
Avaliação da Execução de Aplicações Orientadas à Dados na ... · Avaliação da execução...
63
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE CENTRO DE CIÊNCIAS EXATAS E DA TERRA DEPARTAMENTO DE INFORMÁTICA E MATEMÁTICA APLICADA PROGRAMA DE PÓS-GRADUAÇÃO EM SISTEMAS E COMPUTAÇÃO MESTRADO EM SISTEMAS E COMPUTAÇÃO CHRISTIANE DE ARAÚJO NOBRE Avaliação da Execução de Aplicações Orientadas à Dados na Arquitetura de Redes em Chip IPNoSys Natal/RN Agosto, 2012
-
Upload
truongnhan -
Category
Documents
-
view
215 -
download
0
Transcript of Avaliação da Execução de Aplicações Orientadas à Dados na ... · Avaliação da execução...

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXATAS E DA TERRA
DEPARTAMENTO DE INFORMÁTICA E MATEMÁTICA APLICADA
PROGRAMA DE PÓS-GRADUAÇÃO EM SISTEMAS E COMPUTAÇÃO
MESTRADO EM SISTEMAS E COMPUTAÇÃO
CHRISTIANE DE ARAÚJO NOBRE
Avaliação da Execução de Aplicações Orientadas à Dados
na Arquitetura de Redes em Chip IPNoSys
Natal/RN
Agosto, 2012

CHRISTIANE DE ARAÚJO NOBRE
Avaliação da Execução de Aplicações Orientadas à Dados
na Arquitetura de Redes em Chip IPNoSys
Dissertação submetida ao Programa de Pós-
Graduação em Sistemas e Computação do
Departamento de Informática e Matemática
Aplicada da Universidade Federal do Rio Grande
do Norte como parte dos requisitos para obtenção
do título de Mestre em Sistemas e Computação
(MSc.)
Orientador: Prof. Dr. Márcio Eduardo Kreutz
Natal/RN
Agosto, 2012

Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial
Especializada do Centro de Ciências Exatas e da Terra – CCET.
Nobre, Christiane de Araújo.
Avaliação da execução de aplicações orientadas à dados na arquitetura de redes
em chip IPNoSys / Christiane de Araújo Nobre. – Natal, 2012.
63 f. : il.
Orientador: Prof. Dr. Márcio Eduardo Kreutz.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro
de Ciências Exatas e da Terra. Departamento de Informática e Matemática Aplicada.
Programa de Pós-Graduação em Sistemas e Computação.
1. Arquitetura de redes - Dissertação. 2. Redes em chip - Dissertação. 3.
Sistemas embarcados – Dissertação. 4. Processamento paralelo - Dissertação. 5.
Paralelismo em nível de instruções - Dissertação. 6. Aplicações orientadas a dados.
I. Kreutz , Márcio Eduardo. II. Título
RN/UF/BSE-CCET CDU: 004.72
RN/UF/BSE-CCET CDU 004:577.2


Agradecimentos
À Deus, pela vida, por ter me dado capacidade, sabedoria e persistência para realizar este
trabalho.
À minha mãe Edinilse, por ter me ensinado a ser sempre generosa, modéstia, ter paciência,
esperança e saber perdoar. Ao meu pai Sérgio, por sempre ter me incentivado a aperfeiçoar meus
conhecimentos e a buscar novas conquistas.
Ao meu orientador Márcio Kreutz, pela compreensão, confiança, incentivo, pelos exemplos de
competência e dedicação e por ter aceitado me orientar no mestrado. Agradeço pelo constante bom
humor, e pelo apoio dado nesta conquista.
Aos professores que, de uma forma ou de outra, apresentaram sugestões, ideias e
direcionamentos que foram de grande valia na continuidade e finalização do trabalho.
Ao meu esposo, Thiago, amigo e companheiro incansável, fonte de carinho e força nos
momentos mais difíceis. Pessoa fundamental na minha e na concretização deste trabalho.
Às minhas irmãs Valéria e Isabela, e aos demais familiares, pelo apoio incondicional dado em
todas as etapas da minha vida.
Aos amigos e colegas Sílvio, Jefferson e Jonathan, com quem muito aprendi e cujo trabalho,
ajuda e sugestões serviram como base para os resultados aqui apresentados.
As amigas e colegas Alba, Aparecida, Dayanne, Eliselma, Katyanne, que muito admiro e com
quem sempre posso contar a qualquer hora.
Aos amigos do LASIC, pela amizade, compreensão e ajuda ao longo do mestrado.
À CAPES, pelo apoio financeiro, que possibilitou meus estudos e pesquisas.

RESUMO
A crescente complexidade dos circuitos integrados impulsionou o surgimento de arquiteturas
de comunicação do tipo Redes em chip ou NoC (do inglês, Network-on-Chip), como
alternativa de arquitetura de interconexão para Sistemas-em-Chip (SoC; Systems-on-Chip). As
redes em chip possuem capacidade de reuso de componentes, paralelismo e escalabilidade,
permitindo a reutilização em projetos diversos. Na literatura, têm-se uma grande quantidade
de propostas com diferentes configurações de redes em chip. Dentre as redes em chip
estudadas, a rede IPNoSys possui arquitetura diferenciada, pois permite a execução de
operações, em conjunto com as atividades de comunicação. Este trabalho visa avaliar a
execução de aplicações orientadas a dados na rede IPNoSys, focando na sua adequação frente
às restrições de projeto. As aplicações orientadas a dados são caracterizadas pela comunicação
de um fluxo contínuo de dados sobre os quais, operações são executadas. Espera-se então, que
estas aplicações possam ser beneficiadas quando de sua execução na rede IPNoSys, devido ao
seu elevado grau de paralelismo e por possuírem modelo de programação semelhante ao
modelo de execução desta rede. Uma vez observadas a execução de aplicações na rede
IPNoSys, foram realizadas modificações no modelo de execução da rede IPNoSys, o que
permitiu a exploração do paralelismo em nível de instruções. Para isso, análises das execuções
de aplicações data flow foram realizadas e comparadas.
Palavras-chave: Redes em chip, arquiteturas de sistemas embarcados, processamento
paralelo, paralelismo em nível de instruções, aplicações orientadas a dados.

ABSTRACT
The increasing complexity of integrated circuits has boosted the development of
communications architectures like Networks-on-Chip (NoCs), as an architecture; alternative
for interconnection of Systems-on-Chip (SoC). Networks-on-Chip complain for component
reuse, parallelism and scalability, enhancing reusability in projects of dedicated applications.
In the literature, lots of proposals have been made, suggesting different configurations for
networks-on-chip architectures. Among all networks-on-chip considered, the architecture of
IPNoSys is a non conventional one, since it allows the execution of operations, while the
communication process is performed. This study aims to evaluate the execution of data-flow
based applications on IPNoSys, focusing on their adaptation against the design constraints.
Data-flow based applications are characterized by the flowing of continuous stream of data,
on which operations are executed. We expect that these type of applications can be improved
when running on IPNoSys, because they have a programming model similar to the execution
model of this network. By observing the behavior of these applications when running on
IPNoSys, were performed changes in the execution model of the network IPNoSys, allowing
the implementation of an instruction level parallelism. For these purposes, analysis of the
implementations of dataflow applications were performed and compared.
Keywords: Network-on-chip, embedded systems architecture, parallel processing, instruction
level parallelism, data oriented applications.

Lista de Figuras
Figura 1 – Topologias diretas: (a)Grelha 2D; (b) Torus 2D; (c) Cubo 3D; (d) Cubo 4D ou
Hipercubo; (e) Totalmente Conectada ...................................................................................... 17
Figura 2 – Topologias indiretas: (a) Crossbar; (b) rede multiestágio Ômega ......................... 17
Figura 3 – Exemplos de algoritmos de roteamento e suas rotas para enviar uma mensagem do
nodo A para o nodo B ............................................................................................................... 18
Figura 4 – Composição de uma mensagem: pacotes; flit; phits ............................................... 20
Figura 5 – Abordagens para implementação de árbitros: (a) centralizada; (b)
distribuída.................................................................................................................................21
Figura 6 – Estratégias de memorização utilizando roteador com quatro buffers: (a)SAFC;
(b)SAMQ; (c)DAMQ...............................................................................................................21
Figura 7 – Arquitetura IPNoSys...............................................................................................23
Figura 8 – MAU na Arquitetura IPNoSys................................................................................24
Figura 9 – RPU na Arquitetura IPNoSys..................................................................................25
Figura 10 – Spiral Complement: (a) 1ª espiral; (b) 2ª epiral; (c) 3ª espiral; (d) 4ª espiral........26
Figura 11 – Formato do pacote da rede IPNoSys.....................................................................27
Figura 12 – Programa básico na linguagem a fluxo de dados.................................................32
Figura 13 – Visão geral do sistema .........................................................................................36
Figura 14 – Formato do pacote modificado para programação................................................39
Figura 15 – Formato do pacote modificado para execução......................................................40
Figura 16 – Etapa de programação da rede IPNoSys Dataflow – Parte 1................................42
Figura 17 – Etapa de programação da rede IPNoSys Dataflow – Parte 2................................43
Figura 18 – Etapa de programação da rede IPNoSys Dataflow – Parte 1................................44
Figura 19 – Etapa de execução da rede IPNoSys Dataflow – Parte 1......................................45
Figura 20 – Etapa de execução da rede IPNoSys Dataflow – Parte 2......................................46
Figura 21 – Etapa de execução da rede IPNoSys Dataflow – Parte 3......................................46
Figura 22 – Tempo de Execução da Aplicação SDF: (a) 1 Pacote; (b) 2 Pacotes...................48
Figura 23 – Tempo de Execução da Aplicação SDF: (a) 3 Pacotes; (b) 4 Pacotes.................49

Figura 24 – Potência da Rede IPNoSys: (a) 1 Pacote; (b) 2 Pacotes…...................................50
Figura 25 – Potência da Rede IPNoSys: (a) 3 Pacotes; (b) 4 Pacotes......................................51
Figura 26 – Quantidade de RPUs percorrido no Spiral Complement......................................55
Figura 27 – Roteamento com bloqueio da rede.......................................................................56
Figura 28 – Desempenho estimado para variações da rede com dimensões 4x4....................57
Figura 29 – Desempenho estimado para variações da rede com dimensões 6x6....................58

LISTA DE ABREVIATURAS E SIGLAS
DAMQ Dynamically Allocated Multi-Queue
DCT Discrete Cosine Transform
FIFO First in First Out
IPNoSys Integrated Processing NoC System
IP Intellectual Property
MAU Memory Access Unit
MDFM Manchester Data Flow Machine
MoC Model of Computation
MTTDA MIT Tagged Token Architecture
NoC Network-on-Chip
PDL Package Description Language
QNoC Quality of Service Network-on-Chip
QoS Quality of Service
RPU Routing and Processing Unit
SAFC Statically Allocated Fully Connected
SAMQ Statically Allocated Multi-Queue
SDF Synchronous Data Flow
SoCIN System-on-Chip Interconnection Network
SoC System-on-Chip
ULA Unidade Lógica e Aritmética
VCT Virtual Cut-Through

Sumário
1. INTRODUÇÃO ..................................................................................................... 13
1.1. OBJETIVOS ......................................................................................................................... 15
1.2. ESTRUTURA DO TRABALHO ......................................................................................... 15
2. REFERENCIAL TEÓRICO .................................................................................. 16
2.1. REDES EM CHIP .................................................................................................................. 16
2.1.1. Características das Redes em Chip ........................................................................... 16
2.1.1.1. Topologia ........................................................................................................ 16
2.1.1.2. Roteamento ..................................................................................................... 18
2.1.1.3. Controle de Fluxo .......................................................................................... 19
2.1.1.4. Chaveamento .................................................................................................. 19
2.1.1.5. Arbitragem ..................................................................................................... 20
2.1.1.6. Memorização .................................................................................................. 21
2.1.2. Vantagens e Desvantagens das NoCs ........................................................................ 22
2.2. REDE IPNOSYS .................................................................................................................... 22
2.2.1. Elementos Arquiteturais ............................................................................................ 23
2.2.1.1. MAU - Unidade de Acesso a Memória ......................................................... 23
2.2.1.2. RPU - Unidade de Processamento e Roteamento ....................................... 24
2.2.1.3. Algoritmo Spiral Complement ....................................................................... 25
2.2.1.4. Formato do Pacote ......................................................................................... 26
3. ESTADO DA ARTE ............................................................................................. 30
3.1. MODELO DE COMPUTAÇÃO BASEADO EM FLUXO DE DADOS .......................... 30
3.1.1. Fluxo de Dados Síncrono ........................................................................................... 32
3.1.2. Fluxo de Dados Assíncrono........................................................................................ 33
3.1.3. Fluxo de Dados Dinâmico .......................................................................................... 33

3.2. APLICAÇÕES DATAFLOW ................................................................................................ 33
3.3. ARQUITETURAS DATAFLOW .......................................................................................... 35
4. PROPOSTA DE MODELO DE EXECUÇÃO ORIENTADA A DADOS PARA REDE IPNOSYS .................................................................................................. 38
4.1. FORMATO DOS PACOTES................................................................................................ 38
4.1.1. Formato do pacote de programação ......................................................................... 38
4.1.2. Formato do pacote de execução ................................................................................. 40
4.2. PROGRAMAÇÃO ................................................................................................................. 41
4.3. EXECUÇÃO........................................................................................................................... 44
5. RESULTADOS .................................................................................................... 47
5.1. AVALIAÇÃO ........................................................................................................................ 47
5.2. RESULTADOS ANALÍTICOS ........................................................................................... 52
6. CONSIDERAÇÕES FINAIS ................................................................................. 59
6.1. CONCLUSÕES ...................................................................................................................... 59
6.2. TRABALHOS FUTUROS .................................................................................................... 60
7. REFERÊNCIAS ................................................................................................... 61

13
1. INTRODUÇÃO
Nas ultimas décadas cresceu a necessidade de estudos relacionados com o projeto de
computadores e sistemas periféricos. Contudo, a ênfase de pesquisa tem se deslocado para
uma área muito mais ampla: a de sistemas eletrônicos de uso específico. Sistemas embarcados
são sistemas computacionais que possuem a mesma estrutura geral de um computador, mas a
especificidade de suas tarefas faz com que não sejam usados nem percebidos como um
computador.
HAMMOND (1997) e PATT (1997) já afirmavam que em poucos anos seria
admissível existirem circuitos integrados compostos por mais de um bilhão de transistores, e
atualmente, tal afirmação foi comprovada. Devido a esta capacidade de integração é possível
incluir um sistema computacional completo em um único chip, compondo os chamados SoC
(System-on-Chip) ou Sistemas integrados.
Os SoC são baseados na arquitetura de barramento, que é a forma usual de
interconexão entre os componentes do sistema. A interconexão por barramento é simples, sob
o ponto de vista de implementação, mas apresenta diversas desvantagens (BENINI, 2002): (i)
somente uma troca de dados é realizada por vez, já que o meio físico é compartilhado por
todos os núcleos, provocando a redução do desempenho global do sistema; (ii) necessidade de
mecanismos inteligentes de arbitragem para evitar desperdício; (iii) a escalabilidade é
limitada, ou seja, o número de núcleos que podem ser ligados ao barramento é muito baixo.
Para controlar a complexidade de criar chips contendo bilhões de transistores, é
necessário separar a comunicação da computação. Assim, as NoCs (Network-on-Chip) estão
emergindo como um alternativa para interconexões existentes nos chips, onde a abstração das
camadas de protocolos é utilizada para modularizar o projeto de comunicação. Além disso, a
NoC é uma rede de interconexão chaveada, apresenta largura de banda escalável, usa
conexões ponto a ponto curtas e utiliza o paralelismo na comunicação.
Vários grupos de pesquisa estão estudando as possibilidades arquiteturais das NOCs,
sugerindo soluções para topologias de rede, algoritmos de roteamento, comunicação paralela,
dentre outros. Um dos primeiros resultados efetivos sobre rede em chip foi alcançado usando
a rede NoC SPIN (GUERRIER, 2000), que propôs um modelo de arquitetura baseado em rede
integrada de comutação. E explica porque o barramento compartilhado não cumpre os
requisitos de desempenho e apresenta uma alternativa de interligação que tem origem da
computação paralela.
AGARWAL (2009) sintetiza abordagens e estudos descritos em sessenta artigos de
investigação e contribuições na área do NoC, verificando que é preciso um estudo mais
eficiente nas soluções de baixo custo, área e energia para NoCs, permitindo sua aplicação na

14
indústria de sistemas embarcados. Encontrando soluções adequadas, as redes em chip
são capazes de lidar com as mais diversas áreas, como: sistemas multimídia e de
reconhecimento de voz, jogos 3D, aplicações de tempo-real e algoritmos de codificação e
decodificação de vídeo.
Em uma rede em chip, a topologia é uma das suas principais características,
consistindo na organização da rede sob a forma de grafo, onde os roteadores são os vértices e
os canais os arcos. Um estudo de topologias de NoC irregulares e adaptáveis conforme a
necessidade da aplicação é proposto por STENSGAARD (2008). A arquitetura possibilita a
minimização generalizada da plataforma SoC, incluindo ligações longas e ligações direta
entre blocos IP (Intellectual Property). A topologia é configurada por meio inserção de uma
camada entre roteadores e links, possibilitando uma diminuição de 56% no consumo de
energia em comparação com uma topologia em malha estática 2D.
O chaveamento em NoCs é necessário para definir como as mensagens são
transferidas da entrada dos roteadores para os seus canais de saída. Uma das técnicas de
chaveamento mais importante é a por canais virtuais, já que reduz o bloqueio de um canal por
um determinado pacote na rede. O surgimento de uma arquitetura de buffer centralizado
possibilitou a alocação de canais virtuais em tempo real de acordo com as condições de
trafego da rede, maximizando a taxa de transmissão e a diminuição do buffer, tendo como
resultado a redução da área total e do gasto de energia, obtendo um desempenho semelhante
ao de um roteador genérico (NICOPOULOS et al., 2006).
Em 2004, um grupo de pesquisadores do Israel Institute of Tecnology desenvolveu
uma arquitetura de NoC provendo QoS (Quality of Service). A rede QNoC, foi apresentada
por BOLOTIN et al. 2004, a qual utiliza uma topologia irregular que atende às estruturas
típicas de SoC heterogêneos, usa o chaveamento por pacotes do tipo wormhole e o
mecanismo de controle de fluxo é baseado em créditos combinado com canais virtuais. A QoS
fornecida pela QNoC ocorre por meio da análise do tráfego de comunicação e distribuição das
mensagens em seus níveis de serviço. Uma arquitetura QNoC personalizada pode ser criada
por meio da modificação da sua arquitetura de rede genérica; tal processo de customização
minimiza o custo da rede, mantendo a QoS desejada.
A rede SoCIN (ZEFERINO, 2003) apresenta uma arquitetura de rede em chip,
podendo ser dimensionada para atender aos requisitos de custo e desempenho de sistemas
integrados. Esta rede tem como diferencial um núcleo roteador configurável, que pode ser
dimensionado em função dos requisitos do sistema.
Disso percebe-se a importância e a necessidade de adequação de uma NoC com
propriedades particulares, como é o caso da rede IPNoSys (ARAUJO, 2008) que se diferencia

15
das demais redes em chip encontradas na literatura, pois a mesma utiliza seus próprios
roteadores como elemento de processamento, permitindo a execução de aplicações orientada à
dados. Portanto, a rede IPNoSys pode trazer resultados interessantes para aplicações
especificas, como as aplicações genéricas SDF (Synchronous Data Flow).
1.1. OBJETIVOS
O objetivo mais relevante deste trabalho é avaliar execuções de aplicações SDF na
rede IPNoSys. Pretende-se propor modificações na estrutura da rede visando otimizar as
restrições de projeto.
Como objetivos específicos, este trabalho apresenta:
· Realizar estudos arquiteturais das NoCs.
· Realizar comparações da arquitetura da rede IPNoSys com outras NoCs.
· Mapear aplicações SDF para a rede IPNoSys.
· Analisar a viabilidade da rede IPNoSys, investigando suas vantagens como
NoC ao executar aplicações SDF.
· Propor soluções arquiteturais para rede IPNoSys.
1.2. ESTRUTURA DO TRABALHO
Este trabalho está organizado da seguinte forma: no CAPÍTULO 2 são
apresentados conceitos básicos sobre redes em chip, focando na rede IPNoSys, que foi a
NoC utilizada para o desenvolvimento deste trabalho. O CAPITULO 3, faz uma
introdução ao modelo de computação data flow, e também, é abordada a caracterização
das aplicações e arquiteturas DF. A explicação das modificações que foram feitas na
IPNoSys visando executar aplicações orientada a dados são apresentadas no CAPITULO
4. O CAPITULO 5, apresenta a analise dos resultados obtidos após a proposta de uma
arquitetura IPNoSys baseada em fluxo de dados. O CAPITULO 6 traz a conclusão e os
trabalhos futuros.

16
2. REFERENCIAL TEÓRICO
Nesse capítulo são apresentados os conceitos fundamentais sobre as redes em chip,
discutindo suas principais características e apresentando suas vantagens e desvantagens sobre
as outras redes de interconexão. Além disso, é feita uma revisão sobre a definição do modelo
de computação data flow. Nessa revisão, também são apresentadas as principais variações do
modelo data flow em termos de modelos de execução.
2.1. REDES EM CHIP
A rede em chip vem sendo utilizada como uma nova proposta para conectar múltiplos
processadores em sistemas distribuídos, onde se aplica as ideias de rede de computadores para
dentro de um único chip, conectando-se através de arquiteturas de interconexão muitos
núcleos (Guerrier e Greiner, 2000).
Nos sistemas em chip, a solução ideal é utilizar a rede em chip como mecanismo de
interconexão permitindo um rápido dimensionamento do sistema e um grau maior de
escalabilidade (BENINI; DE MICHELI, 2002). Isso é devido também a sua capacidade de
comunicação paralela entre os elementos do sistema, através da multiplicidade de caminhos
possíveis existentes nela.
2.1.1 Características das Redes em Chip
Uma rede de interconexão pode ser caracterizada pela sua topologia e pelas estratégias
empregadas para roteamento, controle de fluxo, chaveamento, arbitragem utilizada, dentre
outras características. Abaixo serão brevemente definidos e classificados os principais
componentes e algoritmos que constitui uma rede em chip (DUATO, 1997) (ZEFERINO,
2003):
2.1.1.1. Topologia
A topologia de uma rede em chip é a disposição dos nodos e canais sob a forma de um
grafo. Segundo (CARARA, 2004), as topologias podem ser classificadas em duas classes
principais: as redes diretas e as redes indiretas.
Nas topologias da classe de redes diretas cada nodo de chaveamento (roteador) possui
um nodo de processamento, núcleo associado, e esse par pode ser visto como um elemento
único dentro do sistema, tipicamente referenciado pela palavra nodo (DUATO, 97). As
topologias de redes diretas mais utilizadas são a grelha 2D, o toróide 2D, o cubo 3D,
hipercubo (cubo 4D), e a totalmente conectada, exemplificados na Figura 1. Conforme é
ilustrado nessa figura, um nodo é composto pelo processador e pelo roteador.
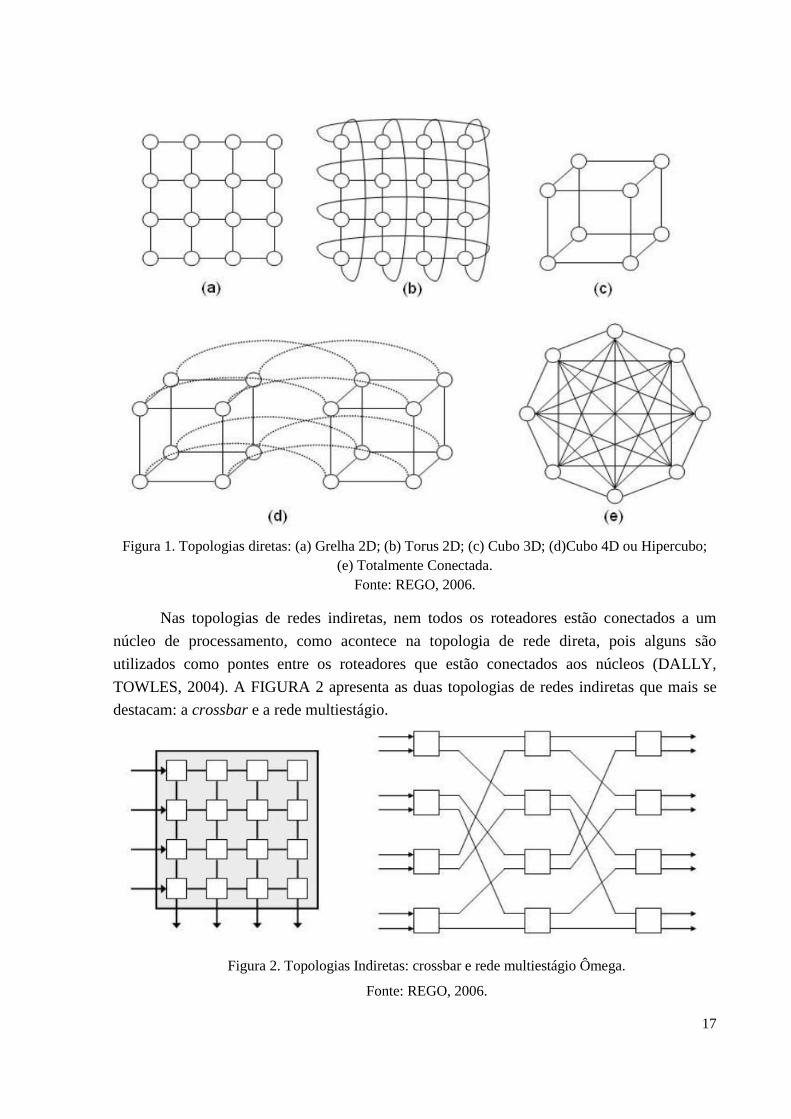
17
Figura 1. Topologias diretas: (a) Grelha 2D; (b) Torus 2D; (c) Cubo 3D; (d)Cubo 4D ou Hipercubo;
(e) Totalmente Conectada.
Fonte: REGO, 2006.
Nas topologias de redes indiretas, nem todos os roteadores estão conectados a um
núcleo de processamento, como acontece na topologia de rede direta, pois alguns são
utilizados como pontes entre os roteadores que estão conectados aos núcleos (DALLY,
TOWLES, 2004). A FIGURA 2 apresenta as duas topologias de redes indiretas que mais se
destacam: a crossbar e a rede multiestágio.
Figura 2. Topologias Indiretas: crossbar e rede multiestágio Ômega.
Fonte: REGO, 2006.

18
2.1.1.2. Roteamento
O algoritmo de roteamento define como um pacote elege um caminho dentro desse
grafo. Para que o pacote chegue ao seu destino, é preciso que ele siga na rede o caminho
indicado pelo algoritmo de roteamento. Podem ser classificados como determinísticos
(algoritmo XY), adaptativos (algoritmo baseado em tabelas) e parcialmente adaptativos
(West-First, North-Last, Negative-Firts) (DUATO, 1997).
Figura 3. Exemplos de algoritmos de roteamento e suas rotas para enviar uma
mensagem do nodo A para o nodo B.
Fonte: MATOS, 2010
De acordo com (DALLY e TOWLES, 2004), é interessante escolher de forma correta
o roteamento mais apropriado para a transmissão do pacote, pois o uso dos recursos da rede
será otimizado; além disso, reduz o caminho percorrido pelo pacote. Logo, a latência da rede
e o tempo necessário para o pacote chegar ao destino são diretamente influenciados pelo
algoritmo de roteamento escolhido.
O objetivo do roteamento é distribuir a circulação de pacotes entre os diversos
caminhos disponibilizados pela topologia de rede, evitando situações de deadlock, livelock e
starvation. Deadlock refere-se a uma interdependência cíclica dos recursos entre os nodos que
bloqueiam indefinidamente certos caminhos da infraestrutura de comunicação. Livelock
ocorre quando pacotes que estão sendo transmitidos pela infraestrutura de comunicação
jamais atingem o seu destino, ou seja, eles ficam circulando na rede. Starvation pode ser

19
definido como uma postergação indefinida de acesso aos recursos de comunicação, ou seja,
um canal de saída fica sempre ocupado (DUATO, 1997).
2.1.1.3. Controle de fluxo
O controle de fluxo determina a alocação de canais e buffers para os pacotes que
circulam na rede em chip. Para diminuir os requisitos de memorização e a latência da NoC é
interessante escolher o mecanismo de controle de fluxo mais apropriado.
A utilização de buffers nos canais de entrada para armazenar os pacotes é a forma
mais comum de controle de fluxo, assegurando que os pacotes não sejam rejeitados e
privando que eles sejam retransmitidos, reduzindo a disputa pelos roteadores ou trafego da
rede. Esta técnica ocasiona a otimização no uso dos recursos da rede.
Os tipos de controle de fluxo mais utilizados existentes na literatura são: handshake,
controle baseado em canais virtuais e controle baseado em créditos (ZEFERINO, 2003). No
mecanismo handshake, o controle define quando um pacote pode ser armazenado nos buffers,
sem verificar o espaço disponível do receptor. Um sinal de ack é enviado do receptor para o
emissor, caso tenha espaço disponível para armazenamento do pacote nos buffers do roteador
receptor. Mas, se não houver buffers disponíveis no roteador, ele envia um sinal nack para o
roteador que emitiu o pacote. O controle de fluxo baseado em canais virtuais realizar a
repartição do buffer de entrada dos roteadores em filas independentes, mas com tamanhos
menores, formando os canais virtuais. Tal mecanismo, tenta resolver os problemas de
deadlock das redes em chip. No controle baseado em créditos o transmissor recebe do
receptor a quantidade de espaço disponível no buffer de entrada, só assim, o transmissor sabe
a quantidade de créditos estão disponíveis para envio de pacotes.
2.1.1.4. Chaveamento
O chaveamento é responsável por determinar como e quando um canal de entrada é
conectado a um canal de saída escolhido pelo algoritmo de roteamento. Antes de explicar os
tipos de chaveamentos, é interessante esclarecer que as mensagens que circulam nas redes em
chip, são quebradas em pacotes, e que cada pacote é dividido em pedaços menores, chamados
de flits, do inglês flow control unit. Todo flit é constituído por um ou mais phits, onde cada
phit é do tamanho da largura do canal físico de dados. A organização da mensagem pode ser
melhor entendida pela FIGURA 4.
Nas redes em chip, os dois métodos de transferências de pacotes mais utilizados são:
chaveamento por circuito e chaveamento por pacotes. No chaveamento por circuito é preciso
estabelecer um caminho do roteador que emite o pacote até o roteador que recebe o pacote,
para só depois o pacote ser enviado pela rede. Nesta metodologia, os buffers só são utilizados
para controlar o cabeçalho que destina os recursos da rede.

20
Figura 4. Composição de uma mensagem: pacotes; flit; phits.
Fonte: MATOS, 2010.
O chaveamento por pacote é baseado na divisão das mensagens em pacotes, onde a
alocação de canais é feita de forma dinâmica, na medida em que o pacote for percorrendo até
o seu destino. Os principais métodos de chaveamento por pacotes são: store-and-forward,
virtual-cut-through e wormhole (RIJPKEMA, 2001). O mecanismo armazena e repassa
(store-and-foward) geralmente é usado quando as mensagens são frequentes e pequenas, pois
cada pacote designa o percurso preciso até o roteador receptor usando as informações de
roteamento contidas no seu cabeçalho.
No tipo de chaveamento transpasse virtual (virtual cut-through) o pacote será enviado
no momento em que o canal de comunicação pelo qual o mensagem será transportada ficar
acessível para receber o pacote, e assim, a latência da comunicação será reduzida. O tamanho
do buffer deve ser, no pior caso, dimensionado para suportar um pacote inteiro. Uma variação
do chaveamento virtual cut-through, é o chaveamento por pacote wormhole que tem como
característica principal diminuir o tamanho do buffer necessário para suportar pacotes
bloqueados na rede. Nas redes baseadas nesta técnica, os pacotes são divididos em flits e um
canal só é liberado depois que todos os flits que formam o pacote passarem pelo canal de
comunicação.
2.1.1.5. Arbitragem
O mecanismo de arbitragem é responsável por controlar as disputas por uma porta de
saída, ou seja, define qual canal de entrada pode usar um canal de saída específico. Tal
mecanismo resolve esses problemas para que não ocorram situações de starvation. A
arbitragem pode ser distribuída ou centralizada, mostrada na FIGURA 5.
Na abordagem centralizada, todas as portas de saída são controladas por um único
módulo roteador, que recebe os cabeçalhos dos pacotes, executa o roteamento e define o canal
de saída a ser usado por cada pacote. Na segunda abordagem, a distribuída, para cada porta do
roteador, o roteamento e a arbitragem são realizados de maneira independente. Ou seja, cada
porta de entrada e de saída, tem um módulo de roteamento e arbitragem, respectivamente. Um
algoritmo, como por exemplo, round robin, é utilizado para definir a prioridade de envio dos

21
buffers que concorrem pelo canal de saída .
Figura 5. Abordagens para implementação de árbitros: (a) centralizada; (b) distribuída.
Fonte: ZEFERINO, 2003.
2.1.1.6. Memorização
É o mecanismo de filas utilizado para armazenar os pacotes designados aos canais de
saída que já fizeram solicitações por outro pacote, e por causa disso, estão bloqueados na
rede. Existem diversas estratégias de memorização, da mais simples (buffer FIFO) às mais
complexas como SAFC (Statically Allocated Fully Connected), SAMQ (Statically Allocated
Multi-Queue) e DAMQ (Dinamically Allocated Multi-Queue). As alternativas de
memorização apresentadas aqui são encontradas em (TAMIR, 1992), onde é feita uma
comparação entre elas.
Figura 6. Estratégias de memorização utilizando rotador com quatro buffers: (a) SAFC; (b)
SAMQ; (c) DAMQ.
Fonte: ZEFERINO, 2003.

22
2.1.2 Vantagens e Desvantagens das NoCs
A cada dia, as redes em chip estão se tornando um dos mais promissores meios de
interconexões chaveadas dentro do chip. E tem como principais vantagens com relação a
barramentos: desempenho constante do relógio com o aumento de núcleos do sistema
(GERRIER; GREINER, 2000); aumento de reuso tanto dos núcleos como da plataforma de
comunicação; largura de banda escalável; canais de comunicação em forma de pipeline;
arbitragem distribuída. A circulação dos pacotes ou dados é de responsabilidade destas redes
de comunicação e, portanto, tem a capacidade de retratar um gargalo ou o forte diferencial de
desempenho entre as propostas de arquiteturas de processadores.
Essas redes possibilitam a estruturação e o gerenciamento dos fios em tecnologias
submicrônicas, ou seja, são utilizados fios mais curtos, ponto a ponto e com uma menor
capacitância parasita (CALAZANS, 2007) e seu compartilhamento possibilita sua utilização
de maneira mais eficiente. Outra vantagem, é que ela permite a reusabilidade dando à
possibilidade de se aproveitar a mesma estrutura de comunicação em aplicações distintas.
Porém, a utilização de NoCs apresenta algumas desvantagens (GERRIER; GREINER,
2000): em relação aos barramentos oferece um considerável consumo de área de silício,
possui maior complexidade de projeto e o elevado tempo para transmissão de pacotes causado
por contenções da rede, podendo aumentar a latência.
2.2. REDE IPNOSYS
A rede IPNoSys (FERNANDES, OLIVEIRA et al., 2008) é um exemplo de NoC, que
oferece um novo modelo arquitetural, onde o processamento das instruções que compõem as
aplicações é realizado durante o roteamento dos pacotes. Percebe-se que essa arquitetura, é
utilizada como sistema de processamento, além da capacidade de interconexão comum nas
redes em chip convencionais.
Para que tais contribuições funcionem, a rede IPNoSys tem características especificas
como: a inclusão de uma ULA em cada processador da rede chamados de Unidades de Acesso
a Memória (MAU – Memory Access Unit); os roteadores tornaram-se Unidades de
Processamento e Roteamento (RPU – Routing and Processing Unit); os dados e instruções
estão em formato de pacote.

23
Figura 7. Arquitetura IPNoSys
Fonte: ARAÚJO, 2012.
A rede IPNoSys é configurada com topologia Grelha 2-D de dimensão quadrada,
possui dois canais virtuais, roteamento do tipo XY, memorização na entrada, controle de
fluxo baseado em créditos e arbitragem distribuída. Tal rede combina o chaveamento VCT
com o wormhole. Suas aplicações precisam estar descritas em formato de pacotes, e durante o
trajeto entre a origem e o destino não é preciso usar os processadores comum nos nós da NoC,
já que as aplicações serão executadas de roteador em roteador.
Para tanto, foi criado um algoritmo chamado por spiral complement, possibilitando o
roteamento de todas as instruções existentes nos pacotes. A utilização desse algoritmo pode
ajudar a resolver grandes desafios do projeto de sistemas integrados em chip. As próximas
seções apresentam as estruturas dos elementos arquiteturais (MAU e RPU), algoritmo spiral
complement, e o formato do pacote.
2.2.1 Elementos Arquiteturais
2.2.1.1. MAU – Unidade de Acesso a Memória
Na rede IPNoSys, os pacotes são injetados pelas MAUs que estão diretamente ligadas
aos módulos de memória, localizadas nos quatro cantos da rede. Sua estrutura interna é
composta por uma unidade de controle, um gerenciador de memória e um gerenciador de
pacotes, como ilustrado na Figura 8. Independentemente das memórias estarem separadas, as
mesmas constituem um ambiente exclusivo de endereçamento (ARAUJO, 2012).

24
Figura 8. MAU na Arquitetura IPNoSys
FONTE: ARAÚJO, 2012.
As MAUs, além de injetar os pacotes na rede para iniciar a execução das aplicações,
são também, responsáveis pelo estabelecimento da comunicação e sincronização dos
resultados encontrados após a execução dos pacotes em cada RPU. A MAU é o único
elemento da arquitetura que tem acesso a memória, possibilitando a leitura e escrita de dados
que estão armazenados na mesma.
2.2.1.2. RPU – Unidade de Processamento e Roteamento
A unidade de roteamento e processamento (RPU) é cada nodo da rede IPNoSys, tem
como objetivos, o processamento e encaminhamento dos pacotes para as próximas RPUs. A
execução pela RPU, das instruções contidas no inicio do pacote, só é possível quando as
aplicações estiverem no formato de pacote.
Com isso, o pacote consegue percorrer a rede IPNoSys funcionando como instruções
em séries. As instruções e as operações só são executadas pela rede, no instante, em que
estiverem no cabeçalho do pacote. Em seguida, o resultado obtido da operação corrente é
capaz de ser armazenado no mesmo pacote, servindo de operando para instruções que forem
executadas no futuro. Por fim, a instrução que foi executada é descartada do pacote, e o
restante do pacote é roteado para a RPU seguinte, assim que o canal de transmissão estiver
disponível. (FERNANDES, OLIVEIRA et al., 2008).
25
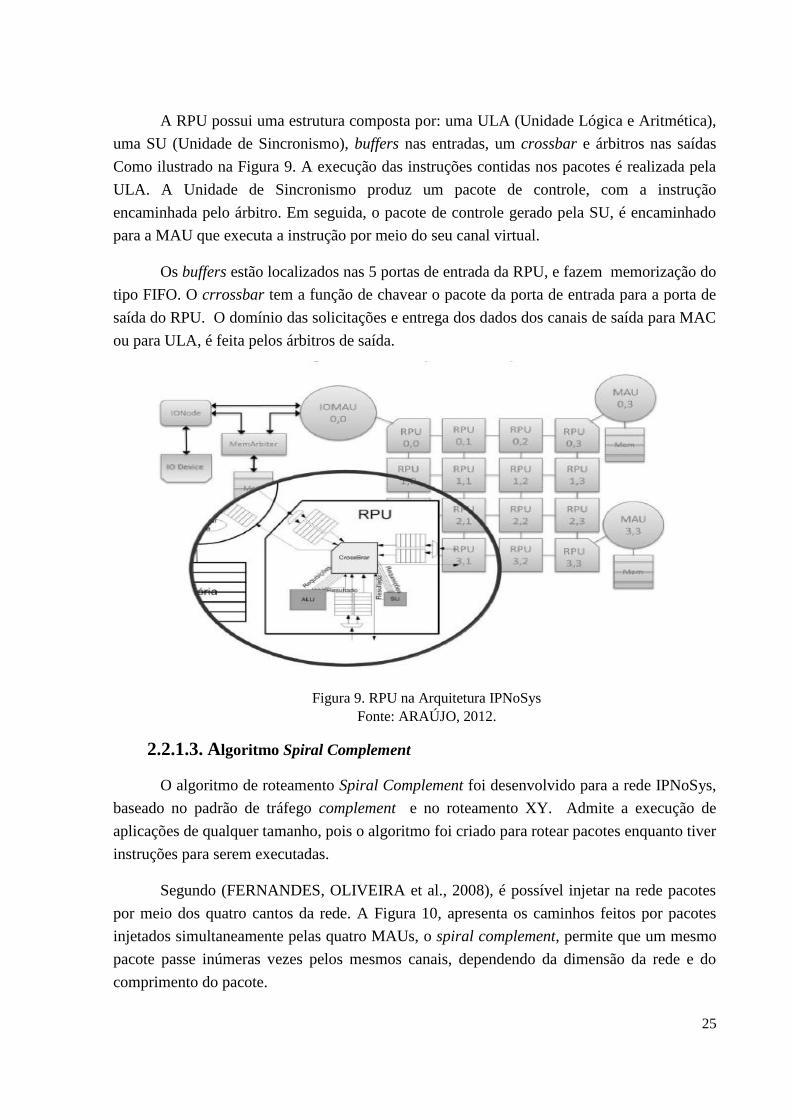
A RPU possui uma estrutura composta por: uma ULA (Unidade Lógica e Aritmética),
uma SU (Unidade de Sincronismo), buffers nas entradas, um crossbar e árbitros nas saídas
Como ilustrado na Figura 9. A execução das instruções contidas nos pacotes é realizada pela
ULA. A Unidade de Sincronismo produz um pacote de controle, com a instrução
encaminhada pelo árbitro. Em seguida, o pacote de controle gerado pela SU, é encaminhado
para a MAU que executa a instrução por meio do seu canal virtual.
Os buffers estão localizados nas 5 portas de entrada da RPU, e fazem memorização do
tipo FIFO. O crrossbar tem a função de chavear o pacote da porta de entrada para a porta de
saída do RPU. O domínio das solicitações e entrega dos dados dos canais de saída para MAC
ou para ULA, é feita pelos árbitros de saída.
Figura 9. RPU na Arquitetura IPNoSys
Fonte: ARAÚJO, 2012.
2.2.1.3. Algoritmo Spiral Complement
O algoritmo de roteamento Spiral Complement foi desenvolvido para a rede IPNoSys,
baseado no padrão de tráfego complement e no roteamento XY. Admite a execução de
aplicações de qualquer tamanho, pois o algoritmo foi criado para rotear pacotes enquanto tiver
instruções para serem executadas.
Segundo (FERNANDES, OLIVEIRA et al., 2008), é possível injetar na rede pacotes
por meio dos quatro cantos da rede. A Figura 10, apresenta os caminhos feitos por pacotes
injetados simultaneamente pelas quatro MAUs, o spiral complement, permite que um mesmo
pacote passe inúmeras vezes pelos mesmos canais, dependendo da dimensão da rede e do
comprimento do pacote.

26
Figura 10.Spiral Complement: (a) 1a. espiral; (b) 2a. espiral; (c) 3a. espiral (d) 4a. espiral. FONTE: ARAUJO, 2008
Para descobrir o destino do pacote que foi injetado por uma das MAUs que estão
localizadas em um dos cantos na rede, é preciso saber a localização da sua origem para depois
fazer seu complemento, dessa forma, o destino inicial é encontrado. Se o pacote que estava
sendo roteado chegar ao destino, e ainda, existir instruções nele, um novo cálculo para
encontrar o próximo destino deve ser feito. O roteamento do pacote termina quando o número
de instruções contidas no pacote for igual à zero, ou seja, quando não tiver no pacote
instruções a serem executadas.
A utilização deste algoritmo proporciona um avanço do paralelismo, já que, permite o
roteamento e execução de até 4 pacotes no mesmo instante na rede, e suas instruções são
executadas de acordo com a disponibilidade dos operandos. Além disso, diminui o
agrupamento de dados no centro da rede, conseguindo difundir o tráfego dos pacotes por toda
rede IPNoSys.
2.2.1.4. Formato do Pacote
A rede IPNoSys utiliza um formato de pacote baseado no pacote desenvolvido para a
rede em chip da plataforma STORM (REGO, 2006). Algumas alterações foram

27
indispensáveis, devido a rede IPNoSys utilizar o algoritmo Spiral Complement e a
modificação do formato do pacote com as instruções da aplicação.
Cada pacote transportar instruções que serão executadas pelas RPUs por onde o pacote
passar. Internamente, o pacote apresenta os seguintes tipos de palavras: cabeçalho, instrução,
operandos e fim de pacote. A descrição completa dos campos de cada palavra pode ser
encontrada em (ARAUJO, 2008).
Figura 11. Formato do pacote da rede IPNoSys
Fonte: ARAÚJO, 2008
Em cada palavra, os 32 bits de largura são utilizados para armazenar informações
sobre as RPUs, os números dos pacotes, e sobre a aplicação (instruções, operando e
resultados), de acordo com seu tipo. Antes dos 32 bits de largura da palavra, são utilizados 4
bits de controle que especifica o tipo de palavra que estar sendo transportada.
A quantidade de instrução e de operandos contido nos pacotes, estar sujeito a
aplicação que pacote for representar. Apenas o cabeçalho e o terminador são obrigatórios em
todos os pacotes. Na rede IPNoSys, os tipos de pacotes são identificados pelos 2 últimos bits
da primeira palavra do seu cabeçalho, como: controle, regular, interrompido e caller,
representados respectivamente pelos bits 00b, 01b, 10b, 11b (ARAUJO, 2008)..

28
A arquitetura da IPNoSys possui modelo de execução compatível com modelos de
computação orientados à dados (como data flow), uma vez que os dados trafegam junto com
as instruções em pacotes dedicados à execução de operações. Seus roteadores são compostos
por uma unidade lógica e aritmética e uma unidade de sincronização, enquanto que os núcleos
de processamento foram substituídos por núcleos de acesso à memória. Utiliza-se um modelo
de computação baseado em passagem de pacotes entre os roteadores, caracterizando um
pipeline e explorando o paralelismo das transmissões. Portanto, a alternativa apresentada pela
IPNoSys para aumentar o desempenho, ocorre através do processamento de instruções da
aplicação nos roteadores da NoC.
De acordo com os resultados, a rede IPNoSys permite um aumento de desempenho na
execução das aplicações, pois o processamento das instruções ocorre durante o deslocamento
do pacote da origem até o destino. Ressalta-se ainda, que ao executar aplicações que tratam
ocorrências de deadlock, é possível verificar a aceleração na execução das aplicações, pois
seu algoritmo de roteamento previne a interrupção da transmissão e do processamento dos
pacotes pela rede.
Na rede IPNoSys, é possível implementar a adição de ponto flutuante baseada no
padrão IEEE 754, permitindo observar e avaliar casos onde serão utilizados rotinas conjunto
de pacotes (software) para execução de uma instrução que não existe implementação
especifica no hardware. Com isso, todas as vezes que existir instruções de ponto flutuante nas
aplicações, o sistema suportará esse tipo de instrução por meio da execução das rotinas de
tratamento, e não será necessário inserir na rede IPNoSys, uma unidade aritmética de ponto
flutuante em hardware.
Além disso, Araujo (ARAUJO, 2008) implementou a Transformada Discreta do
Cosseno (DCT – Discrete Cosine Transform) no sistema IPNoSys para verificar o
comportamento da arquitetura, e em seguida, realizou comparações de desempenho com a
plataforma STORM. Desse experimento, pode-se observar que o sistema IPNoSys oferece um
aumento de eficiência em tempo de execução nas diversas condições de paralelismo
intrínseco por causa dos múltiplos canais ponto-a-ponto disponíveis na NoC.
A linguagem SystemC (OSCI, 2005) foi utilizada para o desenvolvimento da
ferramenta de simulação e validação funcional do sistema IPNoSys. Para tolerar uma maior
acuracidade em relação ao modelo real, a ferramenta foi desenvolvida em nível de precisão de
clock. A dependência de dados foi representada por meio do grafo de fluxo de dados utilizado
como linguagem intermediária para a descrição de pacotes.
Portanto, é possível observar que a rede IPNoSys apresenta relevantes contribuições,
como: alto desempenho e vazão de pacotes proporcionados pela adaptação da topologia e
redução da influencia da rede de comunicação, conseguindo diminuir os problemas

29
relacionados às redes em chip.
A proposta deste trabalho consiste em analisar o comportamento de execução de
aplicações orientadas a dados, na arquitetura da rede IPNoSys, indicando modificações na sua
estrutura e organização, visando, torná-la compatível com restrições de projeto como
desempenho.
Inicialmente, foi feito um estudo de arquiteturas de NoCs existentes e se observou que
a rede IPNoSys apresenta diversas características, como: a execução de aplicações em
paralelo por meio da injeção concorrente de pacotes, reduzindo o tempo de execução, em
comparação com outras plataformas e tratamento de deadlocks.
Considerando-se as características anteriormente comentadas, essa arquitetura pode
ser favorável para a execução de aplicações orientadas a dados.
Partindo da rede IPNoSys (FERNANDES, OLIVEIRA et al., 2008) e aplicações
orientadas a dados, será interessante analisar a execução desses algoritmos na rede IPNoSys,
investigando as vantagens e desvantagens dessa rede.
Como a rede IPNoSys apresenta um novo paradigma de programabilidade, é
necessário desenvolver as aplicações em um conjunto de pacotes com operações e dados.
Nessa metodologia, a linguagem intermediaria empregada é o grafo de fluxo de dados da
aplicação, onde é explicitado o paralelismo e a dependência de dados da aplicação. Em
seguida, é utilizada a linguagem de descrição de pacotes, que a partir do grafo, gera os pacotes
propriamente ditos.
Pode-se perceber que por meio de estudos e experimentos realizados com a rede
IPNoSys, a mesma tem-se mostrado um importante e eficiente sistema integrado baseado em
NoCs. Resultados têm mostrado a aceleração no tempo de execução das aplicações, devido à
possibilidade de se explorar paralelismo entre as operações (ARAUJO, 2008).
Com base no que foi mencionado anteriormente, entende-se a necessidade de
utilização e verificação da rede IPNoSys, visto que a rede possui características particulares,
como a integração de elementos de processamento nos roteadores da rede, bem como a sua
alta capacidade de paralelismo. Com isso, as tarefas desse trabalho visam a busca por
resultados significativos na execução de aplicações orientadas a dados.

30
3. ESTADO DA ARTE
Neste capítulo, serão estudados os conceitos relacionados ao estado da arte do trabalho
proposto, mais especificamente o modelo de computação baseado em fluxo de dados, as
arquiteturas com suas varações, e as aplicações do tipo dataflow, que serão utilizadas no
trabalho.
3.1. MODELO DE COMPUTAÇÃO BASEADO EM FLUXO DE
DADOS
Um modelo de computação (MoC) é uma formulação que possibilita expressar a
dinâmica da computação dos dados de um sistema. Os modelos podem abranger os conceitos
de dependência, concorrência e o tempo parcial ou completo do sistema.
Em geral, entende-se MoC como o modelo para a representação do tempo e da
semântica de comunicação e sincronização entre as entidades comportamentais de um
sistema, tais como: processos, funções, operações lógicas e/ou aritméticas, estados e etc.
Somente assumindo certo modelo de computação é possível analisar os recursos
computacionais requeridos, como tempo de execução e espaço de armazenamento, ou discutir
as limitações dos algoritmos. Alguns exemplos de modelos de computação estabelecidos na
literatura técnica são: Máquina de Turing, Redes de Processos Kahn, Redes Petri e o Modelo
baseado em fluxo de dados.
Como o objetivo do trabalho é estudar os diferentes comportamentos do modelo data
flow, e apresentar uma proposta de uma arquitetura IPNoSys baseada em fluxo de dados,
abaixo serão apenas definidas e classificadas as principais variações que constituem o modelo
de computação baseado em fluxo de dados.
O modelo baseado em fluxo de dados foi apresentado em meados da década de 70 por
Dennis, e desde então, ele tem sido tema de intensa pesquisa. Esse interesse deve-se
principalmente, à facilidade com que o paralelismo existente nas aplicações pode ser
aproveitado pelo modelo (DENNIS, 1998). No inicio dos anos 80, houve um enorme interesse
pelo modelo em função do alto paralelismo apresentado, surgindo diversos projetos, como:
Manchester Data Flow Machine (MDFM) da Universidade de Manchester (GURD, 85), o
projeto Sigma-1 no Japão (SHIMADA, 86) (HIRAKI, 87), a MIT Tagged Token Architecture
(MTTDA) do MIT (ARVIND, 90). No final da década de 80, o interesse pelo modelo foi
reduzido, pois a viabilidade do modelo foi provada durante o desenvolvimento do projeto,
mas foram identificados vários problemas, comprometendo o desempenho das arquiteturas em
questão.

31
O interesse ao modelo baseado em fluxo de dados ressurgiu no início da década de 90,
pois foi percebido que os problemas anteriormente detectados, ou são passiveis de solução
com as novas tecnologias, ou são inerentes ao processamento paralelo. Vários projetos de
pesquisa surgiram, apresentando algumas modificações visando sanar os problemas
apresentados anteriormente como: a arquitetura EM-X/4 (YAMAGUCHI, 91) que surgiu do
projeto Sigma-1 e projeto Monsoon (CULLER, 91) que evoluiu da MTTDA.
O modelo baseado em fluxo de dados suporta a exploração de paralelismo de
granularidade bastante fina, no nível de instrução. Um programa deixa de ser representado por
uma sequencia de instruções com um controle central impondo a ordem da execução, como é
feito no modelo von Neumann. Nas arquiteturas baseada em fluxo de dados não existe o
conceito de memória como nas arquiteturas von Neumann. O conceito de memória em
arquitetura von Neumann torna esse modelo sequencial, pois a passagem dos dados entre as
instruções ocorre pelas atualizações em áreas de memória e um ponteiro de instruções é
responsável por estabelecer o fluxo de controle de uma instrução para outra. Devido a esse
fato, o modelo von Neumann também é chamado de modelo baseado em fluxo de dados de
controle ou control flow (TRELEAVEN et al., 1982).
Segundo (VEEN, 1986) no modelo baseado em fluxo de dados não existe o conceito
de armazenamento de dados em memória. Os dados são simplesmente produzidos por uma
instrução e consumido por outra. A chegada dos dados serve como sinal para habilitar a
execução de uma instrução, excluindo a necessidade de controle de fluxo. Cada instrução é
considerada como um processo separado e quando a instrução produz dados como resultado,
são apresentados ponteiros apontando para todos os seus receptores. Visto que uma instrução
em um programa baseado em fluxo de dados somente contem referencias para outras
instruções, este programa pode ser visto como um grafo.
O modo de execução do modelo baseado em fluxo de dados comporta-se como um
grafo dirigido a dados (data-driven). As operações são atendidas como habilitadas para a
execução com a chegada de todos os dados de entrada. Este tipo de construção exibe todo
paralelismo implícito do programa. Nessa notação de grafo, cada nó representa uma operação
(instrução) e os arcos que interligam esses nós representam a dependência entre as operações.
Nas arquiteturas baseadas em fluxo de dados, as instruções são conhecidas como nós e
os dados como tokens. Um nó emissor é conectado a um nó receptor por um arco e o local no
qual o arco entra no nó é conhecido como porta de entrada. A execução de uma instrução é
chamada de disparo do nó, podendo ocorrer, apenas se o nó estiver habilitado, utilizando uma
regra de habilitação. O termino de execução de uma operação libera valores ou decisões para
os nós do grafo, cuja execução depende deles. A FIGURA 12 apresenta um exemplo de um
programa na linguagem a fluxo de dados.

32
Figura 12. Programa básico na linguagem a fluxo de dados
A FIGURA 12 esboça um grafo a fluxo de dados, composto por quatro nós. Quando
há tokens nas entradas dos nós eles podem ser processados e geram um token de saída. Os nós
habilitados podem ser disparos em tempos não especificados, em qualquer ordem ou
concorrência. O disparo envolve a retirada dos tokens de entrada e a computação do resultado.
3.1.1 Fluxo de Dados Síncrono
É o modelo de computação onde se determina uma ordem de ativação para o
processamento dos dados, garantindo uma sequencia pré-determinada de operações. O
controle de dados é completamente previsível em tempo de compilação.
Esse modelo faz uso de bufferização estática, onde cada nodo da aplicação pode
iniciar o seu processamento assim que um número suficiente de dados estiver disponível nas
suas entradas (chamado também de tokens). Sendo assim, é possível determinar estaticamente
os requisitos de buffer (profundidade das FIFOs) necessários para a aplicação.
Dessa forma, o modelo é orientado a dados síncronos. À medida que dados estejam
disponíveis as instruções podem ser executadas. Sendo assim, a execução não é feita
sequencialmente, mas em função da disponibilidade de dados. Logo, serve para à
manipulação de computações regulares que operam em fluxo sequencial e são capazes de
determinar a ordem de execução da aplicação.
É muito eficiente e não onera os recursos do sistema com dados extras, tendo em vista
que, antes de iniciar a execução em si, uma pré-analise das execuções da aplicação é
realizada. E para alcançar uma boa eficiencia, os valores dos dados consumidos e produzidos
de cada pacote devem ser constantes e declarados.
É um modelo de computação simples que assegura a computação de cada aplicação na
ordem correta. Um pacote consome e produz um número fixo de dados por execuçao. Essa
informação estática torna possível a avaliação da execução antes de executar de fato. É um
modelo adequado para processamento de sinais, onde o baixo overhead de execução é
imperativo.

33
3.1.2 Fluxo de Dados Assíncrono
Faz uso de buffers ilimitados, onde suas aplicações podem produzir e consumir
números variáveis de tokens. Como a produção e o consumo de tokens podem mudar no
tempo de execução, o modelo não pode ser programado estaticamente.
A comunicação (transmissão das mensagens) ocorre através de canais para comunicar
valores de dados entre blocos lógicos de computação.A execução dos dados não são
sincronizados por um sinal de clock global, portanto, todos as execuções procedem
concorrentemente.
3.1.3 Fluxo de Dados Dinâmico
A abordagem do modelo baseado em fluxo de dados dinâmico baseia-se na solução
tagged-token do modelo baseado em fluxo de dados tradicional. Onde os tokens transportam,
além do valor de interesse, um tag que os agrega a certo contexto de execução –
caracteristicamente loops, iterações ou chamadas de funções.
Nesse modelo, não há o controle estático e, assim sendo, uma tarefa pode mudar a
quantidade de informação produzida ou consumida a cada execução. É indicado para
aplicações que utilizam no seu fluxo de execução, laços, ramificações ou outras estruturas de
controle. Em geral, o modelo DDF (Dinamic Data Flow) é uma ótima escolha para se
gerenciar fluxo de execução que contenham o tipo de estrutura if-then-else, onde a interação
depende dos dados ou que exista recursividade.
O modelo baseado em fluxo de dados dinâmico admite que se tenham vários dados,
não apenas um, em cada arco. Na sua implementação é possível que novas instâncias dos
operadores sejam originadas para cada dado que vai chegando ao arco. Assim, é aceitável que
diversas instâncias de um operador sejam geradas.
Conclui-se que o modelo fluxo de dados dinâmico apresenta uma lógica bastante
complexa, com computação paralela e sua execução é bem distribuída.
3.2. APLICAÇÕES DATAFLOW
Descrever aplicações de acordo com um modelo de computação beneficia a aquisição
de resultados que atendam os objetivos desejados, já que suas informações podem ser
exatamente as suficientes e necessárias para uma dada aplicação. Como consequência da
especificidade dos modelos de computação, as seguintes vantagens são decorrentes: menor
área necessária para armazenar as informações que representam a aplicação; maior velocidade
e menor complexidade dos algoritmos que tratam os modelos.

34
O modelo de computação baseado em fluxo de dados sempre despertou interesse na
área de pesquisa devido a sua elegância em explorar e simular de forma simples o paralelismo
encontrado em tarefas de computação. No passado existiram várias experiências de se
implementar máquinas de propósito geral fundamentadas no modelo. No entanto, as
dificuldades em se alcançar uma máquina a fluxo de dados de propósito geral sempre se
revelaram grandes (LEE; HURSON, 1993).
Embora as pesquisas não tenham levado a uma arquitetura de propósito geral
largamente comercial, o modelo baseado em fluxo de dados é amplo o suficiente para ser
aplicado em diversas áreas, como linguagens de programação, no projeto de processadores,
processamento digital de sinais e, computação reconfigurável (NAJJAR; LEE; GAO, 1999)
(COMPTON; HAUCK, 2002).
Esse modelo foi projetado para a execução de aplicações de fluxo de dados, onde é
possível maximizar o fluxo de dados e minimizar a utilização das RPUs. Nesse modelo, é
possível atender o desempenho da aplicação e a racionalização da utilização dos recursos,
permitindo a execução da aplicação no menor tempo possível.
Então, a aplicação síncrona data flow genérica é a que faz soma sucessivas. Para
realização dos testes foram feitas as seguintes variações: diferentes tamanhos, em relação ao
número de instruções e de pacotes. Dessa forma, será possível avaliar o desempenho da rede
em chip IPNoSys, ao executar experimentos data flow, onde as aplicações utilizam o máximo
do datapath e o mínimo do controle.
Tais variações particulares da aplicação foram necessárias para que fosse possível
estimar o desempenho da rede IPNoSys. Essas variações serão apresentadas nos casos a
seguir, enquanto os resultados serão mostrados no CAPITULO 4.
Caso 1: Número de instruções por RPU
Neste caso, é possível variar a quantidade de instruções executadas por cada RPU,
antes de encaminhar o restante do pacote para a próxima RPU. Esse parâmetro é definido em
tempo de compilação das aplicações, possibilitando que cada pacote ou aplicação tenha sua
própria quantidade de instruções executadas por RPU. O número de instruções usadas em
cada simulação foi de 2, 4, 8,16, 32, 64, 128 e 254.
Caso 2: Número de instruções por pacote
Este caso, permite avaliar o desempenho da rede IPNoSys, ao variar o número de
instruções executadas por pacote. O número de instruções usados em cada pacote para a
simulação foi de 2, 4, 8,16, 32, 64, 128 e 254.

35
Caso 3: Número de pacotes
Este caso, permite avaliar o desempenho da rede IPNoSys, ao variar o número de
pacotes executados na rede IPNoSys. O número de pacotes usadas em cada simulação variou
de 1 até 4 pacotes.
3.3. ARQUITETURAS DATAFLOW
São estruturas globais onde se pode encontrar n elementos de processamento (PE),
interconectados por uma rede de interconexão. Em geral, o sistema suporta mecanismos de
interconexão pipeline. Assim, em todos os PE existem um mecanismo para disparo de
instruções, que dispara somente aquelas cujos dados (tokens) já estão disponíveis. (SILVA e
LOPES, 2010).
As instruções são armazenadas em memória de programa, e após serem executadas
geram novos taggeg tokens, que são transmitidos para outras operações. Percebe-se que essa
estrutura em pipeline permite múltiplos dados fluindo pelos arcos, e múltiplas instruções
sendo executadas em paralelo.
As arquiteturas dataflow podem ser classificadas como estáticas e dinâmicas. Na
arquitetura estática é permitido apenas um dado no grafo dataflow, ocasionando uma grande
dificuldade no gerenciamento dos arcos, já que não é permitido mais que um dado presente no
arco, levando a um overhead de comunicação, que mantém apenas um dado em cada arco.As
arquiteturas dinâmicas permitem mais que um dado por arco no grafo dataflow, onde cada
dado recebe um tag, e os dados passam a ser chamados de tagged token. Logo, os dados com
o mesmo tagged token, disparam as instruções em uma máquina dataflow dinâmica.
Na literatura, é possível encontrar diversas referencias de arquiteturas baseada em
fluxo de dados como WASMII - What A Steap Machine Is It (LING & AMANO, 1993).
Arquitetura que utiliza o conceito de hardware virtual, onde é possível ocorre a execução com
apenas uma ou várias unidades de processamento reconfigurável (RPF), sendo aceitável que
vários FPGAs executassem simultaneamente subgrafos, conseguindo assim o paralelismo
máximo de máquinas baseadas em fluxo de dados.
Em seguida, foram feitas evoluções sobre o WASMII. (TAKAYAMA et al., 2000),
desenvolveu um compilador de linguagem de alto nível para a máquina. Além disso, ele
também implementou um algoritmo de escalonamento e particionamento para a arquitetura,
prevenindo possíveis deadlock, obtendo melhorias de quase 40% no desempenho.
A arquitetura SEED (Sistema de Escalonamento e Execução Dataflow), consegue
executar e escalonar código com instruções utilizando o modelo baseado em fluxo de dados,
conseguindo aproveitar o máximo de paralelismo possível dos programas. Geralmente, as
arquiteturas dataflow exploram paralelismo de granularidade fino, mas a arquitetura SEED
explora o paralelismo de granularidade mais grossa com o intuito de diminuir o tráfego dos

36
blocos de dados na arquitetura, atenuando a complexidade estabelecida pelo hardware e o
excesso de ocupação da memória (MAGNA, 1997).
Em (SASSATELLI, TORRES et al., 2002), é proposta uma arquitetura que utiliza um
modelo de execução paralela, dinamicamente reconfigurável com granularidade grossa, que
tem por objetivo principal acelerar o processamento de aplicações orientadas a dados. A visão
geral do sistema é apresentada na Figura 13.
A arquitetura é constituída por 2 camadas e 1 núcleo, denominados como, camada
operativa, camada de configuração e núcleo RISC adaptável com um conjunto de instruções
dedicado como controlador de configurações. Na parte interna da camada operativa, tem o
Dnode, que é componente de granularidade grossa, utilizado para fazer o processamento das
instruções, pois é constituído por registradores e ULA. Na camada de configuração, possui
uma memória RAM (Random Access Memory), onde armazena todas as configurações dos
componentes da arquitetura. Como trabalho futuro, existe a proposta de desenvolver uma
ferramenta de compilação eficiente, que será a chave para o processamento de arquiteturas
reconfiguráveis.
Figura 13. Visão geral do sistema
Fonte: (SASSATELLI, TORRES et al., 2002
Foi proposta por (MADOŠ e BALÁŽ, 2011), uma arquitetura orientada à dados com
uma abordagem moderna, a tile computing. Onde, seus componentes de comunicação, são
utilizados para desenvolver arquiteturas com múltiplos chips. Além dos componentes de
comunicação, sua estrutura contem diversos elementos de processamento, cada PE com uma
unidade de controle e uma ULA, e duas redes: uma para o mapeamento do grafo dataflow, e a
outra, para a comunicação local.

37
A arquitetura (FERLIN, 2008), propõe uma arquitetura paralela reconfigurável
orientada a fluxo de dados. Sendo, formada por uma unidade de controle, tendo como
principal função controlar os Elementos Processadores (EPs) e diversos EPs que concretizam
a execução da operação. Além disso, faz o gerenciamento de caminho de dados que ocorrer
entre os EPs. Sua estrutura prevalecer-se dos benefícios alcançados quando é combinada a
computação reconfigurável com o processamento paralelo. Já que sua utilização possibilita a
aceleração da execução de programas, adequando uma opção de alto desempenho para
soluções que antes eram somente em software.
Portanto, já foi apresentado as redes em chips (NoCs), dentre as redes exibidas houve
um maior aprofundamento da rede IPNoSys que é o objetivo de estudo. Em seguida, foi
estudado sobre o modelo de computação e a arquitetura dataflow. No próximo capítulo, será
proposto uma arquitetura que une tudo que foi estudado antes. Ou seja, vincular aplicações
dataflow e seu modelo de execução na rede IPNoSys Dataflow, assemelhando-se a uma das
arquiteturas apresentadas anteriormente.

38
4. PROPOSTA DE MODELO DE EXECUÇÃO ORIENTADO A
DADOS PARA REDE IPNOSYS
Nesse capítulo será apresentado uma proposta de uma arquitetura para aumentar o
desempenho da rede IPNoSys, através da execução de instruções em paralelo. Sendo possível,
devido a rede possui dentro de cada roteador uma ULA, e pelo seu modelo de execução Spiral
Complement, que proporcionam um paralelismo em nível de instrução. Para validar essa
proposta serão executas aplicações SDF, já que são compatíveis com esse paralelismo em
nível de instrução.
No modelo de execução da rede IPNoSys como concebida originalmente, cada RPU
recebe o pacote e verifica se está com o cabeçalho; em caso afirmativo, executa a instrução,
caso contrário, apenas retransmite o pacote à próxima RPU.
Para permitir um paralelismo a nível de instrução são necessárias modificações nas
RPUs da rede. Essas modificações dizem respeito à maneira como o modelo de execução
orientado à dados será implementado, de modo que instruções possam executar em paralelo.
O modelo de execução proposto funciona em duas etapas: programação e execução.
Para cada uma das etapas será criado um novo tipo de pacote. Além da mudança no
formato do pacote, foram necessárias mudanças na arquitetura da rede, como visto nas
próximas seções.
4.1. FORMATO DOS PACOTES
Como visto, a seção 2.2.1.4 explica o formato geral do pacote original. Nesta seção,
será apresentado o que foi modificado desse original, para existir dois pacotes diferentes: um
pacote de programação e um pacote de execução.
O pacote original da rede IPNoSys, possui o código da instrução e operandos, e assim,
executa as operações sobre os operandos, e os resultados será armazenados para consultado
ou serem utilizados, caso seja necessário. O número instruções e de operandos varia, de
acordo, com aplicação que o pacote estiver representando, mas o cabeçalho e o terminador é
apenas um para todos os pacotes.
4.1.1 Formato do Pacote de Programação
O formato do pacote de programação possui uma sequencia de identificadores de
instruções. O pacote continuará armazenando o endereço da RPU de origem e de destino, e o
número de instruções contidas no pacote. Caso seja necessário, um novo endereço de destino
será calculado utilizando os bits do re-rotear. E também o tipo de pacote que está trafegando
pela rede.

39
Além disso, o identificador da aplicação e do pacote, o endereço da unidade de acesso
a memória onde ocorreu a iniciação do programa, a quantidade de instruções que cada RPU
executará, e o apontador permanecem no pacote de programação.
A primeira alteração necessária para a correta execução do pacote no modelo de
execução proposta, é a troca do bit de controle “o” para “e”, que representa execução, quando
estiver ativado. Também, foi preciso retirar a palavra que armazena os dados utilizados como
operando das instruções, já que essa etapa será feita a programação da rede IPNoSys com os
operadores sendo armazenados na memória de cada RPU.
No pacote de programação que contém as instruções da aplicação, é preciso que se
tenha necessariamente um terminador, indicando o fim do pacote, e consequentemente, a
pacote termina de programar as RPUs necessárias para executar o pacote com os dados da
aplicação corrente.
Figura 14. Formato do pacote modificado para programação.

40
4.1.2 Formato do Pacote de Execução
O pacote de execução não precisará armazenar o número de instruções contidas no
pacote, que era um dado necessário para o pacote original. Da primeira palavra do pacote
original, só será preciso armazenar o endereço da RPU de origem e de destino, um campo
com o re-rotear e outro com tipo de pacote corrente.
Na segunda e na terceira palavra do pacote de execução, todos os campos permanecem
iguais ao do pacote original. A principal diferença, é que o formato do pacote de execução
possui uma sequencia de dados, sem a necessidade de armazenar as instruções.
Figura 15. Formato do pacote modificado para programação.
Então, a primeira alteração que precisa se feita é a mesma do pacote de programação,
onde ocorre a troca do bit de controle “o” para “e”, que representa execução, quando estiver

41
ativado. Também, foi preciso retirar a palavra onde o controle “i” de instrução está ativo, pois
nele os seguintes campos são armazenados: identificador da instrução, número de operandos e
resultados, já que essa etapa será feita a execução do pacote com os dados na aplicação.
No pacote de execução que contém os dados da aplicação, o terminador é opcional,
pois os dados do pacote podem existir infinitamente. Por exemplo, quando a rede IPNoSys
precisar executar aplicações de stream de áudio que esta sempre ligado, assim os dados do
pacote não terminam nunca. Simplesmente, vão existir dados passando pelas instruções
contidas nas RPUS da IPNoSys incessantemente.
4.2. PROGRAMAÇÃO
Na etapa de programação, um novo pacote foi desenvolvido, contendo apenas a
sequencia de instruções que a aplicação dataflow vai executar, de modo que, o pacote trafega
pela rede IPNoSys, programando cada RPU. Quando o pacote de instruções chegar nas RPUs,
estas não o executam, apenas armazenam com o tipo de instrução que estiver no cabeçalho do
pacote. Com isso, as RPUs ficam programadas para executar os dados que chegarem ao
pacote de dados.
Supondo que uma aplicação tenha 10 instruções, e para executar essa aplicação será
necessário injetar o pacote com as operações dessas instruções. Na Figura 16(2º) o pacote é
injetado inicialmente no canto superior esquerdo, sua primeira instrução vai programar a 1ª
RPU, identificou que é uma operação de subtração, Figura16(3º). Então, programa na
memória da RPU, que ela deve executar operações de subtração. Depois, descarta a instrução
do pacote, e encaminha o pacote para a próxima instrução.

42
Figura 16. Etapa de Programação da rede IPNoSys Dataflow - Parte1
A Figura16(4º), mostra que a 2ª RPU vai executar operações de soma, pois a instrução
do pacote de programação tinha o operando para realizar adição. Em seguida, retira a
instrução corrente, e encaminha o pacote para configurar a próxima RPU. Todo o processo de
programação da rede IPNoSys para conseguir executar a aplicação com 10 instruções é
apresentado nas Figuras 16, 17 e 18.

43
Figura 17. Etapa de Programação da rede IPNoSys Dataflow - Parte2

44
Figura 18. Etapa de Programação da rede IPNoSys Dataflow - Parte3
Quando o pacote de programação chegar ao fim, Figura 18(12º), as 10 RPUs estarão
programadas, aguardando o pacote com os dados. Essa etapa será explicada na seção de
execução.
4.3. EXECUÇÃO
Na etapa de execução, um novo pacote foi desenvolvido, contendo apenas os dados
das instruções que a rede IPNoSys dataflow vai executar, já que as RPUs necessárias para
execução da aplicação já estão programadas, aguardando pelos dados. A Figura 19(1º)
apresenta o pacote de execução sendo injetado, em seguida, Figura 19(2º), os dados são
executados na 1ªRPU, ou seja, os dados são os operandos necessários para ocorre a operação
de subtração que aquela RPU esta programada para executar.

45
Figura 19. Etapa de Execução da rede IPNoSys Dataflow – Parte1
Todo o processo de execução de uma aplicação dataflow com 10 instruções na rede
IPNoSys DataFlow é apresentado nas Figuras 19, 20 e 21. Percebe-se pelas figuras, que cada
dado contido no pacote de execução passa pela RPU sendo executado, utilizando as instruções
contidas na memória de cada RPU, e cada dado é executado 10 vezes, como se fosse um laço
que executa 10 instruções 10 vezes.

46
Figura 20. Etapa de Execução da rede IPNoSys Dataflow – Parte2
Figura 21. Etapa de Execução da rede IPNoSys Dataflow – Parte3

47
5. RESULTADOS
Uma solução para melhorar o desempenho dos processadores é a construção de
software e hardware que permitam a exploração da execução de tarefas em paralelo,
aumentando o desempenho geral do sistema. Segundo (DUNCAN, 1990), entre as diversas
maneiras de se implementar o paralelismo em computadores, as arquiteturas baseadas em
fluxo de dados parecem ser uma excelente alternativa para ajudar as arquiteturas usuais em
aplicações especificas com processamento intenso de dados.
A IPNoSys proporciona um paralelismo em nível de instrução, pois ela possui vários
roteadores com poder de processamento: dentro de cada processador há uma ULA. As
aplicações ideais para aproveitar esse paralelismo em nível de instrução, são as aplicações
SDF.
Para avaliar a rede IPNoSys foi preciso comparar como seria a execução de uma
aplicação SDF com paralelismo em nível de pacotes e como seria sua execução em nível de
instruções. Na execução em nível de instrução, as n instruções de uma aplicação executam n
vezes, como se estivessem dentro de um laço.
5.1. AVALIAÇÃO
As simulações deste trabalho foram realizadas na rede, utilizando o simulador
SystemC da rede IPNoSys. Todos os códigos das aplicações foram descritas na Linguagem de
Descrição de Pacotes e submetidos ao assembler da IPNoSys. O assembler gerou o código
objeto da aplicação, que foi utilizado como entrada do simulador gerando os resultados.
O primeiro experimento apresenta a quantidade de ciclos necessários para executar
instruções, variando a quantidade de instruções presente em cada pacote e a quantidade de
instruções executadas em cada RPU. Percebe-se nos gráficos das FIGURAS 22 e 23, com
relação ao tempo de execução, que o desempenho da aplicação se mantém praticamente
constante quando o número de instruções por pacote cresce até 8, independente do número de
instruções executadas em cada RPU, e do número de pacotes presente na rede. A partir do
número de instruções por pacote com valor 16, o tempo de execução vai crescendo cada vez
que o tamanho do pacote é aumentado.
Com relação aos resultados apresentados a seguir, o desempenho da rede não aumenta
quando o paralelismo é incrementado. Com o aumento dos pacotes, a quantidade de ciclos
gastos continua constante para a mesma configuração. A performance da rede é estável,
apresentando crescimento de ciclos linear em função da variação de instruções.
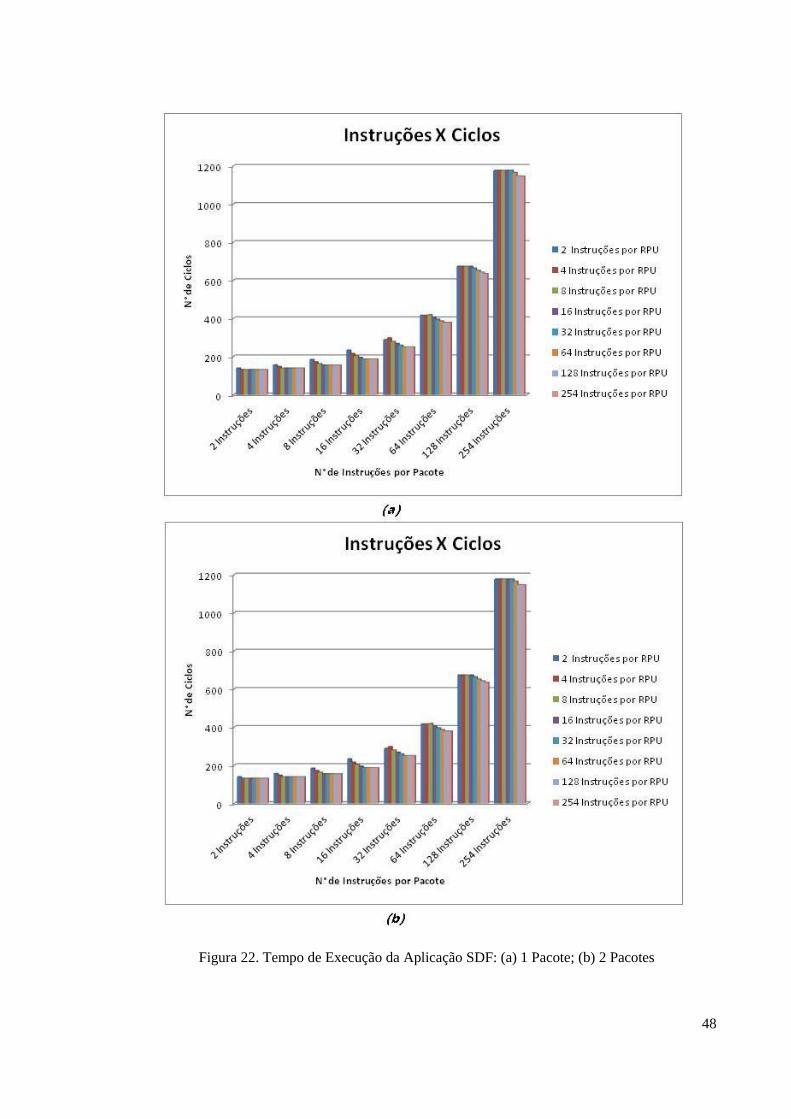
48
Figura 22. Tempo de Execução da Aplicação SDF: (a) 1 Pacote; (b) 2 Pacotes
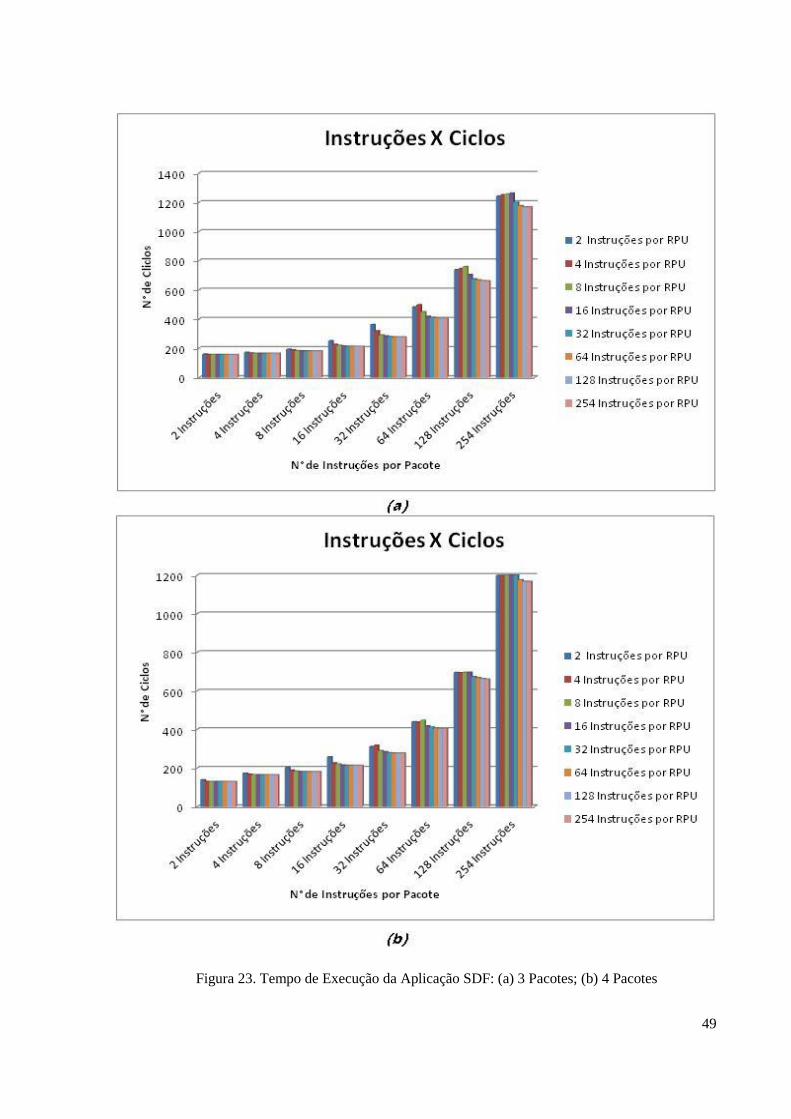
49
Figura 23. Tempo de Execução da Aplicação SDF: (a) 3 Pacotes; (b) 4 Pacotes
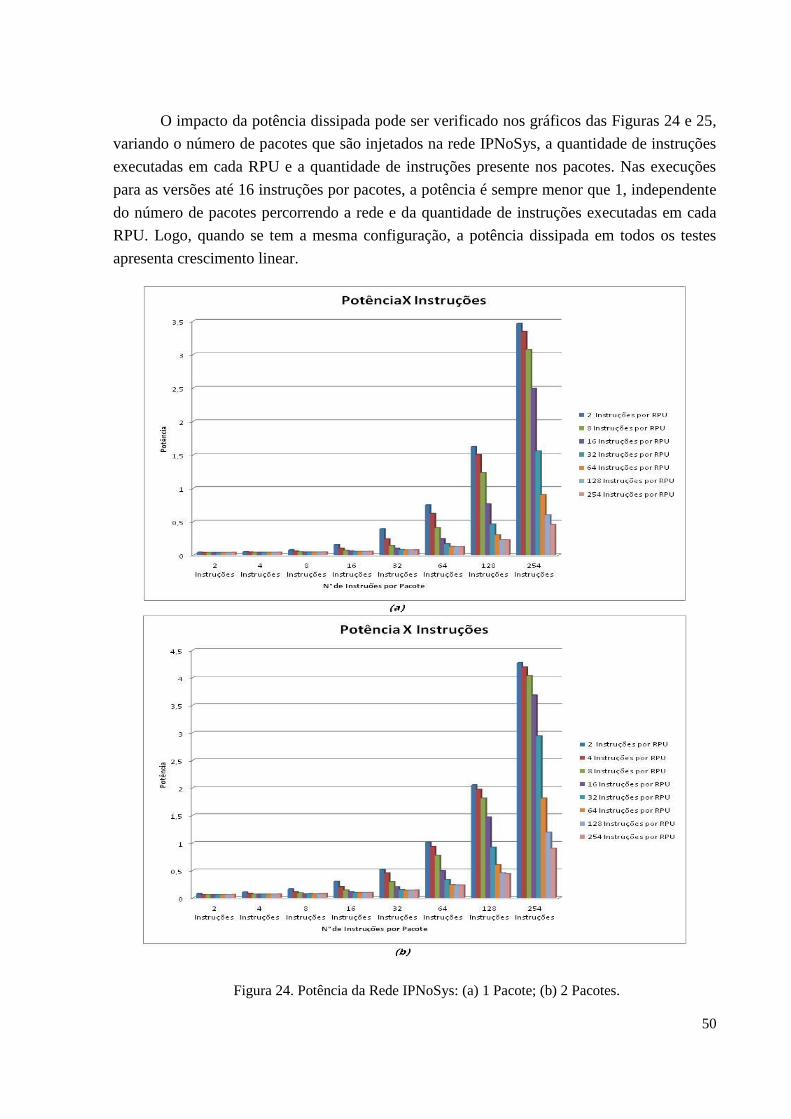
50
O impacto da potência dissipada pode ser verificado nos gráficos das Figuras 24 e 25,
variando o número de pacotes que são injetados na rede IPNoSys, a quantidade de instruções
executadas em cada RPU e a quantidade de instruções presente nos pacotes. Nas execuções
para as versões até 16 instruções por pacotes, a potência é sempre menor que 1, independente
do número de pacotes percorrendo a rede e da quantidade de instruções executadas em cada
RPU. Logo, quando se tem a mesma configuração, a potência dissipada em todos os testes
apresenta crescimento linear.
Figura 24. Potência da Rede IPNoSys: (a) 1 Pacote; (b) 2 Pacotes.
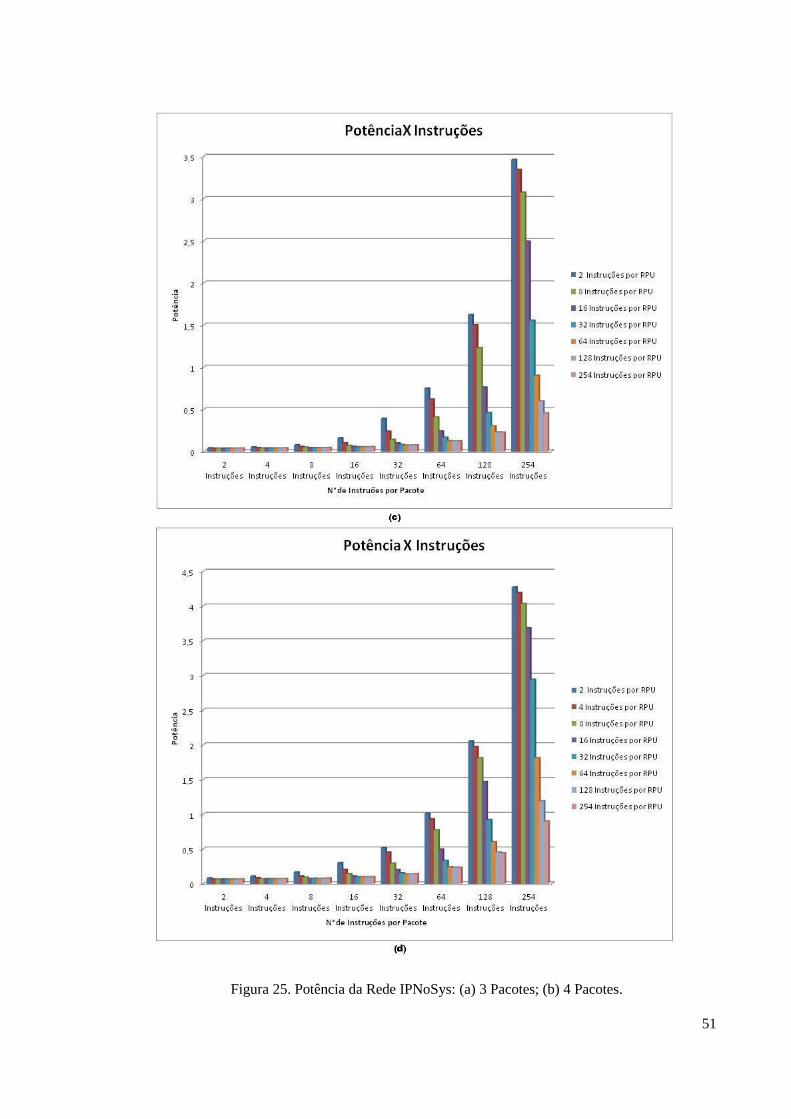
51
Figura 25. Potência da Rede IPNoSys: (a) 3 Pacotes; (b) 4 Pacotes.

52
Observa-se que a estimação de potência encontrada nos experimentos acima de 32
instruções tem um aumento proporcionalmente muito mais significativo que aquelas
dissipadas, pelos experimentos com menos de 32 instruções por pacotes.
Percebe-se, também que a potência é praticamente a mesma entre as implementações
sequenciais e entre as paralelas, pois a quantidade de total de potência é determinada pela
potência dissipada nas RPUs, e não apenas pela transmissão do pacote pela rede. E com o
aumento de pacotes, a quantidade de energia gasta não cresce linearmente em função do
número de instruções, em razão do crescimento linear apresentado pelos resultados.
Os resultados serviram para comprovar que a execução localizada aumenta o
desempenho, pois ocorre uma menor comunicação, pois tal procedimento permite que as
próximas instruções continuem sendo executadas na mesmo RPU, enquanto não é permitido
transmitir o pacote. Quando ocorre a execução localizada, a IPNoSys tem a execução dos
pacotes em nível de instrução. Tanto que foi analisado, que ao aumentar o número de
instruções por RPU, ocorre ganho de desempenho, pois existe uma menor quantidade de
comunicação entre os componentes da rede IPNoSys.
Como foi observado que a execução da IPNoSys é sequencial queremos aproveitar o
potencial de paralelismo na rede, para fazer o paralelismo à nível de instrução. Não só a nível
de pacotes como é na original. E para aproveitar o paralelismo da rede IPNoSys e o
paralelismo a nível de execução é interessante que a aplicação seja a SDF. Para comprovar o
ganho de desempenho das aplicações SDF, executadas como paralelismo à nível de instrução,
será feita uma analise, de maneira analítica como equações baseadas na tese de Zeferino
(ZEFERINO, 2003).
5.2 RESULTADOS ANALÍTICOS
Nesta sessão são apresentados modelos analíticos baseados em (ZEFERINO, 2003),
para a estimativa de desempenho de arquiteturas de comunicação para a rede IPNoSys. As
equações foram desenvolvidas para calcular de maneira analítica, latência em redes em chip,
que são quantos ciclos leva para executar instruções dos pacotes.
Tomando como base as equações de (ZEFERINO, 2003), foi possível modificá-la para
medir latência na rede IPNoSys. Ou seja, as equações foram adaptadas para IPNoSys original
com paralelismo à nível de pacotes e a IPNoSys SDF com paralelismo à nível de instruções,
onde elas serão demonstradas e comparadas.
Para obter as equações que propiciam o modelo de latência é preciso avaliar o tempo
de transferência do pacote e o de arbitragem (Ta). A equação da latência, ao transmitir com
um pacote com f flits no barramento é expressa da seguinte maneira:
Tpct,bus = Ta + (Tbus X f) (7.1)
Considerando que o barramento ajusta um clock para transmitir cada flit de um pacote

53
da IPNoSys, onde sua largura é igual a largura do seu canal de comunicação (Wdata). DUA, 97
apresenta um modelo para a estimativa da latência em NoCs baseadas no chaveamento
wormhole, que foi utilizado para obter um modelo de latência com carga zero para as redes de
interconexão. Onde, a latência alcançada ao transmitir um pacote com f flits entre a fonte e o
destino separados por d enlaces do tipo RPU-RPU com canal de dados igual a Wdata em (7.2).
tpct,wormhole = (tr + ts + tw) x d + max(ts,tw) x [M/Wdata] (7.2)
Considerando que a primeira expressão é composta pela soma dos clocks de três
tempos (tr, ts e tw) vezes d, com ela é possível calcular a latência para transferir o cabeçalho
do pacote. Onde o primeiro tempo, tr, representa o tempo que o roteador demora para realizar
o escalonamento do pacote. O atraso para transmissão dos pacotes, ocasionado pelos canais
existentes nos roteadores, é dado pelo tempo, ts. O último tempo, tw, associa os atrasos para
transmissão dos pacotes pelos canais de enlaces.
Observa-se em (7.2), uma expressão max(ts,tw) que indica o máximo entre os atrasos
de propagação dos pacotes. O último termo, [M/Wdata], onde M é o tamanho do pacote, que
indica o número de flits do pacote e, W é a largura do canal de comunicação, que é a mesma
quantidade bits que cada flit apresenta.
De acordo, com o algoritmo spiral complement é aceitável alcançar o número de
enlaces, d, desde a fonte até o destino. Então, é necessário adaptar a equação (7.2) para
estimar em alto nível o desempenho em comunicação da rede IPNoSys.
A equação (7.2), será adaptada para a IPNoSys original. De posse da equação adaptada
para IPNoSys original, ela será adaptada para possibilitar a captura do paralelismo à nível de
instrução da IPNoSys SDF, onde será possível obter além do tempo gasto para transmitir o
pacote, o tempo gasto para executar cada instrução contida nos pacotes.
A equação encontrada foi derivada de uma equação que calcula o tempo para
transmitir a mensagem entre fonte e destino, na rede. Como a rede IPNoSys já é também
processamento, no instante em que for adaptada uma equação, o resultado da equação, vai
indicar o tempo necessário para transmissão do pacote e, além disso, indica o tempo da
execução da aplicação, pois ao transmitir a mensagem a aplicação também está sendo
executada.
Na IPNoSys original, o número de enlaces d, é a distancia da origem até o destino que
pode ser encontrado em função do tamanho da rede, do tamanho do pacote e do roteamento
spiral complement, quando ocorre o auto bloqueio e inicio da execução localizada. Com esses
dados, será possível saber em quantas RPUs o pacote vai passar e qual RPU o pacote vai
terminar. Enquanto que o destino na IPNoSys com paralelismo à nível de instrução, é onde
inicia a execução localizada que vai variar de acordo com o tamanho da rede. Nessa forma,
também será encontrado o paralelismo máximo em função do tamanho da rede, pois quando
ocorre o bloqueio a execução fica localizada e não vai existir mais roteadores no caminho, ou

54
seja, não vai existir mais transmissão do pacote entras RPUs. O limite de paralelismo máximo
é alcançado quando não houver mais transmissão dos pacotes pelas RPUs e sua execução
começar a ser localizada.
No flit da IPNoSys tem código de operação e dado, assumindo que o tamanho do flit é
a quantidade de bits do código das operação e dado, que é o tamanho total que é a largura do
canal. Cada flit, que corresponde uma instrução e seus operandos, leva um ciclo para executar.
As duas IPNoSys executam instruções da mesma maneira e o tempo que cada uma leva para
executar cada instrução é o mesmo, a diferença é como o pacote flui pela rede e, apresenta ou
não paralelismo à nível de instrução, pois em vez de ter uma instrução executando em
sequencia, são executados as instruções em paralelo.
Considerando, a mesma configuração da rede IPNoSys que utiliza dimensões 4x4,
devido ao algoritmo de roteamento spiral complement. Para encontrar o número de enlaces,
d, foi determinado que r é o tamanho da rede (ou seja, r = 4), o refinamento na rede inteira
será verificada na equação (7.3). Observa-se que o maior número possível de RPUs que uma
rede 4x4 permite pode ser encontrado pela equação abaixo.
despiral = (1 x r + (2 x (r -1)) + (4 x (r - 2)) + (4 x (r - 3))) (7.3)
A Figura 26 ilustra como foi feita a equação que verifica a quantidade máxima de
RPUs que o pacote percorre para completar todo o espiral da rede com topologia 4x4.
A equação (7.3) foi adaptada para obter a equação (7.4), onde é calculado o número
mínimo de RPUs que um pacote pode percorrer para que já inicie a execução localizada, onde
ocorre o bloqueio da rede por ele mesmo. Observa-se na FIGURA 27 que o d, em situações
em que ocorre bloqueio, é igual a quantidade de RPUs percorridos até ele se bloquear.
dbloqueio = (1 x r + (2 x (r -1)) + (3 x (r -2))) (7.4)
Em situações onde a quantidade de flits do pacote for menor que dbloqueio, o valor de d
vai ser a quantidade de flits do pacote, ou seja, podendo ser encontrado por [M/Wdata], onde
M é o tamanho do pacote e, W é a largura do canal de comunicação, que a mesma quantidade
bits que cada flit apresenta.
Como se quer comparar o paralelismo original da IPNoSys, que é a nível de pacotes
com o paralelismo à nível de instrução, a utilização de apenas um pacote já é o suficiente para
analisar o seu auto bloqueio.
A equação utilizada para encontrar o tempo de execução do pacote na IPNoSys original
(7.5) e na IPNoSys Data Flow (7.6) são as seguintes:
t = [((tr + ts + tw) * D + (max(ts,tw)))] * ((M/W) -1) (7.5)
t = D + (D -1) (7.6)
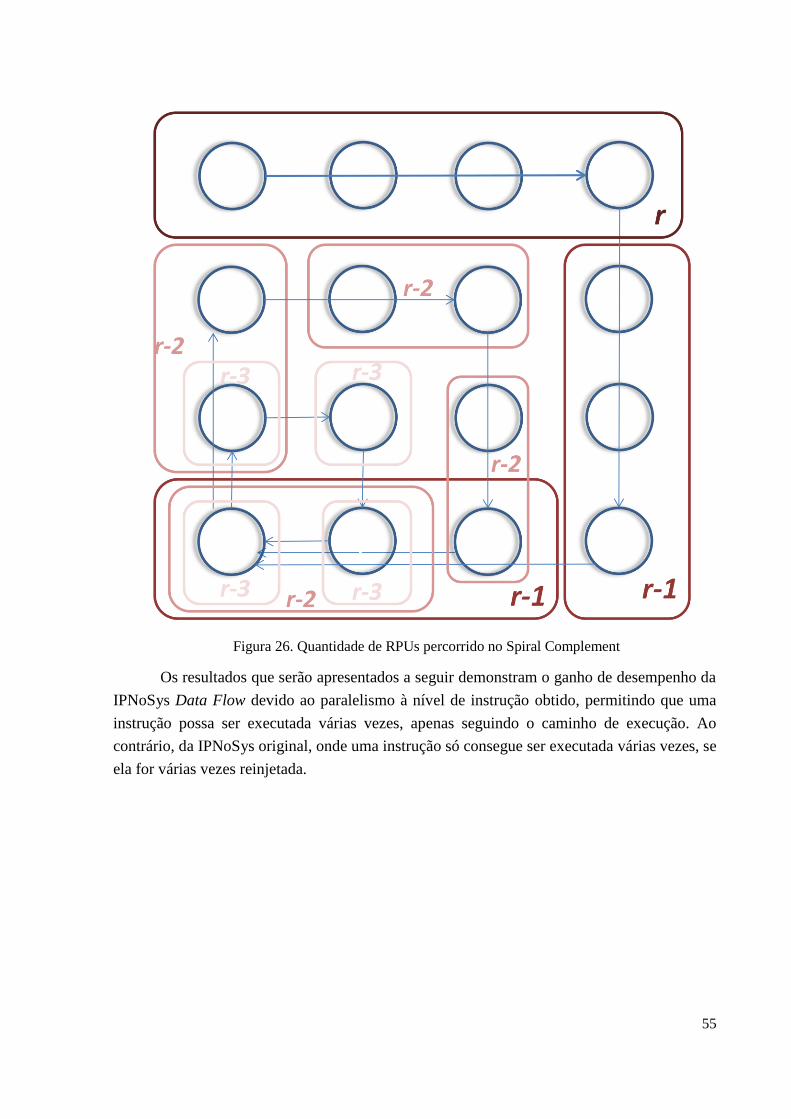
55
Figura 26. Quantidade de RPUs percorrido no Spiral Complement
Os resultados que serão apresentados a seguir demonstram o ganho de desempenho da
IPNoSys Data Flow devido ao paralelismo à nível de instrução obtido, permitindo que uma
instrução possa ser executada várias vezes, apenas seguindo o caminho de execução. Ao
contrário, da IPNoSys original, onde uma instrução só consegue ser executada várias vezes, se
ela for várias vezes reinjetada.
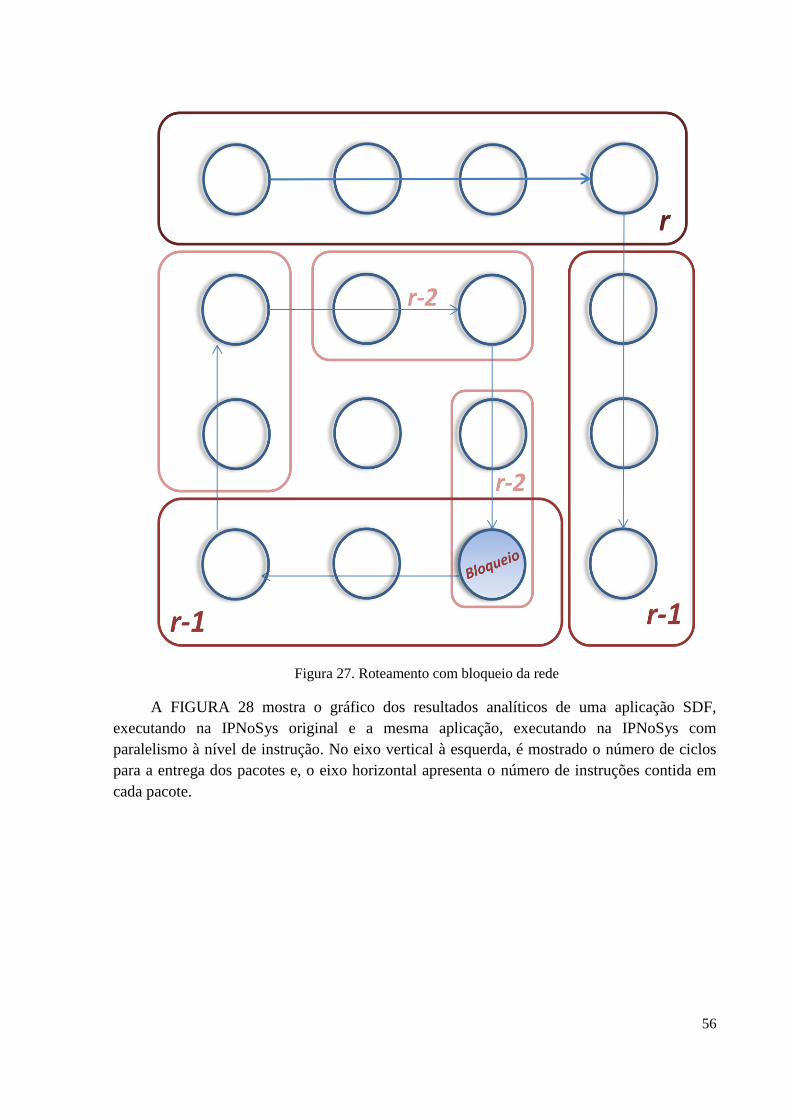
56
Figura 27. Roteamento com bloqueio da rede
A FIGURA 28 mostra o gráfico dos resultados analíticos de uma aplicação SDF,
executando na IPNoSys original e a mesma aplicação, executando na IPNoSys com
paralelismo à nível de instrução. No eixo vertical à esquerda, é mostrado o número de ciclos
para a entrega dos pacotes e, o eixo horizontal apresenta o número de instruções contida em
cada pacote.
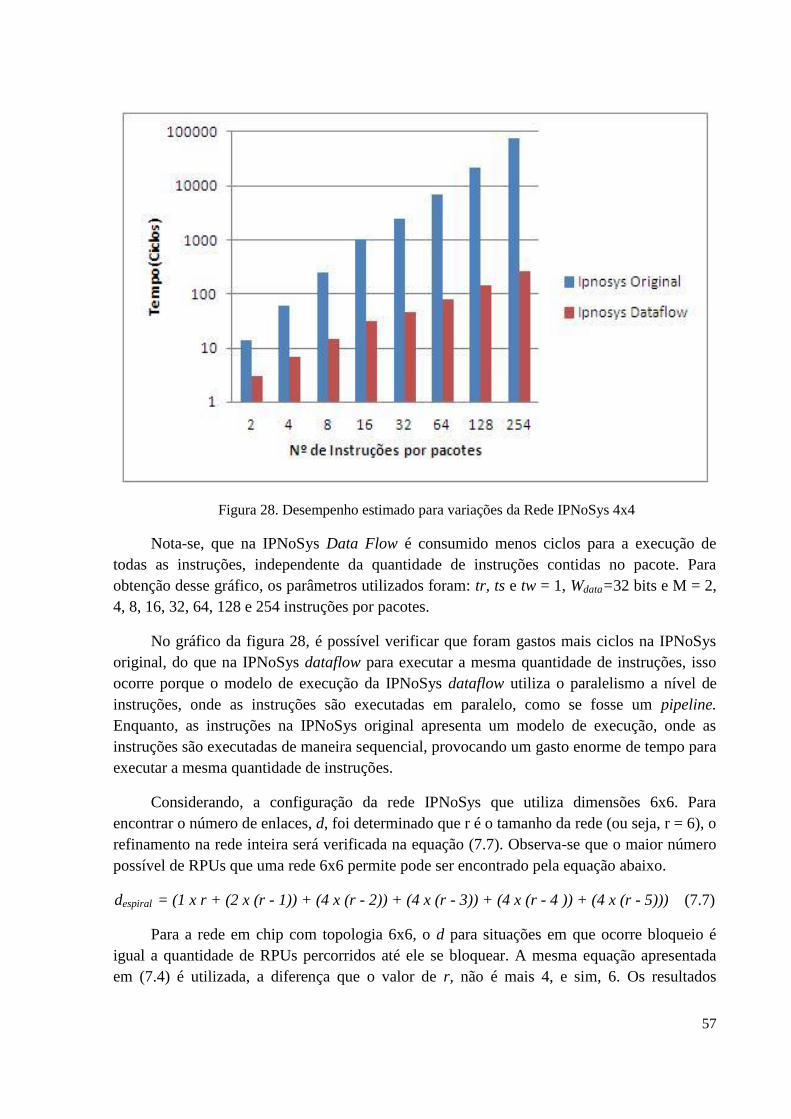
57
Figura 28. Desempenho estimado para variações da Rede IPNoSys 4x4
Nota-se, que na IPNoSys Data Flow é consumido menos ciclos para a execução de
todas as instruções, independente da quantidade de instruções contidas no pacote. Para
obtenção desse gráfico, os parâmetros utilizados foram: tr, ts e tw = 1, Wdata=32 bits e M = 2,
4, 8, 16, 32, 64, 128 e 254 instruções por pacotes.
No gráfico da figura 28, é possível verificar que foram gastos mais ciclos na IPNoSys
original, do que na IPNoSys dataflow para executar a mesma quantidade de instruções, isso
ocorre porque o modelo de execução da IPNoSys dataflow utiliza o paralelismo a nível de
instruções, onde as instruções são executadas em paralelo, como se fosse um pipeline.
Enquanto, as instruções na IPNoSys original apresenta um modelo de execução, onde as
instruções são executadas de maneira sequencial, provocando um gasto enorme de tempo para
executar a mesma quantidade de instruções.
Considerando, a configuração da rede IPNoSys que utiliza dimensões 6x6. Para
encontrar o número de enlaces, d, foi determinado que r é o tamanho da rede (ou seja, r = 6), o
refinamento na rede inteira será verificada na equação (7.7). Observa-se que o maior número
possível de RPUs que uma rede 6x6 permite pode ser encontrado pela equação abaixo.
despiral = (1 x r + (2 x (r - 1)) + (4 x (r - 2)) + (4 x (r - 3)) + (4 x (r - 4 )) + (4 x (r - 5))) (7.7)
Para a rede em chip com topologia 6x6, o d para situações em que ocorre bloqueio é
igual a quantidade de RPUs percorridos até ele se bloquear. A mesma equação apresentada
em (7.4) é utilizada, a diferença que o valor de r, não é mais 4, e sim, 6. Os resultados
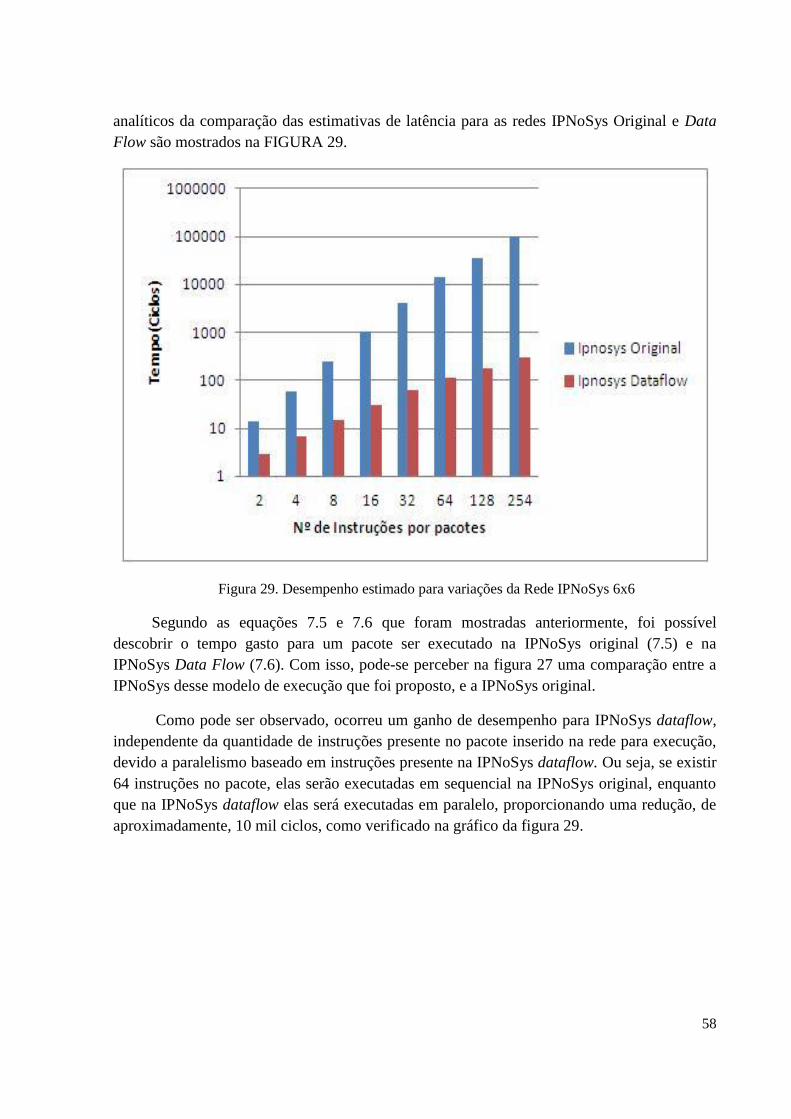
58
analíticos da comparação das estimativas de latência para as redes IPNoSys Original e Data
Flow são mostrados na FIGURA 29.
Figura 29. Desempenho estimado para variações da Rede IPNoSys 6x6
Segundo as equações 7.5 e 7.6 que foram mostradas anteriormente, foi possível
descobrir o tempo gasto para um pacote ser executado na IPNoSys original (7.5) e na
IPNoSys Data Flow (7.6). Com isso, pode-se perceber na figura 27 uma comparação entre a
IPNoSys desse modelo de execução que foi proposto, e a IPNoSys original.
Como pode ser observado, ocorreu um ganho de desempenho para IPNoSys dataflow,
independente da quantidade de instruções presente no pacote inserido na rede para execução,
devido a paralelismo baseado em instruções presente na IPNoSys dataflow. Ou seja, se existir
64 instruções no pacote, elas serão executadas em sequencial na IPNoSys original, enquanto
que na IPNoSys dataflow elas será executadas em paralelo, proporcionando uma redução, de
aproximadamente, 10 mil ciclos, como verificado na gráfico da figura 29.

59
6. CONSIDERAÇÕES FINAIS
6.1. CONCLUSÕES
Devido ao surgimento dos processadores com múltiplos núcleos, esforços para tornar
viável o aumento das taxas de desempenho focam em arquiteturas que conseguem explorar o
paralelismo. Como consequência, diversas pesquisas foram feitas para solucionar problemas
derivados da inserção de vários núcleos no único chip. Segundo a literatura, foi preciso
estudar novas abordagens de arquitetura em oposição às soluções tradicionais de
interconexão.
As Networks on Chip tem se apresentado como a principal alternativa de comunicação
dos núcleos de processamento e outros periféricos nos processadores many core, pois
exploram desempenho em um contexto paralelo, com vários núcleos disponíveis. E um dos
principais motivos de queda de desempenho são as próprias redes de interconexão. À medida
que são intensamente usadas, elas causam contenções e atrasos de pacotes, tal latência
acarreta no aumento do tempo necessário para executar uma determinada aplicação. No
mesmo sentido, é preciso que a NoC apresente uma arquitetura e uma largura de banda que
privilegie a vazão de pacotes.
Durante o estudo das arquiteturas de comunicação, observou-se que a rede IPNoSys
apresenta um aumento de desempenho significativo em relações as outras NoCs, devido a
junção das funções de comunicação e processamento em um único sistema. Também foi
realizado um estudo a respeito do contexto do trabalho, com definições e classificações das
principais variações do MoC Data Flow.
Devido as suas propriedades particulares, a rede IPNoSys foi utilizada para executar
aplicações orientadas a dados. Essas aplicações foram escolhidas após um estudo dos
diferentes comportamentos dos modelos de computação a fluxo de dados. Disso, buscou-se
analisar a desempenho mediante a execução de aplicações puramente orientadas a dados.
Os experimentos possuem tamanhos diversificados em relação a quantidade de
instruções e de pacotes, para poder avaliar os fins da computação na rede IPNoSys. Além
dessas alterações, também foram realizados testes variando o número de instruções
executadas em cada RPU.
A modificação da arquitetura da rede IPNoSys foi proposta, através da utilização do
paralelismo à nível de instrução. A modificação foi possível devido à rede possuir vários
roteadores interligados e dentro de cada um deles tem uma ULA para execução das operações
entre os dados das instruções do pacote.
Os testes de simulação de desempenho e potência desenvolvidos neste trabalho
permitiram obtenção de resultados conclusivos a respeito da execução de aplicações orientada
à dados na rede IPNoSys. Foi possível observar com o aumento de pacotes, que a quantidade
de ciclos gastos continua constante para a mesma configuração. O desempenho na rede é
estável, apresentando crescimento de ciclos lineares em função da variação de instruções. A
potência total dissipada em todos os testes apresentou crescimento linear para a mesma
configuração. Logo, com o aumento de pacotes, a quantidade de energia gasta não cresce

60
linearmente em função do número de instruções, pois a execução localizada aumenta o
desempenho devido a uma menor comunicação. Ou seja, foi observado um ganho elevado de
desempenho, pois várias instruções executam em paralelo e quando maior a rede, mais
instruções executam em paralelo, até o limite que o pacote se auto bloqueia devido ao
algoritmo spiral complement.
Deve-se destacar que a comparação do paralelismo original da IPNoSys, que é a nível
de pacotes com o paralelismo à nível de instrução, foi feito por meio da execução de
aplicações com mesma configuração. Verificou-se que o desempenho da execução, nas redes
com dimensões, 4x4 e 6x6 é sempre maior na IPNoSys Data Flow, devido ao seu paralelismo,
que permite que uma instrução seja processada diversas vezes, apenas adotando o caminho de
execução.
6.2. TRABALHOS FUTUROS
Dentre os diversos trabalhos futuros estão: modificação do algoritmo de roteamento, já
que o algoritmo espiral complement, utilizado pela IPNoSys original, apresenta um limite de
paralelismo que é alcançado quando o pacote se alto bloqueia; Uso de canais virtuais na
transmissão de pacotes na IPNoSys SDF; Desenvolvimento de um simulador para testar as
aplicações com fluxo de dados síncrono; Mapear aplicações reais para a rede IPNoSys
original e para a SDF, analisando a viabilidade da rede ao executar as aplicações.

61
7. Referências
AGARWAL A., ISKANDER C. D., R. SHANKAR. Survey of Network on Chip (NoC)
Architectures & Contributions. Journal of Engineering Computing and Architecture,
Volume 3, Issue 1. 2009.
ARAÚJO, S. R. F. Estudo da Viabilidade do Desenvolvimento de Sistemas Integrados
Baseados em Redes em Chip sem Processadores: Sistema IPNoSys. Departamento de
Informática e Matemática Aplicada. vol. Mestre Natal: UFRN, 2008, p. 87.
ARVIND, K. P.; NIKHIL, R. S. Executing a Programo n the MIT Tagged-Token Data
flow Architecture. IEEE Transactions on Computers, 39(3): 300-318, 1990.
BENINI, L.; DE MICHELI, G. Networks on Chips: A New SOC Paradigm. Computer,
v.35, 2002. p.70-78.
BOLOTIN, E. et al. QNoC: QoS Architecture and Design Process for Network on Chip.
Journal of Systems Architecture, v.50, n.2, p. 1-24, 2004.
CARARA, E. A. Uma Exploração Arquitetural de Redes Intra-Chip com Topologia
Malha e Modo de Chaveamento Wormhole. 2004. 65 Trabalho de Conclusão II, Pontifícia
Universidade Católica do Rio Grande do Sul, Porto Alegre.
CALAZANS, N.; MORAES, F.; CARVALHO, E. Heuristics for Dynamic Task Mapping
in NoC-based Heterogeneous MPSoC, IEEE International Workshop on Rapid System
Prototyping, p. 43-50,2007.
COMPTON, K.; HAUCK, S. Reconfigurable Computing: a servey of systems and
sofware. ACM Comput. Surv., ACM, New York, NY, USA, v. 34, n. 2, p.171-210, 2002.
CULLER, D. E. et al. The Explicit Token Store, Journal of Parallel and Distributed
Computing, 1991.
DALLY, W.; TOWLES, B. Principles and Practices of Interconnection Networks. Morgan
Kaufmann Publishers Inc., 2004. ISBN 0122007514.
DENNIS, J. B. Retrospective: a preliminary architecture for a basic data flow processor. In:
25 years of internacional symposia on Computer architecture (selected papers), 1998.
Barcelona, Sapin. ACM. p.2-4.
DUATO, J. et al. Interconnection Networks: An Engineering Approach. IEEE Computer
Society Press, 1997. 515p.
DUNCAN, R. A survey of parallel computer architectures. ACM Computer, v. 23, n. 2, p.
365-396, 1990.
Ferlin, E. P. Arquitetura paralela reconfigurável baseada em fluxo de dados
implementada em FPGA, Tese de Doutorado, Curitiba, UTFPR, 2008

62
FERNANDES, S., et al., IPNoSys: uma nova arquitetura paralela baseada em redes em
chip, Simpósio em Sistemas Computacionais de Alto Desempenho (WSCAD), pp.53-60,
2008.
GERRIER, P.; GREINER A. A Generic Architecture for On-Chip Packet Switched
Interconnections. In DATE’2000. Internacional conference on Application of Concurrency
to System Design. p. 188-189.
HAMMOND, L.; NAYFEH, B. A.; OLUKOTUN, K. A Single-Chip Multiprocessor. IEEE
Computer, v.30, 1997. p.79-85.
HIRAKI, K. et. al. The Sigma-1 Data flow Supercomputer: A Challenge for New
Generation. Journal of Information Processing, Vol.10, No. 4, 1987.
LEE, B.; HURSON, A. R. Issues in Data flow computing. Advances in Computers, v. 37,
p. 285-333, 1993.
LING, X. P. & AMANO, H. Wasmii: a data drivem computer on a virtual hardware. IN
FPGAs for Custom Computinh Machines, 1993. Proceedings. IEEE Workshop on (PP. 33-
42).
MADOŠ, B.; BALÁŽ, A. Data flow graph mapping techniques of computer architecture
with data driven computation model. In: Applied Machine Intelligence and Informatics
(SAMI), 2011 IEEE 9th International Symposium on, 2011. 27-29 Jan. 2011. p.355-359.
MAGNA, P. Proposta e simulação de uma arquitetura a fluxo de dados d segunda
geração, Tese de Doutorado, USP, 1997.
MATOS, D. S. M. Interfaces Parametrizáveis para Aplicações Interconectadas por uma
Rede-em-Chip, Dissertação de Mestrado, PPGC, UFRGS, 2010.
NAJJAR, W. A.; LEE, E. A.; GAO, G. R. Advances in the Dataflow computational model.
Parallel Comput., Elsevier Science Publishers B. V., Amsterdam, The Netherlands, v. 25, n.
13-14, p. 1907-1929, 1999.
NICOPOULOS, C., PARK, D., KIM, J., VIJAYKRISHNAN, N., YOUSIF, S., DS R.
ViChaR: A Dynamic Virtual Channel Regulator for Network-on-Chip Routers. Int.
Symp. Microarchitecture – MICRO, p.333 – 346, 2006.
OSCI. SystemC, 2005. Disponível em: http://www.systemc.org. Acesso em: 07 abr. 2012
PATT, Y. N. et al. One Billion Transistors, One Uniprocessors, One Chips. IEEE
Computer, v.30, 1997. p.51-57.
REGO, R. S. D. L. S. Projeto e implementação de uma Plataforma MP-SoC usando
SystemC. 2006. 144 Dissertação de Mestrado (Mestrado). Departamento de Informática e
Matemática Aplicada, Universidade Federal do Rio Grande do Norte.
RIJPKEMA, E.; GOOSSENS, K.; WIELAGE, P. Router Architecture for Networks on
Silicon. In: Proceedings of Progress 2001, 2nd
Workshop on Embedded Systems, 2001.
Veldhoven, the Netherlands.

63
SASSATELLI, G. et al. Highly scalable dynamically reconfigurable systolic ring-architecture
for DSP applications. In: Design, Automation and Test in Europe Conference and
Exhibition, 2002. Proceedings, 2002. 2002. p.553-558.
SHIMADA. T.; HIRAKI. K; NISHIDA. K.; SEKIGUSHI, S. Evaluation of a Prototype
Dataflo Processor of the Sigma-1 for Scientific Computations. Proceedings of the 13th
International Symposium on Computer Architecture, 226-234, 1986.
STENSGAARD, B.; SPARSO, J. ReNoC: A Network-on-Chip Architecture with
Reconfigurable Topology, Network-on-Chip – NoCs, p. 55 – 64, 2008.
TAKAYMA, A., SHIBATA, Y., IWAI, K., & AMANO, H. Dataflow partitioning and
scheduling algoritms for WASMII, a virtual hardware. In Field-Programmable Logic and
Applications: The Roadmap to Reconfigurable Computing, volume 1896 of Lecture Notes in
Computer Science, pp. 685- 694, 2000.
TAMIR, Y.; FRAZIER, G. L. Dynamically-Allocated Multi-Queue Buffers for VLSI
Communication Switches. IEEE Trans. On Computers, v. 41, n. 6, Jun. 1992. P. 725-737.
TRELEAVEN, P. C.; BROWNBRIDGE, D. R.; HOPKINS, R. P. Data Driven and Demand
Driven Computer Architecture. Computing Surveys, 93-143, 1982.
VEEN, A. H. Dataflow machine architecture. In:ACM Computing urveys, 1986, p. 365-
396.
YAMAGUCHI, Y. Synchronization Mechanisms of a Highly Parallel Data flow Machine
EM-4. IEICE Transaction, 1991.
ZEFERINO, C. Redes em chip: Arquiteturas e Modelos para Avaliação e Área e
Desempenho. Tese (Doutorado em Ciência da Computação) - Instituto de Informática,
UFRGS, Porto Alegre, 2003.
ZEFERINO, C. A.; SUSIN, A. A. SoCIN: A Parametric and Scalable Network-on-Chip.
In: Symposium on Integrated Circuits and Systems, São Paulo, 2003.


















