
INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E...
45
INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA CATARINENSE – CAMPUS SOMBRIO LUÃ ALFREDO GONÇALVES RONALDO BORGES DE QUADROS IMPLEMENTAÇÃO DE UM AMBIENTE DE ALTA DISPONIBILIDADE COM HEARTBEAT Sombrio (SC) 2013
Transcript of INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E...

INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA
CATARINENSE – CAMPUS SOMBRIO
LUÃ ALFREDO GONÇALVES
RONALDO BORGES DE QUADROS
IMPLEMENTAÇÃO DE UM AMBIENTE DE ALTA DISPONIBILIDADE COM
HEARTBEAT
Sombrio (SC)
2013

LUÃ ALFREDO GONÇALVES
RONALDO BORGES DE QUADROS
IMPLEMENTAÇÃO DE UM AMBIENTE DE ALTA DISPONIBILIDADE COM
HEARTBEAT
Trabalho de Conclusão de Curso apresentado como
requisito parcial para a obtenção do título de
Tecnólogo, no Curso Superior de Tecnologia em
Redes de Computadores, do Instituto Federal de
Educação, Ciência e Tecnologia Catarinense -
Campus Sombrio.
Orientador: Prof. Me. Marco Antonio Silveira de
Souza.
Coorientador: Prof. Jéferson Mendonça de Limas.
Sombrio (SC)
2013

LUÃ ALFREDO GONÇALVES
RONALDO BORGES DE QUADROS
IMPLEMENTAÇÃO DE UM AMBIENTE DE ALTA DISPONIBILIDADE COM
HEARTBEAT
Esta Produção Técnica-Científica foi julgada
adequada para obtenção do título de Tecnólogo e
aprovada pelo Curso Superior de Tecnologia em
Redes de Computadores, do Instituto Federal de
Educação, Ciência e Tecnologia Catarinense -
Campus Sombrio.
Área de concentração: Redes de computadores.
Sombrio, 23 de fevereiro de 2013.
Prof. Marco Antônio Silveira de Souza.
Instituto Federal Catarinense – Campus Sombrio
Orientador(a)
Prof. Vanderlei Freitas Junior
Instituto Federal Catarinense – Campus Sombrio
Membro
Prof. Alexssandro Cardoso Antunes
Instituto Federal Catarinense – Campus Sombrio
Membro

RESUMO
Este trabalho tem como objetivo implementar um cluster de alta disponibilidade com ferramentas open source. Para a realização do trabalho foi feito uma simulação em ambiente virtual utilizando-se o software de virtualização, Virtualbox. Criou-se três máquinas virtuais onde duas são os servidores e uma o cliente. Nos dois servidores instalou-se o servidor web Apache, e o Heartbeat para monitorar os servidores. Com os dois servidores funcionando, um ativo (master) e o outro em modo de espera (slave), e o cliente acessando a página de testes criada para esse fim, fez-se alguns testes com as máquinas, por exemplo, um dos testes foi a desconexão do cabo de rede virtual, simulando uma desconexão real, o que pode acontecer por acidente. Outro teste foi o fechamento da janela do Virtualbox onde estava funcionando o servidor ativo, simulando uma queima de fonte ou de placa de rede. Em todos os testes foi possível constatar que o servidor em modo de espera passava a operar quase que instantaneamente, o que se comprova com o comando ping, ao desligar o servidor ativo, o cliente perde dez segundos de conexão e volta a funcionar novamente. Como comprovou-se com os testes feitos, o Heartbeat atende as necessidades de quem precisa de alta disponibilidade de serviços de rede.
Palavras-chave: Cluster. Alta disponibilidade. Heartbeat. Apache.

ABSTRACT
This paper aims to implement a high availability cluster with open source tools. To conduct the study was done in a simulated virtual environment using virtualization software, VirtualBox. It created three virtual machines are those where two servers and a client. In both servers was installed the Apache web server, and Heartbeat to monitor the servers. With the two servers running, one active (master) and the other in standby (slave), and the client accessing the test page created for this purpose, made up some tests with the machines, for example, one of the tests was disconnect the network cable virtual simulating a real disconnect, which can happen by accident. Another test was closing the window where Virtualbox was running the live server, simulating a burning source or network card. In all tests, we determined that the standby server operating spent almost instantly, as evidenced with the ping command to shut down the active server, the client loses connection ten seconds and back to work again. As demonstrated with the tests, Heartbeat meets the needs of those who need high availability of network services.
Key words: Cluster. High availability. Heartbeat. Apache.

LISTA DE FIGURAS
Figura 1: Cartão perfurado..........................................................................................11
Figura 2: Rede ponto a ponto......................................................................................13
Figura 3: Rede Cliente/Servidor..................................................................................14
Figura 4: Barramento...................................................................................................15
Figura 5: Anel..............................................................................................................15
Figura 6: Estrela..........................................................................................................16
Figura 7: Market share................................................................................................21
Figura 8: Cenário.........................................................................................................24
Figura 9: Virtual Host...................................................................................................27
Figura 10: Hosts..........................................................................................................28
Figura 11: Ha.cf...........................................................................................................29
Figura 12: Authkeys.....................................................................................................30
Figura 13: Haresources...............................................................................................31
Figura 14: Ifconfig........................................................................................................32
Figura 15: Sysv-rc-conf...............................................................................................33
Figura 16: Espelha.sh..................................................................................................34
Figura 17: Crontab.......................................................................................................35
Figura 18: Rc.local.......................................................................................................36
Figura 19: Comando ping............................................................................................37
Figura 20: Heartbeat no servidor sv2..........................................................................38
Figura 21: Estatísticas do comando ping para queima de placa de rede..................38
Figura 22: Estatísticas do comando ping 192.168.1.1 para queima de Fonte...........39
LISTA DE ABREVIATURAS E SIGLAS

AMD - Advanced Micro Devices
ARPANet - The Advanced Research Projects Agency Network
CD - Compact Disc
CRC - Cyclic Redundancy Check
DFSG - Debian Free Software Guidelines
DNS - Domain Name Service
DRDB - Duplicated Redundant Block Device
DVD - Digital Versatile Disc
GB - Gigabytes
HA - High Availability
HASP - Houston Automatic Spooling Priority
HD - Hard Disk
HP - Hewlett-Packard
HPC - High Performance Computing
HTML - HyperText Markup Language
HTTPD - Hypertext Transfer Protocol Daemon
IBM - International Business Machines
ITU - International Telecommunications Union
JES - Job Entry System
LAN - Local Area Network
MAC - Media Access Control
MAN - Metropolitan Area Network
MB - Megabytes
MD5 - Message Digest 5
NAT - Network Address Translation
NCSA - National Center for Supercomputing Applications
OSI - Open Source Initiative
RAM - Random Access Memory
SHA1 - Secure Hash Algorithm 1
SSH - Secure Shell
TCP/IP - Transmission Control Protocol/Internet Protocol
WAN - Wide Area Network

SUMÁRIO
1 INTRODUÇÃO...........................................................................................................8
2 OBJETIVOS.............................................................................................................10
2.1 Objetivos gerais...................................................................................................10
2.2 Objetivos específicos.........................................................................................10
3 REFERENCIAL TEÓRICO.......................................................................................11
3.1 O uso das redes de computadores...................................................................12
3.2 Topologias das redes..........................................................................................14
3.3 Tipos de redes.....................................................................................................17
3.4 Sistemas operacionais.......................................................................................17
3.5 Virtualização........................................................................................................19
3.5 Open source.........................................................................................................19
3.6 Serviços de rede..................................................................................................20
3.7 Cluster..................................................................................................................22
4 MATERIAIS E MÉTODOS.......................................................................................24
5 RESULTADOS E DISCUSSÃO...............................................................................37
6 CONSIDERAÇÕES FINAIS.....................................................................................40
REFERÊNCIAS...........................................................................................................42

8
1 INTRODUÇÃO
Partindo do surgimento das redes de computadores nos anos 60, segundo
Morimoto (2010) até se tornar a realidade diária de milhões de pessoas em 1996
Tanenbaum (2003) e chegar em 2011 passando dos 2 bilhões de pessoas
conectadas a internet, estatística informada no artigo Internet (2013), atualmente fica
difícil imaginar um ambiente onde o computador não esteja inserido, seja no
trabalho, na escola, em casa. Os usuários esperam que seus sistemas estejam
sempre funcionando.
Um portal na internet, sites de jogos on line, sites de notícias, sites de
comércio eletrônico entre outros precisam estar sempre funcionando ou correm o
risco de perder seus usuários para outros sites. Como garantir que os serviços
oferecidos em rede estejam sempre disponíveis? De acordo com Pitanga (2008), um
cluster de alta disponibilidade visa exatamente garantir que os serviços oferecidos
em rede não parem, ou que se ficar indisponível, seja pelo menor tempo possível.
Desde que os computadores começaram a ser ligados em rede se pensou na
criação de clusters para melhorar o aproveitamento dos recursos que as vezes eram
mal utilizados. A ARPAnet (The Advanced Research Projects Agency Network )
utilizou os programas Creeper e Reaper-ran para testes com computação distribuída.
Pode-se dizer que eles vislumbravam que as aplicações se moveriam de um
computador para outro (DANTAS, 2005).
Existe no mercado algumas soluções que tentam garantir a disponibilidade
dos serviços oferecidos em rede, como o HACMP (High Availabylity Cluster Multi-
Processing), que é proprietária da IBM, ou então a Serviceguard da HP (Hewlett-
Packard), ou ainda a da SUN, SPARCcluster (Scalable Processor Architetcure
Cluster) (FERREIRA; SANTOS, 2005). Estes são apenas alguns exemplos. No caso
que será exposto neste artigo, toda a solução será baseada em software livre.
Este trabalho tem como objetivo implementar um cluster de alta
disponibilidade utilizando-se ferramentas open source, onde servidores oferecerão
serviços de rede aos usuários. O sistema será composto por dois computadores
interligados por rede ethernet, sendo que um equipamento estará ativo oferecendo
serviço de web e o outro equipamento será um espelho do primeiro, de forma que se

9
o servidor principal ficar inativo o outro assumirá as suas funções oferecendo o
serviço até que o outro servidor seja reestabelecido.
O presente trabalho esta organizado da seguinte forma: no capítulo 2 são
apresentados os objetivos, sendo o objetivo específico a implementação do cluster e
os objetivos gerais que são o estudo da ferramenta Heartbeat, a instalação e
configuração dos servidores, a instalação e configuração do serviço de rede que
será oferecido e a instalação e configuração das ferramentas de monitoramento do
cluster. No capítulo 3 é apresentado o referencial teórico sobre as redes de
computadores, clusters e os softwares utilizados, e ainda informações que
corroboram com a importância do que é discutido neste trabalho. Nó capítulo 4 é
apresentado de que forma foi realizado o trabalho, neste capítulo é descrito as
configurações que foram feitas em cada uma das máquinas, seus arquivos de
configuração e de que forma foram feitos os testes. O capítulo 5 trás os resultados e
discussões, e finalmente o capítulo 6 com as considerações finais além de ideias
para trabalhos futuros.

10
2 OBJETIVOS
Abaixo a exposição dos objetivos geral e específicos.
2.1 Objetivos gerais
Implementar um ambiente de alta disponibilidade com Heartbeat.
2.2 Objetivos específicos
• Realizar uma revisão bibliográfica sobre alta disponibilidade;
• Estudar a ferramenta Heartbeat;
• Instalar o sistema operacional Ubuntu Server 12.04;
• Instalar e configurar Apache;
• Instalar e configurar o Heartbeat e o Rsync;
• Validar a disponibilidade do sistema.

11
3 REFERENCIAL TEÓRICO
Para que se tenha uma visão mais ampla do desenvolvimento das redes de
computadores é preciso voltar ao passado. Morimoto (2010) diz que a criação das
primeiras redes de computadores foi durante os anos 60. Antes disso, para
transportar dados de uma máquina para outra, utilizava-se cartões perfurados, o que
era um sistema nada prático. Na figura 1, um exemplo destes cartões:
A partir de 1969 começou a ser desenvolvida a Arpanet que acabou dando
origem a Internet dos dias atuais. Com apenas quatro máquinas a Arpanet entrou
em funcionamento em dezembro de 69. A rede que tinha sido criada para testes, se
desenvolveu muito rápido e em 1973 já estavam conectadas trinta instituições,
incluindo universidades e instituições militares (MORIMOTO, 2012).
As primeiras máquinas eram identificadas na rede por nomes, sendo que os
nomes das quatro primeiras máquinas eram: SRI, UCLA, UCSB e UTAH. Nesta
época eram criadas listas dos hosts, conforme se conectavam a rede. Com o
crescimento da rede, conforme mais máquinas foram sendo conectadas, foi ficando
mais difícil manter e distribuir estas listas, até que em 1974 surge o TCP/IP
(Transmission Control Protocol/Internet Protocol), conjunto de protocolos usados até
hoje na internet. Mais tarde em 1980, passou a ser usado nomes de domínio, dando
Figura 1: Cartão perfurado.
Fonte: Wcrivelini, 2012.

12
origem ao DNS (Domain Name Service), também usado atualmente (MORIMOTO,
2012).
Estes primeiros computadores eram grandes máquinas que ficavam em
algumas universidades dos Estados Unidos e foram colocadas em rede, sendo
usadas linhas telefônicas para fazer as conexões.
Paralelamente ao que acontecia nas universidades, em 1973 a Xerox fez o
primeiro teste de transmissão de dados, utilizando o padrão ethernet, fazendo as
conexões através de cabos coaxiais e que permitia a conexão de até 256
computadores. É importante lembrar que nesta época não existiam ainda
computadores pessoais, interfaces gráficas, etc, o lançamento do primeiro PC só
aconteceu em 1981 (MORIMOTO, 2012).
A Arpanet deu origem a internet como conhecemos hoje, e o ethernet acabou
se tornando um padrão utilizado no mundo todo para a criação de redes locais de
computadores. Atualmente temos até geladeiras e micro-ondas que se conectam a
internet (MORIMOTO, 2012).
3.1 O uso das redes de computadores
Conforme Tanenbaum (2003) as redes de computadores eram uma
curiosidade acadêmica em 1980 e era a realidade diária de milhões de pessoas em
1996. O site da ITU (International Telecommunications Union) trás informações de
que em 2011 passamos dos 2 bilhões de pessoas conectadas a internet (INTERNET,
2013). As redes de computadores estão se tornando imprescindíveis nos mais
diversos setores da sociedade e inclusive nas residências. Como salienta Torres
(2001), quando se tem mais de um computador seja em casa ou no escritório, faz
todo o sentido ter uma rede. Uma rede local permite o compartilhamento de
periféricos, como impressora, scanner, driver de CD ou DVD, permite o
compartilhamento de arquivos e também a conexão com a internet. É muito mais
prático e rápido transferir documentos através da rede do que gravar em um CD,
DVD ou mesmo pendrive, para depois copiar em outra máquina.
Ainda segundo Torres (2001), as redes de computadores podem ser dividas
em duas, sendo elas ponto a ponto e cliente/servidor. Nas redes ponto a ponto não

13
existe um servidor dedicado oferecendo serviços aos nós, más cada usuário pode
compartilhar ou não, arquivos, impressoras, drivers, etc. Dessa forma cada máquina
as vezes age como servidor e as vezes como cliente. As questões de segurança são
mais precárias neste tipo de rede e por isso ela é indicada apenas para pequenas
redes com 10 ou menos computadores e onde a segurança não é o fator mais
importante. A rede ponto a ponto tem um custo menor, é mais fácil de configurar,
porém o desempenho da rede é menor que nas redes cliente/servidor, e conforme a
rede aumenta, pior é o desempenho. Na figura 2 abaixo a representação de uma
rede ponto a ponto:
As redes do tipo cliente/servidor diferentemente das redes ponto a ponto tem
uma administração e configuração centralizada, por isso é muito mais segura
(TORRES, 2001). Empresas com 10 ou mais computadores ou onde a segurança é
importante é recomendável a utilização deste tipo de rede. Existem vários serviços
que podem ser oferecidos pelos servidores. Servidores de arquivos, servidor de
impressão, servidor web, etc. Todos os serviços podem estar instalados em uma
máquina ou em máquinas diferentes. Os servidores podem ainda ser dedicados ou
não. Ou seja uma máquina que não é utilizada para uso comum, ou uma máquina
que além de oferecer os serviços, ainda é utilizada para outros trabalhos, o que é
comum em pequenas empresas. Porém um servidor dedicado é mais seguro e traz
Figura 2: Rede ponto a ponto.
Fonte: Os autores, 2013.

14
menos problemas para a rede como um todo. Redes do tipo cliente/servidor
precisam de administradores de rede que configuram o que cada usuário pode ou
não acessar no servidor. Além disso um servidor não precisa necessariamente ser
um computador. Um servidor pode ser uma máquina construída especificamente
para este fim. Na figura 3 um exemplo de rede cliente/servidor (TORRES, 2001).
3.2 Topologias das redes
As redes de computadores também podem ser classificadas de acordo com a
topologia. A topologia diz respeito a distribuição física dos computadores e como
eles estão interligados. Existem várias topologias de rede, entre elas as principais
são: barramento, anel, estrela (MORAES, 2010).
A topologia em barramento foi uma das primeiras topologias de rede e foi uma
das que mais prosperou devido a facilidade de implementação e expansão
(MORAES, 2010). Todas as máquinas são conectadas a um cabo, que é o meio de
transmissão. Nesta topologia as estações precisam escutar o meio antes de
transmitir, já que apenas uma máquina pode transmitir. Se duas transmitirem ao
mesmo tempo pode haver colisão de pacotes. Quanto maior o número de máquinas,
pior o desempenho da rede. A figura 4 ilustra uma topologia em barramento:
Figura 3: Rede Cliente/Servidor.
Fonte: Os autores, 2013.

15
Na Topologia em anel, os computadores ficam conectados em um caminho
fechado, como se formassem um circulo. Cada máquina só pode usar o meio se
tiver autorização que é chamada de token. Quando uma máquina recebe o token, se
ela tiver algo para transmitir, ela transmite, senão passa o token para a próxima
máquina. As mensagens normalmente circulam em um só sentido, por isso não
existe o problema de colisão de pacotes. Porém se ninguém estiver transmitindo e
uma máquina quiser transmitir, ela terá que espera o token (MORAES, 2010). Na
figura 5 um exemplo de topologia em anel:
Ainda, segundo Moraes (2010) as redes em topologia estrela são aquelas em
Figura 4: Barramento.
Fonte: Os autores, 2013.
Figura 5: Anel.
Fonte: Os autores, 2013.

16
que todos os dispositivos da rede convergem para um ponto central, ou seja, um
concentrador. Esse concentrador é um hardware, que pode ser um hub, switch ou
um roteador. Todas as máquinas são conectadas diretamente no concentrador,
portanto se houver um problema com o concentrador, toda a rede fica inoperante.
Por outro lado se uma das máquinas deixar de funcionar, não compromete a rede
que pode continuar sendo usada normalmente. Um ponto limitante na topologia em
estrela é que o número de máquinas fica restrito ao número de portas do
concentrador. Se houver necessidade de mais portas, o concentrador terá que ser
trocado por um modelo com mais portas ou então outro concentrador poderá ser
conectado a esse de forma a aumentar o número de portas. Atualmente, esta é a
topologia mais usada, pois a sua implementação é fácil assim como sua
configuração, além de ter um custo baixo e alta disponibilidade de produtos no
mercado. Na figura 6 tem-se a representação de uma rede com topologia em
estrela:
Além das topologias citadas acima, que são as mais utilizadas, outras
topologias também são conhecidas, como: topologia híbrida, que mistura
características de duas topologias, por exemplo, anel estrela ou barramento estrela.
E ainda há outros tipos. Topologia em árvore, topologia em malha.
Figura 6: Estrela.
Fonte: Os autores, 2013.

17
3.3 Tipos de redes
As redes também podem ser classificadas de acordo com seu tamanho, ou
seja, área de abrangência. Dos quais as mais comum são: LAN (Local Area
Network), MAN (Metropolitan Area Network) e WAN (Wide Area Network).
A definição dessas redes segundo Tanenbaum (2003), serão descritas a
seguir: Redes LAN são pequenas redes, a maioria de uso privado, que interligam
estações dentro de pequenas distâncias. São muito utilizadas para a conexão de
computadores pessoais e estações de trabalho, permitindo o compartilhamento de
recursos e informações. Seu tamanho é restrito, o que permite o conhecimento do
seu tempo de transmissão e a detecção de falhas com antecedência, permitindo
assim um gerenciamento simplificado da rede.
Redes MAN ou redes metropolitanas são praticamente uma versão ampliada
das redes locais, pois utilizam tecnologias semelhantes. As MAN’s podem ser
formadas por escritórios vizinhos ou abranger uma cidade inteira sendo ou redes
públicas ou redes privadas. Tanenbaum (2003) cita como exemplo de MAN as redes
de TV e internet a cabo, que existem na maioria das grandes cidades.
WAN ou redes geograficamente distribuídas são formadas por grandes áreas
geográficas que abrangem países e continentes. São formadas por um conjunto de
hosts, conectados através de uma sub-rede. Esses hosts são computadores
pessoais e a sub-rede é formada por operadoras telefônicas e provedoras de
internet.
3.4 Sistemas operacionais
Um sistema operacional funciona mais ou menos como os demais softwares
instalados em um computador, ou seja, são processos sendo executados pelo
processador. Sendo que é o sistema operacional que controla o hardware da
máquina, compartilhando os recursos entre os diversos processos que estiverem
sendo executados, além dos dispositivos de entrada e saída. (MACHADO, MAIA,
2007).
Tanto o UNIX e suas variantes como o Linux e o Windows são sistemas

18
operacionais de rede, pois ambos trazem nativamente recursos que permitem
interligação em redes e acesso a recursos remotos (COLOURIS et al, 2007).
A Ubuntu Foundation é uma organização que mantém o sistema operacional
Ubuntu. Sendo este um dos sistemas operacionais mais popular atualmente. O
Ubuntu é uma distribuição Linux baseada no Debian que é uma das distribuições
mais antigas ainda ativa (PETERSEN, 2012). Conforme consta no site do
desenvolvedor (UBUNTU, 2013), Ubuntu é uma palavra africana antiga e significa
humanidade para os outros ou eu sou o que sou pelo que nós somos. A ideia do
idealizador do Ubuntu, Mark Shuttleworth é que o Ubuntu fosse um sistema
operacional para desktop fácil de usar . A instalação da versão server do Ubuntu,
que é uma versão voltada para servidores trás uma coleção de servidores como,
servidor web e FTP (File Transfer Protocol)( PETERSEN, 2012).

19
3.5 Virtualização
A virtualização iniciou-se com mainframes com a intenção de reduzir custos e
hoje oferece tantas possibilidades que se tornou um novo campo na área de
tecnologia (SIQUEIRA, 2008).
Com o poder de processamento dos computadores atuais a virtualização foi
introduzida também nos desktops permitindo rodar um sistema operacional completo
dentro de outro. Com a virtualização eliminou-se a subutilização em servidores e
data centers, virtualizando-se sistemas, ferramentas e aplicações consegue-se
utilizar melhor os recursos de hardware (SIQUEIRA, 2008).
Existem diversos softwares disponíveis para virtualização em desktops, como
Xen, VMWare e VirtualBox (SIQUEIRA, 2008).
Virtualbox é um software de virtualização de propriedade da Oracle que é
disponibilizado para as plataformas Intel e AMD e é compatível com os sistemas
operacionais Windows, MAC, Linux e Solaris. Com o Virtualbox é possível criar
máquinas virtuais completas e instalar sistemas operacionais diferente ou não do
sistema operacional hospedeiro. Pode-se executar vários sistemas operacionais
simultaneamente, tendo-se como limite o espaço disponível no HD (Hard Disk) e
memória (DOCUMENTATION, 2012).
3.5 Open source
A OSI (Open Source Initiative) é uma fundação sem fins lucrativos que surgiu
em 1998, com o intuito de defender o desenvolvimento colaborativo de software. O
termo open source foi criado pela organização neste mesmo ano, quando da
liberação do código fonte do navegador Netscape (ABOUT, 2012).
As definições do open source são derivadas do DFSG (Debian Free Software
Guidelines) que falam do desenvolvimento e distribuição de software livre. Para ser
considerado open source ou software livre o software precisa preencher alguns
requisitos como: não pode haver restrições de partes do código, não deve haver
restrições contra pessoas ou áreas de trabalho, o software deve ser disponibilizado
com o código fonte completo, o código pode ser modificado por qualquer pessoa,

20
entre outros (ABOUT, 2012).
3.6 Serviços de rede
Uma rede permite que diversos usuários utilizem recursos compartilhados.
“Em essência, um programa de cliente faz solicitações a partir de outro processo,
que em geral está executando em outro sistema.” (SCRIMGER, et. al. 2002, p.464).
Os servidores normalmente são computadores com mais recursos do que
computadores utilizados por clientes e mantidos em locais protegidos onde apenas
os administradores tem acesso (TANENBAUM, 2011).
Pode-se fazer uma divisão dos servidores em, servidores de rede local e
servidores de internet. Servidor de arquivos e servidor de impressão são exemplos
de servidores de rede local. Servidor web é um exemplo de servidor de internet
(MORIMOTO, 2011).
Os servidores web são peças fundamentais na infraestrutura da internet.
Nestes servidores ficam armazenadas todas as páginas da internet, inclusive as
páginas dos motores de busca e aplicativos web como o webmail (MORIMOTO,
2011).
O Apache, segundo Marcelo (2006), é o servidor web mais conhecido e
utilizado no mundo. O projeto do Apache é mantido pela Apache Software
Foundation. É um projeto de código aberto e é desenvolvido de forma colaborativa
por voluntários dos mais diversos países. Eles se comunicam através da internet,
fazendo correções e implementando melhorias no código. O servidor web Apache
surgiu em 1995. Usando como base o servidor web NCSA (National Center of
Supercomputing Applications) httpd (Hypertext Transfer Protocol Daemon)1.3, que
na época era o mais famoso, mas que havia sido descontinuado em 1994. Apenas
um ano após seu lançamento o Apache ultrapassou o NCSA se tornando o servidor
web mais utilizado na internet, feito que se mantém até hoje (Apache, 2012). No site
Netcraft (2013) que mantém um ranking de servidores web no mundo, o Apache
aparece em primeiro lugar em janeiro de 2013 com 55,26% dos servidores, em
segundo a Microsoft com 16,93%, em terceiro a Nginx com 12,64% e em quarto o
Google com 3,58%, como pode ser visto na figura 7:

21
O SSH (Secure Shell) pode ser visto de várias formas. Dwived (2004) diz que
o SSH “pode ser descrito com protocolo, uma ferramenta de encriptação, uma
aplicação cliente/servidor”.
O SSH é um sistema de segurança baseado em software com uma
arquitetura cliente/servidor. Dados enviados pela rede são criptografados na origem
e descriptografados pelo SSH no destino de forma transparente para o usuário
(BARRETT, SILVERMAN, BYRNES, 2005). Com ele é possível fazer acesso remoto
seguro e também transferir arquivos. O SSH pode ainda ser usado em conjunto com
outros softwares como o Rsync, criando uma espécie de túnel para garantir a
segurança na transferência de dados (MORIMOTO, 2011).
O projeto OpenBSD desenvolve o OpenSSH que é uma versão de código
aberto do SSH (OPENSSH, 2012).
O Rsync é um ótimo programa para quando há necessidade de se programar
backups. Com ele é possível sincronizar dados de dois diretórios na mesma
máquina ou remotamente transferindo apenas as modificações. O Rsync faz
comparações entre arquivos e inclusive de seu conteúdo, transferindo apenas as
modificações dentro deles. Com o Rsync pode-se facilmente realizar backup
Figura 7: Market share.
Fonte: Netcraft, 2013.

22
incremental de um diretório ou até de partições inteiras (MORIMOTO, 2011).
No site do projeto Rsync (2013), estão listadas algumas das funcionalidades
do Rsync, entre os quais o Rsync pode atualizar toda uma árvore de diretórios,
pode-se configurá-lo para manter links simbólicos e hard links, preservar as
propriedades e permissões dos arquivos, trabalha com pipeline interno, e ainda tem
a funcionalidade do Rsync anônimo, que é de grande utilidade quando se quer fazer
espelhamento (RSYNC, 2013).
Heartbeat é uma ferramenta open source normalmente utilizadas em clusters
de alta disponibilidade.
O Heartbeat é uma solução aberta para cluster de alta disponibilidade
desenvolvido pelo projeto Linux-HA, sendo uma da mais utilizadas. O Heartbeat
monitora os servidores do cluster para permitir que um servidor assuma caso o outro
deixe de operar. A comunicação do Heartbeat pode ser feita através de cabos UTP
sobre IPv4 ou ainda através de cabos seriais. O Heartbeat deve ser instalado e
configurado nos dois lados, quando por qualquer motivo, se um servidor ficar
inoperante o Heartbeat inicializa os serviços no outro servidor (LINUX-HA, 2011).
3.7 Cluster
Quando dois ou mais computadores são ligados em rede para a execução de
operações em conjunto, tem-se um cluster (PITANGA, 2008). Foi a IBM
(International Business Machines) quem começou a explorar este sistema nos anos
60 com duas de suas máquinas. HASP (Houston Automatic Spooling Priority) e JES
(Job Entry System), que permitiram a interligação entre mainframes a um custo
moderado.
A computação em cluster ganhou força nos anos 80 principalmente pela
construção de processadores de alto desempenho, redes de comunicação de baixa
latência e padronização de ferramentas para computação paralela (PITANGA, 2008).
Ainda segundo Pitanga (2008), os clusters podem ser divididos em duas categorias
básicas, a saber, os de alta disponibilidade e de alto desempenho de computação.
Cluster de alta disponibilidade (HA - High Availability). Este tipo de cluster visa
garantir que um serviço que é oferecido na rede esteja sempre disponível, ou quase,

23
já que segundo Pitanga (2008), não é possível dar uma garantia total de que o
sistema nunca vai falhar. Atualmente com os computadores invadindo todos os
ambientes, e com usuários cada vez mais conectados, um cluster de alta
disponibilidade torna-se uma ferramenta importante e imprescindível em alguns
ambientes. Neste tipo de cluster os equipamentos são interconectados e ficam
monitorando um ao outro de forma que qualquer um que parar, o outro
automaticamente assumirá a sua função, de forma a manter o serviço disponível
pelo maior tempo possível.
Cluster de alto desempenho de computação (HPC – High Performance
Computing). No cluster de alto desempenho, o objetivo é interconectar
equipamentos para conseguir um maior poder de processamento. Com isso o
cluster se torna uma boa opção para universidades e pequenas empresas que não
podem investir em um supercomputador. As aplicações modernas também exigem
cada vez mais poder de processamento, e com o alto custo dos supercomputadores,
a opção de paralelizar as aplicações em hardware comum se torna bastante atrativo
(PITANGA, 2008).
Cluster de balanceamento de carga (LB – Load Balance). Um cluster
balanceamento de carga é utilizado quando muitos usuários precisam acessar o
mesmo recurso. Dois ou mais computadores são interconectados e todos dispõem
dos recursos que serão acessados. Um software faz o monitoramento e distribuiu as
requisições dos usuários entre os computadores que fazem parte do cluster
(GORINO, 2006).

24
4 MATERIAIS E MÉTODOS
O cenário montado é ilustrado na figura 8, sendo que para a realização dos
testes foi usado um ambiente totalmente virtual, de forma que a figura do switch
desaparece, pois ao se configurar uma interface de rede no Virtualbox escolhendo-
se o modo de rede interna os computadores se reconhecem como que estando na
mesma rede:
O cenário montado são dois servidores, e um cliente. Os dois servidores e o
cliente são conectados estando todos na mesma rede. Por ser um ambiente
virtualizado, as máquinas são configuradas através da interface de rede interna do
Virtualbox para estar na mesma rede e podem se comunicar sem a presença do
switch.
As configurações refente as máquinas foram deixadas os padrões oferecidos
Figura 8: Cenário.
Fonte: Os autores, 2013.

25
pelo Virtualbox na hora da criação das máquinas. Tanto os servidores, como a
máquina cliente ficaram com 512MB de memória RAM (Random Access Memory) e
HD de 8GB.
Nos dois servidores foram instalado o SSH, o Rsync, o Heartbeat e o servidor
web Apache. Quando os servidores são ligados um dos servidores escolhidos será o
principal (master) e o outro será o secundário (slave) e ficará em modo de espera,
sendo que quando o servidor principal ficar inoperante através das simulações que
serão feitas, o segundo servidor assumirá o serviço. Os softwares instalados tem
cada um a sua função, que serão explicitados a seguir: o SSH é requisito para o
funcionamento do Rsync, que por sua vez fará a replicação de dados entre os
servidores para manter os dois atualizados independente de qual esteja atuando
como servidor principal no momento. O servidor web Apache será o serviço
oferecido na rede e o Heartbeat irá monitorar a disponibilidade do Apache de forma
que se o servidor que estiver ativo, por algum motivo deixar de oferecer o serviço, o
Heartbeat que estará instalado no servidor secundário inicializará o Apache,
mantendo assim o serviço disponível.
Para a execução do trabalho foram instaladas três máquinas virtuais com o
Virtualbox. O sistema operacional utilizado em duas das máquinas foi o Ubuntu
server 12.04. Estas duas máquinas formam o cluster, e na terceira máquina foi
instalado o Ubuntu 12.04, versão para desktop, que será o cliente para fazer os
testes. O nome de um dos servidores é sv1 e o outro sv2.
Depois da instalação do sistema operacional o primeiro passo é configurar as
placas de rede. De inicio foi utilizado duas placas de rede, uma em modo NAT
(Network Address Translation) para baixar os pacotes que seriam instalado e a outra
como rede interna para ser usado na rede local.
A placa de rede em modo NAT não necessita de nenhuma configuração. Já
para as placas da rede local foi utilizados os IPs 192.168.1.254 para o servidor sv1 e
192.168.1.253 para o servidor sv2, ambos com máscara de rede 255.255.255.0,
além disso foi utilizado o IP 192.168.1.100 para o cliente também com a mesma
máscara. Todas essas informações constam no quadro 1, para melhor
compreenção.

26
Quadro 1 – Configurações dos computadores.
Computador Nome Endereço IP Máscara de subrede
Servidor 1 sv1 192.168.1.254 255.255.255.0
Servidor 2 sv2 192.168.1.253 255.255.255.0
Cliente cliente 192.168.1.100 255.255.255.0Fonte: Os autores, 2013.
O SSH se faz necessário para a utilização do Rsync, depois de configurar a
rede foi instalado o OpenSSH, foi gerado um par de chaves e foi configurado para
permitir o acesso sem senha, senão seria necessário digitar uma senha toda vez
que o Heartbeat fosse acessar o outro servidor e isso inviabilizaria o trabalho do
Heartbeat.
Depois foi a vez de instalar o Apache que foi o serviço escolhido para ser
oferecido na rede. A seguir os passos que foram seguidos para colocar o servidor
web em operação. O serviço web foi configurado nos dois servidores, foi criado um
diretório chamado website1 com o seguinte comando:
• mkdir /var/www/website1
Dentro do diretório website1 foram criados outros dois diretórios, public_html
e logs, com os seguintes comandos:
• mkdir /var/www/website1/public_html
• mkdir /var/www/website/logs
Sendo o public_html, o diretório para a publicação do site e o diretório logs
para armazenar os logs.
Depois, dentro do diretório /etc/apache2/sites-available/ foi criado o arquivo
website1 e foi editado conforme a figura 9:

27
O diretório sites-available guarda as configurações dos domínios hospedados
em um mesmo servidor.
Foi depois criada uma página em HTML (HyperText Markup Language) para
servir de teste.
Antes de instalação do Heartbeat foi configurado o arquivo /etc/hosts nos dois
servidores sendo adicionadas as linhas abaixo:
• 192.168.1.254 sv1
• 192.168.1.253 sv2
Ficando como mostrado na figura 10:
Figura 9: Virtual Host.
Fonte: Os autores, 2013.

28
O próximo passo é a instalação do Heartbeat em si. A instalação é simples,
bastando usar o comando apt-get, como mostrado na linha abaixo:
• $ sudo apt-get install heartbeat
Após a instalação do Heartbeat, três arquivos devem ser configurados, todos
ficam no diretório /etc/ha.d/. São eles: o ha.cf, authkeys e o haresources.
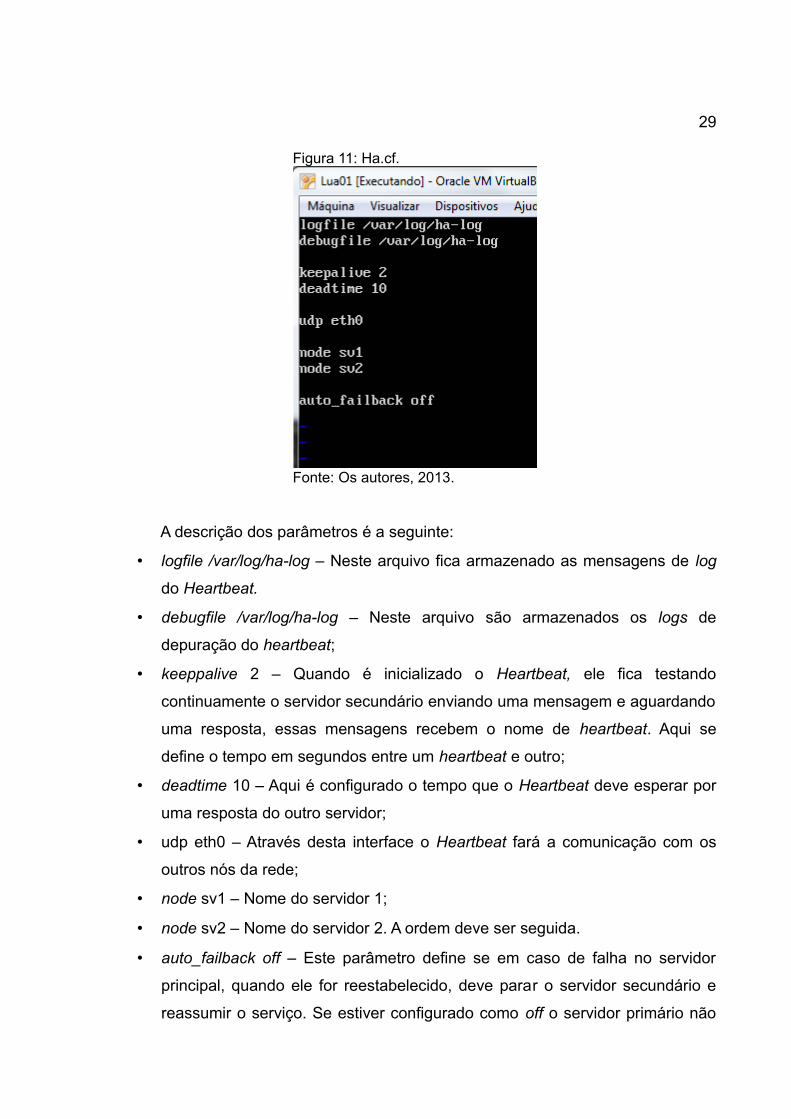
O primeiro deles, o ha.cf foi configurado como na figura 11:
Figura 10: Hosts.
Fonte: Os autores, 2013.
29
A descrição dos parâmetros é a seguinte:
• logfile /var/log/ha-log – Neste arquivo fica armazenado as mensagens de log
do Heartbeat.
• debugfile /var/log/ha-log – Neste arquivo são armazenados os logs de
depuração do heartbeat;
• keeppalive 2 – Quando é inicializado o Heartbeat, ele fica testando
continuamente o servidor secundário enviando uma mensagem e aguardando
uma resposta, essas mensagens recebem o nome de heartbeat. Aqui se
define o tempo em segundos entre um heartbeat e outro;
• deadtime 10 – Aqui é configurado o tempo que o Heartbeat deve esperar por
uma resposta do outro servidor;
• udp eth0 – Através desta interface o Heartbeat fará a comunicação com os
outros nós da rede;
• node sv1 – Nome do servidor 1;
• node sv2 – Nome do servidor 2. A ordem deve ser seguida.
• auto_failback off – Este parâmetro define se em caso de falha no servidor
principal, quando ele for reestabelecido, deve parar o servidor secundário e
reassumir o serviço. Se estiver configurado como off o servidor primário não
Figura 11: Ha.cf.
Fonte: Os autores, 2013.

30
reassume o serviço quando for reestabelecido (LINUX-HA, 2013). A
configuração deste arquivo é igual nos dois servidores.
O segundo arquivo a ser configurado é o authkeys, e também é igual nos dois
servidores, a configuração do authkeys é como o da figura 12:
Este é o arquivo de autenticação do Heartbeat. O dono deste arquivo tem que
ser o root e as permissões devem ser 600, por questões de segurança, já que com
estas permissões apenas o administrador terá acesso ao aquivo.
O linux trabalha com um sistema de permissões onde pode-se configurar
permissões para o dono do arquivo, para o grupo e para outros usuários. As
permissões vão de 0, que não dá nenhuma permissão, até 7 que dá permissão
totalsobre o arquivo ou diretório. No caso acima o dono tem permissão 6, o que
significa que o dono pode ler e escrever, o grupo tem permissão 0 e os outros tem
permissão 0. O sistema de permissão funciona como ilustrado no quadro 2:
Quadro 2 - Permissões no Linux
Permissão Número
--- 0
--x 1
-w- 2
-wx 3
r-- 4
r-x 5
rw- 6
rwx 7Fonte: Adaptado de Morimoto, 2009.
Figura 12: Authkeys.
Fonte: Os autores, 2013.

31
auth 1 – Esta linha define o número de autenticação que será usado,
normalmente é usado apenas um. Exitem três tipos possíveis para o Heartbeat, são
eles: CRC (Cyclic Redundancy Check), MD5 (Message Digest 5), e SHA1 (Secure
Hash Algorithm 1). Com o CRC não se utiliza chave de autenticação, portanto não é
seguro e deve ser utilizado em casos específicos. O SHA1 é o método mais seguro
(LINUX-HA, 2013).
Aqui está sendo usado autenticação md5 e a senha pode ser qualquer texto,
que neste caso foi escrito teste.
O último arquivo do Heartbeat a ser configurado é o haresources, os
parâmetros configurados são mostrados na figura 13:
Os parâmetros aplicados aqui são: sv1 é o nome do servidor primário é o que
o Heartbeat vai inicializar o apache quando for iniciado. O IP 192.168.1.1 é chamado
de IP flutuante, IP compartilhado ou ainda IP virtual. Ele deve estar na mesma rede
que os IPs das placas reais e é este IP que será anunciado na rede. E por fim
apache2 é o serviço que o Heartbeat irá monitorar. Este IP fica associado ao
Apache. Este arquivo é igual nos dois servidores. Este arquivo informa ao Heartbeat
que este é o IP que deve ser anunciado na rede, quando o servidor principal parar
de funcionar o Heartbeat que está trabalhando no servidor secundário assume este
mesmo IP para continuar disponibilizando o Apache. Se houvessem outros serviços
sendo oferecidos na rede, seriam adicionados neste mesmo arquivo de
configuração.
Utilizando-se o comando ifconfig é possível verificar as configurações de rede
e perceber como é criada uma interface virtual (eth0:0) que é a interface que será
usada pelo Heartbeat.
Figura 13: Haresources.
Fonte: Os autores, 2013.

32
O Apache foi retirado da inicialização do servidor porque a partir destas
configurações é o Heartbeat quem fica responsável pela inicialização do Apache.
O Sysv-rc-conf é um utilitário onde se pode configurar o que será inicializado
com o sistema.
Figura 14: Ifconfig.
Fonte: Os autores, 2013.

33
Foi criado um script com o nome espelha.sh que será usado pelo Rsync para
fazer a sincronização dos dados do servidor web. A figura 16 mostra os parâmetros
do script:
Figura 15: Sysv-rc-conf
Fonte: Os autores, 2013.

34
A primeira linha informa ao Rsync para copiar o diretório /var/www/website1
no servidor local e adicionar no /var/www do servidor remoto 192.168.1.253,
excluindo o conteúdo que estiver lá. Os parâmetros -aup e --delete que aparecem
nas linhas são o seguinte:
• -a: arquivo. Informa o Rsync para copiar arquivos;
• -u: updade. O Rsync só substituirá o arquivo, se o que ele estiver copiando for
mais recente;
• -p: permissão. Com este parâmetro as permissões serão mantidas nos
arquivos copiados;
• --delete: esta opção estando no final da linha faz com que o Rsync apague os
arquivos que existem no destino.
A segunda linha informa ao Rsync para copiar o diretório /etc/apache2/sites-
availabe também do servidor local para /etc/apache2 no servidor remoto
192.168.1.253 e também excluir o conteúdo que estiver lá.
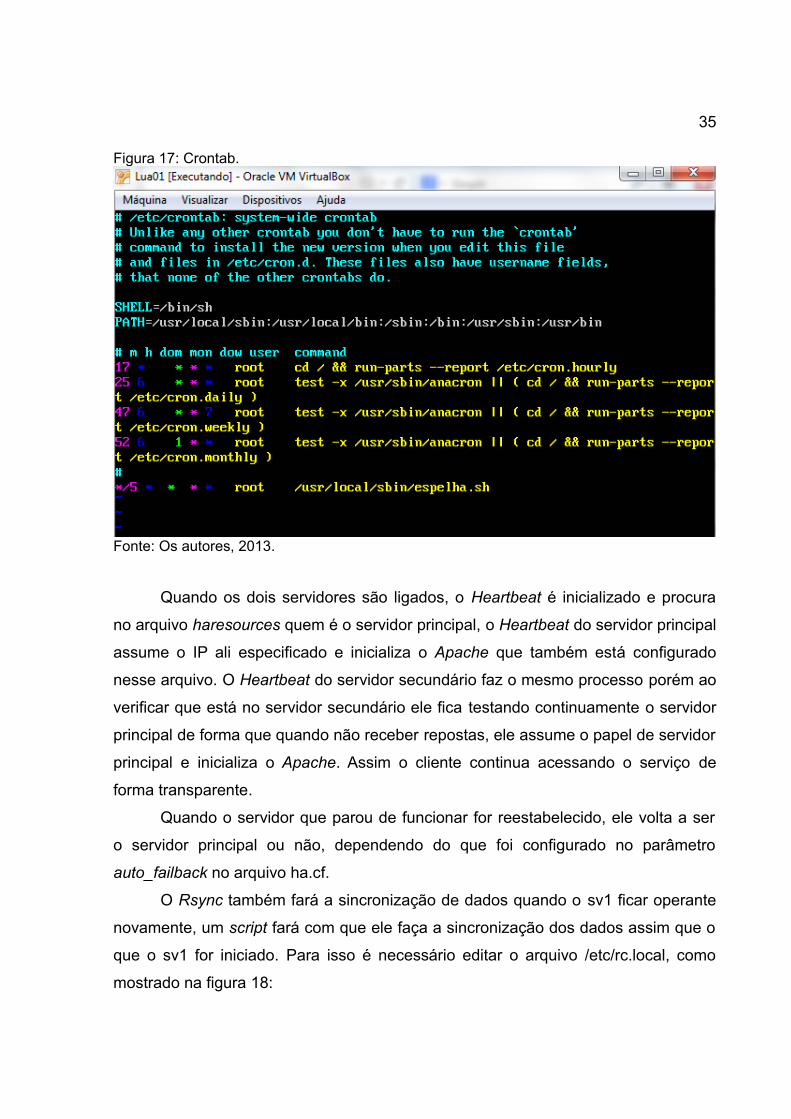
Esse script foi adicionado no Crontab para fazer sincronização de cinco em
cinco minutos, assim a cada cinco minutos ele fará uma comparação entre os
arquivos dos servidores e sempre que houver modificação ele copiará os arquivos
mais novos para o servidor secundário. O utilitário Crontab encontra-se no
diretório /etc e sua configuração pode ser vista na imagem 17:
Figura 16: Espelha.sh
Fonte: Os autores. 2013.
35
Quando os dois servidores são ligados, o Heartbeat é inicializado e procura
no arquivo haresources quem é o servidor principal, o Heartbeat do servidor principal
assume o IP ali especificado e inicializa o Apache que também está configurado
nesse arquivo. O Heartbeat do servidor secundário faz o mesmo processo porém ao
verificar que está no servidor secundário ele fica testando continuamente o servidor
principal de forma que quando não receber repostas, ele assume o papel de servidor
principal e inicializa o Apache. Assim o cliente continua acessando o serviço de
forma transparente.
Quando o servidor que parou de funcionar for reestabelecido, ele volta a ser
o servidor principal ou não, dependendo do que foi configurado no parâmetro
auto_failback no arquivo ha.cf.
O Rsync também fará a sincronização de dados quando o sv1 ficar operante
novamente, um script fará com que ele faça a sincronização dos dados assim que o
que o sv1 for iniciado. Para isso é necessário editar o arquivo /etc/rc.local, como
mostrado na figura 18:
Figura 17: Crontab.
Fonte: Os autores, 2013.

36
As configurações são as mesmas do script espelha.sh, porém com o caminho
inverso, ou seja, no primeiro caso o Rsync instalado no sv1 copia os dados do sv1
para o sv2 de 5 em 5 minutos, no segundo o Rsync instalado no sv1 copia os dados
do sv2 para o sv1 assim que o sv1 é iniciado.
Figura 18: Rc.local.
Fonte: Os autores, 2013.

37
5 RESULTADOS E DISCUSSÃO
Alguns testes foram feitos no ambiente montado e descrito anteriormente para
comprovar-se de que o ambiente de alta disponibilidade realmente estava
funcionando, para tal os arquivos da páginas em HTML de teste, foram deixados
dessincronizados justamente para saber quando se está no servidor v1 ou no sv2.
Para testar a conexão para saber se o cliente está conectado com o apache
utiliza-se o comando ping 192.168.1.1, onde 192.168.1.1 é o IP virtual, conforme
mostra a figura 19.
Primeiramente foi parado o serviço Heartbeat no sv1 com o comando
#/etc/init.d/heartbeat stop, para verificar se o sv2 assumiria o serviço do Apache, o
que realmente aconteceu, pois a página web continua disponível na máquina cliente,
a partir do mesmo IP, conforme mostra a figura 20 na linha SERVER 2 que o sv2
assumiu o serviço e o IP virtual.
Figura 19: Comando ping.
Fonte: Os autores, 2013.

38
Depois de iniciar o serviço no sv1 novamente, fez-se novo teste, com o
comando #ping 192.168.1.1 ativo, em determinado momento foi feito a simulação de
uma queima de placa de rede, desconectado o cabo de rede virtual e verificou-se
uma pequena demora na resposta do ping voltando em seguida. O Heartbeat já
tinha inicializado o Apache assumindo o IP virtual no sv2 e por isso o comando ping
continuou alcançando o destino e perdeu apenas 9 pacotes conforme a figura 21, e
demorando em torno de 10 segundos para que o sv2 assumisse o serviço Apache.
Uma simulação de queima de fonte também foi feita. Com os dois servidores
na posição inicial novamente, foi fechada a máquina virtual sv1 e ao atualizar o
navegador com o atalho Alt+F5, a página web continuava disponível através do sv2,
que ao perceber que o sv1 não respondia mais, assumiu suas funções conforme
mostra a figura 22, que se perdeu 10 pacotes levando 10 segundos para que o sv2
Figura 20: Heartbeat no servidor sv2.
Fonte: Os autores, 2013.
Figura 21: Estatísticas do comando ping para queima de placa de rede.
Fonte: Os autores, 2013.

39
assumisse o serviço do sv1.
Também foi feito testes com o parâmetro autofail_back, ora foi deixado no
modo on, ora no modo off. Em todas as vezes funcionou com deveria, ou seja, em
modo on o sv1 assumia o serviço de volta quando era reestabelecido e em modo off,
o serviço se mantinha com o sv2 e o sv1 ficava em modo de espera. Pareceu ser
mais interessante manter o parâmetro em modo off para garantir a confiabilidade do
sistema pois se algum arquivo for corrompido por qualquer razão, pode acontecer de
o Rsync sincronizar e substituir os arquivos bons pelos corrompidos, o mais seguro
é que administrador verifique a integridade do sistema antes de sincronizar os
dados.
Figura 22: Estatísticas do comando ping 192.168.1.1 para queima de Fonte.
Fonte: Os autores, 2013.

40
6 CONSIDERAÇÕES FINAIS
Foi exposto neste trabalho o porquê da implementação de um cluster de alta
disponibilidade. Os serviços que são oferecidos na rede precisam estar sempre
disponíveis. O usuário não quer ligar o seu computador e descobrir que os serviços
não estão funcionado. Em um servidor web, que foi o serviço testado neste trabalho,
a alta disponibilidade é um fator muito importante.
Com poucas ferramentas e um mínimo de arquivos de configurações
demonstrou-se como é possível manter um servidor web no ar, mesmo falhando
uma máquina. Com os testes feitos pode-se comprovar a eficácia do sistema, com o
Heartbeat inicializando o serviço no outro servidor, assim que o primeiro fica
inoperante, e o Rsync mantendo os dados sincronizados para que o usuário não
tenha que reiniciar o que estava fazendo, ou seja, o usuário nem percebe a troca de
servidor.
No caso de falha em um dos servidores, o administrador da rede deve o mais
rápido possível reestabelecer o servidor que parou de funcionar, o que diminui os
riscos de o serviço ficar indisponível, pois pode acontecer de ocorrer falha no outro
servidor.
Foi pesquisado outros softwares que também tinham os requisitos necessário
para fazer parte deste trabalho, como a ferramenta de monitoramento MON,
também foi pesquisado sobre o DRDB, que faz sincronização em tempo real.
Escolheu-se o Rsync por já se ter alguma familiaridade com a ferramenta e o
Heartbeat apesar de não ter-se nenhuma familiaridade, assim como também com o
MON ou outras ferramentas para monitoramento. Foram escolhidos os softwares
que serviriam aos objetivos propostos. Pesquisar ferramentas para este tipo de
trabalho gera até alguma dificuldade tamanha variedade, pois o mundo do software
livre é cheio de opções para as mais diversas áreas.
Neste trabalho foi configurado para o Rsync fazer a sincronização de tempos
em tempos, no caso de 5 em 5 minutos. É claro que em um ambiente crítico essa
sincronização deve ser feita em tempo real, como um raid em rede. Isso pode ser
feito em trabalhos futuros.
Esta implementação de cluster de alta disponibilidade na verdade é

41
incompleta, pois a ideia neste trabalho foi demonstrar algumas ferramentas. Para
trabalhos futuros existem muitos planos, como fazer redundância de placas de rede,
de switch, de nobreak, para ai sim ter um cluster de alta disponibilidade completo.

42
REFERÊNCIAS
ABOUT the OSI. Open Source Initiative. 2012. Disponível em: <http://opensource.org/about>. Acesso em: 06 fev. 2013.
APACHE: http server project. Apache.org. 2012. Disponível em: <http://httpd.apache.org/ABOUT_APACHE.html>. Acesso em: 06 fev. 2013.
BARRET, D. J. Silverman, R. E. Byrnes, R. G. SSH, the secure shell: the definitive guide. 2. ed. Sebastopol: O'reilly Media Inc, 2005.
COULOURIS, G. DOLLIMORE, J. KINDBERG, T. Sistemas distribuídos: conceitos e projetos. 4. ed. Porto Alegre: Bookman, 2007
DANTAS, M. Computação distribuída de alto desempenho: redes, clusters e grids computacionais. Rio de Janeiro: Axcel, 2005
DOCUMENTATION: user manual. Virtualbox, 2011. Disponível em: <https://www.virtualbox.org/wiki/Documentation>. Acesso em: 02, jan. 2012.
DWIVED, H. Implementing SSH: Strategies for optmizing the secure shell. Indianapolis: Wiley Publishing Inc, 2004.
FERREIRA, F. S. SANTOS, N. C. G. G. Cluster de alta disponibilidade: abordagem OpenSource. Monografia. Escola superior de tecnologia e gestão de Leiria, 2005.
GORINO, F. V. R. Balanceamento de carga em cluster de alto desempenho: uma extensão para LAMP/MPI. Dissertação (Mestrado). Universidade estadual do Marigá, 2006
INTERNET users. ITU, 2013. Disponível em: <http://www.itu.int/ITU-D/ict/statistics/>. Acesso em: 31 jan. 2013.
LINUX-HA. HA High Availability. 2011. Disponível em: <http://www.linux-ha.org/wiki/Main_Page>. Acesso em: 06 fev.2013.
MACHADO, F. B. MAIA, L. P. Arquitetura de sistemas operacionais. 4. ed. Rio de Janeiro: LTC, 2007.
MARCELO, A. Squid. 5. ed. Rio de Janeiro: Brasport, 2006.

43
MORAES, A. F. Redes de computadores: fundamentos. 7. ed. São Paulo: Érica, 2010.
MORIMOTO, C. E. Linux: guia prático. Porto Alegre: Sul editores, 2009.
MORIMOTO, C. E. Redes: guia prático. Porto Alegre: Sul editores, 2010. 2ª reimpressão.
MORIMOTO. C. E. Servidores Linux: guia prático. Porto Alegre: Sul editores, 2012.
NETCRAFT. January 2013 web server survey. 2013. Disponível em: <http://news.netcraft.com/archives/2013/01/07/january-2013-web-server-survey-2.html#more-7696>. Acesso em: 30 jan. 2013.
OPENSSH: keeping your communiqués secret. OpenSSH. 2012. Disponível em: <http://www.openssh.com/>. Acesso em: 06 fev. 2013.
PETERSEN, R. Ubuntu 12.04 Server: Administration and reference. Alameda: Surfing Turtle Press, 2012.
PITANGA, M. Construindo supercomputadores com Linux. 3. ed. Rio de Janeiro. Brasport, 2008.
RSYNC features. Rsync. Disponível em: <http://rsync.samba.org/features.html>. Acesso em: 10 jan. 2013.
SCRIMGER, R. SALLE, P. L. PARIHAR, M. GUPTA, M. TCP/IP: A bíblia. Tradução Edson Furmankievcs, Docware traduções técnicas. Rio de Janeiro: Elsevier, 2002. 5ª reimpressão.
SIQUEIRA, E. Para compreender o mundo digital. São Paulo. Globo, 2008.
SQUID: Optimising web delivery. Squid-cache.org. 2012. Disponível em: <http://www.squid-cache.org/>. Acesso em: 05, jan. 2012.
TANENBAUM, A. S. Redes de computadores. Tradução Vanderberg D. de Souza. Rio de Janeiro: Elsevier, 2003. 16ª reimpressão. Tradução de Computer networks. 4th. ed.
TANENBAUM, A. S. WETHERALL, D. Redes de computadores. Tradução Daniel Vieira. São Paulo: Pearson Prentice Hall, 2011. Tradução de Computer networks. 5th. ed.

44
THE Ubuntu story. Ubuntu. 2013. Disponível em: <http://www.ubuntu.com/project/about-ubuntu>. Acesso em: 28 jan. 2013.
TORRES, G. Redes de computadores. Rio de Janeiro: Axcel, 2001.
WCRIVELINI. Bancos de dados & BI. IBM. 2012. Disponível em: <https://www.ibm.com/developerworks/mydeveloperworks/blogs/ibmacademiccell/entry/no_tempo_dos_cart_c3_b5es_perfurados1?lang=en>. Acesso em: 02 fev. 2013.


















