
Redes Neurais: Classificação e Regressãorvicente/RN_aula2.pdf · Teorema de Bayes Seja dado um...
22
Técnicas Técnicas Bayesianas Bayesianas Renato Vicente Renato Vicente rvicente rvicente @if.usp. @if.usp. br br 10/01, 10/01, mpmmf mpmmf , IME/FEA , IME/FEA – – USP USP
Transcript of Redes Neurais: Classificação e Regressãorvicente/RN_aula2.pdf · Teorema de Bayes Seja dado um...

Técnicas Técnicas BayesianasBayesianas
Renato VicenteRenato [email protected][email protected]
10/01, 10/01, mpmmfmpmmf, IME/FEA , IME/FEA –– USPUSP

Técnicas Técnicas BayesianasBayesianas
Teorema de Teorema de BayesBayesModelos HierárquicosModelos HierárquicosInferência de ParâmetrosInferência de ParâmetrosInferência de Inferência de Hiperparâmetros Hiperparâmetros Seleção de ModelosSeleção de Modelos

Teorema de Teorema de BayesBayesSeja dado um conjunto de dados Seja dado um conjunto de dados DD e um conjunto de e um conjunto de hipóteses sobre os dados hipóteses sobre os dados HH11 , H, H2 2 , ..., , ..., HHnn..
A teoria elementar de probabilidades nos fornece:A teoria elementar de probabilidades nos fornece:
Daí decorre que:Daí decorre que:
( , ) ( ) ( ) ( ) ( )k k k kP D H P D H P H P H D P D= =
( ) ( )( )
( )k k
k
P D H P HP H D
P D=

Bayes Bayes em Palavrasem Palavras
ˆVEROSSIMILHANÇA A PRIORIPOSTERIOR
EVIDENCIA×
=

BayesianosBayesianos X X FreqüencistasFreqüencistasFreqüencistasFreqüencistas: Probabilidades como “freqüência” de ocorrência de : Probabilidades como “freqüência” de ocorrência de um evento ao repetirum evento ao repetir--se o experimento infinitas vezes. se o experimento infinitas vezes.
BayesianosBayesianos: Probabilidades como “grau de crença” na ocorrência de : Probabilidades como “grau de crença” na ocorrência de um evento. um evento.
JaynesJaynes,, ProbabilityProbability: : The Logic The Logic of of ScienceSciencehttphttp://://omegaomega..albanyalbany..eduedu:8008/:8008/JaynesBookJaynesBook..htmlhtml
1
1( ) ( )
( ) 1 , 0 ..
limN
A jjN
A j j
P A xN
x se x A ou c c
χ
χ=→∞
=
= ∈ =
∑
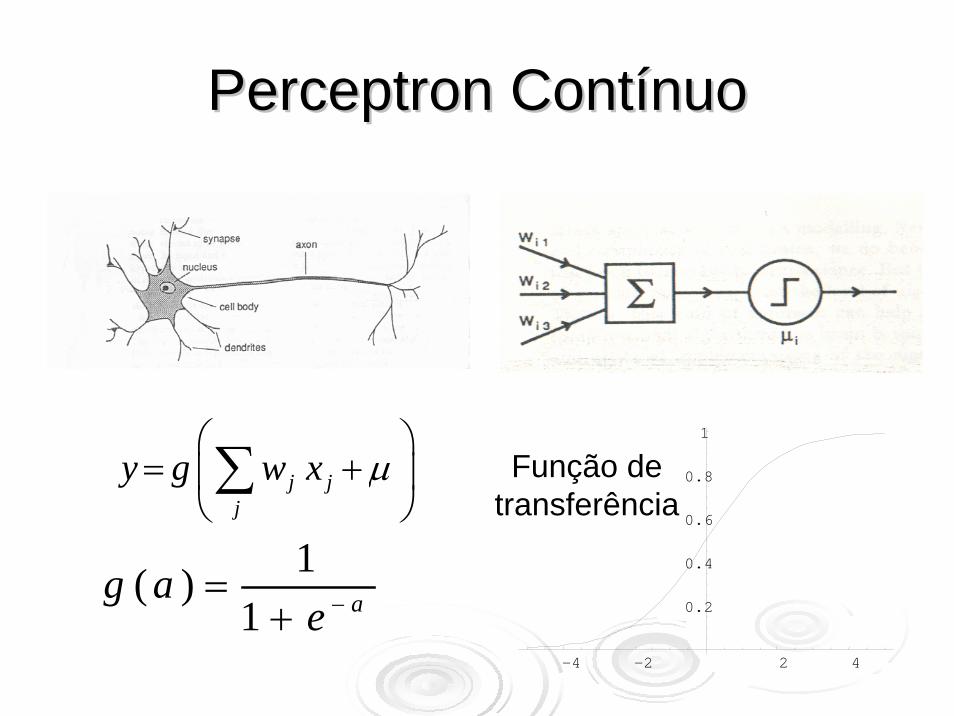
PerceptronPerceptron ContínuoContínuo
j jj
y g w x μ⎛ ⎞
= +⎜ ⎟⎝ ⎠∑
1( )1 ag a
e −=+
-4 -2 2 4
0.2
0.4
0.6
0.8
1
Função de transferência

BayesBayes, , Perceptron Perceptron e Classificaçãoe ClassificaçãoDados em duas classes CDados em duas classes C11 e Ce C22 são geradossão geradosa partir de duas Gaussianas centradas em ma partir de duas Gaussianas centradas em m11 e me m22. Assim:. Assim:
Utilizando o Teorema de Utilizando o Teorema de BayesBayes::
( )1 / 2 1/ 2
1 1( ) exp ( )22 ( )dP C
Detπ⎧ ⎫= − ⋅⎨ ⎬⎩ ⎭
-11 1x x -m Σ (x -m )
Σ
1 11
1 1 2 2
( ) ( )( )
( ) ( ) ( ) ( )P x C P C
P C xP x C P C P x C P C
=+

BayesBayes, , Perceptron Perceptron e Classificaçãoe Classificação
Assumindo a seguinte forma para o posterior P(C1|x):
Retomando o Perceptron:
1
1 1
2 2
1( ) ( )1
( ) ( )ln
( ) ( )
aP C x g ae
P x C P Ca
P x C P C
−= =+
⎡ ⎤≡ ⎢ ⎥
⎣ ⎦
1( | )j jj
y g w x P C xμ⎛ ⎞
= + =⎜ ⎟⎝ ⎠∑

BayesBayes, , Perceptron Perceptron e Classificaçãoe Classificação
Retomando o Perceptron:
Com
1( | )j jj
y g w x P C xμ⎛ ⎞
= + =⎜ ⎟⎝ ⎠∑
1
2
( )
1 1 ( )log2 2 ( )
P CP C
μ
=
⎛ ⎞= − ⋅ + ⋅ + ⎜ ⎟
⎝ ⎠
-11 2
-1 -11 2 1 2
w Σ m -m
m Σ m m Σ m

Modelos HierárquicosModelos Hierárquicos
Dados D são produzidos por um processo estocástico com
parâmetros w , P(D|w).
Os parâmetros w são, por sua vez, produzidos por um processo estocástico com hiperparâmetros α , P(w| α).
A hierarquia pode continuar indefinidamente ...
... inclusive acomodando diversas hipóteses a serem testadas H1 , H2 ,
..., HN e seus respectivos graus de plausibilidade P(w,α|Hk).

Inferência de ParâmetrosInferência de Parâmetros
Dado um conjunto de dados Dado um conjunto de dados D e D e um modelo um modelo HHii , , encontrar os encontrar os parparââmetros mais provmetros mais provááveis veis ww** ..
DeveDeve--se minimizar a funse minimizar a funçãção o ““erroerro”” a seguir a seguir
( | , ) ( | )( | , )( | )
i ii
i
P D H P HP D HP D H
=w ww
max
( ) ln ( | , )ln ( | , ) ln ( | )
i
i i
verossimilhança conhecimento a priori
E P D HP D H P H cte
= − == − − +
w ww w

Ex: Ex: Perceptron Perceptron ContínuoContínuo
: ( , ) ( )iH y x g x= ⋅w w 0
1
, (0, )
{( , )}Nn n n
t t N
D x t
ε ε σ
=
= +
=
∼
[ ]
1
2
22
2
1
1( | ) ( | , ) ( | )
[ ( , ) ]1( | , ) exp22
1( ) ( , )2
N
n n in i
n nn n
N
n nn
P D P t x P H
y x tP t x
E y x t
σπσ
=
=
= =Ω
⎧ ⎫−= −⎨ ⎬
⎩ ⎭
= −
∏
∑
w w w
ww
w w

Intervalos de ConfiançaIntervalos de Confiança
ln ( | , ) ln ( * | , ) ( *) *1 ( *) *( *)2
i iP D H P D H E≈ − − ∇
− − ⋅ −
w w w w
w w H w w
1( | , ) ( * | , ) exp ( *) *( *)2i iP D H P D H ⎡ ⎤≈ − − ⋅ −⎢ ⎥⎣ ⎦
w w w w H w w
-2-1
01
2
-2-1
01
20
0.2
0.4
0.6
0.8

Inferência de Inferência de HiperparâmetrosHiperparâmetros
1
1
{ , } { }
( ) ( )
: ( ) (0, )
Km m j j
K
j jj
m m
D x t H g
y x w g x
Ruido t y x Nε ε σ
=
=
= =
=
= +
∑∼

HiperparâmetroHiperparâmetro da Verossimilhançada Verossimilhança
[ ]1( | , , , ) exp ( | , )( ) D
D
P D H Ruido E D HZ
β ββ
= −w w
( )2 2
2 21
1 1( | , , , ) exp ( )2 2
NN
m mm
PD H Ruido y x tβπσ σ =
⎡ ⎤⎛ ⎞= − −⎜ ⎟ ⎢ ⎥⎝ ⎠ ⎣ ⎦∑w
2
1βσ
=

Hiperparâmetro Hiperparâmetro da Distribuição a Priorida Distribuição a Priori
[ ]{ }
[ ]
[ ]
2
1
, 1
1( | , ) exp ( )( )
: ( ) ( )
1( | , , ) exp ( | , )( )
(
( ) exp ( | ,
| , ) ( )
)
( )
W
y
K
j jj
WW
K
W j ii
W
j ij
P y R dx y xZ
H y x w g x
P H R E H RZ
E H R w w dx g x g
d E H R
x
Z
α αα
α α
α α
α
=
=
′′= −
′′ ′′=
= −
′′ ′=
=
′
−
∫
∑
∫
∑ ∫
w w
w
w w

Estimação de Estimação de hiperparâmetroshiperparâmetros
Pr
( | , , ) ( , | )( , | , )( | )
ior flatverossimilhança
Evidencia
P D H P HP D HP D H
α β α βα β =
( , )( | , , )( ) ( )E
D W
ZP D HZ Z
α βα ββ α
=
( *, *) arg max ( , | , )P D Hα β α β=

Seleção de ModelosSeleção de Modelos
( | ) ( | ) ( )i i iP H D P D H P H∝
Não há necessidade de normalização já que sempre podemos introduzir um novo modelo para comparação
com os demais.
Maximiza-se a evidência

Navalha de Navalha de OccamOccamEntre modelos de mesma capacidade explicativa o mais Entre modelos de mesma capacidade explicativa o mais simples deve ser preferido.simples deve ser preferido.
Ω D
( )P D prior
1( | )P D H2( | )P D H

Avaliando a EvidênciaAvaliando a Evidência
max
( | ) ( | , ) ( | )
( | ) ( | *, ) ( * | )i i i
i i i
Evidencia verossimilhança Fator de Occam
P D H d P D H P H
P D H P D H P H
=
Δ∫ w w w
w w w
D
. . jF OΔ
=Δ 0
ww
0Δw
1Δw2Δw

Aproximação para a EvidênciaAproximação para a Evidência
/ 2
( | ) ( | , ) ( | )
1( | ) ( | *, ) ( * | ) exp ( *) ( *)2
( | *, ) ( * | ) (2 ) ( )
i i i
i i i
Ki i
Fator de Occam
P D H d P D H P H
P D H P D H P H d
P D H P H Det Hπ
=
⎡ ⎤− − ⋅ −⎢ ⎥⎣ ⎦
=
∫
∫
w w w
w w w w w H w w
w w

BibliografiaBibliografia
David MacKay, Information Theory, Inference, and Learning Algorithms (http://wol.ra.phy.cam.ac.uk/mackay/)
David MacKay, Bayesian Methods for Adaptive Models (http://wol.ra.phy.cam.ac.uk/mackay/)
Differential Geometry in Statistical Inference
(Ims Lecture Notes-Monograph Ser.: Vol. 10)by S. Amari















![Una Generalización del Clasificador Naive Bayes para Usarse … · Augmented Naive Bayes (TAN) [6]; Super Parent TAN [7,8]; Improved Naive Bayes (INB) [9]; Weighted NB [10-15]; Taheri](https://static.fdocumentos.com/doc/165x107/5bdd2d7c09d3f2f6568c43de/una-generalizacion-del-clasificador-naive-bayes-para-usarse-augmented-naive.jpg)