
Soft information retrieval / Modelos de recuperação alternativos
32
Lais Oselame Nobrega Vanessa Levati Biff UNIVERSIDADE FEDERAL DE SANTA CATARINA Departamento de Ciência da Informação Programa de Pós-Graduação em Ciência da Informação Disciplina: Recuperação Inteligente da Informação Profº: Dr. Angel Godoy Vieira Março, 2016
-
Upload
vanessa-biff -
Category
Technology
-
view
121 -
download
1
Transcript of Soft information retrieval / Modelos de recuperação alternativos

Lais Oselame Nobrega
Vanessa Levati Biff
UNIVERSIDADE FEDERAL DE SANTA CATARINA
Departamento de Ciência da Informação
Programa de Pós-Graduação em Ciência da Informação
Disciplina: Recuperação Inteligente da Informação
Profº: Dr. Angel Godoy Vieira
Março, 2016
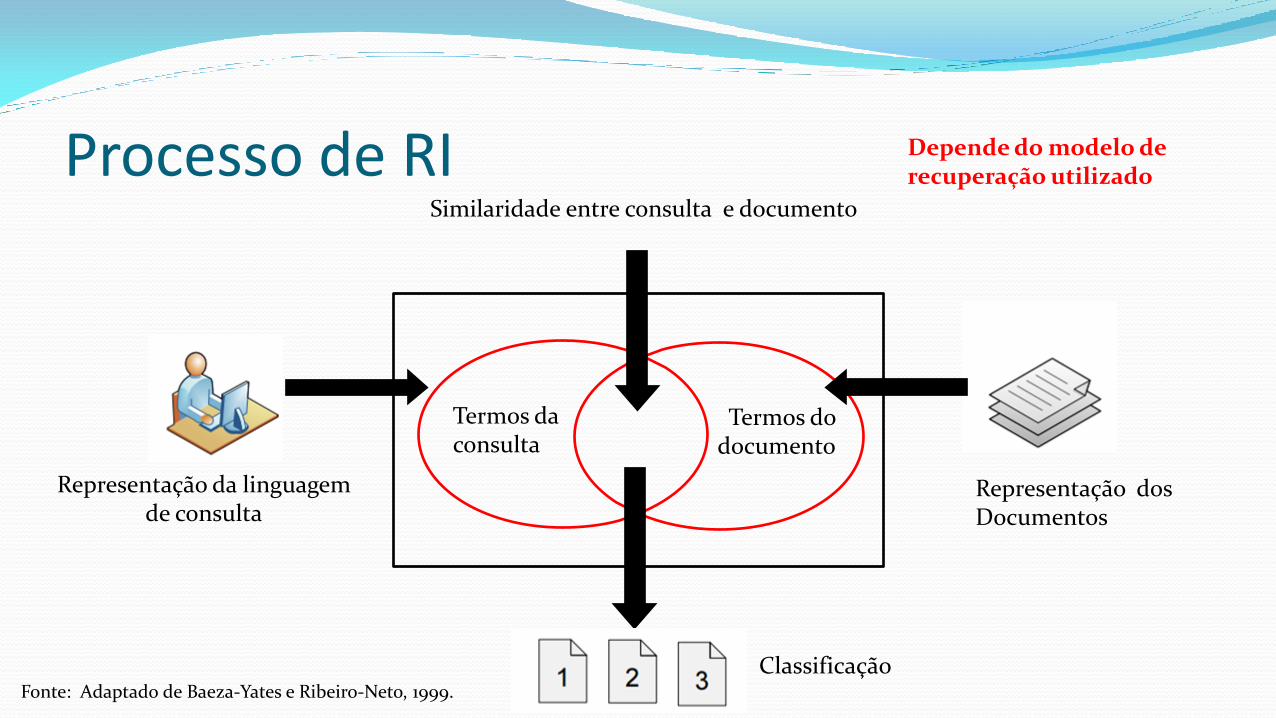
Processo de RI
Fonte: Adaptado de Baeza-Yates e Ribeiro-Neto, 1999.
Depende do modelo de recuperação utilizado
Representação da linguagem de consulta
Representação dos Documentos
Termos da consulta
Termos do documento
Similaridade entre consulta e documento
Classificação

Fonte: Baeza-Yates e Ribeiro-Neto, 1999.

Foram desenvolvidos em ambientes fechados, universo documental é restrito. Não são totalmente aptos a serem úteis na web.
Fonte: Crestani e Pasi, 1999.
Quando...
- O usuário não tem ideia clara da informação de precisa, ou não sabe expressar sua necessidade de informação.

Soft Information Retrieval
Incorporam novas técnicas à recuperação da informação. São capazes de representar a incerteza e imprecisão no processo de recuperação da informação.
Fonte: Crestani e Pasi, 1999.


Teoria dos conjuntos difusos (Fuzzy set theory)
Conjuntos Clássicos Conjuntos Difusos
1 0 [1,0]

Teoria dos conjuntos difusos (Fuzzy set theory)
Baixo
Alto Alto
Baixo
Conjuntos Clássicos Conjuntos Difusos
0,2
0,5

Teoria dos conjuntos difusos (Fuzzy set theory)
Um elemento pode ser membro de um conjunto apenas parcialmente. Um valor entre zero (0) e um (1) indicará o quanto o elemento é membro do conjunto.
A pertinência em um conjunto difuso não é uma questão binária, mas, considera de um grau de intensidade de pertinência.
Fonte: Crestani e Pasi, 1999. Baeza-Yates e Ribeiro-Neto, 1999.

Teoria dos conjuntos difusos (Fuzzy set theory)
Aumentam a flexibilidade dos SRI.
Os principais níveis de aplicação da teoria dos conjuntos difusos para RI compreendem:
Fonte: Crestani e Pasi, 1999.
- A definição de extensões do modelo booleano, no que respeita tanto a representação de documentos e a linguagem de consulta; - A definição de mecanismos associativos, tais como tesauro difuso e agrupamento difuso.

Método booleano estendido
Poluição Rio São Paulo
1 0 1
0 1 1
1 1 1
Consulta conjuntiva:
Poluição do rio de São Paulo
Poluição AND rio AND São Paulo
Doc 1
Doc 2
Doc 3
Método Booleano Clássico
1 Doc 3
Resultado da consulta

Método booleano estendido
Poluição Ri0 São Paulo
0,5 0,4 0,3
0,6 0,7 0
0,8 0,8 0,5
Consulta conjuntiva:
Poluição do rio de São Paulo
Poluição AND rio AND São Paulo
Doc 1
Doc 2
Doc 3
Método Booleano Estendido
0,76
0,55
0,30
Para a consulta AND - ponto 1 é o mais desejável Para a consulta OR - ponto 0 é o menos desejável
Doc 3
Doc 1
Doc 2
Resultado

Método booleano estendido Permite buscas parciais, através da atribuição de pesos aos termos.
Combina características do modelo vetorial com propriedades da álgebra booleana.
Fonte: Crestani e Pasi, 1999.
- O termo pode não aparecer no documento e ser relevante. - O termo pode aparecer no documento e não ser relevante, por não ter outros termos relacionados.
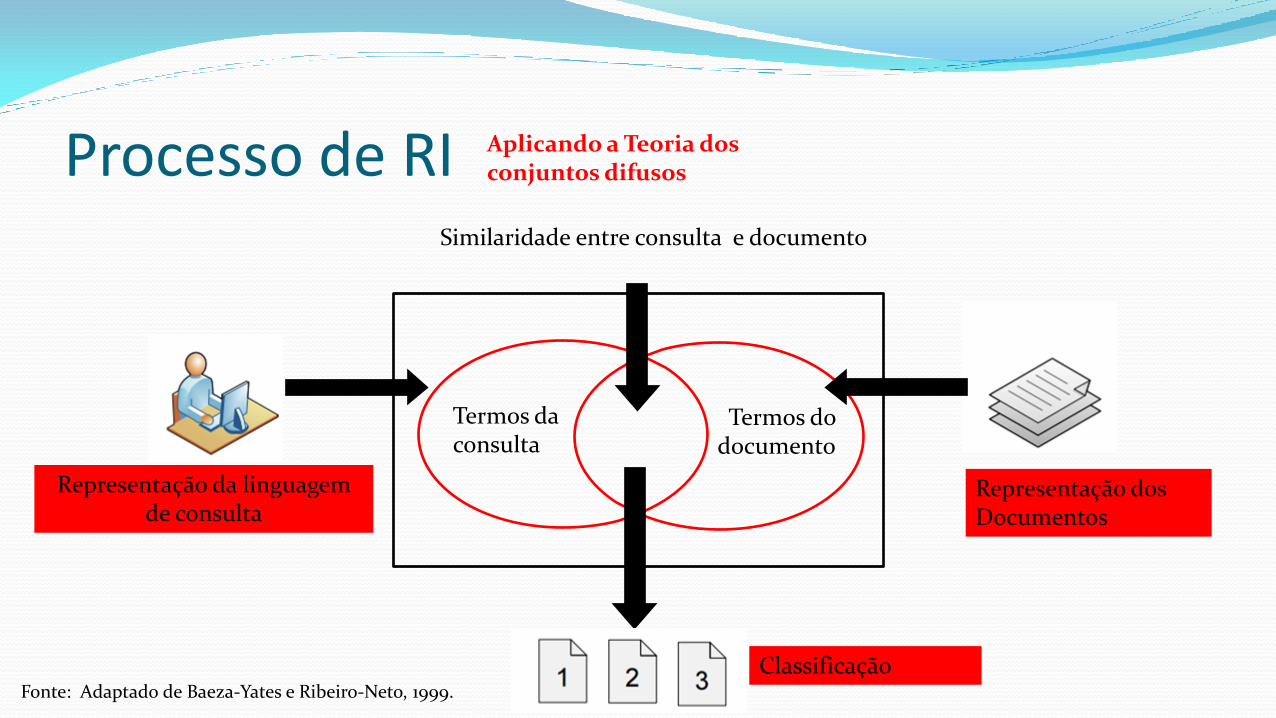
Processo de RI
Fonte: Adaptado de Baeza-Yates e Ribeiro-Neto, 1999.
Representação da linguagem de consulta
Representação dos Documentos
Termos da consulta
Termos do documento
Similaridade entre consulta e documento
Classificação
Aplicando a Teoria dos conjuntos difusos

Representação difusa do documento
É feita com base na definição de uma função de indexação ponderada, que para cada termo produz um valor numérico que varia de 0 à 1, que representa o peso do termo t para o documento d e expressa o quanto esse termo é significativo na descrição do conteúdo do documento.
O uso de pesos faz com que o mecanismo de recuperação seja capaz de classificar os documentos por ordem decrescente de relevância para a consulta do usuário.
Fonte: Crestani e Pasi, 1999.

Representação difusa do documento Geralmente esta função baseia-se no cálculo da frequência de ocorrência
dos termos em todo o texto.
Fonte: Crestani e Pasi, 1999.
Bordogna e Pasi (1995) propõem uma representação difusa para documentos semi estruturados na qual o peso de um termo é atribuído com base na sua localização no texto.

São modelados com base em tesauros e sinônimos, criados a partir de uma matriz de correlação termo-a-termo:
: número de docs que contêm termo Lixo
: número de docs que contêm termo Poluição
: número de docs que contêm ambos os termos Poluição e Lixo
partir daí, temos a noção de proximidade entre termos .
Representação difusa do documento
Fonte: Crestani e Pasi, 1999

Representação difusa do documento
Fonte: Crestani e Pasi, 1999
Lixo Rios Sujeira
D1
Poluição Lixo Sujeira
Termo: Poluição
Se um documento contém o termo Lixo que é fortemente correlacionado a Poluição, então o termo Lixo é um bom índice representativo
mesmo que Poluição não apareça no documento!

Tesauros difusos
Auxilia na definição da proximidade entre os termos.
Pode ser utilizado para expandir os termos de consulta inicial através das relações existentes entre seus índices.
Fonte: Crestani e Pasi, 1999

Extensão difusa da linguagem de consulta Considera termos vagos, ambíguos e imprecisos.
Considera as variáveis linguísticas, determinando critérios por níveis de importância atribuindo pesos.
Cidades quentes T(quente): {muito quente, quente, não tão quente, quase quente, pouco quente} T(quente): {1....0} O critério evolui de um simples sim/não, verdadeiro/falso, [0,1], para algo mais flexível.

Agrupamento difusos de documentos Agrupamento/Clustering é uma técnica de aprendizado de máquina opera agrupando dados semelhantes.
Em vez de identificar dados como pertencentes a grupos específicos , agrupamento difuso tenta identificar o grau em que um conjunto de dados pertence a um grupo .
Na abordagem de agrupamento difuso, um ponto de dados pode pertencer a mais de um grupo .
Fonte: Crestani e Pasi, 1999

Agrupamento difuso
Agrupamento Clássico Agrupamento Difusos
Alto/Baixo


Representação Simplificada de um Neurônio
Os dendritos captam os estímulos recebidos em um determinado período de tempo e os transmitem ao corpo do neurônio, onde são processados. Quando tais estímulos atingirem determinado limite, o corpo da célula envia novo impulso que se propaga pelo axônio e é transmitido às células vizinhas por meio de sinapses. Este processo pode se repetir em várias camadas de neurônios. Como resultado, a informação de entrada é processada, podendo levar o cérebro a comandar reações físicas.

Modelo Matemático Neural
• um conjunto de n conexões de entrada (x1, x2, ..., xn), caracterizadas por pesos (p1, p2, ..., pn); • um somador para acumular os sinais de entrada; • uma função de ativação que limita o intervalo permissível de amplitude do sinal de saída (y) a um valor fixo. As redes neurais artificiais são modelos que buscam simular o processamento de informação do cérebro humano.

Característica Marcante Rede Neural
Uma das propriedades mais importantes de uma rede neural artificial é a capacidade de aprender por intermédio de exemplos e fazer inferências sobre o que aprendeu, melhorando gradativamente o seu desempenho. As redes neurais utilizam um algoritmo de aprendizagem cuja tarefa é ajustar os pesos de suas conexões (BRAGA; CARVALHO; LUDEMIR, 2000, cap. 2).

Redes neurais na recuperação de informação Mozer (1984) foi o pioneiro na utilização de técnicas de redes neurais na recuperação de informação. Os sinais tornam-se mais fracos a cada iteração, e o processo de propagação eventualmente para.

Redes neurais na recuperação de informação Os termos de indexação ativados pelos de termos de busca enviam sinais para os documentos. Os documentos ativados enviam sinais que são conduzidos de volta aos termos de indexação. Entre os documentos resultantes, podem aparecer alguns que não estão diretamente relacionados aos termos utilizados na expressão de busca, mas que foram inferidos durante a pesquisa e possuem certo grau de relacionamento com a necessidade de informação do usuário.
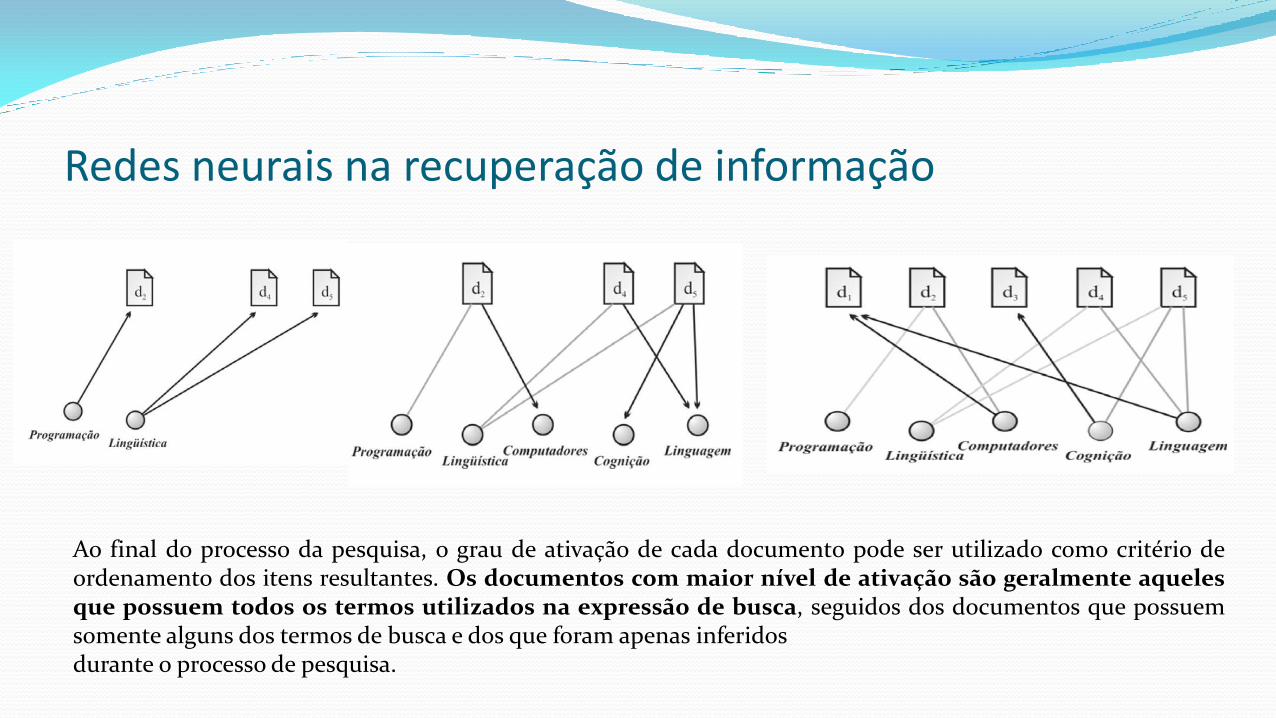
Redes neurais na recuperação de informação
Ao final do processo da pesquisa, o grau de ativação de cada documento pode ser utilizado como critério de ordenamento dos itens resultantes. Os documentos com maior nível de ativação são geralmente aqueles que possuem todos os termos utilizados na expressão de busca, seguidos dos documentos que possuem somente alguns dos termos de busca e dos que foram apenas inferidos durante o processo de pesquisa.

Redes neurais na recuperação de informação
Desenvolvido por Belew (1989), o sistema Adaptative Information Retrieval (AIR). Têm habilidade de aprender por meio da alteração dos pesos associados às ligações entre os nós. Durante a pesquisa, é feita a ativação dos nós da rede e, quando o sistema se estabiliza, os nós e as ligações que foram inferidos são apresentados ao usuário. Para que o usuário possa atribuir um grau de relevância para cada um dos itens recuperados.

CRESTANI, Fabio and PASI,Gabriella. Soft Information Retrieval: Applications of Fuzzy Set Theory and Neural Networks. In: NeuroFuzzy
Techniques for Intelligent Information Systems. Publisher: Physica Verlag (Springer Verlag), 1999. Mohd Wazih Ahma; Dr. M A. Ansari. A Survey: Soft computing in Intelligent Information Retrieval Systems. 2012 12th International
Conference on Computational Science and Its Applications. BAEZA-YATES, Ricardo; RIBEIRO-NETO, Berthier. Chapter 2. Modeling. In: Modern Information Retrieval. New York: Addison Wesley,
1999. p.34-49. Md. Abu Kausar, Md. Nasar and Sanjeev Kumar Singh. Information Retrieval using Soft Computing: An Overview. International Journal
of Scientific & Engineering Research, Volume 4, Issue 4, April, 2013. ISSN 2229. FERNEDA, Edberto. Redes neurais e sua aplicação em sistemas de recuperação de informação. Ciência da Informação, v.35, n.1, p. 25-30,
jan./abr. 2006. TORRA, Vicenço, MIYAMOTO, Sadaaki, LANAU, Sergi. Exploration of textual document archives using a fuzzy hierarchical clustering
algorithm in the GAMBAL system . Information Processing & Management, v. 41, n.3, p. 587-598, maio 2005.
Referências


















