![APOSTILA DE VBA E - dbmanagement.infodbmanagement.info/Microsoft/VBA_para_Excel_MS_Excel_2016.pdfOs blocos de comandos [C omand s 1 ] ou 2 serão executados, caso as condições [Condição](https://static.fdocumentos.com/doc/165x107/5ae547db7f8b9a29048c0d8d/apostila-de-vba-e-blocos-de-comandos-c-omand-s-1-ou-2-sero-executados-caso.jpg)
Dos Dados ao Conhecimento -...
51
13/06/2008 1 Dos Dados ao Conhecimento Diogo Diederichs Prado Felipe Allevato Bernardo Isabele Moura Maria Fernanda Scaranto do Amaral Introdução Pretendemos com a apresentação introduzir os conceitos de Banco de Dados, Data Warehouse e Data Mining, através de um pensamento cronológico. Sempre focaremos em exemplos e ferramentas para uma melhor compreensão do exposto e finalizaremos com um case ilustrativo 2
Transcript of Dos Dados ao Conhecimento -...

13/06/2008
1
Dos Dados ao ConhecimentoDiogo Diederichs Prado
Felipe Allevato Bernardo
Isabele Moura
Maria Fernanda Scaranto do Amaral
Introdução
Pretendemos com a apresentação introduzir os conceitos de Banco de Dados, Data Warehouse e Data Mining, através de um pensamento cronológico. Sempre focaremos em exemplos e ferramentas para uma melhor compreensão do exposto e finalizaremos com um case ilustrativo
2

13/06/2008
2
Agenda
Banco de Dados
Data Warehouse
Data Mining
Case
3
Histórico do Banco de Dados
A tendência das metodologias de armazenamento nos revela a presença de modelos mistos
4
POWELL, G. Beginning Database Design

13/06/2008
3
Histórico do Banco de Dados
A evolução das tecnologias interferem na maneira de se armazenar e visualizar os dados
5
Aplicações individuais com seus relatórios e dados (cartões perfurados e fitas magnéticas)
Crescimento das fitas magnéticas gerou uma grande quantidade de dados e muitas redundâncias
Surgimento do DASD (DirectAccess Storage Device, hardware) e do DBMS (Database Management System). Surge o banco de dados
INMON, H. W. Building the Data Warehouse
Banco de Dados“Por definição, um banco de dados é um objeto estruturado. Ele pode ser uma pilha de papeis, mas, no mundo moderno , existe em computadores. Este objeto consiste em dados e metadados...”
Gavin Powell
6
DadosMetadados
Banco de Dados
Computador
13/06/2008
4
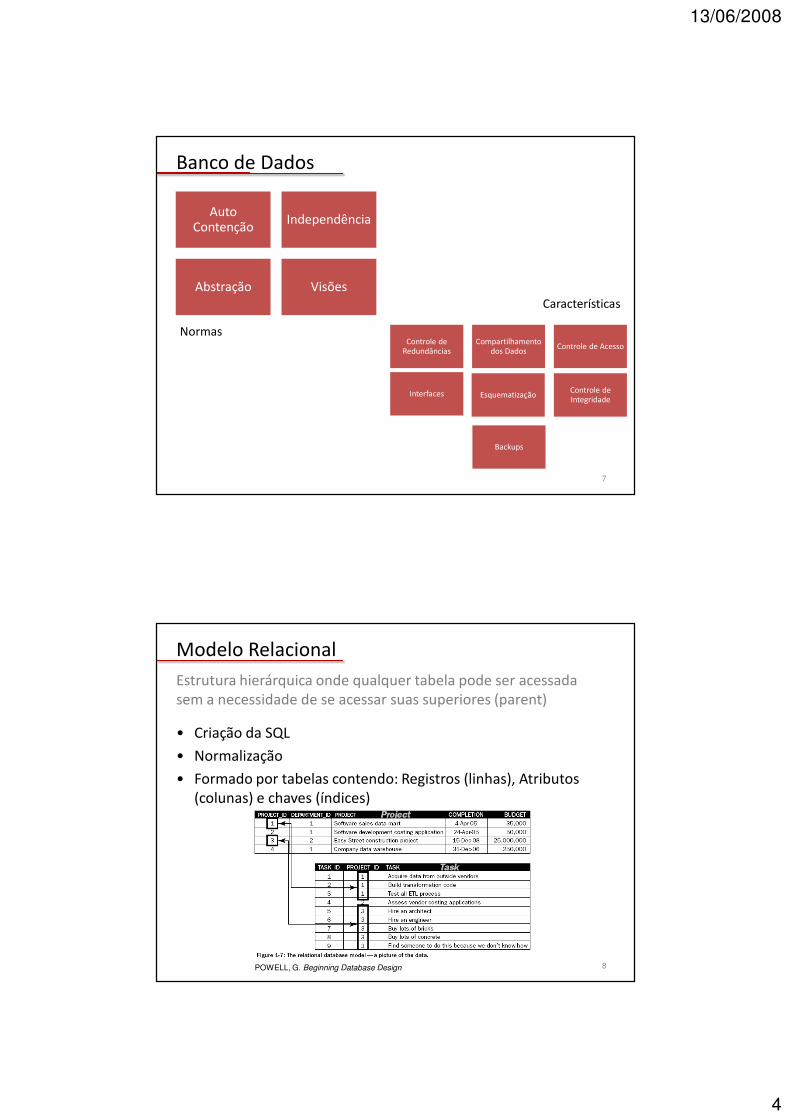
Banco de Dados
7
Auto Contenção
Independência
Abstração Visões
Controle de Redundâncias
Compartilhamento dos Dados
Controle de Acesso
Interfaces EsquematizaçãoControle de Integridade
Backups
Normas
Características
Modelo Relacional
Estrutura hierárquica onde qualquer tabela pode ser acessada sem a necessidade de se acessar suas superiores (parent)
8
• Criação da SQL
• Normalização
• Formado por tabelas contendo: Registros (linhas), Atributos (colunas) e chaves (índices)
POWELL, G. Beginning Database Design

13/06/2008
5
OLTP (Online Transactional Processing)
Dados podem ser acessados e extraídos facilmente
9
• Os dados eram utilizados apenas para decisões operacionais detalhadas
• Surgem os programas de extração de dados, que permitem que os estes sejam operados fora do ambiente de processamento principal. Isso reduz os conflitos quando um dado é acessado em massa.
• O usuário final agora tem controle sobre esses dados extraídos
Histórico do Banco de Dados
A evolução das tecnologias interferem na maneira de se armazenar e visualizar os dados
10
Aplicações individuais com seus relatórios e dados (cartões perfurados e fitas magnéticas)
Crescimento das fitas magnéticas gerou uma grande quantidade de dados e muitas redundâncias
Surgimento do DASD (DirectAccess Storage Device, hardware) e do DBMS (Database Management System). Surge o banco de dados
Surge o OLTP que dava velocidade ao acesso dos dados, difundindo o uso do BD em setores comerciais e empresariais. Poucos dados podem ser acessados por muitos
Com os PCs e linguagens de programação da 4a geração, possibilitou-se que o usuário final tivesse controle do sistema
INMON, H. W. Building the Data Warehouse

13/06/2008
6
Spider WebA expansão dos Bancos de Dados para usuários finais gerou a perda de credibilidade das informações
11
+10%
-15%
Adaptado de:INMON, H. W. Building the Data Warehouse
Motivações Para Novas Técnicas
Alguns dos motivos da perda de credibilidade
12
• Perda da informação tempo
• Diferentes algoritmos de extração
• Diferentes níveis de extração
• Falta de sincronia e de padronização entre as bases
• Bases de dados com períodos curtos

13/06/2008
7
Surge a noção de que essa capacidade de armazenamento poderia ser mais explorada além de simplesmente processar transações online
13
OLAP – Online Analytical Processing
• Modelo Orientado a Objeto: permite uma estruturação tridimensional, possibilitando que dados possam ser achados mais rapidamente
OLTP OLAP
Usuário Operacional Gerencial
Função Operações Diárias Suporte de Decisão
Dados Atual, hierarquizadoHistórico,
Multidimensional
Uso Freqüente Menor probabilidade
Registros Acessados Dezenas Milhões
Usuários Milhares Centenas
Tamanho MB-GB GB-TB
Performance Alta Atenuada
14
OLTP x OLAP

13/06/2008
8
Exemplo de tabelas de pedidos e clientes de uma loja
15
Onde o BD transacional não alcança
Exemplo de tabelas de empregados de uma loja
16
Onde o BD transacional não alcança

13/06/2008
9
17
Onde o BD transacional não alcança
• Quais os produtos vendidos pelo funcionário A?
• Quais os pedidos do cliente B?
• Quais os funcionários com salário maior que 10.000?
• Quais os produtos vendidos pelo funcionário A para o cliente B?
Questões facilmente respondidas pelo modelo transacional
18
Onde o BD transacional não alcança
Questões mais complexas, que necessitam ser respondidas pelo modelo OLAP
• Quais funcionários venderam mais para qual país?
• Quais países possuem preferência por algum método de pagamento?
• Quais os estados possuem preferência por qual tipo de envio?

13/06/2008
10
19
Onde o BD transacional não alcança
O OLAP necessita visualizar dados multidimensionais
• Usualmente (OLTP), dados são visualizados de forma bidimensional, em tabelas.
• Porém, em casos reais, dados são potencialmente multidimensionais.
• Exemplo: Vendas x Mês do ano x Local da loja x Tipo de produto.
Apresentação: “Datawarehousing e OLAP para uso em datamining”, Centro Universitário Carioca - Pós-graduação em Banco de DadosMoutinho, A. M.
Cubo de dados, ou “data cubes”, são cruzamentos multidimensionais (não necessariamente 3D...) dos dados de atributos de um BD.
Cubo 3D
Cubo 4D
O cubo de dados
20

13/06/2008
11
Fonte: INMON, W.H., Como construtir o Data
Warehouse. 2ª ed.. Rio de Janeiro: Campus. 1997.
Apresentação: “Datawarehousing e OLAP para uso em datamining”, Centro Universitário Carioca - Pós-graduação em Banco de DadosMoutinho, A. M.
Problema!
Como gerar o cubo para produzir informações no meio de tantos dados?
21
Agenda
Banco de Dados
Data Warehouse
Data Mining
Case
22

13/06/2008
12
• “Data Warehouse, ou armazém de dados, pode ser definido como um sistema de armazenamento de dados históricos de forma consolidada. Geralmente é utilizado em grandes corporações e coletando dados de sistemas transacionais diversos. Sua vantagem é ter um desenho de base de dados que favoreça suas consultas, relatórios, a obtenção de informações e uma visão única dos dados corporativos. “
• ‘‘Subject-oriented, integrated, time-variant and non-volatile collection of data in support of management’s decision making process’’.
W. Inmon, Building the Data Warehouse, QED Press/Wiley, 1992 (last edition: 3rd edition, Wiley, 2002).
• “A Data Warehouse stores data obtained from operational systems and is organized and managed to support reporting and analytical needs”
J. Zubcoff, J. Trujillo / Data & Knowledge Engineering 63 (2007) 44–62
• ‘‘The data warehouse must have the right data in it to support the decision making”
R. Kimball, The Data Warehousing Toolkit, Wiley, New York, 1996 (last edition: 2nd ed., Wiley, 2002).
Definições
23
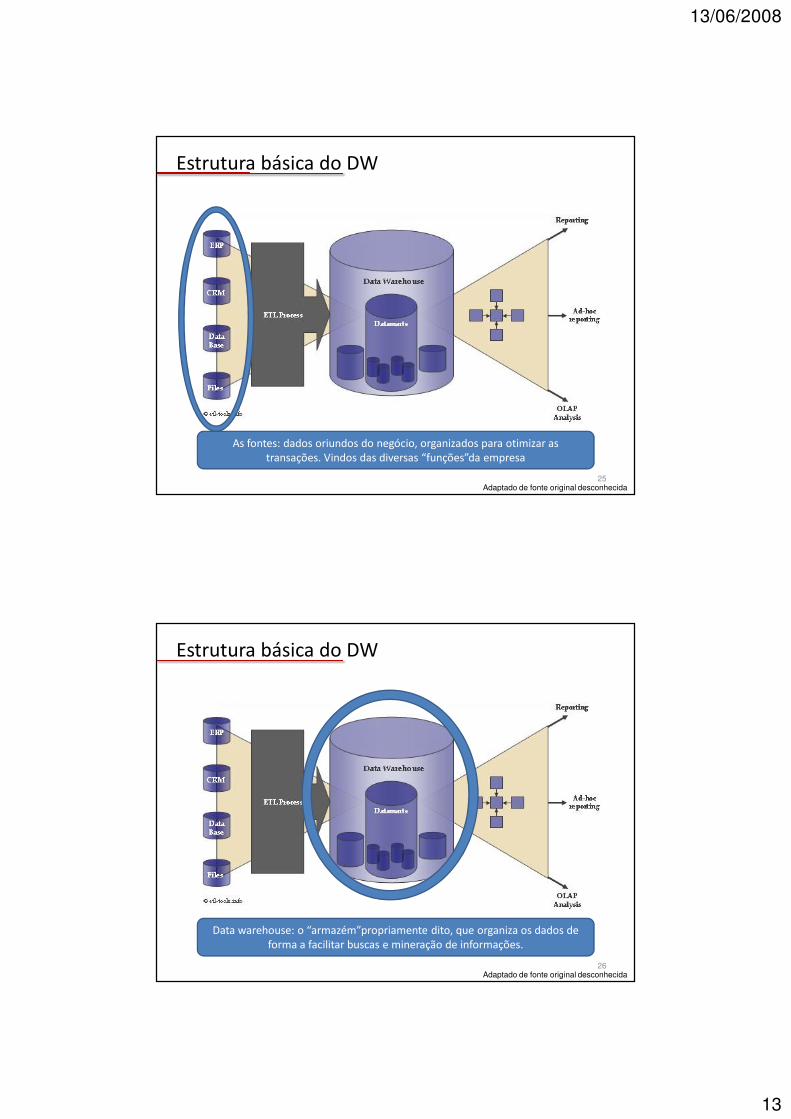
Estrutura básica do DW
Fonte original desconhecida
24
13/06/2008
13
Estrutura básica do DW
Adaptado de fonte original desconhecida
As fontes: dados oriundos do negócio, organizados para otimizar as transações. Vindos das diversas “funções”da empresa
25
Estrutura básica do DW
Data warehouse: o “armazém”propriamente dito, que organiza os dados de forma a facilitar buscas e mineração de informações.
Adaptado de fonte original desconhecida26

13/06/2008
14
Estrutura básica do DW
Datamarts: ambientes onde são feitas análises para resposta a questões pontuais. Podem ser temporárias ou permanentes. Reúne partes úteis do DW
para resolver a questão em foco
Adaptado de fonte original desconhecida27
Estrutura básica do DW
1. Extract: extração de dados de fontes externasconsolidação de dados de diferentes sistemas de origem.Conversão dos dados num formato adequado à transformação.
2. Transform: transformação dos dados aplicação de regras e funções sobre os dados extraídos para obter os dados a serem carregados.Limpeza, deduplicação, codificação, decodificação, fusão, junção, agrupamento, sumarização.
3. Load: carga dos dados transformados no Data
Warehouse.
28

13/06/2008
15
ETL na prática (1)
W. Inmon, Building the Data Warehouse, QED Press/Wiley, 1992 (Última edição: 4a edição, Wiley, 2005).
Um cliente de apólices de seguro....
29
ETL na prática (2)
W. Inmon, Building the Data Warehouse, QED Press/Wiley, 1992 (Última edição: 4a edição, Wiley, 2005). 30

13/06/2008
16
• Conforme a quantidade de fontes de dados e transformações necessárias para a carga no DW aumenta, aumenta a complexidade do processo.
Modelando o ETL
DW
BD
BD
T
T
Assim é “fácil”... Mas e assim ?
DW
BD
BD
T
T
BD
BD
T
T
BD
BD
T
BDT
BD
BD
T
Quando a realidade fica muito complicada... Buscamos um modelo
31
• “O design do backstage de um data warehouse sempre foi um trabalho extenuante devido à complexidade de seu ambiente e ao detalhamento técnico em que o designer deve se envolver(…) As tarefas do desing incluem”:
Modelando o ETL
A method for the mapping of conceptual designs to logical blueprints for ETL processes – Decision Support Systems 45 (2008) 22–40; de Simitsis, A.; Vassiliadis, P.
Modelagem conceitual
•“Mapeamento das fontes de dados e entendimento dos relacionamentos”…;
•“É endereçado ... a gerentes e pessoas com pouca expertise em datawarehousing (...) para facilitar o entendimento das partes interessadas, usa uma linguagem simples.”
Modelagem lógica
•“Design de um workflow de extração dos dados de suas fontes, limpeza de possíveisinconsistências, transformação para seu formato final e carga no data warehouse emquestão”
• É endereçado aos designers e programadores. Possui linguagem mais técnica e rigorosa
32

13/06/2008
17
(a) f:: função; (b) e:: expressão; and (c) t:: textos simples
A method for the mapping of conceptual designs to logical blueprints for ETL processes – Decision Support Systems 45 (2008) 22–40; de Simitsis, A.; Vassiliadis, P.
Exemplo de modelagem conceitual do ETL
33
Um exemplo de modelagem lógica do ETL
34
13/06/2008
18
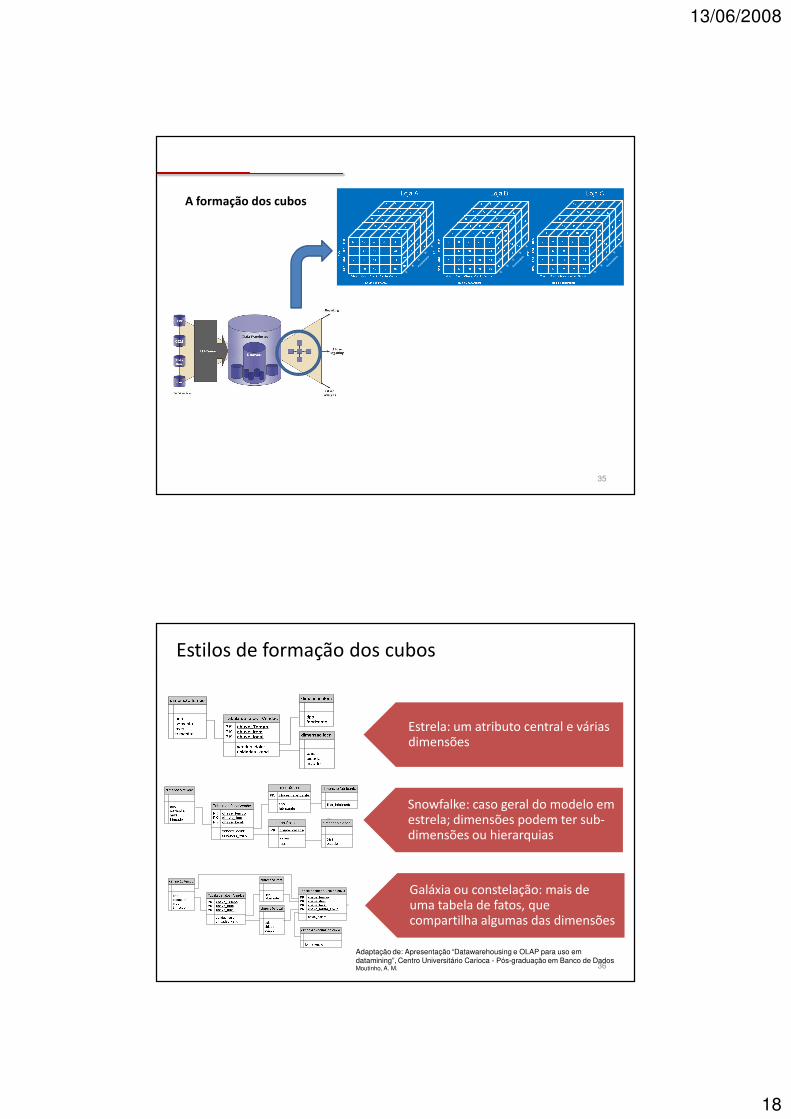
A formação dos cubos
A B C D E
Funcionário
A B C D E
Funcionário
A B C D E
Funcionário
35
Estrela: um atributo central e várias dimensões
Snowfalke: caso geral do modelo em estrela; dimensões podem ter sub-dimensões ou hierarquias
Galáxia ou constelação: mais de uma tabela de fatos, que compartilha algumas das dimensões
Estilos de formação dos cubos
Adaptação de: Apresentação “Datawarehousing e OLAP para uso em datamining”, Centro Universitário Carioca - Pós-graduação em Banco de DadosMoutinho, A. M. 36

13/06/2008
19
• Quando aplicada sobre vários conjuntos e somada tem o mesmo resultado de quando aplicada no total
• Exemplos: Soma, mínimo, máximo, contagensDistributiva
• Obtida através de “n”agregações distributivas aplicadas a uma função (F(n))
• Exemplos: média, desvio padrãoAlgébrica
• Não são divisíveis em partes ou agregações distributivas. Nela, cada “cubóide”deve ser calculado separadamente
• Exemplo: medianaHolística
As operações de formação dos cubos
37
A “cara” de um cubo de dados
Cubo 2D: Estado x tipo de envio
Cubo 3D:Funcionário x país x Tipo de envio
38

13/06/2008
20
39
Os usuários do Datawarehouse
Inmon, W. DW 2.0 The Next Generation of Data Warehousing
40
Os usuários do Datawarehouse
Em seu artigo, “DW 2.0 The Next Generation of Data Warehousing”, Inmon identifica 4 padrões principais de uso de um DW e atribui a cada um deles um personagem, a saber:
O fazendeiro•Previsível•Sabe o que quer do DW e busca freq.•Submetem muitas queries•Buscam o mesmo tipo de informação•Usam os mesmos procedimentos repetidamente
O explorador•Imprevisível•Demanda muito variável•Suas queries normalmente envolvem uma grande quantidade de dados•Normalmente não acham nada.. Mas quando acham...
O turista•Esporádico•Buscas mais amplas e superficiais•Sabem onde achar e como procurar
O minerador•Fazem observações, testam hipóteses, buscam probabilidades•Análises estatísticas envolvendo grande quantidade de dados•Não buscam verdades absolutas, sim relativas (%)•São estatísticos, normalmente
13/06/2008
21
41
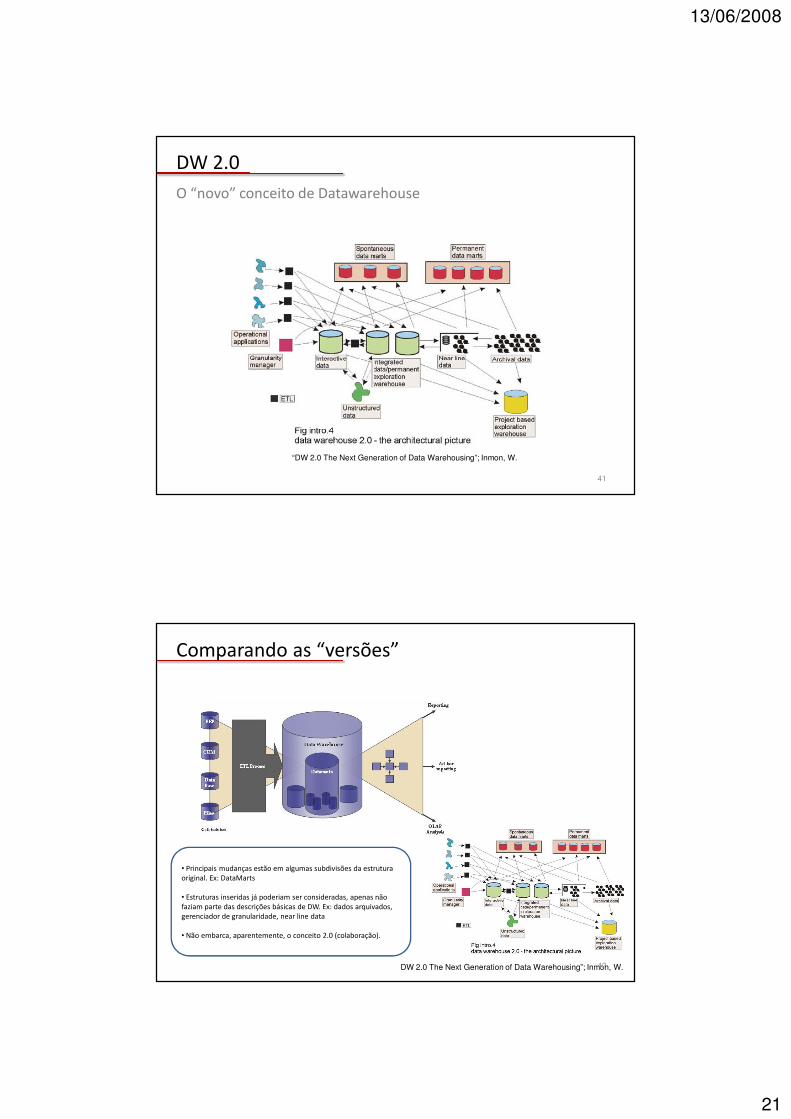
DW 2.0
O “novo” conceito de Datawarehouse
“DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
Comparando as “versões”
• Principais mudanças estão em algumas subdivisões da estrutura original. Ex: DataMarts
• Estruturas inseridas já poderiam ser consideradas, apenas não faziam parte das descrições básicas de DW. Ex: dados arquivados, gerenciador de granularidade, near line data
• Não embarca, aparentemente, o conceito 2.0 (colaboração).
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W. 42
13/06/2008
22
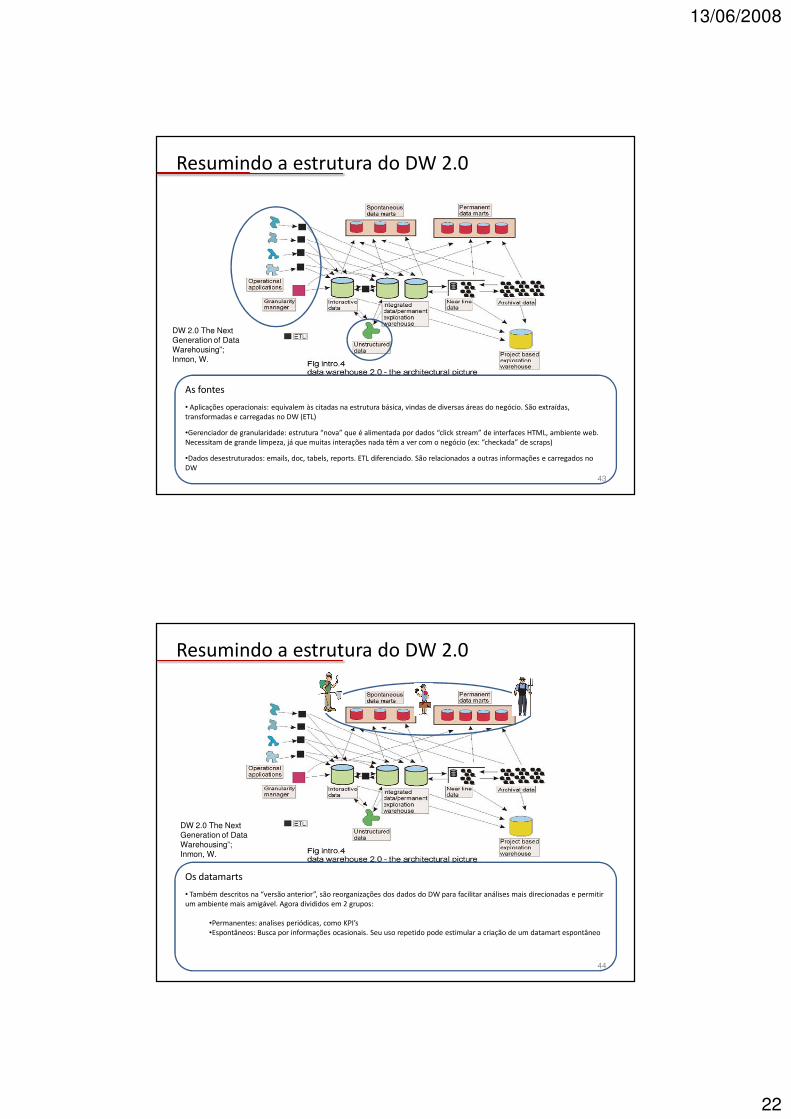
Resumindo a estrutura do DW 2.0
As fontes
• Aplicações operacionais: equivalem às citadas na estrutura básica, vindas de diversas áreas do negócio. São extraídas, transformadas e carregadas no DW (ETL)
•Gerenciador de granularidade: estrutura “nova” que é alimentada por dados “click stream” de interfaces HTML, ambiente web. Necessitam de grande limpeza, já que muitas interações nada têm a ver com o negócio (ex: “checkada” de scraps)
•Dados desestruturados: emails, doc, tabels, reports. ETL diferenciado. São relacionados a outras informações e carregados no DW
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
43
Resumindo a estrutura do DW 2.0
Os datamarts
• Também descritos na “versão anterior”, são reorganizações dos dados do DW para facilitar análises mais direcionadas e permitir um ambiente mais amigável. Agora divididos em 2 grupos:
•Permanentes: analises periódicas, como KPI’s•Espontâneos: Busca por informações ocasionais. Seu uso repetido pode estimular a criação de um datamart espontâneo
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
44

13/06/2008
23
Resumindo a estrutura do DW 2.0
O “armazém”
• O core do DW 2.0 é divido em 2 partes, divididas fisicamente:
• Parte interativa: dados levemente modificados em relação à fonte. Ainda têm chance de atualizações. • Parte integrada: dados não são mais atualizáveis, são registros integrados.
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
45
Resumindo a estrutura do DW 2.0
O “armazém” de exploração por projetos
• Reúne informações detalhadas e históricas, com fim de análises estatísticas, padrões, etc., segundo necessidades, projetos.
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
46
13/06/2008
24
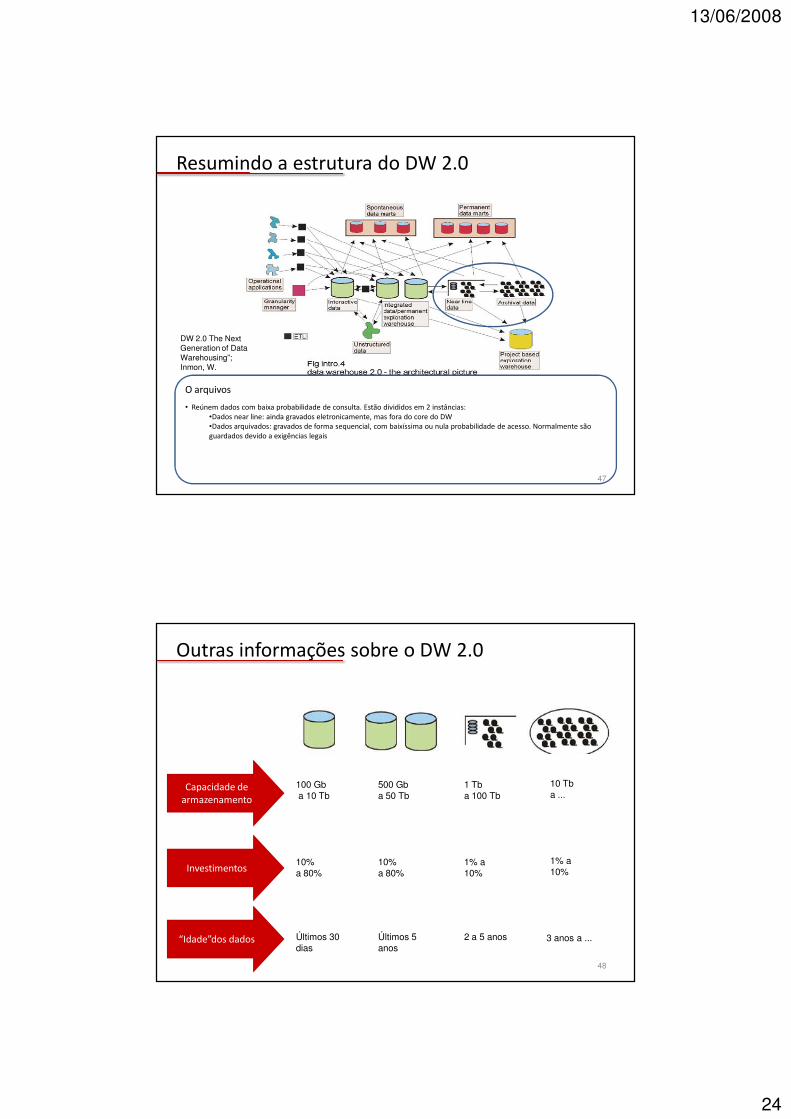
Resumindo a estrutura do DW 2.0
O arquivos
• Reúnem dados com baixa probabilidade de consulta. Estão divididos em 2 instâncias:•Dados near line: ainda gravados eletronicamente, mas fora do core do DW•Dados arquivados: gravados de forma sequencial, com baixíssima ou nula probabilidade de acesso. Normalmente são guardados devido a exigências legais
DW 2.0 The Next Generation of Data Warehousing”; Inmon, W.
47
Capacidade de armazenamento
Investimentos
“Idade”dos dados
100 Gba 10 Tb
500 Gba 50 Tb
1 Tba 100 Tb
10 Tba ...
10%a 80%
10% a 80%
1% a10%
1% a 10%
Últimos 30 dias
Últimos 5 anos
2 a 5 anos 3 anos a ...
Outras informações sobre o DW 2.0
48

13/06/2008
25
Agenda
Banco de Dados
Data Warehouse
Data Mining
Case
49
Ferramentas de Extração de Dados
50
Tipo de ferramenta Questão básica Exemplo de resposta Necessidades atendidas
Relatórios e Consultas "O que aconteceu?"Relatórios mensais devendas, histórico doinventário.
Obtenção de dados históricos.
OLAP"O que aconteceu e porque?"
Vendas mensais versusmudança de preço doscompetidores.
Visões multidimensionais estáticas dainformação; teste de hipótese.
EIS"O que eu preciso saberagora?"
Memorandos, centros decomando.
Informações de alto nível ouresumidas; dados na tela/gráficos paraentendimento da situação-problema.
Data Mining"O que é Interessante?""O que pode acontecer?"
Modelos de previsãoTendências e relações obscuras oudesconhecidas entre os dados.
50

13/06/2008
26
Data Mining e KDD
51
Dados Históricos
Conhecimento
InterpretaçãoSeleção Pré-processamento Transformação Mineração
Data Mining faz parte de um processo maior chamado Knowledge Discovery in Database (KDD), ou seja, a busca de conhecimentos em banco de dados
51
Data Mining
52
Definição
“Data Mining é o uso de técnicas automáticas de exploração de
grandes quantidades de dados de forma a descobrir novos padrões e
relações que, devido ao volume de dados, não seriam facilmente
descobertos a olho nu pelo ser humano” (CARVALHO, 2002).
“Data Mining é “um processo de extração de
informações previamente desconhecidas, válidas e com capacidade de
proporcionar ações, provenientes de uma grande base de dados e
então estudá-las na tomada de decisões de negócios cruciais“ (IBM).

13/06/2008
27
Data Mining
53
Atributos
• Análise de padrões para entender comportamentos
• Identificação de afinidades entre variáveis
• Previsão de valores futuros com base em informações históricas
• Análise de hábitos
• Classificação de dados em agrupamentos descritivos
• Tomada de decisões estratégicas
53
Aplicações do DM
Data Mining
• Marketing & Comércio – comportamento de clientes e/ou de cada filial
• Identificar e criar estratégias para reter os clientes mais rentáveis
• Aumentar a capacidade de cross-seling e de up-selling
• Melhor identificação dos alvos em campanhas de marketing
• E-mails específicos para determinados grupos consumidores (Marketing
eletrônico personalizado) de ligações do usuário - clonagem
54

13/06/2008
28
Aplicações do DM (cont.)
Data Mining
• Finanças – análise de risco de crédito / análise de investimentos
• Seguros – comportamento dos assegurados
• Medicina – correlações entre variáveis médicas imperceptíveis a olho nu
• Governo – identificação ilegalidades, compradores de armas
• Telecomunicações – análise de padrões de ligações do usuário - clonagem
55
Tarefas do Data Mining
O DM é capaz de realizar algumas tarefas de análise de dados através de técnicas estatísticas e de inteligência artificial
56
• Associação
• Classificação
• Estimativa
• Análise de Cluster
56

13/06/2008
29
Tarefas do Data Mining
57
Exemplo: padaria
1) Identificando padrões
ABCXYABCZKABDKCABCTUABEWLABCWO
Associação: Analisa dados e encontra padrões
57
Tarefas do Data Mining
58
Exemplo: padaria
1) Identificando padrões
ABCXYABCZKABDKCABCTUABEWLABCWO
ABCXY ABCZK ABDKCABCTU ABEWL ABCWO
Associação: Analisa dados e encontra padrões
58

13/06/2008
30
Tarefas do Data Mining
59
2) Analisando os padrões
ABCXY ABCZK ABDKCABCTU ABEWL ABCWO
A � aquisição de pãoB � aquisição de leiteC � leite desnatado
AB � Sempre que se compra pão, se compra leite (algumas vezes desnatado)
Associação: Analisa dados e encontra padrões
59
Tarefas do Data Mining
60
ABCXY ABCZK ABDKCABCTU ABEWL ABCWO
X � manteiga sem salZ � manteiga com salT � margarina
V
V � “coisas” que passamos no pão
2) Analisando os padrões
Associação: Analisa dados e encontra padrões
60
13/06/2008
31
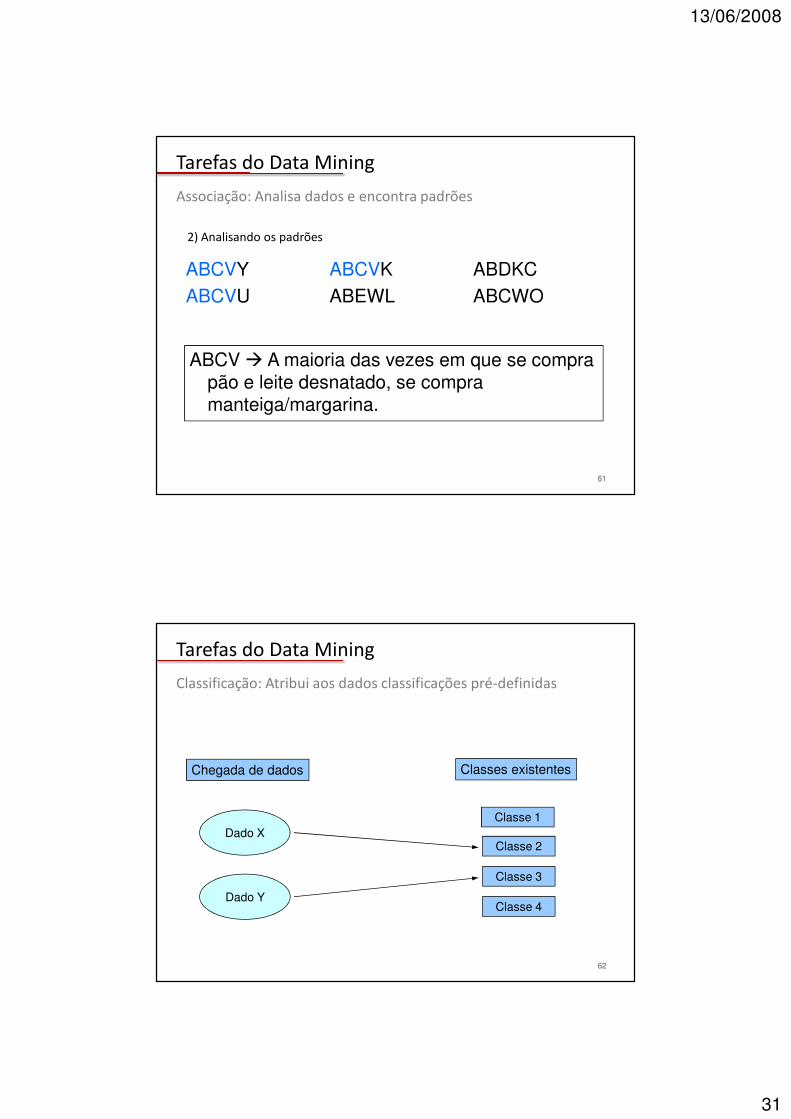
Tarefas do Data Mining
61
ABCVY ABCVK ABDKCABCVU ABEWL ABCWO
ABCV � A maioria das vezes em que se compra pão e leite desnatado, se compra manteiga/margarina.
2) Analisando os padrões
Associação: Analisa dados e encontra padrões
61
Tarefas do Data Mining
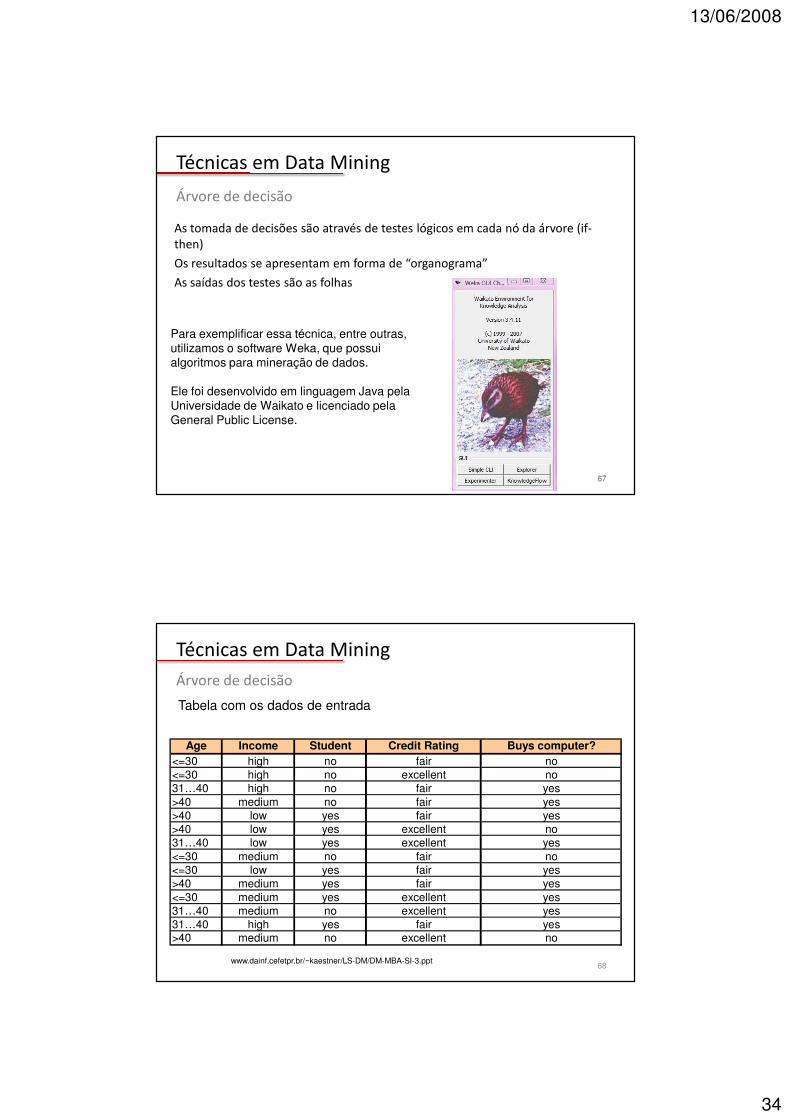
62
Dado XClasse 1
Classe 2
Classe 3
Classe 4Dado Y
Chegada de dados Classes existentes
Classificação: Atribui aos dados classificações pré-definidas
62

13/06/2008
32
Tarefas do Data Mining
63
Exemplo:
Informações disponíveis
Cidades próximas ao pedágio X
Rodovia de localização do pedágio X
Preço do pedágio X
Dias da semana
Quantos carros passam pelo pedágio X?
Estimativa: Previsão de valores futuros através de valores passados conhecidos
63
Tarefas do Data Mining
64
Exemplo:
Doença Sintoma
Dengue Febre alta
Gastrite Dor no estômago
Pneumonia Tosse
Anemia Perda de peso
Tuberculose Tosse
AIDS Perda de peso
Úlcera Dor no estômago
Febre Amarela Febre alta
Doença SintomaDengue e febre amarela Febre alta
Classe 1
Doença Sintoma
Gastrie e úlcera Dor no estômago
Classe 2
Doença Sintoma
Pneumonia e tuberculose Tosse
Classe 3
Doença Sintoma
Anemia e AIDS Perda de peso
Classe 4
Análise de Cluster: Cria classes para os dados existentes - função descritiva
64

13/06/2008
33
Técnicas em Data Mining
Para que o DM realize as tarefas descritas, ele se utiliza de alguns algoritmos conhecidos:
65
• Redes Neurais Artificiais
• Árvore de decisão
• Classificação bayesiana
• Regressão
• Regras rudimentares
• Regras rudimentares com estatística
• Regras de associação
• Análise de grupamento
• Regressão lógica
• Análise discriminante
• Técnicas de visualização
• Algoritmos genéticos
65
Técnicas em Data Mining
66
Sexo
Idade
Fumo
Peso
Altura
Bebidas
Risco de câncer
Camadas ocultas
Redes Neurais Artificiais
Exemplo: Através de neurônios interconectados:
• Avalia valores de entrada (inputs)
• Calcula combinação de valores de entrada em camadas ocultas
• Determina valores de saída (outputs)
66
13/06/2008
34
Técnicas em Data Mining
67
As tomada de decisões são através de testes lógicos em cada nó da árvore (if-then)
Os resultados se apresentam em forma de “organograma”
As saídas dos testes são as folhas
Para exemplificar essa técnica, entre outras, utilizamos o software Weka, que possui algoritmos para mineração de dados.
Ele foi desenvolvido em linguagem Java pela Universidade de Waikato e licenciado pela General Public License.
Árvore de decisão
67
Árvore de decisão
68www.dainf.cefetpr.br/~kaestner/LS-DM/DM-MBA-SI-3.ppt
Tabela com os dados de entrada
Age Income Student Credit Rating Buys computer?
<=30 high no fair no<=30 high no excellent no31…40 high no fair yes>40 medium no fair yes>40 low yes fair yes>40 low yes excellent no31…40 low yes excellent yes<=30 medium no fair no<=30 low yes fair yes>40 medium yes fair yes<=30 medium yes excellent yes31…40 medium no excellent yes31…40 high yes fair yes>40 medium no excellent no
Técnicas em Data Mining
13/06/2008
35
69
Técnicas em Data Mining
Árvore de decisão
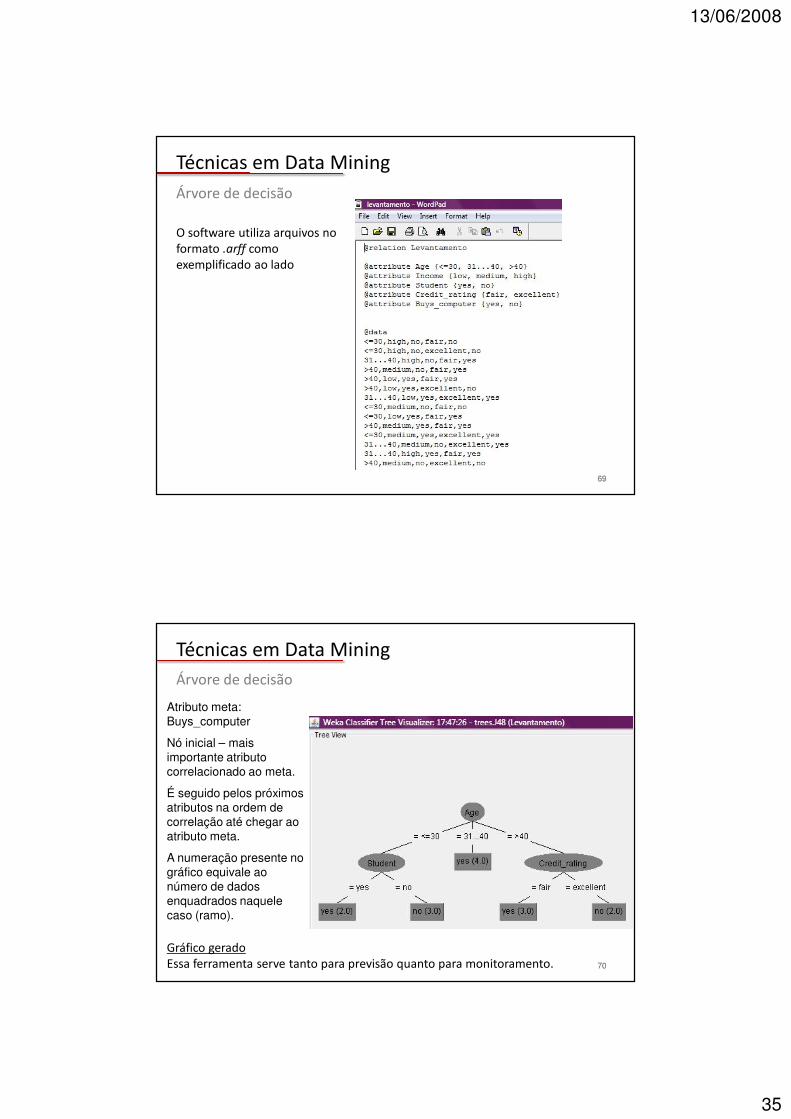
O software utiliza arquivos no formato .arff como exemplificado ao lado
69
70
Gráfico gerado Essa ferramenta serve tanto para previsão quanto para monitoramento.
Atributo meta: Buys_computer
Nó inicial – mais importante atributo correlacionado ao meta.
É seguido pelos próximos atributos na ordem de correlação até chegar ao atributo meta.
A numeração presente no gráfico equivale ao número de dados enquadrados naquele caso (ramo).
Árvore de decisão
Técnicas em Data Mining
70

13/06/2008
36
Técnicas em Data Mining
71
Interpretação dos resultados:
•Pessoas com idade <= 30 que são estudantes compram computador;
•Pessoas com a mesma idade mas que não são estudantes não compram computador;
•Pessoas com idade entre 31 e 40 anos sempre compram computador independente das outras variáveis;
•Pessoas com mais de 40 anos que possuem avaliação de crédito razoável compram computador;
•Pessoas com mais de 40 anos que possuem avaliação de crédito excelente não compram computador.
Árvore de decisão
71
Técnicas em Data Mining
72Gráfico tipo Histograma com os dados do atributo Buys_computer
Árvore de decisão
72

13/06/2008
37
Técnicas em Data Mining
73
Gráficos tipo Histograma com os dados de cada atributo de entrada relacionado pelas cores Azul e Vermelho com os do atributo Buys_computer
Árvore de decisão – visualização dos dados
73
Técnicas em Data Mining
74
Calcula a probabilidade de uma amostra desconhecida pertencer a cada uma das classes de valor do atributo possíveis.
Classificador utilizado: classificador de Naïve Bayes
•Probabilidade de umapessoa de uma amostradesconhecida comprarcomputador: 63%
•Probabilidade de umapessoa de uma amostradesconhecida não comprarcomputador: 38%
•Suposição ingênua: pressupõe independência entre os atributos
Classificação bayesiana
74

13/06/2008
38
Técnicas em Data Mining
75
Calcula a equação linear utilizando os dados como amostra e os atributos como variáveis
Classificador utilizado: Linear Regression
Encontro a Equação de Regração dos dados numéricos
Lápis Borracha Caneta Apontador Caderno Lapiseira Grafite
125 256 6000 256 16 128 199
29 8000 32000 32 8 32 253
29 8000 32000 32 8 32 253
29 8000 32000 32 8 32 253
29 8000 16000 32 8 16 132
26 8000 32000 64 8 32 290
23 16000 32000 64 16 32 381
23 16000 32000 64 16 32 381
23 16000 64000 64 16 32 749
23 32000 64000 128 32 64 1238
… … … … … … ...
Regressão
75
Técnicas em Data Mining
Tabela de exemplo: brincar (play) ou não dependendo das condições climáticas
76

13/06/2008
39
Técnicas em Data Mining
Regras Rudimentares• Para cada valor de cada atributo, contar o número de cada tipo de resposta
• Indicar o valor com maior número de respostas iguais e o erro fracionário
• Repetir para os outros atributos
• Escolhe apenas 1 atributo que funcione melhor
77
Escolhendo o atributo outlook acertaríamos 71% dos casos registrados
Técnicas em Data Mining
Regras Rudimentares com Estatísticas
Semelhante ao algoritmo anterior, porém todos os atributos são utilizados, cada um respeitando sua probabilidade para cada tipo de resposta
78
Se quisermos saber a resposta da seguinte combinação: sunny, cool, high, true.P(sim) = 2/9 x 3/9 x 3/9 x 3/9 x 9/14 = 0,0053P(não) = 3/5 x 1/5 x 4/5 x 3/5 x 5/14 = 0,0206Normalizando, temos:P(sim) = 20,5% e P(não) = 79,5%

13/06/2008
40
Exemplos de aplicação de DM em casos reais
79
Caso Wal-Mart
• Dados de entrada: Volume de vendas, produto, dia da semana
• Informação: As vendas de cerveja cresciam na mesma proporção que as de fraldas às sextas-feiras
• Interpretação/conhecimento: Ao comprar fraldas para seus bebês, os pais aproveitavam para comprar cerveja para o final de semana
• Ação: Posicionar as cervejas próximas às fraldas
• Resultado: a venda de fraldas e cervejas disparou
79
Exemplos de aplicação de DM em casos reais
80
Banco Itaú
• Costumava enviar mais de 1 milhão de malas diretas, para todos os correntistas. No máximo 2% deles respondiam às promoções.
• Dados de entrada: Movimentação financeira de seus 3 milhões de clientes nos últimos 18 meses;
• Informação: Tipos de operações de cada cliente;
• Interpretação/conhecimento: Lista de clientes com maior probabilidade de responder a determinado tipo de promoção;
• Ação: Envio de mala direta apenas para essas pessoas;
• Resultado: A taxa de retorno subiu para 30%. A conta do correio foi reduzida a um quinto.
80

13/06/2008
41
Exemplos de aplicação de DM em casos reais
81
Cortex Intelligence
• Empresa de tecnologia e inteligência de mercado, com mais de 5 anos de pesquisa em Text-Mining
• Text mining extrai informações de dados não-estruturados ou semi-estruturados (base de textos).
• Aplicação cotidiana do text mining: mecanismos de busca em internet.
81
Exemplos de aplicação de DM em casos reais
82
Funcionamento do text mining:
Cortex Intelligence
82

13/06/2008
42
Exemplos de aplicação de DM em casos reais
83
Funcionamento do text mining:
Ao passar o mouse em cima das palavras selecionadas...
Cortex Intelligence
83
Exemplos de aplicação de DM em casos reais
84
Funcionamento do text mining:
Ao clicar o mouse em cima das palavras selecionadas...
Cortex Intelligence
84

13/06/2008
43
Exemplos de aplicação de DM em casos reais
85
Funcionamento do text mining:
Cortex Intelligence
85
Agenda
Banco de Dados
Data Warehouse
Data Mining
Case
86

13/06/2008
44
Um caso de estudoO processo de implantação de um data warehouse para suporte à mineração de dados no setor de saúde
87
Motivação
Por que aplicar técnicas de mineração de dados na Medicina?
• Grande volume de dados clínicos disponíveis nos sistemas operacionais de – Laboratórios– Hospitais– Clínicas
pelo mundo... E aumentando, com a disseminação do uso de registros eletrônicos
• Grande potencial para descobertas de relacionamentos:– Doenças x Doenças– Remédios x Pacientes– Doenças x Procedimentos– Remédios x Pacientes– Época do ano x Doenças x Pacientes– Remédios x Procedimentos x Pacientes x Localização
– ...
• Casos de sucesso– Descoberta de 7 fatores para previsão de nascimento prematuro com 72% de assertividade*– Descoberta de relações entre doenças e medicamentos (ex: ‘‘albuterol–tracheostomy–magnesium’’)
*Prather JC, Lobach DF, Goodwin LK, et al. Medical data mining: knowledge discovery ina clinical data warehouse. Proc AMIA Symp 1997;101–5.
88

13/06/2008
45
“The Development of Health Care Data Warehouses to Support Data Mining”
Autores: Jason A. Lyman, MD, MS; Kenneth Scully, MS; James H. Harrison, Jr, MD, PhD
• Processo de desenvolvimento de um data warehouse no centro clínico da Universidade de Virginia (EUA)
89
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
“A common limitation of systems currently offered by the vendor community is that they are often focused on the business aspects of health care (eg, finances, use) rather than needs of biomedical investigators, which may require different types of queries with different optimal underlying data models and analysis techniques” (os autores supracitados)
• Documentação dos desejos e necessidades dos potenciais usuários– Desafio: natureza diversificada e dinâmica das pesquisas biomédicas -
dificuldade de definir, a priori, a amplitude e profundidade dos dados que serão necessários. “Contraste com as aplicações orientadas ao negócio, tipicamente focadas em um pequeno número de questões às quais o dw suporta”
• Levantamento das pesquisas mais comuns – perfis de uso– Buscas por diagnósticos e medicamentos correspondem a quase 90%
das queries*
90
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
* Murphy SN, Morgan MM, Barnett GO, et al. Optimizing healthcare research data warehousedesign through past COSTAR query analysis. Proc AMIA Symp 1999;892–6

13/06/2008
46
Questões de segurança
• HIPAA (Health Insurance Portability and Accountability Act) define restrições de acesso a informações sobre consultas, exames, etc.– Nome do médico
– Identificadores do paciente
– Datas
• Informações não são críticas para fins da mineração em si, massão de grande importância para:– Convocar pacientes para possíveis estudos posteriores
– Ligar informações externas (de outras clínicas e labs) quandonecessário
91
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
Informações em documentos textuais
• Documentos textuais (ex: fichas médicas) contém informações ricas sobre quadros clínicos, mas são muito sucetíveis a informações “identificadoras”
• Motivação para desenvolvimento, na medicina, de algoritmos de “limpeza textual”*– Busca por termos médicos– Retirada de informações identificadoras do texto– Carga de documentos ricos em informações, porém de-identificados, permitindo pesquisa
* Trabalhos citados
- Concept-match medical data scrubbing. How pathology text can be used in research. - Berman JJ. Arch Pathol Lab Med 2003;127:680–6.
- Evaluation of a de-identification (de-id) software engine to share pathology reports and clinical documents for research. Gupta D, Saul M, Gilbertson J. AmJ Clin Pathol 004;121:176–86.
- Development and evaluation of an open source software tool for deidentification of pathology reports. Beckwith BA, Mahaadevan R, Balis UJ, et al. BMC Med Inform Decis Mak 2006;6:12–21.
92
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM

13/06/2008
47
• Dados disponíveis– Informações administrativas necessárias à cobrança e relatórios
requeridos pelo governo. Incluem:
• Sintomas
• Diagnósticos
• Procedimentos utilizados
• Informações do paciente
• Evolução da doença
Com a vantagem de estarem disponíveis eletronicamente. Em geral, são o core dos data warehouses no setor médico
93
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
• Dados disponíveis (cont)– Exemplo da estrutura de dados em um resultado de teste laboratorial
94
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM

13/06/2008
48
• As fontes– Sistemas operacionais do hospital
– Informações detalhadas e não integradas dos pacientes
95
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
• O processo de ETL– Grande importância na filtragem das informações (Confidencialidade)
– Separação dos dados identificadores em outra base de informações, para permitir re-identificação por pessoal autorizado
96
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM

13/06/2008
49
• O data warehouse– Particionado em três:
• Informações de-identificadas (CDR DB)
• Informações identificadoras (PHI DB)
• Informações externas identificadas (xID DB)
97
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
• A mineração– Ferramentas de análise estatística e mineração de dados
– Diferentes perfis de acesso à informação, permitindo acesso a dados de-identificados e dados com identificação
98
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM

13/06/2008
50
• Interfaces com usuário1. Interface HL7
2. Interface de acesso a PHI e informações de-identificadas
3. Interface de acesso direto a informações de-identificadas e de solicitação de identificadores
99
Levantamento dos requisitos
Mapeamento da estrutura dos
dados disponíveis
Definição das restrições
Design da estrutura
BDs – DW - DM
Referências Bibliográficas
• INMON, H. W. Building the Data Warehouse. 4ª ed. Wiley, 2005.
• WITTEN, I. H.; FRANK, E. Data Mining: Practical Machine Learning Tools and Techniques. 2ª ed. Elsevier, 2005.
• POWELL, G. Beginning Database Design. Wiley, 2006.
• CUNICO, L. H. B. Técnicas em Data Mining Aplicadas na Predição de Satisfação de
funcionários de uma Rede de Lojas do Comércio Varejista. Tese de Pós-Graduação, UFPR, 2005 (achado em http://dspace.c3sl.ufpr.br/dspace/bitstream/1884/3516/1/DISSERTA%C3%87AO%20CORRIGIDA.pdf, visitado em 24/04/2008)
• LYMAN, J. A.; SCULLY, K.; HARRISON, J. H. The Development of Health Care Data
Warehouses to Support Data Mining. Elsevier, 2008. (Clin Lab Med 28 (2008) 55 -71). Artigo utilizado no Case.
• http://www.prsc.mpf.gov.br/biblioteca/novidades/Manual_Referencias_Bibliograficas.pdf (visitado em 27/04/2008)
• RENATO, E.; NAVARRO, L. ; OLIVEIRA, N. Sistemas de Inteligência Artificial e sua
relação com a Organização do Trabalho contemporânea. 2007
• INMON, W. H. DW 2.0 The Next Generation of Data Warehousing. 2006
• INMON, W. H. DW 2.0
100

13/06/2008
51
Referências Bibliográficas• MOUTINHO, A. M. Datawarehousing e OLAP para uso em datamining
• SIMITSIS, A; VASSILIADIS, P. A method for the mapping of conceptual designs to
logical blueprints for ETL processe. (Decision Support Systems 45 (2008) 22–40)
• ZUBCOFF, J.; TRUJILLO, J. A UML 2.0 profile to design Association Rule mining
models in the multidimensional conceptual modeling of data warehouses (Data & Knowledge Engineering 63 (2007) 44–62)
• JUKIC, N.; NESTOROV, S. Comprehensive data warehouse exploration with qualified
association-rule minin. (Decision Support Systems 42 (2006) 859 - 878)
• http://www.pr.gov.br/batebyte/edicoes/2001/bb114/estagiario.htm (visitado em 08/04/2008)
• http://ftp.unipar.br/~izabel/Restricao_Integridade.ppt#7 (visitado em 08/04/2008)
• http://www.apostilando.com/sessao.php?cod=18, segunda apostila (visitado em 08/04/2008)
• http://www.cortex-intelligence.com/engine/ (visitado em 24/04/2008)
• http://www.cs.waikato.ac.nz/ml/weka/ (visitado em 26/04/2008)http://www.devmedia.com.br/articles (visitado em 26/04/2008)
• http://www.wikipedia.org
101










