
Análise da Fiabilidade e Disponibilidade de Sistemas de Navios · iii Resumo Esta dissertação...
106
Análise da Fiabilidade e Disponibilidade de Sistemas de Navios Peter Fekete Klebanowski Nuñez Dissertação para obtenção do Grau de Mestre em Engenharia e Arquitectura Naval Júri Presidente Doutor Yordan Ivanov Garbatov Orientador Doutor Ângelo Manuel Palos Teixeira Coorientador Doutor Carlos António Pancada Guedes Soares Vogal Doutor José Augusto da Silva Sobral Dezembro 2014
-
Upload
vuongtuyen -
Category
Documents
-
view
213 -
download
0
Transcript of Análise da Fiabilidade e Disponibilidade de Sistemas de Navios · iii Resumo Esta dissertação...

Análise da Fiabilidade e Disponibilidade de
Sistemas de Navios
Peter Fekete Klebanowski Nuñez
Dissertação para obtenção do Grau de Mestre em
Engenharia e Arquitectura Naval
Júri
Presidente Doutor Yordan Ivanov Garbatov
Orientador Doutor Ângelo Manuel Palos Teixeira
Coorientador Doutor Carlos António Pancada Guedes Soares
Vogal Doutor José Augusto da Silva Sobral
Dezembro 2014


i
Agradecimentos
Aos meus pais e irmãs por todo o apoio que me foram dando ao longo de todo o curso.
A todos os professores que de alguma forma contribuíram para a minha formação académica.
A todos os meus colegas de faculdade com quem tive a oportunidade de partilhar e discutir diversas
ideias ao longo dos últimos anos.
Ao Professor Marcelo Ramos Martins do Departamento de Engenharia Naval e Oceânica da
Universidade de São Paulo por ter fornecido os dados do sistema de incêndios estudado nesta
dissertação.
Aos meus orientadores, Professor Ângelo Teixeira e Professor Carlos Guedes Soares pela
oportunidade de poder desenvolver uma dissertação no âmbito da fiabilidade e por todo o apoio e
orientação durante a sua realização.

ii

iii
Resumo
Esta dissertação analisa a fiabilidade e disponibilidade de sistemas de navios através da sua
modelação por Petri Nets Estocásticas com predicados e simulação de Monte Carlo, e o impacto de
diferentes políticas de manutenção no desempenho dos sistemas. É feito um estudo da disponibilidade
de um sistema de combate a incêndios e de um sistema de reliquefação de gás natural a ser
implementado a bordo de grandes navios LNG. No primeiro, um sistema de combate a incêndios usado
apenas em casos de emergência, dá-se especial atenção às falhas ocultas ocorridas enquanto o
sistema se encontra em standby e à relação entre a periodicidade das manutenções e a disponibilidade
do sistema. No segundo, um sistema de reliquefação de gás natural, para além da influência que as
políticas de manutenção têm na disponibilidade, faz-se também uma comparação entre os resultados
obtidos pela modelação dos modos de falha por duas distribuições diferentes: Exponencial e Weibull.
Ainda no segundo sistema, analisa-se o impacto que a não modelação das falhas em standby dos
equipamentos redundantes pode ter na disponibilidade de um sistema de operação contínua. Em
ambos os modelos, são implementados modos de falha de equipamentos em reserva (standby), falha
ao arranque e falha em funcionamento, recorrendo-se à distribuição de Weibull para que o desgaste
dos equipamentos ao longo do tempo seja considerado. As redes implementadas permitem considerar
políticas de manutenção preventiva, correctiva e oportunista, podendo estas ser perfeitas ou
imperfeitas. Os resultados mostram que a modelação do desgaste não deve ser desprezada, prática
comum em estudos de fiabilidade ou noutros modelos como as cadeias de Markov. Dependendo das
políticas de manutenção implementadas, a não modelação do desgaste pode mesmo tornar os
resultados menos conservativos e demasiado optimistas, ignorando parte da indisponibilidade e
capacidades de produção dos sistemas. A importância da modelação das falhas em standby varia
consoante o tipo de sistema, sendo fundamental em sistemas pouco utilizados e estando dependente
da quantidade e disposição dos equipamentos redundantes de sistemas de operação contínua.
Demonstra-se que as redes Petri e as simulações de Monte Carlo são uma alternativa viável à
abordagem clássica e permitem que estudos de optimização de recursos sejam feitos.
Palavras-chave: Fiabilidade, Disponibilidade, Manutenção, Optimização, Redes Petri (GSPN),
Simulação de Monte Carlo, Sistemas de Navios

iv

v
Abstract
This thesis analyses the reliability and availability of ship systems using Generalized Stochastic Petri
Nets (GSPN) with predicates coupled with Monte Carlo simulation and the impact that different
maintenance policies may have on the performance of the systems. A study on the availability is done
for a foam fire-fighting system and a reliquefaction system to be implemented aboard of large LNG
ships. On the fire-fighting system, rarely used, special attention is given to the unrevealed failures
occurred while the system is in standby and to the relation between maintenance intervals and system
availability. On the reliquefaction system, besides the influence of different maintenance policies,
availability studies are done for two different cases: considering or disregarding of the wear on the
component with failure times described either by Weibull or Exponential distribution. For the second
system, it is also analysed the impact of disregarding standby failures on the redundant components.
Standby, operational and on demand failures are implemented on both models. The implemented Petri
Nets allow to consider preventive, corrective and opportunistic maintenances and these may be perfect
or imperfect. The results showed that the modelling of wear should not be neglected, a common practice
among reliability studies or in other models such as Markov chains. Depending on the implemented
maintenance policy, the disregard of the wear may turn the results less conservative and too optimistic,
ignoring part of the unavailability and loss of production capacities of the systems. The importance of
modelling the standby failures varies with the type of system, being fundamental in little-used standby
systems and dependent on the amount and arrangement of redundant equipments of continuous
operation systems. It is proven that Petri Nets coupled with Monte Carlo simulation are a viable and
powerful alternative technique to the classical approach on reliability and allow the development of
resource optimization studies.
Keywords: Reliability, Availability, Maintenance, Optimization, Petri Nets (GSPN), Monte Carlo
Simulation, Ship Systems

vi

vii
Índice
Agradecimentos .........................................................................................................................................i
Resumo ................................................................................................................................................... iii
Abstract.....................................................................................................................................................v
Lista de Figuras ....................................................................................................................................... ix
Lista de Tabelas ...................................................................................................................................... xi
Lista de Abreviaturas ............................................................................................................................. xiii
1 Introdução ........................................................................................................................................ 1
1.1 Enquadramento e Motivação ................................................................................................... 1
1.2 Objectivos da Dissertação ....................................................................................................... 3
1.3 Estrutura da Dissertação ......................................................................................................... 4
2 Revisão Teórica ............................................................................................................................... 6
2.1 Fiabilidade ............................................................................................................................... 6
2.2 Taxa de falha ........................................................................................................................... 6
2.3 Tempos médios de falha em Standby ..................................................................................... 8
2.4 Distribuições de tempos de falha ............................................................................................ 8
2.4.1 Distribuição Exponencial ................................................................................................. 8
2.4.2 Distribuição de Weibull ................................................................................................... 9
2.5 Análise de Sistemas Série-Paralelo ...................................................................................... 10
2.5.1 Sistemas em Série .......................................................................................................... 10
2.5.2 Sistemas em Paralelo .................................................................................................... 11
2.5.3 Sistemas Mistos ............................................................................................................. 12
2.6 Manutenção de Sistemas ...................................................................................................... 12
2.6.1 Manutenção Preventiva ................................................................................................ 12
2.6.2 Manutenção Correctiva ................................................................................................. 14
2.7 Redes Petri ............................................................................................................................ 16
3 Revisão de Literatura .................................................................................................................... 19
4 Modelação de Sistemas do Navio ................................................................................................. 25
4.1 Sistema de Combate a Incêndios ......................................................................................... 25
4.1.1 Redes Petri dos componentes individuais ..................................................................... 26
4.1.2 Rede Petri do Sistema Global ........................................................................................ 32

viii
4.2 Reliquefação de BOG a bordo de um LNG ........................................................................... 33
4.2.1 Redes Petri dos componentes individuais ..................................................................... 39
4.2.2 Rede Petri do Sistema Global ........................................................................................ 47
4.3 Eficiência e precisão do processo de simulação ................................................................... 47
5 Simulação e Verificação do modelo e dos seus componentes ..................................................... 49
5.1 Verificação do Componente Individual .................................................................................. 49
5.2 Verificação do subsistema de Compressão do BOG ............................................................ 53
5.3 Verificação do subsistema de Compressão de N2 ................................................................ 55
5.4 Verificação do Sistema em série ........................................................................................... 57
5.5 Verificação do Sistema sujeito a Manutenções Periódicas ................................................... 59
5.6 Verificação do sistema de reliquefação por Kwang et al., (2008) ......................................... 61
5.6.1 Reparações apenas no porto de origem ....................................................................... 63
5.6.2 Reparações disponíveis a bordo .................................................................................... 64
5.6.3 Verificação através dos resultados obtidos................................................................... 65
6 Estudo da Disponibilidade dos sistemas ....................................................................................... 68
6.1 Sistema de Combate a Incêndios ......................................................................................... 68
6.2 Sistema de reliquefação de BOG .......................................................................................... 71
6.2.1 Sistema com falhas em Standby .................................................................................... 73
6.2.2 Sistema com falhas em standby e desgaste nos equipamentos ................................... 75
6.3 Optimização de políticas de manutenção ............................................................................. 81
7 Conclusão e Trabalho Futuro ........................................................................................................ 84
7.1 Conclusão .............................................................................................................................. 84
7.2 Trabalho Futuro ..................................................................................................................... 85
8 Referências Bibliográficas ............................................................................................................. 87

ix
Lista de Figuras
Figura 2.1 – Curva da Banheira .............................................................................................................. 7
Figura 2.2 – Fiabilidade de um Sistema com N componentes em série em função da fiabilidade do
componente ........................................................................................................................................... 11
Figura 2.3 - Fiabilidade de um Sistema com N componentes em Paralelo em função da fiabilidade do
componente ........................................................................................................................................... 12
Figura 2.4 – Efeito da Manutenção Preventiva na Fiabilidade em função do factor de forma ............. 13
Figura 2.5 – Disponibilidade para sistema com falhas ocultas submetido a inspecções periódicas
perfeitas ................................................................................................................................................. 15
Figura 2.6 – Disponibilidade para sistema com falhas ocultas submetido a inspecções reais ............ 16
Figura 2.7 – Elementos de uma rede Petri............................................................................................ 17
Figura 4.1 – Diagrama do Sistema de Combate a Incêndios ............................................................... 26
Figura 4.2 – Rede Principal do Equipamento Genérico ........................................................................ 27
Figura 4.3 – Rede para Actividades de Manutenção Preventiva .......................................................... 29
Figura 4.4 – Rede para actividades de Manutenção Correctiva ........................................................... 29
Figura 4.5 – Rede Petri para contagem do tempo de vida do equipamento ........................................ 30
Figura 4.6 – Rede de comunicação ao protótipo de Inspecções .......................................................... 31
Figura 4.7 – Rede Petri do bloco de Inspecções .................................................................................. 32
Figura 4.8- Diagrama de Blocos Estocástico do Sistema de combate a incêndios .............................. 33
Figura 4.9 – Pormenor do Circuito de Água .......................................................................................... 33
Figura 4.10 – Pormenor do Circuito de Espuma ................................................................................... 33
Figura 4.11 – Diagrama do Sistema de Reliquefação de Gás .............................................................. 35
Figura 4.12 – Diagrama de Blocos do Sistema de Reliquefação ......................................................... 37
Figura 4.13 – Pormenor do subsistema Compressor BOG .................................................................. 38
Figura 4.14 – Pormenor do subsistema Compressor N2 ...................................................................... 38
Figura 4.15 – Modo de falha e reparação colectiva .............................................................................. 41
Figura 4.16 – Rede de capacidades do Ramo activo ........................................................................... 41
Figura 4.17 – Rede gestora dos ramos activos .................................................................................... 42
Figura 4.18 – Rede de Manutenções do bloco do sistema de compressão de BOG ........................... 43
Figura 4.19 - Modo de falha e reparação colectiva ............................................................................... 45
Figura 4.20 - Rede de capacidades do Ramo activo ............................................................................ 46
Figura 4.21 – Calendário de Navegação ............................................................................................... 46
Figura 4.22 – Diagrama de Blocos Estocástico .................................................................................... 47
Figura 4.23 – Convergência do erro e intervalo de confiança .............................................................. 48
Figura 5.1- Curvas de Disponibilidade em função do número de simulações ...................................... 50
Figura 5.2 – Curvas de Disponibilidade para distribuições exponenciais ............................................. 51
Figura 5.3 - Curvas de Disponibilidade para distribuições de Weibull .................................................. 51
Figura 5.4 – Disponibilidade do Equipamento com manutenções correctivas ..................................... 52
Figura 5.5 – Disponibilidade do equipamento sujeito a desgaste e manutenções periódicas ............. 53

x
Figura 5.6 - Curvas de Disponibilidade para distribuições exponenciais .............................................. 54
Figura 5.7 - Curvas de Disponibilidade para distribuições de Weibull .................................................. 55
Figura 5.8 - Curvas de Disponibilidade para distribuições expoenciais ................................................ 56
Figura 5.9 - Curvas de Disponibilidade para distribuições de Weibull .................................................. 57
Figura 5.10 – Curva de Disponibilidade do Sistema ............................................................................. 59
Figura 5.11 – Disponibilidade do Sistema sujeito a intervenções periódicas ....................................... 60
Figura 5.12 - Disponibilidade do Sistema sujeito a intervenções periódicas ........................................ 61
Figura 5.13 – Disponibilidade para os casos em que as reparações apenas são possíveis no porto de
origem .................................................................................................................................................... 64
Figura 5.14 - Disponibilidade para os casos em que as reparações são sempre possíveis ................ 65
Figura 6.1 – Disponibilidade do Sistema de Combate a Incêndios ...................................................... 70
Figura 6.2 – Intervalos de Confiança para a quantidade de BOG queimada para os casos em que as
reparações são feitas no porto de origem ............................................................................................. 74
Figura 6.3– Intervalos de Confiança para a quantidade de BOG queimada para os casos em que as
reparações são feitas a bordo ............................................................................................................... 74
Figura 6.4 – Disponibilidade para s casos em que as reparações apenas são possíveis no porto de
origem .................................................................................................................................................... 76
Figura 6.5 – Disponibilidade para os casos em que as reparações são sempre possíveis ................. 77
Figura 6.6 – Representação equipamentos sujeitos a reparações periódicas ..................................... 77
Figura 6.7 – Representação equipamentos sujeitos a reparações imediatas ...................................... 78
Figura 6.8 – Disponibilidade dos equipamentos sujeitos a manutenções periódicas ........................... 78
Figura 6.9 – Disponibilidade de equipamentos sujeitos a reparações imediatas ................................. 79
Figura 6.10 – Tendência da idade do componente ............................................................................... 80
Figura 6.11 - Custos associados a cada intervalo ................................................................................ 83

xi
Lista de Tabelas
Tabela 2.1 – Expressões Características da distribuição Exponencial .................................................. 9
Tabela 2.2 - Expressões Características da distribuição de Weibull .................................................... 10
Tabela 4.1 – Influência da falha dos componentes na capacidade de reliquefação ............................ 36
Tabela 4.2 – Custos associados à instalação do sistema de reliquefação .......................................... 38
Tabela 5.1 – Erro das curvas de Disponibilidade ................................................................................. 50
Tabela 5.2 - Erro das curvas de Disponibilidade .................................................................................. 52
Tabela 5.3 – Valores obtidos para a disponibilidade assimptótica ....................................................... 52
Tabela 5.4 – Parâmetros das distribuições dos tempos de falha ......................................................... 54
Tabela 5.5 - Erro das curvas de Disponibilidade .................................................................................. 54
Tabela 5.6 - Parâmetros das distribuições dos tempos de falha .......................................................... 56
Tabela 5.7 - Erro das curvas de Disponibilidade .................................................................................. 56
Tabela 5.8 – Parâmetros caracterizadores das distribuições ............................................................... 57
Tabela 5.9 – Disponibilidade e erros do sistema .................................................................................. 60
Tabela 5.10 – Taxas de transição ......................................................................................................... 62
Tabela 5.11 – Resultados para os casos em que as reparações apenas são possíveis no porto de
origem .................................................................................................................................................... 66
Tabela 5.12 - Resultados para os casos em que as reparações são sempre possíveis ..................... 66
Tabela 5.13 – Previsão de BOG queimado segundo estudo de Kwang et al., (2008) ......................... 66
Tabela 6.1 – Parâmetros utilizados na simulação ................................................................................ 69
Tabela 6.2 – Disponibilidade e SIL do Sistema de Combate a Incêndios ............................................ 71
Tabela 6.3 – Número de intervenções e de equipamentos substituídos .............................................. 71
Tabela 6.4 – Parâmetros caracterizadores do sistema de reliquefação de BOG ................................ 72
Tabela 6.5 – Resultados para os casos em que as reparações apenas são possíveis no porto de
origem .................................................................................................................................................... 73
Tabela 6.6 – Resultados para os casos em que as reparações são sempre possíveis ...................... 73
Tabela 6.7 - Resultados para os casos em que as reparações apenas são possíveis no porto de
origem .................................................................................................................................................... 75
Tabela 6.8 - Resultados para os casos em que as reparações são sempre possíveis ....................... 76
Tabela 6.9 – Influência da duração da viagem na disponibilidade do sistema sujeito a reparações
periódicas .............................................................................................................................................. 80
Tabela 6.10 – Resultados obtidos para a optimização do intervalo entre manutenções periódicas .... 82
Tabela 6.11 – Custos associados a cada intervalo .............................................................................. 82

xii

xiii
Lista de Abreviaturas
ABS American Bureau of Shipping
AGREE Advisory Group on Reliability of Electronic Equipment
BOG Boil-off Gas
GCU Gas Combustion Unit
GSPN Generalized Stochastic Petri Nets
LNG Liquefied Natural Gas
MTTF Mean Time to Failure
MTTR Mean Time to Repair
RAMS Reliability, Availability, Maintainability and Safety
SIL Safety Integrity Levels
SOLAS Safety of Life at Sea

xiv

1
1 Introdução
1.1 Enquadramento e Motivação
Com a revolução industrial, a partir da segunda metade do século XVIII, muitos métodos de produção
artesanais puderam ser mecanizados. Com esta mecanização e automação de processos, iniciou-se
uma procura por sistemas com um desempenho cada vez melhor com custos cada vez mais baixos. A
evolução na complexidade e mecanização de processos durante a revolução industrial permitiu um
crescimento económico sustentável imediato no Reino Unido e, em poucas décadas, na Europa
Ocidental e Estados Unidos. Existe consenso quando se afirma que o início da Revolução Industrial é
o evento mais importante na história da humanidade desde a domesticação dos animais e da
agricultura. É também desde este momento, que começa uma procura por optimizar a disponibilidade
dos sistemas com uma diminuição das probabilidades de falha de cada componente.
No início do século XX, a produção em massa para a manufactura de grandes quantidades de bens,
(produção de espingardas no arsenal de Springfield, 1863 e a produção em série do primeiro carro
Ford, 1913) (Saleh & Marais, 2006), serviram como impulsionador de estudos de fiabilidade. No
entanto, o verdadeiro catalisador para o desenvolvimento do conceito de fiabilidade foram as duas
Grandes Guerras Mundiais e os diversos estudos militares no âmbito de equipamentos sujeitos ao clima
de guerra. Este conceito foi, pela primeira vez, sintetizado e consolidado como disciplina científica em
1957 num relatório redigido pelo AGREE (Advisory Group on Reliability of Electronic Equipment) –
associação feita em parceria do Ministério de Defesa Norte Americana com a Indústria Electrónica
Americana (AGREE, 1957).
Nos dias de hoje, pouco mais de cinquenta anos após o relatório da AGREE (AGREE, 1957), a
fiabilidade está bem definida, sendo uma disciplina científica multidisciplinar. Tem como intenções:
desenvolver e aprofundar métodos formais que visam ajudar na criação de sistemas fiáveis, entender
mecanismos de falha e optimizar processos de manutenção (Aven & Jensen, 1999).
No âmbito de quase todos os ramos da engenharia, a integridade dos sistemas implementados tem de
ser determinada, com especial atenção aos de grande dimensão e elevada complexidade. Esta
integridade é determinada pela fiabilidade, disponibilidade, manutenibilidade e segurança de todos os
equipamentos pertencentes ao sistema. Uma boa combinação entre estes quatro parâmetros pode
determinar a qualidade ao longo do tempo de um projecto de engenharia. Num contexto de segurança
dos sistemas, as noções de fiabilidade e disponibilidade estão mais ligadas a eventos raros (baixas
probabilidades de ocorrência) mas com grandes consequências e por isso algumas simplificações
podem ser feitas e modelos como FMEA podem ser suficientes na determinação do risco. No entanto,
em contextos de produção, a capacidade do sistema lida com eventos mais comuns (altas
probabilidades de ocorrência) mas de baixas consequências. Dessa forma, a probabilidade de
ocorrência de diversas falhas ocorrerem num curto intervalo de tempo não pode ser desprezada e
especial atenção deve ser dada à modelação do sistema e às dependências entre os diversos

2
equipamentos. Neste âmbito, e segundo alguns autores (Signoret, 2004), apenas as simulações de
Monte Carlo são capazes de efectuar estes estudos.
Em sistemas mecânicos os equipamentos podem ser submetidos a reparações quando falham ou a
inspecções periódicas de forma a prever e corrigir eventuais falhas que estariam na iminência de
ocorrer. Mesmo em equipamentos que não se encontram em operação, podem ocorrer falhas que não
são reveladas até que se requisite o funcionamento do equipamento ou seja submetido a uma
intervenção periódica. Dessa forma, a disponibilidade dos sistemas que não estão em contínua
operação, principalmente os sistemas de segurança, está largamente associada não só ao tempo
necessário para a reparação do equipamento mas também à regularidade das manutenções. Assim,
quanto mais inspecções forem realizadas, maior é a probabilidade de uma falha oculta ser detectada
de forma precoce e corrigida antes de o sistema ser necessário. No entanto, é necessário encontrar
um equilíbrio entre os custos das inspecções periódicas e o ganho que se tem na disponibilidade do
sistema. Em alguns casos, o excesso de inspecções pode mesmo causar um desgaste acelerado no
equipamento. Nos sistemas de operação contínua, as tarefas de manutenção limita muitas vezes a sua
capacidade, reduzindo-a a zero, durante a intervenção. É portanto também necessário considerar esta
diminuição da capacidade na procura do ponto de equilíbrio.
Ao longo do tempo foram criados modelos matemáticos para o estudo da fiabilidade, intimamente
ligados a conceitos de probabilidade e a formulação que se estabeleceu tem-se revelado bastante
sólida na sua determinação. No entanto, a formulação criada está limitada à análise de componentes
ou sistemas simples. Com o desenvolvimento de sistemas cada vez maiores e com um grau de
complexidade crescente, os modelos matemáticos deixam de ser capazes de caracterizar fielmente a
realidade e soluções computacionais baseadas em simulação têm sido propostas (Signoret et al., 2013;
Zio, 2009). A sua adesão tem sido crescente dado o seu potencial em explorar casos que não são
possíveis apenas pelo modelo matemático. Neste contexto, as redes Petri estocásticas com predicados
e simulação de Monte Carlo têm-se revelado técnicas promissoras no trato de sistemas de elevada
complexidade. Através de uma correcta modelação dos sistemas por redes Petri é possível abordar o
problema de uma forma eficiente e considerar nos estudos questões relacionadas com a operação,
políticas de manutenção e interacções e dependências que existem entre os componentes que
constituem o sistema (Dutuit, et. al., 1997; Pešková, 2013).
Na indústria naval, a grande complexidade dos sistemas implementados, as difíceis condições a que
estão sujeitos e o difícil acesso para reparações, obriga-os a ser sistemas de elevado desempenho.
Sempre com um intuito de optimização, são vários os estudos de fiabilidade que podem ser feitos à
escala do navio. A diversidade de sistemas a bordo é vasta, passando por sistemas de propulsão,
combate a incêndios, manuseamento da carga, comunicações, lastro, etc. As consequências para a
falha dos diversos sistemas são diferentes como tal, atenções diferentes são dadas no momento do
projecto. No âmbito desta dissertação, são estudados dois sistemas marítimos e são demonstradas
algumas das potencialidades de modelação por redes Petri.

3
Com diversas fontes combustível e de ignição a bordo dos navios, a possibilidade de ocorrência de
incêndios em diversos locais do navio é real. Os riscos associados a um incêndio são bastante elevados
e daí nasce a necessidade de se instalar um sistema de combate a incêndios a bordo - imposição da
SOLAS (Safety of Life at Sea). Diversos sistemas para o combate são possíveis, dependendo sempre
do seu local e do tipo de combustível. Uma vez que se trata de um tipo de sistema de segurança que
se encontra em standby na maior parte do seu tempo, a sua disponibilidade é calculada usando as
redes Petri e demonstra-se a potencialidade das redes na modelação de sistemas que se encontram
em standby na maior parte do seu tempo.
Ao longo dos últimos anos, a necessidade de diminuir o preço da mercadoria transportada e um
aumento no volume de carga a distribuir, tem levado a que navios cada vez maiores sejam construídos.
Esta tendência verifica-se também nos navios de transporte de gás natural, levando a que já tenham
sido contratados a construção de navios que ultrapassam os 200 000m3 de capacidade (Stopford,
1997). Com o aparecimento de navios deste tipo e com estas dimensões, sistemas de reliquefação de
gás têm sido apresentados como solução para a grande quantidade de gás que se evapora a cada dia.
É com base no interesse da indústria em resolver os problemas relacionados com a evaporação do
gás, que é apresentado na presente dissertação um estudo da disponibilidade de um possível sistema
de reliquefação, tendo em conta diversos níveis de redundância no sistema. Neste sistema de utilização
praticamente contínua, pretende-se demonstrar a capacidade das redes Petri modelarem um sistema
multiestado submetido a diversos tipos de manutenção.
1.2 Objectivos da Dissertação
O objectivo desta dissertação é a análise da fiabilidade e disponibilidade de sistemas de navios através
da sua modelação por Petri Nets estocásticas e com predicados e da influência das tarefas de
manutenção no seu resultado. De forma a analisar estatisticamente a fiabilidade e disponibilidade dos
sistemas, as redes Petri são acopladas a simulações de Monte Carlo.
A análise da disponibilidade é feita para dois sistemas diferentes. No primeiro, um sistema de combate
a incêndios usado apenas em casos de emergência, dá-se especial atenção às falhas ocultas ocorridas
enquanto o sistema se encontra em standby e à relação entre a periodicidade das manutenções e a
disponibilidade do sistema. No segundo, um sistema de reliquefação de gás natural, para além da
influência que as políticas de manutenção têm na disponibilidade, faz-se também uma comparação
entre os resultados obtidos pela modelação dos modos de falha por duas distribuições diferentes:
distribuição exponencial e distribuição de Weibull. Ainda no segundo sistema, analisa-se qual o impacto
que a não modelação das falhas em standby dos equipamentos redundantes pode ter no resultado de
um sistema de operação contínua. O momento em que se iniciam as tarefas de manutenção também
tem um papel importante na disponibilidade do sistema. Para se entender o peso que as diferentes
políticas podem ter, é feita uma comparação da capacidade do sistema para os casos em que as falhas
apenas podem ser reparadas periodicamente contra o caso em que as tarefas de reparação iniciam-se
imediatamente após a falha do componente.

4
Um dos objectivos desta dissertação passa pela modelação dos sistemas da forma mais real possível.
Dessa forma, são criados protótipos de equipamentos, com modos de falha em standby e em
funcionamento, ambos dependendo da idade acumulada e capazes de serem submetidos a
intervenções correctivas, preventivas, oportunísticas, perfeitas e imperfeitas. Estes módulos protótipo
de equipamento podem também falhar ao arranque e o início das tarefas de manutenção podem estar
dependentes da quantidade de equipas de manutenção e material em stock. Definiu-se ainda que este
protótipo deveria ser genérico e capaz de modelar qualquer componente mecânico, podendo ser
utilizado fora do âmbito dos sistemas desta dissertação.
Para além da análise através das redes Petri, é feita uma análise ao sistema de reliquefação de gás
com base na teórica clássica. Uma vez que a teoria clássica não considera todas as características de
um sistema real, é necessário fazer-se algumas aproximações e simplificações na rede criada. Os
resultados da teoria clássica são usados como verificação da rede Petri modelada.
É ainda demonstrado que os resultados obtidos pelas simulações podem ser facilmente utilizados para
um estudo de optimização de políticas de manutenção, garantindo ser uma ferramenta muito útil nos
processos de decisão e uma alternativa às teorias clássicas.
1.3 Estrutura da Dissertação
O primeiro capítulo de introdução apresenta a motivação que levou ao desenvolvimento do estudo de
fiabilidade em sistemas a bordo de navios. São apresentados também os objectivos que se pretendem
alcançar no âmbito deste trabalho.
No segundo capítulo, são apresentados os conceitos e princípios teóricos básicos de Fiabilidade e de
Disponibilidade. É feita uma diferenciação entre as distribuições Exponencial e de Weibull, distribuições
mais populares na determinação da fiabilidade dos equipamentos. Alguns conceitos e a abordagem
matemática de sistemas redundantes são explicados. Os modelos matemáticos para algumas técnicas
de manutenção simples são também apresentados, assim como a sua influência na disponibilidade
final do sistema. São ainda apresentados os conceitos necessários para o entendimento das redes
Petri implementadas.
No terceiro capítulo é apresentado o estado de arte, nomeadamente os estudos sobre a fiabilidade em
geral e a sua aplicação na indústria naval. São referenciados diversos autores contextualizando os
seus artigos e a indicando qual a relevância que podem ter no âmbito desta dissertação.
No quarto capítulo, procede-se à exposição dos sistemas estudados. Numa primeira secção deste
capítulo é feita uma breve apresentação do programa e dos módulos utilizados no estudo. De seguida,
duas secções distintas apresentam os dois sistemas estudados. O primeiro, um sistema de combate a
incêndios; o segundo, um sistema de reliquefação de gás natural a bordo de navios LNG. Em cada
uma destas secções, são explicados os objectivos, funcionamento do sistema implementado e dos
componentes que o constituem. São apresentadas as diversas redes Petri criadas na modelação de
cada componente individual presente no sistema e a conjugação entre elas para a criação da rede Petri
que modela o sistema global.

5
No quinto capítulo procede-se à verificação do sistema modelado por redes Petri, modelo apresentado
previamente no capítulo quatro. Fazendo algumas considerações, é possível tornar o sistema simples
o suficiente para se efectuar uma verificação dos componentes individuais e da rede Petri global
implementada mas sem perder toda a complexidade que os caracteriza. Esta verificação é feita
comparando os valores obtidos através das simulações com valores teóricos obtidos pela teoria
clássica. Para uma verificação do sistema completo (sem qualquer simplificação) comparam-se os
resultados obtidos com os valores apresentados num estudo de caso semelhante apresentado na
literatura por Kwang et al. (2008). As possíveis diferenças entre os resultados obtidos são comentadas
no fim de cada secção de verificação.
No sexto capítulo, o modelo implementado e verificado no capítulo anterior, é aproximado à realidade.
Esta aproximação é conseguida através da consideração do desgaste dos equipamentos ao longo do
tempo, implementação de políticas de manutenção preventivas, correctivas, de oportunidade e
imperfeitas. A implementação adicional de falha dos equipamentos em standby e ao arranque também
aproximam o sistema da realidade. Para o caso do sistema de combate a incêndios, apresenta-se a
disponibilidade e cálculo do nível de integridade do sistema para quatro casos diferentes, sendo o que
distingue os casos entre si é a periodicidade das intervenções de manutenção. Ainda neste capítulo
são apresentados os valores da disponibilidade do sistema de reliquefação de BOG (Boil-off Gas) e
quantidade de BOG queimado ao longo de um ano de operação, considerando quatro casos distintos
de redundâncias de equipamentos. É também feita uma análise da importância que a modelação das
falhas em standby e da consideração do desgaste dos equipamentos tem nos resultados da
disponibilidade e quantidade de BOG queimado. É ainda apresentado e exemplificado o procedimento
que deve ser seguido num estudo de optimização dos intervalos de manutenção através de um
equilíbrio financeiro que balanceia as perdas relacionadas com a queima e os custos das manutenções.
O sétimo capítulo apresenta uma conclusão do estudo efectuado, dando algumas recomendações
acerca da abordagem a adoptar num estudo de fiabilidade de sistemas. São também dadas sugestões
para um trabalho futuro que possa complementar e aprofundar o estudo apresentado nesta dissertação.
No oitavo capítulo faz-se uma listagem de todas as referências utilizadas e que devem ser consultadas
para um aprofundamento de tudo o que foi exposto.

6
2 Revisão Teórica
2.1 Fiabilidade
A fiabilidade é definida como a probabilidade de um determinado equipamento ou sistema cumprir a
sua função, por um determinado período de tempo e sujeito a um conjunto de condições (Lewis, 1994).
Para complementar esta definição, é necessário clarificar o critério para o qual, considera-se que o
sistema não está capaz de cumprir a sua função. Deste complemento, chega-se à ideia de que a
fiabilidade está fortemente dependente da taxa de falha do sistema e da variável tempo. Isto pode ser
escrito em termos de uma variável aleatória t – tempo para a falha do sistema. A probabilidade de a
falha ocorrer no intervalo de tempo [t – Δt] é obtida através da função densidade de probabilidade
(f.d.p.),
𝒻(t) ∆t=P{ t ≤ t ≤ t+ ∆t } ( 2.1 )
A função de distribuição, F(t) é obtida através do integral apresentado na equação seguinte (Lewis,
1994) e representa a probabilidade da falha ocorrer para um tempo menor ou igual que t.
Ϝ(𝑡) = ∫ 𝒻(𝑡) 𝑑𝑡𝑡
0
= 𝑃{𝒕 ≤ 𝑡} ( 2.2 )
Como afirmado anteriormente, a fiabilidade é a capacidade de o sistema operar sem falhas por um
intervalo de tempo superior a t, podendo ser representado por:
𝑅(𝑡) = 𝑃{𝒕 > 𝑡} ( 2.3 )
Se um sistema não falhar para t≤t, então deve falhar para t>t. Dessa forma, temos que
𝑅(𝑡) = 1 − Ϝ(𝑡) ( 2.4 )
Ou, de forma equivalente,
𝑅(𝑡) = 1 − ∫ 𝒻(𝑡)𝑑𝑡𝑡
0
= ∫ 𝒻(𝑡)𝑑𝑡∞
𝑡
( 2.5 )
Das propriedades da função densidade de probabilidade, é claro que
2.2 Taxa de falha
Uma análise do comportamento da taxa de falha permite uma compreensão sobre os mecanismos de
falha de um sistema. A taxa de falha, λ(t), pode ser definida em função da f.d.p do tempo de falha.
Seja λ(t)Δt a probabilidade do sistema falhar para t<t+Δt sabendo que ainda não falhou em t=t,
λ(t)Δt = P{𝐭 < t + Δt | 𝒕 > 𝑡} ( 2.7 )
𝑅(0) = 1 𝑒 𝑅(∞) = 1 ( 2.6 )

7
Tratando-se de uma probabilidade condicionada, podemos escrevê-la da seguinte forma:
P{𝐭 < t + Δt | 𝒕 > 𝑡} =𝑃{𝒕 > 𝑡) ⋂ (𝒕 < 𝑡 + Δt)}
𝑃{𝒕 > 𝑡} ( 2.8 )
O numerador do lado direito da equação acima apresentada é uma forma alternativa de escrever a
função densidade de probabilidade.
𝑃{𝒕 > 𝑡) ∩ (𝒕 < 𝑡 + Δt)} ≡ P{ t ≤ t ≤ t+ ∆t }=𝒻(t) ∆t ( 2.9 )
Da equação ( 2.3 ), tira-se que o denominador da equação( 2.8 ), é a definição de fiabilidade. Assim,
combinando as equações ( 2.9 ) e ( 2.3 ), temos que
λ(t) =𝒻(t)
𝑅(𝑡) ( 2.10 )
A forma da taxa de falha é um indicativo da maneira como o equipamento envelhece e é bastante útil
na análise do risco a que uma unidade está exposta ao longo do tempo, podendo servir como base de
comparação entre duas unidades de diferentes. Como a taxa de falha permite avaliar o risco de falha
a que um equipamento está sujeito, alguns autores apelidam-na de função de risco.
A taxa de falha pode ser classificada de três formas: taxa de falha crescente, taxa de falha decrescente
e taxa de falha constante. Estas três formas são visíveis na curva da banheira representada na Figura
2.1. Deficiências nos processos de manufactura de um produto levam a falhas precoces e concentram-
se no início da sua vida que, por analogia à distribuição da mortalidade humana, designa-se por zona
de mortalidade infantil. As falhas que incidem durante a vida útil do equipamento devem-se tipicamente
a condições extremas a que estão sujeitos e podem ocorrer, uniformemente, em qualquer momento no
tempo, levando a que a taxa de falha seja constante. O envelhecimento de um equipamento leva
frequentemente a um aumento sucessivo de falhas por desgaste, concentradas no final da vida útil, na
zona de desgaste.
Figura 2.1 – Curva da Banheira

8
2.3 Tempos médios de falha em Standby
A obtenção dos tempos médios de falha de equipamentos é feita estatisticamente e publicada em bases
de dados próprias. No entanto, os dados para falhas em standby não se encontram disponíveis porque
poucos estudos são feitos nesse sentido.
Uma estimativa dos tempos médios de falha em standby é feita por extrapolação linear com base nos
valores que se encontram disponíveis sobre falhas em funcionamento. Para tal, é necessário ter
informação acerca de: tempo tempo médio de falha considerando apenas tempo de funcionamento
(MTTFOperacional); tempo médio de falha considerando todo o tempo decorrido, incluindo os momentos
de funcionamento e momentos em standby (MTTFCalendário); tempo apenas de funcionamento (tfunc); e
tempo total que considera os momentos de funcionamento e os momentos em standby (tcalendário).
Se para um determinado tempo de calendário, o equipamento esteve em utilização durante
𝑡𝑜𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙%, a percentagem do tempo de calendário em que o equipamento esteve em standby é 1 −
𝑡𝑜𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙. Com base nisso, é possível calcular qual a influência que o tempo em standby teve no
tempo médio para a falha: 𝑉𝑎𝑟𝑖𝑎çã𝑜 = 𝑀𝑇𝑇𝐹𝑐𝑎𝑙𝑒𝑛𝑑á𝑟𝑖𝑜/𝑀𝑇𝑇𝐹𝑂𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙. Se fizermos tender o tempo em
standby para 100%, é possível extrapolar o factor 𝑀𝑇𝑇𝐹𝑆𝑡𝑎𝑛𝑑𝑏𝐵𝑦/𝑀𝑇𝑇𝐹𝑂𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙 ,
%𝑡𝑒𝑚𝑝𝑜 𝑝𝑎𝑟𝑎𝑑𝑜
𝑀𝑇𝑇𝐹𝑐𝑎𝑙𝑒𝑛𝑑á𝑟𝑖𝑜
𝑀𝑇𝑇𝐹𝑂𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙
=1
𝑀𝑇𝑇𝐹𝑆𝑡𝑎𝑛𝑑𝐵𝑦
𝑀𝑇𝑇𝐹𝑂𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙
( 2.11 )
Simplificando a equação anterior, temos:
𝑀𝑇𝑇𝐹𝑆𝐵 =𝑀𝑇𝑇𝐹𝑐𝑎𝑙𝑒𝑛𝑑á𝑟𝑖𝑜
1 − %𝑡𝑒𝑚𝑝𝑜 𝑜𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙
( 2.12 )
Ao factor 𝑀𝑇𝑇𝐹𝑂𝑝𝑒𝑟𝑎𝑐𝑖𝑜𝑛𝑎𝑙/𝑀𝑇𝑇𝐹𝑆𝑡𝑎𝑛𝑑𝑏𝑦, necessário para uma correcção de tempos de vida acumulado,
dá-se o nome de age factor. Este será usado mais adiante na modelação do sistema.
2.4 Distribuições de tempos de falha
Em aplicações de fiabilidade, várias distribuições podem ser usadas para a caracterização da variável
tempo de falha. As mais comuns, e utilizadas nesta dissertação, são a distribuição Exponencial e a
distribuição de Weibull. Para cada uma das distribuições, apresenta-se a função densidade de
probabilidade 𝒻(t), função distribuição Ϝ(𝑡), função de fiabilidade 𝑅(𝑡), taxa de falha λ(t) e tempo médio
de falha, MTTF.
2.4.1 Distribuição Exponencial
Trata-se da distribuição contínua mais utilizada na caracterização da duração de um equipamento
(Lewis, 1994). É a simplicidade matemática das expressões utilizadas na distribuição exponencial que
a torna popular em estudos de fiabilidade.
Uma das propriedades desta distribuição é a falta de memória, i.e., a probabilidade de um equipamento
funcionar durante as primeiras mil horas de utilização é igual à probabilidade do mesmo equipamento

9
funcionar mais mil horas, sabendo que já funcionou cinco mil. Matematicamente, esta característica
pode ser escrita da forma apresentada na seguinte equação:
𝑃{𝒕 > 𝑡 + Δt | 𝒕 > 𝑡} = 𝑃{𝒕 > Δt } ( 2.13 )
Devido a esta falta de memória, algum cuidado deve ser tomado com a utilização desta distribuição na
modelação dos tempos de falha em equipamentos sujeitos a desgaste. Esta distribuição apenas pode
ser usada em equipamentos mecânicos sujeitos a desgaste se estes forem submetidos a manutenções
e reparações periódicas, de forma a que permaneçam sempre na zona de taxa de falha constante da
curva da banheira apresentada na Figura 2.1, consideração feita na determinação dos tempos médios
de falha apresentados na base de dados OREDA (2002).
As expressões características da distribuição exponencial são apresentadas na Tabela 2.1.
Tabela 2.1 – Expressões Características da distribuição Exponencial
Função densidade de probabilidade
𝒻(t) 𝒻(t)=λ𝑒𝜆𝑡 ( 2.14 )
Função distribuição, Ϝ(𝑡) 𝐹(𝑡) = 1 − 𝑒−𝜆𝑡 ( 2.15 )
Função de fiabilidade 𝑅(𝑡) 𝑅(𝑡) = 𝑒−𝜆𝑡 ( 2.16 )
Taxa de falha, λ(t) λ ( 2.17 )
Tempo médio de falha, MTTF 1λ⁄ ( 2.18 )
2.4.2 Distribuição de Weibull
A distribuição de Weibull é também uma das mais usadas no cálculo de fiabilidade pois, através de
uma escolha apropriada nos valores dos seus parâmetros, vários comportamentos da taxa de falha
podem ser modelados. Para além de uma possível modelação de um equipamento na zona de
mortalidade infantil e da zona de desgaste, é possível modelar o caso em que a taxa de falha é
constante, tornando-se semelhante à distribuição Exponencial.
As expressões características da distribuição de Weibull com dois parâmetros são apresentadas na
Tabela 2.2.
Nas equações apresentadas na Tabela 2.2, 𝜃 e 𝑚 são parâmetros da distribuição de Weibull. Na
equação ( 2.23 ), Γ(∙) designa a função Gama, um integral indefinido tabelado.

10
Tabela 2.2 - Expressões Características da distribuição de Weibull
Função densidade de
probabilidade 𝒻(t) 𝒻(t)=
𝑚
𝜃(
𝑡
𝜃)
𝑚−1
𝑒𝑥𝑝 [− (𝑡
𝜃)
𝑚
] ( 2.19 )
Função distribuição, Ϝ(𝑡) 𝐹(𝑡) = 1 − exp [−(𝑡𝜃⁄ )
𝑚] ( 2.20 )
Função de fiabilidade 𝑅(𝑡) 𝑅(𝑡) = exp [−(𝑡𝜃⁄ )
𝑚] ( 2.21 )
Taxa de falha, λ(t) λ(𝑡) =𝑚
𝜃(
𝑡
𝜃)
𝑚−1
( 2.22 )
Tempo médio de falha, MTTF 𝜃 ∙ Γ(1 + 1𝑚⁄ ) ( 2.23 )
2.5 Análise de Sistemas Série-Paralelo
Um sistema é o conjunto de componentes interligados segundo um projecto predeterminado, de forma
a realizar um conjunto de funções de forma fiável e com bom desempenho (Fogliatto & Duarte Ribeiro,
2009).
2.5.1 Sistemas em Série
Num sistema em série, n componentes são ligados de forma a que a falha de qualquer um dos
componentes, resulta na falha de todo o sistema.
A probabilidade do sistema estar a funcionar depende da probabilidade de todos os componentes
estarem a funcionar. Matematicamente, esta probabilidade pode ser expressa da seguinte forma:
𝑅𝑠 = 𝑃(𝑥1⋂𝑥2⋂ … ⋂𝑥𝑛) ( 2.24 )
Assumindo que os componentes são todos independentes entre si e que a falha de um não afecta a
probabilidade de falha dos demais, temos que:
𝑅𝑠 = 𝑃(𝑥1) × 𝑃(𝑥2) × … × 𝑃(𝑥𝑛) = ∏ 𝑅𝑖
𝑛
𝑖=1
( 2.25 )
Analisando-se a evolução da fiabilidade de um sistema em série através equação anterior, percebe-se
que a fiabilidade do sistema decresce rapidamente à medida que o número de componentes aumenta
e que o limite superior da fiabilidade do sistema é dado pela fiabilidade do componente menos fiável,
isto é:
𝑅𝑠 ≤ min𝑖
{𝑅𝑖} ( 2.26 )
Na Figura 2.2, pode-se ver qual a influência que o aumento de componentes tem na fiabilidade do
sistema. Para a elaboração do gráfico, consideraram-se equipamentos iguais.

11
Figura 2.2 – Fiabilidade de um Sistema com N componentes em série em função da fiabilidade do componente
2.5.2 Sistemas em Paralelo
Num sistema em paralelo, todos os sistemas devem falhar para que o sistema falhe.
A probabilidade do sistema se encontrar em funcionamento depende da probabilidade de haver pelo
menos um componente em funcionamento. O sistema deixa de estar disponível quando todos os
sistemas falharem. Matematicamente, a probabilidade de todos os equipamentos, independentes entre
si, falharem, pode ser expressa da seguinte forma:
𝑅𝑠̅̅ ̅ = 𝑃(�̅�1⋂𝑥2̅̅ ̅⋂ … ⋂𝑥𝑛̅̅ ̅) = ∏(1 − 𝑅𝑖)
𝑛
𝑖=1
( 2.27 )
A fiabilidade do sistema, é então dada pela probabilidade complementar, tomando a forma de:
𝑅𝑠 = 1 − ∏(1 − 𝑅𝑖)
𝑛
𝑖=1
( 2.28 )
Analisando-se a evolução da fiabilidade de um sistema em paralelo através equação anterior, percebe-
se que a fiabilidade do sistema aumenta à medida que o número de componentes aumenta. Na Figura
2.3 pode-se ver qual a influência que o aumento de componentes tem na fiabilidade do sistema. Para
a elaboração do gráfico, consideraram-se equipamentos iguais.

12
Figura 2.3 - Fiabilidade de um Sistema com N componentes em Paralelo em função da fiabilidade do componente
2.5.3 Sistemas Mistos
Na maior parte das situações reais, os sistemas são compostos por combinações de subsistemas em
série e em paralelo. A forma de os abordar passa pela redução sucessiva de subsistemas a
componentes em série ou em paralelo.
2.6 Manutenção de Sistemas
Para a maior parte dos sistemas é possível praticar dois tipos de manutenção: manutenção preventiva
e manutenção correctiva. A influência que cada um destes tipos de manutenção pode ter na fiabilidade
de um sistema é aqui apresentada de forma breve.
2.6.1 Manutenção Preventiva
Numa manutenção preventiva, substituem-se peças, trocam-se os lubrificantes e alguns ajustes são
feitos antes que o sistema falhe. O principal objectivo é o aumento da fiabilidade, adiando efeitos do
desgaste, corrosão, fadiga, e outros fenómenos relacionados.
No caso em que se efectuam manutenções preventivas no sistema a cada intervalo de tempo T, as
intervenções não têm qualquer efeito na fiabilidade para t<T, tal como apresentado na Figura 2.4.
Assim, a fiabilidade do sistema com manutenção preventiva toma o seguinte valor:
𝑅𝑀(𝑡) = 𝑅(𝑡) 0 ≤ 𝑡 < 𝑇 ( 2.29 )
Assume-se que a intervenção recupera o sistema para uma condição igual à que tinha no instante
inicial. Essa suposição implica que, para qualquer t>T, o sistema não seja influenciado pelo desgaste
causado pela utilização até ao momento da intervenção anterior. Deste modo, a fiabilidade do sistema
entre a primeira e a segunda intervenção toma o valor do produto de R(T) – probabilidade de o
equipamento estar operacional no instante da primeira inspeção – por R(t-T) – probabilidade de um
sistema novo.

13
Esse produto é descrito pela seguinte equação:
𝑅𝑀(𝑡) = 𝑅(𝑇)𝑅(𝑡 − 𝑇) 𝑇 ≤ 𝑡 < 2𝑇 ( 2.30 )
Seguindo a mesma abordagem, a probabilidade do sistema sobreviver no instante t, 2𝑇 ≤ 𝑡 < 3𝑇, é
obtido pela multiplicação de 𝑅𝑀(2𝑇) – probabilidade do sistema estar operacional no instante 2T – com
a probabilidade do sistema novo.
𝑅𝑀(𝑡) = 𝑅(𝑇)2𝑅(𝑡 − 2𝑇) 2𝑇 ≤ 𝑡 < 3𝑇 ( 2.31 )
A expressão geral para a fiabilidade de um sistema sujeito a manutenções preventivas perfeitas e
periódicas toma a forma:
𝑅𝑀(𝑡) = 𝑅(𝑇)𝑁𝑅(𝑡 − 𝑁𝑇) 𝑁𝑇 ≤ 𝑡 < (𝑁 + 1)𝑇 ( 2.32 )
A influência que este tipo de manutenções, preventiva, perfeita e periódica tem na fiabilidade de um
sistema é visível na Figura 2.4.
Figura 2.4 – Efeito da Manutenção Preventiva na Fiabilidade em função do factor de forma
Na Figura 2.4 verifica-se que o factor de forma da distribuição de Weibull determina o efeito que a
manutenção preventiva tem na fiabilidade do sistema. Se este factor tomar o valor unitário (m=1), as
intervenções de manutenção não trazem qualquer benefício. Isto ocorre porque o factor m=1 significa
que a taxa de falha é constante ao longo do tempo e a distribuição da fiabilidade passa a ter a mesma
forma que a distribuição exponencial, distribuição que não considera qualquer fenómeno de
envelhecimento. Para o caso em que m>1, o sistema está sujeito a desgaste e a um aumento da taxa
de falha ao longo do tempo. As manutenções são então benéficas pois anulam o desgaste acumulado
até ao momento da inspecção, voltando a estar sujeito a uma taxa de falha inferior à que teria caso não
fosse submetido a qualquer intervenção. Por oposição, quando m<1, estas intervenções causam um
impacto negativo. Ao ter um factor de forma inferior a um, o equipamento está no período de
mortalidade infantil, onde a taxa de falha é decrescente ao longo do tempo. Sempre que se submete o
sistema a uma inspeção, a taxa de falha volta ao valor inicial, sempre superior ao valor que tinha no
momento da intervenção.

14
2.6.2 Manutenção Correctiva
Nos sistemas sujeitos a manutenção correctiva, para além da probabilidade de falha do sistema,
interessa também saber o número de falhas ocorridas e o tempo necessário para as reparar. Assim, a
disponibilidade do sistema passa a ser a grandeza interessante. Este novo conceito, disponibilidade,
pode ser visto como uma fracção do tempo em que o sistema encontra-se operacional. A
disponibilidade num determinado instante t é representado por 𝐴(𝑡).
Frequentemente é necessário determinar a disponibilidade num determinado intervalo. A
disponibilidade do sistema é então obtido pela disponibilidade média no intervalo de tempo T.
𝐴∗(𝑇) =1
𝑇∫ 𝐴(𝑡)𝑑𝑡
𝑇
0
( 2.33 )
De forma a rejeitar efeitos iniciais transientes e a obter apenas o valor assimptótico da disponibilidade,
deve-se ver o limite da equação anterior quando T tende para mais infinito.
𝐴∗(∞) = lim𝑇→∞
1
𝑇∫ 𝐴(𝑡)𝑑𝑡
𝑇
0
( 2.34 )
2.6.2.1 Falhas Reveladas
No caso em que as falhas são detectadas e a reparação começa imediatamente, o valor da
disponibilidade toma o seguinte valor (Lewis, 1994):
𝐴(𝑡) =𝜈
𝜆 + 𝜈+
𝜆
𝜆 + 𝜈𝑒−(𝜆+𝜈)𝑡 ( 2.35 )
Note-se que a disponibilidade tem valor unitário para t=0 e decresce monotonicamente para o valor
1/(1 + 𝜆/𝜈), dependendo apenas do quociente entre a taxa de falha (𝜆) e a taxa de reparação (𝜈).
A disponibilidade no intervalo T é obtida se substituirmos a equação ( 2.35 ) na equação ( 2.33 ).
𝐴∗(𝑇) =𝜈
𝜆 + 𝜈+
𝜆
(𝜆 + 𝜈)2 ∙ 𝑇[1 − 𝑒−(𝜆+𝜈)∙𝑇] ( 2.36 )
A disponibilidade assimptótica obtém-se com o cálculo do limite quando T tende para mais infinito.
𝐴∗(∞) =𝜈
𝜆 + 𝜈=
𝑀𝑇𝑇𝐹
𝑀𝑇𝑇𝐹 + 𝑀𝑇𝑇𝑅 ( 2.37 )
Esta expressão pode ser usada para o cálculo da disponibilidade mesmo quando nem as falhas ou
reparações são bem caracterizadas por distribuições exponenciais. Isto é suficientemente adequado já
que o valor da disponibilidade é pouco sensível às distribuições da falha e tempo de reparação (Lewis,
1994).
2.6.2.2 Falhas não reveladas
Existem casos onde as falhas nos equipamentos não são imediatamente reveladas. Esta situação
ocorre em sistemas que não operam de forma contínua como sistemas de backup ou outros
equipamentos de segurança. Nestes casos, a principal quebra na disponibilidade está relacionada com

15
a indisponibilidade do sistema quando este deve entrar em operação. Submeter o sistema a testes
periódicos é a principal forma de combater este problema. Quanto maior for a frequência destas
inspecções, mais falhas serão detectadas e menor a probabilidade de o sistema não se encontrar
operacional quando necessário.
Considera-se que o tempo de teste ao sistema e tempo de reparação são desprezáveis e que estas
intervenções de manutenção são perfeitas, i.e., recuperam para uma condição em que o sistema fica
tão bom como novo. Com estas suposições, a disponibilidade toma a forma apresentada na Figura 2.5
e é calculada da seguinte forma:
𝐴(𝑡) = 𝑅(𝑡 − 𝑁𝑇0), 𝑁𝑇0 ≤ 𝑡 < (𝑁 + 1)𝑇0 ( 2.38 )
Na situação apresentada, a disponibilidade para o intervalo T0 e a disponibilidade assimptótica têm o
mesmo valor já que o integral apresentado da equação ( 2.33 ) é feito para um múltiplo de T0.
𝐴∗(𝑚𝑇0) =1
𝑚𝑇0
∫ 𝐴(𝑡) 𝑑𝑡 =1
𝑇0
∫ 𝐴(𝑡)𝑑𝑡𝑇0
0
𝑚𝑇𝑜
0
( 2.39 )
𝐴∗(∞) = lim𝑚→∞
1
𝑚𝑇0
∫ 𝐴(𝑡) 𝑑𝑡 =1
𝑇0
∫ 𝐴(𝑡)𝑑𝑡𝑇0
0
𝑚𝑇𝑜
0
( 2.40 )
No caso em que a falha do sistema é caracterizado por uma taxa de falha constante, a equação ( 2.40
) toma a forma simplificada:
𝐴∗(∞) =1
𝜆𝑇𝑜
(1 − 𝑒−𝜆𝑇0) ( 2.41 )
No caso em que o intervalo 𝑇𝑜 é pequeno quando comparado com o MTTF (𝜆𝑇𝑜 ≪ 1), o exponencial
pode ser expandido e a equação anterior toma a forma:
𝐴∗(∞) ≈ 1 −1
2𝜆𝑇𝑜 ( 2.42 )
Figura 2.5 – Disponibilidade para sistema com falhas ocultas submetido a inspecções periódicas perfeitas

16
Considerando agora que o tempo para o teste, tt, não é desprezável e que a disponibilidade do sistema
durante o teste é igual a zero, a disponibilidade toma a forma apresentada pelo traço contínuo na Figura
2.6. Assumindo novamente que 𝜆𝑇𝑜 ≪ 1 e que 𝑡𝑡 ≪ 𝑇0, o valor da disponibilidade assimptótica reduz-
se a:
𝐴∗(∞) ≈ 1 −1
2𝜆𝑇𝑜 −
𝑡𝑡
𝑇0
( 2.43 )
Caso se considere o efeito de um tempo de reparação distribuído exponencialmente, a disponibilidade
toma a forma apresentada pelo linha tracejada na Figura 2.6 e o valor da disponibilidade assimptótica
toma o valor:
𝐴∗(∞) ≈ 1 −1
2𝜆𝑇𝑜 −
𝑡𝑡
𝑇0
−𝜆
𝜈 ( 2.44 )
Figura 2.6 – Disponibilidade para sistema com falhas ocultas submetido a inspecções reais
2.7 Redes Petri
As redes Petri são uma ferramenta que combina a modelação gráfica com uma formulação matemática
que permite simular e analisar o comportamento de sistemas. Esta ferramenta foi desenvolvida em
1962 por Carl Adam Petri como parte da sua tese de doutoramento.
Originalmente, as redes Petri não transmitiam qualquer noção de tempo. Para uma análise de
desempenho e cálculos de produção e capacidade dos sistemas, foi necessário introduzir a dimensão
tempo aos eventos associados às transições da rede. Dois modelos que contemplam esta dimensão
foram exploradas e surgiram duas linhas principais: redes Petri Estocásticas, associado a durações
aleatórias e Timed Petri Nets, com transições de tempos determinísticos. A conciliação dos métodos
de simulação de Monte Carlo com as potencialidades das redes Petri estocásticas generalizadas têm
sido bastante usadas e têm sido aplicados em diversos domínios como a informática, comunicações e
automação (Dutuit et al., 1997; Malhotra & Trivedi, 1995; Teixeira & Guedes Soares, 2009).
Uma rede Petri é uma estrutura gráfica com apenas dois tipos de elementos: estados e transições. Um
estado modela sempre um componente passivo, onde pode guardar ou acumular matéria, tomando
sempre valores discretos. Graficamente, um estado é representado por círculo. O segundo tipo de

17
elemento, as transições, modelam sempre um componente activo, capaz de produzir, consumir ou
transportar matéria entre estados. É este elemento que provoca os eventos de transição dos tokens
entre estados. Graficamente é representado por um rectângulo. De forma a conectar graficamente
estes dois elementos, utilizam-se arcos. Estes arcos apenas ligam estados a transições e transições a
estados. Entre dois estados, é sempre necessário ter uma transição que regula a sua transição. O
mesmo acontece entre duas transições: é sempre necessário ter um estado entre elas. Assim, não faz
sentido usar um arco para unir dois estados ou duas transições entre si. Os arcos de input ligam um
estado a uma transição e os arcos de output unem uma transição a um estado.
A qualquer momento durante a execução de uma rede de Petri, cada posição pode armazenar um ou
mais tokens. As transições agem nos tokens de entrada por um processo denominado por disparo, que
se diz habilitada apenas quando são verificadas as condições de disparo. Na modelação original, para
que se verificassem as condições de disparo bastava que existisse pelo menos um token em cada um
dos estados de entrada mas nas redes Petri generalizadas, uma variante das redes originais, as
condições de disparo de uma transição já podem ter em consideração um peso associado a cada arco,
definindo assim quantos tokens são necessários no estado de entrada para que a transição fique activa.
Da mesma forma, podem ser também atribuídos pesos aos arcos de saída, definindo quantos tokens
são criados após o disparo. Quando uma transição é disparada, os tokens necessários ao disparo são
destruídos e desaparecem dos estados de entrada. Novos tokens são então criados nos estados de
saída considerando os pesos dos arcos de output.
Os componentes básicos das redes Petri, descritos acima, podem ser vistos na Figura 2.7.
Figura 2.7 – Elementos de uma rede Petri

18
Com o passar do tempo, várias extensões foram feitas ao conceito inicial das redes Petri, tendo como
objectivo, suprir algumas limitações e habilita-las a tratar de sistemas de produção, comunicações e
automação. Recentemente, as técnicas de redes Petri estocásticas foram combinadas com as
simulações de Monte Carlo, tornando possível a análise de fiabilidade, disponibilidade e eficiência de
produção de sistemas industrias. Ainda mais recente é o desenvolvimento das redes Petri estocásticas
com predicados. Estes predicados, nomeadamente guards e assignments, baseiam-se em variáveis e
funções que influenciam a evolução dos estados do sistema de acordo com aquilo que se pretende
modelar. Enquanto os guards são pré-requisitos para activar ou inibir uma transição, os assignments
são instruções para actualização de variáveis após um disparo. Estes predicados podem ser vistos na
Figura 2.7.
Para um aprofundamento da teoria e dos conceitos que definem as redes Petri, é aconselhável a leitura
de (Marsan et al., 1991), (Haas, 2002) e (Reisig, 1998).

19
3 Revisão de Literatura
A revisão bibliográfica pode ser facilmente dividida em cinco secções diferentes. De secção para
secção, os estudos apresentados são cada vez mais próximos do estudo efectuado no âmbito desta
dissertação. Se na primeira secção, a bibliografia apresenta a fiabilidade enquanto disciplina científica,
capaz de estudar problemas relacionados com disponibilidade, segurança e análise de risco, na
segunda secção, apresentam-se os estudos que certificam as redes Petri como uma ferramenta
poderosa no cálculo de disponibilidades, com possíveis recursos no estudo de optimização de recursos
e manutenções. Na terceira secção, embora escassos, são apresentados alguns casos onde são feitos
estudos de fiabilidade no âmbito da engenharia naval. Na quarta secção, apresentam-se estudos de
fiabilidade aplicados a sistemas de combate a incêndios e procede-se à descrição do estado de arte
dos sistemas de liquefação a bordo de navios LNG e de tratamento do BOG proveniente da evaporação
do gás natural liquefeito presente a bordo. Questões relacionadas com políticas de inspecção,
correctivas, preventivas, perfeitas e imperfeitas são abordadas na quinta secção. Ainda na quinta
secção, são apresentadas alguns estudos que apresentam a influência que as diferentes políticas de
manutenção podem ter na estrutura de custos.
A fiabilidade, no sentido lato, está associada à confiança numa operação bem-sucedida e sem avarias.
No entanto, em engenharia a fiabilidade é quantificada como uma probabilidade (Lewis, 1994). Deste
modo, fiabilidade é definida como a probabilidade de um determinado equipamento ou sistema cumprir
a sua função, por um determinado período de tempo e sujeito a um conjunto de condições (Lewis,
1994). Nesta definição, são abordados três elementos fundamentais: função, período de tempo e
conjunto de condições a que está sujeito (Yang, 2007).
Alguns dos desafios com que investigadores de fiabilidade se deparam nos dias de hoje são apresentas
por Zio (2009). Uma das maiores dificuldades prende-se com o facto de os métodos de fiabilidade numa
análise quantitativa, assumirem comummente que os sistemas são compostos por componentes
binários i.e., que os componentes têm apenas dois estados: em funcionamento ou em falha. Basta
olhar para sistemas de produção de gás ou petróleo, para perceber que é possível que o seu
desempenho tome diversos valores de produção entre 0% e 100% - sistemas multiestado. As técnicas
base de fiabilidade não são suficientes para tratar problemas que envolvem componentes com mais do
que dois estados de funcionamento e por isso novas técnicas têm vindo a ser desenvolvidas (Aven,
1993; Griffith, 1980; Trivedi et al., 2012; Wood, 1985). A modelação destes tipos de sistemas tornou-se
fundamental para o cálculo de uma disponibilidade realística da disponibilidade de sistemas multiestado
e são muitos os estudos feitos neste sentido. As simulações de Monte Carlo parecem ser a única forma
praticável para se chegar a uma análise quantitativa do comportamento deste tipo de sistemas
multiestado (Zio, 2009, 2013). As simulações são feitas sobre representações dos sistemas
multiestado, modeladas utilizando p.ex., redes Petri.
É a combinação da utilização da modelação de sistemas através de redes Petri e das simulações de
Monte Carlo que permite que dados quantitativos sobre o sistema multiestado sejam calculados. Os
conceitos básicos de redes Petri, notações e exemplos, são suficientemente abordados em

20
Understanding Petri Nets (Reisig, 1998). A demonstração, através de exemplos simples mas não
triviais, que o método das redes Petri pode ser utilizado para estudos de fiabilidade é apresentado por
Dutuit et al. (1997) e a sua abordagem consiste na criação de várias redes interligadas e da utilização
do método de simulação de Monte Carlo para animação e obtenção de dados do modelo.
Teixeira & Guedes Soares, (2009) introduzem os conceitos básicos usados na modelação de sistemas
por redes Petri estocásticas e demonstram o mérito desta técnica de modelação. Essa demonstração
é feita através de um estudo de caso que consiste na análise da disponibilidade de um processo de
produção petrolífera, sistema multiestado, que considera características de fiabilidade, manutibilidade
e políticas de manutenção. Concluiu-se que as redes Petri juntamente com as simulações de Monte
Carlo possibilitam o estudo de sistemas produtivos reais de uma forma eficiente e precisa.
E. Zio et al. (2007) apresentam uma técnica de simulação de Monte Carlo que permite a avaliação da
disponibilidade de sistemas complexos, multiestado e dinâmicos. A técnica proposta nesse estudo é
verificada com um simples estudo de caso.
Malhotra & Trivedi, (1995) descrevem a metodologia para a construção de modelos para a fiabilidade
usando redes Petri estocásticas. Nesse mesmo artigo propõem algoritmos para a conversão de
modelos feitos em árvores de falhas em modelos equivalentes usando as redes Petri.
A influência das diferentes estratégias logísticas na disponibilidade e custos de manutenção de uma
turbina de energia eólica offshore, usando as redes Petri e simulação de Monte Carlo, é estudada por
Santos et al. (2013).
Um dos conceitos para a medição da garantia com que o sistema irá cumprir a sua função é o nível de
segurança e integridade SIL (Safety Integrity Levels) e foi introduzido durante o desenvolvimento da
norma IEC 61508 pela Comission International Electrotechnical, (1999). No entanto, Dutuit et al. (2008)
levantam alguns problemas desta norma. Entre eles, alegam que os níveis SIL devem ser calculados
tendo em conta o comportamento da indisponibilidade dependente do tempo e não apenas o valor da
sua média. Através da utilização de redes Petri, é feito o cálculo da indisponibilidade a cada instante e
procedem à comparação do nível obtido através do valor médio com aquele onde o sistema passa a
maior parte do seu tempo. A abordagem seguida por Dutuit et al. (2008) é seguida para o cálculo dos
níveis SIL do sistema de combate a incêndios discutido no âmbito desta dissertação.
A informação disponível acerca de redes Petri tem aumentado e uma norma para a sua utilização será
criada em breve (Signoret et al., 2013). Ainda que o número de publicações continue a aumentar, a sua
disseminação é lenta e as redes Petri ainda não são extensamente utilizadas por engenheiros de
fiabilidade. Na verdade, as redes usadas hoje em dia são, muitas vezes, complicadas e difíceis de
entender, mesmo quando se tratam de modelos de sistemas simples. Isso torna-se desencorajador,
tanto para quem as faz como para quem as lê. Nesse sentido, Signoret et al. (2013) propõem algumas
linhas guia para estruturar e melhorar a leitura das redes Petri.

21
O acesso a informação pública acerca da fiabilidade dos sistemas mecânicos é escassa. Ainda mais o
é, se a procura limitar-se a informação na indústria naval. Ainda assim, estudos acerca da fiabilidade,
disponibilidade, manutenção e segurança de um determinado sistema são sempre desejados pelos
seus operadores e demais intervenientes. A importância desses estudos toma especial relevo quando
se trata de sistemas de exploração e produção offshore devido às consequências que um possível
desastre pode ter. Nesse sentido, algumas empresas do ramo, uniram esforços e responderam à
necessidade de criar uma publicação com dados relevantes aos estudos de fiabilidade, disponibilidade,
manutenção e segurança (OREDA, 2002).
Um estudo exaustivo, onde questões como fiabilidade, disponibilidade e manutenção de parques
eólicos offshore é apresentado por Tavner (2012). O estudo pode ser interessante no âmbito desta
dissertação na medida em que, existem semelhanças nas condições a que navios e parques eólicos
estão sujeitos: difícil acesso para manutenção, condições climatéricas e utilização dos sistemas
24horas por dia.
O Centro Europeu da Energia Marítima emitiu um documento para a fiabilidade e manutibilidade de
conversores de energia marítima. Apesar de pouco extenso, esse documento dá algumas directrizes
para definir as metas de fiabilidade, cálculo do risco, apoio na definição da estratégia de manutenção
e projecto dos sistemas de conversão de energia, (The European Marine Energy Centre Ltd, 2009).
Dong et al. (2013) apresentam um estudo da fiabilidade do sistema de propulsão de um navio usando
o método das árvores de falhas. O estudo afirma que as árvores de falhas são capazes de avaliar a
disponibilidade do sistema num certo intervalo de tempo mas não é suficiente para uma aferição para
todo o seu tempo de vida.
Wan et al. (2013) procedem à avaliação da fiabilidade e do risco associado à falha de um motor de
duplo combustível LNG-Diesel. A avaliação é feita com base em matrizes de risco e a partir dos
resultados, são propostas algumas soluções para o controlo do risco. A opção que causa maior impacto
e permite controlar melhor o risco passa por conduzir manutenções periódicas de acordo com as
tabelas técnicas, ajustando os períodos de acordo com as condições de operação a que o sistema é
submetido.
Sobral & Ferreira (2007) apresentam, num contexto industrial, a importância da fiabilidade dos
equipamentos dos sistemas de combate a incêndios. O estudo apresenta um método para a
determinação do peso de cada componente na fiabilidade do conjunto dando a conhecer onde deve
haver uma actuação para que a fiabilidade geral do sistema seja melhorada. Num outro estudo, Sobral
& Ferreira (2005), efectuam uma análise de risco, análise dos modos de falha, efeitos e sua criticidade
(FMECA) e uma análise RAMS ao sistema de protecção de incêndios da Estação do Oriente, no Parque
das Nações em Lisboa.
Durante a viagem de um navio LNG, cerca de [0.1%-0.15%] do gás natural liquefeito evapora-se dentro
dos tanques de carga (Chang et al., 2008). Após evaporação, o volume ocupado pelo gás natural é
substancialmente maior, aumentando a pressão no interior dos tanques do navio. Para evitar que a

22
estrutura colapse com o aumento da pressão, o gás gerado (BOG) deve ser tratado. A forma tradicional
de repor os níveis de pressão no interior dos tanques é conseguida com a queima do BOG no interior
de caldeiras, criando vapor que posteriormente alimenta as turbinas a vapor. Estima-se que a eficiência
deste método é da ordem dos 30.0% (Küver et al. 2002).
Com o aumento da capacidade dos novos navios LNG, a indústria de transporte de gás natural tem
estado focada na escolha de um novo sistema de propulsão mais eficiente. Quatro conceitos
alternativos estão disponíveis para substituir as convencionais turbinas a vapor: dual-fuel diesel electric
(DFDE) propulsion, dual-fuel steam gas turbine electric (DFGE) propulsion, dual-fuel diesel mechanical
(DFDM) propulsion, diesel mechanical propulsion com unidade de liquefação (SFDM+R). Nenhuma
destas propostas é, à partida, melhor que as outras mas a sua disponibilidade e segurança devem ser
garantidas. A escolha do sistema de propulsão deve ter em conta as características específicas de
cada navio como a sua capacidade de carga, condições de viagem e legislação ambiental nos portos
onde opera. Uma comparação da disponibilidade entre os diversos meios de propulsão é apresentada
por Chang et al. (2008) e Küver et al. (2002).
Segundo Küver et al. (2002), um navio LNG com um sistema de propulsão alimentado por uma solução
diesel-electric equipado com uma unidade de liquefação parece ser a solução mais promissora para a
propulsão dos navios actuais e futuros. Esta solução toma ainda mais destaque devido às baixas
emissões de NOx, SOx e CO2.
Um estudo detalhado dos fenómenos de transferência de calor que ocorrem na unidade de liquefação
do gás natural são apresentados por Shin & Lee (2009). Neste estudo, após descrição do processo de
liquefação, é ainda projectado um controlador a ser implementado no sistema.
Anderson et al. (2009) apresentam alguns dos requisitos, impostos pela Qatargas 2 e ExxonMobil, que
o sistema de liquefação deve ter. Entre eles, impõe-se que toda a maquinaria rotativa deve ser
completamente redundante (2x100%); o sistema deve ter uma unidade de combustão de gás, em
regime de backup capaz de queimar todo o BOG com a mesma taxa com que é criado nos tanques de
carga; o sistema deve ser capaz de lidar com 150% da taxa nominal de BOG, com a queima, na unidade
de combustão, daquilo que ultrapassar a capacidade da unidade de liquefação.
A empesa que lidera no desenvolvimento e implementação de unidades de reliquefação do BOG a
bordo de navios LNG é a Wärtsilä Hamworthy. A Wärtsilä Hamworthy é responsável pela instalação
destas unidades em mais de trinta navios LNG com capacidades de 216 000m3 – frota Q-Flex. Todos
os navios desta frota Q-Flex são movidos por motores diesel de baixas rotações (Hamworthy, n.d.).
Todos os sistemas usados na produção de bens estão sujeitos a deterioração (Valdez-flores &
Feldman, 1989) e a maior parte deles podem ser mantidos ou reparados de forma a aumentar a sua
disponibilidade. Assim, uma área importante no seio da fiabilidade é o estudo das diversas políticas de
manutenção que previnem a ocorrência de falhas no sistema e aumentam a sua disponibilidade. Por
ser uma área muito vasta e por abranger diversos pormenores, nas últimas décadas, muito se tem
discutido sobre manutenção, substituição e inspecção.

23
Uma manutenção envolve acções planeadas ou não planeadas de forma a manter ou recuperar um
sistema para uma condição operacional aceitável (Pham & Wang, 1996). Podendo tomar duas formas
diferentes, planeada ou não planeada, é possível dividir a manutenção em dois tipos: manutenção
preventiva e manutenção correctiva. De acordo com a norma militar MIL-STD-721B (1981),
manutenções preventivas englobam todas as intervenções feitas com o intuito de manter um
equipamento numa determinada condição, realizando inspecções periódicas, detecções e prevenção
de falhas eminentes. De acordo com a mesma norma militar MIL-STD-721B (1981), manutenções
correctivas são todas as acções de intervenção realizadas para recuperar o funcionamento de um
equipamento e que resultam da falha do mesmo.
Segundo Rausand & Hoyland (2004), a gestão das manutenções tem sido uma actividade de
engenharia reversa, onde o processo de decisões está altamente relacionado com a educação técnica
das equipas de manutenção e a sua experiência. Ainda que a experiência técnica seja essencial, esta
não deve ser a única base para a tomada de decisões relacionada com as políticas de manutenção. A
escolha do “melhor” tipo de intervenção e da “melhor” altura para a fazer é uma tarefa delicada que não
depende apenas do estado actual do equipamento mas também de factores futuros como as
consequências dessa escolha numa utilização a longo prazo. No entanto, a intensidade e tipo das
actividades de manutenção é determinada maioritariamente pelos seus custos e pelas implicações que
a falha do sistema pode causar (Lewis, 1994).
A American Bureau of Shipping (ABS) desenvolveu um guia para providenciar os armadores, gestores
e operadores de navios e outras estruturas marítimas de uma ferramenta que lhes permita desenvolver
um programa de manutenção. As técnicas usadas no desenvolvimento do programa de manutenção
são usadas noutras indústrias e seguem uma filosofia classificada como Fiabilidade Centrada na
Manutenção (Reliability Centred Maintenance – RCM) (ABS, 2014). A Fiabilidade Centrada na
Manutenção pode ser definida como uma abordagem sistemática na identificação efectiva e eficiente
das tarefas de manutenção, de acordo com procedimentos específicos e usado para estabelecer
intervalos de tempo entre intervenções de manutenção (Rausand & Vatn, 2008). Segundo Rausand &
Vatn (2008), a grande vantagem de uma análise RCM é a determinação do tipo óptimo de manutenção
preventiva através de um processo estruturado. Ainda que os primeiros principais objectivos da RCM
sejam a determinação das manutenções preventivas, os resultados da análise podem ser usados
também nas estratégias de manutenções correctivas, contribuindo para uma optimização do stock das
peças de substituição e outras considerações logísticas. Mais ainda, a RCM contribui na gestão da
segurança do sistema. Uma proposta de estruturação do processo de RCM é apresentado por Rausand
& Vatn (2008) e Rausand (1998).
Wang (2002) faz um levantamento das várias políticas de manutenção. Nesse levantamento, sumariza,
classifica e compara as diversas políticas, tanto para sistemas com apenas um equipamento como
também para sistemas compostos por mais do que um componente. De todas as políticas, as que mais
se enquadram no âmbito desta dissertação são as políticas de manutenção preventiva periódica e
manutenção oportunista.

24
A manutenção de um sistema sujeito a desgaste é geralmente, imperfeito, i.e., um sistema após a sua
reparação não volta a ficar como novo, apenas recupera parte do seu tempo de vida. O estudo da
manutenção imperfeita apresenta-se como um grande avanço na teoria da fiabilidade e levou a que
mais de quarenta modelos matemáticos da manutenção imperfeita fossem propostos nos últimos 30
anos (Pham & Wang, 1996). Pham & Wang (1996) apresentam diversos modelos para o trato de
manutenções imperfeitas. Um dos modelos apresentados tem como conceito a recuperação da idade
com base num factor que dita que após uma reparação imperfeita deste tipo, o tempo de vida do
equipamento será reduzido para uma fracção do tempo de vida que tinha imediatamente antes do início
da intervenção de manutenção. Esse método, usado nesta dissertação, foi também utilizado por Ding
& Tian (2012) num estudo de manutenção de oportunidade e imperfeita em campos de energia eólica
offshore e por Santos et al. (2013) no estudo da influência de alguns parâmetros logísticos na
disponibilidade, também num campo de energia eólica offshore.
Desde que as falhas de um sistema sejam logo detectadas, o factor determinante na disponibilidade
do sistema é o tempo para as reparar. No entanto, quando um sistema não tem um modo de operação
contínua, falhas podem ocorrer e não serem descobertas. Este problema ocorre em sistemas de
segurança ou backup, em que a sua operação é rara. Assim, a principal quebra na disponibilidade
destes sistemas está relacionada com falhas em standby que não são detectadas até que se tente
utilizar o sistema. A principal forma de combater este tipo de problemas é com um teste periódico ao
sistema (Lewis, 1994). Enquanto Lewis (1994), apresenta a formulação matemática para se determinar
o tempo entre cada intervenção para que o equipamento tenha uma disponibilidade superior a um
determinado valor, Assis apresenta um estudo em que determina a periodicidade óptima entre
inspecções para a detecção de falhas ocultas, com base em técnicas de simulação e considerando os
custos de intervenção.
Barata et al. (2002) apresentam um estudo onde o principal objectivo é investigar o uso da simulação
de Monte Carlo na modelação de sistemas sujeitos a desgaste com monotorização constante do seu
estado e encontrar uma estratégia de manutenção com base na condição que minimize o custo total
do sistema ao longo do tempo. A simulação é feita inicialmente para um componente não reparável
sujeito a um desgaste estocástico e depois generalizado para um sistema composto por vários
equipamentos reparáveis.
Para além de toda a bibliografia apresentada acima, outras referências como Stapelberg (2009) e
Jardine & Buzacott (1985) foram também consultadas durante a elaboração desta dissertação.

25
4 Modelação de Sistemas do Navio
Dois sistemas são modelados nesta secção: um sistema simples de combate a incêndios e um sistema
de reliquefação do BOG a bordo de um navio LNG.
A modelação das redes Petri representativa dos sistemas foi toda feita no software comercial GRIF
2013. Esta plataforma foi desenvolvida numa parceria entre a Satodev e a companhia petrolífera
TOTAL sendo fruto de vinte e cinco anos de investigação e desenvolvimento que tornam possível a
análise da fiabilidade, disponibilidade, desempenho e segurança de sistemas. Dos vários módulos
disponíveis, usaram-se apenas dois: Petri e BStok. O primeiro é utilizado para criar as redes Petri
(estocásticas e com predicados) de cada componente do sistema (GRIF, 2014). O segundo é usado
para modelar os sistemas baseado em diagrama de blocos estocásticos. Cada um destes blocos
estocásticos, nada mais é do que uma rede Petri que retorna o estado/produção do equipamento.
Ambos os módulos utilizados servem-se do MOCA-RP, um motor computacional baseado nas
simulações de Monte Carlo e desenvolvido também pela TOTAL, para a realização dos cálculos (“GRIF
Workshop,” n.d.).
4.1 Sistema de Combate a Incêndios
A SOLAS impõe que sejam instalados sistemas de combate a incêndios a bordo dos navios e todos os
requisitos estão descritos no seu documento, capítulo II-2. Num dos possíveis sistemas de combate é
utilizada uma espuma que cobre o combustível e quebra o seu contacto com o oxigénio. Sem acesso
a um comburente, o fogo é extinto.
O sistema estudado foi implementado a bordo do navio tanque ATAULFO ALVES com um porte bruto
(DWT) de 153.000 t, tendo sido construído nos estaleiros da Hyundai Heavy Industries. O estudo foca-
se apenas nos equipamentos que se situam dentro do Foam Room. Todos os outros componentes
(encanamentos, válvulas e difusores) que levam a solução espumosa da divisão onde é criada até ao
local de incêndio são considerados perfeitos e sem falhas, não influenciando a disponibilidade do
sistema. Esta simplificação no sistema foi feita de forma a não tornar a disponibilidade do sistema
dependente da localização do foco de incêndio. Acredita-se que esta simplificação não afecta muito os
resultados porque os tempos médios de falha (MTTF) dos componentes desprezados são
suficientemente altos.
O diagrama esquemático do sistema em estudo pode ser visto na Figura 4.1 e como se pode verificar,
a estrutura do sistema é relativamente simples, sendo essencialmente composto por válvulas, bombas
e encanamentos. Nota-se no diagrama que o único componente redundante no sistema é a bomba que
eleva a água do mar até ao misturador, todos os outros não têm qualquer redundância e qualquer falha
irá sempre limitar o correcto funcionamento do sistema. Assim, considera-se que todos os componentes
estão em série à excepção das duas bombas de água. O seu diagrama de blocos poderá ser visto na
Figura 4.8.

26
Figura 4.1 – Diagrama do Sistema de Combate a Incêndios
4.1.1 Redes Petri dos componentes individuais
4.1.1.1 Equipamento Genérico
Mesmo quando se tratam de sistemas muito simples, a complexidade da rede criada pode ser tal que
se torna difícil a entender. Numa tentativa de tornar o sistema o mais perceptível possível, é criado uma
rede capaz de representar qualquer componente do sistema sendo apenas necessário manipular
alguns dos seus parâmetros. Para além disso, a criação de pequenas sub-redes com objectivos muito
específicos facilita uma leitura da rede criada.
Numa tentativa de se criar um modelo o mais próximo da realidade possível, a rede representativa do
equipamento deve ter as seguintes características:
a) Estado binário: operacional/não operacional;
b) Possuir três modos de falha: falha em funcionamento, falha em standby e falha ao arranque;
c) As falhas em standby são ocultas;
d) Estar dependente da disponibilidade das equipas de manutenção;
e) Estar dependente da quantidade de equipamentos em stock para substituição;
f) Contemplar manutenções preventivas, correctivas e oportunistas, tanto perfeitas como
imperfeitas;
g) O tempo para a sua falha pode ser definido tanto por uma distribuição Exponencial como por
uma Weibull de dois parâmetros, sendo portanto capaz de representar desgaste no
equipamento;
h) Os tempos para inspecção, reparação e substituição poderem seguir qualquer tipo de
distribuição.

27
O facto de se estar a tratar um sistema de segurança em que a maior parte do tempo, todos os seus
componentes estão em Standby, leva a que seja obrigatório modelar (e diferenciar) os modos de falha
em standby e em funcionamento. Ao contrário do que ocorre quando o equipamento está em
funcionamento, no caso em que ocorre uma falha em standby, só se tem conhecimento da mesma no
momento em que o equipamento é requisitado ou quando este é submetido a uma intervenção de
manutenção. A falha ao arranque permite ainda modelar as falhas que se devem à alteração repentina
do sistema quando este é requisitado.
A quantidade de equipas de manutenção é determinante na disponibilidade de um sistema e deve ser
um dos parâmetros a ter em conta na sua análise. Quando uma falha ocorre (e é conhecida) a mesma
só é reparada quando uma equipa estiver disponível. O controlo do stock de equipamentos a bordo
também é um parâmetro a ter em conta.
Numa tentativa de aproximar o modelo ao caso real, é possível determinar o impacto que uma
intervenção de manutenção tem no tempo de vida do equipamento considerando manutenções
imperfeitas, em que o equipamento recupera apenas uma fracção do tempo acumulado de vida ou
perfeitas, em que fica como novo. Na eventualidade de existirem equipamentos em stock, a opção de
se efectuar a substituição do equipamento por um novo é tomada com base numa razão entre o tempo
de vida acumulado e o MTTF – manutenção de oportunidade.
De seguida, apresentam-se as redes Petri que modelam o equipamento.
Figura 4.2 – Rede Principal do Equipamento Genérico
Na rede da Figura 4.2 apenas está representada a rede principal. Nesta, podem-se ver 6 estados, 9
transições, arcos, 4 variáveis e 1 estado que serve de comunicação a outra rede auxiliar. Os estados
Standby, Working e Not working, 1, 2 e 3 respectivamente são denominados estados fundamentais,
todos os outros serão tratados como estados auxiliares pois os tokens não permanecem lá em
nenhuma circunstância.

28
A informação de maior importância da rede é compilada na variável boolena: State. Sempre que a
variável assumir o valor true, o equipamento está operacional (quer esteja, ou não, em utilização) e
sempre que o seu valor for false, o equipamento não está operacional. Todas as outras variáveis são
auxiliares e servem para mediar transições.
Sempre que o token se encontrar no estado Standby, o sistema está operacional mas não está a ser
utilizado. Daqui, o token pode transitar para outros dois estados fundamentais: Working ou Not Working
e essas alterações de estado são determinadas pelas transições StandbyFailure e Mobilization. A
transição StandbyFailure regula a falha do sistema quando este não está a ser utilizado. Sempre que
essa transição é disparada, a variável State assume o valor falso e o token passa para o estado
fundamental NotWorking. A transição Mobilization é activada quando o equipamento é requisitado
(variável StandBy é falso) e dois resultados imediatos podem ocorrer deste disparo: falha ao arranque
ou entrada em funcionamento. A falha ao arranque, determinada apenas por uma probabilidade [0-1],
leva o token para o estado fundamental NotWorking e altera o valor da variável State para falso. Caso
o equipamento não falhe ao arranque, o token fica no estado fundamental Working.
Quando o token se encontra no estado Working, o equipamento está operacional e em utilização. A
transição para os outros dois estados é possível pela ocorrência de uma falha durante o funcionamento
ou desmobilização do equipamento. A transição que modela a falha em funcionamento é a
WorkingFailure e após o seu disparo, o equipamento deixa de estar operacional e a variável State
assume o valor falso. Se nenhuma falha ocorrer até que o equipamento seja desmobilizado (variável
Standby igual a verdadeiro), o token volta ao estado fundamental StandBy.
Quando, por alguma razão, o equipamento falhou, o token fica no estado NotWorking. Deste estado só
é possível voltar a ficar operacional se for submetido a uma reparação. O início dessa intervenção
ocorre imediatamente caso o equipamento seja necessário (variável StandBy igual a falso) ou quando
chega o momento para o qual está agendada uma intervenção (variável MaintenanceRequired igual a
verdadeiro). Da forma como estão dispostos os predicados destas transições, as falhas em standby
são falhas ocultas e só são reparadas nos casos apresentados acima. Para o arranque de uma
intervenção, é sempre necessário que uma equipa de manutenção esteja disponível.
Na rede da Figura 4.3 é apresentada uma rede auxiliar que trata das actividades de manutenção
periódicas. Quando o equipamento deve ser submetido a uma manutenção periódica, a variável
MaintenanceRequired toma o valor verdadeiro. Nesse momento e apenas se o equipamento não estiver
a ser utilizado este é submetido a uma inspecção e a sua profundidade depende do tempo de vida
acumulado. Caso o tempo de vida do equipamento seja inferior a 𝑝 × 𝑀𝑇𝑇𝐹, apenas é feita uma
verificação de que o equipamento está operacional e volta para o estado fundamental StandBy. No
entanto, se o tempo de vida acumulado for superior a 𝑝 × 𝑀𝑇𝑇𝐹, o equipamento será sujeito a uma
intervenção mais profunda, que poderá passar por uma substituição caso haja equipamentos em stock
ou por uma recuperação parcial da idade acumulada. Estas duas intervenções poderão ser vistas na

29
rede da Figura 4.4. Durante as inspecções periódicas, o equipamento não está operacional e a variável
State toma o valor falso.
Figura 4.3 – Rede para Actividades de Manutenção Preventiva
A rede da Figura 4.4 também serve os casos em que o equipamento tem de ser submetido a uma
intervenção correctiva por não estar operacional. A intensidade desta intervenção está igualmente
relacionada com o tempo de vida acumulado como no caso em que era feita a manutenção periódica
de um equipamento com tempo acumulado superior a 𝑝 × 𝑀𝑇𝑇𝐹. Nos casos onde não é feita qualquer
substituição do equipamento, o seu tempo de vida recupera uma fracção q do tempo de vida
acumulado.
Figura 4.4 – Rede para actividades de Manutenção Correctiva
Ao querer-se que as transições StandbyFailure e WorkingFailure tenham em conta o desgaste dos
equipamentos, é necessário caracterizá-las com distribuições de Weibull. Para que o tempo de vida
acumulado seja capaz de influenciar a taxa de falha, recorre-se à distribuição de Weibull Truncada. Da
forma como está implementada no software, são necessários três parâmetros para a caracterizar,
apenas mais um que a distribuição de Weibull original. Esse parâmetro extra é justamente a idade
acumulada até ao momento em que a transição fica activa. É então necessário ter uma forma de se ter
e actualizar essa informação através de uma rede “cronómetro”.

30
O tempo de vida acumulado é dado pelas variáveis semi_age e total_age e alguma atenção deve ser
dada à sua definição. Ambas representam o tempo de vida acumulado mas tomam valores diferentes,
apesar de retratarem a mesma característica do mesmo equipamento. A necessidade de haver estas
duas variáveis está relacionada com o desgaste que, mesmo para intervalos de tempo iguais, é
diferente caso o equipamento esteja em standby ou em funcionamento. Dessa forma, o tempo em
standby não pode ter o mesmo peso que o tempo em funcionamento e deve ser feita uma correcção
tendo em conta um factor ponderador: ageFactor_SB_Working.
𝑡𝑒𝑚𝑝𝑜𝑊𝑜𝑟𝑘𝑖𝑛𝑔 = 𝑡𝑒𝑚𝑝𝑜𝑆𝐵 × 𝑎𝑔𝑒𝐹𝑎𝑐𝑡𝑜𝑟𝑆𝐵/𝑊𝑜𝑟𝑘𝑖𝑛𝑔 ( 4.1 )
Figura 4.5 – Rede Petri para contagem do tempo de vida do equipamento
A rede do lado esquerdo da Figura 4.5 faz o cálculo do tempo em que o sistema se encontra no estado
fundamental StandBy. A do lado direito conta o tempo decorrido enquanto o equipamento se encontra
em funcionamento (estado fundamental Working). A variável semi_age é a variável que tem em conta
o peso inferior do tempo decorrido em standby e como tal, é utilizada na caracterização da transição
WorkingFailure apresentada na rede da Figura 4.2. A variável total_time, conta todo o tempo, em que
o equipamento esteve operacional, sendo portanto utilizado na transição StandbyFailure da rede
principal.
As redes apresentadas acima definem apenas o comportamento do equipamento. A calendarização
das inspecções é definida noutra rede exterior sendo portanto necessário criar uma forma de trocar
informações entre o estado do equipamento e a rede gestora das manutenções. Essa comunicação é
feita através da rede auxiliar do equipamento apresentada na Figura 4.6. As variáveis StartMaintenance
e MaintenanceFinished servem como input e output respectivamente, à rede que define o momento da
inspecção dos equipamentos.

31
Figura 4.6 – Rede de comunicação ao protótipo de Inspecções
Todas as redes apresentadas nesta secção são utilizadas na criação do protótipo que representa um
equipamento genérico. O bloco criado através do protótipo do equipamento genérico é depois utilizado
no módulo BStock e permite, através da alteração dos parâmetros essenciais, representar qualquer
componente do sistema de combate a incêndios.
4.1.1.2 Calendário de Inspecções
A rede feita para o bloco que faz a gestão das manutenções periódicas é muito mais simples do que
as criadas para o equipamento. O conceito de uma rede circular permite criar de forma muito simples
a periodicidade necessária para a modelação da calendarização das inspecções.
Duas vertentes ligeiramente diferentes surgem da definição da periodicidade:
a. Intervalo de tempo fixo entre o início de duas inspecções consecutivas
b. Intervalo de tempo fixo entre o fim de uma inspecção com o início da seguinte.
Qualquer uma das abordagens pode ser utilizada na realidade e por isso, ambas foram contempladas
na criação do bloco de inspecções. Esta decisão é deixada ao critério do utilizador do bloco, que poderá
escolher entre as duas vertentes através do parâmetro ScheduleMaintenance; verdadeiro caso o tempo
entre o início de duas inspecções consecutivas seja fixo ou falso caso o tempo entre o fim da inspecção
anterior e o início da seguinte seja fixo.
Por conveniência, o momento da primeira inspecção pode ser escolhido de forma completamente
independente das restantes inspecções.
Na Figura 4.7 estão as duas redes que definem o bloco de inspecções. A vertente (a) está representada
na rede de baixo e a vertente (b) é modelada através da rede na parte superior da figura. No caso em
que o parâmetro ScheduleMaintenance seja verdadeiro, um token surge automaticamente no estado
número 17. No caso em que o parâmetro seja falso, o token surge no estado 15.

32
Figura 4.7 – Rede Petri do bloco de Inspecções
4.1.2 Rede Petri do Sistema Global
Um dos grandes problemas das redes Petri é que rapidamente ficam com um elevado grau de
complexidade e a sua leitura fica demasiado complicada (Signoret et al., 2013). Apenas uma estrutura
modular e com várias pequenas redes é capaz de ajudar ao entendimento da rede global. O diagrama
de blocos é muito mais intuitivo mas não tem a mesma flexibilidade de modelação e não permite que
sejam criadas as dependências e dinâmicas possíveis através das redes Petri. Com o intuito de
contribuir para uma solução a este problema, o software GRIF Workshop oferece um módulo que
permite utilizar diagramas de blocos estocásticos, que ao contrário dos diagramas de blocos (RBD),
foca-se no comportamento dinâmico dos sistemas (GRIF, n.d.). Dessa forma, permite que o utilizador
tenha uma vista gráfica simples e perceptível (semelhante aos diagramas de blocos) da arquitectura
do sistema estudado sem que tenha de olhar para a complexidade das redes Petri que estão na sua
base.
Com este módulo, a construção do sistema global e as dependências que cada equipamento tem com
o exterior torna-se muito mais fácil, contribuindo para uma diminuição de erros lógicos.
Tendo por base as redes Petri de cada componente apresentado nas secções anteriores, criam-se dois
protótipos de blocos a usar no diagrama de blocos estocásticos: equipamento genérico e calendário de

33
inspecções. Apenas com manipulação dos parâmetros de input de cada componente, o bloco consegue
representar qualquer equipamento do sistema.
Em concordância com o que foi apresentado aquando da descrição do sistema, criou-se o diagrama
de blocos estocástico que será usado para as simulações e obtenção de resultados. O diagrama é
apresentado nas figuras seguintes.
Figura 4.8- Diagrama de Blocos Estocástico do Sistema de combate a incêndios
Figura 4.9 – Pormenor do Circuito de Água
Figura 4.10 – Pormenor do Circuito de Espuma
Na Figura 4.9 e Figura 4.10, é possível ver o interior dos grandes blocos que se apresentam na
Figura 4.8.
Por trás deste simples diagrama, está uma complexa rede Petri que modela 18 equipamentos
recorrendo a 281 estados, 409 transições, 270 variáveis e 57 parâmetros.
4.2 Reliquefação de BOG a bordo de um LNG
Durante a viagem de transporte de gás natural, existem sempre perdas, BOG – Boil-off gas. A queima
destas perdas, sem o aproveitamento da sua energia, teria um impacto extremamente negativo a nível
económico uma vez que cerca de 0.1%-0.15% da carga se evapora a cada dia. Assim, num sistema
de propulsão à base de turbinas, o gás é queimado em caldeiras e a sua energia usada para criar vapor
necessário para o sistema de propulsão do navio. Mas, se outrora, nos navios LNG convencionais
(130 000m3 – 140 000m3), o sistema mais popular de propulsão era o de turbinas a vapor e gás, nos

34
novos navios LNG de grandes dimensões essa opção já não é a mais favorável devido à sua baixa
eficiências energética e ao seu investimento inicial. Alternativas ao sistema de propulsão para substituir
as turbinas a vapor têm então sido propostos (Chang et al., 2008). Perante a escolha de um sistema
em que a energia é gerada pela combinação de motores de baixas velocidades de rotação, o BOG não
pode ser utilizado como combustível. O facto de não haver qualquer aproveitamento da energia gerada
pela queima do gás acarreta um grande impacto financeiro negativo nas contas do operador do navio.
Num navio com uma capacidade de carga de 200 000m3, o BOG chega a ser criado a uma taxa de
0.15% por dia, correspondendo a um volume de 300m3 de BOG por dia, pesando mais de 125 500kg.
A energia que se deixa de aproveitar é de quase 6000 MBtu por dia o que corresponde a perto de
28 000 USD no mercado de energia. Basta que o tempo da viagem entre o porto de origem e o de
destino seja de 14 dias e que o navio realize 12 viagens por ano, para que as perdas associadas sejam
superiores a 4 500 000 USD ao fim de um ano de operação. Uma das possíveis soluções para evitar
estas perdas avultadas passa pela instalação de uma unidade de liquefação do BOG a bordo,
permitindo que o BOG gerado seja transformado novamente em LNG.
Por trás do princípio de liquefação do BOG está um ciclo termodinâmico de refrigeração – o ciclo de
Brayton invertido (Shin & Lee, 2009) - que se serve de um líquido refrigerante, equipamentos
compressores e expansores para a diminuição da temperatura de forma a condensar e tornar liquido o
gás natural. Apesar destes sistemas de liquefação serem comummente usados em unidades terrestres,
a bordo dos navios, o princípio ainda é pioneiro (Anderson et al., 2009). O desempenho destes sistemas
não poderá ser afectada pelos movimentos do navio e a sua instalação a bordo, apesar de todas as
limitações de espaço e peso, tem de ser possível. A simplificação dos procedimentos de arranque,
operação, manutenção e paragem também deve ser uma prioridade, já que se quer uma tripulação
capaz de operar a unidade de liquefação sem colocar em risco a integridade do navio e o meio ambiente
que o envolve.
Desta necessidade de se ser capaz de ter uma unidade de liquefação fiável a bordo do navio, toda a
indústria relacionada com o transporte de LNG (armadores, estaleiros de construção e sociedades
classificadoras) está bastante interessada em determinar uma configuração óptima que permita ter
altas capacidades de liquefação, sem pôr em causa a segurança e sem ter custos de investimento e
manutenção excessivos.
Uma unidade de reliquefação genérica é apresentada na Figura 4.11. O sistema pode ser dividido em
duas partes: ciclo de circulação do gás proveniente dos tanques de carga; e ciclo de circulação do
Azoto (N2), usado como líquido refrigerante. O ciclo de circulação da carga engloba toda a preparação,
compressão e liquefação do BOG. O ciclo de circulação de Azoto conta com sua produção,
arrefecimento e armazenamento.

35
Figura 4.11 – Diagrama do Sistema de Reliquefação de Gás
O BOG passa por cinco fases desde que sai do tanque de carga até que volta. O seu percurso está
representado pela linha sólida da Figura 4.11. Os valores da pressão e temperatura apresentados em
cada fase, baseados no estudo de Shin & Lee, (2009) são apenas indicativos mas contribuem para um
entendimento dos fenómenos termodinâmicos ocorridos durante o processo.
Fase 1: O BOG proveniente dos tanques de carga entra numa unidade de preparação onde é arrefecido
e onde as gotículas presentes são retiradas. A temperatura do BOG é de -120ºC e está a uma pressão
de 1.06bar.
Fase 2: O BOG é comprimido através de compressores aumentando a sua pressão para 7.5bar e a
temperatura para 41.0ºC. Nos grandes navios LNG o BOG é comprimido em duas etapas, tal como
esquematizado. Cada um dos compressores é capaz de lidar com 50% do valor nominal. Mesmo que
a sua disposição seja em série, a falha de um apenas reduz a capacidade de compressão para metade.
Fase 3: Nesta terceira fase, o BOG é arrefecido num permutador de calor após contacto indirecto com
o azoto a baixas temperaturas. Esta troca de calor é feita dentro de uma máquina de congelamento
criogénico e consegue baixar a temperatura de forma a condensar o BOG e transformá-lo novamente
em gás natural liquefeito. A sua temperatura é de -158.0ºC e pressão 7.0bar.
Fase 4: A fracção de BOG que não é liquefeita após a fase 4 é retirada através de um separador.
Fase 5: O produto resultante da fase 4 (LNG) é bombeado de volta para os tanques de carga.

36
A temperatura no interior da caixa onde são feitas as trocas de calor é mantida através de um ciclo de
compressão e expansão do Azoto. Este ciclo está representado na Figura 4.11 pela linha a traço
interrompido e é possível dividi-lo em quatro fases.
Fase 1: O azoto é comprimido pela passagem por compressores. Entre cada fase de compressão, o
azoto é arrefecido em permutadores de calor à base de água salgada. De forma a assegurar a pressão
necessária, o azoto deverá ser comprimido em três etapas. Cada um dos compressores é capaz de
lidar com um terço do valor nominal. Mesmo que a sua disposição seja em série, a falha de um apenas
reduz a capacidade de compressão para dois terços.
Fase 2: O azoto comprimido é guiado para o permutador criogénico de calor e é pré-arrefecido. À saída,
a sua temperatura ronda os -110ºC e a pressão é de 45.4bar.
Fase 3: Nesta fase, o azoto passa por um expansor. Neste processo de expansão ocorre uma
diminuição da temperatura para -161.5ºC e da pressão para 13.0bar.
Fase 4: O azoto é então introduzido de volta no permutador de calor onde ocorrem as trocas de calor.
Nessa passagem, o azoto a baixas temperaturas é capaz de condensar o BOG e transformá-lo de volta
em LNG. Após esta fase, o azoto volta ao início do ciclo.
Um reservatório de azoto é instalado de forma a ser possível o controlo permanente da quantidade de
N2 no circuito.
Alguns equipamentos são críticos e podem levar a que o sistema se torne incapaz de processar o BOG.
Sempre que ocorre uma paragem, o BOG deve ser queimado numa unidade própria para impedir que
a pressão interna dos tanques aumente para valores que façam a estrutura colapsar. Assim, todas as
paragens implicam perda de dinheiro pois o gás queimado não poderá ser recuperado. A consequência
da falha de cada um dos equipamentos pode ser visto na Tabela 4.1.
Tabela 4.1 – Influência da falha dos componentes na capacidade de reliquefação
Falha Capacidade de
liquefação
Permutador de calor 0.0%
Separador 0.0%
Bomba 0.0%
Reservatório 0.0%
1 Compressor BOG 50.0%
2 Compressores BOG 0.0%
Motor do Compressor BOG 0.0%
1 Compressor N2 66.7%
2 Compressores N2 33.3%
3 Compressores N2 0.0%
Motor do Compressor N2 0.0%
Expansor 0.0%

37
A quantidade de BOG está directamente relacionada com a capacidade de liquefação do sistema.
Como o sistema é dimensionado para que a sua capacidade máxima (sem redundâncias) seja igual à
necessidade máxima de reliquefação, uma redução da sua capacidade para um quarto implicaria a
queima de um quarto do BOG gerado. A quantidade de BOG queimado é então dado por:
𝑄𝑢𝑎𝑛𝑡𝑖𝑑𝑎𝑑𝑒 𝑄𝑢𝑒𝑖𝑚𝑎𝑑𝑎 (%) = 1 − 𝐶𝑎𝑝𝑎𝑐𝑖𝑑𝑎𝑑𝑒 𝑆𝑖𝑠𝑡𝑒𝑚𝑎 (%) ( 4.2 )
Um estudo da fiabilidade do sistema toma então um peso importante na ponderação das redundâncias
a instalar.
Quatro opções de sistemas são avaliadas neste estudo:
1. Configuração mínima com apenas uma unidade de reliquefação e uma unidade de combustão
própria GCU (Gas Combustion Unit). Este sistema tem uma configuração em que todos os
componentes estão em série e nenhum deles é redundante.
2. Igual à opção um mas com um sistema completo de compressão do BOG em standby que
poderá ser usado caso o sistema de compressão principal falhe.
3. Igual à opção um mas com um sistema completo de compressão do N2 em standby que poderá
ser usado caso o sistema de compressão principal falhe.
4. Igual à opção um mas com um sistema completo de compressão do BOG e um sistema
completo de compressão do N2, ambos em standby, que poderão ser usados quando os
sistemas principais falharem. Esta opção pode ser vista como uma combinação das opções
dois e três.
Redundâncias nos demais equipamentos não são consideradas praticáveis. O diagrama de blocos do
sistema é apresentado na Figura 4.12. O sistema de compressão do BOG, com a redundância das
opções 2. e 4. pode ser visto na Figura 4.13. O sistema de compressão do N2, com a redundância das
opções 3. e 4. pode ser visto na Figura 4.14.
Figura 4.12 – Diagrama de Blocos do Sistema de Reliquefação

38
Figura 4.13 – Pormenor do subsistema Compressor BOG
Figura 4.14 – Pormenor do subsistema Compressor N2
Cada uma das opções deve ser avaliada comparando o custo associado à queima e desperdício de
BOG com o custo da construção, instalação e manutenção do sistema. Os custos associados aos
componentes e sua instalação a bordo são apresentados na Tabela 4.2. Parte desse estudo é
apresentado adiante na secção de optimização.
Tabela 4.2 – Custos associados à instalação do sistema de reliquefação
Equipamento Custo
Compressor BOG $350 000
Permutador de Calor $120 000
Compressor e Expansor N2 $850 000
Encanamentos/Instrumentação $660 000
Outros Equipamentos $20 000
Unidade de Combustão de Gás $2 000 000
Construção, instalação, etc $6 000 000
Total $10 000 000
Com base na informação apresentada nesta secção, são feitas simulações e os resultados
apresentados na secção 6.

39
4.2.1 Redes Petri dos componentes individuais
No sistema apresentado de reliquefação do BOG, existem três tipos de componentes diferentes:
equipamento genérico simples, subsistema compressor de BOG e subsistema compressor de N2.
4.2.1.1 Equipamento Genérico
A rede criada para o equipamento genérico está criada de forma a que possa representar qualquer um
dos componentes individuas do sistema, sendo apenas necessário alterar os parâmetros que
determinam a frequência das falhas. Esta rede é usada para modelar o permutador de calor, o
separador, a bomba e o reservatório de azoto.
A rede que representa o equipamento genérico é praticamente a mesma que a apresentada na secção
4.1.1.1 dispensando-se então a apresentação da rede numa nova figura. A única diferença prende-se
com o facto de o estado de funcionamento já não ser representado por uma variável booleana mas sim
por uma capacidade entre 0% e 100%.
Relembram-se aqui as características que a rede que modela o equipamento simples é capaz de
representar:
a) Estado binário para a capacidade: 100% (operacional); 0% (não operacional);
b) Possuir três modos de falha: falha em funcionamento, falha em standby e falha ao arranque;
c) As falhas em standby são ocultas;
d) Estar dependente da disponibilidade das equipas de manutenção;
e) Estar dependente da quantidade de equipamentos em stock para substituição;
f) Contemplar manutenções preventivas, correctivas e oportunistas, tanto perfeitas e imperfeitas;
g) O tempo para a sua falha pode ser definido tanto por uma distribuição Exponencial como por
uma Weibull de dois parâmetros, sendo portanto capaz de representar desgaste no
equipamento;
h) Os tempos para inspecção, reparação e substituição poderem seguir qualquer tipo de
distribuição.
4.2.1.2 Subsistema Compressor de BOG
É esta unidade de compressão de BOG que comprime todo o gás proveniente dos tanques de carga e
o prepara para o processo de liquefação no permutador de calor. Este sistema tem como base dois
compressores e o motor necessário ao seu funcionamento. Cada compressor é capaz de lidar com
50% do valor nominal. Assim, a falha de um dos compressores reduz para metade a capacidade de
compressão. A falha do segundo compressor ou do motor auxiliar, impossibilita a compressão de BOG
- capacidade reduzida a 0%, Tabela 4.1.
No caso em que o subsistema é redundante, o ramo escolhido para funcionar é sempre aquele com
maior capacidade de compressão, o outro fica em standby. Não é possível utilizar um compressor de
cada ramo de compressão para perfazer uma capacidade de 100%, Figura 4.13.

40
No momento inicial, os dois ramos encontram-se em funcionamento e qualquer um deles pode ser
escolhido para satisfazer as necessidades do sistema global pois ambos têm uma capacidade de 100%.
Se no decorrer das actividades de compressão um dos componentes falhar, o outro ramo entra em
funcionamento. O tempo necessário para a alteração dos ramos é modelado por uma distribuição
exponencial com uma taxa de 4h-1.
Para uma maior aproximação do modelo à realidade estudada, a rede que determina o funcionamento
do sistema compressor de BOG tem as seguintes características:
a) Três estados de capacidade: 100%, 50% e 0%;
b) Falhas e reparações colectivas dos compressores;
c) Escolha automática e inteligente do ramo com maior capacidade de compressão;
d) Possibilidade de escolher se o sistema é ou não redundante;
e) Todos os equipamentos individuais do sistema possuem as características apresentas nas
secções 4.1.1.1 e 4.1.1.2.
Na rede que modela o subsistema compressor de BOG estão inseridos todos os compressores e
motores necessários ao seu funcionamento. A rede é também composta por um bloco que faz a gestão
do ramo em funcionamento tendo em conta as capacidades de cada um e por um que faz a regulação
da manutenção desta unidade.
Por razões de uniformização, as redes que definem os compressores e os seus motores são
semelhantes às apresentadas nas secções relativas a equipamentos genéricos, 4.1.1.1 e 4.1.1.2. No
entanto, podem ocorrem falhas colectivas em mais do que um compressor num determinado instante.
Assim, uma rede extra que interliga os dois compressores e que permite modelar falhas comuns é
criada e encontra-se apresentada na Figura 4.15.
Com esta rede, ficam então modeladas as falhas colectivas. Sempre que existam tokens nos estados
101 e 201, correspondentes a estados de funcionamento dos dois compressores do ramo, a transição
SimultaneousFailure fica activa e o seu disparo é determinado por uma distribuição exponencial. Após
o seu disparo, os tokens passam dos estados Working (101 e 201) para os estados NotWorking de
ambos os equipamentos (estados 102 e 202 na figura). Assim que os tokens de ambos os
equipamentos se encontrem nos estados inRepair, estes transitam para os estados 914 e 915 e activam
a transição que modela a reparação colectiva. Após esta reparação, ambos os equipamentos voltam a
estar operacionais.

41
Figura 4.15 – Modo de falha e reparação colectiva
Para cada um dos dois ramos de compressão de BOG existe uma rede semelhante à apresentada na
Figura 4.16, que calcula a capacidade do ramo tendo em conta os estados dos equipamentos aí
instalados.
Figura 4.16 – Rede de capacidades do Ramo activo
Quando todos os equipamentos instalados num determinado ramo se encontram operacionais, o token
da rede apresentada na Figura 4.16 encontra-se no estado Capacity_Pr: 1.0 e a sua capacidade toma
o valor de 1.0 – 100%. Deste estado, o token apenas pode evoluir para o estado Capacity_Pr: 0.5 se
um dos dois compressores falhar ou para o estado Capacity_Pr: 0.0 caso haja uma falha no motor
auxiliar dos compressores ou uma falha colectiva dos dois compressores. Enquanto o token se
encontrar no estado Capacity_Pr_0.5, a capacidade do ramo é de 50%. Neste momento, se os dois
equipamentos voltarem a estar operacionais, a capacidade volta a ser 100% e o token circula para o
estado inicial. Se por contrário, houver uma falha no segundo compressor ou no motor, o token irá para
o estado que caracteriza a capacidade do ramo com 0%. Neste caso, a capacidade apenas pode ser

42
aumentada para 50% caso um dos compressores e o motor se encontrarem operacionais ou para 100%
caso todos os equipamentos do ramo se encontrarem novamente operacionais.
Nesta rede, sempre que ocorre uma mudança de estado, a variável check_max toma o valor positivo e
a rede gestora (apresentada de seguida, Figura 4.17) irá ver se existe outro ramo operacional com uma
capacidade superior à do ramo activo.
A rede de gestão tem como objectivo maximizar a capacidade do sistema de compressão de BOG com
uma escolha inteligente de qual dos ramos deve estar em funcionamento. Nesta rede, apresentada na
Figura 4.17, existem apenas quatro estados: três fundamentais e um auxiliar. Sempre que o ramo
principal do circuito de compressão está activo, o token encontra-se no estado 906. Por oposição, o
token encontra-se no estado 907 quando o ramo activo é o secundário/redundante. Sempre que o
sistema estiver em standby (nenhum dos ramos em utilização), o token toma a posição definida pelo
estado 905.
Figura 4.17 – Rede gestora dos ramos activos
Existem três formas de fazer o token circular da posição 905 para a 906 (ou 907, por simetria) e cinco
para o fazer regressar ao estado inicial. Sempre que a capacidade do ramo principal for igual ou
superior à do ramo redundante e o último ramo activo tiver sido o principal, o token evolui do estado
905 para o 906. Como estas duas transições apenas ocorrem no instante t=0h ou quando tiver sido
feita uma verificação de qual dos dois ramos tem maior capacidade, a lei de disparo que as define é

43
dirac 0. No entanto, se o ramo com maior capacidade for o ramo principal mas o ramo utilizado antes
desse instante for o secundário, a transição deverá demorar um certo tempo e é definido por uma
distribuição exponencial. Das cinco transições que fazem o token evoluir do estado 906 para o 905,
uma ocorre quando o sistema entra em standby, outra ocorre quando é necessário fazer uma
verificação do ramo com maior capacidade e as outras três estão relacionadas com a revelação de
falhas ocultas (ocorridas enquanto o ramo estava em standby), uma por cada equipamento do ramo de
compressão de BOG. Em momentos de manutenção, apenas um dos ramos fica em standby e sujeito
a intervenção. Terminada essa manutenção, esse ramo entra em funcionamento deixando o segundo
em standby e em condições de ser inspecionado e reparado. Esta transição ocorre directamente entre
os estados 906 e 907 e o tempo necessário segue uma distribuição exponencial.
No caso em que o sistema de compressão de BOG não é redundante e para que seja possível usar a
mesma rede Petri, a capacidade do ramo auxiliar toma o valor -1. Dessa forma, este módulo gestor
nunca irá por em funcionamento o ramo auxiliar, simulando assim a ausência da redundância.
No momento em que o sistema de compressão de BOG deve ser sujeito a uma manutenção periódica,
o bloco que o representa recebe essa informação através da variável StartMaintenance. Assim que
essa variável toma o valor verdadeiro, a rede do bloco responsável pelas manutenções (Figura 4.18)
passa a informação de que todos os equipamentos desse bloco devem ser submetidos a uma
intervenção. Assim que todos os equipamentos do sistema de compressão tiverem sido inspeccionados
e reparados, a variável MaintenanceFinished toma o valor verdadeiro e essa informação é então
repassada para o exterior do bloco que compõe todas as redes do subsistema de compressão de BOG.
Figura 4.18 – Rede de Manutenções do bloco do sistema de compressão de BOG

44
4.2.1.3 Subsistema Compressor de N2
As baixas temperaturas dentro do permutador de calor são mantidas através da circulação de N2 no
ciclo de compressão/expansão apresentado na Figura 4.11. Tal como apresentado em 4.2, o azoto
passa por três compressores e um expansor para que a sua pressão tenha os valores necessários para
cada um dos diferentes momentos do ciclo.
Este sistema tem como base três compressores, auxiliados por um motor eléctrico e um expansor.
Cada um dos compressores é capaz de lidar com um terço do valor nominal. Por cada compressor em
falha, a capacidade de compressão deste subsistema vê a sua capacidade reduzida em um terço. A
falha do motor eléctrico ou do dispositivo de expansão reduz para zero a capacidade do subsistema de
compressão do azoto. A influência que cada falha tem na capacidade do sistema pode ser vista na
Tabela 4.1.
Quando o subsistema é redundante, o ramo escolhido para funcionar é sempre aquele com maior
capacidade de compressão e o outro fica em standby. À semelhança do sistema de compressão de
BOG, cada ramo é completamente independente do outro e portanto, não é possível combinar o
funcionamento de equipamentos de diferentes ramos para que se atinjam os valores nominais, Figura
4.13.
Para uma maior aproximação do modelo à realidade estudada, a rede que determina o funcionamento
do sistema compressor de N2 tem as seguintes características:
a) Quatro estados de capacidade: 100%, 66.67%, 33.33% e 0%;
b) Falhas e reparações colectivas dos compressores;
c) Escolha automática e inteligente do ramo com maior capacidade de compressão;
d) Possibilidade de escolher se o sistema é ou não redundante;
e) Todos os equipamentos individuais do sistema possuem as características apresentas nas
secções 4.1.1.1 e 4.1.1.2.
Na rede que modela este subsistema compressor, estão inseridos todos os compressores, expansores
e motores necessários ao seu funcionamento. Da mesma forma que a rede apresentada para a
compressão do BOG, esta rede também é composta pelo bloco que faz a gestão do ramo em
funcionamento tendo em conta as capacidades de cada um. Existe também uma rede que tem por
objectivo fazer a regulação da manutenção desta unidade.
As redes que definem o estado de todos os componentes individuais desta unidade compressora (6
compressores, 2 motores eléctricos e 2 Expansores) são semelhantes às apresentadas nas secções
anteriores e dispensam mais comentários. No entanto, a rede que define as falhas colectivas dos
compressores é diferente da anterior pois nesta, estas podem ocorrer sempre que dois ou três
compressores do ramo estejam em funcionamento. A rede Petri que determina o momento da falha
comum é apresentada na Figura 4.19.

45
A transição SimultaneousFailure está activa sempre que houver mais do que um compressor activo.
Assim que esta transição é disparada, as variáveis relacionadas com o funcionamento e com a
necessidade de reparação são actualizadas. Após esse disparo e caso existam equipas de manutenção
disponíveis, a transição Simul_Main que determinará a duração da reparação dos compressores
danificados fica activa.
Como os ramos são independentes entre si, uma rede semelhante à da Figura 4.19 é criada para cada
um: uma para o principal, outra para o ramo redundante.
Figura 4.19 - Modo de falha e reparação colectiva
As outras redes utilizadas no bloco que modela o sistema compressor de BOG, nomeadamente a rede
que apresenta a capacidade de compressão do ramo e a rede que faz a gestão do ramo activo, são
também criadas para este bloco de compressão de N2. O princípio por trás da modelação da rede é
exactamente o mesmo mas o aumento do número de elementos torna-a ligeiramente mais complexa.
A capacidade do ramo é actualizada através da rede apresentada na Figura 4.20. Quando a capacidade
do sistema é de 100%, 66.67%, 33.33% e 0%, o token encontra-se no estado Capacity_Pr:1.0,
Capacity_Pr:2/3, Capacity_Pr:1/3, Capacity_Pr:0.0, respectivamente. Sempre que um dos
compressores entra em falha, o token desce apenas um nível na capacidade. Sempre que um motor
ou expansor falha, o token circula para o estado Capacity_Pr: 0.0, independentemente da sua posição
anterior. A única forma de o sistema voltar a ter um aumento na sua capacidade, é garantindo que o
expansor e o motor e pelo menos um dos compressores encontra-se operacional.

46
Figura 4.20 - Rede de capacidades do Ramo activo
4.2.1.4 Calendário de Navegação
Para a análise dos resultados, é importante saber as alturas em que o navio se encontra a navegar
pois ao longo da viagem de ida e de volta as capacidades que se exigem do sistema são diferentes. É
ainda importante definir os momentos em que o navio está no porto porque em algumas simulações,
as equipas de manutenções apenas estão disponíveis quando o navio se encontra atracado.
A rede para este calendário é bastante simples e é apresentada na Figura 4.21. Sempre que o token
se encontrar no estado Sailing, o navio está em viagem. A rede impede que o navio saia do porto sem
que as tarefas de manutenção das equipas de terra terminem.
Figura 4.21 – Calendário de Navegação
4.2.1.5 Calendário de Inspecções
A rede que determina o calendário de inspecções do sistema global de liquefação de gás natural é
exactamente a mesmo que a descrita na secção 4.1.1.2 e apresentada na Figura 4.7.

47
4.2.2 Rede Petri do Sistema Global
A partir das redes Petri de cada componente apresentado nas secções anteriores, criam-se cinco
protótipos de blocos a usar em diagramas de blocos estocásticos: equipamento genérico, subsistema
de compressão de BOG, subsistema de compressão de N2, calendário de navegação e calendário de
inspecções. Apenas com manipulação dos parâmetros, o protótipo criado para modelar um
equipamento genérico, consegue representar o permutador de calor, separador, bomba e reservatório.
Os protótipos criados com base nas redes apresentas nas secções 4.2.1.2 e 4.2.1.3 representam os
sistemas de compressão de BOG e N2 respectivamente.
Em concordância com o que foi apresentado aquando da descrição do sistema, criou-se o diagrama
de blocos estocástico que será usado para as simulações e obtenção de resultados. O diagrama da
Figura 4.22, criado no módulo BStock, é praticamente igual ao apresentado anteriormente na Figura
4.12. A única coisa que os distingue é a presença de blocos para a calendarização das viagens e das
inspecções, necessários para fazer esta regulação, já que interferem nas capacidades de cada bloco
presente no sistema.
Figura 4.22 – Diagrama de Blocos Estocástico
Por trás deste simples diagrama, está uma complexa rede Petri que modela 20 equipamentos
recorrendo a 338 estados, 579 transições, 310 variáveis e 98 parâmetros.
4.3 Eficiência e precisão do processo de simulação
A quantidade de simulações que devem ser feitas de modo a que os resultados sejam estatisticamente
confiáveis deve ser determinada. A escolha do número de simulações a realizar, é encontrada pelo
equilíbrio entre o tempo de simulação e erros de simulação.
Para este estudo, utilizou-se um bloco simplificado do subsistema de compressão de N2. A forma como
é calculado o valor teórico da disponibilidade é apresentado mais adiante na secção 5.3. Para cada
instante, é calculado o erro relativo através da seguinte equação:
𝑒 =|𝐴𝑡𝑒ó𝑟𝑖𝑐𝑜 − 𝐴𝑆𝑖𝑚𝑢𝑙𝑎çã𝑜|
𝐴𝑡𝑒ó𝑟𝑖𝑐𝑜
( 4.3 )

48
De forma a ser possível uma comparação directa entre as várias simulações, é feita uma média do erro
relativo no domínio estudado. Outro parâmetro utilizado para a determinação do número de simulações
a efectuar é a largura do intervalo de confiança da média da disponibilidade.
Figura 4.23 – Convergência do erro e intervalo de confiança
Analisando o gráfico da Figura 4.23 nota-se que existe uma convergência e estabilização do valor do
erro médio e da largura do intervalo de confiança. O tempo necessário varia entre 0.48s e 21.85s para
a realização de 100 e 5000 simulações respectivamente.
Como o tempo para a realização de 5000 simulações não é exagerado e porque essa quantidade de
simulações permite ter um erro médio inferior a 1% e um intervalo de confiança para a média da
disponibilidade bastante estreito, a maior parte dos estudos no âmbito desta dissertação são feitos com
5000 simulações.

49
5 Simulação e Verificação do modelo e dos seus
componentes
Neste capítulo, procede-se à verificação das redes Petri implementadas. A verificação do modelo
implementado coloca em consideração a qualidade da representação do modelo matemático
subjacente, garantindo que o modelo está livre de erros criados durante o processo de modelação.
Idealmente, a verificação deve ser feita por comparação dos resultados obtidos com soluções
analíticas. No entanto, quando o estudo analítico não é possível devido à complexidade do sistema, o
processo de verificação pode ser feito recorrendo-se a resultados obtidos por outros modelos ou
software. A visualização da evolução dos tokens com o disparar de cada transição também permite que
seja feita uma verificação lógica da rede montada e dos seus predicados e fazer um despiste de erros
cometidos durante o processo de modelação.
Através de algumas simplificações nos parâmetros dos protótipos que representam os equipamentos,
torna-se possível a verificação matemática através da formulação apresentada na secção de Revisão
Teórica. Ainda com os equipamentos simplificados, é possível fazer uma verificação ao sistema
implementado.
O sistema de reliquefação de gás natural será também sujeito a verificação por comparação de
resultados com um estudo de caso semelhante apresentado por Kwang et al., (2008). Possíveis
diferenças nos resultados serão também comentadas nessa secção.
5.1 Verificação do Componente Individual
Este componente individual é usado tanto no sistema de combate a incêndios como no sistema de
reliquefação de gás natural. A melhor forma de se verificar a rede e garantir que esta está bem
modelada é através da comparação da curva de disponibilidade obtida por simulação com a curva
teórica. Com esta comparação é possível verificar imediatamente se os modos de falha são coerentes
e se se aproximam à curva esperada. Três curvas são aqui comparadas: falha com equipamento em
standby; falha com equipamento sempre em funcionamento; e curva de falha em que o estado de
standby e funcionamento vai-se alterando ao longo do tempo. Estas curvas são comparadas com as
teóricas para os casos em que os modos de falha seguem distribuições exponenciais e distribuições
de Weibull.
A forma de se obter estas curvas de disponibilidade dos equipamentos são simples de entender quando
se olha para a Figura 5.1. Quando se faz apenas uma simulação, é gerado apenas um número que
determina o tempo para o qual o equipamento vai falhar e portanto, uma curva com apenas um degrau
é criada: o equipamento encontrava-se em funcionamento (disponibilidade igual a um) até um
determinado instante, t. Após a falha ocorrida nesse instante, a disponibilidade do sistema passa a ser
igual a zero. Com o aumento do número de simulações são criadas cada vez mais curvas de degrau
unitário, tantas quanto o número de simulações feitas e para cada instante, é feita uma média dos
valores de disponibilidade obtidos. Com o aumento do número de simulações, mais instantes de falha

50
t são gerados e é portanto natural que a curva das médias das disponibilidades das curvas de degrau
unitário se aproxime da curva teórica.
Figura 5.1- Curvas de Disponibilidade em função do número de simulações
A curva e os valores teóricos são obtidos recorrendo-se às expressões das Tabela 2.1 e Tabela 2.2,
apresentadas na secção destinada à Revisão Teórica.
Apenas um parâmetro é necessário para uma descrição dos tempos de falha que seguem uma
distribuição exponencial: taxa de falha, λ. Por proximidade a alguns tempos de falha de alguns
componentes dos sistemas estudados, definiu-se que o tempo médio até à falha é de 5000h. Pela
equação ( 2.18 ), λ = 0.0002h−1. Por uma questão de comodidade, foi esse o parâmetro usado em
todas as distribuições estudadas: equipamento sempre em standby, sempre em funcionamento,
funcionamento misto.
As curvas da disponibilidade para os casos em que os tempos de falha são modelados por uma
distribuição exponencial são obtidas pela média de 5000 simulações e são apresentadas na Figura 5.2.
A proximidade entre elas é clara e em quase todo o domínio apresentado, é difícil distinguir as curvas
umas das outras.
Para uma melhor noção da distância média entre as curvas, o erro médio ao longo de toda a simulação
é calculado e apresentado na Tabela 5.1.
Tabela 5.1 – Erro das curvas de Disponibilidade
Modo Erro
StandBy 1.01%
Funcionamento 0.84%
Misto 1.59%

51
Figura 5.2 – Curvas de Disponibilidade para distribuições exponenciais
A mesma abordagem foi feita caso os tempos de falha se regessem pela distribuição de Weibull. Esta
distribuição, tal como apresentado na Tabela 2.2, requer que dois parâmetros sejam definidos: θ e m.
Da equação ( 2.23 ),
𝜃 =𝑀𝑇𝑇𝐹
Γ(1 + 1𝑚⁄ )
( 5.1 )
Com 𝑀𝑇𝑇𝐹 = 5000h e 𝑚 = 2.5, 𝜃 = 5635.30.
As curvas da disponibilidade para os casos em que os tempos de falha são modelados por distribuições
de Weibull são obtidas pela média de 5000 simulações e encontram-se apresentadas na Figura 5.3.
Da mesma forma, os erros relativos são calculados e a sua média apresentada na Tabela 5.2.
Figura 5.3 - Curvas de Disponibilidade para distribuições de Weibull

52
Tabela 5.2 - Erro das curvas de Disponibilidade
Modo Erro
StandBy 1.54%
Funcionamento 1.57%
Misto 4.65%
Outra parte importante de se verificar na rede Petri implementada para o equipamento é a sua
capacidade de recuperar após uma falha. Esta verificação é feita através da comparação da
disponibilidade obtida por simulação com a disponibilidade assimptótica da equação ( 2.37 ).
A rede do componente simplifica-se para que as inspecções não tenham qualquer duração, o parâmetro
de forma da distribuição de Weibull tome o valor unitário, o equipamento esteja sempre em
funcionamento e que este não tenha falhas ao arranque. Impôs-se também que o tempo necessário
para a recuperação do equipamento siga uma distribuição exponencial.
Para esta simulação assumiu-se um tempo médio entre falhas igual a 5000h e um tempo médio para
reparações igual a 50h. Na Tabela 5.3, apresenta-se o valor da disponibilidade obtida por simulação,
o valor obtido pela equação ( 2.37 ) e a diferença relativa entre os dois. Para ignorar os efeitos
relacionados com o regime transiente verificado no início da simulação, visíveis na Figura 5.4,
ignoraram-se as primeiras 50 horas de simulação.
Tabela 5.3 – Valores obtidos para a disponibilidade assimptótica
Disponibilidade
Teórico 99.01%
Simulação 99.02%
Diferença 0.005%
Figura 5.4 – Disponibilidade do Equipamento com manutenções correctivas
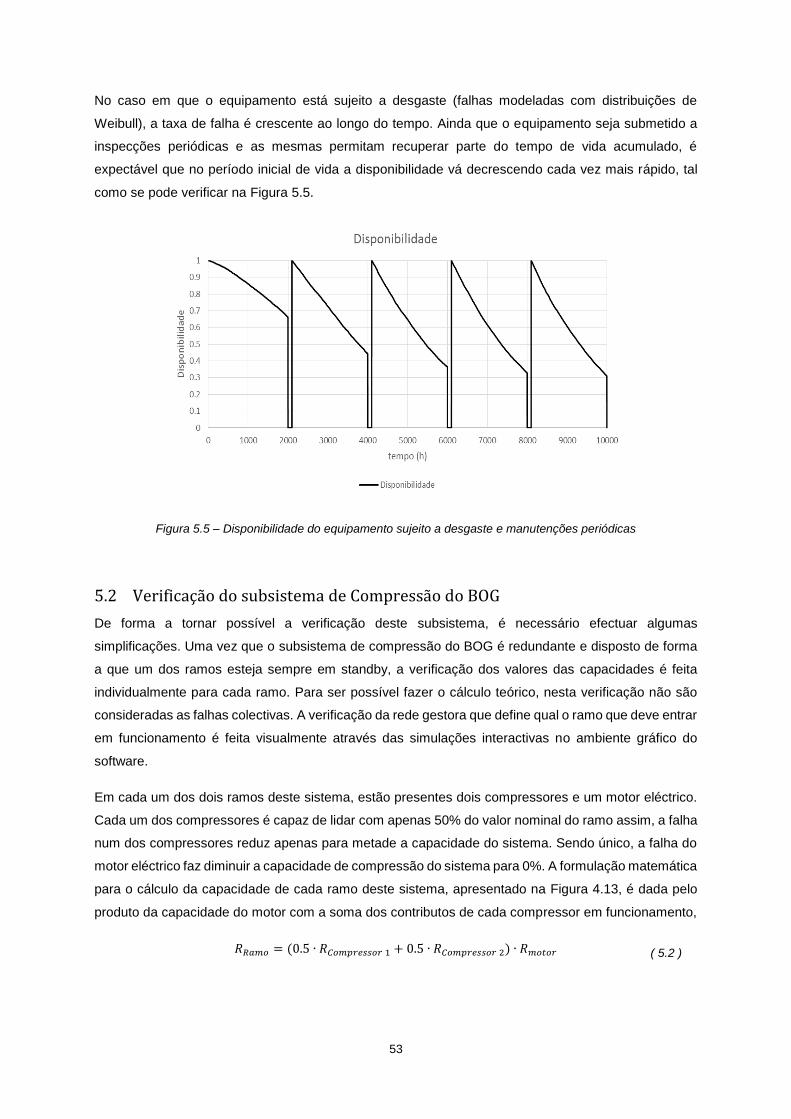
53
No caso em que o equipamento está sujeito a desgaste (falhas modeladas com distribuições de
Weibull), a taxa de falha é crescente ao longo do tempo. Ainda que o equipamento seja submetido a
inspecções periódicas e as mesmas permitam recuperar parte do tempo de vida acumulado, é
expectável que no período inicial de vida a disponibilidade vá decrescendo cada vez mais rápido, tal
como se pode verificar na Figura 5.5.
Figura 5.5 – Disponibilidade do equipamento sujeito a desgaste e manutenções periódicas
5.2 Verificação do subsistema de Compressão do BOG
De forma a tornar possível a verificação deste subsistema, é necessário efectuar algumas
simplificações. Uma vez que o subsistema de compressão do BOG é redundante e disposto de forma
a que um dos ramos esteja sempre em standby, a verificação dos valores das capacidades é feita
individualmente para cada ramo. Para ser possível fazer o cálculo teórico, nesta verificação não são
consideradas as falhas colectivas. A verificação da rede gestora que define qual o ramo que deve entrar
em funcionamento é feita visualmente através das simulações interactivas no ambiente gráfico do
software.
Em cada um dos dois ramos deste sistema, estão presentes dois compressores e um motor eléctrico.
Cada um dos compressores é capaz de lidar com apenas 50% do valor nominal do ramo assim, a falha
num dos compressores reduz apenas para metade a capacidade do sistema. Sendo único, a falha do
motor eléctrico faz diminuir a capacidade de compressão do sistema para 0%. A formulação matemática
para o cálculo da capacidade de cada ramo deste sistema, apresentado na Figura 4.13, é dada pelo
produto da capacidade do motor com a soma dos contributos de cada compressor em funcionamento,
𝑅𝑅𝑎𝑚𝑜 = (0.5 ∙ 𝑅𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑜𝑟 1 + 0.5 ∙ 𝑅𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑜𝑟 2) ∙ 𝑅𝑚𝑜𝑡𝑜𝑟 ( 5.2 )

54
Dado que os parâmetros que definem a fiabilidade de cada compressor são iguais, temos que:
𝑅𝑅𝑎𝑚𝑜 = 𝑅𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑜𝑟 ∙ 𝑅𝑚𝑜𝑡𝑜𝑟 ( 5.3 )
Os parâmetros usados, tanto para falhas modeladas por distribuições exponenciais como para Weibull
são apresentadas na Tabela 5.4.
Tabela 5.4 – Parâmetros das distribuições dos tempos de falha
Componente MTTF λ θ m
Compressor 4000.00 2.50E-04 4508.24 2.5
Motor 11764.71 8.50E-05 13259.54 2.5
As curvas para a disponibilidade do ramo quando as falhas foram definidas por distribuições
exponenciais, são apresentas na Figura 5.6. Tal como anteriormente, cada curva do gráfico à excepção
da curva teórica, é calculada com base em 5000 simulações. Os erros relativos médios de cada curva
são apresentados na Tabela 5.5.
Figura 5.6 - Curvas de Disponibilidade para distribuições exponenciais
Para os casos em que o tempo de vida dos equipamentos é determinado por uma distribuição de
Weibull, as curvas de disponibilidade são apresentadas na Figura 5.7. Os erros relativos médios de
cada curva são apresentados na Tabela 5.5.
Tabela 5.5 - Erro das curvas de Disponibilidade
Distribuição Ramo Erro
Exponencial Principal 2.81%
Secundário 2.81%
Weibull Principal 7.78%
Secundário 7.78%

55
Figura 5.7 - Curvas de Disponibilidade para distribuições de Weibull
Note-se que os erros obtidos para o ramo principal e secundário são iguais porque, apesar de
simulados em momentos diferentes, o programa usou os mesmos valores aleatórios dos tempos de
falha dos componentes.
Deve-se também reparar que no caso em que os equipamentos são modelados por distribuições de
Weibull, o erro médio é elevado. Na zona final das curvas onde o valor da disponibilidade é quase zero,
os erros relativos tomam valores elevados, influenciado negativamente a sua média. Caso se calcule o
erro médio apenas no intervalo [0-8000]h, o erro obtido para ambos os ramos seria de apenas 2.841%.
5.3 Verificação do subsistema de Compressão de N2
A abordagem para a verificação das redes do subsistema de compressão de N2 é exactamente a
mesma que a seguida na verificação do subsistema de compressão de BOG, apresentada na secção
anterior. Embora com mais equipamentos em cada ramo, a redundância continua a ser apenas dupla
e com apenas um dos ramos a operar de cada vez. O princípio de funcionamento e gestão do ramo
activo é exactamente o mesmo: o ramo operacional é sempre aquele com maior capacidade de
compressão.
Para satisfazer as necessidades do sistema, são instalados três compressores, um expansor e um
motor eléctrico em cada um dos ramos. Cada um dos compressores é capaz de lidar apenas com um
terço do valor nominal do ramo assim, reduzindo apenas para dois terços ou um terço caso falhe um
ou dois compressores, respectivamente. Sendo únicos, a falha do motor eléctrico ou do expansor reduz
para 0% a capacidade de compressão do sistema. A formulação matemática para o cálculo da
capacidade de cada ramo deste sistema, apresentado na Figura 4.14, é dada pelo produto da
capacidade do motor com a capacidade do expansor e com a soma dos contributos de cada
compressor em funcionamento,
𝑅𝑅𝑎𝑚𝑜 = (1
3𝑅𝐶1 +
1
3𝑅𝐶2 +
1
3𝑅𝐶3) ∙ 𝑅𝐸𝑥𝑝𝑎𝑛𝑠𝑜𝑟 ∙ 𝑅𝑚𝑜𝑡𝑜𝑟 ( 5.4 )

56
Dado que os parâmetros que definem a fiabilidade de cada compressor são iguais, temos que:
𝑅𝑅𝑎𝑚𝑜 = 𝑅𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑜𝑟 ∙ 𝑅𝐸𝑥𝑝𝑎𝑛𝑠𝑜𝑟 ∙ 𝑅_𝑚𝑜𝑡𝑜𝑟 ( 5.5 )
Os parâmetros usados, tanto para falhas modeladas por distribuições exponenciais como para Weibull
são apresentadas na Tabela 5.6.
Tabela 5.6 - Parâmetros das distribuições dos tempos de falha
Componente MTTF λ θ m
Compressor 3333.33 3.00E-04 3756.87 2.5
Expansor 10000.00 1.00E-04 11270.60 2.5
Motor 11764.71 8.50E-05 13259.54 2.5
As curvas para a disponibilidade do ramo quando as falhas foram definidas por distribuições
exponenciais, são apresentas na Figura 5.6. Tal como anteriormente, cada curva do gráfico à excepção
da curva teórica, é calculada com base em 5000 simulações. Os erros relativos médios de cada curva
são apresentados na Tabela 5.7.
Figura 5.8 - Curvas de Disponibilidade para distribuições expoenciais
Para os casos em que o tempo de vida dos equipamentos é determinado por uma distribuição de
Weibull, as curvas de disponibilidade são apresentadas na Figura 5.9. Os erros relativos médios de
cada curva são apresentados na Tabela 5.7.
Tabela 5.7 - Erro das curvas de Disponibilidade
Distribuição Ramo Erro
Exponencial Principal 2.57%
Secundário 2.57%
Weibull Principal 21.38%
Secundário 21.38%

57
Figura 5.9 - Curvas de Disponibilidade para distribuições de Weibull
Apesar de graficamente as curvas obtidas estarem muito próximas da curva teórica e ser praticamente
impossível distingui-las, o erro é superior a 20% quando os tempos de falha são modelados por
distribuições de Weibull. Apesar de elevado, a magnitude deste erro não é preocupante porque é
largamente influenciado pelos erros obtidos na zona final da curva, onde os valores da disponibilidade
são praticamente zero. Caso esta última região seja ignorada e se calcule o erro apenas para o intervalo
[0-7000]h, obtém-se um valor muito inferior igual a 2.192%.
5.4 Verificação do Sistema em série
Após a verificação individual dos componentes e subsistemas, é necessário verificar se a rede Petri
funciona correctamente e se a comunicação e interacção entre os equipamentos representados por
blocos estocásticos é feita correctamente. É também interessante perceber como os erros de cada
componente evoluem e influenciam o resultado final da capacidade do sistema.
O sistema em série aqui verificado é o sistema apresentado na Figura 4.12. Os parâmetros que
caracterizam as distribuições dos tempos de falha são apresentados na Tabela 5.8.
Tabela 5.8 – Parâmetros caracterizadores das distribuições
Componente MTTF λ θ m
Compressor BOG 4000 2.50E-04 4000 1.0
Compressor N2 3333 3.00E-04 3333 1.0
Expansor 10000 1.00E-04 10000 1.0
Motor 11765 8.50E-05 11765 1.0
ColdBox 50000 2.00E-05 50000 1.0
LNG Separator 28571 3.50E-05 28571 1.0
Bomba 13333 7.50E-05 13333 1.0
Reservatório 16667 6.00E-05 16666 1.0

58
De forma a verificar que o modelo aceita os dois tipos de distribuição para os modos de falha, foram
introduzidos os parâmetros da distribuição de Weibull (com m=1.0) e os resultados obtidos foram
comparados com o valor teórico calculado pelas equações da distribuição exponencial. Assim, fica
verificado que o modelo aceita ambas as distribuições, sendo necessário apenas alterar o parâmetro
m.
Da equação ( 2.25 ), temos que a fiabilidade de um certo sistema com n componentes em série é dado
pelo piatório das fiabilidades de cada componente.
𝑅𝑠 = 𝑃(𝑥1) × 𝑃(𝑥2) × … × 𝑃(𝑥𝑛) = ∏ 𝑅𝑖
𝑛
𝑖=1
( 2.25 )
Caso a fiabilidade siga uma distribuição exponencial, a equação ( 2.25 ) toma a forma
𝑅𝑆 = 𝑒−𝜆1𝑡 × 𝑒−𝜆2𝑡 × ⋯ × 𝑒−𝜆𝑛𝑡 ( 5.6 )
Relembrando as regras do logaritmo (Campos Ferreira, 2008), é possível simplificar a equação acima
apresentada para
𝑅𝑆 = exp (−𝑡 ∑ 𝜆𝑖
𝑛
𝑖=1
) ( 5.7 )
Em que o termo apresentado de seguida pode ser visto como uma taxa de falha equivalente.
𝜆𝑒𝑞 = ∑ 𝜆𝑖
𝑛
𝑖=1
( 5.8 )
A comparação gráfica dos valores obtidos pela simulação do sistema e pela equação ( 5.7 ) pode ser
vista na Figura 5.10. Visualmente, encontram-se erros absolutos máximos de 2.5% no seio da curva,
perto das 2000h de funcionamento. O erro médio relativo entre o valor da simulação e o teórico para o
intervalo apresentado na Figura 5.10 é de 24.263%. Este valor mostra que mesmo que se verifiquem
pequenas diferenças nos valores dos componentes individuais (entre 0.159% e 1.412%), os erros
globais do sistema podem ser elevados. No entanto, este erro relativo elevado é influenciado na maior
parte pelos erros verificados no fim do intervalo estudado e a sua magnitude não é preocupante pois
nas simulações do caso real, nunca nenhum equipamento será submetido a um intervalo tão longo sem
qualquer acesso a reparações. O intervalo máximo sem reparações, no caso do sistema de
reliquefacção, nunca será superior a 1000h e nesse domínio, o erro verificado é de apenas 2.085%.

59
Figura 5.10 – Curva de Disponibilidade do Sistema
5.5 Verificação do Sistema sujeito a Manutenções Periódicas
Grande parte do interesse desta tese está relacionada com a forma como as inspecções podem
influenciar a disponibilidade do sistema. Para os casos em que as tarefas de manutenção apenas são
feitas de forma periódica, a curva da disponibilidade toma a forma dos dentes de uma serra (Figura
2.5).
Para o caso de um sistema sujeito a manutenções periódicas ideal, em que as actividades de inspecção
e reparação não tomam qualquer tempo, é possível o cálculo da disponibilidade do sistema. Nesta
secção, é então feita a simulação do caso em que um sistema é submetido apenas a intervenções
periódicas perfeitas e o resultado comparado com os valores calculados pelas equações ( 2.41 ) e (
2.42 ).
O sistema escolhido para esta verificação é o sistema de reliquefação de gás natural sem qualquer
redundância. Os resultados obtidos para este sistema permitem validar ambos os modelos pois a forma
como os protótipos são integrados em cada um dos sistemas é igual.
O valor da disponibilidade deste sistema obtido pelas equações ( 2.41 ) e ( 2.42 ) e através de simulação
é apresentado na Tabela 5.9. Na terceira coluna apresentam-se as diferenças relativas para o valor
teórico. Note-se que para o valor obtido através da equação ( 2.42 ) é elevado apenas porque o
prossuposto 𝜆𝑇𝑜 ≪ 1 não acontece. Pela equação ( 5.8 ), 𝜆𝑒𝑞 = 1.01 ∙ 10−3. Com um tempo entre
inspecções, 𝑇𝑜 , igual a 1000h, o produto 𝜆𝑇𝑜 é praticamente um, invalidando o uso dessa fórmula.

60
Tabela 5.9 – Disponibilidade e erros do sistema
Disponibilidade Erro
Eq. ( 2.41 ) 0.63 (val. Teórico)
Eq. ( 2.42 ) 0.50 21.36%
Simulação 0.64 1.60%
O gráfico da disponibilidade obtido por simulação é apresentado na Figura 5.11. A semelhança da
Figura 2.5 com a Figura 5.11, juntamente com o erro de apenas 1.60%, garante que a dinâmica de
inspecções periódicas está bem modelada nas redes Petri.
Figura 5.11 – Disponibilidade do Sistema sujeito a intervenções periódicas
Para o caso em que o tempo de inspecção não é desprezável e assumindo que durante essa
intervenção a disponibilidade do sistema é nula, a curva de disponibilidade do sistema toma a forma
apresentada na Figura 5.12. A forma de avaliar e verificar se a mesma representa bem o que se
pretendia não pode ser através da fórmula ( 2.43 ) por não cumprir as suas premissas, tal como
acontecia no caso anterior. Ainda assim, considerando que cada inspecção é perfeita (semelhante à
substituição do equipamento por um novo), é possível comparar o valor obtido da simulação com um
valor teórico dado por:
𝐴(𝑡) = {𝑅(𝑡 − 𝑁𝑇0) , 𝑁𝑇𝑜 ≤ 𝑡 ≤ (𝑁 + 1)𝑇0 − 𝑡𝑡
0 , 𝑁𝑇0 − 𝑡𝑡 ≤ 𝑡 ≤ 𝑁𝑇0 ( 5.9 )
Em que 𝑡𝑡 representa o tempo que cada inspecção toma, N o número de inspecções feitas até ao
instante t e T0 o intervalo entre o início de cada intervenção.
Da forma apresentada pela equação ( 5.9 ), o erro relativo médio da disponibilidade entre cada
inspecção é de 1.50%. Com este pequeno erro e com a forma da curva a assumir o esperado, verifica-

61
se que as redes Petri implementadas são capazes de representar com sucesso as actividades de
manutenção com tempos de inspecção não desprezáveis.
Figura 5.12 - Disponibilidade do Sistema sujeito a intervenções periódicas
5.6 Verificação do sistema de reliquefação por Kwang et al., (2008)
Até ao momento, apenas foi possível verificar algumas das características de cada equipamento e do
sistema simplificado. A consideração de modos de falha e reparação colectiva, alteração do ramo em
funcionamento de forma a maximizar a capacidade do sistema, disponibilidade de equipas e duração
da viagem impossibilitam a obtenção de resultados apenas com as equações usadas até ao momento.
Para estes casos em que os sistemas estudados são complexos e a comparação com valores teóricos
não é possível, é comum recorrer-se a estudos semelhantes e depois proceder à comparação dos
resultados.
Kwang et al., (2008) realizaram um estudo da fiabilidade e capacidade do sistema de reliquefação
apresentado nesta dissertação usando cadeias de Markov. Mesmo que a forma de modelar o sistema
não seja a mesma, os resultados devem ser semelhantes já que se tentou modelar o sistema de forma
a ter um comportamento semelhante ao modelado por Kwang et al., (2008), que por sua vez tentou
simular a realidade de forma mais fiel possível.
No sistema estudado por Kwang et al., (2008), o navio LNG navega durante 28 dias, 14 na viagem
entre o porto de origem e o porto de destino e os restantes 14 na viagem de regresso. Nesse mesmo
estudo assume-se que na viagem de regresso, geralmente em lastro, um terço da capacidade nominal
de liquefação é suficiente para suprir com as necessidades no regresso ao porto de origem.
Quatro opções diferentes para a disposição das redundâncias dos equipamentos, apresentados na
secção 4.2 - Reliquefação de BOG a bordo de um LNG - são estudados. Cada uma das possíveis
configurações de redundância é avaliada para o caso em que existem sempre equipas prontas para

62
efectuar uma tarefa de manutenção e para o caso em que apenas existem equipas disponíveis no porto
de origem. Esta combinação de possibilidades resulta em oito casos diferentes que devem ser
simulados e os resultados devem ser comparados com os obtidos por Kwang et al., (2008).
Como indicado anteriormente, o sistema de Kwang et al., (2008) foi modelado com cadeias de Markov,
consequentemente as transições entre estados apenas podem ser descritas por distribuições
exponenciais. Os parâmetros usados nessas transições, nomeadamente as taxas de falha e reparação,
são apresentados na Tabela 5.10.
Tabela 5.10 – Taxas de transição
Taxa (por hora) Comentários
λG,1 2.50E-04 Taxa de falha de um compressor BOG (individual)
λG,A 8.50E-05 Taxa de falha de todos os compressores BOG (colectivo)
λG,E 8.50E-05 Taxa de falha do motor dos compressores de BOG
µG 3.00E-02 Taxa de reparação de compressores de BOG (colectivo)
µG,1 4.00E-02 Taxa de reparação de um compressor BOG (individual)
µG,E 2.11E-02 Taxa de reparação do motor dos compressores de BOG
γG 4.00E+00 Taxa para o arranque do ramo de compressão BOG em standby
λN,1 3.00E-04 Taxa de falha de um compressor N2 (individual)
λN,A 1.00E-04 Taxa de falha de todos os compressores N2 (colectivo)
λN,Ex 1.00E-04 Taxa de falha do expansor de N2
λN,E 8.50E-05 Taxa de falha do motor dos compressores de N2
µN 3.50E-02 Taxa de reparação de compressores de N2 (colectivo)
µN,1 4.00E-02 Taxa de reparação de um compressor N2 (individual)
µN,Ex 3.00E-02 Taxa de reparação do expansor
µN,E 2.11E-02 Taxa de reparação do motor dos compressores de N2
γN 4.00E+00 Taxa para o arranque do ramo de compressão N2 em standby
λHE 2.00E-05 Taxa de falha da caixa de permutação de calor
µHE 5.50E-02 Taxa de reparação da caixa de permutação de calor
λSep 3.50E-05 Taxa de falha do separador
µSep 2.00E-01 Taxa de reparação do separador
λRP 7.50E-05 Taxa de falha da bomba
µRP 2.00E-01 Taxa de reparação da bomba
λNT 6.00E-05 Taxa de falha do Reservatório de N2
µNT 2.00E-01 Taxa de reparação do Reservatório de N2
Com as transições modeladas de forma a seguirem distribuições exponenciais, foram simulados os oito
casos. O número de simulações feitas para cada caso é de 5000, número discutido na secção 4.3,
obtendo-se uma curva contínua em que o desvio padrão e intervalos de confiança obtidos para a média
são pequenos.

63
5.6.1 Reparações apenas no porto de origem
Primeiramente serão apresentados e discutidos os valores obtidos para os casos em que não é possível
realizar qualquer actividade de reparação a bordo do navio. Neste caso, qualquer equipamento que
falhe, só poderá ser submetido a reparação no porto de origem. Como as reparações apenas são feitas
no porto de abrigo, local onde o navio não tem de reliquefazer BOG, o tempo aqui despendido não irá
influenciar de qualquer forma a quantidade de BOG queimada. Assim, para o cálculo da disponibilidade
média do sistema, interessa apenas saber o tempo em que o navio se encontra a navegar e com o
sistema em falha. Dessa forma, as reparações são realizadas de 28 em 28 dias (reparações periódicas)
e as mesmas não têm qualquer duração. Como neste estudo as falhas dos equipamentos são
modelados por uma distribuição exponencial, os equipamentos não são sujeitos ao desgaste e seria
suficiente a simulação de uma viagem, já que a disponibilidade irá ser sempre igual, quer trate-se da
primeira ou da centésima viagem. Ainda assim, a duração da simulação é de 8736h (364 dias),
englobando 13 viagens completas para se poder verificar graficamente a periodicidade da
disponibilidade.
Sempre que o navio retorna ao porto de origem, 28 dias (672h) após a sua partida, o sistema volta a
ter uma capacidade de 100% pois todos os equipamentos que falharam ao longo da viagem podem ser
reparados. Esta periodicidade e recuperação da capacidade pode ser vista na Figura 5.13.Para além
das reparações feitas nos equipamentos que se encontram em falha, todos os outros são submetidos
a uma inspecção de carácter preventivo.
A média da curva apresentada nos gráficos apenas seria a capacidade média do sistema caso a
necessidade de reliquefação fosse igual tanto na viagem de ida como na de regresso. Como isso não
acontece e aquilo que se exige do sistema na viagem de regresso é inferior a um terço da capacidade
nominal do sistema, apenas devem entrar para a média os valores da disponibilidade da viagem de ida
– intervalo [𝑁 − 336𝑁]h – e valores abaixo de um terço na viagem de regresso – intervalo
[336𝑁 − 672𝑁]h, em que N representa o número da viagem. No entanto, como se pode constatar por
observação das figuras, a capacidade do sistema é sempre superior a um terço. Desta forma, nas
viagens entre o porto de destino e o porto de origem, não se espera que haja queima de BOG pois a
capacidade de reliquefação do sistema é sempre superior ao requerido. Assim, para o cálculo da
percentagem de BOG queimado durante toda a viagem, basta que seja feita a média da disponibilidade
na viagem entre o porto de origem e o porto de destino.

64
Figura 5.13 – Disponibilidade para os casos em que as reparações apenas são possíveis no porto de origem
5.6.2 Reparações disponíveis a bordo
O trato de sistemas complexos e que podem colocar em causa a integridade do navio pode justificar a
presença de uma equipa de manutenção especializada a bordo. A escolha de se ter a bordo uma equipa
técnica capaz de lidar com qualquer componente do sistema deve ser tomada com base na
comparação dos custos relacionados com a indisponibilidade do sistema e com as despesas
associadas à equipa de manutenção. Assim, é importante conhecer-se o valor da indisponibilidade do
sistema durante a viagem nessas condições, valor esse que é apresentado nesta subsecção.
Neste estudo, assume-se que existem sempre equipas disponíveis para efectuar qualquer tarefa de
reparação. Uma vez que as falhas dos equipamentos são modelados por distribuições exponenciais,
que por sua vez não contam com o desgaste, a sua reparação é perfeita e o equipamento volta a estar
numa condição igual a novo. Os tempos de reparação também seguem distribuições exponenciais e
os seus parâmetros podem ser vistos na Tabela 5.10. Nesta simulação os equipamentos apenas são
submetidos a manutenção quando ocorre uma falha, não havendo qualquer tipo de intervenção
periódica.
Este estudo assemelha-se ao estudo da disponibilidade de um equipamento sujeito a falhas e
reparações que seguem distribuições exponenciais e espera-se que o comportamento verificado seja
igual ao apresentado anteriormente na Figura 5.4. Para ignorar os valores iniciais e considerar apenas
aqueles que já convergiram para o valor da disponibilidade médio, as simulações foram feitas para o
intervalo [20160 − 28896]h. Desta forma, apenas os dados estacionários são contabilizados na média
da disponibilidade e a zona de regime transiente inicial é ignorada.

65
Os gráficos da disponibilidade obtidos para os diferentes quatro casos de redundâncias são
apresentados na Figura 5.14.
Figura 5.14 - Disponibilidade para os casos em que as reparações são sempre possíveis
5.6.3 Verificação através dos resultados obtidos
Os valores da disponibilidade obtidos por simulação do modelo implementado são compilados,
apresentados e discutidos nesta secção.
Para além da estimativa pontual para o valor da disponibilidade, é fundamental complementá-lo com
um intervalo que transmita uma ideia da confiança que se pode ter na estimativa pontual. Este intervalo
é, de um modo geral, denominado de intervalo de intervalo de confiança, (Cabral Morais, 2009).
O cálculo do intervalo de confiança é feito com base na equação seguinte,
𝐼𝐶(1−𝛼)×100%(�̅�) = [�̅� − Φ−1 (1 −𝛼
2) ×
𝜎
√𝑛 , �̅� + Φ−1 (1 −
𝛼
2) ×
𝜎
√𝑛] ( 5.10 )
Em que n representa o número de simulações efectuadas e σ o desvio padrão.
Para um grau de confiança associado igual a 90%, α toma o valor 0.1 e a equação ( 5.10 ) reduz-se a:
𝐼𝐶90%(�̅�) = [�̅� − 1.64485 ×𝜎
√𝑛 , �̅� + 1.64485 ×
𝜎
√𝑛] ( 5.11 )
Os resultados para o caso em que as reparações apenas são feitas no porto de origem é apresentado
na Tabela 5.11.

66
Tabela 5.11 – Resultados para os casos em que as reparações apenas são possíveis no porto de origem
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 17.30% 12.17% 10.22% 4.34%
σ 0.0789 0.0757 0.0714 0.0585
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 17.11% 12.00% 10.05% 4.21%
IC superior 17.48% 12.35% 10.38% 4.48%
Como se pode constatar, o número de simulações usado, tanto permite aproximar bem as curvas da
simulação às curvas teóricas (secção 4.3 - Eficiência e precisão do processo de simulação) como
permite também ter uma faixa para os intervalos de confiança bastante estreita.
Tanto a opção 2 como a Opção 3 têm apenas um subsistema redundante, compressão de BOG ou
compressão de N2, respectivamente. Mas porque o subsistema de compressão de N2 é constituído
por mais equipamentos do que o de compressão de BOG, é natural que quando este é tornado
redundante (Opção 3), os benefícios para a disponibilidade geral do sistema sejam maiores e contribua
para uma maior diminuição da quantidade de BOG queimada.
No caso em que existem sempre meios a bordo que permitam uma intervenção directa nos
equipamentos em falha, a quantidade de BOG queimada toma os valores da Tabela 5.12.
Tabela 5.12 - Resultados para os casos em que as reparações são sempre possíveis
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 3.08% 1.94% 1.39% 0.17%
σ 0.0072 0.0056 0.0047 0.0010
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 3.07% 1.92% 1.37% 0.17%
IC superior 3.10% 1.95% 1.40% 0.18%
Novamente, a mesma tendência decrescente verifica-se ao longo das quatro opções estudadas.
Os valores obtidos no estudo realizado por Kwang et al., (2008) são apresentados na Tabela 5.13.
Tabela 5.13 – Previsão de BOG queimado segundo estudo de Kwang et al., (2008)
Opção 1 Opção 2 Opção 3 Opção 4
Reparação apenas no porto de origem
19.00% 15.00% 12.00% 6.00%
Reparação Sempre Possível 2.10% 1.30% 1.00% 0.20%
Como se pode constatar numa comparação da Tabela 5.11, Tabela 5.12 e Tabela 5.13, nota-se à
primeira vista que os valores possuem todos a mesma ordem de grandeza e seguem as mesmas
tendências. Apesar disso, existem algumas diferenças entre os valores obtidos nos dois estudos. No

67
caso em que as reparações apenas são possíveis no porto de origem, os valores obtidos por simulação
para a disponibilidade são superiores ao do estudo usado para referência. Assim, os valores obtidos
pela simulação são um pouco mais optimistas já que a diferença revela-se numa diminuição da
quantidade de BOG queimado. Por outro lado, nos casos em que as reparações são sempre possíveis,
os resultados obtidos indicam que as queimas serão superiores ao anunciado por Kwang et al., (2008).
Este comportamento nas diferenças entre os dois estudos e a não presença dos resultados de
referência dentro do intervalo de confiança obtido, levam a crer que existem pequenos desvios em
alguns dos conceitos relacionados com a reparação e que possam não estar explicitados no estudo
usado para comparação. Contudo, os resultados obtidos são coerentes, seguem as formas esperadas
e conclui-se que o sistema composto pelos componentes individuais e pelos subsistemas de
compressão de BOG e de N2 está bem modelados e isento de erros.

68
6 Estudo da Disponibilidade dos sistemas
Após a verificação dos sistemas e dos componentes, é possível aproximar os sistemas à realidade e
obter os resultados pretendidos. Neste capítulo, ambos os sistemas são estudados e o efeito de
algumas políticas de manutenção são estudadas.
No primeiro sistema estudado – sistema de combate a incêndios - é dada atenção à periodicidade das
actividades de inspecção já que é a única forma de descobrir falhas num sistema que se encontra em
regime de standby na maior parte do seu tempo. Consoante a idade do componente, o mesmo pode
ser submetido a uma manutenção oportunista de forma a recuperar parte do seu tempo de vida.
No segundo caso – sistema de reliquefação de gás natural – estuda-se a influência que as políticas de
manutenção periódicas e as manutenções correctivas têm sobre a disponibilidade do sistema. Estuda-
se também a influência que a escolha de distribuições exponenciais ou distribuições de weibull podem
ter na disponibilidade do sistema. Ambos os estudos são feitos para quatro níveis diferentes de
redundâncias.
6.1 Sistema de Combate a Incêndios
O sistema de combate a incêndios, apresentado na Figura 4.1, é composto por dez válvulas, três
bombas e um motor eléctrico necessário para o funcionamento da bomba. Todos os outros
componentes do sistema – misturador, encanamentos, bilge well e tanque de espuma – são
considerados perfeitos e isentos de falhas críticas que ponham em causa o funcionamento do sistema
tendo portanto uma disponibilidade de 100% em todo o domínio das simulações.
O modelo utilizado nas simulações é o apresentado na secção 4.1. Para se ter em conta o desgaste
dos equipamentos, os tempos de falha dos equipamentos foram modelados de forma a seguirem
distribuições de Weibull.
Os tempos médios de falha em funcionamento, reparação, probabilidade de falha ao arranque foram
obtidos através da base de dados OREDA, (2002). Os tempos médios de falha em standby foram
extrapolados com base na equação ( 2.12 ) tendo como input os valores disponibilizados em OREDA,
(2002). Todos os parâmetros utilizados podem ser vistos na Tabela 6.1.
Relembra-se que o factor AgeFactor é um factor de correcção de forma a que o tempo em standby não
tenha o mesmo peso que o tempo em funcionamento sobre o desgaste do equipamento - equação (
4.1 ).

69
Tabela 6.1 – Parâmetros utilizados na simulação
Válvulas Bombas Motor
Eléctrico
Factor de forma Funcionamento 2.5 2.5 2.5
Factor de forma em Standby 2.5 2.5 2.5
Factor q 0.70 0.70 0.70
Factor p 0.80 0.80 0.80
Taxa de reparação 1.52 0.452 0.45
MTTF Funcionamento (dias) 3750.38 637.11 2147.77
MTTF Standby (dias) 37485.42 3732.80 14604.41
Probabilidade de falha ao Arranque 0.005 0.005 0.003
AgeFactor 0.10 0.17 0.15
A disponibilidade é estudada para os 30 primeiros anos de vida do navio. Considera-se que sempre
que há uma reparação (intervenção activa no equipamento), o tempo de vida do equipamento é
reduzido em 70%. Modelou-se também o sistema para que sempre que o tempo de vida acumulado de
um determinado equipamento for superior a 80% do MTTF em funcionamento, o mesmo será
substituído por um novo equipamento.
O tempo despendido em cada equipamento em tarefas de inspecção é de 6 horas e engloba o tempo
necessário de mobilização da equipa e testes ao funcionamento do componente. Se o equipamento
estiver operacional, não é feita mais nenhuma intervenção e o tempo de vida do equipamento não sofre
qualquer alteração. No entanto, caso este esteja danificado, a equipa que se encontrar no local inicia
a reparação e o tempo necessário para essa tarefa segue uma distribuição exponencial. O tempo
necessário para a troca de um componente também segue uma distribuição exponencial de parâmetro
igual à reparação.
Quatro intervalos diferentes para a periodicidade das manutenções são estudadas:
a) Primeira inspecção: realizada ao fim de três anos. Inspecções seguintes: de dois em dois anos;
b) Primeira inspecção: realizada ao fim de dois anos. Inspecções seguintes: uma vez a cada ano;
c) Primeira inspecção: realizada ao fim de um ano. Inspecções seguintes: uma vez a cada seis
meses;
d) Inspecção feita a cada quadrimestre.
Os standards ANSI/ISA S84.01 e IEC 61508 sugerem que os efeitos de falhas aleatórios sejam
avaliados de uma forma quantitativa utilizando níveis de segurança SIL – Safety Integrity Levels. Os
SIL são uma representação estatística da disponibilidade de um sistema de instrumentação (Bureau
Veritas, 2010). Não obstante de ser uma medida criada para sistemas de instrumentação, estes níveis
podem ser usados como referência em sistemas mecânicos. Existem quatro níveis SIL onde SIL 4 é o
nível mais alto e SIL 1 corresponde ao nível mais baixo.

70
Estes níveis derivam directamente da indisponibilidade (QS) do sistema através da seguinte equação
(Dutuit et al., 2008):
10−(𝐿+1) ≤ 𝑄𝑆(𝑡) < 10−𝐿 ( 6.1 )
Em que L é o número que identifica o nível. Estes níveis podem ser vistos como faixas no gráfico da
indisponibilidade e permitem saber quanto tempo ou com que frequência a curva da indisponibilidade
está nessa faixa.
Os resultados gráficos da disponibilidade a cada instante para os quatro casos é apresentada na Figura
6.1.
Figura 6.1 – Disponibilidade do Sistema de Combate a Incêndios
A informação gráfica mostra a periodicidade das intervenções de manutenção. Quanto menor o
intervalo entre estas intervenções, menor o tempo em que o sistema está indisponível e por isso maior
a disponibilidade média.
Para além da periodicidade, é possível ver que os equipamentos estão sujeitos a desgaste uma vez
que para intervalos de tempo iguais, a disponibilidade do sistema decresce mais rapidamente. A razão
das quedas abruptas na disponibilidade nos momentos das intervenções deve-se à indisponibilidade
do sistema durante as mesmas.
Os valores da disponibilidade média, ao longo de 30 anos, é apresentada na Tabela 6.2 assim como
os níveis SIL em que o sistema passa a maior parte do tempo.

71
Tabela 6.2 – Disponibilidade e SIL do Sistema de Combate a Incêndios
Caso1 Caso2 Caso3 Caso4
Disponibilidade 92.74% 96.28% 98.03% 98.75%
SIL
<1 29.22% 1.74% 0.26% 0.37%
1 57.72% 79.08% 64.82% 41.60%
2 9.94% 17.25% 31.01% 52.61%
>2 3.12% 1.93% 3.91% 5.42%
Olhando apenas para o valor da disponibilidade do sistema, é claro que o melhor cenário entre os
quatro estudados é a calendarização de actividades de inspecção a cada 3 meses (caso 4). No entanto,
é necessário encontrar um equilíbrio entre o valor da disponibilidade e os custos associados para se
manter esse nível.
Não se tendo informação acerca do custo da manutenção de um sistema deste tipo, não é possível
fazer uma optimização da regularidade das inspecções. No entanto, podem-se deixar outros
parâmetros obtidos através da simulação e que influenciariam o estudo da calendarização: número de
inspecções e quantidade de equipamentos substituídos. Esses parâmetros são apresentados na
Tabela 6.3.
Tabela 6.3 – Número de intervenções e de equipamentos substituídos
Caso1 Caso2 Caso3 Caso4
Número de intervenções 14 28 58 120
Bombas 6.36 6.60 7.03 7.27
Motor Eléctrico 0.00 0.00 0.00 0.00
Válvulas 0.00 0.00 0.00 0.00
O número crescente do número de intervenções é natural pois o intervalo de tempo entre eles é menor
e por isso, para o mesmo tempo de estudo, mais inspecções são feitas. No entanto, também se verifica
uma tendência crescente no número de bombas substituídas. Este acontecimento está relacionado
com o facto de o tempo de vida de um componente tender para um valor mais elevado quando este é
submetido a mais intervenções. Este fenómeno será estudado mais adiante. O facto de não haver
qualquer motor eléctrico ou válvula substituída está relacionado com o elevado MTTF em Standby. O
tempo de vida destes equipamentos nunca chegam a atingir os 80% do seu MTTF no domínio da
simulação, condição necessária para a sua substituição.
6.2 Sistema de reliquefação de BOG
O sistema de reliquefação de BOG, apresentado na Figura 4.11, tem como base 12 componentes
diferentes. Dependendo do nível de redundância implementado, pode atingir 20 componentes. Em
relação ao modelo apresentado anteriormente na secção 4.2 e verificado no capítulo anterior,

72
apresenta-se primeiramente a influência que as falhas em standby têm sobre o valor da disponibilidade
do sistema. Será também exposta a forma como a escolha das distribuições para os tempos de falha
podem influenciar o resultado. Com estas alterações, é possível aproximar o modelo apresentado no
capítulo anterior e proposto por Kwang et al., (2008) ao caso real e perceber qual a importância da
modelação destas características.
São sempre feitas simulações para as quatro opções de redundância e para cada uma das políticas de
manutenção apresentadas:
1) Reparações periódicas feitas apenas no porto de origem. Todos os equipamentos em falha são
reparados e os restantes são submetidos a uma inspecção de carácter preventivo. Apenas os
equipamentos sujeitos a reparação sofrem uma redução no tempo de vida acumulado.
2) Reparações sempre possíveis a bordo. A reparação de qualquer equipamento é feita assim
que se toma conhecimento da falha, existindo a bordo todos os meios necessários à reparação.
Apenas manutenções correctivas são feitas nesta opção.
A lista de parâmetros utilizados na caracterização deste sistema é extensa e é apresenta na Tabela
6.4.
Tabela 6.4 – Parâmetros caracterizadores do sistema de reliquefação de BOG
Permutador
Calor Compressor
BOG Compressor
N2 Motor
Eléctrico
Factor de forma Funcionamento 2.5 2.5 2.5 2.5
Factor de forma em Standby 2.5 2.5 2.5 2.5
Factor p 0.8 0.8 0.8 0.8
Factor q 0.3 0.3 0.3 0.3
Factor q na inspecção 0 0 0 0
Taxa de reparação (h-1) 0.055 0.040 0.040 0.021
MTTF Funcionamento (h) 50000.00 4000.00 3333.33 11764.71
MTTF Standby (h) 770176.90 17690.26 14741.89 113071.08
Probabilidade de falha ao Arranque 0 0 0 0
Age Factor 0.065 0.226 0.226 0.104
Expansor Separador Reservatório Bomba
Factor de forma Funcionamento 2.5 2.5 2.5 2.5
Factor de forma em Standby 2.5 2.5 2.5 2.5
Factor p 0.8 0.8 0.8 0.8
Factor q na reparação 0.3 0.3 0.3 0.3
Factor q na inspecção 0 0 0 0
Taxa de reparação (h-1) 0.030 0.200 0.200 0.200
MTTF Funcionamento (h) 10000.00 28571.43 16666.67 13333.33
MTTF Standby (h) 79184.83 142857.14 16666.67 78116.69
Probabilidade de falha ao Arranque 0 0 0 0
Age Factor 0.126 0.200 1.000 0.171

73
6.2.1 Sistema com falhas em Standby
Nesta secção, apenas são adicionados os modos de falha em standby nos diversos equipamentos. No
restante, o sistema é exactamente igual ao apresentado na verificação feita por comparação ao estudo
de Kwang et al., (2008). Uma vez que este sistema está em constante operação, os resultados após a
implementação das falhas em standby não deverá ser muito diferente dos obtidos na secção de
verificação - 5.6 - pois apenas os componentes redundantes poderão estar sujeitos a este modo de
falha.
Neste momento, as falhas em standby e em funcionamento foram modeladas de forma a seguirem
distribuições exponencias e as suas taxas de falha são calculadas com base nos MTTF apresentados
na Tabela 6.4.
Os resultados estatísticos que resultam de 5000 simulações feitas para cada um dos casos, são
apresentados nas tabelas Tabela 6.5 e Tabela 6.6.
Tabela 6.5 – Resultados para os casos em que as reparações apenas são possíveis no porto de origem
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 17.10% 12.30% 10.22% 4.48%
std 0.0778 0.0761 0.0722 0.0572
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 16.92% 12.12% 10.05% 4.34%
IC superior 17.28% 12.48% 10.39% 4.61%
Tabela 6.6 – Resultados para os casos em que as reparações são sempre possíveis
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 3.11% 2.02% 1.48% 0.35%
σ 0.0072 0.0057 0.0048 0.0013
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 3.10% 2.01% 1.47% 0.35%
IC superior 3.13% 2.04% 1.49% 0.35%
No caso em que não existem redundâncias – opção 1 – a quantidade de BOG queimada deve ser igual
aos valores obtidos anteriormente e apresentados em Tabela 5.11 e Tabela 5.12 De facto, ainda que
os valores médios não sejam exactamente iguais, os valores podem ser considerados os mesmos pois
os intervalos de confiança sobrepõem-se, Figura 6.2 – Opção 1 e Figura 6.3 – Opção 1. Nos restantes
casos, verifica-se uma diminuição da disponibilidade e consequentemente um ligeiro aumento da
quantidade de BOG causado pelas falhas em standby. Os valores dos intervalos de confiança em
Tabela 5.11, Tabela 5.12, Tabela 6.5 e Tabela 6.6 são expostos na Figura 6.2 e Figura 6.3. A barra
de erros apresentada do lado direito de cada figura está associada ao intervalo de confiança dos
modelos com o modo de falhas em standby implementado e o da esquerda aos modelos discutidos na
secção 5.6 (sem falhas em standby).

74
Figura 6.2 – Intervalos de Confiança para a quantidade de BOG queimada para os casos em que as reparações são feitas no porto de origem
Figura 6.3– Intervalos de Confiança para a quantidade de BOG queimada para os casos em que as reparações são feitas a bordo

75
A distância entre as barras dos intervalos de confiança mostram a relevância da modelação das falhas
em standby: para cada opção, quanto maior o afastamento destas barras, maior a relevância desta
modelação.
Com o aumento do grau de redundância, existe um aumento do número de equipamentos em standby.
Este aumento leva a que a influência deste modo de falhas seja cada vez maior na disponibilidade do
sistema e portanto aumenta o interesse da modelação destas falhas. No caso em que as reparações
são feitas imediatamente a bordo do navio, as barras do intervalo de confiança estão afastadas uma
das outras, não havendo qualquer sobreposição nos casos onde há algum nível de redundância e isso
leva a crer que as falhas em standby devem ser consideradas. O maior afastamento das barras na
Figura 6.3 em relação às da Figura 6.2 está relacionada com regularidade com que são feitas
inspecções e consequente reparação de falhas ocultas nos equipamentos do sistema do navio sem
meios de reparação a bordo. Relembra-se que no caso em que o navio tem a bordo todas os meios de
reparação, os equipamentos não são sujeitos a inspecções e portanto as falhas ocultas só se revelam
quando se coloca o equipamento em funcionamento.
6.2.2 Sistema com falhas em standby e desgaste nos equipamentos
A modelação dos tempos de falha dos equipamentos com distribuições de Weibull permite introduzir o
desgaste dos equipamentos no modelo. Esta funcionalidade permite tornar o sistema ainda mais
próximo da realidade, já que todos os componentes mecânicos estão sujeito ao envelhecimento e a
taxa de falha é crescente com o avançar do tempo.
Os parâmetros que definem o comportamento do sistema são os apresentados na Tabela 6.4.
De forma a não se ter um valor dependente do tempo, as simulações foram feitas para o regime onde
a disponibilidade já estabilizou. Esta estabilização ocorre no momento em que os tempos de vida dos
equipamentos já tenderam para o seu limite e portanto já não se nota um desgaste mais rápido entre
ciclos consecutivos. Os resultados estatísticos que resultam de 5000 simulações feitas para cada um
dos casos, são apresentados nas tabelas Tabela 6.7 e Tabela 6.8.
Tabela 6.7 - Resultados para os casos em que as reparações apenas são possíveis no porto de origem
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 8.05% 5.10% 3.69% 0.37%
σ 0.0322 0.0265 0.0257 0.0095
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 7.97% 5.04% 3.63% 0.34%
IC superior 8.12% 5.16% 3.75% 0.39%

76
Tabela 6.8 - Resultados para os casos em que as reparações são sempre possíveis
Opção 1 Opção 2 Opção 3 Opção 4
BOG queimado 6.61% 4.31% 3.24% 0.86%
σ 0.0039 0.0032 0.0027 0.0009
n 5000 5000 5000 5000
IC 0.9 0.9 0.9 0.9
IC inferior 6.60% 4.30% 3.23% 0.86%
IC superior 6.62% 4.32% 3.25% 0.87%
A disponibilidade a cada instante pode ser vista nas figuras Figura 6.4 e Figura 6.5.
Figura 6.4 – Disponibilidade para s casos em que as reparações apenas são possíveis no porto de origem
A introdução de falhas dependentes do tempo de vida acumulado do equipamento leva a um fenómeno
interessante. Para o caso em que as reparações são feitas periodicamente no porto de origem, a
quantidade de BOG queimada diminui em relação às estimativas feitas quando as falhas são
modeladas por distribuições exponenciais. Para o caso em que as reparações são sempre possíveis a
bordo, a tendência verificada é exactamente a oposta e existe um aumento da quantidade de BOG
queimado quando as falhas são modeladas por distribuições de Weibull. Isto leva a que a distribuição
exponencial seja conservativa nos casos em que as inspecções são feitas periodicamente e a
subvalorizar a quantidade de BOG queimada quando as reparações iniciam-se imediatamente após a
falha dos equipamentos. Este fenómeno está directamente relacionado com o tempo de vida
acumulado dos equipamentos sujeitos a estas duas diferentes políticas de manutenção.

77
Figura 6.5 – Disponibilidade para os casos em que as reparações são sempre possíveis
Para estudar este acontecimento, foram criadas duas redes Petri auxiliares mais simples. Uma das
redes simula as inspecções periódicas de dois equipamentos, um dos quais tem a falha modelada por
uma distribuição exponencial e o outro por uma distribuição de Weibull, Figura 6.6. A segunda rede,
também composta por um equipamento sujeito a falhas que seguem uma distribuição exponencial e o
outro por distribuição de Weibull, pretende representar o caso em que existe uma mobilização imediata
à reparação, Figura 6.7.
Figura 6.6 – Representação equipamentos sujeitos a reparações periódicas
As duas redes principais relacionam o estado do equipamento com as transições de falha, reparação
ou aguardando reparação. A rede representada no canto superior direito faz a contagem do tempo de
vida do equipamento e a do canto inferior direito representa o calendário das manutenções periódicas.

78
Figura 6.7 – Representação equipamentos sujeitos a reparações imediatas
No caso em que os equipamentos começam a ser reparados imediatamente após a sua falha, a rede
de calendarização deixa de ser necessária e pode ser retirada da rede Petri global.
Com 3000 simulações efectuadas, em ambos os casos, no domínio [0 − 50000]h, obtiveram-se as
curvas das disponibilidades apresentadas nas figuras Figura 6.8 e Figura 6.9.
Figura 6.8 – Disponibilidade dos equipamentos sujeitos a manutenções periódicas

79
Figura 6.9 – Disponibilidade de equipamentos sujeitos a reparações imediatas
Em ambos os gráficos é possível observar-se o desgaste dos equipamentos através de uma
disponibilidade cada vez mais reduzida na zona inicial da simulação. Nas curvas relativas ao modelo
de falhas exponenciais, nota-se a independência do tempo acumulado pelo comportamento igual
verificado em todo o domínio da simulação.
Uma vez que o equipamento recupera 30% do tempo de vida após cada intervenção, a sua idade tende
para um valor constante ao fim de algum tempo. A partir deste momento, a curva da disponibilidade
estabiliza: ciclos iguais para reparações periódicas; disponibilidade média horizontal para o caso de
reparações imediatas.
Com a implementação de uma variável que permita ver a idade acumulada do componente a cada
instante, é possível ver para que valor esta tende. Na Figura 6.10 é possível ver estes valores, para
ambos os casos expostos. O facto de manutenções imediatas fazerem tender o tempo de vida do
componente para um valor mais elevado do que para o caso em que estes são submetidos a
manutenções periódicas torna possível o fenómeno ocorrido e verificado no sistema de reliquefação de
gás: a utilização de uma distribuição exponencial para modelar as falhas pode ser conservativa em
alguns casos e noutros negligenciar uma porção importante dos resultados.

80
Figura 6.10 – Tendência da idade do componente
A diferença entre os dois valores limites de idade acumulada pode ser grande o suficiente para tornar
menos disponível um sistema sujeito a reparações imediatas do que um em que apenas pode ser
reparado periodicamente. No sistema de reliquefação, no caso em que a redundância é máxima, isso
chega mesmo a ocorrer. Olhando novamente para as tabelas Tabela 6.7 e Tabela 6.8 vemos que a
quantidade de BOG queimado no navio sem meios de reparação a bordo é 0.365% contra os 0.864%
de BOG queimado a bordo do navio que tem sempre meios disponíveis para efectuar reparações. Isto
ocorre pelo descrito acima e pela duração da viagem relativamente curta quando comparada com o
tempo médio de falha e tempo de vida acumulado. O sistema estabilizou para uma condição onde é
preferível efectuar apenas reparações periódicas, mantendo a idade de vida acumulada num valor
relativamente baixo e ter assim uma disponibilidade mais alta.
Obviamente, caso a duração da viagem aumentasse, as condições estudadas alterar-se-iam e um novo
estudo deveria ser feito. Para se ter uma ideia da duração máxima que a viagem deveria ter para
continuar a compensar fazer apenas reparações periódicas em detrimento de ter uma equipa
especializada a bordo, tentou-se procurar o ponto onde a disponibilidade seria igual, tanto para o caso
em que as inspecções são realizadas no porto de origem ou a bordo. Para além do caso em que a
viagem toma 28 dias (672h), estudaram-se mais três durações. Depois de feitas estas simulações,
chega-se ao ponto onde a disponibilidade fica igual através de uma interpolação linear - Tabela 6.9.
Tabela 6.9 – Influência da duração da viagem na disponibilidade do sistema sujeito a reparações periódicas
Duração Capacidade Queima
Horas Dias
672.00 28.00 99.64% 0.36%
750.00 31.25 99.47% 0.53%
900.00 37.50 99.25% 0.75%
920.31 38.35 99.14% 0.86%
1000.00 41.67 98.68% 1.32%

81
6.3 Optimização de políticas de manutenção
Depois de uma modelação cuidada dos sistemas, as potencialidades das redes Petri e as informações
que dela se podem retirar são imensas. Para além da disponibilidade do sistema, pode-se ter acesso
a valores e comportamentos de diversas variáveis necessárias à tomada de decisões durante a criação
ou optimização de um sistema. Num sistema mecânico, questões relacionadas com políticas de
manutenção, dimensionamento de equipas de manutenção e de equipamentos em stock,
calendarização de intervenções nos equipamentos, número de falhas ocorridas, entre outros, são
facilmente respondidas pelos dados provenientes das simulações.
Através de uma análise paramétrica é ainda possível saber-se qual a influência que cada parâmetro
pode ter nos resultados, bastante útil na avaliação das consequências de uma variação de uma variável
que não se controla ou se desconhece.
Na maioria dos casos, o ponto óptimo de funcionamento de um determinado sistema é encontrado pelo
equilíbrio entre a capacidade do sistema e dos custos associados: um sistema altamente fiável, com
uma capacidade de produção sempre capaz de suprir as necessidades pode ter custos associados
incomportáveis.
Para o caso do sistema de combate a incêndios, e assumindo que não são feitas alterações à
configuração dos componentes, a optimização seria feita com base na disponibilidade do sistema,
imposições das sociedades classificadoras, custos de manutenção e análise de risco. A rede
apresentada é capaz de dar toda a informação relacionada com a disponibilidade e de ver a influência
de cada política de manutenção.
No sistema de reliquefação de BOG, a escolha do nível de redundância do sistema de reliquefação de
BOG é feita com base em cálculos financeiros que tenham em conta os custos de aquisição,
amortização, quantidade queimada de BOG e perdas financeiras associadas e custos relacionados
com as políticas de manutenção. Com a rede Petri apresentada, é possível ter toda a informação
relacionada com quantidades de falhas dos equipamentos, número de inspecções feitas, tanto
correctivas como preventivas e quantidade de BOG queimada. Com a rede apresentada é também
possível determinar o intervalo óptimo entre inspecções tendo em conta os custos de cada intervenção
correctiva, preventiva e perdas associadas às queimas de BOG.
Para exemplificação do processo de optimização do tempo entre cada inspecção é aqui apresentado o
estudo para uma das opções de redundância. Neste estudo, para além de se ter sempre a possibilidade
de efectuar uma tarefa de manutenção correctiva, o sistema é submetido a inspecções preventivas
periódicas, que para além de recuperarem parte do tempo de vida acumulado, permitem descobrir
componentes em standby que possam estar em falha. O valor óptimo para o intervalo entre inspecções
ocorre quando para o mínimo da função objectivo, dada por:
𝐶(𝜏) = 𝑄𝑡𝑞𝑢𝑒𝑖𝑚𝑎𝑑𝑎(𝜏) × 𝐶𝐹 + 𝑁𝑃𝑀(𝜏) × 𝐶𝑃𝑀 + 𝑁𝐶𝑀(𝜏) × 𝐶𝐶𝑀 ( 6.2 )

82
A quantidade de horas em que o BOG está a ser queimado, 𝑄𝑡𝑞𝑢𝑒𝑖𝑚𝑎𝑑𝑎, ao fim de um ano é dada pelo
produto da indisponibilidade do sistema (%) durante as viagens entre a origem e o porto de destino
com a duração das mesmas. O custo associado à queima e perda de BOG (𝐶𝐹) é de 1160.00USD/h
(Kwang et al., 2008).
O número de intervenções preventivas e correctivas, 𝑁𝑃𝑀 e 𝑁𝐶𝑀, respectivamente, são obtidas pela
contagem do número de vezes que as transições relacionadas com o início destas actividades
estiveram activas e foram disparadas.
O caso aqui apresentado diz respeito ao sistema de liquefação de BOG com o nível de redundância da
opção 2: sistema compressor de BOG redundante. Seis intervalos diferentes para a periodicidade das
inspecções preventivas são estudadas, tomando valores entre 500h e 3000h. Para cada intervalo, são
feitas 4000 simulações e o sistema é estudado por um período de um ano. O número de reparações,
preventivas e correctivas e a percentagem de tempo em que o sistema se encontra indisponível e a
queimar o BOG gerado são apresentados na Tabela 6.10 para cada um dos intervalos estudados.
Tabela 6.10 – Resultados obtidos para a optimização do intervalo entre manutenções periódicas
τ 𝑸𝒕𝒒𝒖𝒆𝒊𝒎𝒂𝒅𝒂 𝑵𝑷𝑴 𝑵𝑪𝑴
500 0.76% 258.33 5.94
1000 1.27% 127.77 11.77
1500 1.70% 84.71 16.31
2000 1.97% 63.34 19.60
2500 2.21% 50.35 22.04
3000 2.48% 42.12 23.94
Através da equação ( 6.2 ) e dos dados apresentados na Tabela 6.10, é possível calcular os custos
associados a cada intervalo. Uma vez que o acesso a informação relacionada com os custos das
manutenções é escassa, assumiu-se que o custo de cada intervenção correctiva é cinco vezes superior
a uma intervenção preventiva. Para cada intervenção preventiva, assumiu-se que a despesa associada
é de 2000.00USD. Estes valores são assumidos de forma grosseira e servem apenas para se entender
e finalizar o processo de optimização.
Com base nos valores assumidos, os valores associados às manutenções e queima são apresentados
na Tabela 6.11 e graficamente na Figura 6.11.
Tabela 6.11 – Custos associados a cada intervalo
τ Custo associado
à queima Manutenção Preventiva
Manutenção Correctiva
Custo Total
500 35 647 USD 516 652 USD 59 348 USD 611 648 USD
1000 59 578 USD 255 535 USD 117 744 USD 432 858 USD
1500 79 619 USD 169 420 USD 163 078 USD 412 118 USD
2000 92 009 USD 126 675 USD 195 972 USD 414 658 USD
2500 103 193 USD 100 699 USD 220 380 USD 424 274 USD
3000 115 914 USD 84 232 USD 239 432 USD 439 579 USD

83
Figura 6.11 - Custos associados a cada intervalo
Pela tabela e pelo gráfico, vemos que para a opção 2 de redundância, o intervalo entre manutenções
preventivas que minimiza os custos associados ao funcionamento do sistema de reliquefação do BOG
é de 1500horas. É claro que, à medida que o intervalo entre manutenções preventivas vai aumentando,
as despesas relacionadas com este tipo de intervenções vai diminuindo e as despesas com inspecções
correctivas aumenta. No entanto, a taxa com que as despesas relacionadas com as reparações
preventivas decrescem não é a mesma com que as despesas das reparações correctivas crescem.
Estas últimas parecem mesmo estabilizar ao fim de algum tempo e aproximar-se de uma assimptota
horizontal. Esta estabilização ocorre no momento em que o tempo de vida acumulado dos diversos
equipamentos do sistema estabilizam, levando a que as falhas dos equipamentos ocorram na maior
parte dos casos antes de se proceder à intervenção de manutenção preventiva seguinte.
A curva do custo total é bastante sensível a dois parâmetros: custo da queima de BOG, intimamente
ligado aos valores de mercado do gás natural e ao rácio entre os custos de uma manutenção correctiva
e de uma manutenção preventiva. Quanto maior for este rácio, i.e. quanto maior for a diferença de
custos entre manutenções correctivas e preventivas, menor será o intervalo óptimo entre as
intervenções periódicas.
Este estudo de optimização tanto pode ser feito para definir os intervalos óptimos entre inspecções a
realizar no sistema completo como para a definição de diferentes intervalos para os diferentes
componentes individuais. O estudo pode ainda ser feito para todas as outras opções de redundância,
de forma a providenciar informação relevante ao órgão decisor para a tomada de decisão da melhor
opção a instalar a bordo. A estes custos seriam somados todos os custos de investimento e
amortização relacionados com cada opção de redundância.

84
7 Conclusão e Trabalho Futuro
7.1 Conclusão
No âmbito desta dissertação estudou-se a fiabilidade e disponibilidade de sistemas de navios. Para a
análise dos sistemas, desenvolveram-se modelos de redes Petri que os representassem e que fossem
capazes de considerar falhas em standby, arranque e funcionamento, desgaste dos equipamentos,
dependência de equipas e equipamento suplente em stock, manutenções correctivas, preventivas, e
oportunistas, perfeitas ou imperfeitas.
A verificação do modelo feita através da abordagem clássica mostrou que os modelos criados são
coerentes e muito próximos aos obtidos pelo cálculo teórico. Com diferenças relativas entre os modelos
teóricos e os valores obtidos por simulação muito pequenas, conclui-se que neste contexto, as redes
Petri estocásticas generalizadas são ferramentas poderosas e eficientes na modelação de operações
e manutenção de sistemas complexos reais e das interacções e dependências entre os componentes.
A coerência de resultados obtidos pela rede Petri do sistema de reliquefação de BOG com os resultados
obtidos pelos modelos de Markov apresentadas por Kwang et al. (2008) também dão garantia de uma
correcta implementação das redes Petri propostas.
As redes Petri criadas para os equipamentos individuais são genéricas e permitem que sejam utilizadas
noutros sistemas mecânicos, contribuindo para uma modelação modular mais fácil e percetível,
apresentando-se então como uma possível solução de um dos problemas apontados por Signoret et
al., (2013), que defendem que a disseminação das redes Petri é lenta e difícil devido à sua difícil leitura.
Nos sistemas que raramente são utilizados, caso dos sistemas de combate a incêndios, a modelação
da falha em standby dos diversos equipamentos é fundamental para o estudo da disponibilidade. Sem
essa modelação, aproximar-se-ia o sistema a sistema perfeito, não oferecendo dados para o apoio da
gestão das intervenções de manutenção e para uma análise de riscos relacionados com a falha do
sistema em caso de necessidade. Para sistemas de utilização contínua, tal como o sistema de
reliquefação de BOG, a importância da modelação das falhas em standby está dependente da política
de manutenção a implementar e da quantidade de equipamentos redundantes que apenas entram em
funcionamento quando os principais entram em falência. Caso os equipamentos do sistema sejam
submetidos a inspecções e reparações periódicas em que o intervalo entre duas inspecções
consecutivas é muito menor que o tempo de simulação, a não modelação das falhas em standby não
revela ser prejudicial para os resultados finais. As inspecções periódicas permitem descobrir e corrigir
com frequência as falhas ocultas, diminuindo o risco de o equipamento ter de entrar em funcionamento
e o mesmo não se encontrar funcional. No caso dos equipamentos de um determinado sistema apenas
serem reparados no momento da falha, o interesse na modelação destas falhas em standby aumenta
com o aumento do número de equipamentos redundantes do sistema.
A modelação das falhas admitindo desgaste dos equipamentos – falhas modeladas por distribuições
de Weibull – deve ser considerada. Para os casos em que as reparações e inspecções são feitas de
forma periódica aos equipamentos, o valor obtido para a disponibilidade revelou ser mais optimista

85
quando comparada com os resultados obtidos sem a consideração deste modo de falhas. No entanto,
esta tendência optimista não se revela quando não há inspecções periódicas e as reparações apenas
são feitas quando se toma consciência da falha do equipamento. Assim, os resultados podem ser
menos ou mais conservativos consoante a modelação das falhas com ou sem desgaste,
respectivamente. Este fenómeno está relacionado com o valor para que tende o tempo de vida
acumulado de cada equipamento tendo em conta que cada reparação permite recuperar parte deste
tempo de funcionamento. O tempo de vida acumulado dos equipamentos tende para um valor maior
quando o mesmo apenas é submetido a intervenções correctivas após a falha.
A associação de custos à indisponibilidade do sistema e às reparações permite uma optimização das
políticas de manutenção, permitindo analisar vários casos e escolher aquele que minimiza as despesas.
Com esta possibilidade, as redes Petri apresentam-se também como uma ferramenta útil para a
optimização de recursos e políticas de manutenção.
7.2 Trabalho Futuro
O trabalho feito poderia ser utilizado como ponto de partida para diversos estudos complementares.
Nesta secção apresentam-se algumas sugestões para eventuais trabalhos futuros que possam
complementar de certa forma o apresentado no âmbito desta dissertação.
Dos 57 e 98 parâmetros que definem o sistema de combate a incêndios e o sistema de reliquefação de
BOG respectivamente, um extenso estudo paramétrico poderia ser feito. Estes estudos paramétricos
avaliariam a influência que cada parâmetro tem na disponibilidade de cada sistema. A relevância desse
estudo justifica-se pelo contributo que poderia dar na optimização do sistema. A escolha de
equipamentos mais fiáveis (maior MTTF), profissionalização e especialização das equipas (menor
MTTR), forma de desgaste do equipamento (parâmetro de forma das distribuições), entre muitos outros,
poderiam ser utilizados nos estudos de optimização, complementando os usados nesta dissertação:
custos associados à indisponibilidade e custos de reparação. Parte desse estudo paramétrico deveria
ser direcionado à definição de diferentes políticas de manutenção. Diferentes intervalos entre
inspecções periódicas para diferentes equipamentos poderiam trazer uma melhoria nos resultados
caso o número de equipas de manutenção fosse limitado. Poderia ser também feito um estudo onde
se condicionasse o tipo de reparações com base na localização do navio, i.e., algumas reparações
poderiam ser feitas a bordo e outras apenas seriam possíveis em portos de origem/destino.
Outro estudo poderia ser feito na área de análise de riscos para avaliar as consequências de uma
eventual falha dos sistemas. O risco associado a uma falha do sistema de combate a incêndios poderá
ser superior ao do risco associado à falha do sistema de reliquefação já que as consequências de um
eventual incêndio trariam maiores danos pois todo o gás que não seja possível reliquefazer poder ser
queimado na unidade de combustão instalado no navio. O estudo do risco associado à falha do sistema
de combate a incêndios deverá ter em conta a localização do foco de incêndio e do tempo necessário
para a extinção do mesmo.

86
O estudo de optimização apresentado poderia ser concluído e complementado com uma análise
financeira sólida que considerasse todos os custos associados à construção e instalação dos
equipamentos a bordo, amortização e despesas de manutenção. Os valores obtidos para os custos
reais do sistema e os valores da disponibilidade seriam comparados e uma opção óptima de
redundância poderia ser escolhida para o sistema de reliquefação de BOG.

87
8 Referências Bibliográficas
ABS. (2014). Guide for survey based on Reliability-Centered Maintenance. American Bureau of Shipping.
AGREE. (1957). Reliability of military electronic equipment. Washington, DC.
Anderson, T. N., Ehrhardt, M. E., Foglesong, R. E., & Bolton, T. (2009). Shipboard Reliquefaction for Large LNG Carriers. Proceedings of the 1st Annual Gas Processing Symposium: 10–12 January 2009, Doha, Qatar (First Edit., Vol. 2, pp. 317–324). Elsevier B.V. doi:10.1016/B978-0-444-53292-3.50039-0
Assis, R. (2012). Periodicidade óptima de inspecções na procura de falhas ocultas. In Encontro Nacional de Riscos, Segurança e Fiabilidade. Faculdade de Engenharia da Universidade Católica Portuguesa.
Aven, T. (1993). On performance measures for multistate monotone systems. Reliability Engineering & System Safety, 41(3), 259–266. doi:10.1016/0951-8320(93)90078-D
Aven, T., & Jensen, U. (1999). Stochastic Models in Reliability. Springer.
Barata, J., Guedes Soares, C., Marseguerra, M., and Zio, (2002). E. Simulation Modelling of Repairable Multi-Component Deteriorating Systems for "On Condition" Maintenance Optimization. Reliability Engineering and System Safety. 2002; 76:255-264.
Bureau Veritas. (2010). Safety Integrity Level ( SIL ). Bureau Veritas. Retrieved October 27, 2014, from http://www.us.bureauveritas.com/wps/wcm/connect/bv_usnew/local/home/our-services/industrial_asset_management_services/safety_integrity_level_%28sil%29_training_and_assessments
Cabral Morais, M. (2009). Notas de Apoio da Disciplina de Probabilidade e Estatística (p. 330).
Campos Ferreira, J. (2008). Introdução à Análise Matemática. (F. C. Gulbenkien, Ed.) (9o Edição.).
Chang, D., Rhee, T., Nam, K., Chang, K., Lee, D., & Jeong, S. (2008). A study on availability and safety of new propulsion systems for LNG carriers. Reliability Engineering & System Safety, 93(12), 1877–1885. doi:10.1016/j.ress.2008.03.013
Comission International Electrotechnical. Functional Safety. , Pub. L. No. IEC 61508 (1999).
Ding, F., & Tian, Z. (2012). Opportunistic maintenance for wind farms considering multi-level imperfect maintenance thresholds. Renewable Energy, 45, 175–182. doi:10.1016/j.renene.2012.02.030
Dong, C., Yuan, C., Liu, Z., & Yan, X. (2013). Marine Propulsion System Reliability Research Based on Fault Tree Analysis. Advanced Shipping and Ocean Engineering(ASOE), 2, 27–33.
Dutuit, Y., Châtelet, E., Signoret, J.-P., & Thomas, P. (1997). Dependability modelling and evaluation by using stochastic Petri nets: application to two test cases. Reliability Engineering & System Safety, 55(2), 117–124.
Dutuit, Y., Innal, F., Rauzy, A., & Signoret, J.-P. (2008). Probabilistic assessments in relationship with safety integrity levels by using Fault Trees. Reliability Engineering & System Safety, 93(12), 1867–1876. doi:10.1016/j.ress.2008.03.024

88
Fogliatto, F. S., & Duarte Ribeiro, J. L. (2009). Confiabilidade e Manutenção Industrial. (Elsevier, Ed.) (p. 265).
GRIF. (n.d.). Stochastic Block Diagram. Retrieved June 10, 2014, from http://grif-workshop.com/grif/bstok-module/
GRIF. (2014). GRIF 2014 Petri Nets with predicates User Manual. GRIF.
GRIF Workshop. (n.d.). Retrieved February 10, 2014, from http://grif-workshop.com/
Griffith, W. S. (1980). Multistate Reliability Models. Journal of Applied Probability, 17(3), 735–744.
Haas, P. J. (2002). Stochastic Petri Nets, Modelling, Stability, Simulation (p. 523). Springer.
Hamworthy, W. (n.d.). Wärtsilä Hamworthy LNG Reliquefaction. Retrieved October 27, 2014, from http://www.wartsila.com/en/gas-systems/LNG-handling/LNG-reliquefaction
Jardine, A. K. S., & Buzacott, J. A. (1985). Equipment reliability and maintenance. European Journal of Operational Research, 19, 285–296.
Küver, M., Clucas, C., & Fuhrmann, N. (2002). Evaluation of propulsion options for LNG carriers. In The 20th international conference and exhibition for the LNG, LPG and natural gas industries (GASTECH 2002).
Kwang Pil, C., Rausand, M., & Vatn, J. (2008). Reliability assessment of reliquefaction systems on LNG carriers. Reliability Engineering & System Safety, 93(9), 1345–1353. doi:10.1016/j.ress.2006.11.005
Lewis, E. E. (1994). Introduction to Reliability Engineering. John Wiley & Sons, Inc., Second Edi.
Malhotra, M., & Trivedi, K. S. (1995). Dependability Modeling Using Petri-Nets. IEEE Transactions on Reliability, 44(3), 428–440.
Marsan, M. A., Balbo, G., Chiola, G., Conte, G., Donatelli, S., & Franceschinis, G. (1991). An introduction to Generalized Stochastic Petri Nets. Microelectronics Reliability, 31(4), 699–725.
MIL-STD-721B. (1981). MILITARY STANDARD: DEFINITIONS OF TERMS FOR RELIABILITY AND MAINTAINABILITY. Department of Defense.
OREDA. (2002). Offshore reliability data handbook. OREDA Participants, SINTEF Industrial Management, Det Norske Veritas (DNV).
Pešková, A. (2013). Modelling Maintenance and Renewal in Petri Nets. Applied Mechanics and Materials, 282, 282–286.
Pham, H., & Wang, H. (1996). Imperfect maintenance. European Journal of Operational Research, 94(3), 425–438. doi:10.1016/S0377-2217(96)00099-9
Rausand, M. (1998). Reliability centered maintenance. Reliability Engineering & System Safety, 60, 121–132.
Rausand, M., & Hoyland, A. (2004). System Reliability Theory (Second Edi., Vol. 30). Wiley Interscience. doi:10.1016/0026-2714(90)90701-N
Rausand, M., & Vatn, J. (2008). Reliability Centred Maintenance. In K. A. H. Kobbacy & D. N. P. Murthy (Eds.), Complex System Maintenance Handbook (pp. 79–108).

89
Reisig, W. (1998). Understanding Petri Nets Modelling Techniques, Analysis Methods, Case Studies. Springer.
Saleh, J. H., & Marais, K. (2006). Highlights from the early (and pre-) history of reliability engineering. Reliability Engineering & System Safety, 91(2), 249–256. doi:10.1016/j.ress.2005.01.003
Santos, F. P., Teixeira, A. P., & Soares, C. G. (2013). Influence of logistic strategies on the availability and maintenance costs of an offshore wind turbine. In R. . D. . J. . M. Steenbergen, P. . H. . A. . J. . M. . van Gelder, S. . Miraglia, & A. . C. . W. . M. . T. . Vrouwenvelder (Eds.), 22nd European Safety and Reliability (ESREL) Conference (pp. 791–799). Amsterdam, Netherlands.
Sobral, J., & Ferreira, L. A. (2005). Análise de Risco num Sistema de Protecção Contra Incêndios de um Edifício Público, com Aplicação da Metodologia RAMS. In C. Guedes Soares, Â. P. Teixeira, & P. Antão (Eds.), Análise e Gestão de Riscos, Segurança e Fiabilidade (Volume 1) (pp. 263–280). Edições Salamandra, Lda.
Sobral, J., & Ferreira, L. A. (2007). A Importância da Fiabilidade dos Equipamentos de Protecção Contra Incêndio na Gestão do Risco Industrial. In C. Guedes Soares, Â. P. Teixeira, & P. Antão (Eds.), Riscos Públicos e Industriais (Volume 1) (pp. 447–466). Edições Salamandra, Lda.
Shin, Y., & Lee, Y. P. (2009). Design of a boil-off natural gas reliquefaction control system for LNG carriers. Applied Energy, 86(1), 37–44. doi:10.1016/j.apenergy.2008.03.019
Signoret, J.-P. (2004). Advances in Production Availability Modelling (p. 32). Documento não publicado com descrição de métodos e ferramentas desenvolvidas em França e usadas pela TOTAL para análise de disponibilidade de sistemas. Acessível em Centro de Engenharia e Tecnologia Naval (IST), Lisboa, Portugal
Signoret, J.-P., Dutuit, Y., Cacheux, P.-J., Folleau, C., Collas, S., & Thomas, P. (2013). Make your Petri nets understandable: Reliability block diagrams driven Petri nets. Reliability Engineering & System Safety, 113, 61–75. doi:10.1016/j.ress.2012.12.008
Stapelberg, R. F. (2009). Handbook of Reliability, Availability, Maintainability and Safety in Engineering Design. Springer.
Stopford, M. (1997). Maritime Economics (2nd ed., p. 815). Routledge.
Tavner, P. (2012). Reliability , availability and maintenance Offshore Wind Turbines (p. 293). Londo,, United Kingdom: The Institution of Engineering and Technology.
Teixeira, A. P., & Guedes Soares, C. (2009). Modelação e Análise da Disponibilidade de Produção de sistemas por redes Petri Estocásticas. In C. Guedes Soares, C. Jacinto, A. P. Teixeira, & P. Antão (Eds.), Riscos Industriais e Emergentes (pp. 469–488). Lisboa: Edições Salamandra, Lda.
The European Marine Energy Centre Ltd. (2009). Guidelines for Reliability , Maintainability and Survivability of Marine Energy Conversion Systems. The European Marine Energy Centre Ltd.
Trivedi, K. S., Kim, D., & Yin, X. (2012). Multi-State Availability Modeling in Practice. In A. Lisnianski & I. Frenker (Eds.), Recent Advances in System Reliability (pp. 165–180). Springer.
Valdez-flores, C., & Feldman, R. M. (1989). A Survey of Preventive Maintenance Models for Stochastically Deteriorating Single-Unit Systems. Naval Research Logistics, 36, 419–446.
Wan, C., Yan, X., Zhang, D., & Fu, S. (2013). Reliability Analysis of a Marine LNG-Diesel Dual Fuel Engine. In E. Zio & P. Baraldi (Eds.), Chemical Engineering Transactions (Vol. 33, pp. 811–816). AIDIC, The Ialian Association of Chemical Engineering. doi:10.3303/CET1333136

90
Wang, H. (2002). A survey of maintenance policies of deteriorating systems. European Journal of Operational Research, 139(3), 469–489. doi:10.1016/S0377-2217(01)00197-7
Wood, A. P. (1985). Multistate Block Diagrams and Fault Trees. IEEE Transactions on Reliability, R-34(3), 236–240. doi:10.1109/TR.1985.5222131
Yang, G. (2007). Life Cycle Reliability Engineering. (I. John Wiley & Sons, Ed.).
Zio, E. (2009). Reliability engineering: Old problems and new challenges. Reliability Engineering & System Safety, 94(2), 125–141. doi:10.1016/j.ress.2008.06.002
Zio, E. (2013). The Monte Carlo Simulation Method for System Reliability and Risk Analysis. Springer.
Zio, E., Marella, M., & Podofillini, L. (2007). A Monte Carlo simulation approach to the availability assessment of multi-state systems with operational dependencies. Reliability Engineering & System Safety, 92(7), 871–882.


















