
Prof. Rodrigo Ramos Nogueira
195
Indaial – 2020 MACHINE LEARNING I – CLASSIFICAÇÃO E REGRESSÃO Prof. Rodrigo Ramos Nogueira 1 a Edição
Transcript of Prof. Rodrigo Ramos Nogueira

Indaial – 2020
Machine learning i – classificação e regressão
Prof. Rodrigo Ramos Nogueira
1a Edição

Copyright © UNIASSELVI 2020
Elaboração:
Prof. Rodrigo Ramos Nogueira
Revisão, Diagramação e Produção:
Centro Universitário Leonardo da Vinci – UNIASSELVI
Ficha catalográfica elaborada na fonte pela Biblioteca Dante Alighieri
UNIASSELVI – Indaial.
Impresso por:
N778m
Nogueira, Rodrigo Ramos
Machine learning I - Classificação e regressão. / Rodrigo Ramos Nogueira. – Indaial: UNIASSELVI, 2020.
186 p.; il.
ISBN 978-65-5663-320-6 ISBN Digital 978-65-5663-316-9
1. Machine learning. - Brasil. II. Centro Universitário Leonardo da Vinci.
CDD 004

apresentação
Caro acadêmico! Seja bem-vindo ao Livro Didático Machine learning I – Classificação e Regressão. Esta disciplina objetiva proporcionar uma introdução aos conceitos fundamentais de Machine learning e aprofundar os estudos sobre as tarefas de classificação e regressão.
Este material conta com recursos didáticos externos, por isso, recomendamos fortemente que você realize todos os exemplos, explore as bases de dados e pratique com os exercícios resolvidos, para um aproveitamento excepcional da disciplina.
Nesse contexto, este livro didático está dividido em: Unidade 1, que apresenta uma introdução ao aprendizado de máquina; Unidade 2, que mostra a classificação das Machine learning e Unidade 3, que trata da regressão.
Destacamos também a importância de realizar as autoatividades, que objetivam a fixação dos conceitos apresentados – lembrando que elas não são opcionais. Em caso de dúvida durante a realização das atividades, sugerimos que entre em contato com seu tutor externo ou com a tutoria do Centro Universitário Leonardo Da Vinci (UNIASSELVI) – não continue as atividades enquanto todas as dúvidas não tiverem sido sanadas.
Bom estudo! Sucesso na sua trajetória acadêmica e profissional!
Prof. Rodrigo Ramos Nogueira

Você já me conhece das outras disciplinas? Não? É calouro? Enfim, tanto para você que está chegando agora à UNIASSELVI quanto para você que já é veterano, há novi-dades em nosso material.
Na Educação a Distância, o livro impresso, entregue a todos os acadêmicos desde 2005, é o material base da disciplina. A partir de 2017, nossos livros estão de visual novo, com um formato mais prático, que cabe na bolsa e facilita a leitura.
O conteúdo continua na íntegra, mas a estrutura interna foi aperfeiçoada com nova diagra-mação no texto, aproveitando ao máximo o espaço da página, o que também contribui para diminuir a extração de árvores para produção de folhas de papel, por exemplo.
Assim, a UNIASSELVI, preocupando-se com o impacto de nossas ações sobre o ambiente, apresenta também este livro no formato digital. Assim, você, acadêmico, tem a possibilida-de de estudá-lo com versatilidade nas telas do celular, tablet ou computador. Eu mesmo, UNI, ganhei um novo layout, você me verá frequentemente e surgirei para apresentar dicas de vídeos e outras fontes de conhecimento que complementam o assun-to em questão.
Todos esses ajustes foram pensados a partir de relatos que recebemos nas pesquisas institucionais sobre os materiais impressos, para que você, nossa maior prioridade, possa continuar seus estudos com um material de qualidade.
Aproveito o momento para convidá-lo para um bate-papo sobre o Exame Nacional de Desempenho de Estudantes – ENADE. Bons estudos!
NOTA


Olá, acadêmico! Iniciamos agora mais uma disciplina e com ela um novo conhecimento.
Com o objetivo de enriquecer seu conhecimento, construímos, além do livro que está em suas mãos, uma rica trilha de aprendizagem, por meio dela você terá contato com o vídeo da disciplina, o objeto de aprendizagem, materiais complemen-tares, entre outros, todos pensados e construídos na intenção de auxiliar seu crescimento.
Acesse o QR Code, que levará ao AVA, e veja as novidades que preparamos para seu estudo.
Conte conosco, estaremos juntos nesta caminhada!
LEMBRETE

suMário
UNIDADE 1 — MACHINE LEARNING ............................................................................................. 1
TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING ........................................................... 31 INTRODUÇÃO .................................................................................................................................... 32 ASPECTOS HISTÓRICOS DE MACHINE LEARNING ............................................................... 53 DEFINIÇÃO DE CONCEITOS ......................................................................................................... 74 CARACTERÍSTICAS DE MACHINE LEARNING ...................................................................... 11RESUMO DO TÓPICO 1..................................................................................................................... 14AUTOATIVIDADE .............................................................................................................................. 15
TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING ............................................................................................... 191 INTRODUÇÃO .................................................................................................................................. 192 LINGUAGEM DE PROGRAMAÇÃO .......................................................................................... 193 JUPYTER NOTEBOOK E GOOGLE COLAB RESEARCH ....................................................... 214 GITHUB ............................................................................................................................................... 245 DATASETS ......................................................................................................................................... 26
5.1 BANCOS DE DADOS E DATA WAREHOUSING .................................................................. 275.2 ÁUDIO, IMAGEM E VÍDEO ....................................................................................................... 275.3 ARQUIVOS DE TEXTOS ............................................................................................................. 285.4 DOCUMENTOS SEMIESTRUTURADOS ................................................................................. 295.5 KAGGLE ........................................................................................................................................ 305.6 UCI MACHINE LEARNING REPOSITORY .............................................................................. 30
RESUMO DO TÓPICO 2..................................................................................................................... 33AUTOATIVIDADE .............................................................................................................................. 34
TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING ...................... 371 INTRODUÇÃO .................................................................................................................................. 372 COLETA DE DADOS ........................................................................................................................ 383 PREPARAÇÃO DOS DADOS ......................................................................................................... 384 ESCOLHA DO MODELO ................................................................................................................ 395 TREINO E TESTE .............................................................................................................................. 416 AVALIAÇÃO ...................................................................................................................................... 447 TUNING DE PARÂMETROS .......................................................................................................... 448 PREDIÇÃO .......................................................................................................................................... 45LEITURA COMPLEMENTAR ............................................................................................................ 46RESUMO DO TÓPICO 3..................................................................................................................... 51AUTOATIVIDADE .............................................................................................................................. 52
REFERÊNCIAS ...................................................................................................................................... 55

UNIDADE 2 — CLASSIFICAÇÃO ................................................................................................... 59
TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO ........................................ 611 INTRODUÇÃO .................................................................................................................................. 612 VISÃO GERAL DA CLASSIFICAÇÃO ....................................................................................... 613 CENÁRIOS DE CLASSIFICAÇÃO ............................................................................................... 634 FERRAMENTAS COMPLEMENTARES ....................................................................................... 64
4.1 LISTAS ........................................................................................................................................... 654.2 NUMPY .......................................................................................................................................... 664.3 ANACONDA ................................................................................................................................ 674.4 SCIPY .............................................................................................................................................. 684.5 SCIKIT-LEARN .............................................................................................................................. 69
5 MÉTRICAS DE AVALIAÇÃO PARA CLASSIFICAÇÃO .......................................................... 69RESUMO DO TÓPICO 1..................................................................................................................... 73AUTOATIVIDADE .............................................................................................................................. 74
TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA .................. 771 INTRODUÇÃO .................................................................................................................................. 772 MÉTODOS BASEADOS EM DISTÂNCIA .................................................................................. 78
2.1 KNN ................................................................................................................................................ 792.1.1 Implementação matemática do método .......................................................................... 80
2.2 IMPLEMENTAÇÃO COM SCIKIT-LEARN .............................................................................. 892.3 CLASSIFICANDO O IRIS DATASET COM O KNN ............................................................... 91
RESUMO DO TÓPICO 2..................................................................................................................... 95AUTOATIVIDADE .............................................................................................................................. 96
TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO ................................................................................................. 991 INTRODUÇÃO .................................................................................................................................. 992 MÉTODOS PROBABILÍSTICOS ................................................................................................... 99
2.1 NAÏVE BAYES .............................................................................................................................. 992.1.1 Implementação matemática do método ........................................................................ 103
2.2 IMPLEMENTAÇÃO COM O SCIKIT-LEARN ........................................................................ 1072.3 CLASSIFICANDO O IRIS DATASET COM O NAÏVE BAYES ............................................ 108
3 OUTROS CLASSIFICADORES .................................................................................................... 1103.1 REGRESSÃO LINEAR .............................................................................................................. 1103.2 REGRESSÃO LOGÍSTICA ........................................................................................................ 1113.3 MÁQUINA DE VETOR DE SUPORTE .................................................................................. 1123.4 PERCEPTRON ............................................................................................................................. 113
LEITURA COMPLEMENTAR .......................................................................................................... 115RESUMO DO TÓPICO 3................................................................................................................... 121AUTOATIVIDADE ............................................................................................................................ 122
REFERÊNCIAS .................................................................................................................................... 123
UNIDADE 3 — REGRESSÃO .......................................................................................................... 127
TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO ............................................... 1291 INTRODUÇÃO ................................................................................................................................ 1292 VISÃO GERAL DA REGRESSÃO ............................................................................................... 1293 MÉTRICAS ....................................................................................................................................... 132

3.1 ERRO QUADRÁTICO MÉDIO ................................................................................................ 1323.2 ERRO ABSOLUTO MÉDIO ....................................................................................................... 1343.3 OVERFITTING E UNDERFITTING .......................................................................................... 1343.4 VALIDAÇÃO CRUZADA ......................................................................................................... 135
RESUMO DO TÓPICO 1................................................................................................................... 136AUTOATIVIDADE ............................................................................................................................ 137
TÓPICO 2 — REGRESSÃO LINEAR ............................................................................................. 1391 INTRODUÇÃO ................................................................................................................................ 1392 UTILIZANDO REGRESSÃO ....................................................................................................... 1403 DERIVADAS ..................................................................................................................................... 1504 GRADIENTE DESCENDENTE .................................................................................................... 1525 IMPLEMENTAÇÃO DA REGRESSÃO LINEAR ...................................................................... 155RESUMO DO TÓPICO 2................................................................................................................... 161AUTOATIVIDADE ............................................................................................................................ 162
TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO ..................................................... 1651 INTRODUÇÃO ................................................................................................................................ 1652 REGRESSÃO LOGÍSTICA ............................................................................................................ 1653 REDES NEURAIS ARTIFICIAIS .................................................................................................. 1694 IMPLEMENTANDO REGRESSÕES COM BIBLIOTECAS DO PYTHON ......................... 175LEITURA COMPLEMENTAR .......................................................................................................... 177RESUMO DO TÓPICO 3................................................................................................................... 183AUTOATIVIDADE ............................................................................................................................ 184
REFERÊNCIAS .................................................................................................................................... 185

1
UNIDADE 1 —
MACHINE LEARNING
OBJETIVOS DE APRENDIZAGEM
PLANO DE ESTUDOS
A partir do estudo desta unidade, você deverá ser capaz de:
• compreender os conceitos fundamentais e históricos sobre Machine learning;
• conhecer exemplos de aplicações de Machine learning no mundo real;
• entender as principais características das aplicações de Machine learning;
• saber quais são as principais ferramentas para codificação;
• conhecer exemplos de aplicações e tipos de conjuntos de dados;
• dominar o desenvolvimento de um algoritmo de Machine learning por meio da apresentação das principais etapas de implementação.
Esta unidade está dividida em três tópicos. No decorrer da unidade, você encontrará autoatividades com o objetivo de reforçar o conteúdo apresentado.
TÓPICO 1 – INTRODUÇÃO AO MACHINE LEARNING
TÓPICO 2 – PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
TÓPICO 3 – ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
Preparado para ampliar seus conhecimentos? Respire e vamos em frente! Procure um ambiente que facilite a concentração, assim absorverá melhor as informações.
CHAMADA

2

3
TÓPICO 1 — UNIDADE 1
INTRODUÇÃO AO MACHINE LEARNING
1 INTRODUÇÃO
A inteligência artificial, por meio das suas mais diversas subáreas, tem alterado a nossa maneira de interagir com os sistemas computacionais, bem como a própria forma de interação com outros seres humanos.
Neste livro didático, estudaremos alguns algoritmos de inteligência artificial. Entretanto, antes de aprofundarmos os conceitos de Machine learning (em português, “aprendizado de máquina”), é preciso ressaltar que você já é um usuário de Machine learning.
Por exemplo, quando acessamos as plataformas de streaming de vídeo, é comum que filmes e vídeos sejam recomendados automaticamente. Para isso são considerados nossos dados pessoais, os filmes que positivamos (curtimos), bem como os dados de navegação do usuário (cookies).
Em 2009, apenas a Netflix, uma das pioneiras dessas plataformas, ofereceu 1 milhão de dólares para quem conseguisse otimizar seu algoritmo de recomendação de filmes. Até hoje, a plataforma investe pesado para ter maior nível de assertividade nesse algoritmo, permitindo manter mais usuários em frente à concorrência.
FIGURA 1 – RECOMENDAÇÕES DE FILMES DA PLATAFORMA NETFLIX
FONTE: O autor

UNIDADE 1 — MACHINE LEARNING
4
Outra situação cotidiana em que nos tornamos usuários de Machine learning são os anúncios e as propagandas que aparecem após procurarmos um termo em um site de buscas ou em uma rede social. Durante a elaboração deste livro didático, pesquisamos as opções para adquirir um novo computador e, adivinha, todos os sites que tinham acesso aos cookies de pesquisa nos apresentaram recomendações relacionadas as minhas buscas anteriores, cuja maioria das propagandas era gerida pelo Google. Segundo Chow (2017), hoje, são poucas as tecnologias do Google que não usam inteligência artificial e machine learning. A inteligência artificial está reinventando nossos produtos, desde o Google Maps até o YouTube, e promovendo novas experiências.
Quando o Google lançou a ferramenta “Ok, Google”, particularmente não vimos grandes vantagens no início, porém, foi a ferramenta que possibilitou o aprendizado de uso de smartphone dos nossos pais, até então avessos à tecnologia. O recurso, agora chamado de “Assistente”, permite reconhecimento de voz e a realização de ações no dispositivo auxilia em diversos contextos da acessibilidade a recursos.
FIGURA 2 – CONVERSA COM O GOOGLE ASSISTENTE
FONTE: O autor
Nas mais diversas ciências, as técnicas de Machine learning têm sido utilizadas para auxiliar os mais diversos processos, como a biologia, a aeronáutica, a física, a economia, entre muitas outras áreas.
Entre os exemplos está a sua aplicação nas ciências da saúde, tanto na realização de diagnósticos quanto de prognósticos. A área da saúde permite trabalhar com cenários interessantes, que vão desde a análise de prontuários e o reconhecimento de imagens até a análise dos dados históricos (por exemplo, utilizando relógios medidores).

TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING
5
FIGURA 3 – APLICAÇÃO DE MACHINE LEARNING NA DETECÇÃO DO CÂNCER
FONTE: <https://cutt.ly/SgVuOv3>. Acesso em: 2 out. 2020.
É fato que o Machine learning está presente em nosso cotidiano e é parte da próxima revolução industrial, em conjunto com Big Data e tecnologias 4.0. Nas próximas seções, compreenderemos melhor seu conceito e seu funcionamento.
2 ASPECTOS HISTÓRICOS DE MACHINE LEARNING
A história do Machine learning teve início em 1959, com o cientista Arthur Lee Samuel (SAMUEL, 1959), do Instituto de Tecnologia de Massachusetts (MIT), considerado pioneiro do desenvolvimento de jogos de computador, inteligência artificial e aprendizado de máquina. Em seu artigo, Samuel (1959) apresenta um estudo sobre algoritmos de inteligência artificial que consultam dados históricos para aprender a jogar damas – aprendendo com acertos e erros, a cada partida, a máquina estava mais aperfeiçoada no jogo.
FIGURA 4 – ARTHUR LEE SAMUEL E A MÁQUINA QUE JOGAVA DAMAS
FONTE: <https://www.appai.org.br/desenrola-machine-learning-aprendizado-de-maquina/>. Acesso em: 2 out. 2020.

UNIDADE 1 — MACHINE LEARNING
6
As redes neurais são um modelo matemático de inteligência artificial que simula o comportamento do cérebro humano, tendo um papel importante na história e na atualidade do desenvolvimento de algoritmos inteligentes. O primeiro algoritmo de redes neurais é conhecido como Perceptron (ROSENBLATT, 1957), utilizado para a realização de tarefas com reconhecimento de padrões. Entretanto, alguns anos depois, Minsky e Papert (1969) realizaram a prova do funcionamento do algoritmo e concluíram que não existia poder computacional suficiente na época para que ele funcionasse.
Nos anos de 1970, já com a existência dos bancos de dados relacionais e o início do desenvolvimento de sistemas de apoio à decisão, um marco para evolução dos sistemas inteligentes foi o algoritmo ID3 (Inductive Decision Tree), utilizado nas chamadas árvores de decisão, tendo novas versões nas décadas seguintes (QUINLAN, 1986; 1993).
Em um paralelo com a história dos computadores, nos anos de 1980, surgiu a segunda geração de computadores, com máquinas menores e poder computacional maior. Com isso, as redes neurais ressurgiram, afinal as máquinas ficaram mais potentes. A partir dessa época, despontou também o uso de metodologias experimentais para validar os experimentos.
A mineração de dados permite a descoberta de conhecimento a partir dos bancos de dados. Nos anos de 1990, essa tecnologia atraiu uma quantidade significativa de atenção da pesquisa e das organizações, por explorar o uso de algoritmos de Machine learning em outras aplicações e ter relação com outras áreas da inteligência artificial (FAYYAD; PIATETSKY-SHAPIRO; SMYTH, 1996).
Por fim, foi na década de 2000 que a internet chegou às casas dos usuários e as redes sociais assumiram seu papel na comunicação virtual, gerando um grande impacto no cotidiano das pessoas e das organizações. Esse momento, com o grande volume de dados, gerando cenários de Big Data, contribuiu para que os algoritmos de Machine learning fossem utilizados pelas empresas.
A Figura 5 sumariza a história do Machine learning, bem como dos demais métodos de inteligência artificial descritos anteriormente.

TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING
7
FIGURA 5 – HISTÓRIA DOS MÉTODOS DE MACHINE LEARNING
FONTE: CAO (2018, p. 3)
3 DEFINIÇÃO DE CONCEITOS
Machine learning, compreendido como o aprendizado de máquina a partir dos dados previamente conhecido, é definido como um campo preocupado com a questão de como construir programas de computador que melhorem automaticamente a experiência do usuário (MITCHELL, 1997).
Para compreendermos melhor essa definição, tomaremos como exemplo o “game of checkers”, proposto no experimento de Arthur Samuel (1959), que tratava de um programa de aprendizado de máquina para jogar damas.
Complementarmente a essa definição, Machine learning também é “Um programa [que] aprende a partir da experiência E, em relação a uma classe de tarefas T, com medida de desempenho P, se seu desempenho em T, medido por P, melhora com E” (Mitchell, 1997).
NOTA

UNIDADE 1 — MACHINE LEARNING
8
FIGURA 6 – GAME OF CHECKERS
FONTE: Samuel (1959, p. 4)
Ao aplicarmos a definição de Machine learning proposta por Mitchell (1997) no exemplo do jogo de damas, têm-se:
• T: tarefa de realizar o jogo de damas.• E: experiência com histórico de vários jogos de damas.• P: a medida de desempenho é a probabilidade de ganhar a próxima partida,
com base em jogos anteriores.
Um exemplo cotidiano na internet são as tarefas relacionadas aos bots, algoritmos que enviam mensagens e fazem postagens simulando serem pessoas na rede. Nesses cenários, algoritmos de Machine learning podem ser utilizados para a detecção de mensagens feitas por bots.
FIGURA 7 – BOTS NA WEB
FONTE: <https://avengering.com/en/bot-chatbot-internet-bot-heres-everything-you-need-to-know/>. Acesso em: 2 out. 2020.
O jogo de damas, com certeza, não é segredo para você. Confira o artigo que deu origem ao primeiro trabalho (SAMUEL, 1959), bem como originou o termo Machine learning: https://hci.iwr.uni-heidelberg.de/system/files/private/downloads/636026949/report_frank_gabel.pdf.
INTERESSANTE

TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING
9
Ao aplicarmos a definição de Machine learning proposta por Mitchell (1997) no exemplo da classificação de bots na web, têm-se:
• T: tarefa de categorizar as mensagens enviadas por bots e por humanos.• E: experiência com histórico de várias mensagens anteriores corretamente
identificadas.• P: a medida de desempenho é a porcentagem de mensagens de bots
corretamente classificadas.
A área médica provê uma grande quantidade de dados para as mais diversas aplicações de Machine learning. Um exemplo é a área de diagnósticos, em que as imagens podem ser analisadas para gerar o diagnóstico com base nos sintomas apresentados pelo paciente.
FIGURA 8 – DIAGNÓSTICO UTILIZANDO INTELIGÊNCIA ARTIFICIAL
FONTE: <https://cutt.ly/GgVoEwx>. Acesso em: 2 out. 2020.
Ao aplicarmos a definição de Machine learning proposta por Mitchell (1997) no exemplo da aplicação para diagnósticos médicos automatizados, têm-se:
• T: tarefa de diagnosticar um paciente de acordo com os sintomas que ele apresentar.
• E: experiência com histórico de pacientes anteriores, que foram diagnosticados conforme seus respectivos sintomas.
• P: a medida de desempenho é a porcentagem de pacientes que obtiverem o diagnóstico correto.
Os bots invadiram a vida dos mais diversos usuários da web, seja para quem joga, utiliza e-mail, aplicativos de mensagens, bem como as mais diversas redes sociais. Por isso, é interessante conhecer mais sobre os bots, uma vez que, no decorrer dos nossos estudos, compreenderemos o seu desenvolvimento e a sua detecção. Leia: https://www.techtudo.com.br/noticias/2018/07/o-que-e-bot-conheca-os-robos-que-estao-dominando-a-internet.ghtml.
INTERESSANTE

UNIDADE 1 — MACHINE LEARNING
10
Até o momento, vimos que um algoritmo de Machine learning funciona por meio de experiência, tarefa e medidas de desempenho. Ao analisar os exemplos apresentados, a experiência é sempre adquirida por meio dos dados, ou seja, os dados são essenciais para a existência do processo de Machine learning.
Machine learning é uma forma de Inteligência Artificial muito utilizada atualmente, que permite o aprendizado, pelo sistema, a partir de dados imputados, que servirão como base de treinamento para que o sistema gere modelos ou saídas que possam servir para análises preditivas ou, ainda, para futuras tomadas de decisão (MOREIRA, 2020, p. 1).
De modo geral, os algoritmos de Machine learning são de inteligência artificial, pois aprendem com dados históricos armazenados. Essa tecnologia utiliza os mais diversos tipos algoritmos, embora, em geral, sejam modelos matemáticos baseados em distância, probabilísticos, baseados em regras, gradiente descendente, e muitos outros que iremos estudar ao longo deste livro didático.
Os modelos matemáticos geram a inteligência dos algoritmos, permitindo
a existência do conhecimento a partir dos dados. A Figura 9 mostra uma maneira simplificada de como os algoritmos de Machine learning funcionam.
FIGURA 9 – FLUXO DE APRENDIZADO DE UM ALGORITMO DE MACHINE LEARNING
FONTE: O autor
Existem diversas aplicações na área médica, desde a medicina avançada até o suporte ao usuário. Um exemplo é a Dra. Lara, uma assistente virtual de apoio e acompanhamento ao pré-natal, desenvolvida no seguinte trabalho sobre o processo de desenvolvimento de um chatbot para área médica: https://www.researchgate.net/profile/Rodrigo_Nogueira16/publication/338668367_DRA_LARA_ASSISTENTE_VIRTUAL_DE_APOIO_E_ACOMPANHAMENTO_AO_PRE-NATAL/links/5e95fd93a6fdcca78915bf24/DRA-LARA-ASSISTENTE-VIRTUAL-DE-APOIO-E-ACOMPANHAMENTO-AO-PRE-NATAL.pdf.
INTERESSANTE

TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING
11
4 CARACTERÍSTICAS DE MACHINE LEARNING
Os sistemas de aprendizado de máquina apresentam características peculiares, que possibilitam uma classificação não exclusiva desses sistemas em função da linguagem de descrição, do modo de aprendizado, do paradigma de aprendizado, das formas e da tarefa de aprendizado (STANGE, 2011). Para elucidar a relação dessas características, o quadro a seguir elenca maneira organizada de acordo com os seus tipos.
QUADRO 1 – CLASSIFICAÇÃO DOS SISTEMAS DE MACHINE LEARNING
Modos de aprendizado
Paradigmas de aprendizado
Formas de aprendizado
Tarefas de aprendizado
Supervisionado Simbólico Incremental Classificação
Não supervisionado Estatístico Não incremental Regressão
Por reforço Conexionista Agrupamento
Genético AssociaçãoFONTE: Adaptado de Stange (2011)
No que se refere à classificação dos métodos de Machine learning, podem acontecer pela característica denominada modo de aprendizado, isto é, a maneira com que os resultados da execução dos algoritmos são influenciados por especialistas externos. Os modos de aprendizado podem ser supervisionados, semissupervisionados, não supervisionados e aprendizado por reforço.
Segundo Zubelli (2017), no aprendizado supervisionado, são apresentados exemplos do que é desejado como entrada e saída, de modo que o objetivo é aprender uma regra que mapeia a entrada na saída. Já no não supervisionado, nenhuma informação é dada a priori, deixando o algoritmo descobrir sozinho estruturas e padrões nas entradas fornecidas.
Complementarmente, o aprendizado semissupervisionado envolve um pequeno grau de supervisão, tal como um conjunto de “sementes”, para começar o processo de aprendizagem.
O aprendizado por reforço envolve a interação com o ambiente circundante, abordando a questão de como um agente autônomo que sente e age em seu ambiente pode aprender a escolher ações ideais para atingir seus objetivos. O comportamento de um agente é recompensado com base nas ações que ele realiza no ambiente. Ele considera as consequências de suas ações e adota medidas ótimas. Um computador jogando xadrez com um ser humano, aprendendo a reconhecer palavras faladas e a classificar novas estruturas astronômicas é um exemplo de aprendizado por reforço (SHOBHA; RANGASWAMY, 2018).

UNIDADE 1 — MACHINE LEARNING
12
Os paradigmas de aprendizado de máquina podem ser simbólicos, estatísticos, conexionistas, baseado em exemplos ou genético. Tais conceitos são descritos por Monard e Baranauskas (2003) como:
• Simbólico: os sistemas de aprendizado simbólico buscam aprender construindo representações simbólicas de um conceito, por meio da análise de exemplos e contraexemplos dele. As representações simbólicas estão tipicamente na forma de alguma expressão lógica, árvore de decisão, regras ou rede semântica.
• Estatístico: pesquisadores em estatística têm criado diversos métodos de classificação, muitos deles semelhantes aos métodos posteriormente desenvolvidos pela comunidade de aprendizado de máquina. A ideia geral consiste em modelos estatísticos para encontrar uma boa aproximação do conceito induzido.
• Baseado em exemplos: uma forma de classificar um exemplo é lembrar de outro similar, cuja classe é conhecida, e assumir que o novo exemplo tem a mesma classe. Essa filosofia demonstra os sistemas baseados em exemplos, que os classificam como nunca vistos por meio de exemplos similares conhecidos. Esse tipo de sistema de aprendizado é denominado lazy (preguiçoso) e necessita manter os exemplos na memória para classificar novos exemplos, em oposição aos sistemas eager (gulosos), que utilizam os exemplos para induzir o modelo, descartando-os logo após.
• Conexionista: de modo geral, essa abordagem trata das redes neurais, que são construções matemáticas simplificadas, inspiradas no modelo biológico do sistema nervoso. A representação de uma rede neural envolve unidades altamente interconectadas e, por isso, o nome conexionismo é utilizado, para descrever a área de estudo.
• Genético: paradigma de aprendizado derivado do modelo evolucionário pro-posto por David Goldberg, em 1989, no livro “Algoritmos genéticos em pesqui-sa, otimização e Machine learning”. Um classificador genético consiste de uma população de elementos de classificação que competem para fazer a predição.
As formas de aprendizado estão ligadas à maneira com que o algoritmo obtém o conhecimento a partir dos dados. Como você aprendeu, os algoritmos de Machine learning aprendem a partir dos dados armazenados, e as formas de aprendizado estão relacionadas à atualização desses dados. No cenário real de implementação de um algoritmo que tem os dados atualizados a todo momento, a cada novo dado, o algoritmo precisa atualizar o modelo matemático; quando o algoritmo precisa ler todo o conjunto de dados, ele é chamado de não incremental, mas se conseguir atualizar o modelo a partir do novo dado é incremental.
As tarefas de aprendizado de máquina são tipicamente divididas conforme os sinais de entrada e as respostas do aprendizado (ZUBELLI, 2017). Essas tarefas podem ser de classificação, regressão, agrupamento ou associação – cada um desses métodos será estudado em seguida.

TÓPICO 1 — INTRODUÇÃO AO MACHINE LEARNING
13
FIGURA 10 - A CIÊNCIA DOS DADOS É MULTIDISCIPLINAR
FONTE: <https://www.quora.com/What-is-machine-learning-and-how-it-is-linked-to-Big--Data-Data-Mining>. Acesso em: 2 out. 2020.
Machine learning, muitas vezes, pode ser confundida com outras áreas do conhecimento, principalmente em sistemas inteligentes, pois, como são áreas próximas, é comum tal confusão. Por isso, é interessante compreender a relação entre essas áreas:
• A ciência de dados é o guarda-chuva de técnicas nas quais você está tentando extrair informações e insights sobre os dados. Isso inclui desde trabalhar com programação em baixo nível até a entrega de informação em nível mais alto.
• A mineração de dados é a ciência de coletar histórico de dados e, em seguida, procurar padrões neles. Você procura padrões consistentes e relacionamentos entre variáveis. Depois de encontrar essas informações, você as válidas aplicando os padrões detectados a novos subconjuntos de dados.
• Análise de dados é qualquer tentativa de entender os dados.
• Estatística é o estudo da coleta, da análise, da interpretação, da apresentação e da organização dos dados. A estatística lida com todos os aspectos dos dados, incluindo o planejamento da coleta de dados, em termos de projeto de pesquisas e experimentos.
• Bancos de dados é uma coleção organizada de dados, com esquemas, tabelas, consultas, relatórios, visualizações e outros objetos. Os dados são normalmente organizados para modelar aspectos da realidade, de maneira a suportar processos que requerem informações.
• Inteligência artificial (IA) é a inteligência exibida por máquinas ou software, isto é, campo de estudo acadêmico sobre como criar computadores e softwares capazes de comportamento inteligente.
• A descoberta de conhecimento em bancos de dados (KDD) é o processo que identifica o conhecimento útil de uma coleção de dados.
• O reconhecimento de padrões se concentra no reconhecimento de padrões e regularidades nos dados, embora em alguns casos seja considerado quase sinônimo de aprendizado de máquina.
• A neurocomputação estuda um programa de software que usa uma rede neural, simulando o cérebro humano, que pode ser treinada para executar tarefas específicas, como reconhecimento de padrões.
FONTE: <https://www.quora.com/What-is-machine-learning-and-how-it-is-linked-to-Big-Data-Data-Mining>. Acesso em: 2 out. 2020.
INTERESSANTE

14
Neste tópico, você aprendeu que:
• O Machine learning está presente no cotidiano dos usuários da web.
• As grandes corporações utilizam essa tecnologia para otimizar seus negócios.
• A história do Machine learning teve início com um jogo de damas que utilizava inteligência artificial.
• Os fundamentos históricos acompanham o de outras tecnologias, como a inteligência artificial e Big Data.
• Um programa aprende a partir da experiência E, em relação a uma classe de tarefas T, com medida de desempenho P; se seu desempenho em T, medido por P, melhora com E.
• Os algoritmos são de inteligência artificial, que aprendem com dados históricos armazenados.
• Os sistemas apresentam diversas características. São elas: modos de aprendizado – supervisionado, não supervisionado e por reforço; paradigmas de aprendizado – simbólico, estatístico, conexionista ou genético; formas de aprendizado – incremental ou não incremental; e tarefas de aprendizado – classificação, regressão, agrupamento ou associação.
RESUMO DO TÓPICO 1

15
1 Leia o texto a seguir:
Os sistemas de Machine learning, em português conhecidos como sistema de aprendizagem automática ou sistemas de aprendizado de máquina, podem ajudar a descobrir padrões, realizar determinadas tarefas através da generalização de casos e na utilização de dados.
FONTE: OLIVEIRA, P. M. M. de. Benchmarking sobre técnicas de otimização para modelos de apoio à decisão na medicina intensiva. 2015. Tese de Doutorado.
Os algoritmos de aprendizado de máquina têm um modo de aprendizado que depende de um especialista externo para avalizar seus resultados. Assinale a alternativa CORRETA que contenha esse modo:
a) ( ) Aprendizado por reforço.b) ( ) Aprendizado supervisionado.c) ( ) Aprendizado não supervisionado.d) ( ) Aprendizado por inteligência.
2 Leia o texto a seguir:
Os algoritmos de Machine learning podem ser aplicados para uma larga gama de situações problema, desde detecção de fraudes fiscais, até recomendações, porém isso só pode ser feito devido à grande quantidade de dados fornecidas pelos datasets.
FONTE: FREITAS, D. W. Recomendação de animes utilizando Machine learning: uma aborda-gem baseada em avaliações dos usuários. Engenharia da Computação, 2018.
Com relação aos algoritmos de Machine learning, assinale a alternativa CORRETA que contenha os paradigmas de aprendizado:
a) ( ) Simbólico, estatístico, conexionista e genético.b) ( ) Supervisionado, estatístico, conexionista e genético.c) ( ) Simbólico, estático, conexionista e genético.d) ( ) Simbólico, estatístico, colaborador e georreferenciado.
3 A internet soma mais de 2 bilhões de sites publicados, sendo a principal fonte de informação deste século. No entanto, cada vez mais opções de sites implicam diversos veículos que não produzem notícias verdadeiras, as ditas fakes news. O sistema desenvolvido por Monteiro, Nogueira e Moser (2019) tem como objetivo implementar um algoritmo de Machine Leaning para classificar notícias em reais e fake news.
AUTOATIVIDADE

16
FONTE: MONTEIRO, R.; NOGUEIRA, R.; MOSER, G. Desenvolvimento de um sistema para a classificação de Fakenews acoplado à etapa de ETL de um Data Warehouse de Textos de No-tícias em língua Portuguesa. In: Anais da XV Escola Regional de Banco de Dados. SBC, 2019. p. 131-140. Disponível em: https://sol.sbc.org.br/index.php/erbd/article/view/8486/8387. Acesso em: 2 out. 2020.
Sobre o problema de Machine learning apresentado no enunciado, indique a experiência, a tarefa e a medida de desempenho.
E:______________________________________________________________________________________________________________________________________T:______________________________________________________________________________________________________________________________________P:______________________________________________________________________________________________________________________________________
4 Leia o texto a seguir:
A lucratividade promovida pelo Google em sua nova plataforma de distribuição de vídeos do YouTube atraiu um número crescente de usuários. No entanto, esse sucesso também atraiu usuários mal-intencionados, que têm como objetivo autopromover seus vídeos ou disseminar vírus e malwares. Como o YouTube oferece ferramentas limitadas para moderação de comentários, o volume de spam aumenta surpreendentemente, o que leva os proprietários de canais famosos a desativar a seção de comentários em seus vídeos.
FONTE: ALBERTO, T. C.; LOCHTER, J. V.; ALMEIDA, T. A. TubeSpam: Comment spam filtering on YouTube. In: 2015 IEEE 14th International Conference on Machine learning and Applica-tions (ICMLA). IEEE, 2015. p. 138-143. Disponível em: http://www.dt.fee.unicamp.br/~tiago/papers/TCA_ICMLA15.pdf. Acesso em: 2 out. 2020.
No trabalho descrito pelo texto, foram implementados algoritmos de Machine learning para a detecção de comentários de publicidade (spam) em vídeos da internet. Sobre o problema de Machine learning apresentado, indique a experiência, a tarefa e a medida de desempenho.

17
E:______________________________________________________________________________________________________________________________________T:______________________________________________________________________________________________________________________________________P:______________________________________________________________________________________________________________________________________
5 Os algoritmos de Machine learning têm seu aprendizado baseado em dados históricos e diversas aplicações: agricultura de precisão, reconhecimento de imagem, classificação de textos, desenvolvimento de chatbots. Torna-se difícil um setor do novo modelo tecnológico que não utilize suas técnicas. Sobre Machine learning, assinale a alternativa CORRETA que contenha as tarefas de aprendizado:
a) ( ) Classificação, revolução, agrupamento e associação.b) ( ) Classificação, regressão, agrupamento e associação.c) ( ) Categorização, regressão, análise e dissociação.d) ( ) Classificação, regressão, agrupamento e dissociação.

18

19
TÓPICO 2 — UNIDADE 1
PREPARANDO O AMBIENTE PARA TRABALHAR
COM MACHINE LEARNING
1 INTRODUÇÃO
Ao desenvolver sistemas que utilizam Machine learning são diversos os itens a serem considerados, desde a compreensão do conceito, as características dos métodos, os tipos de métodos, as tarefas que podem ser realizadas, e as estratégias para otimizar e avaliar o funcionamento.
Este livro didático tem uma abordagem prática sobre Machine learning e, para facilitar a compreensão de cada um desses conceitos, primeiramente, vamos preparar o nosso ambiente, conhecendo e instalando as principais ferramentas.
2 LINGUAGEM DE PROGRAMAÇÃO
O desenvolvimento de sistemas inteligentes, por meio de algoritmos de Machine learning, pode ser feito pelas diversas linguagens de programação. Entre elas, podemos destacar as ferramentas MatLab, R, Scala e Python.
Um ponto importante é que praticamente todas as linguagens de programação da atualidade têm a capacidade de implementar algoritmos de Machine learning, bem como bibliotecas que já contêm esses algoritmos implementados.
Um exemplo é a linguagem Java, que teve um papel importante na implementação do framework de Big Data Apache Hadoop, além de sua aplicabilidade em sistemas distribuídos. A linguagem conta com o JAVA-ML, uma biblioteca que apresenta os algoritmos de Machine learning implementados.
No decorrer dos estudos e da prática sobre programação, a programação vetorial (ou programação matricial) será muito utilizada. Para isso, recomendamos a seguinte leitura: GOLUB, G. H.; VAN LOAN, C. F. Matrix Computations. 4. ed. Baltimore: The Johns Hopkins University Press, 2013.
NOTA

20
UNIDADE 1 — MACHINE LEARNING
A Microsoft, por sua vez, tem evoluído muito no mercado de computação em nuvem, por meio da sua plataforma Microsoft Azure. A linguagem C# e a plataforma .NET têm recursos de integração com as ferramentas de Machine learning, bem como sua própria biblioteca dessa tecnologia, denominada de ML.NET.
Diante de um cenário no qual há diversas linguagens com suas respectivas características, daremos continuidade ao estudo de Machine learning com a linguagem Python. O Python é uma linguagem de código aberto, com diversas bibliotecas para auxiliar na preparação de dados e no desenvolvimento de algoritmos de Machine learning.
Entre suas principais características, o Python pode ser executado na maioria dos sistemas operacionais, desde os tradicionais, como Windows, MacOs e Linux, até sistemas operacionais diversos como FreeBSD, utilizado em servidores, e OpenELEC, uma versão do Linux com poucos recursos utilizada em dispositivos de IoT (Internet of Things).
Para realizar a instalação do Linux, você pode acessar direto a página de downloads da plataforma: https://www.python.org/downloads/. No decorrer do desenvolvimento deste livro didático, foi utilizada a versão 3.8 do Python, porém os códigos desenvolvidos podem ser executados em qualquer instalação da versão 3.X.
No decorrer desta unidade, você irá utilizar algumas das principais bibliotecas do Python para realização de tarefas correlatas aos processos Machine learning, desde coleta de dados, pré-processamento até implementação dos algoritmos. Para instalar bibliotecas, o Python utiliza o gerenciador de pacotes PIP.
Existem diversas características que fazem do Python uma poderosa linguagem de programação. Confira algumas listadas pela ComputerWorld (2019):
1. Python é linguagem de programação popular na ciência e nas empresas. 2. Conhecimentos em Python são exigidos em muitas vagas.3. Python tem muitas bibliotecas e estruturas.4. Python tem bibliotecas poderosas para a ciência de dados.5. Python é muito utilizado em inteligência artificial e Machine learning.
Além de muito usada na ciência de dados, há também muitas bibliotecas eficientes na programação de inteligência artificial e Machine learning. Theano, Scikit-learn, Tensorflow estão entre os módulos mais usados para algoritmos de machine learning. Já o Keras é uma biblioteca de rede neural open source, dedicada para aplicações de inteligência artificial.
6. Python é utilizado no desenvolvimento de aplicações web.7. Python é funcional em diversos sistemas operacionais.8. Tem uma comunidade grande de desenvolvedores contribuindo com sua evolução.9. Python é usado para criar interfaces gráficas de usuário (GUI).10. Python é usado para automação de diversas tarefas.
INTERESSANTE

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
21
3 JUPYTER NOTEBOOK E GOOGLE COLAB RESEARCH
O notebook Jupyter é uma interface gráfica que utiliza os navegadores de internet para executar códigos Python e cria, nele, um rico conjunto de recursos de exibição dinâmica. Além de executar instruções Python, o Jupyter Notebook permite que o usuário inclua texto formatado, visualizações estáticas e dinâmicas, equações matemáticas, widgets JavaScript e muito mais. Ademais, esses documentos podem ser salvos de maneira a permitir que outras pessoas os abram e executem o código em seus próprios sistemas (VANDERPLAS, 2016).
Se você seguiu os passos indicados na seção anterior e realizou a instalação do Python e o gerenciador de pacotes PIP na sua máquina, basta executar o seguinte comando:
Na sequência, para executar o Jupyter Notebook e receber o link para que seja aberto, deve ser executado:
A partir de agora, você já terá o Jupyter instalado em seu computador e estará apto a executar códigos dinâmicos com IPython. A Figura 11 mostra a tela do Jupyter após a instalação – ao clicar em New Python 3, será inicializada uma tela em branco, chamada de Notebook.
Para realizar a instalação do PIP nos principais sistemas operacionais, confira alguns links para o auxiliar:
• Windows: https://dicasdepython.com.br/resolvido-pip-nao-e-reconhecido-como-um-comando-interno/
• Linux: https://python.org.br/instalacao-linux/• MacOS: https://python.org.br/instalacao-mac/
DICAS

22
UNIDADE 1 — MACHINE LEARNING
FIGURA 11 – TELA INICIAL DO JUPYTER NOTEBOOK
FONTE: O autor
Atualmente, nosso mundo é dinâmico no que se refere às equipes de desenvolvimento de sistemas e multidisciplinares. Nesse cenário, pesquisadores e desenvolvedores atuam em projetos de maneira remota, acessando o mesmo código e compartilhando soluções.
Com relação à utilização do Notebook e ao compartilhamento de código, uma solução interessante é o Google Colaboratory, também chamado de Google Colab. Segundo Rosa (2019), trata-se de um serviço na nuvem gratuito, que oferece suporte de processamento (nesse caso, uma GPU Tesla K80) e também pode contar com 12 GB de memória RAM. Por isso, é uma ótima ferramenta para o treinamento de algoritmos de aprendizado de máquina.
Tendo como objetivo aproximar o aluno do conteúdo prático apresentado ao longo deste livro didático, iremos utilizar diversos exemplos desenvolvidos na plataforma Google Colab. Com a utilização dessa ferramenta, os processos de ensino-aprendizagem podem se beneficiar do uso de recursos on-line, permitindo a melhoria da produtividade para alunos e professores, por meio da flexibilidade e do trabalho colaborativo. Particularmente, nos cursos de computação, as ferramentas de código aberto, como o Jupyter Notebook, fornecem um ambiente de programação para o desenvolvimento e o compartilhamento de materiais educacionais, combinando
O termo GPU (Graphics Processing Unit, em português “Unidade de Processamento Gráfico”) é a responsável por dar vida aos jogos eletrônicos. De modo geral, pode-se compreendê-la como as placas de vídeo de aceleração. O motivo de uma placa de vídeo ter destaque em um tema como o nosso é que, com GPU, é possível a execução dos algoritmos utilizando CUDA e OpenCL. Em geral, essas duas tecnologias permitem que os algoritmos sejam executados utilizando a placa de vídeo.
NOTA

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
23
diferentes tipos de recursos, como texto, imagens e código, em várias linguagens de programação em um único documento, acessível pela web do navegador. Esse ambiente também é adequado para fornecer acesso a experimentos on-line e explicar como usá-los (CARDOSO; LEITÃO; TEIXEIRA, 2018).
No decorrer de nossa disciplina, utilizaremos o Google Colab para que você tenha acesso aos exemplos completos desenvolvidos no curso. Caso ainda não tenha experiência com o Google Colab, convido-o a acessar o link do Notebook e dar início ao uso dessa ferramenta, que será importante para o desenvolvimento da disciplina.
A Figura 12 mostra um exemplo da tela de cabeçalho de um documento Colab Notebook. Para ter um melhor aproveitamento desse conteúdo, é necessário conectar-se à plataforma utilizando uma conta Google. Ao abrir o programa, você perceberá que poderá apenas visualizar os códigos disponibilizados, sem poder executá-los – clique em Open in playground para poder habilitar essa função e, a partir desse momento, você irá executar os códigos em seu próprio ambiente, utilizando os recursos de hardware anteriormente mencionados.
FIGURA 12 – TELA INICIAL DO GOOGLE COLAB NOTEBOOK
FONTE: O Autor
O Notebook com o conteúdo deste tópico está disponível no link: https://colab.research.google.com/drive/1SD5qmxVjTtOpbfcSXN1G9WTqsr06ci0w.
ATENCAO
Caso esteja curioso sobre o funcionamento do Google Colab, e para conhecer mais sobre a execução de código utilizando GPU, leia o artigo Google Colab – Guia do Iniciante: https://medium.com/machina-sapiens/google-colab-guia-do-iniciante-334d70aad531
DICAS

24
UNIDADE 1 — MACHINE LEARNING
4 GITHUB
No processo de desenvolvimento de software, seja de cunho comercial ou desenvolvimento de sistemas inteligentes utilizando algoritmos de Machine learning, o código passa por diversas alterações conforme o projeto evolui. Nesse contexto, o versionamento de código permite que sejam geradas diversas versões do código-fonte desenvolvido.
Um sistema de versionamento de código é uma aplicação capaz de gravar as mudanças em um ou mais arquivos durante determinado período. A utilização desse tipo de aplicação torna possível retornar a uma versão específica daquele arquivo em qualquer momento. A principal vantagem do uso desse tipo de sistema é a organização do projeto, visto que se pode manter um histórico do desenvolvimento, possibilitando desenvolver funcionalidades paralelamente a partir do mesmo código. Além disso, viabiliza a criação de uma nova versão do projeto sem alterar a versão principal (GIORDANI, 2019).
Nos mais diversos tipos de projetos de software são utilizadas estratégias de versionamento, cada qual abordada de maneira distinta. Existem diversos softwares de gerenciamento de versões disponíveis no mercado, podendo-se citar CVS, Subversion, TFS e o Git – o qual iremos conhecer mais a fundo.
O Git é um sistema de controle de versão distribuído, utilizado para registrar o histórico de alterações em arquivos e comum em equipes de desenvolvimento de software. Com o uso do Git, é possível reverter um software para versões anteriores de forma rápida e fácil (SILVERMAN, 2013).
O Git utiliza repositórios que armazenam as versões do código-fonte e, embora os repositórios possam ser feitos em servidores das empresas, tradicionalmente, são feitos on-line em serviços próprios, como o GitHub.
O GitHub é um repositório de hospedagem de serviços Git – entre outras tantas características próprias. As interações entre seus usuários são de natureza complexa e ocorrem de diferentes formas, principalmente porque pode ser considerado uma rede social, além de uma plataforma colaborativa. Usando o GitHub, os programadores podem interagir e colaborar em torno de repositórios de código aberto, o que permite que eles façam download, cooperem, compartilhem, entre outras funcionalidades (WEITZEL; SPIES; SANTOS, 2017).

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
25
Para compreender melhor o funcionamento do Git, o ideal é criar um repositório. Para isso, utilizaremos o GitHub (www.github.com) – entretanto, você pode optar por uma alternativa de repositório.
Cada sistema operacional tem sua particularidade durante a instalação do Git; por isso, separamos alguns artigos para auxiliar na instalação de acordo com o seu sistema operacional: • Instalação em Windows: https://woliveiras.com.br/posts/instalando-o-git-windows/.• Instalação no Linux: https://www.digitalocean.com/community/tutorials/como-
instalar-o-git-no-ubuntu-18-04-pt.• Instalação no MacOS: https://git-scm.com/book/pt-br/v2/Come%C3%A7ando-
Instalando-o-Git.
IMPORTANTE
Mesmo o GitHub tendo destaque no mercado há muito tempo são diversas alternativas para criar seu repositório de arquivos versionados na nuvem. Veja, a seguir, a lista criada pelo Imaster (2018) com cinco das principais alternativas:
• GitLab (BSD): certamente, a alternativa mais conhecida. Escrito em Ruby on Rail, é de longe o mais completo (e complexo) de todos, abrangendo outras funcionalidades que não estão presentes, por padrão, no Github (por exemplo, Continous Integration). Pode ser acessado em: https://www.gitlab.com.
• Gogs (MIT): mais simples que o GitLab, mesmo assim consegue oferecer uma boa gama de recursos, aproximando-se bastante das funções mais importantes do GitHub, inclusive na interface de usuário web. Pode ser acessado em: https://www.gogs.io.
• Phabricator: a opção que tenta se afastar mais do GitHub, na tentativa de criar algo melhor e mais completo, que supra a maior parte das necessidades de um projeto de desenvolvimento de software. Pode ser acessado em: https://phacility.com/phabricator/.
• GitBucket: é uma plataforma web escrita em Scala, que conta com a instalação simplificada de um arquivo .war em sistemas que podem rodar Java 8. Pode ser acessada em: https://github.com/gitbucket.
• Kallithea (GPL3): o projeto é membro da Software Freedom Conservancy e suporta Mercurial, além de Git. Escrito em Python, traz alguns outros recursos interessantes. Pode ser acessado em: https://kallithea-scm.org/.
• GitPrep (GPL): um recurso mais simples, mas que tem uma interface semelhante à do GitHub, precisa apenas de Perl 5.10.1+ para rodar e já traz um servidor web integrado. Além disso, possui issue tracker e suporte a CGI, SSL e autenticação por chave pública. Pode ser obtido em: http://gitprep.yukikimoto.com/.
DICAS

26
UNIDADE 1 — MACHINE LEARNING
5 DATASETS
O termo Dataset vem do idioma inglês e tem como significado “conjunto de dados”. Em disciplinas relacionadas a bancos de dados (Relacionais, NoSQL, entre outras), o tema pode ser discutido mais a fundo – com conceito de dados, informação e conhecimento (Figura 13).
FIGURA 13 – DADOS, INFORMAÇÃO E CONHECIMENTO
FONTE: <https://www.gapingvoid.com/blog/2019/03/05/want-to-know-how-to-turn-change-in-to-a-movement/>. Acesso em: 20 maio 2020.
Vamos relembrar os conceitos de dados, informação e conhecimento, uma vez que, no decorrer desta disciplina, nosso objetivo é extrair conhecimento. Na definição de Nogueira (2020):
• Dados: são fatos de um mundo real, que estão armazenados em algum lugar, mas não contêm sentido; pode-se dizer que o dado é a informação em sua forma bruta, ou seja, ainda não lapidada.
• Informação: é quando o dado tem algum tipo de organização, de tal modo que passa a ter algum sentido. Pode-se dizer que a informação é composta por dados organizados, mas de maneira compreensível.
• Conhecimento: vem de discernimento, prática e experiência de vida. O conhecimento é extraído a partir dos dados e das informações armazenadas, sendo aquilo que não pode ser visto por uma perspectiva humana, mas, sim, extraído.
INTERESSANTE
Em nosso estudo sobre Machine learning, consideraremos que um Dataset é literalmente um conjunto de dados, que, quando utilizado, será extraído conhecimento, ou seja, é um conjunto de dados sob qual será aplicado o algoritmo de Machine learning.

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
27
Nesse sentido, para essa aplicação, um conjunto de dados pode ter diversas formas. Na sequência, veremos alguns exemplos de tipos de fontes de dados (datasets) para algoritmos de Machine learning, bem como exemplos de suas aplicações.
5.1 BANCOS DE DADOS E DATA WAREHOUSING
No ambiente empresarial, os dados são armazenados prioritariamente em sistemas gerenciadores de bancos de dados (relacionais ou NoSQL). Os dados organizacionais também podem ser depositados em um ambiente de Business Intelligence, integrados por intermédio de um Data Warehouse.
FIGURA 14 – MACHINE LEARNING EM AMBIENTES ORGANIZACIONAIS
FONTE: <https://pixabay.com/pt/photos/empreendedor-id%C3%A9ia-compet%C3%AAncia-1340649/>. Acesso em: 2 out. 2020.
Do ponto de vista dos ambientes organizacionais, são diversas as aplicações de algoritmos de Machine learning e elas podem variar conforme o segmento de atuação da empresa:
• Detecção de perfil de clientes.• Previsão de falhas na linha de produção.• Predição de lucros e dividendos.• Sugestão de produtos em loja on-line.• Previsão de falhas em equipamentos.• Obtenção de valores que impactam na compra/venda de ações.• Análise automática de mercado financeiro.
5.2 ÁUDIO, IMAGEM E VÍDEO
Os dados não estruturados apresentam diversos formatos, como imagens, áudios e vídeos – esses três tipos, em especial, têm como característica comum a demanda por processamento para que os algoritmos sejam executados. Uma sequência de passos tem que ser executada para que os dados se tornem compreensíveis para os algoritmos de Machine learning.

28
UNIDADE 1 — MACHINE LEARNING
FIGURA 15 – RECONHECIMENTO DE FACES COM MACHINE LEARNING
FONTE: <https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python--and-deep-learning/>. Acesso em: 2 out. 2020.
Apesar da demanda por processamento ser alta, as aplicações com esses tipos de dados estão entre as mais interessantes, podendo-se citar como exemplos:
• Reconhecimento facial.• Detecção de objetos em vídeos.• Reconhecimento por voz.• Classificação de imagens.• Identificação de objetos.
5.3 ARQUIVOS DE TEXTOS
Os textos podem ser coletados de sites de notícias, redes sociais, mensagens SMS, e-mails, além de poderem ser utilizados documentos na forma de texto (PDF, por exemplo). Os documentos de texto também são do tipo não estruturado e demandam preprocessamento para que sejam compreendidos pelos algoritmos de Machine learning.
FIGURA 16 – EXEMPLO DE APLICAÇÃO DE DATASETS DE TEXTO
FONTE: <https://cutt.ly/5gVjQBy>. Acesso em: 2 out. 2020.

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
29
A área que utiliza textos com algoritmos de Machine learning faz parte do NLP (Natural Language Processing, que significa “Linguagem de Processamento Natural”). As tarefas de Machine learning são utilizadas na automatização de diversos tipos de cenários com textos, por exemplo:
• Detecção automática de spams (Ham ou Spam).• Classificação de notícias (esporte, política, economia etc.).• Análise de sentimento (positivo, negativo, neutro).• Agrupamento de textos (juntar textos de acordo com as palavras).• Sumarização de textos (resumo de textos).• Detecção automática de notícias falsas (real ou fake news).• Desenvolvimento de chatbots.
5.4 DOCUMENTOS SEMIESTRUTURADOS Os documentos semiestruturados são aqueles cuja estrutura pode ser
alterada durante a execução de programas. No caso de algoritmos de Machine learning, estes recebem tais documentos para análise. São exemplos de documentos planilhas de Excel, documentos JSON, documentos CSV e arquivos XML.
FIGURA 17 – EXEMPLO DE DOCUMENTO SEMIESTRUTURADO
FONTE: O autor
Os documentos semiestruturados permitem armazenar os mais diversos tipos de dados, mas, principalmente, valores numéricos e discretos. Com isso, existem as mais diversas aplicações, bem como inúmeros conjuntos desses dados. Como são tantas as aplicações que utilizam os dados semiestruturados, desde análises simples, como tipos de folhas de flores, até datasets mais complexos, com dados de células que objetivam a classificação em cancerígena ou não.
Para compreender melhor os muitos exemplos que utilizam dados nos formatos mencionados, vamos estudar, a seguir, alguns sites que disponibilizam datasets gratuitos.

30
UNIDADE 1 — MACHINE LEARNING
5.5 KAGGLE
Uma das fontes de conjuntos de dados que utilizaremos, no decorrer do nosso estudo, é o Kaggle. Considerado um dos maiores repositórios de dados para aplicações de Machine learning, também é uma rede social para cientistas de dados. O Kaggle é uma plataforma feita para a comunidade de Data Science e Machine learning, cujos propósitos são compartilhar conjuntos de dados, fomentar a formação de novos Data-Scientists e engenheiros de Machine learning, e promover competições entre profissionais da área (JORDÃO, 2018).
FIGURA 18 – EXEMPLO DE UTILIZAÇÃO DO KAGGLE
FONTE: O autor
Em seu ambiente, o Kaggle disponibiliza diversos recursos além dos conjuntos de dados. Você poderá codificar on-line, utilizar Jupyters e participar de desafios utilizando os datasets da plataforma.
5.6 UCI MACHINE LEARNING REPOSITORY
Em ambientes de pesquisa científica, o UCI Machine learning Repository está entre os sites mais utilizados para obter datasets para realização de pesquisas, bem como para benchmark para novas bases criadas (MENEZES, 2016).
Acesse o Kaggle, crie sua conta e explore os mais diversos datasets que a plataforma disponibiliza: https://www.kaggle.com/.
DICAS

TÓPICO 2 — PREPARANDO O AMBIENTE PARA TRABALHAR COM MACHINE LEARNING
31
O UCI Machine learning Repository é um site que provê diversos datasets gerados e utilizados pela comunidade para aplicação de algoritmos de Machine learning. Foi criado, inicialmente, em 1987, por David Aha e outros alunos da Universidade da Califórnia.
Esse site tem sido muito utilizado por pesquisadores em todo mundo como um centralizador com diversos conjuntos de dados. Essa centralização permite que possam ser comparados diferentes resultados, metodologias e abordagens que utilizam o mesmo conjunto de dados.
A Figura 19 mostra um trecho do acesso a um Dataset (no caso, Iris Dataset), na qual: Data Set Information traz um texto descrevendo, de maneira geral, do que se trata o conjunto de dados; Attribute Information descreve cada campo e seu respectivo tipo de dados; e Relevant Papers traz a lista de artigos que utilizaram o Dataset para o seu desenvolvimento.
FIGURA 19 – EXEMPLO DA UTILIZAÇÃO DO UCI MACHINE LEARNING REPOSITORY
FONTE: O autor
Link para acesso ao UCI Machine learning Repository: https://archive.ics.uci.edu/ml/index.php.
DICAS

32
UNIDADE 1 — MACHINE LEARNING
Existem diversos outros sites que disponibilizam bases de dados, com duas opções interessantes com dados brasileiros:
• Portal Brasileiro de Dados Abertos: concentra dados do governo brasileiro, distribuindo dados e informações públicas sobre os mais diversos setores do governo. Disponível em: http://www.dados.gov.br/.
• O Brasil em Dados Libertos: é um site mantido pela comunidade de desenvolvedores e cientistas de dados brasileiros, que tem como objetivo aumentar a qualidade dos dados disponibilizados pelo governo, bem como complementá-lo por meio de outras fontes. Disponível em: https://brasil.io/.
ESTUDOS FUTUROS

33
RESUMO DO TÓPICO 2
Neste tópico, você aprendeu que:
• Existem diversas linguagens de programação e bibliotecas para desenvolver algoritmos de Machine learning.
• Por diversas características positivas, o Python é uma das linguagens mais utilizadas para a aplicação de Machine learning.
• O Python pode ser instalado nos principais sistemas operacionais do mercado.
• É possível codificar algoritmos de Machine learning on-line pelo Google Colab Research.
• É possível executar algoritmos de Machine learning utilizando GPU.
• Os versionadores de código permitem uma melhor gestão dos algoritmos desenvolvidos.
• Algoritmos de Machine learning podem consumir dados de diversos tipos de fontes de dados, bem como serem aplicados em vários cenários.
• Existem diversos conjuntos de dados sob os quais podem ser realizados experimentos e desenvolvidas aplicações de Machine learning.

34
1 Leia o texto a seguir:
Machine learning pode ser utilizado para vários objetivos, para ofertar programação de acordo com sua utilização na Netflix, saber o que estão falando sobre sua marca no Twitter e detecção de fraudes em compras com cartão de crédito, por exemplo.
FONTE: STAUDT, J. M. Machine learning para análise do desgaste da força de trabalho. Mo-nografia (Sistemas de Informação). Novo Hamburgo: Universidade Feevale, 2017. Disponível em: https://tconline.feevale.br/NOVO/tc/files/0002_4351.pdf. Acesso em: 2 out. 2020
Assinale a alternativa CORRETA que contenha uma linguagem de programação que pode ser utilizada para desenvolvimento de algoritmos de Machine learning:
a) ( ) Matlab.b) ( ) Python.c) ( ) Java.d) ( ) Todas as alternativas.
2 No desenvolvimento de programas que aplicam algoritmos de Machine learning, a linguagem Python tem sido muito utilizada, principalmente pelo seu grande número de bibliotecas e pela participação da comunidade em sua evolução. Dentro do Python, o PIP tem uma importante contribuição. Assinale a alternativa CORRETA sobre o PIP:
a) ( ) O PIP é o gerenciador de pacotes do Python.b) ( ) O PIP é o gerenciador de arquivos do Python.c) ( ) O PIP é a linguagem de programação do Python.d) ( ) O PIP é o sistema operacional do Python.
3 O Jupyter Notebook permite a execução de códigos Python no navegador, fazendo com que os usuários incluam texto formatado, visualizações estáticas e dinâmicas, equações matemáticas, entre outros recursos. Assinale a alternativa CORRETA com o comando para inicializar o Jupyter Notebook:
a) ( ) pip install jupyter.b) ( ) sudo apt-get jupyter.c) ( ) jupyter notebook.d) ( ) notebook jupyter.
AUTOATIVIDADE

35
4 Leia o texto a seguir:
Machine learning é uma técnica utilizada para auxiliar os programas a aprenderem a partir de informações existentes em bases de dados, cujo principal objetivo é a previsão de resultados futuros, por exemplo, indicando um produto do agrado de um consumidor de acordo com o comportamento de compras dele.
FONTE: STAUDT, J. M. Machine learning para análise do desgaste da força de trabalho. Mo-nografia (Sistemas de Informação). Novo Hamburgo: Universidade Feevale, 2017. Disponível em: https://tconline.feevale.br/NOVO/tc/files/0002_4351.pdf. Acesso em: 2 out. 2020.
Sobre o Google Colab Research, assinale a alternativa CORRETA:
a) ( ) É uma linguagem de programação.b) ( ) É uma plataforma colaborativa para codificação.c) ( ) É um navegador de internet.d) ( ) É um porta-documentos na nuvem.
5 As aplicações de Machine learning estão dominando os mais diversos setores, mandatoriamente os da tecnologia, mas também envolvendo diversas áreas multidisciplinares. Com isso, são gerados cada vez mais dados. Vimos alguns sites de datasets que fornecem dados para pesquisas com Machine learning. Busque na web e liste ao menos outros cinco sites que forneçam dados.
1. _________________________________________________________________2. _________________________________________________________________3. _________________________________________________________________4. _________________________________________________________________5. _________________________________________________________________

36

37
TÓPICO 3 — UNIDADE 1
ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
1 INTRODUÇÃO
Ao atuar no desenvolvimento de software, existe um conjunto de ferramentas que auxilia a garantir a qualidade do software que chegará ao usuário final. Há todo o arcabouço fornecido pela engenharia de software, levantamento de requisitos, diagramas UML (Unified Modeling Language) e também técnicas de teste de software – tudo para garantir que o software desenvolvido atenderá a necessidade de um cliente, o usuário final.
No entanto, neste livro didático não tratamos do simples processo de software que atenderá à necessidade de um usuário. Um algoritmo de Machine learning automatizará importantes processos nas organizações e, muitas vezes, até pode substituir o agente humano em tais operações.
FIGURA 20 – ROBÔS QUE UTILIZAM MACHINE LEARNING
FONTE: <https://cutt.ly/tgBisbb>. Acesso em: 2 out. 2020.
Quando falamos que um algoritmo de Machine learning pode substituir um ser humano, por exemplo, na forma de chatbot, temos que considerar que, se ele falhar, poderá apresentar erros como saudar um cliente com bom dia em vez de boa noite ou, até mesmo, responder a alguma informação de maneira errônea em um FAQ da empresa. E se for um algoritmo que realiza análise e predição de células cancerígenas? Com certeza, ele terá uma responsabilidade maior, trazendo preocupação com quem o desenvolveu e para seus usuários.
Para ambos os exemplos citados, existe um fluxo de implementação (Figura 21) para algoritmos de Machine learning. Trata-se de uma sequência de passos que objetivam ensinar o algoritmo, a partir de um conjunto de dados, a realizar a ação, mas, principalmente, garantir que o algoritmo aprendeu.

38
UNIDADE 1 — MACHINE LEARNING
FIGURA 21 – FLUXO DE UM ALGORITMO DE MACHINE LEARNING
FONTE: Adaptado de <https://cutt.ly/igBiTd0>. Acesso em: 2 out. 2020.
2 COLETA DE DADOS
A etapa de coleta de dados é a primeira do processo de Machine learning e pode ser simples, do ponto de vista de se conectar a um Dataset CSV ou a um banco de dados relacional. No entanto, quando se trabalha com outros tipos de dados, torna-se necessário criar scripts específicos para coletar dados desses cenários.
3 PREPARAÇÃO DOS DADOS
Cada base de dados tem uma característica em especial, sejam números, textos, imagens ou vídeos. Não importa o tipo de dados que exista na fonte na hora da coleta, uma série de procedimentos deve ser realizada, a fim de preparar os dados para a execução de um algoritmo.
Sabe-se que mais de 80% do tempo necessário para realizar qualquer projeto de Machine learning com dados reais, geralmente, é gasto na etapa de preparação dos dados (LOSARWAR; JOSHI, 2012). Essa etapa é responsável por preparar os dados, tornando-os mais limpos e consistentes para a execução de um algoritmo de Machine learning.
A preparação de dados é a etapa em que se deve tratá-los, de forma correta, antes de seu uso ou armazenamento. Pode ser utilizada em conjunto com a análise exploratória de dados, quando se realiza um estudo das características dos dados, geralmente por meio de gráficos (ERBS, 2020, p. 13).
Ao longo dos próximos conteúdos, desenvolveremos exemplos práticos de todas as etapas do processo de Machine learning. No que se refere à etapa de coleta de dados, ela é muito similar ao processo de extração de um Data Warehouse, por isso recomendamos a leitura do livro “Business intelligence na prática: modelagem multidimensional e data warehouse”, disponível na Biblioteca Virtual da UNIASSELVI: https://bibliotecavirtual.uniasselvi.com.br/livros/livro/247328.
IMPORTANTE

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
39
Nos exemplos práticos, aplicaremos alguns dos principais métodos de preparação dos dados, conforme é possível observar no livro Business intelligence na prática: modelagem multidimensional e data warehouse, disponível na sua Biblioteca Virtual: https://bibliotecavirtual.uniasselvi.com.br/livros/livro/247328.
Com relação ao processo de preparação de dados e análise exploratória, recomendamos a leitura do livro Preparação e Análise Exploratória de Dados, disponível em: https://bibliotecavirtual.uniasselvi.com.br/livros/livro/249088.
DICAS
4 ESCOLHA DO MODELO
O processo de desenvolvimento com Machine learning pode envolver um ou vários algoritmos para sua implementação. Esse é o momento de selecionar os algoritmos que serão avaliados e futuramente aplicados em sua aplicação de Machine learning.
No decorrer dos nossos estudos, você aprenderá alguns dos principais algoritmos utilizados em Machine learning. Segundo Mall et al. (2014), existem diversos métodos de Machine learning no mundo, para as mais diversas aplicações.
Então, como escolher o melhor algoritmo para resolver o seu problema? O primeiro passo é seguir os estudos deste livro didático – note que você já conhece os principais tipos de dados e as principais tarefas para os respectivos datasets. No decorrer dos seus estudos, seu conhecimento sobre tarefa de aprendizado de máquina, bem como os principais métodos, será aprofundado – e isso servirá de fundamento para a escolha de um método de Machine learning.
Complementarmente, lembre-se de que você está se tornando um cientista de dados e esse é o momento de recorrer ao método científico. Especificamente, para obter os principais métodos, será necessário realizar uma pesquisa exploratória nas principais bases de dados, tendo como objetivo encontrar artigos científicos relacionados ao problema que deseja resolver.
Pesquisa exploratória: é usada em casos nos quais é necessário definir o problema com maior precisão e identificar cursos relevantes de ação ou obter dados adicionais antes que se possa desenvolver uma abordagem. Como o nome sugere, a pesquisa exploratória procura explorar um problema ou uma situação para prover critérios e compreensão (VIEIRA, 2002).
NOTA

40
UNIDADE 1 — MACHINE LEARNING
Aniceto (2016) é um exemplo de pesquisa exploratória com revisão da literatura para suporte na escolha de um método de Machine learning. Esse estudo visa a identificar técnicas de Machine learning para estimação de risco de crédito.
No trabalho de Aniceto (2016), foi possível listar mais de 50 algoritmos diferentes para resolução do problema, os quais foram obtidos na leitura de 80 artigos distribuídos em dez revistas científicas. A Figura 22 mostra um gráfico de radar que sumariza os principais métodos obtidos e permitiu a continuidade das etapas do processo de Machine learning.
FIGURA 22 – TÉCNICAS DE APRENDIZADO DE MÁQUINA MAIS UTILIZADAS NA ESTIMAÇÃO DE RISCO DE CRÉDITO
FONTE: Aniceto (2016, p. 31)
Confira a lista com algumas das principais bases de dados acadêmicos que podem ajudá-lo a encontrar artigos científicos: https://blog.doity.com.br/sites-de-artigos-cientificos/.
DICAS
Para realizar um estudo mais aprofundado, você pode fazer a leitura do trabalho de Aniceto (2016), disponível em: https://repositorio.unb.br/bitstream/10482/20522/1/2016_Ma%c3%adsaCardosoAniceto.pdf.
DICAS

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
41
5 TREINO E TESTE
Você já sabe que os algoritmos de Machine learning aprendem com determinado conjunto de dados. O objetivo desses algoritmos é realizar a predição de um campo (chamado de output) com base em um conjunto de características (input).
Se o algoritmo utilizar todo o conjunto de dados para aprender, a única maneira de saber até que ponto um modelo está funcionando corretamente é testá-lo em novos casos. Uma maneira de fazer isso é colocar seu modelo em produção e monitorar o seu desempenho, o que, em teoria, não parece ser uma má ideia, mas, se o modelo for horrivelmente ruim, você pode ter sérios problemas (GÉRON, 2019).
Para compreender melhor, imagine que você esteja desenvolvendo um algoritmo para a detecção de células cancerígenas (malignas ou benignas). Para isso, pode considerar o dataset Breast Cancer Wisconsin, que exibe dados extraídos, a partir de uma imagem digitalizada de massa mamária, e cada atributo descreve características dos núcleos celulares presentes na imagem (Figura 23).
FIGURA 23 – EXEMPLO DO DATASET BREAST CANCER WISCONSIN
FONTE: <https://miro.medium.com/max/1200/1*ettn8qdhqVnhGGmnSrDg0A.png>. Acesso em: 2 out. 2020.
O dataset Breast Cancer Wisconsin pode ser acessado pelo link: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic).
DICAS

42
UNIDADE 1 — MACHINE LEARNING
Se você utilizar todo o conjunto de dados históricos para ensinar seu algoritmo de Machine learning, só haverá uma maneira de verificar se ele aprendeu corretamente: testar se o algoritmo está predizendo corretamente com dados reais dos usuários que venham a utilizar esse sistema. Dada a complexidade desse cenário, é possível imaginar a quantidade de problemas que isso pode ocasionar.
Diante disso, a melhor opção é dividir os dados do dataset em dois conjuntos: o conjunto de treinamento (treino) e o conjunto de teste. Como esses nomes sugerem, você treina seu modelo usando o conjunto de treinamento (momento em que o algoritmo estará aprendendo) e o testa utilizando o conjunto de teste (momento em que se verifica se o algoritmo aprendeu com os dados; GÉRON, 2019).
Para compreender melhor como que funciona essa separação no aprendizado, imagine-se ensinando determinado caminho a uma criança. Esse caminho segue um padrão e você guiará a criança até determinado ponto (cerca de 75% do caminho), no qual ela visualizará todas as curvas e obstáculos, aprendendo sobre os padrões.
FIGURA 24 – PROCESSO DE TREINAMENTO NO COTIDIANO
FONTE: <https://teachyourkidscode.com/coding-game-for-kids/>. Acesso em: 2 out. 2020.
Em um segundo momento será a hora de avaliar se a criança aprendeu os padrões do caminho. Lembre-se de que ela não conhece 25% do caminho, os quais serão utilizados para testar se ela aprendeu. A partir da área testada, você poderá avaliar se ela seguiu corretamente o caminho, podendo atribuir um percentual de acerto.

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
43
FIGURA 25 – TESTE NO COTIDIANO: 25% DO CAMINHO DESCONHECIDO
FONTE: <https://teachyourkidscode.com/coding-game-for-kids/>. Acesso em: 2 out. 2020.
O processo de esconder uma parte dos dados permite garantir a capacidade de generalização (erro de generalização ou taxa de generalização). A generalização significa algo genérico, ou seja, a capacidade de o método predizer algo em um cenário desconhecido.
No exemplo do dataset Breast Cancer Wisconsin, o mesmo teste pode ser realizado, ao fatiarmos o conjunto de dados, com 75% dos registros para realizar o treino e 25% para realizar os testes. A Figura 26 mostra um exemplo com as proporções dos dados utilizados – vale ressaltar que, no momento do teste, a coluna a ser predita.
O tamanho da fatia pode variar em diversas abordagens da literatura. Em geral, as fatias de treino variam entre 70%, 75% e 80% (SU, 2020; AGARAP, 2018; GÉRON, 2016).
DICAS

44
UNIDADE 1 — MACHINE LEARNING
FIGURA 26 – DIVISÃO DO DATASET EM TREINO/TESTE
FONTE: O autor
Até o momento, dissertamos, de maneira genérica, sobre o processo de treino e teste, tendo como objetivo fluidez em seus estudos sobre as etapas do processo de Machine learning. A partir da Unidade 2, retomaremos esse conteúdo com uma visão prática, aplicada ao desenvolvimento dos métodos de Machine learning.
ESTUDOS FUTUROS
6 AVALIAÇÃO
Até aqui, aprendemos que é necessário que um conjunto de dados consistente e limpo seja fatiado em treino e teste, para ser consumido por um algoritmo de Machine learning.
A avaliação é responsável por utilizar o conjunto de testes e verificar a capacidade de generalização do algoritmo, ou seja, verificar se o algoritmo aprendeu com os dados de treino. No exemplo do Dataset Breast Cancer Wisconsin, uma das métricas de avaliação, que pode ser utilizada, é a acurácia. Trata-se de uma métrica simples, que retorna a porcentagem de acerto com base no conjunto de teste.

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
45
Cada tarefa de Machine learning tem métricas específicas. No decorrer dos estudos sobre os métodos, abordaremos cada métrica especificamente.
UNI
7 TUNING DE PARÂMETROS
Ao longo dos seus estudos, você conhecerá diversos métodos de Machine learning, cada um com características específicas. A etapa de Tuning tem como objetivo obter os melhores parâmetros, para que os algoritmos obtenham o melhor desempenho possível.
8 PREDIÇÃO
A etapa de predição está relacionada com o funcionamento do Machine learning em si, sendo feita quando toda a preparação dos dados foi realizada, bem como o algoritmo foi selecionado e avaliado. Vale ressaltar que, durante todo o processo, devem ser selecionados o algoritmo e os parâmetros com melhor desempenho, de acordo com as medidas de avaliação.
FIGURA 27 – ALGORITMO DE MACHINE LEARNING EM FUNCIONAMENTO
FONTE: <https://cutt.ly/QgBpDm7>. Acesso em: 2 out. 2020.
A etapa da predição em um sistema que utiliza Machine learning é análoga à etapa de produção de um software de gestão, inclusive podem acontecer em conjunto. É, nesse momento, que o algoritmo irá para funcionamento. No exemplo que utilizamos, a predição será o algoritmo que realizará o diagnóstico dos pacientes com base em imagens.

46
UNIDADE 1 — MACHINE LEARNING
5 HISTÓRIAS DE SUCESSO DE USO DE MACHINE LEARNING
Clint Boulton
Segundo um levantamento do Gartner, 58% das empresas afirmaram que já implantaram inteligência artificial (IA) em seus negócios e que têm, em média, quatro projetos de IA/machine learning (ML) em andamento. Os participantes também revelaram que esperam adicionar mais seis projetos nos próximos 12 meses e outros 15 nos próximos três anos. Até 2022, a expectativa é de que essas organizações tenham uma média de 35 iniciativas de IA ou ML.
De acordo com Whit Andrews, analista do Gartner, a melhor experiência do cliente e a automação de tarefas por meio de assistentes virtuais, para atendimento e tomada de decisão, estão entre os projetos mais populares nas empresas. Apesar disso, os investimentos, por si só, não contribuem para um trabalho de IA mais amplo, já que uma pesquisa com 2.473 organizações, realizada pela IDC, descobriu que apenas 25% desenvolveram estratégias de IA para toda a companhia.
Segundo o relatório da IDC, cerca de 25% dos entrevistados apresentaram taxa de falha de 50% na implantação dos sistemas, por conta da falta de talentos e expectativas irrealistas. Contudo, mesmo com as dificuldades, empresas de todo o mundo parecem estar dispostas a arriscar na tecnologia. Neste artigo, CEOs que estão experimentando, construindo e implementando IA e ML compartilham seus casos e dão alguns conselhos práticos.
Conheça JiLL: assistente de IA para escritório
Muitas pessoas não acreditam que uma empresa de imóveis comerciais utilizaria IA, mas a Jones Lang LaSalle (JLL) se associou ao Google para desenvolver a JiLL, uma assistente de voz que permite que os funcionários do escritório façam reuniões, encontrem colegas, consultem horários ou preencham solicitações de serviço por voz ou texto.
FIGURA 1 – ASSISTENTE DE IA JILL
FONTE: <https://cutt.ly/wgBp3Cs>. Acesso em: 2 out. 2020.
LEITURA COMPLEMENTAR

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
47
“A JiLL pode lidar com solicitações como ‘Hey, JiLL, marcar uma reunião semanal com minha equipe’ ou ‘Hey, JiLL, encontrar uma mesa desocupada no terceiro andar esta tarde’”, explica o diretor de produtos digitais da JLL, Vinay Goel.
Goel diz que JiLL leva em consideração os conjuntos de dados da JLL sobre edifícios, interações de usuários e transações em espaços físicos, que são processados dentro do GCP, bem como containers do Kubernetes. “Com o tempo, esperamos que a JiLL se torne uma plataforma essencial para centenas de habilidades que ajudam os funcionários a melhorarem sua produtividade diária”, acrescenta Goel.
Conselho-chave: para as organizações que procuram mudar os serviços, os assistentes virtuais podem ser um investimento que vale a pena. A JiLL, da JLL, faz parte de uma estratégia para alavancar a tecnologia, para fornecer serviços de valor agregado, idealmente para atrair mais clientes. A JLL planeja adicionar outras habilidades e abrir a plataforma para recursos de terceiros, parte de uma estratégia de mercado projetada para impulsionar a adoção da tecnologia. De forma mais ampla, a iniciativa sugere que assistentes virtuais serão popularizados para o consumo geral.
Machine learning para análise de crédito
Na gigante de análise de crédito Experian, a transformação digital preparou o caminho para um novo produto estratégico, que aproveita os recursos da ML: o Ascend Analytics On Demand, uma plataforma de análise de autoatendimento que permite às empresas criar modelos preditivos para determinar fatores críticos, qualificando os consumidores para a avaliação de solicitações de crédito.
FIGURA 2 – PLATAFORMA DE ANÁLISE DE AUTOATENDIMENTO DA EXPERIAN
FONTE: <https://cutt.ly/FgBakWj>. Acesso em: 2 out. 2020.
Os clientes podem fazer análises robustas de dados em questão de minutos, em comparação com o que atualmente leva várias semanas. Idealmente, a ferramenta permitirá que os consumidores recebam qualificações para crédito a partir de sua demanda.

48
UNIDADE 1 — MACHINE LEARNING
“Os clientes querem a capacidade de ver enormes conjuntos de informações em tempo real”, diz Barry Libenson, CEO da Experian Global, que supervisionou a construção da plataforma. “Já se foram os dias em que poderíamos prescrever coisas. Eles os querem em tempo real, quando querem, da maneira que querem”, acrescenta.
Recomendação importante: você não pode criar novas plataformas de análise em softwares já existentes e esperar que elas tenham um bom desempenho. Para apoiar a Ascend, a Experian adotou uma abordagem de nuvem híbrida e investiu em ferramentas de código aberto, incluindo containers, mecanismos de API e microsserviços. A Experian também padronizou a maneira como constrói e consome software, com aplicativos e códigos que podem ser reutilizados por seus funcionários e clientes em todo o mundo.
Machine learning para combater fraudes em cartão de crédito
Como as empresas de monitoramento de crédito, as empresas de cartão de crédito estão sempre lutando contra as fraudes. Em uma época em que muitos especialistas criticam o digital, como se a tecnologia fosse a ruína para a privacidade e a segurança on-line, as ferramentas de ML e IA podem tornar os serviços mais seguros do que os tradicionais cartões de crédito de plástico.
A Mastercard utiliza diversas camadas de ML e IA para eliminar consumidores com intenção maliciosa. Na base do sistema, está um banco de dados que já salvou a companhia de um prejuízo estimado em US$ 1 bilhão em perdas por fraude desde 2016, afirma Ed McLaughlin, presidente de tecnologia e operações da Mastercard.
FIGURA 3 – DETECÇÃO DE FRAUDES EM CARTÃO DE CRÉDITO
FONTE: <https://cutt.ly/zgBaUWL>. Acesso em: 2 out. 2020.
Para evitar os crimes, o software usa mais de 200 atributos capazes de antecipar e evitar as ações fraudulentas. Esse sistema central, combinado com tokenização, biometria, deep learning e outras abordagens inovadoras, ajudou a Mastercard a manter sua reputação como empresa segura.

TÓPICO 3 — ARQUITETURA DE UM PROJETO DE MACHINE LEARNING
49
Conselho-chave: os seres humanos são o elo mais fraco quando se trata de segurança cibernética. “O mais importante é tirar o humano do circuito” o máximo possível, diz McLaughlin, acrescentando que o software de ML, IA e processamento de linguagem natural são componentes essenciais no kit de ferramentas da Mastercard.
Machine learning para empresa de corridas
A Mercedes-AMG Petronas Motorsport está usando as capacidades de ML para ajudar a visualizar o desempenho dos carros de corrida. Para isso, a companhia coleta diversos canais de dados em seus veículos da Fórmula 1, às vezes até 10.000 pontos por segundo, para tomar decisões importantes, explica Matt Harris, líder de TI da Mercedes.
A empresa usa o software da Tibco para visualizar as variáveis, como clima, temperatura dos pneus e quantidade de combustível em seus carros. O software também permite que os engenheiros analisem detalhes como o desempenho e o desgaste das engrenagens das máquinas. Em geral, os motoristas trocam de marcha 100 vezes a cada volta, e cada vez que o piloto faz uma troca, a Tibco coleta cerca de 1.000 pontos de dados.
FIGURA 4 – USO DE ML PELA MERCEDES NA FÓRMULA 1
FONTE: <https://www.pinterest.at/pin/732890539330718731/>. Acesso em: 2 out. 2020.
“Quando você visualiza esses dados, é realmente possível fazer a caixa de engrenagens durar mais tempo ou, o que é mais importante, fazer mudanças de engrenagens mais duras”, diz Harris. “Você pode descobrir que, se você colocar a caixa de engrenagens em um modo específico, será aproximadamente 50 milissegundos mais rápido por volta. Carros podem ser separados por milésimos de segundo na qualificação, então 50 milissegundos são importantes”, finaliza.
Harris afirma ainda que a companhia está construindo algoritmos de ML para ajudar a “fazer coisas que os humanos não podem". O executivo acredita que essas capacidades acabarão por se tornar um facilitador chave para a equipe, dando vantagem competitiva frente aos concorrentes.
Recomendação importante: por que criar algo que não é sua competência principal? Antes de aterrissar na Tibco, a Mercedes-AMG Petronas usou um software de visualização caseiro que se mostrou ineficiente demais para ser

50
UNIDADE 1 — MACHINE LEARNING
mantido ao longo do tempo. Ao se apoiar na Tibco, a empresa pôde se concentrar em sua força: construir carros de alto desempenho. “O importante é permitir que as pessoas sejam criativas e pensem em resolver problemas”, defende Harris.
Machine learning para prever rotatividade nas empresas
Como a maioria das empresas de reparo automotivo, a Caliber Collision há muito tempo tem um problema de rotatividade, já que mecânicos, pintores e membros das equipes de suporte ao cliente tendem a entrar e deixar as companhias rapidamente.
Parte do problema, segundo a Caliber, é que suas lojas, muitas vezes, não tinham carros suficientes para a equipe consertar, resultando em pagamentos inconsistentes. Isso fez com que o CEO Ashley Denison se perguntasse: e se a Caliber pudesse prever quando um funcionário poderia querer sair e fazer intervenção?
A partir dessa ideia, a companhia começou a trabalhar com a consultora de tecnologia Sparkhound, que criou programas para extrair dados do setor de Recursos Humanos da Caliber, complementando-os com o Microsoft PowerBI para criar um modelo capaz de prever a saída de um funcionário. Em seguida, a Caliber entra em contato com a equipe para aplicar sistemas de intervenção.
FIGURA 5 – VISUALIZAÇÃO DO PROGRAMA AXPULSE DA CALIBER
FONTE: <https://cutt.ly/6gBa9SU>. Acesso em: 2 out. 2020.
Se o pagamento de um funcionário demora a cair, por exemplo, os gerentes regionais da Caliber podem conseguir mais carros para o colaborador trabalhar. Por outro lado, se um funcionário está sobrecarregado, a empresa pode realocar alguns carros para outras equipes. O resultado? A Caliber está economizando até US$ 1 milhão por ano.
Os principais conselhos: eliminar problemas para economizar dinheiro é uma maneira prática de usar algoritmos. “Torna muito mais fácil reter os funcionários depois de sua entrada”, completa Denison.
FONTE: Adaptado de BOULTON, C. 5 histórias de sucesso de uso de Machine Learning. CIO.com. IT MIDIA, 24 jul. 2019. Disponível em: https://cio.com.br/tendencias/5-historias-de-sucesso--de-uso-de-machine-learning/. Acesso em: 2 out. 2020.

51
RESUMO DO TÓPICO 3
Neste tópico, você aprendeu que:
• Para garantir o processo de aprendizagem, os algoritmos de Machine learning são compostos por sete etapas principais.
• O processo de coleta de dados é responsável por coletar os dados das fontes.
• A preparação dos dados realiza todas as operações necessárias para que os dados coletados sejam mais bem compreendidos pelos algoritmos de Machine learning.
• Durante a escolha do modelo, é necessário um conhecimento prévio sobre os algoritmos de Machine learning e saber que a ciência pode ser utilizada para se conhecer problemas já solucionados.
• A etapa de treino e teste é uma das mais importantes, pois é, nesse processo, que será possível avaliar os métodos de Machine learning.
• Existem diversas métricas de avaliação, cada uma para um tipo de tarefa de Machine learning e todas servem para avaliar o aprendizado dos métodos.
• O processo de tuning tem como objetivo ajustar os parâmetros dos métodos para obter melhores resultados.
• A predição é o processo de colocar o algoritmo em produção, realizando tarefas no mundo real.
Ficou alguma dúvida? Construímos uma trilha de aprendizagem pensando em facilitar sua compreensão. Acesse o QR Code, que levará ao AVA, e veja as novidades que preparamos para seu estudo.
CHAMADA

52
1 Considere o texto e a imagem a seguir:
Para que ocorra o armazenamento dos Tweets para posterior uso nas consultas, é efetuada a coleta dos textos, assim como o pré-processamento, compondo a etapa de ETL. Finalmente, após os dados pré-processados e limpos, podem ser realizadas consultas OLAP para explorar o cubo de dados. Com os textos já limpos, seleciona-se a data do registro e é efetuada sua formatação para que possa ser inserido na base. A partir disso, os dados do Tweet estão preparados para que possam ser “quebrados” e se efetue a Bag of Words. Com os dados do Tweet, as palavras são quebradas pelo script e inseridas na base de dados multidimensional. Caso a palavra já exista na base, é apenas atualizada sua frequência.
FONTE: SUTER, J. et al. Um Data Warehouse baseado no Twitter para análise de sentimento em língua portuguesa: estudo de caso das eleições de 2018. In: Anais da XV Escola Regional de Banco de Dados. Anais [...] SBC, 2019. p. 41-50. Disponível em: https://sol.sbc.org.br/index.php/erbd/article/view/8477/8378. Acesso em: 2 out. 2020.
Analisando a imagem e associando com as etapas de aprendizado de um algoritmo de Machine learning, assinale a alternativa CORRETA sobre em qual etapa o processo de fonte de dados e Crawler estão relacionados:
a) ( ) Coleta de dados.b) ( ) Preparação de dados.c) ( ) Escolha do modelo.d) ( ) Divisão em treino/teste.
2 Considere o texto a seguir:
AUTOATIVIDADE
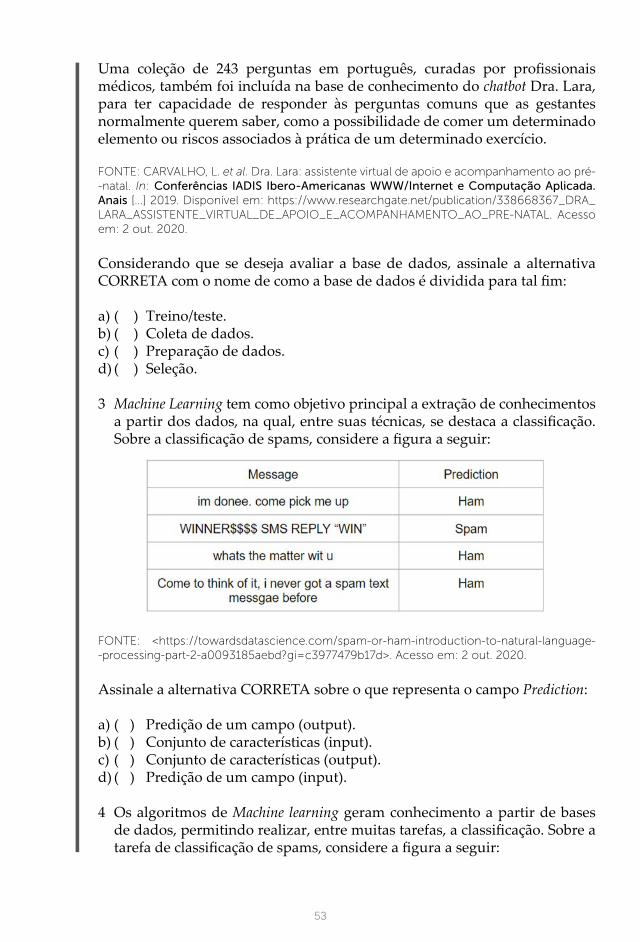
53
Uma coleção de 243 perguntas em português, curadas por profissionais médicos, também foi incluída na base de conhecimento do chatbot Dra. Lara, para ter capacidade de responder às perguntas comuns que as gestantes normalmente querem saber, como a possibilidade de comer um determinado elemento ou riscos associados à prática de um determinado exercício.
FONTE: CARVALHO, L. et al. Dra. Lara: assistente virtual de apoio e acompanhamento ao pré--natal. In: Conferências IADIS Ibero-Americanas WWW/Internet e Computação Aplicada. Anais [...] 2019. Disponível em: https://www.researchgate.net/publication/338668367_DRA_LARA_ASSISTENTE_VIRTUAL_DE_APOIO_E_ACOMPANHAMENTO_AO_PRE-NATAL. Acesso em: 2 out. 2020.
Considerando que se deseja avaliar a base de dados, assinale a alternativa CORRETA com o nome de como a base de dados é dividida para tal fim:
a) ( ) Treino/teste.b) ( ) Coleta de dados.c) ( ) Preparação de dados.d) ( ) Seleção.
3 Machine Learning tem como objetivo principal a extração de conhecimentos a partir dos dados, na qual, entre suas técnicas, se destaca a classificação. Sobre a classificação de spams, considere a figura a seguir:
FONTE: <https://towardsdatascience.com/spam-or-ham-introduction-to-natural-language--processing-part-2-a0093185aebd?gi=c3977479b17d>. Acesso em: 2 out. 2020.
Assinale a alternativa CORRETA sobre o que representa o campo Prediction:
a) ( ) Predição de um campo (output).b) ( ) Conjunto de características (input).c) ( ) Conjunto de características (output).d) ( ) Predição de um campo (input).
4 Os algoritmos de Machine learning geram conhecimento a partir de bases de dados, permitindo realizar, entre muitas tarefas, a classificação. Sobre a tarefa de classificação de spams, considere a figura a seguir:

54
FONTE: <https://towardsdatascience.com/spam-or-ham-introduction-to-natural-language--processing-part-2-a0093185aebd>. Acesso em: 2 out. 2020.
Assinale a alternativa CORRETA sobre o que representa o campo text:
a) ( ) Conjunto de características (input).b) ( ) Predição de um campo (output).c) ( ) Conjunto de características (output).d) ( ) Predição de um campo (input).
5 Considere o texto a seguir:
Os algoritmos de Machine learning, também conhecidos como aprendizes, são diferentes: eles descobrem tudo sozinhos, fazendo inferências a partir de dados. E quanto mais dados têm, melhor ficam seus resultados.
FONTE: DOMINGOS, P. O algoritmo mestre: como a busca pelo algoritmo de Machine lear-ning definitivo recriará nosso mundo. Novatec Editora, 2017.
Assinale a alternativa CORRETA sobre a etapa do processo de Machine learning que tem como objetivo obter os melhores parâmetros para os algoritmos:
a) ( ) Tuning de parâmetros.b) ( ) Predição de parâmetros.c) ( ) Conjunto de parâmetros.d) ( ) Aplicação de parâmetros.

55
REFERÊNCIAS
AGARAP, A. F. M. On breast cancer detection: an application of machine learning algorithms on the wisconsin diagnostic dataset. In: Proceedings of the 2nd In-ternational Conference on Machine Learning and Soft Computing. Proceedings […] 2018. p. 5-9.
ANICETO, M. C. Estudo comparativo entre técnicas de aprendizado de máqui-na para estimação de risco de crédito. 2016, 106f. Dissertação de Mestrado (Pro-grama de Pós-Graduação em Administração). Universidade de Brasília, Brasília, 2016. Disponível em: https://repositorio.unb.br/bitstream/10482/20522/1/2016_Ma%c3%adsaCardosoAniceto.pdf. Acesso em: 2 out. 2020.
CAO, C. et al. Deep learning and its applications in biomedicine. Genomics, Proteomics & Bioinformatics, v. 16, n. 1, p. 17-32, 2018.
CARDOSO, A.; LEITÃO, J.; TEIXEIRA, C. Using the Jupyter notebook as a tool to support the teaching and learning processes in engineering courses. ICL 2018: The Challenges of the Digital Transformation in Education. Springer, Cham, 2018. p. 227-236.
CHOW, M. Inteligência artificial e machine learning: o caminho para a relevância em escala. Think with Google, out. 2017. Disponível em: https://www.thinkwithgoo-gle.com/intl/pt-br/advertising-channels/novas-tecnologias/inteligencia-artificial-e--machine-learning-o-caminho-para-relevancia-em-escala/. Acesso em: 20 abr. 2020.
COMPUTERWORLD. Python: 10 motivos para aprender a linguagem em 2019. COMPUTERWORLD. 15 set. 2019. Disponível em: https://computerworld.com.br/2019/09/15/python-10-motivos-para-aprender-a-linguagem-em-2019/. Acesso em: 20 abr. 2020.
ERBS, S. Preparação e Análise Exploratória de Dados. Indaial: UNIASSELVI, 2020.
FAYYAD, U.; PIATETSKY-SHAPIRO, G.; SMYTH, P. From data mining to knowledge discovery in databases. AI Magazine, v. 17, n. 3, p. 37-37, 1996.
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and Ten-sorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. 2. ed. O’Reilly Media, 2019.
GIORDANI, V. A. et al. Automatização do processo de entrega de softwres. 2019, 75f. Monografia. Universidade Federal de Santa Catarina, Florianópolis, 2019. Disponível em: https://repositorio.ufsc.br/bitstream/handle/123456789/200137/PFC%20Vito%20Archangelo%20Giordani_2019-1.pdf?sequence=1&isAllowed=y. Acesso em: 2 out. 2020.

56
JORDÃO, R. F. P. Um estudo em larga-escala de repositórios Open Source no Github que utilizam containers. 2018, 44f. Monografia. Centro de Informáti-ca, Universidade Federal de Pernambuco, Recife, 2018. Disponível em: https://www.cin.ufpe.br/~tg/2018-2/TG_SI/rfpj.pdf. Acesso em: 2 out. 2020.
LOSARWAR, V.; JOSHI, M. Data preprocessing in web usage mining. In: International Conference on artificial intelligence and embedded systems (ICAIES’2012). Proceedings […] Singapore, jul. 2012.
MALL, R. et al. Representative subsets for big data learning using k-NN graphs. In: 2014 IEEE INTERNATIONAL CONFERENCE ON BIG DATA. Proceedings […] IEEE, 2014. p. 37-42. Disponível em: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7004210. Acesso em: 2 out. 2020.
MENEZES, S. et al. Mineração em grandes massas de dados utilizando hadoop mapreduce e algoritmos bio-inspirados: Uma revisão sistemática. Revista de Informática Teórica e Aplicada, v. 23, n. 1, p. 69-101, 2016.
MINSKY, M.; PAPERT, S. Perceptrons – an introduction to computational geo-metry. Cambridge: MIT Press, 1969. Cited on, p. 1, 1990.
MITCHELL, T. M. et al. Machine learning. McGraw-Hill, 1997. Disponível em: http://profsite.um.ac.ir/~monsefi/machine-learning/pdf/Machine-Learning-Tom--Mitchell.pdf. Acesso em: 2 out. 2020.
MONARD, M. C.; BARANAUSKAS, J. A. Conceitos sobre aprendizado de má-quina. Sistemas inteligentes-fundamentos e aplicações, v. 1, n. 1, p. 32, 2003.
MOREIRA, M. P. Algoritmos de Machine Learning Aplicado ao Marketing. In: XV SEMANA CIENTÍFICA DA UNILASALLE CANOAS – SEFIC. Anais [...] Unilasalle Canoas, 2019, 2020.
NOGUEIRA, R. R. Business Intelligence na prática: Modelagem Multidimensio-nal e Data Warehouse. Indaial: UNIASSELVI, 2020.
QUINLAN, J. R. C4.5: Programming for machine learning. São Francisco: Mor-gan Kaufmann, 1993. p. 48.
QUINLAN, J. R. Induction of decision trees. Machine learning, v. 1, n. 1, p. 81-106, 1986. Disponível em: https://link.springer.com/content/pdf/10.1007/BF00116251.pdf. Acesso em: 2 out. 2020.
QUORA. What is machine learning and how it is linked to Big Data/Data Mi-ning? 2015. Disponível em: https://www.quora.com/What-is-machine-learning--and-how-it-is-linked-to-Big-Data-Data-Mining. Acesso em: 20 abr. 2020.
ROSA, A. L. da. Classificação de imagens de frutas utilizando aprendizado de máquina. 2019, 74f. Monografia. Departamento de Engenharia Elétrica e Eletrô-nica, Universidade Federal de Santa Catarina, Florianópolis, 2019. Disponível em: https://repositorio.ufsc.br/bitstream/handle/123456789/197598/TCC-Ayrton--Lima.pdf?sequence=1&isAllowed=y. Acesso em: 2 out. 2020.

57
ROSENBLATT, F. The perceptron, a perceiving and recognizing automaton. Project Para. Cornell Aeronautical Laboratory, 1957. Disponível em: https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf. Acesso em: 2 out. 2020.
SAMUEL, A. L. Some studies in machine learning using the game of checkers. IBM Journal of Research and Development, v. 3, n. 3, p. 210-229, 1959. Dis-ponível em: https://hci.iwr.uni-heidelberg.de/system/files/private/downlo-ads/636026949/report_frank_gabel.pdf. Acesso em: 5 out. 2020.
SHOBHA, G.; RANGASWAMY, S. Machine learning. In: GUDIVADA, V. N.; RAO, C. R. (Eds.). Handbook of Statistics. Amsterdam: Elsevier, 2018. p. 197-228.
SILVERMAN, R. Git – Guia prático. São Paulo: Novatec, 2013.
STANGE, R. L. Adaptatividade em aprendizagem de máquina: conceitos e estudo de caso. 2011, 98f. Dissertação (Mestrado em Engenharia Elétrica). Uni-versidade de São Paulo, São Paulo, 2011. Disponível em: https://www.teses.usp.br/teses/disponiveis/3/3141/tde-02072012-175054/publico/Dissertacao_RLStan-ge_2011_Revisada.pdf. Acesso em: 5 out. 2020.
SU, X. et al. Automated machine learning based on radiomics features predicts H3 K27M mutation in midline gliomas of the brain. Neuro-oncology, v. 22, n. 3, p. 393-401, 2020. Disponível em: https://academic.oup.com/neuro-oncology/arti-cle-pdf/22/3/393/32794818/noz184.pdf. Acesso em: 5 out. 2020.
VANDERPLAS, J. Python data science handbook: Essential tools for working with data. O’Reilly Media, 2016.
VIEIRA, V. A. As tipologias, variações e características da pesquisa de marke-ting. Revista da FAE, v. 5, n. 1, p. 61-70, 2002. Disponível em: https://revistafae.fae.edu/revistafae/article/download/449/344. Acesso em: 5 out. 2020.
WEITZEL, L.; SPIES, J. H. L.; SANTOS, M. M. Análise do GitHub como rede social e rede de colaboração. In: 6ª CONFERÊNCIA IBERO-AMERICANA DE COMPUTAÇÃO APLICADA (CIACA), 2017. Anais [...] Algarve, Portugal, 2017. p. 252-260. Disponível em: http://www.iadisportal.org/digital-library/mdownlo-ad/an%C3%A1lise-do-github-como-rede-social-e-rede-de-colabora%C3%A7%-C3%A3o. Acesso em: 5 out. 2020.
ZUBELLI, F. S. Métodos de inteligência computacional para clusterização de consumidores no setor de energia elétrica. 2017, 86f. Monografia. Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2017. Disponível em: http://monogra-fias.poli.ufrj.br/monografias/monopoli10022747.pdf. Acesso em: 5 out. 2020.

58

59
UNIDADE 2 —
CLASSIFICAÇÃO
OBJETIVOS DE APRENDIZAGEM
PLANO DE ESTUDOS
A partir do estudo desta unidade, você deverá ser capaz de:
• introduzir os conceitos fundamentais sobre a classificação;• apresentar as ferramentas complementares para a aplicação de algoritmos;• exemplificar onde os métodos de classificação podem ser aplicados;• explanar conceitos matemáticos da implementação de métodos baseados
em distância;• implementar métodos baseados em distância, utilizando a biblioteca
scikit-learn;• explanar conceitos probabilísticos da implementação de métodos
fundamentados em probabilidade;• implementar métodos probabilísticos utilizando a biblioteca scikit-learn;• apresentar demais métodos de classificação.
Esta unidade está dividida em quatro tópicos. No decorrer da unidade, você encontrará autoatividades com o objetivo de reforçar o conteúdo apresentado.
TÓPICO 1 – INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
TÓPICO 2 – MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
TÓPICO 3 – MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
Preparado para ampliar seus conhecimentos? Respire e vamos em frente! Procure um ambiente que facilite a concentração, assim absorverá melhor as informações.
CHAMADA

60

61
UNIDADE 2
1 INTRODUÇÃO
Em aprendizado de máquina, a classificação é uma tarefa que tem como objetivo aprender com os dados e atribuir rótulos (classes). A classificação é uma tarefa de Machine learning que tem como característica o aprendizado supervisionado, no qual é atribuído um rótulo (classe) aos objetos com base nos atributos (HARRISON, 2020).
Em sua definição, um problema de classificação, supervisionado, é um
programa de computador que recebe amostras (entradas) e respostas esperadas (saídas) para elas, e gera uma hipótese genérica capaz de mapear as entradas para as saídas corretas (VON LOCHER, 2015).
Os rótulos contidos em tal conjunto correspondem a classes ou valores obtidos por alguma função desconhecida. Desse modo, um algoritmo de classificação buscará produzir um classificador capaz de generalizar as informações contidas no conjunto de treinamento, com a finalidade de classificar, posteriormente, objetos cujos rótulos sejam desconhecidos.
2 VISÃO GERAL DA CLASSIFICAÇÃO
Compreender a classificação, bem como o significado de método supervisionado, vai além de compreender seus métodos, mas, primeiramente, trata-se de compreender os dados sob os quais você irá atuar.
A terminologia “supervisionado” refere-se ao fato de que existe uma supervisão. Isso significa que há um conjunto de dados previamente rotulado (classificado) e que, por meio desses dados, será possível verificar se o método funciona. Essa capacidade de verificar assertividade do método sem a intervenção humana é a supervisão.
A classificação, também denominada de categorização, é a atividade de rotular dados com suas respectivas categorias temáticas, a partir de um conjunto de dados predefinidos. Os métodos de classificação podem ser de aprendizado on-line ou off-line, de acordo com a capacidade de construir e atualizar do classificador.
TÓPICO 1 —
INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO

UNIDADE 2 — CLASSIFICAÇÃO
62
Os métodos de aprendizado on-line podem atualizar o modelo de predição (ou classificador) a cada novo documento, de maneira incremental, sem necessidade de refazer o treinamento com todos os documentos. Já os métodos de aprendizado off-line, o modelo precisa ser recalculado a cada nova amostra, com todos os documentos do treinamento, incluindo a nova amostra.
Para compreender a classificação, analisaremos um dos principais problemas da literatura: a classificação da flor íris ou íris de Fisher (FISHER, 1936). Esse é um conjunto de dados, desenvolvido pelo biólogo britânico Ronald Fischer, que permite classificar uma flor denominada íris em: versicolor, virginica ou versicolor, tendo como base a largura e altura da pétala e sépala.
FIGURA 1 – CATEGORIAS DA FLOR ÍRIS
FONTE: <https://cutt.ly/xgBfCWB>. Acesso em: 3 nov. 2020.
Agora, vamos compreender o comportamento dos dados, no que se refere à tarefa de classificação. Perceba que os primeiros atributos são as entradas (altura da sépala, largura da sépala, altura da pétala e largura da pétala) e, por último, o atributo Species, que contém as classes de cada linha.
FIGURA 2 – DATASET DA FLOR IRIS
FONTE: O autor
É possível visualizar o conjunto de dados Iris Dataset em sua máquina, por meio do comando apresentado no Quadro 1.

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
63
QUADRO 1 – IMPORTANDO O DATASET ÍRIS
12345
6
import numpy as npimport pandas as pdfrom sklearn.datasets import load_irisiris = load_iris()dados = pd.DataFrame(data= np.c_[iris['data'], iris['tar-get']], columns= iris['feature_names'] + ['target'])dados
FONTE: O autor
3 CENÁRIOS DE CLASSIFICAÇÃO
A classificação é uma tarefa de aprendizado de máquina que gera um algoritmo preditor com base em dados previamente categorizados. No estudo dos cenários de sua aplicação, serão descritos os dois tipos de tarefas: classificação binária e classificação multiclasse.
Entre as tarefas de classificação, existe a tarefa de classificação binária e, como o nome sugere, é uma tarefa que irá classificar os dados com base em duas classes. Segundo Oliveira (2016), é o ato de dividir as observações em um conjunto de dados em dois grupos. Em outras palavras, envolve atribuir uma variável dependente, consistindo em apenas duas categorias à observação baseada na covariável. Em um cenário simples, pode ser que os pesquisadores classifiquem as transações de cartão de crédito como legítimas ou fraudulentas, de acordo com as seguintes informações: o intervalo de tempo entre os usos do cartão de crédito, a faixa de valores usada em comparação com o mês anterior, cartões de crédito muito usados, e assim por diante. Para esse exemplo, a classificação é dada por “Sim” ou “Não”, com base na existência da característica de interesse em um conjunto de variáveis explicativas.
A entrada de um algoritmo de classificação é um conjunto de exemplos rotulados, em que cada rótulo é um número inteiro de 0 ou 1, representando uma das duas possíveis classes. Segundo Microsoft (2019), a saída de um algoritmo de classificação binária é um classificador, que pode ser usado para prever a classe de novas instâncias sem rótulo, na qual cenários de classificação binária incluem:
• reconhecer como “positivo” ou “negativo”;• diagnosticar se um paciente tem determinada doença;• tomar a decisão de marcar um e-mail como spam ou não;• determinar se uma foto contém um item específico ou não (por exemplo, um
cão ou frutas).
Para Almeida (2010), muitos dos problemas de classificação envolvem mais do que duas classes, o que se designa como classificação multiclasse. Podemos facilmente pensar no caso do estado de saúde de um paciente, o qual pode ser definido, por exemplo, com as classes “mau”, “razoável”, “bom”, “muito bom”. Nesse caso, pretende-se classificar o estado de saúde do paciente em uma das classes.

UNIDADE 2 — CLASSIFICAÇÃO
64
Assim, as classificações binária e multiclasse diferem no número de classes existentes para a classificação: na binária, são definidas exatamente duas classes, enquanto, na multiclasse, são definidas n classes (n > 2), ou seja, é um problema que contém duas ou mais classes (rótulos) (ALMEIDA, 2010).
4 FERRAMENTAS COMPLEMENTARES
Com a ascensão dos métodos de Big Data e da aplicação de Machine learning nos mais diversos cenários de suporte à decisão, tais recursos começaram ser explorados cada vez mais em diversas aplicações, e não somente em cenários de suporte à decisão.
A partir dessa expansão do emprego de técnicas de Machine learning, as linguagens de programação passaram a utilizar recursos para sua implementação. A linguagem Java, por exemplo, conta com a biblioteca Java-ML (Java Machine Learning; ABEEL; VAN DE PEER; SAEYS, 2009), que é uma coleção de algoritmos de aprendizado de máquina com uma interface comum para cada tipo de algoritmo. O Java-ML é uma biblioteca destinada a engenheiros de software e programadores, portanto, sem interface gráfica do utilizador ou usuário (GUI, do inglês Graphical User Interface), mas com interfaces claras e implementações de referência para algoritmos descritos na literatura científica, com um código-fonte bem documentado e exemplos de código e tutoriais.
QUADRO 2 – EXEMPLO DE UTILIZAÇÃO DO JAVA-ML
1
234
Dataset data = FileHandler.loadDataset(new File("iris.data"), 4, ",");Classifier knn = new KNearestNeighbors(5);CrossValidation cv = new CrossValidation(knn);Map<Object, PerformanceMeasure> p = cv.crossValidation(data);
FONTE: Adaptado de Abeel; Van de Peer; Saeys (2019)
Em ambientes de programação Microsoft, também houve inovação no desenvolvimento de aplicações de Machine learning. Já em programação DOT.NET, a biblioteca utilizada é o ML.NET, um conjunto de recursos para coleta, pré-processamento de dados e, principalmente, aplicação de algoritmos de Machine learning (AHMED et al., 2019).
O Java-ML contém um conjunto de diversos recursos, biblioteca, entre outros. Para acessar sua documentação, bem como fazer download, visite o site oficial em: http://java-ml.sourceforge.net/.
DICAS

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
65
QUADRO 3 – EXEMPLO DE APLICAÇÃO DO ML.NET
12
3
45
6
7
var ctx = new MLContext();IDataView trainingData = ctx.Data .LoadFromTextFile<ModelInput>(dataPath, hasHeader: true);var pipeline = ctx.Transforms.Text .FeaturizeText("Features", nameof(SentimentIssue.Text)) .Append(ctx.BinaryClassification.Trainers .LbfgsLogisticRegression("Label", "Features"));ITransformer trainedModel = pipeline.Fit(trainingData);var predictionEngine = ctx.Model .CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);var sampleStatement = new ModelInput() { Text = "This is a horrible movie" };var prediction = predictionEngine.Predict(sampleStatement);
FONTE: Adaptado de Ahmed et al. (2019)
São muitas as opções de linguagens de programação, no que se refere ao desenvolvimento de aplicações integradas a métodos de Machine learning. Entre elas, o Python tem um destaque especial. Para muitos pesquisadores, Python é uma ferramenta de primeira classe, principalmente por causa de suas bibliotecas para armazenar, manipular e obter informações a partir de dados, sendo um conjunto completo para profissionais de ciência de dados (VANDERPLAS, 2016). Dessa maneira, vamos conhecer os principais recursos dessa linguagem, a fim de auxiliar na implementação de algoritmos de Machine learning.
4.1 LISTAS
Na linguagem de programação Python, o objeto lista é a sequência mais geral fornecida. As listas são coleções ordenadas de objetos de tipo arbitrário e não têm tamanho fixo (LUTZ, 2013). Também são mutáveis, podem ser modificadas no local, atribuindo deslocamentos, bem como uma variedade de chamadas de método de lista.
O ML.NET permite que você reutilize todo o conhecimento, habilidades, código e bibliotecas que você já possui como um desenvolvedor .NET, para que possa integrar facilmente o aprendizado de máquina em seus aplicativos da web, móvel, desktop, jogos e Internet das coisas (IoT, do inglês Internet of Things). Na documentação oficial, existe um conteúdo completo de como utilizar essa biblioteca. Acesse: https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet.
DICAS

UNIDADE 2 — CLASSIFICAÇÃO
66
Uma lista é uma estrutura de dados que contém uma coleção ordenada de itens, ou seja, você pode armazenar uma sequência de itens em uma lista. Para abrir um dataset no formato CSV (comma separated values) e transformá-lo em uma lista, confira o Quadro 4.
QUADRO 4 – TRABALHANDO COM LISTAS
12345678910111213141516
import csvlista1 = []lista2 = []with open(exemplo.csv') as csvfile: readCSV = csv.reader(csvfile, delimiter=',') dates = [] colors = [] for linha in readCSV: elemento1 = linha[0] elemento2 = linha[1]
lista1.append(elemento1) lista2.append(elemento2)
print(lista2) print(lista2)
FONTE: O autor
Para conhecer mais sobre a manipulação de dados, utilizando a estrutura de dados lista, acesse o código no Google Colab Notebooks: https://colab.research.google.com/drive/1siWWmsChWjyO6kFaItMj4fxALWY05Erd.
DICAS
4.2 NUMPY
O NumPy é o pacote fundamental para a computação científica em Python. É uma biblioteca Python que fornece um objeto de matriz multidimensional, vários objetos derivados (como matrizes e matrizes mascaradas) e uma variedade de rotinas para operações rápidas em matrizes (NASCIMENTO, 2019). Segundo Bressert (2012), tais rotinas incluem manipulação matemática, lógica, de formas, classificação, seleção, entrada/saída, transformadas discretas de Fourier, álgebra linear básica, operações estatísticas básicas, simulação aleatória, e muito mais.

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
67
Um exemplo de como acessar um dataset utilizando a biblioteca Numpy pode ser visto no Quadro 5. Ressalta-se que a utilização de tal biblioteca não se limita à criação de arrays, mas, sim, ao uso de um conjunto de operações algébricas que podem auxiliar na preparação de dados.
QUADRO 5 – TRABALHANDO COM NUMPY
12
from numpy import genfromtxtmy_data = genfromtxt(exemplo.csv', delimiter=',')
FONTE: O autor
4.3 ANACONDA
O Anaconda é um gerenciador de pacotes e ambiente para desenvolvimento de “data science” que utiliza as linguagens Python e R. A plataforma conta com uma coleção de mais de 1.500 pacotes de código aberto. O Anaconda é gratuito e fácil de instalar, e oferece suporte gratuito à comunidade (SCHLICHTING, 2020).
No caso do Colab Notebook, é necessário baixar o pacote e instalá-lo via linha de comando; para isso, utilize o bloco de comandos conforme mostra o Quadro 6.
QUADRO 6 – INSTALANDO O ANACONDA NO COLAB NOTEBOOK
1234567891011
!wget -c https://repo.anaconda.com/miniconda/Miniconda3-4.5.4-Linux-x86_64.sh!chmod +x Miniconda3-4.5.4-Linux-x86_64.sh!bash ./Miniconda3-4.5.4-Linux-x86_64.sh -b -f -p /usr/local!conda install -q -y --prefix /usr/local python=3.6 ujsonimport syssys.path.append('/usr/local/lib/python3.6/site-packages')# Para testar o funcionamentoimport ujsonprint(ujson.dumps({1:2}))
FONTE: O autor
O NumPy é uma biblioteca completa com os mais diversos recursos e operações matemáticas para tratamento de dados. Para saber mais, acesse o Google Colab Notebooks com informações sobre o NumPy em: https://colab.research.google.com/drive/1lgv-CxAUcDY5hxqw_RMMZYtqkHdcCoUE?usp=sharing.
ATENCAO

UNIDADE 2 — CLASSIFICAÇÃO
68
4.4 SCIPY
Segundo Maldaner (2019), o SciPy é a extensão responsável por adicionar ferramentas para otimização, funções especiais, processamento de imagens, integração numérica, resolução de equações diferenciais ordinárias, além de possibilitar a realização de operações com os arranjos introduzidos pelo NumPy.
Em cenários de Machine learning e na preparação de dados, a combinação do SciPy com NumPy possibilita potencializar a aplicação do Python, além de flexibilidade para os desenvolvedores, uma vez que a biblioteca foi desenvolvida para matemáticos, cientistas e engenheiros.
QUADRO 7 – ÁLGEBRA RELACIONAL COM SCIPY
12345678910111213
import numpy as npfrom scipy import linalgA = np.array([[1,2],[3,4]])print(A)linalg.inv(A)b = np.array([[5,6]]) bb.TA*b A.dot(b.T) b = np.array([5,6]) bb.T A.dot(b)
FONTE: O autor
Anaconda é um pacote científico completo para manipulação de dados e suporte a projetos de Machine learning. Para obter a biblioteca Anaconda nas mais diversas plataformas e sistemas operacionais, acesse o site: https://www.anaconda.com/. Por meio do link, é possível realizar a instalação completa, bem como encontrar a documentação oficial.
Confira o Google Colab Notebooks com a instalação e os exemplos de utilização em: https://colab.research.google.com/drive/1uGzDCzyrN7cPNnQMpKfbq5hRGXJh1PB1?usp=sharing
DICAS
Para saber mais sobre o SciPy, sua integração com Numpy, bem como seu funcionamento, de modo geral, acesse o Google Colab Notebooks: https://colab.research.google.com/drive/1leW5OOiXXQ65DEUM81CKsFSfv-dh018c?usp=sharing.
ATENCAO

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
69
4.5 SCIKIT-LEARN
Scikit-learn é um módulo Python que integra uma ampla gama de algoritmos de aprendizado de máquina de última geração para problemas supervisionados e não supervisionados de média escala. Tal pacote se concentra em levar o aprendizado de máquina para não especialistas, utilizando uma linguagem de alto nível de uso geral. A ênfase é colocada na facilidade de uso, desempenho, documentação e consistência da Interface de Programação de Aplicações (API, do inglês Application Programming Interface; PEDREGOSA et al., 2011).
Segundo Oliveira, Muniz e Farrapo (2020), a biblioteca para auxílio em aprendizagem de máquina scikit-learn é um módulo que integra uma vasta quantidade de algoritmos de Machine learning de última geração para problemas supervisionados ou não. Em suma, scikit-learn fornece um ambiente rico para implementação de algoritmos de aprendizagem de máquina, mantendo uma interface fácil para manipulação. Pode-se dizer que isso é reflexo da necessidade da análise de dados estatísticos por não especialistas nas indústrias de software, bem como nos campos externos à informática, como a física e a engenharia.
5 MÉTRICAS DE AVALIAÇÃO PARA CLASSIFICAÇÃO
As métricas de avaliação têm como finalidade avaliar a capacidade de generalização dos métodos de classificação, ou seja, a partir delas, é possível verificar a taxa de acerto desses métodos.
Segundo Rodrigues (2019), para entender melhor cada métrica, é necessário, primeiramente, entender alguns conceitos. Uma matriz de confusão é uma tabela que indica os erros e os acertos do modelo, comparando com o resultado esperado (ou etiquetas/labels). A Figura 3 apresenta um exemplo de uma matriz, bem como o significado de seus elementos na sequência.
No ambiente do Google Colab Notebooks, o scikit-learn é executado de maneira nativa, porém pode ser instalado de forma simples, por meio do PIP. A documentação completa está disponível em: https://scikit-learn.org/stable/.
DICAS

UNIDADE 2 — CLASSIFICAÇÃO
70
FIGURA 3 – MATRIZ DE CONFUSÃO
FONTE: <https://miro.medium.com/max/500/1*t1vf-ofJrJqtmam0KSn3EQ.png>. Acesso em: 3 nov. 2020.
A matriz de confusão é a forma de representação da qualidade obtida de um método de classificação, sendo expressa por meio da correlação de informações dos dados de referência (compreendidos como verdadeiros) com os dados classificados. Essa rotina também pode ser expressa pela análise das amostras de treinamento associada aos dados classificados (PRINA; TRENTIN, 2015). Os elementos da matriz de confusão representam os seguintes:
• verdadeiros positivos: classificação correta da classe positiva;• falsos-negativos: erro em que o modelo previu a classe negativa quando o
valor real era da classe positiva;• falsos-positivos: erro em que o modelo previu a classe positiva quando o valor
real era da classe negativa;• verdadeiros negativos: classificação correta da classe negativa.
Utilizando a matriz de confusão, é possível extrair as principais métricas de avaliação de modelos de classificação: precisão, revocação, f-medida e acurácia (Figura 4).
FIGURA 4 – FÓRMULAS DAS MEDIDAS DE AVALIAÇÃO
FONTE: <https://miro.medium.com/max/500/1*t1vf-ofJrJqtmam0KSn3EQ.png>. Acesso em: 3 nov. 2020.

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE CLASSIFICAÇÃO
71
Entre as métricas, destaca-se a acurácia, que indica a quantidade de exemplos que foram, de fato, classificados corretamente, independentemente da classe. Por exemplo, se temos 100 amostras e 90 delas foram classificadas corretamente, isso significa que a acurácia foi de 90%. A seguir, é possível observar a fórmula da acurácia (Figura 5) e como utilizar essa métrica com o scikit-learn (Quadro 8).
FIGURA 5 – FÓRMULA DA ACURÁCIA
FONTE: Adaptado de <https://miro.medium.com/max/500/1*t1vf-ofJrJqtmam0KSn3EQ.png>. Acesso em: 3 nov. 2020.
QUADRO 8 – MÉTRICA ACURÁCIA COM SCIKIT-LEARN
1234
from sklearn.metrics import accuracy_scorey_classificado = [0, 2, 1, 3]y_original = [0, 1, 2, 3]accuracy_score(y_original, y_classificado)
FONTE: O autor
A precisão é a porcentagem de amostras classificadas como pertencentes à classe positiva e que realmente fazem parte de tal classe (SILVA, 2017). A seguir, veremos a fórmula da precisão (Figura 6) e como utilizar essa métrica com o scikit-learn (Quadro 9).
FIGURA 6 – FÓRMULA DA PRECISÃO
FONTE: Adaptado de <https://miro.medium.com/max/500/1*t1vf-ofJrJqtmam0KSn3EQ.png>. Acesso em: 3 nov. 2020.
QUADRO 9 – MÉTRICA PRECISÃO COM SCIKIT-LEARN
1234
from sklearn.metrics import precision_scorey_classificado = [0, 2, 1, 3]y_original = [0, 1, 2, 3]precision_score(y_original, y_classificado, average='macro'))
FONTE: O autor

UNIDADE 2 — CLASSIFICAÇÃO
72
A revocação, também chamada de sensibilidade ou recall, é uma métrica que, entre todas as situações de classe positiva como valor esperado, indica quantas estão corretas (RODRIGUES, 2019). A seguir, veremos a fórmula da revocação (Figura 7) e como utilizar essa métrica com o scikit-learn (Quadro 10).
FIGURA 7 – FÓRMULA DA REVOCAÇÃO
FONTE: Adaptada de <https://miro.medium.com/max/500/1*t1vf-ofJrJqtmam0KSn3EQ.png>. Acesso em: 3 nov. 2020.
QUADRO 10 – MÉTRICA REVOCAÇÃO COM SCIKIT-LEARN
1234
from sklearn.metrics import precision_scorey_classificado = [0, 2, 1, 3]y_original = [0, 1, 2, 3]recall_score(y_original, y_classificado, average='macro'))
FONTE: O autor

73
Neste tópico, você aprendeu que:
• A classificação é a atividade de rotular dados com suas respectivas categorias temáticas, a partir de um conjunto de dados predefinidos.
• A tarefa de classificação está presente em diversos cenários do cotidiano.
• Os métodos de classificação podem aprender on-line ou off-line.
• O aprendizado on-line pode atualizar o modelo de predição (ou classificador) a cada novo documento de maneira incremental.
• Nos métodos de aprendizado off-line, o modelo precisa ser recalculado a cada nova amostra, com todos os documentos do treinamento.
• Problemas de classificação com classes são denominados binários.
• Problemas de classificação com duas ou mais classes são denominados multiclasse.
• Existe um conjunto de bibliotecas que pode auxiliar no pré-processamento de dados e implementação de algoritmos de classificação.
• As métricas de avaliação auxiliam na avaliação dos modelos.
RESUMO DO TÓPICO 1

74
1 Nas mais diversas áreas do conhecimento, os sistemas de Machine learning podem ajudar a descobrir padrões, realizar determinadas tarefas, por meio da generalização de casos e da utilização de dados. Com relação à classificação, assinale a alternativa CORRETA:
a) ( ) É um método supervisionado.b) ( ) É um método não supervisionado.c) ( ) É um método dessupervisionado.d) ( ) É um método visionado.
2 Os métodos de classificação permitem rotular automaticamente novos registros com base em histórico de dados. Supondo que exista um conjunto de dados que possa receber rótulos 0-negativos ou 1-positivos, qual tipo de tarefa de classificação que será realizada?
a) ( ) Classificação binária.b) ( ) Classificação unária.c) ( ) Classificação ternária.d) ( ) Classificação multiclasse.
3 A categorização de textos de notícias é a tarefa de rotular uma determinada notícia, com base em um conjunto de textos previamente rotulado. Considerando que, em uma base de dados, existam 35 categorias de notícias, qual tipo de tarefa de classificação será realizado?
a) ( ) Classificação multiclasse.b) ( ) Classificação binária.c) ( ) Classificação unária.d) ( ) Classificação ternária.
4 O Python é uma linguagem de alto nível, interpretada, orientada a objetos com uma semântica dinâmica, amplamente utilizada em projetos de Machine learning. Sobre a utilização do Python, assinale a biblioteca que implementa os métodos de Machine learning:
a) ( ) Scikit-learn.b) ( ) Pandas.c) ( ) Matlab.d) ( ) PIP.
AUTOATIVIDADE

75
5 Python é uma linguagem básica, simples, utilizada em diversos cenários da computação, com destaque para projetos de Machine learning. Sobre o Python, assinale qual biblioteca é utilizada para a visualização de dados:
a) ( ) MatplotLib.b) ( ) Scikit-learn.c) ( ) Pandas.d) ( ) Numpy.

76

77
UNIDADE 2
1 INTRODUÇÃO
Os métodos de classificação baseados em distância consideram proximidade entre dados em relação ao espaço cartesiano. Esse tipo de método considera que dados similares tendem a estar em uma mesma região no espaço de entrada.
Segundo Carvalho (2012), esse tipo de método é considerado do tipo aprendizado preguiçoso, pois só olha os dados de treinamento quando precisa classificar um novo objeto. A partir de um novo objeto, de suas características, dispostas no espaço cartesiano, um novo objeto será classificado. Por exemplo, ao entrar um novo objeto que anda e late como um cachorro, então provavelmente é um cachorro (Figura 8).
FIGURA 8 – CLASSIFICAÇÃO POR DISTÂNCIA
FONTE: <https://cutt.ly/bgBzMf2f>. Acesso em: 3 nov. 2020.
Para Soldi (2013), quando objetos são agrupados, a proximidade é usualmente indicada por uma espécie de distância. Por outro lado, as variáveis são usualmente agrupadas com base nos coeficientes de correlação ou outras medidas de associação. Essas medidas podem ser de:
• Similaridade: quanto maior o valor observado, mais parecidos são os objetos. Por exemplo, o coeficiente de correlação.
• Dissimilaridade: quanto maior o valor observado, menos parecidos (mais dissimilares) serão os objetos.
TÓPICO 2 —
MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA

78
UNIDADE 2 — CLASSIFICAÇÃO
2 MÉTODOS BASEADOS EM DISTÂNCIA
A distância euclidiana (Figura 9) é uma das medidas de dissimilaridade entre comunidades mais utilizadas na prática. Quanto menor o valor da distância euclidiana entre dois objetos, mais próximas elas se apresentam em termos de parâmetros quantitativos por classe; logo, quanto menor a distância euclidiana, maior a eficiência do procedimento (BORGES; DA SILVA; CASTRO, 2007).
FIGURA 9 – EQUAÇÃO DA DISTÂNCIA EUCLIDIANA
FONTE: Adaptada de Soldi (2013)
Em que D (x, y) é a distância entre dois objetos (x e y), dada pela equação, na qual i representa as posições no ponto cartesiano de cada objeto (x e y) e n é número de ocorrências. A seguir, veremos a implementação da distância euclidiana utilizando Python (Quadro 11) e NumPy.
QUADRO 11 – CÁLCULO DA DISTÂNCIA EUCLIDIANA EM PYTHON
123456789101112
import numpy as np
x = [1, 2.5, 3.8, 4.5]y = [0.5, 4.5, 9.6, 3.4]
def dist_euclidiana_np(x, y): x, y = np.array(x), np.array(y) diff = x – y quad_dist = np.dot(diff, diff) return math.sqrt(quad_dist)
print('%.2f' % dist_euclidiana_np(x, y))
FONTE: O autor
Complementarmente à distância euclidiana, existem distâncias que podem ser utilizadas na implementação de algoritmos de Machine learning baseados em distância. A medida de distância euclidiana dada à métrica de distância de Minkowski, também conhecida como distância de Minkowski, é apresentada na Figura 10.

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
79
FIGURA 10 – EQUAÇÃO DA DISTÂNCIA MINKOWSKI
FONTE: Adaptada de Tan, Steinbach e Kumar (2016)
Segundo Tan, Steinbach e Kumar (2016), a distância de Minkowski é uma generalização da distância euclidiana, em que r é um parâmetro, n é o número de dimensões (atributos) e pk e qk são, respectivamente, os k-ésimos atributos (componentes) dos objetos de dados p e q.
Na distância de Minkowski, aproveitam-se os recursos do pacote Scipy para realizar sua implementação; nesse caso, poderia ser implementado do zero, tal como a distância euclidiana. Nessa implementação, os primeiros atributos são os vetores x e y, e o último parâmetro é o coeficiente de normalização.
QUADRO 12 – CÁLCULO DA DISTÂNCIA DE MINKOWSKI EM PYTHON E SCIPY
1234
from scipy.spatial import distancedistance.minkowski([1, 0, 0], [0, 1, 0], 1)distance.minkowski([1, 0, 0], [0, 1, 0], 2)distance.minkowski([1, 0, 0], [0, 1, 0], 3)
FONTE: O autor
Agora que já compreendemos uma visão geral do funcionamento das distâncias, vamos entender o funcionamento do método KNN (do inglês K-Nearest Neighbors), baseado em distâncias.
2.1 KNN
O método do vizinho mais próximo (KNN, do inglês K-Nearest Neighbors) trabalha de acordo com a proximidade, ou seja, rotula um determinado objeto conforme os objetos mais próximos. O número de objetos a serem agrupados são os K vizinhos mais próximos.
A ideia básica do KNN é determinar a categoria de um determinado objeto com base em similaridades entre os documentos no espaço. Para calcular a similaridade, usa-se uma métrica de distância. O método KNN percorre todo o conjunto de dados, computando a distância de cada elemento em relação ao documento que está sendo consultado. Uma vez calculadas as distâncias, a categoria será determinada pelos K documentos mais próximos ao documento consultado.

80
UNIDADE 2 — CLASSIFICAÇÃO
Segundo Locher (2015), a etapa de classificação envolve calcular a dissimilaridade de uma nova amostra para todas as amostras conhecidas e classificá-la com a categoria mais frequente entre as “k” amostras mais próximas a ela. O método KNN não gera um modelo a partir das amostras, mas consulta todas para cada nova classificação. Além disso, o algoritmo KNN é bastante penalizado quando uma das classes do problema apresenta muito mais amostras que as demais classes.
2.1.1 Implementação matemática do método
Como o método do KNN explora muito o espaço vetorial e o plano cartesiano, primeiramente, precisamos compreender o funcionamento desses elementos, utilizando a linguagem de programação.
A visualização dos dados é de grande importância para compreender o cenário, bem como seu comportamento; afinal, com ela, conseguimos observar os dados e compreendê-los, uma vez que as pessoas têm muito mais facilidade para captar e processar comunicações visuais (BIGDATACORP, 2019).
Para isso, os dados são dispostos por meio de gráficos que compõem o plano cartesiano e os pares ordenados. Um sistema de eixos ortogonais é constituído por dois eixos perpendiculares, Ox e Oy, que têm a mesma origem.
A partir desses eixos, temos o plano cartesiano, cujos eixos ortogonais o dividem em quatro quadrantes. Para identificar um par ordenado, indicamos por um ponto no plano cartesiano, conforme figura gerada a partir do código-fonte, onde o ponto está sendo indicado por P (1, 1).
QUADRO 13 – PLOTANDO O EIXO CARTESIANO COM MATPLOTLIB
12345
import matplotlib.pyplot as pltplt.plot(1,1,'bo',mfc='none',markersize=20)plt.ylabel('Eixo das ordenadas')plt.xlabel('Eixo das abscissas')plt.show()
FONTE: O autor
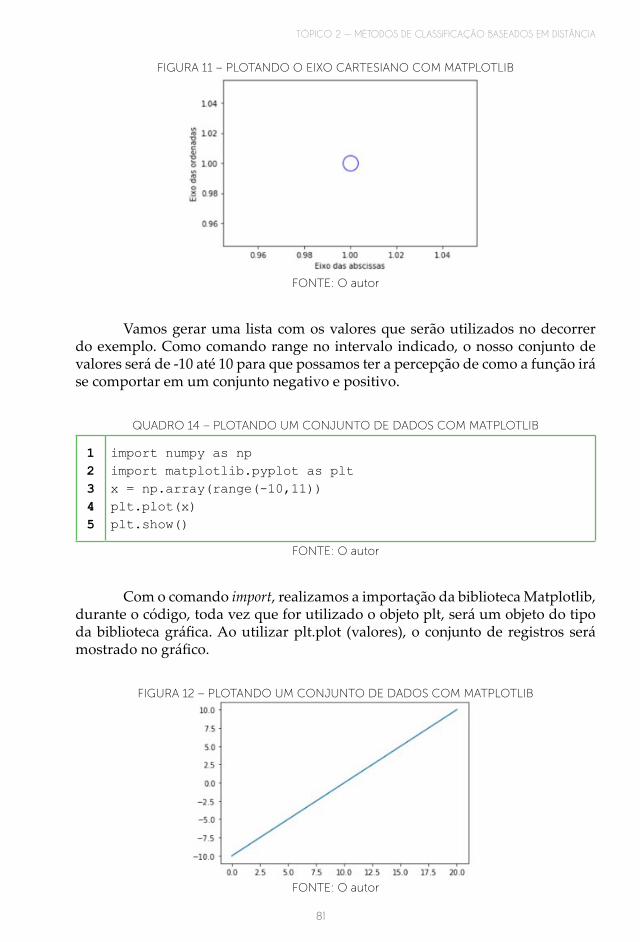
TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
81
FIGURA 11 – PLOTANDO O EIXO CARTESIANO COM MATPLOTLIB
FONTE: O autor
Vamos gerar uma lista com os valores que serão utilizados no decorrer do exemplo. Como comando range no intervalo indicado, o nosso conjunto de valores será de -10 até 10 para que possamos ter a percepção de como a função irá se comportar em um conjunto negativo e positivo.
QUADRO 14 – PLOTANDO UM CONJUNTO DE DADOS COM MATPLOTLIB
12345
import numpy as np import matplotlib.pyplot as pltx = np.array(range(-10,11))plt.plot(x)plt.show()
FONTE: O autor
Com o comando import, realizamos a importação da biblioteca Matplotlib, durante o código, toda vez que for utilizado o objeto plt, será um objeto do tipo da biblioteca gráfica. Ao utilizar plt.plot (valores), o conjunto de registros será mostrado no gráfico.
FIGURA 12 – PLOTANDO UM CONJUNTO DE DADOS COM MATPLOTLIB
FONTE: O autor

82
UNIDADE 2 — CLASSIFICAÇÃO
Com o conjunto x, que representa os valores que serão mostrados no eixo x, codificaremos a função y = f(x). Para definir uma função em Python, utilizaremos o def(). Em um exemplo simples, criaremos a função f(x) = x + 1. Logo em seguida, chamando a função e passando parâmetros para ela.
QUADRO 15 – IMPLEMENTANDO E UTILIZANDO UMA FUNÇÃO F(X)
123456789101112131415
################################################### Criando a f(x) = x + 1###############################################def f(x): return x+1################################################### Gerando f(x) para os dados de x###############################################y = f(x)print("x = ", x)print("\n \n")print("y = f(x) = ", y)
FONTE: O autor
Agora que já temos em mãos o conjunto de dados x e o conjunto f(x) representado por y, é possível plotar os valores e y em função de x. Como a parte matemática já foi realizada por meio da função codificada, basta passar os valores para a função plot().
FIGURA 13 – PLOTANDO DE VALORES DE X EM F(X)
FONTE: O autor
Definido um padrão, vamos reproduzi-lo algumas vezes para facilitar o seu entendimento sobre o tema. Para focar na construção matemática, criaremos uma função no Python para receber x e f(x)/y, exibindo-os em forma de gráfico.

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
83
QUADRO 16 – IMPLEMENTANDO E UTILIZANDO UMA FUNÇÃO F(X)
123456789101113141516
#criando a função para plotar o gráficodef escreve_grafico(x,y): plt.plot(x,y) #escreve a função
plt.plot(x,f(x),'r+') #escreve os pares ordenados
plt.ylabel('Valores de Y em função de X') plt.xlabel('Valores de X') plt.show()
#utilizando a função de plotagemdef f(x): return x**2
escreve_grafico(x,f(x))
FONTE: O autor
Sabe-se que a distância euclidiana é a medida de distância mais frequentemente empregada quando todas as variáveis são quantitativas; é utilizada para calcular medidas específicas, além de distância euclidiana simples e distância euclidiana quadrática ou absoluta, a qual consiste na soma dos quadrados das diferenças, sem calcular a raiz quadrada (SEIDEL et al., 2008).
Para entender melhor a distância euclidiana e a sua aplicação no conceito de um algoritmo de Machine learning, primeiramente, vamos compreender o que ela significa. Considere os pontos 1,2 em vermelho e o ponto 3,6. O objetivo da aplicação de distâncias é utilizar as coordenadas x e y de cada um desses pontos e retornar a um limiar que mensura as distâncias.
QUADRO 17 – PLOTANDO DOIS PONTOS NO ESPAÇO
12345678910
import matplotlib.pyplot as plt#inicializa o gráfico com tamanho de 0 até 7plt.plot(0,0,mfc='none')plt.plot(7,7,mfc='none')
############################################### Inicializa os pontos
plt.plot(1,2,'r+',mfc='none')plt.plot(3,6,'bo',mfc='none')
FONTE: O autor

84
UNIDADE 2 — CLASSIFICAÇÃO
Nota-se que, no exemplo do Quadro 17, cada ponto é composto por duas dimensões (x,y). Desse modo, ao transcrever um somatório que se inicializa em 1 e vai até n, n = 2 (duas dimensões). Ao deduzir a fórmula para esses valores, obtemos a distância apresentada na Figura 14.
FIGURA 14 – DISTÂNCIA EUCLIDIANA ENTRE DOIS PONTOS
FONTE: O autor
Antes de resolver utilizando linguagem de programação, primeiramente, deve-se calcular passo a passo a distância euclidiana entre os pontos p e q. Para isso, utilizaremos a fórmula deduzida para duas dimensões e substituiremos os valores.
FIGURA 15 – APLICANDO VALORES NA DISTÂNCIA EUCLIDIANA
FONTE: O autor
Uma vez compreendido o cálculo da distância, o gráfico gerado pelo código-fonte (Quadro 18) mostra três elementos. A Figura 16 apresenta os pontos p (em vermelho) e q (em azul) e a distância entre os dois pontos (traço verde).
QUADRO 18 – MOSTRANDO PONTOS E TRAÇANDO UMA RETA ENTRE ELES
123456789
import matplotlib.pyplot as plt#inicializa o gráfico com tamanho de 0 até 7plt.plot(0,0,mfc='none')plt.plot(7,7,mfc='none')
plt.plot(1,2,'r+',mfc='none', label="p1")plt.plot(3,6,'bo',mfc='none')

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
85
1011121314
plt.plot([1,3],[2,6], '-')
plt.show()
FONTE: O autor
FIGURA 16 – MOSTRANDO PONTOS E TRAÇANDO UMA RETA ENTRE ELES
FONTE: O autor
Durante a implementação do KNN, qualquer distância pode ser utilizada, como a distância Manhattan e Minkowski. No entanto, agora que já implementamos um algoritmo para calcular a distância euclidiana, prosseguiremos para o método dos K-vizinhos mais próximos, utilizando essa distância. O método KNN usará a distância entre objetos para classificar uma nova entrada sob a qual não se sabe a classe. Para isso, considera os objetos mais próximos, ou seja, os K-vizinhos mais próximos.
FIGURA 17 – ALGORITMO DO KNN
FONTE: <http://computacaointeligente.com.br/algoritmos/k-vizinhos-mais-proximos/>. Acesso em: 3 nov. 2020.

86
UNIDADE 2 — CLASSIFICAÇÃO
Quando iniciamos, falamos sobre números e pontos. Para ficar mais clara a aplicação, vamos criar um conjunto de dados sintético e trabalhar nele. O conjunto de dados (Quadro 19) representa uma base de dados com pessoas, que, a partir de sua renda familiar e idade, receberam créditos pessoais. A primeira coluna representa a idade, a segunda mostra a renda mensal e a terceira, que pode ser chamada de classe ou rótulo, determina se o crédito foi concedido ou não.
QUADRO 19 – GERANDO UM CONJUNTO DE DADOS
123456789101213141516171819
credito = np.array([ [75,4600, "positivo"], [21,850,"negativo"], [39,840,"negativo"], [45,1500,"negativo"], [47,3200,"positivo"], [51,3400,"positivo"], [47,1200,"negativo"], [25,1500,"negativo"], [30,2800,"negativo"], [69,1500,"positivo"], [69,1800,"positivo"], [50,2500,"positivo"], [39,1700,"negativo"], [42,1900,"negativo"], [42,1900,"negativo"], ])
FONTE: O autor
Uma vez criado o conjunto de dados, exploraremos o conceito de pares ordenados, salário e idade, e utilizando a biblioteca Matplotlib vamos plotar, no gráfico, cada ponto que representa o crédito negativo ou positivo.
QUADRO 20 – EXIBINDO OS DADOS
12345678910
import matplotlib.pyplot as pltpositivos = credito[credito[:,2]=="positivo"]negativos = credito[credito[:,2]=="negativo"]
fig = plt.figure()ax1 = fig.add_subplot()ax1.set_ylabel('Salário')ax1.set_xlabel('Idade')ax1.set_title('Controle de Crédito')
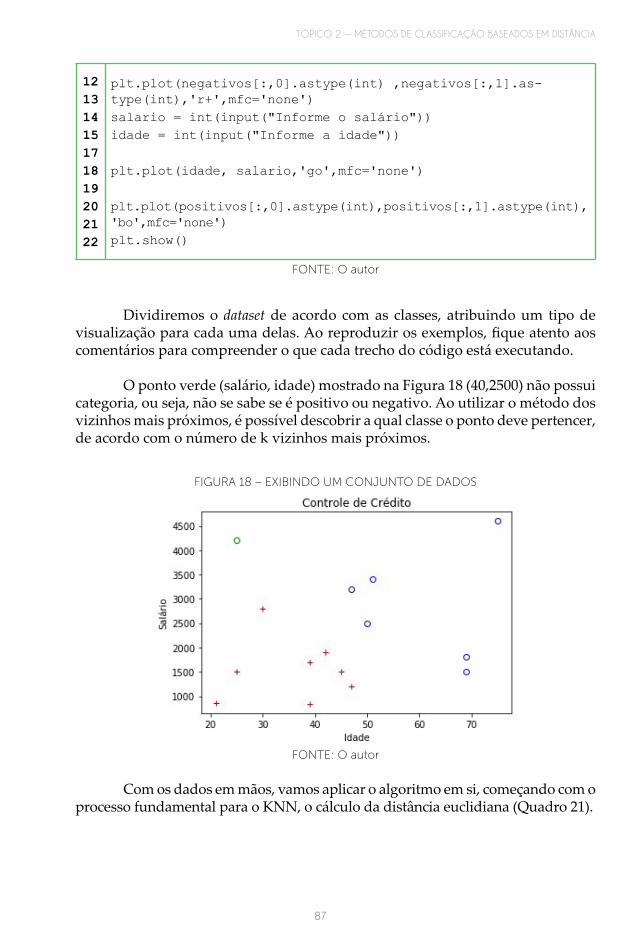
TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
87
12131415171819202122
plt.plot(negativos[:,0].astype(int) ,negativos[:,1].as-type(int),'r+',mfc='none')salario = int(input("Informe o salário"))idade = int(input("Informe a idade"))
plt.plot(idade, salario,'go',mfc='none')
plt.plot(positivos[:,0].astype(int),positivos[:,1].astype(int), 'bo',mfc='none')plt.show()
FONTE: O autor
Dividiremos o dataset de acordo com as classes, atribuindo um tipo de visualização para cada uma delas. Ao reproduzir os exemplos, fique atento aos comentários para compreender o que cada trecho do código está executando.
O ponto verde (salário, idade) mostrado na Figura 18 (40,2500) não possui categoria, ou seja, não se sabe se é positivo ou negativo. Ao utilizar o método dos vizinhos mais próximos, é possível descobrir a qual classe o ponto deve pertencer, de acordo com o número de k vizinhos mais próximos.
FIGURA 18 – EXIBINDO UM CONJUNTO DE DADOS
FONTE: O autor
Com os dados em mãos, vamos aplicar o algoritmo em si, começando com o processo fundamental para o KNN, o cálculo da distância euclidiana (Quadro 21).

88
UNIDADE 2 — CLASSIFICAÇÃO
QUADRO 21 – REALIZANDO O CÁLCULO DA DISTÂNCIA
1234567
89
def distancia_euclidiana(x,y): x1 = x[0].astype(float) x2 = x[1].astype(float) y1 = y[0] y2 = y[1] distancia = math.sqrt(pow(x2-y2,2) + pow(x1-y1,2)) print("Valor de X =",x[0:2], " valor de Y=",y," D(x,y)=", distancia ) return distancia
FONTE: O autor
Uma vez desenvolvida a função que realiza o cálculo da distância, nesse momento, deve-se calcular a distância para o novo objeto para com os demais. Outra abordagem que poderia ser realizada seria criar um array de distâncias, indicando a distância de cada objeto para todos os demais.
QUADRO 22 – REALIZANDO O CÁLCULO DA DISTÂNCIA
123456
78
910
11121314
import mathimport numpy as npdados = creditodistancias = np.zeros((dados.shape[0],1))dados = np.append(dados, distancias, axis=1)print("Calculando as distâncias do novo objeto para todos os outros \n \n")for i in range(0,dados.shape[0]): dados[i,3] = distancia_euclidiana(dados[i,:],[idade, sala-rio])dados[:,3]= dados[:,3].astype(float)dados = dados[dados[:,3].astype(float).argsort(kind='merge-sort')]print("\n \n Conjunto de dados ordenado pela distância \n")print (dados)
FONTE: O autor
Uma vez que as distâncias já foram calculadas, é o momento de aplicar o algoritmo que será o responsável por realizar a classificação com base em K-vizinhos mais próximos.

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
89
QUADRO 23 – IMPLEMENTANDO E EXECUTANDO O KNN
123456789
def knn(array_ordenado, n_vizinhos,indice_classe): resultado = [] for i in range(1,n_vizinhos+1): resultado.append(array_ordenado[i,indice_classe]) return max(resultado,key=resultado.count)print("Executando o KNN")print("Ao executar o método KNN para os dados a classificação será:", knn(dados, 3,2))
FONTE: O autor
2.2 IMPLEMENTAÇÃO COM SCIKIT-LEARN
Como visto anteriormente, a scikit-learn é uma das mais tradicionais bibliotecas do Python, sendo referência para implementar sistemas que utilizam recursos de Machine learning.
Como exemplo prático, vamos reproduzir o que foi realizado anteriormente, quando codificamos o método KNN do zero, utilizando uma base de dados sintética, assumindo que a variável “dados” é a mesma aplicada anteriormente.
Primeiramente, definimos quem serão os nossos atributos de entrada
(input) e o rótulo (a classe, o target). Conforme o exemplo, os dados de entrada serão o conjunto composto por salário e idade; no rótulo, o atributo que gostaríamos de classificar é o tipo (positivo ou negativo). Por convenção, o conjunto de dados de entrada (input) é denominado de X e o rótulo (target output), de y.
Para acessar o código-fonte, bem como o passo a passo das etapas realizadas, acesse o Google Colab Notebooks: https://colab.research.google.com/drive/1u2_R4Ch-tNC5j_98W6fRYMjvnqe0N9h_?usp=sharing.
DICAS

90
UNIDADE 2 — CLASSIFICAÇÃO
FIGURA 19 – FUNCIONAMENTO DO ALGORITMO
FONTE: <https://www.kaggle.com/anniepyim/essential-classification-algorithms-explained>. Acesso em: 3 nov. 2020.
O Quadro 24 mostra a divisão dos dados em entrada e saída.
QUADRO 24 – SEPARANDO OS DADOS EM ENTRADA E SAÍDA
12
X = credito[0:len(credito),0:2]y = credito[0:len(credito),2:3]
FONTE: O autor
Uma vez que os dados estão preparados, basta aplicar o algoritmo. Percebe-se que não existe o comando train (treinar), mas, sim, o fit, que será o comando responsável por ensinar o método a partir dos dados. Em uma tradução aberta, fit significa ajuste, ou seja, ajusta o método aos dados obtidos. Assim, o método aprenderá com os dados fornecidos.
QUADRO 25 – SEPARANDO OS DADOS EM ENTRADA E SAÍDA
123
from sklearn.neighbors import KNeighborsClassifierclassificador = KNeighborsClassifier(n_neighbors=3)classificador.fit(X, y)
FONTE: O autor
Os dados foram divididos em input (X) e output (y), sendo criado o classificador, variável de mesmo nome. O classificador está apto a predizer, ou seja, classificar, novas amostras com base nos dados em que aprendeu. Para predizer o saldo de um indivíduo com 40 anos e uma renda de 5000.

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
91
QUADRO 26 – SEPARANDO OS DADOS EM ENTRADA E SAÍDA
12
novo_campo = (np.array([150,0]).reshape(1,-1))print('Ao realizar a predição o valor será: '+classificador.predict(novo_campo)[0])
FONTE: O autor
2.3 CLASSIFICANDO O IRIS DATASET COM O KNN
Como você já aprendeu sobre o iris dataset, bem como o fluxo geral da implementação do método KNN utilizando scikit-learn, vamos aplicar o método a esse dataset.
QUADRO 27 – ABRINDO O DATASET E SEPARANDO EM INPUT E OUTPUT
12345
import numpy as npfrom sklearn import datasetsiris = datasets.load_iris()X = iris.data[:, [2, 3]]y = iris.target
FONTE: O autor
É válido lembrar que para realizar a validação dos métodos através de métricas, torna-se necessário dividir os dados em treino e teste. Em nosso exemplo utilizaremos o próprio scikit-learn para realizar tal divisão, na qual será 70% dos dados para treino e 30% para teste.
No desenvolvimento de um algoritmo de Machine learning, várias etapas podem ser consideradas. Até o momento, vimos o fluxo de como gerar um classificador utilizando o KNN, no qual podemos perceber alguns pontos até o momento:
• o modelo não foi avaliado, ou seja, não sabemos a sua capacidade de acertar ou errar; • o K utilizado foi 3, conforme visto no seguinte trecho “n_neighbors=3”; esse valor
pode ser alterado em busca de uma maior efetividade do método;• o conjunto de dados foi sintético, ou seja, criado apenas para uma simulação.
IMPORTANTE

92
UNIDADE 2 — CLASSIFICAÇÃO
QUADRO 28 – ABRINDO O DATASET E SEPARANDO EM INPUT E OUTPUT
1234
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)print('Existem {} amostras de treino e {} amostras de teste'.format(X_train.shape[0], X_test.shape[0]))
FONTE: O autor
O pré-processamento de dados é a etapa que mais demanda processamento computacional em tarefas de Machine learning. No que se refere à utilização e à aplicação de algoritmos de Machine learning, a normalização e a padronização dos dados são um processo que traz equidade aos dados, proporcionando melhor desempenho dos algoritmos aplicados.
Segundo Vaz (2019), tais técnicas têm o mesmo objetivo: transformar todas as variáveis na mesma ordem de grandeza. A diferença básica é que padronizar as variáveis irá resultar em uma média igual a 0 e um desvio padrão igual a 1. Já normalizar tem como objetivo colocar as variáveis dentro do intervalo de 0 e 1; caso tenham resultados negativos, -1 e 1.
Para padronizar os dados, normalmente, utiliza-se a fórmula z-score da Figura 20.
FIGURA 20 – FÓRMULA Z-ESCORE
FONTE: O autor
Para normalizar os dados, utiliza-se a fórmula apresentada na Figura 21:
FIGURA 21 – FÓRMULA MIN-MAX
FONTE: O autor
Se a distribuição não é gaussiana ou o desvio padrão é muito pequeno, normalizar os dados é uma escolha a ser tomada. Cuidado com os outliers, pois alguns artigos afirmam que normalizar é o melhor método, enquanto outros defendem que padronizar os dados é uma opção a ser feita. A biblioteca scikit-learn mostra alguns exemplos com outliers – vale a pena conferir como ficam graficamente (VAZ, 2019).
IMPORTANTE
Com os dados já carregados e divididos em treino e teste, aplicaremos a normalização utilizando a biblioteca StandardScaler.

TÓPICO 2 — MÉTODOS DE CLASSIFICAÇÃO BASEADOS EM DISTÂNCIA
93
QUADRO 29 – NORMALIZANDO O DATASET
123456
78
from sklearn.preprocessing import StandardScalersc = StandardScaler()sc.fit(X_train)X_train_normalizado = sc.transform(X_train)X_test_normalizado = sc.transform(X_test)X_normalizado = np.vstack((X_train_normalizado, X_test_norma-lizado))y_normalizado = np.hstack((y_train, y_test))
FONTE: O autor
Para compreender melhor esses dados, utilizaremos o Matplotlib para plotá-los no plano cartesiano, com base em suas respectivas classes. Percebe-se que os dados plotados são apenas do conjunto de teste, pois são os dados que iremos classificar.
QUADRO 30 – PLOTANDO O IRIS DATASET
123456789
from matplotlib.colors import ListedColormapimport matplotlib.pyplot as plt
markers = ('s', 'x', 'o')colors = ('red', 'blue', 'lightgreen')cmap = ListedColormap(colors[:len(np.unique(y_test))])for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], c=cmap(idx), marker=markers[idx], label=cl)
FONTE: O autor
FIGURA 22 – VISUALIZAÇÃO DO DATASET
FONTE: O autor
Até o momento, os dados já foram carregados e preparados, e foi criada uma rotina para a visualização dos dados. A partir agora, partimos para a etapa final da aplicação do método: treinar e avaliar.

94
UNIDADE 2 — CLASSIFICAÇÃO
QUADRO 31 – TREINANDO E AVALIANDO O MÉTODO
12
34
5
from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=5, p=2, metri-c='minkowski')knn.fit(X_train_normalizado, y_train)print('A acurácoa do KNN na base de treino é: {:.2f} '.forma-t(knn.score(X_train_normalizado, y_train)))prrint('A acurácoa do KNN na base de teste é: {:.2f} '.forma-t(knn.score(X_test_normalizado, y_test)))
FONTE: O autor
Para fixar todos esses conceitos, é muito importante manipular o código desenvolvido, alterando, principalmente, o número de K-vizinhos próximos e a quantidade de dados utilizados em treino e teste.

95
RESUMO DO TÓPICO 2
Neste tópico, você aprendeu que:
• Os métodos de classificação baseados em distância consideram proximidade entre dados em relação ao espaço cartesiano.
• As medidas de distância podem ser por similaridade ou dissimilaridade.
• A distância euclidiana é uma das medidas de dissimilaridade, entre comunidades, mais utilizadas na prática.
• A distância de Minkowski é uma generalização da distância euclidiana.
• O KNN, isto é, o método do vizinho mais próximo, trabalha de acordo com a proximidade.
• A etapa de classificação do KNN envolve calcular a dissimilaridade de uma nova amostra para todas as amostras conhecidas e classificá-la com a categoria mais frequente entre as “k” amostras mais próximas.
• A normalização apresenta os dados para uma mesma escala, proporcionando melhor eficiência dos métodos que serão executados sobre ela.
• O scikit-learn implementa o KNN e sua utilização pode ser feita de maneira simples quando comparada com a implementação do zero.

96
1 A distância euclidiana é uma das medidas de dissimilaridade entre comunidades mais utilizadas na prática. Assim, quanto menor o valor da distância euclidiana entre dois objetos, mais próximas elas se apresentam em termos de parâmetros quantitativos. Considere a fórmula da distância euclidiana, apresentada a seguir, e assinale a alternativa CORRETA no que se refere ao n:
FONTE: O autor
a) ( ) O número de objetos.b) ( ) Um ponto no espaçoc) ( ) O somatório do espaço.d) ( ) O erro de desvio.
2 A distância euclidiana é uma das medidas de dissimilaridade entre comunidades mais utilizadas na prática. Quanto menor o valor da distância euclidiana entre dois objetos, mais próximas elas se apresentam em termos de parâmetros quantitativos. Sobre a fórmula da distância euclidiana, assinale a alternativa CORRETA sobre x e y:
a) ( ) Dois pontos no espaço.b) ( ) Erro.c) ( ) O número de objetos.d) ( ) Inicio do vetor.
3 Considere a figura a seguir, na qual o ponto vermelho representa uma nova amostra a ser classificada pelo algoritmo KNN, e responda:
FONTE: O autor
AUTOATIVIDADE

97
a) Considerando que K = 6, qual é a classe da amostra vermelha?
b) Considerando que K = 3, qual é a classe da amostra vermelha?
c) Considerando que K = 1, qual é a classe da amostra vermelha?

98

99
UNIDADE 2
1 INTRODUÇÃO
A probabilidade está presente em nosso cotidiano em diversas maneiras, seja em situações corriqueiras, como a probabilidade da chuva ou de se pegar trânsito, seja em cenários mais complexos, como apostas e investimento em mercado de valores.
Em Machine learning, isso não é diferente, pois a probabilidade está presente desde a análise dos dados, podendo ser utilizada como um método de predição. É possível afirmar que probabilidade e estatística são uma das áreas correlatas do estudo de machine learning, com um destaque especial ao software R, um software estatístico, que cada vez mais é utilizado por profissionais de ciência de dados.
2 MÉTODOS PROBABILÍSTICOS
2.1 NAÏVE BAYES
O Naïve Bayes é um método probabilístico que calcula a probabilidade de um documento pertencer a uma categoria, de acordo com a ocorrência das colunas desse documento estarem nas categorias existentes.
Estudos comparativos entre algoritmos de classificação consideram que o classificador Naïve Bayes é um classificador simples e com um bom desempenho, quando comparado com árvore de decisão, redes neurais, entre outros (MCCALLUM; NIGAM, 1998). Isso acontece porque, ao contrário de métodos que precisam conhecer toda a base de dados, o Naïve Bayes executa um único modelo probabilístico, tornando-o mais rápido.
Além disso, o classificador exibe alta precisão e velocidade quando aplicado a grandes bases de dados. O método tem diversas variações, das quais o Naïve Bayes Multinomial e o Naïve Bayes Bernoulli se destacam na realização de tarefas de categorização de textos (DUDA; HART, 1973).
TÓPICO 3 —
MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS
DE CLASSIFICAÇÃO

100
UNIDADE 2 — CLASSIFICAÇÃO
Nesse tipo de método, cada exemplo de treinamento pode decrementar ou incrementar a probabilidade de uma hipótese ser correta. O conhecimento a priori pode ser combinado com os dados observados, para determinar a probabilidade de uma hipótese. Métodos bayesianos podem acomodar hipóteses que fazem predições probabilísticas (por exemplo, um paciente tem uma chance de 93% de possuir determinada doença). As novas instâncias podem ser classificadas combinando a probabilidade de múltiplas hipóteses ponderadas pelas suas probabilidades (KOERICH, 2012).
O método Naïve Bayes é considerado de aprendizado on-line, uma vez que suas probabilidades podem ser atualizadas a cada novo documento de maneira incremental, sem necessidade de refazer o treinamento com todos os documentos.
Koerich (2012) cita os benefícios da utilização do Naïve Bayes e suas derivações:
• São um conjunto de diversos algoritmos práticos de aprendizagem:o Naïve Bayes.o Redes Bayesianas.o Combinam conhecimento a priori com os dados observados.o Requerem probabilidades a priori.
• Fornecem uma estrutura conceitual útil: o “Norma de ouro” para avaliar outros algoritmos de aprendizagem. o Norma de ouro menor erro possível.
O algoritmo Naïve Bayes pode ser usado de forma incremental, conforme a necessidade de sua revisão probabilística. Existem várias abordagens sobre os modelos de entrada, sendo os principais o modelo binário e o modelo multidimensional. No modelo binário, cada documento é representado por um vetor binário, cuja presença ou ausência de um termo é representada, respectivamente, por 1 e 0. No modelo multidimensional, a representação ocorre por vetores de números inteiros por documento, em que cada índice do vetor representa a quantidade de vezes que um termo acontece no documento (TELES; WEBBER, 2019).
De modo geral, o teorema de Bayes, utilizado na implementação do algoritmo, fornece uma forma de calcular a probabilidade posterior P (c | x) a partir de P (C), P (x) e P (x | c).

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
101
FIGURA 23 – VISUALIZAÇÃO DO DATASET
FONTE: <https://cutt.ly/wgBJVBR>. Acesso em: 3 nov. 2020.
Segundo Zó (2019), cada elemento pertencente à fórmula da Figura 23 representa:
• P (c | x) é a probabilidade posterior da classe (c, alvo) dado preditor (x, atributos).• P (C) é a probabilidade original da classe.• P (x | c) representa a probabilidade de preditor dada a classe.• P (x) é a probabilidade original do preditor.
Segundo Lochter (2015), esse método assume que os atributos são independentes. Essa premissa permite que o cálculo de probabilidade de um evento, para uma classe, seja simplificado conforme mostra a Figura 24.
FIGURA 24 – SIMPLIFICAÇÃO DO MÉTODO PARA CONJUNTOS DE DADOS
FONTE: Lochter (2015, p. 50)
Complementarmente, esse grupo de métodos, baseado no teorema de Bayes, consegue generalizar hipóteses em torno de problemas multiclasses, trabalha bem com atributos categóricos, além de obter bons resultados com base de dados pequenas. Além disso, leva a um classificador probabilístico que oferece uma classe ŷ, conhecendo-se as probabilidades de ocorrência de cada valor e cada atributo para cada classe (LOCHER, 2015).
FIGURA 25 – SELEÇÃO DAS PROBABILIDADES DO NAÏVE BAYES
FONTE: Lochter (2015, p. 50)

102
UNIDADE 2 — CLASSIFICAÇÃO
Para compreender melhor o funcionamento do modelo probabilístico, vamos considerar um exemplo prático, seguindo os dados apresentados na Figura 26.
FIGURA 26 – DADOS PARA APLICAÇÃO DO TEOREMA DE BAYES
FONTE: <https://cutt.ly/ggBKDYO>. Acesso em: 3 nov. 2020.
Utilizando os dados da imagem, a sequência da aplicação do método Naïve Bayes deve ser a seguinte (VOOO, 2016):
• Passo 1: converter o conjunto de dados em uma tabela de frequência.• Passo 2: criar tabela de probabilidade, ao encontrar a probabilidade de tempo
“Nublado = 0,29” e probabilidade de jogar = 0,64.• Passo 3: utilizar a equação Bayesiana Naïve para calcular a probabilidade
posterior para cada classe. A classe com maior probabilidade posterior é o resultado da previsão.
• Problema: os jogadores irão jogar se o tempo está ensolarado –¬ esta afirmação está correta?
• Podemos resolver usando o método discutido para probabilidade posterior.• P (Sim | Ensolarado) = P (Ensolarado | Sim) * P (Sim) / P (Ensolarado)• Aqui temos P (Ensolarado | Sim) = 3/9 = 0,33, P (Ensolarado) = 5/14 = 0,36, P
(Sim) = 9/14 = 0,64• Agora, P (Sim | Ensolarado) = 0,33 * 0,64 / 0,36 = 0,60, que tem maior probabilidade.
Em outro exemplo, considera-se dois times rivais de futebol, Time 0 e Time 1, supondo que o Time 0 vença 65% das vezes e o Time 1 vença as demais partidas. Entre os jogos vencidos pelo Time 0, apenas 30 deles são disputados no campo de futebol do Time 1. Por outro lado, 75 das vitórias para o Time 1 foram obtidas jogando em casa. Se o time f for sediar a partida nert entre os dois times, qual time provavelmente seria o vencedor?
Segundo Tan, Steinbach, Kumar (2016), o teorema de Bayes pode ser usado para resolver o problema de predição apresentado. Por conveniência de notação, seja X a variável aleatória que representa o time que hospeda a partida e Y a variável aleatória que representa o vencedor da partida. Tanto X quanto Y podem assumir valores do conjunto {0,1}. Podemos resumir as informações fornecidas no problema da seguinte forma:

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
103
• A probabilidade de vitória do Time 0 é de P (Y = 0) = 0,65.• A probabilidade de vitória do Time 1 é de P (Y = 1) = 1 – P (Y = 0) = 0,35.• A probabilidade de o Time 1 sediar a partida que ganhou é de P (X = 1 | Y = 1)
= 0,75.• A probabilidade de o Time 1 sediar a partida vencida pelo Time 0 é de P (X =
1 | Y = 0) = 0,3.
FIGURA 27 – DADOS PARA APLICAÇÃO DO TEOREMA DE BAYES
FONTE: Adaptada de Tan, Steinbach e Kumar (2016)
2.1.1 Implementação matemática do método
O Naïve Bayes é um tradicional método de Machine learning utilizado nos mais diversos cenários de classificação, principalmente pelo seu bom desempenho de tempo de execução. Assim, vamos entender um pouco melhor sobre como esse método funciona por meio de sua implementação.
No exemplo apresentado anteriormente, utilizaremos o Iris Dataset e criaremos o método do zero, sendo necessário, previamente, elaborar um método para particionar os dados de acordo com as classes que existem na base de dados.
QUADRO 32 – SEPARANDO OS DADOS PARA O NAÏVE BAYES
12345678910111213
def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated# Testando a separação dos dadosdataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0],

104
UNIDADE 2 — CLASSIFICAÇÃO
141516171819202122232425
[3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]]separated = separate_by_class(dataset)for label in separated: print(label) for row in separated[label]: print(row)
FONTE: Adaptado de Brownlee (2019)
Segundo Brownlee (2019), como parte da probabilística do método, precisamos de duas estatísticas de um determinado conjunto de dados. Para isso, torna-se necessário obter a média e o desvio padrão. Complementarmente, realizaremos a sumarização dos dados para aplicar as devidas estatísticas.
QUADRO 33 – SUMARIZANDO O CONJUNTO DE DADOS E GERANDO ESTATÍSTICAS
1234
56789
10111213141516171819
# calcula o desvio padrãodef stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / floa-t(len(numbers)-1) return sqrt(variance) # calcula média, desvio padrão e conta cada coluna def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(co-lumn)) for column in zip(*dataset)] del(summaries[-1]) return summaries # divide os dados para fazer os cálculos estatísticosdef summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries
FONTE: Adaptado de Brownlee (2019)
Como parte da implantação principal, devem-se calcular as probabilidades. Uma distribuição gaussiana pode ser resumida usando apenas dois números – a média e o desvio padrão (BROWNLEE, 2018). Dessa maneira, com um pouco de matemática, podemos estimar a probabilidade de um determinado valor.

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
105
QUADRO 34 – CALCULANDO AS PROBABILIDADES
12345678910111213
from math import sqrtfrom math import pifrom math import exp # calculando a distribuição gausianadef calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # Testando as probabilidadesprint(calculate_probability(1.0, 1.0, 1.0))print(calculate_probability(2.0, 1.0, 1.0))print(calculate_probability(0.0, 1.0, 1.0))
FONTE: Adaptado de Brownlee (2019)
As probabilidades são calculadas separadamente para cada classe. Isso significa que, primeiramente, calculamos a probabilidade de que um novo dado pertença à primeira classe, em seguida, calculamos as probabilidades de que ele pertença à segunda classe, e assim por diante para todas as classes.
QUADRO 35 – UTILIZANDO AS PROBABILIDADES
12
345
678
91011121314151617181920
def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, count = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities# Testar se as probabilidades estão sendo realizadasdataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]]summaries = summarize_by_class(dataset)

106
UNIDADE 2 — CLASSIFICAÇÃO
21
222324
probabilities = calculate_class_probabilities(summaries, da taset[0]print(probabilities)
FONTE: Adaptado de Brownlee (2019)
Por fim, vamos realizar a aplicação do método com ênfase no Dataset Iris. Para isso, será necessário implementar o método de predição, responsável por analisar os cálculos realizados anteriormente, com ênfase na classificação dos dados.
QUADRO 36 – UTILIZANDO AS PROBABILIDADES
12
345
678
910111213141516171819202122
23
def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, count = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities# Testar se as probabilidades estão sendo realizadasdataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]]summaries = summarize_by_class(dataset)probabilities = calculate_class_probabilities(summaries, da-taset[0])print(probabilities)
FONTE: Adaptado de Brownlee (2019)
QUADRO 37 – UTILIZANDO AS PROBABILIDADES
1234
5
# Método que realiza a predição def predict(summaries, row): probabilities = calculate_class_probabilities(summa-ries, row) best_label, best_prob = None, -1 for class_value, probability in probabilities.items():

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
107
678910111213141516171819202122
if best_label is None or probability > best_prob: best_prob = probability best_label = class_value return best_label #Abrindo o Iris Datasetfilename = 'iris.csv'dataset = load_csv(filename)for i in range(len(dataset[0])-1): str_column_to_float(dataset, i)str_column_to_int(dataset, len(dataset[0])-1)# treinando o modelo model = summarize_by_class(dataset)# inserindo novas amostra para serem preditasrow = [5.7,2.9,4.2,1.3]# predict the labellabel = predict(model, row)print('Data=%s, Predicted: %s' % (row, label))
FONTE: Adaptado de Brownlee (2019)
2.2 IMPLEMENTAÇÃO COM O SCIKIT-LEARN
Agora que já compreendeu o teorema de Bayes, sua aplicação, bem como o processo para o desenvolvimento desse algoritmo, estudaremos a sua implementação com o scikit-learn. No primeiro conjunto de dados utilizados no início deste livro, vamos conferir como fica a divisão dos dados em entrada e saída.
QUADRO 38 – SEPARANDO OS DADOS EM ENTRADA E SAÍDA
12
X = credito[0:len(credito),0:2]y = credito[0:len(credito),2:3]
FONTE: O autor
Assim como na aplicação dos demais métodos que empregam essa biblioteca, uma vez que os dados estão preparados, basta aplicar o algoritmo. O método responsável por ensinar o algoritmo a partir dos dados é o fit – perceba que o Naïve Bayes é instanciado pelo “MultinomialNB”.
QUADRO 39 – GERANDO O CLASSIFICADOR DO NAIVE BAYES
123
from sklearn.naive_bayes import MultinomialNBclassificador_NB = MultinomialNB()classificador_NB.fit(X, y)
FONTE: O autor

108
UNIDADE 2 — CLASSIFICAÇÃO
Dividimos os dados em input (X) e output (y), sendo criado o classificador, variável de mesmo nome. O classificador está apto a predizer, ou seja, classificar novas amostras com base nos dados que aprendeu. Vejamos como predizer o saldo de alguém que tem 40 anos e uma renda de R$ 5000.
QUADRO 40 – SEPARANDO OS DADOS EM ENTRADA E SAÍDA
12
novo_campo = (np.array([150,0]).reshape(1,-1))print('Ao realizar a predição o valor será: '+classificador_NB.predict(novo_campo)[0])
FONTE: O autor
2.3 CLASSIFICANDO O IRIS DATASET COM O NAÏVE BAYES
Como já vimos, todo o roteiro de implementação e utilização do Naïve Bayes com o scikit-learn, agora vamos classificar o exemplo com o Iris Dataset.
QUADRO 41 – ABRINDO O DATASET E PREPARANDO OS DADOS
1234567891011
import numpy as npfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitiris = datasets.load_iris()X = iris.data[:, [2, 3]]y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)print('Existem {} amostras de treino e {} amostras de tes-te'.format(X_train.shape[0], X_test.shape[0]))
FONTE: O autor
Até esse momento, os dados já foram carregados, preparados e normalizados, por isso passaremos para a etapa final da aplicação do método: treinar e avaliar.
Lembre-se de repetir todos os passos de preparação de dados que foram utilizados no algoritmo do KNN.
DICAS

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
109
QUADRO 42 – TREINANDO E AVALIANDO O MÉTODO NAIVE BAYES
1234
5
from sklearn.naive_bayes import MultinomialNBclassificador_NB = MultinomialNB()classificador_NB.fit(X_train_normalizado, y_train)print('A acurácia do Naive Bayes na base de treino é: {:.2f} '.format(classificador_NB.score(X_train_normalizado, y_train)))print('A acurácia do Naive Bayes na base de teste é: {:.2f} '.format(classificador_NB.score(X_test_normalizado, y_test)))
FONTE: O autor
O Naïve Bayes tem variações da sua implementação, com variações em sua fórmula. Um exemplo é o Naïve Bayes Bernoulli, que aplica técnicas para utilizar atributos booleanos discretos. O Quadro 43 mostra como fazer a aplicação Naïve Bayes Bernoulli utilizando o scikit-learn.
QUADRO 43 – TREINANDO E AVALIANDO O MÉTODO NAIVE BAYES BERNOULLI
1234
5
from sklearn.naive_bayes import BernoulliNBclassificador_NB = BernoulliNB()classificador_NB.fit(X_train_normalizado, y_train)print('A acurácia do Naive Bayes Bernoulli na base de treino é: {:.2f} '.format(classificador_NB.score(X_train_normaliza-do, y_train)))print('A acurácia do Naive Bayes Bernoulli na base de teste é: {:.2f} '.format(classificador_NB.score(X_test_normalizado, y_test)))
FONTE: O autor
O Naïve Bayes tem diversas variações de sua implementação, então, para conhecer melhor sobre o seu conceito matemático e como implementá-lo com scikit-learn, acesse a documentação disponível em: https://scikit-learn.org/stable/modules/naive_bayes.html.
DICAS

110
UNIDADE 2 — CLASSIFICAÇÃO
3 OUTROS CLASSIFICADORES
A tarefa de classificação, seja binária ou multiclasse, está presente nos mais diversos cenários de aplicação, como de reconhecimento de caracteres, análise de sentimento, categorização de textos, entre muitos outros. Para obter melhor eficácia nesses cenários, torna-se necessário conhecer os mais diversos métodos de classificação.
Até o momento, conhecemos duas famílias de métodos de classificação, bem como sua origem matemática e sua implementação em scikit-learn. A partir de agora, estudaremos outros métodos, com objetivo de abranger maior conhecimento e reflexão sobre qual o melhor método a ser aplicado na resolução de problemas de Machine learning.
3.1 REGRESSÃO LINEAR
Segundo Ferrero, Maletzke e Zalewski (2009), a regressão linear é uma técnica para modelar a relação entre atributos e classe, na qual cada atributo é ponderado em função de sua contribuição para a previsão da variável resposta. Os atributos são considerados variáveis independentes e a classe, a variável dependente desses atributos.
O objetivo do algoritmo para construção da regressão linear consiste em ajustar os pesos dos atributos, de forma a atingir um critério específico, tal como minimizar o erro quadrático médio.
FIGURA 28 – REGRESSÃO LINEAR
FONTE: <https://usuariosdoexcel.files.wordpress.com/2011/07/conf_estat_02.jpg>. Acesso em: 3 nov. 2020.
Como já realizamos todo o processo de coleta e pré-processamento utilizando os dados do Iris Dataset, vamos usar essa base para aplicar a regressão linear com a biblioteca scikit-learn.

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
111
QUADRO 44 – TREINANDO E AVALIANDO O MÉTODO REGRESSÃO LINEAR
1234
5
from sklearn.linear_model import LinearRegressionclassificador_RL = LinearRegression()classificador_RL.fit(X_train_normalizado, y_train)print('A acurácia da Regressão Linear na base de treino é: {:.2f} '.format(classificador_RL.score(X_train_normalizado, y_train)))print('A acurácia da Regressão Linear na base de teste é: {:.2f} '.format(classificador_RL.score(X_test_normalizado, y_test)))
FONTE: O autor
3.2 REGRESSÃO LOGÍSTICA
O método de regressão logística é uma adaptação da tradicional regressão linear (WALKER; DUNCAN, 1967) com saída binária. A regressão logística é capaz de gerar hipóteses com saídas discretas e mapeia a relação entre uma variável dependente categórica com uma ou mais variáveis independentes.
FIGURA 29 – REGRESSÃO LOGÍSTICA
FONTE: <https://ebmacademy.files.wordpress.com/2015/08/fig5.jpg>. Acesso em: 3 nov. 2020.
A regressão logística pode ser utilizada para modelar uma relação não linear entre a variável resposta e as variáveis explicativas. Entretanto, essa relação não linear tem que ser explicitada pelo desenvolvedor do modelo. O método de regressão logística utiliza a probabilidade de algum evento que ocorre como uma função de regressão linear, para descobrir a categoria de uma determinada variável. Esse método é considerado um método de aprendizado off-line.
Uma vez realizado todo o processo de coleta e pré-processamento utilizando os dados do Iris Dataset, vamos usar essa base para aplicar a regressão linear logística com a biblioteca scikit-learn.
Confira a documentação completa sobre a implementação da regressão linear em: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html.
DICAS

112
UNIDADE 2 — CLASSIFICAÇÃO
QUADRO 45 – TREINANDO E AVALIANDO O MÉTODO REGRESSÃO LOGÍSTICA
1234
5
from sklearn.linear_model import LogisticRegressionclassificador_RLog = LogisticRegression(random_state=0)classificador_RLog.fit(X_train_normalizado, y_train)print('A acurácia da Regressão Linear na base de treino é: {:.2f} '.format(classificador_RLog.score(X_train_normalizado, y_train)))print('A acurácia da Regressão Logística na base de teste é: {:.2f} '.format(classificador_RLog.score(X_test_normalizado, y_test)))
FONTE: O autor
3.3 MÁQUINA DE VETOR DE SUPORTE
As máquinas de vetor de suporte (SVM, do inglês Support Vector Machines; VAPNIK, 1995) compõem uma técnica de aprendizado de máquina amplamente utilizada e com excelentes resultados na classificação de textos. O SVM é um novo método para a classificação de dados lineares e não lineares. Para o cálculo do SVM, são considerados o bias, o tamanho do vetor, o vetor de teste e o vetor de suporte.
FIGURA 30 – MÁQUINA DE VETOR DE SUPORTE
FONTE: <https://jamesmccaffrey.files.wordpress.com/2017/04/supportvectormachineequations.jpg>.Acesso em: 3 nov. 2020.
As máquinas de vetor de suporte são embasadas pela teoria de aprendizado estatístico, que estabelece uma série de princípios a serem seguidos para a obtenção de classificadores com boa generalização, a qual é definida como a sua capacidade de prever corretamente a classe de novos dados do mesmo domínio em que o aprendizado ocorreu. Esse método é considerado de aprendizado off-line.
Confira a documentação completa sobre a implementação da regressão linear logística em: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html.
DICAS

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
113
Agora que já realizamos todo o processo de coleta e pré-processamento utilizando os dados do Iris Dataset, vamos usar essa base para aplicar a regressão linear com a biblioteca scikit-learn.
QUADRO 46 – TREINANDO E AVALIANDO O MÉTODO SVM
1234
5
from sklearn import svmclassificador_SVM = LogisticRegression(random_state=0)classificador_SVM.fit(X_train_normalizado, y_train)print('A acurácia do SVM na base de treino é: {:.2f} '.for-mat(classificador_SVM.score(X_train_normalizado, y_train)))print('A acurácia do SVM na base de teste é: {:.2f} '.forma-t(classificador_SVM.score(X_test_normalizado, y_test)))
FONTE: O autor
3.4 PERCEPTRON
A versão inicial do algoritmo do Perceptron foi proposta na década de 1950 por Rosenblatt (1957). Esse algoritmo, em sua versão inicial, teve como objetivo replicar o funcionamento da mente humana. A implementação inicial é para a aprendizagem de redes neurais simples, de uma camada.
FIGURA 31 – PERCEPTRON
FONTE: Adaptada de <http://blog.zabarauskas.com/img/perceptron.gif>. Acesso em: 3 nov. 2020.
O método Perceptron tem diversas variações, desde o Voted-Perceptron, proposto por Freund, Schapire e Abe (1999), até versões mais complexas que deram origem às redes neurais. Como o erro do Perceptron pode ser calculado a cada iteração, pode-se dizer que esse método tem a capacidade de aprender de maneira incremental.
Confira a documentação completa sobre implementação do SVM em: https://scikit-learn.org/stable/modules/svm.html.
DICAS

114
UNIDADE 2 — CLASSIFICAÇÃO
Uma vez realizados a coleta e o pré-processamento utilizando os dados do Iris Dataset, vamos usar essa base para aplicar o método Perceptron com a biblioteca scikit-learn.
QUADRO 47 – TREINANDO E AVALIANDO O MÉTODO PERCEPTRON
1234
5
from sklearn.linear_model import Perceptronclassificador_Per = Perceptron(tol=1e-3, random_state=0)classificador_Per.fit(X_train_normalizado, y_train)print('A acurácia do Perceptron na base de treino é: {:.2f} '.format(classificador_Per.score(X_train_normalizado, y_train)))print('A acurácia do Perceptron na base de teste é: {:.2f} '.format(classificador_Per.score(X_test_normalizado, y_test)))
FONTE: O autor
Confira a documentação completa sobre implementação do Perceptron em: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Perceptron.html.
DICAS

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
115
RECONHECIMENTO DE IMAGENS COM REDES NEURAIS CONVOLUCIONAIS EM PYTHON
Data Science Academy
Construindo a Rede Neural Convolucional
Nossa rede é uma sequência de camadas e podemos usar o modelo sequencial oferecido pelo Keras, que possui as funções necessárias para construir cada camada de uma rede neural convolucional.
O primeiro passo é carregar os pacotes necessários, o que é feito nas células a seguir.
O Keras utiliza o TensorFlow como backend, pois, na prática, o Keras é apenas uma biblioteca para simplificar a complexidade do TensorFlow. Aqui estão as versões utilizadas:
# Importsfrom keras.models import Sequentialfrom keras.layers import Conv2Dfrom keras.layers import MaxPooling2Dfrom keras.layers import Flattenfrom keras.layers import Dense
Então, inicializamos a nossa rede:
# Inicializando a Rede Neural Convolucionalclassifier = Sequential()
Agora, definimos os parâmetros para o shape dos dados de entrada e a função de ativação. Usaremos 32 features para um array 2D e definiremos nosso array como o formato 3x3.
Converteremos todas as nossas imagens 64x64 pixels em um array 3D (pois as imagens são coloridas com 3 canais de cores).
# Passo 1 - Primeira Camada de Convoluçãoclassifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
Em seguida, aplicamos o agrupamento (pooling) para reduzir o tamanho do mapa de features, resultado da primeira camada de convolução (dividido por 2):
LEITURA COMPLEMENTAR

116
UNIDADE 2 — CLASSIFICAÇÃO
# Passo 2 - Poolingclassifier.add(MaxPooling2D(pool_size = (2, 2)))
Adicionamos, então, a segunda camada de convolução, tornando nossa rede um pouco mais profunda:
# Adicionando a Segunda Camada de Convoluçãoclassifier.add(Conv2D(32, (3, 3), activation = 'relu'))
Mais uma vez, aplicamos a camada de pooling à saída da camada de convolução anterior.
classifier.add(MaxPooling2D(pool_size = (2, 2)))
Agora, aplicamos o “achatamento”, ou apenas Flatten, para converter a estrutura de dados 2D, resultado da camada anterior em uma estrutura 1D, ou seja, um vetor.
# Passo 3 - Flatteningclassifier.add(Flatten())
No próximo passo, conectamos todas as camadas. Usamos uma função de ativação retificadora (relu) e então uma função de ativação sigmoide, para obter as probabilidades de cada imagem conter um cachorro ou um gato. O modelo raramente terá 100% de certeza e o que ele gera como resultado é uma probabilidade.
# Passo 4 - Full connectionclassifier.add(Dense(units = 128, activation = 'relu'))classifier.add(Dense(units = 1, activation = 'sigmoid'))
Finalmente, compilamos nossa rede neural. Para compilar a rede, usamos o otimizador “Adam”, um excelente algoritmo de primeira ordem para otimização baseada em gradiente de funções objetivas estocásticas, que toma como base uma estimativa adaptada de momentos de baixa ordem.
Usamos uma função log loss com “entropia binária cruzada”, pois ela funciona bem com funções sigmoides. Nossa métrica será a acurácia, pois essa é nossa maior preocupação no treinamento desse tipo de modelo.
# Compilando a redeclassifier.compile(optimizer = 'adam', loss = 'binary_crossen-tropy', metrics = ['accuracy'])
Nesse ponto, temos nossa rede construída. Precisamos, agora, treiná-la.

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
117
Treinando a rede neural convolucional
Pré-processamento
Com a rede criada, precisamos realizar o treinamento. Antes, porém, vamos fazer algum pré-processamento nos dados, no nosso caso, as imagens. Para essa tarefa, vamos usar a função “ImageDataGenerator()” do Keras e ajustar escala e zoom das imagens de treino e a escala das imagens de validação.
O pré-processamento dos dados é etapa crucial em qualquer projeto de Machine learning e muitas técnicas podem ser usadas, sempre de acordo com os dados em mãos e o problema que estamos tentando resolver.
# Criando os objetos train_datagen e validation_datagen com as regras de pré-processamento das imagensfrom keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
validation_datagen = ImageDataGenerator(rescale = 1./255)
Aplicamos, então, os dois objetos criados anteriormente para pré-processar os dados de treino e validação. Lembre-se: o tratamento aplicado aos dados de validação deve ser o mesmo aplicado aos dados de treino.
# Pré-processamento das imagens de treino e validaçãotraining_set = train_datagen.flow_from_directory('dataset_trei-no', target_size = (64, 64), batch_size = 32, class_mode = 'binary')
validation_set = validation_datagen.flow_from_directory('data-set_validation', target_size = (64, 64), batch_size = 32, class_mode = 'binary')

118
UNIDADE 2 — CLASSIFICAÇÃO
Treinamento
Usaremos 8.000 passos em nosso conjunto de treinamento para cada época. Escolhemos 2.000 etapas de validação para as imagens de validação – esses hiperparâmetros são definidos por você.
# Executando o treinamento (esse processo pode levar bastante tempo, dependendo do seu computador)classifier.fit_generator(training_set, steps_per_epoch = 8000, epochs = 5, validation_data = validation_set, validation_steps = 2000)
Treinamento concluído com sucesso! Observe que, ao final de cada época, a acurácia aumenta, ou seja, nosso modelo está aprendendo e cometendo cada vez menos erros! Essa é a magia por trás de Machine learning, a pura aplicação de Matemática e Estatística, por meio de Programação e Ciência da Computação. Isso não é maravilhoso? Machine learning está transformando o nosso mundo, à medida que treinamos as máquinas para realizar tarefas, até então, exclusivas dos seres humanos.
Fazendo previsões
Vamos agora testar nosso modelo treinado com imagens que ele ainda não viu e que estão nos dados de teste.
Para cada imagem de teste, carregamos as imagens com as mesmas dimensões usadas nas imagens de treino. Na sequência, convertemos as imagens em um array e expandimos as dimensões. Então, apresentamos as imagens ao classificador treinado nos passos anteriores. Por fim, verificamos o resultado da previsão e emitimos a informação se a imagem é de um gato ou um cachorro.
# Primeira Imagemimport numpy as npfrom keras.preprocessing import image
test_image = image.load_img('dataset_teste/2216.jpg', target_size = (64, 64))test_image = image.img_to_array(test_image)test_image = np.expand_dims(test_image, axis = 0)result = classifier.predict(test_image)training_set.class_indices
if result[0][0] == 1: prediction = 'Cachorro'else: prediction = 'Gato'
Image(filename='dataset_teste/2216.jpg')

TÓPICO 3 — MÉTODOS PROBABILÍSTICOS E OUTROS MÉTODOS DE CLASSIFICAÇÃO
119
Perfeito! Nosso modelo recebeu uma imagem que nunca tinha visto antes e, com base no que aprendeu durante o treinamento, foi capaz de classificar a imagem como de um cachorro! Na prática, isso é o que acontece:
• O modelo treinado nada mais é do que um conjunto de pesos que foram definidos a partir de vetores de imagens de cães e gatos.
• Os pesos do modelo foram definidos com base nas características das imagens de treino.
• Temos pesos que representam patas, outros que representam bigodes, outros que representam orelhas etc.
• Convertemos a imagem de teste em um vetor de pixels e apresentamos ao modelo.
• O modelo compara o vetor da imagem de teste com seus pesos e, então, emite a classificação.
Não há mágica. Há Matemática e Estatística, por meio de Programação e Ciência da Computação!
Conclusão
Obteve-se um resultado final de 95,82% de precisão para o nosso conjunto de treino e 83% para o nosso conjunto de testes. Para as seis imagens de amostra, nosso modelo acertou cinco. Obviamente, mais testes poderiam ser realizados.
Melhorias adicionais para esse modelo:
• Aumentar o número de épocas para 25, para uma aprendizagem mais profunda.
• Aumentar o redimensionamento da imagem de 64x64 para 256x256, o que deve levar a melhores resultados, devido à resolução mais alta.
• Aumentar o tamanho do lote de 32 para 64 também pode levar a melhores resultados.

120
UNIDADE 2 — CLASSIFICAÇÃO
• Usar imagens sintéticas rotacionando a imagem principal, técnica conhecida como Dataset Augmentation.
• Alterar a arquitetura da rede, incluindo mais uma camada convolucional.• Avaliar outras métricas do modelo e ajustar os hiperparâmetros de acordo.• Experimentar outros algoritmos de otimização.
FONTE: Adaptado de Data Science Academy. Capítulo 47 – Reconhecimento de Imagens com Redes Neurais Convolucionais em Python – Parte 4. In: Data Science Academy. Deep Learning Book. Disponível em: http://deeplearningbook.com.br/reconhecimento-de-imagens-com-redes--neurais-convolucionais-em-python-parte-4/. Acesso em: 3 nov. 2020.
Ficou alguma dúvida? Construímos uma trilha de aprendizagem pensando em facilitar sua compreensão. Acesse o QR Code, que levará ao AVA, e veja as novidades que preparamos para seu estudo.
CHAMADA

121
RESUMO DO TÓPICO 3
Neste tópico, você aprendeu que:
• É possível utilizar probabilidade para realizar a classificação de dados.
• O Naïve Bayes é um método probabilístico que calcula a probabilidade de um documento pertencer a uma categoria.
• O método Naïve Bayes tem diversas variações, como o Naïve Bayes Multinomial e o Naïve Bayes Bernoulli.
• O método Naïve Bayes é considerado de aprendizado on-line, uma vez que suas probabilidades podem ser atualizadas a cada novo documento.
• O Naïve Bayes pode ser implementado tanto para classificação binária quanto para multiclasse.
• O método Naïve Bayes assume que os atributos são independentes – essa premissa permite que o cálculo de probabilidade de um evento para uma classe seja simplificado.
• O scikit-learn permite a aplicação de diversas variações do método Naïve Bayes.
• Existem diversos classificadores que podem ser utilizados em Machine learning.
• Em cenários de Machine learning, o ideal é avaliar os métodos para se obter o melhor classificador.
• A regressão linear é uma técnica para modelar a relação entre atributos e classe, na qual cada atributo é ponderado em função de sua contribuição para a previsão da variável resposta.
• A regressão logística é capaz de gerar hipóteses com saídas discretas e mapeia a relação entre uma variável dependente categórica com uma ou mais variáveis independentes.
• Os métodos SVM são embasados pela teoria de aprendizado estatístico, a qual estabelece uma série de princípios que devem ser seguidos para a obtenção de classificadores com boa generalização.
• O Perceptron representa o início das redes neurais, em sua implementação mais simples com um neurônio.

122
1 Considere o texto e a figura a seguir:
O classificador Naïve Bayes é construído utilizando dados de treinamento para estimar a probabilidade de um documento pertencer a uma classe. O teorema de Bayes, mostrado a seguir, é utilizado para estimar estas probabilidades.
FONTE: OLIVEIRA, G. L.; NETO, M. G. M. Expertext: Uma ferramenta de combinação de múl-tiplos classificadores naive bayes. Anales de la 4ª Jornadas Iberoamericanas de Ingeniería de Software e Ingeniería de Conocimiento. Madrid, v. 1, p. 317-32, 2004.
a) Indique o significado de C.b) Indique o significado de x.c) Indique o significado de P (c | x).d) Indique o significado de P (C) e) Indique o significado de P (x | c) f) Indique o significado de P (x).
2 Considere o texto a seguir:
A regressão linear é uma ferramenta estatística utilizada para traçar a tendência de funções com variação linear. Este método, apesar de simples, quando é convenientemente aplicado, pode produzir resultados satisfatórios na previsão de séries temporais, quando estas são lineares.
FONTE: OLIVEIRA, G. L.; NETO, M. G. M. Expertext: Uma ferramenta de combinação de múlti-plos classificadores naive bayes. Anales de la 4ª Jornadas Iberoamericanas de Ingeniería de Software e Ingeniería de Conocimiento. Madrid, v. 1, p. 317-32, 2004.
Sobre a regressão linear e sua implementação no scikit-learn, assinale a alternativa que apresenta o trecho de código que instancia um objeto classificador do tipo regressão linear:
a) ( ) Classificador_RL = LinearRegression()b) ( ) Classificador_RL = RegLIn()c) ( ) Classificador_RL = RegressionMB()d) ( ) Classificador_RL = Bernoullli()
AUTOATIVIDADE

123
REFERÊNCIAS
ABEEL, T.; VAN DE PEER, Y.; SAEYS, Y. Java-ml: A Machine learning library. Journal of Machine learning Research, v. 10, p. 931-934, 2009. Disponível em: https://biblio.ugent.be/publication/697734/file/709516.pdf. Acesso em: 3 nov. 2020.
AHMED, Z. et al. Machine learning at Microsoft with ML. NET. In: PROCEE-DINGS OF THE 25TH ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY & DATA MINING. Proceedings […] KDD, 2019. p. 2448-2458.
ALMEIDA, E. D. Classificação ordinal com opção de rejeição. 2010, 58 f. Disserta-ção (Mestrado) – Engenharia Informática e Computação, Faculdade de Engenharia, Universidade do Porto, 2010. Disponível em: http://www.inescporto.pt/~jsc/stu-dents/2010EzildaAlmeida/2010relatorioEzildaAlmeida.pdf. Acesso em: 3 nov. 2020.
BIGDATACORP. A Importância de uma Boa Visualização de Dados. BIGDATA-CORP. 2019. Disponível em: https://bigdatacorp.com.br/a-importancia-de-uma--boa-visualizacao-de-dados/. Acesso em: 3 nov. 2020.
BORGES, R.; DA SILVA, R. A. A.; CASTRO, S. S. de. Utilização da classificação por distância euclidiana no mapeamento dos focos de arenização no setor sul da alta bacia do Rio Araguaia. In: ANAIS XIII SIMPÓSIO BRASILEIRO DE SEN-SORIAMENTO REMOTO. Anais [...] Florianópolis: INPE, 2007. Disponível em: http://marte.sid.inpe.br/col/dpi.inpe.br/sbsr@80/2006/11.14.12.59/doc/3777-3784.pdf. Acesso em: 3 nov. 2020.
BRESSERT, E. SciPy and NumPy: an overview for developers. O’Reilly Media, 2012
BROWNLEE, J. Naive Bayes Classifier From Scratch in Python. Machine Lear-ning Mastery, 2019. Disponível em: https://machinelearningmastery.com/nai-ve-bayes-classifier-scratch-python/#:~:text=Naive%20Bayes%20is%20a%20classifi-cation,to%20make%20their%20calculations%20tractable. Acesso em: 20 set. 2020. CARVALHO, A. Mineração de Dados em Biologia Molecular. Apostila. Instituto de Ciências Matemáticas e de Computação (ICMC). São Paulo: Universidade de São Paulo, 2012. Disponível em: https://edisciplinas.usp.br/pluginfile.php/54785/mod_resource/content/1/aula09-met-distancia.pdf. Acesso em: 25 ago. 2020.
DUDA, R.; HART, P. Bayes Decision Theory. [S.l.]: John Wiley & Sons, 1973. p. 10-43.
FERRERO, C. A.; MALETZKE, A. G.; ZALEWSKI, W. Modelos de Regressão para a Previsão de Séries Temporais por meio do Algoritmo kNN-TSP. In: ENCONTRO NACIONAL DE INTELIGÊNCIA ARTIFICIAL E COMPUTA-CIONAL (ENIAC). Anais [...] ENIAC, v. 12, p. 1-8, 2009. Disponível em: https://

124
www.researchgate.net/profile/Andre_Maletzke/publication/272086195_Mode-los_de_Regressao_para_a_Previsao_de_Series_Temporais_por_meio_do_Algo-ritmo_kNN-TSP/links/54da02e70cf25013d043a635/Modelos-de-Regressao-para--a-Previsao-de-Series-Temporais-por-meio-do-Algoritmo-kNN-TSP.pdf. Acesso em: 3 nov. 2020.
FISHER, R. A. The use of multiple measurements in taxonomic problems. In: An-nals of Eugenics, v. 7, n. 2, p. 179-188, 1936. Disponível em: https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1469-1809.1936.tb02137.x. Acesso em: 3 nov. 2020.
HARRISON, M. Machine learning – Guia de Referência Rápida: Trabalhando com dados estruturados em Python. O’Reilly, Novatec, 2020.
KOERICH, A. Aprendizagem de Máquina. Apostila. Apresentação. Programa de Pós-Graduação em Informática, Pontifícia Universidade Católica do Paraná (PUCPR), 2012. Disponível em: http://www.ppgia.pucpr.br/~alekoe/AM/2012/0-Apresentacao-AM-2012.pdf. Acesso em: 20 set. 2020.
LUTZ, M. Learning python: Powerful object-oriented programming. O’Reilly Media, Inc., 2013.
MALDANER, L. Desenvolvimento de software acadêmico para engenharia química utilizando linguagem Python: separador de mistura binária. 53f, 2019. Monografia (Engenharia Química) – Universidade Tecnológica Federal do Para-ná, Francisco Beltrão, 2019. Disponível em: http://repositorio.roca.utfpr.edu.br/jspui/bitstream/1/16515/1/FB_COENQ_2019_2_06.pdf Acesso em: 3 nov. 2020.
MCCALLUM, A.; NIGAM, K. A comparison of event models for naïve bayes text classification. In: AAAI. Proceedings of Workshop on Learning for Text Ca-tegorization. Proceedings […] AAAI-98, v. 752, p. 41-48, Wisconsin, 1998.
MICROSOFT. Tarefas de aprendizado de máquina no ML.NET. Microsoft, 2019. Disponível em: https://docs.microsoft.com/pt-br/dotnet/machine-learning/re-sources/tasks. Acesso em: 20 set. 2020.
NASCIMENTO, L. B. F. Desenvolvimento de solução de inteligência artificial aplicada a implementação de smart buildings com base no framework SmartL-VGrid. Monografia (Engenharia Elétrica) – Escola Superior de Tecnologia da Universidade do Estado do Amazonas, Manaus, 2019. Disponível em: https://seer.ufrgs.br/rita/article/view/RITA-VOL23-NR1-69. Acesso em: 3 nov. 2020.
OLIVEIRA, M.; MUNIZ, F.; FARRAPO, R. Células de Estudo de Programação nos Cursos de Engenharia da Universidade Federal do Ceará no Campus Sobral com Aplicação de Metodologia de Ensino Cooperativo. In: Anais da VIII Esco-la Regional de Computação do Ceará, Maranhão e Piauí. Anais [...] SBC, 2020. p. 284-291. Disponível em: https://sol.sbc.org.br/index.php/ercemapi/article/view/11496/11359. Acesso em: 3 nov. 2020.

125
OLIVEIRA, L. M. de. Classificação de dados sensoriais de cafés especiais com resposta multiclasse via Algoritmo Boosting e Bagging. Dissertação (Mestrado em Estatística e Experimentação Agropecuária) ¬– Pós-graduação em Estatística e Experimentação Agropecuária, Universidade Federal de Lavras, Lavras, 2016. Disponível em: http://www.sbicafe.ufv.br/bitstream/handle/123456789/8506/Dissertacao_Lilian%20Maria%20de%20Oliveira.pdf?sequence=1&isAllowed=y. Acesso em: 3 nov. 2020.
PEDREGOSA, F. et al. Scikit-learn: Machine learning in Python. Journal of Machi-ne Learning Research, v. 12, p. 2825-2830, 2011. Disponível em: https://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf. Acesso em: 3 nov. 2020.
PRINA, B. Z.; TRENTIN, R. GMC: Geração de Matriz de Confusão a partir de uma classificação digital de imagem do ArcGIS®. In: SIMPÓSIO BRASILEIRO DE SEN-SORIAMENTO REMOTO Anais [...] João Pessoa: INPE, 2015, v. 17, p. 131-139. Dis-ponível em: http://www.dsr.inpe.br/sbsr2015/files/p0031.pdf. Acesso em: 3 nov. 2020.
RODRIGUES, V. Métricas de Avaliação: acurácia, precisão, recall… quais as diferenças? Medium, 2019. Disponível em: https://medium.com/@vitorborba-rodrigues/métricas-de-avaliação-acurácia-precisão-recall-quais-as-diferenças-c-8f05e0a513c. Acesso em: 20 set. 2020. ROSENBLATT, F. The perceptron, a perceiving and recognizing automaton. Project Para. Cornell Aeronautical Laboratory, 1957. Disponível em: https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf. Acesso em: 3 nov. 2020.
SCHLICHTING, L. Atividades de laboratório de comunicações sem fio com launchpad CC1350. Monografia. Centro Tecnológico, Engenharia Eletrônica, Universidade Federal de Santa Catarina, Florianópolis, 2020. Disponível em: https://repositorio.ufsc.br/bitstream/handle/123456789/204168/TCC_Lucas.pdf?-sequence=1&isAllowed=y. Acesso em: 3 nov. 2020.
SEIDEL, E. J. et al. Comparação entre o método Ward e o método K-médias no agru-pamento de produtores de leite. Ciência e Natura, UFSM, v. 30, n. 1, p. 7-15, 2008.
SILVA, R. M. Da Navalha de Occam a um método de categorização de textos simples, eficiente e robusto. Tese (Doutorado em Engenharia Elétrica) – Fa-culdade de Engenharia Elétrica e de Computação, Universidade Estadual de Campinas, Campinas, 2017. Disponível em: http://www.dt.fee.unicamp.br/~re-natoms/publications/tese_doutorado_renatosilva.pdf. Acesso em: 3 nov. 2020.
SILVERMAN, R. Git – Guia prático. São Paulo: Novatec, 2013.
SOLDI, S. Análise de Agrupamentos. Notas de Aula. Apostilas dos Profs. Jair Mendes Marques e Anselmo Chaves Neto. Universidade Federal do Paraná, 2013. Disponível em: https://docs.ufpr.br/~soniaisoldi/ce076/9ANALISEAGRU-PAMENTOS.pdf. Acesso em: 20 set. 2020.

126
TAN, P.-N.; STEINBACH, M.; KUMAR, V. Introduction to data mining. Pear-son Education India, 2016.
TELES, Á. R.; WEBBER, C. G. Detecção de haters nas redes sociais. Ciência da Computação, Universidade de Caxias do Sul, Caxias do Sul, 2019. Disponível em: https://repositorio.ucs.br/xmlui/bitstream/handle/11338/6356/TCC%20%c3%81lis-son%20Rodrigues%20Teles.pdf?sequence=1&isAllowed=y. Acesso em: 3 nov. 2020.
VANDERPLAS, J. Python data science handbook: Essential tools for working with data. O’Reilly Media, 2016.
VAPNIK, V. N. The Nature of Statistical Learning Theory. New York: Springer--Verlag, 1995.
VAZ, A. L. Normalizar ou padronizar as variáveis? Medium, 2019. Disponível em: https://medium.com/data-hackers/normalizar-ou-padronizar-as-variáveis--3b619876ccc9. Acesso em: 3 nov. 2020.
VON LOCHTER, J. et al. Máquinas de classificação para detectar polaridade de mensagens de texto em redes sociais. Dissertação (Mestre em Ciência da Com-putação) – Programa de Pós-Graduação em Ciência da Computação, Centro de Ciências em Gestão e Tecnologia, Universidade Federal de São Carlos, São Carlos, 2015. Disponível em: https://repositorio.ufscar.br/bitstream/handle/ufscar/7903/LOCHTER_Johannes_2015.pdf?sequence=1&isAllowed=y. Acesso em: 5 nov. 2020.
VOOO. 6 passos fáceis para aprender o algoritmo Naive Bayes. Vooo, 2016. Disponível em: https://www.vooo.pro/insights/6-passos-faceis-para-aprender-o--algoritmo-naive-bayes-com-o-codigo-em-python. Acesso em: 20 set. 2020.
WALKER, S. H.; DUNCAN, D. B. Estimation of the probability of an event as a func-tion of several independent variables. Biometrika, Oxford University Press, v. 54, n. 1-2, p. 167-179, 1967. Disponível em: http://www.medicine.mcgill.ca/epidemiology/hanley/bios601/CandH-ch0102/WalkerDuncan1967.pdf. Acesso em: 3 nov. 2020.
ZÓ, J. G. Clickbait ou Não? Usando Naive Bayes Para Classificar Títulos do Buzzfeed. Medium, 2019. Disponível em: https://medium.com/data-hackers/clickbait-ou-não-usando-naive-bayes-para-classificar-títulos-do-buzzfeed-ad-10108c20d6. Acesso em: 21 set. 2020.

127
UNIDADE 3 —
REGRESSÃO
OBJETIVOS DE APRENDIZAGEM
PLANO DE ESTUDOS
A partir do estudo desta unidade, você deverá ser capaz de:
• introduzir conceitos fundamentais sobre a regressão;• apresentar ferramentas complementares para aplicação de algoritmos;• exemplificar onde os métodos de regressão podem ser aplicados e
explanar conceitos matemáticos para a implementação das regressões;• implementar regressão linear com base matemática e utilizando as
bibliotecas do Python;• compreender conceitos matemáticos sobre a regressão logística; • implementar uma regressão logística com base matemática e utilizando
as bibliotecas do Python;• compreender os conceitos fundamentais e matemáticos sobre redes
neurais artificiais;• implementar uma rede neural artificial com base matemática e utilizando
as bibliotecas do Python.
Esta unidade está dividida em três tópicos. No decorrer da unidade, você encontrará autoatividades com o objetivo de reforçar o conteúdo apresentado.
TÓPICO 1 – INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO
TÓPICO 2 – REGRESSÃO LINEAR
TÓPICO 3 – TÉCNICAS AVANÇADAS DE REGRESSÃO
Preparado para ampliar seus conhecimentos? Respire e vamos em frente! Procure um ambiente que facilite a concentração, assim absorverá melhor as informações.
CHAMADA

128

129
UNIDADE 3
1 INTRODUÇÃO
Já pensou como seria o seu dia se pudesse prever se vai chover? Ou qual a temperatura exata? Ou, até mesmo, ir além e poder prever quais ações irão subir e quais irão cair no mercado da Bolsa de Valores? Essas informações do nosso cotidiano podem ser obtidas por meio de algoritmos de regressão.
A regressão é uma tarefa supervisionada de Machine learning que pode ser implementada por meio de diversos algoritmos. É semelhante à classificação em relação ao seu comportamento preditivo, embora os valores preditos por essa tarefa sejam do tipo contínuo, isto é, para prever um valor numérico, deve-se utilizar uma tarefa de regressão.
A regressão é uma técnica de modelagem preditiva em que a variável de destino a ser estimada é contínua. Exemplos de aplicações de regressão incluem a previsão de um índice do mercado de ações, usando outros indicadores econômicos; a previsão da quantidade de precipitação em uma região, com base nas características do jato; a projeção das vendas totais de uma empresa, com base no valor gasto com publicidade; e a estimativa de idade de um fóssil, de acordo com a quantidade de carbono deixada no material orgânico (TAN; STEINBACH; KUMAR 2016).
2 VISÃO GERAL DA REGRESSÃO
Como uma tarefa de aprendizado supervisionado, similar à classificação, a regressão consiste em realizar aprendizado a partir de dados previamente conhecimentos, ditos históricos. A principal diferença entre os dois problemas está no tipo de saída e em sua avaliação: na regressão, em vez de se estimar a acurácia, estima-se a distância ou o erro entre a saída do estimador (modelo) e a saída desejada (ESCOVEDO; KOSHIYAMA, 2020).
Segundo Geron (2019), um exemplo típico é prever um valor numérico alvo, como o preço de um carro, dado um conjunto de características (quilometragem, idade, marca etc.) conhecido como preditores. Esse tipo de tarefa é denominado regressão, pois, para obter o melhor modelo, é preciso dar a ele muitos exemplos de carros, incluindo seus preditores e suas etiquetas (ou seja, seus preços).
É possível perceber na Figura 1 que, ao inserir uma nova instância, o algoritmo terá o desafio de predizer qual o valor do target, com base em um histórico de dados, em um determinado ponto.
TÓPICO 1 —
INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO

UNIDADE 3 — REGRESSÃO
130
FIGURA 1 – REGRESSÃO DO PREÇO DO CARRO
FONTE: Adaptada de Geron (2019, p. 9)
Dito isso, vamos compreender como um conjunto de dados é descrito como fim de representar uma regressão.
A Figura 2 mostra a equação que representa um conjunto de dados D, composto por dados de entrada (input) xi, associados a um conjunto de dados de saída (target) yi, em que i representa cada registro e N o número total de objetos.
FIGURA 2 – DESCRIÇÃO DOS DADOS PARA A REGRESSÃO
FONTE: Adaptada de Geron (2019)
A partir dos dados existentes, a regressão é representada por uma função f(x) que tem como objetivo prever o target y. Essa função é como uma relação funcional entre x e y, denotado como y = f(x). No contexto da regressão, f(x) pode ser considerada a regressão em si – uma função f, que recebe x e o valor aproximado de y.
Como exemplo simples da matemática, para compreendermos essa relação, considere x = [1,2,3,4,5,6,7,8,9,10] e y = [2,3,4,5,6,7,8,9,10,11]. A função que estima y em função de x será demonstrada pelos dados do Quadro 1 e da Figura 3.
QUADRO 1 – EXIBINDO OS DADOS DE X E Y
12345
import numpy as npimport matplotlib.pyplot as plt
x = np.array([1,2,3,4,5,6,7,8,9,10])y = np.array([2,3,4,5,6,7,8,9,10,11])

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO
131
678
plt.plot(x,y)plt.show()
FONTE: O autor
FIGURA 3 – EXIBINDO OS DADOS DE Y EM FUNÇÃO DE X
FONTE: O autor
Ao olhar os dados de x e y, provavelmente, percebe-se a relação deles, que pode ser mapeada por f(x) = x + 1, uma vez que os valores de y são os valores de x acrescidos de 1.
QUADRO 2 – EXIBINDO OS DADOS DE X E F(X)
1234
def f(x): return x+1 plt.plot(x,f(x))plt.show()
FONTE: O autor
Com f(x) em mãos, essa função torna-se um estimador, ou seja, um preditor baseado em regressão, que permite inferir novas amostras. Agora, se os valores fossem x = [27,38,31.1,45.49,67.5,70.9] e y = [95.8,106.8, 129.56, 175.75, 256.9, 302.9] ou se, em x, cada objeto fosse composto por mais de um objeto, isso tornaria ainda mais complexo.
Nesse momento, é importante compreender que o objetivo principal é, com base em conjunto de dados X e um target Y, obter uma função f(x), que será o preditor.

UNIDADE 3 — REGRESSÃO
132
3 MÉTRICAS
As métricas de avaliação têm como objetivo verificar a eficácia do modelo, comparando com os dados originais. Nos modelos de classificação, os valores são discretos, por isso as métricas são objetivas, ou seja, conseguimos mensurar se o modelo acertou ou não a predição para uma determinada amostra.
Na regressão, os valores são contínuos; isso significa que, se para determinado valor de y = 3.72, o predidor f(x) = 3.77, não se considerar que ele não funcionou, mas, sim, que errou. Esse é o termo utilizado para as métricas de avaliação de regressão: erro ou taxa de erro.
3.1 ERRO QUADRÁTICO MÉDIO
O erro quadrático médio (MSE, do inglês mean squared error) é uma das funções mais comuns, usada em problemas de regressão linear, ou seja, quando se sabe que a relação entre os dados a serem preditos e os dados de entrada é estritamente linear. Essa função mede a diferença entre os resultados obtidos e o resultado real, eleva cada diferença ao quadrado e, depois, calcula a média (CECCON, 2019).
FIGURA 4 – ERRO QUADRÁTICO MÉDIO
FONTE: Adaptada de <https://www.scielo.br/img/revistas/qn/v30n2/19x03.gif>. Acesso em: 5 nov. 2020.
A fórmula do erro médio quadrático contém o valor yi, que representa os valores reais do target, enquanto ŷi equivale aos valores preditos utilizando determinada f(x). A fórmula representa uma iteração, na qual cada elemento de yi irá subtrair um elemento de ŷi, e, posteriormente, será elevado ao quadrado, para que não haja valores negativos. A seguir, vamos colocar em prática essa métrica.
QUADRO 3 – IMPLEMENTANDO O MSE
123456789
def mse(y, y_predito): erro = 0.0 for i in range(len(actual)): diferenca = y[i] – y_predito[i] erro += (diferenca ** 2) mse = erro / float(len(y)) return mse y_true = [3, -0.5, 2, 7]

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO
133
101112
y_pred = [2.5, 0.0, 2, 8]
print(mse(y_true, y_pred))
FONTE: O autor
Agora que já estamos acostumados a utilizar as bibliotecas do Python, vamos conferir a implementação do método utilizando o scikit-learn.
QUADRO 4 – IMPLEMENTANDO O MSE COM SCIKIT-LEARN
1234
from sklearn.metrics import mean_squared_errory_true = [3, -0.5, 2, 7]y_pred = [2.5, 0.0, 2, 8]print(mean_squared_error(y_true, y_pred))
FONTE: O autor
Complementarmente ao erro quadrático médio, existe a raiz do erro quadrático médio (RMSE, do inglês Root Mean Squared Error), cuja fórmula é dada pela Figura 5.
FIGURA 5 – RAIZ DO ERRO QUADRÁTICO MÉDIO
FONTE: Adaptada de <https://www.scielo.br/img/revistas/qn/v30n2/19x03.gif>. Acesso em: 5 nov. 2020.
Como mostra a fórmula, a única alteração para o MSE é a raiz quadrada, por isso, devemos alterar a raiz do retorno na função implementada no Quadro 3. Já a função implementada pelo scikit-learn segue a mesma lógica e pode ser chamada da seguinte maneira:
QUADRO 5 – IMPLEMENTANDO A RMSE COM SCIKIT-LEARN
12345
from sklearn.metrics import mean_squared_errorfrom math import sqrty_true = [3, -0.5, 2, 7]y_pred = [2.5, 0.0, 2, 8]rmse = sqrt(mean_squared_error(y_true, y_pred))
FONTE: O autor

UNIDADE 3 — REGRESSÃO
134
3.2 ERRO ABSOLUTO MÉDIO
Ao fazer o cálculo da RMSE e do MSE, consideramos a média dos erros entre preditos e originais, afinal é esse o cerne das duas métricas. O erro absoluto médio (MAE, do inglês median absolute error) considera os valores absolutos, ou seja, o desvio médio entre o observado e o predito.
Segundo Silva (2017), o MAE é a média do valor absoluto da diferença entre o valor predito e o valor real. Nessa métrica, os erros individuais são ponderados igualmente pela média.
FIGURA 6 – MEDIAN ABSOLUTE ERROR (MAE)
FONTE: <https://miro.medium.com/max/335/1*Z6lLZBRCwsMZWVvrY7-HYQ.png>. Acesso em: 5 nov. 2020.
Vamos conferir como scikit-learn implementa e utilizar o MAE.
QUADRO 6 – IMPLEMENTANDO O MAE COM SCIKIT-LEARN
1234
from sklearn.metrics import median_absolute_errory_true = [3, -0.5, 2, 7]y_pred = [2.5, 0.0, 2, 8]median_absolute_error(y_true, y_pred)
FONTE: O autor
3.3 OVERFITTING E UNDERFITTING
No estudo sobre Machine learning, bem como na avaliação dos métodos de classificação, aprendemos que uma das estratégias para avaliar o desempenho de um método é dividir a base de dados em treino e teste. Entretanto, pode acontecer um desbalanceamento dos dados na base, impactando em overfitting ou underfitting.

TÓPICO 1 — INTRODUÇÃO ÀS TAREFAS DE REGRESSÃO
135
3.4 VALIDAÇÃO CRUZADA
Para complementar o estudo sobre a divisão do dataset em treino e teste, existe uma técnica conhecida como validação cruzada. A validação cruzada tem como objetivo avaliar o modelo de melhor maneira do que simplesmente a divisão dos dados em treino e teste. Com sua aplicação, é possível criar um modelo de validação mais genérico, permitindo obter mais exatidão sobre a capacidade de generalização de cada método.
FIGURA 7 – VALIDAÇÃO CRUZADA
FONTE: <https://minerandodados.com.br/wp-content/uploads/2020/02/image.png >. Acesso em: 5 nov. 2020.
Segundo Santana (2020), com os dados já separados em porções de treino e teste, eles são embaralhados e divididos em k números de grupos; assim, a cada iteração, temos um conjunto diferente de dados para treino e teste. Esse processo é repetido a cada grupo. O resultado do nosso modelo será a média dos valores de cada um desses grupos.
FIGURA 8 – K-FOLD DA VALIDAÇÃO CRUZADA
FONTE: <https://minerandodados.com.br/wp-content/uploads/2020/02/image-1.png>. Acesso em: 5 nov. 2020.

136
Neste tópico, você aprendeu que:
• A regressão é a atividade de predizer dados contínuos com base em um histórico, cuja tarefa está presente em diversos cenários do cotidiano.
• Em uma regressão, existe um conjunto de dados D, composto por dados de entrada (input) xi, associados a um conjunto de dados de saída (target) yi, em que i representa cada registro e n o número total de objetos.
• A partir dos dados existentes, a regressão é representada por uma função f(x)n que tem como objetivo prever o target y. Assim, com base em conjunto de dados x e um target y, ao obter uma função f(x), esta será o preditor.
• O conceito de validação cruzada para otimizar os métodos.
• Os erros são a maneira de mensurar o funcionamento de um método de regressão.
• A Figura 9 mostra um resumo dos principais erros utilizados em tarefas de regressão.
FIGURA 9 – PRINCIPAIS ERROS UTILIZADOS EM TAREFAS DE REGRESSÃO
FONTE: Adaptada de <https://bit.ly/38D9MTF>. Acesso em: 5 nov. 2020.
RESUMO DO TÓPICO 1

137
1 Regressão é uma tarefa que permite gerar modelos preditivos para valores contínuos. Tendo como objetivo encontrar a relação entre um conjunto de atributos de entrada (variáveis preditoras) e um atributo-meta contínuo. Assinale a alternativa CORRETA:
a) ( ) É um método supervisionado.b) ( ) É um método não supervisionado.c) ( ) É um método desupervisionado.d) ( ) É um método visionado.
2 Os sistemas de Machine learning podem ajudar a descobrir padrões, realizar determinadas tarefas por meio da generalização de casos e da utilização de dados. Os métodos de regressão, é possível rotular automaticamente novos registros, com base em histórico de dados. Sobre os tipos de dados em que as regressões atuam, assinale a alternativa CORRETA:
a) ( ) Dados contínuos.b) ( ) Dados discretos.c) ( ) Dados binários.d) ( ) Dados multiclasse.
3 Analise o texto a seguir:
A regressão é um método estatístico para estimar uma variável (y) em função dos valores de outra variável (x). A regressão é dita linear quando a função ajustada é uma função linear, ou seja, uma função de 1º grau.
FONTE: NERY, C. V. M.; OLIVEIRA, D. B.; ABREU, L. H. G. Estudo comparativo entre os índices NDVI obtidos a partir dos sensores Landsat 5-TM e Resourcesat-liss III. Caminhos de Geogra-fia, v. 14, n. 46, 2013.
Assinale a alternativa CORRETA que representa o significado de ŷ:a) ( ) O valor predito.b) ( ) O rótulo original.c) ( ) Os valores de entrada.d) ( ) O erro.
4 As métricas de avaliação tem como objetivo verificar a eficácia do modelo, comparando com os dados originais. Assinale a alternativa CORRETA que contenha um tipo de erro:
a) ( ) MSE.b) ( ) Pandas.c) ( ) Matlab.d) ( ) PIP.
AUTOATIVIDADE

138
5 Python é uma linguagem básica e simples, utilizada em diversos cenários da computação, com destaque para projetos de Machine learning. Sobre o Python, assinale a alternativa CORRETA que indica o elemento utilizado para importar as métricas de avaliação:
a) ( ) sklearn.metrics.b) ( ) Scikit-learn.c) ( ) Pandas.d) ( ) Numpy.

139
UNIDADE 3
1 INTRODUÇÃO
A regressão é uma tarefa de Machine learning que permite gerar modelos preditivos para valores contínuos. Este livro tem como objetivo conhecer os principais modelos de regressão para chegar aos menores erros possíveis.
FIGURA 10 – EXEMPLO DE PREDIÇÃO
FONTE: <https://www.kdnuggets.com/wp-content/uploads/prediction-error.png>. Acesso em: 5 nov. 2020.
De modo geral, o fluxo de implementação e avaliação de uma regressão consiste em treinar um modelo com um conjunto de dados, já dividido em treino e teste, e comparar os resultados da predição com os resultados reais. A distância entre os valores preditos e os valores reais é denominada de erro, sendo que, para isso, são utilizadas as métricas já estudadas.
Para compreender melhor o seu funcionamento, neste tópico, estudaremos a fundo os métodos de regressão, iniciando pela regressão linear.
TÓPICO 2 —
REGRESSÃO LINEAR

140
UNIDADE 3 — REGRESSÃO
2 UTILIZANDO REGRESSÃO
O método de regressão linear é uma tentativa de modelar uma equação matemática linear que descreva o relacionamento entre duas variáveis. Em situações que envolvem duas variáveis, existem várias maneiras de aplicar essas equações de regressão, que, devido a sua natureza, irá modelar apenas problemas lineares (RODRIGUES; MEDEIROS; GOMES, 2013).
Segundo Souza (2019), a análise de regressão, em geral, é feita sob um referencial teórico que justifique a adoção de alguma relação matemática de causalidade. A regressão linear simples é basicamente uma função de primeiro grau, cujo objetivo é gerar um modelo de Machine learning a partir de um conjunto de dados, a fim de entender o padrão dentro dele para que possa ser descrito por uma função de primeiro grau com uma variável.
FIGURA 11 – EQUAÇÃO DA RETA
FONTE: <https://miro.medium.com/max/700/0*oHDc6Fuie1d19a4d.jpg>. Acesso em: 5 nov. 2020.
Para compreender melhor o conceito de regressão linear, descreveremos os conceitos de variável dependente e independente. Lembrando que variável, como o próprio nome indica, é algo que muda de valor, que varia, é “tudo que pode assumir diferentes valores numéricos” (BUNCHAFT; KELLNER, 1998, p. 16). Portanto, as variáveis correspondem a um conjunto de dados comuns sobre diferentes respondentes. Por exemplo, para um questionário que tenta coletar dados sobre a percepção do entrevistado, geralmente haverá uma parte dos dados do entrevistado (ou informações pessoais do entrevistado), como idade, sexo, renda média, nível de escolaridade etc. Cada informação corresponde a uma variável de pesquisa (PRIM; PEREIRA, 2020).
Assim como em outros problemas, em regressão, as variáveis também estão presentes. A formulação mais simples de uma função de regressão é relacionada em apenas duas variáveis, chamadas de variável independente (VI) e variável dependente (VD).

TÓPICO 2 — REGRESSÃO LINEAR
141
Enquanto a VI é controlada pelo pesquisador, seja por uma manipulação intencional ou seleção e mensuração dos valores a serem utilizados, as VDs são aquelas que mudam de acordo com o manuseio das VI (BUNCHAFT; KELLNER, 1998).
A análise de regressão é usada para encontrar equações que se ajustem aos dados. Assim que se obtém a equação de regressão, é possível usar o modelo para fazer previsões. Um tipo de análise de regressão é a análise linear. Quando um coeficiente de correlação mostra que os dados provavelmente são capazes de prever resultados futuros e um gráfico de dispersão dos dados parece formar uma linha reta, pode-se usar a regressão linear simples para encontrar uma função preditiva.
A equação da reta é y = mx + b. A função de regressão linear é representada por:
f(x) = a + bx
A equação da regressão linear também pode ser representada utilizando ŷ, que representa os valores preditos:
ŷ = a + bx
A representação da função de uma regressão linear também pode ser denotada utilizando as letras gregas alpha (α) e beta (β):
ŷ = α + βx
Segundo Glen (2013), a regressão linear é uma forma de modelar a relação entre duas variáveis. Você também pode reconhecer a equação como a fórmula da inclinação. A equação tem a forma y = a + bx, na qual y é a variável dependente (essa é a variável que vai no eixo y), x é a variável independente (ou seja, é plotada no eixo x), b é a inclinação da linha e a é a intercepção de y.
Agora que compreendemos a fórmula da equação de uma regressão linear, estudaremos como obter as variáveis principais que dão origem à fórmula. Uma vez que x pertence ao conjunto de dados, temos que calcular os valores de a e b. Para o cálculo dessas variáveis, considere a fórmula apresentada na Figura 12.
FIGURA 12 – EQUAÇÃO DA RETA
FONTE: <https://cutt.ly/XgMw152>. Acesso em: 5 nov. 2020.
(Eq. 3)
(Eq. 2)
(Eq. 1)
142
UNIDADE 3 — REGRESSÃO
Conhecendo a equação para obter f(x), bem como para chegar nos valores de a e b, vamos a um exemplo prático para descobrirmos como calcular cada um desses valores. Considere a idade como x e o nível de glicose como y.
TABELA 1 – EXEMPLO DE APLICAÇÃO
Idade (x) Nível de glicose (y)
43 9921 6525 7942 7557 8759 81
FONTE: Adaptada de Glen (2013)
Ao estudar a fórmula que dá origem aos valores de a e b, é possível perceber que existe um conjunto de valores que se repete, sendo eles (x*y), x² e y². Complementarmente, a fórmula também considera os respectivos somatórios; assim, uma dica é calcular esses valores previamente e depois realizar o cálculo da fórmula de regressão.
TABELA 2 – REALIZANDO CÁLCULOS PRÉVIOS
Idade (x) Nível de glicose (y) (x · y) x² y²
43 99 4257 1849 980121 65 1365 441 422525 79 1975 625 624142 75 3150 1764 562557 87 4959 3249 756959 81 4779 3481 6561247 486 20485 11409 40022
FONTE: Adaptada de Glen (2013)
Uma vez aplicados os valores parciais obtidos na equação para determinar a variável a, temos:

TÓPICO 2 — REGRESSÃO LINEAR
143
FIGURA 13 – CALCULANDO VALOR DE A
FONTE: O autor
Para o cálculo da variável b, repetiremos o mesmo processo:
FIGURA 14 – CALCULANDO VALOR DE B
FONTE: O autor
Sabendo os valores de a = 65,15 e de b = 0,39, é possível aplicá-los na fórmula da regressão linear, isto é, f(x) = a + bx. Ao realizarmos a substituição, a regressão linear para os dados fornecidos será f(x) = 65,5 + 0,39x.
Também é possível obter ŷ, que representa a predição dos dados utilizando a função encontrada. Em seguida, plotando os dados de y e a função f(x) = 65,5 + 0,39x em forma de uma reta (Figura 15).
TABELA 3 – ESTIMANDO VALORES COM REGRESSÃO LINEAR
x y ŷ43 99 8221 65 7425 79 7542 75 8257 87 8859 81 89
FONTE: O autor
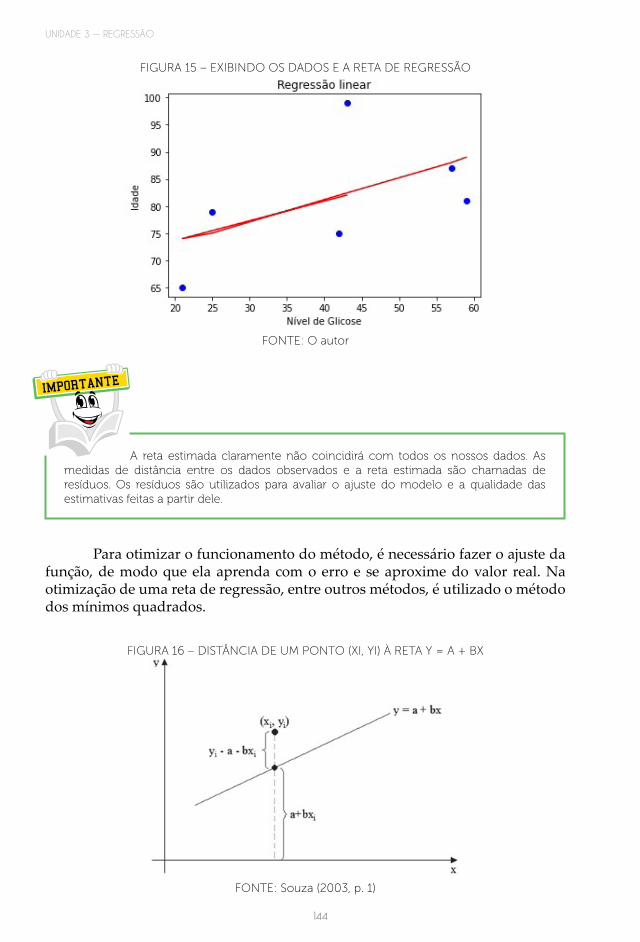
144
UNIDADE 3 — REGRESSÃO
FIGURA 15 – EXIBINDO OS DADOS E A RETA DE REGRESSÃO
FONTE: O autor
A reta estimada claramente não coincidirá com todos os nossos dados. As medidas de distância entre os dados observados e a reta estimada são chamadas de resíduos. Os resíduos são utilizados para avaliar o ajuste do modelo e a qualidade das estimativas feitas a partir dele.
IMPORTANTE
Para otimizar o funcionamento do método, é necessário fazer o ajuste da função, de modo que ela aprenda com o erro e se aproxime do valor real. Na otimização de uma reta de regressão, entre outros métodos, é utilizado o método dos mínimos quadrados.
FIGURA 16 – DISTÂNCIA DE UM PONTO (XI, YI) À RETA Y = A + BX
FONTE: Souza (2003, p. 1)

TÓPICO 2 — REGRESSÃO LINEAR
145
Para obter o erro entre o valor previsto e o valor real, a distância entre esses pontos é | yi −a−bxi | e a soma dos quadrados dessas distâncias pode ser determinado pela fórmula apresentada na Figura 17.
FIGURA 17 – SOMA DOS QUADRADOS DA DISTÂNCIA
FONTE: Souza (2003, p. 2)
Encontrar o ponto mínimo de uma função implica diminuir o erro. Os candidatos a ponto mínimo da função são aqueles para os quais são nulas as derivadas parciais de q em relação a cada um de seus parâmetros, isto é:
FIGURA 18 – MÉTODO DOS MÍNIMOS QUADRADOS
FONTE: Souza (2003, p. 3)
Assim, obtemos o sistema de equações, denominado equações normais do problema, cujas incógnitas são os parâmetros a e b da equação y = a + bx:

146
UNIDADE 3 — REGRESSÃO
FIGURA 19 – MÉTODO DOS MÍNIMOS QUADRADOS
FONTE: Souza (2003, p. 2)
Para compreender melhor, aplicamos a função de custo, visto que o objetivo é diminuir o erro entre os valores originais e os valores preditos. Sabendo que a regressão linear é um modelo que estima uma variável dependente (y) com base em valores independentes (x) e que sua equação é dada por ŷ = a + bx, vamos entender como é possível diminuir o erro entre o valor predito (ŷ) e o valor real (y).
Para compreender a notação da função de custo, consideramos a seguinte representação para uma função linear, a qual pode ser considerada com uma ou múltiplas variáveis de entrada (x):
ŷ = θ₀ + θ1*x
Ao generalizar a função, tendo em vista a possibilidade de vários valores de entrada (x), ela pode ser representada da seguinte maneira:
ŷ = θ₀ + θ₁x₁ + θ₂x₂ + ... + θnxn
Segundo Meier e Júnior (2020), na representação genérica de uma regressão linear, cada um dos elementos tem o seguinte significado:
• ŷ: valor previsto;• n: número de características;• xi: é o valor da i-ésima característica;• θj: são os parâmetros a serem determinados.
Para suportar a futura implementação em linguagem de programação, utilizaremos a notação vetorial para a resolução do problema da regressão linear, bem como a função de custo:
ŷ = hθ(x) = θTx
Segundo Meier e Júnior (2020), na representação vetorial da regressão, cada elemento tem o seguinte significado:
• θ: vetor com os parâmetros do modelo;• θT: vetor transposto de θ;• x: vetor com todas as características do conjunto de dados;
(Eq. 4)
(Eq. 5)
(Eq. 6)

TÓPICO 2 — REGRESSÃO LINEAR
147
• θT·x: produto escalar entre θT e x;• hθ: função hipótese que usa o modelo de parâmetros θ.
FIGURA 20 – EXEMPLOS DA FUNÇÃO HIPÓTESE
θ₀ = 1.5θ₁ = 0
θ₀ = 0θ₁ = 0.5
θ₀ = 1θ₁ = 0.5
FONTE: <https://miro.medium.com/max/700/1*1tYoJysJpVbjKUM7ix46QQ.png>. Acesso em: 5 nov. 2020.
Até aqui, representamos uma regressão com notação e abordagens diferentes. Para uma melhor compreensão do comportamento entre o ajuste e a reta original, vamos analisar o gráfico de dispersão.
FIGURA 21 – GRÁFICO DE DISPERSÃO ENTRE PONTOS E RETA
FONTE: Adaptada de NG (2014)
Para otimizar a função de regressão, diminuindo o seu erro e custo, precisamos conhecer a função de custo. J(θ) é chamada de função de erro (do inglês loss function; pode ser traduzida também como função de custo ou função objetivo) e deve ser otimizada (minimizada) por meio de um determinado procedimento (algébrico ou iterativo), de forma a melhor se ajustar à amostra de dados disponível para treinamento (SILVA, 2017).

148
UNIDADE 3 — REGRESSÃO
O custo é denotado por J(θ) e sua fórmula de cálculo é apresentada na Figura 22. Um método razoável para escolher ou aprender os parâmetros θ parece ser h(x) próximo de y, pelo menos para os exemplos de treinamento trabalhados anteriormente. Para formalizar isso, definimos uma função que mede, para cada valor de θ, quão próximos os h (x (i)) estão dos y(i) correspondentes (NG, 2014).
FIGURA 22 – FUNÇÃO DE CUSTO
FONTE: <https://miro.medium.com/max/700/1*mYZOUDyaqSAKWst-2lEdbQ.png>. Acesso em: 5 nov. 2020.
Na função de custo, as variáveis representam:
• J (θ): função de custo;• θ: parâmetros da função de hipótese h(x);• h(x): rótulo previsto de dados na iteração i;• y: rótulo real dos dados na iteração i;• m: quantidade de dados, em algumas notações pode ser representado por n.
Para compreender o cálculo do custo de uma função, supomos que haja uma regressão linear com uma variável e dois parâmetros θ (a regressão linear simples, cujo passo a passo foi visto anteriormente). A Figura 23 mostra a função de erro quadrada.
FIGURA 23 – FUNÇÃO DE CUSTO
FONTE: <https://miro.medium.com/max/700/1*0JVWM37k7_lOAxy34UrSvQ.png>. Acesso em: 5 nov. 2020.
A partir da hipótese levantada, vamos conferir o gráfico com os dados originais, a reta de regressão, bem como analisar a função de custo gerada.
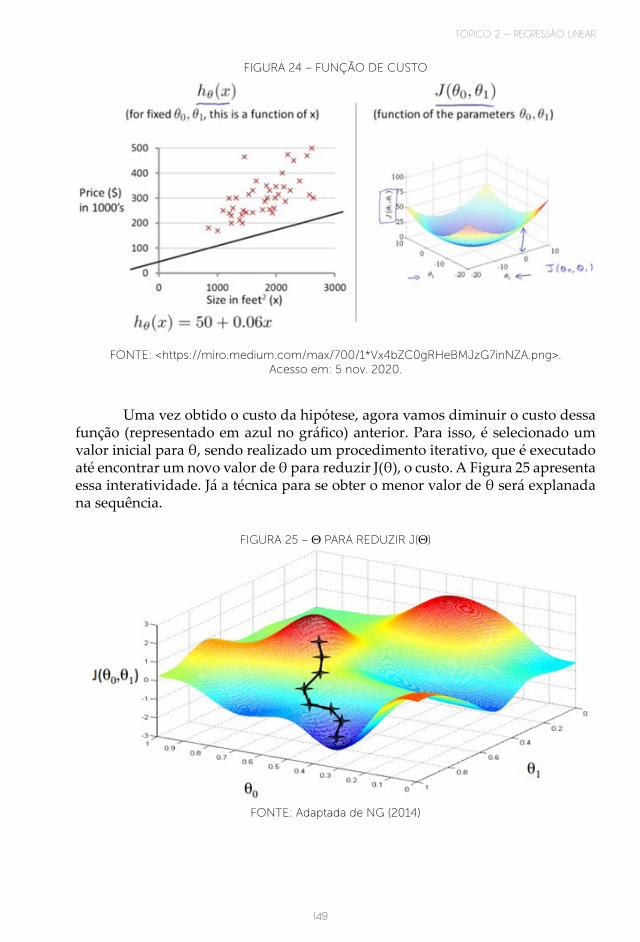
TÓPICO 2 — REGRESSÃO LINEAR
149
FIGURA 24 – FUNÇÃO DE CUSTO
FONTE: <https://miro.medium.com/max/700/1*Vx4bZC0gRHeBMJzG7inNZA.png>. Acesso em: 5 nov. 2020.
Uma vez obtido o custo da hipótese, agora vamos diminuir o custo dessa função (representado em azul no gráfico) anterior. Para isso, é selecionado um valor inicial para θ, sendo realizado um procedimento iterativo, que é executado até encontrar um novo valor de θ para reduzir J(θ), o custo. A Figura 25 apresenta essa interatividade. Já a técnica para se obter o menor valor de θ será explanada na sequência.
FIGURA 25 – Θ PARA REDUZIR J(Θ)
FONTE: Adaptada de NG (2014)
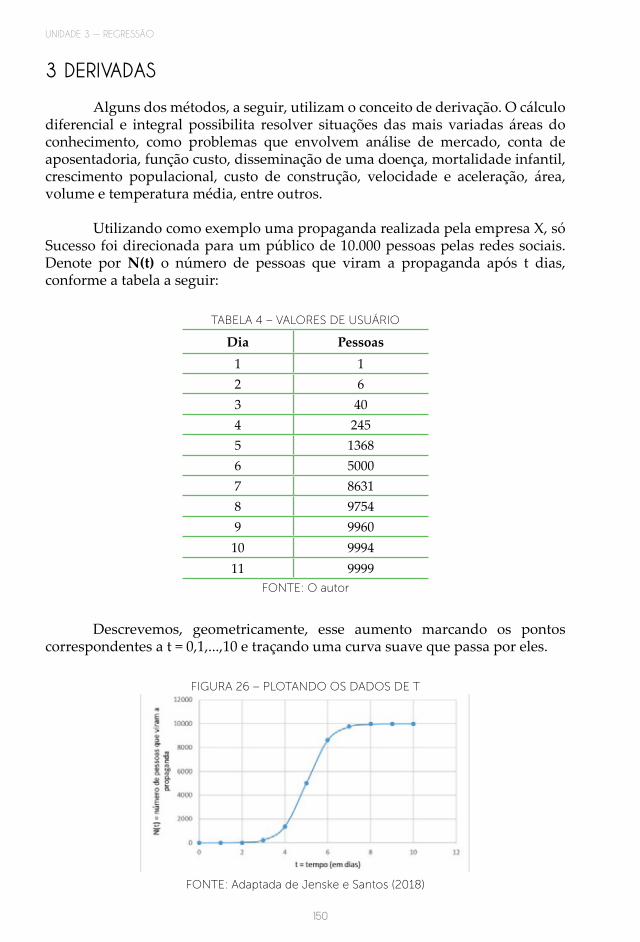
150
UNIDADE 3 — REGRESSÃO
3 DERIVADAS
Alguns dos métodos, a seguir, utilizam o conceito de derivação. O cálculo diferencial e integral possibilita resolver situações das mais variadas áreas do conhecimento, como problemas que envolvem análise de mercado, conta de aposentadoria, função custo, disseminação de uma doença, mortalidade infantil, crescimento populacional, custo de construção, velocidade e aceleração, área, volume e temperatura média, entre outros.
Utilizando como exemplo uma propaganda realizada pela empresa X, só Sucesso foi direcionada para um público de 10.000 pessoas pelas redes sociais. Denote por N(t) o número de pessoas que viram a propaganda após t dias, conforme a tabela a seguir:
TABELA 4 – VALORES DE USUÁRIO
Dia Pessoas1 12 63 404 2455 13686 50007 86318 97549 996010 999411 9999
FONTE: O autor
Descrevemos, geometricamente, esse aumento marcando os pontos correspondentes a t = 0,1,...,10 e traçando uma curva suave que passa por eles.
FIGURA 26 – PLOTANDO OS DADOS DE T
FONTE: Adaptada de Jenske e Santos (2018)
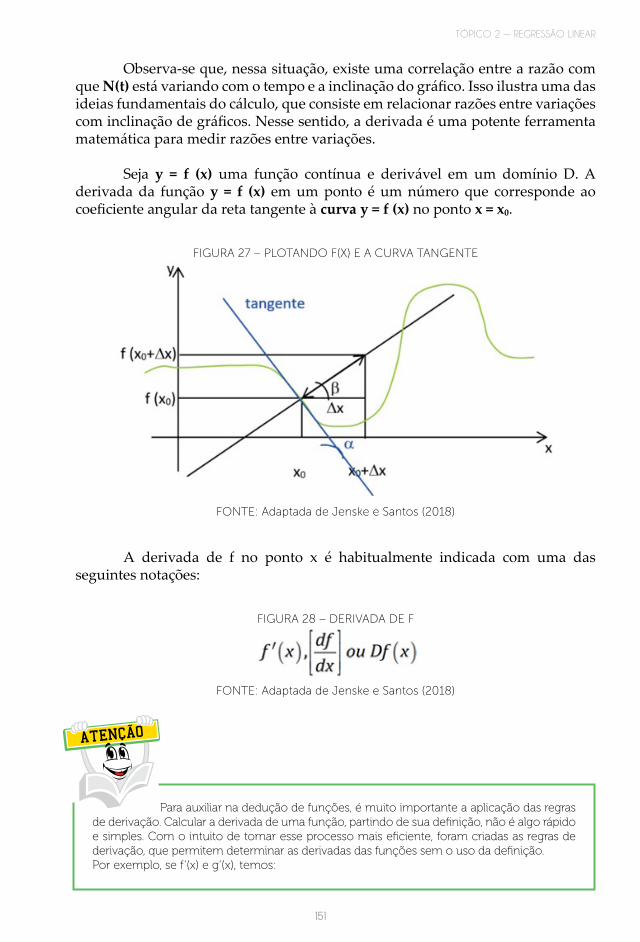
TÓPICO 2 — REGRESSÃO LINEAR
151
Observa-se que, nessa situação, existe uma correlação entre a razão com que N(t) está variando com o tempo e a inclinação do gráfico. Isso ilustra uma das ideias fundamentais do cálculo, que consiste em relacionar razões entre variações com inclinação de gráficos. Nesse sentido, a derivada é uma potente ferramenta matemática para medir razões entre variações.
Seja y = f (x) uma função contínua e derivável em um domínio D. A derivada da função y = f (x) em um ponto é um número que corresponde ao coeficiente angular da reta tangente à curva y = f (x) no ponto x = x₀.
FIGURA 27 – PLOTANDO F(X) E A CURVA TANGENTE
FONTE: Adaptada de Jenske e Santos (2018)
A derivada de f no ponto x é habitualmente indicada com uma das seguintes notações:
FIGURA 28 – DERIVADA DE F
FONTE: Adaptada de Jenske e Santos (2018)
Para auxiliar na dedução de funções, é muito importante a aplicação das regras de derivação. Calcular a derivada de uma função, partindo de sua definição, não é algo rápido e simples. Com o intuito de tornar esse processo mais eficiente, foram criadas as regras de derivação, que permitem determinar as derivadas das funções sem o uso da definição.Por exemplo, se f’(x) e g’(x), temos:
ATENCAO

152
UNIDADE 3 — REGRESSÃO
FIGURA 29 – EXEMPLO DE REGRAS DE DERIVAÇÃO
FONTE: Adaptada de Jenske e Santos (2018)
4 GRADIENTE DESCENDENTE
Agora que conhecemos a função de custo, bem como sua intuição dentro de uma regressão, temos o objetivo de reduzir o custo e, para isso, vamos aplicar o gradiente descendente. Segundo Dorneles (2016), o gradiente descendente é um algoritmo de otimização que realiza o ajuste de parâmetros de forma iterativa, com o objetivo de encontrar o valor θ que minimiza a função de custo, ou seja, a reta (função) que melhor se ajusta aos dados que devem ser preditos.

TÓPICO 2 — REGRESSÃO LINEAR
153
Para escolher θ de forma a minimizar J (θ), vamos usar um algoritmo de pesquisa que começa com alguma “estimativa inicial” para θ e que altera repetidamente θ para tornar J (θ) menor, até que, com sorte, virá convergir para um valor de θ que minimiza J (θ). Especificamente, vamos considerar o algoritmo de descida de gradiente, que começa com algum θ inicial e executa repetidamente a atualização (NG, 2014).
FIGURA 30 – FÓRMULA DO GRADIENTE DESCENDENTE
FONTE: Adaptada de NG (2014)
O método inicia preenchendo θ com valores aleatórios e melhora gradualmente a cada iteração, dando um pequeno passo de cada vez até que o algoritmo convirja para um mínimo. O tamanho dos passos é definido pelo hiperparâmetro denominado taxa de aprendizado. Se a taxa de aprendizado for muito pequena, o algoritmo levará muito tempo para convergir, devido ao grande número de iterações (DORNELES, 2016).
Uma vez obtendo o valor inicial de θ, torna-se necessário iterar e atualizar a equação para que o erro possa ser reduzido. Segundo Coles (2018), no momento em que: θj = θ0, θ1 são atribuídos, passa-se a existir o cálculo do valor de , que corresponde à taxa de aprendizagem do algoritmo ou ao tamanho do passo tomado na direção da minimização da função.
No processo iterativo que objetiva minimizar a função custo, atribuem-se valores iniciais para os parâmetros θ0 e θ1 e inicia-se o processo de mudança dos parâmetros, além do cálculo de J (θ0, θ1). Para θ0 = 1 e θ1 = 0, o algoritmo do gradiente descendente é dado pela equação do gradiente, que é repetida até a convergência, atualizando o parâmetro θj a partir de sua subtração da derivada da função custo a uma certa taxa de aprendizagem . O algoritmo do gradiente descendente deve ser executado simultaneamente, atualizando θ0 e (COLES, 2018).
Esse é um algoritmo muito natural que, repetidamente, dá um passo na direção da diminuição mais acentuada de J (custo). A fim de implementá-lo, temos que calcular qual é o termo derivado parcial no lado direito. Primeiramente, vamos trabalhar no caso de termos apenas um exemplo de treinamento (x, y), de modo que possamos negligenciar a soma na definição de J.

154
UNIDADE 3 — REGRESSÃO
FIGURA 31 – FÓRMULA DO GRADIENTE DESCENDENTE
FONTE: Adaptada de NG (2014)
Ao aplicar a fórmula do gradiente descendente em uma iteração, ou seja, em um único exemplo de treino, é obtida a seguinte função:
FIGURA 32 – FÓRMULA DO GRADIENTE DESCENDENTE PARA UMA AMOSTRA
FONTE: Adaptada de NG (2014)
Na implementação do gradiente descendente, utilizaremos o algoritmo LMS (Last Mean Squares – conhecido como o método dos mínimos quadrados), que mede a diferença quadrática média entre os valores reais e previstos de uma observação. A saída é um único número que representa o custo, ou pontuação, associado ao nosso conjunto atual de pesos. O objetivo é minimizar o erro para melhorar a precisão do nosso modelo (ML GLOSSARY, 2017).
A aplicação do algoritmo LMS é uma regra que tem várias propriedades que parecem naturais e intuitivas. Segundo NG (2014), a magnitude da atualização é proporcional ao termo de erro (y (i) – hθ (x (i))). Por exemplo, em um exemplo de treinamento cuja previsão quase corresponde ao valor real de y (i), há pouca necessidade de alterar os parâmetros. Contudo, uma mudança maior nos parâmetros deve ser feita se a previsão hθ (x (i)) tiver um grande erro (ou seja, se estiver muito longe de y (i)).
Derivamos a regra LMS para quando havia apenas um único exemplo de treinamento. Existem duas maneiras de modificar esse método para um conjunto de treinamento de mais de um exemplo, obtendo o seguinte algoritmo:
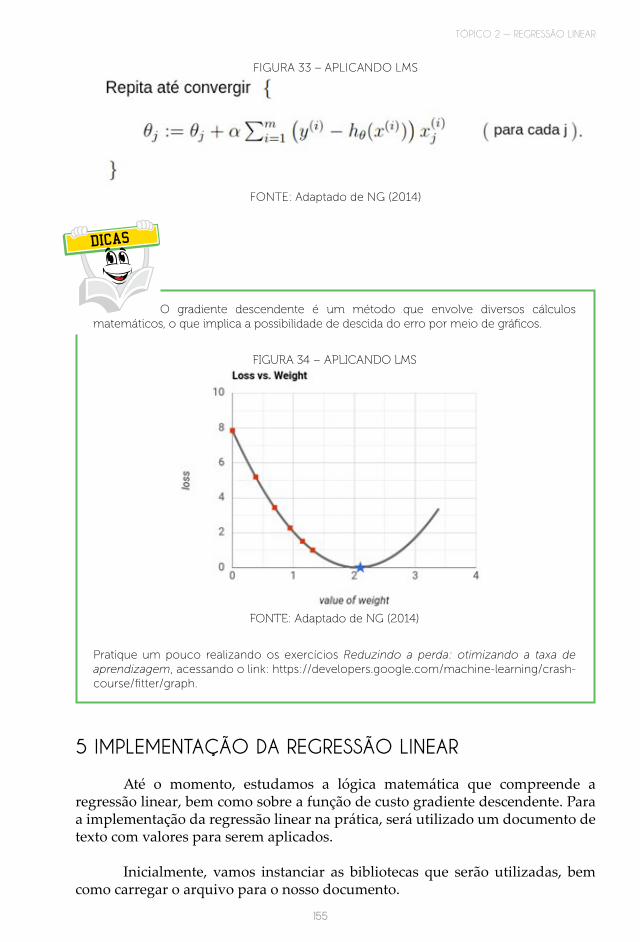
TÓPICO 2 — REGRESSÃO LINEAR
155
FIGURA 33 – APLICANDO LMS
FONTE: Adaptado de NG (2014)
O gradiente descendente é um método que envolve diversos cálculos matemáticos, o que implica a possibilidade de descida do erro por meio de gráficos.
FIGURA 34 – APLICANDO LMS
FONTE: Adaptado de NG (2014)
Pratique um pouco realizando os exercícios Reduzindo a perda: otimizando a taxa de aprendizagem, acessando o link: https://developers.google.com/machine-learning/crash-course/fitter/graph.
DICAS
5 IMPLEMENTAÇÃO DA REGRESSÃO LINEAR
Até o momento, estudamos a lógica matemática que compreende a regressão linear, bem como sobre a função de custo gradiente descendente. Para a implementação da regressão linear na prática, será utilizado um documento de texto com valores para serem aplicados.
Inicialmente, vamos instanciar as bibliotecas que serão utilizadas, bem como carregar o arquivo para o nosso documento.

156
UNIDADE 3 — REGRESSÃO
QUADRO 7 – PREPARANDO O ARQUIVO PARA IMPLEMENTAR A REGRESSÃO LINEAR
import numpy as npimport matplotlib.pyplot as pltimport pandas as pddata=pd.read_csv("Dados.txt", header=None)data.head()
FONTE: O autor
Para compreender nosso cenário de dados, vamos criar a visualização desses dados no plano.
QUADRO 8 – VISUALIZAÇÃO DOS DADOS
plt.scatter(data[0],data[1])plt.xticks(np.arange(5,30,step=5))plt.yticks(np.arange(-5,30,step=5))plt.xlabel("População da Cidade")plt.ylabel("Lucro ")plt.title("Predição de Lucros")
FONTE: O autor
FIGURA 35 – VISUALIZAÇÃO DOS DADOS
FONTE: O autor
Acesse o documento utilizado com os dados para o desenvolvimento do exemplo em: https://drive.google.com/file/d/1RaN6VNLx4xrwqXKOVZDLLWS2PgsIK5nH/view?usp=sharing.
DICAS

TÓPICO 2 — REGRESSÃO LINEAR
157
Como vimos todo o processo de adaptação e vetorização da função de regressão f(x) = a + bx, transformando-a em uma hipótese, a qual aplicamos a função de custo, além de utilizarmos o gradiente descendente para reduzir tal custo, trabalharemos a função de custo. Uma vez implementada, utilizando os dados já carregados, aplicaremos tal função para computar o custo da regressão.
QUADRO 9 – IMPLEMENTANDO A FUNÇÃO DE CUSTO
#Criando a função de custodef ComputaCusto(X,y,theta): m = len(y) predicoes = X.dot(theta) erro_quadratico = (predictions – y)**2 return 1/(2*m) * np.sum(erro_quadratico)
#Utilizando a função custodata_n = data.valuesm = data_n[:,0].sizeX = np.append(np.ones((m,1)),data_n[:,0].reshape(m,1),axis=1)y = data_n[:,1].reshape(m,1)theta = np.zeros((2,1))
ComputaCusto(X,y,theta)
FONTE: Adaptado de NG (2014)
Com o cálculo do custo de uma função, agora é possível diminui-lo por meio da aplicação do gradiente descendente. Para isso, vamos iterar calculando o custo até convergir.
QUADRO 10 – IMPLEMENTANDO O GRADIENTE DESCENDENTE
def GradienteDescente(X,y,theta,alpha,num_iters): m=len(y) J_history=[] for i in range(num_iters): predictions = X.dot(theta) error = np.dot(X.transpose(),(predictions -y))descent=alpha * 1/m * error theta-=descent J_history.append(ComputaCusto(X,y,theta)) return theta, J_history
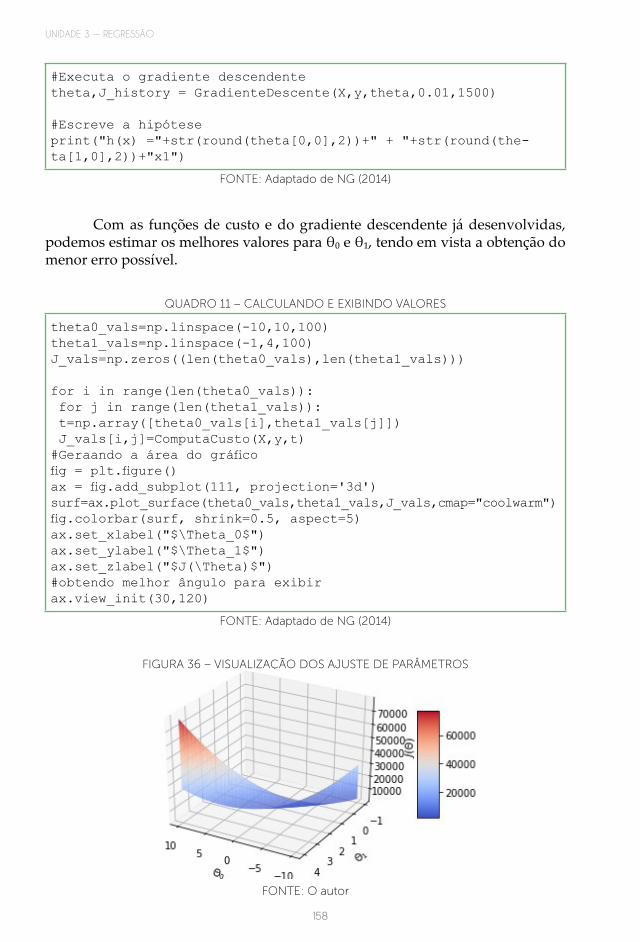
158
UNIDADE 3 — REGRESSÃO
#Executa o gradiente descendentetheta,J_history = GradienteDescente(X,y,theta,0.01,1500)
#Escreve a hipóteseprint("h(x) ="+str(round(theta[0,0],2))+" + "+str(round(the-ta[1,0],2))+"x1")
FONTE: Adaptado de NG (2014)
Com as funções de custo e do gradiente descendente já desenvolvidas, podemos estimar os melhores valores para θ₀ e θ₁, tendo em vista a obtenção do menor erro possível.
QUADRO 11 – CALCULANDO E EXIBINDO VALORES
theta0_vals=np.linspace(-10,10,100)theta1_vals=np.linspace(-1,4,100)J_vals=np.zeros((len(theta0_vals),len(theta1_vals)))
for i in range(len(theta0_vals)): for j in range(len(theta1_vals)): t=np.array([theta0_vals[i],theta1_vals[j]]) J_vals[i,j]=ComputaCusto(X,y,t)#Geraando a área do gráfico fig = plt.figure()ax = fig.add_subplot(111, projection='3d')surf=ax.plot_surface(theta0_vals,theta1_vals,J_vals,cmap="coolwarm")fig.colorbar(surf, shrink=0.5, aspect=5)ax.set_xlabel("$\Theta_0$")ax.set_ylabel("$\Theta_1$")ax.set_zlabel("$J(\Theta)$")#obtendo melhor ângulo para exibirax.view_init(30,120)
FONTE: Adaptado de NG (2014)
FIGURA 36 – VISUALIZAÇÃO DOS AJUSTE DE PARÂMETROS
FONTE: O autor

TÓPICO 2 — REGRESSÃO LINEAR
159
Um dos processos mais importantes no gradiente descendente é a diminuição do custo conforme as iterações. Tal compreensão é útil não somente para a regressão linear, mas também para outras técnicas de regressão.
QUADRO 12 – PLOTANDO O ERRO
plt.plot(J_history)plt.xlabel("Iterações")plt.ylabel("$J(\Theta)$")plt.title("Custo da função utilizando Gradiente Descendente")
FONTE: Adaptado de NG (2014)
FIGURA 37 – VISUALIZAÇÃO DA DIMINUIÇÃO DO CUSTO
FONTE: O autor
Agora com os melhores parâmetros para a regressão, vamos implementar a função de custo, bem como o gradiente descendente para diminuir o custo. Nesse momento, podemos visualizar a função de regressão e predizer novas amostras. Vamos partir da implementação da reta que representa a regressão.
QUADRO 13 – PLOTANDO A RETA DE REGRESSÃO
plt.scatter(data[0],data[1])x_value=[x for x in range(25)]y_value=[y*theta[1]+theta[0] for y in x_value]plt.plot(x_value,y_value,color="r")plt.xticks(np.arange(5,30,step=5))plt.yticks(np.arange(-5,30,step=5))plt.xlabel("População da Cidade")plt.ylabel("Lucro ")plt.title("Predição de Lucros")
FONTE: Adaptado de NG (2014)
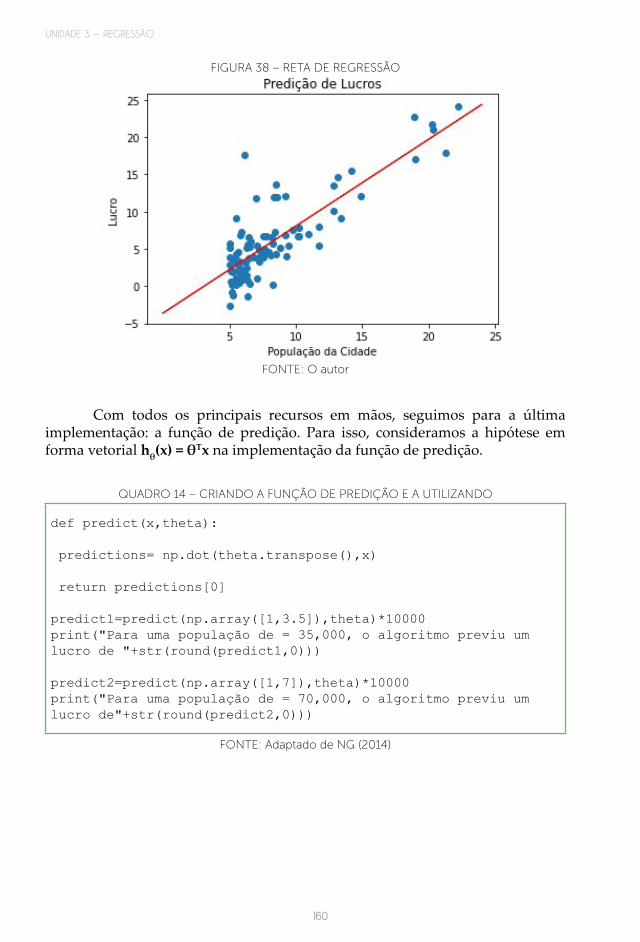
160
UNIDADE 3 — REGRESSÃO
FIGURA 38 – RETA DE REGRESSÃO
FONTE: O autor
Com todos os principais recursos em mãos, seguimos para a última implementação: a função de predição. Para isso, consideramos a hipótese em forma vetorial hθ(x) = θTx na implementação da função de predição.
QUADRO 14 – CRIANDO A FUNÇÃO DE PREDIÇÃO E A UTILIZANDO
def predict(x,theta): predictions= np.dot(theta.transpose(),x) return predictions[0]
predict1=predict(np.array([1,3.5]),theta)*10000print("Para uma população de = 35,000, o algoritmo previu um lucro de "+str(round(predict1,0)))
predict2=predict(np.array([1,7]),theta)*10000print("Para uma população de = 70,000, o algoritmo previu um lucro de"+str(round(predict2,0)))
FONTE: Adaptado de NG (2014)

161
RESUMO DO TÓPICO 2
Neste tópico, você aprendeu que:
• A regressão é uma tarefa de Machine learning que permite gerar modelos preditivos para valores contínuos.
• A regressão linear é uma tentativa de modelar uma equação matemática linear que descreve o relacionamento entre duas variáveis.
• A regressão linear simples é basicamente uma função de primeiro grau que tem como objetivo gerar um modelo de Machine learning a partir de um conjunto de dados.
• A regressão pode ser representada por f(x) = a + bx.
• Os valores de a e b são calculados com base nos valores de entrada.
• A função de custo traz a relação entre os valores reais (y) e os valores preditos (ŷ).
• Obter o custo é importante para que se possa otimizar o funcionamento de uma regressão.
• A notação vetorial de uma regressão linear é ŷ = hθ(x) = θTx.
• O gradiente descendente é utilizado para reduzir o custo de uma regressão.
• Utilizando os conceitos matemáticos, é possível implementar a regressão linear no Python.

162
1 A regressão linear é uma tentativa de modelar uma equação matemática linear que descreva o relacionamento entre duas variáveis. Assinale a alternativa CORRETA que contenha uma função que represente a regressão linear.
a) ( ) f(x) = a + bx.b) ( ) f(x) = x+ 1.c) ( ) f(x) = ax + b.d) ( ) f(x) = x.
2 A regressão linear permite estimar valores com base em um conjunto de entrada e um rótulo esperado. Considere os seguintes dados:
X 1 2 3 4 5 6
Y 80,5 81,6 82,1 83,7 83,9 85,0FONTE: O autor
Qual a equação da regressão linear para os valores anteriores?a) ( ) ŷ = 79,9 + 0,886x.b) ( ) ŷ = 79,9x+ 0,886.c) ( ) ŷ = 80,5 + 0,81x.d) ( ) ŷ =81,6 + 0,821x.
3 Para o conjunto de dados a seguir, considere o modelo de regressão linear hθ (x) = θ0 + θ1x. Assinale a alternativa CORRETA que contenha os valores de θ0 e θ1 na descida do gradiente descendente?
X 1 2 4 0
Y 0,5 1 2 0FONTE: O autor
a) ( ) θ0 = 0,θ1 = 0.5.b) ( ) θ0 = 0.5,θ1 = 0.c) ( ) θ0 = 0.5,θ1 = 0.5.d) ( ) θ0 = 1,θ1 = 0.5.
4 Para a hipótese de uma regressão linear, definimos θ₀ = −1, θ₁ = 0,5. Assinale a alternativa CORRETA para hθ (4):
a) ( ) 1.b) ( ) –1.c) ( ) 4.d) ( ) 0,5.
AUTOATIVIDADE

163
5 Considere os seguintes dados:
X 1 2 3 4 5 6
Y 80,5 81,6 82,1 83,7 83,9 85,0FONTE: O autor
Assinale a alternativa CORRETA que contenha o valor de m:a) ( ) 6.b) ( ) 82.c) ( ) 2.d) ( ) 5.

164

165
UNIDADE 3
1 INTRODUÇÃO
Os algoritmos de regressão utilizados no processo de mineração de dados normalmente recebem esses dados em diferentes formatos de representação. Assim, um mesmo conjunto de dados pode ser submetido a diversos algoritmos de regressão, para obter o menor custo de aprendizado (DOSUALDO, 2003).
A regressão permite analisar os mais diversos tipos de dados, desde dados climáticos, dados de sensores, até mesmo análise preditiva na bolsa de valores. Para tais fins, são diversos os métodos utilizados, desde simples interpolações até técnicas de redes neurais artificiais.
2 REGRESSÃO LOGÍSTICA
A regressão logística foi descoberta no século XIX para descrever o crescimento das populações e as reações químicas de autocatálise. A ideia básica do desenvolvimento logístico é simples e usada nos dias atuais para modelar o crescimento populacional e muitas outras técnicas, como descrever a chance de ocorrência de um determinado evento, ou seja, a chance de desistência de um aluno; a chance de um cliente de um banco se tornar inadimplente; entre outras (BARISTELA; RODRIGUES; BONONI, 2009).
Segundo Silva e Periçaro (2009), a regressão logística é um método, ou uma abordagem de modelagem matemática, que objetiva descrever a relação entre uma variável resposta (dependente) e uma ou mais variáveis explicativas (independentes) ou relacionando variáveis quantitativas e qualitativas. Para Baristela, Rodrigues e Bononi (2009), a regressão logística pode ser considerada uma extensão da regressão linear, pois, assim como esta, estuda relações entre variáveis, buscando as variáveis que podem influenciar, de alguma forma, em uma variável dependente – na regressão logística, essa variável deve ser categórica. Assim, pode-se afirmar que regressão linear dá uma resposta em valor numérico, enquanto a regressão logística mostra a probabilidade de chances de ocorrer o fato que está sendo estudado.
TÓPICO 3 —
TÉCNICAS AVANÇADAS DE REGRESSÃO
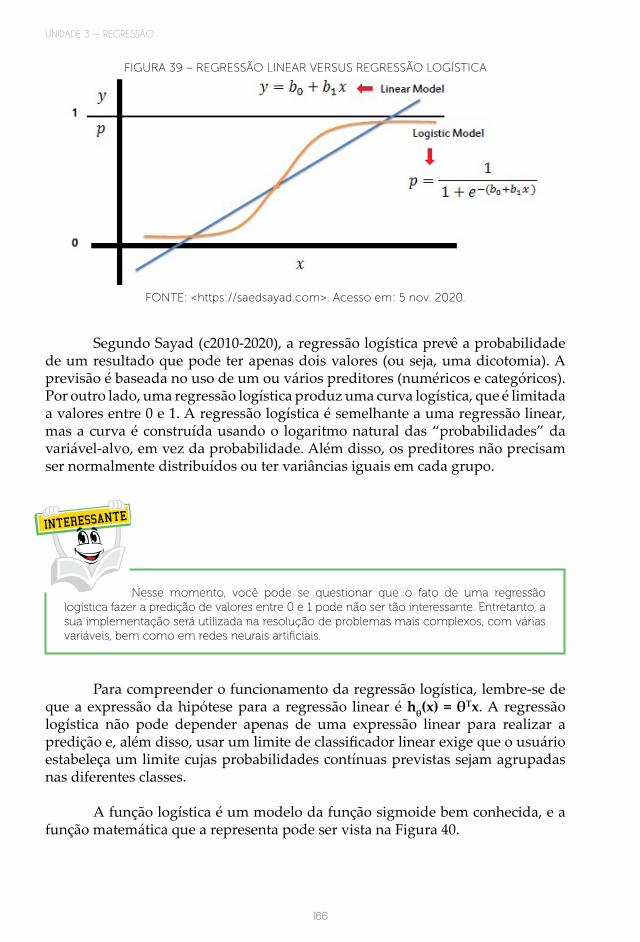
166
UNIDADE 3 — REGRESSÃO
FIGURA 39 – REGRESSÃO LINEAR VERSUS REGRESSÃO LOGÍSTICA
FONTE: <https://saedsayad.com>. Acesso em: 5 nov. 2020.
Segundo Sayad (c2010-2020), a regressão logística prevê a probabilidade de um resultado que pode ter apenas dois valores (ou seja, uma dicotomia). A previsão é baseada no uso de um ou vários preditores (numéricos e categóricos). Por outro lado, uma regressão logística produz uma curva logística, que é limitada a valores entre 0 e 1. A regressão logística é semelhante a uma regressão linear, mas a curva é construída usando o logaritmo natural das “probabilidades” da variável-alvo, em vez da probabilidade. Além disso, os preditores não precisam ser normalmente distribuídos ou ter variâncias iguais em cada grupo.
Para compreender o funcionamento da regressão logística, lembre-se de que a expressão da hipótese para a regressão linear é hθ(x) = θTx. A regressão logística não pode depender apenas de uma expressão linear para realizar a predição e, além disso, usar um limite de classificador linear exige que o usuário estabeleça um limite cujas probabilidades contínuas previstas sejam agrupadas nas diferentes classes.
A função logística é um modelo da função sigmoide bem conhecida, e a função matemática que a representa pode ser vista na Figura 40.
Nesse momento, você pode se questionar que o fato de uma regressão logística fazer a predição de valores entre 0 e 1 pode não ser tão interessante. Entretanto, a sua implementação será utilizada na resolução de problemas mais complexos, com várias variáveis, bem como em redes neurais artificiais.
INTERESSANTE
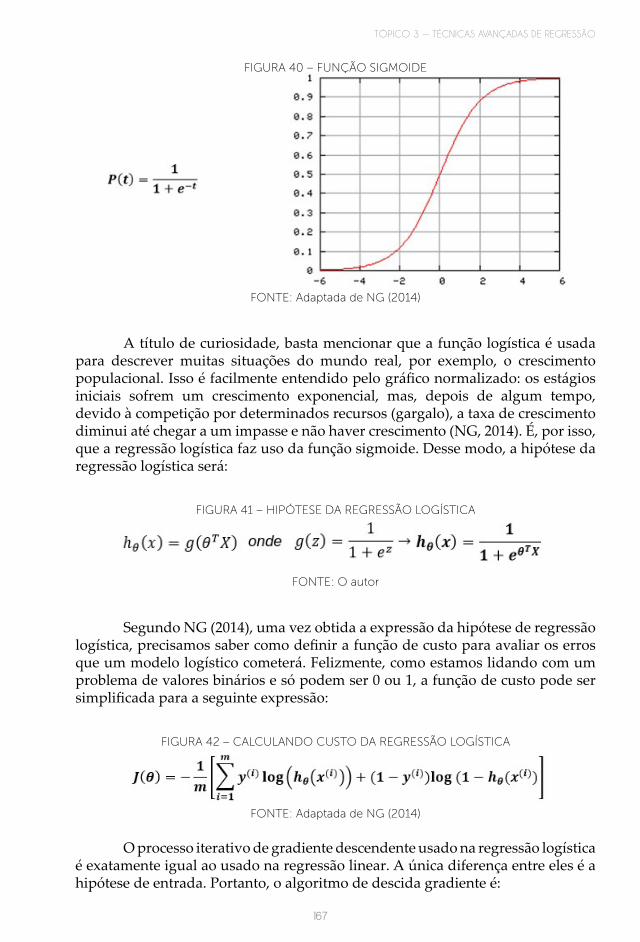
TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
167
FIGURA 40 – FUNÇÃO SIGMOIDE
FONTE: Adaptada de NG (2014)
A título de curiosidade, basta mencionar que a função logística é usada para descrever muitas situações do mundo real, por exemplo, o crescimento populacional. Isso é facilmente entendido pelo gráfico normalizado: os estágios iniciais sofrem um crescimento exponencial, mas, depois de algum tempo, devido à competição por determinados recursos (gargalo), a taxa de crescimento diminui até chegar a um impasse e não haver crescimento (NG, 2014). É, por isso, que a regressão logística faz uso da função sigmoide. Desse modo, a hipótese da regressão logística será:
FIGURA 41 – HIPÓTESE DA REGRESSÃO LOGÍSTICA
FONTE: O autor
Segundo NG (2014), uma vez obtida a expressão da hipótese de regressão logística, precisamos saber como definir a função de custo para avaliar os erros que um modelo logístico cometerá. Felizmente, como estamos lidando com um problema de valores binários e só podem ser 0 ou 1, a função de custo pode ser simplificada para a seguinte expressão:
FIGURA 42 – CALCULANDO CUSTO DA REGRESSÃO LOGÍSTICA
FONTE: Adaptada de NG (2014)
O processo iterativo de gradiente descendente usado na regressão logística é exatamente igual ao usado na regressão linear. A única diferença entre eles é a hipótese de entrada. Portanto, o algoritmo de descida gradiente é:

168
UNIDADE 3 — REGRESSÃO
FIGURA 43 – GRADIENTE DESCENDENTE DA REGRESSÃO LOGÍSTICA
FONTE: Adaptada de NG (2014)
Para fixar os conceitos matemáticos, vamos realizar a implementação em Python. Para isso, torna-se importante compreender a função logística ou sigmoide:
FIGURA 44 – FUNÇÃO SIGMOIDAL
FONTE: <kaggle.com/jeppbautista/logistic-regression-from-scratch-python/notebook>. Acesso em: 5 nov. 2020.
Os elementos que compõem a função são:
• e = número de Euler que é 2,71828;• x₀ = o valor do ponto médio da sigmoide no eixo x;• L = o valor máximo;• k = inclinação da curva.
Entretanto, outra definição de função logística para a regressão logística é (BAUTISTA, 2018):
FIGURA 45 – FUNÇÃO LOGÍSTICA
FONTE: <kaggle.com/jeppbautista/logistic-regression-from-scratch-python/notebook>.Acesso em: 5 nov. 2020.
Sabendo os principais elementos da uma regressão logística, vamos para a sua implementação, por meio de sua principal função, a sigmoide.

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
169
QUADRO 15 – CRIANDO A FUNÇÃO SIGMOIDE
def sigmoid(X, weight): z = np.dot(X, weight) return 1 / (1 + np.exp(-z))
FONTE: Adaptado de <kaggle.com/jeppbautista/logistic-regression-from-scratch-python/notebook>. Acesso em: 5 nov. 2020.
Para continuar, é necessário implementar a função de custo.
QUADRO 16 – CRIANDO A FUNÇÃO CUSTO PARA REGRESSÃO LOGÍSTICA
def custo(h, y): return (-y * np.log(h) – (1 – y) * np.log(1 – h)).mean()
FONTE: Adaptado de <kaggle.com/jeppbautista/logistic-regression-from-scratch-python/note-book>. Acesso em: 5 nov. 2020.
Com a função logística (sigmoide) e a de custo determinadas, será possível implementar o gradiente descendente para reduzir o custo da função.
QUADRO 17 – CRIANDO O GRADIENTE DESCENDENTE PARA REGRESSÃO LOGÍSTICA
def gradient_ascent(X, h, y): return np.dot(X.T, y – h)def update_weight_mle(weight, learning_rate, gradient): return weight + learning_rate * gradient
FONTE: Adaptado de <kaggle.com/jeppbautista/logistic-regression-from-scratch-python/notebook>. Acesso em: 5 nov. 2020.
3 REDES NEURAIS ARTIFICIAIS
Redes neurais artificiais (RNAs – em inglês, Artificial Neural Networks – ANN) são sistemas que mimetizam o comportamento e a estrutura do cérebro humano, embora possuam um conjunto muito limitado de neurônios. Esses neurônios, por sua vez, processam paralelamente os dados e os propagam por uma complexa malha de interconexão. Analogamente ao cérebro humano, as RNAs têm a capacidade de interagir com o meio externo e adaptar-se a ele. Essas características conferem às RNAs uma importância multidisciplinar, razão pela qual essa ferramenta vem ganhando destaque em diferentes áreas do conhecimento, como engenharia, matemática, física, informática, entre outras (FINOCCHIO, 2014).

170
UNIDADE 3 — REGRESSÃO
FIGURA 46 – REDES NEURAIS
FONTE: Adaptada de: <https://miro.medium.com/max/610/1*SJPacPhP4KDEB1AdhOFy_Q.png>. Acesso em: 5 nov. 2020.
Sob a ótica computacional, pode-se dizer que, em um neurônio, é realizado o processamento sobre uma ou, geralmente, várias entradas, a fim de gerar uma saída. O neurônio artificial é uma estrutura lógico-matemática que procura simular a forma, o comportamento e as funções de um neurônio biológico. Pode-se, grosso modo, associar o dendrito à entrada, o soma ao processamento e o axônio à saída; portanto, o neurônio é considerado uma unidade fundamental processadora de informação. Os dendritos são as entradas, cujas ligações com o corpo celular artificial são realizadas por meio de canais de comunicação associados a um determinado peso (simulando as sinapses). Os estímulos captados pelas entradas são processados pela função do soma, e o limiar de disparo do neurônio biológico é substituído pela função de transferência (FURTADO, 2018).
Segundo Marques Filho (2018), as propriedades de uma rede neural são:
• não linearidade, que reflete a natureza das entradas; • mapeamento de entrada-saída;• adaptabilidade a novos ambientes, mediante retreino dinâmico ou com
professor; • resposta a evidências, como confiança estatística sobre respostas dadas; • disposição natural para lidar com informação contextual; • tolerância a falhas, devido a sua natureza distribuída; • implementa tecnologias de integração em larga escala; • uniformidade de análise e projeto; • analogia neurobiológica, o que as torna naturalmente transdisciplinar.
Para compreender, matematicamente, como é composta uma rede neural artificial, vamos partir de sua arquitetura.

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
171
FIGURA 47 – REDES NEURAIS
FONTE: <https://miro.medium.com/max/564/1*KDiqpWOgtCnO8x3wZJHmDA.png>. Acesso em: 5 nov. 2020.
Segundo Leite (2018), os sinais da entrada no neurônio são representados pelo vetor x = [x1, x2, x3, …, xN], podendo corresponder aos pixels de uma imagem, por exemplo. Ao chegarem ao neurônio, são multiplicados pelos respectivos pesos sinápticos, que são os elementos do vetor w = [w1, w2, w3, …, wN], gerando o valor z, comumente denominado como potencial de ativação, de acordo com a expressão:
FIGURA 48 -FÓRMULA DA ATIVAÇÃO
FONTE: <https://miro.medium.com/max/210/1*jjwieh-AVz1uA96f1Tuqlg.png>. Acesso em: 5 nov. 2020.
O conceito-chave da equação de uma rede neural é o cálculo da expressão ∂E/∂w, que consiste em computar as derivadas parciais da função de erro E em relação a cada peso do vetor w. Para auxiliar, vamos considerar a Figura 49, que ilustra uma rede MLP com duas camadas e servirá de base para a explicação do backpropagation. Uma conexão entre um neurônio j e um neurônio i da camada seguinte possui peso w(j,i). Repare que os números sobrescritos, entre parênteses, indicam o número da camada à qual a variável em questão pertence, podendo, nesse exemplo, valer 1 ou 2 (LEITE, 2018).

172
UNIDADE 3 — REGRESSÃO
FIGURA 49 – REDES NEURAIS COM BACKPROPAGATION
FONTE: <https://miro.medium.com/max/1000/1*96WV4tWwjLMGdxaKIQuADg.png>. Acesso em: 5 nov. 2020.
Partindo do princípio já estudado anteriormente, no qual x representa um conjunto de valores de entrada, y equivale ao valor original e ŷ é o valor predito por uma regressão, no caso, por uma rede neural. A Figura 50 apresenta a função de custo, denominada função de erro, que tem o objetivo de obter a distância entre o valor predito e o valor original.
FIGURA 50 – CALCULANDO O ERRO DE UMA REDE NEURAL
FONTE: <https://miro.medium.com/max/297/1*uBPfsMoVLUs29d1dpMXRfg.png>. Acesso em: 5 nov. 2020.
Segundo Leite (2018), simplesmente estamos calculando a somatória dos quadrados das diferenças entre os elementos dos dois vetores. Agora, vamos calcular a derivada parcial do erro em relação à camada de saída, ŷ. Este valor é o gradiente local em relação ao i-ésimo neurônio da camada (2) e, para não tornar as fórmulas excessivamente extensas, será simplesmente indicado como δ. Esse δ a que igualamos o resultado segue a mesma ideia anterior: é o gradiente local em relação ao i-ésimo neurônio da camada (1).

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
173
FIGURA 51 – ATUALIZANDO OS PESOS DE UMA REDE NEURAL
FONTE: <https://miro.medium.com/max/700/1*tZQybbroYzW6zWHQWINtLg.png>. Acesso em: 5 nov. 2020.
Para fixar os conceitos matemáticos sobre uma rede neural artificial, vamos implementar uma versão de uma rede neural utilizando Python, a partir da criação da função de ativação, bem como do cabeçalho principal.
QUADRO 18 – CRIANDO FUNÇÃO DE ATIVAÇÃO
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_bostonfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_error
def relu(z): a = np.maximum(0,z) return a
def initialize_params(layer_sizes): params = {} for i in range(1, len(layer_sizes)): params['W' + str(i)] = np.random.randn(layer_sizes[i], layer_sizes[i-1])*0.01 params['B' + str(i)] = np.random.randn(layer_sizes[i],1)*0.01 return params
FONTE: Adaptado de <https://towardsdatascience.com/an-introduction-to-neural-networks-wi-th-implementation-from-scratch-using-python-da4b6a45c05b>. Acesso em: 5 nov. 2020.
Uma vez inicializada a nossa rede neural, vamos calcular o custo (erro) e iterar até obter o menor erro possível. Para isso, realizaremos a descida do gradiente e atualizaremos os parâmetros, diminuindo o custo, fazendo a propagação direta novamente e iterando até que a convergência seja alcançada.
QUADRO 19 – IMPLEMENTANDO A REDE NEURAL
def backward_propagation(params, values, X_train, Y_train): layers = len(params)//2 m = len(Y_train) grads = {} for i in range(layers,0,-1): if i==layers: dA = 1/m * (values['A' + str(i)] – Y_train)

174
UNIDADE 3 — REGRESSÃO
dZ = dA else: dA = np.dot(params['W' + str(i+1)].T, dZ) dZ = np.multiply(dA, np.where(values['A' + str(i)]>=0, 1, 0)) if i==1: grads['W' + str(i)] = 1/m * np.dot(dZ, X_train.T) grads['B' + str(i)] = 1/m * np.sum(dZ, axis=1, keepdims=True) else: grads['W' + str(i)] = 1/m * np.dot(dZ,values['A' + str(i--1)].T) grads['B' + str(i)] = 1/m * np.sum(dZ, axis=1, keepdims=True)return grads
def update_params(params, grads, learning_rate): layers = len(params)//2 params_updated = {} for i in range(1,layers+1): params_updated['W' + str(i)] = params['W' + str(i)] – lear-ning_rate * grads['W' + str(i)] params_updated['B' + str(i)] = params['B' + str(i)] – lear-ning_rate * grads['B' + str(i)] return params_updated
FONTE: Adaptado de <https://towardsdatascience.com/an-introduction-to-neural-networks-wi-th-implementation-from-scratch-using-python-da4b6a45c05b>. Acesso em: 5 nov. 2020.
Por fim, criaremos funções que permitam com que a rede neural seja utilizada: a função para instanciar o modelo, realizar a predição e avaliar a rede neural.
QUADRO 20 – UTILIZAÇÃO E AVALIAÇÃO DA REDE NEURAL
def model(X_train, Y_train, layer_sizes, num_iters, learning_rate): #trains the model params = initialize_params(layer_sizes) for i in range(num_iters): values = forward_propagation(X_train.T, params) cost = compute_cost(values, Y_train.T) grads = backward_propagation(params, values,X_train.T, Y_train.T) params = update_params(params, grads, learning_rate) print('Custo da iteração ' + str(i+1) + ' = ' + str(cost) + '\n') return params
def compute_accuracy(X_train, X_test, Y_train, Y_test, params): values_train = forward_propagation(X_train.T, params) values_test = forward_propagation(X_test.T, params) train_acc = np.sqrt(mean_squared_error(Y_train, values_train['A' + str(len(layer_sizes)-1)].T))

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
175
test_acc = np.sqrt(mean_squared_error(Y_test, values_test['A' + str(len(layer_sizes)-1)].T)) return train_acc, test_acc
def predict(X, params): values = forward_propagation(X.T, params) predictions = values['A' + str(len(values)//2)].T return predictions
FONTE: Adaptado de <https://towardsdatascience.com/an-introduction-to-neural-networks-wi-th-implementation-from-scratch-using-python-da4b6a45c05b>. Acesso em: 5 nov. 2020.
4 IMPLEMENTANDO REGRESSÕES COM BIBLIOTECAS DO PYTHON
No decorrer dos estudos, temos utilizado os recursos da linguagem
Python para suportar a construção dos modelos de Machine learning. A seguir, vamos utilizá-los na construção de modelos de regressão, dando início à regressão linear, começando pela instância das bibliotecas e pelo pré-processamento.
QUADRO 21 – REGRESSÃO LINEAR COM SCIKIT-LEARN
from sklearn import datasetsfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.metrics import mean_squared_error
boston = datasets.load_boston()print(type(boston))print('\n')print(boston.keys())print('\n')print(boston.data.shape)print('\n')print(boston.feature_names)bos = pd.DataFrame(boston.data, columns = boston.feature_names)
print(bos.head())print(boston.target.shape)bos['PRICE'] = boston.targetprint(bos.head())bos.isnull().sum()print(bos.describe())
FONTE: O autor
Uma vez carregados os arquivos, vamos carregar os valores dividindo os conjuntos de dados em treino e teste, bem como especificando quem será X e y.

176
UNIDADE 3 — REGRESSÃO
QUADRO 22 – REGRESSÃO LINEAR COM SCIKIT-LEARN
X_rooms = bos.RMy_price = bos.PRICE
X_rooms = np.array(X_rooms).reshape(-1,1)y_price = np.array(y_price).reshape(-1,1)
print(X_rooms.shape)print(y_price.shape)X_train_1, X_test_1, Y_train_1, Y_test_1 = train_test_split(X_rooms, y_price, test_size = 0.2, random_state=5)
print(X_train_1.shape)print(X_test_1.shape)print(Y_train_1.shape)print(Y_test_1.shape)
FONTE: O autor
Por fim, com os dados preparados, vamos instanciar o regressor do scikit-learn, bem como treinar os dados e avaliar o método.
QUADRO 23 – REGRESSÃO LINEAR COM SCIKIT-LEARN
reg_1 = LinearRegression()reg_1.fit(X_train_1, Y_train_1)y_train_predict_1 = reg_1.predict(X_train_1)rmse = (np.sqrt(mean_squared_error(Y_train_1, y_train_pre-dict_1)))r2 = round(reg_1.score(X_train_1, Y_train_1),2)
print("Performance do modelo nos dados de teste ")print("--------------------------------------")print('RMSE é {}'.format(rmse))print('R2 é {}'.format(r2))print("\n")
FONTE: O autor

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
177
COMO PREVER O VALOR DE VENDA DE UMA CASA?
Wesin Alves
Em um problema de regressão, pretendemos prever a saída que contém um valor contínuo, representando um preço ou uma probabilidade. Isso é diferente de um problema de classificação, em que pretendemos prever um rótulo discreto (por exemplo, quando uma imagem contém um cachorro ou um gato).
Este texto tem o objetivo de construir um modelo para prever o preço médio das casas em um subúrbio de Boston, em meados da década de 1970. Para fazer isso, forneceremos ao modelo alguns pontos de dados sobre o subúrbio, como a taxa de criminalidade e a taxa de imposto sobre a propriedade local. Ao terminar esta leitura, você será capaz de:
• carregar o conjunto de dados Boston housing prices;• explorar e pré-processar os dados de treinamento;• construir seu modelo com o TensorFlow;• treinar, avaliar e fazer predições com seu modelo;• visualizar o histórico de erros e desempenho.
Assim como visto anteriormente, vamos usar o pacote tf.keras, uma api de alto nível do TensorFlow para construir e treinar o modelo. O trecho do código, a seguir, importa os pacotes necessários para o script rodar tranquilamente.
import tensorflow as tffrom tensorflow import keras
import numpy as np
Esse conjunto de dados é acessível diretamente no TensorFlow. Faça o download e embaralhe o conjunto de treinamento:
boston_housing = keras.datasets.boston_housing
(train_data, train_labels), (test_data, test_labels) = boston_housing.load_data()
# Shuffle the training setorder = np.argsort(np.random.random(train_labels.shape))train_data = train_data[order]train_labels = train_labels[order]
LEITURA COMPLEMENTAR

178
UNIDADE 3 — REGRESSÃO
Esse conjunto de dados é muito menor do que outros: ele tem 506 exemplos no total, divididos entre 404 exemplos de treinamento e 102 exemplos de teste:
print("Training set: {}".format(train_data.shape)) # 404 exam-ples, 13 featuresprint("Testing set: {}".format(test_data.shape)) # 102 exam-ples, 13 features
O conjunto de dados contém 13 atributos diferentes:
1. Taxa de criminalidade per capita.2. A proporção de terrenos residenciais zoneada para lotes com mais de 25.000
pés quadrados.3. A proporção de acres comerciais não varejistas por cidade.4. Variável dummy de Charles River (= 1 se o setor limite rio; 0 caso contrário).5. Concentração de óxidos nítricos (partes por 10 milhões).6. O número médio de quartos por habitação.7. A proporção de unidades ocupadas pelo proprietário, construídas antes de 1940.8. Distâncias ponderadas para cinco centros de emprego em Boston.9. Índice de acessibilidade às autoestradas radiais.10. Taxa de imposto sobre propriedades de valor integral por US$ 10.000.11. Relação aluno-professor por cidade.12. 1000 * (Bk – 0,63) ** 2 onde Bk é a proporção de negros por cidade.13. Percentagem de status inferior da população.
Cada um desses atributos é armazenado usando uma escala diferente. Alguns atributos são representados por uma proporção entre 0 e 1; outros são intervalos entre 1 e 12; alguns são intervalos entre 0 e 100; e assim por diante. Isso ocorre com frequência com dados do mundo real, e entender como explorar e limpar esses dados é uma habilidade importante a ser desenvolvida.
Como cientista de dados, pense em possíveis benefícios e danos que as previsões de um modelo podem causar. Um modelo como esse poderia reforçar preconceitos e disparidades sociais. Sua aplicação trará um recurso relevante para o problema que você deseja resolver ou irá introduzir um viés?
Use a biblioteca pandas para exibir as primeiras linhas do conjunto de dados em uma tabela bem formatada:
import pandas as pd
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
df = pd.DataFrame(train_data, columns=column_names)df.head()

TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
179
É recomendado normalizar atributos que usam escalas e intervalos diferentes. Para cada atributo, subtraia a média do recurso e divida pelo desvio padrão:
# Test data is *not* used when calculating the mean and std
mean = train_data.mean(axis=0)std = train_data.std(axis=0)train_data = (train_data - mean) / stdtest_data = (test_data - mean) / std
print(train_data[0]) # First training sample, normalized
Vamos construir nosso modelo. Aqui, usaremos um modelo sequencial com duas camadas ocultas densamente conectadas e uma camada de saída que retornará um único valor contínuo. As etapas de construção do modelo são agrupadas em uma função, build_model, pois criaremos um segundo modelo, mais adiante.
def build_model(): model = keras.Sequential([ keras.layers.Dense(64, activation=tf.nn.relu, input_shape=(train_data.shape[1],)), keras.layers.Dense(64, activation=tf.nn.relu), keras.layers.Dense(1) ])
optimizer = tf.train.RMSPropOptimizer(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae']) return model
model = build_model()model.summary()return model
model = build_model()model.summary()
# Display training progress by printing a single dot for each completed epochclass PrintDot(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs): if epoch % 100 == 0: print('') print('.', end='')
EPOCHS = 500

180
UNIDADE 3 — REGRESSÃO
# Display training progress by printing a single dot for each completed epochclass PrintDot(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs): if epoch % 100 == 0: print('') print('.', end='')
EPOCHS = 500
# Store training statshistory = model.fit(train_data, train_labels, epochs=EPOCHS, validation_split=0.2, verbose=0, callbacks=[PrintDot()])
import matplotlib.pyplot as plt
def plot_history(history): plt.figure() plt.xlabel('Epoch') plt.ylabel('Mean Abs Error [1000$]') plt.plot(history.epoch, np.array(history.history['mean_abso-lute_error']), label='Train Loss') plt.plot(history.epoch, np.array(history.history['val_mean_absolute_error']), label = 'Val loss') plt.legend() plt.ylim([0, 5])
plot_history(history)
Visualize o progresso do treinamento do modelo usando as estatísticas armazenadas no objeto de histórico. A ideia é usar esses dados para determinar quanto tempo treinar antes que o modelo pare de progredir.
import matplotlib.pyplot as plt
def plot_history(history): plt.figure() plt.xlabel('Epoch') plt.ylabel('Mean Abs Error [1000$]') plt.plot(history.epoch, np.array(history.history['mean_abso-lute_error']), label='Train Loss') plt.plot(history.epoch, np.array(history.history['val_mean_absolute_error']), label = 'Val loss') plt.legend() plt.ylim([0, 5])
plot_history(history)
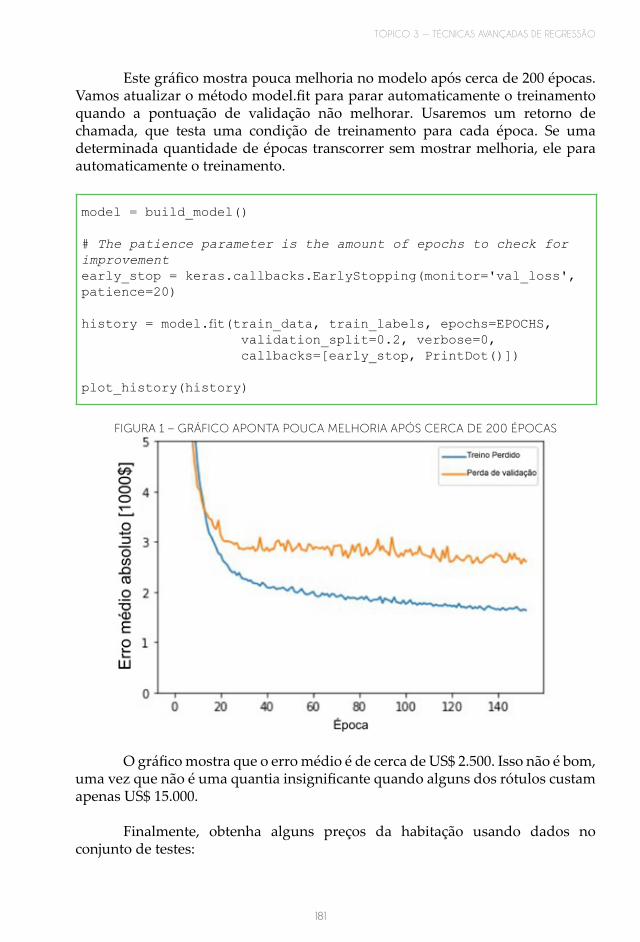
TÓPICO 3 — TÉCNICAS AVANÇADAS DE REGRESSÃO
181
Este gráfico mostra pouca melhoria no modelo após cerca de 200 épocas. Vamos atualizar o método model.fit para parar automaticamente o treinamento quando a pontuação de validação não melhorar. Usaremos um retorno de chamada, que testa uma condição de treinamento para cada época. Se uma determinada quantidade de épocas transcorrer sem mostrar melhoria, ele para automaticamente o treinamento.
model = build_model()
# The patience parameter is the amount of epochs to check for improvementearly_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20)
history = model.fit(train_data, train_labels, epochs=EPOCHS, validation_split=0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)
FIGURA 1 – GRÁFICO APONTA POUCA MELHORIA APÓS CERCA DE 200 ÉPOCAS
O gráfico mostra que o erro médio é de cerca de US$ 2.500. Isso não é bom, uma vez que não é uma quantia insignificante quando alguns dos rótulos custam apenas US$ 15.000.
Finalmente, obtenha alguns preços da habitação usando dados no conjunto de testes:

182
UNIDADE 3 — REGRESSÃO
test_predictions = model.predict(test_data).flatten()
plt.scatter(test_labels, test_predictions)plt.xlabel('True Values [1000$]')plt.ylabel('Predictions [1000$]')plt.axis('equal')plt.xlim(plt.xlim())plt.ylim(plt.ylim())_ = plt.plot([-100, 100], [-100, 100])
FIGURA 2 – PREÇOS REAIS DE HABITAÇÃO
FONTE: Adaptado de ALVES, W. Como prever o valor de venda de uma casa? 2018. Disponível em: https://wesinalves.github.io/tensorflow/2018/10/22/regression.html. Acesso em: 5 nov. 2020.

183
RESUMO DO TÓPICO 3
Neste tópico, você aprendeu que:
• Existem diversos métodos de regressão e é possível avaliar todos para um mesmo cenário de dados.
• A regressão logística pode ser considerada uma extensão da regressão linear, pois, assim como esta, estuda relações entre variáveis.
• A regressão logística é um método ou uma abordagem de modelagem matemática, que objetiva descrever a relação entre uma variável resposta (dependente).
• A regressão linear dá uma resposta em valor numérico, enquanto a regressão logística apresenta uma resposta em probabilidade de chances de ocorrer o fato estudado.
• A função sigmoide representa uma função logística.
• Redes neurais artificiais são sistemas que mimetizam o comportamento e a estrutura do cérebro humano, embora possuam um conjunto limitado de neurônios.
• Em uma rede neural, os sinais da entrada no neurônio são representados pelo vetor x = [x1, x2, x3, …, xN].
• Em uma rede neural, os respectivos pesos sinápticos, que são os elementos do vetor w = [w1, w2, w3, …, wN], geram o valor de ativação.
Ficou alguma dúvida? Construímos uma trilha de aprendizagem pensando em facilitar sua compreensão. Acesse o QR Code, que levará ao AVA, e veja as novidades que preparamos para seu estudo.
CHAMADA

184
1 Para as próximas questões, considere texto e fórmula a seguir:
A regressão logística é um método de associação de variáveis no qual se prediz a presença ou ausência de uma característica (no caso, o cancelamento da assinatura) por meio de um conjunto de variáveis preditoras ou explicativas.
FONTE: SILVA, L. P. M. da. O mercado de produtos digitais: um estudo de Churn de migrados de assinatura de jornal. Monografia (Administração) – Departamento de Ciências Adminis-trativas, Escola de Administração, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2017. Disponível em: https://lume.ufrgs.br/bitstream/handle/10183/169919/001051430.pdf?-sequence=1&isAllowed=y. Acesso em: 5 nov. 2020.
a) Na equação apresentada, indique o significado de e.
b) Na equação apresentada, indique o significado de x₀.
c) Na equação apresentada, indique o significado de L.
d) Na equação apresentada, indique o significado de k.
AUTOATIVIDADE

185
REFERÊNCIAS
BARISTELA, G. C.; RODRIGUES, S. A.; BONONI, J. T. C. M. Estudo sobre a evasão escolar usando regressão logística: análise dos alunos do curso de admi-nistração da Fundação Educacional de Ituverava. Tékhne & Lógos, Botucatu, v.1, n. 1, p. 21-34, 2009. Disponível em: https://www.researchgate.net/publi-cation/312597157_Estudo_sobre_a_evasao_escolar_usando_regressao_logisti-ca_analise_dos_alunos_do_curso_de_Administracao_da_Fundacao_Educacio-nal_de_Ituverava. Acesso em: 5 nov. 2020.
BUNCHAFT, G.; KELLNER, S. R. O.; HORA, L. H. M. Noções de amostragem. In: BUNCHAFT, G.; KELLNER, S. R. O. (Orgs.). Estatística sem mistérios. Petrópolis: Vozes, 1998.
CECCON, D. Fundamentos de ML: funções de custo para problemas de regressão. IA Expert Academy, 2019. https://iaexpert.academy/2019/08/19/fundamentos-de-ml--funcoes-de-custo-para-problemas-de-regressao/. Acesso em: 5 nov. 2020.
DORNELES, B. Regressão Linear com Gradiente Descendente. Medium, 2016. Disponível em: https://medium.com/@bruno.dorneles/regress%C3%A3o-linear--com-gradiente-descendente-d3420b0b0ff. Acesso em: 1 out. 2020.
DOSUALDO, D. G. Investigação de regressão no processo de mineração de dados. Dissertação (Mestrado em Ciências da Computação e Matemática Com-putacional) – Instituto de Ciências Matemáticas e Computação, Universidade de São Paulo, São Carlos, 2003. Disponível em: https://teses.usp.br/teses/disponi-veis/55/55134/tde-12112014-101732/publico/DanielGomesDosualdo.pdf. Acesso em: 5 nov. 2020.
ESCOVEDO, T.; KOSHIYAMA, A. Introdução a Data Science – Algoritmos de Machine learning e métodos de análise. São Paulo: Casa do Código, 2020.
GLEN, S. Excel 2013 Regression analysis: Easy steps and video. StatisticsHow-To.com. Elementary Statistics for the rest of us! 2013. Disponível em: https://www.statisticshowto.com/how-to-perform-excel-2013-regression-analysis-ex-cel-2013/. Acesso em: 5 nov. 2020.
JENSKE, G.; SANTOS, L. G. Matemática para Economistas. Indaial: UNIASSEL-VI, 2018.
MARQUES FILHO, M. Redes neurais artificiais: do neurônio artificial à con-volução. Monografia (Tecnologia em Sistemas de Computação) – Universidade Federal Fluminense, Niterói, 2018. Disponível em: https://app.uff.br/riuff/bits-tream/1/8926/1/TCC_MAUR%C3%8DCIO_MARQUES_SOARES_FILHO.pdf. Acesso em: 5 nov. 2020.

186
ML GLOSSARY. Linear Regression. ML GLOSSARY, 2017. Disponível em: https://ml-cheatsheet.readthedocs.io/en/latest/linear_regression.html. Acesso em: 2 out. 2020.
MEIER, R.; JUNIOR, E. Treinamento de Modelos. Apostila. Universidade Fede-ral de Santa Catarina, Florianópolis, 2020. Disponível em: https://geam.paginas.ufsc.br/files/2020/02/Treinando-modelos.pdf. Acesso em: 30 set. 2020.
NG, A. Linear Regression. Computer & Information Science, University of Pennsylvania, 2014. Disponível em: https://www.cis.upenn.edu/~cis519/fall2014/lectures/04_LinearRegression.pdf. Acesso em: 30 set. 2020.
PRIM, A. L.; PEREIRA, P. E. Métodos Quantitativos. Indaial: Editora Uniasselvi, 2020.
SAYAD, S. An Introduction to Data Science. c2010-2020. Disponível em: https://saedsayad.com. Acesso em: 9 out. 2020.
SILVA, R. A. M. da. Combinando regressão linear clusterwise e k-means com ponderação automática das variáveis explicativas. Dissertação (Mestrado em Ciência da Computação) – Programa de Pós-graduação em Ciência da Computa-ção, Universidade Federal de Pernambuco, Recife, 2017. Disponível em: https://repositorio.ufpe.br/bitstream/123456789/26011/1/DISSERTA%c3%87%c3%83O%20Ricardo%20Azevedo%20Moreira%20da%20Silva.pdf. Acesso em: 5 nov. 2020.
SILVA, T. C. da; PERIÇARO, G. A. Classificação dos candidatos ao vestibular da FE-CILCAM via técnicas estatísticas multivariadas. In: CONGRESSO NACIONAL DE MATEMÁTICA PURA E APLICADA, Cuiabá. Anais [...] XXXII CNMAC, v. 2, p. 566-571, 2009. Disponível em: https://docplayer.com.br/6786832-Classificacao-dos--candidatos-ao-vestibular-da-fecilcam-via-tecnicas-estatisticas-multivariadas.html
SOUZA, E. G. Implementando Regressão Linear Simples em Python. Data Hacke-rs, Medium, 2019. Disponível em: https://medium.com/data-hackers/implemen-tando-regressão-linear-simples-em-python-91df53b920a8. Acesso em: 29 set. 2020.
SOUZA, M. J. F. Ajuste de curvas pelo método dos quadrados mínimos. Notas de aula de Métodos Numéricos. Departamento de Computação, Instituto de Ciências Exatas e Biológicas, Universidade Federal de Ouro Preto, 2003. Dispo-nível em: http://www.decom.ufop.br/prof/marcone/Disciplinas/MetodosNume-ricoseEstatisticos/QuadradosMinimos.pdf. Acesso em: 5 nov. 2020.
TAN, P.-N.; STEINBACH, M.; KUMAR, V. Introduction to data mining. Pear-son Education India, 2016.


















