
lista prática II
32
Departamento de Economia ECO1800 – TPE (2010.1) Professor: Marco Cavalcanti Alunos: Pedro Abinader e Rafael Mattos Séries Temporais: Importações de Elementos Químicos Lista de Exercícios Práticos II Entrega: 24/06/2010 1.1) a) Claramente vemos que existe um efeito sazonal. Normalmente, ao final de cada ano, temos o menor valor da variável. Para isso rodamos uma regressão de ld_Q em ld_P com as quatro dummies sazonais, sem a constante, evitando o problema de colinearidade exata, o que omitiria a quarta dummy sazonal. Modelo 2: Mínimos Quadrados (OLS), usando as observações 1997:2-2008:4 (T = 47) Variável dependente: ld_Q Coeficiente Erro P adrão razão-t p-valor
Transcript of lista prática II

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 1/32
Departamento de EconomiaECO1800 – TPE (2010.1)Professor: Marco Cavalcanti
Alunos: Pedro Abinader e Rafael MattosSéries Temporais: Importações de Elementos Químicos
Lista de Exercícios Práticos II
Entrega: 24/06/2010
1.1)
a)
Claramente vemos que existe um efeito sazonal. Normalmente, ao final de cada ano,temos o menor valor da variável. Para isso rodamos uma regressão de ld_Q em ld_Pcom as quatro dummies sazonais, sem a constante, evitando o problema decolinearidade exata, o que omitiria a quarta dummy sazonal.
Modelo 2: Mínimos Quadrados (OLS), usando as observações 1997:2-2008:4 (T = 47)Variável dependente: ld_Q
Coeficiente Erro Padrão razão-t p-valor
8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 2/32
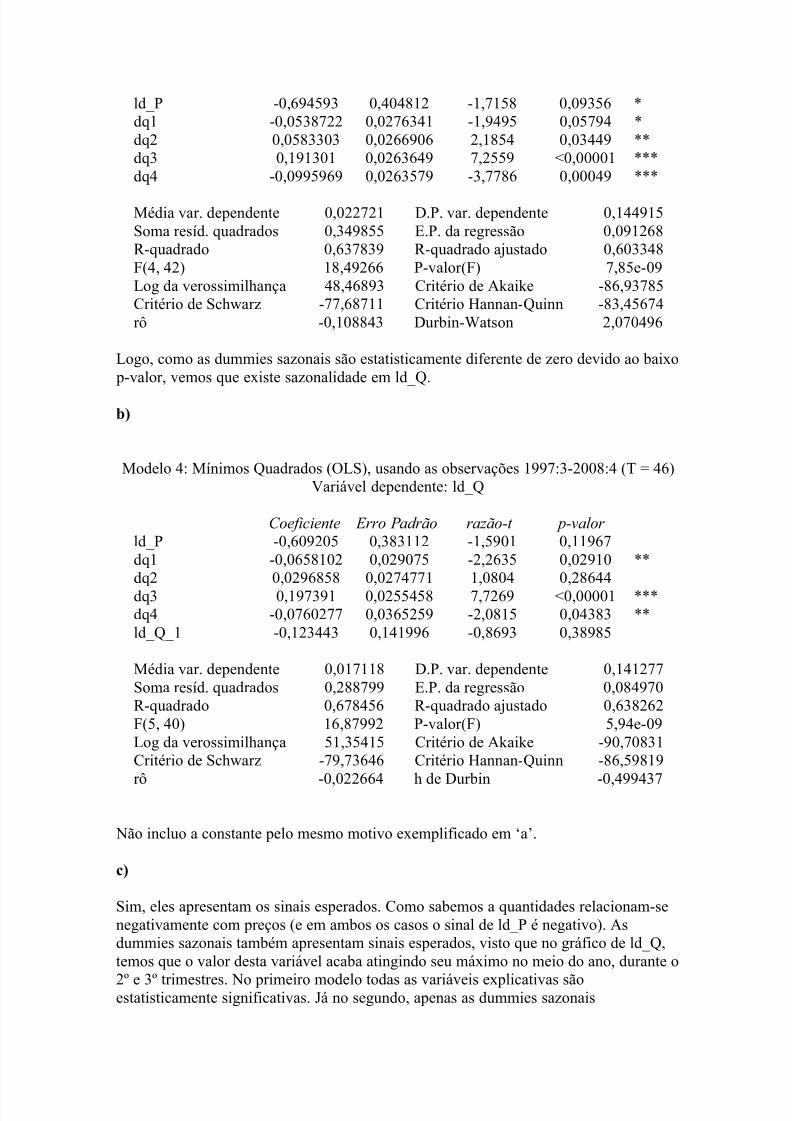
ld_P -0,694593 0,404812 -1,7158 0,09356 *dq1 -0,0538722 0,0276341 -1,9495 0,05794 *dq2 0,0583303 0,0266906 2,1854 0,03449 **dq3 0,191301 0,0263649 7,2559 <0,00001 ***dq4 -0,0995969 0,0263579 -3,7786 0,00049 ***
Média var. dependente 0,022721 D.P. var. dependente 0,144915Soma resíd. quadrados 0,349855 E.P. da regressão 0,091268R-quadrado 0,637839 R-quadrado ajustado 0,603348F(4, 42) 18,49266 P-valor(F) 7,85e-09Log da verossimilhança 48,46893 Critério de Akaike -86,93785Critério de Schwarz -77,68711 Critério Hannan-Quinn -83,45674rô -0,108843 Durbin-Watson 2,070496
Logo, como as dummies sazonais são estatisticamente diferente de zero devido ao baixo p-valor, vemos que existe sazonalidade em ld_Q.
b)
Modelo 4: Mínimos Quadrados (OLS), usando as observações 1997:3-2008:4 (T = 46)Variável dependente: ld_Q
Coeficiente Erro Padrão razão-t p-valor ld_P -0,609205 0,383112 -1,5901 0,11967dq1 -0,0658102 0,029075 -2,2635 0,02910 **dq2 0,0296858 0,0274771 1,0804 0,28644dq3 0,197391 0,0255458 7,7269 <0,00001 ***dq4 -0,0760277 0,0365259 -2,0815 0,04383 **ld_Q_1 -0,123443 0,141996 -0,8693 0,38985
Média var. dependente 0,017118 D.P. var. dependente 0,141277Soma resíd. quadrados 0,288799 E.P. da regressão 0,084970R-quadrado 0,678456 R-quadrado ajustado 0,638262F(5, 40) 16,87992 P-valor(F) 5,94e-09Log da verossimilhança 51,35415 Critério de Akaike -90,70831Critério de Schwarz -79,73646 Critério Hannan-Quinn -86,59819
rô -0,022664 h de Durbin -0,499437
Não incluo a constante pelo mesmo motivo exemplificado em ‘a’.
c)
Sim, eles apresentam os sinais esperados. Como sabemos a quantidades relacionam-senegativamente com preços (e em ambos os casos o sinal de ld_P é negativo). Asdummies sazonais também apresentam sinais esperados, visto que no gráfico de ld_Q,temos que o valor desta variável acaba atingindo seu máximo no meio do ano, durante o
2º e 3º trimestres. No primeiro modelo todas as variáveis explicativas sãoestatisticamente significativas. Já no segundo, apenas as dummies sazonais

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 3/32
correspondentes aos 1º, 3º e 4º trimestres são significativas. Em ambas situações esperoque o estimador seja viesado, pelo fato do mesmo não atender a condição deexogeneidade estrita.
Temos que a exogeneidade contemporânea pode ser claramente violado. Por exemplo,
nessa equação não temos uma variável explicativa que traduza um possível efeito deuma tarifa de importação para produtos químicos. Logo, essa variável seria relevante eomitida para os modelos, tendo efeito direto sobre as quantidades importadas enaturalmente se correlacionando com o preço (quanto mais alta a tarifa maior o preço).Assim,, como exogeneidade contemporânea e estrita são violadas, creio que o estimador é viesado e não é consistente.
d)
Pelos motivos evidenciados acima, temos que essa estatística não é válida para asequações sob análise. Mas, caso os regressores fossem estritamente exógenos, no
primeiro caso, como o valor é bem próximo de 2, temos que não haveria auto-correlação do erro. Já no segundo caso, como o valor da estatística é negativa(consequentemente < 2), temos que há uma auto-correlção positiva dos erros.
e)
Teste de Breush-Godfrey para autocorrelação de primeira-ordemMínimos Quadrados (OLS), usando as observações 1997:2-2008:4 (T = 47)Variável dependente: uhat
coeficiente erro padrão razão-t p-valor-----------------------------------------------------------ld_P 0,0679154 0,417955 0,1625 0,8717dq1 -0,000199936 0,0277955 -0,007193 0,9943dq2 -0,000716312 0,0268636 -0,02666 0,9789dq3 -0,000163715 0,0265186 -0,006174 0,9951dq4 0,000128198 0,0265112 0,004836 0,9962uhat_1 -0,114707 0,159428 -0,7195 0,4759
R-quadrado não-ajustado = 0,012469
Estatística de teste: LMF = 0,517671,com p-valor = P(F(1,41) > 0,517671) = 0,476
Estatística alternativa: TR^2 = 0,586028,com p-valor = P(Qui-quadrado(1) > 0,586028) = 0,444
Ljung-Box Q' = 0,591556,com p-valor = P(Qui-quadrado(1) > 0,591556) = 0,442
Teste de Breush-Godfrey para autocorrelação de primeira-ordemMínimos Quadrados (OLS), usando as observações 1997:3-2008:4 (T = 46)Variável dependente: uhat
coeficiente erro padrão razão-t p-valor---------------------------------------------------------ld_P 0,0356650 0,404114 0,08825 0,9301dq1 0,00760898 0,0382505 0,1989 0,8434dq2 0,00441714 0,0312095 0,1415 0,8882dq3 -0,00430150 0,0293061 -0,1468 0,8841
dq4 -0,0156054 0,0622994 -0,2505 0,8035ld_Q_1 0,0826503 0,302012 0,2737 0,7858uhat_1 -0,109368 0,351556 -0,3111 0,7574

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 4/32
R-quadrado não-ajustado = 0,002475
Estatística de teste: LMF = 0,096782,com p-valor = P(F(1,39) > 0,0967818) = 0,757
Estatística alternativa: TR^2 = 0,113870,
com p-valor = P(Qui-quadrado(1) > 0,11387) = 0,736
Ljung-Box Q' = 0,0251367,com p-valor = P(Qui-quadrado(1) > 0,0251367) = 0,874
Como ambos os p-valores são altos, podemos aceitar a hipótese nula de que não háauto-correlação sobre os erros.
f)
Teste de Breush-Godfrey para autocorrelação até a ordem 4Mínimos Quadrados (OLS), usando as observações 1997:2-2008:4 (T = 47)Variável dependente: uhat
coeficiente erro padrão razão-t p-valor-----------------------------------------------------------ld_P 0,117282 0,453894 0,2584 0,7975dq1 -0,000335549 0,0274289 -0,01223 0,9903dq2 -0,000394659 0,0265682 -0,01485 0,9882dq3 0,000878629 0,0261050 0,03366 0,9733dq4 -0,000207332 0,0260853 -0,007948 0,9937uhat_1 -0,148849 0,166907 -0,8918 0,3781uhat_2 -0,149073 0,166672 -0,8944 0,3767uhat_3 0,117373 0,169656 0,6918 0,4932uhat_4 0,239665 0,159825 1,500 0,1420
R-quadrado não-ajustado = 0,114180
Estatística de teste: LMF = 1,224526,com p-valor = P(F(4,38) > 1,22453) = 0,317
Estatística alternativa: TR^2 = 5,366460,com p-valor = P(Qui-quadrado(4) > 5,36646) = 0,252
Ljung-Box Q' = 6,08007,com p-valor = P(Qui-quadrado(4) > 6,08007) = 0,193
Teste de Breush-Godfrey para autocorrelação até a ordem 4Mínimos Quadrados (OLS), usando as observações 1997:3-2008:4 (T = 46)Variável dependente: uhat
coeficiente erro padrão razão-t p-valor--------------------------------------------------------ld_P 0,0688343 0,449633 0,1531 0,8792dq1 0,00840194 0,0400862 0,2096 0,8352dq2 0,00506116 0,0321565 0,1574 0,8758dq3 -0,00328332 0,0295472 -0,1111 0,9121dq4 -0,0155550 0,0655125 -0,2374 0,8137ld_Q_1 0,0805598 0,320015 0,2517 0,8027uhat_1 -0,131510 0,362896 -0,3624 0,7192uhat_2 -0,0866781 0,185249 -0,4679 0,6427uhat_3 0,136264 0,172395 0,7904 0,4345uhat_4 0,249673 0,165856 1,505 0,1410
R-quadrado não-ajustado = 0,093026
Estatística de teste: LMF = 0,923103,com p-valor = P(F(4,36) > 0,923103) = 0,461

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 5/32
Estatística alternativa: TR^2 = 4,279181,com p-valor = P(Qui-quadrado(4) > 4,27918) = 0,37
Ljung-Box Q' = 4,87724,com p-valor = P(Qui-quadrado(4) > 4,87724) = 0,3
Novamente, como ambos os p-valores são altos, podemos aceitar a hipótese nula de quenão há auto-correlação sobre os erros.
g)
Caso os estimadores tenham correlação serial dos erros, temos que os estimadores nãosão BLUE, ou seja, eficientes. Como nos testes realizados anteriores temos p-valoresaltos, podemos concluir que a hipótese nula é aceita por esses testes, e que não há auto-correlação entre os erros.Porém tais testes só valem se a hipótese de exogeneidade estrita valer, logo, pelos
motivos explicados nos itens anteriores, esses testes não são válidos.
1.2)
a)
Model 1: OLS, using observations 1998:1-2008:4 (T = 44)Dependent variable: ld_Q
Coefficient Std. Error t-ratio p-valueconst -0.0704812 0.0427036 -1.6505 0.10833ld_P -0.55724 0.459121 -1.2137 0.23347ld_P_1 -0.0772672 0.424282 -0.1821 0.85661ld_P_2 0.757991 0.416449 1.8201 0.07782 *ld_P_3 -0.488874 0.505434 -0.9672 0.34046dq1 0.0285017 0.0634929 0.4489 0.65644dq2 0.0893542 0.0658163 1.3576 0.18379dq3 0.256527 0.0540379 4.7472 0.00004 ***ld_Q_1 -0.0852824 0.184727 -0.4617 0.64735
ld_Q_2 -0.127359 0.179506 -0.7095 0.48300ld_Q_3 0.0401537 0.169405 0.2370 0.81410
Mean dependent var 0.019021 S.D. dependent var 0.139043Sum squared resid 0.227065 S.E. of regression 0.082950R-squared 0.726860 Adjusted R-squared 0.644090F(10, 33) 8.781713 P-value(F) 8.24e-07Log-likelihood 53.43426 Akaike criterion -84.86853Schwarz criterion -65.24244 Hannan-Quinn -77.59023rho 0.023020 Durbin-Watson 1.906095

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 6/32

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 7/32
with p-value = P(Chi-square(4) > 1.52296) = 0.823
Ljung-Box Q' = 0.359864,with p-value = P(Chi-square(4) > 0.359864) = 0.986
Como ambos os p-valores são altos, podemos aceitar a hipótese nula de que não háauto-correlação sobre os erros.
2)
a)nulldata 101setobs 1 1 --time-seriessmpl 1 1series y=0
series x=0series u=0series v=0smpl 2 101scalar rej = 0scalar somacoef = 0loop 1000 --quietgenr u=normal()genr v=normal()genr y=y(-1)+ugenr x=x(-1)+vols y const x --quietgenr somacoef=somacoef+$coeff(x)genr est_t=abs($coeff(x)/$stderr(x))genr p_valor=pvalue(t,98,est_t)if p_valor < 0.025genr rej = rej+1endif endloopgenr rej_pct = rej/1000genr mediacoef=somacoef/1000
b)
gretl versão 1.8.4Sessão atual: 2010-06-22 10:21? nulldata 101
periodicidade: 1, máxobs: 101,intervalo das observações: 1-101? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 101 (n = 101)
? smpl 1 1Intervalo completo dos dados: 1 - 101 (n = 101)

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 8/32
Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0
Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 101Intervalo completo dos dados: 1 - 101 (n = 101)Amostra atual: 2 - 101 (n = 100)
? scalar rej = 0Gerou-se o escalar rej = 0
? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=y(-1)+u> genr x=x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,98,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,761? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = 0,0266714
c)
A proporção de casos que H0 foi rejeitada foi de 0.761 (ou 76.1%). Essa proporção éclaramente alta. Isso significa que em mais de três quartos das 1000 observações, ahipótese nula foi rejeitada, fazendo com que B0 seja estatisticamente diferente de 0 em76.1% dos casos.
d)
Sim, o valor (0,0266714) parece bem próximo de zero. Creio não fazer sentido porquese em quase 80% dos casos B0 foi significativamente diferente de zero ao nível designificância de 5%, creio que a média dos coeficientes deveria ser um pouco mais
afastada de zero.

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 9/32
e)
gretl versão 1.8.4Sessão atual: 2010-06-22 10:27? nulldata 201
periodicidade: 1, máxobs: 201,intervalo das observações: 1-201? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 201 (n = 201)
? smpl 1 1Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)
? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 201Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 2 - 201 (n = 200)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=y(-1)+u> genr x=x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)
> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,198,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,854? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,00167077
Comparando, temos uma proporção de rejeição quase que 10% maior e a média decoeficientes é ainda mais próxima de zero.

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 10/32
f)
gretl versão 1.8.4Sessão atual: 2010-06-22 10:29
? nulldata 501 periodicidade: 1, máxobs: 501,intervalo das observações: 1-501? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 501 (n = 501)
? smpl 1 1Intervalo completo dos dados: 1 - 501 (n = 501)Amostra atual: 1 - 1 (n = 1)
? series y=0
Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 501Intervalo completo dos dados: 1 - 501 (n = 501)Amostra atual: 2 - 501 (n = 500)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=y(-1)+u> genr x=x(-1)+v> ols y const x --quiet
> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,498,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,903? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = 0,000468254
gretl versão 1.8.4

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 11/32
Sessão atual: 2010-06-22 10:30? nulldata 1001
periodicidade: 1, máxobs: 1001,intervalo das observações: 1-1001? setobs 1 1 --time-series
Intervalo completo dos dados: 1 - 1001 (n = 1001)
? smpl 1 1Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0
Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 1001Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 2 - 1001 (n = 1000)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=y(-1)+u> genr x=x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,998,est_t)> if p_valor < 0.025
> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,91? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,00873848
A medida em que o número de amostras aumenta, vemos claramente uma maior rejeição da hipótese nula e cada vez um valor para o beta mais próximo de zero.Isso claramente demonstra um agravamento do problema da regressão espúria quando
aumentamos o número da amostra. Creio que esse fenômeno vem a ocorrer porquequando temos amostras menores, esse erro não é cometido tantas vezes pelo menor

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 12/32
número de observações. Porém, quanto maior for a amostra, maior a chance de haver uma maior quantidade de rejeições errôneas, e o coeficiente ficará cada vez mais pertode 0, visto que na verdade, deveríamos estar validando cada vez mais a hipótese nula amedida em que o número de amostras aumenta (isso de a regressão não fosse espúria).
g)
gretl versão 1.8.4Sessão atual: 2010-06-22 10:40? nulldata 101
periodicidade: 1, máxobs: 101,intervalo das observações: 1-101? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 101 (n = 101)
? smpl 1 1Intervalo completo dos dados: 1 - 101 (n = 101)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 101Intervalo completo dos dados: 1 - 101 (n = 101)Amostra atual: 2 - 101 (n = 100)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet
> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,98,est_t)> if p_valor < 0.025> genr rej = rej+1> endif
> endloop? genr rej_pct = rej/1000

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 13/32
Gerou-se o escalar rej_pct = 0,138? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,00338993
gretl versão 1.8.4
Sessão atual: 2010-06-22 10:40? nulldata 201
periodicidade: 1, máxobs: 201,intervalo das observações: 1-201? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 201 (n = 201)
? smpl 1 1Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 201Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 2 - 201 (n = 200)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v
> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,198,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,117? genr mediacoef=somacoef/1000
Gerou-se o escalar mediacoef = -0,0032129

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 14/32
gretl versão 1.8.4Sessão atual: 2010-06-22 10:41? nulldata 501
periodicidade: 1, máxobs: 501,intervalo das observações: 1-501
? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 501 (n = 501)
? smpl 1 1Intervalo completo dos dados: 1 - 501 (n = 501)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)
? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 501Intervalo completo dos dados: 1 - 501 (n = 501)Amostra atual: 2 - 501 (n = 500)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,498,est_t)
> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,142? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,0004707231
gretl versão 1.8.4Sessão atual: 2010-06-22 10:42
? nulldata 1001 periodicidade: 1, máxobs: 1001,

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 15/32
intervalo das observações: 1-1001? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 1001 (n = 1001)
? smpl 1 1
Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)
? smpl 2 1001Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 2 - 1001 (n = 1000)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,998,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop
? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,114? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,00248415
Temos agora índices de rejeição muito mais baixos que os anteriores. Agora o índice derejeição nesse processo estacionário fica em torno de 10 - 15%. A proporção de casosem que H0 é rejeitada ainda é elevada (pelo menos ao nível de significância de 5%) mas
já demonstra grande melhora quando comparamos com os resultados obtidos nos itensanteriores. Erros auto-correlacionados, tanto em processos estacionários ou não, acabam
por gerar uma estimação de MQO não eficiente.

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 16/32
h)
gretl versão 1.8.4Sessão atual: 2010-06-22 10:49
? nulldata 101 periodicidade: 1, máxobs: 101,intervalo das observações: 1-101? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 101 (n = 101)
? smpl 1 1Intervalo completo dos dados: 1 - 101 (n = 101)Amostra atual: 1 - 1 (n = 1)
? series y=0
Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 101Intervalo completo dos dados: 1 - 101 (n = 101)Amostra atual: 2 - 101 (n = 100)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet --robust
> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,98,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,1? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = 0,00387423
gretl versão 1.8.4

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 17/32
Sessão atual: 2010-06-22 10:50? nulldata 201
periodicidade: 1, máxobs: 201,intervalo das observações: 1-201? setobs 1 1 --time-series
Intervalo completo dos dados: 1 - 201 (n = 201)
? smpl 1 1Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0
Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 201Intervalo completo dos dados: 1 - 201 (n = 201)Amostra atual: 2 - 201 (n = 200)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet --robust> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,198,est_t)> if p_valor < 0.025
> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,089? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = 0,00212529
gretl versão 1.8.4Sessão atual: 2010-06-22 10:51? nulldata 501
periodicidade: 1, máxobs: 501,intervalo das observações: 1-501

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 18/32
? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 501 (n = 501)
? smpl 1 1Intervalo completo dos dados: 1 - 501 (n = 501)
Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 501
Intervalo completo dos dados: 1 - 501 (n = 501)Amostra atual: 2 - 501 (n = 500)
? scalar rej = 0Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet --robust> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,498,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000
Gerou-se o escalar rej_pct = 0,064? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = -0,000626232
gretl versão 1.8.4Sessão atual: 2010-06-22 10:51? nulldata 1001
periodicidade: 1, máxobs: 1001,intervalo das observações: 1-1001? setobs 1 1 --time-seriesIntervalo completo dos dados: 1 - 1001 (n = 1001)
? smpl 1 1

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 19/32
Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 1 - 1 (n = 1)
? series y=0Gerou-se a série temporal y (ID 2)
? series x=0Gerou-se a série temporal x (ID 3)? series u=0Gerou-se a série temporal u (ID 4)? series v=0Gerou-se a série temporal v (ID 5)? smpl 2 1001Intervalo completo dos dados: 1 - 1001 (n = 1001)Amostra atual: 2 - 1001 (n = 1000)
? scalar rej = 0
Gerou-se o escalar rej = 0? scalar somacoef = 0Gerou-se o escalar somacoef = 0? loop 1000 --quiet> genr u=normal()> genr v=normal()> genr y=0.5*y(-1)+u> genr x=0.5*x(-1)+v> ols y const x --quiet --robust> genr somacoef=somacoef+$coeff(x)> genr est_t=abs($coeff(x)/$stderr(x))> genr p_valor=pvalue(t,998,est_t)> if p_valor < 0.025> genr rej = rej+1> endif > endloop? genr rej_pct = rej/1000Gerou-se o escalar rej_pct = 0,056? genr mediacoef=somacoef/1000Gerou-se o escalar mediacoef = 0,00113056
Ela ainda é um pouco elevada para amostras pequenas. No entanto, a mediada em queessas amostras vão aumentando, vemos que os níveis rejeições de H0 acabam por suavez chegando perto de 5%. Isso pode ser evidenciado nos resultados acima, onde na
primeira situação onde há 100 observações, temos um índice de rejeição de H0 em 10%,enquanto na última situação, onde temos uma amostra de tamanho 1000, vemos que oíndice de rejeição cai para 5,6% (bem mais condizente com o nível de significância de5%).
i)
As lições que extraio desse exercício é que sempre precisamos tomar cuidado ao fazer
as regressões e realizar testes de hipótese. Como vimos nos primeiros exemplos, quandotemos um passeio aleatório, tais testes de hipótese são, em grande maioria dos casos,

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 20/32
rejeitados erroneamente. Se não tomarmos cuidado, podemos achar que tais rejeiçõesestão corretas, errando totalmente qualquer resultado que pretendíamos obter atravésdas regressões. Ao realizarmos tais testes em processos estacionários ou/e com errosrobustos, temos resultados muito mais confiáveis, que fazem algum sentidoeconométrico. Assim, devemos tomar cuidado com as regressões espúrias, corrigindo o
problema que elas nos traz através de “ferramentas” vistas nesse exercício.
3.1)
a) No Gretl
b) No Gretl
c)
Teste Aumentado de Dickey-Fuller, para l_Qd
incluindo 4 desfasagens de (1-L)l_Qddimensão de amostragem 43hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,051diferenças defasadas: F(4, 36) = 2,402 [0,0678]valor estimado de (a - 1): -0,395566estatística de teste: tau_ct(1) = -2,62932p-valor assintótico 0,267
Regressão aumentada de Dickey-Fuller Mínimos Quadrados (OLS), usando as observações 1998:2-2008:4 (T = 43)Variável dependente: d_l_Qd
coeficiente erro padrão razão-t p-valor ---------------------------------------------------------const -0,204456 0,0763274 -2,679 0,0111 **l_Qd_1 -0,395566 0,150444 -2,629 0,2670d_l_Qd_1 -0,0171440 0,197572 -0,08677 0,9313
d_l_Qd_2 -0,00509246 0,194521 -0,02618 0,9793d_l_Qd_3 0,0986937 0,179074 0,5511 0,5849d_l_Qd_4 0,391689 0,154161 2,541 0,0155 **time 0,00802509 0,00264628 3,033 0,0045 ***
Teste Aumentado de Dickey-Fuller, para l_QTdincluindo 5 desfasagens de (1-L)l_QTddimensão de amostragem 42hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + e
coeficiente de 1ª ordem para e: -0,054diferenças defasadas: F(5, 34) = 1,975 [0,1076]valor estimado de (a - 1): -0,977791

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 21/32
estatística de teste: tau_ct(1) = -4,11548p-valor assintótico 0,005909
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1998:3-2008:4 (T = 42)Variável dependente: d_l_QTd
coeficiente erro padrão razão-t p-valor---------------------------------------------------------const -0,464583 0,119045 -3,903 0,0004 ***l_QTd_1 -0,977791 0,237588 -4,115 0,0059 ***d_l_QTd_1 0,452810 0,218392 2,073 0,0458 **d_l_QTd_2 0,527920 0,227901 2,316 0,0267 **d_l_QTd_3 0,327218 0,214523 1,525 0,1364d_l_QTd_4 0,548984 0,195964 2,801 0,0083 ***d_l_QTd_5 0,304683 0,177236 1,719 0,0947 *time 0,0170486 0,00413729 4,121 0,0002 ***
Teste Aumentado de Dickey-Fuller, para l_Pincluindo 2 desfasagens de (1-L)l_P
dimensão de amostragem 45hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,006diferenças defasadas: F(2, 40) = 3,359 [0,0448]valor estimado de (a - 1): 0,0782857estatística de teste: tau_ct(1) = 1,59235p-valor assintótico 1
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1997:4-2008:4 (T = 45)Variável dependente: d_l_P
coeficiente erro padrão razão-t p-valor---------------------------------------------------------const -0,401653 0,227393 -1,766 0,0850 *l_P_1 0,0782857 0,0491635 1,592 1,0000d_l_P_1 -0,201096 0,158414 -1,269 0,2116d_l_P_2 -0,391760 0,158681 -2,469 0,0179 **time 0,00189435 0,000419956 4,511 5,54e-05 ***
Teste Aumentado de Dickey-Fuller, para l_PTincluindo 6 desfasagens de (1-L)l_PTdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,044diferenças defasadas: F(6, 32) = 3,790 [0,0058]valor estimado de (a - 1): 0,049093estatística de teste: tau_ct(1) = 1,10539p-valor assintótico 0,9999
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1998:4-2008:4 (T = 41)Variável dependente: d_l_PT
coeficiente erro padrão razão-t p-valor--------------------------------------------------------
const -0,257411 0,200833 -1,282 0,2092l_PT_1 0,0490930 0,0444125 1,105 0,9999d_l_PT_1 0,258783 0,188510 1,373 0,1794

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 22/32
d_l_PT_2 -0,225888 0,197847 -1,142 0,2620d_l_PT_3 -0,205263 0,209419 -0,9802 0,3344d_l_PT_4 0,584877 0,211572 2,764 0,0094 ***d_l_PT_5 -0,0270013 0,232269 -0,1163 0,9082d_l_PT_6 -0,625475 0,231659 -2,700 0,0110 **time 0,00177134 0,000609873 2,904 0,0066 ***
d)
Teste Aumentado de Dickey-Fuller, para d_l_Qdincluindo 6 desfasagens de (1-L)d_l_Qddimensão de amostragem 40hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,093diferenças defasadas: F(6, 31) = 2,469 [0,0455]valor estimado de (a - 1): -2,52964estatística de teste: tau_ct(1) = -3,75396p-valor assintótico 0,01895
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1999:1-2008:4 (T = 40)Variável dependente: d_d_l_Qd
coeficiente erro padrão razão-t p-valor----------------------------------------------------------const -0,00902421 0,0365178 -0,2471 0,8064d_l_Qd_1 -2,52964 0,673858 -3,754 0,0190 **d_d_l_Qd_1 1,07600 0,608697 1,768 0,0870 *d_d_l_Qd_2 0,800318 0,547501 1,462 0,1539d_d_l_Qd_3 0,743751 0,482831 1,540 0,1336d_d_l_Qd_4 0,899062 0,392244 2,292 0,0288 **d_d_l_Qd_5 0,696866 0,284315 2,451 0,0201 **
d_d_l_Qd_6 0,377673 0,169712 2,225 0,0335 **time 0,00203566 0,00138157 1,473 0,1507
Teste Aumentado de Dickey-Fuller, para d_l_QTdincluindo 6 desfasagens de (1-L)d_l_QTddimensão de amostragem 40hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,084diferenças defasadas: F(6, 31) = 1,101 [0,3843]valor estimado de (a - 1): -2,39784estatística de teste: tau_ct(1) = -3,37186
p-valor assintótico 0,05518
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1999:1-2008:4 (T = 40)Variável dependente: d_d_l_QTd
coeficiente erro padrão razão-t p-valor------------------------------------------------------------const 0,0323460 0,0341150 0,9481 0,3504d_l_QTd_1 -2,39784 0,711134 -3,372 0,0552 *d_d_l_QTd_1 1,07481 0,629182 1,708 0,0976 *d_d_l_QTd_2 0,913246 0,556931 1,640 0,1112d_d_l_QTd_3 0,700881 0,500513 1,400 0,1713d_d_l_QTd_4 0,736145 0,411405 1,789 0,0833 *d_d_l_QTd_5 0,633034 0,326440 1,939 0,0616 *
d_d_l_QTd_6 0,338278 0,201688 1,677 0,1036time 0,000397310 0,00118653 0,3348 0,7400

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 23/32
Teste Aumentado de Dickey-Fuller, para d_l_Pincluindo uma desfasagem de (1-L)d_l_Pdimensão de amostragem 45hipótese nula de raiz unitária: a = 1
com constante e tendência
modelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: 0,015valor estimado de (a - 1): -1,40148estatística de teste: tau_ct(1) = -6,41988p-valor assintótico 9,995e-008
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1997:4-2008:4 (T = 45)Variável dependente: d_d_l_P
coeficiente erro padrão razão-t p-valor----------------------------------------------------------const -0,0400009 0,0113879 -3,513 0,0011 ***d_l_P_1 -1,40148 0,218304 -6,420 9,99e-08 ***
d_d_l_P_1 0,293060 0,148784 1,970 0,0557 *time 0,00175529 0,000418397 4,195 0,0001 ***
Teste Aumentado de Dickey-Fuller, para d_l_PTincluindo 5 desfasagens de (1-L)d_l_PTdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,023diferenças defasadas: F(5, 33) = 3,932 [0,0066]valor estimado de (a - 1): -0,877714estatística de teste: tau_ct(1) = -2,60475p-valor assintótico 0,2782
Regressão aumentada de Dickey-FullerMínimos Quadrados (OLS), usando as observações 1998:4-2008:4 (T = 41)Variável dependente: d_d_l_PT
coeficiente erro padrão razão-t p-valor----------------------------------------------------------const -0,0360668 0,0154538 -2,334 0,0258 **d_l_PT_1 -0,877714 0,336966 -2,605 0,2782d_d_l_PT_1 0,221089 0,357651 0,6182 0,5407d_d_l_PT_2 0,0547629 0,356222 0,1537 0,8788d_d_l_PT_3 -0,0931659 0,317173 -0,2937 0,7708d_d_l_PT_4 0,536100 0,284470 1,885 0,0683 *d_d_l_PT_5 0,557049 0,223985 2,487 0,0181 **
time 0,00167875 0,000606121 2,770 0,0091 ***
e)
Para as variáveis l_Qd, l_P, l_PT (e sua primeira diferença: d_l_PT), temos p-valoresaltos, o que nos faz concluir que aceitamos a hipótese nula de que, fazendo com que asvariáveis analisadas possuam uma raiz unitária nos seus respectivos processosgeradores. Já nas outras não mencionadas, vemos p-valores significativamente baixos,rejeitando a hipótese nula, demonstrando que tais variáveis não possuem uma raizunitária em seus processos geradores.Logo, para as variáveis que possuem uma raiz unitária em seu respectivo processo
gerador (l_Qd, l_P, l_PT (e sua primeira diferença: d_l_PT)), temos que as mesmas

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 24/32
possuem um grau de integração igual a 1, enquanto as demais possuem um grau deintegração igual a 0.3.2)
Modelo 4: Mínimos Quadrados (OLS), usando as observações 1997:1-2008:4 (T = 48)
Variável dependente: l_P
Coeficiente Erro Padrão razão-t p-valor const 2,25212 0,187236 12,0282 <0,00001 ***l_PT 0,515993 0,0412466 12,5100 <0,00001 ***
Média var. dependente 4,592409 D.P. var. dependente 0,111740Soma resíd. quadrados 0,133305 E.P. da regressão 0,053833R-quadrado 0,772838 R-quadrado ajustado 0,767900F(1, 46) 156,4989 P-valor(F) 2,08e-16Log da verossimilhança 73,16250 Critério de Akaike -142,3250
Critério de Schwarz -138,5826 Critério Hannan-Quinn -140,9107rô 0,826686 Durbin-Watson 0,272634
Modelo 5: Mínimos Quadrados (OLS), usando as observações 1997:1-2008:4 (T = 48)Variável dependente: l_Qd
Coeficiente Erro Padrão razão-t p-valor const 0 0,0101843 -0,0000 1,00000l_QTd 1,01222 0,0395682 25,5817 <0,00001 ***
Média var. dependente 0,000000 D.P. var. dependente 0,272385Soma resíd. quadrados 0,229014 E.P. da regressão 0,070559R-quadrado 0,934325 R-quadrado ajustado 0,932898F(1, 46) 654,4223 P-valor(F) 7,63e-29Log da verossimilhança 60,17508 Critério de Akaike -116,3502Critério de Schwarz -112,6078 Critério Hannan-Quinn -114,9359rô 0,621795 Durbin-Watson 0,757679
a)Devido a um alto R² (acima de 75% em ambos os casos) e um baixo p-valor (para os
regressores das variáveis explicativas) o que nos leva a conclusão de que os coeficientessão significantemente diferentes de 0 em um nível de significância de 1%, podemosconcluir que essas regressões parecem ser boas.
b)Creio que possa haver problemas com as mesmas porque o processo gerador delas écomposto por uma raiz unitária, fazendo assim com que tais regressões não sejamestacionárias, gerando problemas para essas regressões.
c)Como os valores de ambas estatísticas DW para as duas regressões não são próximas de
2, vemos que há uma auto-correlação dos erros, e como ambos valores são menores doque 2, temos que essa auto-correlação é positiva.

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 25/32
-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0.2
1998 2000 2002 2004 2006 2008
r e s í d u o
Resíduos da regressão (= observados - ajustados l_Qd)
-0.1
-0.08
-0.06
-0.04
-0.02
0
0.02
0.04
0.06
0.08
0.1
0.12
1998 2000 2002 2004 2006 2008
r e s í d u o
Resíduos da regressão (= observados - ajustados l_P)

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 26/32
Ao analisar a série de resíduos, vemos que o grau de persistência dos resíduos é bem baixo, pelo fato da série temporal demonstrar alta volatilidade ao longo dos trimestres.Esse tipo de persistência parece ser mais compatível com processos estacionários.
d)
Passo 1: teste para uma raiz unitária em l_P
Teste Aumentado de Dickey-Fuller, para l_Pincluindo 2 desfasagens de (1-L)l_Pdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,013
diferenças defasadas: F(2, 36) = 2,634 [0,0856]valor estimado de (a - 1): 0,0612593estatística de teste: tau_ct(1) = 1,12573p-valor assintótico 0,9999
Passo 2: teste para uma raiz unitária em l_PT
Teste Aumentado de Dickey-Fuller, para l_PTincluindo 6 desfasagens de (1-L)l_PTdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,044diferenças defasadas: F(6, 32) = 3,790 [0,0058]valor estimado de (a - 1): 0,049093estatística de teste: tau_ct(1) = 1,10539p-valor assintótico 0,9999
Passo 3: regressão de cointegração
Regressão de cointegração -Mínimos Quadrados (OLS), usando as observações 1997:1-2008:4 (T = 48)Variável dependente: l_P
coeficiente erro padrão razão-t p-valor ----------------------------------------------------------const 1,59223 0,0947495 16,80 5,15e-021 ***l_PT 0,683726 0,0217185 31,48 2,71e-032 ***time -0,00411736 0,000295332 -13,94 6,09e-018 ***
Média var. dependente 4,592409 D.P. var. dependente 0,111740Soma resíd. quadrados 0,025061 E.P. da regressão 0,023599

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 27/32
R-quadrado 0,957294 R-quadrado ajustado 0,955396Log da verossimilhança 113,2743 Critério de Akaike -220,5487Critério de Schwarz -214,9351 Critério Hannan-Quinn -218,4273rô 0,230267 Durbin-Watson 1,535189
Passo 4: teste para uma raiz unitária em uhat
Teste Aumentado de Dickey-Fuller, para uhatincluindo 6 desfasagens de (1-L)uhatdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
modelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,107diferenças defasadas: F(6, 34) = 0,775 [0,5947]valor estimado de (a - 1): -0,899056
estatística de teste: tau_ct(2) = -2,74618p-valor assintótico 0,3869
Existe evidência de uma relação de cointegração se:(a) A hipótese de raiz unitária não é rejeitada para as variáveis individuais.(b) A hipótese de raiz unitária é rejeitada para os resíduos (uhat) da
regressão de cointegração.
Como os p-valores das variáveis individuais são altos, aceitamos H0, fazendo com que ahipótese de raiz unitária seja satisfeita. Porém, como o p-valor para os resíduos daregressão de cointegração também é alto, não rejeitamos a hipótese de raiz unitária.Logo, não existe evidência de uma relação de cointegração, e sim de uma regressãoespúria.
Passo 1: teste para uma raiz unitária em l_Qd
Teste Aumentado de Dickey-Fuller, para l_Qdincluindo 4 desfasagens de (1-L)l_Qddimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,041
diferenças defasadas: F(4, 34) = 1,914 [0,1306]valor estimado de (a - 1): -0,407417estatística de teste: tau_ct(1) = -2,43401p-valor assintótico 0,3617
Passo 2: teste para uma raiz unitária em l_QTd
Teste Aumentado de Dickey-Fuller, para l_QTdincluindo 5 desfasagens de (1-L)l_QTddimensão de amostragem 41hipótese nula de raiz unitária: a = 1
com constante e tendênciamodelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,064
diferenças defasadas: F(5, 33) = 1,959 [0,1109]valor estimado de (a - 1): -0,97101estatística de teste: tau_ct(1) = -4,02751

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 28/32
p-valor assintótico 0,007956
Passo 3: regressão de cointegração
Regressão de cointegração -Mínimos Quadrados (OLS), usando as observações 1997:1-2008:4 (T = 48)Variável dependente: l_Qd
coeficiente erro padrão razão-t p-valor----------------------------------------------------------const 0,0675204 0,0575889 1,172 0,2472l_QTd 1,15294 0,124539 9,258 5,50e-012 ***time -0,00275593 0,00231386 -1,191 0,2399
Média var. dependente 0,000000 D.P. var. dependente 0,272385Soma resíd. quadrados 0,222015 E.P. da regressão 0,070240R-quadrado 0,936332 R-quadrado ajustado 0,933503Log da verossimilhança 60,91999 Critério de Akaike -115,8400Critério de Schwarz -110,2264 Critério Hannan-Quinn -113,7186rô 0,576463 Durbin-Watson 0,836465
Passo 4: teste para uma raiz unitária em uhat
Teste Aumentado de Dickey-Fuller, para uhatincluindo 2 desfasagens de (1-L)uhatdimensão de amostragem 41hipótese nula de raiz unitária: a = 1
modelo: (1-L)y = b0 + b1*t + (a-1)*y(-1) + ... + ecoeficiente de 1ª ordem para e: -0,070diferenças defasadas: F(2, 38) = 4,040 [0,0256]valor estimado de (a - 1): -0,243307estatística de teste: tau_ct(2) = -1,2667p-valor assintótico 0,9548
Existe evidência de uma relação de cointegração se:
(a) A hipótese de raiz unitária não é rejeitada para as variáveis individuais.(b) A hipótese de raiz unitária é rejeitada para os resíduos (uhat) da
regressão de cointegração.
Como o p-valor de uma das variáveis individuais é significativamente baixo, rejeitamosH0, fazendo com que a hipótese de raiz unitária não seja satisfeita. Logo, não existeevidência de uma relação de cointegração, e sim de uma regressão espúria.
e)
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!Não Faço Idéia
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Se você também não fizer, me liga que agente tenta colocar alguma coisa!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
4)
a) No Gretl
b) No Gretl
c)

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 29/32
Sistema VAR, grau de defasagem 6Estimativas Mínimos Quadrados (OLS), observações 1998:3-2008:4 (T = 42)
Log da verossimilhança = 151,27897Determinante da matriz de covariâncias = 2,5497519e-006
AIC = -5,9657BIC = -4,8900HQC = -5,5714
Teste de Portmanteau: LB(10) = 15,51, gl = 16 [0,4877]
Equação 1: l_Qd
Coeficiente Erro Padrão razão-t p-valor const 0,510535 0,775053 0,6587 0,51528l_Qd_1 0,891613 0,201241 4,4306 0,00012 ***l_Qd_2 -0,0602205 0,255266 -0,2359 0,81516
l_Qd_3 0,110954 0,232508 0,4772 0,63679l_Qd_4 0,394989 0,210129 1,8797 0,07022 *l_Qd_5 -0,459827 0,220849 -2,0821 0,04627 **l_Qd_6 0,187478 0,189219 0,9908 0,32998l_P_1 -0,697598 0,591454 -1,1795 0,24780l_P_2 1,35377 0,7367 1,8376 0,07639 *l_P_3 -1,80327 0,805923 -2,2375 0,03310 **l_P_4 1,58069 0,852448 1,8543 0,07389 *l_P_5 -0,584085 0,854147 -0,6838 0,49952l_P_6 0,0443346 0,654365 0,0678 0,94645
Média var. dependente 0,034244 D.P. var. dependente 0,272721Soma resíd. quadrados 0,224322 E.P. da regressão 0,087950R-quadrado 0,926439 R-quadrado ajustado 0,895999F(12, 29) 30,43569 P-valor(F) 3,47e-13rô -0,044889 Durbin-Watson 1,970065
Testes-F com zero restrições:Todas as defasagens de l_Qd F(6, 29) = 20,498 [0,0000]Todas as defasagens de l_P F(6, 29) = 1,083 [0,3956]
Todas as variáveis, defasagem 6 F(2, 29) = 0,506 [0,6081]
Equação 2: l_P
Coeficiente Erro Padrão razão-t p-valor const 0,113729 0,243228 0,4676 0,64358l_Qd_1 0,0910528 0,0631536 1,4418 0,16008l_Qd_2 0,0356085 0,0801078 0,4445 0,65998l_Qd_3 0,0101249 0,072966 0,1388 0,89060l_Qd_4 -0,057311 0,0659429 -0,8691 0,39193l_Qd_5 0,0292768 0,0693072 0,4224 0,67583l_Qd_6 0,0637929 0,0593809 1,0743 0,29155
l_P_1 0,678971 0,185611 3,6580 0,00100 ***l_P_2 -0,0754796 0,231192 -0,3265 0,74641

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 30/32
l_P_3 0,173064 0,252916 0,6843 0,49923l_P_4 -0,0038617 0,267516 -0,0144 0,98858l_P_5 0,0672979 0,26805 0,2511 0,80353l_P_6 0,137445 0,205354 0,6693 0,50859
Média var. dependente 4,578606 D.P. var. dependente 0,112756Soma resíd. quadrados 0,022092 E.P. da regressão 0,027601R-quadrado 0,957618 R-quadrado ajustado 0,940081F(12, 29) 54,60500 P-valor(F) 1,36e-16rô 0,041665 Durbin-Watson 1,884136
Testes-F com zero restrições:Todas as defasagens de l_Qd F(6, 29) = 4,1284 [0,0041]Todas as defasagens de l_P F(6, 29) = 58,376 [0,0000]
Todas as variáveis, defasagem 6 F(2, 29) = 0,66732 [0,5208]
Para o sistema como um todoHipótese nula: a maior defasagem é 5
Hipótese alternativa: a maior defasagem é 6Teste de razão de verossimilhança: Qui-quadrado(4) = 4,4784 [0,3451]
d)
Após analisar o p-valor dos testes, concluo que a variável l_Qd causa l_P no sentido deGranger. Isso acontece porque o p-valor é baixo rejeitando a hipótese de ausência decausalidade. Assim, concluímos que as defasagens de l_Qd são importantes na equaçãode l_P.
e)
f)!!!!!!!!!!!!!!!!!!!!!!!!!
Não sei porque o Gretl não está gerando o gráfico para esses dois itens.
!!!!!!!!!!!!!!!!!!!!!!!!!
g)Sistema VAR, máximo grau de defasagem 12
Os asteriscos abaixo indicam os melhores (isto é, minimizados) valores
dos respectivos critérios de informação. AIC = critério de Akaike,BIC = critério Bayesiano de Schwartz, e HQC = critério de Hannan-Quinn.
defasagens log.L p(LR) AIC BIC HQC
1 117,67511 -6,204173 -5,940253* -6,112058*2 118,98885 0,62196 -6,054936 -5,615070 -5,9014113 122,84778 0,10248 -6,047099 -5,431286 -5,8321644 127,19170 0,06939 -6,066206 -5,274446 -5,7898615 130,37387 0,17354 -6,020771 -5,053065 -5,6830156 131,27495 0,77209 -5,848608 -4,704956 -5,4494437 132,75732 0,56374 -5,708740 -4,389141 -5,2481648 136,39004 0,12251 -5,688336 -4,192790 -5,1663509 141,20117 0,04730 -5,733398 -4,061906 -5,150003
10 145,16195 0,09449 -5,731220 -3,883781 -5,086414
11 152,78673 0,00421 -5,932596 -3,909211 -5,22638112 162,61711 0,00058 -6,256506* -4,057174 -5,488881

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 31/32
Com base no critério de Informação Bayesiano de Schwarz, a melhor opção é termos 1defasagem, enquanto pelo critério de Akaike é melhor termos 12.
h)
Sistema VAR, grau de defasagem 1Estimativas Mínimos Quadrados (OLS), observações 1997:2-2008:4 (T = 47)
Log da verossimilhança = 148,2854Determinante da matriz de covariâncias = 6,2322622e-006
AIC = -6,0547BIC = -5,8185HQC = -5,9658
Teste de Portmanteau: LB(11) = 44,9003, gl = 40 [0,2740]
Equação 1: l_Qd
Coeficiente Erro Padrão razão-t p-valor const -0,230407 0,678999 -0,3393 0,73597l_Qd_1 0,944829 0,0577524 16,3600 <0,00001 ***l_P_1 0,0544029 0,147989 0,3676 0,71492
Média var. dependente 0,008466 D.P. var. dependente 0,268871Soma resíd. quadrados 0,425152 E.P. da regressão 0,098298R-quadrado 0,872151 R-quadrado ajustado 0,866340F(2, 44) 150,0778 P-valor(F) 2,23e-20rô -0,148941 Durbin-Watson 2,206930
Testes-F com zero restrições:Todas as defasagens de l_Qd F(1, 44) = 267,65 [0,0000]Todas as defasagens de l_P F(1, 44) = 0,13514 [0,7149]
Equação 2: l_P
Coeficiente Erro Padrão razão-t p-valor const 0,12571 0,190413 0,6602 0,51257l_Qd_1 0,0783524 0,0161957 4,8379 0,00002 ***l_P_1 0,973714 0,041501 23,4624 <0,00001 ***
Média var. dependente 4,590069 D.P. var. dependente 0,111753Soma resíd. quadrados 0,033435 E.P. da regressão 0,027566R-quadrado 0,941799 R-quadrado ajustado 0,939154F(2, 44) 356,0020 P-valor(F) 6,74e-28rô -0,152749 Durbin-Watson 2,260790
Testes-F com zero restrições:Todas as defasagens de l_Qd F(1, 44) = 23,405 [0,0000]Todas as defasagens de l_P F(1, 44) = 550,48 [0,0000]
Os resultados são praticamente os mesmos apesar dos p-valores serem bem inferiores
no caso onde vemos que l_Qd causa l_P no sentido de Granger.

8/6/2019 lista prática II
http://slidepdf.com/reader/full/lista-pratica-ii 32/32
i)
!!!!!!!!!!!!!!!!!!!!!!!
Também não sei porque, nesse item ao fazer a regressão o gretl para de funcionar.Já tentei baixar uma versão mais recente, mas nada muda
!!!!!!!!!!!!!!!!!!!!!!!


















