
ANÁLISE DE DESEMPENHO DO BANCO DE DADOS … · sistemas operacionais onde ... Este documento...
12
ANÁLISE DE DESEMPENHO DO BANCO DE DADOS POSTGRESQL NOS SISTEMAS LINUX E WINDOWS Rodrigo Buzzi Schiochet, Osmar de Oliveira Braz Junior Pós-Graduação em Engenharia de Software – PGES Centro de Educação Superior do Alto Vale do Itajaí – CEAVI Universidade do Estado de Santa Catarina – UDESC [email protected], [email protected] Resumo O desempenho dos sistemas de informação está diretamente ligado ao bom funcionamento do banco de dados utilizado para armazenamento e recuperação de informações. Existem diversos sistemas operacionais onde um banco de dados pode ser instalado e mantido. Consequentemente, estes diferentes ambientes fazem com que o desempenho do banco de dados apresente variações na eficiência do sistema. Este documento apresenta um estudo comparativo de desempenho do banco de dados relacional PostgreSQL nos sistemas operacionais Windows e Linux. A medição do desempenho foi realizada pela ferramenta Apache jMeter, onde foram verificadas métricas de desempenho, como tempo médio, mínimo e máximo de resposta por requisição, menor desvio padrão por requisição, volume de transferência de dados por segundo e tamanho do pacote por solicitação. Para a análise, é utilizado um servidor exclusivo para hospedagem do PostgreSQL e outro servidor é utilizado para execução da aplicação e testes. Como resultado, é observado que o Linux possui um melhor desempenho em comparação ao Windows, nos testes de desempenho, com 100 iterações realizando as mesmas operações. Palavras-chave: PostgreSQL. Windows. Linux. Desempenho. DATABASE PERFORMANCE ANALYSIS POSTGRESQL SYSTEMS IN LINUX AND WINDOWS Abstract The information systems performance is directly bound to the good function of a database used to store and recover the information. There are many operating systems where a database could be installed and maintained. As a consequence, those different environments make the database performance to show variations in the system efficiency. This document presents a relational PostgreSQL database performance comparative study on Windows and linux operating systems. The performance measurement is made using Apache jMeter tool, where it verifies performance metrics, like average time, minimum and maximum reply by request, lower standard deviation by request, data transfer volume per second and packet size by request. To the analysis is used a dedicated server to host PostgreSQL and other server to run the application and tests. As a result, we can see that linux has a better performance comparing to windows, in the performance tests with a hundred iterations performing the same operations. Keywords: PostgreSQL. Windows. Linux. Desempenho. 1. Introdução A utilização de Sistemas de Gerenciamento de Banco de Dados é uma necessidade cada vez mais comum. Em paralelo a esta necessidade, é crescente a complexidade e o volume de dados que os sistemas precisam gerenciar para garantir a eficiência de suas aplicações.
Transcript of ANÁLISE DE DESEMPENHO DO BANCO DE DADOS … · sistemas operacionais onde ... Este documento...

ANÁLISE DE DESEMPENHO DO BANCO DE DADOS
POSTGRESQL NOS SISTEMAS LINUX E WINDOWS
Rodrigo Buzzi Schiochet, Osmar de Oliveira Braz Junior
Pós-Graduação em Engenharia de Software – PGES
Centro de Educação Superior do Alto Vale do Itajaí – CEAVI
Universidade do Estado de Santa Catarina – UDESC [email protected], [email protected]
Resumo
O desempenho dos sistemas de informação está diretamente ligado ao bom funcionamento do
banco de dados utilizado para armazenamento e recuperação de informações. Existem diversos sistemas operacionais onde um banco de dados pode ser instalado e mantido. Consequentemente,
estes diferentes ambientes fazem com que o desempenho do banco de dados apresente variações na eficiência do sistema. Este documento apresenta um estudo comparativo de desempenho do banco de dados relacional PostgreSQL nos sistemas operacionais Windows e Linux. A medição
do desempenho foi realizada pela ferramenta Apache jMeter, onde foram verificadas métricas de desempenho, como tempo médio, mínimo e máximo de resposta por requisição, menor desvio
padrão por requisição, volume de transferência de dados por segundo e tamanho do pacote por solicitação. Para a análise, é utilizado um servidor exclusivo para hospedagem do PostgreSQL e outro servidor é utilizado para execução da aplicação e testes. Como resultado, é observado que
o Linux possui um melhor desempenho em comparação ao Windows, nos testes de desempenho, com 100 iterações realizando as mesmas operações.
Palavras-chave: PostgreSQL. Windows. Linux. Desempenho.
DATABASE PERFORMANCE ANALYSIS POSTGRESQL
SYSTEMS IN LINUX AND WINDOWS
Abstract
The information systems performance is directly bound to the good function of a database used to store and recover the information. There are many operating systems where a database could
be installed and maintained. As a consequence, those different environments make the database performance to show variations in the system efficiency. This document presents a relational PostgreSQL database performance comparative study on Windows and linux operating systems.
The performance measurement is made using Apache jMeter tool, where it verifies performance metrics, like average time, minimum and maximum reply by request, lower standard deviation by
request, data transfer volume per second and packet size by request. To the analysis is used a dedicated server to host PostgreSQL and other server to run the application and tests. As a result, we can see that linux has a better performance comparing to windows, in the performance
tests with a hundred iterations performing the same operations.
Keywords: PostgreSQL. Windows. Linux. Desempenho.
1. Introdução
A utilização de Sistemas de Gerenciamento de Banco de Dados é uma necessidade cada vez mais
comum. Em paralelo a esta necessidade, é crescente a complexidade e o volume de dados que os sistemas precisam gerenciar para garantir a eficiência de suas aplicações.

Um mesmo SGBD pode ser instalado em sistemas operacionais diferentes e cada sistema
operacional pode conter diferentes sistemas de arquivos. Portanto, Um SGBD pode ser utilizado em diversos ambientes com diferentes características.
Segundo Carneiro (2011), efetuar operações sobre grandes coleções de dados é uma questão pontual, pois a avaliação de desempenho de um SGBD (Sistema Gerenciador de Banco de Dados) é medida, usando como base sua eficiência diante de consultas e alterações.
O bom desempenho de um banco de dados não depende exclusivamente de sua estrutura ou de como ele foi desenvolvido. Este desempenho depende de uma série de variáveis, como o
potencial do hardware onde ele encontra-se instalado, que a sua configuração seja parametrizada de acordo com os recursos disponíveis no respectivo hardware e que o sistema operacional, juntamente com o sistema de arquivos, gerencie e processe os dados e as instruções que partem
do SGBD da maneira mais eficiente possível. Em sistemas que efetuam altas quantidades de requisições e transações em um banco de
dados, qualquer diferença no desempenho e efetividade de uma única instrução, pode ser a diferença entre o bom ou um mal desempenho do sistema como um todo. Isto, porque uma única e simples transação, dependendo do seu objetivo e da sua importância, pode ser disparada
milhares de vezes. Por este motivo, a necessidade de medições de desempenho e da busca pelo melhor ambiente para a hospedagem do banco de dados se torna muito importante.
Segundo Jain (2010), os erros mais comuns na análise de desempenho podem ser evitados executando simulações, fazendo medições de desempenho e realizando análise de desempenho estatístico.
A análise de desempenho contém uma abordagem quantitativa, onde os resultados são quantificados, se centrando na objetividade. Os resultados são compreendidos com base na
análise de dados brutos obtidos com o auxílio de ferramentas (FONSECA, 2002). Já de acordo com Gil (2007), a pesquisa exploratória tem como objetivo proporcionar maior
familiaridade com o problema, e torná-lo mais explícito e geralmente envolve a análise de
exemplos que estimulem a compreensão do problema. Segundo Almeida (2009), a análise de desempenho de um sistema é feita através de medições,
análise quantitativa e utilização de métricas de desempenho O objetivo deste artigo é realizar uma análise do desempenho do banco de dados PostgreSQL
em diferentes sistemas operacionais para que seja possível determinar o ambiente onde este
banco de dados apresenta o melhor desempenho. Para esta análise, serão utilizados os sistemas operacionais Windows Server 2012 R2 e o Linux CentOS, versão 7.
Será também realizado um teste utilizando uma máquina virtual, com sistema operacional CentOS, na versão 7. Esta máquina virtual, por sua vez, estará hospedada sobre um servidor Microsoft Windows Server 2012 R2. Tal teste será realizado, pois atualmente a virtualização de
servidores é uma realidade presente no ambiente de quase todas as empresas, devendo assim ser considerada neste estudo.
Para a medição do desempenho do banco de dados PostgreSQL, foi desenvolvido um programa que executa as quatro instruções básicas existentes nos bancos de dados relacionais, sendo elas o insert, o update, o delete e o select. Estas quatro instruções foram utilizadas dentro
de uma função criada no PostgreSQL para a importação e processamento de um arquivo de texto.
O artigo está organizado da seguinte forma, além desta introdução, são apresentados os trabalhos correlatos, na seção 3 é apresentado o ambiente utilizado para testes, em seguida são apresentadas as metodologias da pesquisa e os resultados obtidos neste artigo, e por fim, são
feitas as considerações finais sobre o trabalho.

2. Trabalhos Correlatos
Para a criação deste trabalho foi realizado um estudo de três artigos existentes no contexto de análise de desempenho de banco de dados.
Ferreira e Trad (2012) efetuaram uma análise de desempenho dos bancos de dados Firebird 2.5, PostgreSQL 9.2.1, MySQL 5.5 e SQL Server 2008. Ao final da coleta dos resultados, concluíram que o PostgreSQL obteve um melhor desempenho nos testes de inserção e
atualização de registros em massa. Já o MySQL obteve o melhor desempenho na execução das consultas e o SQL Server obteve os melhores resultados em relação ao tamanho da base de dados
no disco. Silva (2011) efetuou uma análise comparando ORACLE 10G e PostgreSQL 8.4. Neste
estudo, ele concluiu que o desempenho do ORACLE se mostrou superior em quase todos os
testes realizados. Porém, ressaltou que mesmo sendo uma ferramenta de código aberto, o PostgreSQL fornece todos os recursos esperados de um banco de dados e possui a robustez e a
agilidade desejadas em um banco de dados relacional, possuindo ainda a vantagem de ser gratuito.
Castanhede, Dill, Padoin, Sausen e Camargo (2009) fizeram uma análise do desempenho do
banco de dados PostgreSQL nos sistemas de arquivos ReiserFS, Ext3, JFS e XFS. Após a coleta dos tempos e análise dos dados, constataram que o sistema de arquivos XFS foi o que obteve o
melhor desempenho, seguido pelo JFS, ReiserFS e Ext3 respectivamente. Com os resultados obtidos, concluíram que os sistemas de arquivos exercem uma influência muito significativa no desempenho do banco de dados relacional.
Cabe salientar que entre os sistemas de arquivos comparados, ReiserFS, Ext3 e XFS são comumente utilizados pelo sistema operacional Linux e JFS é geralmente utilizado para Unix.
Portanto, não foi possível encontrar alguma comparação entre sistemas de arquivos Linux e os sistemas de arquivos Windows, sendo estes, especificamente FAT, NTFS e ReFS, que é utilizado nas versões mais recentes do Windows Server.
3. Ambiente de testes
Para a execução dos testes e coleta do desempenho das amostras foi necessário montar um
ambiente de testes, utilizando um servidor exclusivo para a instalação do PostgreSQL e utilizando outro servidor para execução do programa que executa os testes e coleta os dados para compilação das estatísticas. O PostgreSQL foi instalado em três ambientes, onde os testes foram
aplicados. O primeiro ambiente utilizado para a instalação do PostgreSQL foi o Linux, na distribuição
CentOS, versão 7. Segundo Silva e Silva (2013), o crescimento do Linux em servidores se deve pelas suas vantagens sobre o Windows.
De acordo com Noyes (2010), o Linux tem maior estabilidade e segurança e não exige
atualizações de hardware para suportar demandas crescentes, além de ser mais leve e consumir menos espaço de armazenamento.
O segundo ambiente utilizado para hospedagem do PostgreSQL foi o sistema operacional Windows Server 2012. Neste sistema, foi feita a atualização para a versão R2, considerada mais estável.
De acordo com Leite, Jordano e Morales (2012), a adoção de melhores práticas de instalação e configuração do Windows Server faz com que a infraestrutura da empresa seja estável,
mantendo os requisitos básicos de segurança que são confidencialidade, integridade e disponibilidade.
No terceiro ambiente foi utilizada uma máquina virtual. O programa VirtualBox For Linux
Hosts foi instalado no Windows Server 2012 R2. Neste ambiente virtual, foi instalado o Linux,

na distribuição CentOS, versão 7, sendo que para esta máquina virtual, foram disponibilizados 2
GB de memória RAM, do servidor que possui capacidade física total de 4GB. Segundo Mattos (2008), a virtualização permite que em uma mesma máquina sejam
executadas simultaneamente dois ou mais ambientes distintos e isolados. Algumas utilizações cada vez mais comuns da virtualização são a consolidação de servidores e a virtualização da infraestrutura de TI.
A ferramenta de teste utilizada nos testes de desempenho foi o Apache jMeter versão 3.0. O Apache jMeter é uma ferramenta desenvolvida em java, com o objetivo de aplicar testes de
desempenho e estresse em aplicações cliente/servidor. O projeto que deu origem a ferramenta jMeter foi iniciado pelo desenvolvedor Stefanno Mazzochi, membro do Apache Software Foundation e atualmente é Open Source e sua continuação acontece através da contribuição de
milhares de pessoas ao redor do mundo (JMETER, 2016). O jMeter possui um componente que gerencia as requisições que são feitas quando o plano de
testes é executado. Entre as requisições que podem ser testadas com este componente, as mais comuns são as requisições FTP, HTTP e JDBC.
Para os testes aplicados foram utilizadas requisições JDBC executando chamadas para uma
função. Esta por sua vez, foi desenvolvida exclusivamente para a importação de um arquivo de texto e alimentação da estrutura de tabelas criadas no banco de dados.
A escolha do jMeter para a execução dos testes foi feita porque ele fornece diversos recursos para medição e aplicação de testes, sendo todos de forma gratuita. Outras ferramentas com as mesmas características, como o WebLoad por exemplo, possuem limitações na disponibilidade
de recursos em versões de avaliação e necessitam da aquisição de licença para que seja possível utilizar todas as funcionalidades.
O PostgreSQL foi o banco de dados relacional escolhido para a execução dos testes e comparação de desempenho em cada um dos ambientes. Este é um SGBD de código aberto gerado pelo projeto POSTGRES, da Universidade de Berkeley. Atualmente, é mantido por um
grupo profissionais de várias partes do mundo, estando disponível sob a flexível licença BSD, que é uma licença de código aberto, inicialmente utilizada por alguns sistemas operacionais.
Segundo o PostgreSQL Global Development Group (2009), o PostgreSQL pode ser utilizado, modificado e distribuído livre de custos para qualquer propósito, seja ele comercial, privado ou acadêmico.
De acordo com Ferreira e Trad (2012), o PostgreSQL segue a padronização SQL (Structured Query Language - Linguagem Estruturada de Consulta), uma linguagem de interface para
SGBD. O PostgreSQL é um descendente de código fonte aberto, que suporta muitas funcionalidades,
como chaves estrangeiras, gatilhos, visões, integridade transacional e comandos complexos.
A versão do PostgreSQL escolhida para os testes foi a 9.5, que é a versão mais atual disponível e, consequentemente, é a versão que apresenta a maior quantidade de recursos.
As características do servidor onde o PostgreSQL 9.5 foi hospedado e do servidor utilizado como cliente, para a execução das instruções a partir do jMeter são ilustradas na Tabela 1. O servidor dedicado ao banco de dados ficou reservado exclusivamente para a instalação do
PostgreSQL 9.5 e neste foi instalado o sistema operacional Linux CentOS, versão 7, e posteriormente o Windows Server 2012 R2.
Tabela 1 – Configuração da máquina local e remota utilizadas para os testes de desempenho
Servidor PostgreSQL Servidor Cliente
Modelo LG R490 ASUS Z450L
Processador Intel(R) Core(TM) i7-3612QM
CPU @2.10GHz
Intel Core I5 – 5200U
2.2GHz
Memória RAM 4GB – DDR3 – 1333 Mhz 8GB – DDR3 – 1600
Mhz
Disco Samsung 5400RPM 640GB Toshiba 5400RPM 1TB
Fonte: elaborada pelo próprio autor
Para o PostgreSQL, não foi utilizada a configuração padrão aplicada pela instalação. A configuração foi alterada seguindo as instruções do site http://pgtune.leopard.in.ua, desenvolvido
pelo arquiteto de software Alexey Vasiliev. Esta alteração foi realizada para que o desempenho do PostgreSQL esteja alinhado com a quantidade de memória disponibilizado para a execução do banco de dados.
Na parametrização do cálculo da nova configuração, foi utilizado 2GB de memória, 100 conexões e o PostgreSQL na versão 9.5.
A configuração ilustrada na Tabela 2 foi aplicada no arquivo postgresql.conf e foi replicada nos três ambientes.
Tabela 2 – Configuração realizada no PostgreSQL
Nome da configuração
PostgreSQL
Valor da configuração
padrão PostgreSQL
Valor da configuração
realizada para testes
max_connections 100 100
shared_buffers 128MB 512MB
effective_cache_size 4GB 1536MB
work_mem 4MB 5242KB
maintenance_work_mem 64MB 128MB
min_wal_size 80MB 1GB
max_wal_size 1GB 2GB
checkpoint_completion_target 0.5 0.7
wal_buffers 128MB 16MB
default_statistics_target 100 100
Fonte: elaborada pelo próprio autor
Para permitir o acesso do servidor onde o jMeter foi instalado, no servidor onde o PostgreSQL foi hospedado, foi necessário alterar duas configurações. O arquivo pghba.conf foi
modificado, acrescentando o IP do servidor com o jMeter e o método de autenticação foi alterado para trust.
Para padronizar os testes e para realizar a limpeza de cache, o serviço do PostgreSQL foi
reiniciado após cada execução da função. Depois de cada execução de teste no jMeter, foi utilizado o botão para limpeza de histórico para que as antigas estatísticas não fossem exibidas
ou utilizadas nos cálculos de média.
4. Metodologia
O cenário utilizado para a realização dos testes de desempenho foi baseado na importação dos
dados de um arquivo de texto para uma estrutura de dados predefinida. Este cenário foi escolhido porque a troca e importação de informações através de arquivos de texto é um meio muito
comum para exportação e importação de dados entre sistemas de informação, sendo também uma realidade comum nas empresas que lidam com alguns destes sistemas.
Para a aplicação dos testes, foi montada uma estrutura que permite o cadastramento de
informações para a realização de cobrança de uma determinada pessoa. A estrutura registra os dados cadastrais da pessoa, os dados referentes a cobrança, incluindo o contrato e os títulos
herdados por esta pessoa, além das informações de contato e localização, registrados como endereço.
Para o armazenamento e manutenção dos dados que foram importados através do arquivo de
texto, foram criados os conjuntos de dados representados na Tabela 3, que ilustra o nome tabela criada no banco de dados, descreve seu propósito, ou seja, quais dados serão armazenados na

mesma. Nesta tabela também são exibidos os índices que foram criados para que a consulta dos
dados seja otimizada, de acordo com as chaves primárias.
Tabela 3 – Tabelas utilizadas para registro dos dados e índices criados
Nome da Tabela Propósito Índices
Devedor Manter informações cadastrais do
devedor.
devedor_iu_01: Coluna devcpf (CPF)
Pessoa Manter informações cadastrais da
pessoa, que poderá ser uma
referência ou avalista.
pessoa_iu_01: Coluna pescpf (CPF)
Contrato Manter as informações relacionadas
ao contrato
contrato_iu_01: Coluna connumcon
(Número do contrato)
contrato_parcela Manter as parcelas herdadas pelo
devedor
Contrato_parcela_iu_01: Colunas
connumcon (Número do contrato) e
conpardatven (Vencimento do título).
Endereco Manter os endereços relacionados a
pessoa
endereco_iu_01: Colunas endcep (CEP),
endrua (rua), endcid (cidade), endbai
(bairro) e enduf (estado)
Fonte: elaborada pelo próprio autor
O arquivo que contém os dados que serão importados durante os testes possui dois tipos de
registros, identificados pelas letras C e P que estão localizados logo no primeiro caractere de
cada linha do arquivo. Os registros do tipo C contêm todas as informações cadastrais do cliente, além das informações relacionadas ao endereço.
O registro do tipo P possui as informações de contrato, com o tipo de produto adquirido pelo cliente, além das informações de cobrança, como data de vencimento dos títulos e valor da dívida.
Para os testes de importação utilizando a Function do PostgreSQL, foi criada uma tabela temporária que irá armazenar o conteúdo do arquivo de texto, antes da gravação na estrutura das
tabelas. Para gravar as informações contidas no arquivo de texto na tabela temporária, foi utilizado o recurso copy do PostgreSQL, que permite a importação de arquivos para estruturas contidas no banco de dados, além do contrário, ou seja, exportar dados contidos nas estruturas do
PostgreSQL para determinados arquivos.
Figura 1 – Registro “C” do arquivo de texto para importação
Fonte: elaborada pelo próprio autor
A Figura 1 ilustra o registro “C” do arquivo importação, que contêm as informações cadastrais do cliente que serão inseridas nas tabelas devedor, pessoa e endereco. Este registro possui o CPF do cliente, contido na coluna 4 do arquivo, que é utilizado como chave primária
nas tabelas devedor e pessoa. A chave primária para armazenamento das informações de endereço são a rua, CEP, bairro, cidade e estado, nas colunas 8, 11, 12, 13 e 14, respectivamente.
Figura 2 – Registro “P” do arquivo de texto para importação
Fonte: elaborada pelo próprio autor
A Figura 2 ilustra o registro “P” do arquivo importação, que contêm as informações de dívida, que serão armazenadas nas tabelas contrato e contrato_parcela. Este registro possui o CPF do

cliente, contido na coluna 2 do arquivo e o número do contrato, contido na coluna 4, que são
utilizados como chave primária na tabela contrato. A chave primária da tabela contrato_parcela é composta pelo número do contrato, localizado na coluna 4 e pela data de vencimento do título,
localizada na coluna 7 deste registro.
Figura 2 – Função que efetua a leitura do arquivo de texto e gravação na estrutura de dados
Fonte: elaborada pelo próprio autor
A Figura 2 ilustra a função desenvolvida no PostgreSQL, utilizando a linguagem PGPLSQL,
que faz a importação do arquivo de texto contendo a carga de dados. Entre as linhas 1 e 15 é possível visualizar a criação da função e declaração de variáveis. Na linha 18 é possível ver
como são removidos os dados da tabela temporária e na linha 19 está o copy que faz a leitura do arquivo e insere os dados na tabela temporária. Na linha 20 é utilizado o comando for, que efetua a leitura nas linhas da tabela temporária. Na linha 25 é utilizada uma condição para identificar o
tipo de registro a ser processado e na linha 28 é feita uma consulta através do CPF, que verifica se o devedor existe.
Para a navegação entre os registros da tabela temporária que contém os dados do arquivo, foi definido uma variável do tipo Record, também conhecida em outros bancos de dados relacionais como cursor.
Utilizando esta navegação, cada um dos registros é lido e identificado. Usando sua chave, se este registro lido não existir, será inserido na sua respectiva tabela dentro da estrutura
predefinida.

Figura 3 – Lógica do registro de inclusão de contratos e parcelas
Fonte: elaborada pelo próprio autor
Na Figura 3, é possível visualizar a lógica utilizada para o processamento dos registros de contrato e títulos. Na linha 140 é utilizada uma condição que verifica o tipo de registro. Na linha 143, o código do cliente é localizado através do CPF e é utilizado para a busca do código do
contrato, juntamente com o número do contrato obtido através do arquivo na linha 149. Na linha 156, a data de atualização é sobrescrita. Na linha 164, um novo registro é inserido na tabela
contrato. As demais linhas da função não foram ilustradas ou explicadas, pois seguem a mesma lógica e
utilizam as mesmas instruções demonstradas nas duas figuras acima.
Após a primeira execução da função, os registros estarão inseridos na base de dados. Com o comando select, tais registros serão localizados através das chaves das tabelas criadas, e nestas
tabelas serão reescritas apenas as datas de atualização. Todos os selects foram feitos utilizando identificadores únicos das linhas do arquivo de importação, portanto, não foi utilizado join entre tabelas na função de importação.
Para coletar e analisar os resultados obtidos, foram adicionados ouvintes no jMeter denominados relatório de sumário e relatório agregado.
Para a configuração do jMeter, foi necessário informar o local do arquivo contendo o driver do PostgreSQL. Além do driver, foi necessário informar o IP do servidor que hospedou o PostgreSQL, a base de dados criada para o teste e usuário e senha do banco de dados. Na
configuração da requisição JDBC, foi necessário inserir a chamada da função fu_importao_remessa(), que inicia a iteração e efetua a realização do teste.
5. Resultados
A análise dos resultados é demonstrada de forma comparativa entre as requisições realizadas no PostgreSQL, instalado sobre um servidor com sistema operacional Windows Server, e
posteriormente Linux, e em seguida utilizando um servidor virtualizado com sistema operacional
Linux sobre um host de virtualização em Windows Server. Para fazer a análise, a quantidade de amostras coletadas nos três ambientes foi exatamente a
mesma, com testes realizados 30 vezes com 1 iteração, 30 vezes com 10 iterações e 30 vezes com 100 iterações. Após a execução dos testes e armazenamento das estatísticas, a média de cada um dos grupos de iterações foi calculada.
Para a análise de cada métrica, foram selecionados os resultados obtidos com os testes realizados com 100 iterações.
A iteração é iniciada no momento que o jMeter efetua uma requisição JDBC, disparando a função fu_importao_remessa, que efetua a leitura do arquivo de carga hospedado no mesmo servidor onde o banco de dados está instalado e insere ou atualiza os dados nas tabelas da
estrutura predefinida. A iteração termina quando a execução da função é finalizada. Para cada linha do arquivo, a função executa 7 vezes o comando select, 5 vezes o comando insert e 5 vezes
o comando update. O comando delete é utilizado apenas uma vez na execução da função, para remover os registros da tabela temporária utilizada.
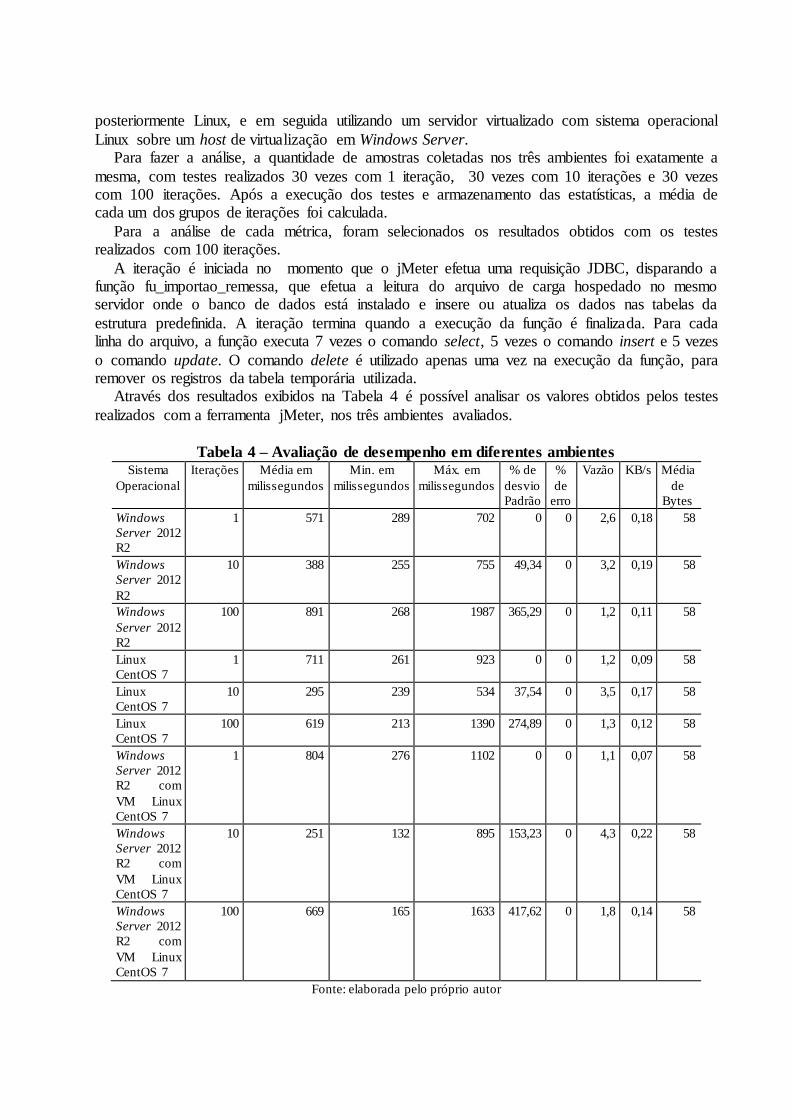
Através dos resultados exibidos na Tabela 4 é possível analisar os valores obtidos pelos testes
realizados com a ferramenta jMeter, nos três ambientes avaliados.
Tabela 4 – Avaliação de desempenho em diferentes ambientes Sistema
Operacional
Iterações Média em
milissegundos
Min. em
milissegundos
Máx. em
milissegundos
% de
desvio
Padrão
%
de
erro
Vazão KB/s Média
de
Bytes
Windows
Server 2012
R2
1 571 289 702 0 0 2,6 0,18 58
Windows
Server 2012
R2
10 388 255 755 49,34 0 3,2 0,19 58
Windows
Server 2012
R2
100 891 268 1987 365,29 0 1,2 0,11
58
Linux
CentOS 7
1 711 261 923 0 0 1,2 0,09 58
Linux
CentOS 7
10 295 239 534 37,54 0 3,5 0,17 58
Linux
CentOS 7
100 619 213 1390 274,89 0 1,3 0,12 58
Windows
Server 2012
R2 com
VM Linux
CentOS 7
1 804 276 1102 0 0 1,1 0,07 58
Windows
Server 2012
R2 com
VM Linux
CentOS 7
10 251 132 895 153,23 0 4,3 0,22 58
Windows
Server 2012
R2 com
VM Linux
CentOS 7
100 669 165 1633 417,62 0 1,8 0,14 58
Fonte: elaborada pelo próprio autor

O sistema operacional Linux CentOS obteve o melhor desempenho no teste com 100
iterações, com uma média de 619 milissegundos, enquanto no Windows, a média foi de 891 milissegundos para cada execução. Na comparação direta, o Linux foi 43,94% mais eficiente do
que o Windows. Nos testes com a máquina virtual com Linux, a média foi de 669 milissegundos, sendo esta média apenas 8,07% mais lenta do que a média do Linux instalado diretamente sobre o host físico, e 33,18% mais rápida do que os testes realizados no Windows.
Na análise do tempo mínimo, a máquina virtual obteve o melhor desempenho, com o tempo de 165 milissegundos para a amostra mais rápida, enquanto o Windows obteve o pior resultado,
com o tempo de 268 para a amostra mais rápida, sendo o desempenho da máquina virtual 62,42% melhor do que o tempo do Windows. A amostra mais rápida do Linux executou em 213 milissegundos, sendo este tempo 29,09% mais lento do que a máquina virtual e 25,82% mais
rápida do que a amostra do Windows. Em relação ao tempo máximo, a amostra com maior tempo no Linux executou em 1390
milissegundos, enquanto a amostra com maior tempo no Windows executou em 1987 milissegundos, sendo o Linux 42,94% mais eficiente nesta comparação. A amostra mais lenta da máquina virtual executou em 1633 milissegundos, sendo este resultado 17,48% mais lento do
que o Linux instalado diretamente sobre o host físico e 21,68% mais rápido do que a amostra do Windows.
Na avaliação do desvio padrão, o maior desvio foi da máquina virtual, sendo este desvio de 417,62%. O segundo maior desvio foi do Windows, com o valor de 365,29%. O menor desvio padrão foi o do Linux, com 274,89%.
Não foram registrados erros nos testes realizados, portanto, o valor percentual de erro para os três ambientes avaliados foi zero.
A métrica de vazão, que é a medição da velocidade de retorno das requisições, obteve um valor de 1,8 para a máquina virtual. Para o Linux, este valor foi de 1,3, e para o Windows foi de 1,2, sendo esta a menor vazão.
Na medição de Kilo Bytes por segundo, análise que mede o volume de transferência de dados por segundo, o melhor resultado foi da máquina virtual, com 0,14, enquanto o Windows obteve
um resultado de 0,11, sendo a máquina virtual 27,27% mais eficiente do que o Windows. O Linux obteve um desempenho de 0,12, sendo 16,67% mais ineficiente do que a máquina virtual e 9,09% mais eficiente do que o Windows.
Figura 5 – Comparativo de desempenho entre Windows, máquina Virtual Linux e Linux
Fonte: elaborada pelo próprio autor
A Figura 5 ilustra o desempenho dos três ambientes em um gráfico, exibindo o tempo médio de execução das amostras em milissegundos. Para os testes com uma iteração, o Windows obteve

o melhor resultado, o Linux ficou em segundo e a máquina virtual obteve o pior resultado. Nos
testes com 10 iterações, a máquina virtual obteve o melhor resultado, o Linux o segundo e o Windows obteve o pior desempenho. Nos testes com 100 iterações, o Linux CentOS instalado
diretamente sobre o host físico foi o ambiente mais eficiente, seguido pela máquina virtual com o Linux CentOS. O Windows Server obteve a pior média, sendo ela 44,64% inferior ao resultado obtido pelo Linux CentOs.
Considerações Finais
Com o resultado, é possível afirmar que entre os três ambientes avaliados, o ambiente que
apresentou o melhor desempenho foi o sistema operacional Linux CentOS. Este ambiente obteve o melhor resultado no tempo médio de execução por requisição. O tempo médio pode ser considerado o parâmetro de medição mais importante desta comparação, uma vez que ele
influencia diretamente no tempo total de execução dos testes, consequentemente, fazendo com que o PostgreSQL termine de processar a mesma tarefa mais rapidamente no Linux do que nos
outros ambientes. Além do melhor tempo médio, o Linux também apresentou o menor tempo máximo de
execução de uma amostra, resultado que colabora diretamente com o excelente tempo médio
obtido por este ambiente. A execução dos testes na máquina virtual apresentou resultados muito positivos, obtendo o
melhor desempenho na avaliação do menor tempo mínimo, a melhor vazão e a melhor taxa de transferência de dados por segundo. A máquina virtual também apresentou um bom desempenho no tempo médio de execução, sendo este apenas 8,96% inferior ao ambiente com Linux CentOS
não virtualizado. O Windows Server 2012 R2 obteve o pior desempenho entre os três ambientes avaliados,
apresentando os piores resultados para tempo médio, tempo mínimo e tempo máximo de execução por requisição. Além disto, também apresentou os piores resultados de vazão e volume de transferência de dados. O Windows apenas não apresentou o pior resultado na avaliação do
desvio padrão, onde ele ficou com o segundo desempenho entre os três ambientes avaliados. Portanto, avaliando os resultados obtidos, é possível determinar que se o fator mais relevante
para a escolha do sistema operacional onde o PostgreSQL deve ser instalado for o desempenho, o melhor sistema operacional será o Linux. Se for necessário utilizar o Windows, uma boa opção é a instalação de uma máquina virtual com Linux na distribuição CentOS, pois este ambiente
alternativo se mostrou muito eficiente nos testes realizados. Inclusive, mostrou-se um ambiente melhor do que o ambiente onde o PostgreSQL está instalado sobre um servidor com sistema
operacional Windows. Em trabalhos futuros, pode ser comparado o desempenho do PostgreSQL com outros bancos
de dados relacionais. Também pode ser avaliado o desempenho do PostgreSQL em diferentes
distribuições do Linux. Além disso, pode-se realizar uma medição das requisições do PostgreSQL em diferentes sistemas de arquivos utilizados no Windows, para que seja possível
determinar o sistema de arquivos que apresenta o melhor desempenho entre os sistemas operacionais.
Referências
ALMEIDA, V. Análise e Modelagem de Desempenho de Sistemas de Computação. Belo
Horizonte, Universidade Federal de Minas Gerais, 2009. CARNEIRO, A.P; MOREIRA, J.L; FREITAS, A.L.C. Técnicas de otimização de Banco de
Dados, um estudo comparativo: MYSQL e PostgreSQL. Trabalho de Especialização, Universidade Federal do Rio Grand, Rio Grande, 2011.

CASTANHEDE, T.; DILL, S.L.; PADOIN, E.; SAUSEN P.; CAMARGO, R. Avaliando o
desempenho do SGBD PostgreSQL considerando os diferentes sistemas de arquivos : Trabalho de Especialização, Universidade Regional do Noroeste do Estado do Rio Grande do
Sul, Ijuí, 2009.
FERREIRA, E; TRAD S. Análise de desempenho de Banco de Dados . Trabalho de Especialização, Universidade Presidente Antônio Carlos, Barbacena, 2012.
FONSECA, J. J. S. Metodologia da pesquisa científica. Fortaleza: UEC, 2002. Apostila.
GIL, A. C. Como elaborar projetos de pesquisa. 4. ed. São Paulo: Atlas, 2007.
JAIN, R. Computer Systems Performance Analysis. Disponível em: http://www.cse.wustl.edu/~jain/iucee/ftp/k_01int.pdf. Acesso em: 02 Nov. 2016.
JMETER, A. The apache software foundation. Disponível em: http://jmeter.apache.org/. Acesso
em: 28 Ago. 2016.
LEITE, C.E.F; GIORDANO, J.P.L; MORALES, I.L. Melhores práticas de instalação e
segurança do active directory no Windows Server 2008. Faculdades integradas de Bauru, Bauru, 2012.
MATTOS, D.M.F. Virtualização: VMWare e Xen. Universidade Federal do Rio de Janeiro,
Rio de Janeiro, 2008.
NOYES, K. Veja porque o Linux está à frente do Windows em servidores. Disponível em:
<http://pcworld.uol.com.br/noticias/2010/08/31/veja-porque-olinux-esta-a-frente-do-windows-em-servidores/> Acesso em: 13 Out. 2016.
POSTGRESQL GLOBAL DEVELOPMENT GROUP. Documentation PostgreSQL
8.4.22. Disponível em: http://www.postgresql.org/docs/8.4/static/index.html. Acesso em: 29 Ago. 2016.
SILVA, M. Estudo comparativo entre as linguagens procedureis PLSQL e PLPGSQL
aplicadas aos bancos de dados Oracle 10G XE e PostgreSQL 8.4. Trabalho de Conclusão de Curso, Universidade Tecnológica Federal do Paraná, 2011.
SILVA, L.R.C; SILVA, A.P.S. Softwares para criação de mecanismo de segurança baseado
na plataforma Linux. Trabalho de Especialização, Universidade Paranaense, Paranavaí, 2013.
VASILIEV, A. Configuration calculator for PostgreSQL. Disponível em: http://pgtune.leopard.in.ua/. Acesso em: 16 Ago.2016


















