
Área de Inteligência Artificial por Claudio Eduardo ...siaibib01.univali.br/pdf/Claudio Eduardo...
78
UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR CURSO DE CIÊNCIA DA COMPUTAÇÃO REDES NEURAIS ARTIFICIAIS X ANÁLISE MULTIVARIADA NA PREDIÇÃO DE JAR TEST Área de Inteligência Artificial por Claudio Eduardo Moreira Cordeiro Rudimar Luís Scaranto Dazzi, Dr Orientador Itajaí (SC), novembro de 2010
-
Upload
truongdien -
Category
Documents
-
view
216 -
download
3
Transcript of Área de Inteligência Artificial por Claudio Eduardo ...siaibib01.univali.br/pdf/Claudio Eduardo...

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
REDES NEURAIS ARTIFICIAIS X ANÁLISE MULTIVARIADA NA PREDIÇÃO DE JAR TEST
Área de Inteligência Artificial
por
Claudio Eduardo Moreira Cordeiro
Rudimar Luís Scaranto Dazzi, Dr Orientador
Itajaí (SC), novembro de 2010

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
REDES NEURAIS ARTIFICIAIS X ANÁLISE MULTIVARIADA NA PREDIÇÃO DE JAR TEST
Área de Inteligência Artificial
por
Claudio Eduardo Moreira Cordeiro Relatório apresentado à Banca Examinadora do Trabalho de Conclusão do Curso de Ciência da Computação para análise e aprovação. Orientador: Rudimar Luís Scaranto Dazzi, Dr
Itajaí (SC), novembro de 2010

- ii -
SUMÁRIO
LISTA DE ABREVIATURAS................................................................ iv LISTA DE FIGURAS ............................................................................... v LISTA DE TABELAS ............................................................................. vi LISTA DE EQUAÇÕES ........................................................................ vii RESUMO ................................................................................................ viii ABSTRACT .............................................................................................. ix 1 INTRODUÇÃO ..................................................................................... 1 1.1 PROBLEMATIZAÇÃO ...................................................................................... 2 1.1.1 Formulação do Problema ................................................................................ 2 1.1.2 Solução Proposta .............................................................................................. 2 1.2 OBJETIVOS ......................................................................................................... 2 1.2.1 Objetivo Geral .................................................................................................. 2 1.2.2 Objetivos Específicos........................................................................................ 3 1.3 METODOLOGIA ................................................................................................ 3 1.4 ESTRUTURA DO TRABALHO ........................................................................ 5
2 FUNDAMENTAÇÃO TEÓRICA........................................................ 7 2.1 ENSAIO DE COAGULAÇÃO ............................................................................ 7 2.2 REDES NEURAIS ARTIFICIAIS ..................................................................... 9 2.2.1 Modelos de um neurônio ............................................................................... 11 2.2.2 Arquiteturas de Rede Neural Artificial ....................................................... 15 2.2.3 Processos de Aprendizagem .......................................................................... 17 2.2.4 Perceptrons de Múltiplas Camadas .............................................................. 19 2.3 ANÁLISE MULTIVARIADA ........................................................................... 23 2.3.1 Regressão Múltipla ......................................................................................... 24 2.3.2 R2 Ajustado e coeficiente de correlação amostral ....................................... 27 2.3.3 Análise de componentes principais ............................................................... 29 2.4 TRABALHOS SIMILARES ............................................................................. 29 2.4.1 Redes neurais artificiais aplicadas ao processo de coagulação .................. 30 2.4.2 Rede neural artificial aplicada à previsão de vazão da Bacia Hidrográfica do Rio Piancó ............................................................................................................. 31 2.4.3 O uso de Redes Neurais e Regressão Linear Múltipla na engenharia de avaliações: determinação dos valores venais de imóveis urbanos ........................ 33 2.5 FERRAMENTAS PARA CRIAÇÃO DE RNA .............................................. 36 2.5.1 SNNS – Stuttgart Neural Network Simulator ............................................. 36 2.5.2 JavaNNS – Java Neural Network Simulator ............................................... 37 2.5.3 SIMBRAIN....................................................................................................... 38 2.5.4 MATLAB ......................................................................................................... 40

- iii-
2.6 FERRAMENTAS PARA ANÁLISE ESTATÍSTICA .................................... 42 2.6.1 Calc ................................................................................................................... 42 2.6.2 Statistica ........................................................................................................... 44 2.7 Comparativo das ferramentas para modelagem e simulação de RNA ......... 45 3 DESENVOLVIMENTO........................................................................46 3.1 PROJETO......... .................................................................................................. 46 3.2 MODELOS UTILIZANDO RNA.....................................................................49 3.2.1 Resultados das RNAs..... .................................................................................. 52 3.2.2 Programa para criar os arquivos de padrões..... ........................................... 53 3.2.3 Programa para treinar as RNAs treinadas no JavaNNS..... ........................ 54 3.4 REGRESSÃO MÚLTIPLA.............................................................................. 55 3.4.1 Normalidade e Linaridades das variáveis......................................................55 3.4.2 Resultados dos modelos de Regressão Linear Múltipla................................57 3.5 COMPARAÇÃO DOS MODELOS...................................................................58
4 CONCLUSÕES......................................................................................63 4.1 PROJETOS FUTUROS......................................................................................64
REFERÊNCIAS BIBLIOGRÁFICAS ................................................ .65 GLOSSÁRIO ......................................................................................... ..67

- iv -
LISTA DE ABREVIATURAS
AESA Agência Executiva de Gestão da Águas do Estado da Paraíba ANA Agência Nacional de Águas ETA Estação de Tratamento de Água IPTU Imposto Predial e Territorial Urbano IPVR Institute for Parallel and Distributed High Performance Systems ITBI Imposto sobre Transmissão de Bens Imóveis MLP Multilayer Perceptron RNA Redes Neurais Artificiais SNNS Stuttgart Neural Network Simulator TCC Trabalho de Conclusão de Curso UNIB Unidade de Insumos Básicos da Braskem UNIVALI Universidade do Vale do Itajaí UTA Unidade de Tratamento de Água X11R4 X Window System - Version 11 release 4 of the X protocol X11R5 X Window System - Version 11 release 5 of the X protocol

- v -
LISTA DE FIGURAS
Figura 1. Metodologia utilizada .................................................................................... 5 Figura 2. Aparelho de jar test ........................................................................................ 9 Figura 3. Modelo não-linear de um neurônio.............................................................. 11 Figura 4. Outro modelo não-linear de um neurônio .................................................... 13 Figura 5. Função de Limiar ......................................................................................... 13 Figura 6. Função Linear .............................................................................................. 14 Figura 7. Função Limiar por Partes ............................................................................. 14 Figura 8. Função Sigmóide ......................................................................................... 15 Figura 9. Rede alimentada adiante com camada única ............................................... 16 Figura10.RNA alimentada adiante com uma camada oculta e uma camada de saída .16 Figura11.RNA recorrente sem laços de auto-alimentação e sem neurônios ocultos .. 17 Figura 12. Aprendizagem supervisionada ................................................................... 18 Figura 13. Aprendizado por reforço ............................................................................ 19 Figura 14. Aprendizagem não-supervisionada ............................................................ 19 Figura 15. Rede MLP com duas camadas ocultas ...................................................... 21 Figura 16. Ambiente de desenvolvimento do SNNS .................................................. 37 Figura 17. Ambiente de desenvolvimento do JavaNNS ............................................. 38 Figura 18. Ambiente de trabalho do Simbrain ............................................................ 39 Figura 19. Duas RNAs interagindo no Simbrain ........................................................ 40 Figura 20. Ambiente de trabalho do MATLAB .......................................................... 41 Figura 21.Neural Network Toolbox ............................................................................ 42 Figura 22. Ambiente de trabalho do Calc ................................................................... 43 Figura 23. Ambiente de trabalho do Statistica ............................................................ 44 Figura 24. Valores da turbidez da água bruta..............................................................47 Figura 25. Valores do pH da água bruta.......................... ........................................... 47 Figura 26. Uma Arquitetura de RNA MLP com nove neurônios na camada oculta. . 49 Figura 27. Arquivo de padrões para predição do teste do jarro............ ...................... 51 Figura 28. Ferramenta snns2c em funcionamento ............................ ......................... 52 Figura 29. Programa para criação de arquivos de padrões................ ......................... 54 Figura 30. Programa para simular a RNA...................................................................54 Figura 31. Gráfico de probabilidades normal das variáveis........................................56 Figura 32. Valores preditos X valores observados da turbidez decantada..................61 Figura 33. Valores preditos X valores observados do pH decantada..........................62

- vi -
LISTA DE TABELAS
Tabela 1. Dados para Regressão Linear Múltipla ....................................................... 26 Tabela 2. Grau de relacionamento entre as variáveis .................................................. 29Tabela 3. Melhor Arquitetura para o período de teste ................................................ 33 Tabela 4. Resultado das melhores simulações ............................................................ 34 Tabela 5. Ajuste do modelo de regressão. ................................................................... 35 Tabela 6. Ferramentas de simulação de RNA ............................................................. 45 Tabela 7. Frequências da turbidez da água bruta........................................................ 48 Tabela 8. Frequências do pH da água bruta.................................................................48 Tabela 9. Arquiteturas de RNA treinadas e simuladas................................................50 Tabela 10. Fatores de ormalização..............................................................................50 Tabela 11. Resultados dos modelos de RNA..............................................................53 Tabela 12. Resultados dos Modelos de Regressão......................................................57 Tabela 13. Desempenho dos melhores modelos ........................................................ 58 Tabela 14. Resultados das simulações dos modelos................................................... 59

- vii -
LISTA DE EQUAÇÕES
Equação 1.. .................................................................................................................. 12 Equação 2.. .................................................................................................................. 12 Equação 3.. .................................................................................................................. 12 Equação 4.. .................................................................................................................. 13 Equação 5.. .................................................................................................................. 14 Equação 6.. .................................................................................................................. 14 Equação 7.. .................................................................................................................. 15 Equação 8.. .................................................................................................................. 22 Equação 9.. .................................................................................................................. 22 Equação 10.. ................................................................................................................ 23 Equação 11.. ................................................................................................................ 23 Equação 12. ................................................................................................................. 23 Equação 13.. ................................................................................................................ 24 Equação 14.. ................................................................................................................ 25 Equação 15.. ................................................................................................................ 27 Equação 16.. ................................................................................................................ 28 Equação 17.. ................................................................................................................ 28 Equação 18..................................................................................................................52

- viii -
RESUMO
MOREIRA CORDEIRO, Claudio Eduardo. Redes Neurais Artificiais X Análise Multivariada na Predição de Jar Test. Itajaí, 2010. 77 f. Trabalho de Conclusão de Curso (Graduação em Ciência da Computação)–Centro de Ciências Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2010.
Em Estações de Tratamento de Água (ETA) são realizadas vários tipos de análises para se conhecer as características da água a ser tratada para depois ser fornecida para a população. Uma dessas análises é o Teste do Jarro (Jar Test). O Teste do Jarro serve para saber a dosagem ótima de coagulante que deve ser usada na água bruta em uma Estação de Tratamento de Água. Com o Teste do Jarro é realizado em laboratório a repetição das três fases consideradas na prática, como essenciais na formação da coagulação nas estações de tratamento de água. As três fases são, respectivamente: mistura rápida, mistura lenta e decantação. Saber a dosagem correta de coagulante para misturar na água bruta é fundamental em uma ETA, pois é a fase de coagulação que vai determinar se a água bruta vinda do rio, irá sair cristalina e livre de impurezas no final do tratamento. As características da água que é utilizada no teste do jarro têm grande influência no processo de coagulação e consequentemente no resultado final do teste do jarro. Algumas destas características são: turbidez, pH, alcalinidade, temperatura e cor. Este trabalho tem o objetivo de realizar um estudo para conhecer a viabilidade de um modelo teórico conhecendo-se apenas a turbidez, o pH e a alcalinidade da água bruta. Foram utilizados três modelos para realizar o estudo; um utilizando Redes Neurais Artificiais e outros dois utilizando Análise Multivariada. Os resultados gerados pelos três modelos foram confrontados com resultados do teste real para verificar sua eficácia. Foram obtidos bons resultados para a predição do pH da água decantada. Também foram obtidos resultados satisfatórios para a predição da turbidez da água decantada, levando em conta que os modelos utilizaram poucas variáveis explicativas.
Palavras-chave: Teste do Jarro, Redes Neurais Artificiais, Análise Multivariada.

- ix -
ABSTRACT
In water treatment stations are carried out several types of analysis to know the characteristics of
water to be treated and then provided to the population. One such analysis is the Jar Test. The Jar
Test is used to find out the optimum dose of coagulant to be used in raw water at a water treatment
stations. With Jar Test is conducted in the laboratory to repeat the three phases considered in
practice as essential in the formation of coagulation in water treatment stations. These three phases
are, respectively, rapid mixing, slow mixing and sedimentation. Knowing the correct dosage of
coagulant to mix in raw water is key in an water treatment station, it is the coagulation phase that
will determine if the raw water from the river, you will leave crystalline and free of impurities at the
end of treatment. The characteristics of water that is used in the jar test has a great influence on the
clotting process and hence the final outcome of the jar test. Some of these features are: turbidity,
pH, alkalinity, temperature and color. This paper aims to conduct a study to assess the viability of a
theoretical model knowing only the turbidity, pH and alkalinity of raw water. Three models will be
used to conduct the study, using an Artificial Neural Networks and two using Multivariate Analysis
and Factorial Regression. The results generated by the two models will be confronted with the
actual test results to verify its effectiveness. If both models are effective, will occur which is right
and what it offers greater precision in predicting outcomes. Good results were obtained to predict
the pH of the decanted water. Were also obtained satisfactory results for predicting the turbidity of
settled water, taking into account that the models used little explanatory variables.
Keywords: Jar Test, Artificial Neural Networks, Multivariate Analysis.

1 INTRODUÇÃO
Em Estações de Tratamento de Água (ETA) são realizadas vários tipos de análises para se
conhecer as características da água a ser tratada para depois ser fornecida para a população. Uma
dessas análises é o Teste do Jarro (Jar Test). O Teste do Jarro serve para se saber a dosagem ótima
de coagulante que deve ser usada na água bruta em uma Estação de Tratamento de Água. Com o
Teste do Jarro é realizado em laboratório a repetição das três fases consideradas na prática como
essenciais na formação da coagulação, nas estações de tratamento de água. Estas três fases são,
respectivamente: mistura rápida, mistura lenta e decantação. Saber a dosagem correta de coagulante
para misturar na água bruta é fundamental em uma ETA, pois é a fase de coagulação que vai
determinar se a água bruta vinda do rio irá sair cristalina e livre de impurezas no final do
tratamento.
Na época de estiagem é suficiente apenas um teste por dia, desde que as características físico-
químicas da água permaneçam inalteradas. Na época de chuva o pH varia constantemente exigindo
grande atenção do operador e neste caso deverá executar dois ou mais Jar Test por dia
(CARVALHO e SANTOS, 2010).
Para realizar essa tarefa sem precisar fazer o teste real, utilizou-se três métodos: dois por meio
de Análise Multivariada e outro com Redes Neurais Artificiais (RNA). Os resultados alcançados
com a aplicação desses métodos foram comparados com valores de referência para verificar sua
eficácia. Inicialmente pretendia-se utilizar apenas Regressão Linear Múltipla como técnica de
Análise Multivariada, mas durante a realização do trabalho, decidiu-se utilizar também Regressão
Fatorial para tentar melhorar os resultados do modelo de Regressão Linear.
Segundo Menezes et al.(2009), ensaios de teste de jarro demoram a ser executados, não
respondendo em tempo real às mudanças das características da água bruta. As técnicas de predição
aqui apresentadas, visam superar esta limitação.

- 2 -
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
Calcular os resultados de um teste do jarro, fornecendo os valores dos parâmetros de entrada
do teste e obtendo como resultados, valores próximos aos resultados de uma análise de Jar Test real.
Conhecer os resultados do Teste do Jarro sem precisar fazê-lo é útil e permite uma maior
agilidade no tratamento, pois o procedimento é demorado e despende completa atenção por parte do
operador ou monitor, que poderia estar sendo usada para outras finalidades.
1.1.2 Solução Proposta
Como resultado final deste trabalho, obteve-se os seguintes modelos para predizer os valores
de turbidez e pH da água decantada nos jarros ao final de um jar test:
• 1 RNA que realiza previsões, simultaneamente, dos valores de turbidez e pH da água
decantada;
• 2 Equações de Regressão Linear Múltipla. Uma para realizar previsões dos valores
de turbidez, e outra, para fazer previsões do pH da água decantada, ao final de um jar
test;
• 2 Equações desenvolvidas por meio de Regressão Fatorial. Uma para realizar
previsões dos valores de turbidez, e outra, para fazer previsões do pH da água
decantada, ao final de um jar test.
O problema proposto neste trabalho foi resolvido de duas formas, a primeira utilizando uma
RNA e, a segunda, utilizando Análise Multivariada. Os resultados obtidos foram comparados com
valores de referência retirados de testes reais, para verificar sua eficácia. Os modelos
implementados pelos dois métodos foram comparados, para verificar qual é o mais adequado para o
problema em questão.
1.2 OBJETIVOS
1.2.1 Objetivo Geral

- 3 -
Fazer um estudo para determinação dos resultados de um Jar Test utilizando Redes Neurais
Artificiais e Análise Multivariada, para identificar qual dos dois métodos é mais indicado para essa
aplicação.
1.2.2 Objetivos Específicos
Para atingir o objetivo geral serão necessários os seguintes objetivos específicos:
• Pesquisar e analisar soluções existentes;
• Modelar uma RNA para determinação dos resultados de um Jar Test;
• Modelar uma Análise Multivariada para determinação dos resultados de um Jart Test;
• Testar os modelos para determinar sua eficácia;
• Testar os modelos para determinar qual é o mais indicado ou eficiente; e
• Documentar o resultado da pesquisa juntamente com o estudo feito sobre o tema
escolhido.
1.3 Metodologia
Para a realização deste projeto, foi seguida a seguinte metodologia:
1. Estudo do Jar Test: Realizado um estudo sobre o funcionamento do teste do jarro e os
fatores que influenciam na coagulação da água;
2. Estudo das RNAs: Realizado um estudo aprofundado sobre RNAs, principalmente as RNAs
MLP, que foram as arquiteturas de redes neurais artificiais utilizadas neste trabalho;
3. Estudo sobre Análise Multivariada: Realizado estudo sobre Análise Multivariada,
principalmente as técnicas de Regressão Linear Múltipla e Regressão Fatorial;
4. Estudo de trabalhos similares: Foi realizado estudo sobre trabalhos que utilizaram RNAs e
Análise Multivariada;
5. Definição da arquitetura de Rede Neural Artificial a ser utilizada: Incluindo número de
neurônios na camada de entrada, número de neurônios na camada de saída, quantidade de
camadas intermediárias, número de neurônios nas camadas intermediárias, paradigma de
aprendizagem e algoritmo de treinamento. Optou-se por uma arquitetura do tipo RNA MLP,
com uma camada oculta;

- 4 -
6. Definição da técnica multivariada mais adequada para a construção dos modelos estatísticos;
7. Definição do ambiente a ser utilizado no treinamento das RNAs: Após análise de quatro (4)
ambientes de desenvolvimento de RNAs, optou-se pela ferramenta Java Neural Network
Simulator – JavaNNS, desenvolvida na Whilhelm Schickard Institute for Computer Science
(WSI) em Tübingen, Alemanha;
8. Definição do software estatístico para a construção dos modelos estatísticos: Optou-se pelo
software STATISTICA 6.0;
9. Criação dos arquivos de padrões das RNAs: Definida a quantidade de neurônios na camada
de entrada e na camada de saída, os dados a serem utilizados e o ambiente de treinamento
das RNAs a ser utilizado, realizou-se o estudo do layout dos arquivos de treinamento e
validação. Foi implementada uma ferramenta utilizando a linguagem C++, afim de
automatizar a criação dos arquivos de treinamento e validação utilizados pelo JavaNNS.
10. Fazer a Análise de Componentes Principais, com o propósito de avaliar a importância
relativa das variáveis que compõem a amostra de dados: Foi realizada uma análise de
componentes principais afim de melhorar o desempenho do modelo de Regressão Linear
Múltipla, que foi a técnica escolhida primeiramente para gerar o modelo estatístico.
11. Simular as RNAs treinadas: Para a simulação das RNAs foi utilizada a ferramenta
snns2c.exe que vem junto com o ambiente SNNS. Também foi utilizado o ambiente de
programação Dev C++ para a criação dos simuladores das RNAs utilizando a linguagem C;
juntamente com o código-fonte que contém os pesos das RNAs ajustados, gerado pela
ferramenta snns2c.
12. Realizar análise estatística dos resultados das RNAs: Após o treinamento e simulação das
RNAs foram realizadas análises estatísticas para se conhecer a RNA que obteve melhor
desempenho na simulação dos resultados reais.
13. Construção dos modelos estatísticos: Foram construídos dois modelos estatísticos. Um para
realizar a predição da turbidez da água decantada no jarro, e outra, para fazer a predição do
pH da água decantada no jarro após o tempo de decantação do jar test;

- 5 -
14. Comparar valores simulados pelos modelos estatísticos com valores reais: Foi realizada
análise estatística para conhecer o grau de eficácia dos modelos estatísticos para simular os
valores de turbidez e pH da água decantada do jar test;
15. Comparar o desempenho do modelo de RNA com os modelos estatísticos: Foram realizadas
análises estatísticas com a finalidade de comparar o desempenho dos modelos gerados; e
16. Documentação do projeto: Todo o projeto foi documentado. Os dados das análises de jar
test, os arquivos de padrões de treinamento e validação das RNAs e os resultados dos
principais modelos gerados encontram-se nos anexos desse documento. A Figura 1 mostra o
mapa conceitual da metodologia utilizada.
Figura 1. Metodologia utilizada
1.4 Estrutura do trabalho
Este TCC divide-se em quatro capítulos: Introdução, Fundamentação Teórica,
Desenvolvimento e Conclusões.

- 6 -
Na Introdução apresenta-se uma descrição do contexto, importância e justificativa do
projeto, os objetivos gerais e específicos, a metodologia e a estrutura do trabalho.
Na Fundamentação Teórica descrevem-se todos os conceitos necessários para a realização
do projeto.
No desenvolvimento é mostrado como foi realizado a construção dos modelos para a
solução do problema e os resultados conseguidos.
No último capítulo, Conclusões, apresentam-se as conclusões sobre os resultados
conseguidos, os problemas encontrados, uma avaliação sobre a metodologia utilizada e soluções
propostas.

- 7 -
2 FUNDAMENTAÇÃO TEÓRICA
Em uma Estação de Tratamento de Água (ETA), conhecer a dosagem correta de coagulante
que deve ser despejada na água bruta é fundamental para um tratamento eficaz e eficiente da água,
evitando custos e excesso de residuais químicos na água fornecida para a população. O teste do
jarro (jar test), é uma análise realizada nas ETAs para se saber a dosagem ótima de coagulante que
deve ser despejada na água bruta durante o tratamento.
Para Rauber (?), uma das áreas de pesquisa mais fascinante presentemente é a simulação de
capacidades cognitivas de um ser humano. Projetam-se máquinas capazes de exibir um
comportamento inteligente, como se fossem reações humanas. As RNAs procuram imitar o
funcionamento do cérebro humano em um ambiente técnico, utilizando hardwares e softwares. As
RNAs têm sido muito utilizadas na resolução de problemas, dentre os quais destacam-se: análise de
processamento de sinais, robótica, classificação de dados, predição, e otimização.
Para Vicini e Souza (2005), estabelecer relações, descobrir leis explicativas ou propor novas
leis para os diversos fenômenos que nos cercam, é característica da ciência. Para isso, é necessário
trabalhar com as variáveis que são consideradas importantes para o entendimento do fenômeno
analisado. Existe muita dificuldade em transformar as informações obtidas em conhecimento,
principalmente quando se trata da avaliação estatística dos dados.
“Os métodos estatísticos, para analisar variáveis, estão dispostos em dois grupos: um que
trata da estatística que olha as variáveis de maneira isolada – a estatística univariada, e outro que
olha as variáveis de forma conjunta – a estatística multivariada. A denominação “Análise
Multivariada” corresponde a um grande número de métodos e técnicas que utilizam,
simultaneamente, todas as variáveis na interpretação teórica do conjunto de dados obtidos” (NETO
apud VICINI e SOUZA, 2005, p. 10).
2.1 Ensaio de coagulação
O Ensaio de Coagulação ou Teste do Jarro, é um procedimento muito utilizado em Estações
de Tratamento de Água para determinar a dosagem ótima de coagulante a ser despejada na água
bruta. Segundo o Manual Prático de Análise de Água (FUNDAÇÃO NACIONAL DE SAÚDE,
2004), podemos dizer que o teste do jarro é uma simulação do que ocorre na ETA.

- 8 -
Basicamente, o teste do jarro é composto por seis jarros de um ou dois litros onde a água
bruta é colocada junto com uma solução de coagulante. As águas dos jarros são agitadas por hastes
com pás que simulam as misturas rápidas e lentas ocorridas nos floculadores das ETAs. De acordo
com Carvalho e Santos (?), deve-se determinar a cor, turbidez, pH e alcalinidade da água bruta
utilizada para realizar o teste.
Para o Manual Prático de Análise de Água (FUNDAÇÃO NACIONAL DE SAÚDE, 2004),
é necessário que se conheça previamente as seguintes características da água bruta: turbidez, pH,
Alcalinidade, cor e temperatura; além de parâmetros hidráulicos da ETA, como: vazão, tempo de
detenção no floculador, velocidade de sedimentação no decantador, etc.
Para o Manual Prático de Análise de Água (FUNDAÇÃO NACIONAL DE SAÚDE, 2004),
o produto químico mais comum usado como coagulante é o sulfato de alumínio. O sulfato de
alumínio é um composto de alumínio utilizado em tratamento de esgotos, na purificação de água
potável e na indústria de papel.
A turbidez é a palavra usada para descrever as partículas em suspensão na água. Essas
partículas podem ser: areia, argila, material mineral, resíduo orgânico, plâncton e outros
microorganismos que impedem a passagem de luz através da água. Uma turbidez da água tratada
acima de cinco já é perceptível, e consequentemente, é um fator importante que pode acarretar a
rejeição da água pelo consumidor (Ibidem).
O pH mede a intensidade de acidez e basicidade, podendo sua escala variar de zero a
quatorze. Valores do pH abaixo de 7,0 é ácido e valores acima de 7,0 é básico. Água com pH igual
a 7,0 é considerado neutro. O pH é importante no tratamento de água, e determinante no controle de
coagulação, que é o processo simulado pelo jar test (Ibidem).
De acordo com Carvalho e Santos (?), a cor é causada pela existência de substâncias
coloridas em solução, na grande maioria dos casos, de natureza orgânica. Lagos e represas
apresentam águas coloridas com freqüência, devido a material orgânico, ferro e manganês. A cor
constitui uma característica de ordem estética e seu acentuado teor pode causar repugnância ao
consumidor que, consequentemente, pode rejeitá-la.
A alcalinidade da água é causada por íons e é importante para que as partículas em
suspensão na água bruta reajam com o sulfato de alumínio (Ibidem).

- 9 -
A Figura 2 mostra o aparelho de jar test que será utilizado na obtenção dos dados para a realização deste trabalho.
Figura 2. Aparelho de jar test
2.2 Redes Neurais Artificiais
As Redes Neurais Artificiais também são conhecidas como conexionismo ou sistemas de
processamento paralelo e distribuído. Segundo Braga, Ludermir e Carvalho (2000), as RNAs são
caracterizadas por sistemas que relembram a estrutura do cérebro humano, e que, por não ser
baseada em regras ou programas, a computação neural se constitui em uma alternativa à
computação algorítmica convencional.

- 10 -
Para Braga, Ludermir e Carvalho(2000), RNAs são sistemas paralelos distribuídos
compostos por unidades de processamento simples (nodos) que calculam determinadas funções
matemáticas, que geralmente são não-lineares.
Haykin (2001), apresenta a seguinte definição de RNA adaptada de Aleksander e Morton
(1990 apud HAYKIN, 2001. p. 28):
Uma rede neural é um processador maciçamente paralelamente distribuído constituído de unidades de processamento simples, que têm a propensão natural para armazenar conhecimento experimental e torná-lo disponível para o uso. Ela se assemelha ao cérebro em dois aspectos: 1. O conhecimento é adquirido pela rede a partir de seu ambiente através de um processo de aprendizagem. 2. Forças de conexão entre neurônios, conhecidas como pesos sinápticos, são utilizadas para armazenar o conhecimento adquirido.
Segundo Braga, Ludermir e Carvalho (2000), a forma como problemas são representados
internamente pela RNA e o paralelismo natural inerente à arquitetura das RNAs possibilitam um
desempenho superior ao dos modelos convencionais.
Para Braga, Ludermir e Carvalho (2000), em RNAs, o procedimento usual na solução de
problemas passa primeiro por uma fase de aprendizagem, em que um conjunto de exemplos é
fornecido para a RNA, a qual extrai automaticamente as características necessárias para representar
a informação fornecida. As características extraídas do conjunto de exemplos são posteriormente
utilizadas para gerar respostas para o problema.
Haykin (2001), afirma que uma RNA extrai seu poder computacional através de sua
estrutura maciçamente paralelamente distribuída e também de sua habilidade de generalizar. A
generalização se refere ao fato de a RNA produzir saídas adequadas para entradas que não foram
usadas durante o treinamento. Segundo Haykin (2001), Estas duas capacidades de processamento
de informação tornam possível para as RNAs resolver problemas complexos (de grande escala) que
atualmente são intratáveis.
Haykin (2001), adverte que, na prática, as RNAs não podem oferecer uma solução para
problemas de grande escala trabalhando individualmente e que, é preciso decompor o problema em
um número relativamente simples de tarefas, e atribuir às RNAs as tarefas que coincidem com suas
capacidades inerentes.

- 11 -
Sousa e Sousa (2009), afirmam que, modelos RNAs são particularmente úteis em situações
nas quais as relações dos processos físicos ainda não são completamente compreendidas e que eles
podem substituir os modelos matemáticos e estatísticos convencionais ou se associar a eles.
2.2.1 Modelos de um neurônio
Segundo Braga, Ludermir e Carvalho (2000), o primeiro modelo de um neurônio artificial
foi proposto em um trabalho pioneiro por Warren McCulloch e Walter Pitts em 1943 e era uma
simplificação do que se sabia na época a respeito do neurônio biológico.
Kovács (1996), comenta que o modelo de McCulloch e Pitts, embora rudimentar quando
comparado ao potencial dos modelos atualmente disponíveis, foi inovador e seminal. Segundo
Kovács (1996), vários fundadores de algumas das chamadas modernas áreas de conhecimento,
como Marvin Minsky em inteligência artificial, John Von Neumann em ciência da computação e
Norbert Wiener em cibernética, tiveram em algum momento de suas carreiras, inspiração no
trabalho de McCulloch e Pitts.
Para Haykin (2001), um neurônio artificial é uma unidade de processamento de informação
que é fundamental para a operação de uma RNA. A Figura 3, segundo Haykin (2001), mostra o
modelo de um neurônio, que forma a base para o projeto de RNAs.
Figura 3. Modelo não-linear de um neurônio Fonte: Haykin (2001).

- 12 -
Haykin (2001), identifica três elementos básicos do modelo neuronal:
1. Um conjunto de sinapses ou elos de conexão, cada uma caracterizada por um peso.
Especificando, um sinal xj na entrada da sinapse j conectada ao neurônio k é multiplicado
pelo peso sináptico wkj. O primeiro índice do peso sináptico wkj se refere ao neurônio em
questão e o segundo se refere ao terminal de entrada da sinapse à qual o peso se refere. O
peso sináptico de um neurônio artificial pode estar em um intervalo que inclui tanto valores
positivos quanto negativos.
2. Um somador para somar os sinais de entrada, ponderados pelas respectivas sinapses do
neurônio; estas operações constituem um combinador linear.
3. Uma função de ativação para restringir a amplitude de saída de um neurônio. A função de
ativação restringe (limita) o intervalo permissível de amplitude do sinal de saída a um valor
finito. A função de ativação também é referida como função restritiva. Geralmente, o
intervalo normalizado da amplitude da saída de um neurônio é escrito como o intervalo
unitário fechado [0,1] ou alternativamente [-1,1].
O modelo de neurônio artificial da Figura 3 inclui também um bias aplicado externamente,
representado por bk. Segundo Haykin (2001), o bias tem o efeito de aumentar ou diminuir a entrada
líquida da função de ativação. Se o bias for positivo ele aumenta, se for negativo, diminui.
Em termos matemáticos, podemos descrever um neurônio k, escrevendo o seguinte par de
equações:
∑=
=m
j
jkjk xwu1
Equação 1
( )kkk buy +∂= Equação 2
onde uk é a saída do combinador linear devido aos sinais de entrada; x1, x2,...,xm são os sinais de
entrada; wk1, wk2, ..., wkm são os pesos sinápticos do neurônio k; bk é o bias; ∂(.) é a função de
ativação; e yk é o sinal de saída do neurônio. O uso do bias bk aplica um transformação afim à saída
uk do combinador linear no modelo da Figura 3. Temos então que:
kkk buv += Equação 3

- 13 -
Para Haykin (2001), podemos reformular o modelo do neurônio k da Figura 3 como no
modelo da Figura 4.
Figura 4. Outro modelo não-linear de um neurônio Fonte: Adaptado de Haykin (2001).
Tipos de Função de Ativação
Haykin (2001), identifica três tipos básicos de função de ativação: função de limiar, função
linear por partes e função sigmóide. Braga, Ludermir e Carvalho (2000), apontam também a função
de ativação linear.
1. Função de Limiar
( )
<
≥=∂
0 se 0
0 se 1
ν
νv
Equação 4
Figura 5. Função de Limiar Fonte: Adaptado de Haykin (2001)
- 14 -
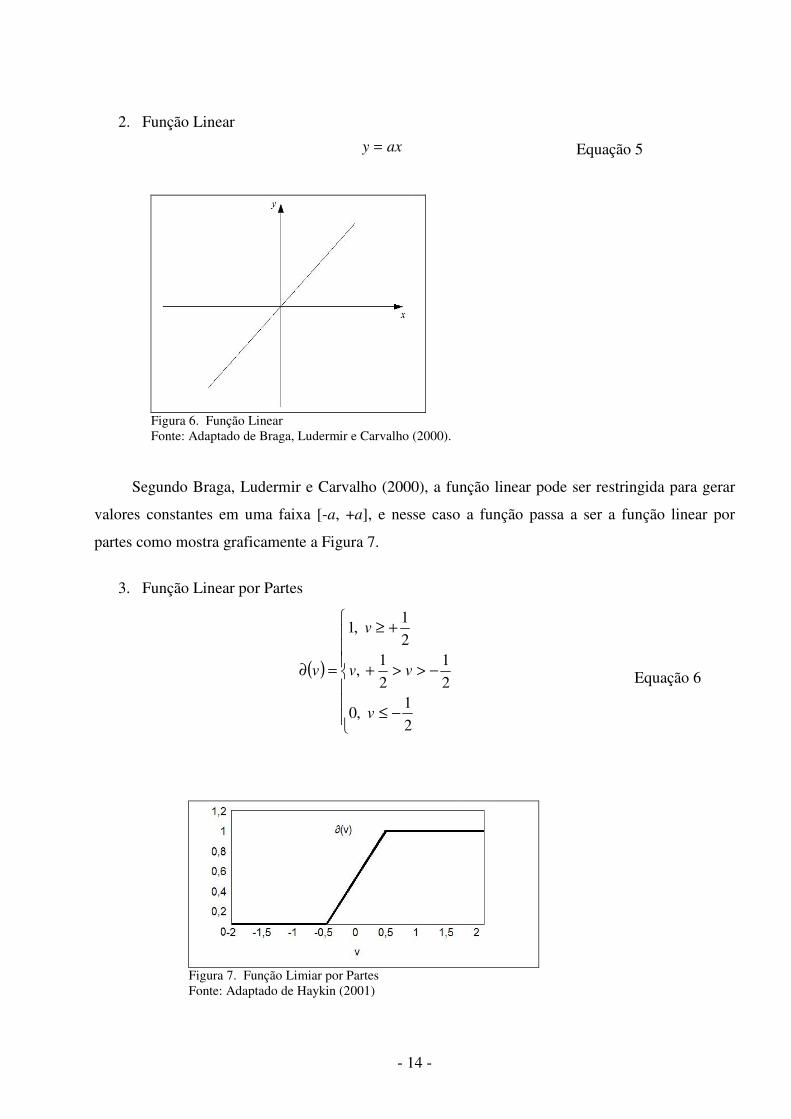
2. Função Linear
axy = Equação 5
Figura 6. Função Linear Fonte: Adaptado de Braga, Ludermir e Carvalho (2000).
Segundo Braga, Ludermir e Carvalho (2000), a função linear pode ser restringida para gerar
valores constantes em uma faixa [-a, +a], e nesse caso a função passa a ser a função linear por
partes como mostra graficamente a Figura 7.
3. Função Linear por Partes
( )
−≤
−>>+
+≥
=∂
2
1,0
2
1
2
1,
2
1,1
v
vv
v
v
Equação 6
Figura 7. Função Limiar por Partes Fonte: Adaptado de Haykin (2001)

- 15 -
4. Função Sigmóide
( )( )av
vexp1
1
+=∂
Equação 7
Figura 8. Função Sigmóide Fonte: Adaptado de Haykin (2001)
Segundo Haykin (2001), a função sigmóide, cujo gráfico tem a forma de S, é a forma mais
comum de função de ativação utilizada na construção de RNAs. Um exemplo de função sigmóide é
a função logística, definida pela Equação 7, onde a é o parâmetro de inclinação da função sigmóide.
2.2.2 Arquiteturas de Rede Neural Artificial
Segundo Braga, Ludermir e Carvalho (2000), a definição da arquitetura é um parâmetro
importante na concepção de uma RNA, pois a arquitetura restringe o tipo de problema que pode ser
tratado pela rede. Eles ainda comentam que, RNAs com uma camada única de neurônios só
conseguem resolver problemas linearmente separáveis e que RNAs recorrentes são mais
apropriadas para resolver problemas que envolvem processamento temporal.
Para Haykin (2001), podemos identificar três classes de arquiteturas de RNA
fundamentalmente diferentes:
1. Redes Alimentadas Adiante com Camada Única
A RNA da Figura 9 é chamada de rede de camada única, sendo que o nome “camada única”
se refere à camada de saída de neurônios. “Não contamos a camada de entrada de nós de fonte,
porque lá não é realizada qualquer computação” (HAYKIN, 2001).

- 16 -
Figura 9. Rede alimentada adiante com camada única Fonte: Haykin (2001)
2. RNAs Alimentadas Diretamente com Múltiplas Camadas
A RNA alimentada adiante (Figura 10) se diferencia pela presença de uma ou mais camadas
ocultas, cujos nós computacionais são chamados correspondentemente de neurônios ocultos ou
unidades ocultas. “A função dos neurônios ocultos é intervir entre a entrada externa e a saída da
rede de uma maneira útil. Adicionando-se uma ou mais camadas ocultas, tornamos a rede capaz de
extrair estatísticas de ordem elevada” (HAYKIN, 2001).
Figura 10. RNA alimentada adiante com uma camada oculta e uma camada de saída Fonte: Haykin (2001)
3. Redes Recorrentes

- 17 -
Segundo Haykin (2001), uma rede neural artificial recorrente se distingue de uma rede neural
artificial alimentada adiante por ter pelo menos um laço de realimentação. Uma rede neural
recorrente pode consistir de uma única camada de neurônios com cada neurônio alimentando seu
sinal de saída de volta para as entradas de todos os outros neurônios, como ilustrado na Figura 11.
Embora a rede da Figura 11 não possua neurônios ocultos e nem laços de auto-realimentação, uma
RNA recorrente também pode ter neurônios ocultos e laços de auto-realimentação.
Figura 11. RNA recorrente sem laços de auto-alimentação e sem neurônios ocultos Fonte: Haykin (2001)
2.2.3 Processos de Aprendizagem
Para Haykin (2001), a habilidade de aprender a partir de seu ambiente e de melhorar o seu
desempenho através da aprendizagem, é uma propriedade de primordial importância para uma rede
neural artificial.
Uma RNA aprende acerca do seu ambiente através de um processo interativo de ajustes
aplicados a seus pesos sinápticos e níveis de bias. Idealmente, a rede se torna mais instruída sobre o
seu ambiente após cada iteração do processo de aprendizagem. (HAYKIN, 2001).
Para que se possa resolver um problema usando-se RNA, o primeiro passo é estabelecer um
conjunto de pesos para suas conexões, ativar um conjunto de unidades que correspondam a um
padrão de entrada e observar o padrão para que o qual a rede converge e em que se estabiliza
(AZEVEDO;BRASIL;OLIVEIRA, 2000).
Caso o padrão final não corresponda ao que se deseja associar, como resposta ao padrão de
entrada, “é preciso fazer ajustes nos pesos e ativar novamente o padrão de entrada. Por causa de sua

- 18 -
semelhança com o aprendizado humano, esse processo de ajustes sucessivos das RNA é chamado
de aprendizagem” (AZEVEDO;BRASIL;OLIVEIRA, 2000, p.22).
Paradigmas de aprendizagem
1. Aprendizagem com um professor
Segundo Haykin (2001), um professor tem o conhecimento sobre o ambiente, com este
conhecimento sendo representado por um conjunto de exemplos de entrada-saída. Porém, o
ambiente é desconhecido pela RNA de interesse. Supondo que o professor e a RNA sejam expostos
a um vetor de treinamento retirado do ambiente. O professor, em virtude de seu conhecimento
prévio, é capaz de fornecer à RNA uma resposta desejada para aquele vetor de treinamento.
(HAYKIN, 2001).
Para Haykin(2001), a resposta desejada para uma RNA é a ação ótima a ser realizada pela
rede neural.
A Figura 12 mostra um diagrama que ilustra a aprendizagem com um professor, também
conhecida como aprendizagem supervisionada.
Figura 12. Aprendizagem supervisionada Fonte: Haykin (2001)
2. Aprendizagem sem um professor
Na aprendizagem com um professor, a aprendizagem acontece sob a supervisão de um
professor. No paradigma conhecido como aprendizagem sem um professor, não há um professor

- 19 -
para supervisionar o processo de aprendizagem, o que significa que não existem exemplos rotulados
da função a ser aprendida pela rede. (HAYKIN, 2001).
Para Haykin (2001), neste paradigma são identificadas duas subdivisões:
• Aprendizagem por reforço: Na aprendizagem por reforço, o aprendizado de um mapeamento
de entrada-saída é realizado através da interação contínua com o ambiente, visando
minimizar um índice escalar de desempenho. (HAYKIN, 2001). A Figura 13 mostra o
processo de aprendizado por reforço.
Figura 13. Aprendizado por reforço Fonte: Haykin (2001)
• Aprendizagem não-supervisionada: Na aprendizagem não-supervisionada não há um
professor externo para supervisionar o processo de aprendizado da rede neural. Porém, são
dadas condições para realizar uma medida independente da tarefa da qualidade da
representação que a rede neural artificial deve aprender, e os parâmetros livre da rede são
otimizados em relação a esta medida. (HAYKIN, 2001). A Figura 14 mostra o processo de
aprendizado não-supervisionado.
Figura 14. Aprendizagem não-supervisionada Fonte: Haykin (2001)
2.2.4 Perceptrons de Múltiplas Camadas
As redes perceptrons de múltiplas camadas (MLP, multilayer perceptron) são uma
importante classe de redes neurais artificiais. O sinal de entrada de uma rede MLP se propaga para
frente através da rede, camada por camada. A rede consiste, tipicamente, de um conjunto de

- 20 -
unidades sensoriais (nós de fonte) que constituem a camada de entrada, uma ou mais camadas
ocultas de nós computacionais e uma camada de saída de nós computacionais. (HAYKIN, 2001).
Segundo Haykin (2001), os MLP têm sido aplicados com sucesso para resolver diversos
problemas complexos, utilizando um algoritmo conhecido como algoritmo de retropropagação de
erro (error back-propagation) que realiza o treinamento da rede de forma supervisionada. O
algoritmo de retropropagação de erro é também conhecido como algoritmo de retropropagação
(back-propagation).
RNAs MLP apresentam um poder computacional muito maior do que aquele apresentado
pelas RNAs sem camadas intermediárias (ocultas). MLPs podem tratar com dados que não são
linearmente separáveis (BRAGA, LUDERMIR e CARVALHO, 2000).
Segundo Braga, Ludermir e Carvalho (2000), a implementação da função objetivo e a
precisão obtida dependem do número de neurônios utilizados na camada intermediária.
Para Haykin (2001), uma rede MLP possui três características distintivas:
1. O modelo de cada neurônio da rede inclui uma função de ativação não-linear. A não-
linearidade deve ser suave, ou seja, diferenciável em qualquer ponto.
2. A rede contém uma ou mais camadas de neurônios ocultos, que não fazem parte da entrada
ou da saída da rede.
3. A rede exibe um alto grau de conectividade, determinado pelas sinapses da rede.
O perceptron de múltiplas camadas deriva seu poder computacional através da combinação
destas características, juntamente com a habilidade de aprender da experiência através de
treinamento. A Figura 15 mostra uma rede MLP com duas camadas ocultas (HAYKIN, 2001).

- 21 -
Figura 15. Rede MLP com duas camadas ocultas Fonte: Haykin (2001)
Algoritmo de Retropropagação
O algoritmo de retropropagação (back-propagation) é um algoritmo supervisionado que
utiliza pares (entrada, saída desejada) para ajustar os pesos da rede utilizando um mecanismo de
correção de erros. O treinamento ocorre em duas fases, em que cada fase percorre a rede em um
sentido. Estas duas fases são conhecidas como fase forward e fase backward. A fase forward é
utilizada para definir a saída da rede para um dado padrão de entrada. A fase forward utiliza a saída
desejada e a saída fornecida pela rede para atualizar os pesos de suas conexões. (BRAGA;
CARVALHO; LUDERMIR, 2000).
Segundo Braga, Carvalho e Ludermir (2000), a fase forward é composta pelos seguintes
passos:
1. A entrada é apresentada à primeira camada da rede, a camada C0.
2. Para a camada Ci a partir da camada de entrada
2.1 Após os nodos da camada Ci (i > 0) calcularem seus sinais de saída, estes servem como
entrada para a definição das saídas produzidas pelos nodos da camada Ci+1.

- 22 -
3. As saídas produzidas pelos nodos da última camada são comparadas às saídas desejadas.
Braga, Carvalho e Ludermir (2000), comentam que a fase backward envolve as seguintes
etapas:
1. A partir da última camada, até chegar na camada de entrada:
1.1 Os nodos da camada atual ajustam seus pesos de forma a reduzir seus erros.
1.2 O erro de um nodo das camadas intermediárias é calculado utilizando os erros dos
nodos da camada seguinte conectados a ele, ponderados pelos pesos das conexões entre
eles.
Braga, Carvalho e Ludermir (2000), apresentam o algoritmo back-propagation a seguir:
1. Inicializar pesos e parâmetros.
2. Repetir até o erro ser mínimo ou até a realização de um dados número de ciclos:
2.1 Para cada padrão de treinamento X
2.1.1 Definir saída da rede através da fase forward.
2.1.2 Comparar saídas produzidas com as saídas desejadas.
2.1.3 Atualizar pesos dos nodos através da fase backward.
Fórmulas utilizadas pelo algoritmo back-propagation para atualização dos pesos da
rede MLP:
Segundo Braga, Carvalho e Ludermir (2000), as fórmulas de ajuste de pesos utilizadas pelo
algoritmo back-propagation em uma rede MLP são as mostradas pelas Equação 8 e Equação 9:
ijij xw ηδ=∆ Equação 8
( ) ( ) ( ) ( )txttwtw ijjiji ηδ+=+1 Equação 9

- 23 -
Onde η é a taxa de aprendizado da rede e δj é o erro do nodo j. Braga, Carvalho e Ludermir
(2000), comentam que, caso o nodo for de saída, o erro δj será definido pela Equação 10, caso
contrário, δj será definido pela Equação 11.
( ) ( )jjjj netfyd '−=δ Equação 10
( )∑∂=l
ljljj wnetf 'δ Equação 11
A Equação 11 define o termo netj.
∑=
=n
i
jiij wxnet1
Equação 12
2.3 Análise Multivariada
Para Vicini e Souza (2005), podemos dispor em dois grupos os métodos estatísticos para
analisar variáveis: um grupo trata da estatística que olha as variáveis de maneira isolada, também
chamada de estatística univariada, e um outro grupo que olha as variáveis de forma conjunta,
chamada de estatística multivariada.
Segundo Vicini e Souza (2005), quando um fenômeno depende de muitas variáveis,
geralmente a estratégica de analisar as variáveis de forma isolada e a partir dessa análise fazer
inferências sobre a realidade falha, pois não basta conhecer informações estatísticas isoladas, mas
também é necessário conhecer a totalidade dessas informações fornecidas pelo conjunto das
variáveis e suas relações.
Para Vicini e Souza (2005), o advento dos computadores apoiou e ampliou drasticamente a
capacidade de obter informações de acontecimentos e fenômenos que estão sendo analisados.
“A denominação Análise Multivariada corresponde a um grande número de métodos e
técnicas que utilizam, simultaneamente, todas as variáveis na interpretação teórica do conjunto de
dados obtidos.” (NETO apud VICINI e SOUZA, 2005, p. 10).

- 24 -
Podemos entender a Análise Multivariada como a técnica estatística que “explora o poder de
explicação que um conjunto de variáveis independentes têm, quando tomadas em conjunto.”
(DINIZ, 2000).
Para Diniz (2000), em Análise Multivariada se pode formular a seguinte pergunta: É possível
predizer uma variável (Y) a partir de um conjunto de outras (Xn)?
Segundo Vicini e Souza (2005), existem vários métodos de análise multivariada, com
finalidades bem diversas entre si, e que, antes de utilizar um desses métodos é preciso saber que
tipo de hipótese se quer gerar a respeito dos dados.
De acordo com Vicini e Souza (2005), os métodos de análise multivariada são escolhidos de
acordo com os objetivos da pesquisa, pois a análise multivariada é uma análise exploratória de
dados, que tem o objetivo de gerar hipóteses sobre os dados.
Este trabalho usará a técnica de Regressão Múltipla para tentar predizer os resultados do teste
do jarro utilizando modelos estatísticos multivariados. Mais especificamente, será usado o modelo
de regressão linear múltipla.
2.3.1 Regressão Múltipla
Para Montgomery e Runger (2003), “análise de regressão é uma técnica estatística para
modelar e investigar a relação entre duas ou mais variáveis”.
Várias aplicações da análise de regressão envolvem situações em que existem mais de uma
variável independente. Um modelo de regressão que contenha mais de uma variável independente é
chamado de um modelo de regressão múltipla. (MONTGOMERY e RUNGER, 2003).
Montgomery e Runger (2003), descrevem um exemplo supondo que a vida útil de uma
ferramenta de corte é dependente da velocidade de corte e do ângulo da ferramenta. Um modelo de
regressão múltipla que pode descrever essa relação é
εβββ 22110 +++= xxY Equação 13

- 25 -
Na Equação 13, Y representa a vida da ferramenta, x1 representa a velocidade de corte, x2
representa o ângulo de corte e ε é um termo de erro aleatório. Esse é um modelo de regressão linear
múltipla com dois regressores. O termo linear é usado porque a Equação 13 é uma função linear
dos parâmetros desconhecidos β0, β1 e β2.(MONTGOMERY e RANGER, 2003).
Montgomery e Runger (2003), afirmam que, em geral, a variável dependente ou de resposta,
y, pode estar relacionada a k variáveis independentes ou regressores.
Segundo os mesmos autores, a Equação 14 apresenta o modelo de regressão linear múltipla
com k regressores.
εββββ +++++= kk xxxY K22110 Equação 14
Os parâmetros βj, j= 0, 1, ..., k, são chamados de coeficientes de regressão. Segundo
Montgomery e Ranger (2003), esse modelo descreve um hiperplano no espaço k-dimensional dos
regressores {xj}. O parâmetro βj representa a variação esperada na resposta Y por unidade de
variação unitária em xj, quando todos os outros regressores xi(i ≠ j) forem mantidos constantes.
Para Montgomery e Ranger (2003), modelos de regressão linear múltipla são frequentente
usados como aproximações de funções. Isto significa que a verdadeira relação funcional entre Y e
x1, x2, ..., xk não é conhecida, porém, em determinadas faixas de variáveis independentes, o modelo
de regressão linear é considerado uma aproximação adequada.
Segundo Diniz (2000), a regressão linear múltipla:
• Traça através dos pontos marcados no diagrama de dispersão das variáveis x e y, um plano
que minimiza as distâncias entre os pontos plotados; e
• Minimiza a soma dos quadrados de todos os desvios verticais dos valores reais em relação
ao plano.
Estimação de parâmetros pelo método dos mínimos quadrados
Segundo Montgomery e Ranger (2003), o método dos mínimos quadrados pode ser usado
para estimar os coeficientes de regressão no modelo de regressão linear múltipla da Equação 14.

- 26 -
Supondo que n > k observações estejam disponíveis e fazendo xij denotar a i-ésima
observação ou nível da variável xj. As observações são
(xi1, xi2, ..., xik, yi), i= 1, 2, ..., n e n > k
Geralmente apresenta-se os dados para regressão múltipla em uma tabela parecida com a
Tabela 1. (MONTGOMERY e RANGER, 2003).
Tabela 1. Dados para Regressão Linear Múltipla
Y x1 x2 ... xk y1 x11 x12 ... x1k y2 x21 x22 ... xk . . .
.
.
.
.
.
.
. . .
yn xn1 xn2 ... xnk
A Equação 15 mostra as equações normais de mínimos quadrados. (MONTGOMERY e
RANGER, 2003).
Montgomery e Ranger (2003), chamam a atenção para o número de equações normais. É
uma equação para cada um dos coeficientes desconhecidos da regressão. Ou seja, o número de
equações normais é p = k + 1. A solução para as equações normais serão os estimadores de mínimos
quadrados dos coeficientes de regressão, k
^
1
^
0
^
,,, βββ K . As equações normais podem ser resolvidas
utilizando qualquer método de resolução de sistemas de equações lineares.

- 27 -
∑∑∑∑====
=++++n
i
i
n
i
ikk
n
i
i
n
i
i yxxxn11
^
122
^
111
^
0
^
ββββ K
MM
KMM ∑ ∑
∑∑∑
= =
===
=++
++
n
i
n
i
ikik
n
i
ii
n
i
i
n
i
i
xxx
xxxx
1 11
^
1212
^
1
12
1
^
110
^
β
βββ
∑ ∑
∑∑∑
= =
===
=++
++
n
i
n
i
ikk
n
i
iik
n
i
iik
n
i
i
xx
xxxxx
1 1
2^
122
^
111
^
110
^
β
βββ
K
Equação 15
2.3.2 R2 Ajustado e coeficiente de correlação amostral
Segundo Triola (2008), o R2 representa o coeficiente de determinação múltipla, que é uma
medida de quão bem a equação de regressão múltipla se ajusta aos dados amostrais.
Segundo Triola (2008), para se ter um ajuste perfeito deve-se ter R2 = 1. Quanto mais
próximo de 1 é o valor de R2, melhor será o ajuste. Tem-se um ajuste ruim, quando o valor de R2 é
próximo de 0.
Triola (2008), comenta que, conforme variáveis vão sendo incluídas no modelo, R2 cresce.
“Obtém-se um R2 maior pela simples inclusão de todas as variáveis disponíveis, mas a
melhor equação e regressão não usa, necessariamente, todas essas variáveis”(TRIOLA, 2008).
Por causa dessa falha, é recomendável que a comparação de diferentes equações de
regressão múltipla seja feita com um ajuste no coeficiente de determinação, que é o R2 ajustado para
o número de variáveis e o tamanho amostral.

- 28 -
O coeficiente de determinação ajustado pode ser definido como “o coeficiente de
determinação múltipla R2 modificado para levar em conta o número de variáveis e o tamanho
amostral (TRIOLA, 2008).
O coeficiente de determinação ajustado é calculado usando a Equação 16.
R2 ajustado = ( )( )[ ]
( )211
11 R
kn
n−
+−
−−
Equação 16
Onde n = tamanho amostral
k = número de variáveis previsoras
O coeficiente de correlação amostral é uma media de associação linear entre duas variáveis
que não depende da unidade de mensuração. O coeficiente de correlação amostral é definido pela
Equação 17.
( )( )
( ) ( )∑∑
∑
==
=
−−
−−
=n
j
kjk
n
j
iji
kjk
n
j
iji
ik
xxxx
xxxx
r
1
22
1
1
Equação 17
A correlação amostral r possui as seguintes propriedades:
1. Os valores de r devem ficar entre -1 e +1;
2. Se r = 0, então não existe associação linear entre as variáveis. Porém, se r < 0, há uma
tendência de um dos valores do par ser maior que sua média, quando o outro for menor do
que a sua média, e r > 0 indica que quando um valor do par for grande o outro também o
será, além de ambos os valores tender a serem pequenos juntos;
3. Os valores de rik não se alteram com a alteração da escala de uma das variáveis.
Segundo Baptistella (2005), o relacionamento entre as variáveis, definido pelo valor de r,
pode ser interpretado conforme a Tabela 2.

- 29 -
Tabela 2. Grau de relacionamento entre as variáveis
Coeficiente Correlação
|r| = 0 Relação nula
0 < |r| ≤ 0,30 Relação fraca
0,30 < |r| ≤ 0,70 Relação média
0,70 < |r| ≤ 0,90 Relação forte
0,90 < |r| ≤ 0,99 Relação fortíssima
|r| = 1 Relação perfeita
Baptistella (2005), adverte que, nem sempre uma elevada correlação entre duas variáveis
significa a existência de relação de causa e efeito entre as mesmas.
2.3.3 Análise de Componentes Principais
Segundo Vicini e Souza (2005), Análise de Componentes Principais (ACP) é uma técnica da
análise multivariada, que possibilita pesquisas com um grande número de dados disponíveis.
Permite, também, a identificação das medidas responsáveis pelas maiores variações entre os
resultados, sem perdas significativas de informações. A ACP também transforma um conjunto
original de variáveis em outro conjunto: os componentes principais de dimensões equivalentes.
Para Baptistella (2005), a ACP é utilizada para investigar as relações em um conjunto de
dados de p variáveis correlacionadas. Para isso, o conjunto de variáveis originais deve ser
transformado em um conjunto de variáveis não-correlacionadas chamadas de componentes
principais, que tem propriedades especiais em termos de variâncias.
O desenvolvimento da ACP foi conduzido, em parte, pela necessidade de se analisar
conjunto de dados com muitas variáveis correlacionadas. “A idéia matemática do método é
conhecida há muito tempo, apesar do cálculo das matrizes dos autovalores e autovetores não ter
sido possível até o advento da evolução dos computadores” (VICINI e SOUZA, 2005).
A ACP tem se mostrado muito útil como método auxiliar em Regressão Multivariada e
RNA.

- 30 -
2.4 Trabalhos Similares
A seguir são relacionados trabalhos que utilizaram redes neurais artificiais e análise
multivariada dentro do contexto de predição de funções ou valores.
2.4.1 Redes neurais artificiais aplicadas ao processo de coagulação
A Unidade de Insumos Básicos da Braskem (UNIB), através de sua Unidade de Tratamento
de Água (UTA), fornece cerca de 90% da água demandada pelo Pólo Industrial de Camaçari,
localizado a 45 quilômetros de Salvador. Nessa UTA, acontece o processo de clarificação de água.
O processo de clarificação compreende as seguintes operações unitárias: coagulação, floculação e
sedimentação (MENEZES et al 2009).
Segundo Menezes et al (2009), no processo de coagulação realizado na UTA, o agente
coagulante utilizado é o sulfato de alumínio, e o agente químico de ajuste de pH é o hidróxido de
sódio. O sulfato de alumínio tem a função de reduzir as forças que tendem a manter separadas as
partículas em suspensão, e o hidróxido de sódio tem por função manter o pH da solução durante o
processo de coagulação dentro de uma faixa desejável para que a ação do coagulante seja
satisfatória. A dosagem correta destes produtos depende da qualidade da água a ser tratada e é
obtida por meio do teste do jarro.
A água que abastece a UTA da UNIB vem do rio Joanes, que caracteriza-se por amplas
variações de qualidade da água bruta. O tempo necessário para a execução do teste do jarro e as
baixas freqüências da sua realização, não permitem respostas em tempo real às mudanças na
qualidade da água a ser tratada (MAIER et al, 2004, apud MENEZES et al 2009).
O objetivo principal deste trabalho é desenvolver um modelo de RNA que forneça predições
de sulfato de alumínio e hidróxido de sódio, utilizados no tratamento de água na UTA. Foram
construídos diversos modelos de RNAs, validados e testados com os resultados dos testes do jarro e
das medidas de qualidade de água tratada, considerando uma série histórica de seis anos.
A arquitetura de RNA utilizada na construção dos modelos foi a MLP. O número de
camadas intermediárias e neurônios intermediários foram estimados por tentativa e erro. O número
máximo de neurônios intermediários utilizados foi 22 e foram utilizadas no máximo duas camadas

- 31 -
intermediárias. As RNAs foram treinadas usando a versão do algoritmo de retropropagação
momentum e os seus parâmetros de passo e momentum foram encontrados por tentativa e erro; as
faixas testadas incluíram de 0,15 a 0,85 para cada parâmetro. Também foram testadas as funções
sigmoidal e tangente hiperbólica como funções de transferência da camada intermediária. Os
modelos foram construídos utilizado-se o pacote comercial Neurosolutions Professional (versão
3.0).
O uso de RNAs permitiu o desenvolvimento de modelos para a criação de uma metodologia
para a construção de uma ferramenta computacional com o objetivo de auxiliar no processo de
coagulação.
Os modelos desenvolvidos a partir de RNAs MLP forneceram resultados de predição
compatíveis com os dados experimentais.
Segundo Menezes et al (2009), o modelo desenvolvido a partir de RNAs MLP forneceu
melhores resultados de predição em comparação aos modelos construídos a partir de regressão
linear múltipla com os mesmos dados (MENEZES, 2008 apud MENEZES et al (2009), devido a
não-linearidade das inter-relações das variáveis que estão envolvidas no processo de coágulo-
floculação e que podem ser captadas pelas RNAs.
Contudo, Menezes et al (2009), advertem que as RNAs não permitem uma abordagem sobre
aspectos físicos do sistema, pelo fato de que os pesos sinápticos criados na fase de modelagem não
possuem nenhum significado físico.
2.4.2 Rede neural artificial aplicada à previsão de vazão da Bacia Hidrográfica
do Rio Piancó
Para Sousa e Sousa (2008), um dos principais desafios relacionados ao conhecimento
integrado da climatologia e hidrologia é a previsão de vazão em um sistema hídrico, que é uma das
técnicas utilizadas para minimizar o impacto das incertezas do clima sobre o gerenciamento dos
recursos hídricos.
Segundo Sousa e Sousa (2008), o modelo de RNA deste trabalho foi escolhido dentre os
vários modelos existentes por ser um modelo empírico que tem tido ampla aceitação como forma

- 32 -
potencialmente eficaz de se modelar sistemas não-lineares e complexos com grande quantidade de
dados.
O objetivo deste estudo foi propor um modelo baseado em técnicas de RNA que sirva para
predizer e simular vazões médias mensais na estação fluviométrica localizada na cidade de Piancó,
no semiárido paraibano, com base em dados da precipitação média mensal, a montante dessa
estação envolvendo, parte da bacia hidrográfica do rio Piancó.
Sousa e Sousa (2008) comentam que, neste trabalho foram considerados valores da vazão
média mensal referente à estação fluviométrica de Piancó, cedidos pela (ANA, 2010), e valores de
precipitação média mensal de cinco postos pluviométricos: Piancó, Santa dos Garrotes, Nova
Olinda, Itaporanga e Boa Ventura, obtidos junto à (AESA, 2010). “O período de análise
compreende janeiro de 1964 a dezembro de 2003, totalizando 120 meses de observação, enquanto a
avaliação referente à qualidade dos dados foi feita por inspeção visual analisando-se a consistência
e o tamanho das séries” (SOUSA e SOUSA, 2008, p. 175).
As RNAs utilizadas para construir o modelo foram do tipo MLP com três camadas. A
camada de entrada, uma única camada oculta e a camada de saída. Os neurônios da camada oculta
possuem função de ativação sigmóide e, os da camada de saída, possuem neurônios com função de
ativação linear.
Neste estudo foram utilizadas diversas arquiteturas a fim de escolher aquela que melhor
prediga as vazões médias mensais da bacia em estudo. A metodologia utilizada na pesquisa da
arquitetura da RNA foi a de variar o número de neurônios na camada de entrada, o número de
neurônios e a função de transferência na camada oculta.
Em todas as RNAs, o treinamento foi realizado utilizando-se a técnica de otimização de
Levenberg-Marquardt. “A motivação pela utilização deste método no treinamento das RNAs se
justifica não só por se tratar de uma ótima técnica para aproximação de relações não-lineares mas
também por ser rápida e já ter produzido bons resultados” (SOUSA e SOUSA, 2008, p. 175).
Foram utilizados 120 dados, os quais foram separados em 72 valores para treinamento, 24
valores para validação e 24 valores para teste. Antes de iniciar o treinamento, todos os dados de
entrada foram normalizados e no final de cada treinamento, com os pesos e vieses ajustados, as
RNAs foram simuladas para gerar resultados. O processo de criação, treinamento e simulação da
RNA, foi desenvolvido utilizando o software MATLAB.

- 33 -
Apenas os 24 melhores, dos 120 resultados obtidos foram utilizados para análise. Para
selecionar as melhores arquiteturas, foi avaliado o desempenho de generalização da RNA através de
análises estatísticas entre os dados calculados e os observados para o período de teste.
A arquitetura de RNA que apresentou melhor resultado em todos os parâmetros estatísticos,
teve coeficiente de determinação de 0,95, coeficiente de eficiência de 0,94, e erro padrão de
estimativa de 4,62, considerando-se o período de teste. Para esta arquitetura foram utilizados dez
neurônios na camada intermediária e a função de transferência foi a log-sig; o resultado foi obtido
em uma segunda inicialização.
A Tabela 3 mostra a arquitetura que obteve melhor resultado para o período de teste.
Tabela 3. Melhor arquitetura para o período de teste
Arquitetura Treinamento Validação Teste
R2 E EPE R2 E EPE R2 E EPE
RC310L2 0,67 0,66 9,56 0,97 0,94 4,23 0,95 0,94 4,62
2.4.3 O uso de Redes Neurais e Regressão Linear Múltipla na engenharia de
avaliações: determinação dos valores venais de imóveis urbanos
O objetivo deste trabalho é determinar o valor venal de imóveis urbanos utilizando RNAs e
Regressão Linear Múltipla. Foram comparadas as técnicas de Redes Neurais Artificiais e Análise de
Regressão Múltipla, analisadas as suas eficiências na determinação dos valores venais de imóveis
edificados, e comparadas as duas técnicas entre si com a finalidade de avaliar a técnica mais
eficiente para o problema em questão.
Neste trabalho, a determinação do valor venal de imóveis urbanos é utilizada para fins de
tributação como IPTU (Imposto Predial e Territorial Urbano) e ITBI (Imposto sobre Transmissão
de Bens Imóveis) da cidade de Guarapuava/PR. Para tanto, foram utilizados os dados de Cadastro
Imobiliário, fornecido pelo setor de Planejamento da Prefeitura Municipal de Guarapuava. As
variáveis escolhidas foram: localização (bairro), setor, pavimentação, iluminação púbica, esgoto,
área do terreno, pedologia, topografia, situação, área edificada, tipo, estrutura, conservação e valor
venal. Foi utilizada uma técnica chamada de Análise das Componentes Principais, para reduzir o

- 34 -
número de variáveis de 13 para 9 e preservar o máximo de informação possível sobre as entradas.
Neste estudo foram utilizados dados de 256 unidades.
Modelo utilizando RNA
Para modelar as RNAs foi utilizado o software Matlab 6.5 e foi utilizada a topologia MLP,
com uma camada de entrada, consistindo de 9 nós, uma camada oculta, e uma camada de saída com
um único neurônio que fornece o valor venal do imóvel. O número de neurônios na camada oculta
variou de 0 a 12 neurônios.
Foi empregada neste estudo, na camada oculta e na camada de saída, a função de ativação
não-linear do tipo sigmoidal (logsig), que assume um intervalo contínuo de valores entre 0 e 1. Para
o treinamento, foi utilizado o algoritmo de Levenberg Marquardt.
Para a avaliação do desempenho da RNA, utilizou-se o erro quadrático médio (MSE – mean
squared error), “que é a média do somatório dos quadrados dos erros de cada caso”, tanto do
conjunto de treinamento, quanto do conjunto de testes (BAPTISTELLA, 2005).
A amostra foi dividida em dois grupos. O grupo de treinamento com 170 imóveis (66%) da
amostra e o grupo para teste com 86 imóveis (34%), tomando-se o cuidado de manter a mesma
proporção de valores dos imóveis nos dois conjuntos.
A Tabela 4 mostra os melhores resultados das simulações.
Tabela 4. Resultado das melhores simulações
Rede Treinamento (rmse) Teste (rmse)
9E4N1N50 6,96% 12,50%
9E5N1N50 6,28% 10,40%
9E6N1N50 5,62% 12,09%
9E7N1N50 3,91% 13,94%
9E8N1N50 4,96% 11,13%
9E9N1N50 3,91% 13,81%
9E10N1N50 4,64% 12,88%
9E11N1N50 3,14% 12,23%
9E12N1N50 2,81% 15,81%
- 35 -
Modelo utilizando Análise de Regressão Múltipla
O software utilizado para a construção do modelo de Análise de Regressão Múltipla e da
tabela de dados foi o software Excel. Foi usado o software Statistica v.5 para fazer a validação dos
resultados.
Foram realizados três experimentos com Regressão Linear Múltipla. O primeiro modelo de
Regressão Linear Múltipla foi ajustado utilizando a matriz obtida após a Análise de Componentes
Principais. No ajuste do modelo, verificou-se que as variáveis setor, pedologia e topografia, não são
significativamente importantes, por isso, estas variáveis também foram excluídas do modelo.
Assim, as variáveis independentes do modelo são: localização, estrutura, serviços urbanos,
característica, área edificada e situação. Verificou-se que as previsões geradas pelo modelo se
aproximam dos valores reais.
No segundo experimento foram utilizadas cinco variáveis independentes para a construção
do modelo. Estas variáveis são: esgoto, localização, conservação, situação e topografia. Verificou-
se que as previsões geradas pelo modelo têm uma boa linearidade, indicando que este modelo
também apresenta respostas próximas dos valores reais.
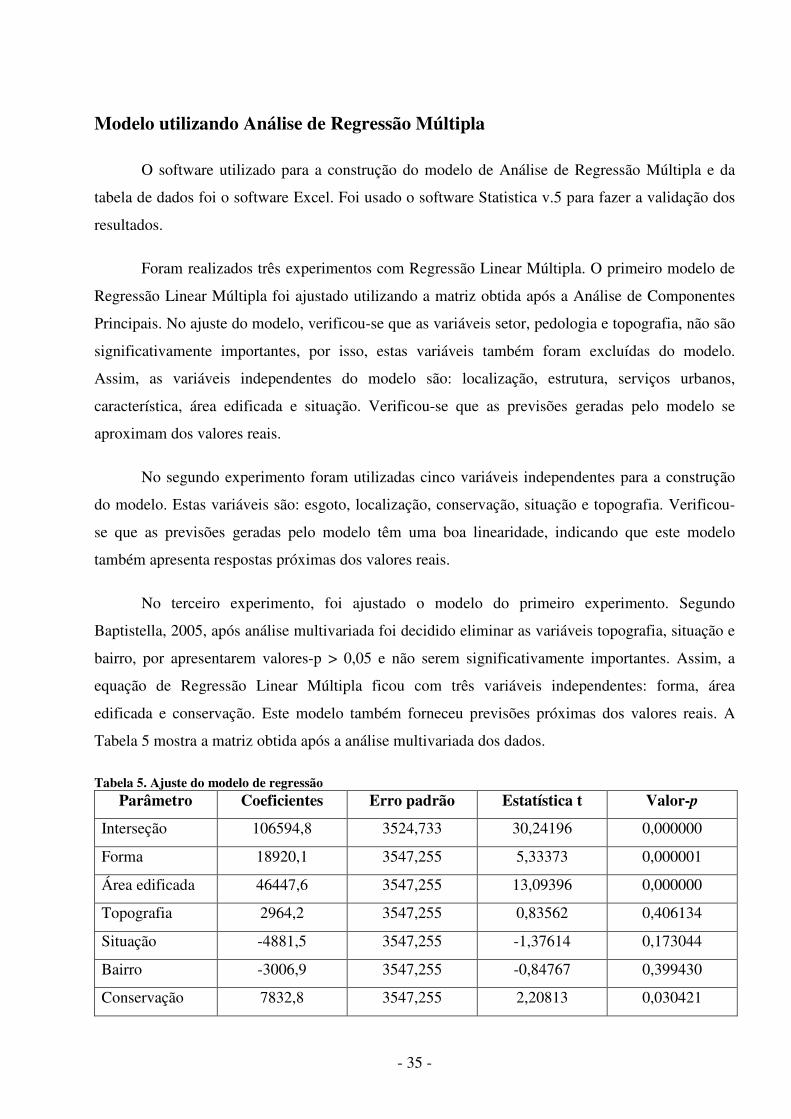
No terceiro experimento, foi ajustado o modelo do primeiro experimento. Segundo
Baptistella, 2005, após análise multivariada foi decidido eliminar as variáveis topografia, situação e
bairro, por apresentarem valores-p > 0,05 e não serem significativamente importantes. Assim, a
equação de Regressão Linear Múltipla ficou com três variáveis independentes: forma, área
edificada e conservação. Este modelo também forneceu previsões próximas dos valores reais. A
Tabela 5 mostra a matriz obtida após a análise multivariada dos dados.
Tabela 5. Ajuste do modelo de regressão Parâmetro Coeficientes Erro padrão Estatística t Valor-p
Interseção 106594,8 3524,733 30,24196 0,000000
Forma 18920,1 3547,255 5,33373 0,000001
Área edificada 46447,6 3547,255 13,09396 0,000000
Topografia 2964,2 3547,255 0,83562 0,406134
Situação -4881,5 3547,255 -1,37614 0,173044
Bairro -3006,9 3547,255 -0,84767 0,399430
Conservação 7832,8 3547,255 2,20813 0,030421

- 36 -
Analisando-se os resultados dos erros e as variáveis para cada modelo, verifica-se que é
possível melhorar os resultados obtidos, “incluindo novas variáveis que tenham maior relevância e
expliquem melhor a formação do valor venal de um imóvel” (BAPTISTELLA, 2005).
As duas técnicas tiveram desempenho satisfatório, porém, o modelo com RNA apresentou
desempenho superior ao estatístico, na predição dos valores venais.
Verificou-se que a RNA e a Regressão Linear Múltipla apresentaram melhores resultados
quando se constrói o modelo com grupos homogêneos de itens para cada tipo de imóvel. Baptistella
(2005), comenta que neste estudo não foi utilizada nenhuma técnica específica para esta finalidade,
mas que, os métodos multivariados de agrupamentos poderiam ser muito úteis para este tipo de
análise.
2.5 Ferramentas para criação de RNA
Durante o desenvolvimento deste trabalho foram pesquisadas diversas ferramentas para a
criação de RNAs, que serão apresentadas brevemente na sequência.
2.5.1 SNNS - Stuttgart Neural Network Simulator
O SNNS (Stuttgart Neural Network Simulator) é um software para modelagem e simulação
de RNAs que roda em ambientes Unix. O SNNS foi desenvolvido no Institute for Parallel and
Distributed High Performance Systems (IPVR) na Universidade de Stuttgart. O SNNS consiste de
dois componentes principais:
• O núcleo do simulador, escrito em C
• Interface gráfica do usuário sob X11R4 ou X11R5
O núcleo do simulador atua na rede interna de estruturas de dados da rede neural e realiza
todas as operações de aprendizagem e memória. O SNNS pode ser estendido pelo usuário com a
definição de funções de ativação, funções de saída, funções de peso e procedimentos de
aprendizagem; que são escritas como programas em C simples e ligadas ao núcleo do simulador. O
SNNS possui uma grande gama de algoritmos de aprendizado, muitos deles, variações do algoritmo
Backpropagation. A Figura 16 mostra o ambiente de desenvolvimento do SNNS.

- 37 -
Figura 16. Ambiente de desenvolvimento do SNNS. Fonte: (Zell et al., 2010)
2.5.2 JavaNNS – Java Neural Network Simulator
Java Neural Network Simulator (JavaNNS) é um simulador para RNA desenvolvido no
Wilhelm-Schickard-Institute for Computer Science (WSI) em Tübingen, Alemanha. O JavaNNS é
baseado no núcleo do SNNS 4.2, com uma nova interface gráfica escrita em Java. O JavaNNS é
mais intuitivo e fácil de usar e suas capacidades são similares ao do SNNS.
Algumas características complexas do SNNS, mas não muito utilizadas, como visualização
tridimensional de redes neurais, foram deixadas de fora ou adiada para uma versão posterior,
todavia, algumas características novas, como o painel de log, foram introduzidas.
Além da nova interface gráfica, uma grande vantagem do JavaNNS é o aumento de sua
independência quanto a plataforma de utilização. O JavaNNS também funciona em computadores
pessoais, desde que o Java Runtime Environment esteja instalado.
- 38 -
“O JavaNNS foi testado em Windows NT, Windows 2000, Windows XP, RedHat Linux 6.1,
Solaris 7 e Mac OS X” (ZELL et al. Apud SOUZA FILHO, 2009, p. 30).
Durante a escrita deste trabalho, o JavaNNS também foi testado no Windows Vista e
funcionou bem.
O JavaNNS é gratuito mas não é de domínio público, pois o código-fonte não é aberto ao
púbico. Pode-se distribuir livremente cópias do JavaNNS, mas é proibida a distribuição de cópias
modificadas. Pode-se entretanto, distribuir modificações do JavaNNS como arquivos separados,
juntamente com o JavaNNS inalterado.
A Figura 17 mostra o ambiente de desenvolvimento do JavaNNS.
Figura 17 Ambiente de desenvolvimento do JavaNNS Fonte: Fischer et al. (2002)
2.5.3 SIMBRAIN
O Simbrain é uma ferramenta gratuita para a construção, execução e análise de RNA. O
Simbrain tem o objetivo de ser uma ferramenta o mais visual e intuitiva quanto possível.
- 39 -
O Simbrain é escrito em Java e roda em Windows, Mac OS X e Linux. O Simbrain é open
source e está em constante evolução.
A Figura 18 mostra o ambiente de trabalho do Simbrain.
Figura 18. Ambiente de trabalho do Simbrain Fonte: Yoshimi et. al. (2010)
O espaço de trabalho do Simbrain é um quadro abrangente que inclui todos os componentes
da simulação: redes, mundos e indicadores.
O componente de rede do Simbrain representa um circuito neural simulado. As redes são o
principal componente de uma simulação no Simbrain. Elas são construídas utilizando uma interface
gráfica simples.
Mundos são componentes que interagem com componentes de rede, dando e/ ou recebendo
informações. A Figura 19 mostra um componente mundo realizando uma simulação da habilidade
de dois ratos se guiarem pelo cheiro.

- 40 -
Os estados que ocorrem em uma RNA correspondem a pontos em um espaço de alta
dimensão. Esses estados e os padrões que forma pode ser inspecionados visualmente utilizando os
componentes do indicador. Isso permite a análise visual das estruturas de representação que se
desenvolvem em uma RNA.
Figura 19. Duas RNAs interagindo no Simbrain Fonte: Yoshimi et. al. (2010) 2.5.4 MATLAB
MATLAB (MATrix LABoratory) é um software de alta performance voltado para o cálculo
numérico. O MATLAB pode tratar problemas de análise numérica, cálculo com matrizes,
processamento de sinais e construção de gráficos.
No começo, o MATLAB foi usado por engenheiros de projeto de controle, mas logo se
espalhou para outros campos de aplicação. Atualmente o MATLAB é utilizado nas áreas da
educação, no ensino da álgebra linear e análise numérica, e também é muito utilizado em
processamento de imagens.

- 41 -
O MATLAB também é bastante popular entre cientistas e engenheiros que trabalham com
RNA aplicada a estudos de predição. É possível modelar RNAs no MATLAB através do Neural
Network Toolbox, uma extensão do MATLAB que contém ferramentas para a concepção,
execução, visualização e simulação de redes neurais. A Figura 20 mostra o ambiente de trabalho do
MATLAB.
Figura 20. Ambiente de Trabalho do MATLAB Fonte: www.programasde.com/wp-content/interface-matlab.JPG

- 42 -
Figura 21. Neural Network toolbox Fonte: Demuth, Beale, Hagan (2010)
O Neural Network Toolbox fornece suporte abrangente comprovado para muitos
paradigmas de rede, bem como interface gráfica de usuário (GUI), que lhe permitem projetar e
gerenciar suas redes. A janela Ferramenta de Reconhecimento de Padrões do Neural Network
Toolbox é mostrada pela Figura 21.
2.6 Ferramentas para Análise Estatística
Durante o desenvolvimento deste trabalho foram pesquisadas duas ferramentas para realizar
Análise Estatística.
2.6.1 Calc
O Calc é uma planilha eletrônica que acompanha o pacote de tarefas de escritório
BrOffice.org. O BrOffice.org é um software livre e possui versões para rodar em diversos sistemas
operacionais. O Calc é muito similar ao Excel, tanto no seu funcionamento, quanto na sua
aparência..O Calc permite ao usuário criar tabelas com texto, números e fórmulas, realizar cálculos
e produzir relatórios. O Calc também possui uma grande variedade de funções estatísticas que serão
úteis na realização deste trabalho.

- 43 -
O Calc possui os seguintes recursos que serão úteis neste trabalho:
• Cálculos: O Calc oferece funções que o usuário pode utilizar para criar fórmulas que
executem cálculos complexos dos dados;
• Cálculos de Hipóteses: Possibilidade de exibir imediatamente os resultados das alterações
realizadas em um fator em cálculos compostos de diversos fatores. Por exemplo, é possível
ver como a alteração do período de tempo em um cálculo de empréstimo afeta as taxas de
juros ou os montantes de reembolso.
• Gráficos Dinâmicos: O Calc permite a apresentação dos dados de uma planilha em gráficos
dinâmicos, atualizados automaticamente quando ocorrem alterações nos dados.
A Figura 22 mostra o ambiente de trabalho do Calc.
Figura 22. Ambiente de trabalho do Calc

- 44 -
2.6.2 STATISTICA O STATISTICA é um software de métodos estatísticos que possui um conjunto de ferramentas para
análise, gestão e visualização de bases de dados e Data Mining. As suas técnicas incluem uma
seleção de modelação preditiva, agrupamentos (clustering) e ferramentas exploratórias. O
STATISTICA também possui um simulador de redes neurais.
O STATISTICA vem sendo aplicado nas mais diversas áreas incluindo:
• Controle de qualidade de processos e monitoramento de industrias química,
petroquímica, farmacêutica, produtos de consumo e indústrias.
• Garantia de Análise e aplicações de monitoramento remoto da indústria
transformadora de equipamentos pesados.
• Análise de risco, finanças e seguros industriais.
A Figura 23 mostra o ambiente de trabalho do Statistica.
Figura 23. Ambiente de trabalho do Statistica
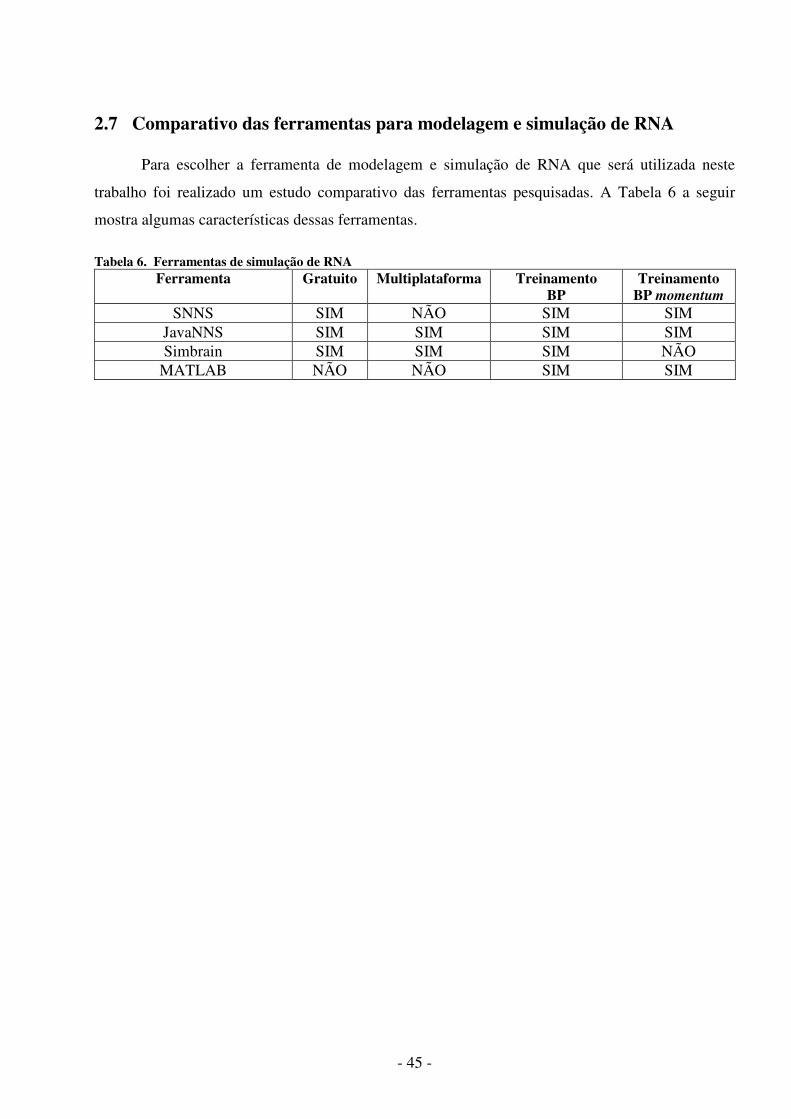
- 45 -
2.7 Comparativo das ferramentas para modelagem e simulação de RNA
Para escolher a ferramenta de modelagem e simulação de RNA que será utilizada neste
trabalho foi realizado um estudo comparativo das ferramentas pesquisadas. A Tabela 6 a seguir
mostra algumas características dessas ferramentas.
Tabela 6. Ferramentas de simulação de RNA Ferramenta Gratuito Multiplataforma Treinamento
BP Treinamento
BP momentum SNNS SIM NÃO SIM SIM
JavaNNS SIM SIM SIM SIM Simbrain SIM SIM SIM NÃO
MATLAB NÃO NÃO SIM SIM

- 46 -
3 DESENVOLVIMENTO
Trata-se de um projeto capaz de predizer os resultados de um ensaio de coagulação
utilizando duas técnicas diferentes. Uma por meio de RNA e outra utilizando Análise Multivariada.
A arquitetura de RNA utilizada foi a do tipo MLP (Multilayer Perceptron). Os modelos criados
utilizando Análise Multivariada foram de dois tipos: Modelos de Regressão Linear Múltipla e
Modelos de Regressão Fatorial. Inicialmente esperava-se utilizar apenas os modelos de RNA e de
Regressão Linear Múltipla, mas, ao final do projeto, na tentativa de melhorar os resultados preditos
dos valores de turbidez decantada, utilizou-se também o modelo de Regressão Fatorial. Neste
trabalho foram implementados somente os modelos de RNA e de Regressão Linear Múltipla. Os
modelos de Regressão Fatorial foram criados automaticamente utilizando o software Statistica 6.0,
pois esses modelos foram utilizados apenas como comparação, para verificar a viabilidade de
utilizar outra técnica estatística para realizar as predições dos resultados do jar test.
Neste projeto foram considerados valores da água bruta provenientes do Rio Itajaí Mirim e
do Rio Canhanduba, ambos localizados no município de Itajaí. Para a construção dos modelos
foram considerados os seguintes parâmetros: coagulante, turbidez da água bruta, pH da água bruta e
alcalinidade da água bruta.
Os valores utilizados para alimentar os modelos foram retirados de análises de jar test
realizadas ao longo do TCC I e do TCC II. Foram realizados 59 ensaios de coagulação para a
realização deste trabalho, incluindo dados para treinamento/modelagem, validação e teste.
3.1 PROJETO
Antes de iniciar a construção dos modelos, os valores obtidos através de análises reais foram
analisados com a ajuda de tabelas de frequências e histogramas. O propósito desta pré-análise é a
possibilidade de identificar possíveis padrões simples que podem ser úteis na criação dos modelos.
As Figuras 24 e 25 mostram os valores de turbidez e pH da água bruta, respectivamente. As
Tabelas 7 e 8 mostram a quantidade absoluta de casos, a quantidade absoluta acumulada, a
quantidade relativa (percentual) e a quantidade relativa acumulada do intervalo inicial ao intervalo
atual; para os intervalos de valores de turbidez e pH da água bruta.
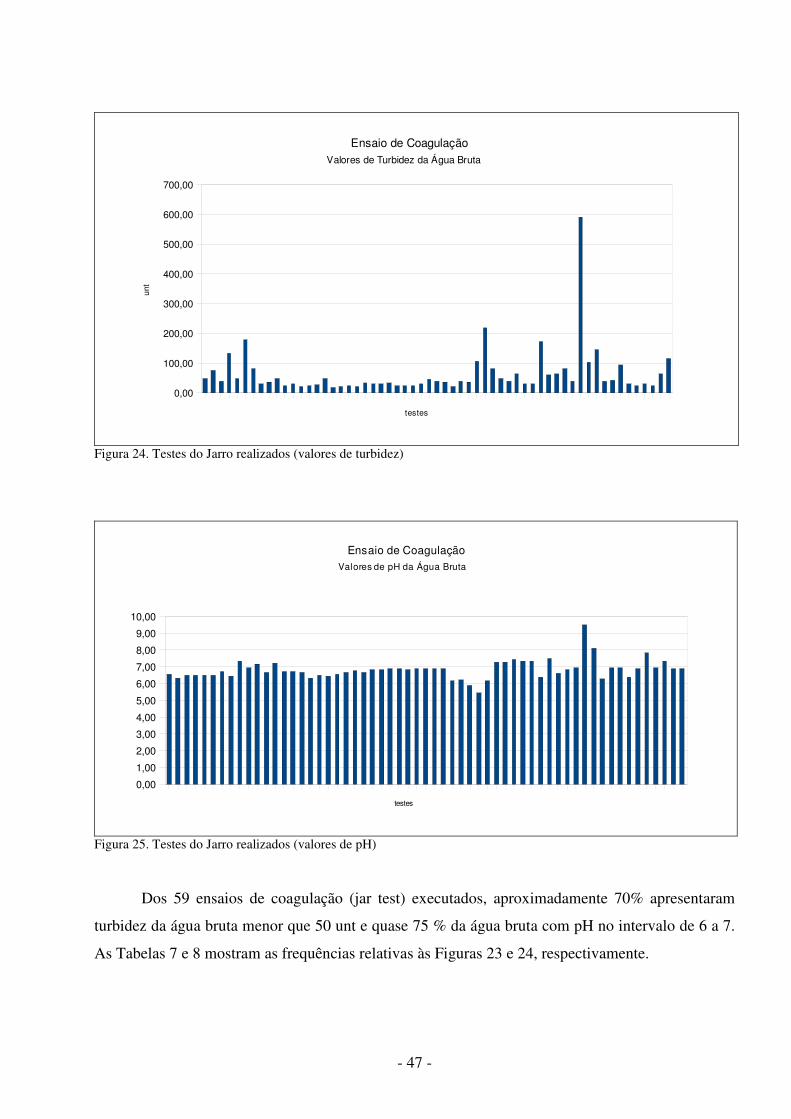
- 47 -
0,00
100,00
200,00
300,00
400,00
500,00
600,00
700,00
Ensaio de CoagulaçãoValores de Turbidez da Água Bruta
testes
unt
Figura 24. Testes do Jarro realizados (valores de turbidez)
0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
8,00
9,00
10,00
Ensaio de CoagulaçãoValores de pH da Água Bruta
testes
Figura 25. Testes do Jarro realizados (valores de pH)
Dos 59 ensaios de coagulação (jar test) executados, aproximadamente 70% apresentaram
turbidez da água bruta menor que 50 unt e quase 75 % da água bruta com pH no intervalo de 6 a 7.
As Tabelas 7 e 8 mostram as frequências relativas às Figuras 23 e 24, respectivamente.
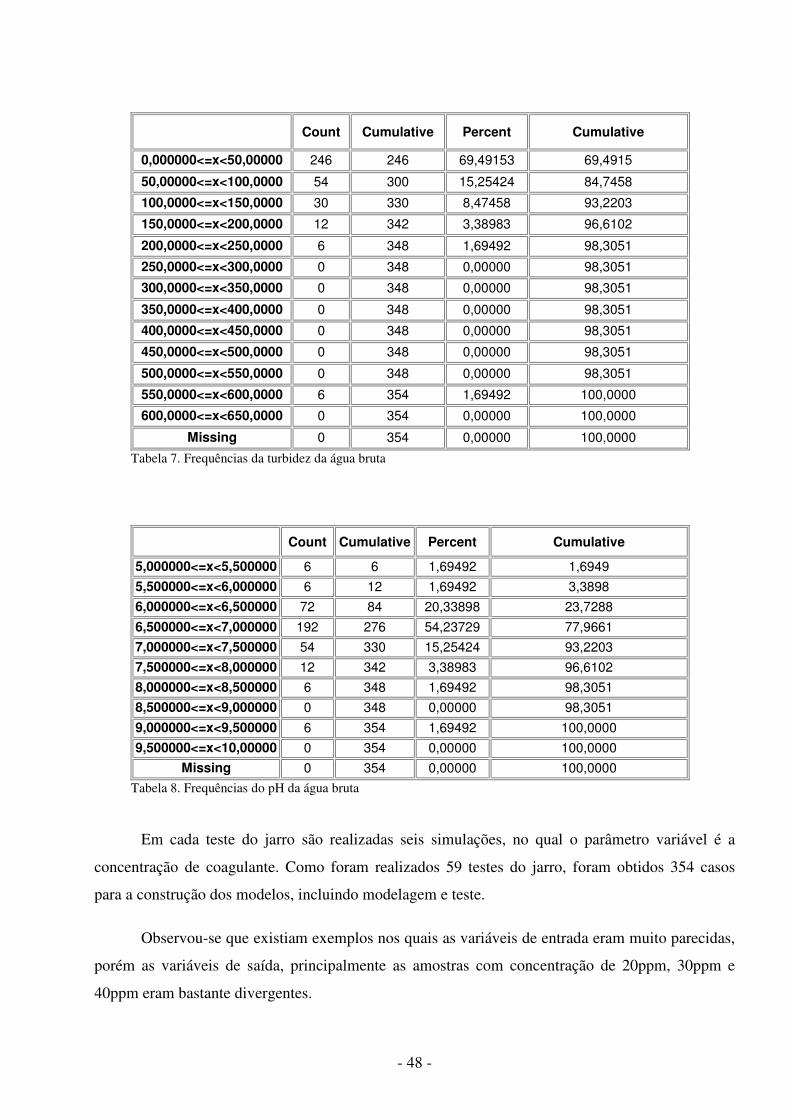
- 48 -
Count Cumulative Percent Cumulative
0,000000<=x<50,00000 246 246 69,49153 69,4915
50,00000<=x<100,0000 54 300 15,25424 84,7458
100,0000<=x<150,0000 30 330 8,47458 93,2203
150,0000<=x<200,0000 12 342 3,38983 96,6102
200,0000<=x<250,0000 6 348 1,69492 98,3051
250,0000<=x<300,0000 0 348 0,00000 98,3051
300,0000<=x<350,0000 0 348 0,00000 98,3051
350,0000<=x<400,0000 0 348 0,00000 98,3051
400,0000<=x<450,0000 0 348 0,00000 98,3051
450,0000<=x<500,0000 0 348 0,00000 98,3051
500,0000<=x<550,0000 0 348 0,00000 98,3051
550,0000<=x<600,0000 6 354 1,69492 100,0000
600,0000<=x<650,0000 0 354 0,00000 100,0000
Missing 0 354 0,00000 100,0000
Tabela 7. Frequências da turbidez da água bruta
Count Cumulative Percent Cumulative
5,000000<=x<5,500000 6 6 1,69492 1,6949
5,500000<=x<6,000000 6 12 1,69492 3,3898
6,000000<=x<6,500000 72 84 20,33898 23,7288
6,500000<=x<7,000000 192 276 54,23729 77,9661
7,000000<=x<7,500000 54 330 15,25424 93,2203
7,500000<=x<8,000000 12 342 3,38983 96,6102
8,000000<=x<8,500000 6 348 1,69492 98,3051
8,500000<=x<9,000000 0 348 0,00000 98,3051
9,000000<=x<9,500000 6 354 1,69492 100,0000
9,500000<=x<10,00000 0 354 0,00000 100,0000
Missing 0 354 0,00000 100,0000
Tabela 8. Frequências do pH da água bruta
Em cada teste do jarro são realizadas seis simulações, no qual o parâmetro variável é a
concentração de coagulante. Como foram realizados 59 testes do jarro, foram obtidos 354 casos
para a construção dos modelos, incluindo modelagem e teste.
Observou-se que existiam exemplos nos quais as variáveis de entrada eram muito parecidas,
porém as variáveis de saída, principalmente as amostras com concentração de 20ppm, 30ppm e
40ppm eram bastante divergentes.

- 49 -
3.2 Modelos utilizando RNA
Os modelos de RNA apresentam os valores de pH e turbidez da água do jarro ao final do jar
test. Para inferir estes resultados foram utilizadas quatro variáveis de entrada, são elas: turbidez da
água bruta, pH da água bruta, alcalinidade da água bruta e dosagem de coagulante.
Portanto, os modelos de RNA possuem quatro neurônios na camada de entrada e dois
neurônios na camada de saída. O tipo de arquitetura da RNA escolhida foi a do tipo MLP com
apenas uma camada oculta. Utilizou-se diversas arquiteturas com o propósito de escolher aquela
que melhor prediz os valores de turbidez e pH da água decantada do jarro após o tempo de
decantação.
A escolha de utilizar apenas uma camada oculta foi baseada em trabalhos similares. A
maioria dos trabalhos pesquisados utilizam modelos com uma única camada oculta. Esta decisão de
utilizar apenas uma camada intermediária é baseada no fato em que uma camada oculta é suficiente
para uma RNA MLP calcular uma aproximação uniforme para os padrões de treinamento. Este fato
tem fundamentação matemática e é conhecido como Teorema da Aproximação Universal.
A metodologia adotada na investigação da arquitetura da RNA foi a de variar o número de
neurônios na camada oculta. Realizou-se treinamento com o número de neurônios variando entre 1
a 10 na camada oculta. A função de ativação deve ser contínua e diferenciável, por isso, nos
neurônios da camada oculta e de saída, utilizou-se a função de ativação do tipo sigmoidal, que
assume um intervalo contínuo de valores entre 0 e 1.
A Figura 26 mostra uma das arquiteturas de RNA que foi treinada e simulada durante a
realização deste trabalho.
Figura 26. Uma arquitetura de RNA MLP com 9 neurônios na camada oculta.
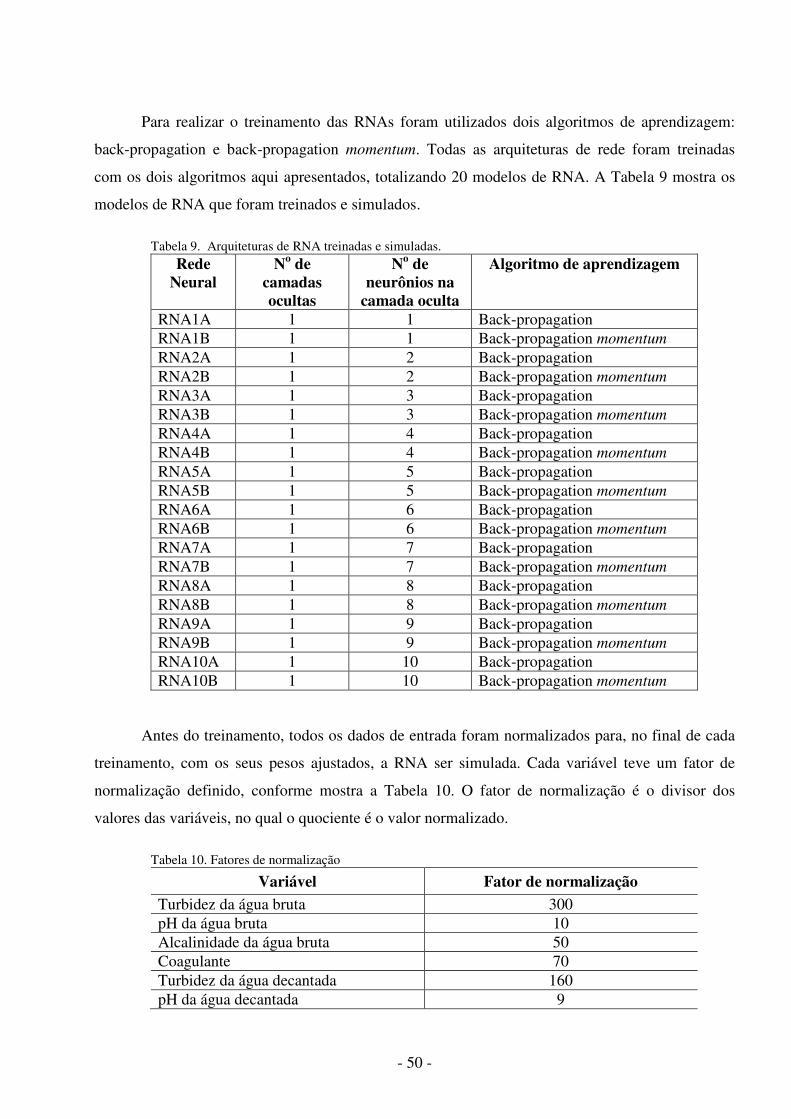
- 50 -
Para realizar o treinamento das RNAs foram utilizados dois algoritmos de aprendizagem:
back-propagation e back-propagation momentum. Todas as arquiteturas de rede foram treinadas
com os dois algoritmos aqui apresentados, totalizando 20 modelos de RNA. A Tabela 9 mostra os
modelos de RNA que foram treinados e simulados.
Tabela 9. Arquiteturas de RNA treinadas e simuladas.
Antes do treinamento, todos os dados de entrada foram normalizados para, no final de cada
treinamento, com os seus pesos ajustados, a RNA ser simulada. Cada variável teve um fator de
normalização definido, conforme mostra a Tabela 10. O fator de normalização é o divisor dos
valores das variáveis, no qual o quociente é o valor normalizado.
Tabela 10. Fatores de normalização
Variável Fator de normalização Turbidez da água bruta 300 pH da água bruta 10 Alcalinidade da água bruta 50 Coagulante 70 Turbidez da água decantada 160 pH da água decantada 9
Rede Neural
No de camadas ocultas
No de neurônios na
camada oculta
Algoritmo de aprendizagem
RNA1A 1 1 Back-propagation RNA1B 1 1 Back-propagation momentum RNA2A 1 2 Back-propagation RNA2B 1 2 Back-propagation momentum RNA3A 1 3 Back-propagation RNA3B 1 3 Back-propagation momentum RNA4A 1 4 Back-propagation RNA4B 1 4 Back-propagation momentum RNA5A 1 5 Back-propagation RNA5B 1 5 Back-propagation momentum RNA6A 1 6 Back-propagation RNA6B 1 6 Back-propagation momentum RNA7A 1 7 Back-propagation RNA7B 1 7 Back-propagation momentum RNA8A 1 8 Back-propagation RNA8B 1 8 Back-propagation momentum RNA9A 1 9 Back-propagation RNA9B 1 9 Back-propagation momentum RNA10A 1 10 Back-propagation RNA10B 1 10 Back-propagation momentum

- 51 -
Para realizar o treinamento das RNAs foi utilizado o software JavaNNS por ser gratuito e
por suportar as técnicas de treinamento back-propagation e back-propagation momentum. Embora a
ferramenta SNNS também possua as mesmas características anteriores, ela não funciona no
ambiente Windows, que é o sistema operacional utilizado pelo computador que realizou as
simulações.
Antes de realizar o treinamento das RNAs realizou-se uma filtragem de dados para eliminar
os exemplos de padrões discrepantes. Observou-se que exemplos com valores de entrada muito
parecidos apresentavam valores de saída muito divergentes. Foram eliminados 47 exemplos,
sobrando 307 exemplos para realizar o treinamento, validação e teste das RNAs. Para o treinamento
foram utilizados aproximadamente 60% dos dados do conjunto de exemplos e o restante dos dados
para validação e teste das redes, portanto, 20% para validação e 20% para teste.
Os exemplos de padrões para o JavaNNS são armazenados em arquivos com extensão
“.pat”. Nesses arquivos tem-se a definição da configuração das entradas e saídas, bem como o
número de padrões a serem treinados ou validados. A Figura 27 mostra o arquivo de padrões
utilizado para treinar as RNAs utilizadas neste trabalho. Por razões de espaço foram omitidos dados
do padrão de treinamento.
Foi desenvolvida uma ferramenta para automatizar a criação dos arquivos de treinamento e
validação das RNAs. A ferramenta foi desenvolvida em linguagem C++. Esta ferramenta
transforma os dados contidos num arquivo de texto em um arquivo de padrões do JavaNNS. Assim,
pode-se facilmente colar os dados contidos numa tabela do Calc ou do Excel em um arquivo de
texto e obter o arquivo de padrões do JavaNNS.
Figura 27. Arquivo de padrões para predição do teste do jarro

- 52 -
Para realizar as simulações foi utilizado o aplicativo snns2c que transforma uma RNA
treinada com o JavaNNS em um código-fonte na linguagem C que contém os pesos ajustados da
rede treinada. Foi implementado um simulador de RNA específico para o problema em questão,
utilizando o código-fonte da estrutura da RNA treinada, gerado pelo snns2c. A Figura 28 mostra o
snns2c.exe em funcionamento.
Figura 28. O snns2c convertendo uma rede treinada no JavaNNS em linguagem C.
3.2.1 Resultados das RNAs
Das 20 (vinte) RNAs treinadas, apenas 12 (doze) foram simuladas, porque nem todas
obtiveram resultados significativos na fase de validação. Nesta seção serão apresentadas as 8 (oito)
arquiteturas de RNAs que obtiveram melhores resultados. A Tabela 11 mostra as arquiteturas de
RNAs com melhores resultados.
Para a comparação dos resultados utilizou-se o erro quadrático médio (MSE), que é a média
do somatório dos quadrados dos erros de cada caso. Segundo BAPTISTELA (2005), é comum
adotar-se a raiz quadrada do erro quadrático médio (rmse) no cálculo do erro da RNA. O rmse é
determinado pela equação 18.
rmse =
−∑n
ÿy2)(
Equação 18
onde:
y = saídas reais normalizadas
ÿ = saídas normalizadas previstas pela RNA
n = número de casos
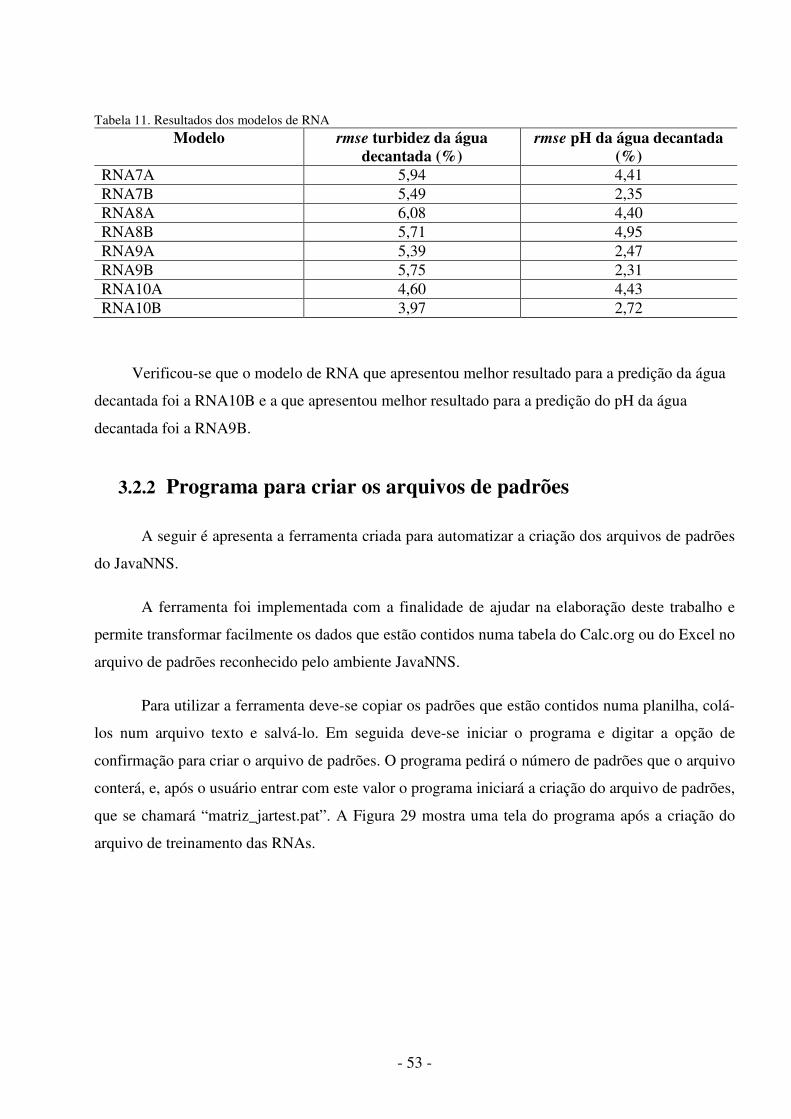
- 53 -
Tabela 11. Resultados dos modelos de RNA
Modelo rmse turbidez da água decantada (%)
rmse pH da água decantada (%)
RNA7A 5,94 4,41 RNA7B 5,49 2,35 RNA8A 6,08 4,40 RNA8B 5,71 4,95 RNA9A 5,39 2,47 RNA9B 5,75 2,31 RNA10A 4,60 4,43 RNA10B 3,97 2,72
Verificou-se que o modelo de RNA que apresentou melhor resultado para a predição da água
decantada foi a RNA10B e a que apresentou melhor resultado para a predição do pH da água
decantada foi a RNA9B.
3.2.2 Programa para criar os arquivos de padrões
A seguir é apresenta a ferramenta criada para automatizar a criação dos arquivos de padrões
do JavaNNS.
A ferramenta foi implementada com a finalidade de ajudar na elaboração deste trabalho e
permite transformar facilmente os dados que estão contidos numa tabela do Calc.org ou do Excel no
arquivo de padrões reconhecido pelo ambiente JavaNNS.
Para utilizar a ferramenta deve-se copiar os padrões que estão contidos numa planilha, colá-
los num arquivo texto e salvá-lo. Em seguida deve-se iniciar o programa e digitar a opção de
confirmação para criar o arquivo de padrões. O programa pedirá o número de padrões que o arquivo
conterá, e, após o usuário entrar com este valor o programa iniciará a criação do arquivo de padrões,
que se chamará “matriz_jartest.pat”. A Figura 29 mostra uma tela do programa após a criação do
arquivo de treinamento das RNAs.
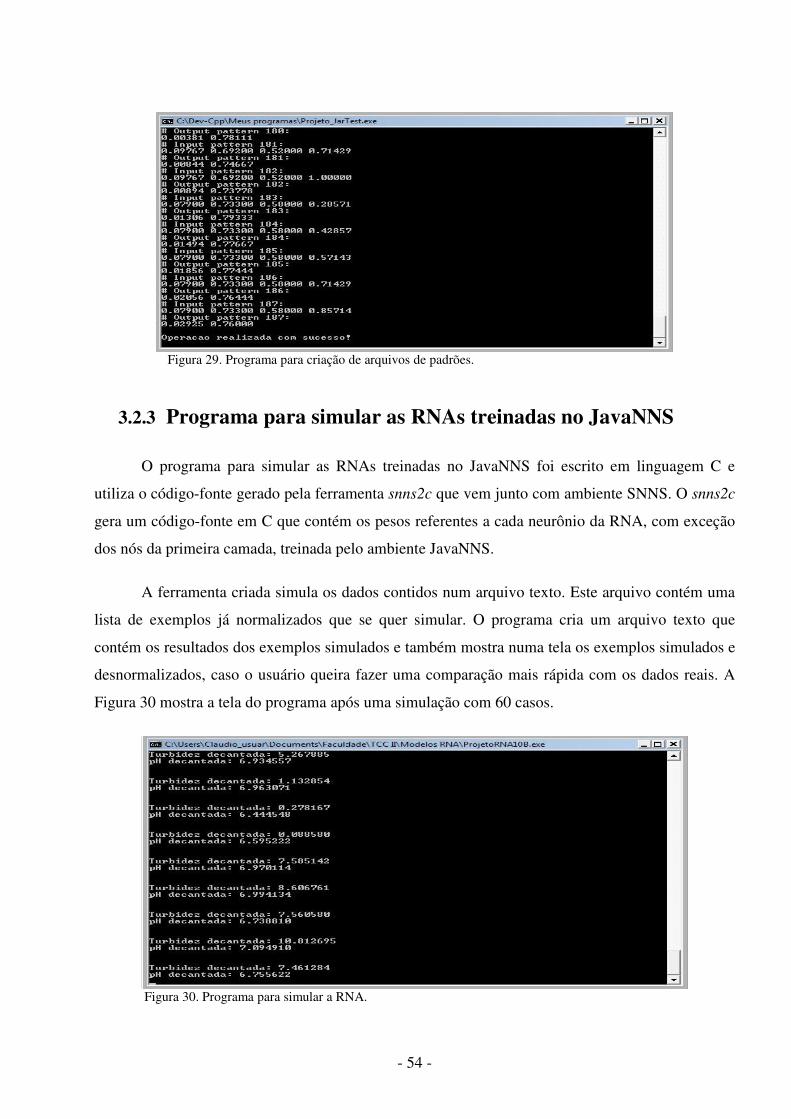
- 54 -
Figura 29. Programa para criação de arquivos de padrões.
3.2.3 Programa para simular as RNAs treinadas no JavaNNS
O programa para simular as RNAs treinadas no JavaNNS foi escrito em linguagem C e
utiliza o código-fonte gerado pela ferramenta snns2c que vem junto com ambiente SNNS. O snns2c
gera um código-fonte em C que contém os pesos referentes a cada neurônio da RNA, com exceção
dos nós da primeira camada, treinada pelo ambiente JavaNNS.
A ferramenta criada simula os dados contidos num arquivo texto. Este arquivo contém uma
lista de exemplos já normalizados que se quer simular. O programa cria um arquivo texto que
contém os resultados dos exemplos simulados e também mostra numa tela os exemplos simulados e
desnormalizados, caso o usuário queira fazer uma comparação mais rápida com os dados reais. A
Figura 30 mostra a tela do programa após uma simulação com 60 casos.
Figura 30. Programa para simular a RNA.

- 55 -
3.3 Regressão Múltipla
Os modelos de Regressão Linear Múltipla foram modelados no software Calc. Após a
criação dos modelos, Realizou-se a mesma modelagem no software Statistica, afim de verificar se
os parâmetros dos modelos implementados no Calc correspondiam a uma modelagem correta. O
software Statistica permite criar modelos de Regressão Linear Múltipla de forma automática,
levando alguns segundos para realizar a modelagem.
Para realizar a modelagem e teste dos modelos estatísticos utilizou-se os mesmos dados que
foram utilizados para as RNAs. Ao contrário da RNA, que foi criado um modelo para se obter dois
resultados, para a Regressão Linear Múltipla foram criados dois modelos, um para predizer o
resultado da turbidez da água decantada e outro para predizer o pH.
Para a criação dos modelos de Regressão Linear Múltipla, utilizou-se 247 dados. Como não
são utilizados dados para validação, diferentemente da RNA, pôde-se utilizar mais dados para
construir os modelos de Regressão Linear Múltipla.
3.4.1 Normalidade e Linearidade das variáveis
Segundo Hair et. al.(2005), a suposição mais fundamental em análise multivariada é a
normalidade. A normalidade se refere à forma da distribuição de dados para uma variável individual
e sua correspondência com a distribuição normal. Neste trabalho, foi avaliada a normalidade para
todas as variáveis envolvidas.
Para o diagnóstico da normalidade das variáveis foi utilizado o gráfico de probabilidade
normal, que segundo Hair et. al.(2005), compara a distribuição cumulativa de valores de dados reais
com a distribuição cumulativa de uma distribuição normal. A Figura 31 mostra o gráfico de
probabilidade normal para as variáveis do modelo. Percebe-se que para as variáveis turbidez da
água bruta e turbidez da água decantada a um desvio significativo da linha diagonal, indicando
desvio da normalidade. Foram testadas varias formas de transformar os valores das variáveis para se
conseguir uma boa normalidade, porém não foi obtido sucesso. Por fim, preferiu-se utilizar valores
reais para a construção dos modelos.
Uma suposição implícita em regressão múltipla é a linearidade. A linearidade é usada para
expressar que os modelos que possuem esta propriedade prevêem valores que recaem em uma linha
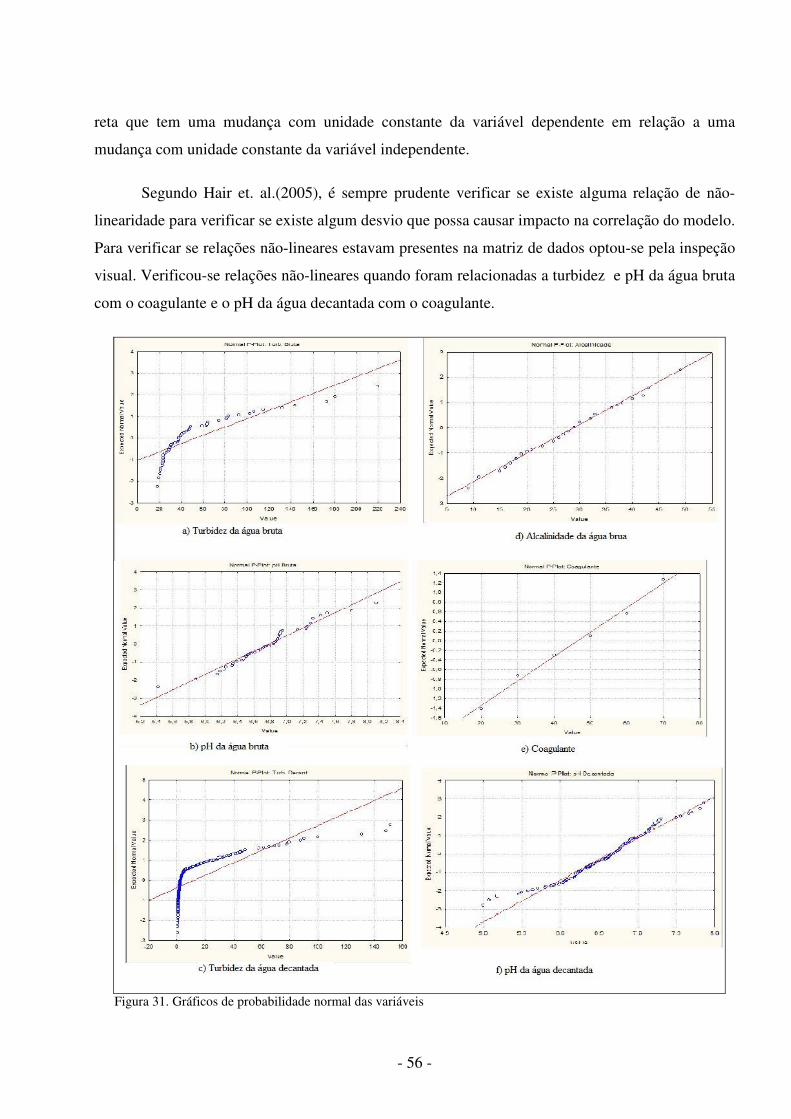
- 56 -
reta que tem uma mudança com unidade constante da variável dependente em relação a uma
mudança com unidade constante da variável independente.
Segundo Hair et. al.(2005), é sempre prudente verificar se existe alguma relação de não-
linearidade para verificar se existe algum desvio que possa causar impacto na correlação do modelo.
Para verificar se relações não-lineares estavam presentes na matriz de dados optou-se pela inspeção
visual. Verificou-se relações não-lineares quando foram relacionadas a turbidez e pH da água bruta
com o coagulante e o pH da água decantada com o coagulante.
Figura 31. Gráficos de probabilidade normal das variáveis
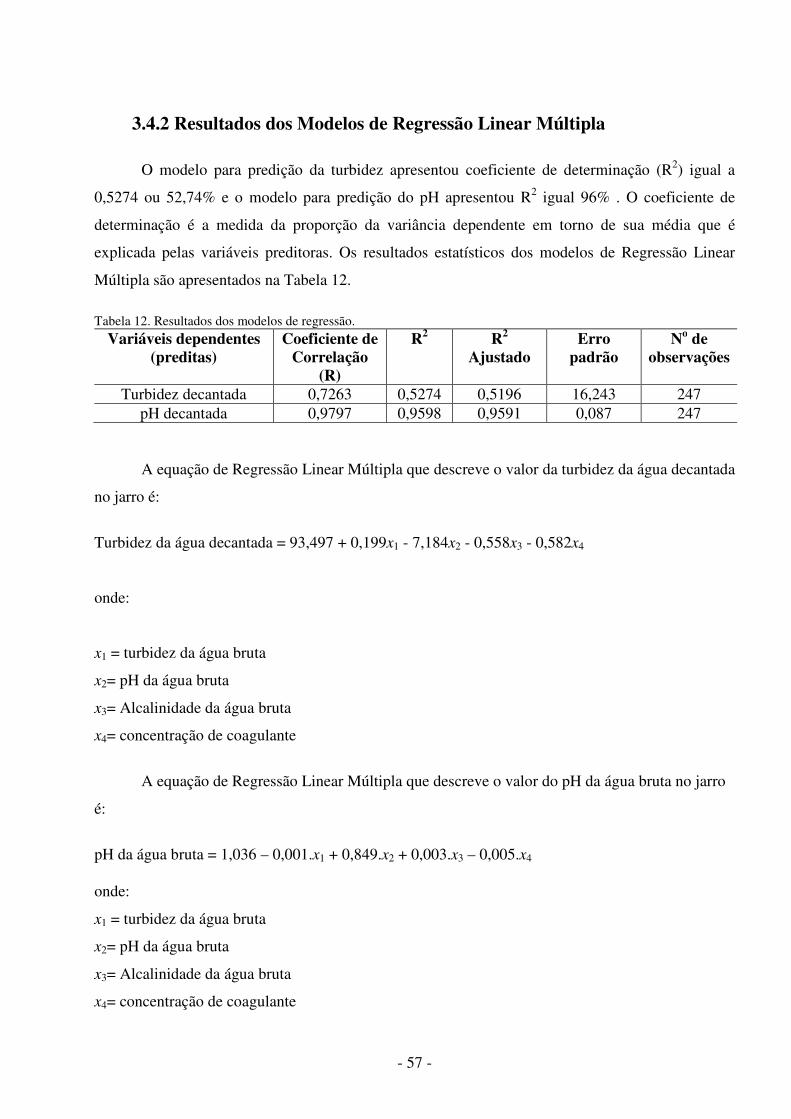
- 57 -
3.4.2 Resultados dos Modelos de Regressão Linear Múltipla
O modelo para predição da turbidez apresentou coeficiente de determinação (R2) igual a
0,5274 ou 52,74% e o modelo para predição do pH apresentou R2 igual 96% . O coeficiente de
determinação é a medida da proporção da variância dependente em torno de sua média que é
explicada pelas variáveis preditoras. Os resultados estatísticos dos modelos de Regressão Linear
Múltipla são apresentados na Tabela 12.
Tabela 12. Resultados dos modelos de regressão.
Variáveis dependentes (preditas)
Coeficiente de Correlação
(R)
R2 R2 Ajustado
Erro padrão
No de observações
Turbidez decantada 0,7263 0,5274 0,5196 16,243 247 pH decantada 0,9797 0,9598 0,9591 0,087 247
A equação de Regressão Linear Múltipla que descreve o valor da turbidez da água decantada
no jarro é:
Turbidez da água decantada = 93,497 + 0,199x1 - 7,184x2 - 0,558x3 - 0,582x4 onde:
x1 = turbidez da água bruta
x2= pH da água bruta
x3= Alcalinidade da água bruta
x4= concentração de coagulante
A equação de Regressão Linear Múltipla que descreve o valor do pH da água bruta no jarro
é:
pH da água bruta = 1,036 – 0,001.x1 + 0,849.x2 + 0,003.x3 – 0,005.x4 onde:
x1 = turbidez da água bruta
x2= pH da água bruta
x3= Alcalinidade da água bruta
x4= concentração de coagulante

- 58 -
3.4 Comparação dos Modelos
A RNA apresentou melhor desempenho para a predição da turbidez da água decantada e o
modelo de Regressão Linear Múltipla apresentou melhor desempenho para predição do pH. Ambos
os modelos tiveram desempenho bastante superior em relação ao outro. No caso da turbidez da água
decantada o modelo de RNA apresentou melhores resultados que o modelo estatístico e, no caso do
pH da água decantada, o modelo de Regressão Linear Múltipla teve melhor desempenho.
Foi realizada uma pesquisa para encontrar um outro método de Análise Multivariada que
pudesse obter melhores resultados em relação a turbidez da água decantada. Foi criando, então, um
modelo estatístico baseado em Regressão Fatorial. Este modelo foi criado no software Statistica e
então, com os parâmetros da regressão em mãos, foram simulados os valores de turbidez e pH da
água decantada utilizando o software Calc.
Verificou-se que quando se usa o modelo de Regressão Fatorial obtem-se melhora nas duas
variáveis preditas (turbidez e pH da água decantada), sendo que a melhora na predição da turbidez
foi bastante significativa, embora as RNAs simuladas tenham obtido melhores resultados.
Para comparar os modelos foi utilizado o erro quadrático médio. A Tabela 13 mostra o
desempenho dos modelos que obtiveram melhores resultados.
Tabela 13. Desempenho dos melhores modelos
Modelo Variável predita Erro quadrático médio
RNA10B Turbidez decantada 40,3 Equação de Regressão Mútlipla Turbidez decantada 247,5 Equação de Regressão Fatorial Turbidez decantada 123,11
Regressão Fatorial pH decantada 0,0051 Equação de Regressão Múltipla pH decantada 0,0074
RNA9B pH decantada 0,043
A Tabela 14 mostra os resultados obtidos de simulações dos modelos e os dados reais
utilizados para teste. Embora ocorram discrepâncias nos resultados, pode-se observar que os
modelos seguem um comportamento parecido com o padrão dos dados reais. Na maioria dos casos
os resultados simulados aumentam e diminuem de acordo com os dados de referência. Os modelos
de Regressão Linear Múltipla e Regressão Fatorial podem ser usados para realizar predições do pH
da água decantada com bastante precisão. Quanto à predição da turbidez da água decantada, embora
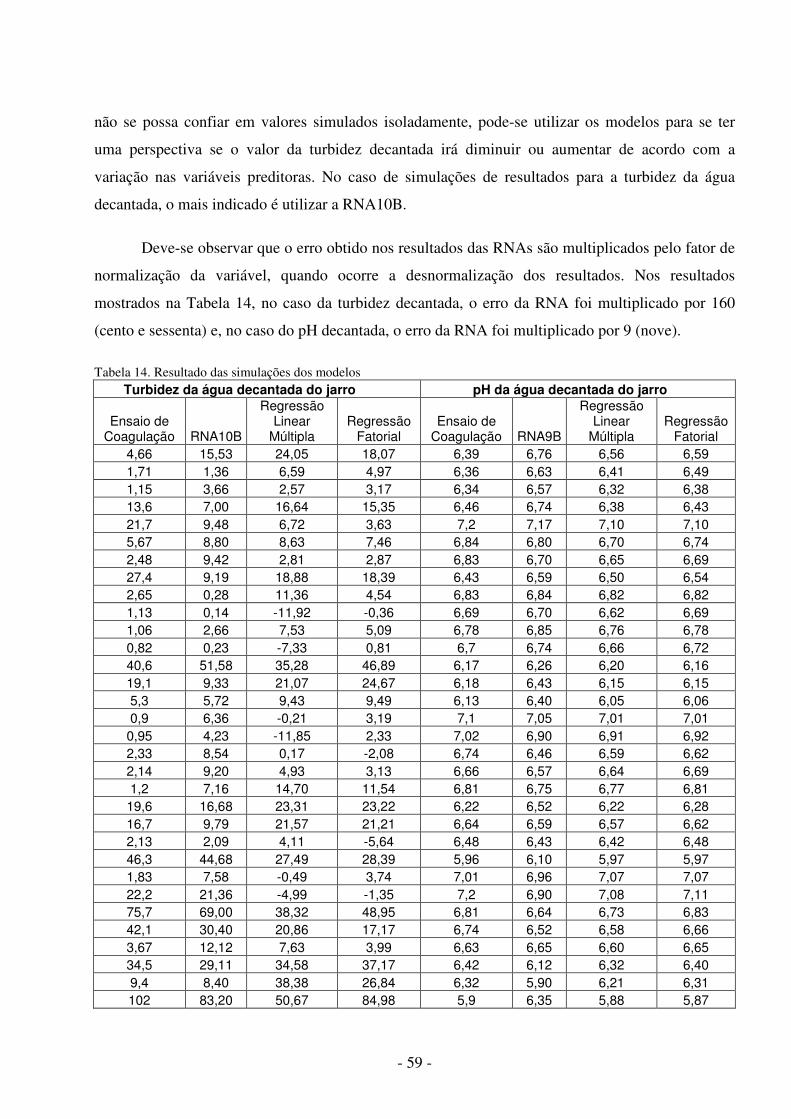
- 59 -
não se possa confiar em valores simulados isoladamente, pode-se utilizar os modelos para se ter
uma perspectiva se o valor da turbidez decantada irá diminuir ou aumentar de acordo com a
variação nas variáveis preditoras. No caso de simulações de resultados para a turbidez da água
decantada, o mais indicado é utilizar a RNA10B.
Deve-se observar que o erro obtido nos resultados das RNAs são multiplicados pelo fator de
normalização da variável, quando ocorre a desnormalização dos resultados. Nos resultados
mostrados na Tabela 14, no caso da turbidez decantada, o erro da RNA foi multiplicado por 160
(cento e sessenta) e, no caso do pH decantada, o erro da RNA foi multiplicado por 9 (nove).
Tabela 14. Resultado das simulações dos modelos Turbidez da água decantada do jarro pH da água decantada do jarro
Ensaio de Coagulação RNA10B
Regressão Linear
Múltipla Regressão
Fatorial Ensaio de
Coagulação RNA9B
Regressão Linear
Múltipla Regressão
Fatorial 4,66 15,53 24,05 18,07 6,39 6,76 6,56 6,59 1,71 1,36 6,59 4,97 6,36 6,63 6,41 6,49 1,15 3,66 2,57 3,17 6,34 6,57 6,32 6,38 13,6 7,00 16,64 15,35 6,46 6,74 6,38 6,43 21,7 9,48 6,72 3,63 7,2 7,17 7,10 7,10 5,67 8,80 8,63 7,46 6,84 6,80 6,70 6,74 2,48 9,42 2,81 2,87 6,83 6,70 6,65 6,69 27,4 9,19 18,88 18,39 6,43 6,59 6,50 6,54 2,65 0,28 11,36 4,54 6,83 6,84 6,82 6,82 1,13 0,14 -11,92 -0,36 6,69 6,70 6,62 6,69 1,06 2,66 7,53 5,09 6,78 6,85 6,76 6,78 0,82 0,23 -7,33 0,81 6,7 6,74 6,66 6,72 40,6 51,58 35,28 46,89 6,17 6,26 6,20 6,16 19,1 9,33 21,07 24,67 6,18 6,43 6,15 6,15 5,3 5,72 9,43 9,49 6,13 6,40 6,05 6,06 0,9 6,36 -0,21 3,19 7,1 7,05 7,01 7,01 0,95 4,23 -11,85 2,33 7,02 6,90 6,91 6,92 2,33 8,54 0,17 -2,08 6,74 6,46 6,59 6,62 2,14 9,20 4,93 3,13 6,66 6,57 6,64 6,69 1,2 7,16 14,70 11,54 6,81 6,75 6,77 6,81 19,6 16,68 23,31 23,22 6,22 6,52 6,22 6,28 16,7 9,79 21,57 21,21 6,64 6,59 6,57 6,62 2,13 2,09 4,11 -5,64 6,48 6,43 6,42 6,48 46,3 44,68 27,49 28,39 5,96 6,10 5,97 5,97 1,83 7,58 -0,49 3,74 7,01 6,96 7,07 7,07 22,2 21,36 -4,99 -1,35 7,2 6,90 7,08 7,11 75,7 69,00 38,32 48,95 6,81 6,64 6,73 6,83 42,1 30,40 20,86 17,17 6,74 6,52 6,58 6,66 3,67 12,12 7,63 3,99 6,63 6,65 6,60 6,65 34,5 29,11 34,58 37,17 6,42 6,12 6,32 6,40 9,4 8,40 38,38 26,84 6,32 5,90 6,21 6,31 102 83,20 50,67 84,98 5,9 6,35 5,88 5,87
- 60 -
110 118,11 75,66 131,74 5,34 5,78 5,30 5,26 70,6 75,57 69,84 97,37 5,23 5,67 5,25 5,19 14,6 15,37 46,92 44,42 6,14 5,68 6,05 6,17 22 24,70 28,90 29,97 7,85 7,44 7,79 7,92
87,8 87,56 51,42 78,77 6,1 6,10 6,09 6,18 4,46 13,69 39,78 36,65 5,94 5,82 5,99 6,05 1,77 1,64 28,14 -5,48 5,74 5,69 5,89 5,93 2,65 0,79 -10,65 -0,62 6,59 6,63 6,44 6,55 0,79 0,96 -13,37 3,74 6,96 7,07 6,99 6,98 1,39 4,60 8,70 5,71 6,57 6,85 6,61 6,66 10,4 5,35 14,74 14,44 6,41 6,58 6,38 6,39 4,81 5,90 8,92 10,28 6,33 6,57 6,33 6,34 1,49 3,66 -0,70 3,36 6,42 6,54 6,38 6,44 4,49 5,23 1,73 3,43 6,49 6,56 6,43 6,49 0,68 5,76 -0,20 2,69 6,68 6,62 6,55 6,60 1,85 5,76 17,80 12,86 6,68 6,79 6,61 6,64 1,7 7,02 1,94 3,2 6,67 6,58 6,55 6,60 1,71 5,18 7,64 4,41 6,77 6,90 6,72 6,75 1,85 2,62 2,99 0,29 6,87 6,95 6,80 6,82 1,32 5,27 6,92 3,52 6,84 6,91 6,76 6,79 2,05 1,13 8,50 -0,45 6,75 6,90 6,80 6,81 0,75 0,28 -14,78 1,25 6,62 6,72 6,60 6,69 1,39 0,09 -14,18 1,04 6,88 6,87 6,72 6,79 1,16 7,59 3,22 1,2 7,18 7,20 7,11 7,09 1,17 8,61 5,35 1,72 7,15 7,16 7,10 7,10 1,44 7,56 0,85 2,53 6,66 6,62 6,64 6,68 1,19 10,81 2,34 -7,2 7,42 7,78 7,60 7,48 1,54 7,46 0,19 2,35 6,68 6,63 6,66 6,70
As Figuras 32 e 33 mostram que os modelos apresentam linearidades para os modelos de
predição da turbidez decantada e do pH decantada, respectivamente, indicando que as previsões se
aproximam dos valores reais. Na Figura 32 pode-se observar que a RNA10B é o modelo que
apresenta melhor linearidade e, que na Figura 33, os modelos de Regressão Linear Múltipla e
Regressão Fatorial apresentam capacidade de realizar previsões muito parecidas e com um bom
grau de precisão.
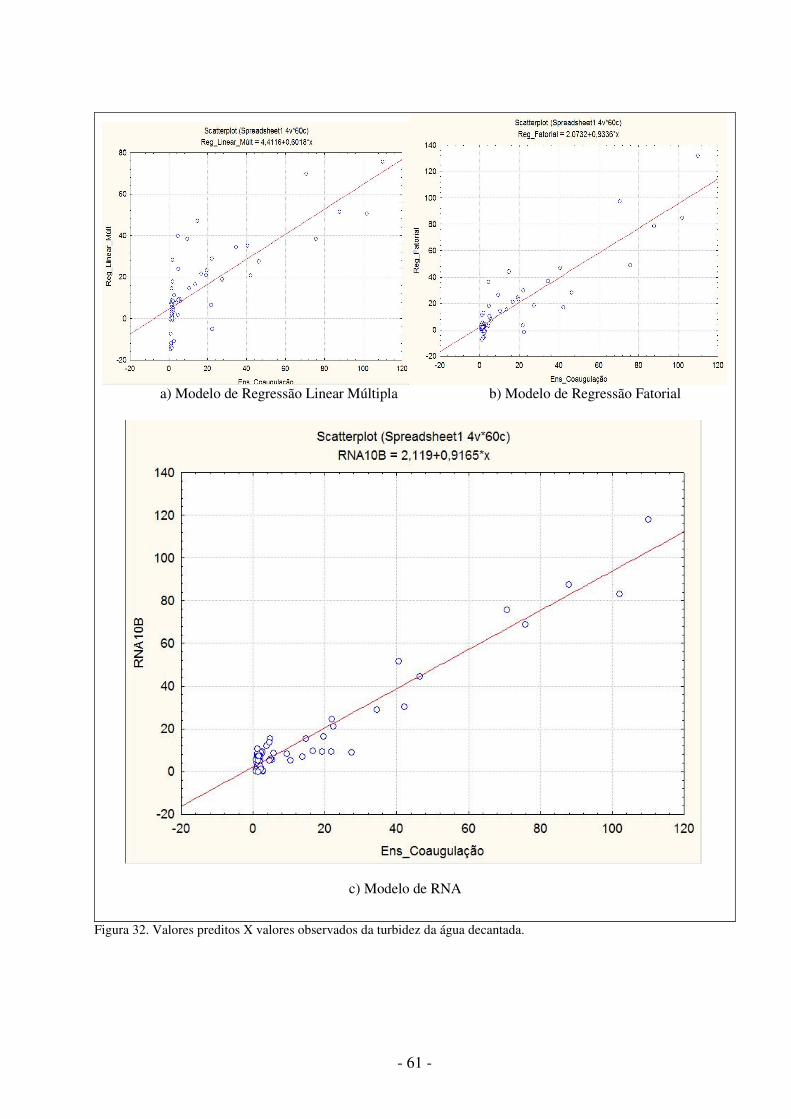
- 61 -
a) Modelo de Regressão Linear Múltipla b) Modelo de Regressão Fatorial
c) Modelo de RNA
Figura 32. Valores preditos X valores observados da turbidez da água decantada.
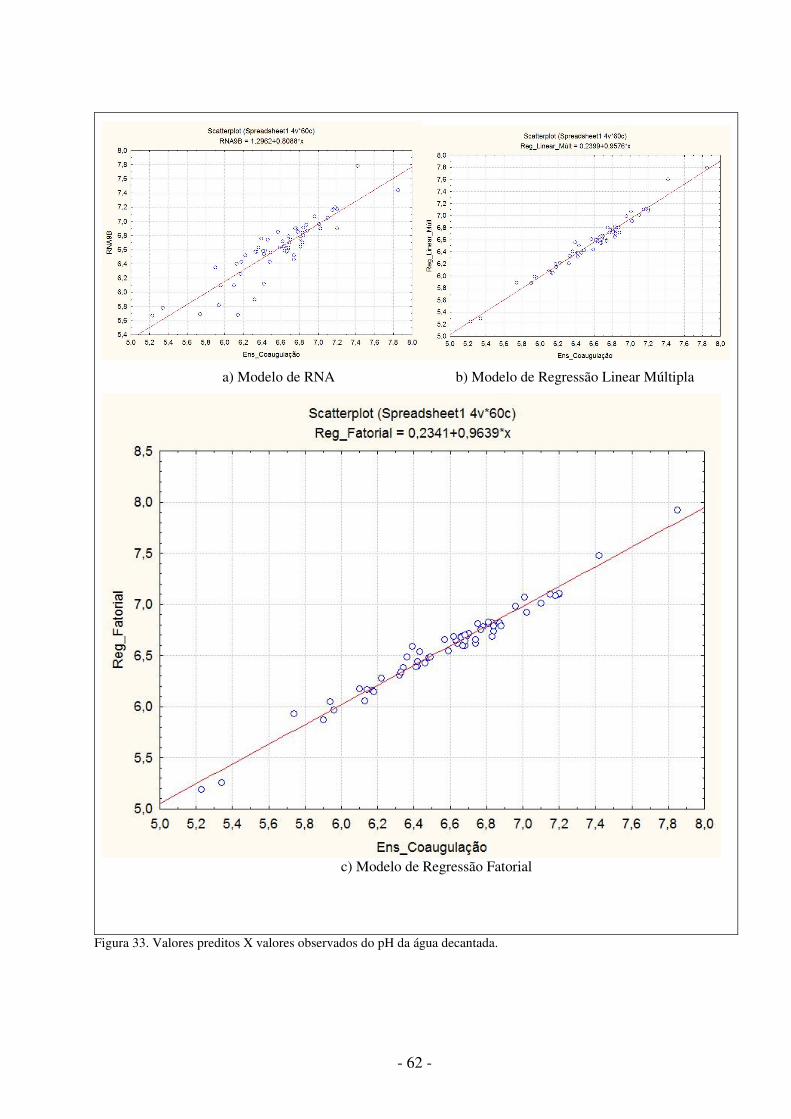
- 62 -
a) Modelo de RNA b) Modelo de Regressão Linear Múltipla
c) Modelo de Regressão Fatorial
Figura 33. Valores preditos X valores observados do pH da água decantada.

- 63 -
4 CONCLUSÕES
As utilidades dos métodos de predição são indiscutivelmente importantes para as mais
diversas áreas do conhecimento. O ensaio de coagulação (jar test) é uma análise usada em Estações
de Tratamento de Água (ETA), que serve para encontrar a concentração ideal de coagulante que
deve ser despejada na água bruta para que ocorra o processo de clarificação da água. Este trabalho
tem o objetivo de predizer os resultados de turbidez e pH de um jar test utilizando redes neurais
artificiais e regressão linear múltipla. As técnicas de predição utilizadas foram modeladas a partir de
dados reais provenientes de análises de jar test realizadas anteriormente numa ETA.
Foram encontradas diversas dificuldades no decorrer deste trabalho. Uma delas foi encontrar
os parâmetros dos algoritmos de treinamento das RNAs que fizessem as redes convergirem para um
resultado aproximado. Outra dificuldade foi transformar os dados para atenderem o melhor possível
os requisitos de uma Regressão Linear Múltipla com aceitável capacidade de precisão. Foram
testadas várias transformações e foi realizada a análise de componentes principais, mas não se
conseguiu ajustar os dados de forma adequada. Como o modelo de Regressão Linear Múltipla ficou
comprometido por causa do comportamento das variáveis, foi criado um modelo que utiliza
Regressão Fatorial, apenas como teste, para verificar se havia um método de regressão mais
apropriado para realizar predições dos resultados do Jar Test.
Para a modelagem e simulação das RNAs e da Regressão Linear Múltipla, foram utilizados
softwares específicos. Para a modelagem e simulação das RNAs foi utilizado o software JavaNNS,
por ser uma ferramenta intuitiva, gratuita e que oferece os recursos necessários. Também foi usado
o aplicativo snns2c que vem junto com o SNNS. O aplicativo snns2c foi usado como ferramenta
auxiliar para desenvolver um programa simples em linguagem C que simula a rede treinada no
JavaNNS. Também foi utilizado um programa escrito em linguagem C++ para automatizar a
criação dos arquivos de treinamento e validação das RNAs. Para os modelos de Regressão Linear
Múltipla foram utilizados o software Calc e o software Statistica, que oferece uma ampla gama de
recursos e ferramentas para Análise Multivariada.
Após a construção e simulação dos modelos, estes tiveram sua eficácia testada por métodos
estatísticos, para então, verificar se os resultados alcançados são significativos. Foram obtidos bons
resultados para as previsões do pH da água decantada nos jarros nos 3 métodos testados. No
começo acreditava-se que os resultados para a predição da turbidez decantada seriam pouco

- 64 -
significativos. Porém, quando foram analisados os diagramas de dispersão verificou-se que o
modelo de RNA atingiu bons resultados apesar de faltarem variáveis explicativas no modelo e
conjunto de exemplos da amostra ser relativamente pequeno. Os resultados obtidos com os modelos
estatísticos não obtiveram resultados bons como as RNA. Entre os 2 modelos estatísticos o de
regressão fatorial obteve resultados melhores do que o de regressão linear. Os resultados podem ser
confirmados nos gráficos das figuras 32 e 33.
O modelo de RNA RNA10B é capaz de realizar previsões da turbidez e pH da água
decantada, o modelo de Regressão Fatorial também realiza predições da turbidez e do pH, já o
modelo de Regressão Linear Múltipla implementado neste trabalho, realiza predições confiáveis
apenas para o pH da água decantada. Para predizer o pH da água decantada os modelos de
Regressão Fatorial e de Regressão Linear Múltipla apresentaram desempenho superior ao da RNA,
porém a RNA10B pode prever valores da turbidez com maior precisão. O modelo baseado em RNA
tem a vantagem de realizar predições para as duas variáveis simultaneamente, com boa precisão.
4.1 PROJETOS FUTUROS
Os modelos implementados neste projeto possuem poucas variáveis explicativas. Existem
outros fatores que influenciam no processo de coagulação, tanto mecânicos como químicos. Como
o gradiente de velocidade e o tempo de decantação utilizados no Jar Test são constantes, poderia-se
acrescentar variáveis de entrada que exprimissem as características da água bruta. Algumas destas
variáveis que interferem significativamente na coagulação e que não foram consideradas neste
trabalho são: cor, temperatura e interferentes químicos na água.
Acrescentando nos modelos as variáveis descritas acima e, aumentando o número de
exemplos de padrões, poderão ser obtidos resultados com maior precisão, de forma a mostrar a
força das técnicas de predição.

- 65 -
REFERÊNCIAS BIBLIOGRÁFICAS
AESA – Agência Executiva de Gestão das Águas do Estado da Paraíba. Disponível em <HTTP://www.aesa.pb.gov.br>. Acesso em 30 de abril de 2010. ANA – Agência Nacional de Águas. Disponível em <http://www.ana.gov.br>. Acesso em 30 de abril de 2010. AZEVEDO, Fernando Mendes; BRASIL, Lourdes Mattos; OLIVEIRA, Roberto Célio Limão. Redes neurais com Aplicações em controle e em sistemas especialistas. Florianópolis: Bookstore, 2000. BAPTISTELLA, Marisa. O uso de redes neurais e regressão linear múltipla na engenharia de avaliações: determinação de valores venais. 2005. 123 f. Dissertação (Mestrado em Métodos Numéricos em Engenharia) – Universidade Federal do Paraná, Curitiba, 2005. BRAGA, Antônio de Pádua; LUDERMIR, Teresa Bernarda; CARVALHO, André Ponce de Leon. Redes neurais artificiais – teoria e aplicações. Rio de Janeiro: LTC, 2000. CARVALHO, Caio César Guedes; SANTOS, Maria Fátima. Manual de operação e manutenção de estação de tratamento de água. ALCON Química Ltda. Disponível em: <www.alconquimica.com.br/cursos/download.asp?cod=6>. Acesso em 25 de março de 2010. FUNDAÇÃO NACIONAL DE SAÚDE. Manual Prático de Análise de Água. Brasília: Assessoria de Comunicação e Educação em Saúde, 2004. HAIR, Joseph F. Jr. et al. Análise Multivariada de Dados. 5. Ed. Porto Alegre: Bookman, 2005. HAYKIN, Simon. Redes neurais: princípios e prática. 2.ed. Porto Alegre: Bookman, 2001. KOVÁCS, Zsolt László. Redes neurais artificiais: fundamentos e aplicações. 2.ed. São Paulo: Edição Acadêmica, 1996. MENEZES, F.C. et al. Redes neurais artificiais aplicadas ao processo de coagulação. Engenharia Sanitária e Ambiental, v.14, n.4, p. 449-454, out/dez 2009.

- 66 -
MONTGOMERY, Douglas C.; RUNGER, George C. Estatística Aplicada e Probabilidade para Engenheiros. Rio de Janeiro: LTC, 2003. RAUBER, Thomas Walter. Redes Neurais Artificiais. Disponível em: <http://www.inf.ufes.br/~thomas>. Acesso em 06 de abril de 2010. SOUZA FILHO, Marlos Roberto. Rede neural artificial para o deslocamento de um robô autônomo. 2009. 191 f. Trabalho de Conclusão de Curso (Bacharelado em Ciência da Computação) – Universidade do Vale do Itajaí, Itajaí, 2009. SOUSA, Wanderson dos S.; SOUSA, Francisco de A. S. Rede neural artificial aplicada à previsão de vazão da Bacia Hidrográfica do Rio Piancó. Revista Brasileira de Engenharia Agrícola e Ambiental, Campina Grande, v.14, n.2, p.173-180, 2010. TRIOLA, Mario F. Introdução à estatística. 10. ed. Rio de Janeiro: LTC, 2008. VICINI, Lorena; SOUZA, Adriano Mendonça. Análise multivariada da teoria à prática. Santa Maria: UFSM, CCNE, 2005. FISCHER, Igor; HENNECKE, Fabian; ZELL , Andreas. Java Neural Network Simulator: User Manual, Version 1.0 beta. Disponível em: < http://www.cis.cau.edu/675/JavaNNS-manual.pdf >. Acesso em 18 de maio de 2010.

- 67 -
GLOSSÁRIO
Água bruta Água de uma fonte de abastecimento, antes de receber qualquer
tratamento.
Água decantada Água obtida após o processo de decantação, na qual, as partículas em
suspensão são removidas.
Água tratada Água de uma fonte de abastecimento, submetida a um tratamento
prévio, através de processos físicos, químicos e biológicos com a
finalidade de torná-la apropriada ao consumo humano.
Alcalinidade Mede a capacidade da água em neutralizar os ácidos. A medida da
alcalinidade tem importância fundamental no processo de tratamento
de água, pois é em função de seu teor que se estabelece a dosagem de
produtos químicos utilizados.
Coagulação Processo que tem a finalidade de transformar as impurezas da água
que se encontram em suspensão fina em estado coloidal.
Coagulante Composto, geralmente de ferro ou alumínio, capaz de produzir
hidróxidos gelatinosos insolúveis e englobar impurezas. Tem por
objetivo aglomerar as impurezas em estado coloidal, que possam ser
removidas por decantação ou filtração.
Decantação Etapa de tratamento de água que consiste na remoção de partículas em
suspensão mais densas que a água por ação da gravidade.
Estado coloidal Tipo de dispersão na qual as partículas dispersas têm dimensão entre 1
a 100 nm.
Jar Test Aparelho usado em ensaios de coagulação que estabelece e avalia as
condições de tratabilidade de água e efluentes. É uma ferramenta
básica em Estações de Tratamento de Água. Jar Test ou Teste do Jarro
também pode ser entendido como sinônimo de ensaio de coagulação.

- 68 -
Floculação Etapa de tratamento de água na qual, a água é submetida à agitação
mecânica para possibilitar que os flocos se agreguem com os sólidos
em suspensão, permitindo uma decantação mais rápida.
Manancial Fonte de água utilizada para abastecimento humano e manutenção de
atividades econômicas. Pode ser superficial ou subterrânea.
pH Representa a concentração de íons hidrogênio em uma solução. Na
água, este fator é de excepcional importância nos processos de
tratamento.
Turbidez É um indicador sanitário e padrão de aceitação da água de consumo
humano. A turbidez da água é provocada pela presença de materiais
sólidos em suspensão, que reduzem sua transparência.


















