em SystemC para a execução no sistema embarcado. Visto que não
foi possível compilar toda a biblioteca SystemC para a plataforma PPC440,
confeccionou-se uma biblioteca C++ que implementasse os tipos de dados
necessários ao correto funcionamento do software existente (notadamente os
números em ponto fixo).
3.2.4 Especificação e dimensionamento da arquitetura
A partir do desenvolvimento dos modelos de aplicação (seções 3.2.1 e
3.2.2.1) é possível especificar e dimensionar a arquitetura do projeto, que será
discutida nessa seção.
3.2.4.1 Visão geral
De uma maneira geral e simplificada, a arquitetura de hardware do sistema
h3dge é a exposta na figura 21.
Figura 21 – Arquitetura simplificada do sistema h3dge

54
Conforme discutido na seção (3.2.3), cada um dos componentes do sis-
tema tem uma função bem determinada, a saber:
• O processador é responsável pela indexação espacial e o coprocessa-
dor é responsável pelo algoritmo de ray tracing e pelo cálculo da intensi-
dade luminosa;
• O controlador de memória oferece acesso à memória DDR2 presente
na placa de desenvolvimento;
• O controlador UART fornece uma interface de comunicação serial com
um PC;
• O controlador de vídeo possibilita a saída da imagem gerada em uma
interface DVI;
• E todos os componentes se comunicam por meio de vias de dados
internas.
As próximas seções detalham o funcionamento da parte majoritária dos
elementos dessa estrutura.
3.2.4.2 Processador
Inicialmente, foi proposta a utilização do processador PicoBlaze para co-
mandar as atividades do circuito. O PicoBlaze é um soft core altamente otimi-
zado para as FPGAs da Xilinx, que permite sintetizar em um pequeno número
de slices uma unidade de processamento funcional e flexível. Suas principais
características são (CHU, 2008):
• Palavra de dados de 8 bits;

55
• 16 registradores de 8 bits;
• Memória de dados de 64 bytes;
• Instruções de 18 bits de largura;
• Endereços de instrução de 10 bits de largura, suportando um programa
de até 1024 instruções;
• 256 portas de entrada e 256 portas de saída;
• 2 ciclos de relógio por instrução;
• 5 ciclos de relógio para tratamento de uma interrupção.
O PicoBlaze é uma boa alternativa para executar programas que fazem
essencialmente E/S. Entretanto, após estudo aprofundado de suas caracte-
rísticas, é possível perceber que ele não é apropriado às necessidades de
processamento do h3dge, pelas seguintes razões:
• O algoritmo de criação da árvore k -d será executado em software, visto
que essa etapa do processo não pode ser paralelizada. Como o Pi-
coBlaze só pode ser programado em linguagem assembly, a escrita do
algoritmo seria dificultada;
• Mesmo se a decisão de implementar o algoritmo em assembly fosse
tomada, a realização seria trabalhosa, visto o tamanho dos registradores
e da unidade lógica e aritmética (ULA) - uma operação de adição de dois
números de 32 bits necessitaria da metade dos registradores;
• Mesmo se o algoritmo fosse implementado com sucesso, ele dificilmente
caberia na memória de programa de 1024 instruções;

56
• O PicoBlaze não tem um controlador de memória externa embutido. As-
sim, seria necessário adicioná-lo como uma IP, e escrever o driver para
utilizá-lo - driver este que, por sua vez, ocuparia espaço na já escassa
memória de programa.
Tendo em vista essas limitações, optou-se pelo uso do core PowerPC 440
embutido na FPGA. Tal processador possui funcionalidades muito mais favo-
ráveis às necessidades deste projeto, tais como (XILINX, 2010a):
• Arquitetura RISC 32 bits;
• 32 registradores de 32 bits;
• Caches de instrução e de dados de 32 KB cada;
• Interfaces PLB (Processor Local Bus) para conexão de processadores
adicionais;
• Interface JTAG;
• Suporte à programação em C/C++ via gcc.
Além das funcionalidades superiores, um outro argumento a favor da utili-
zação desse core é seu "custo zero", visto que o bloco está presente em silício
(sua utilização não necessita de slices adicionais).
3.2.4.3 Coprocessador
Conforme dito na seção 3.2.3 o coprocessador engloba todas as funções
necessárias para o cálculo em ponto fixo e pela execução do algoritmo de ray
tracing. Esta seção dedica-se a especificar a arquitetura do coprocessador.

57
O primeiro passo no projeto do coprocessador consistiu no desenvolvi-
mento de uma estimativa do tamanho de sua memória por meio da implemen-
tação dos modelos de aplicação (seção 3.2.1). O propósito da memória do
coprocessador é acelerar o processo de cálculo dos raios refletidos e refrata-
dos, evitando-se um número exagerado de requisições à memória DDR2 para
conseguir os dados necessários para tais cálculos.
A partir da especificação das estruturas de dados necessárias para o al-
goritmo de ray tracing, foi possível calcular o tamanho dos tipos de dados rela-
cionados com o funcionamento do coprocessador. Estes cálculos detalhados
encontram-se no apêndice A.
Após estes primeiros cálculos, estipulou-se que a quantidade máxima de
triângulos que podem ser referenciados por um único nó folha de uma árvore
k -d é 1024. Em outras palavras, convencionou-se que um pacote de triângulos
pode no máximo possuir 1024 elementos; um pouco mais que 1% da quantia
máxima de triângulos que pode ser armazenada. Tal número mostrou-se sa-
tisfatório para todos os testes realizados na plataforma de desenvolvimento.
Caso o número de triângulos seja maior que o estipulado, uma nova requisi-
ção à memória deve ser feita para para carregar os próximos 1024 triângu-
los. Cabe destacar que, embora seja possível, é improvável que exista um
nó folha com mais que 1024 triângulos, pois o propósito de uma árvore k -d é
justamente dividir os triângulos entre seus nós folhas para diminuir o número
de objetos com os quais o teste de interseção será feito. No caso de imagens
com um número muito alto de triângulos, será necessário aumentar a quantia
máxima de triângulos que podem estar referenciados em um nó folha.
Além disso, estimou-se a quantidade de espaço necessária para arma-
zenar um conjunto de raios refletidos e refratados, considerando um número
máximo de reflexões de cada raio igual a cinco (seção 3.1.2). Como cada raio

58
pode refletir-se e, se possível, refratar-se então, no caso em que a quantidade
de raios é máxima, há a possibilidade de obtenção de um conjunto de raios or-
ganizados em uma estrutura similar a uma árvore binária de busca na qual os
filhos à esquerda são os raios gerados após uma reflexão e os filhos a direita
são os raios gerados após uma refração. O tamanho máximo desta árvore é
dado por uma árvore binária de busca balanceada de altura cinco cujo cálculo
está disponível no apêndice A. Deve-se ressaltar que o número máximo de
materiais, meios e luzes é igual a dezesseis conforme já discutido na seção
3.1.2.
A lista a seguir enumera todos as estruturas que serão armazenadas na
memória do coprocessador e seu respectivo tamanho, de acordo com os cál-
culos disponíveis no apêndice A:
• nó da árvore em processamento - 56 bytes;
• vetor para 1024 triângulos - 49152 bytes;
• vetor para os materiais - 320 bytes;
• vetor para as luzes - 384 bytes;
• vetor para os meios - 64 bytes;
• variável para a cor do pixel - 12 bytes;
• tamanho da pilha a qual armazena os raios refletidos e refratados - 4032
bytes;
A partir dos dados anteriores conclui-se que o tamanho da memória do
coprocessador é de 52.76 kbytes. Após o dimensionamento da memória,
elaborou-se para o processador a arquitetura descrita na figura 22.

59
Figura 22 – Arquitetura do coprocessador
O bloco de Direct Memory Access (DMA) é composto por uma interface
disponível na plataforma de desenvolvimento com a qual é possível acessar
a memória DDR2 externa e assim carregar os dados necessários para o fun-
cionamento do coprocessador em sua memória local. A unidade de cálculo
em ponto fixo concentra as rotinas matemáticas para os cálculos executados
pelo algoritmo de ray tracing. O módulo responsável pela execução do algo-
ritmo contém as descrições dos fenômenos ópticos de reflexão e refração e
as estruturas para o preparo da execução destas descrições.
Cabe ressaltar que devido a restrições temporais (prazo de entrega) e às
dificuldades envolvidas na execução deste projeto (seção 5.2), não foi possível
descrever em hardware a arquitetura supracitada. Após uma série de simpli-
ficações, decidiu-se descrever em hardware a operação de interseção de um
raio com um triângulo, pois trata-se de uma operação frequente no algoritmo

60
e que proporciona ganho de desempenho se descrita em hardware. Os cálcu-
los empregados na interseção são descritos na seção 2.1.2 e a arquitetura do
fluxo de dados descrito em hardware é ilustrada na figura 23.
Figura 23 – Fluxo de dados do módulo de interseção de um raio com um triângulo.
A unidade de controle deste módulo possui quatro estados. No primeiro
calcula-se o determinante, o qual é necessário para o cálculo dos parâmetros
u e v, respectivamente obtidos no segundo e terceiro estados. Após isso é
possível calcular, no quarto estado, o resultado t e obter o ponto de interseção

61
por meio da equação R(t) = O + t. ~D (seção 2.1.2).
3.2.4.4 Vias de dados
Embora a arquitetura exposta na figura 21 seja adequada para um enten-
dimento global do funcionamento do hardware, ela não é exata do ponto de
vista das vias de dados. Isso porque o bus de interconexão nela indicado é na
verdade implementado por duas vias de dados organizados em uma estrutura
hierárquica: a crossbar e um bus PLB v4.6.
A crossbar é uma via de dados extremamente simples, localizada no inte-
rior do bloco de processamento no qual encontra-se o processador PowerPC
440. Como pode-se observar na figura 24, ela, representada por um “X”, age
como unidade central de arbitragem entre todos os elementos mestres e es-
cravos do bloco, funcionando basicamente como um switch.
Embedded Processor Block Reference Guide www.xilinx.com 29UG200 (v1.8) February 24, 2010
R
Chapter 2
Embedded Processor Block Overview
The embedded processor block in Virtex-5 FXT devices contains several additional modules along with the PowerPC 440 processor. These additional modules allow system designers to improve the performance and reduce the cost of their designs. This chapter provides an overview of the embedded processor block in Virtex-5 FPGAs and briefly describes each of the additional modules and interfaces.
Embedded Processor Block ComponentsThe main components of the embedded processor block in Virtex-5 FXT FPGAs are the processor, the crossbar and its interfaces, the Auxiliary Processing Unit (APU) controller, and the control (clock and reset) module. Figure 2-1 shows the embedded processor block and its components.
The processor is described in detail in Chapter 1, “PowerPC 440 Embedded Processor.” The processor has three PLB interfaces: one for instruction reads, one for data reads, and one for data writes. Typically, all three interfaces access a single large external memory. Peripheral access in PowerPC 440 systems is memory mapped, and the data PLB interfaces typically connect to various peripherals directly or via bridges. Some of these peripherals
Figure 2-1: Embedded Processor Block in Virtex-5 FPGAs
Virtex-5 FXT PlatformEmbedded Processor Block
PowerPC 440Processor
ICURDAPUControl
FCMInterface
LocalLink0
LocalLink1
LocalLink2
LocalLink3
SPLB0
SPLB1
MPLB
MemoryControllerInterface
ControlInterface
DCRInterface
DMA
DMA
DMA
DMA
CPM/Control
DCR
DCURD
DCUWR
UG200_c2_01_010708
Figura 24 – Estrutura interna do bloco de processamento das FPGAs Virtex-5. Extraído de(XILINX, 2010a).
A crossbar localiza-se entre as cinco interfaces escravas do bloco de

62
processamento (três vindo diretamente do processador e duas, SPLB01 e
SPLB12, fazendo a conexão com um bus PLB externo) e as duas interfaces
mestras (MPLB3, ligada ao bus PLB externo, e MCI4, conectada ao controlador
de memória). Somente comunicações entre mestre e escravo, e vice-versa,
são permitidas; assim, não é possível enviar dados de um periférico conec-
tado à interface SPLB0 a um outro presente na interface SPLB1.
As principais funcionalidades da crossbar são:
• Pipeline de até 5 transações para as interfaces MPLB e MCI;
• Transmissões em ciclo único ou em modo burst ;
• Arbitragem independente para MPLB e MCI;
• Fases de arbitragem e de dados independentes;
• Suporte a palavras de 128, 64 ou 32 bits;
• Espaço de endereçamento de 64 Gb (34 bits de endereço), a ser dividido
entre os dispositivos escravos.
Tipicamente, a crossbar funciona a uma frequência mais alta que a do bus
externo e dos escravos/mestres sintetizados na FPGA, e um mecanismo de
prioridades round-robin é utilizado para a arbitragem. A descrição em detalhes
do funcionamento dessa via de dados está além do escopo deste trabalho;
para mais detalhes, aconselha-se a leitura de (XILINX, 2010a).
O Processor Local Bus (PLB), por sua vez, é a via de dados utilizada para
a conexão do bloco de processamento com os periféricos. Trata-se de um bus1Slave PLB 02Slave PLB 13Master PLB4Memory Controller Interface

63
padronizado, parte da arquitetura CoreConect proposta pela IBM para vias de
dados em Systems-on-Chip (SoC).
DS531 September 21, 2010 www.xilinx.com 2Product Specification
LogiCORE IP Processor Local Bus (PLB) v4.6 (v1.05a)
Functional DescriptionThe Xilinx PLB consists of a central bus arbiter, the necessary bus control and gating logic, and all necessary busOR/MUX structures. The Xilinx PLB provides the entire PLB bus structure and allows for direct connection with aconfiguration number of masters and slaves. Figure 1 provides an example of the PLB connections for a system withthree masters and three slaves.
Basic Operation
The Xilinx PLB has three-cycle arbitration during the address phase of the transaction as shown in Figure 2. Thereis a two-cycle delay from Mn_request to PLB_PAValid. If the slave can respond combinatorially in the samecycle—the optimistic assumption shown and theoretically possible for a write transaction—the whole transactiontakes three cycles.
The two-cycle delay from Mn_request to PLB_PAValid holds for the case where there are two or more attachedmasters and allows one cycle for a priority arbitration to occur and one cycle to route the selected master’stransaction data and qualifiers to the slaves. If there is a single master, arbitration is not necessary and transactiondata and qualifiers can be driven to the slaves without multiplexing. This allows PLB_PAValid to be driven afterone clock, saving a cycle of latency.
X-Ref Target - Figure 1
Figure 1: PLB Interconnect Diagram
Central Bus Arbiter
PLB Masters PLB Core PLB Slaves
R ead Data B u s
S t a t us & C o nt r o l
Bu s Co n t r o l & Gat i ng Log i c
Re a d Da ta Bu s
S t a t us & C ont rol
DS531_01_061608
Shared Bus
Arbitration
Address and Transfer Qualifiers
Write Data Bus
Control
Address and Transfer Qualifiers
Write Data Bus
Control
Figura 25 – Arquitetura do bus PLB v4.6. Extraído de (XILINX, 2010b).
A estrutura de uma via de dados PLB v4.6, conforme ilustrado na figura 25,
consiste em uma unidade de arbitragem centralizada e toda a lógica necessá-
ria para o controle da via compartilhada. A implementação utilizada, descrita
em (XILINX, 2010b), possibilita a conexão de até 16 mestres e escravos, e
possui como funções principais:
• Árbitro com número configurável de mestres;
• Suporte a palavras de 128, 64 e 32 bits para mestres e escravos;
• Pipeline de endereçamento;
• Quatro níveis de prioridade para os mestres;

64
• Esquema de prioridades configurável (round-robin ou prioridades fixas);
• Temporizador watchdog;
• Circuito de reset dedicado.
3.2.4.5 Controlador de vídeo
O controlador de vídeo utilizado foi o XPS Thin Film Transistor (TFT) Con-
troller (XILINX, 2009). Esse controlador é uma IP capaz de exibir até 256 mil
cores em uma resolução de 640 por 480 pixels. A saída pode ser feita via uma
uma interface VGA ou DVI, mas visto que no kit de desenvolvimento utilizado
há somente uma porta DVI, a opção VGA não foi utilizada5.
De um ponto de vista pragmático, o XPS TFT Controller exibe em um moni-
tor o conteúdo de um frame buffer armazenado em memória. Tal buffer deve
estar organizado em 1024 colunas e 512 linhas de pixels de 32 bits (totali-
zando 2 MB), das quais somente as primeiras 640 colunas e 480 linhas serão
realmente exibidas na tela. Como usual, cada pixel é uma composição de três
cores: vermelho, verde e azul; cada cor tem um valor de 6 bits, e o pixel é
organizado como mostrado na tabela 1 (bits em ordem big endian).
Tabela 1 – Organização de um pixel na memória. Adaptado de (XILINX, 2009).
Bits Descrição
[31 : 24] Não definido[23 : 18] Vermelho: 0b000000 (mais escuro)→ 0b111111 (mais claro)[17 : 16] Não definido[15 : 10] Verde: 0b000000 (mais escuro)→ 0b111111 (mais claro)[9 : 8] Não definido[7 : 2] Azul: 0b000000 (mais escuro)→ 0b111111 (mais claro)[1 : 0] Não definido
O Embedded Development Kit (EDK) fornece ainda uma API para a utili-
zação dessa IP em software. Por meio dessa biblioteca, é possível configurar5Entretanto, o mesmo kit inclui um adaptador DVI-VGA para paliar essa limitação.

65
e iniciar facilmente o periférico, efetuar algumas operações de renderização
básicas (e.g. limpar tela, desenhar um retângulo preenchido com uma cor),
assim como escrever alguns caracteres na tela usando as funções básicas de
renderização de texto inclusas.
3.2.4.6 Dimensionamento da memória DDR2 externa
As principais estruturas que são armazenadas na memória externa e que
ocupam uma quantia significativa de espaço são a lista de triângulos e a árvore
k -d. Esta seção mostra a metodologia adotada para estimar o tamanho da
memoria necessária para executar o algoritmo de ray tracing do h3dge.
No projeto considera-se um máximo de 70000 triângulos os quais são su-
ficientes para executar o h3dge com as duas imagens testes utilizadas (seção
4.1) e para construir árvores k -d com um tamanho razoável, o que garante a
estabilidade do sistema. Maiores árvores geram cenários mais específicos de
divisão de planos e de interseção de triângulos, os quais são muito interessan-
tes para encontrar possíveis erros no código. Outro aspecto importante a ser
ressaltado é que a árvore k -d possui profundidade máxima igual a dezesseis.
A profundidade máxima é necessária para se evitar árvores muito profundas
as quais diminuem drasticamente o rendimento da indexação espacial (para
maiores informações consultar as seções 3.1.3 e 4.2).
Além disso, deve-se ressaltar que na árvore k -d as referências dos triân-
gulos indexados em cada pacote são alocadas apenas nos nós folha por meio
de listas ligadas. Dessa forma, para poupar espaço em disco, é interessante
que as listas ligadas sejam compostas por referências (ou ponteiros) para os
triângulos alocados inicialmente em outro intervalo da memória, evitando-se
repetições desnecessárias de triângulos nos nós da árvore. O espaço alo-
cado na memória para as referências deve ser suficiente para alocar mais que

66
70000 triângulos, pois no momento da divisão de uma região do espaço, o
plano frequentemente cruza alguns triângulos. Inicialmente adotou-se alocar
espaço suficiente para alocar 140000 referências de triângulos, ilustrando o
caso no qual o plano intercepta todos os triângulos que devem ser repetidos
em ambos os lados dos filhos originados pelo plano divisor. Esta abordagem
funciona para figuras menores e mais simples, contudo, para figuras mais
complexas são necessárias 280000 referências de triângulos para referenciá-
los de maneira segura (sem estouros) na árvore k -d. O aumento do número de
referências decorre justamente do fato da imagem ser mais complexa, o que
aumenta os casos de triângulos interceptados pelo plano divisor nos vários
níveis da árvore.
A partir de todas estas considerações tornou-se possível estimar o espaço
em memória ocupado pelos triângulos, pela árvore k -d e pelas listas ligadas
de referências de triângulos alocadas em seus nós folhas. O total de espaço
em memória necessário é de 12.34 Megabytes. Para maiores detalhes sobre
os cálculos realizados, consultar o apêndice B.
3.2.4.7 Considerações a respeito do número de coprocessadores emparalelo
O número de coprocessadores depende diretamente da capacidade do
barramento de transferência de dados entre a memória e a FPGA. Os ganhos
de desempenho na execução paralela existem até o momento em que o barra-
mento atinge sua capacidade máxima de transferência de dados. Após esse
momento, a adição de novos coprocessadores torna-se inadequada, pois a la-
tência para o acesso ao barramento crescerá de tal forma que anulará os ga-
nhos de performance obtidos com a maior capacidade de coprocessamento.
No momento em que um coprocessador está acessando a memória, outro

67
coprocessador pode estar calculando a intensidade luminosa de seu respec-
tivo ponto. A situação limite ocorre quando a frequência conjunta dos acessos
à memória de todos os processadores se iguala à capacidade do barramento
de acesso à memória. É importante ressaltar que no projeto há o controlador
de vídeo que também utiliza o barramento para acessar a memória, logo seu
uso também deve ser considerado para a estimativa de quantos coprocessa-
dores podem ser acoplados ao barramento. De acordo com (XILINX, 2009), a
frequência dos acessos a memória do controlador de vídeo é de 25MHz e, de
acordo com (XILINX, 2010a), o barramento PLB funciona a 100MHz, portanto
sobram 75MHz para os coprocessadores acessarem a memória.
Segundo (XILINX, 2011a), o clock de funcionamento da memoria DDR2 da
plataforma de desenvolvimento é de 267MHz e seu tempo de latência (latência
CAS) é de cinco ciclos de relógio (XILINX, 2010c). Dessa forma, o tempo de
resposta da memória é de 53MHz, sendo menor que os 75MHz resultantes da
atuação do controlador de vídeo. Assim conclui-se que são necessários dois
ciclos de relógio do barramento para ler um dado da memória.
Após a síntese do módulo de execução do algoritmo de ray tracing, foi pos-
sível obter sua análise temporal e seu ciclo de máquina que é de 210ns, logo
sua frequência é de 4.5MHz. Assim conclui-se que são necessários 23 ciclos
de clock para calcular um raio refletido e, se existir, um raio refratado. Para
que estes raios sejam calculados, é necessário saber quais são os triângulos
contidos dentro da sub-região na qual o raio está imerso, logo necessitam-se
de acessos à memória. A execução do cálculo de um raio leva dez vezes mais
vezes que a de um acesso a memória, assim nota-se que o o barramento
PLB não estará muito ocupado durante o cálculo dos fenômenos ópticos ne-
cessários para determinar as intensidades luminosas nos pontos da janela de
observação, o que abre espaço para o paralelismo.

68
Nota-se que o grau de paralelismo depende da quantidade média de tri-
ângulos por pacote pois, para conseguir cada triângulo, é necessário acessar
a memória. Se houver até 10 triângulos por nó folha da árvore k -d, o copro-
cessador não precisará esperar pelo barramento para obter os dados neces-
sários para os cálculos de interseção. Desta forma, o paralelismo é possível
para figuras pouco complexas e se resume a 2 processadores por conta da
limitação do barramento único e da latência da memória. Para acelerar o pro-
cesso, podem ser utilizado outros barramentos e módulos para DMA e assim
possibilitar o acesso a memória com mais frequência. Neste trabalho não foi
possível devido a limitação do barramento único disponível na plataforma de
desenvolvmento da Xilinx.

69
4 RESULTADOS
Este capítulo dedica-se ao detalhamento de todos os resultados consegui-
dos na elaboração do projeto do raytracer h3dge. Na primeira seção exibe-se
as imagens geradas a partir da execução do algoritmo. Após isso, inicia-se o
detalhamento de como as árvores de indexação espacial melhoram a execu-
ção do algoritmo por meio da drástica redução dos testes de interseção entre
um raio e um triângulo. Enfim, são apresentados os resultados obtidos por
meio da sintetização da arquitetura proposta em hardware.
4.1 Imagens geradas
As imagens geradas pelo algoritmo de ray tracing do h3dge foram três:
• A primeira delas é o poliedro (figura 26), o qual contém oitenta faces.
• A segunda e terceira imagens são do célebre Stanford bunny, composto
por setenta mil triângulos. A seguir há duas imagens do coelho: a pri-
meira (figura 27) com a visão frontal e a segunda (figura 28) com a visão
traseira, respectivamente.

70
Figura 26 – O poliedro, uma das figuras geradas pelo algoritmo de ray tracing utilizado noh3dge. Nota-se os efeitos de transparência causados pela refração dos raios de luz.
Figura 27 – Stanford bunny, uma das figuras geradas pelo algoritmo de ray tracing utilizadono h3dge: visão frontal.

71
Figura 28 – Stanford bunny, uma das figuras geradas pelo algoritmo de ray tracing utilizadono h3dge: visão traseira.
4.2 Melhoria de desempenho causada pelo usode uma árvore k -d
Para verificar a influência da árvore k-d no desempenho do sistema, foi
executado um experimento em software. Tal experimento consistiu em variar
a altura máxima permitida à arvore (que pode ser diferente da altura real, visto
que a construção da árvore pode parar antes da atingir a altura máxima se o
custo de divisão dos nós aumentar demasiadamente) e verificar o tempo de
execução do algoritmo de ray tracing. Os resultados obtidos para o poliedro
(figura 26) são apresentados na tabela 2 e na figura 29.
A interpretação desses resultados mostra que a SAH, apesar de levar a ár-
vores k-d de qualidade, não garante o menor tempo de execução global. Isso
porque ela só visa a minimizar o tempo gasto percorrendo a árvore e o pa-
cote de triângulos, e não o tempo de construção da árvore; assim, vemos que
uma árvore k-d de altura máxima 5 tem performance superior à uma árvore
de altura máxima 16.
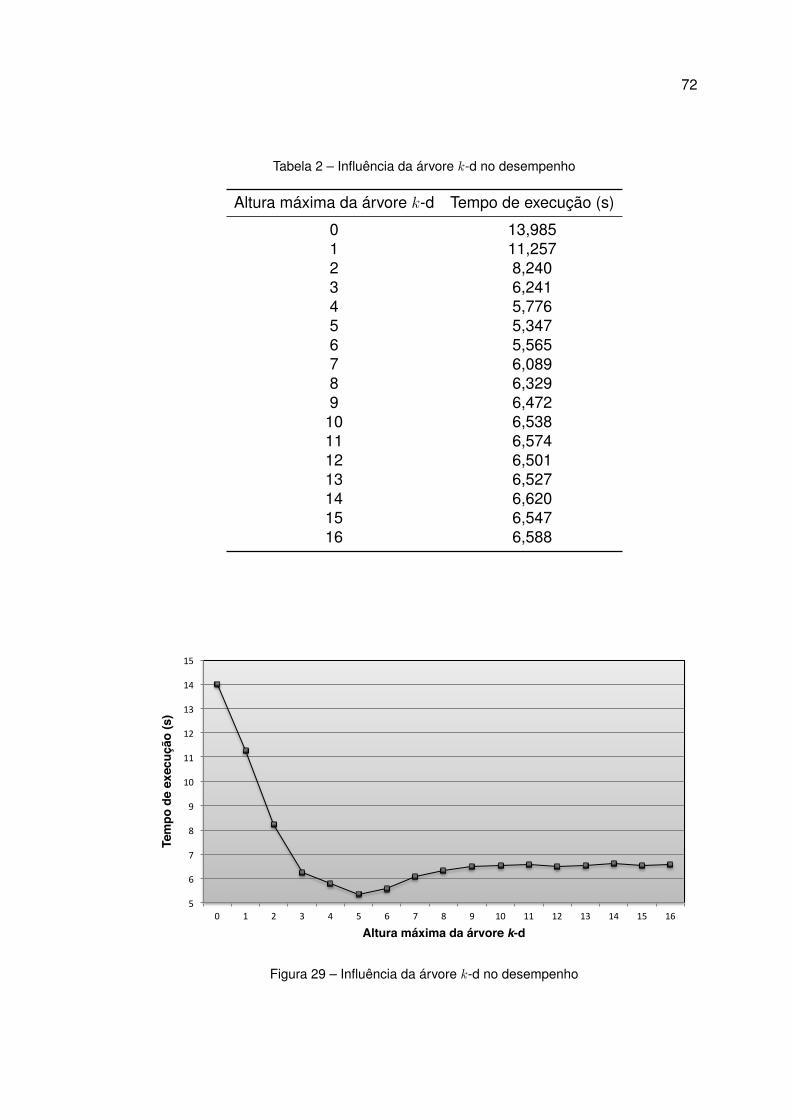
72
Tabela 2 – Influência da árvore k-d no desempenho
Altura máxima da árvore k-d Tempo de execução (s)
0 13,9851 11,2572 8,2403 6,2414 5,7765 5,3476 5,5657 6,0898 6,3299 6,472
10 6,53811 6,57412 6,50113 6,52714 6,62015 6,54716 6,588
5
6
7
8
9
10
11
12
13
14
15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Tem
po d
e ex
ecuç
ão (s
)!
Altura máxima da árvore k-d!
Figura 29 – Influência da árvore k-d no desempenho

73
Mesmo com essa limitação, vemos que o uso da árvore k-d permite a
obtenção de ganhos de performance significativos. Com uma árvore de altura
3 o ganho ultrapassa 55%, e no melhor caso temos um ganho de mais de
61%. Assim, a validade desse método para a aceleração do algoritmo de ray
tracing fica atestada.
4.3 Resultados do sistema sintetizado em hard-ware
Esta seção discute os resultados obtidos na sintetização da arquitetura
proposta na seção 3.2.4 em hardware. Primeiramente são apresentados os
dados referentes ao sistema-base; em seguida, são detalhados os resultados
da sintetização do coprocessador.
4.3.1 Sistema base
O sistema base é constituído pelo processador, controlador de memória,
controlador UART, controlador de vídeo, bus PLB e outros periféricos essen-
ciais e de debug. Após a síntese, a ocupação da FPGA reportada pela ferra-
menta Xilinx Platform Studio é a apresentada na tabela 3.
Tabela 3 – Ocupação da FPGA para o sistema-base
Elemento Utilização (absoluta) Utilização (%)
Número de slices 4545 de 11200 40Número de registradores nas slices 7243 de 44800 16
Número usado como Flip Flop 7243Número usado como Latch 0Número usado como LatchThru 0
Número de LUTs nas slices 8151 de 44800 18Número de pares LUT-Flip Flop nas slices 10916 de 44800 24
Observando os dados de ocupação, podemos notar que o sistema-base
corresponde a uma grande parcela da área total da FPGA, tomando 40% dos

74
slices disponíveis. Tal ocupação poderia ser diminuída por meio da exclusão
dos componentes adicionados para facilitar a depuração, tais como botões e
LEDs.
Do ponto de vista de performance, o sistema satisfaz a todas as condições
para operar a 100 MHz, velocidade atribuída ao bus PLB — com a exceção
do controlador de vídeo, que funciona a 25 MHz. Para testar a velocidade
do sistema “puro”, sem a aceleração em hardware, foi executada a síntese
dos modelos da seção 4.1 somente em software, utilizando o algoritmo em
C++ com cálculos em ponto flutuante (acelerados graças à presença de uma
FPU). Os resultados desse experimento são exibidos na tabela 4.
Tabela 4 – Desempenho do algoritmo de ray tracing em software no sistema base
Modelo Tempo de execução
Poliedro 9min20sStanford bunny > 60min
4.3.2 Coprocessador
Esta seção dedica-se a mostrar os dados da síntese dos módulos imple-
mentados no coprocessador. A princípio tentou-se sintetizar os módulos de in-
terseção raio-triângulo, reflexão e refração de maneira combinatória utilizando
o comando assign do SistemVerilog. Apesar do ganho de velocidade que
seria obtido com tal estratégia, ela revelou-se inadequada, pois a superfície
ocupada seria de 916% das LUTs da FPGA do kit de desenvolvimento. Dessa
forma, foi necessário modificar esta implementação inicial visando à redução
da área ocupada.
A princípio alterou-se o módulo de interseção de um raio com um triângulo,
já que esta é uma operação bem frequente no algoritmo de ray tracing. Para a
redução da área ocupada foi adotada uma arquitetura de unidade de controle

75
e fluxo de dados, documentada na seção 3.2.4.3. Após a síntese utilizando o
ISE Project Navigator, os dados exibidos na tabela 5 foram obtidos.
Tabela 5 – Ocupação da FPGA para o módulo de interseção
Elemento Utilização (absoluta) Utilização (%)
Número de slices 2049 de 11200 18Número de registradores nas slices 572 de 44800 1
Número usado como Flip Flop 326Número usado como Latch 192Número usado como LatchThru 54
Número de LUTs nas slices 7457 de 44800 16Número de pares LUT-Flip Flop nas slices 7592 de 44800 16
A partir destes dados foi possível executar a síntese do módulo de inter-
seção em hardware conforme descrito na seção 3.2.4.3. Após isso tentou-se
sintetizar o módulo de cálculo da normal, abrindo caminho para a posterior
síntese dos módulos de reflexão e refração, adotando-se a estratégia de pro-
jeto composto por uma unidade de controle e por um fluxo de dados. Apesar
dos esforços para a redução de superfície, a síntese no Synplify mostrou que
os módulos de interseção e cálculo de normal ocupariam juntos 108% da área
da FPGA, impossibilitando o processo de posicionamento e interligação de
células.
É importante ressaltar que a redução de superfície ainda é possível, pois
na arquitetura testada para o módulo da normal havia três módulos de divisão
(os quais ocupam muita superfície em hardware) operando em paralelo. Pode-
se reduzir este número para um módulo, contudo isto adicionaria mais dois
estados para a unidade de controle o que demandaria mais tempo para que
o cálculo da normal fosse efetuado. A proximidade da data de entrega deste
projeto impossibilitou que o módulo de cálculo da normal fosse implementado
de uma maneira apropriada, logo sua execução será deixada neste trabalho
como uma atividade em aberto.

76
5 CONCLUSÕES
Os capítulos anteriores dedicaram-se cada um a introduzir os assuntos
abordados neste trabalho, ou a descrever uma parte específica de sua reali-
zação. Esta seção, por sua vez, discute os resultados globais do projeto, bem
como suas contribuições acadêmicas e suas perspectivas futuras.
5.1 Objetivos alcançados
Este trabalho teve como objetivo propor, implementar e testar uma arquite-
tura em hardware para a execução do algoritmo de ray tracing. Tal arquitetura
deveria, a partir de informações fornecidas por meio de um arquivo de en-
trada, gerar a imagem sintetizada correspondente e exibi-la em um terminal
de vídeo.
Nesse escopo, pode-se dizer que o projeto foi concluído com sucesso. A
partir do estudo aprofundado do algoritmo de ray tracing, foi proposta uma
arquitetura para sua realização em hardware, que evoluiu conforme o avanço
do projeto para se adequar a novos requisitos, impostos tanto pela própria
natureza do projeto (tempo e recursos disponíveis) quanto pela complexidade
do problema em si. Finalmente, como resultado desse processo, a descrição
em SystemVerilog de módulos de um coprocessador que pudesse executar
o algoritmo e um protótipo atendendo aos requisitos funcionais puderam ser
finalizados.

77
Entretanto, alguns pontos do projeto permanecem como objetivos para
projetos futuros; em especial, a integração entre o coprocessador e o sistema
base para a realização efetiva da aceleração em hardware. Outras perspecti-
vas futuras serão apresentadas na seção 5.4.
5.2 Dificuldades encontradas
Apesar dos êxitos, as dificuldades encontradas no decorrer do projeto fo-
ram numerosas. Tais dificuldades tiveram grande impacto sobre o cronograma
do projeto, limitando, às vezes severamente, o avanço dos trabalhos. Dentre
os principais obstáculos que surgiram, destacam-se:
• A dificuldade na depuração: a depuração de um algoritmo de ray tra-
cing é uma tarefa árdua. Embora a observação dos resultados não seja
difícil — a apresentação gráfica da saída, característica comum a pro-
jetos da área da computação gráfica, facilita a verificação do correto
funcionamento do algoritmo —, encontrar a origem de um defeito não
é trivial, principalmente se considerado que o algoritmo em alto nível foi
descrito em C++/SystemC. Muitas vezes foi necessário executar o pro-
grama passo a passo com um debugger, repetidamente, acompanhando
as mudanças em grande parte das variáveis, somente para encontrar a
causa de um erro em um único pixel. E em alguns casos, a interação
entre as várias partes do programa era tão complexa que a única solu-
ção viável era reescrever completamente as funções afetadas — durante
meses, por exemplo, tentou-se lidar com um “buraco” que se formava na
frente do poliedro (figura 26) sem sucesso, até que se decidiu pela rees-
crita do algoritmo de construção e percurso da árvore k-d1;1A causa de tal “buraco” era a forma como o percurso da árvore k-d era implementado.
Inicialmente, o algoritmo percorria a árvore sempre a partir da raiz, o que pode acarretar a

78
• Problemas com as ferramentas: a manipulação do ambiente de desen-
volvimento mostrou-se outra fonte de atrasos no cronograma. Primeira-
mente, a ferramenta de síntese da Xilinx surpreendeu negativamente
ao não suportar a linguagem SystemVerilog, que contudo era extre-
mamente necessária, haja vista a complexidade das estruturas de da-
dos envolvidas. Dessa forma, foi necessário optar por um arranjo mal-
coordenado de três ferramentas (Active-HDL, Synplify e Xilinx ISE) para
obter um suporte a essa linguagem (ainda que incompleto, visto que vá-
rias funcionalidades importantes, como as arrays de duas dimensões,
não estavam implementadas). Em segundo lugar, a documentação in-
cipiente fornecida com o Xilinx XPS, bem como os bugs inesperados e
a política de não suportar arquivos de versões anteriores da ferramenta,
apresentaram-se como um obstáculo à realização do sistema base —
uma tarefa que em princípio não deveria apresentar grandes dificulda-
des.
• As mudanças excessivas na arquitetura: embora a metodologia ado-
tada previsse uma evolução gradual dos requisitos e do particionamento
hardware-software do sistema, a presença dos problemas acima men-
cionados afetou negativamente a organização do projeto, visto que al-
gumas vezes foi necessário tomar decisões baseadas mais no crono-
grama que em critérios técnicos. Um exemplo desse tipo de situação
foi a tradução do código em SystemC para C++ visando à execução no
processador embarcado. Embora importante para acelerar o desenvol-
vimento do protótipo, ela acabou introduzindo ainda mais dificuldades,
visto que, uma vez que não era possível compilar a biblioteca para o am-
biente PowerPC utilizado, foi necessário reescrever uma boa parte do
código para realizar as operações em ponto fixo.
perda de pacotes de triângulos por conta de imprecisões nos cálculos.

79
5.3 Contribuições
A grande contribuição deste trabalho está na proposição de uma arquite-
tura completa para a execução do algoritmo de ray tracing em FPGAs, assim
como na realização do protótipo correspondente.
Focando-se na realização de um ray tracer embarcado, o projeto h3dge
se insere em uma categoria alternativa aos atuais esforços para a realização
de ray tracing em tempo real — notadamente a execução do algoritmo para-
lelizado em clusters com grande capacidade de processamento. Entretanto,
seus fundamentos, notadamente a otimização por meio de árvores k-d e a
paralelização dos cálculos por meio de processadores dedicados, podem ser
aproveitados em sistema de qualquer escala.
5.4 Trabalhos futuros
Ao mesmo tempo em que contribui ao esforço de desenvolvimento de ray
tracers mais rápidos e eficientes, este trabalho fornece muitos pontos para
evolução futura, dentre os quais destacam-se:
• Melhorar a integração entre o coprocessador e o sistema base;
• Acelerar a construção da árvore k-d em hardware, por meio da utilização
de algoritmos mais eficientes e paralelizados;
• Aumentar o grau de realismo das imagens geradas pela incorporação
de mais efeitos ópticos ao algoritmo, tais como dispersão ou aberração
cromática;
• Melhorar a interface do sistema com o PC por meio da utilização de um
barramento mais eficiente, como o bus PCI express, que permitiria a

80
efetiva utilização da FPGA como uma “placa de vídeo”;
5.5 Considerações finais
De um modo geral, este projeto foi uma ocasião frutífera, possibilitando o
estudo de um problema complexo e a investigação de possíveis soluções. A
combinação de duas áreas completamente distintas — a saber, computação
gráfica e arquitetura de computadores — possibilitou uma oportunidade única
de aprendizado e de utilização de todos os conceitos apreendidos durante o
curso de Engenharia Elétrica com Ênfase em Computação na Escola Politéc-
nica da Universidade de São Paulo, desde álgebra linear e cálculo vetorial até
os métodos de gerenciamento de projetos. Assim, na opinião do grupo, este
trabalho pode ser chamado com justeza de “trabalho de formatura”, síntese e
apogeu de seis anos de dedicação ao estudo da engenharia.

81
REFERÊNCIAS
ALDEC. Active-HDL 9.1. 2011. Disponível em: <http://www.aldec.com/activehdl/>. Acesso em: 24 nov. 2011.
CHU, P. FPGA prototyping by VHDL examples: Xilinx Spartan-3 version. [S.l.]:Wiley-Interscience, 2008. ISBN 9780470185315.
CHU, P. P. RTL hardware design using VHDL: coding for efficiency, portability,and scalability. [S.l.]: Wiley-IEEE Press, 2006. ISBN 0471720925.
ERBAS, C. System-level modeling and design space exploration formultiprocessor embedded System-on-Chip architectures. Tese (Doutorado)— Informatics Institute, Univ. of Amsterdam, Nov. 2006.
FOLEY, T.; SUGERMAN, J. Kd-tree acceleration structures for a GPUraytracer. In: Proceedings of the ACM SIGGRAPH/EUROGRAPHICSconference on Graphics hardware. New York, NY, USA: ACM, 2005. (HWWS’05), p. 15–22.
GREVE, B. de. Reflections and refractions in ray tracing. 2007. Disponível em:<http://www.flipcode.com/archives/reflection_transmission.pdf>.Acesso em: 4 out. 2011.
GROTKER, T. System design with SystemC. Norwell, MA, USA: KluwerAcademic Publishers, 2002. ISBN 1402070721.
HANIKA, J. Fixed point hardware ray tracing. Tese (Doutorado) — UniversitatUlm, 2007.
HAVRAN, V. Heuristic ray shooting algorithms. Tese (Doutorado) — CzechTechnical University, 2000.
HOWARD, J. Real time ray-tracing: the end of rasterization? 2007. Disponívelem: <http://blogs.intel.com/research/2007/10/real_time_raytracing_the_end_o.php>. Acesso em: 12 dez. 2011.
MÖLLER, T.; TRUMBORE, B. Fast, minimum storage ray-triangle intersection.Journal of graphics tools, v. 2, n. 1, p. 21–28, 1997.
OYONALE. Oyonale - 3D art and graphic experiments. 2009. Disponível em:<http://www.oyonale.com/modeles.php?lang=en&page=40>. Acesso em:12 nov. 2011.

82
PIROMSOPA, K.; APORNTEWAN, C.; CHOGSATITVATAA, P. An FPGAimplementation of a fixed-point square root operation. In: Proceedings of theInternational Symposium on Communications and Information Technology.Thailand: [s.n.], 2001. v. 14–16, p. 587–589. ISSN 0730-0301.
PURCELL, T. J. et al. Ray tracing on programmable graphics hardware. ACMTrans. Graph., ACM, New York, NY, USA, v. 21, p. 703–712, July 2002. ISSN0730-0301. Disponível em: <http://doi.acm.org/10.1145/566654.566640>.
SHILANE, P. et al. The Princeton shape benchmark. In: Shape modelinginternational. [S.l.: s.n.], 2004.
SILICONARTS. Siliconarts launches RayCore R© IP Core. Julho 2011.Disponível em: <http://www.siliconarts.co.kr/recent-announcements/siliconartslaunchesraycoreipcore>. Acesso em: 4 ago. 2011.
STRATTON, J. State of ray tracing (in games). 2008. Disponível em:<http://www.cs.utah.edu/~jstratto/state_of_ray_tracing/>. Acessoem: 12 nov. 2011.
SYNOPSYS. Synplify Premier. 2011. Disponível em: <http://www.synopsys.com/Tools/Implementation/FPGAImplementation/FPGASynthesis/Pages/SynplifyPremier.aspx>. Acesso em: 24 nov. 2011.
SYSTEMVERILOG. System Verilog overview. 2011. Disponível em:<http://www.systemverilog.org/overview/overview.htm>. Acesso em:24 nov. 2011.
WHITTED, T. An improved illumination model for shaded display.Communications of the ACM, v. 23, n. 6, p. 343–349, 1980.
WOOP, S.; SCHMITTLER, J.; SLUSALLEK, P. RPU: a programmable rayprocessing unit for realtime ray tracing. ACM Trans. Graph., ACM, New York,NY, USA, v. 24, p. 434–444, July 2005. ISSN 0730-0301. Disponível em:<http://doi.acm.org/10.1145/1073204.1073211>.
XILINX. XPS Thin Film Transistor (TFT) Controller. setembro 2009. Disponívelem: <http://www.xilinx.com/support/documentation/ip_documentation/xps_tft.pdf>. Acesso em: 28 nov. 2011.
. Embedded Processor Block in Virtex-5 FPGAs. fevereiro 2010.Disponível em: <http://www.xilinx.com/support/documentation/user_guides/ug200.pdf>. Acesso em: 15 nov. 2011.
. LogiCORE IP Processor Local Bus (PLB) v4.6 (v1.05a). setembro2010. Disponível em: <http://www.xilinx.com/support/documentation/ip_documentation/plb_v46.pdf>. Acesso em: 28 nov. 2011.
. Virtex-5 FPGA Data Sheet: DC and Switching Characteristics. maio2010. Disponível em: <http://www.xilinx.com/support/documentation/data_sheets/ds202.pdf>. Acesso em: 28 nov. 2011.

83
. LogiCORE IP DDR2 Memory Controller for PowerPC 440 Processors.março 2011. Disponível em: <http://www.xilinx.com/support/documentation/ip_documentation/ppc440mc_ddr2.pdf>. Acesso em: 28nov. 2011.
. ML505/ML506/ML507 Evaluation Platform User Guide. maio 2011.Disponível em: <http://www.xilinx.com/support/documentation/boards_and_kits/ug347.pdf>. Acesso em: 15 nov. 2011.

84
APÊNDICE A -- ESTIMATIVAS PARA OCOPROCESSADOR
Tabela 6 – Dimensionamento da memória do coprocessador
Estrutura Elemento Total
Triângulo v1 96
v2 96
v3 96
materialId 32
medium1 32
medium2 32
Total (bits) 384
Total (bytes) 48
Raio point start 96
vector direction 96
Ray* next 32
Int depth 32
RayType type 32
KdTreeNode* currentNode 32
currentNRefraction 32
amplitude 32
Triangle* triangleHit 32

85
Tabela 6 – Dimensionamento da memória do coprocessador (continuação)
Estrutura Elemento Total
point intersection 96
Total (bits) 512
Total (bytes) 64
Material cor RGB 96
coeff reflection 32
coeff transmission 32
Total (bits) 160
Total (bytes) 20
Meio indiceRefracao 32
Total (bits) 32
Total (bytes) 4
Luz point posicao 96
point color 96
Total (bits) 192
Total (bytes) 24
Memória nó em processamento da árvore (bytes) 56
coprocessador vetor para 1024 triangulos (bytes) 49152
vetor para os materiais (bytes) 320
vetor para as luzes (bytes) 384
vetor para os meios (bytes) 64
variavel para cor do pixel - RGB (bytes) 12
máximo de reflexões 5
Total pilha de reflexões e refrações (bytes) 4032

86
Tabela 6 – Dimensionamento da memória do coprocessador (continuação)
Estrutura Elemento Total
Total (kbytes) 52,76

87
APÊNDICE B -- ESTIMATIVAS PARA AÁRVORE K-D
Tabela 7 – Dimensionamento da memória DDR2 necessária para a alocação de uma árvorek -d de 70000 triângulos
Estrutura Elemento Eixo Total
Triângulo v1 32 96
v2 32 96
v3 32 96
materialId 32
medium1 32
medium2 32
Total (bits) 384
Total (bytes) 48
Total triângulos (MB) 3,20
Nó da árvore left* 32
right* 32
parent* 32
next1* 32
trig* 32
nbTriangles 32
minbounds 32 96

88
Tabela 7 – Dimensionamento da memória DDR2 necessária para a alocação de uma árvorek -d de 70000 triângulos (continuação)
Estrutura Elemento Eixo Total
maxbounds 32 96
splitAxis 32
depth 32
Total (bits) 448
Total (bytes) 56
Total nós da árvore (MB) - profund. 16 7,00
Ref. triângulo triangle* 32
next* 32
Total (bits) 64
Total (bytes) 8
Total referências (MB) 2,14
Total árvore k-d (MB) 12,341


















