
MÉTODOS DE ESTIMAÇÃO PARA RISCOS COMPETITIVOS · se torna importante garantir o funcionamento...
81
UNIVERSIDADE FEDERAL DE SÃO CARLOS- DEPARTAMENTO DE ESTATÍSTICA MÉTODOS DE ESTIMAÇÃO PARA RISCOS COMPETITIVOS Agatha S. Rodrigues UFSCar - DEs
Transcript of MÉTODOS DE ESTIMAÇÃO PARA RISCOS COMPETITIVOS · se torna importante garantir o funcionamento...

UNIVERSIDADE FEDERAL DE SÃO CARLOS- DEPARTAMENTO DE ESTATÍSTICA
MÉTODOS DE ESTIMAÇÃO PARA RISCOS
COMPETITIVOS
Agatha S. Rodrigues
UFSCar - DEs

UNIVERSIDADE FEDERAL DE SÃO CARLOS- DEPARTAMENTO DE ESTATÍSTICA
Relatório de Iniciação Científica -
Bolsa PIADRD
MÉTODOS DE ESTIMAÇÃO PARA RISCOS
COMPETITIVOS
Agatha S. Rodrigues
UFSCar - DEs
Orientador: Adriano Polpo
UFSCar - DEs
Co-Orientador: Teresa C. M. Dias
UFSCar – Des
São Carlos
2010

i
RESUMO
O problema de confiabilidade de sistemas vem sendo tratado há muito tempo. Cada vez mais
se torna importante garantir o funcionamento destes sistemas. Neste trabalho estudamos a
teoria de riscos competitivos (especificamente, problemas com dois fatores de risco), através
da comparação de três métodos de estimação. São eles: frequentista paramétrico, o estimador
de Kaplan-Meier e Bayesiano paramétrico; em que no caso paramétrico utilizamos o modelo
Weibull para estimar a função de sobrevivência. Devido à complexidade matemática da
distribuição a posteriori do método Bayesiano, recorreu-se ao algoritmo de Metropolis
Hasting. As comparações foram realizadas através de simulação de vários conjuntos de dados,
com diferentes tamanhos amostrais. As métricas de comparação utilizadas foram: erro
quadrático médio (EQM) e erro máximo absoluto (EMA) dos estimadores em relação à
verdadeira distribuição. Os resultados das comparações mostraram que o estimador de
Kaplan-Meier foi o de pior desempenho e as estimativas paramétricas pelo método
frequentista e Bayesiano foram equivalentes.

ii
GLOSSÁRIO
Confiabilidade é a probabilidade de um item desempenhar uma função, sob condições
específicas, de forma adequada durante um período de tempo pré-determinado. Assim, é a
procura, análise, avaliação e correção de todas as falhas que podem ocorrer com um produto,
em todo o seu ciclo de vida.
Sistema é um conjunto de elementos interconectados harmonicamente que pode
consistir de componentes, entidades, partes ou elementos. Neste projeto, os sistemas em
estudo são formados por fatores de risco, ou seja, o primeiro fator de risco a falhar provoca a
falha do sistema.
Riscos Competitivos são riscos que competem entre si para ser o responsável pela
falha no sistema.
Falha é a causa de um erro, o que impossibilita um componente de executar suas
funções.
Dados Censurados são dados cujo tempo de vida foram interrompidos e assim temos
apenas a informação do tempo de censura e não até quando eles conseguiriam sobreviver.

iii
ÍNDICE
1. Introdução -------------------------------------------------------------------------------------------- 01
2. Metodologia------------------------------------------------------------------------------------------- 04
2.1 O Estimador de Kaplan-Mier ------------------------------------------------------------ 05
2.2 Distribuição Weibull ---------------------------------------------------------------------- 06
2.3 Verossimilhança na aplicação de riscos competitivos sob o Modelo Weibull --- 07
2.4 Método Frequentista Paramétrico ------------------------------------------------------- 08
2.5 Método Bayesiano Paramétrico --------------------------------------------------------- 08
2.6 Algoritmo de Metropolis-Hastings ------------------------------------------------------ 09
2.7 Monitoramento de Convergência ------------------------------------------------------- 10
3. Resultados de Simulação --------------------------------------------------------------------------- 14
4. Considerações Finais ------------------------------------------------------------------------------- 38
Apêndice A ---------------------------------------------------------------------------------------------- 40
Apêndice B ---------------------------------------------------------------------------------------------- 48
Referências Bibliográficas ---------------------------------------------------------------------------- 76

1
1. INTRODUÇÃO
Em várias áreas de aplicação da Estatística, aparecem situações que envolvem riscos
competitivos, ou seja, componentes competindo para ver qual deles é o responsável pela falha
do sistema. Para esse problema de confiabilidade é importante estudar os fatores que
contribuem para a ocorrência da falha e assim garantir o funcionamento destes sistemas.
A análise estatística de dados incompletos tem motivado um grande número de
pesquisas. Em várias áreas de aplicação de métodos estatísticos, como engenharia e medicina,
problemas de estimação, quando as observações podem estar aleatoriamente censuradas,
aparecem com bastante freqüência: Cox [5], Breslow e Crowley [2] e Kaplan e Meier [8].
Exemplos práticos podem ser encontrados quando os dados representam os tempos de vida de
componentes ou os tempos de vida de pacientes submetidos a um tratamento médico. Há, na
literatura, vários trabalhos relacionados ao problema de riscos competitivos (sistema de
componentes em série), como Aalen [1], Tsiatis [15], Peterson [11] e Salinas-Torres et al.
[14], Polpo et al. [12].
Consideramos um problema com dois fatores de risco, C1 e C2, em que é possível
observar seu tempo de falha e identificar o primeiro fator a falhar. Estes fatores competem até
que um deles falhe e o sistema para de funcionar (para definição de sistema vide Glossário).
Sejam X1 e X2 os tempos de falha dos fatores C1 e C2. Considerando T o tempo de
falha do sistema, temos T = min(X1; X2). Se o fator que falhou primeiro é conhecido,
definimos uma variável aleatória indicadora, δ, do fator responsável pela falha do sistema, em
que δ=1 se o fator 1 (C1) falhou primeiro e δ=0 se o fator 2 (C2) foi o responsável pela falha
do sistema. Suponha agora que o experimento possa ser repetido várias vezes (n vezes) e que
observamos (Ti; δi), com i = 1,..., n. Note que, cada Ti contém a informação sobre o fator que

2
falhou e para o outro fator um limite inferior, mas que não se sabe até quando poderia
funcionar, ou seja, o fator foi censurado.
Desejamos, por exemplo, estimar o tempo que levará até uma máquina de café
automática apresentar uma falha. Simplificando o exemplo, considere que esta máquina pode
falhar por dois fatores de risco distintos, um deles é o que moe o grão e o outro é o
responsável por esquentar a água para fazer o café. Quer dizer, sem água quente não tem
como fazer café, ao mesmo tempo em que sem o grão moído também não é possível. Então
esta máquina está sujeita a dois fatores de risco competindo entre si para saber qual deles foi o
responsável pela falha da máquina. Ainda, a empresa que monta essas máquinas de café
compra o moedor e o ebulidor de água de fornecedores distintos. Com isso, é preciso saber
como é o funcionamento de cada uma destas partes, para montar a melhor máquina de café
possível (neste caso, a de maior confiabilidade). Porém, para testar estas peças, é preciso que
elas estejam funcionando, e isto só pode ser feito com a máquina montada. O problema que
surge então é: como estimar a confiabilidade de cada componente, uma vez que os tempos de
falha destes podem ser censurados?
Para responder esta pergunta, avaliamos o desempenho de três métodos de estimação
das curvas de sobrevivência para os fatores e o sistema. O modelo paramétrico utilizado neste
trabalho é o modelo Weibull, estimados do ponto de vista Bayesiano e frequentista. O terceiro
método é o estimador não paramétrico de Kaplan-Meier. Sendo assim, os objetivos
desenvolvidos neste trabalho foram:
Descrever o problema de riscos competitivos, com dois fatores.
Usar a família Weibull como família de probabilidade do tempo de vida dos
componentes nos métodos paramétricos.
Combinar a confiabilidade dos fatores de risco que compõem o sistema para obter a
sua confiabilidade global.

3
Comparar os três métodos de estimação através do Erro Quadrático Médio (EQM) e
Erro Máximo Absoluto (EMA).
Utilizamos a metodologia proposta em exemplos de dados simulados considerando
diferentes distribuições para os componentes e diferentes tamanhos amostrais.
No caso da estimação paramétrica, é desejável o uso de um modelo probabilístico que,
apenas por mudanças nos valores de seus parâmetros, possa representar o comportamento
crescente, decrescente ou constante das falhas ao longo do tempo. Como sugere Coque-Jr [4],
a família de distribuições Weibull é rica o bastante para representar todos esses tipos de
situações.
A utilização do modelo Weibull na estimação Bayesiana faz com que a função a
posteriori como densidade de probabilidade não seja conhecida e nesse caso é necessário
recorrer a métodos de simulação para os cálculos das medidas de interesse; em que a
metodologia mais adequada é a simulação Monte Carlo via Cadeia de Markov,
especificamente o Metropolis-Hastings.
No Capítulo 2, apresentamos a metodologia utilizada e uma breve descrição dos
métodos de estimação. Para o método Bayesiano paramétrico descrevemos também o
algoritmo de Metropolis-Hastings e monitoramento de convergência das cadeias. O Capítulo
3 é dedicado aos resultados e discussão das simulações realizadas. Por fim, no Capítulo 4,
apresentamos as considerações finais e conclusões do estudo realizado.

4
2. METODOLOGIA
As etapas desenvolvidas no projeto foram:
1. Estudo da literatura sobre o problema de confiabilidade em sistemas.
2. Estudo da literatura sobre riscos competitivos.
3. Estudo da literatura sobre o modelo Weibull, suas propriedades e aplicações sob o
ponto de vista frequentista e Bayesiano.
4. Estudo da teoria de estimadores não paramétricos, dando uma ênfase maior ao
estimador de Kaplan-Meier.
5. Estudo da literatura sobre Monte Carlo via cadeias de Markov para a programação
do algoritmo de Metropolis-Hastings e também o estudo das propriedades deste
método estocástico.
6. Após todo o embasamento teórico, colocar em prática o conhecimento adquirido
implementando todos os métodos de estimação em estudo utilizando o software
livre R.
7. Simulações com diferentes sistemas (diferentes distribuições dos componentes) para
avaliar os métodos.
Nas seções seguintes abordamos uma revisão dos três métodos de estimação em
estudo, assim como considerações relevantes do modelo Weibull, da verossimilhança
associada ao problema proposto e monitoramento de convergência do algoritmo de
Metropolis-Hastings, utilizado no método Bayesiano paramétrico.

5
2.1 O estimador de Kaplan-Meier
A obtenção das estimativas de Kaplan-Meier (estimador não-paramétrico) proposto
por Kaplan e Meier (1958) envolve uma sequência de passos em que o próximo depende do
anterior. Por exemplo:
S(6)=P(T ≥ 6)= P(T ≥ 1, T ≥ 6)=P(T ≥ 1). P(T ≥ 6|T ≥ 1).
Assim, para o indivíduo sobreviver por 6 semanas, ele precisa primeiro sobreviver à
primeira semana para depois sobreviver à sexta, sabendo que ele sobreviveu à primeira.
Os passos são gerados a partir de intervalos definidos pela ordenação dos tempos de
falha de forma que cada um deles começa em um tempo observado e termina no próximo
tempo. Considerando, assim, S(t) uma função discreta com probabilidade maior nos tempos
de falha , k=1,...,p, temos que:
com Desta forma, a expressão geral de S(t) é
escrita em termos de probabilidades condicionais. O estimadorde Kaplan-Meier se reduz a
estimar que, é dado por:
para k=1,...,p, em que , os p tempos distintos e ordenados de falha.
Assim, o estimador de Kaplan-Meier é definido por:
As principais propriedades do estimador de Kaplan-Meier são:
i) Não viesado para amostras grandes;
ii) Converge assintoticamente para um processo gaussiano (processo aleatório no qual
todas as funções de densidade que descrevem o processo são normais);

6
iii) É estimador de máxima verossimilhança de S(t).
Mais detalhes ver Colosimo e Giolo [3].
Para os métodos paramétricos, o modelo Weibull foi utilizado para estimar as funções
de sobrevivência. Na seção seguinte, abordamos este modelo de probabilidade.
2.2 Distribuição Weibull
O modelo Weibull foi utilizado, pois ele pode representar o comportamento crescente,
decrescente ou constante das falhas ao longo do tempo. Na sua forma mais completa, a
distribuição Weibull é dada com três parâmetros. Neste trabalho, consideramos o parâmetro
de locação γ igual a zero e, portanto, a função densidade de probabilidade da distribuição
Weibull de dois parâmetros é dada por:
e sua função de sobrevivência é:
em que β > 0 é o parâmetro de forma e η > 0 é o parâmetro de escala.
A escolha desta distribuição Weibull para solução do problema proposto se deve ao
fato que a ela possui uma boa aderência a dados de falha e também é uma versátil distribuição
que assume características de outras distribuições baseada nos valores do parâmetro de forma
β. Segundo Rinne [13], alguns casos especiais são:
β=1, a Weibull é uma distribuição Exponencial;
β=2, a Weibull é uma distribuição Rayleigh;
β=2,5, a Weibull se aproxima de uma distribuição LogNormal;
β=3,6, a Weibull se aproxima de uma distribuição Normal.

7
Dado o modelo Weibull, na seção a seguir definimos a verossimilhança na aplicação
de riscos competitivos.
2.3 Verossimilhança na aplicação de riscos competitivos sob o Modelo
Weibull
Consideramos n tempos t1,..., tn com as respectivas indicações de falha δ1,..., δn, em
que:
δi=1 se o indivíduo i que falhou for o componente 1;
δi=0 se o indivíduo i que falhou for o componente 2.
Temos disponíveis os dados (t1, δ1), ..., (tn, δn). Note que, quando um fator é
responsável pela falha do sistema, temos o seu tempo de falha exato e consequentemente o
tempo de falha do outro fator é censurado. A função de verossimilhança é dada por:
em que fj é a função de densidade da Weibull definida em (4) e Sj é a função de sobrevivência
da Weibull definida em (5), para j= 1,2.
Tomando um i fixo e δi=1 a função de verossimilhança fica resumida a f1(ti) S2(ti), ou
seja, para a i-ésima amostra, o fator de risco 1 (δi=1) foi o causador da falha. Logo, temos sua
informação não censurada e usamos no modelo sua função de densidade f1. Para o risco 2,
sabemos apenas que ele falhou após o tempo ti, utilizando no modelo S2 que é a P(C2 > ti).
Outros detalhes sobre o modelo Weibull para dados censurados pode ser obtido em Lawless
[9].

8
Com a função de verossimilhança definida, descrevemos na próxima seção o método
frequentista de estimação dos parâmetros do modelo Weibull.
2.4 Método Frequentista Paramétrico
Substituindo (4) e (5) na verossimilhança (6), obtemos:
Supondo os fatores de risco são independentes, podemos escrever (7) como:
e assim obter as estimativas dos parâmetros de cada fator de risco individualmente. Logo,
para o fator 1, temos:
Os estimadores de máxima verossimilhança são os valores de β1 e η1 que maximizam a
função (9). Como não é possível obter esses estimadores de forma analítica, utilizamos um
método numérico (como Newton-Raphson). Os estimadores dos parâmetros para o fator de
risco 2 são obtidos de forma análoga.
Na seção seguinte, descrevemos o método Bayesiano de estimação dos parâmetros do
modelo Weibull.
2.5 Método Bayesiano Paramétrico
O método Bayesiano no processo de estimação é baseado na função de
verossimilhança e na distribuição a priori. Como queremos que a informação dos dados seja
dominante, utilizamos uma distribuição a priori não-informativa. Neste caso, a priori não-

9
informativa proposta por Jeffreys foi utilizada. Segundo Jeffreys [7], a priori no caso
multiparamétrico é dado por:
em que,
A distribuição a priori para os parâmetros desconhecidos da distribuição Weibull de
dois parâmetros é abordada por Martins [10]:
Assim, considerando a equação (12) e a (7), calculamos a distribuição a posteriori,
que fica dada por:
Para a posteriori definida em (13) ser uma função de densidade de probabilidade,
temos que calcular a constante de proporcionalidade dada por:
Como esta equação não possui solução analítica, recorremos ao método de Monte-Carlo via
Cadeia de Markov, mais especificamente o algoritmo Metropolis-Hastings que abordamos na
seção a seguir.
2.6 Algoritmo de Metrolopis-Hasting
Temos um problema de densidades condicionais incompletas, neste caso usamos o
algoritmo de Metropolis-Hastings. Este método permite gerar valores de uma distribuição de

10
interesse ( ) através de uma densidade proposta (q) e decidindo aceitar ou rejeitar o valor
gerado (y) segundo uma probabilidade de aceitação ( ), em que:
Resumindo o algoritmo, se u, um ponto gerado de uma distribuição uniforme entre
(0,1) for menor ou igual a , então o ponto gerado (y) é aceito e , caso
contrário, o ponto gerado (y) é rejeitado e , em que m é o contador de
iterações.
O sucesso do método depende da convergência da simulação e das taxas de aceitação
não muito baixas. A taxa de aceitação é definida como a razão entre o número de vezes que se
aceita o valor proposto (y) e o número total de simulações. Alguns textos da literatura
propõem uma taxa de aceitação por volta de 20% (Gamerman [6]).
Para a execução do algoritmo, utilizamos a distribuição Gama como densidade
proposta, pois esta apresenta como suporte, valores positivos e apresentou resultados
satisfatórios quanto a convergência.
Para que os resultados obtidos através da simulação de Metropolis-Hastings sejam
eficientes, precisamos monitorar a convergência das cadeias de Markov. Na seção a seguir
abordamos alguns métodos de verificação de convergência.
2.7 Monitoramento de Convergência
É importante considerar quão eficiente um algoritmo de Metropolis-Hasting fornece
informações úteis sobre o problema de interesse. Eficiência pode ter vários significados no
contexto, mas aqui nós focamos em quão rápido a cadeia “esquece” seus valores iniciais e
quão rápido a cadeia explora completamente o suporte da distribuição alvo. Uma preocupação
relacionada ao monitoramento de convergência é quão distante precisam estar as sequências

11
de observações para que possam ser consideradas independentes. Para isso, descrevemos
quatro métodos de monitoramento de convergência: gráfico de médias ergódicas, teste de
Gelman e Rubin, gráfico de série de tempo e gráfico de autocorrelação.
2.7.1 Gráfico de Médias Ergódicas
Teorema Ergódico: Seja t(Ɵ) uma função dos parâmetros, as médias ergódicas onde
convergem quase certamente para quando j -> ∞.
O gráfico de médias ergódicas é definido como um gráfico da série de tempo de .
Então, a convergência pode ser verificada se esse gráfico, após um período inicial, se
convergir (assintoticamente) para um único ponto.
As primeiras simulações dependem dos valores iniciais dos parâmetros. Essa etapa de
iterações pré-convergência é conhecida como período de aquecimento da cadeia ou período
de burn-in. Uma forma mais prática (e informal) de escolher o burn-in é através do gráfico
das médias ergódicas de uma cadeia ao longo das iterações. Através deste gráfico, após
apresentar convergência, determinamos o período de aquecimento (burn-in) e excluímos os
valores iniciais.
2.7.2 Teste de Gelman e Rubin
O método de Gelman e Rubin é baseado em técnicas de análise de variância,
utilizando várias cadeias em paralelo a partir de diferentes chutes iniciais. Desta forma, para
que haja convergência, todas as cadeias devem apresentar o mesmo comportamento.
Haverá convergência da cadeia apenas quando a variância entre as cadeias for bem
menor que a variância dentro das mesmas. Essas variâncias são definidas a seguir:
Variância entre as cadeias: ; 2
_
1
_
)(1
ttm
nE
m
i
i

12
Variância dentro das cadeias: ,
em que é a média das observações da i-ésima cadeia e é a média de todas as observações.
Um estimador consistente para a variância de t (dados gerados pelo algoritmo de
Metropolis-Hastings) é dado por:
. (15)
De acordo com Gamerman [6], enquanto as cadeias não tiverem convergido, ainda
haverá influência dos pontos iniciais, que foram escolhidos de forma a ter dispersão maior que
t, portanto, superestima a verdadeira variância. Em contrapartida, antes de se atingir a
convergência, D subestimaria a verdadeira variância, visto que cada cadeia não teria coberto
adequadamente todo o espaço de estados.
Um indicador de convergência pode ser a redução potencial de escala. O fator de
redução é dado por: . (16)
Portanto, um indicador de convergência da cadeia será dado pela sua proximidade do
valor 1 (variância de t próxima da variância dentro das cadeias).
2.7.3 Convergência para a distribuição estacionária – Gráfico de série temporal
Uma abordagem empírica para controlar a convergência é desenhar as séries de tempo
das cadeias simuladas para se detectar comportamentos de não-estacionariedade. A ideia é
desenhar a sequência dos pontos gerados versus t (dados gerados pelo algoritmo de
Metropolis-Hastings).
Se uma cadeia não converge, ela ficará perto ou no mesmo valor por muitas iterações.
Uma cadeia que converge “bem” se ela muda rapidamente o seu valor inicial para a região de
EDtVnn
**1)( 11^
1,/)(^
sempreDtVR
m
i
n
j
ij
i ttnm
D1 1
2)( )()1(
1

13
interesse e não permanece sempre no mesmo ponto, oscilando seus valores dentro de um
mesmo espaço.
2.7.4 Convergência das amostras iid
Como estamos lidando com Cadeias de Markov e por isso as iterações do algoritmo
são dependentes, precisamos usar um método para “retirar” a dependência das iterações e
assim trabalhar apenas com aquelas que são independentes uma das outras.
Um gráfico de autocorrelação resume a correlação em uma sequência de X(t)
em
diferentes lags. Uma cadeia que tem um ritmo lento para “chegar” na distribuição estacionária
irá exibir uma decaída lenta de autocorrelação à medida que a lag entre as iterações aumenta.
Uma solução para tirar a dependência das iterações é usar saltos (retirar iterações
dependentes), isto é: , em que k é o tamanho do salto. Tomando η(t)
como a
amostra gerada do método de Metropolis-Hastings.
Com isso, abordamos a teoria de riscos competitivos necessária para o
desenvolvimento desse trabalho e os métodos de estimação propostos. No próximo capítulo,
aplicamos a teoria apresentada em dados simulados com diferentes distribuições dos fatores
de risco e tamanhos amostrais.

14
3. RESULTADOS DE SIMULAÇÃO
Realizamos simulações considerando diferentes tipos de sistemas (diferentes
distribuições para os riscos) e diferentes tamanhos amostrais. Para que o resultado obtido de
cada simulação não seja devido ao acaso, geramos mil conjuntos de dados distintos para cada
tipo de sistema e analisamos o comportamento de cada método de estimação levando em
conta as mil situações e não apenas um caso isolado. Em todos os tipos de sistemas gerados
consideramos dois tamanhos de amostra: 30 e 100 observações.
Para comparação dos métodos de estimação, utilizaremos o Erro Quadrático Médio
(EQM) e Erro Máximo Absoluto (EMA). Assim, o método que tiver as menores medidas
dessas duas quantidades é considerado o melhor em relação aos outros dois.
Consideramos sistemas com dois componentes em que:
i) Sistema 1: fator 1 possui distribuição Weibull com parâmetros 1 e 2 (média 1,88 e variância
4,37), e o fator 2 possui distribuição Weibull com parâmetros 2 e 1 (média 0,9 e variância
0,21).
ii) Sistema 2: fator 1 possui distribuição Gama com parâmetros 3 e 6 (média 0,5 e variância
0,1), e o fator 2 possui distribuição Gama com parâmetros 2 e 5 (média 0,41 e variância 0,08).
iii) Sistema 3: fator 1 possui distribuição Log-Normal com parâmetros 0,4 e 1 (média de 2,38
e variância 9) e o fator 2 possui distribuição Gama com parâmetros 5 e 2 (média 2,48 e
variância 1,5).
iv) Sistema 4: fator 1 possui distribuição Normal com valores absolutos com parâmetros 3 e 5
(média 4,7 e variância 11) e o fator 2 possui distribuição Normal com valores absolutos com
parâmetros 5 e 2 (média 5 e variância 6).

15
Considerando os quatro sistemas com os dois tamanhos amostrais (30 e 100
observações) e as 1000 replicações, ao final de todas simulações, geramos 4.30.1000 +
4.100.1000 = 520000 dados.
Para o método Bayesiano paramétrico, precisamos verificar a convergência das
cadeias através do gráfico de médias ergódicas, série de tempo, autocorrelação e valor do teste
de Gelman e Rubin, como foram descritos na seção 2.7. O monitoramento de convergência do
Metropolis-Hastings dos quatro sistemas está no Apêndice B, em que: B.1 está o
monitoramento de convergência do Metropolis-Hastings do sistema 1 com tamanho amostral
30, B.2 do sistema 1 com tamanho 100, B.3 do sistema 2 com tamanho 30, B.4 do sistema 2
com tamanho 100, B.5 do sistema 3 com tamanho 30 e B.6 do sistema 3 com tamanho 100,
B.7 do sistema 4 com tamanho 30 e B.8 do sistema 4 com tamanho amostral 100. Como para
cada sistema geramos 1000 situações ficaria inviável apresentar os gráficos de monitoramento
de convergência de todos eles. Por isso, para cada sistema, apresentamos os resultados de
convergência de uma amostra, mostrando sua convergência e extrapolando para as outras 999
situações.
i) Sistema 1
i.1) Sistema 1 com amostra de tamanho 30
16
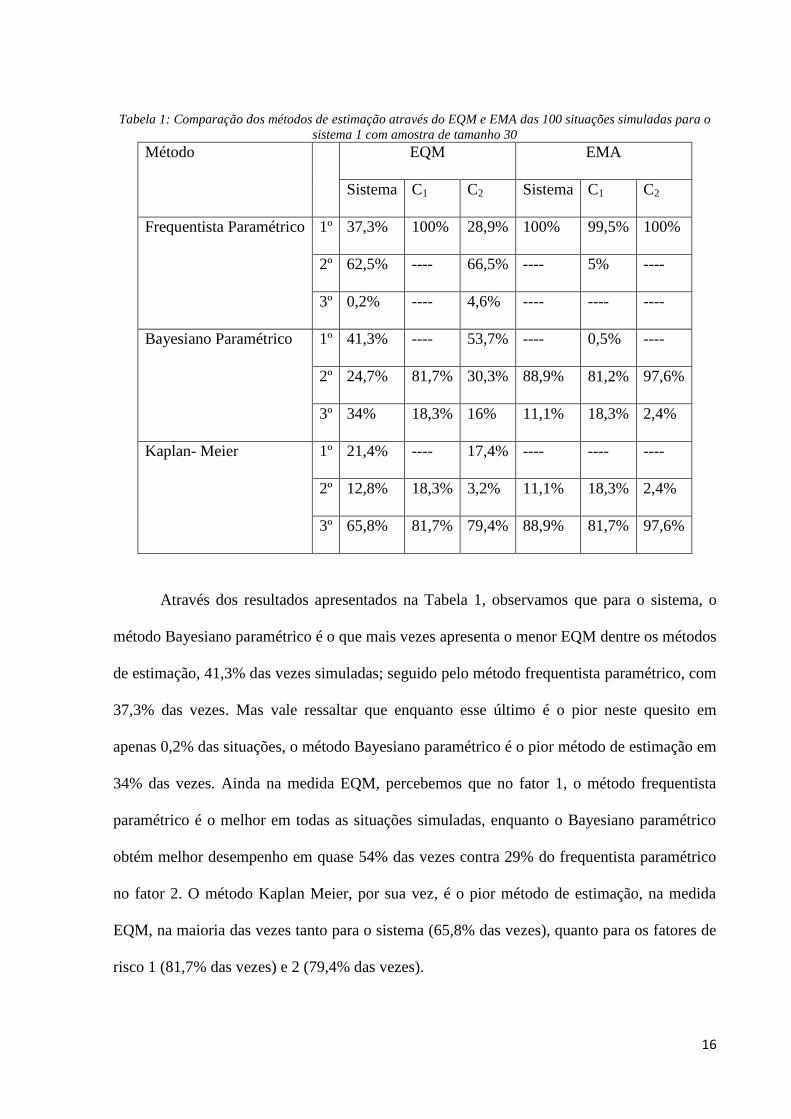
Tabela 1: Comparação dos métodos de estimação através do EQM e EMA das 100 situações simuladas para o
sistema 1 com amostra de tamanho 30
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 37,3% 100% 28,9% 100% 99,5% 100%
2º 62,5% ---- 66,5% ---- 5% ----
3º 0,2% ---- 4,6% ---- ---- ----
Bayesiano Paramétrico 1º 41,3% ---- 53,7% ---- 0,5% ----
2º 24,7% 81,7% 30,3% 88,9% 81,2% 97,6%
3º 34% 18,3% 16% 11,1% 18,3% 2,4%
Kaplan- Meier 1º 21,4% ---- 17,4% ---- ---- ----
2º 12,8% 18,3% 3,2% 11,1% 18,3% 2,4%
3º 65,8% 81,7% 79,4% 88,9% 81,7% 97,6%
Através dos resultados apresentados na Tabela 1, observamos que para o sistema, o
método Bayesiano paramétrico é o que mais vezes apresenta o menor EQM dentre os métodos
de estimação, 41,3% das vezes simuladas; seguido pelo método frequentista paramétrico, com
37,3% das vezes. Mas vale ressaltar que enquanto esse último é o pior neste quesito em
apenas 0,2% das situações, o método Bayesiano paramétrico é o pior método de estimação em
34% das vezes. Ainda na medida EQM, percebemos que no fator 1, o método frequentista
paramétrico é o melhor em todas as situações simuladas, enquanto o Bayesiano paramétrico
obtém melhor desempenho em quase 54% das vezes contra 29% do frequentista paramétrico
no fator 2. O método Kaplan Meier, por sua vez, é o pior método de estimação, na medida
EQM, na maioria das vezes tanto para o sistema (65,8% das vezes), quanto para os fatores de
risco 1 (81,7% das vezes) e 2 (79,4% das vezes).

17
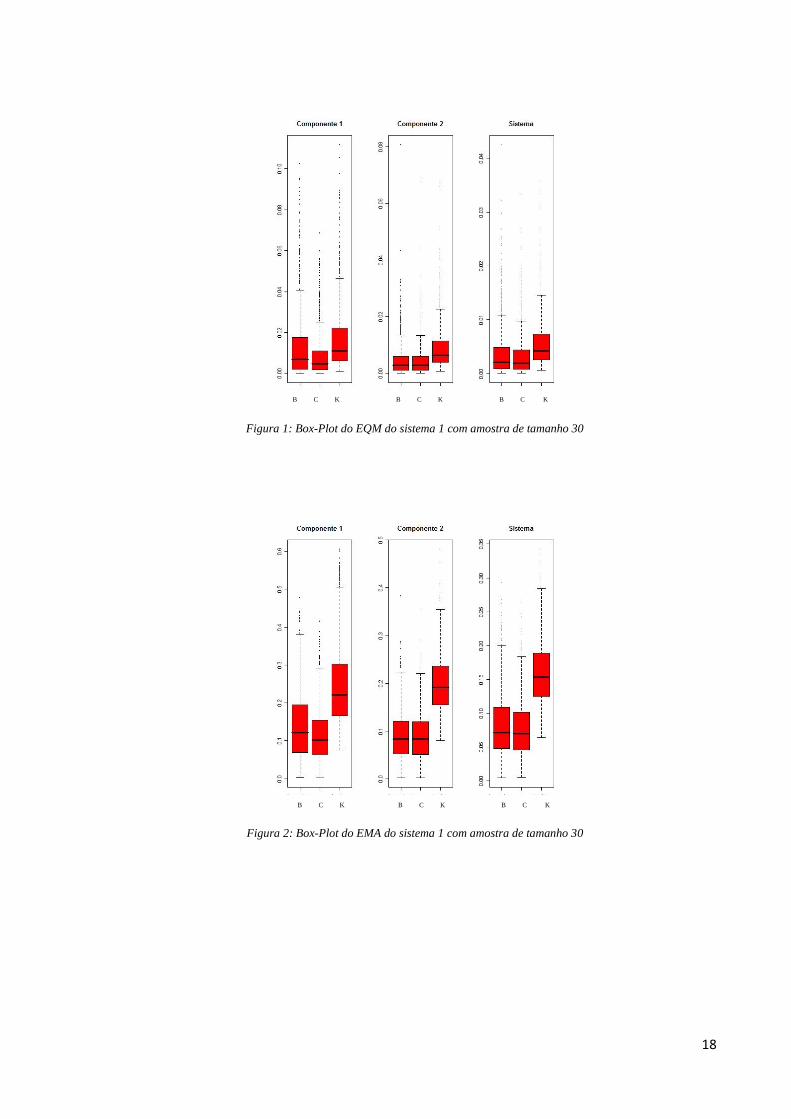
Quando levamos em conta apenas quem foi o menor EQM, não consideramos o
quanto a medida de um método é menor que a medida de outro. Assim, pelos gráficos box-
plot da Figura 1, percebemos que apesar do Bayesiano paramétrico ser o método que em mais
vezes obteve o menor EQM para o sistema, as suas medidas não diferem das medidas do
método frequentista paramétrico e também no fator 2, não existe diferença dos valores do
EQM entre estes dois métodos. Já no fator 1, as medidas do frequentista paramétrico tem uma
variabilidade menor, sendo concentradas nos menores valores para o erro. Tanto para o
sistema quanto para os fatores de risco, o método Kaplan Meier apresenta a maior
variabilidade do EQM e os maiores valores desse erro.
Na medida EMA, é evidente a superioridade do método frequentista paramétrico, pois
em 100% das vezes, tanto no sistema quanto nos fatores de risco, ele obtém sempre o menor
erro máximo absoluto; enquanto o método Bayesiano paramétrico está em segundo lugar 89%
das vezes no sistema, 81,2% das vezes no fator de risco 1 e quase 98% das vezes no fator de
risco 2. O método frequentista não-paramétrico, Kaplan-Meier, obtém o pior desempenho na
grande maioria das vezes também no EMA para os fatores de risco e sistema. Pela Figura 2,
podemos perceber que os valores do EMA para este método são consideravelmente maiores
que erro máximo dos outros métodos em comparação e vale frisar que nos baseando na
Tabela 1, em nenhuma das situações simuladas ele foi o método com menor EMA.
Nas Figuras A.1.1, A.1.2 e A.1.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações
realizadas.
18
Figura 1: Box-Plot do EQM do sistema 1 com amostra de tamanho 30
Figura 2: Box-Plot do EMA do sistema 1 com amostra de tamanho 30
B C K B C K B C K
B C K B C K B C K
19
i.2) Sistema 1 com amostra de tamanho 100
Tabela 2: Comparação dos métodos de estimação através do EQM e EMA das 1000 situações simuladas para o
sistema 1 com amostra de tamanho 100
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 41,4% 51,2% 39,6% 54,5% 55,6% 46,1%
2º 58,4% 44,9% 60% 45,5% 43,8% 53,8%
3º 0,2% 3,9% 0,4% ---- 0,6% 0,1%
Bayesiano Paramétrico 1º 43,1% 42,2% 49,2% 44,6% 43,9% 53,6%
2º 28,6% 34,6% 34,5% 52,3% 50,7% 45,7%
3º 28,3% 23,2% 16,3% 3,1% 5,4% 0,7%
Kaplan- Meier 1º 15,5% 6,6% 11,2% 0,9% 0,5% 0,3%
2º 13% 20,5% 5,5% 2,2% 5,5% 0,5%
3º 71,5% 72,9% 83,3% 96,9% 94% 99,2%
Pela Tabela 2, o método que apresenta melhor desempenho para o sistema entre as
1000 situações simuladas no EQM é o Bayesiano paramétrico com 43,1% das vezes em
primeiro lugar. Como no caso da amostra de tamanho 30, o método frequentista paramétrico é
o pior dentre os métodos comparados em apenas 0,2% das vezes, enquanto que o Bayesiano
paramétrico é o pior 28,3% das vezes.
No fator de risco 1, ainda na medida EQM, o método frequentista paramétrico é o
melhor em 51,2% das situações simuladas, enquanto o Bayesiano paramétrico obtém melhor
desempenho em um pouco mais de 42% das vezes. Enquanto que no fator de risco 2, a
situação se inverte: o frequentista obtém melhor desempenho em 39,6% das vezes e o
Bayesiano paramétrico em 49,2% das simulações. O método Kaplan Meier é o pior método de

20
estimação na maioria das vezes tanto para o sistema (71,5% das vezes), quanto para os fatores
de risco 1 (72,9% das vezes) e 2 (83,3% das vezes).
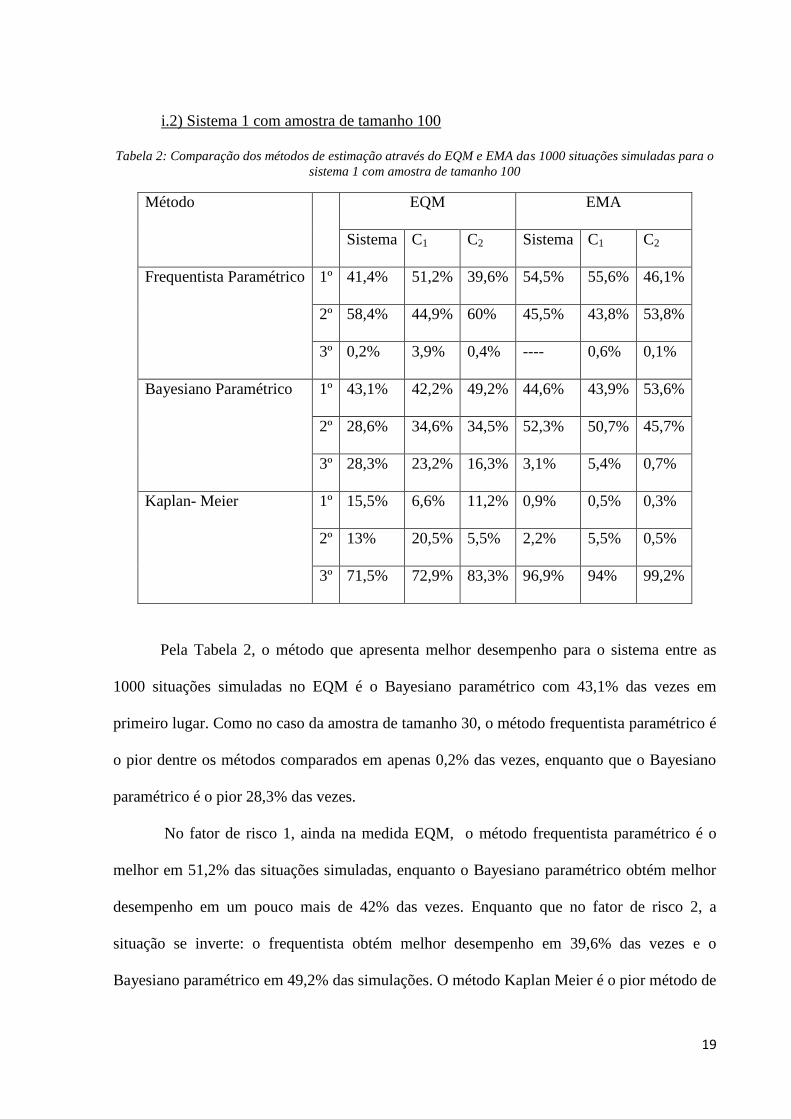
Pelos gráficos box-plot da Figura 3, percebemos que apesar do Bayesiano paramétrico
ser o método que em mais vezes obteve o menor EQM para o sistema, as suas medidas não
diferem das medidas do método frequentista paramétrico e também nos fatores de risco 1 e 2
não existe diferença dos valores do EQM entre estes dois métodos. Tanto para o sistema
quanto para os fatores de risco, o método Kaplan Meier apresenta a maior variabilidade do
EQM e os maiores valores desse erro.
Na medida EMA do sistema, diferente do que acontece com o tamanho amostral de
30, há certo equilíbrio entre o desempenho do frequentista e Bayesiano paramétrico, em que
no fator de risco 1, o frequentista é o melhor em 55,6% das vezes e no fator de risco 2 o
Bayesiano é melhor em 53,6%.
O método frequentista não-paramétrico, Kaplan-Meier, obtém um pior desempenho no
EMA tanto para o sistema (pior em quase 97% das vezes), e para os fatores de risco 1 e 2
sendo o pior método em 94% e 99,2% das vezes, respectivamente. Pela Figura 4, podemos
perceber que os valores do EMA para este método são consideravelmente maiores que erro
máximo dos outros métodos em comparação.
Nas Figuras A.2.1, A.2.2 e A.2.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações
realizadas.
Podemos também comparar o sistema 1 nos dois tamanhos amostrais simulados (i.1 e i.2).
Nesta comparação, observamos que o método Kaplan-Meier obtém pior desempenho no
sistema quando aumentamos o tamanho da amostra, pois com amostra de tamanho 30 ele é o
pior em 65,8% e com amostra de tamanho 100 ele ficou em terceiro em 71,5% das vezes.
21
Ainda para o sistema, o método Bayesiano obteve uma melhora de 5,7% quando aumentamos
o tamanho amostral, pois ele é o pior método de estimação em 34% das vezes na amostra de
tamanho 30 e na amostra de tamanho 100 diminuiu para 28,3% das vezes.
Em relação ao EMA, podemos perceber que houve uma grande diferença quando
mudamos o tamanho amostral. Na amostra de tamanho 30, o frequentista paramétrico é o
melhor em 100% das vezes tanto no sistema quanto nos fatores de risco. Já na amostra de
tamanho 100, houve um equilíbrio no desempenho entre o frequentista e Bayesiano em que o
primeiro é melhor no fator de risco 1 e o Bayesiano tem maior porcentagem de melhor
desempenho no fator de risco 2.
Figura 3: Box-plot do EQM do sistema 1 com tamanho amostral 100
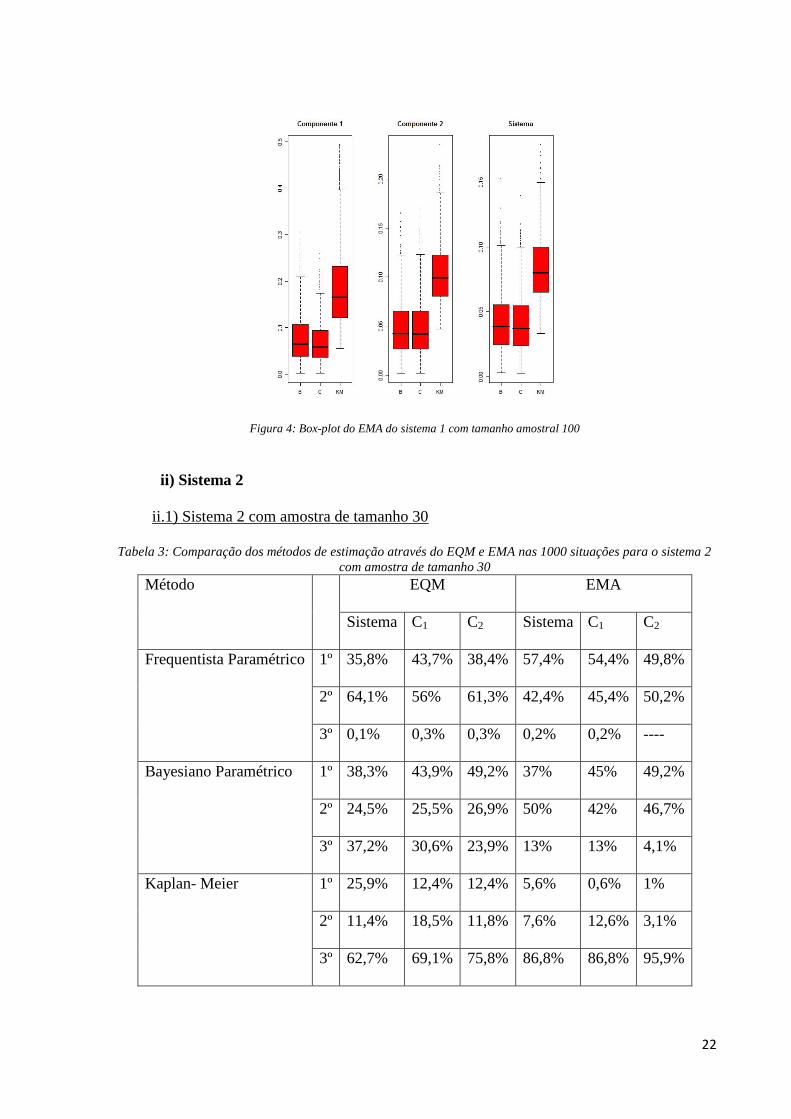
22
Figura 4: Box-plot do EMA do sistema 1 com tamanho amostral 100
ii) Sistema 2
ii.1) Sistema 2 com amostra de tamanho 30
Tabela 3: Comparação dos métodos de estimação através do EQM e EMA nas 1000 situações para o sistema 2
com amostra de tamanho 30
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 35,8% 43,7% 38,4% 57,4% 54,4% 49,8%
2º 64,1% 56% 61,3% 42,4% 45,4% 50,2%
3º 0,1% 0,3% 0,3% 0,2% 0,2% ----
Bayesiano Paramétrico 1º 38,3% 43,9% 49,2% 37% 45% 49,2%
2º 24,5% 25,5% 26,9% 50% 42% 46,7%
3º 37,2% 30,6% 23,9% 13% 13% 4,1%
Kaplan- Meier 1º 25,9% 12,4% 12,4% 5,6% 0,6% 1%
2º 11,4% 18,5% 11,8% 7,6% 12,6% 3,1%
3º 62,7% 69,1% 75,8% 86,8% 86,8% 95,9%

23
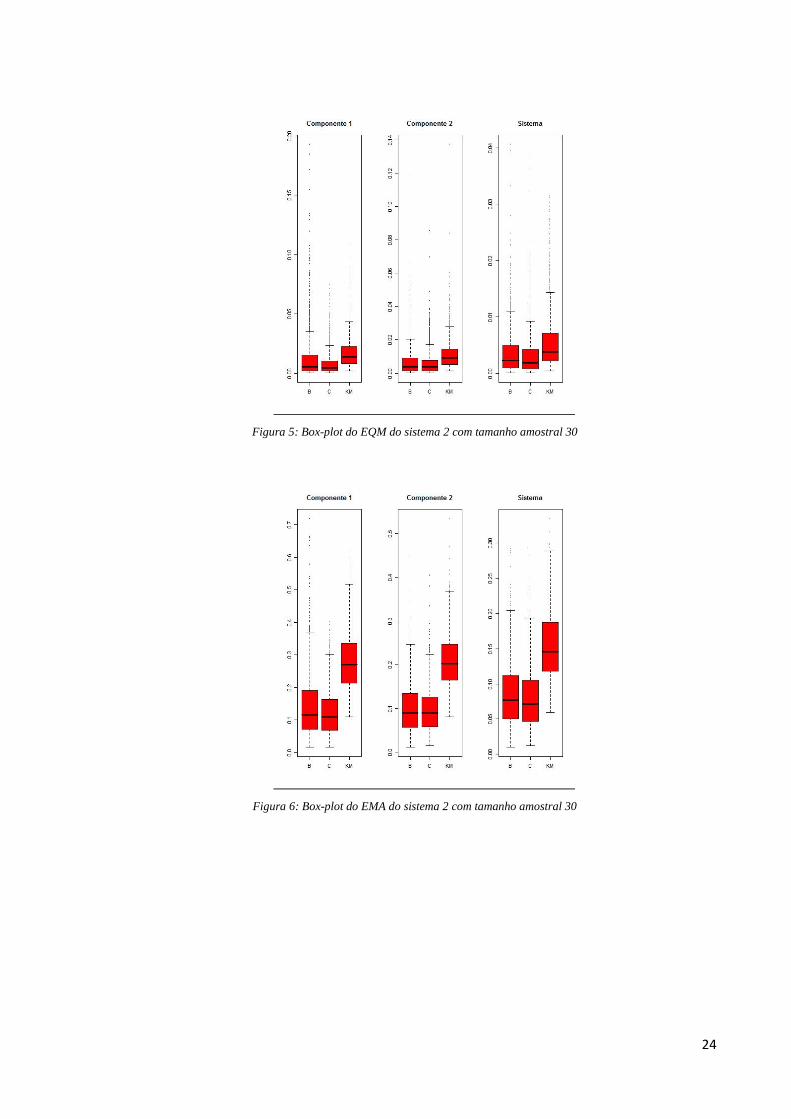
No EQM para o sistema, o método Bayesiano é o melhor em 38,3% das vezes e o
frequentista paramétrico em 35,8% das vezes. Percebemos também através da Tabela 3 que o
método Bayesiano paramétrico é o que apresenta as maiores porcentagens de melhor
desempenho entre os métodos comparados nos fatores de risco 1 e 2, 43,9% e 49,2% das
vezes, respectivamente. Mas vale ressaltar que enquanto o Bayesiano paramétrico obtém o
pior desempenho entre os métodos em 30,6% das vezes no fator de risco 1 e 23,9% no fator
de risco 2, o frequentista é o pior em apenas 0,3% das vezes para os dois fatores de risco.
Por sua vez, o método Kaplan Meier é o pior método de estimação na maioria das
vezes tanto para o sistema (62,7% das vezes), quanto para os fatores de risco 1 (69,1% das
vezes) e 2 (75,8% das vezes).
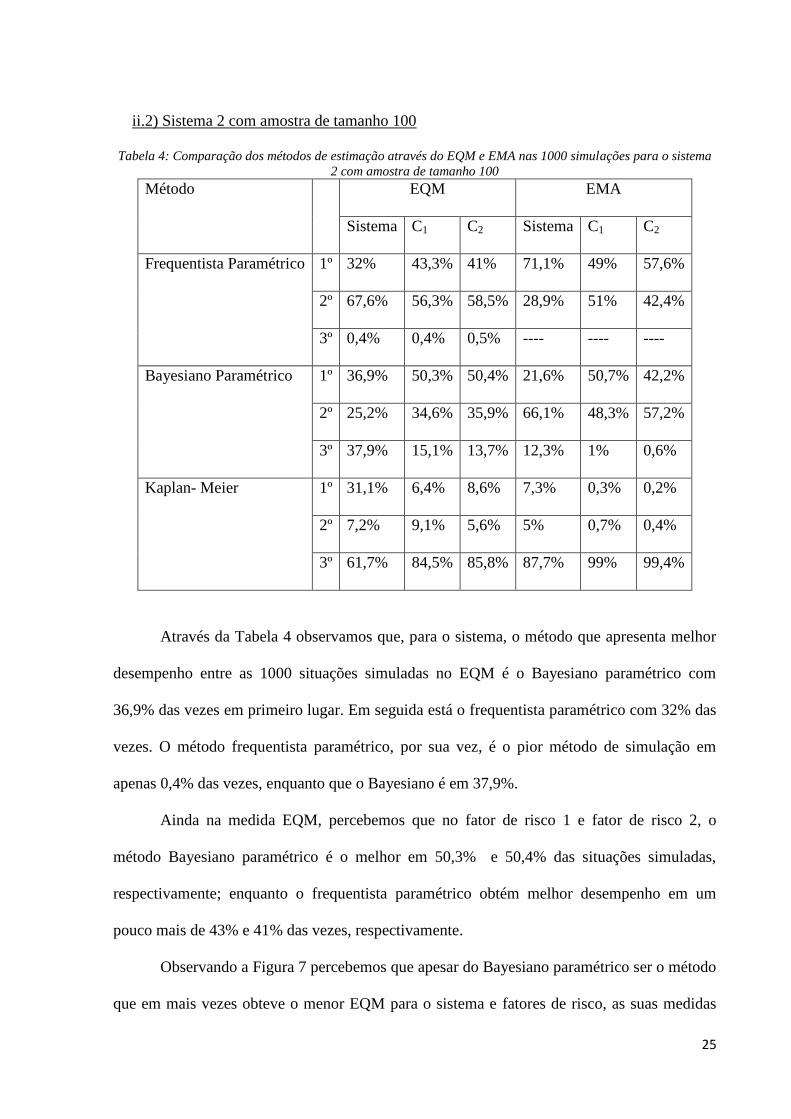
Já na medida EMA do sistema, o método de estimação frequentista paramétrico obtém
maior porcentagem de menores EMA, tanto para os fatores de risco quanto para o sistema.
Mesmo tendo a maior porcentagem de melhor desempenho dentre as situações simuladas no
fator de risco 2, não há grande diferença entre ele e o método Bayesiano paramétrico em que
esse obtém o menor EMA em 49,2% das vezes e o frequentista em 49,8%. Assim como na
medida EQM, o Kaplan-Meier apresentou a maior porcentagem de pior desempenho tanto no
sistema quanto nos fatores de risco e na Figura 6 podemos notar que nos gráficos do EMA
tanto para o sistema quanto fatores de risco, o método não paramétrico é o que apresenta
maiores valores desse erro.
Nas Figuras A.3.1, A.3.2 e A.3.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações.
24
Figura 5: Box-plot do EQM do sistema 2 com tamanho amostral 30
Figura 6: Box-plot do EMA do sistema 2 com tamanho amostral 30
25
ii.2) Sistema 2 com amostra de tamanho 100
Tabela 4: Comparação dos métodos de estimação através do EQM e EMA nas 1000 simulações para o sistema
2 com amostra de tamanho 100
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 32% 43,3% 41% 71,1% 49% 57,6%
2º 67,6% 56,3% 58,5% 28,9% 51% 42,4%
3º 0,4% 0,4% 0,5% ---- ---- ----
Bayesiano Paramétrico 1º 36,9% 50,3% 50,4% 21,6% 50,7% 42,2%
2º 25,2% 34,6% 35,9% 66,1% 48,3% 57,2%
3º 37,9% 15,1% 13,7% 12,3% 1% 0,6%
Kaplan- Meier 1º 31,1% 6,4% 8,6% 7,3% 0,3% 0,2%
2º 7,2% 9,1% 5,6% 5% 0,7% 0,4%
3º 61,7% 84,5% 85,8% 87,7% 99% 99,4%
Através da Tabela 4 observamos que, para o sistema, o método que apresenta melhor
desempenho entre as 1000 situações simuladas no EQM é o Bayesiano paramétrico com
36,9% das vezes em primeiro lugar. Em seguida está o frequentista paramétrico com 32% das
vezes. O método frequentista paramétrico, por sua vez, é o pior método de simulação em
apenas 0,4% das vezes, enquanto que o Bayesiano é em 37,9%.
Ainda na medida EQM, percebemos que no fator de risco 1 e fator de risco 2, o
método Bayesiano paramétrico é o melhor em 50,3% e 50,4% das situações simuladas,
respectivamente; enquanto o frequentista paramétrico obtém melhor desempenho em um
pouco mais de 43% e 41% das vezes, respectivamente.
Observando a Figura 7 percebemos que apesar do Bayesiano paramétrico ser o método
que em mais vezes obteve o menor EQM para o sistema e fatores de risco, as suas medidas

26
não diferem das medidas do método frequentista paramétrico, pois o comportamento dos
gráficos dos dois métodos, tanto para o sistema quanto para os fatores de risco não se difere.
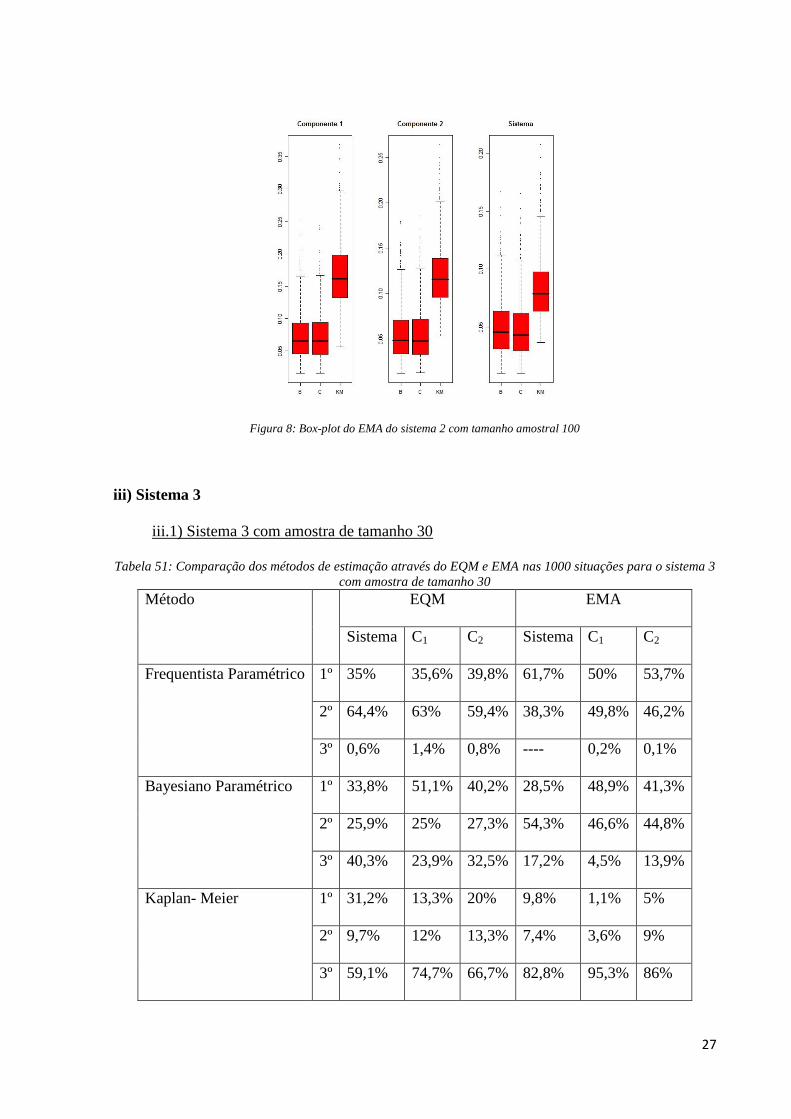
Já na medida EMA do sistema, o método frequentista paramétrico é o melhor em
71,1% das situações simuladas no sistema e 57,6% no fator de risco 2, enquanto o Bayesiano
paramétrico obtém melhor desempenho em quase 22% das vezes no sistema e um pouco mais
de 42% no fator de risco 2. Para o fator de risco 1, a situação se inverte: o frequentista obtém
melhor desempenho em 49% das vezes e o Bayesiano em 50,7 %.
O método frequentista não-paramétrico, Kaplan-Meier, obtém um pior desempenho
que os outros métodos para o sistema quanto para os fatores de risco com relação às duas
medidas de comparação: EQM e EMA; em que para esta última obtém valores superiores que
dos outros dois métodos, o que pode ser verificado na Figura 8.
Nas Figuras A.4.1., A.4.2 e A.4.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha).
Figura 7: Box-plot do EQM do sistema 2 com tamanho amostral 100
27
Figura 8: Box-plot do EMA do sistema 2 com tamanho amostral 100
iii) Sistema 3
iii.1) Sistema 3 com amostra de tamanho 30
Tabela 51: Comparação dos métodos de estimação através do EQM e EMA nas 1000 situações para o sistema 3
com amostra de tamanho 30
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 35% 35,6% 39,8% 61,7% 50% 53,7%
2º 64,4% 63% 59,4% 38,3% 49,8% 46,2%
3º 0,6% 1,4% 0,8% ---- 0,2% 0,1%
Bayesiano Paramétrico 1º 33,8% 51,1% 40,2% 28,5% 48,9% 41,3%
2º 25,9% 25% 27,3% 54,3% 46,6% 44,8%
3º 40,3% 23,9% 32,5% 17,2% 4,5% 13,9%
Kaplan- Meier 1º 31,2% 13,3% 20% 9,8% 1,1% 5%
2º 9,7% 12% 13,3% 7,4% 3,6% 9%
3º 59,1% 74,7% 66,7% 82,8% 95,3% 86%

28
Na Tabela 5 temos que, para o sistema, não há diferença alarmante entre os três
métodos, pois o Bayesiano, frequentista paramétrico e Kaplan-Meier estão em 33,8%, 35% e
31,2% das vezes em primeiro lugar, respectivamente.
Ainda na medida EQM, percebemos que no fator de risco 1 e fator de risco 2, o
método Bayesiano paramétrico é o melhor em 51,1% e 40,2% das situações simuladas,
respectivamente; enquanto o frequentista paramétrico obtém melhor desempenho em um
pouco mais de 35% e 39% das vezes, respectivamente. Mas vale frisar que mesmo o
Bayesiano sendo o melhor na maioria das vezes, o método frequentista paramétrico é o pior
método de simulação em apenas 1,4% das vezes no fator de risco 1 e 0,8% no fator de risco 2
enquanto o Bayesiano paramétrico é o pior método dentre os três comparados 23,9% no fator
de risco 1 e 32,5% no fator de risco 2.
Já na medida EMA do sistema, o método frequentista paramétrico é o melhor em
61,7% das situações simuladas no sistema, 50% no fator de risco 1 e 53,7% no fator de risco
2, enquanto o Bayesiano paramétrico tem melhor desempenho em 28,5% das vezes no
sistema, quase 49% no fator de risco 1 e 41,3% no fator de risco 2.
O método Kaplan-Meier obtém um desempenho pior que os outros métodos com
relação ao EMA tanto para o sistema quanto para os fatores de risco. Pela Figura 10 temos
que este método apresenta um desempenho de maiores valores do erro, sendo visivelmente
maior que os outros dois métodos comparados.
Nas Figuras A.5.1, A.5.2 e A.5.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações.
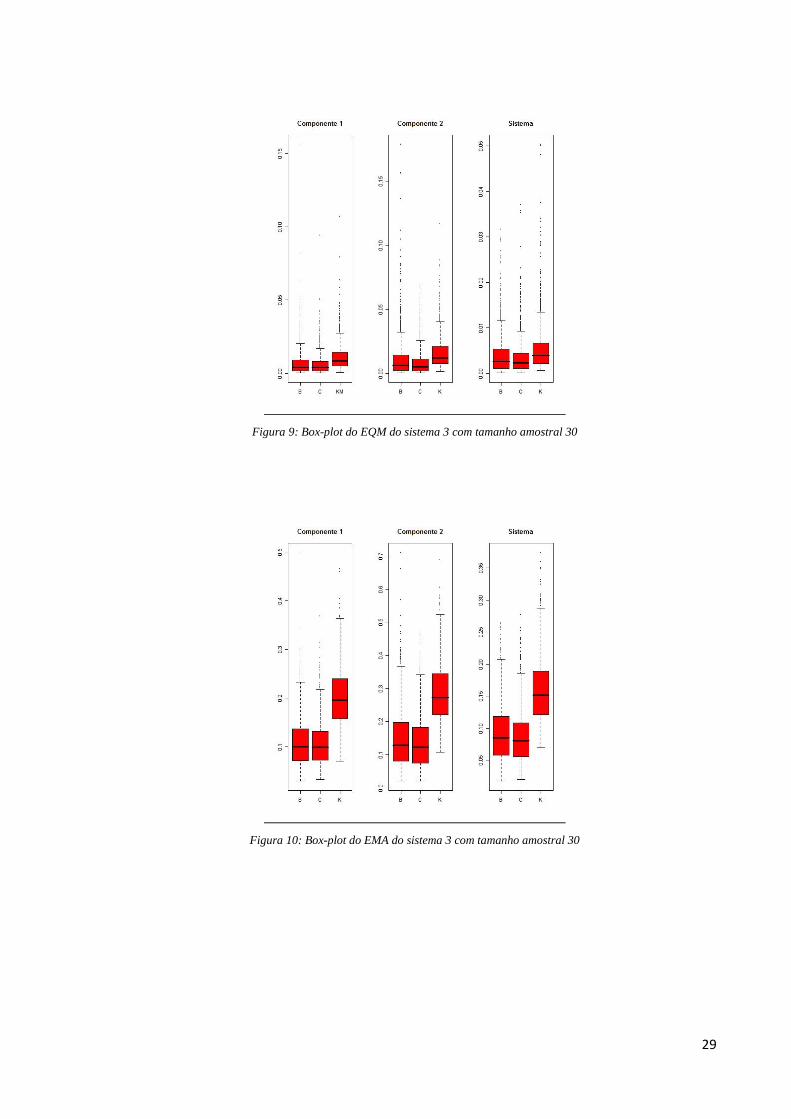
29
Figura 9: Box-plot do EQM do sistema 3 com tamanho amostral 30
Figura 10: Box-plot do EMA do sistema 3 com tamanho amostral 30
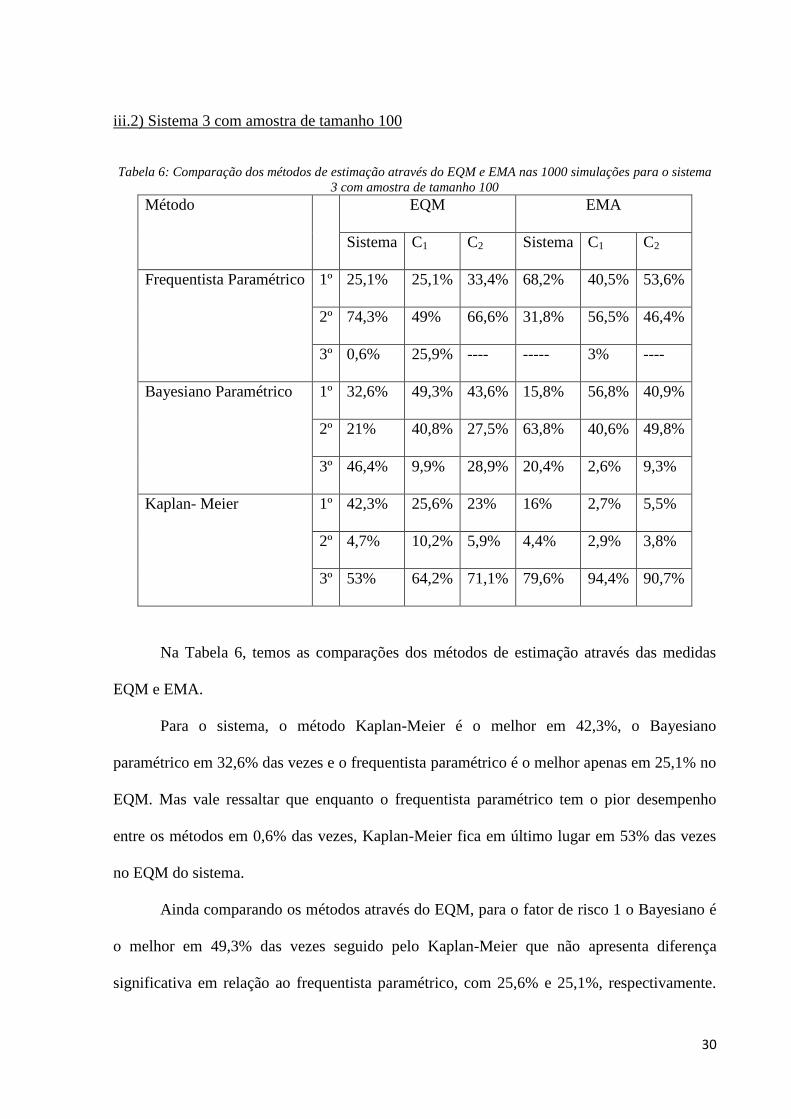
30
iii.2) Sistema 3 com amostra de tamanho 100
Tabela 6: Comparação dos métodos de estimação através do EQM e EMA nas 1000 simulações para o sistema
3 com amostra de tamanho 100
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 25,1% 25,1% 33,4% 68,2% 40,5% 53,6%
2º 74,3% 49% 66,6% 31,8% 56,5% 46,4%
3º 0,6% 25,9% ---- ----- 3% ----
Bayesiano Paramétrico 1º 32,6% 49,3% 43,6% 15,8% 56,8% 40,9%
2º 21% 40,8% 27,5% 63,8% 40,6% 49,8%
3º 46,4% 9,9% 28,9% 20,4% 2,6% 9,3%
Kaplan- Meier 1º 42,3% 25,6% 23% 16% 2,7% 5,5%
2º 4,7% 10,2% 5,9% 4,4% 2,9% 3,8%
3º 53% 64,2% 71,1% 79,6% 94,4% 90,7%
Na Tabela 6, temos as comparações dos métodos de estimação através das medidas
EQM e EMA.
Para o sistema, o método Kaplan-Meier é o melhor em 42,3%, o Bayesiano
paramétrico em 32,6% das vezes e o frequentista paramétrico é o melhor apenas em 25,1% no
EQM. Mas vale ressaltar que enquanto o frequentista paramétrico tem o pior desempenho
entre os métodos em 0,6% das vezes, Kaplan-Meier fica em último lugar em 53% das vezes
no EQM do sistema.
Ainda comparando os métodos através do EQM, para o fator de risco 1 o Bayesiano é
o melhor em 49,3% das vezes seguido pelo Kaplan-Meier que não apresenta diferença
significativa em relação ao frequentista paramétrico, com 25,6% e 25,1%, respectivamente.

31
No fator de risco 2, o método Bayesiano paramétrico também foi o melhor método na maioria
das vezes, 43,6% delas.
Quando levamos em conta apenas quem foi o menor EQM não consideramos o quanto
a medida de um método é menor que a medida de outro. Assim, pelos gráficos box-plot da
Figura 11 , percebemos que apesar do Bayesiano paramétrico ser o método que em mais vezes
obteve o menor EQM para os fatores de risco, os valores de suas medidas não diferem das
medidas do método frequentista paramétrico.
Já na medida EMA do sistema, o método de estimação frequentista paramétrico é o
melhor em 68,2% no sistema e 53,6% no fator de risco 2, enquanto o Bayesiano paramétrico
tem menor EMA em 56,8% das vezes no fator de risco 1.
Nas Figura 12 observamos que o método Kaplan-Meier apresenta maiores valores do
EMA tanto para o sistema quanto para os fatores de risco, sendo visivelmente maior que os
valores dos outros métodos. Pela Tabela 6 temos também que ele foi o pior método de
estimação, levando em conta o EMA, na grande maioria das vezes tanto para o sistema quanto
para os fatores de risco (79,6% das vezes no sistema, 94,4% no fator de risco 1 e 90,7% no
fator de risco 2).
Nas Figuras A.6.1, A.6.2 e A.6.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha), considerando uma das 1000 situações
simuladas.
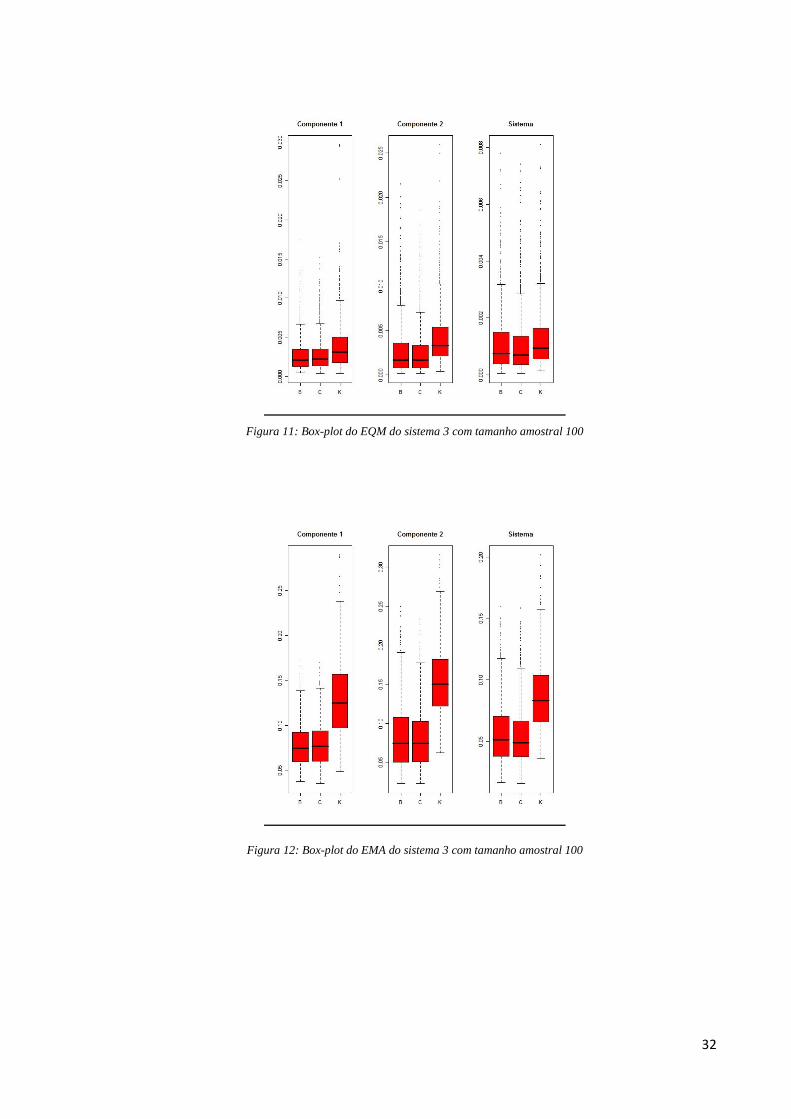
32
Figura 11: Box-plot do EQM do sistema 3 com tamanho amostral 100
Figura 12: Box-plot do EMA do sistema 3 com tamanho amostral 100
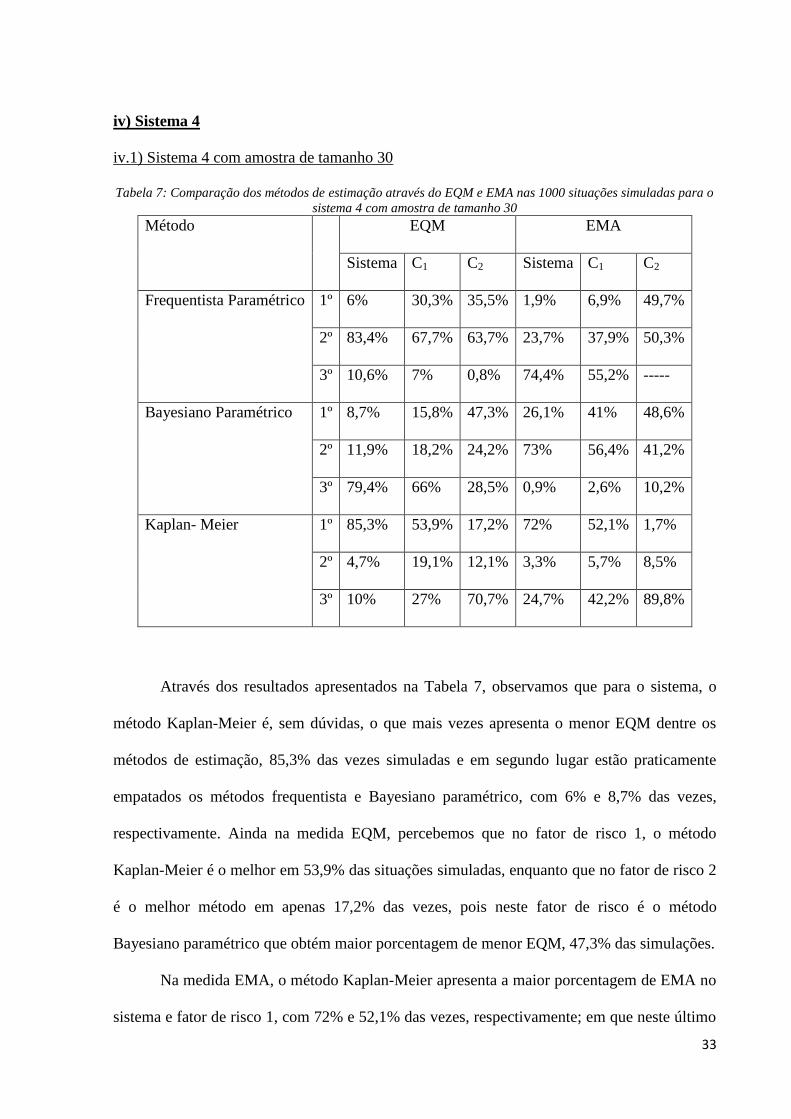
33
iv) Sistema 4
iv.1) Sistema 4 com amostra de tamanho 30
Tabela 7: Comparação dos métodos de estimação através do EQM e EMA nas 1000 situações simuladas para o
sistema 4 com amostra de tamanho 30
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 6% 30,3% 35,5% 1,9% 6,9% 49,7%
2º 83,4% 67,7% 63,7% 23,7% 37,9% 50,3%
3º 10,6% 7% 0,8% 74,4% 55,2% -----
Bayesiano Paramétrico 1º 8,7% 15,8% 47,3% 26,1% 41% 48,6%
2º 11,9% 18,2% 24,2% 73% 56,4% 41,2%
3º 79,4% 66% 28,5% 0,9% 2,6% 10,2%
Kaplan- Meier 1º 85,3% 53,9% 17,2% 72% 52,1% 1,7%
2º 4,7% 19,1% 12,1% 3,3% 5,7% 8,5%
3º 10% 27% 70,7% 24,7% 42,2% 89,8%
Através dos resultados apresentados na Tabela 7, observamos que para o sistema, o
método Kaplan-Meier é, sem dúvidas, o que mais vezes apresenta o menor EQM dentre os
métodos de estimação, 85,3% das vezes simuladas e em segundo lugar estão praticamente
empatados os métodos frequentista e Bayesiano paramétrico, com 6% e 8,7% das vezes,
respectivamente. Ainda na medida EQM, percebemos que no fator de risco 1, o método
Kaplan-Meier é o melhor em 53,9% das situações simuladas, enquanto que no fator de risco 2
é o melhor método em apenas 17,2% das vezes, pois neste fator de risco é o método
Bayesiano paramétrico que obtém maior porcentagem de menor EQM, 47,3% das simulações.
Na medida EMA, o método Kaplan-Meier apresenta a maior porcentagem de EMA no
sistema e fator de risco 1, com 72% e 52,1% das vezes, respectivamente; em que neste último
34
o método Bayesiano está em segundo lugar com 41% das simulações com menor EMA. Já no
fator de risco 2 a situação do Kaplan-Meier se inverte: ele é o pior método em 89,8% das
simulações enquanto que os métodos Bayesiano e frequentista paramétrico estão praticamente
empatados quando levamos em consideração aqueles com maior porcentagem de menor erro
máximo absoluto (48,6% e 49,7%, respectivamente).
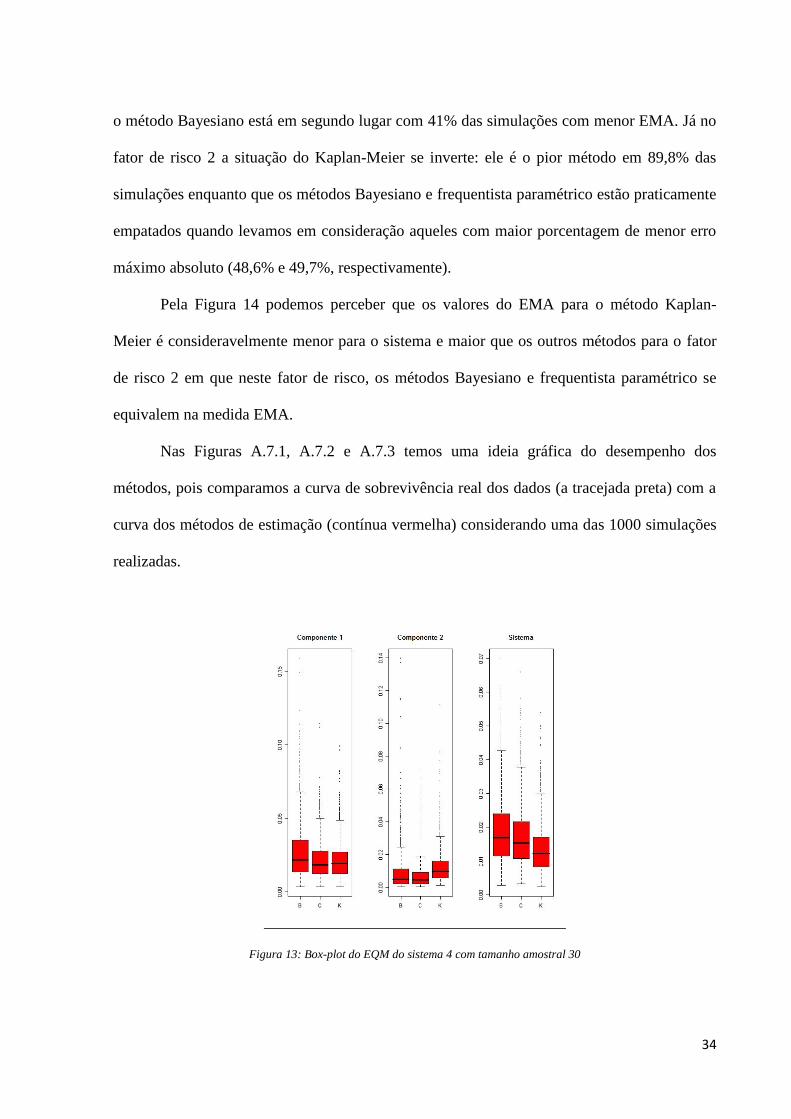
Pela Figura 14 podemos perceber que os valores do EMA para o método Kaplan-
Meier é consideravelmente menor para o sistema e maior que os outros métodos para o fator
de risco 2 em que neste fator de risco, os métodos Bayesiano e frequentista paramétrico se
equivalem na medida EMA.
Nas Figuras A.7.1, A.7.2 e A.7.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações
realizadas.
Figura 13: Box-plot do EQM do sistema 4 com tamanho amostral 30
35
Figura 14: Box-plot do EMA do sistema 4 com tamanho amostral 30
iv.2) Sistema 4 com amostra de tamanho 100
Tabela 8: Comparação dos métodos de estimação através do EQM e EMA nas 1000 situações simuladas para o
sistema 4 com amostra de tamanho 100
Método EQM EMA
Sistema C1 C2 Sistema C1 C2
Frequentista Paramétrico 1º 15,6% 49,6% 37,9% ----- ----- 45,9%
2º 71,9% 48,1% 59,1% 22,2% 34,8% 53,4%
3º 12,5% 2,3% 3% 77,8% 65,2% 0,7%
Bayesiano Paramétrico 1º 1,8% 7,9% 41,9% 23,8% 36,5% 51,9%
2º 23% 34,5% 32,3% 76,2% 63,5% 44,1%
3º 75,2% 57,6% 25,8% ------ ----- 4%
Kaplan- Meier 1º 82,6% 42,5% 20,2% 76,2% 63,5% 2,2%
2º 5,1% 17,4% 8,6% 1,6% 1,7% 2,5%
3º 12,3% 40,1% 71,2% 22,2% 34,8% 95,3%

36
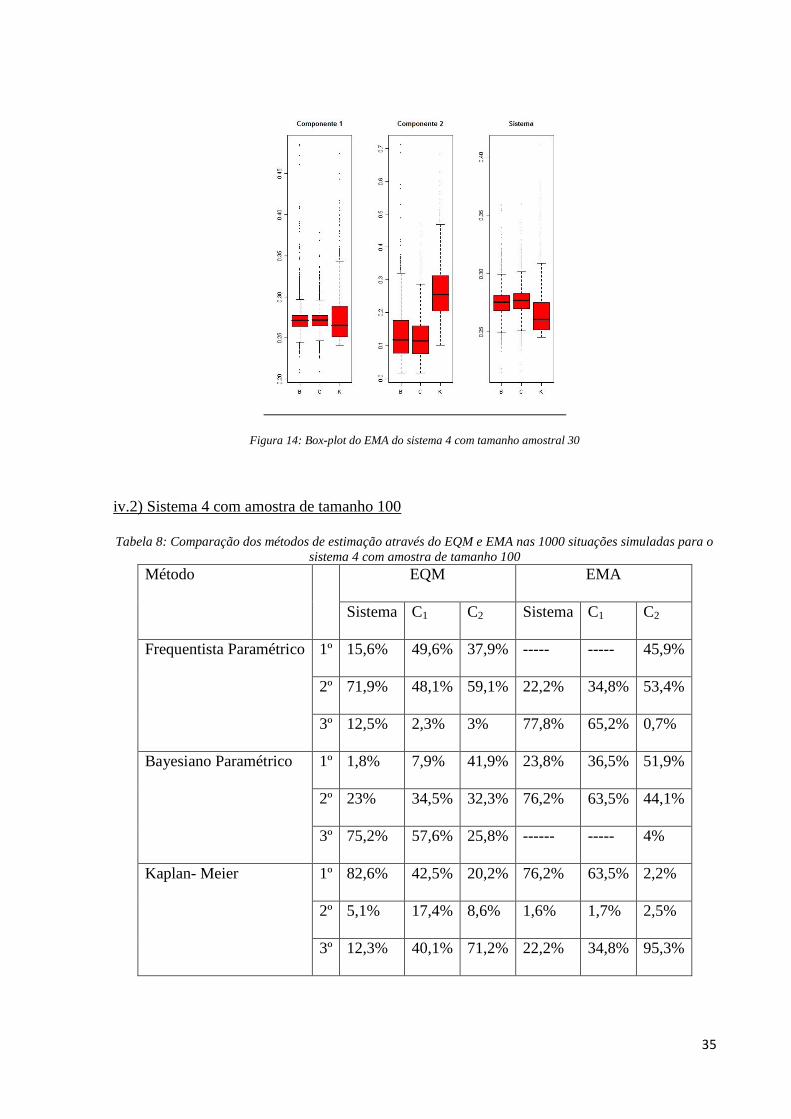
Através dos resultados apresentados na Tabela 8, observamos que para o sistema, o
método Kaplan-Meier é, sem dúvidas, o que mais vezes apresenta o menor EQM dentre os
métodos de estimação, 85,3% das vezes simuladas e em último lugar está o método
Bayesiano paramétrico, com apenas 1,8% das simulações com menor EQM no sistema. Ainda
na medida EQM, percebemos que o método frequentista paramétrico é o melhor em 49,6%
das situações simuladas no fator de risco 1, seguido pelo Kaplan-Meier com 42,5% das vezes
com menor EQM neste fator de risco. Já no fator de risco 2 o método com maior porcentagem
de menor EQM dentre os três comparados é o Bayesiano paramétrico, com 41,9% das
situações simuladas.
Na medida EMA, o método Kaplan-Meier apresenta a maior porcentagem de EMA no
sistema e fator de risco 1, com 76,2% e 63,5% das vezes, respectivamente; em que nestes
casos o método frequentista paramétrico não obtém menor EMA em nenhuma das 1000
simulações. Já no fator de risco 2 a situação do Kaplan-Meier se inverte: ele é o pior método
em 95,3% das simulações enquanto que o método Bayesiano apresenta maior porcentagem de
menor erro máximo absoluto, 51,9% das simulações.
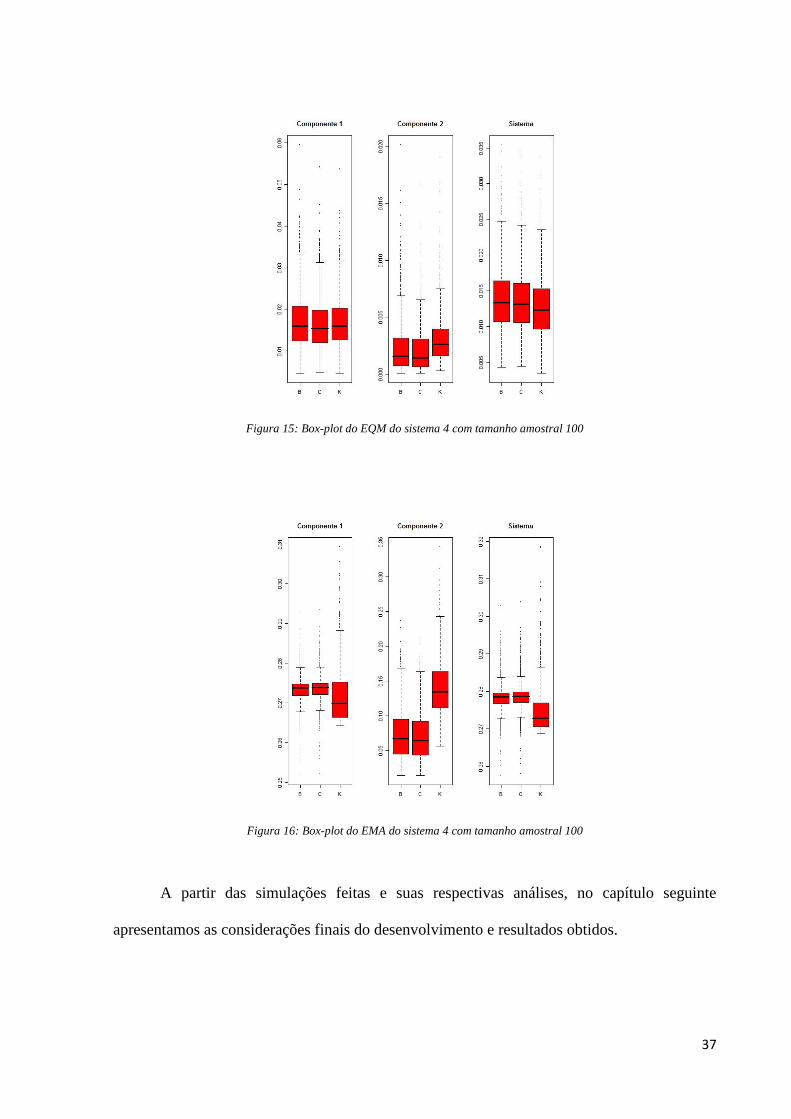
Pela Figura 15, podemos perceber que diferentemente dos outros sistemas estudados,
não existe diferença aparente entre os valores dos EQM do método Kaplan-Meier em relação
aos outros dois métodos de estimação tanto para o sistema quanto para os fatores de risco.
Nas Figuras A.8.1., A.8.2 e A.8.3 temos uma ideia gráfica do desempenho dos
métodos, pois comparamos a curva de sobrevivência real dos dados (a tracejada preta) com a
curva dos métodos de estimação (contínua vermelha) considerando uma das 1000 simulações
realizadas.
37
Figura 15: Box-plot do EQM do sistema 4 com tamanho amostral 100
Figura 16: Box-plot do EMA do sistema 4 com tamanho amostral 100
A partir das simulações feitas e suas respectivas análises, no capítulo seguinte
apresentamos as considerações finais do desenvolvimento e resultados obtidos.

38
4. CONSIDERAÇÕES FINAIS
Estudamos a literatura de riscos competitivos, assim como os métodos de estimação
para o sistema e fatores de risco. Este estudo envolve o estimador de Kaplan-Meier, o modelo
Weibull sob o enfoque frequentista e Bayesiano. Para o desenvolvimento da metodologia
Bayesiana, aplicamos o algoritmo de Metropolis-Hastings.
Com os resultados obtidos no capítulo 3, observamos que o método Bayesiano
paramétrico é o método que obteve mais vezes melhor desempenho de EQM para o sistema e
fatores de risco; seguido, na grande maioria das vezes, pelo método frequentista paramétrico.
Ainda comparando os métodos, o frequentista paramétrico apresenta porcentagens
insignificantes de ser o pior método de estimação entre os três comparados. Em contrapartida
está o método Bayesiano paramétrico que mesmo sendo o que apresenta maiores proporções
de ser o melhor método, apresenta também altas porcentagens de ser o método com maior
EQM para o sistema e fatores de risco.
O método de estimação Kaplan-Meier apresenta as maiores porcentagens de pior
desempenho tanto para o sistema quanto para os fatores de risco; a única exceção é o sistema
4, em que os tempos de falha dos fatores de risco são os valores absolutos de uma distribuição
normal. Neste caso, o estimador de Kaplan-Meier é equivalente ou até mesmo superior que os
outros dois métodos para o sistema e o fator de risco 1 nos dois tamanhos amostrais
considerados.
Através da análise realizada, concluímos que os métodos de estimação frequentista e
Bayesiano paramétrico com a priori de Jefreys, sob o modelo Weibull, são equivalentes. Eles
competiram entre eles sendo na maioria das vezes os melhores métodos, ora um ora outro. Tal
fato era esperado uma vez que trabalhamos com uma priori não informativa no caso
Bayesiano, dando importância apenas aos dados. Enquanto que o método de Kaplan-Meier

39
obteve desempenho inferior aos outros dois. Com isso, podemos dizer que o modelo
paramétrico Weibull obteve melhor desempenho em relação ao modelo não-paramétrico de
Kaplan-Meier.
40
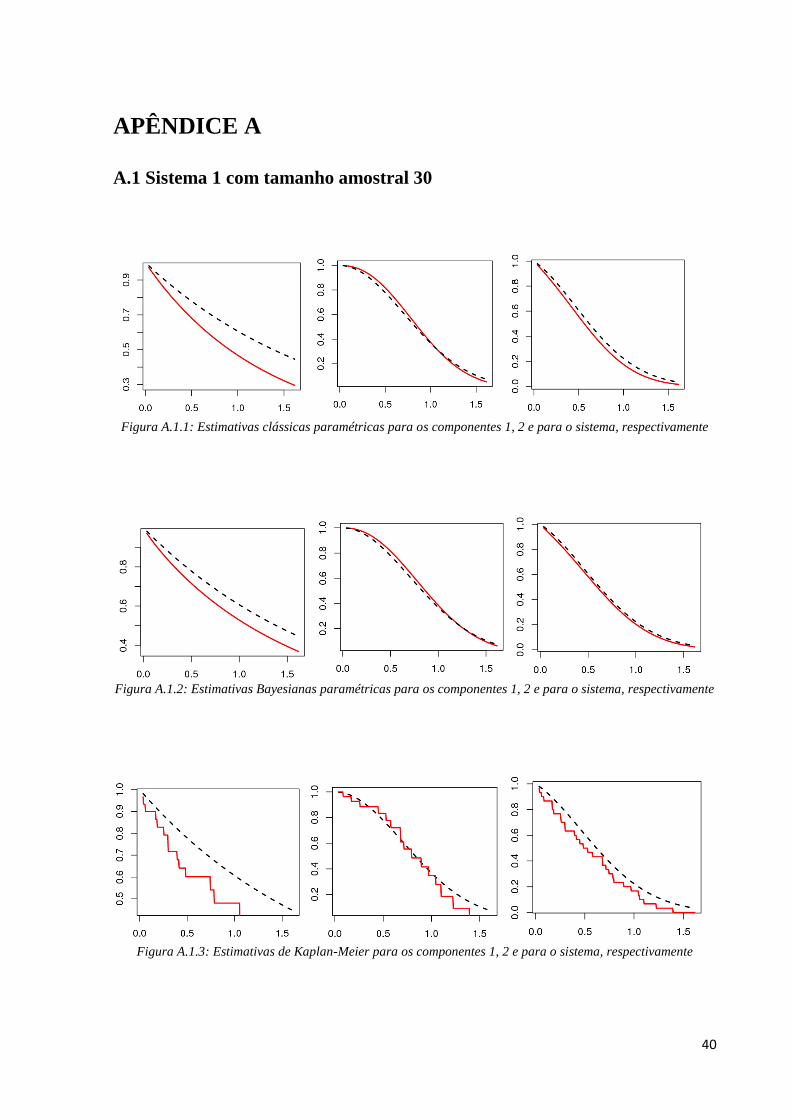
APÊNDICE A
A.1 Sistema 1 com tamanho amostral 30
Figura A.1.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.1.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.1.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
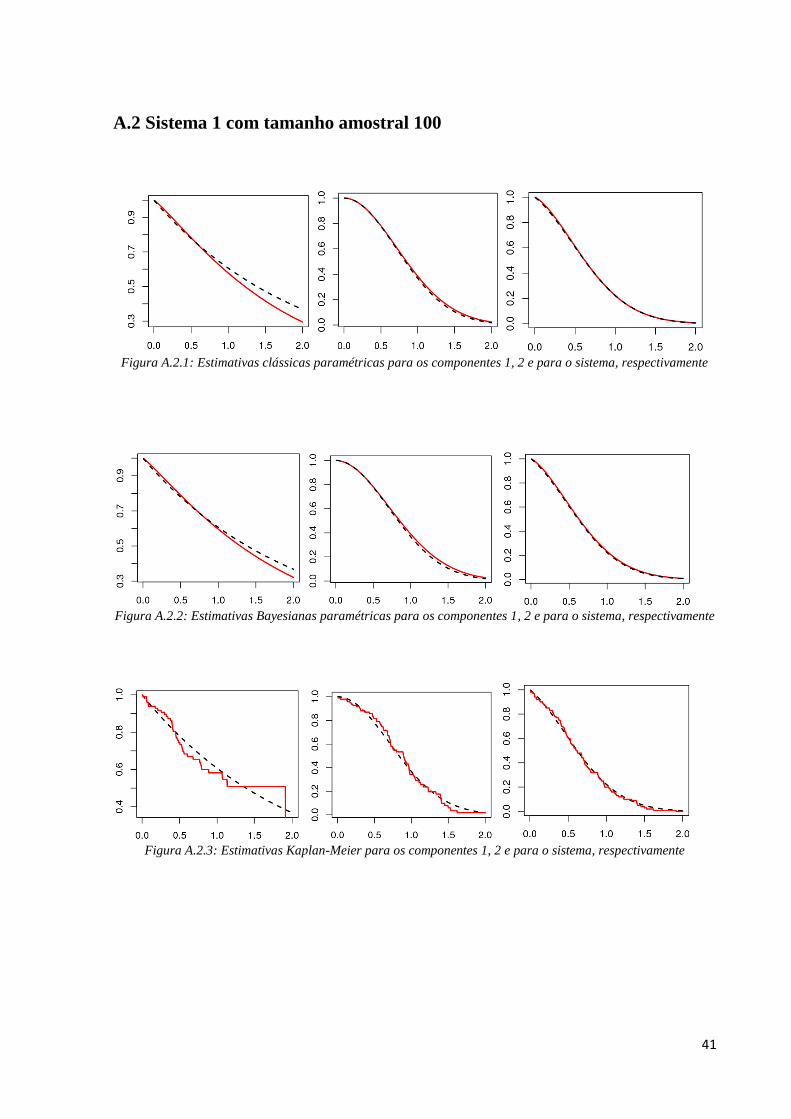
41
A.2 Sistema 1 com tamanho amostral 100
Figura A.2.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.2.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.2.3: Estimativas Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
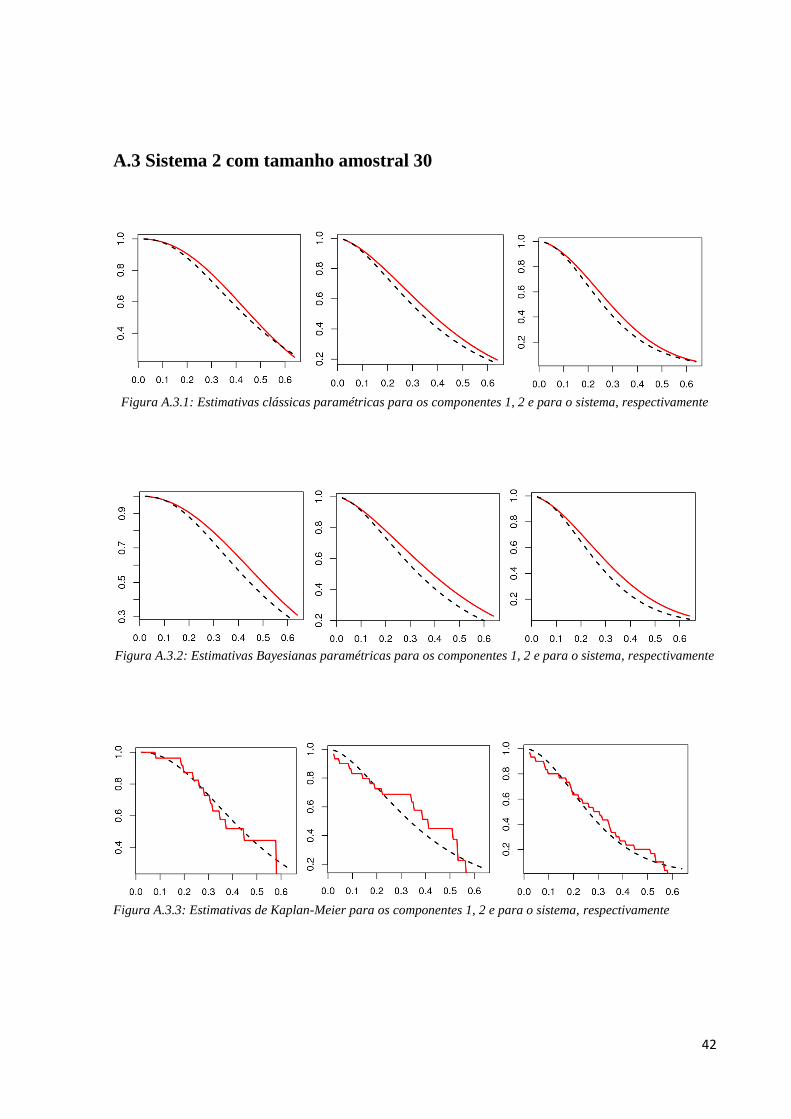
42
A.3 Sistema 2 com tamanho amostral 30
Figura A.3.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.3.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.3.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
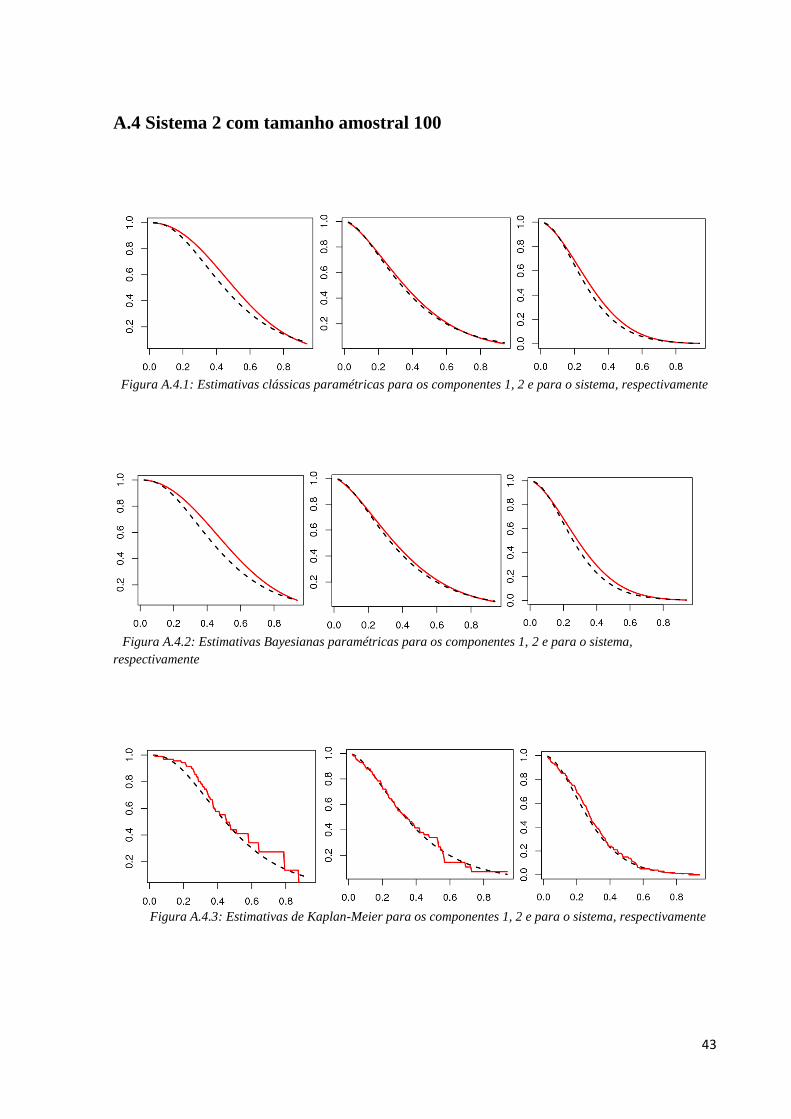
43
A.4 Sistema 2 com tamanho amostral 100
Figura A.4.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.4.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema,
respectivamente
Figura A.4.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
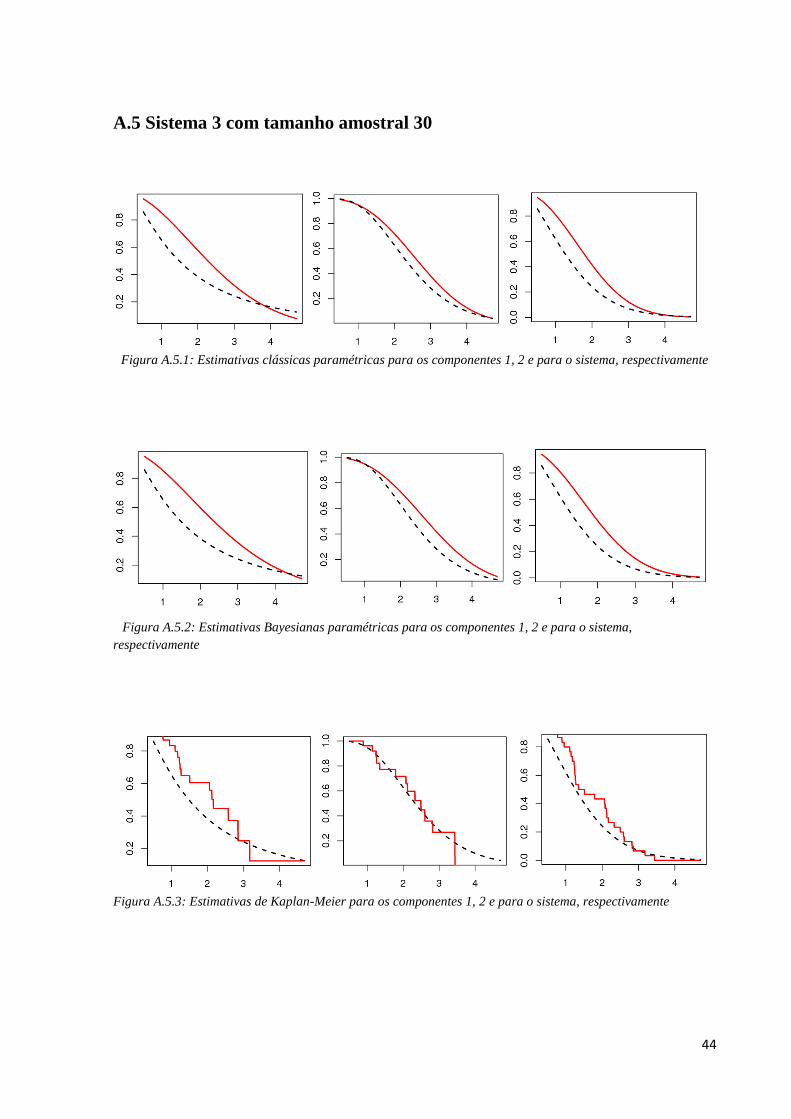
44
A.5 Sistema 3 com tamanho amostral 30
Figura A.5.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.5.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema,
respectivamente
Figura A.5.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
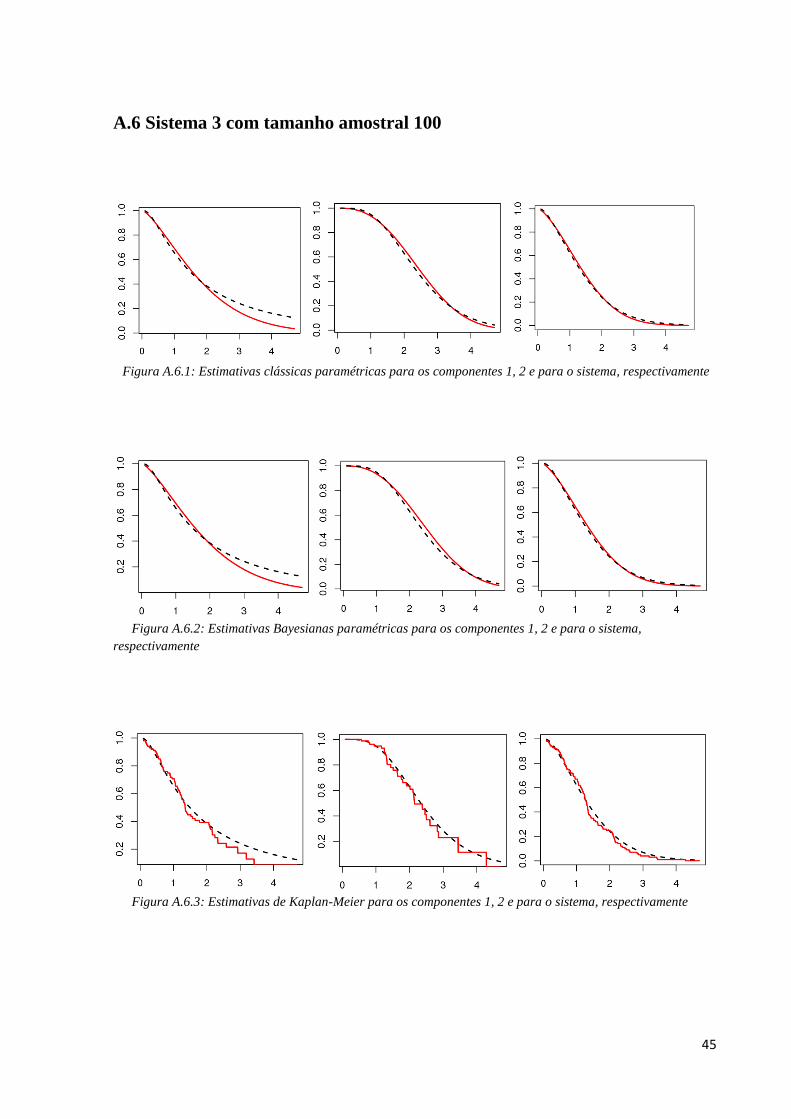
45
A.6 Sistema 3 com tamanho amostral 100
Figura A.6.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.6.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema,
respectivamente
Figura A.6.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
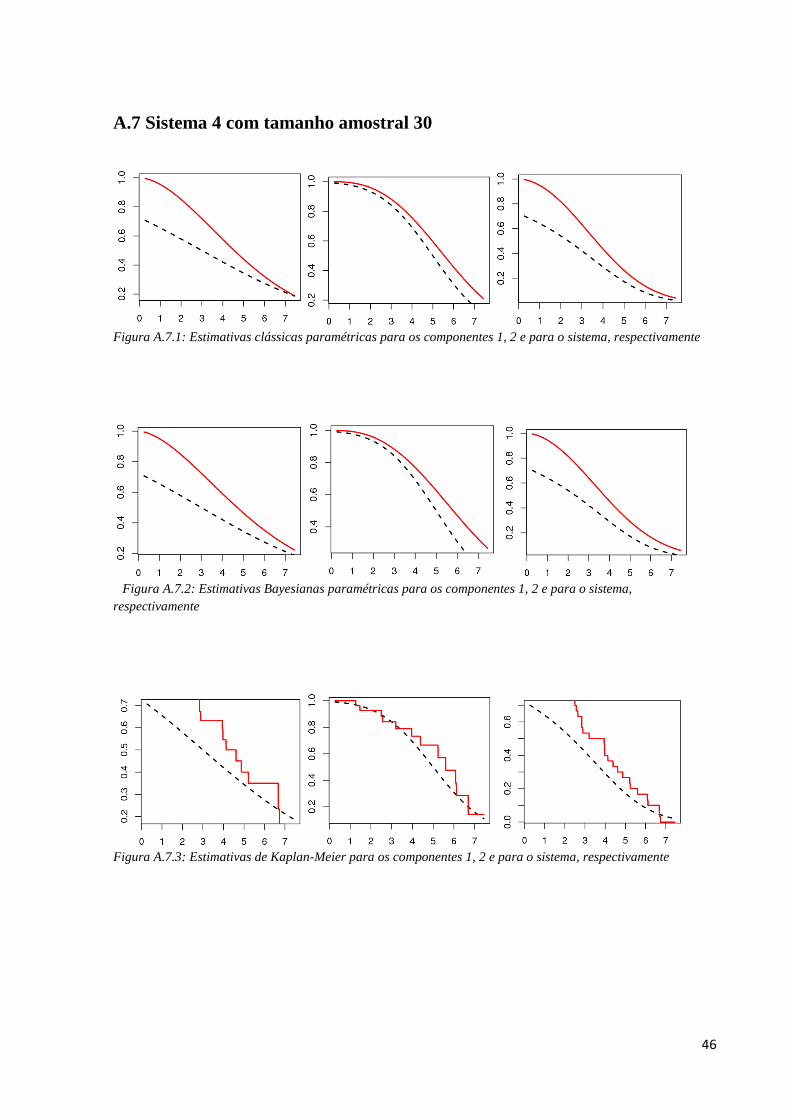
46
A.7 Sistema 4 com tamanho amostral 30
Figura A.7.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.7.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema,
respectivamente
Figura A.7.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente
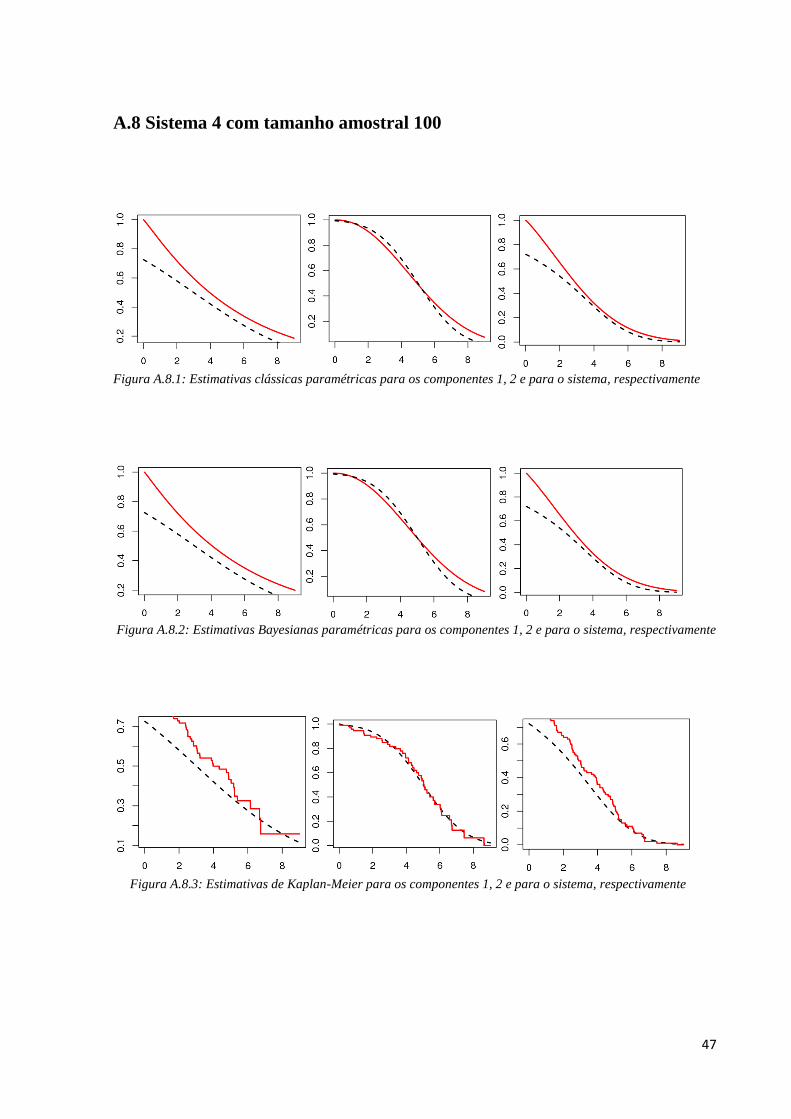
47
A.8 Sistema 4 com tamanho amostral 100
Figura A.8.1: Estimativas clássicas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.8.2: Estimativas Bayesianas paramétricas para os componentes 1, 2 e para o sistema, respectivamente
Figura A.8.3: Estimativas de Kaplan-Meier para os componentes 1, 2 e para o sistema, respectivamente

48
APÊNDICE B
B.1 - Monitoramento de Convergência do sistema 1 com tamanho amostral 30
Tabela B.2: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 1 com tamanho
de amostra 30
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
22%
1,000178
η 1,000104
Componente 2 β
25%
1,000046
η 1,000486
Como podemos ver na Tabela B.1, para o fator de risco 1, obtivemos uma taxa de
aceitação de 22% e para o 2, a taxa de aceitação obtida é de 25%.
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.1.1) de cada
parâmetro podemos verificar que a partir da iteração 20000 as cadeias apresentam
convergência, então os 20000 pontos iniciais gerados foram excluídos. Em seguida,
verificamos se existe correlação entre as iterações. Utilizamos salto de tamanho 100, pois com
essa distância entre as iterações resolvemos o problema de iterações dependentes. Após retirar
o salto, na Figura B.1.2 podemos ver os gráficos de autocorrelação dos parâmetros e
percebemos não existir nenhum lag significativo, indicando iterações não-correlacionadas.
Para verificar a convergência para a distribuição estacionária, analisamos os gráficos
de série temporal da Figura B.1.3 em que não identificamos problemas, indicando
convergência para a distribuição de interesse. Por fim, pela Tabela B.1, os valores de Gelman
e Rubin dos parâmetros beta e eta são, respectivamente, ^
R =1,000178 e ^
R = 1,000104, o que é
próximo de 1 indicando formalmente convergência das cadeias.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.1.4) de cada
parâmetro podemos verificar que a partir da iteração 10000 as cadeias apresentam
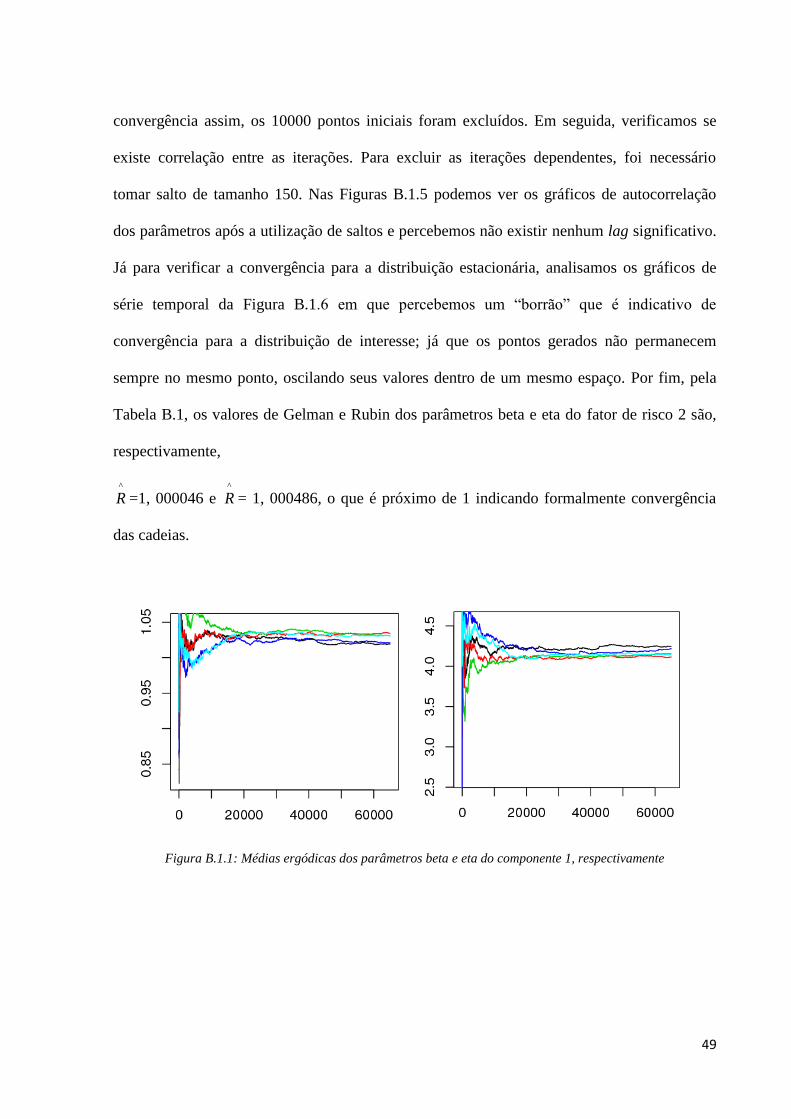
49
convergência assim, os 10000 pontos iniciais foram excluídos. Em seguida, verificamos se
existe correlação entre as iterações. Para excluir as iterações dependentes, foi necessário
tomar salto de tamanho 150. Nas Figuras B.1.5 podemos ver os gráficos de autocorrelação
dos parâmetros após a utilização de saltos e percebemos não existir nenhum lag significativo.
Já para verificar a convergência para a distribuição estacionária, analisamos os gráficos de
série temporal da Figura B.1.6 em que percebemos um “borrão” que é indicativo de
convergência para a distribuição de interesse; já que os pontos gerados não permanecem
sempre no mesmo ponto, oscilando seus valores dentro de um mesmo espaço. Por fim, pela
Tabela B.1, os valores de Gelman e Rubin dos parâmetros beta e eta do fator de risco 2 são,
respectivamente,
^
R =1, 000046 e ^
R = 1, 000486, o que é próximo de 1 indicando formalmente convergência
das cadeias.
Figura B.1.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
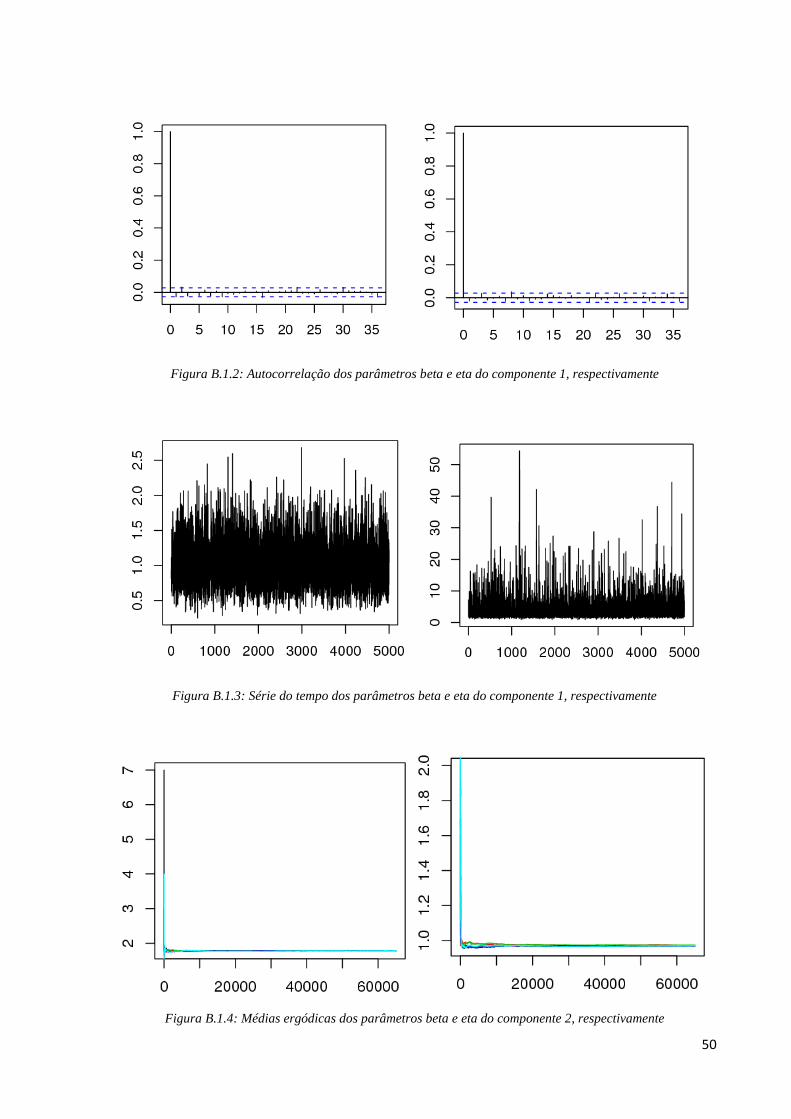
50
Figura B.1.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.1.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
Figura B.1.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
51
Figura B.1.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
Figura B.1.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente
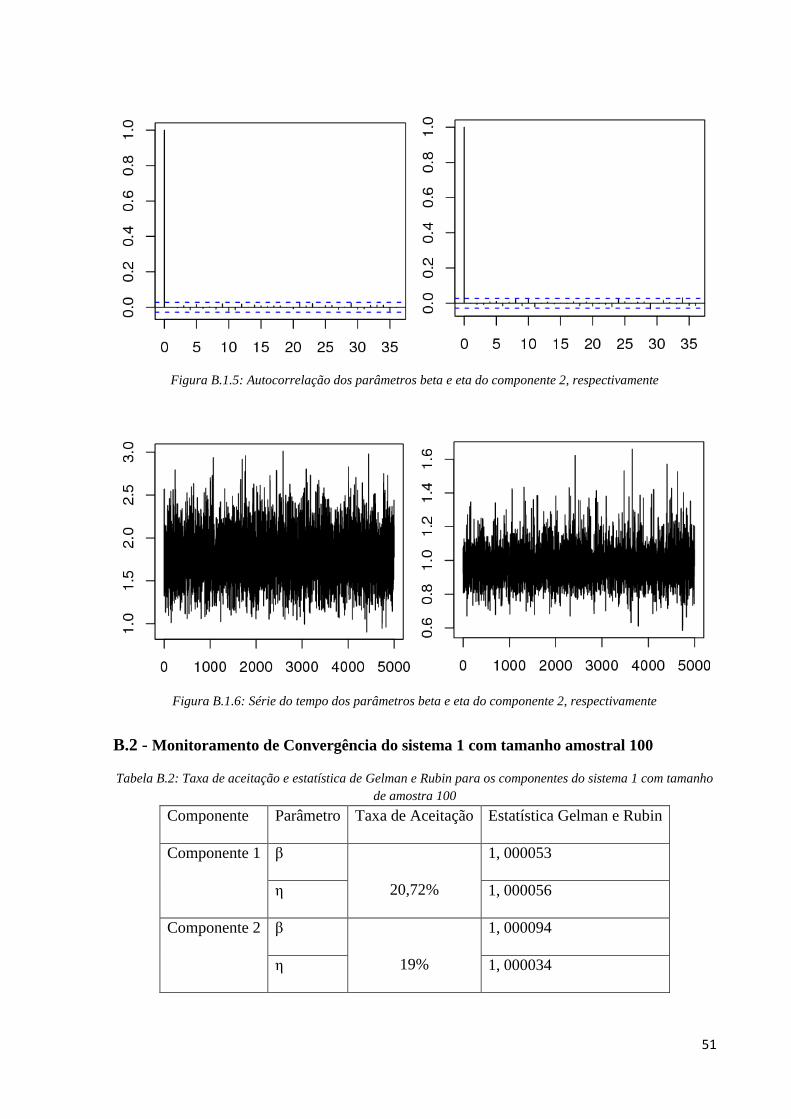
B.2 - Monitoramento de Convergência do sistema 1 com tamanho amostral 100
Tabela B.2: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 1 com tamanho
de amostra 100
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
20,72%
1, 000053
η 1, 000056
Componente 2 β
19%
1, 000094
η 1, 000034

52
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.2.1) de cada
parâmetro podemos verificar que sendo um pouco rigoroso, a partir da iteração 70000, as
cadeias apresentam convergência. Assim, os 70000 pontos iniciais gerados foram excluídos.
Em seguida, na análise de correlação entre as iterações, utilizamos salto de tamanho 150; em
que na Figura B.2.2 podemos ver os gráficos de autocorrelação dos parâmetros após a
utilização do salto e percebemos não existir mais correlação entre as iterações. Para verificar a
convergência para a distribuição estacionária, analisamos os gráficos de série temporal da
Figura B.2.3 em que percebemos um “borrão”, indicando convergência para a distribuição de
interesse. Pela Tabela B.2, os valores de Gelman e Rubin dos parâmetros beta e eta são,
respectivamente, ^
R =1, 000053 e ^
R = 1, 000056, o que é próximo de 1 indicando
formalmente convergência das cadeias e também uma boa taxa de aceitação: 20,72%.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.2.4) de cada
parâmetro podemos verificar que a partir da iteração 60000 as cadeias apresentam
convergência e por isso, os 60000 primeiros pontos foram excluídos. Em seguida, verificamos
se existe correlação entre as iterações. Para excluir as iterações dependentes, tomamos salto
de tamanho 150 e na Figura B.2.5 percebemos não existir nenhum lag significativo nos
gráficos de autocorrelação dos parâmetros após a utilização de saltos. Já para verificar a
convergência para a distribuição estacionária, analisamos os gráficos de série temporal da
Figura B.2.6 em que percebemos um “borrão”, indicativo de convergência para a distribuição
de interesse. Por fim, pela Tabela B.2, os valores de Gelman e Rubin dos parâmetros beta e
eta do fator de risco 2 são, respectivamente, ^
R =1, 000094 e ^
R = 1, 000034, o que é próximo
de 1 indicando formalmente convergência das cadeias e a taxa de aceitação obtida foi de 19%.
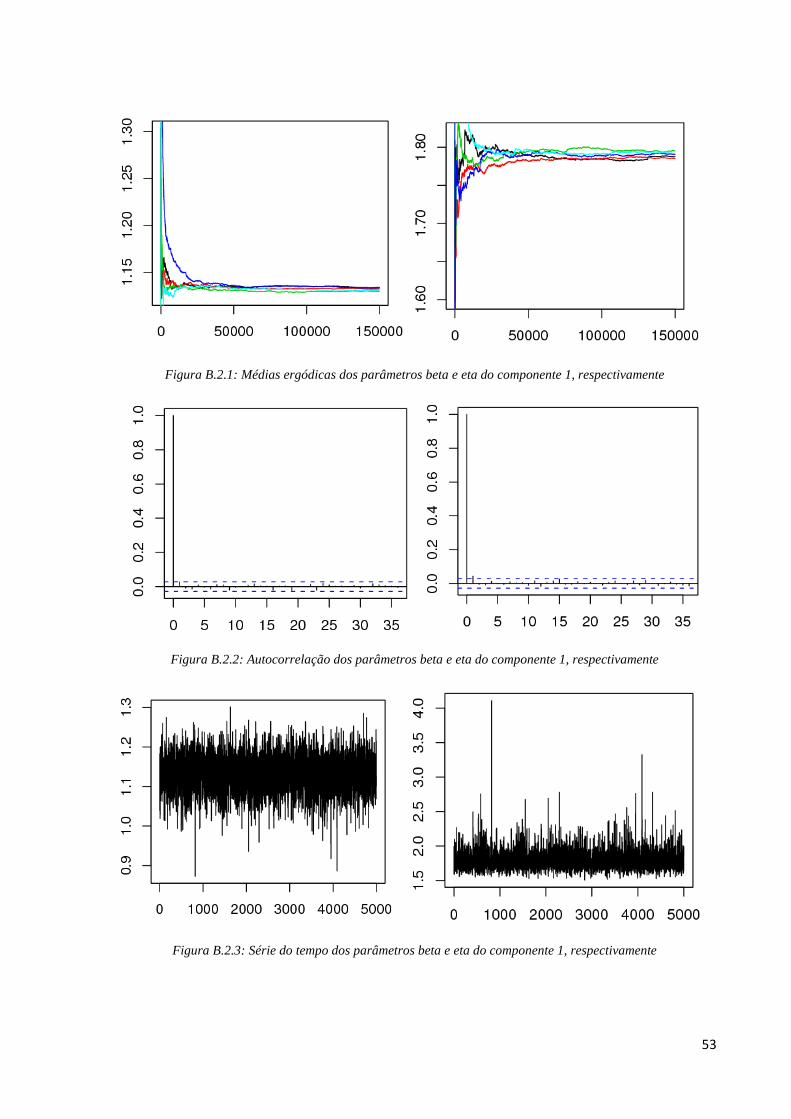
53
Figura B.2.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
Figura B.2.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.2.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
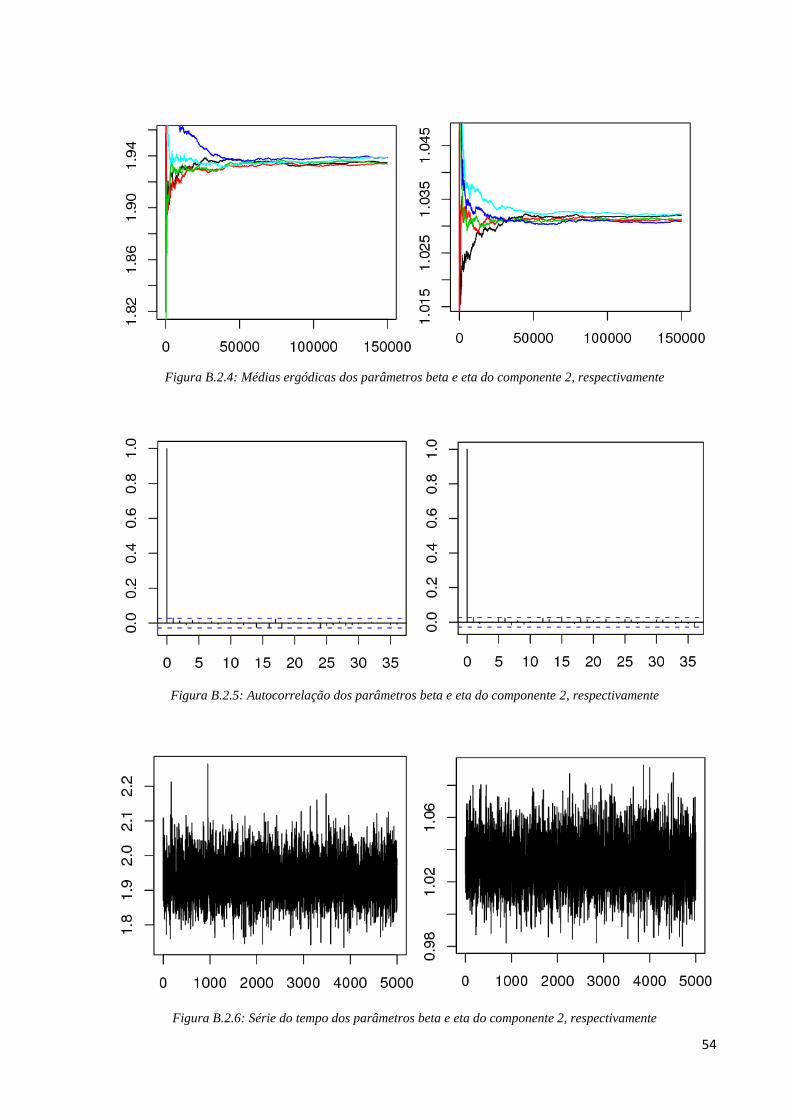
54
Figura B.2.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
Figura B.2.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
Figura B.2.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente

55
B.3 - Monitoramento de Convergência do sistema 2 com tamanho amostral 30
Tabela B.3: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 2 com tamanho
de amostra 30
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
22,732%
1, 000395
η 1, 000535
Componente 2 β
20,13%
1, 000151
η 1, 000027
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.3.1) de cada
parâmetro podemos verificar que a partir da iteração 80000, as cadeias apresentam
convergência. Assim, os 80000 primeiros pontos gerados foram excluídos. Em seguida, na
análise de correlação entre as iterações, utilizamos salto de tamanho 280; em que na Figura
B.3.2 podemos ver os gráficos de autocorrelação dos parâmetros após a utilização de saltos e
percebemos não existir mais autocorrelação entre as iterações. Na Figura B.3.3, percebemos
um “borrão” nos gráficos de série temporal indicando convergência para a distribuição de
interesse. Pela Tabela B.3, os valores de Gelman e Rubin dos parâmetros beta e eta são,
respectivamente, ^
R =1, 000395 e ^
R = 1, 000535, o que é próximo de 1 indicando
formalmente convergência das cadeias e também observa-se uma boa taxa de aceitação:
22,732%.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.3.4) de cada
parâmetro verificamos que a partir da iteração 80000 as cadeias apresentam convergência e
por isso, os 80000 primeiros pontos foram excluídos. Em seguida, analisamos se existe
correlação entre as iterações. Para excluir as iterações dependentes, tomamos salto de
tamanho 150 e na Figura B.3.5 percebemos não existir mais autocorrelação após a utilização
de saltos. Para verificar a convergência para a distribuição estacionária, analisamos os
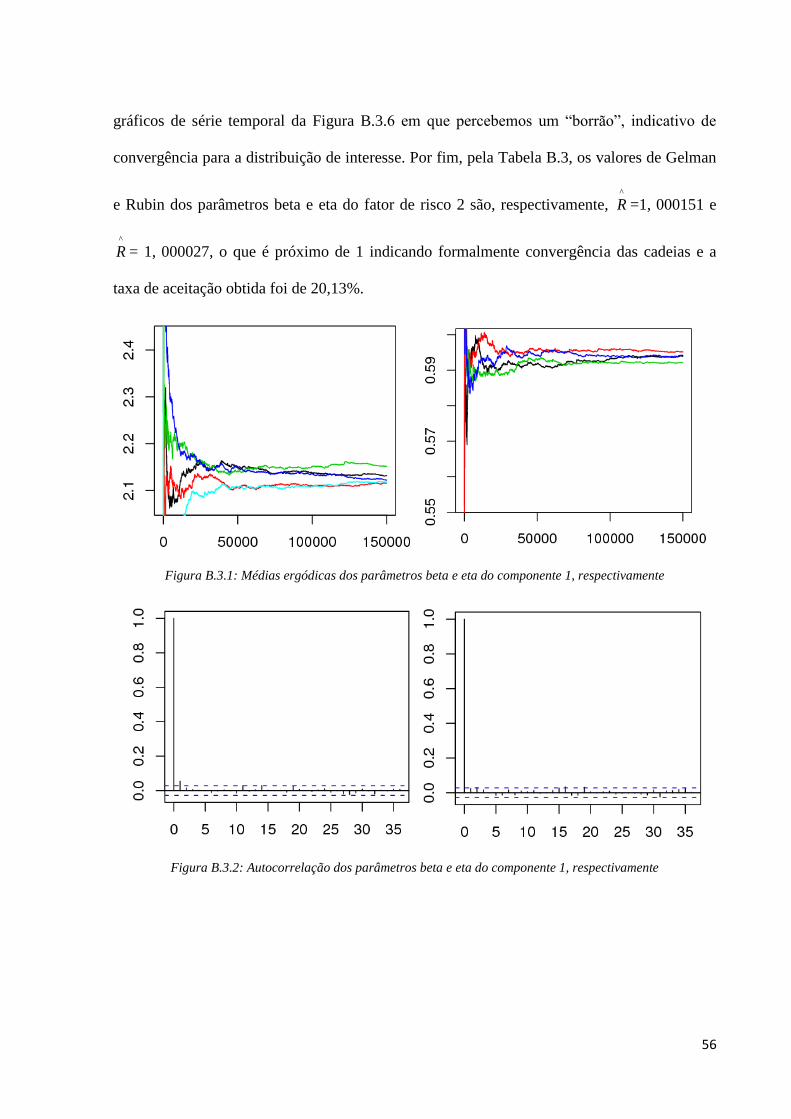
56
gráficos de série temporal da Figura B.3.6 em que percebemos um “borrão”, indicativo de
convergência para a distribuição de interesse. Por fim, pela Tabela B.3, os valores de Gelman
e Rubin dos parâmetros beta e eta do fator de risco 2 são, respectivamente, ^
R =1, 000151 e
^
R = 1, 000027, o que é próximo de 1 indicando formalmente convergência das cadeias e a
taxa de aceitação obtida foi de 20,13%.
Figura B.3.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
Figura B.3.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
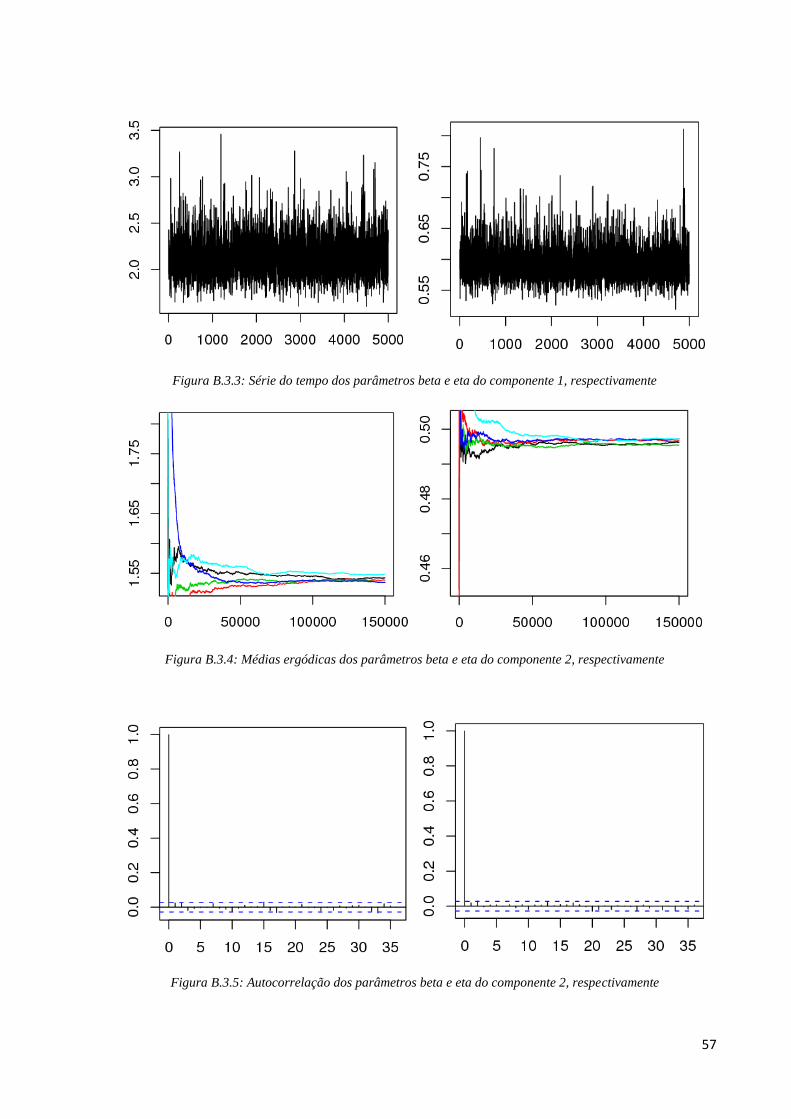
57
Figura B.3.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
Figura B.3.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
Figura B.3.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
58
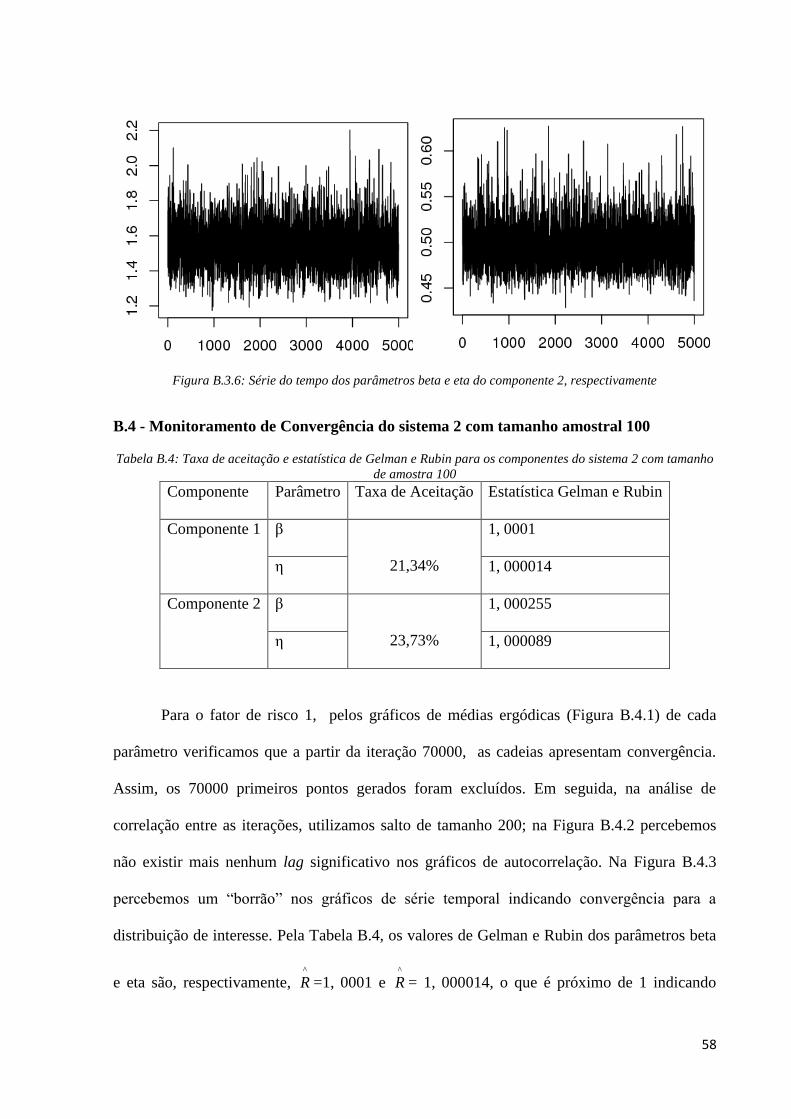
Figura B.3.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente
B.4 - Monitoramento de Convergência do sistema 2 com tamanho amostral 100
Tabela B.4: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 2 com tamanho
de amostra 100
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
21,34%
1, 0001
η 1, 000014
Componente 2 β
23,73%
1, 000255
η 1, 000089
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.4.1) de cada
parâmetro verificamos que a partir da iteração 70000, as cadeias apresentam convergência.
Assim, os 70000 primeiros pontos gerados foram excluídos. Em seguida, na análise de
correlação entre as iterações, utilizamos salto de tamanho 200; na Figura B.4.2 percebemos
não existir mais nenhum lag significativo nos gráficos de autocorrelação. Na Figura B.4.3
percebemos um “borrão” nos gráficos de série temporal indicando convergência para a
distribuição de interesse. Pela Tabela B.4, os valores de Gelman e Rubin dos parâmetros beta
e eta são, respectivamente, ^
R =1, 0001 e ^
R = 1, 000014, o que é próximo de 1 indicando
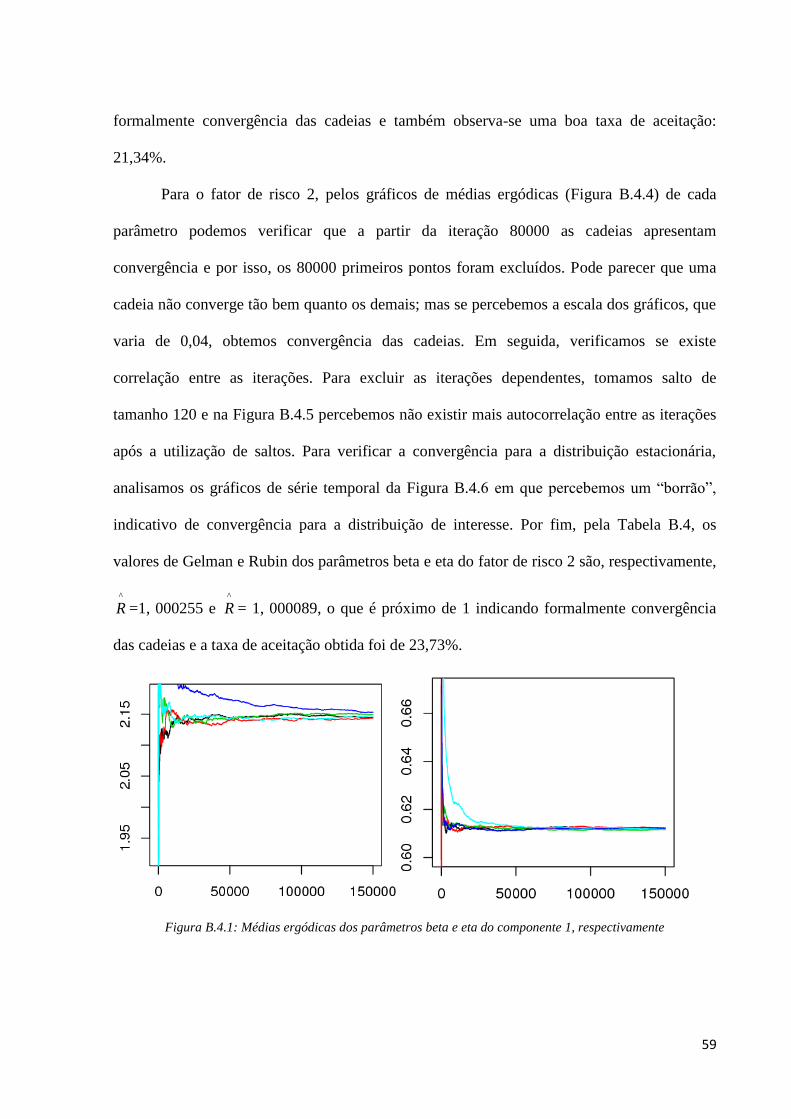
59
formalmente convergência das cadeias e também observa-se uma boa taxa de aceitação:
21,34%.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.4.4) de cada
parâmetro podemos verificar que a partir da iteração 80000 as cadeias apresentam
convergência e por isso, os 80000 primeiros pontos foram excluídos. Pode parecer que uma
cadeia não converge tão bem quanto os demais; mas se percebemos a escala dos gráficos, que
varia de 0,04, obtemos convergência das cadeias. Em seguida, verificamos se existe
correlação entre as iterações. Para excluir as iterações dependentes, tomamos salto de
tamanho 120 e na Figura B.4.5 percebemos não existir mais autocorrelação entre as iterações
após a utilização de saltos. Para verificar a convergência para a distribuição estacionária,
analisamos os gráficos de série temporal da Figura B.4.6 em que percebemos um “borrão”,
indicativo de convergência para a distribuição de interesse. Por fim, pela Tabela B.4, os
valores de Gelman e Rubin dos parâmetros beta e eta do fator de risco 2 são, respectivamente,
^
R =1, 000255 e ^
R = 1, 000089, o que é próximo de 1 indicando formalmente convergência
das cadeias e a taxa de aceitação obtida foi de 23,73%.
Figura B.4.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
60
Figura B.4.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.4.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
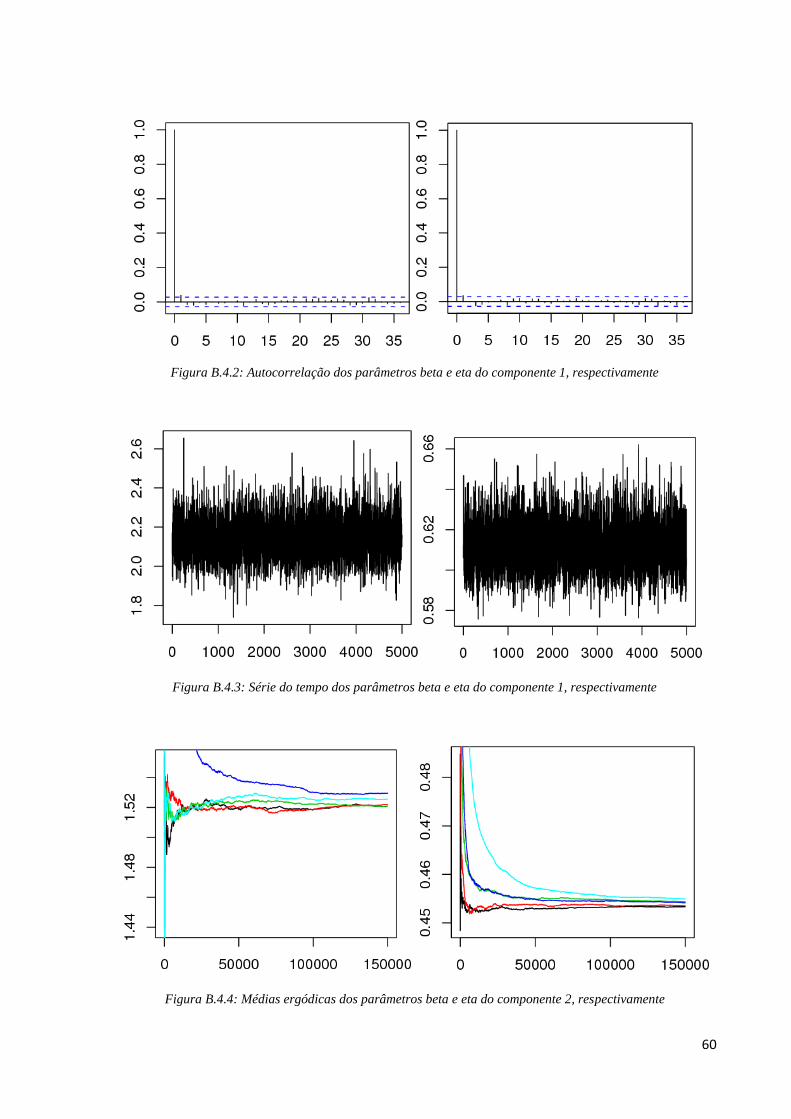
Figura B.4.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
61
Figura B.4.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
Figura B.4.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente
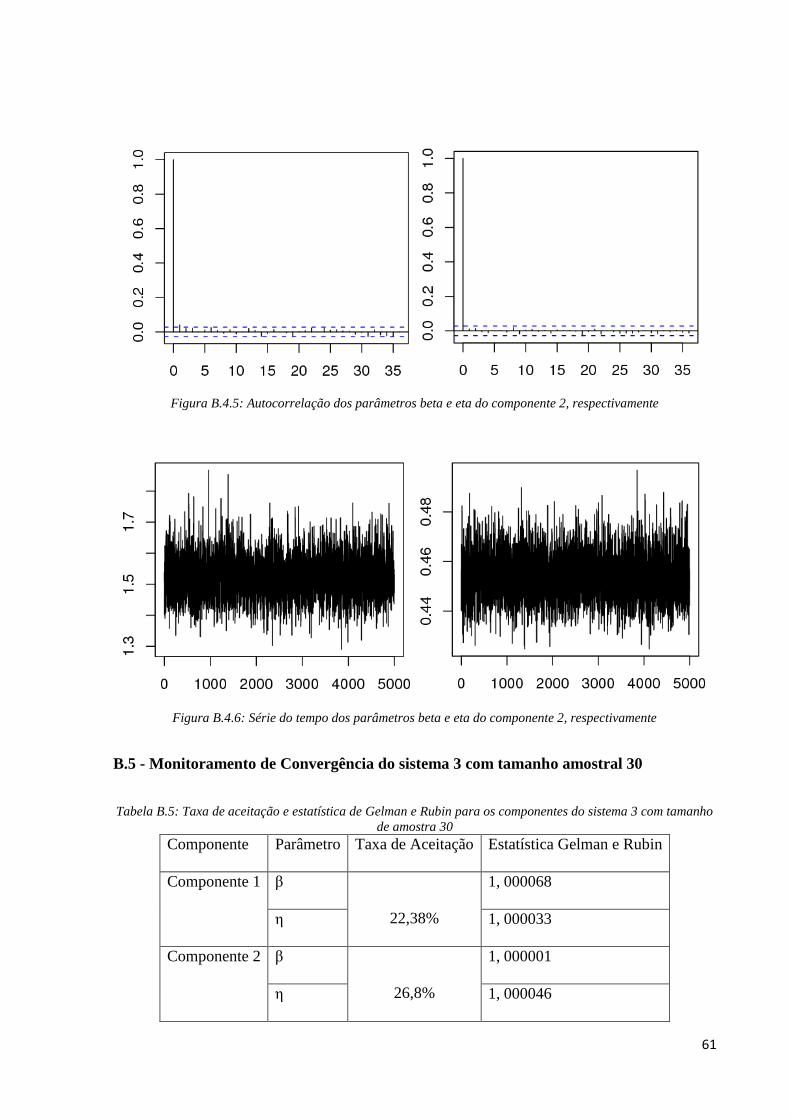
B.5 - Monitoramento de Convergência do sistema 3 com tamanho amostral 30
Tabela B.5: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 3 com tamanho
de amostra 30
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
22,38%
1, 000068
η 1, 000033
Componente 2 β
26,8%
1, 000001
η 1, 000046

62
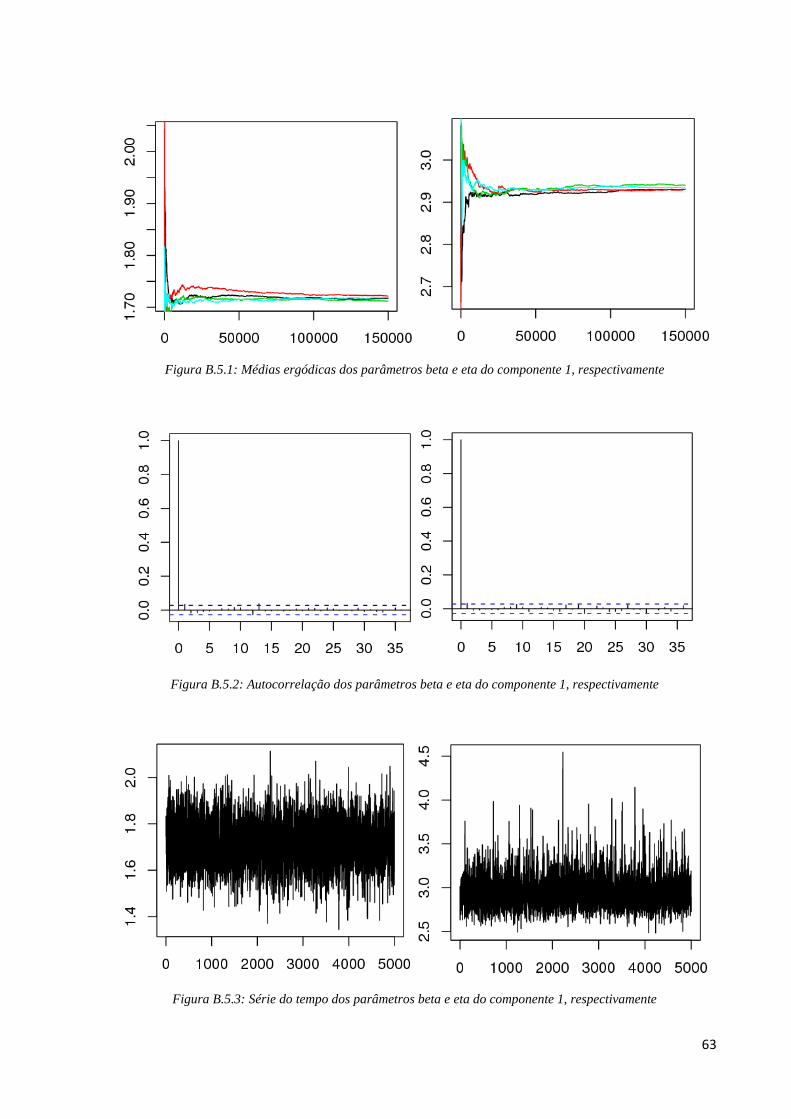
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.5.1) de cada
parâmetro verificamos que a partir da iteração 60000, as cadeias apresentam convergência.
Assim, os 60000 primeiros pontos gerados foram excluídos. Em seguida, na análise de
correlação entre as iterações, utilizamos salto de tamanho 100; em que na Figura B.5.2
percebemos não existir mais nenhum lag significativo nos gráficos de autocorrelação. Na
Figura B.5.3, percebemos um “borrão” nos gráficos de série temporal indicando convergência
para a distribuição de interesse. Pela Tabela B.5, os valores de Gelman e Rubin dos
parâmetros beta e eta são, respectivamente, ^
R =1, 000068 e ^
R = 1, 000033, o que é próximo
de 1 indicando formalmente convergência das cadeias e também observa-se uma boa taxa de
aceitação: 22,38%.
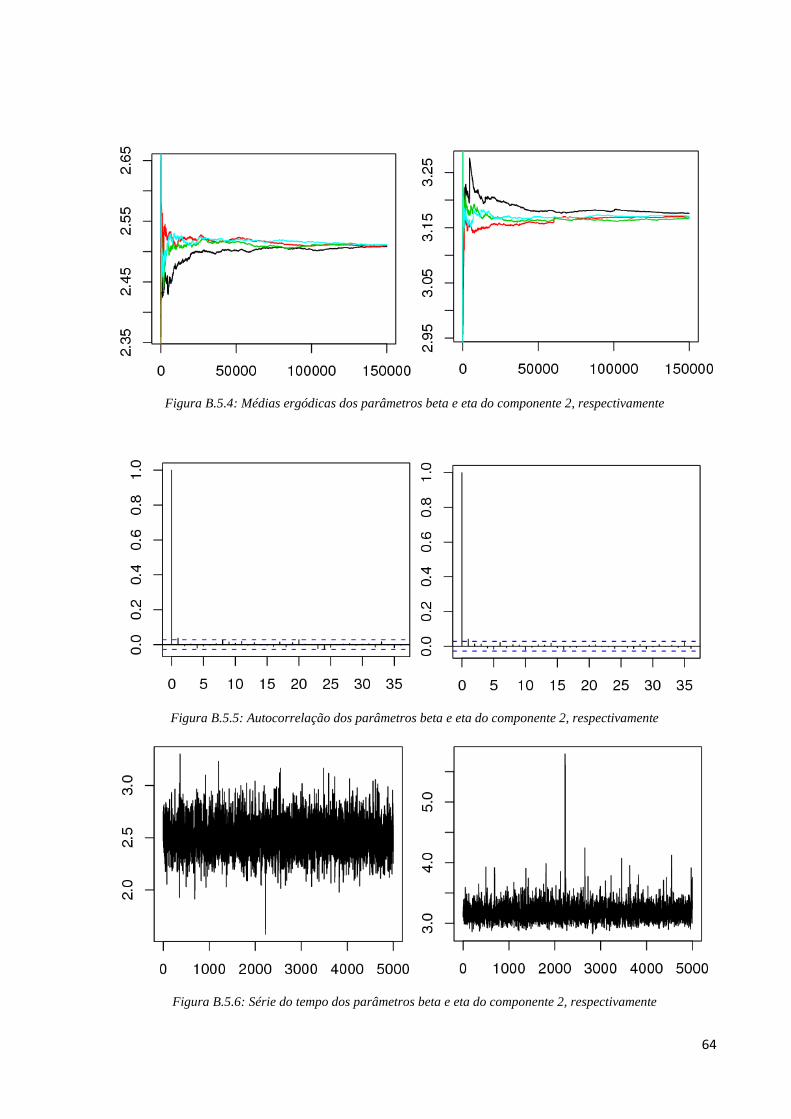
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.5.4) de cada
parâmetro podemos verificar que a partir da iteração 80000 as cadeias apresentam
convergência e por isso, os 80000 primeiros pontos foram excluídos. Em seguida, verificamos
se existe correlação entre as iterações. Para excluir as iterações dependentes, tomamos salto
de tamanho 100 e na Figura B.5.5 percebemos não existir nenhum lag significativo nos
gráficos de autocorrelação dos parâmetros após a utilização de saltos. Para verificar a
convergência para a distribuição estacionária, analisamos os gráficos de série temporal da
Figura B.5.6 em que percebemos um “borrão”, indicativo de convergência para a distribuição
de interesse. Por fim, pela Tabela B.5, os valores de Gelman e Rubin dos parâmetros beta e
eta do fator de risco 2 são, respectivamente, ^
R =1, 000001 e ^
R = 1, 000046, o que é próximo
de 1 indicando formalmente convergência das cadeias e a taxa de aceitação obtida foi de
26,8%.
63
Figura B.5.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
Figura B.5.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.5.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
64
Figura B.5.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
Figura B.5.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
Figura B.5.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente

65
B.6 - Monitoramento de Convergência do sistema 3 com tamanho amostral 100
Tabela B.6: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 3 com tamanho
de amostra 100
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β
25,1%
1, 00003
η 1, 000020
Componente 2 β
21,93%
1, 000069
η 1, 000011
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.6.1) de cada
parâmetro (beta e eta) podemos verificar que a partir da iteração 60000 as cadeias apresentam
convergência. Por isso, os 60000 pontos iniciais gerados foram excluídos. Em seguida,
verificamos se existe correlação entre as iterações e para excluir iterações dependentes,
utilizamos salto de tamanho 100; na Figura B.6.2 podemos ver que após a utilização de saltos
não existe nenhum lag significativo. Para verificar a convergência para a distribuição
estacionária, analisamos os gráficos de série temporal da Figura B.6.3 em que percebemos um
“borrão”, indicando convergência para a distribuição de interesse. Pela Tabela B.6, os valores
de Gelman e Rubin dos parâmetros beta e eta são, respectivamente, ^
R =1, 00003 e ^
R = 1,
00002 e a taxa de aceitação é de 25,1% .
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.6.4) de cada
parâmetro (beta e eta) verificamos que a partir da iteração 50000 as cadeias apresentam
convergência assim, os 50000 primeiros pontos foram excluídos. Em seguida para excluir as
iterações dependentes, tomamos salto de tamanho 150 e na Figura B.6.5 podemos ver que
após a utilização de saltos, percebemos não existir nenhum lag significativo. Já para verificar
a convergência para a distribuição estacionária, analisamos os gráficos de série temporal da
Figura B.6.6 em que percebemos um “borrão”, indicativo de convergência para a distribuição
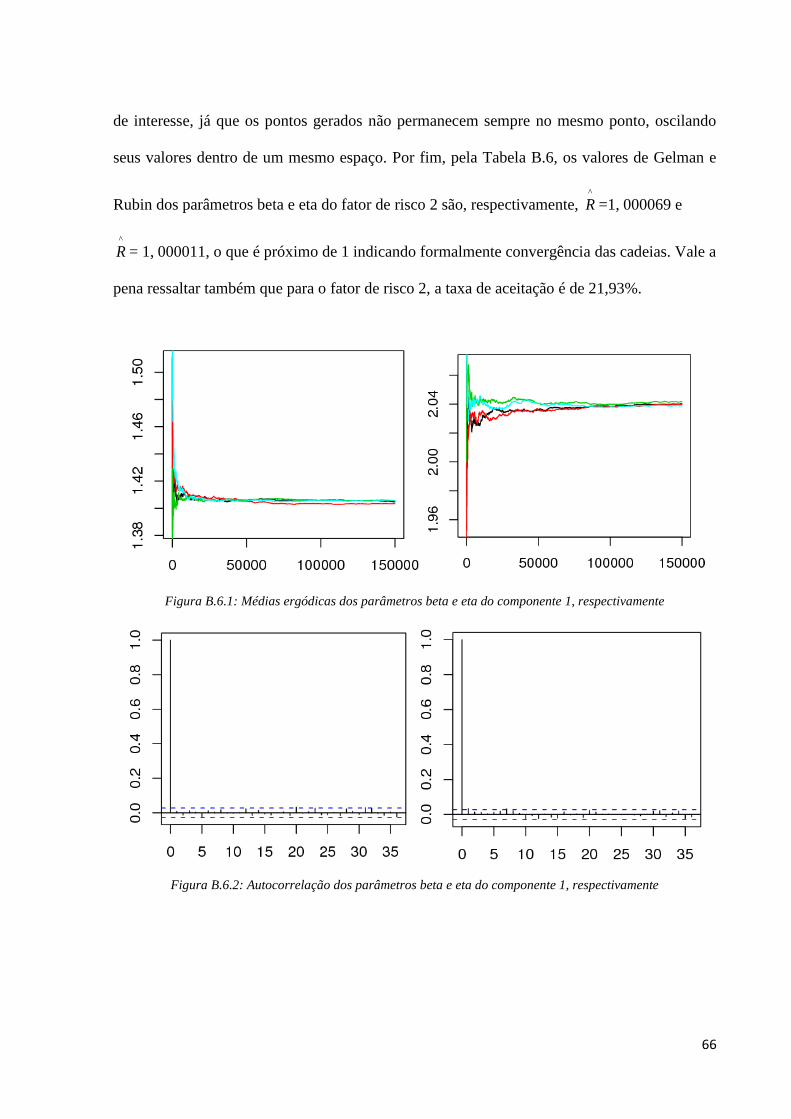
66
de interesse, já que os pontos gerados não permanecem sempre no mesmo ponto, oscilando
seus valores dentro de um mesmo espaço. Por fim, pela Tabela B.6, os valores de Gelman e
Rubin dos parâmetros beta e eta do fator de risco 2 são, respectivamente, ^
R =1, 000069 e
^
R = 1, 000011, o que é próximo de 1 indicando formalmente convergência das cadeias. Vale a
pena ressaltar também que para o fator de risco 2, a taxa de aceitação é de 21,93%.
Figura B.6.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente
Figura B.6.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
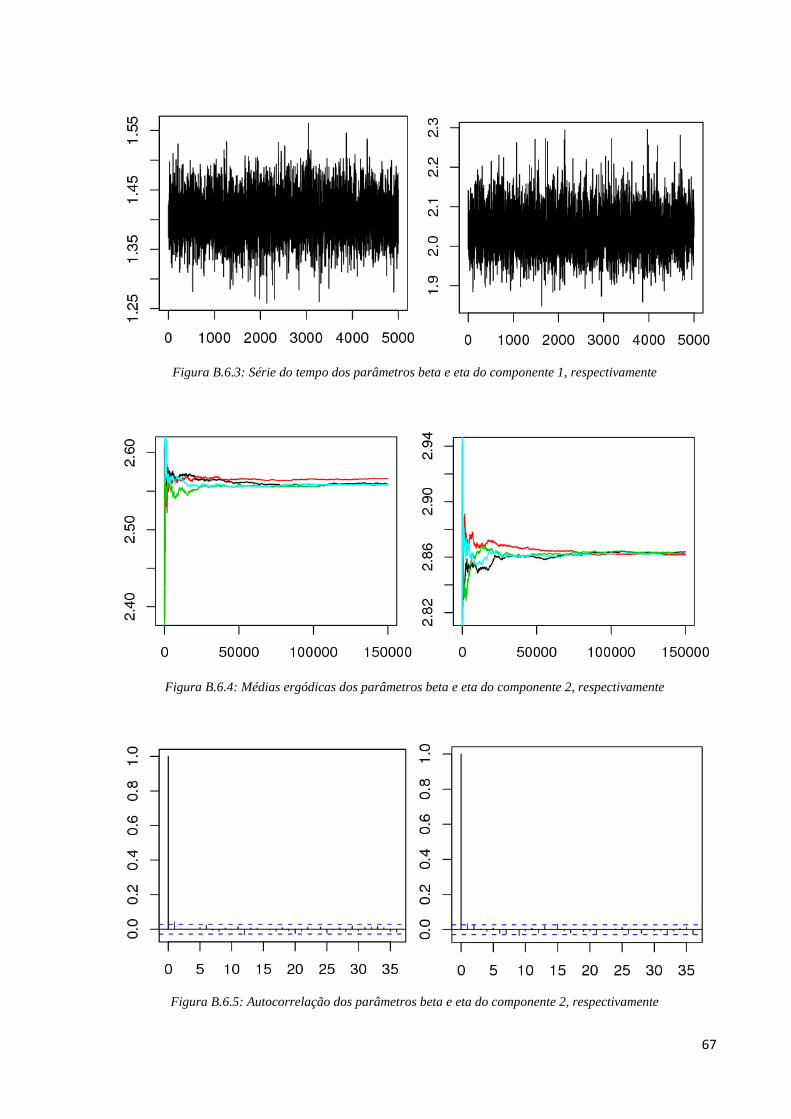
67
Figura B.6.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
Figura B.6.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
Figura B.6.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
68
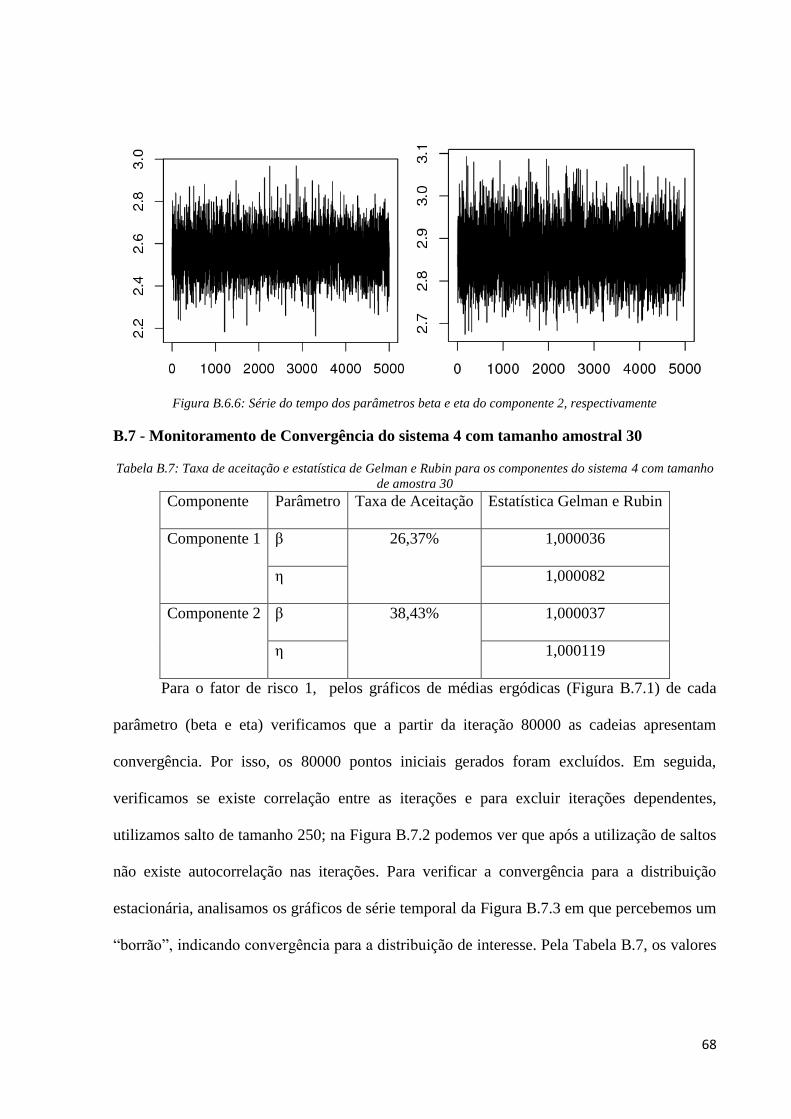
Figura B.6.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente
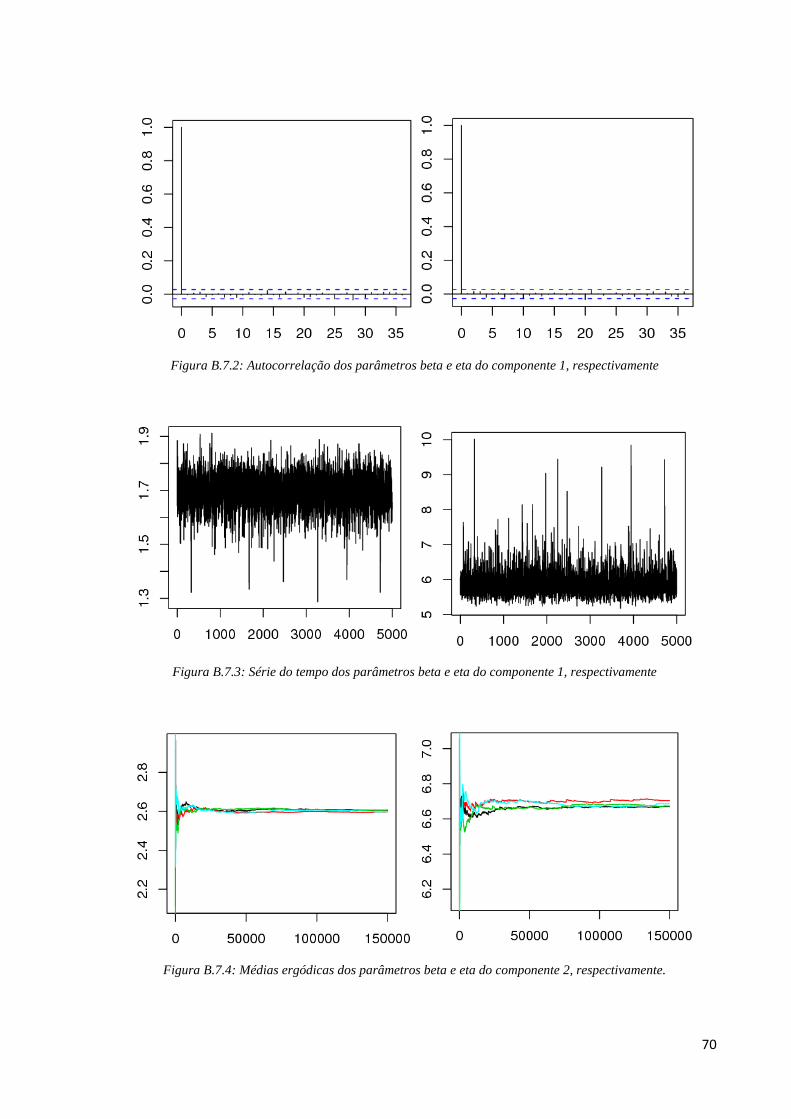
B.7 - Monitoramento de Convergência do sistema 4 com tamanho amostral 30
Tabela B.7: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 4 com tamanho
de amostra 30
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β 26,37% 1,000036
η 1,000082
Componente 2 β 38,43% 1,000037
η 1,000119
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.7.1) de cada
parâmetro (beta e eta) verificamos que a partir da iteração 80000 as cadeias apresentam
convergência. Por isso, os 80000 pontos iniciais gerados foram excluídos. Em seguida,
verificamos se existe correlação entre as iterações e para excluir iterações dependentes,
utilizamos salto de tamanho 250; na Figura B.7.2 podemos ver que após a utilização de saltos
não existe autocorrelação nas iterações. Para verificar a convergência para a distribuição
estacionária, analisamos os gráficos de série temporal da Figura B.7.3 em que percebemos um
“borrão”, indicando convergência para a distribuição de interesse. Pela Tabela B.7, os valores
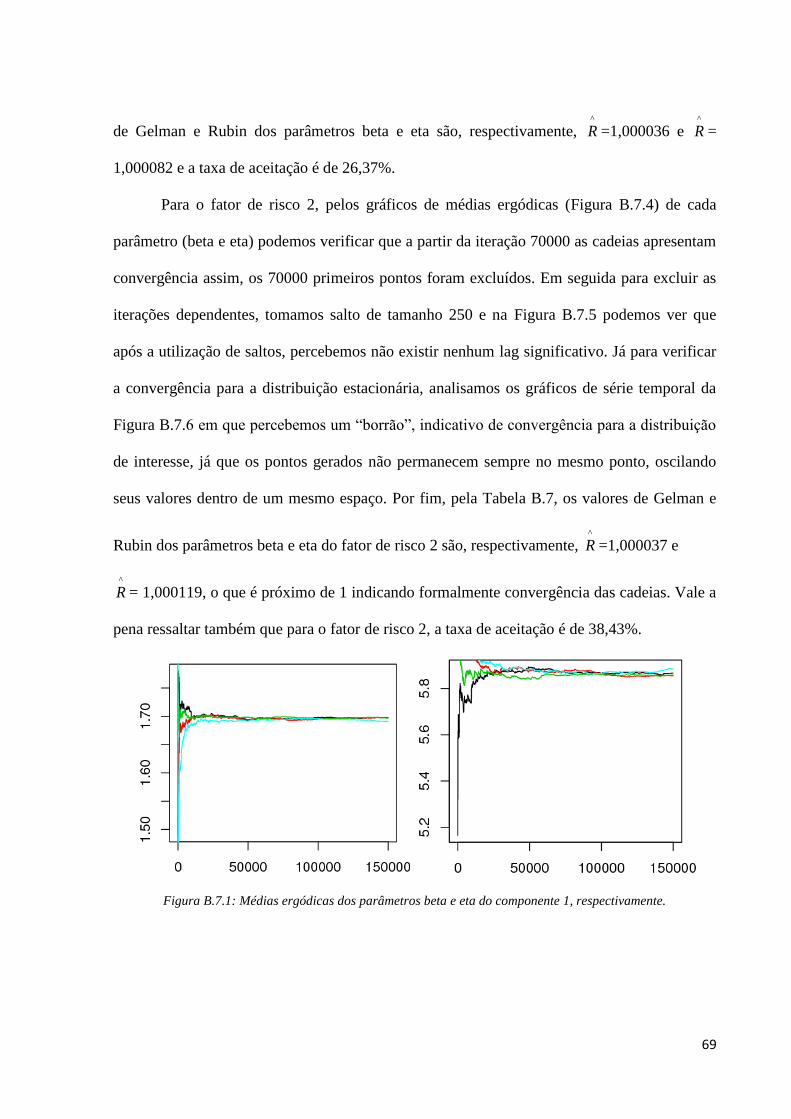
69
de Gelman e Rubin dos parâmetros beta e eta são, respectivamente, ^
R =1,000036 e ^
R =
1,000082 e a taxa de aceitação é de 26,37%.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.7.4) de cada
parâmetro (beta e eta) podemos verificar que a partir da iteração 70000 as cadeias apresentam
convergência assim, os 70000 primeiros pontos foram excluídos. Em seguida para excluir as
iterações dependentes, tomamos salto de tamanho 250 e na Figura B.7.5 podemos ver que
após a utilização de saltos, percebemos não existir nenhum lag significativo. Já para verificar
a convergência para a distribuição estacionária, analisamos os gráficos de série temporal da
Figura B.7.6 em que percebemos um “borrão”, indicativo de convergência para a distribuição
de interesse, já que os pontos gerados não permanecem sempre no mesmo ponto, oscilando
seus valores dentro de um mesmo espaço. Por fim, pela Tabela B.7, os valores de Gelman e
Rubin dos parâmetros beta e eta do fator de risco 2 são, respectivamente, ^
R =1,000037 e
^
R = 1,000119, o que é próximo de 1 indicando formalmente convergência das cadeias. Vale a
pena ressaltar também que para o fator de risco 2, a taxa de aceitação é de 38,43%.
Figura B.7.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente.
70
Figura B.7.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.7.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
Figura B.7.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente.
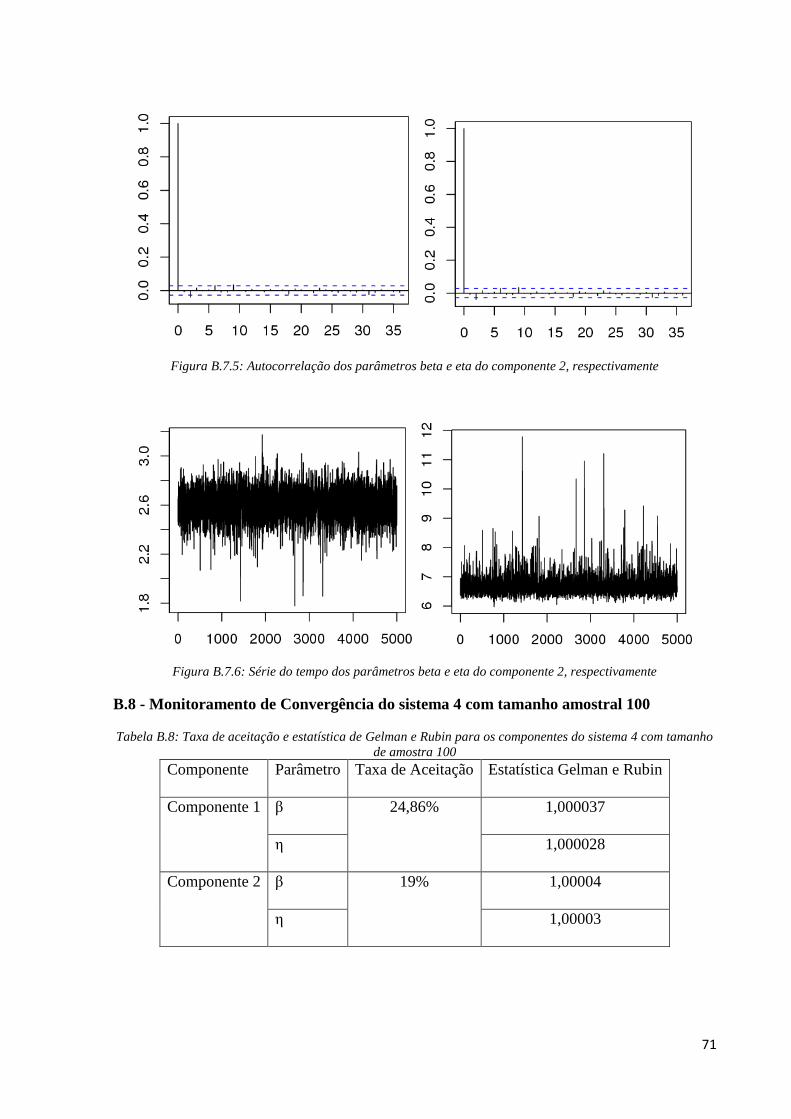
71
Figura B.7.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
Figura B.7.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente
B.8 - Monitoramento de Convergência do sistema 4 com tamanho amostral 100
Tabela B.8: Taxa de aceitação e estatística de Gelman e Rubin para os componentes do sistema 4 com tamanho
de amostra 100
Componente Parâmetro Taxa de Aceitação Estatística Gelman e Rubin
Componente 1 β 24,86% 1,000037
η 1,000028
Componente 2 β 19% 1,00004
η 1,00003

72
Para o fator de risco 1, pelos gráficos de médias ergódicas (Figura B.8.1) de cada
parâmetro verificamos que a partir da iteração 70000, as cadeias apresentam convergência.
Assim, os 70000 primeiros pontos gerados foram excluídos. Em seguida, na análise de
correlação entre as iterações, utilizamos salto de tamanho 150; na Figura B.8.2 percebemos
não existir mais nenhum lag significativo nos gráficos de autocorrelação. Na Figura B.8.3,
percebemos um “borrão” nos gráficos de série temporal indicando convergência para a
distribuição de interesse. Pela Tabela B.8, os valores de Gelman e Rubin dos parâmetros beta
e eta são, respectivamente, ^
R =1,000037 e ^
R =1,000028, o que é próximo de 1 indicando
formalmente convergência das cadeias e também observa-se uma boa taxa de aceitação:
24,86%.
Para o fator de risco 2, pelos gráficos de médias ergódicas (Figura B.8.4) de cada
parâmetro podemos verificar que a partir da iteração 60000 as cadeias apresentam
convergência e por isso, os 60000 primeiros pontos foram excluídos. Em seguida, verificamos
se existe correlação entre as iterações. Para excluir as iterações dependentes, tomamos salto
de tamanho 100 e na Figura B.8.5 percebemos não existir mais correlação entre as iterações
após a utilização de saltos. Para verificar a convergência para a distribuição estacionária,
analisamos os gráficos de série temporal da Figura B.8.6 em que percebemos um “borrão”,
indicativo de convergência para a distribuição de interesse. Por fim, pela Tabela B.8, os
valores de Gelman e Rubin dos parâmetros beta e eta do fator de risco 2 são, respectivamente,
^
R =1,00004 e ^
R = 1,00003, o que é próximo de 1 indicando formalmente convergência das
cadeias e a taxa de aceitação obtida foi de 19%.
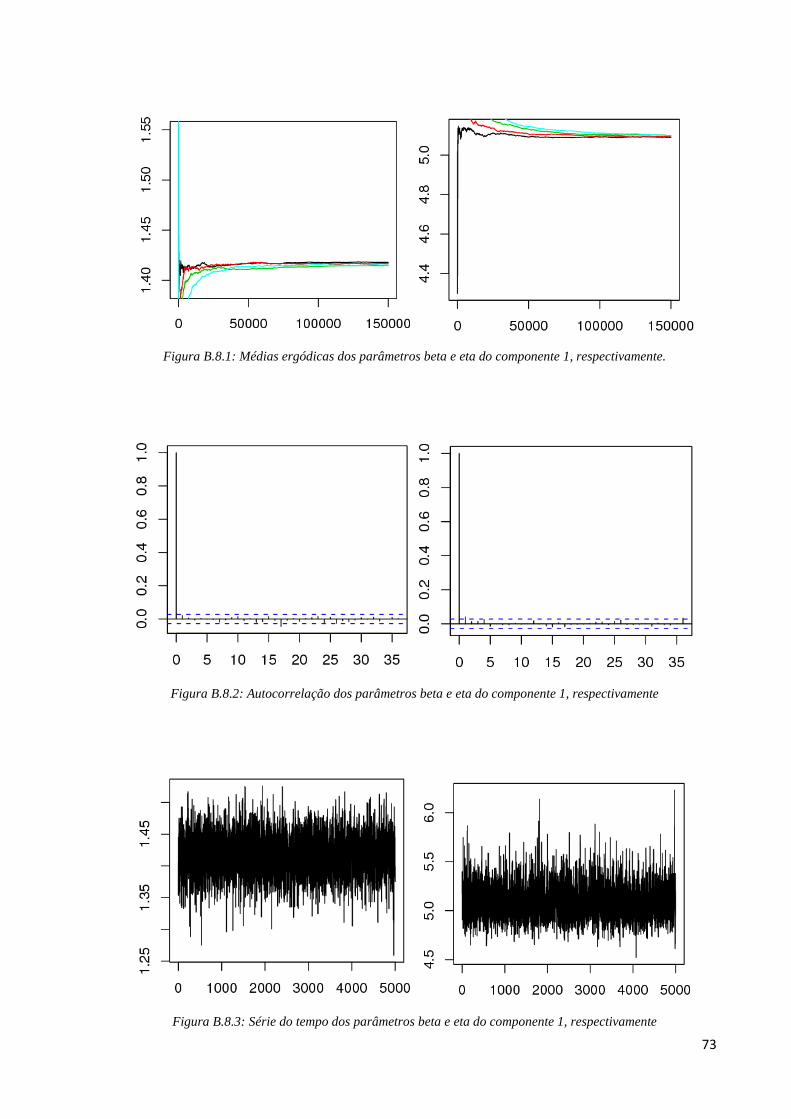
73
Figura B.8.1: Médias ergódicas dos parâmetros beta e eta do componente 1, respectivamente.
Figura B.8.2: Autocorrelação dos parâmetros beta e eta do componente 1, respectivamente
Figura B.8.3: Série do tempo dos parâmetros beta e eta do componente 1, respectivamente
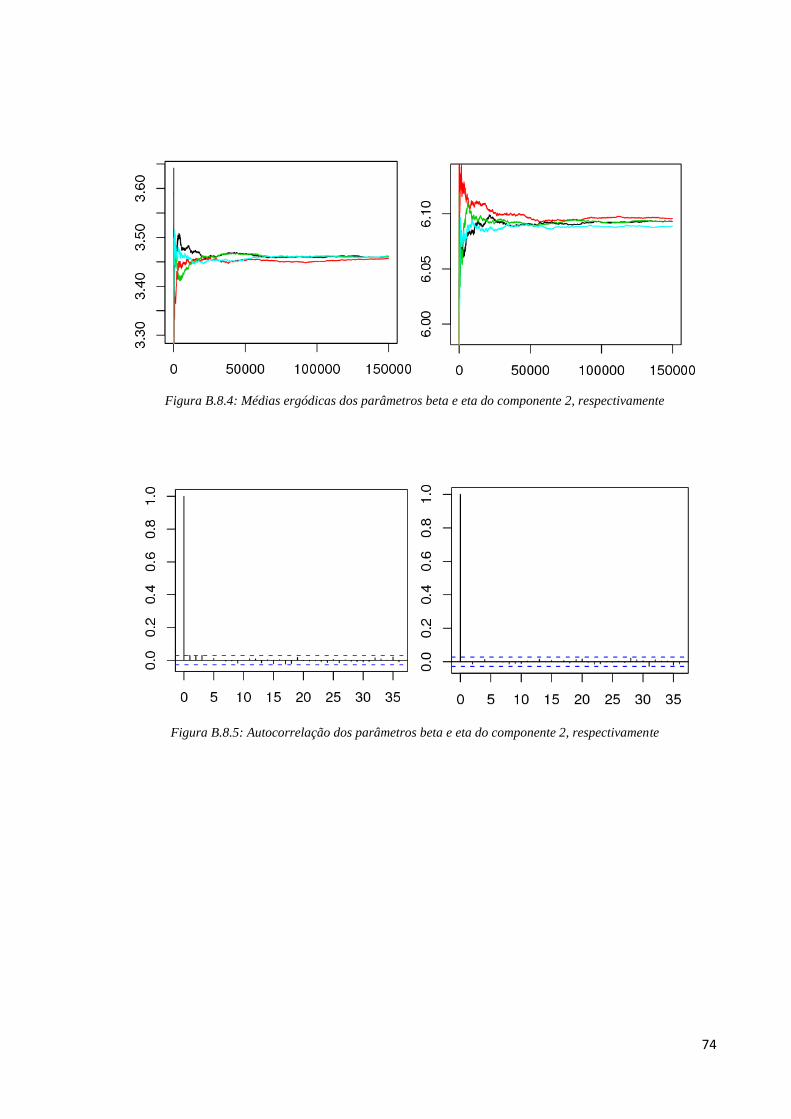
74
Figura B.8.4: Médias ergódicas dos parâmetros beta e eta do componente 2, respectivamente
Figura B.8.5: Autocorrelação dos parâmetros beta e eta do componente 2, respectivamente
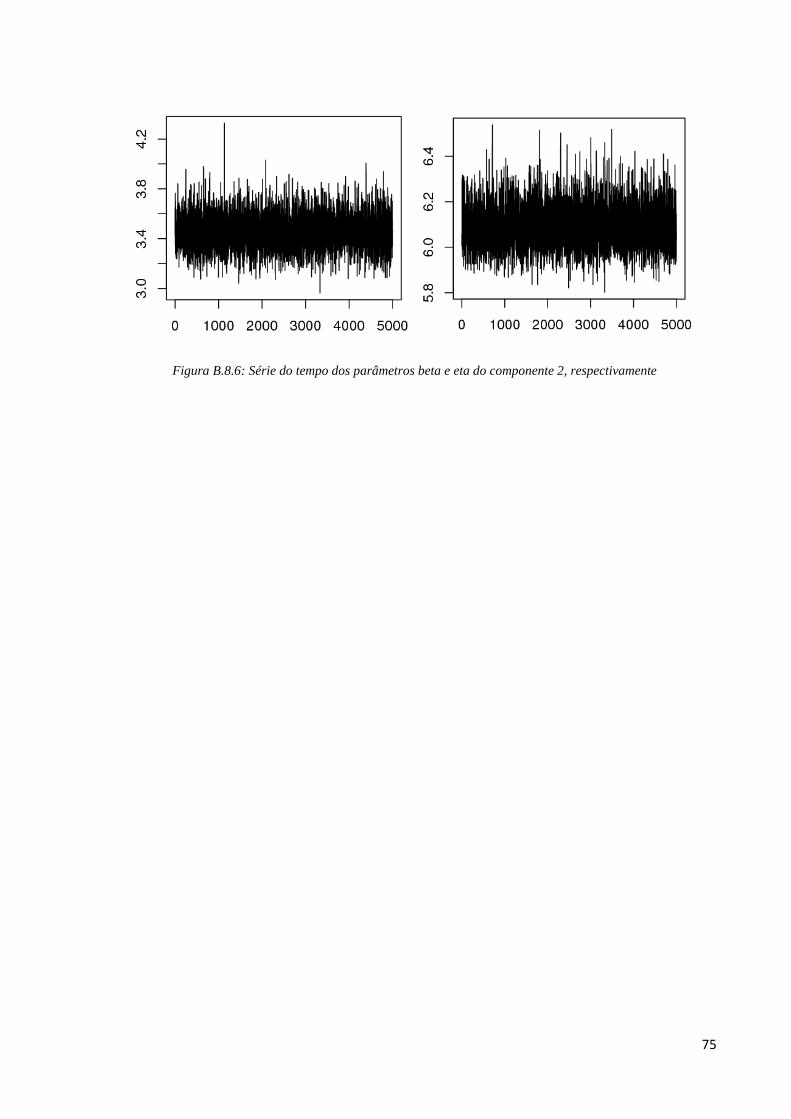
75
Figura B.8.6: Série do tempo dos parâmetros beta e eta do componente 2, respectivamente

76
REFERÊNCIAS BIBLIOGRÁFICAS
[1] Aalen, O. Nonparametric Inference in connection with Multiple Decrement Models.
Scandinavian Journal of Statistics, 3:15-27, 1976.
[2] Breslow, N.E. e Crowley, J. A Large Sample study of the Life Table and Product Limit
Estimates Under Random Censorship. Annals of Statistics, 2:437-453, 1974.
[3] Colosimo, E. A.; Giolo, S. R., Análise de Sobrevivência Aplicada, São Paulo, Editora
Blucher, 2006.
[4] Coque Jr., M. A., Fatores Competitivos de Risco sob o Modelo Weibull: Uma Perspectiva
Bayesiana, Dissertação de Mestrado, Universidade de São Paulo, 2004.
[5] Cox, D.R. Regression Models and Life-Table. Journal of the Royal Statistical Society, Ser.
B, 34:187–202, 1972.
[6] Gamerman, D. Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference.
London, England, Chapman and Hall, 1997.
[7] Jeffreys, H. Theory of Probability. Oxford: Clarendon Press, 1961.
[8] Kaplan, E. L.; Meier, P. Nonparametric estimation from incomplete observations. Journal
of the American Statistical Association, 53:457-481, 1958.
[9] Lawless, J.F. Statistical Models and Methods for Lifetime Data. 2a. ed., John Wiley and
Sons, Hoboken, 2003.
[10] Martins, C.B. Análise de referência Bayesiana para o modelo Weibull na aplicação de
riscos competitivos. Dissertassão de Mestrado, Departamento de Estatística-UFSCar, São
Carlos, 2009.
[11] Peterson, A. V. Jr., Expressing the Kaplan-Meier Estimator as a Function of Empirical
Subsurvival Functions. Journal of the American Statistical Association, 72(360):854-
858, 1977.
[12] Polpo, A., Coque-Jr, M. e Pereira, C.A.B. Statistical Analysis for Weibull Distributions
in Presence of Right and Left Censoring. The Proceedings of 2009 8th International
Conference on Reliability, Maintainability and Safety, v. 1., p. 219-223, 2009.
[13] Rinne, H. The Weibull Distriution: A Handbook. Chapman & Hall/CRC, Boca Raton,
2009.
[14] Salinas-Torres, V.; Pereira, C. A. B.; Tiwari, R. Bayesian nonparametric estimation in a
competing risks model or a series system. Journal of Nonparametric Statistics, 14:449-
458, 2002.
[15] Tsiatis, A. A Nonidentifiability Aspect of the Problem of Competing Risks. PNAS,
72(1):20–22, 1975.

















