
Métodos Usados para Em muitos casos, datasets possuem …wanderson/Aulas/MT803_Aula3_Reducao... ·...
21
Métodos Usados para Redução e Sintetização de Dados Stanley Robson de M. Oliveira Dados Originais Síntese dos Dados 2 MT-803: Tópicos em Matemática Aplicada – Aula 3. Em muitos casos, datasets possuem um número elevado de atributos e de observações (objetos). Análise de dados complexa (muitos atributos): Pode ficar muito cara computacionalmente se todo o conjunto de dados (dataset) for considerado; Dependendo do tamanho do dataset, os algoritmos podem não rodar satisfatoriamente. Solução ⇒ Sintetização de dados. Redução de atributos e/ou objetos. Redução de dados 3 MT-803: Tópicos em Matemática Aplicada – Aula 3. Redução de dados … Abordagem para redução de dados: Obter uma representação reduzida do dataset que é muito menor em volume, mas que produza os mesmos (ou quase os mesmos) resultados analíticos. A1 A2 A3 A4 A5 . . . A125 A1 A2 A3 A4. . . A68 1 2 3 . . . 10800 1 2 . . . 5425 4 MT-803: Tópicos em Matemática Aplicada – Aula 3. Estratégias para redução de dados Agregação. Amostragem (Sampling). Sintetização de dados. Discretização e hierarquia de conceito.
Transcript of Métodos Usados para Em muitos casos, datasets possuem …wanderson/Aulas/MT803_Aula3_Reducao... ·...

Métodos Usados para Redução e Sintetização de Dados
Stanley Robson de M. Oliveira
DadosOriginais
Síntesedos Dados
2MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Em muitos casos, datasets possuem um número elevado de atributos e de observações (objetos).
� Análise de dados complexa (muitos atributos):
� Pode ficar muito cara computacionalmente se todo o conjunto de dados (dataset) for considerado;
� Dependendo do tamanho do dataset, os algoritmos podem não rodar satisfatoriamente.
� Solução⇒ Sintetização de dados.
� Redução de atributos e/ou objetos.
Redução de dados
3MT-803: Tópicos em Matemática Aplicada – Aula 3.
Redução de dados …
� Abordagem para redução de dados:
� Obter uma representação reduzida do dataset que émuito menor em volume, mas que produza os mesmos (ou quase os mesmos) resultados analíticos.
A1 A2 A3 A4 A5 . . . A125A1 A2 A3 A4. . . A681
23...
10800
12...
5425
4MT-803: Tópicos em Matemática Aplicada – Aula 3.
Estratégias para redução de dados
� Agregação.
� Amostragem (Sampling).
� Sintetização de dados.
� Discretização e hierarquia de conceito.

5MT-803: Tópicos em Matemática Aplicada – Aula 3.
Agregação
�Combinar dois ou mais atributos (ou objetos) em um atributo único (ou objeto).
�Objetivo final:� Redução de dados:
� Reduz o número de atributos ou objetos.
� Mudança de escala (granularidade dos dados):� Cidades agregadas em estados, regiões, países, etc.
� Dados mais estáveis:� Agregação de tendências nos dados para reduzir a variabilidade.
6MT-803: Tópicos em Matemática Aplicada – Aula 3.
Agregação …
Desvio padrão da precipitação média mensal.
Desvio padrão da precipitação média anual.
Variação da Precipitação na Austrália
7MT-803: Tópicos em Matemática Aplicada – Aula 3.
Dados agregados na Agricultura� Na agricultura, muitos conjuntos de dados contêm variáveis
com valores diários, decendiais, mensais, entre outros.
� Esse nível de detalhe em que os dados estarão disponíveis para a análise chama-se granularidade.
� Exemplo: transformação de dados relacionais em multidimensionais para dados acumulados de chuva (precipitação em mm), na Estação Granja São Pedro, RS.
8MT-803: Tópicos em Matemática Aplicada – Aula 3.
Dados agregados na Agricultura ...� Exemplo de Cubo de Dados: forma de visualização e interpretação dos dados no modelo multidimensionalpara dados acumulados de chuva nos anos de 2003 a 2006, em algumas cidades do Rio Grande do Sul.

9MT-803: Tópicos em Matemática Aplicada – Aula 3.
Observações Importantes
� A metáfora denominada CUBO é apenas uma aproximação da forma como os dados estão organizados.
� Nós podemos representar um modelo tridimensional por um cubo, mas um modelo multidimensional pode ter mais de três dimensões – hipercubo.
� Visualizar graficamente um hipercubo é muito difícil, desta forma utiliza-se a palavra cubo como referência para qualquer modelo multidimensional.
� Um modelo multidimensional é formado por três elementos:
� Fatos, dimensões e medidas.
10MT-803: Tópicos em Matemática Aplicada – Aula 3.
Fatos
� Fato é uma coleção de itens de dados (valores numéricos) composta de medidas e de contexto.
� Um fato é evolutivo; muda suas medidas com o tempo.
� Exemplos:
� As vendas de cereais aumentaram em 20% nos últimos dois anos.
� O número de veranicos no RS aumentou em 6% nos últimos 10 anos.
� O consumo de bebidas alcóolicas aumentou, em SP, de 2005 a 2010.
� Os índices de criminalidade aumentaram no ano atual 50% sobre os últimos dois anos.
11MT-803: Tópicos em Matemática Aplicada – Aula 3.
Dimensões
� São os elementos que participam de um fato (assunto de negócio).
� São as possíveis formas de visualizar os dados, ou seja, são os “por” dos dados:
� Exemplo: “por mês”, “por país”, “por produto”.
� As dimensões determinam o contexto de um assunto de negócios.
� Dimensões são unidades de análise com dados agregados.
� Dimensão tempo: dados agregados em dias, meses, anos.
� Dimensão local: dados agrupados em cidade, estado, país.
12MT-803: Tópicos em Matemática Aplicada – Aula 3.
Membros de uma Dimensão
� Uma dimensão pode conter muitos membros.
� Hierarquia de uma dimensão é uma classificação de dados dentro de uma dimensão.
Ano
Trimestre Trimestre
Mês Mês
Dia ... ... ...
... ...
Hierarquia 1
Semana
Dia Dia
Hierarquia 2

13MT-803: Tópicos em Matemática Aplicada – Aula 3.
Medidas (Variáveis)
� São os atributos numéricos que representam um fato.
� Exemplo de medidas (métricas):
� O número de enchentes na região Nordeste;
� O número de unidades de produtos vendidas;
� A quantidade em estoque;
� O custo de venda;
� Percentagem de lucro;
� Número de veranicos, etc.
14MT-803: Tópicos em Matemática Aplicada – Aula 3.
Exemplo – Modelo de Compras
� Quando analisamos compras, aplicamos o princípio dos quatro pontos cardeais:
� Uma estrela no centro representando um fato;
� As pontas representando as dimensões.
Elementos participantes de uma compra:
• Quando foi realizada a compra?
• Onde foi realizada a compra?
• Quem realizou a compra?
• O que foi comprado?
Compra
Onde?
Quem?
Quando?
O quê?
15MT-803: Tópicos em Matemática Aplicada – Aula 3.
O Modelo Estrela (Star)
DimensãoTempo
DimensãoLocalidade
DimensãoProduto
DimensãoVendedor
DimensãoCliente
Fatos deVendas
� Exemplo de um modelo estrela para o fato: vendas.
16MT-803: Tópicos em Matemática Aplicada – Aula 3.
Modelo Snowflake (Floco de Neve)� O modelo snowflake é o resultado da decomposição de uma
ou mais dimensões que possuem hierarquias entre seus membros.
DimensãoTempo
DimensãoRegião
DimensãoProduto
DimensãoVendedor
DimensãoCliente
Fatos deVendas
DimensãoEstado
DimensãoCidade

17MT-803: Tópicos em Matemática Aplicada – Aula 3.
Exercício
� Uma empresa de produtos agropecuários necessita avaliar a evolução de vendas mensal dos seus clientes, nos últimos 5 anos. Considere as dimensões: Tempo, Cliente, Produto e Local. As dimensões Tempo e Local devem possuir uma hierarquia de 3 níveis (cada dimensão), enquanto a dimensão Produtodeve possuir uma hierarquia de 2 níveis. Pede-se:
� Esboce o modelo estrela (hipercubo de dados) para esta empresa.
� Esboce o modelo floco de neve para esta empresa.
� Elabore pelo menos oito perguntas distintas que esse hipercubo de dados pode responder sobre a evolução de vendas nos últimos 5 anos.
18MT-803: Tópicos em Matemática Aplicada – Aula 3.
Estratégias para redução de dados
� Agregação.
� Amostragem (Sampling).
� Sintetização de dados.
� Discretização e hierarquia de conceito.
19MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Amostragem é uma das principais técnicas empregadas para a redução de dados.
� É geralmente usada em investigações preliminares de dados e também na análise final dos dados.
� Estatísticos usam bastante as técnicas de amostragemporque trabalhar com o conjunto de dados completo écaro e demorado, computacionalmente.
� Amostragem pode ser usada em mineração de dadosquando o conjunto de dados, sob análise, é grande (em termos de objetos e atributos).
Amostragem
20MT-803: Tópicos em Matemática Aplicada – Aula 3.
Amostragem …
�O princípio chave da amostragem eficaz:
� Uma amostra produzirá resultados de qualidadesemelhantes aqueles produzidos pelo conjunto de dados completos (se a amostra for representativa).
� Uma amostra é representativa se ela tem aproximadamente as mesmas propriedades (de interesse) do conjunto de dados original.

21MT-803: Tópicos em Matemática Aplicada – Aula 3.
Tipos de Amostragem
� Amostragem Aleatória Simples (Sampling without replacement)� Existe uma probabilidade igual para a seleção de qualquer item.� Um item é selecionado e removido da população.
� Amostragem com Reposição (Sampling with replacement)� Objetos não são removidos da população à medida em que são
selecionados para a amostra. � O mesmo objeto pode ser selecionado mais de uma vez.
� Amostragem Estratificada (Stratified Sampling)� Separa os dados em diversas partições (estratos). Toma-se de
cada partição uma amostra percentual igual à porcentagem do estrato em relação à população.
22MT-803: Tópicos em Matemática Aplicada – Aula 3.
Amostragem Simples e c/ Reposição
Amostrag
em
Simples
Amostragemcom Reposição
Conjunto de Dados
23MT-803: Tópicos em Matemática Aplicada – Aula 3.
Exemplo: Amostragem Estratificada
� Para obter uma estatística de intenção de votospara prefeito de um certo município, deseja-se uma amostragem estratificada por bairro. No município em questão 25% dos eleitores são de um bairro A. Supondo uma amostra de 1000 eleitores, tomam-se 25% deles, ou seja, 250 do bairro A.
� Para os demais bairros (B, C, D, ...), a seleção do número de elementos por bairro (partição), segue a mesma proporção.
24MT-803: Tópicos em Matemática Aplicada – Aula 3.
Amostragem Estratificada …

25MT-803: Tópicos em Matemática Aplicada – Aula 3.
Amostragem Estratificada
Dados Brutos Cluster/Amostra Estratificada
26MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Permite um algoritmo de mineração rodar em complexidadeque é potencialmente sub-linear com relação ao tamanho dos dados (dataset).
� Sugestões para o uso de amostragem:
� Amostragem aleatória simples pode ter uma performance muito baixa se os dados tiverem uma distribuição assimétrica.
� Amostragem estratificada:
� Alternativa usada quando o conjunto de dados tem distribuição assimétrica.
� Pode ser usada na seleção de dados para o conjunto de treinamento (Classificação), quando o número de elementos por classe não é balanceado (Amostragem c/ Reposição também pode ser usada).
Amostragem: Aspectos Importantes
27MT-803: Tópicos em Matemática Aplicada – Aula 3.
Estratégias para redução de dados
� Agregação.
� Amostragem (Sampling).
� Sintetização de dados.
� Discretização e hierarquia de conceito.
28MT-803: Tópicos em Matemática Aplicada – Aula 3.
� O dataset pode ser reduzido por meio de uma representação adequada para os dados.
� Métodos Paramétricos:� Um modelo ou função estimam a distribuição dos dados.
� Regressão Linear: Os dados são modelados para estabelecer uma equação matemática (reta) – relacionamento entre duas variáveis.
� Regressão Múltipla: uma variável dependente Y pode ser modelada como uma função linear de um vetor multidimensional.
� Métodos Não-paramétricos:� Não assume modelos;
� Principais famílias: histogramas, clusterização, amostragem.
Sintetização de Dados
29MT-803: Tópicos em Matemática Aplicada – Aula 3.
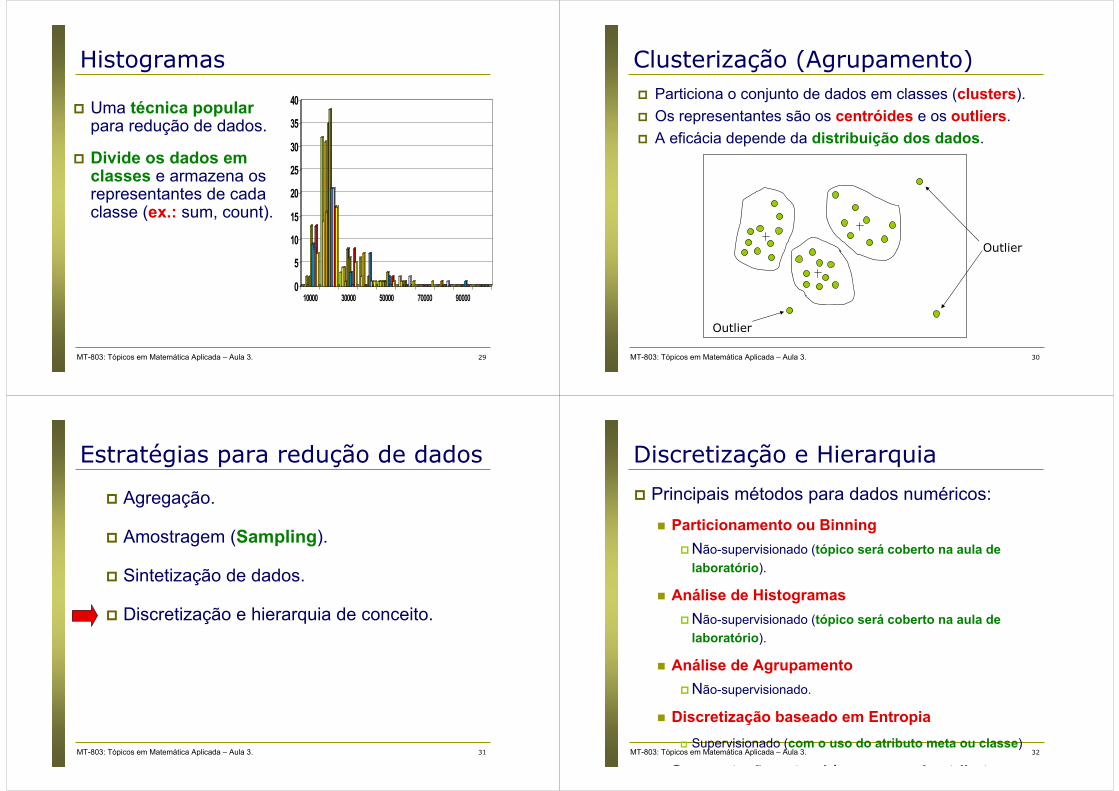
� Uma técnica popularpara redução de dados.
� Divide os dados em classes e armazena os representantes de cada classe (ex.: sum, count).
0
5
10
15
20
25
30
35
40
10000 30000 50000 70000 90000
Histogramas
30MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Particiona o conjunto de dados em classes (clusters).
� Os representantes são os centróides e os outliers.
� A eficácia depende da distribuição dos dados.
Clusterização (Agrupamento)
Outlier
Outlier
31MT-803: Tópicos em Matemática Aplicada – Aula 3.
Estratégias para redução de dados
� Agregação.
� Amostragem (Sampling).
� Sintetização de dados.
� Discretização e hierarquia de conceito.
32MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Principais métodos para dados numéricos:
� Particionamento ou Binning
�Não-supervisionado (tópico será coberto na aula de
laboratório).
� Análise de Histogramas
�Não-supervisionado (tópico será coberto na aula de
laboratório).
� Análise de Agrupamento
�Não-supervisionado.
� Discretização baseado em Entropia
� Supervisionado (com o uso do atributo meta ou classe)
� Segmentação natural (sem o uso do atributo
Discretização e Hierarquia

33MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Dado um conjunto de amostras S, se S é particionado em dois intervalos S1 e
S2 usando um valor (threshold) T, o ganho de informação é:
� A entropia é calculada com base na distribuição de classes das amostras do
conjunto. Dadas m classes, a entropia de S1 é dada por:
onde pi é a probabilidade da classe i pertencer a S1
� O valor de T que minimiza a função entropia sobre todos possíveis intervalos
é selecionado para a discretização binária.
� O processo é aplicado recursivamente nas partições obtidas até que algum
critério de parada seja satisfeito.
� O valor de T pode reduzir o tamanho dos dados e melhorar a precisão da
classificação.
)(||
||)(
||
||),( 2
21
1SEntropy
S
SSEntropy
S
STSI +=
∑=
−=m
i
ii ppSEntropy1
21 )(log)(
Discretização baseada em entropia
34MT-803: Tópicos em Matemática Aplicada – Aula 3.
�Método baseado na entropia.
3 categorias para ambos x e y 5 categorias para ambos x e y
Discretização usando Classes
35MT-803: Tópicos em Matemática Aplicada – Aula 3.
Dados Originais Intervalos com mesmo tamanho
Intervalos com mesma frequência K-means
Discretização sem o uso de Classes
36MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Especificação de uma ordem parcial/total dos atributosexplicitamente por meio dos usuários ou especialistas:� Rua < Cidade < Estado < País
� Especificação de uma hierarquia para um conjunto de valores através de agrupamento de dados:� {Feagri, Unicamp, Barão Geraldo} < Campinas
� Especificação de um conjunto parcial de atributos:� Ex.: somente Rua < Cidade, não outros atributos.
� Geração automática de hierarquias (ou nível de atributo) pela análise do número de valores distintos:� Ex.: para um conjunto de atributos: {Rua, Cidade, Estado, País}
Geração de Hierarquia (categórico)

37MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Algumas hierarquias podem ser automaticamentegeradas com base na análise do número de valores distintos por atributo no conjunto de dados.
� O atributo com mais valores distintos é colocado no últimonível da hierarquia.
� Exceções (Ex.: dia da semana, mês, semestre, ano) - ordem.
País
Estado
Cidade
Rua
15 valores distintos
365 valores distintos
3.567 valores distintos
674.339 valores distintos
Geração de Hierarquia (categórico)
Métodos para Redução de Dimensionalidade
Stanley Robson de M. Oliveira
A1 A2 A3 A4 A5 . . . A250A1 A2 A3 A4. . . A451
23...
10800
12...
10800
39MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Redução de dimensão:
� Necessidade, motivação e aplicações.
� Principais Abordagens:
� Extração de atributos (não-Supervisionada);
� Seleção de atributos (Supervisionada).
� Métodos para extração de atributos (filtros):
� Projeção Aleatória (Random Projection);
� Análise de Componentes Principais (PCA);
� Multidimensional Scaling (MS);
� Decomposição do Valor Singular (SVD);
� Latent Semantic Indexing (LSI).
Aspectos Relevantes
40MT-803: Tópicos em Matemática Aplicada – Aula 3.
Por que redução de dimensão?
� Muitas técnicas de aprendizado de máquina e mineração de dados podem não ser eficientespara dados com alta dimensionalidade:
� A maldição da dimensionalidade.
� A precisão e a eficiência de uma consulta degradamrapidamente à medida em que a dimensão aumenta.
� A dimensão intrínseca pode ser menor.
� Muitos atributos são irrelevantes.
� Exemplo: o número de genes responsáveis por um certo tipo de doença pode ser menor.

41MT-803: Tópicos em Matemática Aplicada – Aula 3.
Por que redução de dimensão? ...
� Visualização: projeção de dados com alta dimensionalidade em 2D ou 3D.
� Compressão de dados: eficiência no armazenamento e recuperação.
� Remoção de ruído: efeito positivo na acurácia de modelos e de consultas.
42MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Quando a dimensionalidade aumenta, os dados tornam-se progressivamente esparsos no espaço em que ocupam.
� Definição de distância entre pontos, que é critica para agrupamento e detecção de outliers, torna-se menos significativa.
� A análise de dados pode ficar muito cara se todos os atributos forem considerados.
• 500 pontos gerados aleatoriamente.
•Cálculo da diferença entre a distância max e min para os pares de pontos.
Motivação
43MT-803: Tópicos em Matemática Aplicada – Aula 3.
Motivação …
� Os alvos principais do proceso de redução de dimensionalidade são:
� Melhorar a performance dos algoritmos de aprendizado de máquina.
� Simplificar os modelos de predição e reduzir o custocomputacional para “rodar” esses modelos.
� Fornecer um melhor entendimento sobre os resultados encontrados, uma vez que existe um estudo prévio sobre o relacionamento entre os atributos.
44MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Relacionamento com clientes (CRM).
� Mineração e/ou processamento de textos.
� Recuperação de informação em banco de imagens.
� Análise de dados de microarrays.
� Classificação de proteínas.
� Reconhecimento de face.
� Aplicações com dados meteorológicos.
� Química combinatorial.
� etc.
Aplicações

45MT-803: Tópicos em Matemática Aplicada – Aula 3.
Classificação de documentos
Bibliotecas Digitais
� Tarefa: classificar documentos em categorias.
� Desafio: milhares de termos.
� Solução: aplicar técnicas de redução de dimensão.
46MT-803: Tópicos em Matemática Aplicada – Aula 3.
Outros exemplos de aplicações
Reconhecimento de face Reconhecimento de dígitos manuscritos
47MT-803: Tópicos em Matemática Aplicada – Aula 3.
Principais Abordagens
� Seleção de atributos
� O assunto será estudado na próxima aula.
� Extração de atributos (redução)
� Cria novos atributos a partir dos atributos originais.
� Diferenças entre as duas abordagens.
48MT-803: Tópicos em Matemática Aplicada – Aula 3.
Seleção de Atributos
� IDÉIA GERAL: Processo que escolhe um subconjunto ótimo de atributos de acordo com uma função objetivo.
� Objetivos:
� Reduzir dimensionalidade e remover ruído.
� Melhorar a performance da mineração de dados:
�Aumenta a velocidade do aprendizado.
�Melhora a acurácia de modelos preditivos.
�Facilita a compreensão dos resultados minerados.

49MT-803: Tópicos em Matemática Aplicada – Aula 3.
Extração de Atributos
� IDÉIA GERAL: Ao invés de escolher um subconjunto de atributos, define novas dimensões em função de todos os atributos do conjunto original.
�Não considera o atributo classe, somente os atributos numéricos (vetores de dados).
50MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Idéia:� Dado um conjunto de pontos no espaço d-dimensional,
� Projetar esse conjunto de pontos num espaço de menordimensão, preservando ao máximo as informações dos dados originais.
� Em particular, escolher uma projeção que minimize o erroquadrático na reconstrução dos dados originais.
� Principais Métodos:� Projeção Aleatória (Random Projection);
� Análise de Componentes Principais (PCA);
� Multidimensional Scaling (MS);
� Decomposição do Valor Singular (SVD);
� Latent semantic indexing (LSI).
Extração de Atributos ...
51MT-803: Tópicos em Matemática Aplicada – Aula 3.
Seleção versus Extração (redução)
� Extração de atributos:
� Todos os atributos originais são usados.
� Os novos atributos são combinação linear dos atributos originais.
� Seleção de atributos:
� Somente um subconjunto dos atributos originais são selecionados.
� Atributos contínuos versus discretos.
Análise de Componentes Principais (PCA)
x2
x1
e1a. Componente
2a. Componente

53MT-803: Tópicos em Matemática Aplicada – Aula 3.
Análise de Componentes Principais
� Método para transformar variáveis correlacionadas em um conjunto de variáveis não-correlacionadas que melhor explica os relacionamentos entre os dados originais.
� Método para identificar as dimensões que exibem as maiores variações em um conjunto de dados.
� Método que possibilita encontrar a melhor aproximação dos dados originais usando um conjunto menor de atributos.
54MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Idéia Geral
x2
x1
e
• A linha verde tem uma representação reduzida dos dados originais que captura o máximo da variação original dos dados.
• A segunda linha (azul), perpendicular à primeira (verde), captura menos variação nos dados originais.
•Idéia geral: encontrar os autovetores da matriz de covariânciados dados. Os autovetores definem o novo espaço.
55MT-803: Tópicos em Matemática Aplicada – Aula 3.
Autovalores e Autovetores
� Dado um operador linear T: V → V, estamos interessados em um vetor v ∈ V e um escalar λ ∈ ℜ tais que T(v) = λv.
� Neste caso T(v) será um vetor de mesma "direção" que v, ou melhor, T(v) e v estão sobre a mesma reta suporte.
� Um autovalor de uma matriz An×n é um escalar λ tal que existe um vetor v (não-nulo), com Av = λv, onde v é chamado de autovetor de A associado a λ.
� Podemos encontrar os autovalores λ e autovetores v pela função característica definida como:
p(λ) = det(A - λI) onde:
p(λ) é chamado de polinômio característico de A;
I é a matriz identidade.
56MT-803: Tópicos em Matemática Aplicada – Aula 3.
Interpretação geométrica em ℜ2
• u é autovetor de T pois ∃ λ∈ ℜ / T(u) = λu.
• v não é autovetor de T pois ∃ λ∈ ℜ / T(v) = λv.

57MT-803: Tópicos em Matemática Aplicada – Aula 3.
Exemplo: Autovalores e Autovetores
� Calcular os autovalores e autovetores da matriz:
� T: ℜ2 → ℜ2 (x, y) → (4x + 5y, 2x + y)
� Cálculo dos autovalores: det (A – λI) = 0
� det (A – λI) = 0 ⇔ (4 – λ )(1 – λ ) – 10 = 0 ⇔ λ2 – 5λ – 6 = 0
� Os autovalores são λ1 = –1 e λ2 = 6.
� Para cada autovalor encontrado, resolvemos o sistema linear (A –λI)v = 0. Os respectivos autovetores são: v1 = (-1, 1) e v2 = (5/2, 1).
−
−=
−
=−
λ
λλλ
12
54det
10
01
12
54det)det( IA
=
12
54A
58MT-803: Tópicos em Matemática Aplicada – Aula 3.
Redução de Dimensão: PCA …
1o principal vetor
� As componentes principais são vetores ortogonais.
� Minimizar o erro quadrático (RootMean Square).
� RMS representa a diferença entre os pontos originais e os novos pontos calculados pela transformação.
-5 -4 -3 -2 -1 0 1 2 3 4 5-5
-4
-3
-2
-1
0
1
2
3
4
5
1a. Componente
2a. Componente
59MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Algoritmo
� Algoritmo PCA:
� X � Matriz de dados (N x d), em que cada linha é um vetor xn.
� X � Em cada linha, subtrair a média x de cada elemento do vetor xn em X.
� Σ � matriz de covariância de X.
� Encontrar os autovalores e autovetores de Σ.
� PC’s � os K autovetores com os maiores autovalores.
60MT-803: Tópicos em Matemática Aplicada – Aula 3.
Algoritmo PCA no Matlab% generate data
Data = mvnrnd([5, 5],[1 1.5; 1.5 3], 100);
figure(1); plot(Data(:,1), Data(:,2), '+');
%center the data
for i = 1:size(Data,1)
Data(i, :) = Data(i, :) - mean(Data);
end
DataCov = cov(Data); %covariance matrix
[PC, variances, explained] = pcacov(DataCov); %eigen
% plot principal components
figure(2); clf; hold on;
plot(Data(:,1), Data(:,2), '+b');
plot(PC(1,1)*[-5 5], PC(2,1)*[-5 5], '-r’)
plot(PC(1,2)*[-5 5], PC(2,2)*[-5 5], '-b’); hold off
% project down to 1 dimension
PcaPos = Data * PC(:, 1);

61MT-803: Tópicos em Matemática Aplicada – Aula 3.
Qual é o número ideal de componentes?� Verifique a distribuição dos autovalores.
� Selecione um número de autovetores que cubra 80 a 90% da variância.
62MT-803: Tópicos em Matemática Aplicada – Aula 3.
Exemplo: Dados sobre a eficiência de cana-de-açúcar para 20 municípios em SP, em 2002.
63MT-803: Tópicos em Matemática Aplicada – Aula 3.
Resultado da Análise (Minitab)
É possível explicar aproximadamente 90% da variabilidade total observada nos
dados com apenas três componentes principais:
64MT-803: Tópicos em Matemática Aplicada – Aula 3.
Resultado da Análise (Minitab) …
A Figura acima evidencia a importância das três primeiras componentes,em relação às demais (quanto maior é o autovalor, maior será a porcentagem de variação explicada pela componente correspondente).

65MT-803: Tópicos em Matemática Aplicada – Aula 3.
A Figura acima ilustra geometricamente como as seis variáveisdo exemplo podem ser adequadamente representadas por duas componentes principais (Z1 e Z2).
Resultado da Análise (Minitab) …
66MT-803: Tópicos em Matemática Aplicada – Aula 3.
As duas componentes descrevem, de uma forma geral, características das cidades vizinhas que possuem climas e condições de cultivosemelhantes.
Resultado da Análise (Minitab) …
67MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Dados N vetores no espaço n-dimensional, encontrar k ≤ n
vetores ortogonais (componentes principais) que podem ser melhor usados para representar os dados.
� Passos:� Normalizar dados originais: todos atributos ficam na mesma faixa
(intervalo).
� Calcular k vetores ortogonais, i.e., componentes principais.
� Cada vetor (original) é uma combinação linear dos k vetores (componentes principais).
� As componentes principais são ordenadas (ordem decrescente) representando a “significância” ou “força”.
� Como as componentes são ordenadas, o tamanho dos dados pode ser reduzido eliminando-se as componentes fracas, i.e., aquelas com baixa variância.
PCA: Descarte de Atributos
68MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Descarte de Atributos ...
� IDÉIA GERAL:
� Executar PCA sobre uma matriz de correlação com p variáveis.
� Inicialmente, k variáveis são selecionadas (retidas).
� No final, (p – k) variáveis serão descartadas.

69MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Descarte de Atributos ...
� Algoritmo:
� Selecione o autovetor (componente) correspondente ao menor autovalor;
� Rejeite a variável com maior coeficiente (valor absoluto) na componente.
� O processo continua até que os (p – k) menores autovalores sejam considerados.
Princípio para descarte de variáveis: uma componente
com baixo autovalor é menos importante e, consequente-
mente, a variável que domina essa componente deve ser
menos importante ou redundante.
70MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Descarte de Atributos ...
� A escolha de k (variáveis retidas):
� Jolliffe (1972) recomenda o threshold λ0 = 0.70 depois de investigar vários conjuntos de dados;
� Qualquer autovalor λ ≤ λ0 = 0.70 contribui muito pouco para a explicação dos dados.
Jolliffe, I. T. (1972). Discarding variables in principal component analysis I: artificial data. Appl. Statist., 21,
160-173.
Jolliffe, I. T. (1973). Discarding variables in principal component analysis II: real data. Appl. Statist., 22, 21-31.
71MT-803: Tópicos em Matemática Aplicada – Aula 3.
PCA: Descarte de Atributos ...
Dataset: IRIS
� Variáveis descartadas: petallength, sepallength.
� Variáveis retidas: sepalwidth, petalwidth.
λi< 0.70
Projeção Aleatória
A1 A2 A3 A4 A5 . . . AdK1 K2 K3 K4. . . Kp1
23...n
12...n
Projeção Aleatória de d para p dimensões, p << d

73MT-803: Tópicos em Matemática Aplicada – Aula 3.
Projeção Aleatória
� Fundamento do método:� Quando um vetor no espaço d-dimensional é projetado em um subespaço aleatório k-dimensional (k << d), as distâncias entre os pares de pontos são quase que totalmente preservadas.
� Lema de Johnson e Lindenstrauss (1984).
� Na prática: os pares de pontos não são distorcidos mais do que um fator de (1 ± ε), para 0 < ε < 1, com probabilidade O(1/n2), onde n é o número de pontos (objetos) em análise.
74MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Projeção Aleatória de d para k dimensões:
� D’ n×××× k = Dn×××× d • Rd×××× k (transformação linear), onde:
D é a matriz original;
D’ é a matriz reduzida;
R é a matriz aleatória.
� A matriz R tem as seguintes características:
� As colunas de R são compostas de vetores ortonormais. Esses vetores têm comprimento (norma) igual a um.
� Os elementos rij de R têm média zero e variância um.
Projeção Aleatória ...
75MT-803: Tópicos em Matemática Aplicada – Aula 3.
Projeção Aleatória ...
� A matriz R é gerada da seguinte maneira:
� (R1): rij ~ N(0,1) e as colunas são normalizadas;
� (R2): rij =
6/1
3/2
6/1
1
0
1
3
−
+
×
adeprobabilidcom
adeprobabilidcom
adeprobabilidcom
76MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Passos:
� Passo 1 – Separação dos atributos numéricos;
� Passo 2 – Normalização de atributos;
� Passo 3 – Redução de dimensão usando projeção aleatória.
� Passo 4 – Cálculo do erro que as distâncias (d-k) sofrem:
Onde: é a distância entre os pontos i e j;
é a distância entre os pontos i e j no espaço reduzido.
)/())ˆ((,
2
,
22 ∑∑ −=ji
ij
ji
ijij dddErro
Projeção Aleatória ...
ijd
ijd̂

77MT-803: Tópicos em Matemática Aplicada – Aula 3.
Projeção Aleatória ...
�Vantagens:
� Complexidade: O(m), onde m é o número de objetos;
� Facilidade de implementação;
� Baixo custo computacional.
�Desvantagens:
� Só pode ser aplicada para atributos numéricos.
� Não é útil para as tarefas de classificação e associação.
78MT-803: Tópicos em Matemática Aplicada – Aula 3.
� Proteção de privacidade (mascarar dados):
�Lema: Uma projeção aleatória de d para kdimensões, onde k <<<<<<<< d, é uma transformação linear não inversível.
� Recuperação de Informação:
�Redução de atributos representando os índices.
� Agrupamento (ou clusterização):
�Algoritmos baseados em distância são beneficiados com o uso de projeção aleatória.
Aplicações de Projeção Aleatória
79MT-803: Tópicos em Matemática Aplicada – Aula 3.
12810944689044286
2518340765828446
1297724705240254
1748124536456342
1939132638075123
PR_intQRSInt_defheart
rate
weightageID
Amostra do dataset “cardiac arrhythmia”(UCI Machine Learning Repository)
Matriz Original
-102.76-50.22-88.5018.1637.64-62.72286
-72.74-140.87-85.50-17.58-31.66-37.61446
-66.97-70.43-65.50-0.6620.69-55.86254
-83.13-84.29-51.0012.226.27-37.08342
-107.93-95.26-55.5012.3117.33-50.40123
Atr3Atr2Atr1Atr3Atr2Atr1ID
Matriz Transformada
RP1: Matriz aleatória com base na Distribuição Normal.
RP2: Matriz aleatória com base na Distributição mais simples.
RP1
RP2
Exemplo de Projeção Aleatória
80MT-803: Tópicos em Matemática Aplicada – Aula 3.
Referências para consulta
� Wall, Michael E., Andreas Rechtsteiner, Luis M. Rocha. Singular value decomposition and principal component analysis. In A
Practical Approach to Microarray Data Analysis. D.P. Berrar, W. Dubitzky, M. Granzow, eds. pp. 91-109, Kluwer: Norwell, MA, 2003.
� Papadimitriou CH, Tamaki H, Raghavan P, Vempala S. Latent semantic indexing: a probabilistic analysis. In: Proceedings of the 17th ACM symposium on principles of database systems. Seattle, WA, USA; June 1998. p. 159–68.
� Jolliffe, I. T. Discarding Variables in a Principal Component Analysis. In Applied Statistics, Vol. 21, No. 2 (1972), pp. 160-173.
� Jolliffe, I. T. Principal Component Analysis: Springer-Verlag, New York, 1986.

81MT-803: Tópicos em Matemática Aplicada – Aula 3.
Referências para consulta ...
� Kaski S. Dimensionality reduction by random mapping. In: Proceedings of the international joint conference on neural networks. Anchorage, Alaska; May 1999. p. 413–18.
� Kruskal JB, Wish M. Multidimensional scaling. Beverly Hills, CA, USA: Sage Publications; 1978.
� Larsen B, Aone C. Fast and effective text mining using linear-time document clustering. In: Proceedings of the fifth ACM SIGKDD international conference on knowledge discovery and data mining. San Diego, CA, USA; August 1999. p. 16–22.
� Faloutsos C, Lin K-I. FastMap: a fast algorithm for indexing, datamining and visualization of traditional and multimedia datasets. In: Proceedings of the 1995 ACM SIGMOD international conference on management of data. San Jose, CA, USA; June 1995. p. 163–74.
82MT-803: Tópicos em Matemática Aplicada – Aula 3.
Referências para consulta ...
� Bingham E, Mannila H. Random projection in dimensionality reduction: applications to image and text data. In: Proceedings of the seventh ACM SIGKDD international conference on knowledge discovery and data mining. San Francisco, CA, USA; 2001. p. 245–50.
� Johnson WB, Lindenstrauss J. Extensions of Lipshitz mapping into Hilbert space. In: Proceedings of the conference in modern analysis and probability. Contemporary mathematics, vol. 26; 1984. p. 189–206.
� Achlioptas D. Database-friendly random projections. In: Proceedings of the 20th ACM symposium on principles of database systems. Santa Barbara, CA, USA; May 2001. p. 274–81.
� Fern XZ, Brodley CE. Random projection for high dimensional data clustering: a cluster ensemble approach. In: Proceedings of the 20th international conference on machine learning (ICML 2003). Washington DC, USA; August 2003
83MT-803: Tópicos em Matemática Aplicada – Aula 3.
Referências para consulta ...� M.A. Hall. Correlation-based feature selection for machine
learning. PhD thesis, Department of Computer Science, University of Waikato, Hamilto, New Zealand, 1998.
� U. Fayyad and K. Irani. Multi-interval discretization of continuous-valued attributes for classification learning. Proceedings of the
13th International Joint Conference on Artificial Intelligence, pages 1022–1029, 1993.
� H. Liu and R. Setiono. Chi2: Feature selection and discretization of numeric attributes. Proceedings of the IEEE 7th International
Conference on Tools with Artificial Intelligence, pages 388–391, November 1995.
� T.M. Mitchell. Machine Learning. McGrawHill, USA, 1997.
� P.J. Park, M. Pagano, and M. Bonetti. A non-parametric scoring algorithm for identifying informative genes from microarray data. Pacific Symposium on Biocomputing, pages 52–63, 2001.
84MT-803: Tópicos em Matemática Aplicada – Aula 3.
Referências para consulta ...
� R. Sandy. Statistics for Business and Economics. McGrawHill, USA, 1989.
� F. Wilcoxon. Individual comparisons by ranking methods. Biometrics, 1:80–83, 1945.
� E.P. Xing and R.M. Karp. Cliff: Clustering of high-dimensional microarray data via iterative feature filtering using normalizedcuts. Proceedings of The Ninth International Conference on
Intelligence Systems for Molecular Biology, published on
Bioinformatics, 17(suppl):S306–S315, 2001.
� Kenney, J. F. and Keeping, E. S. Mathematics of Statistics, Pt. 2, 2nd
ed. Princeton, NJ: Van Nostrand, 1951.
� Weisstein, Eric W. Chi-Squared Test. From MathWorld – A Wolfram Web Resource. http://mathworld.wolfram.com/Chi-SquaredTest.html


















