
Instituto Superior Técnico · ... uma vez que a função logarítmica é monótona crescente. ......
164
Instituto Superior Técnico Departamento de Engenharia Electrotécnica e de Computadores FUNDAMENTOS DE TELECOMUNICAÇÕES Victor Barroso Professor Associado 1999
Transcript of Instituto Superior Técnico · ... uma vez que a função logarítmica é monótona crescente. ......

Instituto Superior Técnico
Departamento de Engenharia Electrotécnica e de Computadores
FUNDAMENTOS DE TELECOMUNICAÇÕES
Victor Barroso Professor Associado 1999


INDÍCE DE CONTEÚDOS 1. Teoria da Informação: Codificação de Fonte
2. Sinais Aleatórios em Tempo Contínuo. Parte I: Espaço de Probabilidade e Variáveis Aleatórias
3. Sinais Aleatórios em Tempo Contínuo. Parte II: Modelos de Fontes de Informação e de Ruído
4. Digitalização de Fontes Analógicas em Tempo Contínuo
5. Sistemas de Transmissão
6. Desempenho dos Sistemas de Transmissão Analógicos na Presença de Ruído
7. Teoria da Detecção e da Estimação em Problemas de Telecomunicações
8. Teoria da Informação: Capacidade do Canal de Transmissão
9. Codificação de Canal: Códigos de Bloco Lineares


1-1
1 Teoria da Informação: Codificação de Fonte
O estudo de um sistema de comunicações digitais envolve dois aspectos cruciais:
1. a eficiência da representação da informação gerada pela fonte; 2. a taxa de transmissão à qual é possível enviar a informação com fiabilidade
através de um canal ruidoso.
A teoria da informação estabelece os limites fundamentais associados às questões acima referidas. A saber:
I. o número mínimo de unidades de informação binária (bit) por símbolo necessário para representar completamente a fonte;
II. o valor máximo da taxa de transmissão que garante fiabilidade da comunicação através de um canal ruidoso.
Começaremos por abordar o primeiro dos problemas acima enunciados, isto é, o da
codificação de fontes discretas (ou digitais).
1.1 Modelo de uma Fonte Discreta
Consideremos, a título de exemplo, uma fonte discreta que gera símbolos binários. Observemos as duas sequências binárias seguintes:
A: 0011010110001101… B: 1000100010001000…
Enquanto a sequência B parece ser constituída pela repetição periódica do padrão
1000, a lógica de ocorrência dos símbolos binários na sequência A é imperceptível, tornando difícil ou mesmo impossível predizer as ocorrências futuras. No entanto, ambas as sequências poderiam ter sido geradas pela mesma fonte binária. Por outro lado, no outro extremo do sistema de comunicações o destinatário não tem conhecimento da sequência gerada pela fonte.
Estas considerações mostram que a escolha de um modelo determinístico para representar o comportamento da fonte de informação não é o mais adequado. Com efeito, para um observador externo, a saída da fonte digital num dado instante tem sempre associada alguma incerteza. Voltemos ao exemplo das sequências A e B e suponhamos que o observador não tem memória, isto é, observa a saída num dado instante e esquece-a antes que um novo símbolo seja gerado. Suponhamos ainda que o número de ocorrências de "0" e de "1" vai sendo actualizado. Após ter sido observado um número significativo de saídas da fonte, o grau de incerteza associado à ocorrência de cada um dos símbolos binários é naturalmente diferente conforme se considera a sequência A ou a sequência B. Enquanto que em B a incerteza associada à ocorrência de "0" é menor do que a associada à ocorrência de "1", em A o grau de incerteza é igual para ambos os símbolos. O conceito de incerteza associada a um acontecimento está assim intimamente ligado à probabilidade de ocorrência desse acontecimento. Em consequência deste facto, podemos ainda avançar com a seguinte ideia: se a um valor baixo da probabilidade de ocorrência de um acontecimento corresponde um valor elevado da incerteza associada, então da ocorrência desse acontecimento deve resultar um ganho de informação também ele elevado.
À luz das ideias anteriores, deve concluir-se que a fonte de informação deve ser representada usando um modelo aleatório.

1-2
1.1.1 Fonte Discreta sem Memória
Consideremos uma fonte digital que gera símbolos de um alfabeto
M,,2,1i,mi K== A
com probabilidade ii mPrp = tal que:
.1pM
1ii =∑
= (1.1)
Def. 1.1: Uma fonte discreta sem memória gera ao longo do tempo símbolos estatisticamente independentes.
De acordo com a definição anterior, a probabilidade de ocorrência de qualquer sequência gerada pela fonte é dada pelo produto das probabilidades de ocorrência dos símbolos que a constituem.
Exemplo 1.1: Consideremos a sequência temporal 3551M1 m,m,m,m,mS −= gerada pela fonte A. Supondo que esta fonte não tem memória, então
.ppppSPr 3251M1 −=
1.2 Informação e Entropia
Consideremos uma sequência muito longa de K símbolos do alfabeto A gerados pela fonte discreta definida na subsecção 1.1.1. Uma maneira possível de avaliar o conteúdo informativo da fonte, isto é, a informação própria, consiste em determinar o número total de mensagens (ou sequências) de comprimento K que a fonte pode gerar. Note-se que a informação própria da fonte cresce com o número de mensagens possíveis. Portanto, é equivalente usar o número de mensagens ou o respectivo logaritmo, uma vez que a função logarítmica é monótona crescente.
O número Ω de mensagens de comprimento K, incluindo 1K ocorrências do símbolo ,m1 2K do símbolo ,m 2 etc., MK do símbolo ,m M é dado por
,!K!K!K
!K
M21 L=Ω (1.2)
onde
.KKM
1ii∑
== (1.3)
Supondo que K é tão elevado que qualquer dos iK é também muito grande, podemos calcular uma aproximação de Ω usando a fórmula de Stirling
( ) 21KK2
1Ke2!K
+−π≅
em (1.2), obtendo-se

1-3
( )( )
.Ke2
Ke2M
1i21K
i
M
1i
K2M
21KK2
1
ii ∏∏=
+
=
−
+−
π
π≅Ω (1.4)
Como
,KK ,21KK ,
21KK ,eee
M
1i
KKii
KKM
1i
K i
M
1ii
i ∏∏=
−−
=
− =+≅+≅=∑
= =
de (1.4), vem:
( ) ( ) .KK2
iKM
1i i
21M ∏=
−−
π≅Ω
Aplicando a função log em ambos os membros da relação anterior, e tendo em conta que a probabilidade de ocorrência do símbolo im é o número ip para o qual converge a razão
KK i quando ∞+→ K,K i , vem
( ) ( ) ,plogpK2log1M21log
M
1iii∑
=−π−−≅Ω
ou, tendo em conta que o 2º termo se torna dominante para K suficientemente elevado,
.plogpKlogM
1iii∑
=−≅Ω (1.5)
A fórmula anterior dá o valor aproximado da informação própria de uma fonte discreta com M símbolos, ou dito de outra forma, de uma mensagem de comprimento muito longo K gerada pela mesma fonte.
Observando a fórmula (1.5), verificamos que, em média, a informação por símbolo é medida pela quantidade
.plogpK
log M
1iii∑
=−≅Ω (1.6)
Por outro lado, a quantidade iplog− está associada à ocorrência do símbolo im , ou seja, é uma variável aleatória discreta que toma o valor real ( ) ii plogmI −= com probabilidade ip . Note-se que o 2º membro de (1.6), não é mais do que o valor expectável (média) desta variável aleatória.
1.2.1 Medida de Informação
A discussão anterior sugere então a seguinte definição para o ganho de informação associado à ocorrência de um símbolo:
Def. 1.2: Considere-se a fonte discreta sem memória introduzida na subsecção 1.1.1. A informação associada à ocorrência de um símbolo desta fonte é definida por:
( ) ( ) M.1,2,i K=−== ,plogp1logmI iii (1.7)

1-4
Esta medida quantitativa da informação gerada pela ocorrência de um símbolo na saída de uma fonte discreta foi introduzida por Claude E. Shannon no seu trabalho intitulado The Mathematical Theory of Communication, publicado em 1948 no nº de Outubro do Bell System Technical Journal. É interessante notar que, sendo o conceito de informação relativamente subjectivo, a medida (1.7) dá conta de algumas das suas propriedades qualitativas:
1. ( ) 1p se 0mI ii == (1.8) 2. ( ) 0mI i ≥ (1.9) 3. ( ) ( ) jiji pp se mImI <> (1.10)
ou seja,
1. o ganho de informação resultante da ocorrência do acontecimento certo é nulo; 2. excepto no caso do acontecimento certo, a ocorrência de um qualquer
acontecimento conduz a um ganho de informação; 3. quanto menor for a probabilidade de ocorrência de um acontecimento maior é o
ganho de informação que lhe está associado. Tendo em conta (1.7), verificamos que a informação associada à ocorrência simultânea de dois acontecimentos estatisticamente independentes
( ) ( )( )
( ) ( )ji
ji
ji
jiji
mImIplogplog
pplogm,mPrlogm,mI
+=−−=
−=−=
(1.11)
é a soma da informação associada a cada uma das ocorrências.
Nas expressões anteriores é usual considerar a função logarítmica definida na base 2. A unidade de medida de informação define-se como se segue.
Def. 1.3: a unidade binária de informação (bit) é a informação própria associada a cada um dos símbolos de uma fonte binária com símbolos equiprováveis:
( ) ( ) bit 121log1I0I 2 =−== (1.12)
1.2.2 Entropia de uma Fonte Discreta sem Memória
Já foi sublinhado anteriormente que a informação própria de um símbolo, ver Def. 1.2, é uma variável aleatória discreta em que cada realização ( ) M,,1,i ,mI i K= ocorre com probabilidade M.,1,i ,pi K= Recorde-se que esta distribuição de probabilidade verifica (1.1).
Def. 1.4: A entropia de uma fonte discreta sem memória é o valor expectável da informação própria dos símbolos da fonte:
( ) ( ) ( ) ∑∑==
−===M
1ii2i
M
1iii plogpmIpmIEAH (1.13)
1-5
Exemplo 1.2: Consideremos uma fonte binária com símbolos equiprováveis. De acordo com (1.13), a entropia desta fonte vale
( ) símbolobit121log
2
1i2
21-AH == ∑
=
Consideremos agora o caso mais geral em que
p11Pr
p0Pr−=
=. (1.14)
Recorrendo novamente a (1.13), podemos escrever
( ) ( ) ( ) símbolo.bitp1logp1plogp 22 AH −−−−= (1.15)
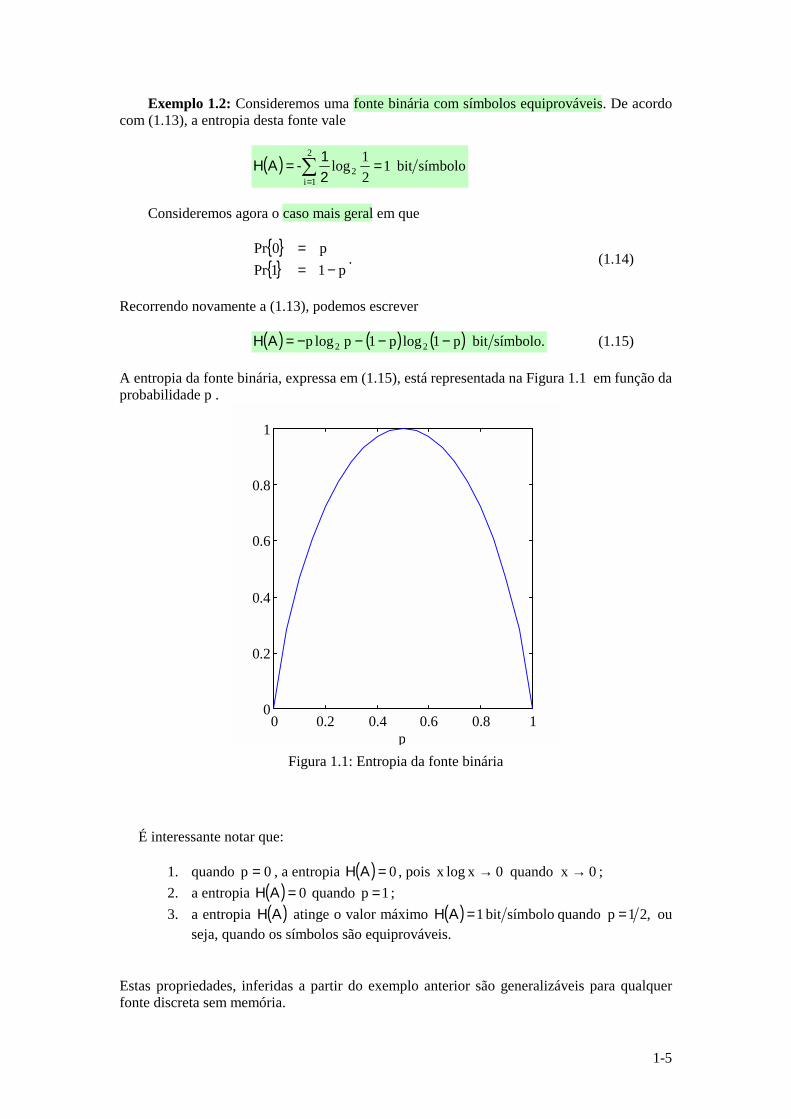
A entropia da fonte binária, expressa em (1.15), está representada na Figura 1.1 em função da probabilidade p .
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
p Figura 1.1: Entropia da fonte binária
É interessante notar que:
1. quando 0p = , a entropia ( ) 0=AH , pois 0xquando0xlogx →→ ; 2. a entropia ( ) 0=AH quando 1p = ; 3. a entropia ( )AH atinge o valor máximo ( ) símbolobit1 AH = quando ,21p = ou
seja, quando os símbolos são equiprováveis.
Estas propriedades, inferidas a partir do exemplo anterior são generalizáveis para qualquer fonte discreta sem memória.

1-6
1.2.2.1 Propriedades da Entropia de uma Fonte Discreta sem Memória
A entropia ( )AH da fonte discreta sem memória A , definida na subsecção 1.2.2, é limitada de acordo com a seguinte desigualdade:
( ) ,Mlog0 2≤≤ AH (1.16)
onde M é o número de símbolos do alfabeto A. Podemos mostrar que: P1. ( ) 0=AH sse 1pi = para algum i e .M,,1i,1i,,1j,0p j KK +−== O limiar inferior da
entropia corresponde portanto à ausência de incerteza sobre a saída da fonte. P2. ( ) Mlog2=AH sse ,M,,1i,M1pi K=∀= isto é, sse todos os símbolos forem
equiprováveis. O limiar superior da entropia corresponde assim ao máximo da incerteza.
A expressão (1.13) da Def. 1.4 pode escrever-se na forma
( ) ( ).p1logpM
1ii2i∑
==AH (1.17)
Como 1p0 i ≤≤ , conclui-se que todas as parcelas de (1.17) são não negativas. Portanto,
( ) 0=AH sse todas as parcelas forem nulas. Como a distribuição de probabilidade verifica a restrição (1.1), conclui-se que o limiar inferior da entropia só é atingido na ausência de incerteza, como se diz em P1.
O problema da maximização de (1.17) pode ser formulado do seguinte modo:
Determinar a distribuição ,M,,1i,pi K= que maximiza
( ) ( )∑=
=M
1ii2i p1logpAH
sujeita à restrição
.1pM
1ii =∑
=
Para o resolver podemos usar o método dos multiplicadores de Lagrange. Definindo a Lagrangeana
( ) ,p1plogpp,,pM
1ii
M
1ii2iM1
−λ+−= ∑∑
==KL (1.18)
onde λ é o multiplicador de Lagrange, verificamos que maximizar (1.18) é o mesmo que maximizar ( )AH , pois a segunda parcela de (1.18) é sempre nula. Diferenciando ( )⋅L em ordem a cada um dos ip , e igualando a zero, obtém-se o seginte sistema de equações1:
1 Recorda-se que
x1
2ln1
dxxlogd 2 =

1-7
.M,,1i,2ln
1plog i2 K=λ+=−
Concluímos assim que, mesmo sem calcular o valor de λ que garante a restrição, todos os ip são iguais. Portanto, como se diz em P2, a distribuição de probabilidade que maximiza2 a entropia é
.M,,1i,M1pi K==
Deste modo, o valor máximo da entropia é ( ) .MlogMlogM1
2
M
1i2max ==∑
=AH
1.2.2.2 Desigualdade Fundamental P3. Seja ,M,,1i ,pi K= uma distribuição de probabilidade associada aos símbolos
.M,,1i,mi K=∈ A Obviamente, a restrição (1.1) é verificada. Sendo M,,1i,q i K= , uma outra distribuição de probabilidade,
,1qM
1ii =∑
= (1.19)
então
,0pq
logpM
1i i
i2i ≤
∑=
(1.20)
sendo atingido o valor máximo quando
.M,,1i,pq ii K== (1.21) A demonstração deste facto resulta directamente da resolução do seguinte problema:
Sendo M,,1i,pi K= , uma distribuição de probabilidade, determinar os valores de ,M,,1i ,q i K= que maximizam
,pq
logpM
1i i
i2i∑
=
(1.22)
sujeitos à restrição
.1qM
1ii =∑
=
2 Pode verificar-se que com esta distribuição de probabilidade a segunda derivada da Lagrangeana é
negativa. De facto, .02ln
Md
M1p2
2
i
<−==idp
L

1-8
Usando (1.19) e (1.22) podemos escrever a Lagrangeana
( ) .q1plogpqlogpq,,qM
1ii
M
1ii2i
M
1ii2iM1
−λ+−= ∑∑∑
===KL
Diferenciando em ordem aos ,M,,1i,q i K= e igualando a zero, obtém-se o sistema de equações
( ) .M,,1i ,pq 2ln ii K==λ (1.23)
Tendo em conta (1.1) e (1.19) e somando membro a membro todas as equações do sistema (1.23), conclui-se que .2ln1=λ Usando este valor em (1.23), obtém-se a distribuição que maximiza3 (1.22):
.M,,1i,pq ii K== (1.24)
Usando este resultado, verifica-se facilmente que o máximo de (1.22) é nulo e, portanto, a desigualdade (1.20) fica demonstrada.
A desigualdade (1.20) é conhecida por desigualdade fundamental e será usada mais
adiante para obter outros resultados importantes da Teoria da Informação.
1.3 Codificação de Fonte
Consideremos o problema da codificação de símbolos pertencentes a um alfabeto estendido de símbolos estatisticamente independentes. Em particular, consideremos um alfabeto de 37 símbolos equiprováveis: 26 letras, o espaço em branco, e 10 dígitos. Suponhamos que para codificar estes símbolos dispomos apenas de símbolos binários (bits4) e, naturalmente por razões de eficiência de representação, pretendemos usar palavras de código de comprimento mínimo. Suponhamos, a título de exemplo, que codificamos individualmente cada um dos 37 símbolos. Como 65 2372 << precisamos de usar pelo menos 6 bits por símbolo. No entanto, esta estratégia de codificação resulta em desperdício uma vez que sobram 273726 =− palavras de código às quais não corresponde qualquer símbolo do alfabeto original. Outro modo de avaliar este desperdício consiste em verificar que a entropia da fonte vale símbolobit 21.537log2 ==H (note-se que os símbolos são equiprováveis e portanto a entropia é igual à informação própria de cada símbolo). Como se vê, a informação média por símbolo é inferior ao comprimento da palavra de código indicando que este código corresponde a uma representação redundante do alfabeto considerado. Consideremos agora um novo alfabeto (extensão de 2ª ordem) em que cada símbolo estendido corresponde a um dos 237 pares de símbolos do alfabeto original. Para codificar cada um dos símbolos da extensão são necessários 11 bits, enquanto que a respectiva entropia é agora .estendidosímbolobit42.1037log 2
22 H == Isto corresponde de facto a usar, em média, 5.5 bits por cada símbolo original, resultando numa estratégia de codificação mais eficiente. Este exercício pode ser continuado para extensões de ordem crescente, obtendo-se os resultados que se mostram na tabela 1.1. Da consulta desta tabela conclui-se:
3 Pode verificar-se que, com esta distribuição, a segunda derivada da Lagrangeana é negativa. 4 Aqui "bit" designa um símbolo binário e não deve ser confundido com a unidade binária de informação.

1-9
1. à medida que aumenta a ordem da extensão, vai diminuindo o número médio de bits necessários para codificar cada símbolo do alfabeto original;
2. esta diminuição não é uniforme, embora pareça convergir para a entropia do alfabeto original.
ordem da extensão entropia
comprimento da palavra de
código
comprimento médio por símbolo
1 5.21 6 6.00 2 10.42 11 5.50 3 15.63 16 5.33 4 20.84 21 5.25 5 26.05 27 5.40 6 31.26 32 5.33 7 36.47 37 5.29 8 41.68 42 5.25 9 46.89 47 5.22
10 52.09 53 5.30
Tabela 1.1: Eficiência da codificação de alfabetos estendidos
Este exercício, embora não seja conclusivo de um ponto de vista estritamente formal, sugere que a eficiência dos códigos está associado a extensões de ordem superior do alfabeto da fonte discreta.
1.3.1 Extensão de Fonte
Def. 1.5: Consideremos a fonte discreta sem memória definida na subsecção 1.1.1. A extensão de ordem K desta fonte é ainda uma fonte discreta sem memória com alfabeto
( ) A A ∈=σσσσ=kK21K iiiiiM21
K m,m,,m,m,,,, KK (1.25)
e distribuição de probabilidade
.M,,2,1i,mPrmPrmPrPrp Kiiiii K21
KL ==σ= (1.26)
1.3.2 Entropia da Fonte Estendida
Antes de calcularmos a entropia da fonte KA , extensão de ordem K da fonte A, vamos verificar que a distribuição (1.26) é de facto uma distribuição de probabilidade. Em primeiro lugar, qualquer dos ip em (1.26) é um produto de probabilidades e portanto .1p0 i ≤≤ Notemos ainda que a extensão de ordem K se pode obter da extensão de ordem 1K − , isto é,
( ) (( )
,m,,m1K
i
1K1 iiK
i 44 344 21K
−
−
σ
=σ )
M
2
1
m
mm
M, (1.27)

1-10
cada símbolo da extensão de ordem K−1 dá origem a M símbolos da extensão de ordem K. Portanto
( ) ( ) ( ) .PrmPrPrPr1K1KK M
1l
1Kl
1
M
1ii
M
1l
1Kl
M
1i
Ki ∑∑∑∑
−−
=
−
=
==
−
=σ=σ=σ
43421
(1.28)
Prosseguindo o mesmo raciocínio, verificamos que esta igualdade se mantém válida seja qual for a ordem da extensão considerada. Em particular,
( ) .1mPrPrKM
1i
M
1ii
Ki ==σ∑ ∑
= =
(1.29)
Por definição, Def. 1.4, eq. (1.13), a entropia da extensão de ordem K da fonte A é
( ) ( ) ( ) ,PrlogPr Ki2
M
1i
Ki
KK
σσ−= ∑=
AH
ou seja,
( ) ( ) ( ) ( )( ) ( )
( )
( ) ( )
.mPrlogmPrPr
mPrPrlogPr
mPrPrlogmPrPr
M
1ii2i
1
M
1l
1Kl
1
M
1ii
M
1l
1Kl2
1Kl
M
1l
M
1ii
1Kl2i
1Kl
K
1K
1K
1K
1K
−σ+
σσ−=
σσ−=
∑∑
∑∑
∑ ∑
=
=
=
−
=
==
−−
= =
−−
−
−
−
−
4444 34444 214434421
4342144444 344444 21
AH
AH
AH
Finalmente, podemos escrever
( ) ( ) ( ),1KK AHAHAH += − e, repetindo argumentos, concluímos que:
A entropia da extensão de ordem K de uma fonte discreta sem memória é igual a K vezes a entropia da fonte original, isto é,
( ) ( ).KK AHAH = (1.30)
1.3.3 Comprimento Médio do Código
A codificação de fonte consiste em atribuir uma palavra de código única a cada uma das mensagens geradas pela fonte. Aqui a palavra mensagem é usada indiscriminadamente para designar um símbolo da fonte original ou um símbolo de uma qualquer extensão do alfabeto fonte. Como vimos em discussão anterior, a eficiência da codificação está associada à parsimónia que se usa na escolha do comprimento das palavras de código. Por outro lado, para uma dada taxa de geração de símbolos, quanto maior for o comprimento das palavras de código maiores serão as necessidades em termos de taxa de transmissão. Como, em geral, os símbolos do alfabeto fonte não são equiprováveis, é razoável pensar em códigos de

1-11
comprimento variável: o comprimento de cada palavra de código deverá ser tanto menor quanto maior for a probabilidade de ocorrência do símbolo correspondente. Este procedimento tenderá a minimizar o comprimento médio do código (ou das palavras do código) sendo, portanto, eficiente.
O processo de codificação consiste em atribuir rótulos ou símbolos às saídas de uma fonte de informação. Temos então que distinguir entre os símbolos da fonte e os símbolos do alfabeto do código.
Def. 1.6: Sejam
M1 m,,m K=A e r,, αα= K1C
os alfabetos fonte e do código, respectivamente. Nos códigos de blocos,
( ) C, A ji ∈αααα=→←∈=∀ ,,,,cm:M,,1i
il21 iiiii KK
isto é, a cada símbolo do alfabeto fonte faz-se corresponder uma e uma só palavra de código, cujo comprimento é variável.
Obviamente que o problema inverso da codificação tem de ter solução única, isto é, qualquer código de fonte tem de ser univocamente descodificável. Nos códigos de comprimento fixo basta que a cada palavra ci do código se faça corresponder uma e uma só mensagem
A∈im para que se garanta a descodificação única. No entanto, tal não é suficiente quando se trata de códigos de comprimento variável, sendo necessária uma condição adicional: a estrutura do código deve permitir identificar sem ambiguidade o início e o fim de cada palavra de código. Para ilustrar esta ideia consideremos os exemplos de códigos que se mostram na Tabela 1.2.
símbolo fonte
probabilidade de
ocorrência
código I
código II
código III
código IV
m1 0.500 00 00 000 0000 m2 0.250 01 11 010 0001 m3 0.125 10 00 110 0011 m4 0.125 11 11 111 0111
Tabela 1.2: Exemplos de códigos de fonte
O código I é um código binário simples e, portanto, univocamente descodificável. Neste
caso, o comprimento médio do código
∑=
=M
1iii lpL (1.31)
é obviamente igual a 2. Os restantes códigos usam comprimentos variáveis, sendo as palavras mais longas aquelas que correspondem aos símbolos menos prováveis. Ao contrário do que acontece no código IV, nenhuma palavra do código III constitui prefixo de outra. Estes códigos são designados por códigos de prefixo. Os códigos de prefixo são sempre univocamente descodificáveis. Com efeito, estes códigos são completamente descritos por uma estrutura em árvore com um estado inicial e M estados finais, como se pode ver na Figura 1.2 para o caso do código III. Partindo do estado inicial, o descodificador vai descendo ao longo da árvore à medida que recebe cada bit e até atingir um dos quatro estados terminais.

1-12
Quando isto acontece, o símbolo foi descodificado e o descodificador retorna ao estado inicial. O comprimento médio deste código de prefixo vale .75.1L = O código III é, como seria de esperar, mais eficiente do que o código I. O código IV tem comprimento 875.1L = e, embora não sendo um código de prefixo, é também univocamente descodificável. Basta notar que nenhuma palavra de código exibe dois bits “0” consecutivos e que todas elas são iniciadas por “0”. Quando é detectado um “0” o descodificador sabe que se inicia uma palavra do código, bastando contar o número de bits “1” consecutivos para identificar o símbolo fonte correspondente. Finalmente, é fácil verificar que o código II, sendo aparentemente o mais eficiente ( )25.1L = , não é univocamente descodificável.
Figura 1.2: Árvore de descodificação de um código de prefixo
Os códigos de prefixo, como o código III, são códigos instantâneos pois qualquer palavra
de código é descodificada assim que a totalidade dos símbolos que a constituem é recebida. Ao contrário, no código IV o símbolo “0” funciona como separador, pelo que cada palavra é descodificada com atraso de um bit.
1.3.4 Desigualdade de Kraft
Como se conclui da discussão anterior, é necessário impor restrições na estrutura de um código instantâneo de comprimento variável de modo a garantir a unicidade da descodificação.
A desigualdade de Kraft estabelece uma condição necessária e suficiente de existência de um código instantâneo formado por palavras de comprimento variável li:
,1rM
1i
li ≤=ξ ∑=
− (1.32)
onde r é o número de símbolos do alfabeto do código. A soma ξ é designada por soma de Kraft.
Consideremos o exemplo da Figura 1.2, onde 4M = e 2r = : a soma de Kraft vale 12222 3321 =+++=ξ −−−− , e portanto a desigualdade de Kraft (1.32) é verificada. Este
facto garante que existe um código binário instantâneo, univocamente descodificável, e cuja distribuição dos comprimentos das palavras de código é o do exemplo. Sublinha-se que a verificação da desigualdade de Kraft não define o código, garantindo tão somente a sua existência.
Para provar a desigualdade de Kraft podemos usar um raciocínio simples baseado na árvore de codificação. Consideremos uma árvore r – ária onde cada nó tem r descendentes.
estado inicial
1
1
1
0
0
0
m1
m2
m3
m4

1-13
Suponhamos ainda que cada ramo representa um símbolo da palavra de código. Por exemplo, os r ramos que partem da raíz representam os r possíveis valores do primeiro símbolo da palavra de código. Portanto, cada palavra de código corresponde a um nó terminal da árvore. O percurso entre a raíz e um destes nós terminais identifica os símbolos que fazem parte da palavra de código. A Figura 1.3 ilustra estas ideias para o caso binário, r=2.
Figura 1.3: Árvore de codificação para a desigualdade de Kraft
A condição de o código ser de prefixo implica que nenhuma palavra de código seja ascendente de qualquer outra palavra de código na árvore. Assim, cada palavra de código elimina os seus descendentes como possíveis palavras do código.
Seja lmax o comprimento da palavra mais longa do código. Consideremos todos os nós ao nível lmax da árvore. Alguns são palavras de código, outros são descendentes de palavras de código e os restantes nem uma coisa nem outra. Qualquer palavra de código ao nível li terá
imax llr − descendentes no nível lmax. Estes conjuntos de descendentes têm de ser disjuntos e, por outro lado, o número total de nós neles incluídos deverá ser inferior ou igual a maxlr . Portanto, somando para todas as palavras de código, tem-se
,rr maximax lM
1i
ll ≤∑=
− (1.33)
ou seja,
1rM
1i
li ≤∑=
− (1.34)
que é exactamente a desigualdade de Kraft (1.32).
Por outro lado, dado um conjunto de comprimentos l1, l2, …, lM de palavras do código que satisfazem a desigualdade de Kraft, é sempre possível construir uma árvore semelhante à da Figura 1.3 de modo a obter um código de prefixo cujas palavras têm os comprimentos especificados.
1.3.5 1º Teorema de Shannon
Consideremos um código instantâneo, univocamente descodificável, para o qual se verifica necessariamente a desigualdade de Kraft (1.32). Consideremos ainda as quantidades
.M,,1i,rq il1
i K=ξ= −− (1.35) Note-se que
raíz 0
0
0
01
11
10
111 110

1-14
1r
rq
M,,1i1r
rq0
M
1m
l
M
1i
lM
1ii
M
1m
l
l
i
m
i
m
i
==
=≤=≤
∑
∑∑
∑
=
−
=
−
=
=
−
−
K
ou seja, as quantidades qi formam uma distribuição de probabilidade. Então, sendo pi a probabilidade de ocorrência de cada um dos símbolos do alfabeto fonte, podemos afirmar que as distribuições qi e pi, ,M,,1i K= verificam a desigualdade fundamental (1.20). Tendo em conta a definição de entropia (1.13), aquela desigualdade pode ser escrita na forma
( ) .0qlogpM
1iii ≤+∑
=AH (1.36)
Por outro lado, e usando (1.35) e (1.31), podemos escrever
( )
.rlogLlog
lprloglog
rlogllogpqlogp
ii
ii
M
1iii
−ξ−=
−ξ−=
−ξ−=
∑
∑∑=
(1.37)
Usando (1.37) em (1.36), obtém-se
( ) .rlogL≤AH (1.38) Este resultado é independente da base da função logarítmica, pelo que se usarmos a função
rlog (no caso de um alfabeto de código com r símbolos) concluímos que a entropia constitui o limiar inferior do comprimento médio de qualquer código instantâneo univocamente descodificável. Este facto, agora demonstrado formalmente, tinha já sido antecipado na sequência da discussão em torno do exemplo apresentado na Tabela 1.1. Da análise deste mesmo exemplo, verificou-se que, embora de forma não uniforme, o comprimento médio do código parecia convergir para a entropia da fonte à medida que se consideravam extensões do alfabeto de ordem crescente.
Naturalmente, a cada palavra ci do código corresponde uma probabilidade de ocorrência ,mPrcPrp iii == onde mi é um dos M símbolos do alfabeto da fonte A. Suponhamos que
cada palavra ci tem um comprimento que obedece às restrições
,M,,1i,1ploglplog iriir K=+−≤≤− (1.39)
garantindo-se que aos símbolos menos prováveis correspondem palavras de código mais longas. Note-se que (1.39) garante ainda que existe o código instantâneo univocamente descodificável, pois a desigualdade de Kraft é verificada. Com efeito, temos
M,,1i,rpr iir li
plog K=≥= −

1-15
e (1.32) resulta imediatamente somando de 1 a M ambos os membros da desigualdade anterior. Multiplicando por pi todos os termos de (1.39), somando de 1 até M, e tendo em conta (1.13) e (1.31), obtém-se
( ) ( ) .1L +≤≤ AHAH (1.40)
Obviamente que, sendo esta desigualdade verificada para a fonte A e para o código que verifica (1.39), então
( ) ( ) ,1L KK
K +≤≤ AHAH (1.41)
onde KL é o comprimento médio do código usado para codificar os símbolos da fonte KA . Recordando (1.30), de (1.41) obtém-se
( ) ( ) .K1
KLK +≤≤ AHAH (1.42)
Este resultado demonstra que existe pelo menos um código instantâneo univocamente descodificável cujo comprimento médio KLK é arbitrariamente póximo da entropia da fonte A; basta notar que em (1.42) a parcela K1 vai para zero quando K cresce, enquanto
KLK é sempre uma quantidade finita. Portanto a codificação eficiente da fonte discreta sem memória obtém-se considerando extensões de ordem mais elevada. O custo da eficiência tem como contrapartida a crescente complexidade do código.
Estamos neste momento em condições de enunciar formalmente o 1º Teorema de Shannon para a codificação de fonte.
1º Teorema de Shannon É possível codificar (e descodificar univocamente) uma fonte discreta sem memória com entropia símbolobit H usando um código instantâneo de comprimento médio
símbolobitL tal que, para qualquer 0>ε , .L ε+=H A codificação é impossível no caso em que H.<L
Def. 1.7: A eficiência do código é definida por
.LH=η (1.43)
1.4 Código de Huffman
O código de Huffman é formado por palavras cujo comprimento médio se aproxima do limiar inferior especificado pela entropia de uma fonte discreta sem memória.
O código de Huffman é óptimo no sentido em que, para uma dada fonte discreta sem memória, não existe outro conjunto de palavras de código com descodificação unívoca e que tenha um comprimento médio inferior.
A essência do algoritmo de codificação consiste na substituição da estatística da fonte discreta sem memória por uma outra mais simples. Este processo de redução é conduzido passo a passo até que se atinja um conjunto final das estatísticas correspondentes a apenas dois símbolos e para os quais os símbolos binários 0 e 1 são um código óptimo.
1-16
Mais concretamente, o algoritmo de codificação é o seguinte: 1. os símbolos fonte são ordenados por ordem decrescente das respectivas
probabilidades de ocorrência, sendo atribuídos os bits 0 e 1 aos dois símbolos de menor probabilidade;
2. estes dois símbolos são associados formando um novo símbolo cuja probabilidade de ocorrência é a soma das probabilidades dos símbolos associados, reduzindo-se a lista de símbolos de uma unidade; a nova lista é reordenada por ordem decrescente das probabilidades de ocorrência;
3. os procedimentos anteriores são repetidos até que se atinja uma lista final com apenas dois símbolos aos quais são atribuídos os bits 0 e 1;
4. a palavra de código associada a cada símbolo original é construída seguindo da frente para trás a sequência de 0's e 1's que foram sendo atribuídos ao referido símbolo e respectivos sucessores.
Vamos socorrer-nos de um exemplo para perceber melhor o mecanismo do algoritmo de codificação que acabámos de descrever.
Exemplo 1.3: Na Tabela 1.3 estão listados os símbolos de uma fonte discreta sem memória e as respectivas probabilidades de ocorrência.
m1 m2 m3 m4 m5 m6 m7 m8 m9 0.200 0.150 0.130 0.120 0.100 0.09 0.08 0.07 0.06
Tabela 1.3: Estatísticas dos símbolos de uma fonte discreta sem memória
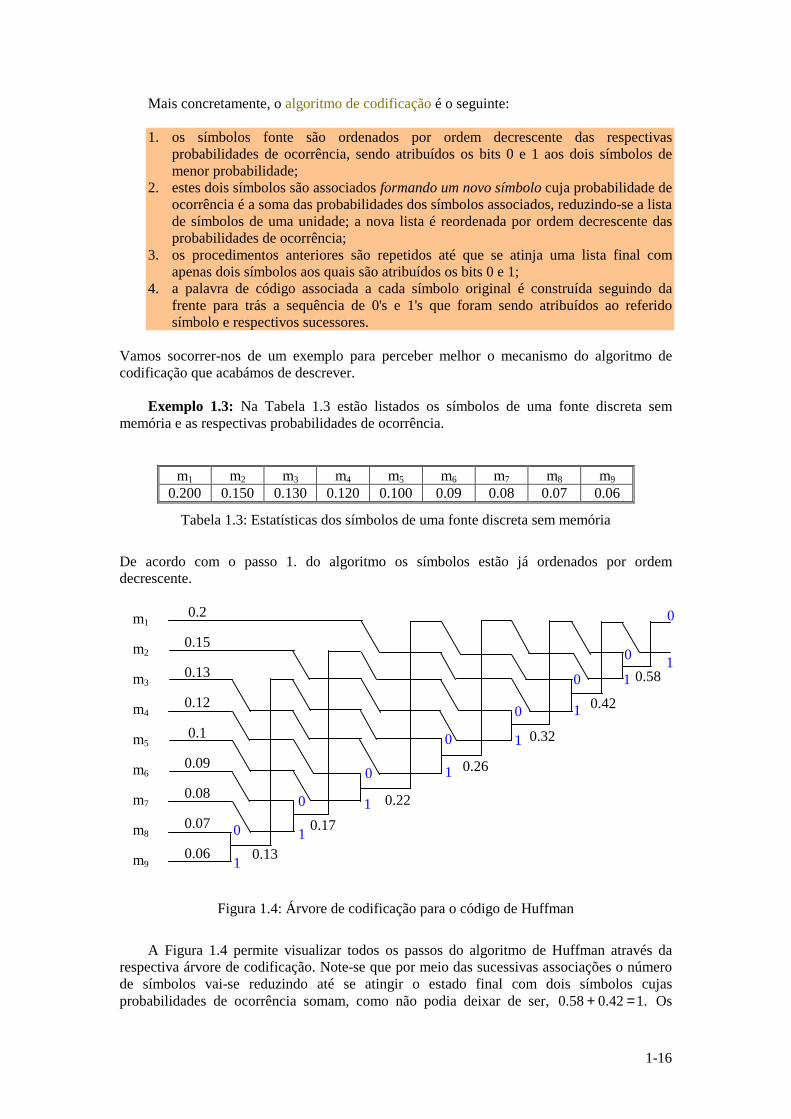
De acordo com o passo 1. do algoritmo os símbolos estão já ordenados por ordem decrescente.
m1 0.2
m2 0.15
m3 0.13
m4 0.12
m5 0.1
m6 0.09
m7 0.08
m8 0.07
m9 0.06
Figura 1.4: Árvore de codificação para o código de Huffman
A Figura 1.4 permite visualizar todos os passos do algoritmo de Huffman através da
respectiva árvore de codificação. Note-se que por meio das sucessivas associações o número de símbolos vai-se reduzindo até se atingir o estado final com dois símbolos cujas probabilidades de ocorrência somam, como não podia deixar de ser, .142.058.0 =+ Os
0.13 0
1
1
0 0.17
0.221
0 0.26
0.321
0 0.42 0
1
0.581
0 1
0
0
1

1-17
resultados da codificação estão resumidos na Tabela 1.4. Como se pode ver, o código resultante é um código de prefixo. Por outro lado, aos símbolos menos prováveis correspondem as palavras de código mais longas. Pode também verificar-se que a entropia da fonte é símbolobit0371.3 H = e que o comprimento médio do código é símbolobit1.3L = 5.
mi ci pi li
m1 11 0.2 2 m2 001 0.15 3 m3 011 0.13 3 m4 100 0.12 3 m5 101 0.1 3 m6 0000 0.09 4 m7 0001 0.08 4 m8 0100 0.07 4 m9 0101 0.06 4
Tabela 1.4: Resultados da codificação de Huffman
Como se vê o comprimento médio do código, embora superior, tem um valor muito próximo da entropia da fonte. Tal significa que o código obtido tem muito pouca redundância e, neste caso, constitui a representação mais eficiente da fonte original. Neste caso e de acordo com (1.43), temos ,9797.01.30371.3 ==η isto é, muito próximo dos 100%. Naturalmente, e como foi visto anteriormente, a eficiência da codificação poderia ser melhorada se considerássemos extensões da fonte de ordem superior.
Exemplo 1.4: Consideremos o alfabeto especificado na Tabela 1.5.
m1 m2 m3
0.70 0.15 0.15
Tabela 1.5: Alfabeto fonte
5 Chama-se a atenção para o facto de as unidades em que se exprimem a entropia e o comprimento médio terem significados diferentes: no primeiro caso bit significa unidade binária de informação, enquanto que no segundo a mesma designação é usada com o significado de símbolo binário.
mi ci pi li
m1 0 0.70 1 m2 10 0.15 2 m3 11 0.15 2
Tabela 1.6: Resultados da codificação
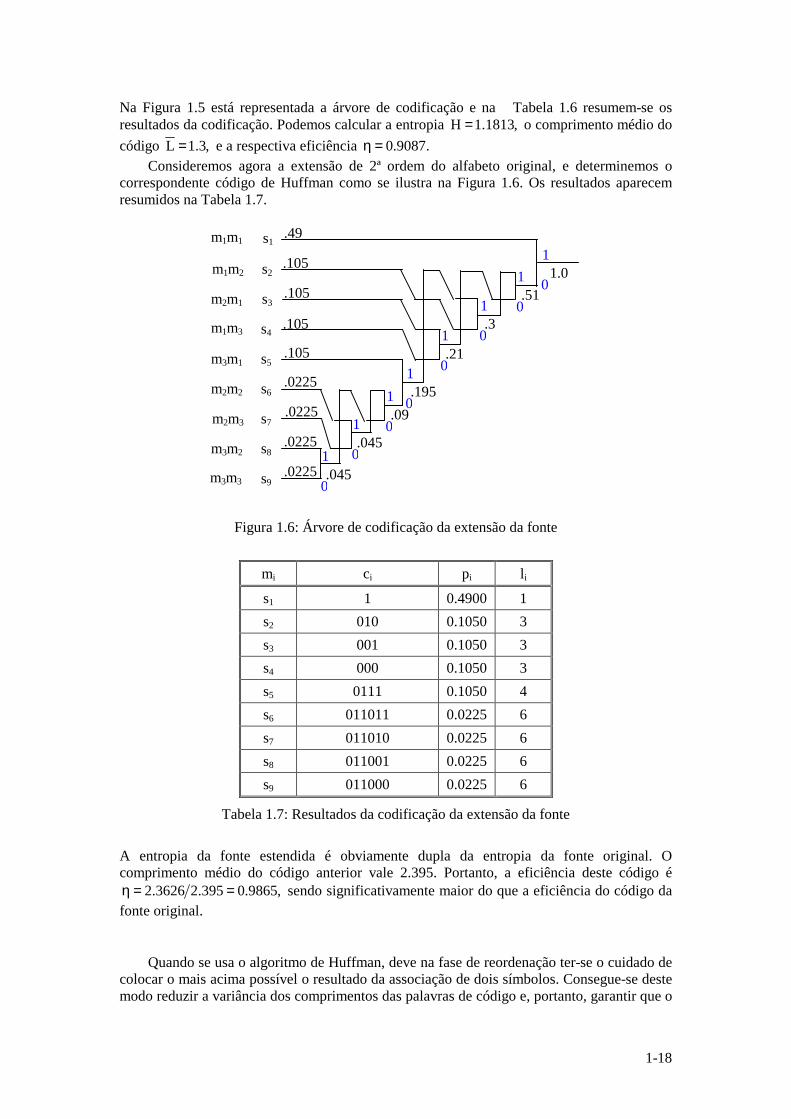
Figura 1.5: Árvore de codificação
m1
m2
m3
0.7
0.15
0.15 0.3
0
1
0
1
1.0
1-18
Na Figura 1.5 está representada a árvore de codificação e na Tabela 1.6 resumem-se os resultados da codificação. Podemos calcular a entropia ,1813.1H = o comprimento médio do código ,3.1L = e a respectiva eficiência .9087.0=η
Consideremos agora a extensão de 2ª ordem do alfabeto original, e determinemos o correspondente código de Huffman como se ilustra na Figura 1.6. Os resultados aparecem resumidos na Tabela 1.7.
Figura 1.6: Árvore de codificação da extensão da fonte
mi ci pi li
s1 1 0.4900 1 s2 010 0.1050 3 s3 001 0.1050 3 s4 000 0.1050 3 s5 0111 0.1050 4 s6 011011 0.0225 6 s7 011010 0.0225 6 s8 011001 0.0225 6 s9 011000 0.0225 6
Tabela 1.7: Resultados da codificação da extensão da fonte
A entropia da fonte estendida é obviamente dupla da entropia da fonte original. O comprimento médio do código anterior vale 2.395. Portanto, a eficiência deste código é
,9865.0395.23626.2 ==η sendo significativamente maior do que a eficiência do código da fonte original.
Quando se usa o algoritmo de Huffman, deve na fase de reordenação ter-se o cuidado de colocar o mais acima possível o resultado da associação de dois símbolos. Consegue-se deste modo reduzir a variância dos comprimentos das palavras de código e, portanto, garantir que o
m1m1
m1m2
s1
s2
s3
m2m2
m2m1
s5
s4 m1m3
m3m1
s6
m2m3 s7
m3m2 s8
m3m3 s9
.49
.105
.105
.105
.105
.0225
.0225
.0225
.0225
.045 1
.045 1
0
0
.09 1
0
.21 1
0
.195 1
0
1.0 1
0
.3 1
0
.51 1
0

1-19
tempo gasto na descodificação das palavras de código é semelhante para todas elas. Recordemos que a variância do comprimento das palavras do código vale
( )∑ −=σ .Llp 2ii
2l (1.44)
Mais uma vez vamos socorrer-nos de um exemplo para ilustrar este facto.
Exemplo 1.5: Consideremos uma fonte discreta sem memória cujo alfabeto e respectivas
estatísticas se mostram na Tabela 1.8.
m1 m2 m3 m4 m5 m6 m7
0.30 0.20 0.20 0.10 0.10 0.05 0.05
Tabela 1.8: Alfabeto e estatísticas da fonte
A entropia desta fonte vale .símbolobit5464.2 H = A Tabela 1.9 apresenta os resultados obtidos quando se aplica o algoritmo de Huffman tal como nos Exemplos 1.3 e 1.4. Neste caso, o valor médio e a variância do comprimento das palavras do código valem
símbolobit6.2L = e .44.02l =σ
mi ci pi li
m1 10 0.30 2 m2 00 0.20 2 m3 111 0.20 3 m4 011 0.10 3 m5 010 0.10 3 m6 1101 0.05 4 m7 1100 0.05 4
Tabela 1.9: Resultados da codificação
Vejamos agora a situação em que o resultado de uma associação não é colocado o mais
acima possível na tabela de probabilidades, como se mostra na Figura 1.7.
Figura 1.7: Árvore de codificação alternativa
m1
m2
m3
m4
m5
m6
m7
0.3
0.2
0.2
0.1
0.1
0.05
0.05 0
0
10.1 0
10.2
0
10.3
0.40
10.6
0
1
1

1-20
A Tabela 1.10 resume os resultados obtidos quando o algoritmo de Huffman é aplicado do modo acima descrito.
mi ci pi li
m1 11 0.30 2 m2 01 0.20 2 m3 00 0.20 2 m4 100 0.10 3 m5 1011 0.10 4 m6 10101 0.05 5 m7 10100 0.05 5
Tabela 1.10: Resultados da codificação alternativa
Verifica-se facilmente que neste caso o comprimento médio das palavras de código mantém-se, mas a variância aumenta para .04.12
l =σ
1.5 Outras Leituras Recomendadas [1]- C.E. Shannon, "A Mathematical Theory of Communication," Collected Papers, eds.
N.J.A. Sloane e Aaron D. Wyner, IEEE Press, 1993.

2-1
2 Sinais Aleatórios em Tempo Contínuo. Parte I: Espaço de Probabilidade e Variáveis Aleatórias.
Na Figura 2.1 está representado um modelo simplificado de um sistema de comunicação.
No Capítulo 1 justificou-se a opção por um modelo aleatório para representar uma fonte de informação. Embora a discussão se tenha focado no caso de fontes digitais, as razões apresentadas mantêm-se válidas quando a fonte de informação gera sinais analógicos em tempo contínuo. Assim sendo, utilizaremos um modelo estocástico (ou aleatório) para representar a classe de sinais passíveis de serem gerados por uma fonte de informação analógica. Em geral, o sinal transmitido resulta de uma ou mais transformações realizadas sobre o sinal fonte, aqui representadas de forma integrada num único bloco genericamente designado por emissor. Embora o sinal transmitido seja em geral diferente do sinal fonte, as transformações envolvidas preservam a informação original, e têm por objectivo adaptar a transmissão ao canal de comunicação e combater o efeito do ruído.
Figura 2.1: Modelo simplificado de um sistema de comunicação
Por natureza própria dos fenómenos físicos envolvidos o mecanismo de geração do ruído é aleatório, pelo que o modelo mais adequado para o representar é também do tipo estocástico. De acordo com o modelo da Figura 2.1, o sinal recebido à entrada do receptor é uma versão do sinal transmitido, eventualmente distorcida pelo canal de comunicação, e corrompida por uma amostra de ruído aditivo:
( ) ( )[ ] ( )( ) ( )[ ]Ettra
Ctratrec
TxEtxtnTxCtx
∈τ=+∈τ=
(2.1)
onde Ct e Et representam as transformações, em geral não instantâneas, realizadas pelo canal e pelo emissor sobre os respectivos sinais de entrada. x, xtra e xrec são o sinal fonte, o sinal transmitido e o sinal recebido, respectivamente, e n é uma amostra do ruído. Note-se que o sinal disponível à entrada do receptor é desconhecido pois nem o sinal fonte nem o ruído são conhecidos. Embora o canal, isto é, a transformação Ct, possa também ser desconhecido, iremos admitir que dispomos de um modelo adequado para o representar. Tendo em conta a falta de conhecimento prévio sobre um conjunto de componentes importantes do sistema, torna-se óbvio que é impossível o receptor fornecer ao destinatário uma réplica exacta do sinal fonte. O problema consiste então em desenhar o emissor e o receptor de modo a que este último possa, a partir do sinal recebido, gerar a melhor réplica possível do sinal fonte. Para tal, e também para avaliar a qualidade do sistema, isto é, o grau de semelhança entre o sinal fonte e a respectiva estimativa, torna-se necessário estudar o modelo de representação da fonte e do ruído.
Fonte Canal Destino
Ruído
Emissor Receptor+
sinal fonte sinal transmitido
sinal recebido estimativa do sinal fonte

2-2
2.1 Introdução aos Processos Estocásticos
O conceito de processo estocástico constitui uma extensão da noção de variável aleatória e permite modelar uma classe de sinais cujo comportamento ao longo do tempo é não determinístico. A interpretação deste modelo pode fazer-se com base na Figura 2.2 A idea básica é a de que cada sinal ou função amostra daquela classe ocorre de acordo com os resultados de um modelo experimental probabilístico. Com efeito, um processo estocástico
( )tX não é mais do que um conjunto de sinais ( )i;tx ξ , designados por funções amostra, onde
iξ é um dos resultados elementares de um fenómeno físico completamente caracterizado pelo conjunto de todos os resultados experimentais directos. Antes de avançar mais na descrição deste modelo, convém recordar as noções de espaço de probabilidade e de variável aleatória.
Figura 2.2: Modelação de um Processo Estocástico
2.1.1 Espaço de Probabilidade
Consideremos o conjunto formado pelos elementos ξi∈ , os quais simbolizam os resultados elementares de uma experiência. Por exemplo, ξi pode representar a ocorrência de uma das faces resultante do lançamento de um dado ou o intervalo de tempo que decorre entre duas chamadas telefónicas consecutivas. é portanto um modelo experimental. Qualquer subconjunto de é um acontecimento: a ocorrência de uma face par corresponde à ocorrência das alternativas face2, face4 ou face6. Neste contexto, o conjunto vazio ∅ corresponde ao acontecimento impossível e é o acontecimento certo. O conjunto de todos os subconjuntos de constitui o espaço de amostras Ω. Note-se que os elementos de Ω são a união de acontecimentos elementares de os quais, por definição, são mutuamente exclusivos. Recorde-se que dois acontecimentos A e B são mutuamente exclusivos sse .BA ∅=∩ Para completar este modelo probabilístico é necessário atribuir uma medida de probabilidade a todos os acontecimentos de Ω. A probabilidade é uma função dos elementos de Ω que verifica os axiomas:
(i) P(A) ≥ 0
(ii) P( ) = 1 (2.2) (iii) P(A∪ B) = P(A) + P(B) se A∩B = ∅
( )20;tx ξ ( )30;tx ξ
( )i0;tx ξξ1 ξ2
ξ3
ξi
ξj ξ7
t ( )1;tx ξ
( )2;tx ξ
( )3;tx ξ
( )i;tx ξ⊥⊥⊥⊥ = ( ,ΩΩΩΩ,P( ⋅⋅⋅⋅ ) )
t0
( )10;tx ξ
3
0

2-3
O triplete ( ,Ω,P( ⋅ )) é designado por espaço de probabilidade. Note-se que o espaço de amostras Ω, sendo o conjunto formado por todos os subconjuntos de , satisfaz as seguintes propriedades:
(i) ∈Ω (ii) se A∈Ω então AC∈Ω (2.3)
(iii) ∀ i, Ai∈Ω então ∪ iAi∈Ω A partir de (2.2) e (2.3) é possível derivar algumas propriedades adicionais da medida de probabilidade P( ⋅ ), tais como1:
1. P(AC) = 1-P(A) (2.4) 2. P(∅ ) = 0 (2.5) 3. P(A∪ B) = P(A) + P(B) – P(A∩B) (2.6) 4. A⊂ B ⇒ P(A) ≤ P(B) (2.7)
2.1.1.1 Probabilidade Condicional e Independência Estatística
Def. 2.1: Dado um acontecimento M tal que P(M) ≠ 0, a probabilidade de ocorrência do acontecimento A condicionada na certeza da ocorrência de M é definida por
( ) ( )( )MP
MAPM|AP ∩= . (2.8) €
Suponhamos que A e M são acontecimentos pertencentes ao espaço de amostras Ω
associado ao espaço de probabilidade ⊥ = ( ,Ω,P( ⋅ )). Admitamos ainda que em N repetições da experiência representada pelo modelado experimental os acontecimentos M e A∩M ocorrem NM e NA⋅M vezes, respectivamente. É sabido que para um valor de N suficientemente elevado para que NM e NA⋅M tomem também valores muito elevados se verifica
( ) ( )N
NMAP e N
NMP MAM ⋅≅∩≅ ,
isto é,
( )( ) M
MA
NN
MPMAP ⋅≅∩ .
Note-se que o acontecimento A∩M ocorre sse A e M ocorrerem em simultâneo; NA⋅M conta assim o número de vezes que, na série de ocorrências de M, o acontecimento A também ocorre. Este raciocínio explica, ainda que de forma empírica, a definição de probabilidade condicional expressa em (2.8). A probabilidade condicional goza das seguintes propriedades:
1. P(A|M) ≥ 0 (2.9) 2. P( |M) = 1 (2.10) 3. A∩B = ∅ ⇒ P(A∪ B|M) = P(A|M) + P(B|M) (2.11)
1 Por ser relativamente simples, deixa-se como exercício a demonstração destas propriedades.

2-4
A propriedade (2.9) resulta directamente do facto de A∩M ser um acontecimento em Ω. De facto, tendo em conta que a medida de probabilidade é não negativa, P(A∩M) ≥ 0, e a quantidade definida em (2.8) é não negativa. Como ∩M = M, a igualdade (2.10) é imediata. Usando (2.8), temos
( ) ( )( )( )
( ) ( )( )( )MP
MBMAPMP
MBAPM|BAP ∩∪∩=∩∪=∪ .
Sendo A e B mutuamente exclusivos, o mesmo acontece com A∩M e B∩M. Assim,
( ) ( )( )( )
( )( )
( )( )MP
MBPMP
MAPMP
MBMAP ∩+∩=∩∪∩
e, tendo em conta (2.8), obtém-se (2.11).
Def. 2.2: Dois acontecimentos A e B são estatisticamente independentes sse
( ) ( ) ( )BPAPBAP =∩ . (2.12) €
Desta relação e de (2.8) conclui-se ainda que se dois acontecimentos A e B são estatisticamente independentes, então
( ) ( )( ) ( )BPA|BP
APB|AP==
. (2.13)
2.1.1.2 Probabilidade Total
Consideremos o conjunto de todos os acontecimentos elementares associados a um determinado modelo experimental. Suponhamos que, tal como se mostra na Figura 2.3, se define a partição [ ]M21 A,,A,A K de .
Figura 2.3: Partição do conjunto
Seja B um acontecimento qualquer definido em , isto é, B∈Ω . Como = A1∪ A2∪ L∪ AM, então
A1
A2
AM
B
…

2-5
( )( ) ( ) ( )M21
M21
ABABABAAABB
∩∪∪∩∪∩=∪∪∪∩=
L
L
Como se vê na Figura 2.3, os acontecimentos A1,...,AM são mutuamente exclusivos e portanto também com os acontecimentos (B∩A1),..., (B∩AM) são mutuamente exclusivos. Logo
( ) ( ) ( ) ( )M21 ABPABPABPBP ∩++∩+∩= L ,
ou, atendendo a (2.8),
( ) ( ) ( )∑=
=M
1mmm APA|BPBP . (2.14)
Este resultado é conhecido por Teorema da Probabilidade Total e permite calcular a
probabilidade de um acontecimento B se as probabilidades condicionais P(B|Am) e a priori P(Am) forem conhecidas.
2.1.1.3 Teorema de Bayes
Suponhamos que os acontecimentos B e Am, m=1,2,...,M, verificam o teorema da probabilidade total. Então, o Teorema de Bayes diz que as probabilidades a posteriori P(Am|B), m=1,2,...,M, se exprimem em termos das probabilidades a priori P(Am), m=1,2,...,M, do seguinte modo
( ) ( ) ( )( ) ( )∑
=
= M
1mmm
mmm
APA|BP
APA|BPB|AP . (2.15)
Este resultado deriva directamente da definição de probabilidade condicional (2.8) e do
teorema da probabilidade total (2.14) e, como veremos mais tarde, desempenha um papel muito importante em muitos problemas de engenharia, em particular, no desenho de receptores em sistemas de comunicações digitais.
2.1.2 Variáveis Aleatórias
Uma variável aleatória é uma função ( )ξX cujo domínio é o conjunto de resultados experimentais elementares ξ, sendo o conjunto dos números reais o respectivo contradomínio2. Formalmente, a especificação de uma variável aleatória assenta no espaço de probabilidade ⊥ =( ,Ω,P( ⋅ )), isto é, no conjunto de acontecimentos elementares, no espaço de amostras Ω, e na medida de probabilidade P( ⋅ ) definida para cada elemento de Ω. Para ilustrar a construção do modelo de uma variável aleatória consideremos a Figura 2.4. Como se pode verificar, a cada elemento de faz-se corresponder um e um só número real. No entanto, pode acontecer que a mais de um elemento de corresponda um único valor de 3. 2 Uma variável aleatória complexa define-se por ( ) ( ) ( )ξ+ξ=ξ ir jXXX , onde ( )ξrX e ( )ξiX são
variáveis aleatórias reais e 1j −= é a unidade imaginária.

2-6
Figura 2.4: Modelação de um Variável Aleatória Real
Note-se que qualquer acontecimento em Ω é representado por um intervalo em 3. Por
exemplo, os acontecimentos A e B são representados pelos intervalos
21 xXxBexXA ≤<=≤= ,
onde x, x1 e x2 são números reais. No exemplo da Figura 2.4 o contradomínio da variável aleatória X é constituído por um conjunto contável de números reais. Quando assim é diz-se que a variável aleatória é discreta. Uma variável aleatória X é contínua se o seu contradomínio for uma união de intervalos em 3. Finalmente, se o contradomínio for a união de intervalos de 3 com um conjunto contável de números reais, a variável aleatória é do tipo misto. A especificação de uma variável aleatória completa-se recorrendo à medida de probabilidade P( ≈ ) associada ao espaço de probabilidade ⊥ .
2.1.2.1 Função de Distribuição Cumulativa
Def. 2.3: A função de distribuição cumulativa de uma variável aleatória X é dada por3:
( ) ( )xXPxFX ≤= . (2.16)
A função de distribuição goza das seguintes propriedades4:
1. ( ) ( )( ) ( ) 1XPF
0XPF
X
X
=+∞≤=∞+=−∞≤=∞−
(2.17)
2. ( )⋅XF é monotónica crescente, isto é,
( ) ( )2X1X21 xFxFentãoxxse ≤< . (2.18)
3 A função de distribuição será sempre representada por F; o subíndice em letra maiúscula designa a variável aleatória a que se refere F. 4 Por ser relativamente simples, deixa-se como exercício a demonstração destas propriedades.
ξi A B
x x1 x2
X(ξi) 3
2-7
3. ( ) ( )xF1xXP X−=> . (2.19)
4.
( ) ( ) ( )1X2X21 xFxFxXxP −=≤< . (2.20)
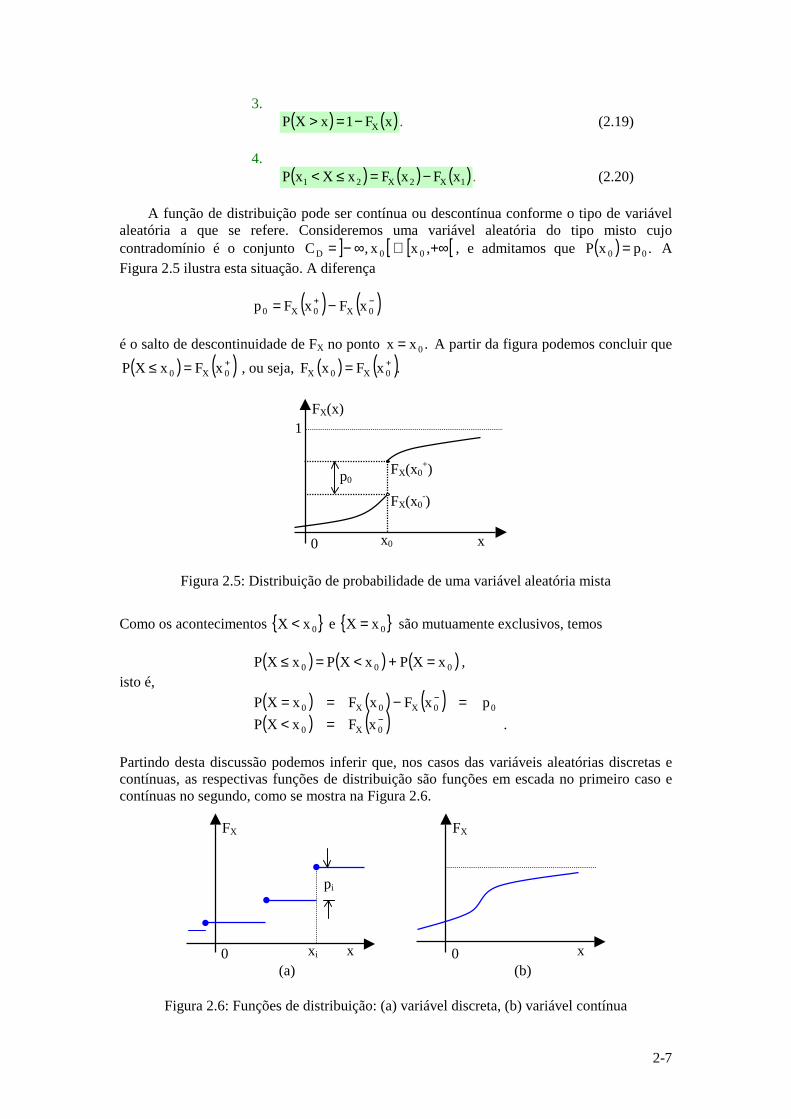
A função de distribuição pode ser contínua ou descontínua conforme o tipo de variável aleatória a que se refere. Consideremos uma variável aleatória do tipo misto cujo contradomínio é o conjunto ] [ [ [+∞∪∞−= ,xx,C 00D , e admitamos que ( ) .pxP 00 = A Figura 2.5 ilustra esta situação. A diferença
( ) ( )−+ −= 0X0X0 xFxFp
é o salto de descontinuidade de FX no ponto .xx 0= A partir da figura podemos concluir que
( ) ( )+=≤ 0X0 xFxXP , ou seja, ( ) ( ).xFxF 0X0X+=
Figura 2.5: Distribuição de probabilidade de uma variável aleatória mista
Como os acontecimentos 0xX < e 0xX = são mutuamente exclusivos, temos
( ) ( ) ( )000 xXPxXPxXP =+<=≤ , isto é,
( ) ( ) ( )( ) ( ) . xFxXP
pxFxFxXP
0X0
00X0X0−
−
=<=−==
Partindo desta discussão podemos inferir que, nos casos das variáveis aleatórias discretas e contínuas, as respectivas funções de distribuição são funções em escada no primeiro caso e contínuas no segundo, como se mostra na Figura 2.6.
Figura 2.6: Funções de distribuição: (a) variável discreta, (b) variável contínua
x
FX(x)
0
p0
1
FX(x0-)
FX(x0+)
x0
pi
x xi 0
FX
x 0
FX
(a) (b)
2-8
2.1.2.2 Função Densidade de Probabilidade
Para além da função de distribuição, a função densidade de probabilidade pode ser usada para caracterizar uma variável aleatória de forma equivalente.
Def. 2.4: Seja X uma variável aleatória contínua com função de distribuição FX(x). A função densidade de probabilidade de X é definida por5:
( ) ( ).
dxxdF
xf XX = (2.21)
A função densidade de probabilidade goza das seguintes propriedades6:
1. Uma vez que FX é não decrescente, ver (2.18), então
0f X ≥ . (2.22) 2. De (2.20) resulta
( ) ( )∫ µµ=≤<2
1
x
xX21 d fxXxP . (2.23)
3.
( ) ( )∫∞
µµ=x
-xX d fxF . (2.24)
4.
( ) ( )∫+∞
∞
µµ=∞+=-
XX d fF1 . (2.25)
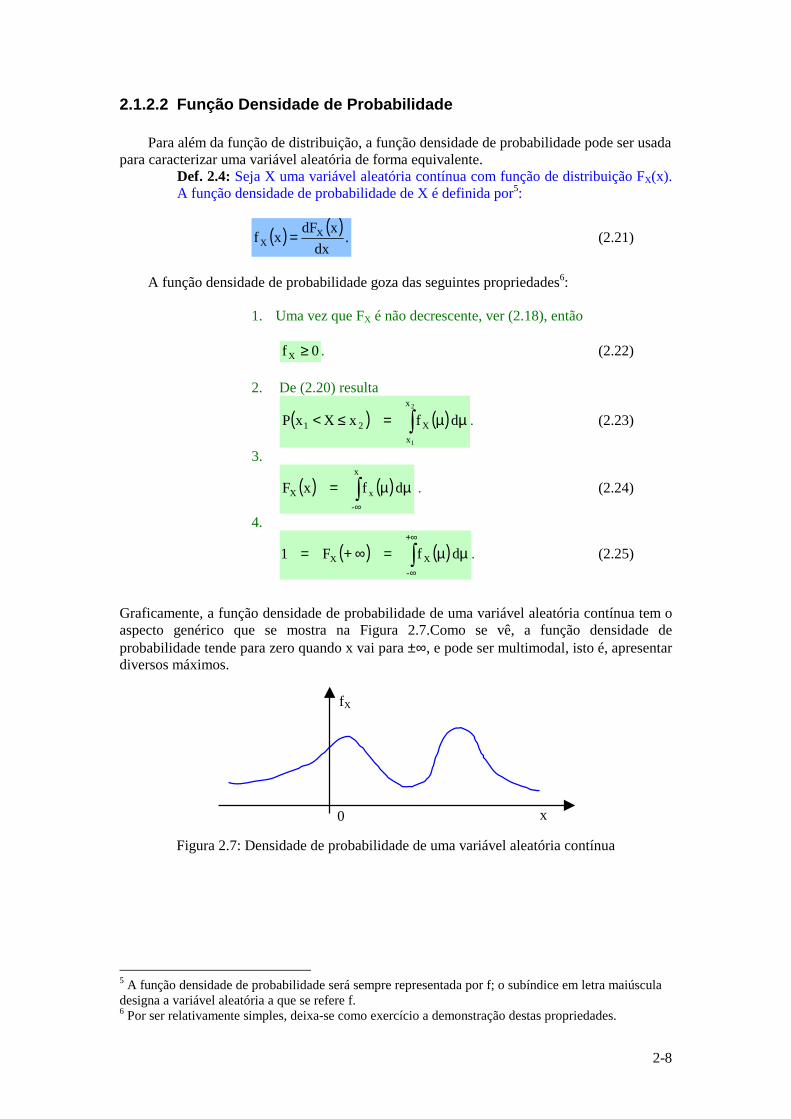
Graficamente, a função densidade de probabilidade de uma variável aleatória contínua tem o aspecto genérico que se mostra na Figura 2.7.Como se vê, a função densidade de probabilidade tende para zero quando x vai para ±∞, e pode ser multimodal, isto é, apresentar diversos máximos.
Figura 2.7: Densidade de probabilidade de uma variável aleatória contínua
5 A função densidade de probabilidade será sempre representada por f; o subíndice em letra maiúscula designa a variável aleatória a que se refere f. 6 Por ser relativamente simples, deixa-se como exercício a demonstração destas propriedades.
x
fX
0
2-9
2.1.2.2.1 Densidade de Probabilidade de uma Variável Aleatória Discreta
No caso de variáveis aleatórias discretas, a função de distribuição não é contínua e portanto (2.21) em Def. 2.1 não tem sentido. Uma variável aleatória discreta X toma valores xk com probabilidade P(X=xk) = pk = FX(xk
+)-FX(xk-), pelo que podemos usar a notação
( ) K,2,1k ,pxf kkX == (2.26)
que especifica a densidade de probabilidade pontual. Neste contexto, fX não é a derivada de FX, sendo definida pelas amplitudes dos saltos de descontinuidade da função de distribuição. Graficamente, fX representa-se como se ilustra na Figura 2.8.
Figura 2.8: Densidade de probabilidade de uma variável aleatória discreta
Neste contexto, as propriedades da função densidade de probabilidade pontual
equivalentes a (2.23), (2.24) e (2.25) são7:
1. Sejam xi e xj os valores de X imediatamente superior a a e inferior ou igual a b, respectivamente. Ver exemplo da Figura 2.8. Então
( ) ( )∑∑==
==≤<j
ikkX
j
ikk xfpbXaP . (2.27)
2. Seja xj o valor de X imediatamente inferior ou igual a a. Então
( ) ( )∑−∞=
=j
kkXX xfaF . (2.28)
3.
( ) ( )∑+∞
−∞===∞+
kkXX xf1F . (2.29)
Alternativamente, podemos estender o espaço onde se definem as funções densidade de
probabilidade definidas por (2.21) de modo a incluir a distribuição ( )⋅δ de Dirac
( ) ≤≤
=−δ∫ contrário. caso0bca se1
dx cxb
a
(2.30)
7 A propriedade (2.22) mantém-se.
xk+2
pk+2pk
pk-1
pk-2
pk+1
xk-2 xk-1 xk xk+1
fX
x•• ba

2-10
Deste modo, a densidade de probabilidade pontual de uma variável aleatória discreta é generalizável de modo a suportar a dedinição (2.21), e escreve-se na forma
( ) ( )∑+∞
−∞=−δ=
kkkX xxpxf . (2.31)
Usando esta definição em (2.23), (2.24) e (2.25) e tendo em conta (2.30), recuperam-se facilmente as expressões (2.27), (2.28) e (2.29), respectivamente.
2.1.2.3 Operador Valor Expectável
Considere-se a variável aleatória X caracterizada pela densidade de probabilidade fX e a transformação
( )XgY = (2.32)
a partir da qual se define uma nova variável aleatória Y.
Def. 2.5: O valor expectável da variável aleatória Y é definido por
( ) ( ) µµµ= ∫+∞
∞
d fgYE X-
. (2.33)
Note-se que se, em particular, a transformação ( )⋅g for a identidade, isto é, XY = , então de (2.33) resulta
( )∫+∞
∞−
µµµ= dfXE X , (2.34)
ou seja, o valor expectável da variável aleatória X. Pode também mostrar-se, como veremos mais adiante, que o operador valor expectável é linear, isto é,
.YEYEYEYYY 22112211 α+α=⇒α+α= (2.35)
2.1.2.3.1 Momentos
Def. 2.6: Fazendo em (2.32) nXY = , e usando (2.33), obtém-se o momento de ordem n da variável aleatória X:
( ) ( )∫+∞
∞
µµµ==-
Xnnn
X d fXEm . (2.36)
O momento de primeira ordem, abreviadamente representado por Xm , é o valor expectável de X já introduzido em (2.34). O momento de segunda ordem,
( ) 22X XEm = , é normalmente designado por correlação.

2-11
2.1.2.3.2 Momentos Centrados
Def. 2.7: Fazendo em (2.32) ( )nXmXY −= e usando (2.33), obtém-se o momento
centrado de ordem n da variável aleatória X:
( ) ( ) ( ) ( )∫+∞
∞
νν−ν=−=µ-
Xn
Xn
Xn
X d fmmXE . (2.37)
O momento centrado de primeira ordem é nulo. O momento centrado de segunda ordem é designado por variância: ( )2
X2X µ=σ .
É fácil verificar que a variância verifica a igualdade
( ) 2
X2
X2X mm −=σ , (2.38)
ou seja, é a diferença entre a correlação e quadrado do valor expectável. Portanto, no caso em que X tem valor expectável (média) nulo, a variância coincide com a correlação.
2.1.2.3.3 Desigualdade de Chebyshev
Na caracterização estatística de uma variável aleatória é frequente fazer-se uso de um outro parâmetro, relacionado com a variância, e designado por desvio padrão:
( ) ( )( ) 212
X2
X2
12XX mm −=σ=σ . (2.39)
Para se entender que tipo de estatística é medida pelo desvio padrão consideremos uma variável aleatória qualquer Z e um número real arbitrário 0>ε infinitésimal. Qualquer que seja 0a > ,
( ) ( ) ( )∫∫∫+∞
ε−
−
∞−
+∞
∞−
µµµ+µµµ≥µµµ=a
Z2
a
Z2
Z22 d fd fd fZE ;
em qualquer das parcelas do termo mais à direita da relação anterior, o factor µ2 toma, em qualquer das duas integrandas, valores não inferiores a a2. Portanto, podemos ainda escrever
( ) ( ) ( )aZPad fd faZE 20
aZ
a
Z22 ≥ →
µµ+µµ≥ →ε
+∞
ε−
−
∞−∫∫ ,
ou ainda
( ) 2
2
aZEaZP ≤≥ . (2.40)
Fazendo em (2.40) XmXZ −= e Xka σ= , k∈9 +, obtém-se a desigualdade de Chebyshev, a qual se pode escrever em qualquer das formas alternativas seguintes:

2-12
( ) 2XX k1kmXP ≤σ≥− ; (2.41)
( ) 2XX k11kmXP −>σ<− . (2.42)
A desigualdade de Chebyshev permite afirmar que, independentemente da função fX, a probabilidade de X tomar valores fora de um intervalo centrado em torno do respectivo valor expectável e com comprimento igual a 2k desvios padrão é sempre não superior a .K1 2 Um valor pequeno do desvio padrão significa um pequeno espalhamento dos valores mais prováveis de X em torno do valor médio. Por exemplo, para 2k = , qualquer variável aleatória X toma valores entre mX-2σX e mX+2σX com probabilidade superior a 0.75.
2.1.2.4 Exemplos de Variáveis Aleatórias
Neste parágrafo iremos dar exemplo de algumas variáveis aleatórias de grande interesse para o desenho e análise de sistemas de telecomunicações. 1. Bernoulli
Variável aleatória discreta cujo contradomínio é o conjunto 1,0CD = com distribuição de probabilidade
( )( ) 1p0com
p11Pp0P
≤≤−=
=. (2.43)
Esta variável aleatória é usada para modelar fontes binárias e a ocorrência de erros de transmissão num sistema de comunicações digitais.
2. Binomial
Variável aleatória discreta cujo contradomínio é o conjunto CD = 90+ dos inteiros não
negativos e que representa, por exemplo, o número de 0's que ocorrem numa sequência de n ocorrências de Bernoulli. A respectiva densidade de probabilidade pontual é da forma
( ) ( )
>
≤≤−
==−
nk0
nk0p1pkn
kXPknk
(2.44)
A distribuição binomial serve, por exemplo, para modelar o número total de símbolos recebidos com erro numa sequência de n símbolos estatisticamente independentes, sendo p a probabilidade de erro por símbolo.
3. Uniforme Variável aleatória contínua cuja função densidade de probabilidade é definida como
( )
≤≤
−=contrário caso0
bxaab
1xf X (2.45)
A distribuição uniforme pode ser usada para representar a fase de uma sinusoide num intervalo de comprimento 2π.

2-13
4. Laplace Variável aleatória contínua cuja densidade de probabilidade é definida por
( ) ( ) +∞<<∞−α−α= xxexp2
xf X (2.46)
Neste caso X pode ser usada para modelar a amplitude de um sinal de voz.
5. Gaussiana ou Normal
A variável aleatória gaussiana é de grande importância na análise do desempenho de sistemas de comunicações pois o ruído térmico, uma das fontes de ruído mais típicas neste tipo de sistemas, tem uma distribuição de amplitude gaussiana. A respectiva densidade de probabilidade é dada por
( ) ( ) +∞<<∞−
σ
−−σπ
= x2
mxexp2
1xf 2X
2X
XX (2.47)
onde mX e σX são a média e o desvio padrão de X, respectivamente.
2.1.2.5 Transformação de Uma Variável Aleatória
Consideremos uma variável aleatória X com densidade de probabilidade fX e a transformação
( )XgY = , (2.32) onde g é uma função conhecida para a qual existe a transformação inversa
( )ygx 1−= . (2.48)
Em geral, g pode ser não monotónica pelo que a solução da equação y = g(x) dada por (2.48) não é única. O problema que iremos abordar é o de calcular a densidade de probabilidade fY dadas a tranformação (2.32) e a densidade fX. Para simplificar, começaremos por assumir que g é uma função monotónica, isto é, a solução dada por (2.48) é única. Consideremos a ilustração deste problema apresentada na Figura 2.9. Note-se que ao acontecimento ]x0 , x0 + dx0] definido sobre o espaço de amostras da variável X corresponde o mesmo acontecimento ]y0 , y0 + dy0], este definido sobre o espaço de amostras de Y, e determinado pela transformação g. Porque se trata do mesmo acontecimento, podemos concluir que
( ) ( )000000 dyyYyPdxxXxP +≤<=+≤< ;
Admitindo que dx0 e dy0 são infinitesimais, as probabilidades da igualdade anterior, dadas pelas áreas sombreadas na Figura 2.9, podem ser aproximadas por
( ) ( ) 00Y00X dy yfdx xf ≅ ,
ou seja,
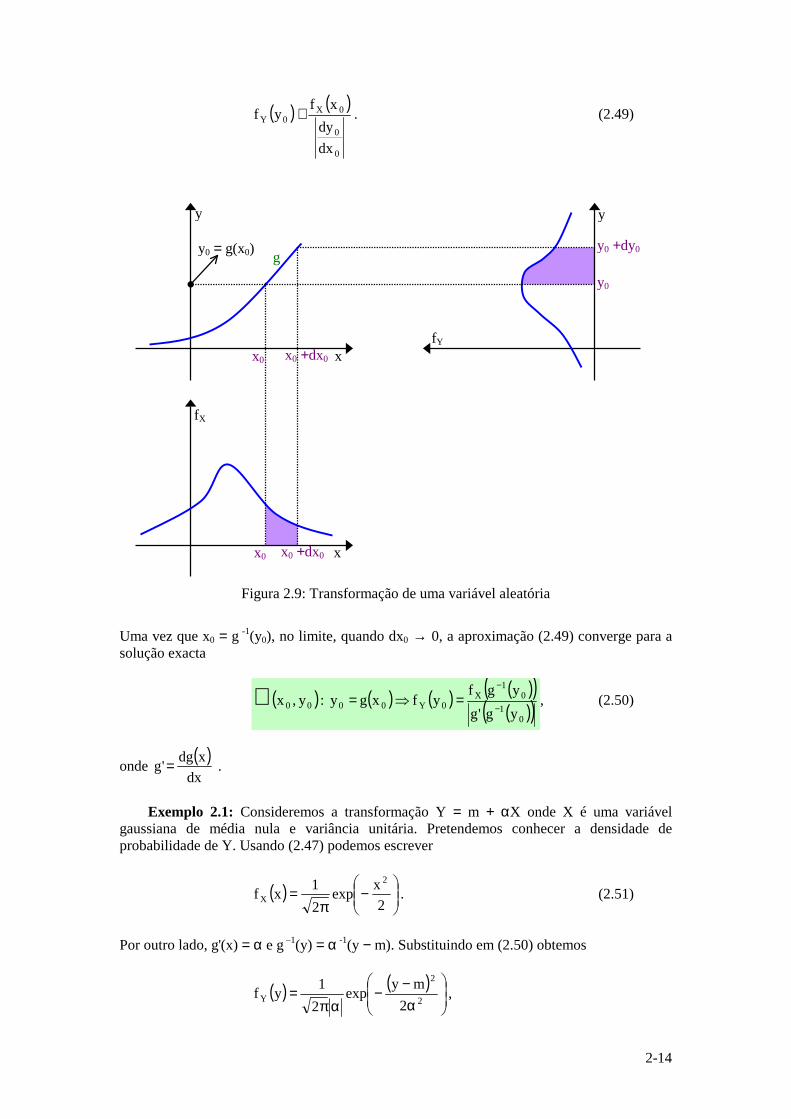
2-14
( ) ( )
0
0
0X0Y
dxdy
xfyf ≅ . (2.49)
Figura 2.9: Transformação de uma variável aleatória
Uma vez que x0 = g -1(y0), no limite, quando dx0 → 0, a aproximação (2.49) converge para a solução exacta
( ) ( ) ( ) ( )( )( )( )0
10
1X
0Y0000yg'gygf
yfxgy :y,x −
−
=⇒=∀ , (2.50)
onde ( )dx
xdg'g = .
Exemplo 2.1: Consideremos a transformação Y = m + αX onde X é uma variável
gaussiana de média nula e variância unitária. Pretendemos conhecer a densidade de probabilidade de Y. Usando (2.47) podemos escrever
( )
−
π=
2xexp
21xf
2
X . (2.51)
Por outro lado, g'(x) = α e g –1(y) = α -1(y − m). Substituindo em (2.50) obtemos
( ) ( )
α−−
απ= 2
2
Y 2myexp
21yf ,
g
y y
x
x
fX
fY
y0 = g(x0)
x0
x0
x0 +dx0
x0 +dx0
y0
y0 +dy0
2-15
isto é, uma gaussiana de média m e variância α2.
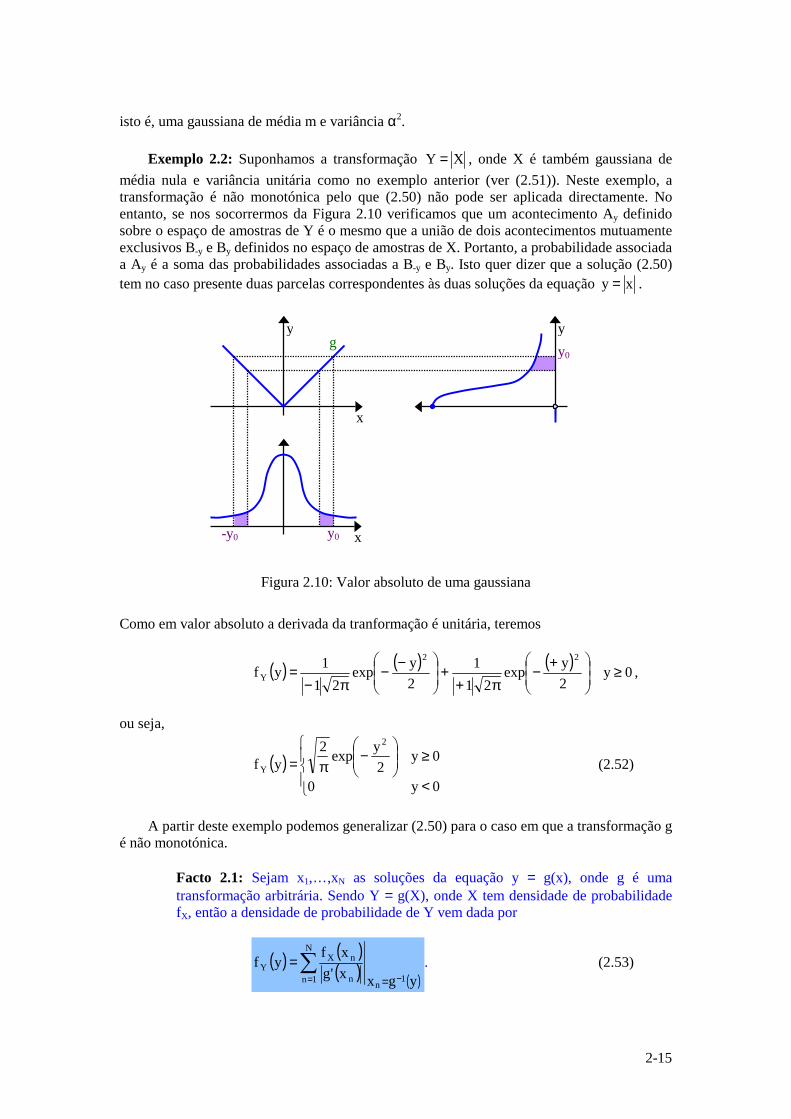
Exemplo 2.2: Suponhamos a transformação XY = , onde X é também gaussiana de
média nula e variância unitária como no exemplo anterior (ver (2.51)). Neste exemplo, a transformação é não monotónica pelo que (2.50) não pode ser aplicada directamente. No entanto, se nos socorrermos da Figura 2.10 verificamos que um acontecimento Ay definido sobre o espaço de amostras de Y é o mesmo que a união de dois acontecimentos mutuamente exclusivos B-y e By definidos no espaço de amostras de X. Portanto, a probabilidade associada a Ay é a soma das probabilidades associadas a B-y e By. Isto quer dizer que a solução (2.50) tem no caso presente duas parcelas correspondentes às duas soluções da equação xy = .
Figura 2.10: Valor absoluto de uma gaussiana
Como em valor absoluto a derivada da tranformação é unitária, teremos
( ) ( ) ( ) 0y 2yexp
211
2yexp
211yf
22
Y ≥
+−π+
+
−−π−
= ,
ou seja,
( )
<
≥
−
π=0y0
0y2
yexp2yf
2
Y (2.52)
A partir deste exemplo podemos generalizar (2.50) para o caso em que a transformação g
é não monotónica.
Facto 2.1: Sejam x1,…,xN as soluções da equação y = g(x), onde g é uma transformação arbitrária. Sendo Y = g(X), onde X tem densidade de probabilidade fX, então a densidade de probabilidade de Y vem dada por
( ) ( )( ) ( )
∑= −=
=N
1n 1nn
nXY
ygxx'gxf
yf . (2.53)
y y
x
x
g y0
y0-y0

2-16
2.1.3 Distribuições Conjuntas e Condicionais
Os conceitos introduzidos na secção anterior podem ser generalizados para o caso de vectores aleatórios, isto é, cujos componentes são variáveis aleatórias. Por questões de simplicidade, iremos conduzir a apresentação para o caso de vectores bidimensionais.
2.1.3.1 Função de Distribuição Conjunta
Consideremos duas variáveis aleatórias X e Y definidas sobre o conjunto associado a um determinado modelo experimental. Naturalmente, as propriedades estatísticas de cada uma das variáveis aleatórias quando consideradas isoladamente são completamente determinadas pelas respectivas funções de distribuição FX e FY. No entanto, o mesmo não acontece quando se consideram as propriedades conjuntas de X e Y. Em particular, o conhecimento de FX e de FY não é em geral suficiente para calcular a probabilidade ( ) DY,XP ∈ de que o par ( )Y,X tome valores numa região D ⊆ 32.
Def. 2.8- A função de distribuição conjunta das variáveis aleatórias X e Y é definida como
( ) ( )yY,xXPy,xFXY ≤≤= , (2.54)
onde yYxXyY,xX ≤∩≤=≤≤ .
Figura 2.11: Acontecimentos em 32
Uma vez que ( )y,xFXY representa a probabilidade de o par ( )Y,X tomar valores na região D0 representada na Figura 2.11, é fácil verificar a partir de (2.54) que as probabilidades de ocorrência ( )Y,X nas regiões D1, D2, e D3 são, respectivamente,
( ) ( ) ( )1XY2XY21 y,xFy,xFyYy,xXP −=≤<≤ ; (2.55)
( ) ( ) ( )y,xFy,xFyY,xXxP 1XY2XY21 −=≤≤< ; (2.56)
( ) ( ) ( )( ) ( )11XY12XY
21XY22XY121
y,xFy,xFy,xFy,xFyYy,xXxP
+−−=≤<≤<
. (2.57)
D2
D0
D1 D3
x x1 x x2
yy y1
y1
y2y2

2-17
2.1.3.2 Densidade de Probabilidade Conjunta
Def. 2.9- A função densidade de probabilidade conjunta das variáveis aleatórias X e Y é definida como
( ) ( )yx
y,xFy,xf XY2
XY ∂∂∂= . (2.58)
Desta definição resulta que
( ) ( )∫∫ νµνµ=∈
DXY dd ,fDY,XP (2.59)
e, em particular,
( ) ( )∫ ∫∞ ∞−
νµνµ=x
-
y
XYXY dd ,fy,xF . (2.60)
Exemplo 2.3: Consideremos a região D3 definida na Figura 2.11; fazendo uso de (2.59) e
de (2.58) obtém-se sucessivamente:
( ) ( )
( ) ( )[ ]
( ) ( ) ( ) ( )11XY12XY21XY22XY
1XY2XY
x
x
x
x
y
yXY3
y,xFy,xFy,xFy,xF
d y,Fy,Fdd
dd ,fDY,XP
2
1
2
1
2
1
+−−=
νµ−µµ
=
νµνµ=∈
∫
∫ ∫
Note-se finalmente que
( ) 0y,xfXY ≥ (2.61) e que
( ) ( ) 1dd ,f,F2
XYXY =νµνµ=+∞∞+ ∫∫!
. (2.62)
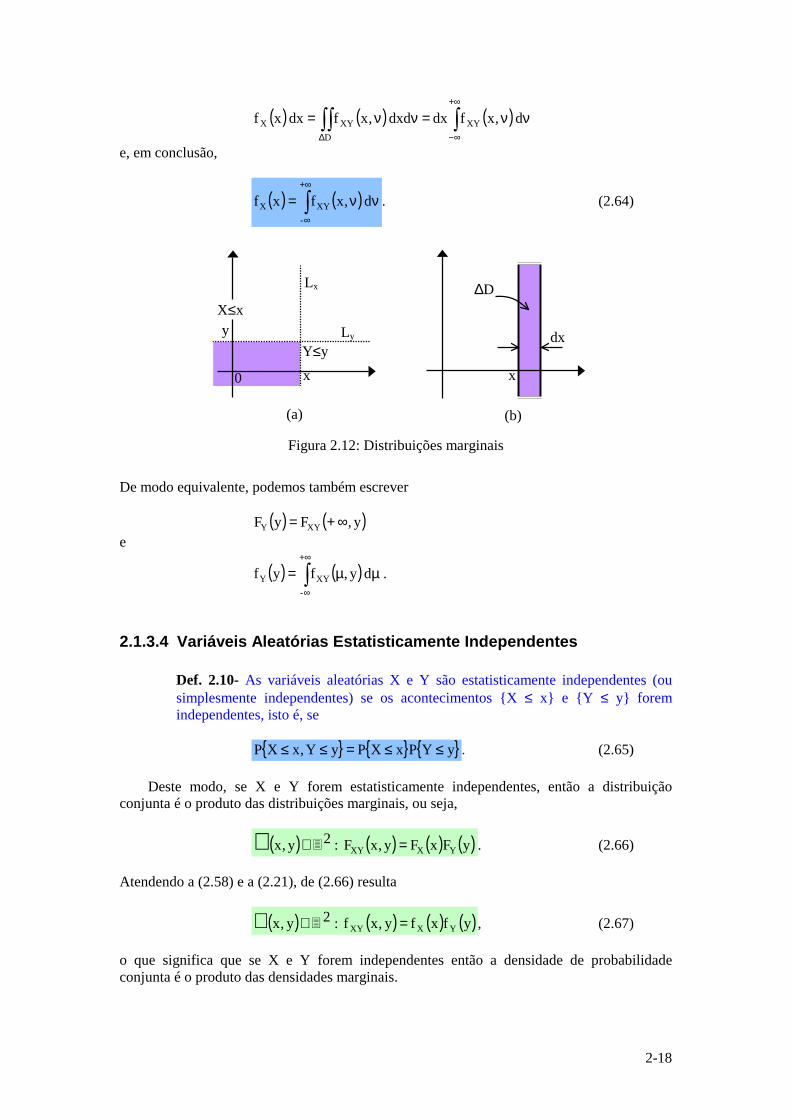
2.1.3.3 Distribuições e Densidades Marginais Relativamente ao par de variáveis aleatórias (X,Y), diz-se que FX (ou FY) e fX (ou fY) são, respectivamente, a distribuição e a densidade de probabilidade marginal da variável X (ou Y). Consideremos a Figura 2.12(a). Naturalmente, +∞≤≤=≤ Y,xXxX é o conjunto de todos os pares (X,Y) à esquerda de Lx e, portanto,
( ) ( )+∞= ,xFxF XYX . (2.63)
Por outro lado, e relativamenta à Figura 2.12(b), podemos observar que
( ) DXPdxxXxPdx xfX ∆∈=+≤<= , ou seja,
2-18
( ) ( ) ( )∫∫∫+∞
∞−∆
νν=νν= d ,xfdxdxd ,xfdx xf XYD
XYX
e, em conclusão,
( ) ( )∫+∞
∞
νν=-
XYX d ,xfxf . (2.64)
Figura 2.12: Distribuições marginais
De modo equivalente, podemos também escrever
( ) ( )y,FyF XYY ∞+= e
( ) ( )∫+∞
∞
µµ=-
XYY d y,fyf .
2.1.3.4 Variáveis Aleatórias Estatisticamente Independentes
Def. 2.10- As variáveis aleatórias X e Y são estatisticamente independentes (ou simplesmente independentes) se os acontecimentos X ≤ x e Y ≤ y forem independentes, isto é, se
yYPxXPyY,xXP ≤≤=≤≤ . (2.65)
Deste modo, se X e Y forem estatisticamente independentes, então a distribuição conjunta é o produto das distribuições marginais, ou seja,
( ) ( ) ( ) ( )yFxFy,xF :2y,x YXXY =∈∀ ! . (2.66)
Atendendo a (2.58) e a (2.21), de (2.66) resulta
( ) ( ) ( ) ( )yfxfy,xf :2y,x YXXY =∈∀ ! , (2.67)
o que significa que se X e Y forem independentes então a densidade de probabilidade conjunta é o produto das densidades marginais.
X≤xy
x 0
Y≤y
Lx
Ly
x
∆D
dx
(a) (b)

2-19
2.1.3.5 Média, Correlação e Covariância
Consideremos a variável aleatória ( )Y,XgZ = , onde g é uma função 32 → 3 conhecida. Seja ∆Dz a região de 32 onde z ≤ g(X,Y) ≤ z + dz; para cada dz corresponde uma região ∆Dz onde g(X,Y) ≅ z e
( ) zDY,XPdzzZzP ∆∈=+≤≤ .
À medida que dz cobre a recta real, as correspondentes regiões ∆Dz, disjuntas, cobrem o plano 32 e, portanto,
( ) ( ) ( ) ,dxdy y,xfy,xgdzzf zZE2 XY
-Z ∫∫∫ ==
+∞
∞!
isto é, ( ) ( ) ( ) .dxdy y,xfy,xgY;XgE
2 XY∫∫=!
(2.68)
Estamos agora em condições de demonstrar a linearidade do operador valor expectável.
Com efeito, sendo 2211 YYY α+α= , podemos então sucessivamente escrever
( ) ( )( ) ( )( ) ( )
( ) ( ) 2211
22y2211y11
2121YY221221YY11
2121YY222121YY11
2121YY2211
YEYEdyyfydyyfy
dydyy,yfydydyy,yfy
dydyy,yfydydyy,yfy
dydyy,yfyyYE
21
2121
2 2 2121
2 21
α+α=α+α=
α+α=
α+α=
α+α=
∫ ∫∫ ∫ ∫ ∫∫∫ ∫∫
∫∫
! !
! ! ! !
! !
!
A correlação entre as variáveis aleatórias X e Y define-se por
.XYER XY = (2.69)
Sendo 2Y
2X e σσ as variâncias de X e Y, respectivamente, então o coeficiente de correlação
entre X e Y é
,C
YX
XYXY σσ
=ρ (2.70)
onde
( )( ) YXXY mYmXEC −−= (2.71)
é a covariância entre X e Y, e mX e mY os respectivos valores expectáveis. Usando (2.71) e (2.69), obtém-se a seguinte relação:
.mmRC YXXYXY −= (2.72)
Def. 2.11- As variáveis aleatórias X e Y são incorrelacionadas sse
.mmR00C YXXYXYXY =⇔=ρ⇔= (2.73) H

2-20
Def. 2.12- As variáveis aleatórias X e Y são ortogonais sse
.0R XY = (2.74) H
Facto 2.2: Sejam X e Y variáveis aleatórias estatisticamente independentes. Então X e Y são variáveis aleatórias incorrelacionadas.
Se X e Y são estatisticamente independentes então ( ) ( ) ( ).yfxfy,xf YXXY = Portanto, de
(2.69) e (2.68) vem ( )
( ) ( )YX
YX
XYXY
mmdyyf ydxxf x
dxdyy,xf xyR
==
=
∫ ∫∫∫! !
!"
o que, de acordo com a Def. 2.11, significa que X e Y são incorrelacionadas. Sublinha-se que, em geral, duas variáveis aleatórias incorrelacionadas não são necessariamente estatisticamente independentes. H
Exemplo 2.4: Variáveis aleatórias conjuntamente gaussianas. Sejam X e Y duas variáveis aleatórias conjuntamente gaussianas com médias Xm e Ym e variâncias 2
Xσ e 2Yσ ,
respectivamente. Então, sendo ρ o coeficiente de correlação entre X e Y,
( ) ( )( )
( )( )
( )( )( )
ρ−σσ−−ρ
+ρ−σ
−−
ρ−σ−
−ρ−σπσ
= 2YX
YX22
Y
2Y
22X
2X
2YX
XY 1mymx
12my
12mx
exp12
1y,xf
(2.75)
Facto 2.3: A correlação entre duas variáveis aleatórias X e Y verifica a desigualdade de Schwarz
.YEXEXYE 222 ≤ (2.76)
A igualdade é verificada quando X e Y são proporcionais, isto é, quando XcY 0= .
Consideremos a seguinte igualdade onde c é uma constante arbitrária:
( ) ( ) .XEcXYcE2YEcXYEcI 2222 +−=−= Note-se que ( ) 0cI ≥ representa uma parábola. Portanto, a equação ( ) 0cI = não pode ter mais do que uma solução real. Por outras palavras, o binómio descriminante da fórmula resolvente da equação algébrica do 2º grau deve verificar
0YEXE4XYE4 222 ≤− ,
de onde (2.76) resulta imediatamente. Por outro lado, a solução real única obtém-se quando o binómio descriminante é nulo e vale precisamente .XYc0 = H
Facto 2.4: O coeficiente de correlação entre duas variáveis aleatórias X e Y verifica a desigualdade
1XY ≤ρ , (2.77)

2-21
atingindo o valor máximo quando XcY 0= .
Este facto resulta directamente do Facto 2.3 e das definições (2.70) e (2.71). H
2.1.3.6 Funções de duas Variáveis Aleatórias
O problema que aqui consideramos é o de, dadas as variáveis aleatórias
( )( )Y,XhW
Y,XgZ==
(2.78)
e as transformações ( )⋅⋅,g e ( )⋅⋅,h , exprimir a função densidade de probabilidade conjunta
( )⋅⋅,f ZW em termos de ( )⋅⋅,f XY . Assume-se que as transformações (2.78) têm inversa. O resultado constitui uma generalização natural de (2.53) pelo que não será aqui demonstrado. Sejam ( ) N,,1,2,n ,y,x nn K= as N soluções do sistema de equações (2.78) e
( )( ) ( )
( ) ( )
∂∂
∂∂
∂∂
∂∂
=
yy,xh
xy,xh
yy,xg
xy,xg
dety,xJ (2.79)
o respectivo Jacobeano. Então,
( ) ( )( )∑
=
=N
1n nn
nnXYZW y,xJ
y,xfw,zf , (2.80)
onde os pares ( ) N,,1,2,n ,y,x nn K= aparecem expressos em termos de z e w.
Exemplo 2.5: Pretende-se determinar ( )zf Z , sabendo que YXZ += e conhecendo ( )y,xf XY . Começamos por definir a variável aleatória YW = , formando o par de
transformações
=+=
YWYXZ
.
Qualquer que seja o par ( )w,z , o sistema anterior tem apenas uma solução ( ) ( )w,wzy,x −= . Por outro lado, ( ) 1y,xJ = e, portanto,
( ) ( )w,wzfw,zf XYZW −= . (2.81)
Note-se que ( )zf Z é uma das densidades marginais de ( )w,zf ZW , ou seja, atendendo a (2.64) e (2.81),
( ) ( )∫+∞
∞−
−= dww,wzfzf XYZ . (2.82)
No caso particular em que as variáveis aleatórias X e Y são estatisticamente independentes,
( ) ( ) ( )⋅⋅=⋅⋅ YXXY ff,f , e (2.82) toma a forma de um integral de convolução

2-22
( ) ( ) ( )∫+∞
∞−
−= dwwfwzfzf YXZ . (2.83)
Facto 2.5: A função densidade de probabilidade da soma de duas variáveis aleatórias estatisticamente independentes é dada pelo integral de convolução das densidades de probabildade das parcelas.
2.1.3.7 Teorema do Limite Central
Seja N21 XXXZ +++= L a soma de N variáveis aleatórias N1nnX = estatisticamente
independentes e com distribuições de probabilidade arbitrárias. O teorema do limite central diz que a variável aleatória Z tem uma distribuição de probabilidade que tende para a de uma gaussiana quando ∞→N .
2.1.3.8 Distribuições Condicionais
Def. 2.13- A função de distribuição da variável aleatória X dada a ocorrência do acontecimento A é dada por
( ) .AP
A,xXPA|xXPA|xF A|X≤=≤= (2.84)
Note-se que esta definição é coerente com as Defs. 2.3 e 2.1 de função de distribuição de
uma variável aleatória e de probabilidade condicional, respectivamente.
Def. 2.14- A função densidade de probabilidade da variável aleatória X dada a ocorrência do acontecimento A é dada por
( ) ( ).
dxA|xdF
A|xf A|XA|X = (2.85)
Do teorema da probabilidade total, ver (2.14), e fazendo xXB ≤= , podemos escrever
( ) ( ) ( )∑=
=M
1mmmA|XX APA|xFxF
m, (2.86)
onde M1mmA = é uma partição arbitrária do conjunto e ( ) M,1,2,m ,AP m K= , são as
respectivas probabilidades de ocorrência. De (2.86), (2.21) e (2.85) decorre ainda que
( ) ( ) ( )∑=
=M
1mmmA|XX APA|xfxf
m. (2.87)
A fórmula de Bayes pode também ser generalizada para o contexto das variáveis aleatórias. Se em
( ) ( )( ) ( )APBP
A|BPB|AP =

2-23
fizermos xXB ≤= , então
( ) ( )( ) ( )APxF
A|xFxX|AP
X
A|X=≤ (2.88)
e, de modo análogo,
( ) ( ) ( )( ) ( ) ( )AP
xFxFA|xFA|xF
xXx|AP1X2X
1A|X2A|X21 −
−=≤< . (2.89)
Usando o facto de ( ) ( )xxXx|APlimxX|AP
0x∆+≤<==
→∆, e fazendo xx1 = e xxx 2 ∆+=
em (2.89), obtemos
( ) ( )( ) ( )APxf
A|xfxX|AP
X
A|X== . (2.90).
Multiplicando ambos os membros de (2.90) por ( )xf X e integrando em x, vem
( ) ( ) ( )∫+∞
∞−
== dxxfxX|APAP X , (2.91)
pois a área limitada por ( )A|xf A|X é obviamente unitária. Note-se que (2.91) constitui uma outra forma de apresentar o teorema da probabilidade total. Finalmente, de (2.90) e (2.91) obtém-se a correspondente fórmula de Bayes
( ) ( ) ( )
( ) ( )dxxfxX|AP
xfxX|APA|xf
X
XA|X
∫∞+
∞−
=
== . (2.92)
Facto 2.6: A função de densidade de probabilidade conjunta de duas variáveis aleatórias X e Y é, em geral, dada por
( ) ( ) ( ).yfyY|xfy,xf YXXY == (2.93)
X e Y são estatisticamente independentes sse ( ) ( )xfyY|xf XX == . Neste caso, de (2.93) obtém-se a relação (2.67).
Retomando (2.84) e fazendo yyYyA ∆+≤<= , podemos escrever
( ) ( ) ( )yyYyPyyYy|xFyyYy,xXP A|X ∆+≤<∆+≤<=∆+≤<≤ , ou seja,
( ) ( ) ( ) ( ) ( )[ ].yFyyFyyYy|xFy,xFyy,xF YYA|XXYXY −∆+∆+≤<=−∆+
Dividindo ambos os membros da igualdade anterior por ∆y e tomando o limite, quando ∆y→0, obtém-se
( ) ( ) ( )dy
ydFyY|xF
yy,xF Y
XXY ==
∂∂
,
resultando (2.93) após derivação de ambos os membros em ordem a x.

2-24

3-1
3 Sinais Aleatórios em Tempo Contínuo. Parte II: Modelos de Fontes de Informação e de Ruído.
No capítulo anterior tivemos oportunidade de recordar os conceitos básicos da teoria das probabilidades e das variáveis aleatórias. Neste capítulo faremos uso destas ferramentas de modo a construir o modelo de um processo estocástico. Este tipo de sinais será então usado para introduzir alguns modelos de fontes de informação e de ruído.
3.1 Conceitos Básicos
Como vimos anteriormente, um processo estocástico1 ( )tX pode ser visto como um conjunto de sinais determinísticos ( )i;tx ξ , designados por funções amostra, onde iξ é um dos resultados elementares de um fenómeno físico completamente caracterizado pelo conjunto de todos os resultados experimentais directos. Neste caso, dado o espaço de probabilidade ⊥ , faz-se corresponder a cada elemento ξ∈ um sinal determinístico ( )ξ;tx tal como se representa na Figura 3.1 para i321 ,,, ξξξξ=ξ . Note-se que este tipo de modelação é muito semelhante à de uma variável aleatória. A diferença reside no facto de cada realização
( )ξx de uma variável aleatória X ser um número real, enquanto que uma realização do processo ( )tX é um sinal ( )ξ;tx que varia ao longo do tempo. A cada instante t0 e a cada elemento ξ∈ corresponde um número ( )ξ;tx 0 , como também se ilustra na Figura 3.1. Estes números correspondem a realizações da variável aleatória ( )0tX . Por outras palavras: em qualquer instante de tempo, o "valor" de um processo estocástico é uma variável aleatória.
Figura 3.1: Modelação de um processo estocástico
O facto anterior sugere outro modo de modelar um processo estocástico. Embora menos
intuitivo, o modelo que a seguir introduzimos é mais apropriado para um desenvolvimento matemático preciso da teoria dos processos estocásticos.
Def. 3.1- Um processo estocástico é uma coleção de variáveis aleatórias
( ) ( ) K,tX,tX 21 definidas nos instantes !∈K,t,t 21 ou, com generalidade,
1 Um processo estocástico será sempre designado por uma letra maiúscula em itálico.
( )20;tx ξ ( )30;tx ξ
( )i0;tx ξξ1 ξ2
ξ3
ξi
ξj ξ7
t ( )1;tx ξ
( )2;tx ξ
( )3;tx ξ
( )i;tx ξ⊥⊥⊥⊥ = ( ,ΩΩΩΩ,P( ⋅⋅⋅⋅ ) )
t0
( )10;tx ξ
3
0

3-2
( ) ( ) !∈= t,tXtX .
Deste ponto de vista, um processo estocástico é representado por uma coleção de variáveis aleatórias indexadas por um conjunto em 3: se aquele conjunto for 3, então o processo é contínuo; se for um conjunto contável de pontos em 3, então o processo não é mais do que uma sequência temporal de variáveis aleatórias.
3.2 Descrição de um Processo Estocástico
A descrição completa de um processo estocástico ( )tX envolve a especificação da densidade de probabilidade conjunta das variáveis aleatórias ( ) ( ) ( ) n21 tX,,tX,tX K para todas as escolhas possíveis de "!∈n21 t,,t,t K e para todos os inteiros positivos,
K,2,1n = A descrição de ordem N de um processo estocástico ( )tX define-se como a anterior mas
agora para N,,2,1n K= . Um caso particular, muito importante no estudo de sistemas de telecomunicações, é o de 2N = . Neste caso, descrição de segunda ordem, são conhecidas: a densidade de probabilidade ( ) ( )⋅tXf de ( )tX para todos os valores de !∈t , e a densidade de probabilidade conjunta ( ) ( ) ( )⋅⋅,f
21 tXtX do par ( ) ( ) 21 tX,tX para todos os pares de valores
221 t,t !∈ . Note-se que, em geral, ( ) ( )⋅tXf e ( ) ( ) ( )⋅⋅,f
21 tXtX variam com t e 21 t,t , respectivamente.
Embora existam problemas cuja abordagem implica o recurso a descrições de ordem superior, outros, como os que iremos considerar, podem ser tratados usando apenas descrições de segunda ordem. Daí que, no que se segue, venhamos a considerar apenas descrições de segunda ordem.
3.2.1 Médias Estatísticas
A média, ou valor expectável, de um processo ( )tX é uma função determinística do tempo ( )tm X que se define em cada instante !∈t como o valor expectável da variável aleatória ( )tX .
Def. 3.2- Média. Seja ( ) ( )⋅tXf a função densidade de probabilidade da variável aleatória ( )tX que em cada instante !∈t constitui a descrição de primeira ordem do processo ( )tX . Então, a média de ( )tX é
( ) ( ) ( ) ( ) !!
∈∀µµµ== ∫ t ,df tXEtm tXX . (3.1)
Como foi evidenciado anteriormente, ( ) ( )⋅tXf é, em geral, variante com t o que implica a
variabilidade temporal da média de um processo estocástico.
Def. 3.3- Autocorrelação. Seja ( ) ( ) ( )⋅⋅,f21 tXtX a função densidade de probabilidade
conjunta das variáveis aleatórias ( ) ( ) 21 tX,tX que para cada par de instantes

3-3
221 t,t !∈ constituem a descrição de segunda ordem do processo ( )tX . Então, a
autocorrelação de ( )tX é
( ) ( ) ( )
( ) ( ) ( ) 221
tXtX
2121t,t ,
dd,f
tXtXEt,tR
2 21
!
!
∈∀νµνµµν=
=
∫∫X
. (3.2)
Aqui repete-se o comentário feito a propósito da média. Uma vez que ( ) ( ) ( )⋅⋅,f
21 tXtX depende de 21 t,t , o mesmo acontece, em geral, com a autocorrelação.
3.3 Estacionariedade de Processos de Segunda Ordem
Muitas das propriedades dos processos mais frequentemente usados em problemas de interesse prático são convenientemente interpretáveis recorrendo às descrições até à segunda ordem. Nesta secção, iremos introduzir o conceito de estacionariedade.
Def. 3.4- Estacionariedade em sentido estrito. Um processo ( )tX é estacionário em sentido estrito sse: 1. ( ) ( ) ( ) ( )⋅=⋅∈∆∀ ∆+tXtX ff ,t ! ; (3.3)
2. ( ) ( ) ( ) ( ) ( ) ( )⋅⋅=⋅⋅∈∆∀ ∆+∆+ ,f,f ,t,t
2121 tXtXtXtX21 ! . (3.4)
A estacionariedade estrita é uma propriedade muito particular que poucos processos físicos verificam. A condição (3.3) significa que ( ) ( )⋅tXf é invariante no tempo, enquanto que (3.4) afirma que ( ) ( ) ( )⋅⋅,f
21 tXtX é invariante relativamente a qualquer translação ∆ do intervalo [ ]21 t,t .
Podemos também introduzir uma outra noção de estacionariedade, menos restritiva, e que tem domínio de aplicabilidade mais amplo.
Def. 3.5- Estacionariedade em sentido lato. Um processo ( )tX é estacionário em sentido lato sse: 1. ( ) XmtXE t =∈∀ ! ; (3.5)
2. ( ) ( ) ( )τ=τ−∈τ∀ XRtXtXE ,t ! . (3.6)
Ao contrário da estacionariedade em sentido estrito que impõe restrições muito fortes
directamente sobre a descrição probabilística do processo ( )tX , a estacionariedade em sentido lato apenas restringe as estatísticas de ( )tX . Mais especificamente, (3.5) implica que a média de ( )tX é constante no tempo, e (3.6) diz que a respectiva autocorrelação não depende explicitamente dos instantes 21 t,t mas apenas da diferença 21 tt −=τ entre os extremos do intervalo [ ]21 t,t .

3-4
Facto 3.1: Seja ( )tX um processo estacionário em sentido estrito. Então ( )tX é estacionário em sentido lato. O contrário não é, em geral, verdadeiro. €
A demonstração deste facto não é aqui feita, sendo deixada como exercício. No seguimento, e salvaguardadas algumas situações que serão devidamente explicitadas, consideraremos apenas processos estacionários em sentido lato.
3.3.1 Propriedades da Autocorrelação de Processos Estacionários
A função de autocorrelação de um processo ( )tX , estacionário em sentido lato, goza das seguintes propriedades:
P1. A autocorrelação é uma função par:
( ) ( ) ( ) ( ) ( ) ( )τ−=τ−=
τ−=τ∈τ∀
X
X
RtXtXE
tXtXER :! (3.7)
P2. A autocorrelação tem um máximo em :0=τ
( ) ( )0RR : XX ≤τ∈τ∀ ! . (3.8)
Fazendo uso de P1 e do facto de ( ) ( )[ ] 2tXtXE τ−± ser uma quantidade não negativa, a propriedade P2 é facilmente demonstrada.
A autocorrelação providencia um meio de descrever a interdependência de duas variáveis aleatórias ( )tX e ( )τ−tX que modelam as realizações do processo ( )tX em dois instantes de tempo separados de τ segundos. É aparente que quanto maior for a taxa de variação temporal de ( )tX , mais rapidamente a autocorrelação decrescerá relativamente ao máximo ( )0R X quando τ aumenta. Este decrescimento pode ser quantificado pelo tempo de descorrelação, isto é, o valor de τ a partir do qual ( )τXR permanece abaixo de um limiar previamente especificado.
3.4 Ergodicidade
Para um processo ( )tX , estacionário em sentido estrito, podemos definir dois tipos de média:
1. a média de conjunto já introduzida na Def. 3.2, eq. (3.1), e cuja particularização para o
caso de interesse aqui se apresenta:
( )∫ µµµ=!
df m XX , (3.9)
onde se fez desaparecer a dependência explícita no tempo da densidade de probabilidade da amplitude ( ) !∈ t,tX ;

3-5
2. a média temporal
( ) ( ) ( )∫+
∞→ξ=ξ=ξ
2T
2T- iTii dt;tx T1lim;txm X , (3.10)
calculada directamente a partir de uma função amostra ( )i;tx ξ do processo ( )tX .
Note-se que a média temporal ( )im ξX deve ser encarada como uma amostra da variável aleatória
( )∫+
∞→=
2T
2T-TdttX
T1limM X , (3.11)
onde ( ) !∈ t,tX , é a variável aleatória que em cada instante de tempo determina a descrição de primeira ordem do processo ( )tX (ver discussão no início da secção 3.2).
3.4.1 Ergodicidade na Média
Def. 3.6- Ergodicidade na média. O processo ( )tX , estacionário em sentido estrito, é ergódico na média sse
( )ii mm ξ=ξ∀ XX . (3.12) €
Por outras palavras, podemos afirmar que, sendo o processo ergódico na média, então podemos usar o operador média temporal (3.10) aplicado a qualquer função amostra e obter o valor expectável da amplitude do processo considerado. Note-se que a igualdade expressa em (3.12) só é válida no limite quando ∞→T . Na prática, usa-se o estimador
( ) ( )∫+
ξ=ξ2T
2T- ii dt;tx T1;Tm X , (3.13)
obtendo-se uma amostra da variável aleatória
( ) ( )∫+
=2T
2T-dttX
T1TM X . (3.14)
Facto 3.2: Uma condição necessária e suficiente para que o processo ( )tX , estacionário em sentido estrito, seja ergódico na média com probabilidade 1 é:
( ) ( ) 0lim
mTMElim
TMT
T
=σ
=
∞→
∞→2
XX
X
. (3.15)
A condição na média, impondo que, no limite, o valor expectável das estimativas iguale o valor expectável da grandeza estimada, garante que o estimador é não enviezado. A condição na variância (recorde-se a desigualdade de Chebishev introduzida no capítulo 2) garante que, no limite, o estimador produz uma estimativa que é igual à grandeza a estimar com probabilidade 1.

3-6
3.4.2 Ergodicidade na Correlação
Def. 3.7- Ergodicidade na correlação. O processo ( )tX , estacionário em sentido estrito, é ergódico na correlação sse
( ) ( ) ( ) ( ) ( )∫+
−∞→τξτ−ξ=τ−=τξτ∀
2T
2T iiTi d;tx;tx T1limtXtXER , X .
(3.16) Tal como no caso da média, a igualdade anterior só é válida no limite quando ∞→T . Na prática, usa-se o estimador
( ) ( ) ( )∫+
−τξτ−ξ=ττ∀
2T
2T ii d;tx;tx T1R X . (3.17)
Facto 3.3: O processo ( )tX , estacionário em sentido estrito, é ergódico na correlação com probabilidade 1 sse, no limite quando T → ∞, o estimador (3.17) for não enviezado e a variância das estimativas for nula.
3.5 Potência e Energia
Como se sabe, os sinais determinísticos dividem-se em duas grandes classes: os sinais de energia e os sinais de potência. Consideremos um processo ( )tX e uma qualquer das respectivas funções amostra ( )i;tx ξ . Por definição, a energia iE e a potência iP de ( )i;tx ξ são dadas por
( )
( ) .dt;txT1limP
dt;txE2T
2T i2
Ti
i2
i
∫∫
+
−∞→
+∞
∞−
ξ=
ξ=
Note-se que iE e iP dependem da função amostra ( )i;tx ξ e, portanto, são realizações de duas variáveis aleatórias XE e XP , respectivamente. A potência média e a energia média do processo ( )tX são então definidas como
,EE
PE
XX
XX
=
=
E
P (3.18)
respectivamente. Formalmente,
( )
( ) .dttXE
dttXT1limP
2
2T
2T
2
T
∫
∫∞+
∞−
+
−∞→
=
=
X
X
(3.19)
Substituindo (3.19) em (3.18) e tendo em conta a Def. 3.3, eq. (3.2), obtém-se

3-7
( ) ( )
( ) ( )∫∫
∫∫∞+
∞−
∞+
∞−
+
−∞→
+
−∞→
=
=
=
=
dtt,tRdttXE
dtt,tRT1limdttX
T1limE
2
2T
2TT
2T
2T
2
T
XX
XX
E
P (3.20)
Supondo que ( )tX é estacionário, então de (3.20) resulta, para o caso da energia,
( )∫+∞
∞−
= dt0R XXE .
Se o processo ( )tX fosse de energia, tal implicaria que XE fosse uma quantidade finita, o que só seria possível se ( ) ( ) 0tXE0R ,t 2 ==∀ X , ou seja, se ( ) 0tX ,t =∀ com probabilidade 1. Em conclusão, no caso dos processos estacionários, apenas os processos de potência têm interesse teórico e prático. Atendendo a (3.20), podemos então concluir o seguinte:
Facto 3.4: Os processos estocásticos estacionários pertencem à classe dos sinais de potência, e têm potência média
( ) ( ) tXE0R 2== XXP . (3.21) No caso dos processos ergódicos de segunda ordem,
( ) ( ) ii2 PtXE0R ξ∀=== XXP (3.22)
A propósito das conclusões do estudo anterior, podemos ainda acrescentar o seguinte
comentário: as representações de frequência normalmente usadas não têm aplicação directa no caso dos sinais não determinísticos. Com efeito, a transformada de Fourier define-se, salvo casos muito particulares, apenas para sinais de energia e a série de Fourier aplica-se no caso dos sinais periódicos. Os sinais aleatórios pertencem, como vimos, à classe dos sinais de potência mas não são necessariamente periódicos. Portanto, não podemos, em geral, usar quer a transformada quer a série de Fourier para representar na frequência as funções amostra de um processo estocástico.
3.6 Processos Múltiplos
Def. 3.8- Independência estatística. Dois processos ( )tX e ( )tY são estatisticamente independentes sse, para todos os pares ( ) 2
21 t,t !∈ , as variáveis aleatórias ( )1tX e ( )2tY forem estatisticamente independentes. Def. 3.9- Processos incorrelacionados. Dois processos ( )tX e ( )tY são incorrelacionados sse, para todos os pares ( ) 2
21 t,t !∈ , as variáveis aleatórias ( )1tX e ( )2tY forem incorrelacionadas.
Def: 3.10- Processos ortogonais. Dois processos ( )tX e ( )tY são ortogonais sse, para todos os pares ( ) 2
21 t,t !∈ , as variáveis aleatórias ( )1tX e ( )2tY forem ortogonais.

3-8
Def. 3.11- Correlação cruzada. A correlação entre dois processos ( )tX e ( )tY é definida por
( ) ( ) ( ) ( )122121 t,tRtYtXEt,tR YXXY == . (3.23)
Def. 3.12- Estacionariedade conjunta. Dois processos ( )tX e ( )tY são conjuntamente estacionários sse ( )tX e ( )tY forem estacionários e ( )21 t,tR XY só depender explicitamente de 21 tt −=τ .
3.7 Transmissão de Processos Estocásticos através de Sistemas Lineares Invariantes no Tempo (SLITs)
Nesta secção vamos estabelecer as relações de entrada – saída de SLITs quando a entrada
é um processo estocástico. No estudo deste problema, consideraremos as representações no tempo e na frequência.
3.7.1 Relações Entrada – Saída no Domínio do Tempo
Consideremos um SLIT descrito pela respectiva resposta impulsional2 ( )th , como se ilustra na Figura 3.2, onde ( )tX e ( )tY representam os processos de entrada e de saída, respectivamente.
Figura 3.2: Sistema linear invariante no tempo
Se a entrada do SLIT for uma realização3 ( )tx i do processo ( )tX , teremos na saída uma
realização ( )tyi do processo ( )tY dada por
( ) ( ) ( )∫+∞
∞−
ττ−τ= dtxhty ii , (3.24)
isto é, pelo integral de convolução entre a entrada e a resposta impulsional do SLIT. Mais uma vez se sublinha que, ocorrendo a entrada ( )tx i aleatoriamente, então a saída ( )tyi é também aleatória. De acordo com o modelo que temos vindo a usar, o processo ( )tY é representado no instante t pela variável aleatória ( )tY e o processo ( )tX é representado no instante τ−t pela variável aleatória ( )τ−tX . Formalmente podemos então escrever
( ) ( ) ( ) ( )tXhdtXhtY ∗=ττ−τ= ∫+∞
∞−
. (3.25)
2 A resposta impulsional de um SLIT é o sinal de saída quando a entrada é um impulso de Dirac. 3 Para simplificar a notação, passaremos a usar ( )tx i para designar a função amostra ( )i;tx ξ .
( )tX ( )tY( )th

3-9
3.7.1.1 Média da Saída
Tendo em conta que o valor expectável é linear e que a resposta impulsional é determinística, de (3.25) vem
( ) ( ) ( ) ( ) ( )tmhtXEhtXhEtYEtm XY ∗=∗=∗== , (3.26)
ou seja, a média do processo de saída é dada pelo integral de convolução entre a resposta impulsional do SLIT e a média do processo de entrada.
Entrada estacionária na média. No caso em que o processo de entrada é estacionário, ( ) XX mtm = , e de (3.26) resulta imediatamente
( ) ( ) ( ) ( ) XXY mdhdmthtm
ττ=τττ−= ∫∫
+∞
∞−
+∞
∞−
,
isto é, ( ) XY m0Hm = , (3.27)
onde
( ) ( )∫+∞
∞−
π−= dtethfH ft2j (3.28)
é a função de transferência do SLIT dada pela transformada de Fourier da respectiva resposta impulsional. Portanto, se o processo de entrada do SLIT for estacionário na média, então a saída é também estacionária na média.
3.7.1.2 Correlações Cruzadas Entrada – Saída
Usando a Def. 3.11, eq. (3.23), podemos calcular a correlação entre o processo de saída do SLIT ( )tY e o de entrada ( )tX :
( ) ( ) ( )
( ) ( ) ( )
( ) ( ) ( )∫
∫∞+
∞−
∞+
∞−
τ−−=
τ−
−=
τ−=τ−
duuhtXutXE
tXduuhutXE
tXtYEt,tR YX
e, portanto,
( ) ( ) ( )∫+∞
∞−
τ−−=τ− duuht,utRt,tR XYX . (3.29)
Recorrendo ainda à Def. 3.11, eq. (3.23), e a (3.29), podemos também concluir que

3-10
( ) ( ) ( ) ( )∫+∞
∞−
−τ−=τ−=τ− duuht,utRt,tRt,tR XYXXY . (3.30)
Entrada estacionária na correlação. No caso em que o processo de entrada é estacionário na correlação, ( ) ( )τ→τ− XX Rt,tR , isto é, a autocorrelação depende apenas da diferença entre os instantes de tempo t e t − τ. Fazendo intervir este facto em (3.29) e (3.30) obtemos, respectivamente,
( ) ( ) ( ) ( ) ( )τ∗=τ⇔−τ=τ ∫+∞
∞−XYXXYX RhRduuhuRR (3.31)
e
( ) ( ) ( ) ( )τ∗⇔+τ=τ −+∞
∞−∫ XXXY RhduuhuRR , (3.32)
onde se usa a notação
( ) ( )thth −=− . (3.33)
3.7.1.3 Autocorrelação da Saída
Por ser a situação de maior interesse para os assuntos que iremos estudar, consideraremos aqui apenas o caso em que o processo de entrada é estacionário.
Entrada estacionária na correlação. Neste caso,
( ) ( ) ( ) ( ) ( )[ ] ( )τ∗=τ−∗=τ−=τ− −YXY RhtXhtYEtYtYEt,tR ,
onde se fez uso de (3.25) e (3.33). Finalmente, e tendo em conta (3.31),
( ) ( )τ∗∗=τ −XY RhhR . (3.34)
Portanto, se o processo de entrada for estacionário na correlação, então o processo de
saída também o é e tem autocorrelação dada por (3.34). Síntese. A conclusão mais importante a reter da discussão conduzida nesta secção
resume-se no seguinte:
Facto 3.5: Seja ( )tX um processo estacionário de segunda ordem. Suponhamos ainda que um SLIT caracterizado pelas respectivas resposta impulsional ( )th e função de transferência ( )fH processa funções amostra ( )tx i de ( )tX . Então as saídas ( )tyi constituem as funções amostra de um processo ( )tY . O processo ( )tY é também estacionário de segunda ordem: a relação entre as médias de saída e de entrada é dada por (3.27), e a relação entre as autocorrelaçãoes de saída e de entrada expressa-se em (3.34).

3-11
3.7.2 Relações Entrada – Saída no Domínio da Frequência
Antes de estudarmos o problema das representações na frequência das relações de entrada – saída no contexto dos sinais aleatórios, é necessário introduzir o conceito de densidade espectral de potência.
3.7.2.1 Densidade Espectral de Potência
Em discussão anterior, ver secção 3.5, concluímos que os processos de interesse teórico e prático pertencem à classe dos sinais de potência. Consideremos então um processo de segunda ordem ( )tX , estacionário, e cuja potência média pode, de acordo com (3.20), ser escrita na forma
( )
= ∫+∞
∞−∞→
dttXT1Elim 2
TTXP , (3.35)
onde
( )( )
T. ocompriment I tendo,I t0,
I t,tt T
T
TT !⊂
∉
∈=
XX (3.36)
Obviamente, as funções amostra ( ) ( )tx i
T do processo ( )tTX têm duração limitada e, portanto, pertencem à classe dos sinais de energia. Portanto, têm transformada de Fourier ( ) ( )fx~ i
T . Seja ( )tX T a variável aleatória que em cada instante t representa a amplitude das amostras do
processo ( )tTX . Formalmente, podemos então definir a variável aleatória
( ) ( ) ,dtetXfX~ ft2jTT ∫
+∞
∞−
π−= (3.37)
cujas amostras são
( ) ( ) ( ) ( )∫+∞
∞−
π−= dtetxfx~ ft2jiT
iT . (3.38)
É conhecido que qualquer sinal de energia e a respectiva transformada de Fourier verificam o teorema de Rayleigh, isto é,
( ) ( ) ( ) ( ) ( ) ( )∫∫∫+∞
∞−
+∞
∞−
+∞
∞−
== dffx~dttxdttx2i
T2i
T2i
T ,
onde se teve em conta que estamos a considerar processos reais. A relação anterior reporta-se às amostras das variáveis aleatórias ( )tX T e ( )fX~ T e, portanto, formalmente,
( ) ( )∫∫+∞
∞−
+∞
∞−
= dffX~dttX2
T2T . (3.39)
Substituindo (3.39) em (3.35) e rearranjando os diversos termos, obtemos a expressão

3-12
( )∫+∞
∞−∞→
= dffX~E
T1lim
2TTXP ,
a qual se pode ainda escrever na forma
( )∫+∞
∞−
= dffG XXP , (3.40)
onde
( ) ( )
=
∞→
2TT
fX~ET1limfG X . (3.41)
O ponto importante a salientar desde já é que a potência média total do processo
estacionário de segunda ordem ( )tX vem dada pela área delimitada por uma função da frequência. Por outro lado, esta função tem, como se pode ver a partir de (3.41), as dimensões físicas de uma potência. Veremos em seguida que ( )fG X , tal como definida em (3.41), goza de propriedades muito importantes.
3.7.2.1.1 Teorema de Wiener – Khintchine
Seja ( )tX um processo estacionário em sentido lato com função de autocorrelação ( )τXR . Então ( )τXR e ( )fG X , tal como definida em (3.41), formam um par de Fourier:
( ) ( )∫+∞
∞−
τπ− ττ= deRfG f2jXX , (3.42)
( ) ( )∫+∞
∞−
τπ=τ dfefGR f2jXX . (3.43)
Voltando a (3.41), podemos escrever
( ) ( ) ( )
ττ=
∫∫
+∞
∞−
τπ++∞
∞−
π− deXdtetXEfX~E f2jT
ft2jT
2T ,
onde podemos substituir ( )⋅TX por ( )⋅X desde que se ajustem os limites de integração em conformidade. Assim,
( ) ( ) ( ) ττ−=
τ−π−∫∫ dtdetRfX~E tf2j
D
2T
1X , (3.44)
onde D1 é a região de integração ilustrada na Figura 3.3. Fazendo a mudança de variáveis indicada na Figura 3.3, (3.44) toma a forma equivalente
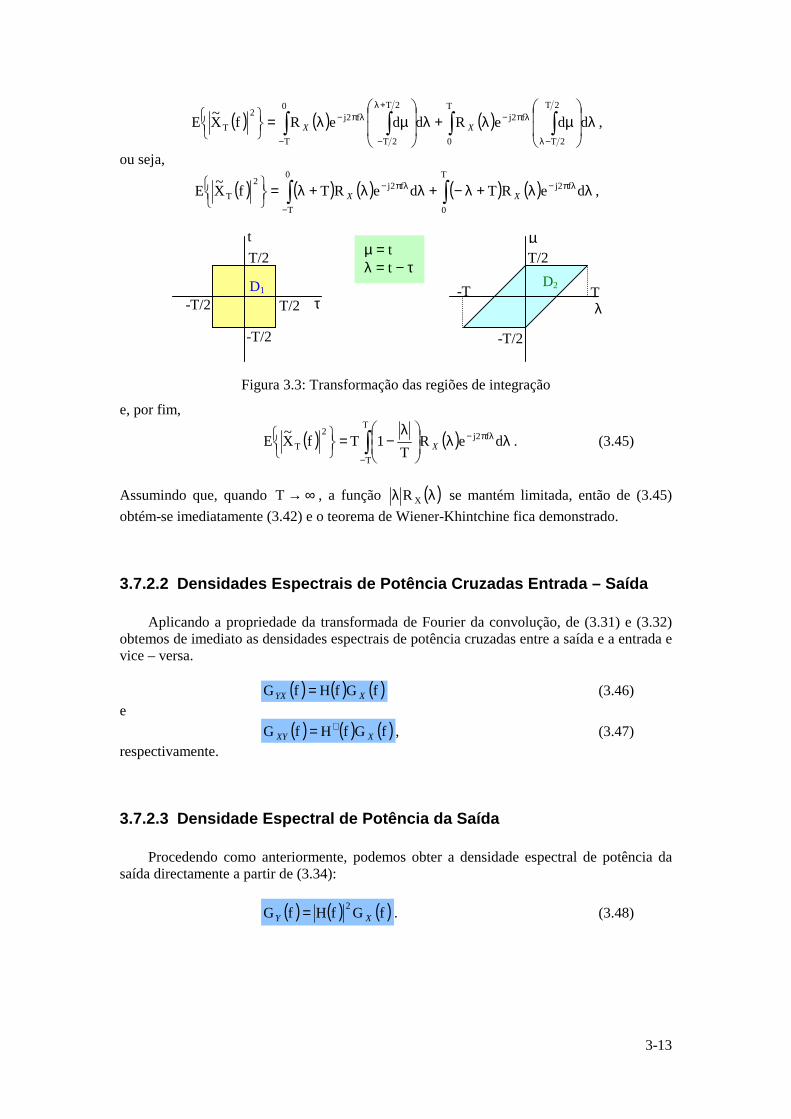
3-13
( ) ( ) ( )∫ ∫∫ ∫ λ
µλ+λ
µλ=
−λ
λπ−
−
+λ
−
λπ−T
0
2T
2T
f2j0
T
2T
2T
f2j2T ddeRddeRfX~E XX ,
ou seja,
( ) ( ) ( ) ( ) ( )∫∫ λλ+λ−+λλ+λ=
λπ−
−
λπ−T
0
f2j0
T
f2j2T deRTdeRTfX~E XX ,
Figura 3.3: Transformação das regiões de integração
e, por fim,
( ) ( )∫−
λπ− λλ
λ−=
T
T
f2j2T deR
T1TfX~E X . (3.45)
Assumindo que, quando ∞→T , a função ( )λλ XR se mantém limitada, então de (3.45) obtém-se imediatamente (3.42) e o teorema de Wiener-Khintchine fica demonstrado.
3.7.2.2 Densidades Espectrais de Potência Cruzadas Entrada – Saída
Aplicando a propriedade da transformada de Fourier da convolução, de (3.31) e (3.32) obtemos de imediato as densidades espectrais de potência cruzadas entre a saída e a entrada e vice – versa.
( ) ( ) ( )fGfHfG XYX = (3.46) e
( ) ( ) ( )fGfHfG XXY∗= , (3.47)
respectivamente.
3.7.2.3 Densidade Espectral de Potência da Saída
Procedendo como anteriormente, podemos obter a densidade espectral de potência da saída directamente a partir de (3.34):
( ) ( ) ( )fGfHfG 2
XY = . (3.48)
-T/2
-T/2 -T/2
T/2
T/2 T/2
-T T D1
t
τ
µ
λ
D2
µ = t λ = t − τ

3-14
Exemplo 3.1: Considere o diagrama de blocos da Figura 1.4, onde ( )
Π=
00 B2
fHfH ,
( )
Λ=
BffG X e BB0 > . A potência média total do processo de entrada é, de acordo com
(3.40), a área delimitada pela densidade espectral de potência ( )fG X , isto é, a área do triângulo: B=XP . Por outro lado, a densidade espectral de potência da saída ( )fGY , dada por (3.48), adquire a forma ilustrada na Figura 1.4. Portanto, calculando a área delimitada por
( )fGY , obtém-se
−=B
B2BH 0
02
0YP .
Figura 1.4: Filtragem de um processo estacionário
Tendo em conta que a função ( )fGY se pode escrever na forma
( )
Λ+
Π
−=0
0
0
020 B
fB
BB2f
BB
1HfGY ,
podemos obter a autocorrelação ( )τYR recorrendo a (3.43):
( ) ( ) ( )
τ+τ
−=τ 020
00
02
0 BsincB
B2Bsinc
BB
12BHR Y .
Note-se ainda que
( ) YY P=
−=B
B2BH0R 0
02
0 ,
o que confirma o Facto 3.4, eq. (3.21).
3.8 Caracterização da Soma de Processos Estocásticos
Nesta secção vamos estudar a descrição estatística do processo que resulta da soma de vários processos estocásticos. Para simplificar a apresentação, e porque os resultados que vamos obter são imediatamente generalizáveis para o caso geral, consideraremos apenas o caso da soma de dois processos.
Seja ( ) ( ) ( )ttt YXZ += (3.49)
a soma de dois processos ( )tX e ( )tY com médias ( )tm X e ( )tmY , respectivamente. Da Def. 3.2, eq. (3.1), e atendendo ainda à linearidade do operador valor expectável, resulta o seguinte:
( )fH1
( )fG X
fB
H02 ( )fGY
f B0

3-15
Facto 3.6: A média da soma de dois processos estocásticos é a soma das médias das parcelas
( ) ( ) ( )tmtmtm YXZ += . (3.50)
Se ambos os processos ( )tX e ( )tY forem estacionários na média, então a soma é também estacionária na média.
Usando as Def. (3.3), eq. (3.2), Def. (3.11), eq. (3.23), e a linearidade do operador valor
expectável, a autocorrelação de ( )tZ é
( ) ( ) ( )( ) ( )τ−+τ−+
τ−+τ−=τ−
t,tRt,tR
t,tRt,tRt,tR
YYX
XYXZ; (3.51)
Se ( )tX e ( )tY forem estacionários na correlação, então
( ) ( ) ( )( ) ( )τ+τ−+
τ−+τ=τ−
YYX
XYXZ
Rt,tR
t,tRRt,tR, (3.52)
isto é, o facto de ( )tX e ( )tY serem estacionários na correlação não é suficiente para que a sua soma também o seja. No entanto, se forem conjuntamente estacionários, então XYR e
YXR dependem apenas da diferença entre os argumentos, (3.52) toma a forma
( ) ( ) ( )( ) ( )τ+τ+
τ+τ=τ
YYX
XYXZ
RR
RRR, (3.53)
e o processo ( )tZ é também estacionário na correlação. Ou seja:
Facto 3.7: O processo ( ) ( ) ( )ttt YXZ += é estacionário na correlação se os processos ( )tX e ( )tY forem conjuntamento estacionários de segunda ordem.
Se em (3.53) usarmos o Facto 3.4, eq. (3.21), concluímos que
( ) ( ) YYXXYXZ PPP +++= 0R0R , (3.54)
ficando claro que a potência da soma de dois processos não é, em geral, igual à soma das potências das parcelas.
Facto 3.8: Se os processos ( )tX e ( )tY forem ortogonais, então da Def. 3.10 concluímos que
( ) ( ) 0t,tRt,tR ,t =τ−=τ−τ∀ YXXY
e de (3.51) vem
( ) ( ) ( )τ−+τ−=τ− t,tRt,tRt,tR YXZ . (3.55)

3-16
Facto 3.9: No caso de processos estacionários ortogonais, (3.53) e (3.54) tomam a forma particular
( ) ( ) ( )τ+τ=τ YXZ RRR (3.56)
e YXZ PPP += , (3.57)
respectivamente. Por outro lado, de (3.56) e (3.42) resulta ainda
( ) ( ) ( )fGfGfG YXZ += . (3.58)
Em resumo:
• a correlação do processo soma é a soma das correlações das parcelas apenas no caso de estas serem processos ortogonais;
• no caso de processos conjuntamente estacionários, a potência média (correlação/densidade espectral de potência) do processo soma é a soma das potências médias (correlações/densidades espectrais de potência) das parcelas apenas no caso de estas serem processos ortogonais.
3.9 Processos Gaussianos
Def. 3.13- Considere-se a funcional
( ) ( )∫β
α
=T
T
dttXtgY , (3.59)
onde ( )tg é tal que 2YE é finito, e ( )tX é a variável aleatória que modela a amplitude do processo ( )tX definido no intervalo βα ≤≤ TtT . Se Y for uma variável aleatória gaussiana, então o processo ( )tX é gaussiano.
Individualizar os processos gaussianos relativamente a outras classes de processos
estocásticos encontra justificação em duas ordens de razões. A primeira, pragmática, tem a ver com as propriedades particulares dos processos gaussianos que facilitam o tratamento analítico de muitos problemas. A segunda resulta do facto de os processos físicos que se pretendem modelar serem tais que o teorema do limite central é aplicável e, portanto, o modelo gaussiano torna-se o mais adequado.
Os processos gaussianos gozam de um conjunto de propriedades, das quais salientaremos as que se seguem. P1. Seja ( )tX o processo de entrada de um sistema linear estável. Se ( )tX for um
processo gaussiano, então o processo de saída ( )tY é também um processo gaussiano. P2. Seja ( ) n
1kktX = o conjunto de variáveis aleatórias que modelam observações do
processo ( )tX nos instantes n1kkt = . Se o processo ( )tX for gaussiano, então para

3-17
qualquer valor de n aquelas variáveis aleatórias são conjuntamente gaussianas, sendo completamente definidas pela especificação das médias ( ) ( ) n
1kkk tXEtm ==X e das
funções de correlação ( ) ( ) ( ) n1k,iikik tXtXEttR ==−X .
P3. Se um processo gaussiano for estacionário em sentido lato, então é também
estacionário em sentido estrito. P4. Seja ( ) n
1kktX = o conjunto de variáveis aleatórias que modelam observações do
processo gaussiano ( )tX nos instantes n1kkt = . Se aquelas variáveis aleatórias forem
incorrelacionadas, isto é,
( ) ( ) n,1,2,ki ,0Cik tXtX K=≠=
então são também estatisticamente independentes.
Seja ( )tY o processo de saída de um siatema linear cuja entrada é um processo gaussiano
( )tX . Então, podemos escrever
( ) ( ) ( ) δγ ≤≤τττ= ∫β
α
TtT ,dX,thtYT
T
. (3.60)
Na relação anterior, ( )τ,th é a resposta no instante t do sistema linear quando a entrada é um impulso de Dirac que ocorre no instante τ. Assume-se que ( )τ,th é tal que
( ) δγ ≤≤∞< TtT ,tYE 2 . Tendo em conta a Def. 3.13, é claro que ( ) δγ ≤≤ TtT ,tY , é uma variável aleatória gaussiana. Para mostrar que ( )tY é um processo gaussiano basta mostrar que qualquer funcional
( ) ( )∫δ
γ
=T
TY dttYtgZ , (3.61)
onde ( )tg Y é tal que ∞<2ZE , é uma variável aleatória gaussiana. Usando (3.60), podemos escrever
( ) ( ) ( ) dtdX,thtgZT
T
T
TY∫ ∫
δ
γ
β
α
τττ=
ou
( ) ( )∫β
α
τττ=T
T
dXgZ , (3.62)
onde se definiu
( ) ( ) ( )∫δ
γ
τ=τT
TY dt,thtgg .
Uma vez que ( )tX é um processo gaussiano, então, por definição, Z é uma variável aleatória gaussiana. A propriedade P1 fica assim demonstrada. A propriedade P2 resulta directamente da definição de processo gaussiano e implica de imediato as propriedades P3 e P4.

3-18
3.10 Modelos de Fontes de Informação
Iremos considerar dois tipos fundamentais de fontes de informação: analógicas em tempo contínuo e digitais em tempo discreto ou contínuo. Consideraremos ainda o caso de processos digitais em tempo contínuo.
3.10.1 Fontes Analógicas em Tempo Contínuo
A Figura 1.5 mostra uma função amostra gerada por uma fonte analógica em tempo contínuo. Neste caso, a fonte é modelada por um processo estocástico ( )tX cuja amplitude é modelada por uma variável aleatória ( ) !∈ t,tX .
Figura 1.5:Amostra gerada por uma fonte analógica em tempo contínuo
Em geral, assumiremos que o processo ( )tX é gaussiano, estacionário, com média nula e
correlação conhecida. Naturalmente, a respectiva densidade espectral de potência, sendo uma representação na frequência, determina a largura de banda da fonte.
3.10.2 Fontes Digitais em Tempo Discreto
Neste caso, a fonte digital é modelada por um processo ( )tX especificado pelo conjunto de variáveis aleatórias discretas ( ) ( ) ( ) KK ,tX,,tX,tX n21 definidas nos instantes
!∈KK ,t,,t,t n21 . Tipicamente, consideraremos variáveis aleatórias binárias definidas em instantes distribuídos uniformemente ao longo da recta real. A Figura 1.6 ilustra uma sequência binária aleatória …1001110… passível de ser gerada por uma fonte do tipo aqui considerado.
Figura 1.6: Amostra gerada por uma fonte digital em tempo discreto
3.10.3 Fontes Digitais em Tempo Contínuo
Este tipo de fontes resulta do caso anterior quando se faz uso de um qualquer esquema de sinalização. Este pode consistir no uso de impulsos ( )tp do tipo rectangular com duração igual ao espaçamento temporal entre ocorrências consecutivas de símbolos. A Figura 1.7 mostra um sinal amostra de uma fonte do tipo aqui considerado quando se aplica o esquema de sinalização referido à sequência aleatória da Figura 1.6.
t
( )i;tx ξ
kx
t• • •kt

3-19
Figura 1.7: Amostra gerada por uma fonte digital em tempo contínuo
3.11 Ruído Branco Gaussiano
O termo ruído branco é usado para indicar o processo estocástico caracterizado pelo facto de todas as suas componentes de frequência terem a mesma potência, isto é, o espectro (ou densidade espectral) de potência é constante. Este é um conceito paralelo ao de luz branca, a qual é constituída por uma mistura de todas as cores.
Def. 3.14- Um processo ( )tX é um processo branco se tiver um espectro de potência constante, isto é,
( ) !∈∀η= t ,2
fG X . (3.63)
A importância dos processo brancos na prática prende-se ao facto de o ruído térmico ter um espectro de potência aproximadamente constante numa banda de frequências muito larga, da ordem de 1012 Hz. Portanto, para as larguras de banda dos sinais e sistemas que iremos considerar, o ruído térmico é adequadamente modelado como um processo branco. Por outro lado, o processo físico (movimento aleatório de electrões por efeito térmico) de geração do ruído térmico leva a que, por recurso ao teorema do limite central, seja modelado como um processo gaussiano.
Nos estudos que iremos desenvolver, consideraremos então que o ruído térmico é modelado como um processo branco gaussiano, cujo espectro de potência é dado por (3.63) e cuja correlação é, por consequência, dada por
( ) ( ) !∈∀δη= t ,t2
tR X . (3.64)
Como comentário final, chama-se a atenção para o facto de um processo branco não ter
significado do ponto de vista físico. Com efeito, de (3.63) conclui-se que a potência média total é infinita. Portanto, deve sempre ter-se em conta que este tipo de processos são usados como modelos abstractos de processos físicos com propriedades semelhantes.
t ktt0
( )tp

3-20

4-1
4 Digitalização de Fontes Analógicas em Tempo Contínuo
Neste capítulo vamos estudar métodos de digitalização de Fontes Analógicas em Tempo Contínuo (FATCs) viabilizando-se assim a utilização de técnicas digitais de comunicação para transmissão da informação gerada por fontes analógicas. A digitalização dos sinais gerados por FATCs origina sinais modulados por codificação de impulsos que passaremos a designar por sinais PCM1. Estes sinais são, como veremos, funções amostra de Fontes Digitais em Tempo Contínuo (FDTCs).
4.1 Arquitectura do Sistema Gerador de Sinais PCM
A Figura 4.1 mostra a arquitectura do sistema de geração de sinais PCM a partir de sinais amostra gerados por uma FATC que será modelada como um processo de segunda ordem ( )tX , estacionário e de média nula, com largura de banda B.
Figura 4.1: Arquitectura de um gerador de sinais PCM
Os blocos fundamentais desta arquitectura são o amostrador com retenção, aqui designado por S&H (Sample & Hold), responsável pela amostragem temporal da função amostra ( )tx i gerada pela FATC, o quantizador que em cada instante de amostragem discretiza a amplitude da amostra adquirida, e o codificador que codifica a amostra temporal quantizada, geralmente recorrendo ao código binário natural. A saída do conversor paralelo – série é portanto uma sequência de símbolos binários. O modulador implementa um esquema de sinalização que gera o sinal PCM mais adequado para transmissão através de um determinado canal de comunicação. Nas secções seguintes, estudaremos em maior detalhe cada um dos blocos aqui referidos.
4.2 Teorema da Amostragem
Começaremos por abordar o problema da amostragem temporal no contexto dos sinais determinísticos de banda limitada. Consideremos um sinal ( )tx de banda limitada B, a partir do qual se geram as amostras temporais ( )akTx , onde Ta é o período de amostragem. Suponhamos que as referidas amostras são obtidas a partir do sistema de amostragem ideal representado na Figura 4.2 . O sinal resultante deste processo de amostragem vem dado por
1 PCM – Pulse Code Modulation.
( )tQX
( )taX( )tXFATC FPBx S&H Quantizador
Codificador Conversor
Paralelo-Série Moduladorsinal PCM
aT
LTa
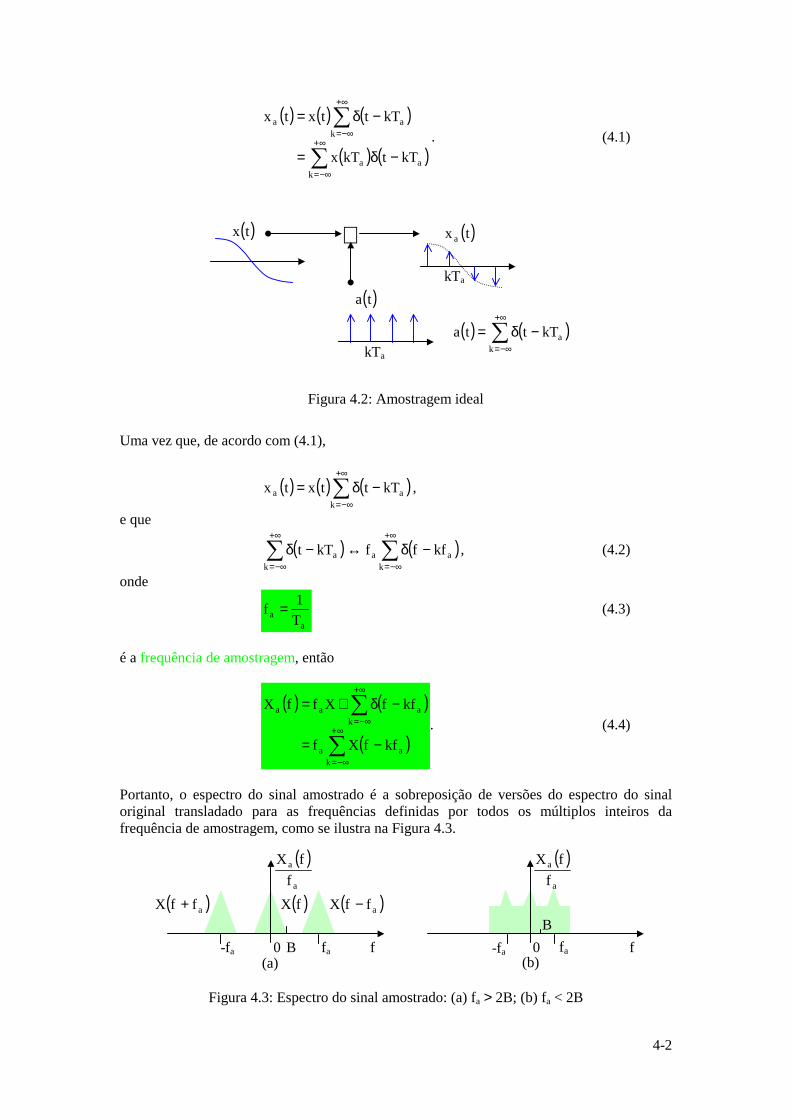
4-2
( ) ( ) ( )
( ) ( )∑
∑∞+
−∞=
+∞
−∞=
−δ=
−δ=
kaa
kaa
kTtkTx
kTttxtx. (4.1)
Figura 4.2: Amostragem ideal
Uma vez que, de acordo com (4.1),
( ) ( ) ( )∑+∞
−∞=
−δ=k
aa kTttxtx ,
e que
( ) ( )∑∑+∞
−∞=
+∞
−∞=
−δ↔−δk
aak
a kfffkTt , (4.2)
onde
aa T
1f = (4.3)
é a frequência de amostragem, então
( ) ( )
( )∑
∑∞+
−∞=
+∞
−∞=
−=
−δ∗=
kaa
kaaa
kffXf
kffXffX. (4.4)
Portanto, o espectro do sinal amostrado é a sobreposição de versões do espectro do sinal original transladado para as frequências definidas por todos os múltiplos inteiros da frequência de amostragem, como se ilustra na Figura 4.3.
Figura 4.3: Espectro do sinal amostrado: (a) fa > 2B; (b) fa < 2B
( )tx ( )tx a
( )ta
⊗
kTa
kTa
( ) ( )∑+∞
−∞=
−δ=k
akTtta
( )a
a
ffX
ffa-fa 0
( )fX ( )affX −( )affX +
( )a
a
ffX
f fa -fa 0B
B (a) (b)

4-3
Como se pode ver, as réplicas do espectro do sinal original surgem perfeitamente individualizadas apenas no caso (a) em que a frequência de amostragem é superior a duas vezes a largura de banda de ( )tx . É óbvio que nesta situação se pode recuperar o sinal original ( )tx , filtrando passa-baixo o sinal amostrado ( )tx a como se mostra na Figura 4.4.
Figura 4.4: Reconstrução do sinal original por filtragem ideal passa – baixo
No caso em que B2fa = temos
( ) ( ) ( )2Btsincth B2f
B21fH =↔
Π= (4.5)
e de (4.1) obtém-se
( ) ( ) ( ) ( )( )∑+∞
∞=
==-k
aa kT-t2BsinckTxtxty . (4.6)
Este resultado mostra que, qualquer que seja o instante t considerado, a amplitude do sinal ( )tx com largura de banda limitada B se pode obter exclusivamente a partir das respectivas
amostras temporais ( )akTx através de uma operação de interpolação usando como funções interpoladoras ( )( ) KK,-1,0,1,k ,kT-t2Bsinc a = Esta operação de interpolação é realizada pelo filtro passa – baixo ideal da Figura 4.4, o qual é neste contexto usualmente designado por filtro de interpolação. É ainda interessante notar que
( )( ) ( )( )
( )
≠
===
⇒==∫+∞
∞−−
kn 0,
kn ,B21k-nsinc
B21
dtnT-t2BsinckT-t2Bsinc
B2fTaa
a1
a , (4.7)
ou seja, (4.6) constitui uma representação do sinal ( )tx como uma combinação linear de componentes ortogonais. Usando (4.6) e (4.7)
( ) ( ) ( )( )∫+∞
∞−
=∈∀ dtkT-t2BsinctxB2kT x,k aa! , (4.8)
o que mostra que ( )akTx representa a projeção de ( )tx segundo a "direção"
( )( )akT-t2Bsinc . O conjunto de funções ( )( ) +∞−∞=kakT-t2Bsinc forma então uma base ortogonal de dimensão infinita que gera todos os sinais de energia com largura de banda limitada B.
( )
Π=
B2f
f1fHa
( )tx a ( ) ( )txty =
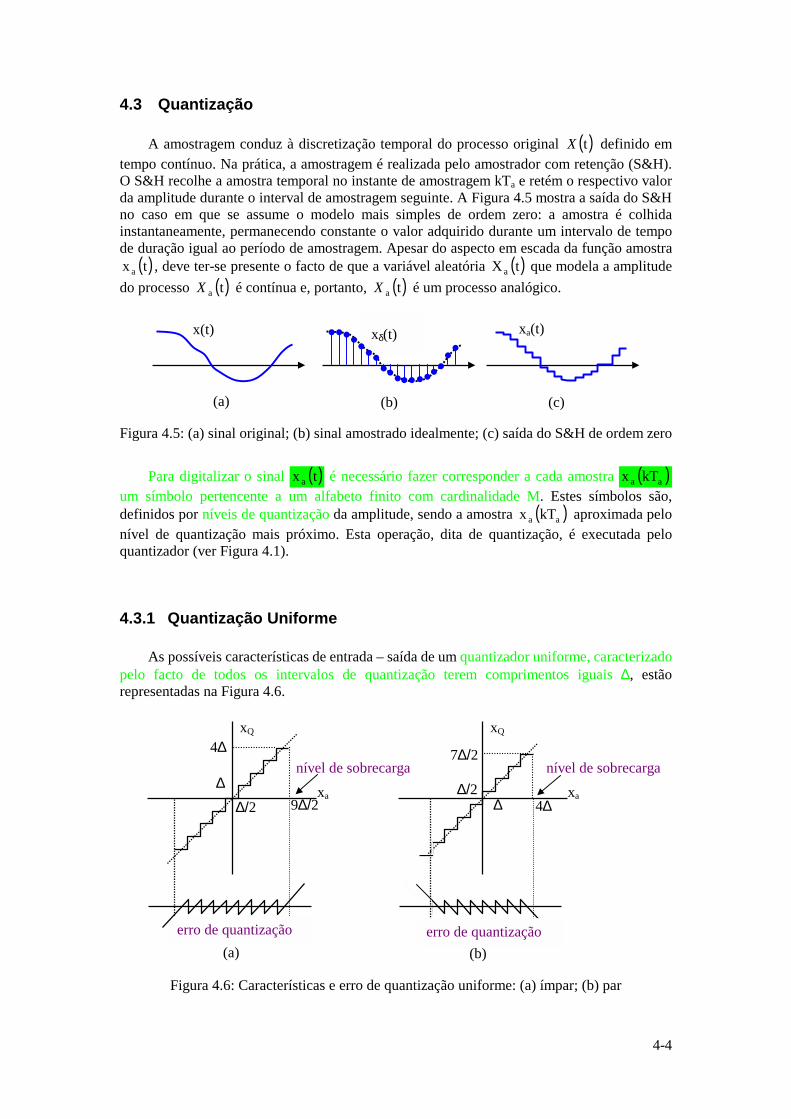
4-4
4.3 Quantização
A amostragem conduz à discretização temporal do processo original ( )tX definido em tempo contínuo. Na prática, a amostragem é realizada pelo amostrador com retenção (S&H). O S&H recolhe a amostra temporal no instante de amostragem kTa e retém o respectivo valor da amplitude durante o interval de amostragem seguinte. A Figura 4.5 mostra a saída do S&H no caso em que se assume o modelo mais simples de ordem zero: a amostra é colhida instantaneamente, permanecendo constante o valor adquirido durante um intervalo de tempo de duração igual ao período de amostragem. Apesar do aspecto em escada da função amostra
( )tx a , deve ter-se presente o facto de que a variável aleatória ( )tXa que modela a amplitude do processo ( )taX é contínua e, portanto, ( )taX é um processo analógico.
Figura 4.5: (a) sinal original; (b) sinal amostrado idealmente; (c) saída do S&H de ordem zero
Para digitalizar o sinal ( )tx a é necessário fazer corresponder a cada amostra ( )aa kTx
um símbolo pertencente a um alfabeto finito com cardinalidade M. Estes símbolos são, definidos por níveis de quantização da amplitude, sendo a amostra ( )aa kTx aproximada pelo nível de quantização mais próximo. Esta operação, dita de quantização, é executada pelo quantizador (ver Figura 4.1).
4.3.1 Quantização Uniforme
As possíveis características de entrada – saída de um quantizador uniforme, caracterizado pelo facto de todos os intervalos de quantização terem comprimentos iguais ∆, estão representadas na Figura 4.6.
Figura 4.6: Características e erro de quantização uniforme: (a) ímpar; (b) par
xδ(t)x(t) xa(t)
(a) (b) (c)
nível de sobrecarga
∆/2 9∆/2 ∆
4∆
xa
xQ
nível de sobrecarga∆/2
7∆/2
∆ 4∆ xa
xQ
erro de quantização erro de quantização (a) (b)

4-5
Os dois tipos de característica de quantização ilustradas na Figura 4.6 diferem apenas na forma como cruzam a origem, dando origem a um número ímpar Figura 4.6-(a) ou par Figura 4.6-(b) de níveis de quantização. Em qualquer caso, e designando o nível de sobrecarga por xmax, o número de níveis de quantização e o comprimento do intervalo de quantização verificam a relação
maxx2M =∆ . (4.9) Uma vez que o número M de níveis de quantização tem de ser finito é necessário ter algum cuidado na especificação do nível de sobrecarga. Com efeito, seja qual for o valor especificado para o nível de sobrecarga, a probabilidade ( ) amaxa kT , xXP ∀> , é, em geral, não nula, sendo todas as amostras identificadas pelo acontecimento maxa xX > quantizadas pelos níveis extremos. Nestes casos, o erro de quantização definido pela variável aleatória
( ) ( ) ( )aaQa kTXkTXkT −=Ε (4.10)
tomará valores que em módulo podem ser muito elevados, como se ilustra na Figura 4.6. Devemos então dimensionar o nível de sobrecarga de modo que ( ) amaxa kT , xXP ∀< , seja suficientemente grande para que com elevada probabilidade o erro de quantização verifique
( )2
kTa∆≤Ε . (4.11)
4.3.2 Relação Sinal – Ruído de Quantização
O erro de quantização definido em (4.10) pode ser interpretado como tendo resultado de uma amostragem do processo que designaremos por ruído de quantização e, portanto, podemos escrever
( ) ( ) ( ) ( ) ( )ak
aak
aQ kTt kTkTt kT −δ+−δ= ∑∑+∞
−∞=
+∞
−∞=
XtX Ε . (4.12)
Se este for o processo cujas funções amostra se apresentam à entrada do filtro de reconstrução (4.5), então de (4.6) resulta
( ) ( ) ( )( ) ( )tkTt2Bsinc kT ak
a XtY +−= ∑+∞
−∞=
Ε , (4.13)
onde
( ) ( ) ( )( )ak
a kTt2Bsinc kT −= ∑+∞
−∞=
ΕΕ t (4.14)
modela o ruído de quantização. Portanto, podemos concluir que o sinal reconstruído é uma versão do sinal original distorcida aditivamente pelo ruído de quantização. Para quantificar o desempenho (precisão) do processo de digitalização – reconstrução usa-se como medida a relação sinal – ruído de quantização aqui designada por SQNR2:
ΕPPX=SQNR . (4.15)
2 SQNR: Signal to Quantization Noise Ratio.

4-6
Por definição a potência do ruído de quantização é dada por
( )
Ε= ∫+
−∞→
2T
2T
2
Tdtt
T1limEΕP ,
ou, fazendo 1BT2 a = e usando a aproximação que explora o facto de as funções sinc(⋅) decrescerem com t1
( ) ( ) ( )( )a
K
Kka kTt2Bsinc kT −≈ ∑
+
−=
ΕΕ t ,
( )
Ε+
≈ ∑−=
∞→
K
Kka
2
KkT
1K21limEΕP . (4.16)
Na falta de conhecimento mais preciso, assumiremos que o erro de quantização está limitado ao intervalo [ ]2,2 ∆+∆− e tem distribuição uniforme, isto é,
( )
∆εΠ
∆=εΕ∀ 1f ,k .
Nestas condições, de (4.16) resulta
12
2∆≈ΕP . (4.17)
Facto 4.1: Seja ∆ o comprimento dos intervalos de quantização de um quantizador uniforme. Assumindo que a probabilidade de o quantizador ser sujeito a sobrecarga é desprezável, então a SQNR vale3
12SQNR 2U ∆
≈ XP. (4.18)
Como seria de esperar, a SQNR diminui quando o comprimento do intervalo de
quantização aumenta, o que se traduz numa reconstrução menos precisa do sinal original. Uma das estratégias possíveis para combater este efeito consistiria em, para o mesmo nível de sobrecarga, aumentar o número M de níveis de quantização. Como veremos de seguida, uma simples análise qualitativa do problema mostra que esta não é necessariamente a estratégia mais adequada.
4.4 Taxa de Geração de Dados Binários num Sistema PCM
Recorrendo à Figura 4.1, verificamos que a jusante do quantizador existe um bloco de codificação que, em geral, gera palavras do código binário natural. Isto significa que cada um dos M níveis de quantização é codificado por uma palavra binária de comprimento4
MlogMlogL 22 ≥= . (4.19) 3 O índice U é usado para sublinhar que o resultado obtido se refere ao quantizador uniforme. 4 Uma vex mais a notação ( ) ⋅ designa o menor inteiro imediatamente superior ou igual a ( )⋅ .

4-7
Naturalmente, o conversor paralelo – série terá de gerar sequência binárias de comprimento L num intervalo de tempo que não pode exceder a duração do período de amostragem. Atendendo a (4.19), concluímos que a taxa de geração de dados binários na saída do conversor paralelo – série deve verificar a desigualdade
a
2
TMlog
r ≥ . (4.20)
Finalmente, porque o teorema da amostragem tem de ser respeitado, podemos concluir o seguinte:
Facto 4.2: Um sistema gerador de sinais PCM desenhado para sinais fonte com largura de banda não superior a B que use um quantizador de M níveis e o código binário natural gera dados binários a uma taxa nunca inferior a
MlogB2r 2= . (4.21)
Portanto, quanto maior for quer a largura de banda da fonte quer a precisão requerida na reconstrução do sinal original, maior é a taxa de geração de dados binários necessária para transmitir o sinal fonte analógico usando técnicas de comunicação digital.
4.5 Quantização Não Uniforme
No parágrafo 4.3.2 acabámos por concluir que uma das estratégias possíveis para reduzir a SQNR resultante de um processo de quantização uniforme consistiria em, uma vez especificado previamente o nível de sobrecarga, aumentar o número M de níveis de quantização (portanto, o equivalente à diminuição do comprimento do intervalo de quantização). Se nos reportarmos ao Facto 4.2, eq. (4.21), somos obrigados a concluir que tal estratégia teria por consequência o aumento da taxa de geração de dados binários, ou seja, da taxa de transmissão necessária. O aumento da velocidade de transmissão requer por outro lado respostas temporais mais rápidas do canal de transmissão ou, de modo equivalente, bandas de transmissão mais largas. Tal facto, traduzir-se-ia necessariamente por uma maior sensibilidade do sistema de transmissão face ao ruído de canal ( ruído branco) com evidente reflexo negativo na respectiva fiabilidade. Adoptando a estratégia atrás descrita, estariamos assim a privilegiar a precisão da quantização em troca da fiabilidade de transmissão o que, em situações limite, pode ter efeitos desastrosos no desempenho global do sistema de transmissão PCM. Existem, no entanto, estratégias alternativas. Uma delas é baseada no seguinte raciocínio.
Em geral, os sinais de interesse para transmissão recorrendo a sistemas PCM, como os sinais de voz, audio e vídeo, têm média nula e as respectivas amplitudes tomam com maior probabilidade valores em intervalos mais próximos do valor médio. O quantizador uniforme não faz uso deste facto, pesando do mesmo modo os erros de quantização associados a qualquer dos valores possíveis da amplitude de entrada, ocorram eles em intervalos de maior ou menor probabilidade. Uma vez que no intervalo de funcionamento do quantizador (determinado pelo nível de sobrecarga) o erro de quantização é, para cada intervalo de quantização n com comprimento n∆ , limitado em valor absoluto por 2n∆ , faz sentido pensar em quantizadores não uniformes que usem intervalos de quantização mais longos para amostras que ocorrem em intervalos de menor probabilidade e intervalos de quantização de menor comprimento no caso contrário. A escolha destes comprimentos deverá portanto ser feita por forma a optimizar, de acordo com determinado critério, o desempenho do processo de digitalização – reconstrução do sinal gerado pela FATC.

4-8
Um quantizador não uniforme pode ser representado pelo modelo da Figura 4.7, onde o compressor é usado como uma não linearidade que transforma intervalos de quantização não uniformes em intervalos de quantização de igual comprimento.
Figura 4.7: Modelo conceptual de um quantizador não uniforme
O compressor é descrito pela característica ( )xCz = que se exemplifica na Figura 4.8.
Claramente, os intervalos de comprimento uniforme no eixo vertical (saída z do compressor) resultam de intervalos no eixo horizontal (entrada xa do compressor) cujos comprimentos crescem com o afastamento relativamente à origem.
Figura 4.8: Quantização não uniforme – compressão, quantização uniforme, expansão
A quantização não uniforme gera amostras quantizadas
( ) ( ) ( )
( )( ) ( )aa
aaaQ
kT~kTxC
kT~kTzkTz
ε+=
ε+=, (4.22)
onde ε~ designa uma amostra do erro de quantização uniforme relativamente a z. De (4.22) fica claro que, mesmo que 0~ ≡ε , da interpolação das amostras Qz resultaria uma versão completamente distorcida do sinal de origem ( )tx . Tal deve-se à presença da não linearidade
( )xCz = introduzida pelo compressor. Portanto, antes de se proceder à filtragem de
( )aQ kTzCompressor
Quantizadoruniforme
( )aa kTx ( )akTz
Quantizador não uniforme
zz
xa
c(xa)
zQ
zQ
c -1(zQ)
compressor
expa
nsor
x0Ikzk
zk
c -1(zk)
∆k
∆

4-9
reconstrução é necessário compensar o efeito distorcivo do compressor recorrendo a um dispositivo também não linear, o expansor, cuja caraterística é a transformação inversa5
( )zCx 1−= . Supondo que ( ) ( )( )aa kTxCkT~ <<ε , resulta
( ) ( )( ) ( )( ) ( )[ ]( ) ( )axa
aa1
aQ1
akTkTx
kT~kTxCCkTzCkTy
kε+≅
ε+== −−,
(4.23) onde o erro de quantização ( )ax kT
kε depende localmente da entrada ( )akTx .
4.5.1 Relação Sinal – Ruído de Quantização
Com generalidade, a característica do compressor deve exibir as seguintes características: P1. C(x)é monótona crescente; P2. C(x) tem simetria ímpar: C(−x) = −C(x); P3. C(0) = 0 e C(xmax) = xmax, onde xmax é o nível de sobrecarga. Consideremos o intervalo kI delimitado por kx e 1kx + e com comprimento
k1kk xx −=∆ + . (4.24)
Como se observa na Figura 4.8, qualquer valor do sinal original k0 Ix ∈ é quantizado pelo nível kz que se assume valer
2xx
z k1kk
+= + . (4.25)
Seja ( )⋅Xf a função densidade de probabilidade da amplitude ( )tX das amostras do processo ( )tX , e que se assume ser simétrica, isto é,
( ) ( )xfxf XX =− . (4.26)
Suponhamos que o número total M de níveis de quantização definido em (4.9) é suficientemente elevado para que seja válida a aproximação
( ) ( ) ( ) kkX
x
xXkk zfduufIxPrp
1k
k
∆≈=∈= ∫+
. (4.27)
Definindo o erro de quantização
kkk IX ,Xz ∈−=Ε , (4.28) então, por definição, a variância do erro de quantização é 5 No parágrafo 4.5.1 apresentaremos as propriedades que a característica de compressão deve exibir para garantir, entre outras coisas, a existência e unicidade da transformação inversa.

4-10
( ) ( )∫−
Ε −=σmax
max
x
xX
2k
2 duufuz . (4.29)
Particionando o intervalo de integração em intervalos de quantização Ik, e fazendo uso de (4.27), então (4.29) toma a forma
( ) ( )
( )∑ ∫
∑ ∫−
=
−
=Ε
−∆
≈
−=σ
1M
0k I
2k
k
k
1M
0k IX
2k
2
k
k
duuzp
duufuz
;
finalmente, recorrendo a (4.24) e (4.25),
∑−
=Ε ∆≈σ
1M
0k
2kk
2 p121 . (4.30)
Voltando à Figura 4.8, e na hipótese que temos vindo a assumir de M ser suficientemente elevado, temos
( )k
max
k0k0 M
x2xC Ix
∆=
∆∆≈∈∀ & ,
o que, uma vez substituído em (4.30), dá
( )[ ]∑−
=Ε ≈σ
1M
0k
20k2
2max2 xCpM3
x &
ou, voltando a recorrer a (4.27),
( )[ ] ( )∫−
−Ε ≈σ
max
max
x
xX
2
2
2max2 duufuCM3
x & . (4.31)
Note-se que no caso da quantização uniforme ( ) [ ],x,x-x ,xxC maxmax∈∀= e de (4.31) resulta 1222 ∆≈σΕ , como seria de esperar. Seguindo um raciocínio semelhante ao usado no parágrafo 4.3.2, concluíriamos facilmente que a potência média do ruído de quantização é, no caso geral, aproximadamente dada por
( )[ ] ( )∫−
−≈
max
max
x
xX
2
2
2max duufuCM3
x &ΕP
e, portanto, a SQNR definida em (4.15), vale

4-11
( )
( )[ ] ( )∫
∫
−
−
−≈max
max
max
max
x
xX
2
x
xX
2
2max
2
duufuC
duufu
xM3SQNR
&
. (4.32)
O resultado obtido mostra que, com generalidade, a SQNR depende explicitamente da
densidade de probabilidade da amplitude do sinal quantizado. Isto sugere que se possam desenhar quantizadores cuja característica minimize a potência do ruído de quantização. Tal é de facto possível e constitui um dos problemas fundamentais abordados na teoria da distorção (rate distortion theory) intimamente ligada ao problema da compressão de informação. Este tópico não será aqui prosseguido. Pelo contrário, abordaremos uma perspectiva diversa que tem sido adoptada, em particular, nos sistemas digitais de transmissão de voz (telefonia digital).
4.5.2 Quantização Robusta
Se observarmos a expressão (4.32) com sentido crítico, verificamos que a condição
( ) ,xx ,xKxC max≤=& (4.33)
onde K é uma constante arbitrária, garante que a SQNR se torne independente de ( )⋅Xf , tornando o quantizador robusto face às propriedades estatísticas da amplitude do sinal a quantizar. De facto, nestas condições,
12K
xM3KSQNR 2
2
2max
22
∆=≈ . (4.34)
Usando a propriedade P3 da característica ( )xC como condição fronteira da solução da equação diferencial (4.33), obtemos
( )
+=
maxmax x
xlnKxxC . (4.35)
Faz-se notar que a característica ( )xC especificada por (4.35) não se define em 0x = . Na prática, é usual definir a característica de compressão de modo que seja aproximadamente (ou mesmo) linear na vizinhança de 0x = , garantindo-se ( ) 00C = , seguindo uma lei logarítmica nos restantes valores de x.
4.5.3 Normas Internacionais de Quantização de Sinais de Voz
As normas internacionais usadas para quantização de sinais de voz em sistemas telefónicos digitais são a lei-µ
( ) ( )( ) ,1
xx
0 ,1ln
xx1lnx
xC
max
max
max≤≤
µ+µ+
= (4.36)
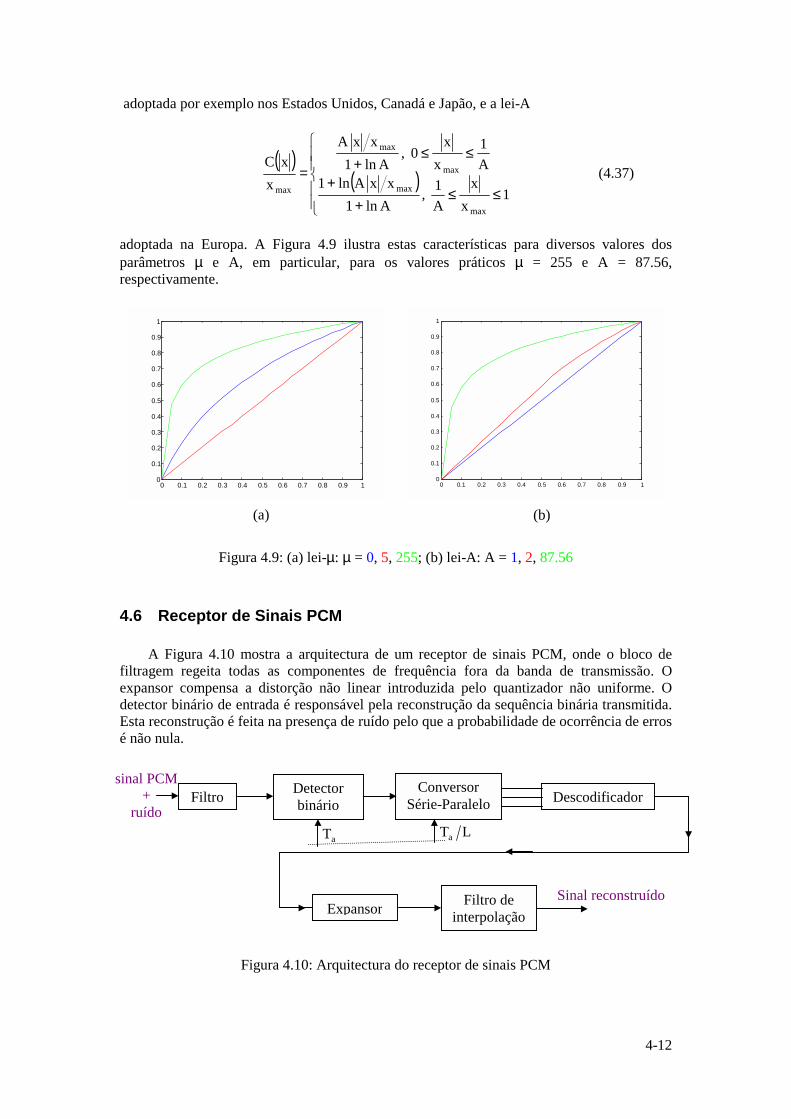
4-12
adoptada por exemplo nos Estados Unidos, Canadá e Japão, e a lei-A
( )( )
≤≤+
+
≤≤+=
1x
xA1 ,
Aln1xxAln1
A1
xx
0 ,Aln1
xxA
xxC
max
max
max
max
max (4.37)
adoptada na Europa. A Figura 4.9 ilustra estas características para diversos valores dos parâmetros µ e A, em particular, para os valores práticos µ = 255 e A = 87.56, respectivamente.
Figura 4.9: (a) lei-µ: µ = 0, 5, 255; (b) lei-A: A = 1, 2, 87.56
4.6 Receptor de Sinais PCM
A Figura 4.10 mostra a arquitectura de um receptor de sinais PCM, onde o bloco de filtragem regeita todas as componentes de frequência fora da banda de transmissão. O expansor compensa a distorção não linear introduzida pelo quantizador não uniforme. O detector binário de entrada é responsável pela reconstrução da sequência binária transmitida. Esta reconstrução é feita na presença de ruído pelo que a probabilidade de ocorrência de erros é não nula.
Figura 4.10: Arquitectura do receptor de sinais PCM
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
(a) (b)
sinal PCM +
ruído
Filtro de interpolação
Filtro Detector binário Descodificador
Conversor Série-Paralelo
aT LTa
ExpansorSinal reconstruído

4-13
Portanto, o sinal reconstruído constitui uma versão do sinal original gerado pela FATC distorcida pelo ruído de quantização e pelo efeito dos erros de transmissão induzidos pelo ruído de canal. A importância destes dois efeitos distorcivos será avaliada mais tarde quando estudarmos o desempenho deste tipo de sistema.

4-14

5-1
5 Sistemas de Transmissão
Neste capítulo iremos introduzir alguns sistemas básicos de transmissão, incluindo os sistemas de transmissão digital em banda de base e os sistemas de transmissão por modulação de portadoras sinusoidais.
5.1 Transmissão Digital em Banda de Base
A escolha dos sinais usados como suporte à transmissão dos símbolos produzidos por fontes digitais (ou resultantes da digitalização de fontes analógicas como no caso dos sistemas PCM) constitui um ponto importante no estudo de sistemas de comunicações digitais. Por exemplo, os canais de banda limitada induzem o espalhamento temporal do sinais transmitidos, como se mostra na Figura 5.1 para o caso de um canal passa-baixo. Se a entrada do canal for uma sequência de impulsos rectangulares, então a resposta a cada um dos impulsos vai interferir com os seguintes (região sombreada), o que se traduz na ocorrência de IIS1.
Figura 5.1: Espalhamento temporal induzido por um canal de banda limitada
Outro problema importante é o da sincronização temporal entre o emissor e o receptor no
que diz respeito ao ritmo de transmissão de símbolos, T1 baud. A sinalização usada deve incluir informação temporal que permita ao receptor sincronizar-se com o ritmo de transmissão por forma a que o instante em que se decide qual o símbolo transmitido seja o mais próximo possível do óptimo2. Ainda outro aspecto importante da escolha do esquema de sinalização prende-se com a eficiência espectral da transmissão, isto é, o número de símbolos transmitidos em média por segundo e por Hz.
5.1.1 Formatos de Sinalização Binária
Na Figura 5.2, e para o caso da sequência binária 0110100011, ilustram-se alguns dos formatos de sinalização (também designados por códigos de linha) mais usados. Os formatos (a), (c) e (e) estão neste exemplo baseados em impulsos rectangulares ( )tp de duração T, e T/2 nos casos (b) e (d) em que há retorno a zero. Em todas as situações ilustradas a taxa de transmissão é T1r = baud.
O formato unipolar corresponde a uma sinalização do tipo on-off, isto é, o impulso só é transmitido quando ocorre, por exemplo, o bit 1. Como o impulso ocupa todo o intervalo de símbolo, este formato é dito unipolar sem retorno a zero. No caso do formato unipolar com
1 IIS – Interferência Inter Simbólica. 2 Por exemplo, no sentido de garantir a mínima probabilidade de erro.
B
|H(f)|
0 T 0 T
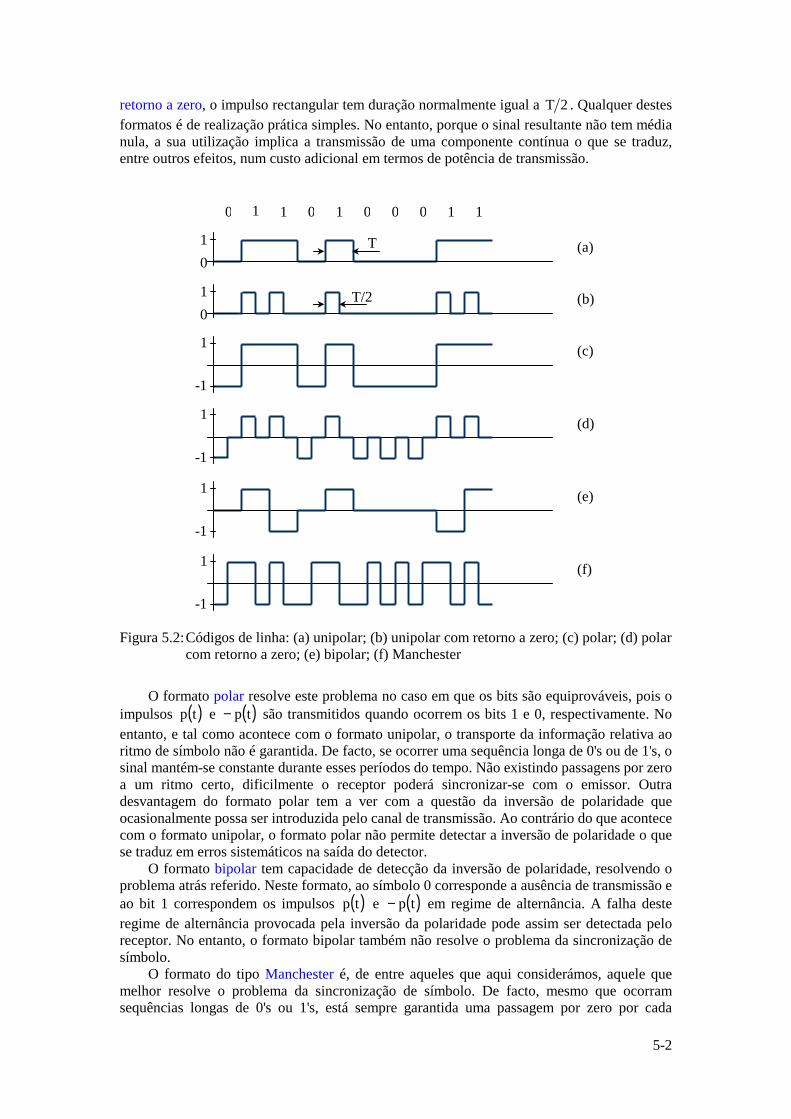
5-2
retorno a zero, o impulso rectangular tem duração normalmente igual a 2T . Qualquer destes formatos é de realização prática simples. No entanto, porque o sinal resultante não tem média nula, a sua utilização implica a transmissão de uma componente contínua o que se traduz, entre outros efeitos, num custo adicional em termos de potência de transmissão.
Figura 5.2: Códigos de linha: (a) unipolar; (b) unipolar com retorno a zero; (c) polar; (d) polar com retorno a zero; (e) bipolar; (f) Manchester
O formato polar resolve este problema no caso em que os bits são equiprováveis, pois o
impulsos ( )tp e ( )tp− são transmitidos quando ocorrem os bits 1 e 0, respectivamente. No entanto, e tal como acontece com o formato unipolar, o transporte da informação relativa ao ritmo de símbolo não é garantida. De facto, se ocorrer uma sequência longa de 0's ou de 1's, o sinal mantém-se constante durante esses períodos do tempo. Não existindo passagens por zero a um ritmo certo, dificilmente o receptor poderá sincronizar-se com o emissor. Outra desvantagem do formato polar tem a ver com a questão da inversão de polaridade que ocasionalmente possa ser introduzida pelo canal de transmissão. Ao contrário do que acontece com o formato unipolar, o formato polar não permite detectar a inversão de polaridade o que se traduz em erros sistemáticos na saída do detector.
O formato bipolar tem capacidade de detecção da inversão de polaridade, resolvendo o problema atrás referido. Neste formato, ao símbolo 0 corresponde a ausência de transmissão e ao bit 1 correspondem os impulsos ( )tp e ( )tp− em regime de alternância. A falha deste regime de alternância provocada pela inversão da polaridade pode assim ser detectada pelo receptor. No entanto, o formato bipolar também não resolve o problema da sincronização de símbolo.
O formato do tipo Manchester é, de entre aqueles que aqui considerámos, aquele que melhor resolve o problema da sincronização de símbolo. De facto, mesmo que ocorram sequências longas de 0's ou 1's, está sempre garantida uma passagem por zero por cada
0 0 0 0 01 1 1 1 1
1
-1
10
10
1
-1
1
-1
1
-1
(a)
(b)
(c)
(d)
(e)
(f)
T
T/2

5-3
intervalo de sinalização com duração T. Naturalmente que, ocorrendo um maior número de transições por unidade de tempo, este formato é aquele que requer a banda de transmissão mais larga, o que se traduz numa menor eficiência espectral.
5.1.2 Densidade Espectral de Potência
No sentido de caracterizar a eficiência espectral dos métodos de sinalização referidos no parágrafo anterior, começaremos por calcular a densidade espectral de potência do sinal PAM3 genérico
( ) ( ) , kTtpAtk
k∑+∞
−∞=
−=X (5.1)
onde kA é a variável aleatória discreta que modela a fonte digital, e ( )tp é o impulso de sinalização. Recordemos, eq. (3.41), que o espectro de potência é definido por
( ) ( ) , fX~ET1limfG
2T
0T 00
=
∞→X (5.2)
onde ( )fX~
0T é, de um ponto de vista formal, a transformada de Fourier da variável aleatória ( )tX
0T que modela em cada instante do tempo a amplitude de um troço com duração T0 do processo ( )tX definido em (5.1). Fazendo ( )T1K2T0 += , podemos escrever
( ) ( ) , kTtpAtXK
KkkT0 ∑
+
−=
−=
ou seja,
( ) ( ) . fkT2jefPAfX~K
KkkT0 ∑
+
−=
π−=
Substituindo em (5.2), obtém-se sucessivamente
( ) ( ) ( )
( ) ( ) ( ) , Tmkf2jeAAET1K2
1limfP
fmT2jeAfkT2jeAfPET1K2
1limfG
K
Kk
K
KmmkK
2
K
Kmm
K
Kkk
2
K
∑ ∑
∑∑
−= −=
∗
∞→
−=
∗
−=∞→
−π−+
=
π+
π−+
=X
ou ainda,
( ) ( ) ( ) ( ) ( ) , Tmkf2je mkRT1K2
1limfPfGK
Kk
K
KmAK
2 ∑ ∑−= −=
∞→
−π−−+
=X
(5.3)
3 PAM – Pulse Amplitude Modulation.
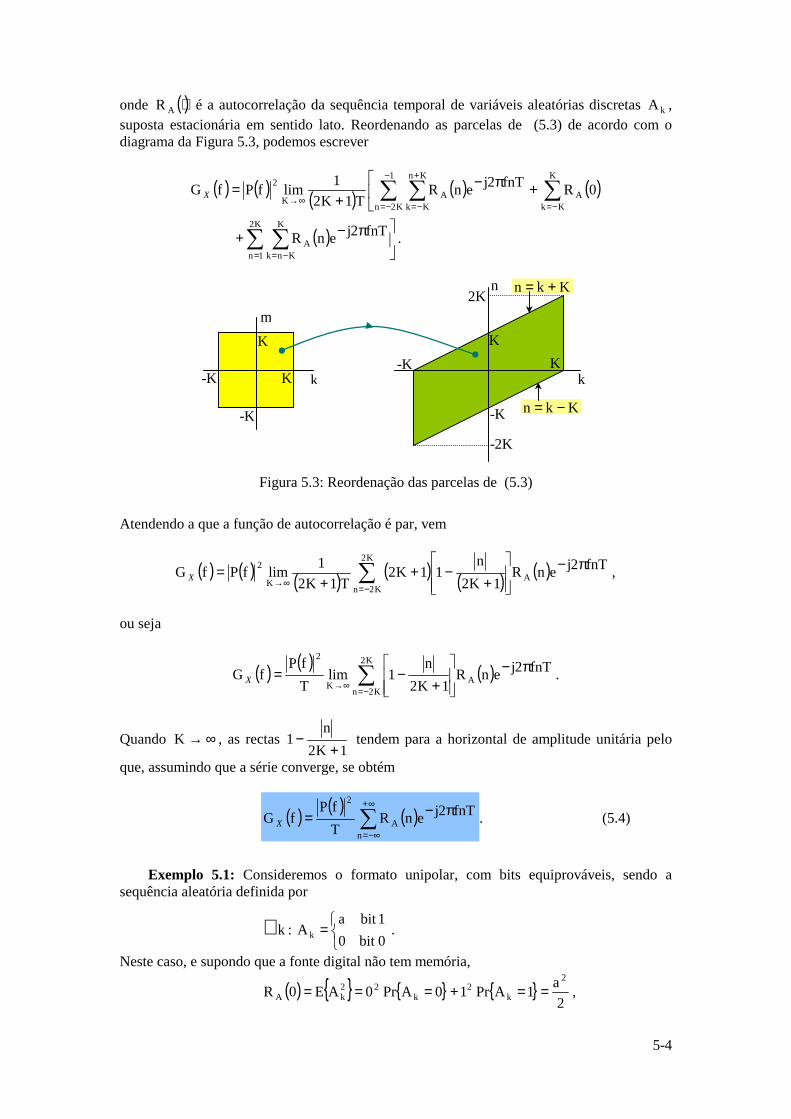
5-4
onde ( )⋅AR é a autocorrelação da sequência temporal de variáveis aleatórias discretas kA , suposta estacionária em sentido lato. Reordenando as parcelas de (5.3) de acordo com o diagrama da Figura 5.3, podemos escrever
( ) ( ) ( ) ( ) ( )
( ) . fnT2jenR
0RfnT2jenRT1K2
1limfPfG
K2
1n
K
KnkA
1
K2n
K
KkA
Kn
KkAK
2
π−+
+π−
+=
∑ ∑
∑ ∑∑
= −=
−
−= −=
+
−=∞→X
Figura 5.3: Reordenação das parcelas de (5.3)
Atendendo a que a função de autocorrelação é par, vem
( ) ( ) ( ) ( ) ( ) ( ) , fnT2jenR1K2
n11K2
T1K21limfPfG
K2
K2nAK
2 ∑−=
∞→
π−
+−+
+=X
ou seja
( ) ( ) ( ) . fnT2jenR1K2
n1lim
TfP
fGK2
K2nAK
2
∑−=
∞→
π−
+−=X
Quando ∞→K , as rectas 1K2
n1
+− tendem para a horizontal de amplitude unitária pelo
que, assumindo que a série converge, se obtém
( ) ( ) ( )∑∞+
−∞=
π−=n
A
2fnT2jenR
TfP
fG X . (5.4)
Exemplo 5.1: Consideremos o formato unipolar, com bits equiprováveis, sendo a sequência aleatória definida por
=∀0bit 01 bita
A :k k .
Neste caso, e supondo que a fonte digital não tem memória,
( ) 2
a1APr10APr0AE0R2
k2
k22
kA ==+=== ,
k
m
K
K K
-K
-K
K
-K
-K
2K
-2K
k
n Kkn +=
Kkn −=

5-5
e, para 0n ≠∀ , ( ) nkkA AAEnR −= , onde o par nkk AA − pode tomar quatro configurações possíveis possíveis: 00, 0a, a0, e aa; portanto, ( ) 4anR 2
A = . Em conclusão, para o formato unipolar considerado neste exemplo, obtivemos
( )
≠==
0n4a0n2anR 2
2
A ,
o que, substituído em (5.4), conduz a
( ) ( )
π−+= ∑∞+
−∞=n
222fnT2je
4a
4a
TfP
fG X .
Supondo que ( )tp é um impulso rectangular de duração T e amplitude unitária, então
( ) ( )fTsincTTfP 2
2
= ,
e, portanto,
( ) ( ) ( )∑+∞
−∞=
π−+=n
22
22 fnT2jefTsinc
4TafTsinc
4TafG X .
Atendendo ainda à identidade
∑∑+∞
−∞=
+∞
−∞=
−δ=π−
nn Tnf
T1fnT2je
e ao facto de ( )fTsinc ter zeros nos múltiplos de T1 , resulta finalmente
( ) ( ) ( )f4
afTsinc4TafG
22
2
δ+=X . (5.5)
Deixa-se como exercício, a verficação dos seguintes resultados:
1. Polar ( ) ( ) ( )fTsincTafG 22=X . (5.6)
2. Bipolar ( ) ( ) ( ) ( )fTsinfTsincTafG 222 π=X . (5.7)
3. Manchester ( ) ( )
π
=
2Tfsin
2TfsincTafG 222
X . (5.8)
Na Figura 5.4 estão representados os espectros de potência (normalizados por Ta 2 dos códigos de linha atrás considerados. Para a mesma amplitude a, o formato unipolar exige uma potência de transmissão que vale 2a 2 , metade da qual gasta na transmissão da componente
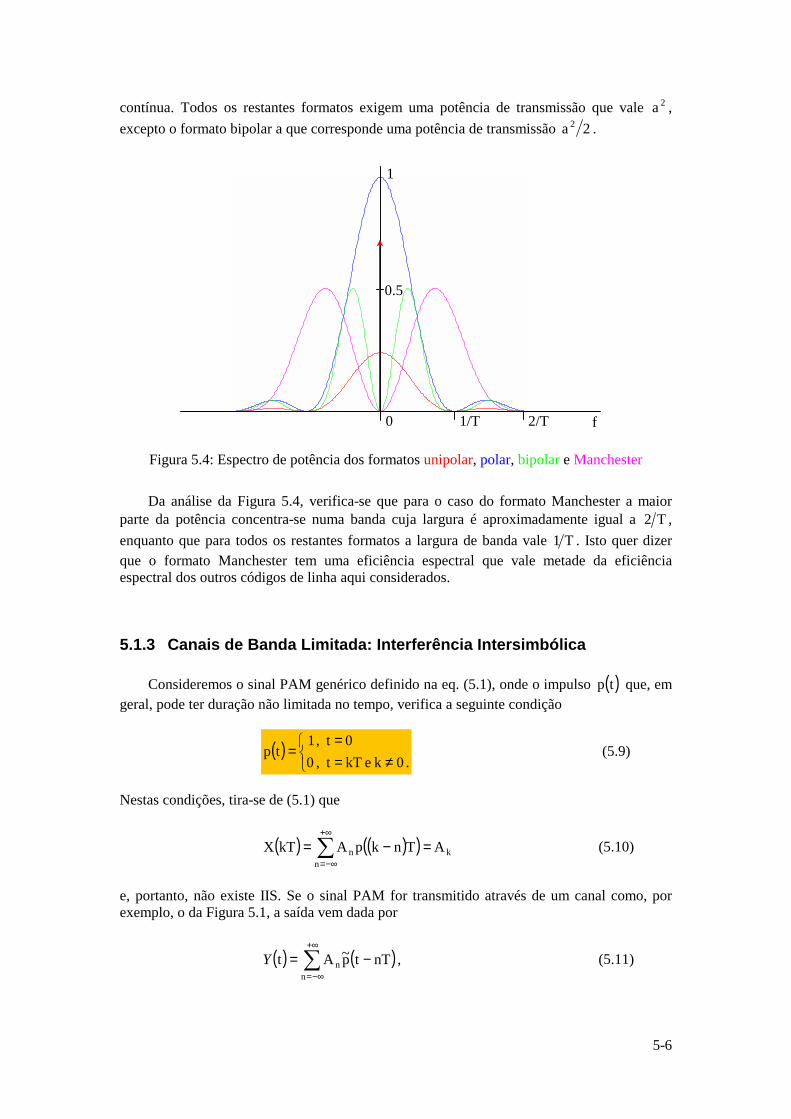
5-6
contínua. Todos os restantes formatos exigem uma potência de transmissão que vale 2a , excepto o formato bipolar a que corresponde uma potência de transmissão 2a 2 .
Figura 5.4: Espectro de potência dos formatos unipolar, polar, bipolar e Manchester
Da análise da Figura 5.4, verifica-se que para o caso do formato Manchester a maior
parte da potência concentra-se numa banda cuja largura é aproximadamente igual a T2 , enquanto que para todos os restantes formatos a largura de banda vale T1 . Isto quer dizer que o formato Manchester tem uma eficiência espectral que vale metade da eficiência espectral dos outros códigos de linha aqui considerados.
5.1.3 Canais de Banda Limitada: Interferência Intersimbólica
Consideremos o sinal PAM genérico definido na eq. (5.1), onde o impulso ( )tp que, em geral, pode ter duração não limitada no tempo, verifica a seguinte condição
( )
≠==
=. 0k e kTt , 0
0t , 1tp (5.9)
Nestas condições, tira-se de (5.1) que
( ) ( )( ) kn
n ATnkpAkTX =−= ∑+∞
−∞=
(5.10)
e, portanto, não existe IIS. Se o sinal PAM for transmitido através de um canal como, por exemplo, o da Figura 5.1, a saída vem dada por
( ) ( ) , nTtp~Atn
n∑+∞
−∞=
−=Y (5.11)
1
0 1/T 2/T
0.5
f

5-7
onde ( )tp~ é a resposta do canal ao impulso ( )tp . Em geral, ( )tp~ não verifica a condição (5.9) e, portanto,
( ) ( ) ( )( )∑+∞
≠−∞=
−+=
knn
nk Tnkp~A0p~AkTY ,
onde a segunda parcela representa o termo de IIS sobre o símbolo kA . Este termo de IIS pode ser responsável por uma detecção incorrecta do símbolo kA , mesmo em situações de ruído fraco. Este tipo de situação ocorre sempre que o canal introduz dispersão temporal, seja porque tem banda limitada, seja porque induz propagação em percursos múltiplos. Neste último caso, representado na Figura 5.5, o receptor recebe uma combinação linear de réplicas do sinal transmitido, as quais apresentam atrasos relativos que podem ser significativos.
Figura 5.5: Propagação em percursos múltiplos
Consideremos então um canal passa-baixo de banda limitada e com largura de banda 0B .
Para que não exista IIS, é necessário que na saída do canal o impulso ( )tp verifique a condição (5.9). Se amostrarmos o impulso ( )tp nos instantes múltiplos de T, obtemos
( ) ( ) ( ) ( ) ( )∑∑+∞
−∞=
+∞
−∞=δ −δ=−δ=
kk
kTt kTpkTt tptp . (5.12)
Por outro lado, e tendo em conta que
( ) ∑∑+∞
−∞=
+∞
−∞=
−δ−δ ↔
kk Tkf
T1 kTt
formam um par de Fourier, temos
( ) ∑+∞
−∞=δ
−=
k TkfP
T1fP . (5.13)
Usando (5.12), podemos escrever
( ) ( )
( ) ; ftTj2-e kTp
dtftj2-e kT-t kTpTkfP
T1
k
kk
∑
∑∑∞+
−∞=
+∞
∞−
∞+
−∞=
∞+
−∞=
π=
πδ=
− ∫
percursodirecto
percurso reflectido
E
R

5-8
no entanto, como ( )kTp só é diferente de zero para 0k = , conclui-se que
( ) 10pTkfP
T1
k
==
−∑
+∞
−∞=
,
ou ainda,
( ) TkrfPk
=−∑+∞
−∞=
. (5.14)
O critério de Nyquist, definido pela relação (5.14), exprime no domínio da frequência uma condição equivalente a (5.9) implicando, portanto, ausência de IIS. A condição (5.14) exige que a soma ponto a ponto em f de todas as versões de ( )fP transladadas de kr seja constante. Como o sinal ( )tp tem largura de banda 0B , o valor máximo de r que garante (5.14) é
0B2r = (5.15) desde que o espectro de ( )tp seja
( )
= Π
00 B2f
B21fP , (5.16)
isto é, um rectângulo de amplitude 0B21 em 0Bf < , como se mostra na Figura 5.6. Note-se que se 0B2r < o espectro ali representado tomaria valores iguais 0B21 e 0B1 , enquanto que para 0B2r > tomaria os valores 0B21 e zero. Aliás é fácil verificar que a escolha
0B2r > é impossível pois não garante a condição (5.14) seja qual for o espectro ( )fP com largura de banda 0B . No entanto, como veremos mais adiante, podem ser usados valores da taxa de transmissão 0B2r < desde que se escolha convenientemente a forma de ( )fP .
Figura 5.6: Critério de Nyquist
O ponto importante a realçar para já é que, de modo a garantir ausência de IIS e para
uma banda de transmissão 0B , a taxa máxima de transmissão admissível é dada por (5.15). Esta taxa de transmissão é atingida se os impulsos ( )tp tiverem o espectro dado (5.16), ou seja, se
( ) ( )t2Bsinctp 0= . (5.17) Na Figura 5.7 estão representados o espectro do impulso óptimo ( )fPB2 0 em função de
0Bf , e a respectiva forma de onda ( )tp em função de ( )rttB2 Tt 0 == . Estão também
( )0B2fP + ( )0B2fP −( )fP
L L
0B0B− 0B30B3− 0
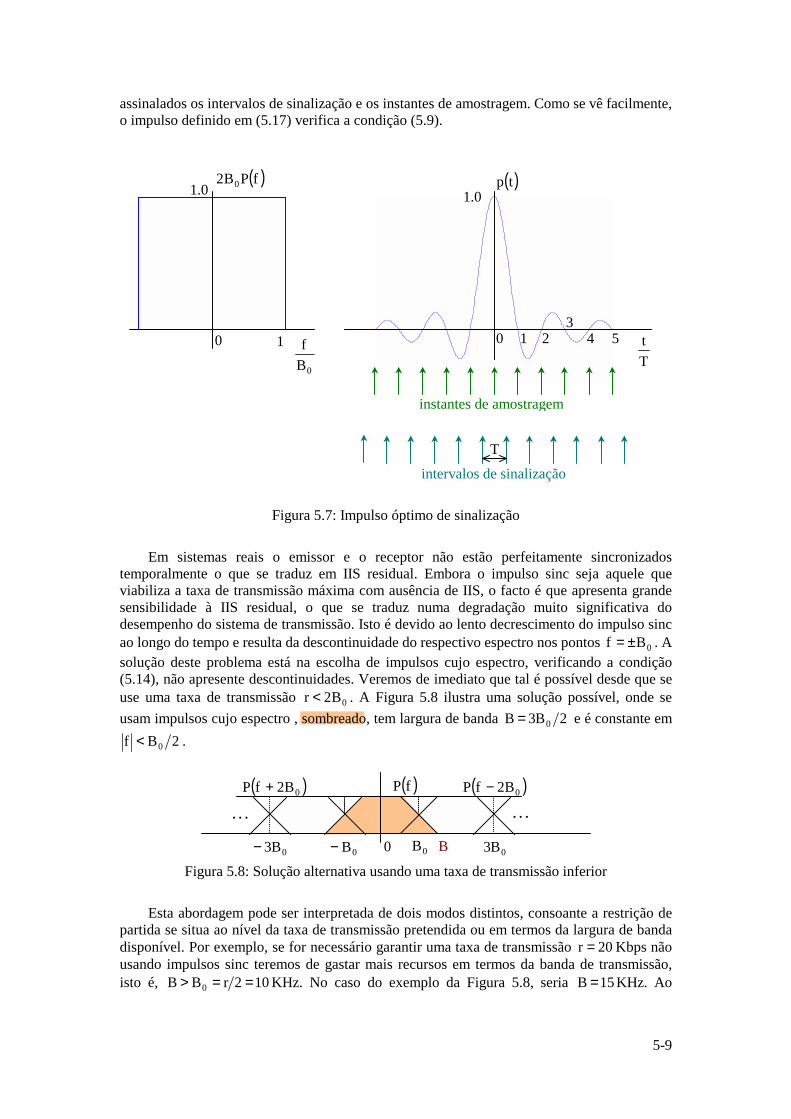
5-9
assinalados os intervalos de sinalização e os instantes de amostragem. Como se vê facilmente, o impulso definido em (5.17) verifica a condição (5.9).
Figura 5.7: Impulso óptimo de sinalização
Em sistemas reais o emissor e o receptor não estão perfeitamente sincronizados
temporalmente o que se traduz em IIS residual. Embora o impulso sinc seja aquele que viabiliza a taxa de transmissão máxima com ausência de IIS, o facto é que apresenta grande sensibilidade à IIS residual, o que se traduz numa degradação muito significativa do desempenho do sistema de transmissão. Isto é devido ao lento decrescimento do impulso sinc ao longo do tempo e resulta da descontinuidade do respectivo espectro nos pontos 0Bf ±= . A solução deste problema está na escolha de impulsos cujo espectro, verificando a condição (5.14), não apresente descontinuidades. Veremos de imediato que tal é possível desde que se use uma taxa de transmissão 0B2r < . A Figura 5.8 ilustra uma solução possível, onde se usam impulsos cujo espectro , sombreado, tem largura de banda 2B3B 0= e é constante em
2Bf 0< .
Figura 5.8: Solução alternativa usando uma taxa de transmissão inferior
Esta abordagem pode ser interpretada de dois modos distintos, consoante a restrição de
partida se situa ao nível da taxa de transmissão pretendida ou em termos da largura de banda disponível. Por exemplo, se for necessário garantir uma taxa de transmissão 20r = Kbps não usando impulsos sinc teremos de gastar mais recursos em termos da banda de transmissão, isto é, 102rBB 0 ==> KHz. No caso do exemplo da Figura 5.8, seria 15B = KHz. Ao
Tt
( )tp1.0
0 1 2 3
4 5
T
instantes de amostragem
intervalos de sinalização
( )fPB2 0
0Bf0 1
1.0
( )0B2fP + ( )0B2fP −( )fP
L L
0B0B− 0B30B3− 0 B

5-10
contrário, e para o mesmo exemplo, não sendo possível dispor de uma banda de transmissão maior do que 10B = Khz, teriamos de usar uma taxa de transmissão 3.13r = KHz. Impulsos raised-cosine. Em situações práticas é frequente usar impulsos cujo espectro é da forma raised-cosine4 como se mostra na Figura 5.9, juntamente com as respectivas formas de onda temporais.
Figura 5.9: Impulsos raised-cosine: α = 0, α = 0.5 e α = 1
Os espectros do tipo raised-cosine são definidos por
( )
( )
( )( ) ( ) ( )
( )
α+>
α+≤≤α−
α−−
απ+
α−<
=
0
00000
00
B1f, 0
B1fB1, B1fB2
cos1B41
B1f, B21
fP
(5.18) O parâmetro α é designado por factor de decaímento (rolloff factor) e mede o excesso de banda de transmissão, relativamente à banda mínima, usado para garantir uma determinada taxa de transmissão com ausência de IIS. Aos espectros (5.18) correspondem os sinais
( ) ( ) ( )( )2
0
00
tB241tB2cos
tB2sinctpα−πα
= . (5.19)
Note-se que para 0=α se recupera o impulso sinc que corresponde à sinalização ideal. O caso 1=α corresponde à utilização de um excesso de banda de 100%. Embora não seja bem visível na Figura 5.9, o impulso que corresponde a 1=α tem zeros adicionais nos instantes
K 2,3T ,2T ±± , como se pode verificar facilmente a partir de (5.19). Este facto é importante pois pode ser usado no receptor para efeito da sincronização de símbolo.
4 Na falta de uma tradução adequada, manteremos a designação anglo-saxónica.
Tt0 1 2 3 4
1.0( )tp
0Bf
21
23 0 1 2
1.0 ( )fPB2 0

5-11
5.2 Transmissão Analógica por Modulação de Portadoras Sinusoidais
Modulação é o processo pelo qual se faz depender do sinal a transmitir (mensagem) um dos parâmetros característicos de uma portadora sinusoidal: amplitude, frequência e fase. O objectivo é transferir o conteúdo informativo do sinal modulante, normalmente do tipo passa-baixo, para bandas do espectro de frequências muito afastadas da origem. Por efeito da modulação resultam, entre outros, os seguintes efeitos:
• maior eficiência da radiação do sinal a transmitir; • maior imunidade face à presença do ruído e de interferências; • melhor aproveitamento do espectro de frequências.
Consideremos o processo
( ) ( )ccc tf2cosAt Θ+π=P , (5.20)
onde cA é a amplitude, cf é a frequência (Hz) e cΘ é a fase (rad), modelada como uma variável aleatória uniforme num intervalo de comprimento 2π. Como se sabe, as funções amostra do processo (5.20) são periódicas, com período
cc f
1T = (5.21)
e frequência angular (rad/seg)
cc f2π=ω . (5.22)
É fácil verificar que o processo ( )tP é estacionário de segunda ordem em sentido lato. Com efeito,
( ) ( ) 0dtf2cosA21tEm ccc
=θθ+ππ
== ∫π+
π−
Θ PP (5.23)
e ( ) ( ) ( )
( ) ( )( )
( ). f2cos2
A
tf2costf2cos21A
ttER
c
2c
cc2c
c
τπ=
θ+τ−πθ+ππ
=
τ−=τ
∫π+
π−
Θ PPP
(5.24)
O espectro de potência é, portanto,
( ) ( ) ( )[ ]cc
2c ffff
4A
fG −δ++δ=P . (5.25)
No que segue vamos assumir que o sinal modulante (mensagem) ( )tx é uma função
amostra de um processo passa-baixo ( )tX , estacionário de segunda ordem em sentido lato, de média nula, e com largura de banda B.

5-12
5.2.1 Modulação de Amplitude
Na modulação de amplitude (AM5) a amplitude instantânea da portadora sinusoidal varia linearmente com o sinal modulante
( ) ( )[ ] ( )ccdccAM tf2costxAt Θ+π+= XX , (5.26) onde dcx é uma constante. A Figura 5.10 mostra o diagrama de blocos do modulador de AM.
Figura 5.10: Modulador de AM
O processo ( )tX é naturalmente independente da variável aleatória cΘ e, portanto,
também da portadora ( )tP . Daqui resulta que a autocorrelação do processo definido em (5.26) é, tendo em conta (5.24),
( ) ( )[ ] ( )τπτ+=τ c2dc
2c f2cosRx
2A
RAM XX , (5.27)
onde ( )τXR é a autocorrelação de ( )tX . Tendo em conta (5.25) e usando as propriedades da transformada de Fourier, concluímos que o espectro de potência do sinal de AM é
( ) ( ) ( )[ ] ( ) ( )[ ] cc2dccc
2dc
2c ffGffxffGffx
4A
fGAM
−+−δ++++δ= XXX ,
(5.28) onde ( )fG X é o espectro de potência de ( )tX . A Figura 5.11 ilustra em termos dos espectros de potência o efeito da modulação de amplitude.
Figura 5.11: Espectros de potência da mensagem (a) e do sinal de AM (b) 5 AM – Amplitude Modulation
⊕ ⊗( )tx
dcx ( )tp
( )tx AM
GX (f)
f0-B B
( ) ( )[ ]cc2dc
2c ffGffx
4A
−+−δ X( ) ( )[ ]cc2dc
2c ffGffx
4A
+++δ X
( )fGcX
f 0
BT = 2B
fc -fc
(a)
(b)

5-13
Como se vê, a modulação de amplitude envolve uma translação espectral do espectro do sinal modulante para a frequência da portadora. Verifica-se também que a largura da banda de transmissão é
B2BT = . (5.29) De (5.27) ou de (5.28) podemos também concluir que a potência de transmissão de um sistema de AM vale
( )XPP += 2dc
2c
T x2
A, (5.30)
onde XP é a potência do processo ( )tX .
A Figura 5.12 dá exemplos de sinais de AM gerados a partir da mesma mensagem ( )tx . A vermelho está representada a envolvente do sinal de AM
( ) ( )tXxAtA dcc += . (5.31)
Figura 5.12: Modulação de Amplitude: (a) mensagem, (b) sinal AM sobremodulado, (c) sinal AM não sobremodulado
No caso do sinal sobremodulado (Figura 5.12 (b)), onde se fez 0x dc = , a envolvente tem uma forma diferente da mensagem original e a portadora apresenta inversões da fase sempre que o sinal ( )tx passa por zero. Ao contrário, quando não há sobremodulação (Figura 5.12 (c)), ou seja, quando
( ) 0txx:t dc ≥+∀ , (5.32) a envolvente e a mensagem original têm a mesma forma.
5.2.1.1 Receptor Coerente
A translação espectral induzida pela modulação de amplitude pode ser usada para proceder à desmodulação do sinal de AM. A Figura 5.13 mostra o diagrama da blocos do receptor coerente.
t
t
t
(a)
(b)
(c)
( )tx

5-14
Figura 5.13: Receptor coerente
Suponhamos que à entrada temos uma amostra do sinal de AM definido em (5.26).
Então, o sinal na saída do multiplicador é
( ) ( )[ ] ( ) ( )( )[ ] ( ) ( )[ ] . costxxAtf4costxxA
tf2costf2costxxA2ty
dcccdcc
ccdcc
θ++θ+π+=πθ+π+=
O filtro passa-baixo elimina a componente de alta frequência (em cf2 ) e o condensador bloqueia a componente contínua, pelo que a saída do receptor será
( ) ( ) θ= costxAtx cD . Note-se que θ é a diferença de fase entre a portadora e o oscilador local e pode tomar qualquer valor no intervalo [ ]π+π− , , em particular 2π , o que resultaria na anulação da saída. É portanto necessário que o receptor seja coerente em fase com a portadora. A sincronização de fase é um problema muito importante, mas não iremos abordá-lo aqui. De qualquer modo, estando garantida a coerência de fase entre a portadora e o oscilador local, a saída do receptor coerente de AM será
( ) ( )txAtx cD = . (5.33)
5.2.1.2 Detector de Envolvente
Como vimos, no caso em que não há sobremodulação, isto é, quando se verifica a condição (5.32), a forma da envolvente coincide com a da mensagem original. Portanto, qualquer sistema capaz de extrair a envolvente da portadora poderá funcionar como desmodulador de amplitude. Este é o caso do sistema representado na Figura 5.14.
Figura 5.14: Detector de envolvente
1H(f)
fB
⊗
( )tf2cos2 cπ
XR(t) XD(t)
FPBx LB = B
rectificador
XR(t) AR(t) XD(t)
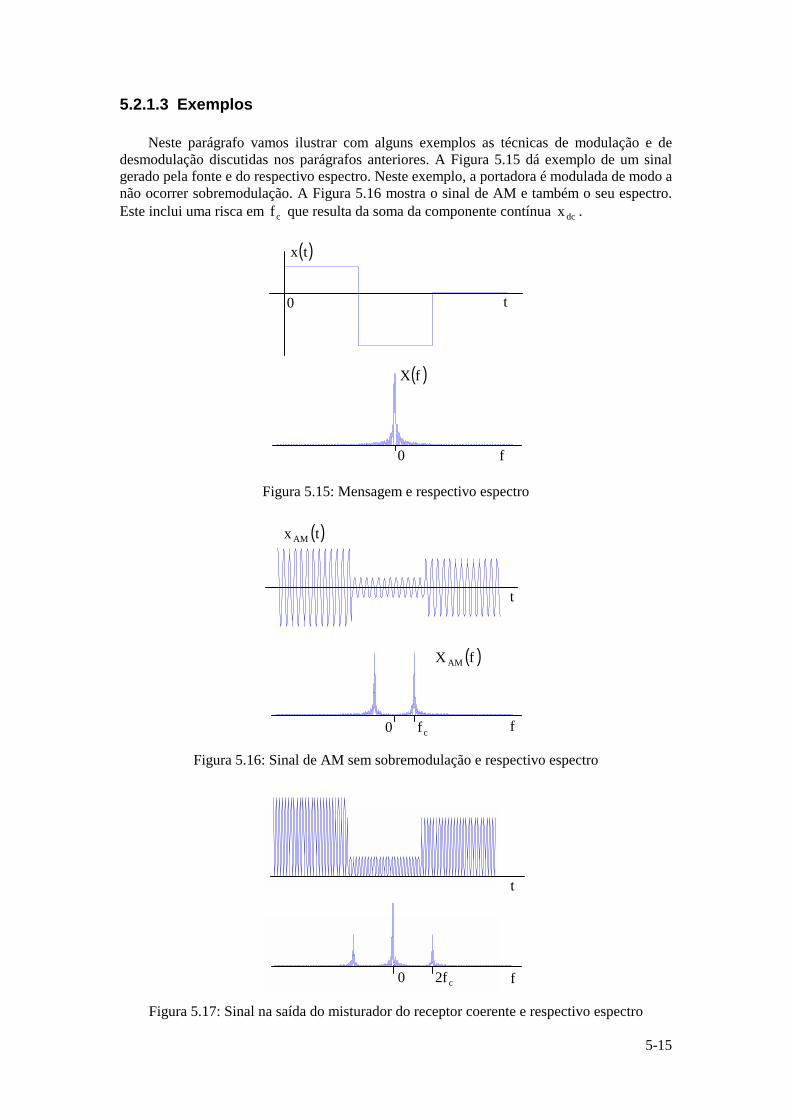
5-15
5.2.1.3 Exemplos
Neste parágrafo vamos ilustrar com alguns exemplos as técnicas de modulação e de desmodulação discutidas nos parágrafos anteriores. A Figura 5.15 dá exemplo de um sinal gerado pela fonte e do respectivo espectro. Neste exemplo, a portadora é modulada de modo a não ocorrer sobremodulação. A Figura 5.16 mostra o sinal de AM e também o seu espectro. Este inclui uma risca em cf que resulta da soma da componente contínua dcx .
Figura 5.15: Mensagem e respectivo espectro
Figura 5.16: Sinal de AM sem sobremodulação e respectivo espectro
Figura 5.17: Sinal na saída do misturador do receptor coerente e respectivo espectro
t
f
0
0
( )tx
( )fX
t
f0 cf
( )tx AM
( )fX AM
t
f0 cf2

5-16
Como se vê na Figura 5.13, onde se representa o diagrama de blocos do receptor coerente, o sinal de AM é multiplicado pela réplica da portadora gerada localmente. O resultado desta operação está ilustrada na Figura 5.17. Como se vê, o espectro do sinal resultante tem uma componente na banda de base e outra na banda centrada em cf2 . O sinal de saída do receptor coerente ( )tx está representado na Figura 5.18 (note-se que a componente contínua não foi eliminada), bem como o respectivo espectro ( )fX . Chama-se a atenção para o facto de o filtro usado não ser ideal, pelo que o sinal reconstruído apresenta alguma distorção quando comparado com o sinal original.
Figura 5.18: Saída do receptor coerente
Na Figura 5.19 está representado o sinal de saída do detector de envolvente. Mostra-se
também o sinal na saída do rectificador. Mais uma vez se chama a atenção para a ligeira distorção apresentada pelo sinal ( )tx que se deve à operação de filtragem.
Figura 5.19: Saída do detector de envolvente
5.2.2 Modulação de Ângulo
A modulação de ângulo consiste em fazer variar a fase instantânea de uma portadora sinusoidal linearmente com o sinal modulante. Tal pode ser feito actuando directamente sobre a fase ou sobre a frequência, gerando-se um sinal PM6 ou FM7, respectivamente. Vamos designar
( ) ( )ttf2t c ΦΘ +π= (5.34) por fase instantânea da portadora. Sinal PM. Neste caso
( ) ( )( )ttf2cosAt ccPM Φ+π=X , (5.35) 6 PM – Phase Modulation 7 FM – Frequency Modulation
f t0
( )fX
( )tx
( )tx
t t
saída do rectificador( )tx
( )tx

5-17
onde o desvio instantâneo de fase
( ) ( )tt X∆ϕ=Φ (5.36) é proporcional ao sinal fonte. ∆ϕ é o índice de modulação em fase. Sinal FM. Neste caso, ( )tFMX tem a mesma forma definida em (5.35), agora com
( ) ( ) ( )tftdt
td21 XF ∆==π
Φ , (5.37)
onde ( )tF é o desvio instantâneo de frequência, e ∆f é o índice de modulação em frequência. Portanto, podemos escrever
( ) ( )
ττπ+π= ∫
∞−∆
t
ccFM dXf2tf2cosAtX . (5.38)
5.2.2.1 Relação entre PM e FM
Tendo em conta as definições (5.35), (5.36) e (5.37), é fácil verificar que um modulador de fase pode ser realizado a partir de um modulador de frequência, como se ilustra na Figura 5.20. O desmodulador de fase pode também ser realizado usando um desmodulador de frequência como se vê na Figura 5.21.
Figura 5.20: Modulador PM realizado a partir de um modulador FM
Figura 5.21: Desmodulador PM realizado a partir de um desmodulador FM
Modulador PM
dtd Modulador
FM( )tx ( )tx
• ( )tx PM
Desmodulador PM
( )∫ ∞−•
tdtDesmodulador
FM
( )tx( )tx•
( )tx PM

5-18
5.2.2.2 Modulador de FM
O modulador de frequência pode ser realizado com um VCO8, isto é, um oscilador que gera uma sinusoide cuja frequência instantânea varia linearmente com atensão de entrada. A Figura 5.22 mostra a característica do VCO. A inclinação da recta é naturalmente determinada pelo índice de modulação ∆f .
Figura 5.22: Modulador FM e característica do VCO FM de banda estreita. De (5.38), e supondo que ∆f é tal que
( ) ( ) 1dxf2tt
<<ττπ=ϕ ∫∞−
∆ ,
então
( ) ( ) ( ) ( ) ( )( ) ( ) ( ). tf2sintAtf2cosA
tsintf2sinAtcostf2cosAtx
cccc
ccccFM
πϕ−π≈ϕπ−ϕπ=
Isto significa que o sinal de FM (PM) de banda estreita não é mais do que um sinal de AM cuja largura de banda é dupla da largura de banda de ( )tϕ . Note-se que a transformada de Fourier de ( )tϕ é ( ) ffXf∆ e, portanto, o sinal de FM de banda estreita terá uma largura de banda B2BT ≈ , onde B é a largura de banda do processo fonte ( )tX . FM de banda larga. No caso do sinal de FM de banda larga, temos
Bf >>∆ . (5.39) A análise do sinal de FM de banda larga não é simples, pelo que apresentaremos sem demonstrar o facto essencial.
Aproximação quasiestacionária: consideremos o sinal modulante ( )tx , função amostra de um processo estacionário ( )tX com largura de banda B e densidade de probabilidade da amplitude ( )tX , ( )xf X , invariante no tempo. Se Bffc >>>> ∆ , então o espectro de potência do sinal de FM é aproximadamente dado por
( )
−+
−−=
∆∆∆ fff
ff
fff
f22A
fG cX
cX
2c
FMX . (5.40)
8 VCO – Voltage Controlled Oscilator
VCO( )tx ( )tx FM
M
cf
( )tX
( )tF
0
( ) ( )tXfftF c ∆+=

5-19
Daqui decorre que a potência de transmissão vale
2A 2cT =P (5.41)
e que a largura de banda de transmissão é aproximadamente dada por
( )maxT tXf2B ∆≈ . (5.42)
Note-se que, verficando-se (5.39), concluímos que a largura de banda de transmissão dos sistemas FM de banda larga é, de acordo com (5.42), muito maior do que a dos sistemas AM.
5.2.2.3 Discriminador de Frequência
Consideremos o sistema da Figura 5.23, onde o detector de envolvente é o sistema da Figura 5.14.
Figura 5.23: Discriminador de frequência
Usando (5.38), podemos verificar que
( ) ( )( ) ( )
ττπ+π+π−= ∫ ∞−∆∆
• t
cccFM dxf2tf2sintxffA2tx ,
isto é, a saída do diferenciador não é mais do que uma portadora sinusoidal cuja envolvente, de acordo com as hipóteses formuladas ( )∆>> ff c , vale ( )( )txffA2 cc ∆+π . Assim
( ) ( )txfA2tx co ∆π= .
5.2.2.4 Exemplos
A Figura 5.24 mostra um sinal de FM bem como o respectivo sinal modulante. O desvio instantâneo de fase deste último está ilustrado na Figura 5.25.
Figura 5.24: Modulação de frequência: mensagem e sinal de FM
Detector de
Envolventedtd( )tx FM ( )tx FM
•( )tx o
t0
mensagem
t0
sinal de FM

5-20
Figura 5.25: Desvio instantâneo de fase do sinal de FM da Figura 5.24
Finalmente, a Figura 5.26 mostra o sinal de saída do discriminador de frequência, sobreposto com a mensagem original e devidamente escalado. Os artefactos presentes nas extremidades do referido sinal são resultado, não só do algoritmo numérico de diferenciação usado na simulação, mas também do filtro usado no detector de envolvente.
Figura 5.26: Sinal reconstruído pelo discriminador de frequência
t0
desvio instantâneo de fase
t0
mensagem reconstruída

6-1
6 Desempenho dos Sistemas de Transmissão Analógicos na Presença de Ruído
Neste capítulo estudaremos o desempenho dos sistemas de transmissão analógicos na
presença do ruído de canal. Consideraremos em particular os sistemas de transmissão em banda de base, e com modulação de portadoras sinusoidais em amplitude (AM1) e em frequência (FM2). Nestes casos, AM e FM, o canal de transmissão é do tipo passa-banda, pelo que começaremos por estudar o modelo de ruído mais adequado para estudar estes sistemas.
6.1 Ruído Passa-Banda
Como sabemos, as técnicas de modulação de portadoras sinusoidais conduzem a sinais do tipo passa-banda cujo espectro é centrado na frequência nominal da portadora. Tendo em conta que o canal introduz ruído aditivo com largura de banda muito superior à largura de banda de transmissão, será natural impor que o primeiro bloco do receptor execute uma operação de filtragem das componentes espectrais do ruído (e de outras interferências) que estejam fora da banda de transmissão. Assim sendo, a arquitectura básica de um sistema de transmissão por modulação de portadoras sinusoidais é a que se mostra no diagrama de blocos da Figura 6.1, onde ( )tW é um processo branco e gaussiano com espectro de potência
( )2
fG η=W . (6.1)
Figura 6.1: Arquitectura básica de um sistema de transmissão por modulação de portadoras sinusoidais
Deste modo, o sinal à entrada do desmodulador é
( ) ( ) ( )ttt cR NXX += , (6.2)
onde ( )tcX é o sinal transmitido (portadora modulada) e ( )tN é um processo passa-banda resultante da filtragem do ruído branco ( )tW . Como hipótese simplificativa que não interfere directamente com o assunto que iremos abordar, admitimos que o canal de transmissão é ideal. A partir de (6.1) e usando a função de transferência ( )fH definida na Figura 6.1, verificamos que o espectro de potência do ruído passa-banda é o que está representado na Figura 6.2. Como neste tipo de sistemas se verifica sempre a desigualdade Tc Bf >> , o processo passa-banda ( )tN é ainda designado por processo de banda estreita. De (6.2) concluímos que à entrada do desmodulador a componente de sinal tem uma potência
1 AM – Amplitude Modulation 2 FM – Frequency Modulation
X (t) Modulador Desmodulador
fc-fc f
1H(f)
0BT⊕
Xc (t)
W (t)
XR (t) XD (t)
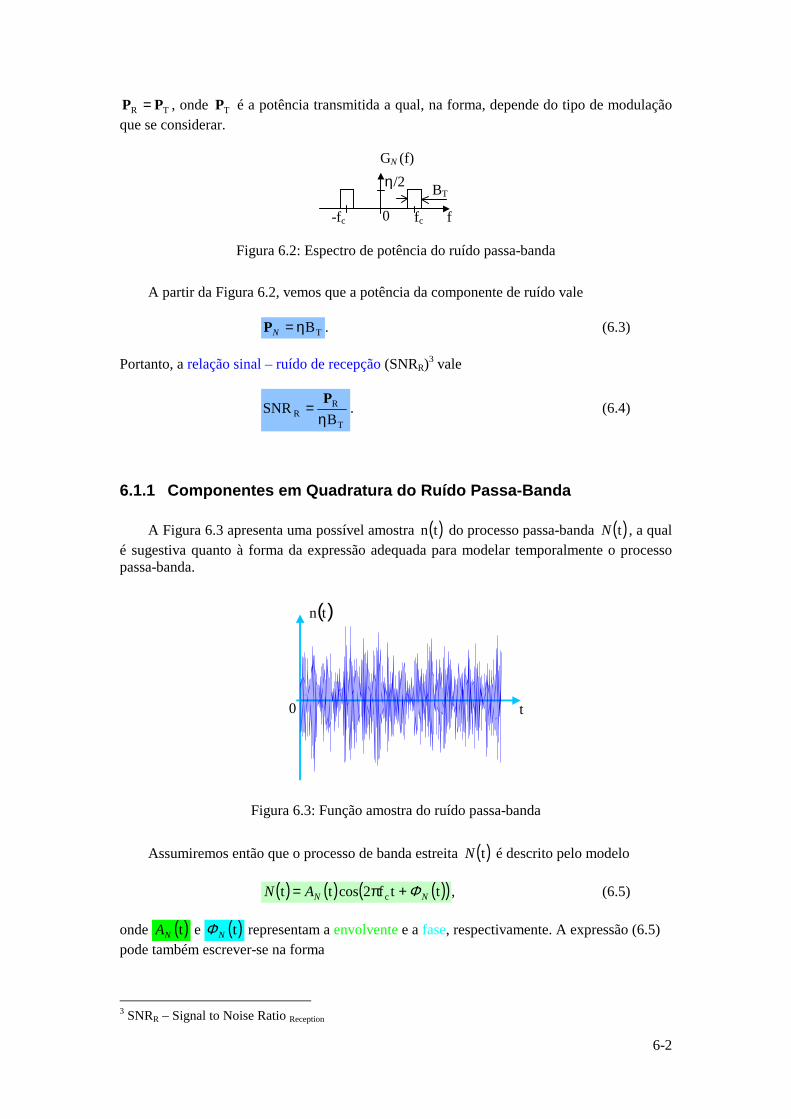
6-2
TR PP = , onde TP é a potência transmitida a qual, na forma, depende do tipo de modulação que se considerar.
Figura 6.2: Espectro de potência do ruído passa-banda
A partir da Figura 6.2, vemos que a potência da componente de ruído vale
TBη=NP . (6.3)
Portanto, a relação sinal – ruído de recepção (SNRR)3 vale
T
RR B
SNRη
=P
. (6.4)
6.1.1 Componentes em Quadratura do Ruído Passa-Banda
A Figura 6.3 apresenta uma possível amostra ( )tn do processo passa-banda ( )tN , a qual é sugestiva quanto à forma da expressão adequada para modelar temporalmente o processo passa-banda.
Figura 6.3: Função amostra do ruído passa-banda
Assumiremos então que o processo de banda estreita ( )tN é descrito pelo modelo
( ) ( ) ( )( )ttf2costt c NNAN Φ+π= , (6.5)
onde ( )tNA e ( )tNΦ representam a envolvente e a fase, respectivamente. A expressão (6.5) pode também escrever-se na forma
3 SNRR – Signal to Noise Ratio Reception
fc -fc f
η/2GN (f)
0
BT
t
( )t n
0
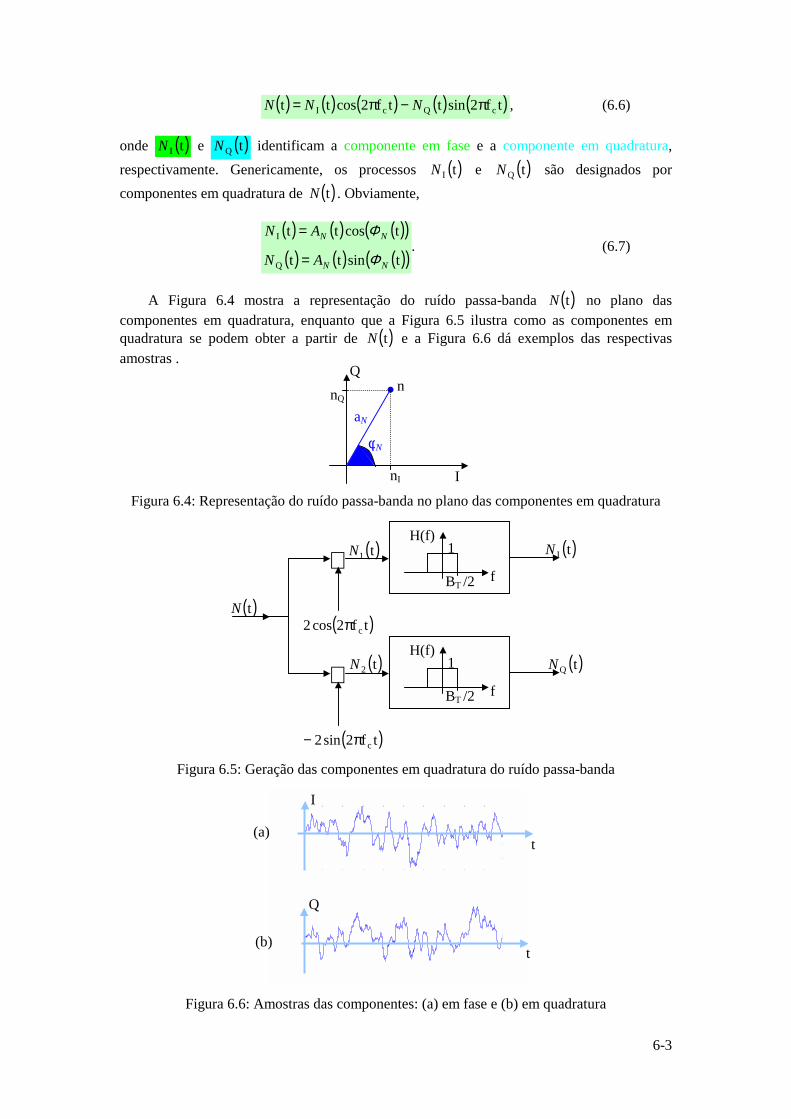
6-3
( ) ( ) ( ) ( ) ( )tf2sinttf2costt cQcI π−π= NNN , (6.6)
onde ( )tIN e ( )tQN identificam a componente em fase e a componente em quadratura, respectivamente. Genericamente, os processos ( )tIN e ( )tQN são designados por componentes em quadratura de ( )tN . Obviamente,
( ) ( ) ( )( )( ) ( ) ( )( )tsintt
tcostt
Q
I
NN
NN
AN
AN
Φ
Φ
=
=. (6.7)
A Figura 6.4 mostra a representação do ruído passa-banda ( )tN no plano das
componentes em quadratura, enquanto que a Figura 6.5 ilustra como as componentes em quadratura se podem obter a partir de ( )tN e a Figura 6.6 dá exemplos das respectivas amostras .
Figura 6.4: Representação do ruído passa-banda no plano das componentes em quadratura
Figura 6.5: Geração das componentes em quadratura do ruído passa-banda
Figura 6.6: Amostras das componentes: (a) em fase e (b) em quadratura
Q
aN
φN
InI
nQn
1H(f)
fBT /2⊗
( )tf2cos2 cπ
1H(f)
fBT /2⊗
( )tf2sin2 cπ−
( )tN
( )tIN
( )tQN
( )t1N
( )t2N
0 100 200 300 400 500 600 700 800 900 1000-60
-40
-20
0
20
40Componente em Fase
Tempo
0 100 200 300 400 500 600 700 800 900 1000-40
-20
0
20
40
60Componente em Quadratura
Tempo
Q
t
t
I
(a)
(b)

6-4
6.1.2 Propriedades das Componentes em Quadratura
Embora não o façamos aqui pode mostrar-se o seguinte
Facto 6.1: O processo de banda estreita ( )tN é gaussiano e as respectivas componentes em fase ( )tIN e em quadratura ( )tQN são conjuntamente gaussianas.
€ Do diagrama de blocos da Figura 6.5 conclui-se que os espectros de potência de ( )tIN e
de ( )tQN se obtêm ambos a partir de
( ) ( ) ( ) ( ) ( )[ ]cc2 ffGffGfHfGfG
QI−++== NNNN ,
ou seja,
( ) ( )
Πη==
TBffGfG
QI NN , (6.8)
como se mostra na Figura 6.7.
Figura 6.7: Espectro de potência das componentes em quadratura do ruído passa-banda
Como já vimos, a potência do ruído passa-banda vale TBη=NP , ver eq. (6.3), pelo que,
da observação da Figura 6.7, concluímos
TBQI
η=== NNN PPP , (6.9) isto é, a potência do ruído passa-banda é igual às potências das respectivas componentes em quadratura.
Consideremos os processos ( )t1N e ( )t2N indicados na Figura 6.5 e que se escrevem na forma
( ) ( ) ( )( ) ( ) ( )Θ+π−=
Θ+π=
tf2sint2t
tf2cost2t
c2
c1
NN
NN, (6.10)
onde Θ é uma variável aleatória com distribuição uniforme no intervalo [ ]π+π− , e independente de ( )tN 4. Nestas condições, mostra-se facilmente a partir de (6.10) que a correlação cruzada entre ( )t1N e ( )t2N é
4 Recorda-se que, de acordo com a notação que temos usado, ( )tN é a variável aleatória que modela a amplitude das amostras do processo ( )tN .
( ) ( )fGfGQI NN =
fBT /20
η

6-5
( ) ( ) ( ) ( ) ( )τπτ=
τ−=τ Θ
c
21N
f2sinR2
tNtNER21
N
NN, (6.11)
e, portanto,
( ) ( ) ( )[ ]cc ffGffGjfG21
+−−= NNNN , (6.12) como se mostra na Figura 6.8. Por outro lado, pode verificar-se que
( ) ( ) ( ) ( )∫∫ −+τ=τ2 21QI
dudv uvR vh uhR!
NNNN , (6.13)
onde ( )⋅h representa a resposta impulsional dos filtros passa-baixo ideais da Figura 6.5. De (6.13), obtém-se
( ) ( ) ( )fGfHfG21QI
2NNNN = , (6.14)
Figura 6.8: Espectro de potência cruzado entre ( )t1N e ( )t2N
pelo que, sendo ( )fH a função de transferência de um filtro passa-baixo com largura de banda BT/2, se conclui de imediato que ( ) ,f ,0fG
QI∀=NN e portanto
( ) τ=τ ∀ ,0R
QI NN , (6.15)
ou seja, as componentes em quadratura do ruído passa-banda são incorrelacionadas. Atendendo ao Facto 6.1, podemos ainda concluir que são também estatisticamente independentes. Os resultados aqui obtidos podem ser resumidos no seguinte
Facto 6.2: As componentes em fase e em quadratura do ruído passa-banda são processos conjuntamente estacionários cujos espectros de potência são definidos na eq. (6.8). Em cada instante, as respectivas amplitudes são conjuntamente gaussianas e independentes:
( ) ( ) ( ) ( ) 2
T
22
TNN vu, ,
B2vuexp
B21v,uf
QI!∈
η+−
ηπ= . (6.16)
( )fjG21NN−
f
BT
0
η/2
-η/2
2fc
-2fc

6-6
6.1.3 Propriedades da Envolvente e da Fase
Usando as relações (6.7) como a transformação ( )⋅⋅,g que, em cada instante t, relaciona a envolvente e a fase do ruído passa-banda com as amplitudes das respectivas componentes em fase e em quadratura, isto é,
NN
NN
Φ=
Φ=
sinAN
cosAN
Q
I, (6.17)
é possível, fazendo uso de (6.16), caracterizar estatisticamente a envolvente e a fase. Com efeito, recorrendo a um resultado conhecido da teoria das variáveis aleatórias (ver Cap. 2, eq. (2.80)), podemos escrever
( ) ( ) gNNA J sina,cosaf,afQI
φφ=φΦNN,
onde gJ é o Jacobeano da transformação ( )⋅⋅,g definida em (6.17). Assim, temos
( ) ( ) ( ) [ ]π+π∈φ≥
η
−ηπ
=φΦ ,- 0,a ,B2
aexpB2
a,afT
2
TA NN
.
(6.18)
Integrando (6.18) em a e em φ, obtemos as densidades de probabilidade marginais da fase e da envolvente, respectivamente. Verifica-se ainda que o produto destas densidades marginais iguala a densidade de probabilidade conjunta.
Facto 6.3: Em cada instante de tempo, a envolvente e a fase do ruído passa-banda são estatisticamente independentes e têm distribuições de Rayleigh e uniforme, respectivamente:
( )
( ) [ ]π+π∈φπ
=φ
≥
η
−η
=
Φ ,- 21f
0a B2
aexpBaaf
T
2
TA
N
N
. (6.19)
Note-se que, multiplicando as densidades de probabilidade expressas em (6.19), se obtém (6.18), o que mostra que a envolvente e a fase são estatisticamente independentes.
6.2 Desempenho dos Sistemas de Transmissão em Banda de Base
No caso da transmissão em banda de base o sinal transmitido é a própria mensagem. Esta é suposta ser um sinal amostra de um processo estacionário ( )tX tal que:
M1. mX = 0;
M2. GX tem suporte no intervalo [-B,+B] e a potência é PX .

6-7
A Figura 6.9 dá exemplo de um possível espectro de potência da mensagem.
Figura 6.9: Espectro de potência da mensagem
A arquitectura representada na Figura 6.1 simplifica-se de acordo com o diagrama de
blocos da Figura 6.10, onde
( )
Π=
B2ffH D , (6.20)
isto é, um filtro passa-baixo ideal de ganho unitário e com largura de banda igual à da mensagem.
Figura 6.10: Arquitectura de um sistema de transmissão em banda de base
Temos então
( ) ( ) ( )ttt DD NXX += , (6.21)
onde ( )tDN é a componente de ruído que resulta da filtragem do ruído branco ( )tW pelo FPBx da Figura 6.10.
O desempenho de um sistema de transmissão avalia-se pelo valor da relação sinal-ruído (SNRD)5 de saída que se define do seguinte modo:
Def. 6.1- O valor da SNRD é dado por
N
DDSNR
PP
= ,
onde PD: potência de saída quando W ≡ 0 PN: potência de saída quando X ≡ 0.
Na ausência de ruído, ( ) 0t ≡W , a saída (6.21) é apenas ( ) ( )ttD XX = , pelo que
atendendo a M2, RD PPP == X , onde RP é a potência da componente do sinal recebido que
5 SNRD – Signal to Noise Ratio Detection
FPBx ⊕X(t)
W (t)
XD (t)
( )fH D
GX (f)
f0-B B

6-8
depende da mensagem. Quando não se transmite a mensagem, ( ) 0t ≡X , a saída (6.21) só depende do ruído, ( ) ( )tt DD NX = . Usando (6.1) e (6.20), obtemos
( )
Πη=
B2f
2fG
DN
e, portanto, a potência da componente de ruído na saída vale BN η=P . Então, fazendo uso da Def. 6.1, obtemos
γ=η
=B
SNR RD
P. (6.22)
O parâmetro γ, definido em (6.22), representa a SNRD de um sistema de transmissão analógico em banda de base. Iremos usá-lo como termo de comparação dos desempenhos dos restantes sistemas de transmissão.
6.3 Desempenho dos Sistemas AM
No caso dos sistemas de modulação de amplitude, o processo ( )tcX da eq. (6.2) é dado por
( ) ( )[ ] ( )Θ+π+= tf2costxAt cdccc XX , (6.23)
onde o processo ( )tX representa a fonte e verifica as hipóteses M1 e M2 especificadas na secção 6.2 e na Figura 6.9, dcx é uma constante, e Θ é uma variável aleatória independente de ( )tX com distribuição uniforme,
( )
πθΠ
π=θΘ 22
1f . (6.24)
De acordo com estas condições, a autocorrelação do processo ( )tcX é
( ) ( )[ ] ( )τπτ+=τ c2dc
2c f2cosRx
2A
Rc XX (6.25)
a que corresponde um espectro de potência
( ) ( ) ( )[ ] ( ) ( )[ ] cccc2dc
2c ffGffGffffx
4A
fGc
−+++−δ++δ= XXX ,
(6.26) ilustrado na Figura 6.11. A potência transmitida e a largura de banda de transmissão são respectivamente dadas por
( )XPP += 2dc
2c
T x2
A (6.27)
e B2BT = . (6.28)

6-9
Figura 6.11: Espectro de potência do sinal de AM
Sem perda de generalidade, consideremos a seguinte função amostra do processo passa-
banda ( )tcX
( ) ( )[ ] ( )tf2costxxAtx cdccc π+= , (6.29) a qual tem componentes em fase e em quadratura
( ) ( )[ ]( ) 0tx
txxAtx
Q
I
c
dccc
=
+= (6.30)
como se mostra na Figura 6.12, onde se representa (6.29) no plano das componentes em quadratura. Como se vê, a fase é nula quando não existe sobremodulação (Figura 6.12-(a)); quando existe sobremodulação a fase dá saltos de ±π nos instantes t0 em que ( )0dc txx + cruza a origem.
Figura 6.12: Sinal de AM no plano das componentes em quadratura: (a) sem sobremodulação; (b) com sobremodulação
Voltando à eq. (6.2) e à Figura 6.1, e tendo em conta (6.23), verificamos que o sinal à
entrada do receptor é dado por
( ) ( )[ ] ( ) ( )ttf2costxAt cdccR NXX +Θ+π+= , (6.31) onde ( )tN é o ruído passa-banda estudado na secção 6.1. Usando (6.9), (6.27) e (6.28), podemos escrever
[ ]B2B
x2
A
SNR R
T
2dc
2c
Rc
η=
η
+==
PP
PP X
N
X , (6.32)
ou, usando (6.22),
( ) ( )[ ]cc2dc
2c ffGffx
4A
−+−δ X( ) ( )[ ]cc2dc
2c ffGffx
4A
+++δ X
( )fGcX
f 0
BT = 2B
fc -fc
I
Q
Acxdc
xc(t)
I
Q
Acxdc
xc(t)
(a) (b)
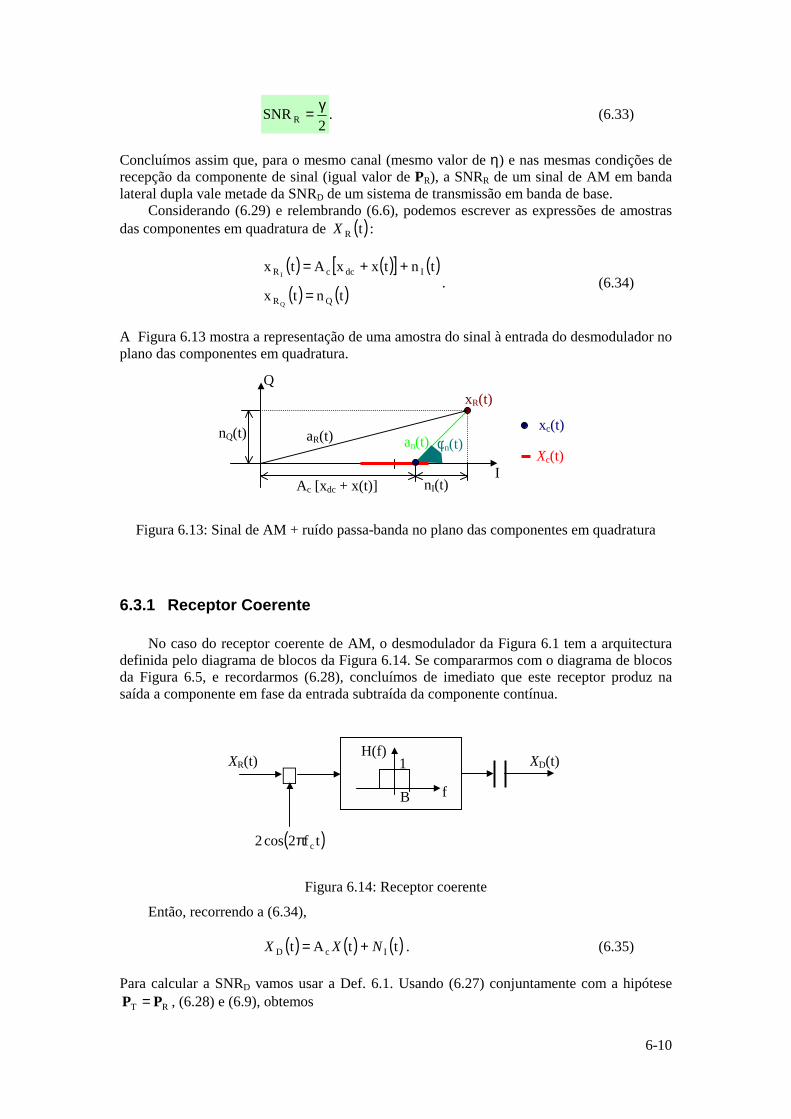
6-10
2SNR R
γ= . (6.33)
Concluímos assim que, para o mesmo canal (mesmo valor de η) e nas mesmas condições de recepção da componente de sinal (igual valor de PR), a SNRR de um sinal de AM em banda lateral dupla vale metade da SNRD de um sistema de transmissão em banda de base.
Considerando (6.29) e relembrando (6.6), podemos escrever as expressões de amostras das componentes em quadratura de ( )tRX :
( ) ( )[ ] ( )( ) ( )tntx
tntxxAtx
QR
IdccR
Q
I
=
++=. (6.34)
A Figura 6.13 mostra a representação de uma amostra do sinal à entrada do desmodulador no plano das componentes em quadratura.
Figura 6.13: Sinal de AM + ruído passa-banda no plano das componentes em quadratura
6.3.1 Receptor Coerente
No caso do receptor coerente de AM, o desmodulador da Figura 6.1 tem a arquitectura definida pelo diagrama de blocos da Figura 6.14. Se compararmos com o diagrama de blocos da Figura 6.5, e recordarmos (6.28), concluímos de imediato que este receptor produz na saída a componente em fase da entrada subtraída da componente contínua.
Figura 6.14: Receptor coerente
Então, recorrendo a (6.34),
( ) ( ) ( )ttAt IcD NXX += . (6.35) Para calcular a SNRD vamos usar a Def. 6.1. Usando (6.27) conjuntamente com a hipótese
RT PP = , (6.28) e (6.9), obtemos
I
Q
aR(t)
Ac [xdc + x(t)] nI(t)
nQ(t) an(t) φn(t)
xR(t)
xc(t)
Xc(t)
1H(f)
fB
⊗
( )tf2cos2 cπ
XR(t) XD(t)

6-11
( )
B2
xA2
N
2dccRD
η=
−=
P
PP (6.36)
e, tendo em conta (6.22),
( )γ
−=
2xA1SNR
R
2dcc
D P. (6.37)
Note-se que o factor
( )X
X
PP
PP
P +=−=−=ζ 2
dcR
p
R
2dcc
x 1
2xA1 , (6.38)
onde ( ) 2xA 2
dccp =P é a potência gasta na transmissão da portadora, mede precisamente a percentagem da potência total transmitida usada na transmissão da mensagem. No caso dos sistemas de transmissão AM que usam o receptor coerente, a transmissão da portadora destina-se à sincronização do oscilador local, podendo ser usados valores de ζ bastante próximos dos 100%. Este é um valor limite apenas atingível no caso da modulação AM em banda lateral dupla com supressão de portadora, para o qual (6.38) toma a forma particular
γ= SNR D . (6.39)
6.3.2 Detector de Envolvente
Como é sabido, o detector de envolvente é um receptor de AM (em termos de realização prática, mais simples do que o receptor coerente) que pode ser usado exclusivamente no caso em que não há sobremodulação, isto é, quando com probabilidade muito elevada
( ) 0tXx :t dc ≥+∀ , onde ( )tX é a variável aleatória que modela em cada instante t a amplitude da mensagem. Esta é a situação ilustrada na Figura 6.13, onde ( )ta R representa a função amostra da envolvente do sinal recebido. A Figura 6.15 mostra a arquitectura do detector de envolvente.
Figura 6.15: Detector de envolvente
Por observação da Figura 6.13, verificamos que
( ) ( )( ) ( )[ ] ( )[ ]( ) 212
Q2
IdccR tttxAt NNXA +++= , (6.40)
FPBx LB = B
rectificador
XR(t) AR(t) XD(t)

6-12
ficando claro que ( )tRA depende de modo não linear quer da mensagem quer do ruído. Este facto dificulta uma análise rigorosa do desempenho do detector de envolvente, pelo que iremos fazer uso de algumas simplificações as quais, no entanto, permitem ainda retirar alguns resultados fundamentais. Comecemos por considerar as duas situações limite: ruído forte e ruído fraco. Ruído forte. Neste caso, a eq. (6.40) pode escrever-se na forma
( ) ( )[ ] ( )[ ] ( ) ( )
( ) ( )( ) 1tt
2t
tttxA2txAt
I2
2Idcc
2dc
2cR
+ε+ε=
++++=
NN
N
AN
A
ANXXA
(6.41) onde
( ) ( ) ( )
( )[ ]( ) . t
txA
ttt
dcc
2Q
2I
N
N
AX
NNA
+=ε
+=
Na situação de ruído forte podemos assumir que durante a maior parte do tempo (com elevada probabilidade) ( ) ( )[ ] 0txAt dcc ≈ε⇔+>> XAN e, portanto, tomando a aproximação de 1ª ordem do desenvolvimento em série de Taylor de (6.41), obtemos
( ) ( ) ( )[ ] ( )( ) ( ) ( )[ ] ( )tcostxAtt
ttxAtt dcc
IdccR NN
NN XA
ANX
AA Φ++=+
+≈ ,
Nestas condições, a saída do detector de envolvente é constituída por duas parcelas: a primeira é a envolvente do ruído, e na segunda o sinal é mutilado por um factor multiplicativo que depende da fase do ruído. Em conclusão, quando a SNRR é baixa, a saída do detector de envolvente não tem componente de sinal, tornando-se inútil o seu uso para obter uma reconstrução da mensagem. Ruído fraco. Neste caso, fazemos
( ) ( )[ ] ( )[ ] ( ) ( )
( )[ ] ( )( ) 1tt
2txA
tttxA2txAt
I2dcc
2Idcc
2dc
2cR
+ε+ε+=
++++=
N
N
ANX
ANXXA
com ( )
( )[ ]txAt
dcc XAN
+=ε .
Recorrendo à mesma metodologia usada na situação anterior, obtemos
( ) ( )[ ] ( )ttxAt IdccR NXA ++≈ . (6.42) Conclusão. A qualidade do desempenho do detector de envolvente em presença de ruído é fortemente condicionada pelo valor de SNRR. Para valores baixos de SNRR, a mensagem é eliminada pelo ruído na saída do detector de envolvente. Para valores elevados de SNRR, o

6-13
detector de envolvente funciona de modo aproximadamente equivalente ao receptor coerente. Estes factos sugerem a existência de um limiar de SNRR abaixo do qual o desempenho do detector de envolvente se degrada drasticamente, correspondendo à mutilação da mensagem. Para valores de SNRR acima daquele limiar, a expressão (6.37) dá o valor aproximado de SNRD,
( )γ
−≈
2xA1SNR
R
2dcc
D P. (6.43)
Importa ainda realçar uma diferença fundamental entre o desempenho do detector de
envolvente acima do limiar e o do receptor coerente. Neste último, o factor ζ definido em (6.38) pode, no limite, atingir os 100% conduzindo ao máximo valor possível de SNRD dado por (6.39) e que corresponde à supressão da portadora. No caso do detector de envolvente, tal é impossível pois é necessário garantir a condição ( ) .t ,0tXx dc ∀≥+ Por exemplo, se escolhermos XP=dcx , vem 21=ζ e (6.43) dá 2SNR D γ≈ . Neste caso, e supondo que a densidade de probabilidade de ( )tX é uma função par, verifica-se a partir da desigualdade de Chebyshev que a probabilidade de ocorrer sobremodulação é limitada superiormente por 1/2, valor demasiado elevado para garantir um bom desempenho do detector de envolvente ainda que na ausência de ruído. Mesmo assim, usaremos esta situação para estabelecer o limite superior de SNRD:
2SNR D
γ≤ . (6.44)
6.4 Desempenho dos Sistemas FM de Banda Larga
No caso do receptor de FM o sinal de entrada do desmodulador, ver Figura 6.1, é
( ) ( )( ) ( )tttf2cosAt ccR NX ++π= Φ , (6.45) onde o desvio de fase ( )tΦ verifica a relação
( ) ( ) ( )tfdt
td21t XF ∆=π
= Φ . (6.46)
Como se vê, o desvio de frequência ( )tF é proporcional à mensagem ( )tX que se admite ser um processo ergódico. Sem perda de generalidade, vamos assumir que a mensagem verifica a seguinte restrição
( ) 11tXP ≈≤ , ou seja, a amplitude do sinal modulante é, em valor absoluto, e durante a maior parte do tempo inferior à unidade. Portanto, podemos assumir que a densidade de probabilidade ( )⋅Xf da variável aleatória ( )tX é definida no intervalo [ ]1,1 +− . Sendo válida a aproximação quasiestacionária, é sabido que o espectro de potência do sinal de FM é aproximadamente dado por

6-14
( )
−+
−−=
∆∆∆ fff
ff
fff
f22A
fG cX
cX
2c
cX . (6.47)
Portanto, a potência de transmissão e a largura da banda de transmissão valem, respectivamente,
. f2B
2A
T
2cT
∆≈
=P (6.48)
Usando (6.7), podemos tirar as componentes em quadratura do sinal recebido e definido em (6.45)
( ) ( )( ) ( ) ( )( )( ) ( )( ) ( ) ( )( )tsinttsinAt
tcosttcosAt
cR
cR
Q
I
NN
NN
AX
AX
ΦΦ
ΦΦ
+=
+=
bem como a envolvente
( ) ( ) ( ) ( ) ( )( )ttcostA2tAt c22
cR NNN AAA ΦΦ −++= e a fase
( ) ( )( ) ( ) ( )( )( )( ) ( ) ( )( )tcosttcosA
tsinttsinAarctgt
c
cR
NN
NN
AA
ΦΦΦΦΦ
++
= . (6.49)
Como se vê, a envolvente do sinal recebido não é constante no tempo o que impõe a inclusão de um limitador na entrada do discriminador de frequência, como se mostra na Figura 6.16, onde o discriminador de frequência inclui o diferenciador, o detector de envolvente e o condensador de bloqueio da componente contínua. O sinal na saída do limitador é
( ) ( )( )tcosAt RL Φ=X .
Figura 6.16: Desmodulador de frequência
Atendendo a (6.3), (6.22) e (6.48), podemos escrever
γ
=
∆
fB
21SNR R , (6.50)
o que, relembrando que em FM de banda larga Bf >>∆ , e quando comparado com (6.33), mostra que, para a mesma potência de transmissão e para o mesmo canal, as condições de recepção em FM são muito piores que as disponíveis em AM.
Como se vê na Figura 6.16, a saída do desmodulador de frequência é o sinal
( )tRXLimitador
Discriminador de
frequência
( )tLX ( ) ( )dt
td21t R
DΦ
π=X
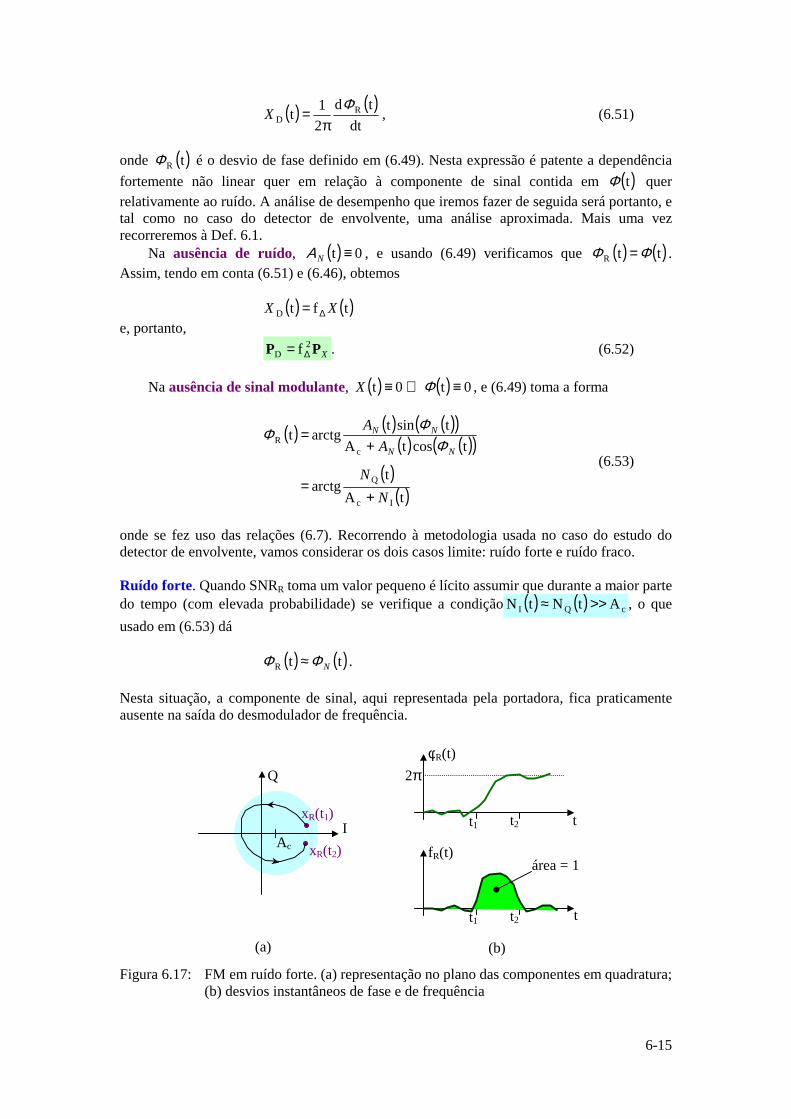
6-15
( ) ( )dt
td21t R
DΦ
π=X , (6.51)
onde ( )tRΦ é o desvio de fase definido em (6.49). Nesta expressão é patente a dependência fortemente não linear quer em relação à componente de sinal contida em ( )tΦ quer relativamente ao ruído. A análise de desempenho que iremos fazer de seguida será portanto, e tal como no caso do detector de envolvente, uma análise aproximada. Mais uma vez recorreremos à Def. 6.1.
Na ausência de ruído, ( ) 0t ≡NΑ , e usando (6.49) verificamos que ( ) ( )ttR ΦΦ = . Assim, tendo em conta (6.51) e (6.46), obtemos
( ) ( )tftD XX ∆= e, portanto, XPP 2
D f∆= . (6.52)
Na ausência de sinal modulante, ( ) ( ) 0t0t ≡⇔≡ ΦX , e (6.49) toma a forma
( ) ( ) ( )( )( ) ( )( )
( )( )tA
tarctg
tcostAtsint
arctgt
Ic
Q
cR
NN
AA
NN
NN
+=
+=
ΦΦΦ
(6.53)
onde se fez uso das relações (6.7). Recorrendo à metodologia usada no caso do estudo do detector de envolvente, vamos considerar os dois casos limite: ruído forte e ruído fraco. Ruído forte. Quando SNRR toma um valor pequeno é lícito assumir que durante a maior parte do tempo (com elevada probabilidade) se verifique a condição ( ) ( ) cQI AtNtN >>≈ , o que usado em (6.53) dá
( ) ( )ttR NΦΦ ≈ . Nesta situação, a componente de sinal, aqui representada pela portadora, fica praticamente ausente na saída do desmodulador de frequência.
Figura 6.17: FM em ruído forte. (a) representação no plano das componentes em quadratura; (b) desvios instantâneos de fase e de frequência
Ac
xR(t1)
xR(t2)I
Q
t1 t2
t1 t2
área = 1
2πφR(t)
fR(t)
t
t
(a) (b)
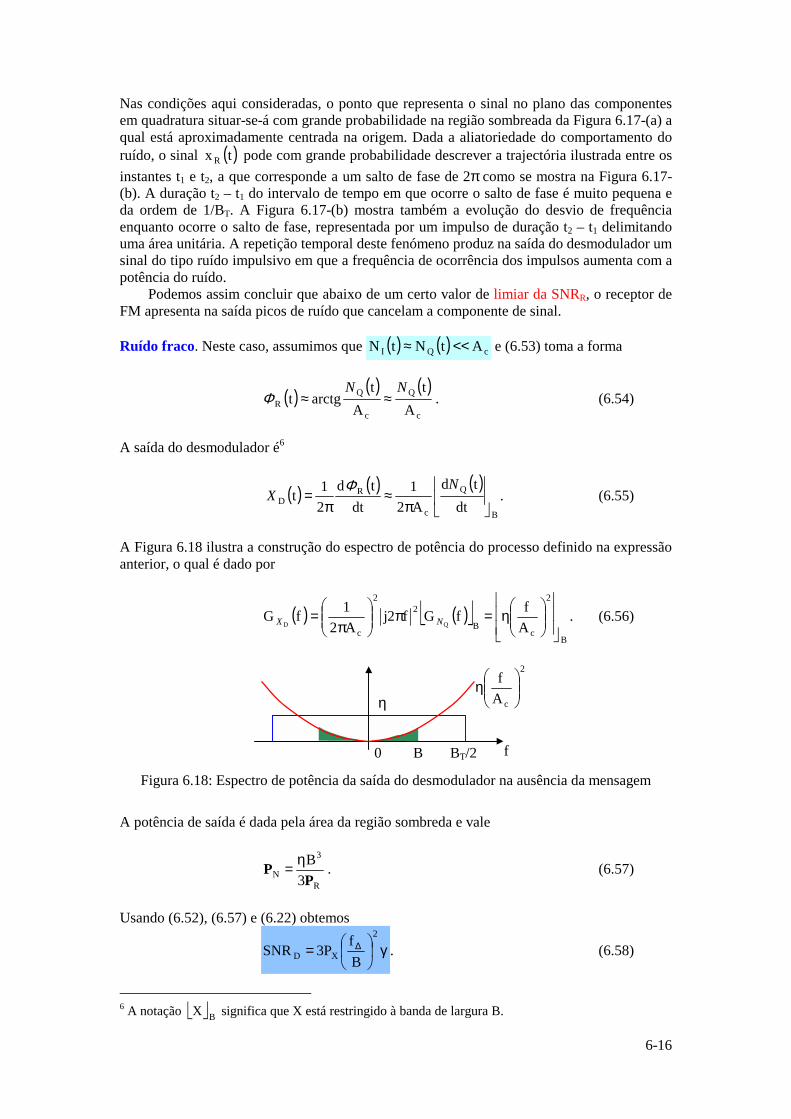
6-16
Nas condições aqui consideradas, o ponto que representa o sinal no plano das componentes em quadratura situar-se-á com grande probabilidade na região sombreada da Figura 6.17-(a) a qual está aproximadamente centrada na origem. Dada a aliatoriedade do comportamento do ruído, o sinal ( )tx R pode com grande probabilidade descrever a trajectória ilustrada entre os instantes t1 e t2, a que corresponde a um salto de fase de 2π como se mostra na Figura 6.17-(b). A duração t2 – t1 do intervalo de tempo em que ocorre o salto de fase é muito pequena e da ordem de 1/BT. A Figura 6.17-(b) mostra também a evolução do desvio de frequência enquanto ocorre o salto de fase, representada por um impulso de duração t2 – t1 delimitando uma área unitária. A repetição temporal deste fenómeno produz na saída do desmodulador um sinal do tipo ruído impulsivo em que a frequência de ocorrência dos impulsos aumenta com a potência do ruído.
Podemos assim concluir que abaixo de um certo valor de limiar da SNRR, o receptor de FM apresenta na saída picos de ruído que cancelam a componente de sinal. Ruído fraco. Neste caso, assumimos que ( ) ( ) cQI AtNtN <<≈ e (6.53) toma a forma
( ) ( ) ( )c
Q
c
QR A
tA
tarctgt
NN≈≈Φ . (6.54)
A saída do desmodulador é6
( ) ( ) ( )B
Q
c
RD dt
tdA21
dttd
21t
π
≈π
=N
XΦ
. (6.55)
A Figura 6.18 ilustra a construção do espectro de potência do processo definido na expressão anterior, o qual é dado por
( ) ( ) B
2
cB
22
c AffGf2j
A21fG
QD
η=π
π
= NX . (6.56)
Figura 6.18: Espectro de potência da saída do desmodulador na ausência da mensagem
A potência de saída é dada pela área da região sombreda e vale
R
3
N 3BP
P η= . (6.57)
Usando (6.52), (6.57) e (6.22) obtemos
γ
= ∆2
XD Bf
P3SNR . (6.58)
6 A notação BX significa que X está restringido à banda de largura B.
2
cAf
η
BT/2B
η
f0

6-17
Portanto, acima do limiar, a SNRD do receptor de FM cresce com o quadrado da razão entre as larguras de banda de transmissão e da mensagem. No entanto, é necessário ter em conta que um aumento indiscriminado de ∆f conduz a uma degradação significativa da SNRR, como se verifica facilmente a partir de (6.40). O crescimento da banda de transmissão com o consequente acréscimo da qualidade da reconstrução da mensagem tem de ser controlado por forma a garantir que a SNRR seja ainda superior ao valor do limiar.
6.5 Desempenho dos Sistemas PCM em Presença de Ruído de Canal
Consideremos um sistema de transmissão PCM que usa um código binário natural de comprimento ν . Devido à presença de ruído de canal existe sempre uma probabilidade não nula de ocorrerem erros de transmissão, i.e., trocas de bits. Para cada amostra ( )aa kTx do sinal original, o quantizador gera o símbolo ( )aQ kTx , e é transmitida a palavra de código correspondente, i.e., o vector binário kx de comprimento ν . Na ausência de ruído, o receptor reconstruiria o vector kx sem erros. No entanto, no caso geral obtém-se
knkk εεεε+= xy , (6.59)
onde knεεεε é o vector de erro, i.e., um vector binário de comprimento ν com "1" nas posições onde ocorrem os erros de transmissão (troca de bits) e "0" nas restantes. Na saída do descodificador obtém-se
( ) ( ) ( )anaQa kTkTxkTy ε+=
ou, tendo em conta (4.10),
( ) ( ) ( ) ( )anaaa kTkTekTxkTy ε++= , (6.60)
onde ( )akTe é o erro de quantização e
( ) ∑ν
=
−ε∆=ε1j
kjnan1j2kT (6.61)
é o erro resultante dos erros de transmissão. A saída do filtro de reconstrução, quando a entrada é dada por (6.60) é então
( ) ( ) ( ) ( )ttetxty nε++= , (6.62)
onde ( )tx é o sinal original, ( )te é o ruído de quantização e ( )tnε é o termo residual de ruído resultante dos erros de transmissão provocados pelo ruído de canal.
A relação sinal - ruído de saída do receptor PCM é definida por
ne
xDSNR
PPP+
= , (6.63)
onde xP é a potência do sinal original, eP é a potência do ruído de quantização, e nP é a potência do ruído residual. Com base num raciocínio semelhante ao que foi usado no capítulo 4 para calcular a potência do ruído de quantização, pode concluir-se que a potência do ruído residual é aproximada por

6-18
( )
. 1j4E
1j2EkTE
1j 1ikinkjn
2
2
1jkjn
2a
2nn
∑∑
∑
ν
=
ν
=
ν
=
−εε∆=
−ε∆=ε≈P
Seja eP a probabilidade de ocorrer um erro de transmissão e vamos supor que estes erros são independentes. Então, o vector knεεεε é constituído por símbolos binários "1" e "0"
estatisticamente independentes e com probabilidades de ocorrência eP e eP1− , respectivamente. Assim sendo,
( )( ) ( )
≠=−××+−×××+××==−×+×=εε
ij, PP100P1P012P11ij, PP10P1E 2
e2
eee2e
ee2
e2
kinkjn
Admitindo que 1Pe << , então os termos em 2eP podem ser desprezados, obtendo-se
3
14P 1j4P e2
1je
2n
−∆=−∆≈νν
=∑P . (6.64)
Tendo em conta (4.17) e (6.64), de (6.63) resulta
( )[ ] 1e2
xD 14P41
12SNR
−ν −+∆
=P
. (6.65)

7-1
7 Teoria da Detecção e da Estimação em Problemas de Telecomunicações
Neste capítulo iremos introduzir os conceitos fundamentais da Teoria da Detecção e da
Estimação bem como as técnicas básicas de processamento de sinal que decorrem da sua aplicação em problemas típicos das telecomunicações. As técnicas que iremos considerar, embora introduzidas naquele âmbito encontram aplicação em muitas outras áreas da engenharia e, em particular, na robótica.
7.1 Modelo Conceptual de um Sistema de Comunicação Digital
De seguida iremos abordar alguns tópicos da Teoria da Detecção e da Estimação com aplicação nos sistemas de comunicação digital que temos vindo a estudar. Comecemos por recordar o modelo conceptual de um sistema de comunicação digital ilustrado na Figura 7.1.
Figura 7.1: Modelo conceptual de um sistema de comunicação digital
A fonte de informação gera símbolos im de um alfabeto M-ário a uma taxa T/1r = símbolos por segundo (baud). Como é sabido, o transmissor faz corresponder a cada símbolo um sinal de energia de duração finita T, ( )tsi . O conjunto destes sinais forma um espaço vectorial (espaço de sinal) de dimensão finita MN ≤ , o qual pode ser representado por uma base ortonormada de sinais ( )tnφ , .N,,2,1n K= A cada sinal ( )tsi corresponde assim um vector1
M,,1,2,i ,
s
s
s
iN
2i
1i
i KM
=
=s (7.1)
cujos componentes se obtêm por projecção ortogonal de ( )tsi em cada um dos sinais da base ( )tnφ , ,N,,2,1n K= isto é,
( ) ( ) N.1,2,n M,,1,2,i , dt t ts,ssT
0 niniin KK ==φ=φ= ∫
(7.2)
Em termos operacionais, estes componentes obtêm-se recorrendo a um banco de correladores como se mostra na Figura 7.2-(a). Por outro lado, dado o vector is , pode sintetizar-se o sinal ( )tsi usando a combinação linear
( ) ( ) M.,1,2,i , tstsN
1nnini K=φ=∑
=
(7.3)
1 Vectores e matrizes serão denotados por letras a bold minúsculas e maiúsculas, respectivamente.
Fonte Transmissor
vectorial Modulador Canal
ruídoTransmissor Receptor
imis ( )tsi
( )tx
xDetector
Receptor vectorial
m

7-2
Esta operação de síntese pode ser realizada como se mostra na Figura 7.2-(b). Sublinhe-se ainda que, de acordo com a relação de Parseval, a energia do sinal ( )tsi é dada por
( ) M.,1,2,i , sdt tsEN
1n
2in
T
02ii K=== ∑∫
= (7.4)
Figura 7.2: (a) banco de correladores; (b) síntese de ( )tsi
Sobre o canal de transmissão assumem-se as seguintes hipóteses:
H1. é um sistema linear invariante que não introduz distorção sobre os sinais transmitidos;
H2. introduz ruído aditivo branco gaussiano. Deste modo, e para cada intervalo de sinalização, o sinal de saída do canal de transmissão vem dado por
( ) ( ) ( ) M,,1,2,i T,t0 , ttst i K=≤≤+= WX (7.5)
onde W(t) representa o ruído de média nula, cujas funções de autocorrelação e densidade espectral de potência são, respectivamente,
( ) ( )τδη=τ2
RW (7.6)
e
( ) .2
fG η=W (7.7)
O problema que aqui se põe é o de, dada a observação x(t) (amostra do processo X(t)) ou a sua representação equivalente x no espaço de sinal, determinar o símbolo transmitido .mi A representação equivalente x obtém-se por projecção ortogonal usando o banco de correladores representado na Figura 7.2-(a). Na hipótese de ter sido transmitido o sinal ( )tsi , então
( ) ( ) ( ) M,,1,2,i , ttst :H ii K=+= WX (7.8)
a saída de cada correlador é constituída por uma componente nx dada por N.1,2,n , ws,w,s ,xx ninnninn K=+=φ+φ=φ=
(7.9)
( )t2φ
( )dt T
0∫ •
( )dt T
0∫ •
( )dt T
0∫ •
M
⊗
⊗
⊗
( )t1φ
( )tNφ
( )tsi
1is
2is
iNs
( )tsi
⊗
( )t2φ
⊗
⊗
( )t1φ
( )tNφ
1is
2is
iNs
⊕
M
(a) (b)

7-3
Em notação vectorial, pode escrever-se
M,,1,2,i , :H ii K=+= wsx (7.10) onde w representa o vector de ruído cujas componentes estão definidas em (7.9). A Figura 7.3 dá conta da interpretação geométrica do modelo (7.10). É a partir deste modelo que o receptor tem de identificar o símbolo transmitido no intervalo de sinalização correspondente, naturalmente baseado num critério de optimização do respectivo desempenho, por exemplo, a probabilidade de erro por símbolo. Para resolver este problema é conveniente começar por caracterizar o vector de ruído w.
Figura 7.3: Representação do sinal observado x(t) no espaço de sinal
7.2 Resposta de um Banco de Correladores a Ruído Branco Gaussiano
Da definição de produto interno (7.2), concluímos que
( ) ( ) N.,1,2,n , dt t tw,wwT
nnn K=φ=φ= ∫= (7.11)
Note-se que as componentes de w se obtêm através de uma transformação linear de um processo gaussiano e, portanto, são também gaussianas. Como W(t) tem média nula, o vector w tem também média nula. Por outro lado, usando (7.11) pode escrever-se
( ) ( ) ( ) ( )
ννφνµµφµ= ∫∫T
0n
T
0nmn d wd wEwwE .
Rearranjando termos, permutando o operador valor expectável com a integração, e tendo em conta (7.6),
( ) ( ) ( ) ( )
( ) ( ) ( )
( ) ( )
≠
=η=µµφµφη=
νµνφµφν−µδη=
νµνφµφνµ=
∫
∫∫
∫∫
mn , 0
mn , 2d
2
dd 2
dd w wEwwE
T
0nn
T
0nn
T
0
T
0nn
T
0mn
isto é, a matriz de covariância do vector aleatório w é dada por
si wx
x(t)
w(t)

7-4
NT
2E IwwCw
η== . (7.12)
onde NI é a matriz identidade de dimensão N. Portanto, em (7.10), o vector de ruído é gaussiano, tem média nula e matriz de covariância dada por (7.12). Assim, tendo em conta que a função densidade de probabilidade de um vector gaussiano x, N-dimensional, de média
xm e matriz de covariância
( )( ) TE xxx mxmxC −−= é dada por
( ) ( ) ( ) ( ) ( )
−−−π= −−−
xxxx muCmuCu 1212N
21expdet2f ,
(7.13) a função densidade de probabilidade do vector de ruído na saída do banco de correladores é
( ) ( ) ( )T12N expf uuuw−− η−πη= . (7.14)
7.3 Critério de Bayes: Receptor de Máxima Verosimilhança
Para simplificar o problema vamos considerar o caso de uma fonte binária, M=2, cujos símbolos têm probabilidades de ocorrência 0p e 1p , respectivamente. Sejam 0H e 1H as hipóteses que se verificam pela transmissão dos sinais ( )ts0 e ( )ts1 , correspondentes aos símbolos 0m e 1m , respectivamente. Teremos assim
( ) ( ) ( ) wsx +=→+= 000 twtst x:H (7.15)
( ) ( ) ( ) wsx +=→+= 111 twtst x:H . (7.16) A Figura 7.4 ilustra de forma simbólica o sistema de comunicação binário cujo receptor se pretende construir. O canal de transmissão é regido por um mecanismo de transição caracterizado pelas funções
0H|f x e 1H|f x , isto é, as densidades de probabilidade das
observações condicionadas pela vericação das hipóteses 0H e 1H , respectivamente. Tendo em conta as relações (7.15) e (7.16), e sabendo que w é um vector gaussiano de média nula e matriz de covariância dada por (7.12), isto é, ( )( )N2/,N~ I0w w η , (ver(7.14)), conclui-se que ( )( )N00 2/,N~H| Isx x η e ( )( )N11 2/,N~H| Isx x η , ou seja, (ver (7.13)),
( ) ( )
−
η−πη= − 2
02N
H1expf
0suux (7.17)
( ) ( )
−
η−πη= − 2
12N
H1expf
1suux . (7.18)

7-5
Figura 7.4: Representação simbólica de um sistema de comunicações binário
Seja Z o espaço de observações, o qual, no presente contexto, se identifica com o espaço de sinal . O problema de identificação dos símbolos transmitidos resume-se à determinação de uma partição [ ]10 Z,Z de Z tal que: se a observação 0Z∈x , então o receptor decide pela hipótese 0H e, caso contrário, pela hipótese 1H . De acordo com o critério de Bayes, as regiões 0Z e 1Z são escolhidas por forma a minimizar a função de custo
.a verdadeiré H|Hdecidir PrpC
a verdadeiré H|Hdecidir PrpC
a verdadeiré H|Hdecidir PrpC
a verdadeiré H|Hdecidir PrpC
10101
11111
01010
00000
+
+
+
=ℜ
(7.19)
Na expressão anterior, 10C e 01C são os factores de risco que penalizam as decisões erradas, enquanto que 00C e 11C penalizam as decisões correctas. Em geral, é razoável escolher os factores de custo de modo que 0010 CC > e 1101 CC > . Em particular, se fizermos
====
, 1CC0CC
1001
1100
e
−==
, p1ppp
1
0
então a função de custo (7.19) degenera na probabilidade de erro
( ) ( ) 0110
1001e
ZH|xPrp1ZH|xPrp
a verdadeiré H|Hdecidir Prp1a verdadeiré H|Hdecidir PrpP
∈−+∈=
−+=
ou seja,
( ) ( ) ( )∫∫ −+=0 11 0 Z H|Z H|e dfp1dfpP uuuu xx . (7.20)
Uma vez que
Fonte x
xZ0
Z1
Z1
fx|H1
fx|H0
decide H1
decide H0
espaço de observações
Z

7-6
( ) ( ) ( )∫∫∫ −==∪=0 01 00 Z H|Z H|Z H|10 df1dfe 1df,ZZZ uuuuuu xxx ,
então minimizar (7.21) é o mesmo que minimizar
( ) ( ) ( )[ ] ∫ −−+=0 01Z H|H|e dpffp1pP uuu xx . (7.22)
A primeira parcela do lado direito de (7.22) é um parâmetro fixo, enquanto que a segunda representa o custo (em termos de probabilidade de erro) que é controlado pelos pontos x que são atribuídos à região 0Z . Por outro lado, os dois termos entre [ ] são ambos positivos. Então, os vectores x para os quais o segundo destes termos é superior ao primeiro devem ser atribuídos à região 0Z , pois só assim contribuem para diminuir o valor do integral. Ao contrário, os vectores x que contribuiriam positivamente para o valor do integral devem ser atribuídos à região 1Z . Nestas condições, a regra de decisão que deve ser realizada pelo receptor de modo a minimizar a probabilidade de erro é a seguinte
( )( ) ( ) ( ) γ<
>λ⇔−<
>
0
1
0
1
0
1
H
H
H
H
H|
H|
p1p
ff
xxx
x
x , (7.23)
onde ( )xλ é a razão de verosimilhança e γ é o limiar de decisão. Note-se que a equação em x
( ) γ=λ x define a fronteira entre as duas regiões de decisão Z0 e Z1. Nos pontos que constituem a fronteira, a decisão por H0 ou H1 é indiferente.
No caso que temos vindo a estudar, em que o ruído é gaussiano, é completamente caracterizado pelas densidades de probabilidade condicionais (7.17) e (7.18) e pelo parâmetro p, a regra de decisão (7.23) toma a forma particular
( )p1
p1exp
0
1
H
H
20
21 −<
>
−−−
η− sxsx ,
ou ainda
−
η−>
<−−−
p1pln
0
1
H
H
20
21 sxsx . (7.24)
Finalmente, se os símbolos binários forem equiprováveis, 21p = , e (7.24) simplifica-se para
20
H
H2
1
0
1
sxsx −><− , (7.25)
isto é, o receptor decide pelo símbolo associado ao vector sinal cujo afixo está mais próximo do ponto observado x. Chama-se a atenção para o facto de que esta regra de decisão, sendo, digamos assim, uma regra intuitiva, é óptima (no sentido em que minimiza a probabilidade de erro) apenas quando o ruído é gaussiano e de média nula, e os símbolos gerados pela fonte são equiprováveis. Usando a definição de norma, temos

7-7
,1,0i , ,2 i2
i22
i =−+=− sxsxsx e a regra de decisão (7.25) passa à forma equivalente
2E
,2
E, 0
0H
H1
1
0
1
−<>− sxsx , (7.26)
onde ,1,0i ,E 2
ii == s é a energia do sinal ( ) .1,0i ,tsi = As regras (7.25) e (7.26) são como vimos equivalentes e definem o receptor de máxima verosimilhança, caso particular do receptor de mínima probabilidade de erro que resulta da equiprobabilidade dos símbolos fonte.
7.3.1 Probabilidade de Erro Mínima
A probabilidade de erro pode ser calculada em termos da probabilidade de decidir correctamente. Num sistema M-ário, a probabilidade de decidir pelo símbolo im sendo que foi este o símbolo transmitido é obviamente dada por
( )∫=i
iZ H|iii dfpH,mPr uux .
Sendo aP a probabilidade de ser tomada a decisão correcta, então a probabilidade de erro vale
( )∑ ∫=
−=−=M
1iZ H|iae
ii
dfp1P1P uux . (7.27)
O cálculo da probabilidade de erro em forma fechada pode ser, em muitos casos, complicado ou mesmo impossível. No entanto, para os casos mais simples, como os apresentados nos parágrafos seguintes, é possível obter expressões em forma fechada. A dificuldade associada ao cálculo da probabilidade de erro está sobretudo dependente da forma das regiões de decisão iZ e das funções densidade de probabilidade condicional ( ).f
iH| ux
7.3.2 Sinais Ortogonais com Igual Energia
Consideremos os sinais ( )ts0 e ( )ts1 com igual energia E representados na Figura 7.5-(a), os quais, como se pode verificar, são ortogonais. O espaço de sinal tem assim dimensão dois e é gerado pela base ortonormada formada pelos sinais ( )t0φ e ( )t1φ tais que ( ) ( ) 0,1.i , tEts ii =φ= Nestas condições, a regra (7.26) simplica-se ainda mais
( ) ( ) ( ) ( )t,txxxt,tx 00H
H
11
0
1
φ=<>=φ
e pode ser levada à prática pelo receptor que se mostra na Figura 7.5-(c). Da expressão anterior, conclui-se ainda que a fronteira entre as regiões de decisão Z0 e Z1 é definida pela
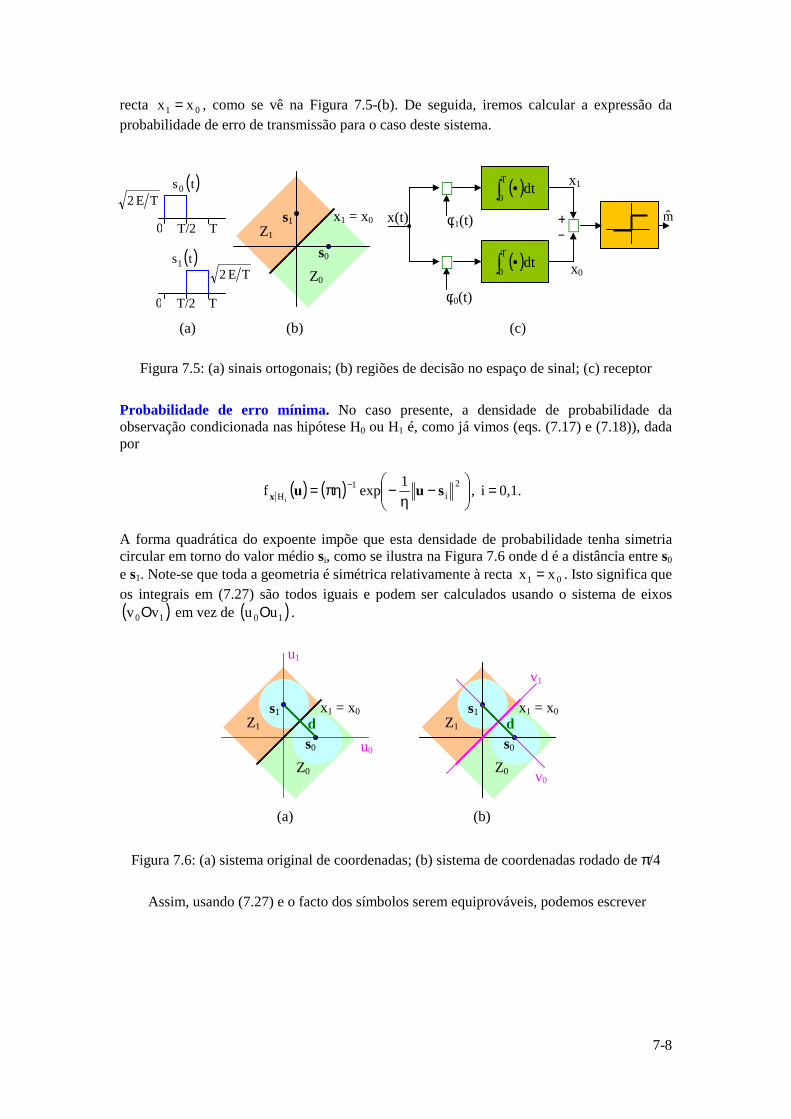
7-8
recta 01 xx = , como se vê na Figura 7.5-(b). De seguida, iremos calcular a expressão da probabilidade de erro de transmissão para o caso deste sistema.
Figura 7.5: (a) sinais ortogonais; (b) regiões de decisão no espaço de sinal; (c) receptor
Probabilidade de erro mínima. No caso presente, a densidade de probabilidade da observação condicionada nas hipótese H0 ou H1 é, como já vimos (eqs. (7.17) e (7.18)), dada por
( ) ( ) 0,1.i , 1expf 2i
1Hi
=
−
η−πη= − suux
A forma quadrática do expoente impõe que esta densidade de probabilidade tenha simetria circular em torno do valor médio si, como se ilustra na Figura 7.6 onde d é a distância entre s0 e s1. Note-se que toda a geometria é simétrica relativamente à recta 01 xx = . Isto significa que os integrais em (7.27) são todos iguais e podem ser calculados usando o sistema de eixos ( )10 vv Ο em vez de ( )10 uu Ο .
Figura 7.6: (a) sistema original de coordenadas; (b) sistema de coordenadas rodado de π/4
Assim, usando (7.27) e o facto dos símbolos serem equiprováveis, podemos escrever
TE2
T/2 T 0
( )ts0
TE2
T/2 T 0
( )ts1
s1
s0
Z0
Z1
x1 = x0
( )∫ •T
0dt
( )∫ •T
0dt
⊗
⊗
⊕
x1
x0
+−
φ0(t)
φ1(t)x(t) m
(a) (b) (c)
Z0
Z1
x1 = x0s1
s0
d u0
u1
Z0
Z1
x1 = x0s1
s0
d
v0
v1
(a) (b)

7-9
( )( )
( ) ( )( )( )( ) ( ) ( ) ( )( )∫ ∫
∞+
∞− ∞−
−−−−
∞+
∞− ∞−
−−
+η−πηη−πη−=
++η−πη−=
−=
−=
∫ ∫
∫∫
0
02
0121
121
121
0
1021
20
11
Z H|x
Z H|xe
. dv 2dvexpdv vexp1
dvdv v2dvexp1
d f1
d f1P
11
11
vv
uu
Note-se que no sistema de eixos ( )10 vv Ο o ponto [ ]0 2d1 −=s . Na última linha da expressão anterior o integral em v1 é igual a 1 pois a integranda é uma gaussiana de média nula e variância 2η . Se no integral em v0 fizermos a mudança de variável
( )2dv021 +η=µ − , obtemos
( ) ( )( )
( ) ( )( )∫
∫∞+
η
η
∞−
µµ−π=
µµ−π−=
2d
2
2d2
e
, d exp1
d exp11P
ou seja,
η=
2Eerfc
21Pe , (7.28)
onde se fez E2d = e se usou a definição da função erro complementar
( ) ( ) 0. x, dexp2xerfcx
2 ≥µµ−π
= ∫+∞
(7.29)
7.3.3 Sinais Antipodais com Igual Energia
Consideremos agora o caso em que ( ) ( )tsts 10 −= e, de novo, com energia E. Neste caso, os dois sinais são linearmente dependentes e, portanto, o espaço de sinal tem dimensão 1. Pode escolher-se, por exemplo, ( ) ( )tsEt 0=φ para versor da recta real que constitui o espaço de sinal. Usando (7.26), a regra de decisão é agora
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( )ts,txt,txExxt,txEts,tx 0H
H
1
0
1
=φ=<>−=φ−=
ou seja,
0x1
0
H
H
<> .
A Figura 7.7 ilustra este esquema de sinalização (a), mostrando o espaço de sinal (b) e o diagrama de blocos do receptor (c).
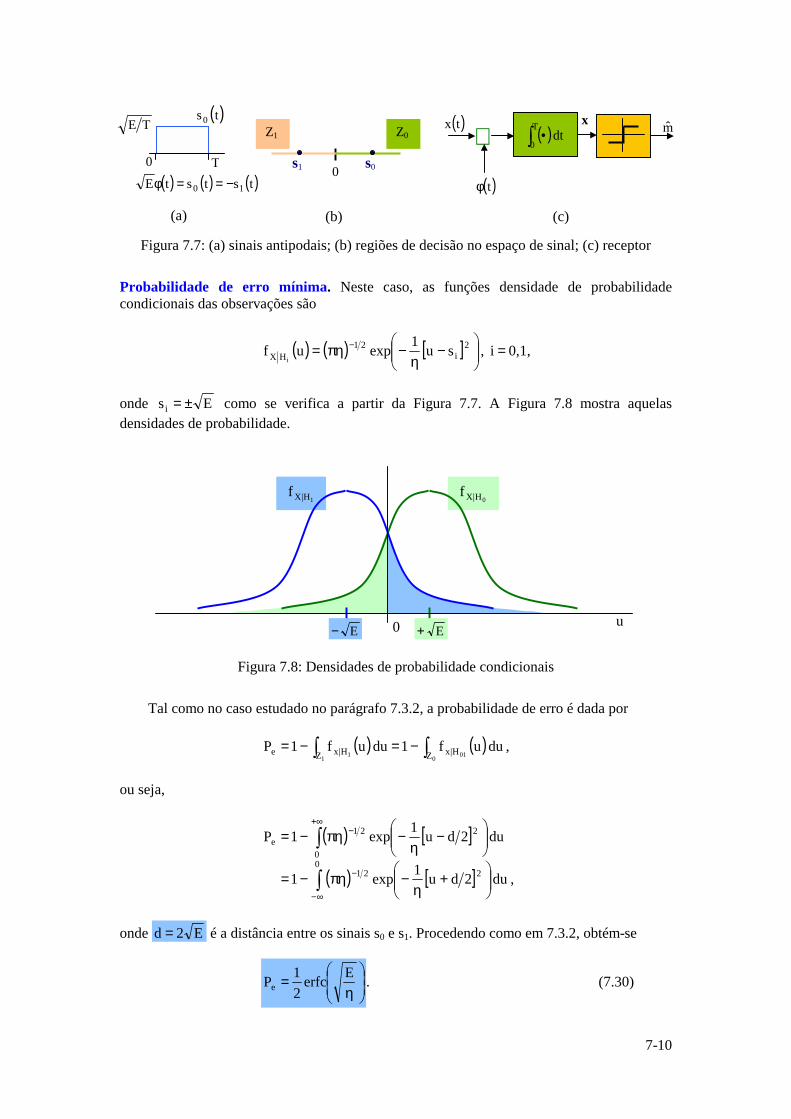
7-10
Figura 7.7: (a) sinais antipodais; (b) regiões de decisão no espaço de sinal; (c) receptor
Probabilidade de erro mínima. Neste caso, as funções densidade de probabilidade condicionais das observações são
( ) ( ) [ ] 0,1,i , su1expuf 2i
21HX i
=
−
η−πη= −
onde Esi ±= como se verifica a partir da Figura 7.7. A Figura 7.8 mostra aquelas densidades de probabilidade.
Figura 7.8: Densidades de probabilidade condicionais
Tal como no caso estudado no parágrafo 7.3.2, a probabilidade de erro é dada por
( ) ( )∫∫ −=−=
0 011 1 Z H|xZ H|xe du uf1du uf1P ,
ou seja,
( ) [ ]
( ) [ ]∫
∫
∞−
−
+∞−
+
η−πη−=
−
η−πη−=
0221
0
221e
,du 2du1exp1
du 2du1exp1P
onde E2d = é a distância entre os sinais s0 e s1. Procedendo como em 7.3.2, obtém-se
η= Eerfc
21Pe . (7.30)
TE
0 T
( )ts0
( ) ( ) ( )tststE 10 −==φ
Z1 Z0
s0s1 0
( )∫ •T
0dt ⊗
( )tx
( )tφ
x m
(a) (b) (c)
1H|Xf0H|Xf
u 0 E+E−

7-11
É fácil verificar que este valor da probabilidade de erro corresponde a qualquer das áreas sombreadas na Figura 7.8. Comparando (7.30) com (7.28), e tendo em conta que erfc é uma função decrescente, concluímos que a probabilidade de erro é menor no caso da sinalização antipodal. Com efeito, embora a energia por bit seja a mesma, neste caso a distância entre os sinais é maior do que na sinalização ortogonal.
7.4 Filtro Adaptado
Nesta secção vamos estudar uma realização equivalente do receptor de mínima probabilidade de erro baseada no filtro adaptado. Este filtro é desenhado de modo a maximizar a razão entre a energia instantânea do sinal de saída no instante de amostragem T e a potência do ruído de saída.
Figura 7.9: Receptor baseado no filtro adaptado
Suponhamos que a entrada do filtro representado na Figura 7.9 é a soma de um sinal conhecido ( )tφ com uma amostra w(t) de ruído branco gaussiano ( )tW com densidade espectral de potência ( ) 2fG η=W . A saída do filtro vem dada por
( ) ( ) ( )ttt 0 NY +φ= , (7.31) onde
( ) ( ) ( ) ( )∫+∞
∞−
πΦ=φ∗=φ df e f fHtht ft2j0 (7.32)
é a componente de sinal na saída, e o ruído ( )tN tem espectro de potência
( ) ( ) 2fH2
fG η=N . (7.33)
O objectivo é determinar a função de transferência H(f) (ou a resposta impulsional h(t)) tal que a razão
( ) ( ) ( )
( )∫
∫∞+
∞−
∞+
∞−
π
η
Φ
=φ
=dffH
2
dfe f fHT
SNR2
2fT2j
20
NP (7.34)
seja máxima. Em (7.34), PN é a potência média do ruído ( )tN . Para resolver este problema, podemos recorrer à desigualdade de Shwarz
h(t) ↔ H(f)⊕ T
ruído branco
φ(t)y(t) y(T)

7-12
( ) ( ) ( ) ( )∫∫∫∞+
∞−
π∞+
∞−
∞+
∞−
π Φ≤Φ dfe fdffHdfe f fH2fT2j2
2fT2j , (7.35)
onde a igualdade se verifica quando
( ) ( ) fT2j*opt e f K fH π−Φ= . (7.36)
Substituindo (7.36) em (7.34), obtemos
η= φE2
SNR opt , (7.37)
onde ( )∫+∞
∞−φ Φ= dffE 2 é a energia do sinal φ(t). Note-se que SNRopt não depende da constante arbitrária K, pelo que podemos escolher sem perda de generalidade K = 1. Então, de (7.36) tira-se que
( ) ( )tTth opt −φ= . (7.38) No caso em que o ruído de canal é branco, a resposta impulsional do filtro adaptado é uma réplica do sinal φ(t), atrasada de T, e definida no sentido reverso do tempo. Na Figura 7.10 exemplifica-se este facto.
Figura 7.10: Resposta impulsional do filtro adaptado ao sinal φ(t)
Para concluir, podemos usar (7.38) para verificar que
( ) ( ) ( ) ( ) ( )∫∫+∞
∞−
+∞
∞−
ττ+−φτ=ττ−τ= dtTxdthxty opt , (7.39)
onde x(t) é uma amostra do processo de entrada
( ) ( ) ( )ttt WX +φ= . Como ( ) [ ]T0, t,0t ∉=φ , então (7.39) toma a forma
( ) ( ) ( )∫−
ττ+−φτ=t
Tt
dtTxty
e, portanto,
( ) ( ) ( )∫ ττφτ=T
0
dxTy . (7.40)
0 0 TT
φ(t) h(t)

7-13
Daqui se conclui que o sistema da Figura 7.9 é, em termos funcionais, equivalente a qualquer dos correladores da Figura 7.2-(a). Assim o banco de correladores ali representado é equivalente a um banco de filtros adaptados como se ilustra na Figura 7.11. Como se vê, cada filtro é adaptado a um dos sinais da base ortonormada que gera o espaço de sinal.
Figura 7.11: Equivalência entre um banco de correladores e um banco de filtros adaptados
7.5 Estimação de Máxima Verosimilhança em Ruído Branco Gaussiano
Nesta secção faremos uma introdução à teoria da estimação, tratando uma classe de problemas particular com aplicação em telecomunicações. Comecemos por considerar o seguinte problema. Estimação de parâmetros Dada a observação
( ) ( ) ( ) T,t0 , tw;tstx ≤≤+= θθθθ (7.41) onde ( )θθθθ;ts representa um sinal conhecido a menos de um conjunto de parâmetros colecionados no vector θθθθ, e ( )tw é uma amostra de ( )tW que se assume ser ruído branco gaussiano com espectro de potência ( ) 2fG W η= , pretende-se determinar a estimativa θθθθ do vector θθθθ. A Figura 7.12 ilustra o problema da estimação de parâmetros. A fonte gera um sinal s(t) que se assume aqui ser conhecido pelo receptor a menos de um vector de parâmetros θθθθ, o qual pertence a um conjunto designado por espaço de parâmetros. Através de um qualquer mecanismo de transição imposto pelo canal de transmissão, o sinal x(t) observado é uma versão ruidosa e, eventualmente distorcida, do sinal s(t).
( )t2φ
( )dt T
0∫ •
( )dt T
0∫ •
( )dt T
0∫ •
M
⊗
⊗
⊗
( )t1φ
( )tNφ
( )tsi
1is
2is
iNs
1is
2is
iNs
( ) ( ))tTth 11 −φ=
M
( )tsi( ) ( ))tTth 22 −φ=
( ) ( ))tTth NN −φ=
T

7-14
Figura 7.12: Problema da estimação de parâmetros
Suponhamos que o mecanismo de transição do canal é modelizado pela relação (7.41). Ao estimador compete, a partir do sinal observado x(t) e mediante determinadas hipóteses, encontrar no espaço de soluções (coincidente com o espaço de parâmetros), o vector desejado θθθθ. Naturalmente que o algoritmo que permite calcular a estimativa θθθθ não é arbitrário. Ao contrário, executa uma regra de estimação que deve satisfazer um determinado critério de optimalidade. A escolha deste critério depende do grau de conhecimento apriori disponível sobre o vector de parâmetros a estimar. Podemos assim considerar dois tipos de abordagem do problema da estimação de parâmetros:
A1. estimação de parâmetros aleatórios; A2. estimação de parâmetros determinísticos.
No estudo que a seguir apresentamos, vamos considerar apenas a classe de problemas A2. Neste caso, a estimativa do vector θθθθ pode obter-se por maximização da chamada função de verosimilhança que introduziremos de seguida. Por ser mais simples, começaremos por abordar o problema partindo de uma formulação em tempo discreto.
7.5.1 Formulação em Tempo Discreto
Neste caso, as observações definidas em (7.41) são escritas na forma
( ) ,1,K-,1,0k , wsx kkk K=+= θθθθ (7.42) onde ,1,K-,1,0k , w k K= é uma sequência branca gaussiana de média nula e variância 2η , ou seja,
( ) ( ) ,1K,,1,0k , w
expwf2k21
kWk−=
η−πη= − K (7.43)
é a densidade de probabilidade da variável aleatória Wk, cuja amostra é wk. Podemos então escrever
( ) ( ) ( )[ ].1K,,1,0k ,
sxexpxf
2kk21
k|Xk−=
η−
−πη= −K
θθθθθθθθ
(7.44)
Fonte
x(t)
θθθθ
ΘΘΘΘ
mecanismo de transição
estimadorespaço de soluções
Z
espaço de observações

7-15
Uma vez que as variáveis aleatórias ,1,K-,1,0k , Wk K= são estatisticamente independentes, o mesmo acontece com .1,K-,1,0k , X k K= Definindo o vector (coluna) de amostras
[ ]T1K10 x,,x,x −= Lx , concluímos que a densidade de probabilidade conjunta das observações 1K10 X,,X,X −K é o produto das marginais (7.44).
Def. 7.1- Função de verosimilhança. A função de verosimilhança das amostras (vector x) e do vector de parâmetros θθθθ a estimar é dada pela densidade de probabilidade conjunta das observações condicionadas em θθθθ. Sendo
( ) ( ) ( ) ( )[ ]T1K10 s,,s,s θθθθθθθθθθθθθθθθ −= Ls , então
( ) ( ) ( )[ ]
( ) ( )
−
η−πη=
−
η−πη=Λ
−
−
=
− ∑
22K
1K
0k
2kk
2K
1exp
sx1exp;
θθθθ
θθθθθθθθ
sx
x (7.45)
No caso presente, em que a função de verosimilhança é do tipo gaussiano, podemos em alternativa a (7.45) usar a chamada função logarítmica de verosimilhança
( ) ( ) ( ) ( )[ ]
( ) ( ) 2
1K
0k
2kk
1ln2K
sx1ln2K;ln;L
θθθθ
θθθθθθθθθθθθ
sx
xx
−η
−πη−=
−η
−πη−=Λ= ∑−
= . (7.46)
Def. 7.2- Estimativa de máxima verosimilhança. A estimativa de máxima verosimilhança do vector de parâmetros θθθθ é o vector
( ) ( ) ( )θθθθθθθθ
θθθθθθθθ
θθθθ ;L max arg; max argˆmv xxx =Λ= . (7.47)
Comentário: a estimativa de máxima verosimilhança depende explicitamente dos dados x que são amostras de observações aleatórias. Portanto o vector ( )xmvθθθθ é ele próprio um vector aleatório. Usando (7.46) em (7.47), e eliminando as parcelas que não dependem explicitamente dos parâmeteros a estimar, podemos finalmente escrever
( ) ( )[ ]
( )
−
η−=
−
η−= ∑
−
=
2
1K
0k
2kkmv
1 max arg
sx1 max argˆ
θθθθθθθθ
θθθθθθθθ
θθθθ
sx
x. (7.48)
A determinação de mvθθθθ passa portanto por resolver um problema de cálculo de extremos, por exemplo, aplicando a condição necessária de existência desses extremos. Se existirem, os extremos verificam o sistema de equações

7-16
( ) 0sx ==
−
η−∇
mv
2
ˆ1
θθθθθθθθθθθθθθθθ , (7.49)
onde 0 designa o vector nulo e θθθθ∇ é o operador gradiente, isto é, o vector cujos elementos são as derivadas parciais em ordem a cada um dos elementos de θθθθ. As soluções da equação (7.49) não são em geral únicas, sendo necessário determinar as que constituem de facto maximizantes e, destas, isolar aquela que conduz ao máximo global. Uma alternativa a este método pode basear-se numa técnica de busca, o que passa por calcular a função de verosimilhança para todos os valores de θθθθ no espaço de soluções. Naturalmente, esta técnica pode conduzir a tempos de cálculo incomportáveis.
Exemplo 7.1: Estimação de amplitude. Consideremos o caso em que
( ) ( ) ss aa1-K,0,1,k , asas kk =⇔== K onde a amplitude a é o parâmetro que se pretende estimar. De (7.49) vem, então,
0aa
a1a
mv
2 ==
−
η−
∂∂ sx ,
equação com solução única
∑−
===
1K
0kkk
Tmv sx
E1
E1a sx (7.50)
onde ∑ −
=== 1K0k
2k
2 sE s é a energia do sinal 1.-K,0,1,k ,sk K= Pode verificar-se que a solução anterior constitui de facto um máximo pois a segunda derivada da função de verosimilhança naquele ponto é negativa. Por outro lado, se não existisse ruído,
kk asx:k =∀ , e de (7.50) resultaria aa mv = , como seria de esperar.
7.5.1.1 Análise de Desempenho
Em discussão anterior concluímos que a estimativa de máxima verosimilhança é uma quantidade aleatória. Faz, portanto, todo o sentido investigar as propriedades estatísticas do erro de estimação
mvmv θθθθθθθθεεεε −= . (7.51)
Def. 7.3- Estimador não enviezado. O estimador é não enviezado sse
θθθθθθθθεεεε =⇔= mvmvˆEE 0 . (7.52)
Portanto, se o estimador for não enviezado, a estimativa é em média igual ao valor nominal do(s) parâmetro(s). Esta informação, sendo útil, não é no entanto suficiente como medida de qualidade do estimador, pois para conjuntos de observações diferentes nada diz sobre a dispersão dos erros de estimação obtidos. Como se sabe, esta medida de dispersão pode ser quantificada com uma análise de segunda ordem.

7-17
Def. 7.4- Matriz de Fisher. Seja N a dimensão do vector de parâmetros θθθθ. Os elementos da matriz de Fisher J são dados por
[ ] ( ) .N,,2,1j,i , ;LEji
2
ij K=
θ∂θ∂∂−= θθθθxJ (7.53)
Uma vez definida a matriz de Fisher, podemos enunciar o seguinte facto que aqui não demonstraremos.
Facto 7.1: Limiar de Cramér-Rao. Suponhamos que se verifica a condição (7.52) e que [ ] [ ]ii1ii −= JJ é o i-ésimo elemento da diagonal da inversa da matriz de Fisher. Seja [ ]( )imv
2i var εεεε=σ a variância do erro de estimação do parâmetro iθ . Então
[ ] N,,2,1i , 2
iii K=σ≤J , (7.54)
onde cada um dos [ ] ,N,,2,1i ,ii K=J é designado por limiar de Cramér-Rao.
Este facto mostra que existe um valor teórico limite abaixo do qual a variância do erro de uma estimativa não enviezada não pode cair.
Def. 7.5- Estimativas eficientes. Uma estimativa não enviezada é dita eficiente se (7.54) se verificar pela igualdade, isto é, quando a variância do erro atinge o valor limite estabelecido pelo limiar de Cramér-Rao.
Exemplo 7.1 (continuação). Sendo wsx += a e Ea Tmv sx= , onde ssTE = , de (7.51)
vem
( ) swsws TTTmv E
1aE1a −=+−=ε (7.55)
e, portanto
0E mv =ε , (7.56) pois E e s são quantidades determinísticas e o vector de ruído w tem média nula. Portanto, a estimativa de máxima verosimilhança da amplitude é não enviezada. Particularizando (7.46)
( ) ( ) 2a1ln2Ka;L sxx −
η−πη−= ,
de (7.53), e tendo em conta o Facto 7.1, obtemos o limiar de Cramér-Rao
E2
aa
E1LCR
1
2
22 η=
∂−∂
η=
−sx
. (7.57)

7-18
Por outro lado, de (7.55) e (7.56), e recordando ainda que as amostras de ruído são estatisticamente independentes e têm igual variância 2η , tiramos
E2
2E1
EE1
E1E
KT
2
TT2
2T2
η=
η=
=
−=σε
sIs
swwssw
o que, de acordo com a Def. 7.5, mostra que a estimativa é eficiente.
7.5.2 Formulação em Tempo Contínuo
Dadas as observações definidas pelo modelo (7.41), temos
( ) ( ) ( )[ ]
−
η−= ∫
T
0
2mv dt;tstx1 max argˆ θθθθ
θθθθθθθθ x , (7.58)
o que constitui uma generalização imediata de (7.48). A solução pode ser obtida recorrendo à metodologia dual da expressa em (7.49),
( ) ( )[ ] 0==
−
η−∇ ∫
mv
T
0
2
ˆdt;tstx1
θθθθθθθθθθθθθθθθ , (7.59)
ou ainda usando um método de busca exaustivo.
No que diz respeito à análise de desempenho, a discussão apresentada no parágrafo 7.5.1.1 pode ser directamente transportada para o presente contexto, tendo em atenção a dualidade de (7.58) e (7.59) relativamente a (7.48) e (7.49), respectivamente.
Exemplo 7.2: Estimação da fase de uma portadora sinusoidal. Consideremos o
modelo de observações
( ) ( ) ( ) ,Tt0 , twtf2cosTE2tx c ≤≤+θ+π=
onde se mantêm as hipóteses formuladas no início da secção 7.5. Aqui
( ) ( ) +∈>>=≤≤θ+π=θ !)1(nTf T,t0 , tf2cosTE2;ts cc
(7.60) e [ ]π+π−∈θ , é o parâmetro a estimar. Estamos portanto a assumir que θ se mantém constante durante o intervalo de observação de duração T. Usando (7.59), e tendo em conta que
( ) ( ) 0dttf2sintf2cosnTfT
0ccc =θ+πθ+π⇒∈= ∫+! ,
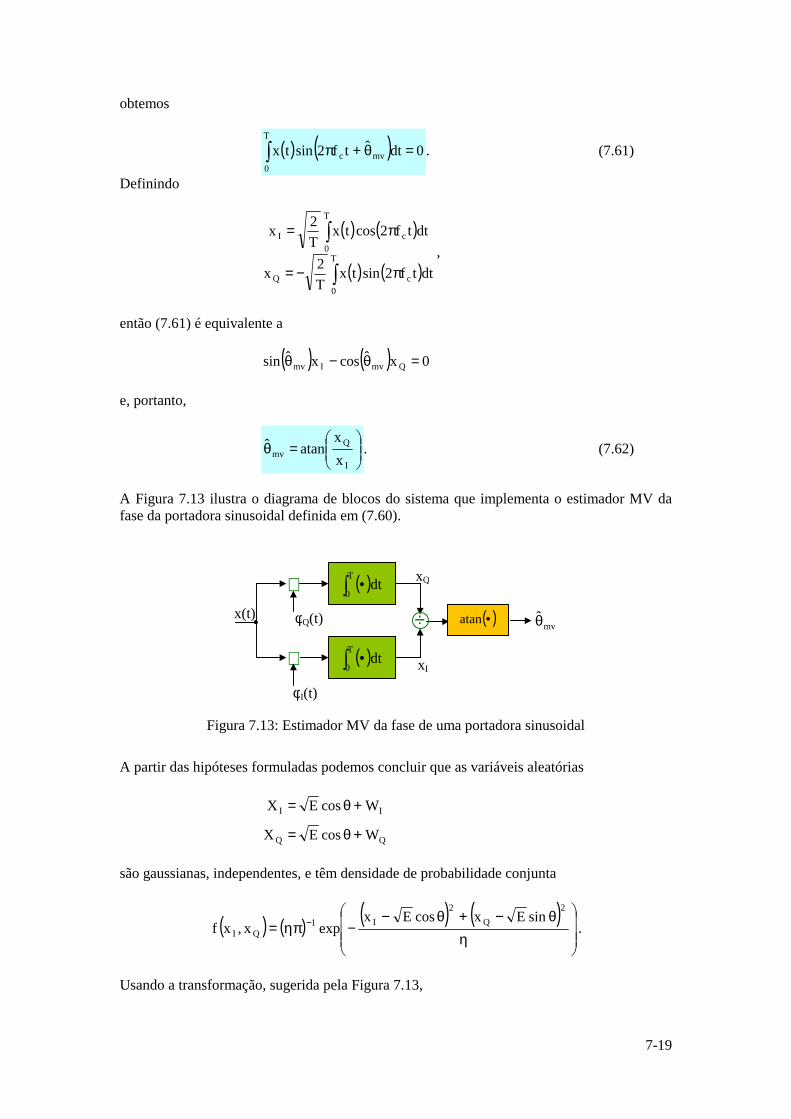
7-19
obtemos
( ) ( )∫ =θ+πT
0mvc 0dtˆtf2sintx . (7.61)
Definindo
( ) ( )
( ) ( )∫
∫
π−=
π=
T
0cQ
T
0cI
dttf2sintx T2x
dttf2costx T2x
,
então (7.61) é equivalente a
( ) ( ) 0xˆcosxˆsin QmvImv =θ−θ e, portanto,
=θ
I
Qmv x
xatanˆ . (7.62)
A Figura 7.13 ilustra o diagrama de blocos do sistema que implementa o estimador MV da fase da portadora sinusoidal definida em (7.60).
Figura 7.13: Estimador MV da fase de uma portadora sinusoidal
A partir das hipóteses formuladas podemos concluir que as variáveis aleatórias
II
WcosEX
WcosEX
+θ=
+θ=
são gaussianas, independentes, e têm densidade de probabilidade conjunta
( ) ( ) ( ) ( )
ηθ−+θ−
−ηπ= −2
Q2
I1QI
sinExcosExexpx,xf .
Usando a transformação, sugerida pela Figura 7.13,
( )∫ •T
0dt
( )∫ •T
0dt
⊗
⊗
÷
xQ
xI
φI(t)
x(t) φQ(t) ( )•atan mvθ

7-20
mvQ
mvI
ˆsinRX
ˆcosRX
θ=
θ=
podemos então calcular a densidade de probabilidade conjunta de R e de mvθ
( ) ( ) ( )
ηθ−θ+θ−θ
−ηπ
=θ2
mv2
mvmv
sinEˆsinRcosEˆcosRexpRˆ,Rf ,
a qual, após alguma manipulação algébrica, se pode escrever na forma
( )( ) ( )( )
ηθ−θ−
−ηπ
θ−θγ−=θ
2mv
mv22
mv
ˆcosERexp R
ˆsineˆ,Rf ,
onde
η=γ E (7.63)
fornece uma medida da SNR. Uma vez que mvmv θ−θ=ε , então a densidade de probabilidade do erro é dada por
( ) ( )∫+∞
−
ε−η−
ηπ
εγ−=ε
0
2mv
1mv
22
mv dR cosERexp R sinef
ou, fazendo a mudança de variável ( )mvcosER2x ε−η= ,
( ) ( )∫+∞
εγ−
−εγ+π
εγ−=ε
mvcos2
2mv
mv22
mv dx 2xe cos2x 2
sinef .
O factor integral pode ainda ser trabalhado, obtendo-se
( )
−
πεγ
π
εγ−+
π
γ−=ε ∫
∞+
εγ− mvcos2
2mv
mv222
mv dx 2xe 21cos
sine2
ef
(7.64) Para analisar este resultado vamos considerar as duas situações limite: ruído forte e ruído fraco. Ruído forte (γγγγ →→→→ 0) Neste caso, a segunda parcela em (7.64) anula-se, pelo que

7-21
( ) [ ]π+π−∈επ
→ε <<γ , , 21f mv1mv .
Isto significa que a estimativa toma com igual probabilidade valores em intervalos próximos ou afastados do valor nominal θ, o que corresponde a um mau desempenho do estimador. Ruído fraco (γγγγ →→→→ ∞∞∞∞) Nestas condições podemos assumir que, com probabilidade muito grande, a estimativa mvθ não se afasta de θ mais do que π/2 em valor absoluto. Tal implica que 0cos mv ≥ε , e (7.64) rescreve-se do seguinte modo
( ) ( )[ ]mv*mv
mv222
mv cos2erfc1cos sine
2ef εγ−εγ
π
εγ−+
π
γ−=ε ,
onde
( ) 2xex2
1du2ue21xerfc
2
x
1x
2
*−
π →−
π= ∫
+∞
>> .
Usando este limite para o caso em que 1>>γ , obtém-se finalmente
( ) mv22
mv1mvsinecos 1f εγ−εγ
π →ε >>γ . (7.65)
Comecemos por notar que a função limite indicada em (7.65) é uma função par o que implica que o estimador é assimptoticamente não enviezado, isto é, o valor expectável do erro tende para zero quando γ cresce. Por outro, para valores do erro próximos do seu valor médio assimptótico, ou seja, se mvmvmvmv sin ,1cos0 ε≈ε≈ε⇒≈ε e (7.65) é aproximada por uma gaussiana de média nula e variância E221 2 η=γ . Se calcularmos o LCR deste estimador de fase obtemos exactamente este resultado. Portanto, podemos também afirmar que o estimador MV da fase é assimptoticamente eficiente. Malha de Seguimento de Fase 2 Voltemos à condição (7.61) e usemos a definição do sinal ( )tx
( ) ( ) ( ) ( ) 0dt ˆtf2sintwdt ˆtf2sintf2cosTE2
T
0
mvc
T
0
mvcc =θ+π+θ+πθ+π ∫∫
o que é equivalente a
0sin mv =∆+ε , onde ∆ corresponde a uma média temporal de uma amostra de ruído. Na hipótese de ruído fraco, ∆ toma com elevada probabilidade valores pequenos e pode ser interpretado como uma pequena perturbação da medida do erro de fase mvsin ε . Por outro lado, vimos na análise de desempenho feita anteriormente que na hipótese de ruído fraco, o erro toma com elevada
2 Malha de seguimento de fase: PLL (Phase Locked Loop)

probabilidade valores 0mv ≈ε , logo mvmvsin ε≈ε , e o erro de estimação deve verificar a condição aproximada
0mv ≈∆+ε . (7.66)
Figura
A Figura 7.14 mostra o diagramade fase. Se na saída do integestabilizada com θ=θmv
ˆ . Se aumentando ligeiramente o erro
mvθ o que vai, naturalmente conestando a funcionar perto do regde reagir a pequenas perturbaçõobservação ruidosa de uma poréplica com sincronismo de fasemuito simples de realizar).
⊗ x(t) ( )ˆtf2sin θ+π
7.14: Malha de segu
de blocos para uma rador o erro mv =ε
o efeito da perturb, então o VCO reflectribuir para um decr
ime permanente ondees no sentido de vortadora sinusoidal é (a menos de um desv
( )dt T
0∫ •mvcε
VCOfc
imento de
implemen0 , então ação ∆ ste esta varéscimo do o erro é ltar ao po assim poio constan
7-22
fase
tação alternativa do estimador a saída do VCO mantém-se e fizer sentir, por exemplo, iação num ligeiro aumento de novo valor de erro. Portanto,
muito pequeno, o PLL é capaz nto de equilíbrio. A partir da ssível gerar localmente uma te de π/2, cuja compensação é

8-1
8 Teoria da Informação: Capacidade do Canal de Transmissão
Comecemos por recordar a introdução ao capítulo 1: o estudo de um sistema de
comunicações digitais envolve dois aspectos cruciais: 1. a eficiência da representação da informação gerada pela fonte; 2. a taxa de transmissão à qual é possível enviar a informação com fiabilidade através de um
canal ruidoso.
A teoria da informação estabelece os limites fundamentais associados às questões acima referidas. A saber: I. número mínimo de unidades de informação binária (bit) por símbolo necessário para
representar completamente a fonte; II. o valor máximo da taxa de transmissão que garante fiabilidade da comunicação através de
um canal ruidoso.
No capítulo 1 fizemos o estudo do primeiro problema no contexto do modelo de fonte discreta sem memória. Aqui iremos abordar a segunda questão estabelecendo o resultado referido em II usando o modelo de canal discreto sem memória que iremos introduzir na secção seguinte.
8.1 Canais Discretos sem Memória
Um canal discreto é um modelo estatístico que a um alfabeto de entrada representado por uma variável aleatória discreta X faz corresponder, de acordo com uma qualquer lei de transição, uma variável aleatória discreta Y. A variável aleatória discreta X modela o alfabeto de entrada do canal, e Y modela o alfabeto de saída. O modelo descrito está ilustrado na Figura 8.1. Note-se que, em geral, a cardinalidade do alfabeto de saída pode ser diferente da do alfabeto de entrada.
Figura 8.1: Modelo de um canal discreto
Def. 8.1- Canal discreto sem memória: um canal discreto sem memória é determinado pelo mecanismo estatístico que descreve o transporte de informação entre a fonte e o destinatário e que se define pelo conjunto de probabilidades condicionais
( ) K,,2,1k ; M,,2,1m , x|yp mk KK == . (8.1)
X
Y
( )mk x|ypxm
yk

8-2
Note-se que cada símbolo de saída só depende de um símbolo de entrada e não de uma sequência. Daí a designação de canal sem memória. Em geral,
( ) mk , 0x|yp :M,,2,1m mk ≠≠=∀ K , ou seja, o processo de transmissão está sujeito a erros. A ocorrência de erros de transmissão decorre do facto de o canal ser ruidoso. Assim, à emissão do símbolo particular mx pode corresponder a recepção de qualquer um dos símbolos do alfabeto de saída e, portanto,
( ) M,,2,1m , 1x|ypK
1kmk K==∑
=. (8.2)
A medida de fiabilidade da transmissão através de um canal discreto é dada pela probabilidade média de erro por símbolo. Seja
( ) ( ) M,,2,1m , xXPxp mm K=== , (8.3) a probabilidade de o símbolo mx ser transmitido. Naturalmente, ocorre um erro de transmissão se o símbolo recebido for um qualquer ,mk , yk ≠ isto é,
( )∑≠=
==K
mk1k
ke yYPP . (8.4)
Sendo conhecidas as distribuições de probabilidade apriori (8.3) e de transição (8.1), então a partir da distribuição conjunta
( ) ( ) ( ) K,1,2,k ; M,1,2,m , xpx|ypx,yp mmkmk KK === , (8.5)
podemos calcular a distribuição de probabilidade marginal da saída
( ) ( ) ( )∑=
===M
1mmkkk x,ypyYPyp . (8.6)
Usando (8.5) e (8.6) em (8.4), obtém-se
( ) ( )∑∑≠= =
=K
mk1k
M
1mmmke xpx|ypP . (8.7)
Verificamos assim que, no caso de um canal discreto sem memória, a probabilidade média de erro de transmissão por símbolo é completamente determinada pela distribuição apriori e pelas probabilidades de transição (8.3) e (8.1), respectivamente.
Exemplo 8.1: Canal binário simétrico. Consideremos o caso do canal binário simétrico de grande interesse teórico e importância prática. Neste caso 2MK == , o alfabeto de entrada é 0x 0 = e 1x1 = , e o de saída é 0y0 = e 1y1 = . O canal é designado como simétrico porque a probabilidade p de receber 1 supondo ter sido transmitido 0 é igual à probabilidade de receber 0 supondo ter sido transmitido 1, como se ilustra no diagrama da Figura 8.2. Independentemente da distribuição apriori, pPe = .

8-3
Figura 8.2: Canal binário simétrico
8.2 Informação Mútua e Informação Condicional
O conceito de entropia, introduzido no capítulo 1, pode ser estendido a alfabetos conjuntos.
Def. 8.2- Entropia conjunta. Sejam X e Y os alfabetos de entrada e de saída de um canal discreto sem memória, cuja distribuição de probabilidade conjunta é dada por (8.5). Então, a entropia conjunta dos alfabetos X e Y é
( ) ( ) ( )km2
M
1m
K
1kkm y,xplogy,xpY,X ∑∑
= =−=H . (8.8)
Recordemos que ( )[ ]m2 xplog− mede a incerteza inicial (apriori) associada à transmissão do símbolo mx . Por outro lado, ( )[ ]km2 y|xplog− mede a incerteza final sobre a transmissão do símbolo mx após ter sido recebido o símbolo ky . O ganho de informação sobre o símbolo de entrada mx após observação do símbolo de saída ky é então dado pela diferença entre a incerteza inicial e a incerteza final, ou seja,
( ) ( ) ( )m2km2km xplogy|xplogy,xI −= . (8.9) A relação anterior pode escrever-se na forma
( ) ( )( )m
km2km xp
y|xplogy,xI = ; (8.10)
como é sabido,
( )( )
( )( )k
mk
m
km
ypx|yp
xpy|xp
= (8.11)
e, portanto,
( ) ( )( )k
mk2mk yp
x|yplogx,yI = (8.12)
e
( ) ( )mkkm x,yIy,xI = . (8.13)
0 0
1 1p
p
1−p
1−p

8-4
É devido a esta relação de simetria que a quantidade ( ) ( )( )mkkm x,yIou y,xI é designada por informação mútua entre os acontecimentos mxX = e kyY = . A informação mútua média entre os alfabetos X e Y será então dada por
( ) ( ) ( )∑∑= =
=M
1m
K
1kkmkm y,xpy,xIY,XI . (8.14)
Usando (8.10) e a identidade (equivalente a (8.11))
( )( )
( )( ) ( )km
km
m
km
ypxpy,xp
xpy|xp
=
em (8.14), obtemos
( ) ( ) ( )( ) ( )∑∑
= =
=
M
1m km
km2
K
1kkm ypxp
y,xplogy,xpY,XI . (8.15)
Para interpretar o conceito de informação mútua média, comecemos por recordar que
( )[ ]km2 y|xplog− determina a incerteza final sobre a transmissão do símbolo mx , uma vez observado o símbolo de saída ky , isto é, representa a informação própria de mx condicionada pela observação de ky :
( ) ( )km2km y|xplogy|xI −= . (8.16)
Def. 8.3- Entropia condicional. A entropia condicional mede, em termos médios, o acréscimo de informação sobre o símbolo de entrada do canal ganho pela observação do símbolo de saída:
( ) ( ) ( )∑∑= =
−=M
1m
km2
K
1k
km y|xplogy,xpY|XH . (8.17)
Rescrevendo (8.15)
( ) ( ) ( ) ( )[ ]
( ) ( ) ( ) ( )
( ) ( ) ( ) ( ) , xpxplogy|xplogy,xp
y,xpxplogy|xplogy,xp
xplogy|xplogy,xpY,XI
M
1mmm2
M
1mkm2
K
1kkm
M
1m
K
1kkmm2
M
1mkm2
K
1kkm
M
1mm2km2
K
1kkm
∑∑∑
∑ ∑∑∑
∑∑
== =
= == =
= =
−=
−=
−=
e comparando com (8.17), verificamos que a primeira parcela do lado direito é exactamente
( )Y|XH− enquanto que a segunda é a entropia do alfabeto de entrada. Temos então
( ) ( ) ( )( ) ( ) ( ). X,YIX|YY
Y|XXY,XI
=−=
−=
HH
HH (8.18)

8-5
A informação mútua média mede, portanto, a incerteza média existente apriori sobre o símbolo de entrada do canal que é resolvida (também em média) pela observação da saída do canal. A relação anterior pode ainda escrever-se noutra forma. Com efeito, a expressão (8.8) da entropia conjunta pode rescrever-se como
( ) ( ) ( )( ) ( ) ( ) ( )
−= ∑∑
= =km
km
km2
M
1m
K
1kkm ypxp
ypxpy,xp
logy,xpY,XH ,
ou ainda como
( ) ( ) ( )( ) ( )
( )
( )
( )
( )
( )
( ) ; xplog
xp
y,xp
yplog
yp
y,xp
ypxpy,xp
logy,xpY,X
m2
M
1m
m
K
1kkm
k2
K
1k
k
M
1mkm
km
km2
M
1m
K
1kkm
∑ ∑
∑ ∑
∑∑
= =
= =
= =
−
−
−=
44 344 21
44 344 21
H
Identificando as parcelas uma a uma, concluímos que
( ) ( ) ( ) ( )Y,XYXY,XI HHH −+= . (8.19) A Figura 8.3 ilustra de modo simbólico as relações entre as diversas quantidades introduzidas e que caracterizam a fonte, o canal, e a respectiva saída.
Figura 8.3: Relações entre as quantidades que caracterizam a fonte, o canal, e a saída do canal
8.3 Capacidade de um Canal Discreto sem Memória
Já anteriormente se fez notar que um canal discreto sem memória é caracterizado pelas probabilidades de transição definidas em (8.1). No entanto, a informação mútua média entre os alfabetos de entrada (fonte) e de saída do canal depende também da distribuição apriori definida em (8.3). Sendo o canal independente da fonte, e sendo a informação mútua média o ganho de informação sobre a entrada do canal após observação da correspondente saída, é natural pensar-se em optimizar a eficiência de utilização do canal, maximizando o ganho de informação atrás referido. Uma vez que as probabilidades de transição caracterizam o canal e
( )Y,XH
( )Y,XI
( )YH( )X|YH( )XH ( )Y|XH

8-6
estão fora do contolo de quem pretende desenhar o sistema de comunicações, o processo de optimização referido terá de assentar sobre a distribuição de probabilidade apriori.
Def. 8.4- Capacidade do canal discreto sem memória. A capacidade de um canal discreto sem memória é o máximo da informação mútua média, por cada utilização do canal, e relativamente a todas as possíveis distribuições de probabilidade apriori, isto é,
( )( )Y,XI
M,1,2,m ,xpmaxC
m K== . (8.20)
A capacidade de canal mede-se em unidades binárias de informação (bit) por intervalo de sinalização (tempo de transmissão de um símbolo ou duração de cada utilização do canal).
Exemplo 8.2: Canal binário simétrico. Consideremos o canal binário simétrico já introduzido no Exemplo 8.1, Figura 8.2, e completamente especificado pelo parâmetro p, probabilidade de erro. Seja ( )00 xXPrp == ; obviamente ( ) 011 p1xXPrp −=== . Usando estes dados em (8.18) e maximizando em ordem a 0p , conclui-se que
( ) 21ppY,XIC10 === , (8.21)
isto é, a informação mútua média é máxima quando os símbolos de entrada são equiprováveis e a capacidade deste canal vale
( ) ( )p1logp1plogp1C 22 −−++= . (8.22) Note-se que (8.22) se pode escrever como
( )p1C H−= , onde
( ) ( ) ( )p1logp1plogpp 22 −−−−=H é a função (1.15) representada na Figura 1.1 do capítulo 1. Recordando essa figura, podemos concluir que
1. quando não existe ruído de canal, 0p = e a capacidade atinge o seu valor máximo de um bit por cada intervalo de transmissão;
2. quando o canal é ruidoso, 0p ≠ e a capacidade atinge o valor mínimo de 0 bit por intervalo de transmissão quando 21p = .
8.4 Teorema da Codificação de Canal
O teorema da codificação de canal é um dos resultados mais importantes derivados por Shannon no contexto da Teoria da Informação. Este teorema estabelece um limite fundamental sobre o valor da taxa média de transmissão fiável de informação através de um canal ruidoso.

8-7
Teorema da Codificação de Canal Considere-se uma fonte discreta sem memória com alfabeto X, entropia ( )XH , e que gera um símbolo em cada sT segundos. Consideremos também um canal discreto sem memória com capacidade C e que é usado uma vez em cada cT segundos. Então, se
( )
cTC≤
sTXH (8.23)
existe um código segundo o qual a saída da fonte pode ser transmitida através do canal e reconstruída com probabilidade de erro arbitrariamente pequena. Ao contrário, se
( )
cTC>
sTXH
não é possível garantir a reconstrução fiável da informação transmitida.
A demonstração deste teorema que não faremos aqui não é construtiva1. Isto é, apenas se
garante a existência do código não o definindo. Embora o problema da codificação de canal venha a ser discutido mais tarde em maior detalhe, faz sentido introduzir as ideias fundamentais.
O objectico da codificação de canal é aumentar a resistência do sistema de comunicações digital face aos efeitos do ruído de canal. No caso particular dos códigos de bloco, a cada bloco de k bits da sequência binária gerada pela fonte faz-se corresponder um bloco de n bits (palavra de código) com .kn > Este processo de codificação deve ser concebido de modo que a descodificação tenha solução única. Note-se que do universo de n2 blocos binários de comprimento n apenas k2 são palavras de código (as que correspondem numa relação de um para um aos blocos binários de comprimento k gerados pela fonte). Este esquema está representado simbolicamente na Figura 8.4. No caso de a transmissão se efectivar sem erros, o processo de descodificação conduz ao bloco de comprimento k que havia sido gerado pela fonte. Quando ocorrem erros de transmissão, a palavra de comprimento n recebida pode não ser uma palavra de código e o erro é detectado e/ou corrigido. Daqui resulta naturalmente uma probabilidade de erro por bit inferior à que existiria se não fosse usada a codificação de canal. A codificação de canal pode ser encarada como o processo dual da codificação de fonte. Enquanto neste caso se elimina redundância para melhorar a eficiência, na codificação de canal controla-se a redundância introduzida para melhorar a fiabilidade.
Figura 8.4: Codificação de canal
1 Referência indicada no fim do capítulo 1.
k2
k2k2
k2
n2 n2
transmissão sem erros
transmissão com erros
codificação descodificação
detecção de erros

8-8
Exemplo 8.3: Canal binário simétrico. Consideremos uma fonte binária sem memória que gera bits equiprováveis a uma taxa de um bit em cada sT segundos, ou seja, sT1 bps. Neste caso a entropia da fonte é 1, pelo que a taxa de geração de informação é de
sT1 bit/segundo2. A sequência fonte é codificada com base num codificador de razão nkr = e que produz um símbolo em cada cT segundos. À saída do codificador a taxa de transmissão de dados é cT1 baud. O canal binário simétrico é assim usado uma vez em cada cT segundos. Portanto, a capacidade do canal por unidade de tempo é cTC bit/segundo, onde C é dada por (8.22). De acordo com o teorema da codificação de canal, se
cs TC
T1 ≤ , (8.24)
então pode forçar-se a probabilidade de erro por bit a tomar um valor arbitrariamente pequeno através de uma codificação adequada. Como sc TTnkr == , a condição (8.24) pode ser modificada para a forma equivalente
Cr ≤ . (8.25) Deste modo, podemos afirmar que existe um código com razão r que, verificando (8.25), garante uma probabilidade de erro por bit tão pequena quanto queiramos.
Suponhamos que o parâmetro que caracteriza o canal binário simétrico vale 210p −= e que queremos construir um código para o qual 8
e 10P −≤ . Usando aquele valor de p em (8.22), obtemos 9192.0C = bit/segundo. Consideremos agora um código de repetição que para cada bit gerado pela fonte transmite 1m2n += bits iguais, ou seja n1r = . Por exemplo, para 1m = , as palavras do código são 000 e 111. Suponhamos ainda que o descodificador funciona por maioria: escolhe 0 se a palavra recebida tiver mais 0's do que 1's e vice-versa. Se for gerado um 0, transmite-se 000, e o descodificador erra se receber 2 1's e um 0 ou 3 1's. Portanto, para o caso geral, a probabilidade de erro por bit vem dada por
( )∑+=
−−
=
n
1mi
inie p1p
in
P . (8.26)
Calculando o valor de eP para diversos valores de n1r = , podemos construir a Tabela 8.1.
r 1 31 51 71 91 111
eP 210− 4103 −× 610− 7104 −× 810− 10105 −×
Tabela 8.1: Probabilidade de erro média nos códigos de repetição
Verificamos assim que eP decresce à medida que r diminui, e que se atinge o valor máximo especificado de 8
e 10P −= quando 91r = . Repare-se que neste caso transmitimos 9 bits em representação de um único bit da fonte, o que se traduz no facto de C9192.01111.0r =<<= . Ao contrário, o que o teorema da codificação de fonte diz é que basta que Cr < (igual no limite). Portanto, os códigos de repetição não são deste ponto de vista os mais eficientes existindo, como veremos mais tarde, métodos de codificação mais adequados. 2 A distinção entre taxa de geração de dados binários e taxa de geração de informação é muito importante no contexto aqui considerado. Note-se que aqui, ambas têm o mesmo valor pois os símbolos são equiprováveis.

8-9
8.5 Entropia Diferencial
O conceito de entropia, introduzido no contexto das variáveis aleatórias discretas, pode ser de algum modo generalizado para o caso das variáveis aleatórias contínuas desde que se tenham em conta alguns detalhes técnicos que discutiremos adiante.
Def. 8.5- Entropia diferencial. Consideremos uma fonte analógica modelada pelo processo ( )tX . Seja X a variável aleatória contínua que descreve estatisticamente a amplitude ( )tX do referido processo em qualquer instante t , e ( )xf X a respectiva densidade de probabilidade. A entropia diferencial de X é
( ) ( ) ( )[ ]∫+∞
∞−
−= dx xflogxfX X2Xh . (8.27)
O termo entropia diferencial é usado para marcar as diferenças relativamente ao conceito de entropia de fontes discretas. Suponhamos que X tem uma distribuição uniforme
( ) ≤≤=
−
; contrário caso , 0ax0 , axf
1
X
substituindo em (8.27), obter-se-ia ( ) alogX 2=h , a qual toma valores negativos quando 1a < e torna-se singular quando ∞→a . Recorde-se que a entropia de uma fonte discreta é sempre positiva e limitada. Portanto, ao contrário da entropia de fontes discretas, a entropia diferencial definida para fontes analógicas não pode ser interpretada como uma medida de aleatoriedade ou de incerteza. Suponhamos que a variável aleatória X constitui a forma limite de uma variável aleatória discreta que toma os valores KK ,1,0,1,k , kx xk −=∆= , e onde
0x >∆ é arbitrariamente pequeno. Assim sendo, podemos assumir que
( ) ( ) xkXxkk xfxXxPr ∆≈∆+≤< e, no limite quando 0x →∆ , a entropia da fonte contínua seria
( ) ( ) ( )( )
( ) ( )( ) ( ) ( )
∆∆−∆−
→∆=
∆∆−
→∆=
∑∑
∑∞+
−∞=
∞+
−∞=
∞+
−∞=
k
xx2kX
k
xkX2kXx
k
xkX2xkXx
logxfxflogxf0
lim
xflogxf0
limXH
ou, atendendo a (8.27),
( ) ( ) ( ) ( )∑+∞
−∞=
∆∆→∆
−=k
xkXx2x
xflog0
limXX hH . (8.28)
Consideremos a segunda parcela do lado direito de (8.28) e notemos que para valores de x∆ suficientemente pequenos se tem

8-10
( ) ( ) ( )x2xkXxkX logxfxf ∆∆<∆ ; quando 0x →∆ , o termo à direita nesta desiguladade torna-se infinitamente maior do que o termo da esquerda, pelo que, embora
( ) ( )∑ ∫+∞
−∞=
+∞
∞−
==∆→∆
k
XxkXx
1dxxfxf0
lim ,
( )∑+∞
−∞=
∆∆→∆
k
xkXx2x
xflog0
lim
não existe. Daqui se conclui que a entropia (8.28) de uma fonte contínua é infinitamente grande. Esta conclusão deriva do facto de ser infinita a quantidade de informação associada ao acontecimento +∞<<∞−= 00 x , xX , quando X é uma variável aleatória contínua. No entanto, e voltando a (8.28), a entropia diferencial pode ser interpretada como a entropia da fonte contínua medida relativamente à referência
( )∑+∞
−∞=
∆∆→∆
−k
xkXx2x
xflog0
lim .
Neste contexto, supondo que X e Y são, respectivamente, a entrada e a saída de um canal
sem memória, podemos generalizar o conceito de informação mútua entre X e Y. Em particular,
( ) ( ) ( )( ) ( )∫ ∫
+∞
∞−
+∞
∞−
= dudv
vfufv,uf
logv,ufY,XIYX
XY2XY . (8.29)
Entre outros factos, pode mostrar-se que, sendo a entropia diferencia condicional dada por
( ) ( ) ( )[ ]∫ ∫+∞
∞−
+∞
∞−
=−= dudvvY|uflogv,ufY|X Y|X2XYh , (8.30)
então
( ) ( ) ( )( ) ( )X|YY
Y|XXY,XIhhhh
−=−=
. (8.31)
Como em (8.31), o termo de referência no cálculo da entropia é o mesmo, a informação mútua pode continuar a ser interpretada tal como no caso de fontes e canais discretos.
8.5.1 Máxima Entropia
Neste parágrafo, vamos resolver um problema cujos resultados serão necessários mais adiante, e cuja formulação se apresenta de seguida.

8-11
Calcular a função densidade de probabilidade fX que maximiza
( ) ( ) ( )[ ]∫+∞
∞−
−= dx xflogxfX X2Xh (8.27)
sob as restrições
( ) 1duuf X =∫+∞
∞−
(8.32)
e
( ) ( ) 2X
2X duufmu σ=−∫
+∞
∞−
(8.33)
onde
( )∫+∞
∞−
= duuf um XX . (8.34)
Para resolver este problema, vamos novamente recorrer à técnica dos multiplicadores de
Lagrange, começando por determinar os pontos de estacionariedade da Lagrangeana
( ) ( ) ( )[ ] ( ) ( ) ( )
σ−−λ+
−λ+−= ∫∫∫
+∞
∞−
+∞
∞−
+∞
∞−
2X
2X2X1X2XX du ufmu1du ufdu ufloguffL .
(8.35) No entanto, é necessário ter em conta que o problema em causa exige a maximização de (8.35) relativamente a uma função definida sobre o conjunto dos números reais e não relativamente a um parâmetro. Suponhamos que fX é a função que maximiza (8.27), cumprindo as restrições (8.32) e (8.33). Então, podemos definir
)(f)(f)(f~ XX ⋅ε+⋅=⋅ ε , (8.36) onde )(f ⋅ε ε representa uma perturbação relativamente à função maximizante )(f X ⋅ . Sublinhe-se que ε é um parâmetro real arbitrário, tal como )(f ⋅ε . Os pontos de estacionariedade de (8.35) são aqueles que verificam a condição necessária de existência do máximo
.00
L ==εε∂
∂ (8.37)
Se em (8.35), substituirmos )(f X ⋅ por )(f~X ⋅ definido em (8.36), e em seguida usarmos (8.37), obteremos
( ) ( ) ( )[ ] 0du mueloguflneloguf 2X212X2 =−λ+λ+−⋅−∫
+∞
∞−
ε ,

8-12
o que, atendendo ao facto de )(f ⋅ε ser uma função arbitrária, só se verifica se o factor entre [ ] da integranda for nulo, ou seja
( ) ( ) !∈−λ
+λ
+−= ∀ u , muelogelog
1ufln 2X
2
2
2
1X . (8.38)
Usando esta relação, podemos impor as restrições (8.32) e (8.33) e, após resolver o sistema de equações resultante, obtemos os multiplicadores de Lagrange
, 2
elog2
elog21
22
2
221
σ−=λ
πσ=λ
os quais, uma vez subsituídos em (8.38), permitem obter o resultado final
( )( )
+∞<<∞−σ−−
σπ= x , 2
mx
e21xf
2
2X
X .
Conclusão: a entropia diferencial da variável aleatória X, cuja variância é 2σ , é máxima se X for gaussiana. Por outras palavras, se X e Y forem variáveis aleatórias contínuas, ambas com a mesma variância, e se X for gaussiana, então
( ) ( )YX hh ≥ .
8.6 Teorema da Capacidade de Canal
Consideremos o processo ( )tX , estacionário, de média nula e com largura de banda B. Suponhamos que ( )tX é amostrado uniformemente com período sT . Sejam ( )sk kTXX = as variáveis aleatórias que modelam estatisticamente as amostras ( )tx do processo ( )tX nos instantes skTt = . Admitamos que as amostras kx são transmitidas através de um canal perturbado por ruído aditivo, branco e gaussiano, com espectro de potência constante e igual a
2η . Se o canal de transmissão tiver largura de banda B, então a respectiva saída é modelada pela variável aleatória
1K,,1,0k , NXY kKk −=+= K , (8.39) onde kN é uma variável aleatória gaussiana, independente de kX , com média nula e variância
B2 η=σ . (8.40) Admitamos ainda que
1-K,0,1,k , XE 2k K==XP . (8.41)

8-13
Supondo que a amostragem é feita ao ritmo de Nyquist, então o número K de amostras transmitidas num intervalo de tempo com duração T é
BT2K = . (8.42) Por analogia com (8.20), a capacidade do canal gaussiano será
( )( )kk
X
Y,XI uf
maxC
k
= , (8.43)
onde ( )kk Y,XI é a informação mútua entre kX e kY , definida em (8.29) e que verifica (8.31), isto é,
( ) ( ) ( )kkkkk X|YYY,XI hh −= . (8.44) Note-se que, de acordo com (8.39) e (8.40), a variável aleatória kkk xX|Y = é gaussiana com média kx e variância B2 η=σ . Por outro lado, usando a definição de entropia diferencial (8.27), verifica-se facilmente que a entropia diferencial de uma gaussiana com variância 2σ não depende do respectivo valor médio e vale ( ) 2e2log 2
2 σπ . Portanto, podemos escrever
( ) ( ) ( )kkkk NYY,XI hh −= . (8.45) Como kN é independente de kX , então o cálculo da capacidade do canal (8.43) envolve apenas a maximização de ( )kYh , onde kY tem variância Bη+XP . Este problema foi resolvido no parágrafo 8.5.1: ( )kYh é máxima com kY gaussiana. Temos então
( ) ( )[ ]Be2log21Y 2k η+π= XPh (8.46)
e
( ) [ ]Be2log21N 2k ηπ=h . (8.47)
O valor máximo da informação mútua (8.45) resulta de (8.46) e (8.47) pelo que, tendo em conta (8.43), obtém-se a capacidade do canal gaussiano
η
+=B
1log21C 2
XP bit/utilização.
Finalmente, como o canal é usado K vezes em T segundos, usando (8.42), vem
η
+=B
1logBC 2XP
bit/segundo. (8.48)
De acordo com o teorema da codificação de canal sabemos que, desde que se use o código adequado, é possível transmitir através do canal gaussiano com largura de banda B à taxa máxima C dada por (8.48) com probabilidade de erro arbitrariamente pequena. Para uma largura de banda B fixa, a taxa de transmissão de informação exequível aumenta com a razão
ηXP . No entanto, se estes parâmetros se mantiverem fixos, aquela taxa de transmissão aumenta com a largura de banda B aproximando-se de um valor limite quando
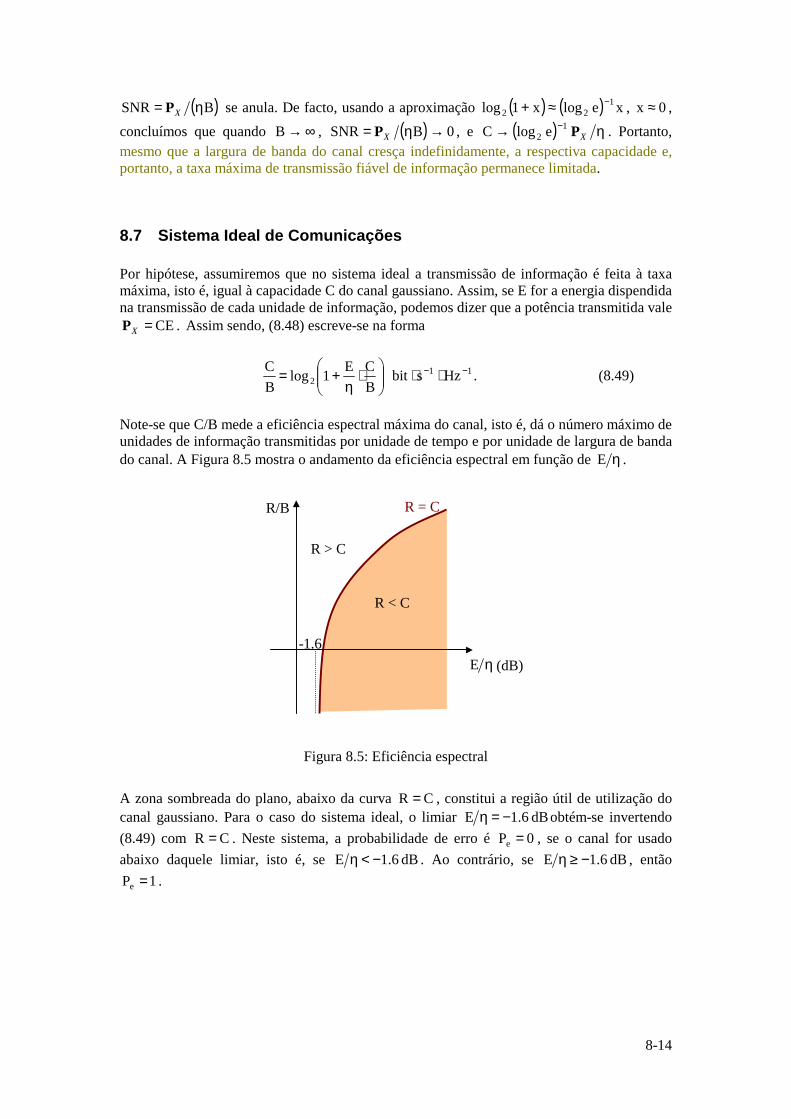
8-14
( )BSNR η= XP se anula. De facto, usando a aproximação ( ) ( ) 0 x, xelogx1log 122 ≈≈+ − ,
concluímos que quando ∞→B , ( ) 0BSNR →η= XP , e ( ) η→ −XP1
2 elogC . Portanto, mesmo que a largura de banda do canal cresça indefinidamente, a respectiva capacidade e, portanto, a taxa máxima de transmissão fiável de informação permanece limitada.
8.7 Sistema Ideal de Comunicações Por hipótese, assumiremos que no sistema ideal a transmissão de informação é feita à taxa máxima, isto é, igual à capacidade C do canal gaussiano. Assim, se E for a energia dispendida na transmissão de cada unidade de informação, podemos dizer que a potência transmitida vale
. CE=XP Assim sendo, (8.48) escreve-se na forma
⋅
η+=
BCE1log
BC
2 11 Hzsbit −− ⋅⋅ . (8.49)
Note-se que C/B mede a eficiência espectral máxima do canal, isto é, dá o número máximo de unidades de informação transmitidas por unidade de tempo e por unidade de largura de banda do canal. A Figura 8.5 mostra o andamento da eficiência espectral em função de ηE .
Figura 8.5: Eficiência espectral
A zona sombreada do plano, abaixo da curva CR = , constitui a região útil de utilização do canal gaussiano. Para o caso do sistema ideal, o limiar dB 6.1E −=η obtém-se invertendo (8.49) com CR = . Neste sistema, a probabilidade de erro é 0Pe = , se o canal for usado abaixo daquele limiar, isto é, se dB 6.1E −<η . Ao contrário, se dB 6.1E −≥η , então
1Pe = .
ηE (dB)
R/B R = C
R < C
R > C
-1.6

9-1
9 Codificação de Canal: Códigos de Bloco Lineares
Em capítulos anteriores estudámos com alguma profundidade dois dos problemas mais importantes associados ao desenho de sistemas de comunicações: o problema da codificação de fonte, e o problema da transmissão de informação através de canais ruidosos. O primeiro destes problemas aborda a questão da representação eficiente dos símbolos (ou de sequências de símbolos) gerados pela fonte, recorrendo a códigos univocamente descodificáveis cujo comprimento médio seja o menor possível. Para o caso de fontes discretas sem memória, verificámos que o comprimento médio mínimo daqueles códigos é determinado pela entropia da fonte, a que corresponde uma representação sem redundância. O problema da transmissão digital através de canais ruidosos foi abordado pela via da definição de técnicas de modulação e do desenho dos respectivos receptores tendo como objectivo a minimização da probabilidade de erro de transmissão. Verificámos também a existência de um compromisso fundamental entre a probabilidade de erro (desempenho do sistema de transmissão) e a largura de banda de transmissão. Este compromisso traduz-se numa medida da capacidade do canal, isto é, o valor máximo da taxa de transmissão de informação que garante, pelo uso do código adequado, uma probabilidade de erro arbitrariamente pequena.
Consideremos a sequência de bits
76543210 bbbbbbbb (9.1) com base na qual formamos a palavra binária
pbbbbbbbb 76543210 (9.2) onde o bit p, designado por bit de paridade,1
==
=⊕⊕⊕=pars1' de nº se , 0ímpars1' de nº se , 1
bbbp 710 L (9.3)
Suponhamos que a sequência (9.2) é a palavra de código transmitida quando a fonte gera o bloco de 8 bits em (9.1). Tendo em conta (9.3), podemos verificar que todas as palavras de código têm um nº par de 1’s, isto é, têm paridade par. Isto quer dizer que qualquer palavra binária de 9 bits com paridade ímpar não faz parte deste código. Assim, se a transmissão de uma palavra de código envolver um nº ímpar de bits errados, então a paridade da palavra recebida é ímpar, e os erros de transmissão são detectados. Este efeito resultou da inclusão do bit de paridade p, o qual, sendo determinado pelos bits ,b,,b 70 K não introduz informação adicional. A inclusão nos símbolos transmitidos detes tipo de redundância controlada é a chave para a construção de códigos de canal capazes de detectar e/ou corrigir eventuais erros de transmissão.
Basicamente, existem dois tipos de técnicas de controlo dos erros de transmissão. Uma, baseada em códigos correctores de erro, é designada na literatura por controlo de erro sem retroacção (FEC)2. A outra estratégia exige a retransmissão dos blocos de dados onde tenham
1 O símbolo ⊕ designa o operador adição mod 2, o qual, como é sabido, é equivalente ao operador “ou exclusivo”. 2 FEC – Forward Error Control.

9-2
sido detectados erro de transmissão através de pedidos destinados ao emissor e gerados automaticamente pelo receptor (ARQ)3. Ao contrário das técnicas do tipo FEC, os métodos ARQ, embora recorrendo a códigos menos complexos, envolvem normalmente uma utilização menos eficiente do canal de transmissão.
Os tipos de códigos de canal normalmente usados podem agrupar-se em duas grandes categorias: os códigos de bloco e os códigos convolucionais. Ao contrário dos primeiros, estes últimos são realizados recorrendo a codificadores com memória. Na secção seguinte, iremos introduzir os códigos de bloco lineares.
9.1 Códigos de Bloco Lineares
Seja 1k10 m,,m,m −K um bloco arbitrário de k bits gerados pela fonte. Tipicamente, o codificador de bloco usa estes k bits para gerar uma palavra de código com kn > bits, acrescentando n-k bits de controlo. A palavra de código assim construída é constituída pelos símbolos binários
−+−−=−−=
= 1n,,1kn,kn i , m
1kn,,1,0i , bx
i
ii K
K (9.4)
e tem a estrutura ilustrada na Figura 9.1. Este é um código ( )k,n e tem uma taxa de codificação definida por
nkR = . (9.5)
Figura 9.1: Palavra de código ( )k,n
No caso de um código de bloco linear, os bits de paridade 1kn10 b,,b,b −−K dependem
linearmente (numa aritmética binária mod 2) dos bits da mensagem 1k10 m,,m,m −K . Ou seja, definindo os vectores linha
[ ]1kn10 bbb −−= Lb (9.6) e
[ ]1k10 mmm −= Lm , (9.7) podemos escrever
mPb = , (9.8)
3 ARQ – Automatic ReQuest for retransmission.
1k101kn10 mmmbbb −−− LL

9-3
onde P é uma matriz binária ( )knk −× que determina o código. Portanto, sendo
[ ]mbx = , (9.9) de (9.8) resulta
[ ]kIPmx = , (9.10) onde kI é a matriz identidade de dimensão ( )kk × . Definindo a matriz geradora do código
[ ]kIPG = , (9.11) de dimensão ( )nk × , usando (9.10) temos
mGx = . (9.12) É fácil verificar que o código formado pelas palavras x, geradas pela matriz G a partir das
k2 mensagens m, é um código linear. Com efeito, sendo Gmx ii = e Gmx jj = palavras do código, então ( )GmmGmGmxx jijiji ⊕=⊕=⊕ ; como ji mm ⊕ é necessariamente uma mensagem, ji xx ⊕ é uma palavra do código.
Definindo a matriz de verificação de paridade
[ ]Tkn PIH −= , (9.13)
de dimensão ( )nkn ×− , e usando (9.11), verifica-se que4
[ ] 0PPIPPIHG =⊕=
= −
TT
k
TT
knT . (9.14)
Assim sendo, de (9.12) vem
TTT mGx = , o que, tendo em conta (9.14), conduz a
0xH0Hx =⇔= TT . (9.15) Esta é uma condição necessária e suficiente para que x seja uma palavra do código ( )k,n gerado pela matriz G. No entanto, a verificação de (9.15) à saída do canal ruidoso não significa necessariamente que não tenham ocorrido erros de transmissão. Com efeito, se for transmitida a palavra de código x, então a palavra y recebida é, em geral,
exy += , (9.16)
4 Mais uma vez se chama a atenção para o facto de estarmos a usar aritmética binária mod 2.

9-4
onde
[ ] , contrário caso , 0
ibit no errohouver se , 1e , eee i1ni0
== −LLe
(9.17) é o vector de erro. Se usarmos (9.16) em (9.15), obtemos
≠=
=+=contrário caso ,
código do palavrafor se , TTTT
0e0
eHeHxHyH
o que significa que sendo o vector de erro uma palavra do código, a palavra y, recebida com erros de transmissão, cumpre o teste de verificação de paridade (9.15), e os erros de transmissão não são detectados.
9.1.1 Descodificação pelo Sindroma
Para proceder à descodificação, isto é, à detecção e/ou correcção de erros de transmissão, o descodificador começa por calcular o sindroma da palavra recebida y, isto é, o vector binário
TyHs = (9.18) de dimensão kn − . Tendo em conta (9.16) e (9.15), verificamos que o sindroma só depende do padrão de erros, ou seja,
TeHs = . (9.19) Por outro lado, todos os padrões de erro que diferem entre si de uma palavra de código têm o mesmo sindroma. Com efeito, dado um vector e que verifique (9.19), então todos os vectores de erro
12,,1,0i , kii −=⊕= Kxee , (9.20)
onde os 12,,1,0i , k
i −= Kx , são todas as palavras do código, verificam também (9.19). Assim, define-se o coset do padrão de erros e como sendo o conjunto dos vectores de erro definido em (9.20) que têm o mesmo sindroma (9.19). Uma vez que um código de bloco linear ( )k,n tem k2 palavras admissíveis, num total de n2 palavras binárias de comprimento n, conclui-se que existem kn2 − cosets, isto é, kn2 − sindromas distintos.
O sindroma contém alguma informação sobre o correspondente padrão de erros, embora geralmente insuficiente para o identificar sem ambiguidade. Se assim fosse, qualquer padrão de erros poderia ser corrigido. De qualquer modo, o conhecimento do sindroma s reduz o espaço de busca de uma n2 dimensão para k2 . Uma vez calculado s, o descodificador deve escolher o elemento do respectivo coset que optimize um determinado critério. Por exemplo, a respectiva probabilidade de ocorrência. Para valores relativamente baixos da probabilidade

9-5
de ocorrência de erros de transmissão, o padrão de erros mais provável corresponde àquele que tem menos 1's, isto é, aquele cujo peso
( ) ∑−
==
1n
0iiew e (9.21)
é mínimo. Algoritmo de descodificação de máxima verosimilhança Dada a palavra recebida y:
1. Calcular o sindroma s = yHT a) s = 0000 ⇔ y é uma palavra do código ⇒ yo = y b) s ≠ 0000 ⇒ executar passo 2.
2. Calcular o coset de y, ei = y ⊕ xi , i = 0,1,…,2k−1, escolher o padrão eo de menor peso, e executar o passo 3.
3. Construir a palavra corrigida yo = y ⊕ eo.
Comentário: sendo o0 xye ⊕= , com 0Hx =T
o , tem-se
, oo
oo
xxyyeyy
=⊕⊕=⊕=
(9.22)
isto é, a saída do descodificador é a palavra de código que difere da palavra recebida num número mínimo de posições (correspondentes às posições dos 1's em eo). Ainda por outras palavras, é a palavra de código para a qual y ⊕ xo tem peso mínimo.
9.1.2 Distância de Hamming
Def. 9.1- Distância de Hamming. Sejam xi e xj duas palavras binárias de comprimento n. A distância de Hamming entre xi e xj,
( ) ( )jiji w,d xxxx ⊕= , (9.23) onde w é o peso definido em (9.21), mede o número de bits distintos em xi e xj.
Usando esta definição em (9.22), obtemos
( ) ( ) ( )ooo w,d,d eyxyy == .
Portanto, o critério de máxima verosimilhança usado para desenhar o descodificador é equivalente a minimizar a distância de Hamming entre a palavra recebida e cada palavra admissível do código.
Def. 9.2- Distância mínima do código. A distância mínima do código é dada por

9-6
( ) 12,,1,0j,i , ,d
j,imind k
jimin −== Kxx , (9.24)
ou seja, é o valor mínimo da distância de Hamming entre todos os pares de palavras do código.
Consideremos então um padrão de erros te com peso t correspondendo, portanto, a t bits
errados. Sejam ix e jx duas palavras do código tais que ( ) minji d,d =xx . Naturalmente, ti ex ⊕ está mais próximo de ix do que de jx , e tj ex ⊕ está mais próximo de jx do que de ix se e só se
1t2d min +≥ . (9.25) Como se mostra na Figura 9.2, qualquer padrão de erro com peso inferior a t conduz a uma palavra recebida que cai num dos círculos de raio t. Verificando-se (9.25), a palavra recebida só pode resultar da transmissão da palavra de código que está no centro daquele círculo. Portanto, (9.25) constitui uma condição necessária e suficiente para que o código tenha capacidade de corrigir padrões de erro com peso não superior a t.
Figura 9.2: Distância mínima e capacidade correctora do código
Seguindo a mesma linha de raciocínio, podemos concluir que o código é capaz de detectar
todos os padrões de erro com peso não superior a t0 se e só se
1td 0min +≥ . (9.26)
9.2 Códigos de Hamming
Os códigos de Hamming constituem uma família de códigos lineares ( )k,n que verificam
. mnk12n:3m para m
−=−=≥ (9.27)
No caso em que 3m = obtém-se um código ( )4,7 . Os códigos de Hamming são desenhados por forma a garantir que, independentemente do valor de m, 3d min = . Portanto, e tendo em conta as
2t + 1
xi ⊕ etxj ⊕ et
xi xj xk
xm

9-7
condições (9.25) e (9.26), estes códigos têm capacidade para corrigir até um bit errado por bloco ( )1t = e de detectar até dois bits errados por bloco ( )2t 0 = .
Uma vez que as matrizes geradora G e de verificação de paridade H são directamente relacionáveis, é indiferente definir o código pela especificação de G ou de H. Por outro lado, qualquer que seja a palavra x do código, verifica-se
[ ] 0PIxxH == −TT
knT . (9.28)
De acordo com a Def. 9.2, eq. (9.24), mind pode ser interpretada como o valor mínimo dos pesos de todas as palavras do código, excepto ( ) 0w == 0x 5. À luz da condição (9.28), concluímos que
mind coincide com o número mínimo de colunas de H cuja soma mod 2 dá um vector nulo. Para que tal se verifique, dada a estrutura da matriz H, basta impor que qualquer coluna de TP tenha dois ou mais 1's. Por exemplo, para um código de Hamming ( )4,7
=
111010001110101101001
H . (9.29)
A estrutura dos códigos de Hamming pode ainda ser explorada para levar à prática um método de descodificação bastante eficiente. Com efeito, e como se ilustra a seguir,
111010001110101101001
5763421
as colunas de H codificam em bínário natural os dígitos de 1 a 7. Podemos assim construir a seguinte tabela
dígito 1 2 3 4 5 6 7 coluna de H 1 2 4 3 7 5 6
Tabela 9.1: Colunas de H onde estão codificados os dígitos de 1 a 7
Suponhamos que a palavra transmitida foi [ ]1001110=x , onde o bloco da direita corresponde à mensagem [ ]1001=m , e que [ ]1011110=y é a palavra recebida. O vector de erro é [ ]0010000=e e o sindroma resultante é o vector [ ]110=s (seja qual for o padrão de erro singular com 1 no bit i, o sindroma é sempre a coluna i da matriz H). O conteúdo deste vector constitui o código binário natural para o dígito 6. Se consultarmos a Tabela 9.1, verificamos que este dígito identifica a coluna 5 da matriz H. Daqui se conclui que basta trocar o 5º bit de y para recuperar x e identificar a mensagem m.
5 Faz-se notar que a palavra x = 0000 é sempre uma palavra admissível de qualquer código de bloco linear.

9-8


















