
Nunes^J Felipe Schneider - Departamento de Engenharia de ... · Agência Nacional de Petróleo...
100
Felipe Schneider Nunes UM MODELO DE IDENTIFICAÇÃO DE SAL EM IMAGENS SÍSMICAS DE CAMADAS SUBTERRÂNEAS COM A APLICAÇÃO DE REDES NEURAIS CONVOLUCIONAIS Trabalho de Conclusão de Curso apresentado ao Departamento de Engenharia de Produção e Sistemas da Universidade Federal de Santa Catarina como requisito parcial para a obtenção do título em Engenharia, área Elétrica, habilitação em Engenharia de Produção Elétrica. Orientador: Prof.: Carlos Ernani Fries, Dr. Florianópolis 2018
Transcript of Nunes^J Felipe Schneider - Departamento de Engenharia de ... · Agência Nacional de Petróleo...

Felipe Schneider Nunes
UM MODELO DE IDENTIFICAÇÃO DE SAL EM IMAGENS SÍSMICAS DE CAMADAS SUBTERRÂNEAS COM A
APLICAÇÃO DE REDES NEURAIS CONVOLUCIONAIS
Trabalho de Conclusão de Curso apresentado ao Departamento de Engenharia de Produção e Sistemas da Universidade Federal de Santa Catarina como requisito parcial para a obtenção do título em Engenharia, área Elétrica, habilitação em Engenharia de Produção Elétrica. Orientador: Prof.: Carlos Ernani Fries, Dr.
Florianópolis 2018

Ficha de identificação da obra elaborada pelo autor através do Programa de Geração Automática da Biblioteca Universitária
da UFSC.

Felipe Schneider Nunes
UM MODELO DE IDENTIFICAÇÃO DE SAL EM IMAGENS SÍSMICAS DE CAMADAS SUBTERRÂNEAS COM A
APLICAÇÃO DE REDES NEURAIS CONVOLUCIONAIS
Este Trabalho de Conclusão de Curso foi julgado adequado e aprovado, em sua forma final, pelo Curso de Graduação em Engenharia de Produção Elétrica, da Universidade Federal de Santa Catarina.
Florianópolis, 30 de novembro de 2018.
________________________ Profª. Marina Bouzon, Dra.
Coordenadora do Curso
Banca Examinadora:
________________________ Prof. Carlos Ernani Fries, Dr.
Orientador Universidade Federal de Santa Catarina
________________________ Prof. Sérgio Fernando Mayerle, Dr.
Universidade Federal de Santa Catarina
________________________ Prof. Lynceo Falavigna Braghirolli, Dr. Universidade Federal de Santa Catarina


Este trabalho é dedicado aos meus pais, minha namorada, meus amigos e familiares em geral.


AGRADECIMENTOS
Ao Professor Dr. Carlos Ernani Fries, por toda disponibilidade que teve para comigo, pela total compreensão das minhas dificuldades e por compartilhar sua experiência e conhecimento. Pela indicação do tema e pelas incansáveis horas de orientação disponibilizadas.
Ao Professor Dr. Ricardo Faria Giglio, por todo apoio prestado durante o trabalho, sendo quase um “coorientador informal” deste trabalho.
Aos meus pais, Durval e Selita, por todo o apoio prestado durante toda a minha caminhada até aqui. E por me fornecer a estrutura imprescindível para desenvolver todas as minhas atividades acadêmicas durante a graduação.
À minha namorada Jheannine, pela compreensão nos momentos em que estive ausente, e por todo apoio prestado ao longo de todos esses semestres.
A todos meus amigos e familiares em geral, pela contribuição com vários momentos de descontração e lazer, fundamentais também para a realização deste trabalho.


Deixem que o futuro diga a verdade e avalie cada um de acordo com o seu trabalho e realizações. O presente pertence a eles, mas o futuro pelo qual eu sempre trabalhei pertence a mim (Nikola Tesla, início do século XX)


RESUMO Este trabalho trata da aplicação de um modelo que permite identificar segmentos de sal em imagens sísmicas de camadas subterrâneas. Depósitos de sal estão localizados em diversas regiões, abaixo da superfície terrestre, sendo indicadores da presença de outros recursos minerais de grande interesse econômico como o petróleo. Porém, identificá-los de forma precisa é uma tarefa desafiadora, realizada por meio de imagens obtidas por testes sísmicos controlados, à grande profundidade. Estas imagens requerem interpretação humana especializada para identificação da presença de minerais, trazendo muitas vezes conclusões subjetivas e imprecisas que podem conduzir a situações de alto risco à sua exploração, especialmente àquelas relativas a combustíveis fósseis. No intuito de se buscar soluções automatizadas de predição da presença de minerais, algoritmos específicos de reconhecimento de padrões têm sido objeto de inúmeros estudos na área de Ciência de Dados. Nesse contexto, este trabalho vem ao encontro do emergente campo da Análise de Dados envolvendo técnicas de Inteligência Artificial como Aprendizado de Máquina (Machine
Learning) e Aprendizagem Profunda (Deep Learning). O modelo de predição utilizado está fundamentado na arquitetura denominada Rede Neural Convolucional (Convolution Neural Network - CNN) cujas características são especificamente desenhadas para o reconhecimento de padrões que podem estar incluídos em imagens, áudios e vídeos. O treinamento de CNN’s permite minimizar os erros de predição na identificação de padrões nas imagens sísmicas que indicam a presença de sal. O modelo proposto, resultado da adaptação de um modelo referencial da literatura, foi capaz de processar e predizer a presença do mineral com razoável acurácia, demonstrando ser uma promissora alternativa na identificação de minerais presentes à grande profundidade. Palavras-chave: Segmentos de depósitos de sal. Redes neurais Convolucionais. Análise de dados. Aprendizagem profunda. Processamento de imagens.


ABSTRACT This work deals with the application of a model that allows the identification of salt segments in seismic images of underground layers. Salt deposits are located in several regions, below the surface of the earth, and are indicative of the presence of other mineral resources of great economic interest, such as oil. However, identifying them accurately is a challenging task, accomplished through images obtained by controlled seismic tests, to the great depth. These images require specialized human interpretation to identify the presence of minerals, often leading to inaccurate and subjective conclusions that can lead to high risk situations for their exploitation, especially those related to fossil fuels. In order to search for automated solutions to predict the presence of minerals, specific algorithms for pattern recognition have been the subject of numerous studies in the area of Data Science. In this context, this work is in line with the emerging field of Data Analysis involving Artificial Intelligence techniques such as Machine Learning and Deep Learning. The prediction model used is based on the Convolution Neural Network (CNN) architecture whose characteristics are specifically designed for the recognition of patterns that can be included in images, audios and videos. The training of CNN's allows to minimize the errors of prediction in the identification of patterns in the seismic images that indicate the presence of salt. The proposed model, a result of the adaptation of a reference model of the literature, was able to process and predict the presence of the mineral with reasonable accuracy, proving to be a promising alternative in the identification of minerals present at great depth. Keywords: Segments of salt deposits. Convolutional Neural Networks. Data analysis. Deep Learning. Image processing.


LISTA DE FIGURAS Figura 1 – Diagrama de Venn do levantamento bibliométrico ............. 33 Figura 2 - Representação do sistema nervoso em diagramas em blocos35 Figura 3 – Estrutura básica de um neurônio natural .............................. 36 Figura 4 – Modelo não-linear de um neurônio artificial ....................... 38 Figura 5 – Curva da função de limiar .................................................... 38 Figura 6 – Função linear por partes ...................................................... 39 Figura 7 – Função sigmóide .................................................................. 39 Figura 8 – Função ReLU ....................................................................... 40 Figura 9 – Função Tanh ........................................................................ 40 Figura 10 – Modelo multicamadas de uma Rede Neural ...................... 41 Figura 11 – Ilustração da técnica da Descida do Gradiente .................. 44 Figura 12 – Rede de grafos ................................................................... 45 Figura 13 – Aplicação do backpropagation em uma rede de grafos ..... 46 Figura 14 – Uma arquitetura típica de Rede Neural Convolucional ..... 47 Figura 15 – Processo de mapeamento de uma figura de 5×5 pixels ...... 50 Figura 16 – Exemplo de arquitetura de Rede Neural Convolucional aplicada com o modelo LeNet-5 ........................................................... 53 Figura 17 – Exemplo de arquitetura de CNN aplicada no processamento de imagem ............................................................................................. 54 Figura 18 – Esquema do processo de divisão do conjunto de dados para treinamento e teste do modelo ............................................................... 55 Figura 19 – Curvas de erro de teste e de treino de um modelo considerando a sua complexidade ......................................................... 56 Figura 20 – Curvas de acurácia de um modelo qualquer ...................... 57 Figura 21 – Representação esquemática da camada de sal e adjacências das costas brasileira e africana .............................................................. 58 Figura 22 – Fluxograma dos passos executados.................................... 62 Figura 23 – Epiciclo da análise de dados .............................................. 64 Figura 24 - Fluxograma do tipo de pergunta de análise de dados ......... 66 Figura 25 – Mapa de pixels de uma imagem fictícia 10×10 .................. 72 Figura 26 – Representação da união e interseção entre dois conjuntos . 75 Figura 27 – Arquitetura U-Net .............................................................. 78 Figura 28 – Ilustração da rede U-Net considerada no modelo primário proposto ................................................................................................. 81 Figura 29 – Curva de erros do modelo primário ................................... 83 Figura 30 – Curva de acurácia do modelo primário .............................. 83 Figura 31 – Curva de erros do modelo secundário 1 ............................. 87 Figura 32 – Curva de acurácia do modelo secundário 1........................ 87 Figura 33 – Curva de erros do modelo secundário 2 ............................. 88

Figura 34 – Curva de acurácia do modelo secundário 2 ....................... 89 Figura 35 - Curva de erros do modelo secundário 3 ............................. 90 Figura 36 – Curva da métrica de avaliação IoU do modelo secundário 3 .............................................................................................................. 90 Figura 37 – Comparativo entre modelos primário e secundários pela métrica da Kaggle ................................................................................. 91

LISTA DE QUADROS
Quadro 1 - Síntese de palavras-chave utilizadas na pesquisa bibliográfica ............................................................................................................... 30 Quadro 2 – Artigos selecionados para leitura de resumo ...................... 32 Quadro 3 – Componentes principais das CNN’s ................................... 48 Quadro 4 – Componentes de melhorias das CNN’s .............................. 49 Quadro 5 – Características dos tipos de questões de análise de dados .. 65 Quadro 6 – Exemplos de imagens de treino e suas respectivas máscaras ............................................................................................................... 70 Quadro 7 – Exemplos de imagens de teste ............................................ 71 Quadro 8 - Exemplo da lista de pares de valores de uma determinada máscara .................................................................................................. 72 Quadro 9 - Ilustração do arquivo train.csv ........................................... 73 Quadro 10 – Ilustração do arquivo depths.csv....................................... 73 Quadro 11 - Resumo das camadas utilizadas no modelo de Hönigschmid (2018) .................................................................................................... 80


LISTA DE TABELAS Tabela 1 - Número de artigos publicados contendo cada uma das palavras-chave nas três bases de dados definidas ................................................ 30 Tabela 2 – Número de artigos publicados combinando palavras-chave nas três bases de dados ................................................................................ 31 Tabela 3 – Lista de parâmetros utilizados no modelo primário ............ 82 Tabela 4 – Acurácia e erro final do treinamento do modelo primário... 83 Tabela 5 – Acurácia e erro final do treinamento do modelo secundário 1 ............................................................................................................... 86 Tabela 6 – Acurácia e erro final do treinamento do modelo secundário 2 ............................................................................................................... 88 Tabela 7 – Métrica IoU e erro final do treinamento do modelo secundário 3 ............................................................................................................. 89


LISTA DE ABREVIATURAS E SIGLAS
ABEPRO Associação Brasileira de Engenharia de Produção ANP Agência Nacional de Petróleo API Application Programming Interface
AWS Amazon Web Services
CNN Convolutional Neural Network
FN Falso Negativo FP Falso Positivo GPU Graphics Processing Unit
IA Inteligência Artificial IoU Intersection over Union (Interseção sobre União) LR Learning rate
MSE Mean Squared Error
PDP Processamento Distribuído Paralelo ReLU Unidade Linear Retificada RNA Rede Neural Artificial SGD Stochastic Gradient Descent
Tanh Tangente Hiperbólica TGS Tomlinson Geophysical Services Inc.
TP True Positive (Verdadeiro Positivo)


SUMÁRIO
1 INTRODUÇÃO ................................................................... 25 1.1 JUSTIFICATIVA .................................................................. 25
1.2 OBJETIVOS ......................................................................... 26
1.2.1 Objetivo geral ...................................................................... 26
1.2.2 Objetivos específicos ........................................................... 26
1.3 LIMITAÇÕES DO TRABALHO ......................................... 27
1.4 ESTRUTURA DO TRABALHO .......................................... 27
2 REFERENCIAL TEÓRICO .............................................. 29 2.1 REVISÃO DE LITERATURA ............................................. 29
2.2 REDES NEURAIS ................................................................ 34
2.2.1 O cérebro humano e a rede neural biológica .................... 35
2.2.2 As redes neurais e seu funcionamento ............................... 36
2.2.3 Redes Neurais Convolucionais ........................................... 46
2.2.3.1 Componentes básicos e melhorias das Redes Neurais Convolucionais ...................................................................................... 47
2.2.3.2 Processamento de imagens com Redes Neurais Convolucionais 49
2.2.3.3 Acurácia e validação da Rede Neural Convolucional ........... 55
2.3 A EXPLORAÇÃO DE SAL ................................................. 57
3 PROCEDIMENTOS METODOLÓGICOS ..................... 61 3.1 ROTEIRO METODOLÓGICO ............................................ 61
3.2 A ANÁLISE DE DADOS ..................................................... 62
3.3 CLASSIFICAÇÃO DA QUESTÃO DE ANÁLISE DE DADOS... .............................................................................................. 64
4 APLICAÇÃO DOS MÉTODOS E ANÁLISE DOS RESULTADOS .................................................................................... 67 4.1 DESCRIÇÃO DO PROBLEMA ........................................... 67
4.1.1 Descrição dos dados ............................................................ 68
4.1.2 Métrica de avaliação ........................................................... 74

4.2 REDES NEURAIS CONVOLUCIONAIS – UMA ABORDAGEM PROMISSORA .......................................................... 76
4.2.1 Descrição do modelo primário proposto ........................... 79
4.2.2 Descrição de modelos secundários promissores ............... 83
4.3 APLICAÇÃO DOS MODELOS .......................................... 84
4.4 REFINAMENTO E AJUSTE DOS MODELOS .................. 85
4.5 ANÁLISE DOS RESULTADOS ......................................... 90
5 CONCLUSÕES E RECOMENDAÇÕES ......................... 93 REFERÊNCIAS .................................................................. 95

25
1 INTRODUÇÃO A perceptível ascensão da Inteligência Artificial (IA) e da Ciência
de Dados vem se refletindo na indústria do petróleo e gás. Segundo Mello (2018), um dos principais desafios deste setor é encontrar novos recursos. À medida que cresce o consumo global de energia, aumenta a necessidade de tecnologias avançadas em Análise de Dados e elevado poder computacional para encontrar e avaliar novas reservas de hidrocarbonetos. Neste sentido, recentemente, a International Business
Machines Research Brasil (IBM Research Brasil) anunciou o desenvolvimento, em parceria com a empresa portuguesa Galp e a Agência Nacional de Petróleo (ANP), de uma ferramenta que, utilizando IA e outras tecnologias de ponta, atua como um assistente para geocientistas na identificação e avaliação de prospectos exploratórios e na interpretação de imagens sísmicas (MELLO, 2018).
Além de petróleo e gás, enormes depósitos de sal estão acumulados abaixo da superfície da Terra (KAGGLE, 2018). Entretanto, segundo Dramsch (2018), identificá-los de forma precisa pode ser considerada uma tarefa complexa. As imagens sísmicas profissionais requerem interpretação humana especializada e isso pode levar a conclusões subjetivas e imprecisas, trazendo situações perigosas para as empresas de exploração de petróleo (KAGGLE, 2018).
Dada a necessidade de identificar regiões que contenham sal e a crescente utilização de Inteligência Artificial pela indústria de mineração para a solução desses problemas, este trabalho visa adaptar um modelo de predição no reconhecimento de padrões que permita identificar, com razoável acurácia, segmentos de sal em imagens sísmicas de camadas subterrâneas profundas. Fundamentado nos conceitos de Redes Neurais Convolucionais, o objetivo do modelo proposto consiste em minimizar os erros de predição na identificação de padrões da presença de sal em imagens sísmicas.
1.1JUSTIFICATIVA
A motivação deste trabalho se originou do avanço recente de
estudos na área de Inteligência Artificial. O conceito de IA pode ser considerado antigo; nasceu em meados da década de 1950 (BITTENCOURT, 2006). Contudo, na última década, o interesse por algumas técnicas de IA como Aprendizado de Máquina (Machine
Learning) e Aprendizado Profundo (Deep Learning) vem crescendo de forma mais contundente. Inúmeros estudos e modelos com essas técnicas

26
vêm sendo desenvolvidos com o intuito de solucionar problemas reais do cotidiano das pessoas (DEEP LEARNING BOOK, 2018). As ferramentas de IA estão sendo utilizadas por grandes empresas nos mais variados setores da economia como redes sociais, grifes de roupa, montadoras de automóveis, indústrias de mineração, entre várias outras. Estima-se que nos próximos quatro anos, a Inteligência Artificial movimente cerca de US$ 70 bilhões na economia mundial, e mais, a previsão é que até 2025, 75% das equipes desenvolvedoras incluam IA em seus serviços e o mercado de computação cognitiva represente mais de US$ 2 trilhões (TUPINAMBÁ e TABOAS, 2018).
Como o modelo proposto neste estudo envolve conceitos de Inteligência Artificial e Ciência de Dados visando solucionar um problema real na detecção de regiões que possam conter segmentos de sal, o tema deste trabalho pode ser considerado relevante e atual perante às áreas das Engenharias, Ciências da Computação, Geologia e à sociedade como um todo. Segundo as categorias existentes na Associação Brasileira de Engenharia de Produção (ABEPRO), este pode ser classificado como um estudo na área de Pesquisa Operacional e subárea de Inteligência Computacional. 1.2 OBJETIVOS
1.2.1 Objetivo geral
Identificar segmentos de sal em imagens de camadas subterrâneas
profundas, utilizando redes neurais para o reconhecimento de padrões que indicam a presença do mineral.
1.2.2 Objetivos específicos
• Realizar levantamento sobre a aplicação de técnicas de Inteligência
Artificial na identificação de padrões em imagens; • Realizar análise exploratória de dados considerando as
especificidades da identificação de segmentos de sal em imagens sísmicas de camadas subterrâneas profundas.
• Selecionar e adequar modelo de predição, cujo algoritmo de aprendizagem seja capaz de identificar a presença de sal em imagens sísmicas de camadas subterrâneas.
• Aplicar o modelo em um cenário de estudo para validação do mesmo.

27
1.3 LIMITAÇÕES DO TRABALHO
Neste trabalho foram utilizadas imagens sísmicas reais para a
aplicação do modelo proposto e o mesmo foi validado por meio de outras imagens sísmicas reais. Todavia, a execução deste modelo foi limitada a um cenário de estudo teórico, isto é, este modelo não foi utilizado para identificação prática de regiões que permitam a exploração de sal. O trabalho foi limitado apenas a avaliar imagens sísmicas, não sendo utilizado por empresas de exploração de minerais.
O modelo proposto está apto a identificar segmentos de sal em imagens sísmicas com grau de acurácia que pode ser considerado satisfatório. Entretanto, o modelo limita-se a avaliar imagens de resolução de 101×101 pixels. As imagens utilizadas para a construção e avaliação do modelo foram fornecidas por meio da plataforma de dados Kaggle, sendo que não há como garantir a mesma acurácia com a utilização de imagens sísmicas de outros padrões. 1.4 ESTRUTURA DO TRABALHO
Este trabalho está estruturado da seguinte maneira: 1) introdução;
2) referencial teórico; 3) procedimentos metodológicos; 4) aplicação dos métodos e análise dos resultados e 5) conclusões e recomendações.
No primeiro capítulo é estabelecida a contextualização do tema escolhido, bem como a justificativa para tal escolha. Ainda apresenta os objetivos e limitações do trabalho.
O referencial teórico faz a abordagem sobre o que são as Redes Neurais, suas principais características e aplicações, assim como apresenta definições e conceitos relativos à exploração de sal. Inclui, além disso, o levantamento bibliométrico elaborado para o trabalho sobre estudos relacionados a este tema.
O terceiro capítulo contempla os métodos que foram adotados, bem como o roteiro das etapas que foram cumpridas.
No quarto capítulo é descrita a implementação e aplicação dos métodos utilizados. É neste capítulo que é apresentado o modelo proposto e discute-se os resultados alcançados.
Por fim, no quinto capítulo, uma análise geral sobre este trabalho e o tema que foi objeto de estudo são apresentados. Isto é, são estabelecidas as conclusões e as recomendações para trabalhos futuros.

28

29
2 REFERENCIAL TEÓRICO Este capítulo tem como finalidade apresentar a base teórica que
permita elucidar os principais conceitos relacionados ao tema deste trabalho. No início do capítulo mostra-se a revisão da literatura de estudos realizados com temas semelhantes a este estudo. Posteriormente, traz-se definições sobre as Redes Neurais, suas principais características e propriedades. Destaca-se, nesta exposição, os conceitos relacionados às Redes Neurais Convolucionais cuja arquitetura foi utilizada no modelo proposto deste trabalho. Por fim, apresenta-se alguns conceitos sobre a exploração de sal e, por conseguinte, na exploração de petróleo.
2.1 REVISÃO DE LITERATURA
Este tópico tem como objetivo relatar o levantamento
bibliométrico realizado para este trabalho. A revisão de literatura teve o intuito de identificar, em bases de dados relevantes, artigos e publicações que contemplassem temas semelhantes a este estudo. Para a construção deste levantamento, utilizou-se procedimento semelhante ao adotado por Vieira (2012), em que a autora se baseou na proposta do Laboratório de Metodologias Multicritério em Apoio à Decisão da UFSC (LAbMCDA) para construção de portfólios de artigos, composto por oito etapas: definição das base de dados, definição de palavras-chave, busca e filtragem na base de dados, seleção de artigos por alinhamento do título à pesquisa, seleção por reconhecimento científico, repescagem de referências excluídas, leitura de resumos e fichamento e seleção dos artigos para compor o portfólio de leitura (VIEIRA, 2012).
Nesse sentido, foram definidas as seguintes bases de dados: Society
of Exploration Geophysicists (SEG), ScienceDirect e IEEE Xplore. A escolha da primeira base de dados se deve à indicação de Dramsch (2018) e pela relevância de uma fonte especializada em exploração e geofísica. As demais bases foram selecionadas por apresentarem quantidade expressiva de periódicos com foco em ciências exatas e nas engenharias em geral.
Na sequência, três grupos de palavras-chave foram definidos. O primeiro grupo busca por palavras relacionadas às Redes Neurais. O segundo grupo tem o objetivo de identificar trabalhos relacionados com a exploração de sal e imagens sísmicas. Por fim, o último grupo é formado por palavras relacionadas ao reconhecimento de padrões e processamento de imagens. Todas as pesquisas foram realizadas somente com palavras

30
na língua inglesa, desta forma o Quadro 1 apresenta todas as palavras-chave que foram utilizadas nesta pesquisa. Quadro 1 - Síntese de palavras-chave utilizadas na pesquisa bibliográfica
Grupo Palavras-chave Redes Neurais - Neural Network
- Convolution Neural Network
- Deep Learning
Sal e Imagens Sísmicas - Salt
- Rock salt
- Seismic
- Seismic Images
Processamento de Imagens e Reconhecimento de Padrões
- Pattern Recognition
- Analysis Images
- Image processing
Fonte: elaborado pelo autor (2018) Inicialmente, fez-se o levantamento quantitativo de cada uma das
palavras-chave nas três bases de dados definidas. A Tabela 1 apresenta a quantidade de artigos presentes nas bases de dados. Tabela 1 - Número de artigos publicados contendo cada uma das palavras-chave nas três bases de dados definidas
Palavras-chave SEG Science Direct IEEE Xplore Neural Network 1.729 304.030 157.470 Convolution Neural
Network
276 13.096 4.974
Deep Learning 1.585 193.022 14.108 Salt 10.576 1.164.974 14.173 Rock salt 4.692 84.164 102 Seismic 45.747 132.654 5.564 Seismic Images 27.022 38.351 1.031 Pattern Recognition 4.935 589.257 87.393 Image analysis 25.562 2.343.009 212.189 Image processing 27.283 2.190.456 320.652
Fonte: elaborado pelo autor (2018) Por meio deste levantamento inicial, percebeu-se que a base de
dados da ScienteDirect é a que contém a maior quantidade de artigos publicados, considerando as pesquisas individuais de cada uma das palavras-chave definidas. Na sequência, aparece a IEEE Xplore, que apresenta uma quantidade considerável de artigos comparado com a base SEG. No entanto, considerando apenas o grupo referente a palavras

31
envolvendo Sal e Imagens Sísmicas, a SEG demonstra ter uma base de dados mais densa.
A partir deste ponto, buscou-se realizar pesquisas mais restritivas. Foram efetuadas pesquisas que cruzaram palavras dos três grupos definidos anteriormente, isto é, foram propostas combinações de palavras com o objetivo de direcionar para que as pesquisas retornassem resultados contendo artigos mais semelhantes a este trabalho. A Tabela 2 apresenta a quantidade de artigos publicados para cada uma das combinações propostas nas bases de dados.
Tabela 2 – Número de artigos publicados combinando palavras-chave nas três bases de dados
Palavras-chave SEG Science Direct IEEE Xplore Convolution Neural
Network, Salt
87 610 18
Convolution Neural
Network, Rock Salt 67 139 0
Convolution Neural
Network, Seismic 264 313 7
Convolution Neural
Network, Seismic, Salt 87 49 0
Convolution Neural
Network, Seismic Images 190 221 7
Convolution Neural
Network, Salt, Pattern
Recognition
65 340 1
Convolution Neural
Network, Salt, Image
Analysis
76 494 6
Neural Network, Salt,
Seismic Images
270 301 0
Fonte: elaborado pelo autor (2018) A seguir, com o objetivo de restringir ainda mais os resultados das
pesquisas, foram selecionados artigos por meio do alinhamento dos títulos de cada um deles. Desta forma, pôde-se filtrar oito artigos para realizar a leitura dos seus respectivos resumos. O Quadro 2 traz o título, autor e ano de publicação dos oito artigos previamente selecionados. Destaca-se que todos os artigos foram publicados no ano de 2018, mostrando a ascendência deste tema na literatura.

32
Quadro 2 – Artigos selecionados para leitura de resumo Título Autor (Ano)
Learning to label seismic structures with deconvolution
networks and weak labels
ALAUDAH et al. (2018)
Why using CNN for seismic interpretation? An
investigation
DI et al. (2018)
Deep-learning seismic facies on state of the art CNN
architectures
DRAMSCH E LÜTHJE (2018)
Automated interpretation of top and base salt using deep
convolutional networks
GRAMSTAD E NICKEL (2018)
Automatic salt-body classification using a deep
convolutional neural network
SHI et al. (2018)
Convolutional neural networks for automated seismic
interpretation
WALDELAND et al. (2018)
Seismic Waveform Classification and First-Break Picking
Using Convolution Neural Networks
YUAN et al. (2018)
Seismic facies classification using different deep
convolutional neural networks
ZHAO (2018)
Fonte: elaborado pelo autor (2018).
Após a leitura do resumo dos artigos citados no Quadro 2, pôde-se ressaltar cinco publicações: Shi et al. (2018), Waldeland et al. (2018), Gramstad e Nickel (2018), Di et al. (2018) e Dramsch e Lüthje (2018). A Figura 1 ilustra, por meio do Diagrama de Venn, o levantamento bibliométrico realizado considerando as três palavras-chave principais deste estudo. Considerou-se no diagrama, desde a pesquisa das palavras soltas em todas as bases de dados até a seleção dos cinco artigos de destaque. Na sequência, expõe-se as principais abordagens de cada um destes trabalhos.

33
Figura 1 – Diagrama de Venn do levantamento bibliométrico
Fonte: elaborado pelo autor (2018).
Shi et al. (2018) propõem a utilização de Redes Neurais Convolucionais para detectar corpos salinos em imagens sísmicas. A arquitetura proposta foi inspirada nos modelos Segnet e U-Net e as soluções foram consideradas promissoras. Segundo os autores, os resultados indicaram que a arquitetura da rede e o fluxo de trabalho propostos são capazes de capturar recursos sutis automaticamente sem a necessidade de processamento manual das imagens.
O trabalho de Waldeland et al. (2018) traz uma revisão teórica sobre a utilização de Redes Neurais Convolucionais na interpretação de imagens sísmicas. Os autores ressaltam como este modelo está revolucionando o campo da análise de imagens. Por fim, ainda é demonstrado o exemplo de utilização das Redes Neurais Convolucionais no contexto de imagens sísmicas usando-as para delinear rochas salinas. Os resultados foram considerados satisfatórios, quando comparados com a interpretação manual.
Gramstad e Nickel (2018) utilizam Redes Neurais Convolucionais para automatizar a interpretação de topo e base do sal. Foram propostas

34
duas arquiteturas de redes neurais, os resultados de ambas mostraram que foram capazes de atingir uma cobertura de 92% da interpretação manual correspondente. Os autores destacam que o tempo de resposta para produzir os resultados é reduzido em comparação com a interpretação manual.
Di et al. (2018) trazem um trabalho comparativo entre Rede Neural Convolucional e Rede Perceptron Multicamada. Os autores investigam o porquê das Redes Convolucionais estarem sendo tão utilizadas em interpretações de imagens sísmicas. As duas arquiteturas foram comparadas aplicando-as na identificação de corpos salinos. A Rede Convolucional obteve resultados melhores e os autores apontam dois motivos para isto: a Rede Convolucional gera automaticamente um conjunto de recursos e otimiza-os durante o processo de treinamento; a sua classificação é baseada em patches que incorpora padrões de reflexão sísmica local na construção da relação de mapeamento entre os sinais sísmicos e as estruturas alvo.
Por fim, Dramsch e Lüthje (2018) estabelecem um comparativo entre três arquiteturas de Redes Neurais Convolucionais: Waldeland CNN, ResNet50 e VGG16 CNN, na interpretação de imagens sísmicas. Segundo os autores, os modelos VGG16 CNN e Waldeland CNN apresentaram bons resultados, isto é, obtiveram desempenho semelhante. A arquitetura ResNet50, no entanto, mostrou-se ineficaz no tratamento de imagens sísmicas.
2.2 REDES NEURAIS
As redes neurais são conhecidas na literatura pelos seguintes
termos: Conexionismo, Redes Neurais Artificiais (RNA), Processamento Distribuído Paralelo (PDP), Redes Adaptativas e Computação Coletiva (BITTENCOURT, 2006). As redes neurais artificiais são a base de algoritmos de Deep Learning e Machine Learning, técnicas inerentes à Inteligência Artificial (DEEP LEARNING BOOK, 2018).
Para entender o que são as redes neurais e como funcionam é importante que se tenha uma compreensão básica sobre o cérebro humano, ou mais especificamente sobre os neurônios biológicos, inspiração das redes neurais (LINDEN, 2012). Portanto, inicialmente, apresenta-se uma introdução sobre o funcionamento do cérebro humano. Na sequência, as redes neurais artificias são apresentadas.

35
2.2.1 O cérebro humano e a rede neural biológica O cérebro humano pode ser visto como o ponto centralizador de
um sistema de três estágios, constituído por receptores, atuadores e a rede neural, que representa o cérebro. Este sistema é o chamado “sistema nervoso humano”. Os receptores recebem estímulos do corpo humano ou do ambiente externo e os convertem em impulsos elétricos que transmitem informações para o cérebro. Os atuadores, por sua vez, transformam impulsos elétricos gerados pela rede neural em respostas discerníveis como saída do sistema. A rede neural tem a função de receber e processar as informações e a partir destas tomar decisões apropriadas (HAYKIN, 2001). A Figura 2 representa o sistema nervoso como um diagrama em blocos, facilitando a compreensão.
Figura 2 - Representação do sistema nervoso em diagramas em blocos
Fonte: adaptado de Haykin (2001)
A rede neural biológica é composta por uma série de neurônios
interconectados. O neurônio é o ponto central do sistema nervoso. É uma unidade processamento de informação que é essencial para a operação de uma rede neural (HAYKIN, 2001). O neurônio é constituído basicamente de um corpo celular central e de dois tipos de prolongamento: o axônio e os dendritos (a Figura 3 mostra a estrutura de um neurônio natural). O corpo celular também é chamado de pericárdio e é responsável pela produção dos impulsos nervosos. Os dendritos têm a função de receber os impulsos nervosos provenientes dos órgãos receptores, ao passo que o axônio transmite os impulsos nela originados. Normalmente, os neurônios não trabalham de forma individual, e sim em conjunto uns com os outros, estabelecendo o contato entre dendrito de um neurônio e axônio de outro. Tal associação é chamada de sinapse, que pode ser elétrica ou química (LINDEN, 2012). As sinapses são unidades estruturais e funcionais elementares que medeiam às interações entre os neurônios. O tipo mais comum é a sinapse química (HAYKIN, 2001).

36
Figura 3 – Estrutura básica de um neurônio natural
Fonte: Brasil Escola (2018)
Pode-se entender o neurônio como um processador que vai somando de forma ponderada os sinais de entrada e a partir do momento que este somatório atinge um valor mínimo, é ativado um valor de saída (BITTENCOURT, 2006). Na sequência deste trabalho, mostra-se que esta definição é a base das redes neurais artificiais.
2.2.2 As redes neurais e seu funcionamento
A visão moderna das redes neurais partiu do artigo A Logical
Calculus of the Ideas Immnent in Nervous Activity de Warren McCulloch e Walter Pitts, em 1943. Pitts e McCulloch (1943) mostraram que as redes de neurônios artificiais poderiam, em princípio, computar qualquer função aritmética ou lógica. Posteriormente, no fim da década de 50, Frank Rosenblatt e alguns colegas construíram a chamada “rede perceptron”, a qual demonstrou capacidade de realizar reconhecimento de padrões (algum tempo depois a rede perceptron se mostrou bastante limitada, funcionando apenas para alguns tipos de problemas). Essa pode ser considerada a primeira aplicação prática de redes neurais. (HAGAN et al., 2014; McCULLOCH e PITTS, 1943; BITTENCOURT, 2006).
De maneira geral, uma rede neural artificial pode ser definida como uma máquina que simula a maneira como o cérebro realiza uma tarefa ou função (HAYKIN, 2001). A partir da ótica de que uma rede neural é uma máquina adaptativa, Haykin (2001, p. 28) define ainda de forma mais específica o seguinte:

37
“Uma rede neural é um processador maciçamente paralelo e distribuído, constituído de unidades de processamento simples, que têm a propensão natural para armazenar conhecimento experimental e torná-lo disponível para o uso. Ela se assemelha ao cérebro em dois aspectos: 1. o conhecimento é adquirido pela rede a partir de seu
ambiente através de um processo de aprendizagem; 2. forças de conexão entre neurônios, conhecidas como
pesos sinápticos, são utilizadas para armazenar o conhecimento adquirido.”
Conforme visto preliminarmente, na seção anterior, o neurônio
pode ser modelado como um bloco somador de entradas e saídas. Dessa forma, o diagrama em blocos da Figura 4 mostra o modelo de um neurônio, que é a base para o projeto de redes neurais artificiais. Identifica-se neste modelo três elementos básicos (HAYKIN, 2001):
a) um conjunto de sinapses ou elos de conexão, cada um
caracterizado por um peso ou força própria. Isto é, um sinal de entrada xj na entrada da sinapse j conectada ao neurônio k é multiplicada pelo peso sináptico wkj;
b) um somador para somar os sinais de entrada; c) uma função de ativação para restringir a amplitude de
saída de um neurônio. Haykin (2001) ressalta o bias, que é aplicado externamente ao
neurônio, representado no diagrama da Figura 4 pelo símbolo θk. Os sinais de saída são representados pelo símbolo yk, a função de ativação por φ e uk representa o sinal de saída da função soma. Em termos matemáticos, pode-se descrever um neurônio k com o seguinte par de equações:
ukj = ∑ nj=1 wkj.xj (2.1)
yk = φ (vk + θk) (2.2)

38
Figura 4 – Modelo não-linear de um neurônio artificial
Fonte: Haykin (2001).
No modelo inicial de McCulloch e Pitts, a função de ativação possuía apenas valores binários, ou seja, zeros ou uns. Essa era a grande limitação deste modelo (McCULLOCH e PITTS, 1943; BITTENCOURT, 2006). Posteriormente, foi proposto que a função de ativação pudesse assumir valores contínuos no intervalo [0,1], ou até mesmo entre -1 e 1. Haykin (2001) destaca três tipos de função de ativação:
a) Função de limiar (Figura 5):
���� = �1 � � ≥ 00 � � < 0 (2.3)
Figura 5 – Curva da função de limiar
Fonte: Haykin (2001)

39
b) Função linear por partes (Figura 6):
���� = ⎩⎪⎨⎪⎧ 1 � � ≥ 12
� � − 12 < � < 10 � � ≤ − 12
(2.4)
Figura 6 – Função linear por partes
Fonte: Haykin (2001)
c) Função sigmóide (Figura 7):
ave1
1)v(
-+=ϕ (2.5)
Figura 7 – Função sigmóide
Fonte: Haykin (2001) Segundo Deep Learning Book (2018), atualmente, existem diversas funções de ativação, destacando-se a tangente hiperbólica (Tanh) e a unidade linear retificada (ReLU):

40
d) Função ReLU (Figura 8):
φ�v� = �0, � < 0�, � ≥ 0 (2.6)
Figura 8 – Função ReLU
Fonte: elaborado pelo autor (2018)
e) Função Tanh (Figura 9):
���� = 21 + ���� − 1 (2.7)
Figura 9 – Função Tanh
Fonte: elaborado pelo autor (2018)
Visto o modelo de um neurônio artificial e sabendo que uma rede
neural é composta por uma série de neurônios, pode-se representar uma rede neural artificial de modo simplificado por meio de grafos orientados

41
(HAYKIN, 2001). Esta representação ilustra a etapa de feedfoward, que consiste no encadeamento dos neurônios. Isto é, a saída de uma camada se torna a entrada da próxima, a saída dessa se torna a entrada da próxima e assim por diante (TURING, 2018). Neste sentido, as redes neurais podem ser classificadas em redes de única ou múltiplas camadas, sendo a última a mais utilizada (LINDEN, 2012). A Figura 10 mostra a representação de um modelo multicamadas.
Figura 10 – Modelo multicamadas de uma Rede Neural
Fonte: Araújo (2015)
Segundo Deep Learning Book (2018), as camadas de uma Rede Neural podem ser classificadas em camadas de entrada, oculta (intermediária) e saída. Em geral, o design das camadas de entrada e saída é direto e padrão, isto é, são dependentes dos dados de entrada do problema a ser estudado e das informações que devem ser extraídas do modelo proposto. No entanto, existem inúmeras formas de se construir as camadas ocultas. Esta variação do design nas camadas ocultas é chamada de arquitetura da rede neural. (DEEP LEARNING BOOK, 2018). Não há como compor uma lista com todas as arquiteturas existentes, nem mesmo determinar qual utilizar para cada tipo de problema. Entretanto, estudos recentes mostram que algumas arquiteturas vêm se destacando em determinas situações (VEEN, 2016). Na seção 2.2.3 é apresentada a revisão mais detalhada sobre Redes Neurais Convolucionais, arquitetura que vem sendo utilizada em modelos de reconhecimento de padrões e processamento de imagens.

42
Linden (2012) faz o seguinte destaque: “A propriedade mais importante das redes neurais é a habilidade de aprender de seu ambiente e com isso melhorar seu desempenho”. Bittencourt (2006) define que treinar uma rede neural significa ajustar sua matriz de pesos de forma que os valores de saída coincidam com certo valor esperado. Bittencourt (2006) ressalta que uma rede neural pode ser treinada com três objetivos diferentes:
a) auto-associação: após o treinamento com um conjunto
de vetores, quando submetida a um vetor similar a um dos exemplos, mas deturpado, reconstituir o vetor original;
b) heteroassociação: após o treinamento com um conjunto de pares de vetores, quando submetida a um vetor similar ao primeiro elemento de um par, mas deturpado, reconstituir o segundo elemento do par;
c) detecção de regularidades: descobrir as regularidades inerentes aos vetores de treinamento e criar padrões para classifica-los de acordo com tais regularidades.
Segundo Deep Learning Book (2018) e Turing (2017), o treinamento da rede neural consiste em encontrar valores de pesos (w) e bias (b) que minimizem a sua função de custo C(w,b) (também denominada de função de erro E(w,b)), que pode ser definida da seguinte maneira:
���, �� = ��, �� = 12! "�#$�%� −&
$'( ÿ$��, ���² (2.8)
Sendo que,
m = número total de entradas no treinamento; x = vetor de entradas ; yi(x) = vetor de saídas correspondente ao vetor de entradas x para cada dado de entrada i; ÿi (w, b) = vetor de saídas da rede treinada para cada dado de entrada i; ÿi (w, b) Є ℜn
w = vetor de pesos; b = vetor de bias;

43
Neste sentido, Turing (2017) aponta que o objetivo básico do treinamento é comparar a saída gerada pela rede ÿi(w, b) com a saída “real” yi(x), de modo que a rede neural seja capaz de retornar valores de ÿi(w, b) mais próximos possíveis de yi(x), para cada entrada x. Deep Learning Book (2018) ressalta que a função de custo definida na Equação 2.8 é conhecida como Mean Squared Error (MSE) ou Erro Quadrático Médio, no entanto, outras funções de erro podem ser utilizadas com o mesmo objetivo; mean
absolute error, mean absolute percentage error, squared hinge, hinge,
categorical hinge, categorical crossentropy, binary crossentropy, entre outras. Dentre essas, destaca-se a função binary crossentropy, utilizada no modelo aplicado neste trabalho e que pode ser definida da seguinte maneira:
E�w, b� = 1m "[y1�x� × log7ÿ1�w, b�89
1'(+�1-y1 �x�� × log�1 − ÿ1�w, b��]
(2.9)
Sendo que,
m = número total de entradas no treinamento; x = vetor de entradas ; yi(x) = vetor de saídas correspondente ao vetor de entradas x para cada dado de entrada i; ÿi (w, b) = vetor de saídas da rede treinada para cada dado de entrada i; ÿi (w, b) Є ℜn
w = vetor de pesos; b = vetor de bias;
Neste contexto, como medida para minimizar a função de custo,
utiliza-se a técnica da Descida do Gradiente (TURING, 2017). Segundo Deep Learning Book (2018), a Descida do Gradiente é uma ferramenta para otimizar funções complexas iterativamente dentro de um programa de computador, o objetivo desta técnica é: dada uma função, encontrar o seu mínimo. A Descida do Gradiente está fundamentada na influência de cada peso e cada bias no erro, isto é, para cada um dos dados é possível calcular a derivada parcial do custo em função de cada um dos pesos e obter um novo peso (TURING, 2017). A Equação 2.10 apresenta a definição matemática da técnica da Descida do Gradiente, ao passo que a

44
Figura 11 ilustra este processo de aprendizagem para uma função de erro qualquer.
<= = <= − > ∂CA<= (2.10)
Sendo que,
Wn = vetor de pesos e bias para cada iteração n;
α = taxa de aprendizagem1 (learning rate);
C = função de custo ou erro. Figura 11 – Ilustração da técnica da Descida do Gradiente
Fonte: Turing (2017)
O processo de calcular os gradientes das funções de erro pode ser considerado essencial para o desempenho das redes neurais (DEEP
LEARNING BOOK, 2018). Este processo pode ser estabelecido por meio de algoritmos de treinamento, entre os mais utilizados estão o
1A taxa de aprendizagem é um hiperparâmetro (constante que não é
aprendida durante o treinamento, mas é estabelecida preliminarmente) da rede neural. Trata-se de uma constante definida arbitrariamente entre 0 e 1.

45
backpropagation, RProp e Quickprop (LINDEN, 2012). Deep Learning
Book (2018) define: “O backpropagation é, indiscutivelmente, o algoritmo mais importante da história das redes neurais.” O backpropagation é um algoritmo que faz o treinamento de modelos de redes neurais algo computacionalmente tratável, reduzindo o tempo de treinamento em até 10 milhões de vezes. Trata-se de uma técnica para calcular derivadas de maneira rápida. Além da utilização em Deep
Learning, é aplicada em diversas outras áreas (DEEP LEARNING BOOK, 2018).
O algoritmo backpropagation pode ser definido, de maneira resumida, como o cálculo das derivadas parciais do sinal de saída de um grafo em relação a cada um dos nós deste mesmo grafo. Isto é, ao invés de calcular as derivadas parciais do sinal de entrada até o sinal de saída, faz-se o caminho inverso, no modo de retro propagação. Basicamente, aplica-se a regra da cadeia dentro da teoria dos grafos. Nesse sentido, o treinamento das redes neurais ocorre com o cálculo da derivada parcial do erro do treinamento em função dos pesos e bias da rede, fazendo isto iterativamente e ajustando os valores dos pesos para que minimizem o valor do erro do treinamento. Com isto, reduz-se a carga computacional do modelo e, por conseguinte, o tempo de treinamento (HAYKIN, 2001; DEEP LEARNING BOOK, 2018). A Figura 12 apresenta uma rede de grafos qualquer, ao passo que a Figura 13 ilustra a aplicação do backpropagation nesta rede.
Figura 12 – Rede de grafos
Fonte: Deep Learning Book (2018)

46
Figura 13 – Aplicação do backpropagation em uma rede de grafos
Fonte: Deep Learning Book (2018)
Com tantas características e propriedades presentes nas Redes Neurais, pode-se ter uma noção de quão poderosa ela pode ser. Com isso, as redes neurais apresentam uma série de benefícios e capacidades, que dentre outras, cita-se: não-linearidade, mapeamento de entrada-saída, adaptabilidade, respostas a evidências, informação contextual, tolerância a falhas e analogia neurobiológica (HAYKIN, 2001).
2.2.3 Redes Neurais Convolucionais
Rede Neural Convolucional (Convolutional Neural Network) é
uma arquitetura de Deep Learning inspirada no mecanismo natural de percepção visual dos seres vivos (GU et al., 2018). Le Cun et al. (1990) desenvolveram uma rede neural artificial multicamadas chamada Le-Net, que pode reconhecer dígitos manuscritos e classificá-los. Assim como outras arquiteturas, o modelo LeNet pode ser treinado com algoritmo de backpropagation. Em 1998, Le Cun et al. (1998) apresentaram melhorias no modelo LeNet-5 utilizando a partir dali, a nomenclatura de Convolution Neural Network (CNN). O modelo proposto por Le Cun et al. (1998) pode obter representações efetivas de uma imagem, tornando possível reconhecer padrões visuais diretamente de pixels brutos com pouco ou nenhum pré-processamento (GU et al., 2018).
Deep Learning Book (2018) define: “As Redes Neurais Convolucionais (ConvNets ou CNN’s) são redes neurais artificiais profundas que podem ser usadas para classificar imagens, agrupá-las por similaridade e realizar reconhecimento de objetos dentro de cenas”. A Figura 14 apresenta uma arquitetura típica de rede neural convolucional.

47
Figura 14 – Uma arquitetura típica de Rede Neural Convolucional
Fonte: Adaptado de Veen (2016)
2.2.3.1 Componentes básicos e melhorias das Redes Neurais Convolucionais
O recente estudo de Gu et al. (2018) apresenta a história das Redes
Neurais Convolucionais, mostrando a evolução desta técnica de Deep
Learning desde o modelo proposto por Le Cun et al. (1990) até os modelos implementados recentemente. Gu et al. (2018) classificam as arquiteturas das CNN’s de acordo com seus componentes básicos e suas melhorias. Os componentes básicos são aqueles que estão presentes em qualquer modelo de Rede Neural Convolucional, enquanto os componentes de melhorias representam ajustes que foram incorporados a algumas arquiteturas com o objetivo de otimizar os resultados em determinadas aplicações. As diversas variações que existem para cada componente permitem que sejam construídos inúmeros modelos de Redes Neurais Convolucionais. O Quadro 3 apresenta a descrição de cada um dos componentes principais, bem como possíveis variações que podem ser utilizadas nos modelos de CNN. À medida que o Quadro 4 expõe a descrição e possíveis variações dos componentes de melhorias.
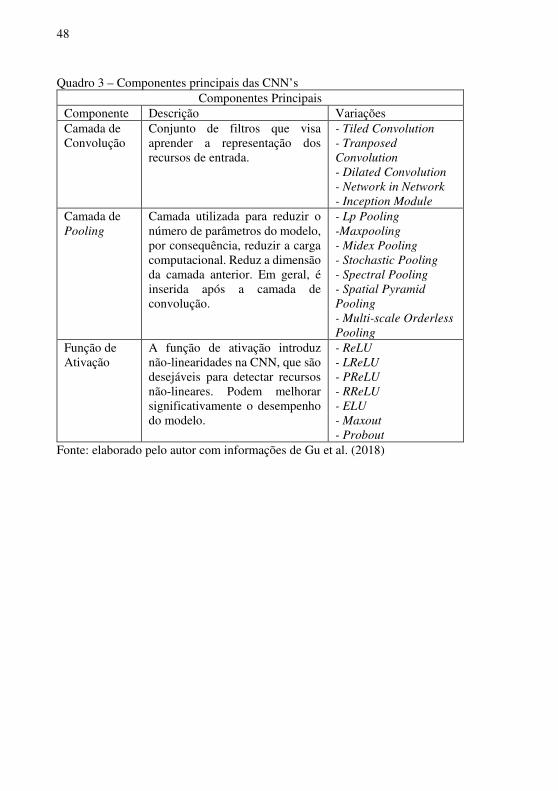
48
Quadro 3 – Componentes principais das CNN’s Componentes Principais
Componente Descrição Variações Camada de Convolução
Conjunto de filtros que visa aprender a representação dos recursos de entrada.
- Tiled Convolution
- Tranposed
Convolution
- Dilated Convolution
- Network in Network
- Inception Module
Camada de Pooling
Camada utilizada para reduzir o número de parâmetros do modelo, por consequência, reduzir a carga computacional. Reduz a dimensão da camada anterior. Em geral, é inserida após a camada de convolução.
- Lp Pooling
-Maxpooling
- Midex Pooling
- Stochastic Pooling
- Spectral Pooling
- Spatial Pyramid
Pooling
- Multi-scale Orderless
Pooling
Função de Ativação
A função de ativação introduz não-linearidades na CNN, que são desejáveis para detectar recursos não-lineares. Podem melhorar significativamente o desempenho do modelo.
- ReLU
- LReLU
- PReLU
- RReLU
- ELU
- Maxout
- Probout
Fonte: elaborado pelo autor com informações de Gu et al. (2018)

49
Quadro 4 – Componentes de melhorias das CNN’s Componentes de Melhorias
Melhorias Descrição Variações Função de perdas É a Função de Custos do
modelo, que deve ser treinado com o objetivo de minimizar esta função.
- Hinge Loss
- Softmax Loss
- Contrastive Loss
- Triplet Loss
- KL Divergence
Regularização Técnica utilizada para reduzir o overfitting2 da CNN.
- Lp-norm
- Dropout
- DropConnect
Otimização Técnicas aplicadas para otimizar o treinamento das redes convolucionais, por conseguinte, otimizar a acurácia das mesmas.
- Data Augmentation
- Weight Initialization
- SGD
- Batch Normalization
- Shortcut Connections
Processamento Rápido
Técnicas utilizadas para reduzir o tempo de treinamento e processamento da CNN.
- FFT
- Structured Transforms
- Low Precesion
- Weight Compression
- Sparse Convolution
Fonte: elaborado pelo autor com informações de Gu et al. (2018)
Por meio das inúmeras combinações possíveis entre as variações dos componentes das CNN’s é exequível construir variadas arquiteturas de Redes Neurais Convolucionais. Desse modo, Gu et al. (2018) apontam alguns modelos que se sobressaíram em aplicações nos últimos anos: AlexNet, ZFNet, VGGNet, GoogleNet e ResNet. Destaca-se, também, o modelo U-Net, proposto por Ronneberger et al. (2015), que foi utilizado na segmentação de imagens biomédicas.
2.2.3.2 Processamento de imagens com Redes Neurais Convolucionais
O funcionamento das CNN’s no processamento de imagens
começa a partir de uma varredura nos dados de entrada que não se destina a analisar tudo de uma única vez. Por exemplo, para uma imagem de 100×100 pixels, não é criada uma camada com dez mil nós que
2 Segundo Deep Learning Book (2018), Overfitting é o fenômeno que
ocorre quando a rede neural está super-adaptada, isto é, o modelo aprendeu (ou “decorou”) as especificidades dos dados de entrada no treinamento, mas não é capaz de generalizar para outras entradas. Dessa forma, tornando-se o treinamento inútil. A subseção 2.2.3.3 detalha este fenômeno.

50
processarão cada um dos pixels individualmente. Ao invés disso, cria-se uma camada de entrada que varre a imagem por regiões, normalmente quadradas (por exemplo, 10×10 pixels). Essas regiões são os filtros, que funcionam como um “scanner” que vai “rastejando” sobre a imagem e filtrando informações sobre a mesma. Em geral, esse mapeamento começa do canto superior esquerdo da imagem, enquanto que o tamanho dos passos (strides) entre uma região e outra, bem como a dimensão dos filtros, são arbitrados (VEEN, 2016), (DEEP LEARNING BOOK, 2018). A Figura 15 ilustra o mapeamento de uma figura 5×5 pixels utilizando filtros de 3×3 e strides de 2×2.
Figura 15 – Processo de mapeamento de uma figura de 5×5 pixels
a) primeiro passo
b) segundo passo
c) terceiro passo
d) quarto passo
e) quinto passo
f) sexto passo
g) sétimo passo
h) oitavo passo
i) nono passo
Fonte: adaptado de Mendes (2018)

51
Os dados da camada de entrada alimentam camadas convolucionais, que visam aprender as representações dos recursos de entrada (GU et al., 2018). Os nós das camadas convolucionais não estão totalmente conectados, cada nó se comunica apenas com as células mais próximas. Conforme essas camadas convolucionais vão ficando mais profundas, as mesmas vão encolhendo em fatores divisíveis pelos valores de entrada (costuma-se trabalhar com valores de potência de 2, por exemplo: 128, 64, 32, 16, 8, 4, 2, 1). Além das camadas convolucionais, há as camadas de pooling, que têm a função de filtrar detalhes de cada uma das regiões mapeadas. Em geral, utiliza-se o critério de maxpooling, o qual seleciona em uma região filtrada de uma imagem em escala de cinza, por exemplo, o pixel de maior valor (VEEN, 2016). As camadas de pooling visam alcançar a invariância de deslocamento, reduzindo a resolução dos mapas de recursos (GU et al., 2018).
Gu et al. (2018) resumem o funcionamento de uma rede convolucional aplicada a imagens da seguinte forma:
“Os núcleos da primeira camada convolutiva são projetados para detectar recursos de baixo nível, como bordas e curvas, enquanto os núcleos das camadas profundas são treinados para codificar recursos mais abstratos. Ao empilhar várias camadas convolucionais e de pool, pode-se extrair gradualmente representações de recursos de nível mais alto. Depois de várias camadas convolucionais e de pooling, pode haver uma ou mais camadas totalmente conectadas que visam realizar um raciocínio de alto nível. Essas pegam todos os neurônios da camada anterior e os conectam a cada neurônio da camada atual para gerar informações semânticas globais. Nem sempre a camada totalmente conectada é necessária, pois pode ser substituída por uma camada de convolução 1×1. A última camada das CNN’s é a camada de saída.”
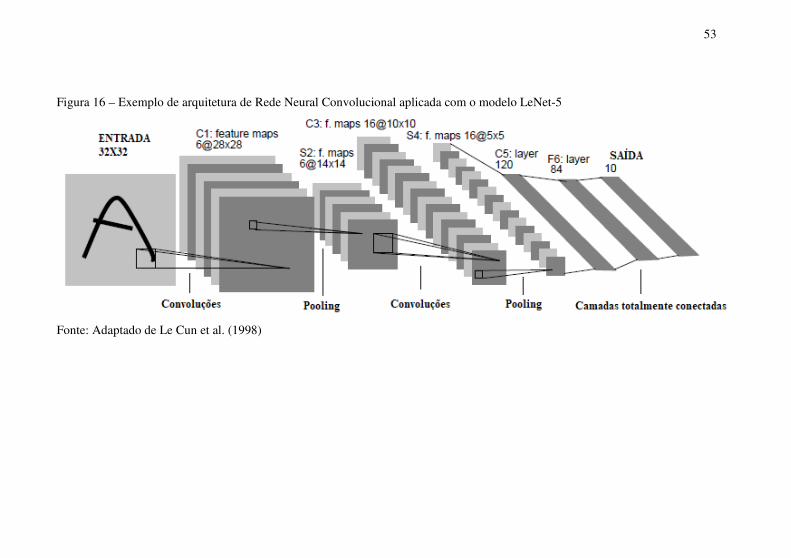
A Figura 16 ilustra um exemplo da arquitetura de Rede Neural Convolucional aplicada com o modelo LeNet-5. Neste exemplo, a imagem da letra “A” na forma manuscrita é o dado de entrada, o modelo tem a função de processar a imagem e reconhecer que a figura de entrada representa, de fato, a letra “A”, fornecendo esta informação na saída do modelo (LE CUN et al., 1998).
À medida que a Figura 17 ilustra o processamento da imagem de uma placa de trânsito, que indica o limite velocidade de uma rodovia, utilizando uma arquitetura de rede neural convolucional. Ao final do

52
processamento, o modelo é capaz de predizer qual o limite de velocidade indicado na placa. Esta figura ilustra o processamento que a imagem sofre ao passar pelo treinamento da CNN, permitindo detectar os padrões ali inseridos.
53
Figura 16 – Exemplo de arquitetura de Rede Neural Convolucional aplicada com o modelo LeNet-5
Fonte: Adaptado de Le Cun et al. (1998)

54
Figura 17 – Exemplo de arquitetura de CNN aplicada no processamento de imagem
Fonte: Peemen (2018)

55
2.2.3.3 Acurácia e validação da Rede Neural Convolucional
A acurácia dos modelos de CNN pode ser verificada,
preliminarmente, por meio de gráficos que ilustram o comportamento do erro e da precisão dos acertos de predição durante o processo de treinamento da rede (DEEP LEARNING BOOK, 2018).
O treinamento pode ser estabelecido com a divisão dos dados de entrada em training (treinamento) e test (teste). Isto é, à medida que ocorre o treinamento com os dados de training como vetores de entrada do modelo, simultaneamente, pode ser verificada a acurácia desse por meio dos dados de test. Estes não são implementados dentro do conjunto de treinamento, entretanto, possuem vetores de saída conhecidos e podem ser utilizados para analisar a capacidade de generalização do modelo treinado (DEEP LEARNING BOOK, 2018). A Figura 18 ilustra esse processo de divisão do conjunto de dados disponíveis. Figura 18 – Esquema do processo de divisão do conjunto de dados para treinamento e teste do modelo
Fonte: elaborado pelo autor com informações de Deep Learning Book (2018)
Segundo Deep Learning Book (2018), avaliar a acurácia de uma
CNN consiste em verificar quão bem o modelo é capaz de generalizar seus dados de treinamento. Isto é, pode-se comparar a predição que o modelo treinado realizou para os dados de training e test. Segundo Rocha (2017), o modelo de redes neurais pode ser considerado adequado quando o mesmo está equilibrado, isto é, sem underfitting ou overfitting, que consistem em problemas na capacidade de generalização do modelo. Rocha (2017) define esses problemas da seguinte forma:

56
a) underfitting: ocorre quando o modelo está sub-adaptado, ou seja, a taxa de erros de predição é elevada tanto para os dados de training como test;
b) overfitting: ocorre quando o modelo está super-adaptado, isto é, a taxa de erros de predição para os dados de training
é baixa, no entanto, alta para os dados de test, mostrando incapacidade de generalização.
A Figura 19 ilustra as curvas de erro para os dados de treinamento e teste de um modelo qualquer, apontando as regiões de overfitting, underfitting
e equilíbrio. À medida que a complexidade do modelo implementado varia, os erros de predição também variam (DEEP LEARNING BOOK, 2018). Figura 19 – Curvas de erro de teste e de treino de um modelo considerando a sua complexidade
Fonte: elaborado pelo autor com informações de Deep Learning Book (2018)
Segundo Deep Learning Book (2018), um parâmetro que pode ser considerado importante dentro do processo de treinamento é o valor das épocas (epochs), que consiste na quantidade de vezes em que o modelo é treinado. Nesse sentido, à medida que o valor epochs utilizado aumenta em demasia, o modelo pode apresentar problema de overfitting. Sendo que o contrário, isto é, utilizar quantidades reduzidas de epochs pode ocasionar modelos com problemas de underfitting. A Figura 20 apresenta as curvas de acurácia (accuracy) em função da quantidade de épocas utilizadas em um modelo qualquer.

57
Figura 20 – Curvas de acurácia de um modelo qualquer
Fonte: adaptado de Deep Learning Book (2018)
Neste contexto, Gu et al. (2018) apontam que problemas de overfitting são inerentes às Redes Neurais Convolucionais. Ao passo que ajustes podem ser efetuados com o intuito de diminuir este problema. Deep Learning Book (2018) expõe que os modelos devem ser treinados, analisados e ajustados por diversas vezes, até concluir-se que o modelo está conseguindo fazer predições com acurácia e taxa de erro aceitáveis, podendo assim ser validado. Segundo Gu et al. (2018), os ajustes da CNN compreendem em alterar os hiperparâmetros e componentes básicos e de melhorias da rede neural, apresentados na seção 2.2.3.1. Alterações na arquitetura da CNN também podem ser estabelecidas como medida para aumentar a capacidade de generalização do modelo. 2.3 A EXPLORAÇÃO DE SAL
A exploração de sal faz parte de atividades de desenvolvimento do
ser humano desde o início da civilização. É um material geológico que ao longo dos séculos tem despertado o interesse das mais diversas áreas de pesquisa, sobretudo da geologia e da engenharia. Entretanto, na última década, com a descoberta de reservatórios de hidrocarbonetos subjacentes a camadas de sal - o pré-sal - a procura por regiões com rochas salinas tem se intensificado (FIRME, 2013).
Firme (2013) define: “rochas salinas são evaporítos, isto é, rochas formadas a partir da cristalização de minerais precipitados pela evaporação da água salgada.”. Segundo Falcão (2009), as rochas salinas, por possuírem permeabilidade muito baixa, funcionam como selos quase perfeitos para acumulações de materiais como petróleo e gás. A Figura 21

58
ilustra a camada de sal e suas adjacências presentes nas costas brasileira e africana.
Figura 21 – Representação esquemática da camada de sal e adjacências das costas brasileira e africana
Fonte: Koning (2014)
Florencio (2009) menciona a importância dos evaporítos perante à economia pelo fato de serem matérias-primas de vários produtos, além de despertarem o interesse da indústria de mineração pela possibilidade ao acúmulo de potássio. Costal et al. (2005) ressaltam que, na indústria do petróleo, camadas de sal sugerem a presença de hidrocarbonetos abaixo delas, podendo indicar o sucesso na produção.
No tocante à perfuração e escavação, Firme (2013, p. 29-30) aponta que a exploração de rochas salinas exige cuidados especiais, citando:
“Problemas relacionados à escavação ou perfuração de maciços compostos por rochas salinas são usuais na mineração de potássio (...) Obras de engenharia civil em rochas salinas também demandam cuidados especiais com as deformações e com a agressividade do meio, uma vez que além de móvel, o sal é solúvel, podendo formar cavidades por dissolução na geometria projetada. Os fatores de segurança, limites de deformação e especificações construtivas são mais restritivos (...) Na engenharia de perfuração no ambiente do pré-sal, à vista

59
dos problemas operacionais inerentes à exploração, observa-se que as incertezas omitidas em análises determinísticas podem representar custos financeiros e ambientais severos.”
Neste contexto, pode-se inferir que a identificação de regiões que contenham rochas salinas pode ser relevante a pesquisadores, exploradores de sal, petróleo, gás, entre outros. Permitindo possíveis novas oportunidades de negócios e redução de custos financeiros e ambientais inerentes à exploração deste mineral.


61
3 PROCEDIMENTOS METODOLÓGICOS Este capítulo visa abordar, de maneira objetiva, os métodos
aplicados neste trabalho. Possui o intuito de descrever e classificar as principais características do mesmo, assim como apresentar um roteiro dos procedimentos adotados. 3.1 ROTEIRO METODOLÓGICO
Nesta seção é abordado o passo a passo sistematizado das etapas
que foram cumpridas neste trabalho. Silva e Menezes (2005) propõem que a execução de uma pesquisa deve seguir onze etapas sequenciais: 1) escolha do tema; 2) revisão de literatura; 3) justificativa; 4) formulação do problema; 5) determinação de objetivos; 6) metodologia; 7) coleta de dados; 8) tabulação de dados; 9) análise e discussão dos resultados; 10) conclusão da análise dos resultados; 11) redação e apresentação do trabalho científico.
Este trabalho tem sua estrutura básica fundamentada segundo as etapas descritas anteriormente. Entretanto, há algumas diferenças pontuais devido ao tema escolhido, o qual tem peculiaridades que o difere de outros. Ao longo deste trabalho essas distinções serão evidenciadas. Todavia, destaca-se aqui que o problema veio formulado e com os dados disponíveis. Dessa forma, a Figura 22 mostra o fluxograma que descreve os passos que foram executados para a realização deste estudo.

62
Figura 22 – Fluxograma dos passos executados
Início
Escolha do Tema
Revisão da Literatura
Procedimentos Metodológicos
Aplicação dos métodos e técnicas
Análise e discussão dos
resultados
Resultados satisfatórios?
Revisão das técnicas
aplicadas
Conclusão da análise dos resultados
Redação, ajustes finais e
apresentação do trabalho
Fim
NÃO
SIM
Fonte: elaborado pelo autor (2018) 3.2 A ANÁLISE DE DADOS
O escopo básico deste trabalho é realizar a análise de dados para a
identificação de segmentos de sal em imagens sísmicas de camadas subterrâneas. Tal tema é um desafio proposto pela Tomlinson
Geophysical Services Inc. (TGS) – empresa do ramo de geociência – na plataforma de ciência de dados Kaggle. A descrição do problema, a questão e os dados necessários para atendê-la são disponibilizados aos interessados na solução do problema na página da plataforma de desafios online Kaggle (KAGGLE, 2018). Com o problema definido e os dados disponibilizados, algumas etapas pertinentes à análise de dados são suprimidas neste trabalho, conforme está demonstrado na sequência.
Segundo Peng e Matsui (2016) não há uma fórmula específica que descreva os procedimentos a serem adotados para resolver um problema de análise de dados, isto é, cada problema é único e deve ser resolvido de maneira única. Entretanto, os autores propõem um processo geral que pode ser aplicado a uma variedade de situações. Tal processo é denominado por Peng e Matsui (2016) como Epiciclo da Análise de Dados. Esta denominação, inspirada na visão ptolomaica de sistemas planetários (COUPER e HENBEST, 2009), decorre da experiência de que a análise de dados não é um processo linear que pode ser executado passo a passo. Trata-se de um processo altamente interativo e não linear,

63
podendo ser representado por uma série de epiciclos, onde a informação é processada incorporada em cada etapa, informando o que melhorar na etapa anterior e como prosseguir no próximo passo (PENG e MATSUI, 2016).
Peng e Matsui (2016) apontam que o epiciclo da análise de dados compreende cinco macro etapas:
a) estabelecimento e refinamento da questão; b) exploração de dados; c) construção de modelos formais estatísticos; d) interpretação de resultados; e) comunicação de resultados.
Em cada uma destas macro etapas deve-se engajar em outras três etapas:
a) estabelecer expectativas; b) coletar informações e comparar com as expectativas; c) revisar expectativas ou consertar os dados para que seus
dados e suas expectativas sejam compatíveis.
A Figura 23 ilustra as macroetapas e etapas do Epiciclo da Análise de Dados e como estes elementos interagem entre si quando o analista executa uma das funções do epiciclo. Dessa forma, buscou-se seguir, neste trabalho, esse processo cíclico para a proposta de um procedimento de análise de dados referente à identificação de segmentos de sal, em camadas subterrâneas, considerando as informações constantes em imagens derivadas de ondas sísmicas geradas com o intuito de detectar padrões referentes à presença ou não do mineral. Tendo-se em vista que o problema se encontra detalhadamente especificado e delimitado pela empresa TGS, as etapas de estabelecimento e refinamento da questão podem ser suprimidas do escopo deste estudo.

64
Figura 23 – Epiciclo da análise de dados
Fonte: Peng e Matsui (2016). 3.3 CLASSIFICAÇÃO DA QUESTÃO DE ANÁLISE DE DADOS
Consoante ao que foi descrito na seção 3.2.1, a definição da
questão é uma das macroetapas inerentes ao Epiciclo de Análise de Dados. O problema em análise deste estudo tem sua questão definida, logo, a aplicação de tal processo não se faz necessária. No entanto, autores como Peng e Matsui (2016) e Leek (2015) ressaltam a importância de definir qual o tipo de questão em análise. Segundo Peng e Matsui (2016), entender a classe de pergunta que está sendo analisada pode ser o passo mais fundamental para poder garantir que, no fim, a interpretação dos resultados esteja correta.

65
Leek (2015) define seis categorias básicas de questões para análise de dados: descritiva, exploratória, inferencial, preditiva, causal e mecanicista. O Quadro 5 mostra algumas características e objetivos de cada tipo de questão, enquanto que a Figura 24 apresenta o fluxograma que permite definir, de forma sequencial e lógica, a classe da questão em análise.
Quadro 5 – Características dos tipos de questões de análise de dados
Questão Características Descritiva Busca resumir as medidas em um
único conjunto de dados sem interpretação adicional.
Exploratória Se baseia em uma análise descritiva, buscando descobertas, padrões, correlações ou relações entre as medidas de múltiplas variáveis para gerar hipóteses.
Inferencial Vai além de uma análise exploratória, quantifica se um padrão observado provavelmente se manterá além do conjunto de dados coletados.
Preditiva Usa um subconjunto de medidas (recursos) para prever outra medição (o resultado) em uma única unidade.
Causal Procura descobrir o que acontece com uma medição, caso seja feita alteração em um outro fator.
Mecanicista Busca entender efeitos médios que ocorram entre variáveis distintas e como ocorrem.
Fonte: elaborado pelo autor com informações de Leek (2015).

66
Figura 24 - Fluxograma do tipo de pergunta de análise de dados
Fonte: adaptado de Leek (2015)
Peng e Matsui (2016) ressaltam que muitas análises de dados não respondem a apenas um tipo de questão, mas vários. Sendo que para poder responder questões do tipo preditiva (principal questão deste trabalho), por exemplo, é necessário realizar, preliminarmente, análises descritivas e exploratórias.
Neste sentido, este estudo visa, inicialmente, realizar a coleta de dados da plataforma Kaggle, cujos dados tratam-se essencialmente de imagens sísmicas. Posteriormente, busca-se explorar estes dados a fim de entender suas respectivas características. Por fim, procura-se selecionar e adaptar um modelo com capacidade de reconhecer padrões no conjunto de dados fornecidos pela Kaggle e predizer se há ou não sal em um outro conjunto de imagens.
Portanto, este trabalho procura responder questões do tipo descritiva, exploratória e preditiva.

67
4 APLICAÇÃO DOS MÉTODOS E ANÁLISE DOS RESULTADOS
Após a realização da revisão teórica e definição dos procedimentos metodológicos adotados, pode-se tratar dos pontos práticos aplicados neste trabalho. Nesse sentido, a partir deste tópico os assuntos a serem discutidos referem-se estritamente aos problemas referentes a este estudo. Descreve-se neste capítulo: o problema do presente trabalho, apresenta-se os dados que foram analisados e suas respectivas características. Traz-se aqui a promissora abordagem de Redes Neurais Convolucionais para o problema, bem como o modelo proposto e as melhorias aplicadas. Por fim, discute-se os resultados obtidos. 4.1 DESCRIÇÃO DO PROBLEMA
Este trabalho busca identificar segmentos de sal em imagens
sísmicas de camadas subterrâneas profundas. Conforme descrito no Capítulo 3, o problema foi trazido a público pela empresa TGS por meio da plataforma de dados Kaggle.
A TGS é a maior empresa de dados de geociências do mundo. Fundada em 1981, a empresa possui sua sede corporativa em Asker, Noruega e sua sede operacional em Houston, Texas, Estados Unidos. A TGS fornece produtos e serviços de dados geocientíficos globais para a indústria de petróleo e gás, auxiliando nas etapas de licenciamento e na preparação de programas regionais de dados. A empresa oferece estudos e serviços de interpretação que integram dados sísmicos, registros de poços, dados bioestratigráficos, dados básicos e outros dados geocientíficos (TGS, 2018).
A Kaggle é a maior comunidade do mundo de cientistas de dados e aprendizes de máquinas (machine learners). Trata-se de uma plataforma digital, fundada em 2010 com o objetivo de disponibilizar ao público competições de Machine Learning, Análise de Dados e Inteligência Artificial. Em março de 2017, a plataforma foi adquirida pelo Google. Atualmente, conta com cerca de cem mil membros ativos e oferece quinze competições abertas ao público interessado. Alguns dos desafios promovidos na plataforma podem premiar os vencedores com quantias em dinheiro, sendo que o maior prêmio oferecido até então foi de US$ 1,5 milhão. Algumas das empresas e organizações mais conhecidas do mundo lançaram desafios por intermédio da Kaggle, das quais destaca-se: Mercedes Benz, Walmart, Santander, Porto Seguro, Ford e Facebook (KAGGLE, 2018; WIKIPEDIA, 2018; MOYER, 2017; LARDINOIS, 2018).

68
Neste contexto, em julho de 2018, por meio da plataforma Kaggle, a empresa TGS lançou o desafio que consiste em detectar regiões que contenham rochas salinas. A competição foi lançada com o seguinte nome: TGS – Salt Identification Challenge, Segment salt deposits beneath
the Earth’s surface (TGS – Competição de Identificação do Sal, Segmento de depósitos de sal sob a superfície da Terra). Kaggle (2018) define o problema da competição da seguinte maneira:
“Para criar imagens sísmicas e renderizações 3D mais precisas, a TGS espera que a comunidade de aprendizado de máquina da Kaggle possa criar um algoritmo que identifique automática e precisamente se uma região da subsuperfície contém sal ou não.”
O desafio proposto pela TGS teve duração de três meses (de 19 de
julho a 19 de outubro de 2018) e ofereceu uma premiação de US$ 100 mil (US$ 50 mil para o primeiro colocado, US$ 25 mil para o segundo, US$ 15 mil para o terceiro e US$ 10 mil para o quarto). Em geral, a premiação é proporcional à dificuldade da competição, sendo que alguns dos desafios têm caráter apenas educativo, não oferecendo qualquer recompensa financeira. Dos desafios publicados na Kaggle no último ano, este lançado pela TGS é um dos que distribuíram maior premiação. Nesse sentido, pode-se inferir que o mesmo possui grau elevado de relevância e complexidade.
Na sequência desta seção, mostra-se a descrição dos dados disponibilizados pela TGS em seu desafio e a métrica de avaliação utilizada. Por meio desses, pode-se ter maior compreensão sobre o problema deste trabalho.
4.1.1 Descrição dos dados
Os dados fornecidos pela TGS na plataforma Kaggle se
caracterizam em duas categorias básicas: imagens (formato .png) e arquivos de texto (formato .csv). As imagens estão divididas em train (treino), masks (máscaras) e test (teste), ao passo que os arquivos de texto estão segmentados em train e depths (profundidades).
As imagens de treino e teste correspondem a dados sísmicos de vários locais da subsuperfície da Terra, escolhidos aleatoriamente pela TGS. Segundo a Kaggle (2018), os dados sísmicos são coletados usando sismologia de reflexão ou reflexão sísmica. Os dados são produzidos a partir da imagem da reflexão vinda dos limites da rocha. As imagens

69
sísmicas mostram os limites entre os diferentes tipos de rochas, entretanto, não costumam dar muita informação sobre quais rochas estão ali contidas, sendo algumas classes mais fáceis de identificar que outras. Nesse sentido, Kaggle (2018) define:
“Um dos desafios da imagiologia sísmica é identificar a parte da subsuperfície que contém sal. O sal tem características que o tornam simples e, ao mesmo tempo, difícil de identificar. A densidade do sal é geralmente 2,14 g/cm³, o que é mais baixo que a maioria das rochas circundantes. A velocidade sísmica do sal é de 4,5 km/s, que geralmente é mais rápida do que as rochas circundantes. Essa diferença cria uma reflexão nítida na interface sal-sedimento. Normalmente o sal é uma rocha amorfa sem muita estrutura interna. Isso significa que normalmente não há muita refletividade dentro do sal, a menos que haja sedimentos presos dentro dele. A velocidade sísmica excepcionalmente alta do sal pode criar problemas com imagens sísmicas.”
Ao todo, foram fornecidas vinte e seis mil imagens: dezoito mil de
teste, quatro mil de treino e quatro mil máscaras. Todas essas possuem resolução de 101×101 pixels. Consoante ao parágrafo anterior, as imagens de treino e teste são imagens sísmicas e possuem características gerais semelhantes. As máscaras, no entanto, são figuras monocromáticas (preto e branco) que funcionam como uma espécie de gabarito das imagens de treino, isto é, indicam para cada imagem sísmica de treino quais regiões (pixels) que contêm sal ou não. Dessa forma, para cada imagem de treino há uma máscara correspondente, sendo que os pixels em branco nas máscaras indicam as regiões com sal e os pixels em preto representam sedimentos sem sal. O Quadro 6 apresenta exemplos de imagens sísmicas de treino com suas respectivas máscaras e ID (Identidade, do inglês Identity), enquanto que o Quadro 7 contempla exemplos de imagens sísmicas de teste.
As figuras de treino e as suas máscaras são fornecidas com o intuito de que, por meio de modelos computacionais, possam ser reconhecidos padrões nas imagens sísmicas, em especial nos pixels que contenham sal. À medida que as imagens de teste são disponibilizadas para a finalidade deste trabalho, isto é, o objetivo deste problema é identificar segmentos de sal nas dezoito mil imagens de teste.

70
Quadro 6 – Exemplos de imagens de treino e suas respectivas máscaras ID Imagens sísmicas de
treino Máscaras
0b73b427d1
0aabdb423e
0a1742c740
Fonte: elaborado pelo autor com imagens de Kaggle (2018)

71
Quadro 7 – Exemplos de imagens de teste ID Imagens sísmicas de
teste
00a6bfc7a7
00c153007b
00efd96e2c
Fonte: elaborado pelo autor com imagens de Kaggle (2018) Os arquivos de texto são disponibilizados como dados auxiliares
para o problema. Estes arquivos são basicamente duas tabelas no formato .csv que contêm informações referentes às máscaras e à profundidade de cada uma das vinte e duas mil imagens sísmicas fornecidas (imagens de treino e imagens de teste).
O arquivo train.csv é uma representação numérica das máscaras, ou seja, informa quais os pixels das imagens de treino que contêm segmentos de sal. Segundo Kaggle (2018), cada pixel em uma imagem possui um número de identificação, a codificação começa com o número 1 a partir do ponto mais acima e mais à esquerda da figura, seguindo a sequência de cima para baixo e posteriormente da esquerda para a direita

72
(a Figura 25 ilustra isto para uma imagem fictícia de resolução 10×10 pixels). Nesse sentido, o arquivo train.csv mostra, para cada uma das quatro mil imagens de treino, pares de valores que registram os pixels que possuem sal, enquanto aqueles que não contêm são omitidos. Esses pares indicam a posição inicial e a quantidade de pixels posteriores àquela posição que devem indicar a presença de sal. Por exemplo, ‘1 3 10 5’ implica que há sal nos pixels 1, 2, 3, 10, 11, 12, 13 e 14. O Quadro 8 exemplifica a lista de pares de valores de uma determinada máscara, ao passo que o Quadro 9 apresenta parte do arquivo train.csv. Figura 25 – Mapa de pixels de uma imagem fictícia 10×10
1 11 21 31 41 51 61 71 81 91
2 12 22 32 42 52 62 72 82 92
3 13 23 33 43 53 63 73 83 93
4 14 24 34 44 54 64 74 84 94
5 15 25 35 45 55 65 75 85 95
6 16 26 36 46 56 66 76 86 96
7 17 27 37 47 57 67 77 87 97
8 18 28 38 48 58 68 78 88 98
9 19 29 39 49 59 69 79 89 99
10 20 30 40 50 60 70 80 90 100
Fonte: elaborado pelo autor (2018)
Quadro 8 - Exemplo da lista de pares de valores de uma determinada máscara ID Máscara Lista de pares
de valores Observação
50d3073821
‘1 2121 9293 909’
Indica que contém sal do pixel 1 até o 2121 e do pixel 9293 até o 10201.
Fonte: elaborado pelo autor com informações da Kaggle (2018)

73
Quadro 9 - Ilustração do arquivo train.csv
id rle_mask
575d24d81d
a266a2a9df 5051 5151
9842f69f8d
50d3073821 1 2121 9293 909
d4d34af4f7 8788 1414
7845115d01 7677 2525
d67e3a11d8
a5471f53d8 9797 1 9891 8 9986 14 10081 20 10176 26
Fonte: adaptado de Kaggle (2018). O arquivo depths.csv apresenta as profundidades, na unidade de
pés, das localizações de todas as imagens sísmicas fornecidas. A profundidade pode ser utilizada como variável de entrada do modelo. O Quadro 10 contempla parte deste arquivo.
Quadro 10 – Ilustração do arquivo depths.csv
id z
4ac19fb269 306
1825fadf99 157
f59821d067 305
5b435fad9d 503
e340e7bfca 783
2ffea0c397 429
6cf284fb9e 600
d0244d6c38 51
cffbfab33b 755
Fonte: adaptado de Kaggle (2018). A relação dos dados fornecidos com o objetivo deste trabalho pode
ser sintetizada da seguinte maneira: as imagens de treino e suas respectivas máscaras, em conjunto com os arquivos train.csv e depths.csv, foram utilizados para treinar o modelo com capacidade de reconhecer segmentos de sal em imagens sísmicas. As imagens de teste são processadas pelo modelo treinado e o mesmo executa a predição das

74
regiões que contenham sal dentro dessas figuras. Ao final, é gerado um arquivo de texto (submission.csv) com o mesmo padrão do train.csv, que
informa, por meio de listas de pares de valores, quais pixels em cada imagem de teste devem possuir sal, segundo o modelo. Esse arquivo pode ser submetido a Kaggle para a avaliação das predições realizadas. Após a análise, o resultado da submissão é listado em um ranking que contém as submissões de todos os demais participantes que submeteram resultados à competição. Esse ranking pode ser utilizado como critério comparativo da acurácia do modelo proposto. 4.1.2 Métrica de avaliação
A metodologia de avaliação desta competição pode ser sintetizada como a comparação entre o arquivo submetido à plataforma Kaggle e as máscaras (não fornecidas aos competidores) das imagens de teste. Dessa forma, detecta-se todos os segmentos de sal que foram corretamente preditos e por meio da métrica de avaliação utilizada chega-se a um índice médio da exatidão das predições realizadas.
A métrica de avaliação utilizada nesta competição é fundamentada nos conceitos do Índice de Jaccard, ou Intersection over Union (IoU). O Índice de Jaccard é uma técnica estatística usada para comparar a similaridade e a diversidade de conjuntos de amostras. O coeficiente IoU mede a similaridade entre conjuntos de amostras finitas, sendo definido como o tamanho da interseção dividido pelo tamanho da união dos conjuntos de amostras (ROSEBROCK, 2016). Dessa forma, o índice varia entre 0 e 1, quanto maior o grau de similaridade entre duas amostras, mais próximo de 1 o mesmo deve estar. A Equação 4.1 representa esta definição, enquanto a Figura 26 ilustra a interseção e a união entre dois conjuntos quaisquer.
BCD �E, F� = G�E, F� =
E ∩ FE ∪ F �4.1�

75
Figura 26 – Representação da união e interseção entre dois conjuntos
Fonte: adaptado de Wikipedia (2018).
Nesse sentido, esta competição é avaliada por meio da média da
precisão média em diferentes limites (thresholds) de IoU. Segundo Kaggle (2018), a métrica varre um intervalo de limites de IoU e em cada ponto deste intervalo calcula um valor de precisão médio. Os valores limites variam de 0,5 a 0,95 com um tamanho de passo de 0,05: (0,5, 0,55, 0,6, 0,65, 0,70, 0,75, 0,80, 0,85, 0,90, 0,95). Por exemplo, em um threshold de 0,5, a predição de uma imagem é considerada correta se sua IoU com a sua máscara real for maior que 0,5. Em cada valor limite t, um valor de precisão é calculado com base na quantidade de positivos verdadeiros (TP), falsos negativos (FN) e falsos positivos (FP) resultantes da comparação dos objetos previstos (pixels) com todos os objetos reais do solo. A precisão média de uma única imagem é calculada como a média dos valores de precisão em cada limite t de IoU, conforme a Equação 4.2.
LM�NOãCQéSOT = 1|VℎM�ℎCXS| " YL�V�YL�V� + ZL�V� + Z[�V�\ (4.2)
Sendo que,
TP (t), FP (t), FN (t) Є {0,1} Um valor TP(t) é contado quando uma imagem prevista corresponde a uma máscara com IoU acima do limite t. Um FP(t) indica que um previsto não possui um objeto real associado, ao passo que um FN(t) indica que um objeto real não possui um objeto previsto associado. Dessa forma, quando TP (t) for igual a 1, FN(t) e FP(t) serão 0; e quando TP(t) for igual a 0, FN (t) e FP (t) serão 1 (KAGGLE, 2018).

76
Por fim, a pontuação retornada pela métrica da competição é a média obtida sobre as precisões médias individuais de cada imagem no conjunto de dados de teste. Este valor é limitado entre 0 e 1 e pode ser simplificado como o percentual médio de acertos nas predições realizadas nas imagens de teste; isto é, quanto mais próximo de 1 o valor estiver, mais acertos ocorreram.
4.2 REDES NEURAIS CONVOLUCIONAIS – UMA ABORDAGEM PROMISSORA
A plataforma Kaggle se caracteriza por conter fóruns que permitem
a troca de informações entre os seus membros. Destaca-se os kernels, espaço aberto em cada uma das competições promovidas pela Kaggle
com o objetivo de estimular o debate entre os competidores e fomentar o conhecimento sobre Machine Learning. Por meio dos kernels, os concorrentes explanam e sanam suas dúvidas, publicam seus modelos computacionais, pedem sugestões e, principalmente, discutem constantemente o problema em questão. Mediante os kernels referentes ao problema proposto pela TGS, foi possível obter inspirações e soluções para o modelo aplicado neste trabalho. Nos kernels desta competição, as discussões entre os cientistas de dados apontavam para soluções utilizando Redes Neurais Convolucionais, estando coerente com a Revisão Bibliográfica (Capítulo 2) deste estudo e mostrando ser uma abordagem promissora para o problema.
O kernel publicado por Jesper Dramsch – Mestre em Geofísica e especialista em Machine Learning – foi o maior destaque da competição promovida pela TGS, sendo aquele com a melhor avaliação entre os competidores. Dramsch (2018) traz em seu kernel uma revisão teórica sobre o sal, imagens sísmicas, utilização de Deep Learning pela geofísica em geral e sugere a utilização do modelo U-Net de CNN. Amaral (2018), Hönigschmid (2018), Liao (2018) e Shao (2018) também trouxeram kernels que foram bem avaliados pela comunidade da Kaggle, sendo que todos esses apresentaram modelos utilizando U-Net. Desta forma, o modelo U-Net pôde ser considerado propício para a predição de segmentos de sal em imagens sísmicas.
Conforme mencionado no item 2.2.3.2 deste trabalho, a arquitetura U-Net é uma das tantas derivações das Redes Neurais Convolucionais. Foi idealizada e aplicada por Ronneberger et al. (2015) na segmentação

77
de imagens biomédicas. Ronneberger et al. (2015) definem a U-Net3 da seguinte forma:
“Consiste em um caminho de contração e um caminho de expansão. O caminho de contração segue a arquitetura típica de uma rede convolucional, isto é, possui a aplicação repetida de duas convoluções 3×3, cada uma seguida de uma função de ativação ReLU e uma operação maxpool de 2×2 com stride de 2 para redução da amostragem. Em cada etapa de redução de amostragem, dobramos o número de neurônios. Cada passo no caminho de expansão consiste em: um aumento de amostragem do mapa de características seguido por uma convolução 2×2 (upconvolution4) que divide pela metade o número de neurônios, uma concatenação com o mapa de recursos cortados correspondente ao caminho de contração e duas convoluções 3×3, cada uma delas seguida por uma ReLU. A concatenação é necessária devido à perda de pixels de borda em todas as convoluções. Na camada final, uma convolução de 1×1 é usada para mapear cada vetor de recurso de 64 componentes para o número desejado de classes. No total, a rede tem 23 camadas convolucionais. Para permitir um mosaico uniforme do mapa de segmentação de saída, é importante selecionar o tamanho do bloco de entrada de forma que todas as operações de maxpool de 2×2 sejam aplicadas a uma camada com tamanhos pares de x e y.”
A Figura 27 ilustra, de maneira simplificada, a arquitetura utilizada por Ronneberger et al. (2015). De modo que as setas indicam as camadas das operações realizadas (convolução, maxpool e concatenação), enquanto os blocos em azul e branco representam as entradas e saídas de cada uma das camadas utilizadas. Esta figura tem o intuito de substituir e simplificar a representação de grafos, pois com tantos neurônios e camadas utilizadas, a representação de todas as conexões, por meio de grafos, ficaria “poluída” e de difícil compreensão.
3 O termo U-Net deriva da forma da letra U, que representa
visualmente a arquitetura do modelo (Figura 27). 4 Segundo Gu et al. (2018), a upconvolution é uma camada de
convolução transposta, também conhecida como deconvolução. Ao contrário da convolução tradicional, que conecta múltiplas entradas a uma única saída, a deconvolução associa uma única entrada a múltiplas saídas.

78
Figura 27 – Arquitetura U-Net
Fonte: Ronneberger et al. (2015)

79
4.2.1 Descrição do modelo primário proposto Inicialmente, o modelo implementado para a solução deste estudo
foi inspirado no kernel publicado por Hönigschmid (2018). A arquitetura U-Net desenvolvida por Hönigschmid (2018) é semelhante àquela produzida por Ronneberger et al. (2015), isto é, possui os caminhos de contração e expansão e 23 camadas de convolução ao total.
O caminho de contração se resume a se dispor de imagens sísmicas na resolução de 128×128 pixels5 e reduzi-las até 8×8 pixels. A cada compactação das imagens há duas camadas repetidas de convolução 3×3, seguidas por uma função de ativação ReLU, uma operação maxpool e uma operação de regularização dropout. À medida que a resolução das imagens diminui, a quantidade de neurônios utilizados em cada camada aumenta em proporção igual.
O caminho de expansão pode ser visto como o oposto do caminho de contração, ou seja, consiste em ampliar a resolução das imagens de 8x8 pixels até 128×128 pixels. Em cada nível de ampliação das imagens há 3 camadas repetidas de convolução 3x3, seguidos da função de ativação ReLU, camada de concatenação com a camada simétrica do caminho de contração e uma função de regularização dropout. De forma exatamente oposta ao caminho de contração, enquanto a resolução das imagens aumenta, a quantidade neurônios utilizados em cada camada diminui em proporção igual. Por fim, a camada de saída é uma camada de convolução 1x1 totalmente conectada com função de ativação sigmoid. O Quadro 11 contempla, de forma sintetizada, as camadas utilizadas na arquitetura U-Net do modelo de Hönigschmid (2018) e as suas características, ao passo que a Figura 28 ilustra esta arquitetura.
5 Salienta-se que as imagens originais fornecidas estão na resolução
101×101, ou seja, incompatíveis com as exigências a rede U-Net, que necessita de valores pares de pixels, de preferência que sejam do conjunto de valores da potência de 2. Desta forma, as imagens originais são transformadas por funções auxiliares de redimensionamento de imagens, desenhadas para este fim, aumentando-as para a resolução 128×128.

80
Quadro 11 - Resumo das camadas utilizadas no modelo de Hönigschmid (2018) Resolução Camadas Função de
Ativação Nº de Neurônios
Obs.
128×128 - 2 conv2D - 1 maxpool - 1 dropout (0,25)
ReLU 16 Camada de Entrada
64×64 - 2 conv2D - 1 maxpool - 1 dropout (0,50)
ReLU 32 Caminho de contração
32×32 - 2 conv2D - 1 maxpool - 1 dropout (0,50)
ReLU 64 Caminho de contração
16×16 - 2 conv2D - 1 maxpool - 1 dropout (0,50)
ReLU 128 Caminho de contração
8×8 - 2 conv2D ReLU 256 Camada Central 16×16 - 1 conv2D transposed
- 2 conv2D - 1 concatenate - 1 dropout (0,50)
ReLU 128 Caminho de Expansão
32×32 - 1 conv2D transposed - 2 conv2D - 1 concatenate - 1 dropout (0,50)
ReLU 64 Caminho de Expansão
64×64 - 1 conv2D transposed - 2 conv2D - 1 concatenate - 1 dropout (0,50)
ReLU 32 Caminho de Expansão
128×128 - 1 conv2D transposed - 2 conv2D - 1 concatenate - 1 dropout (0,50)
ReLU 16 Caminho de Expansão
128×128 - 1 conv2D Sigmoid 1 Camada de Saída
Fonte: elaborado pelo autor com informações de Hönigschmid (2018)

81
Figura 28 – Ilustração da rede U-Net considerada no modelo primário proposto
Fonte: elaborado pelo autor baseado em recomendações de Hönigschmid (2018)
Além das propriedades da arquitetura, Hönigschmid (2018)
utilizou algumas funções auxiliares e hiperparâmetros no seu modelo. Dentre as funções, destaca-se o Early Stoping e Reduce LR. Segundo Deep Learning Book (2018), estas funções são técnicas auxiliares utilizadas, em conjunto, como medida para reduzir o overfitting. Essas técnicas comparam a acurácia e os erros do modelo ao longo do treinamento, de modo que a partir do momento em que não são mais verificadas melhorias nas taxas de erros do modelo, a learning rate (LR) é reduzida por meio da função Reduce LR. Após esta redução, o treinamento continua por mais algumas épocas. Persistindo a estagnação do valor do erro, a função Early Stoping encerra antecipadamente o treinamento. Este procedimento pode evitar que o modelo seja treinado em demasia, por conseguinte, que ocorra overfitting ou que este fenômeno seja, pelo menos, reduzido (DEEP LEARNING BOOK, 2018). Nesse sentido, o parâmetro patience define por até quantas épocas, em sequência, o modelo pode ser treinado sem que haja redução do valor do erro, ao passo que o parâmetro factor ajusta em quanto a LR pode ser reduzida. A Tabela 3 apresenta os valores implementados por Hönigschmid (2018), em seu modelo, para esses e outros parâmetros, dos

82
quais, destaca-se: otimizador, epochs, train_test_split6 e learning rate inicial.
Tabela 3 – Lista de parâmetros utilizados no modelo primário
Parâmetro Valor utilizado Epochs 200 Factor Reduce LR 0.0001 Função de erro binary crossentropy
Learning Rate 0,01 Otimizador SGD7 Patience Early Stoping 10 Patience Reduce LR 5 train_test_split 0,2
Fonte: elaborado pelo autor com informações de Hönigschmid (2018) Um teste piloto com o modelo de Hönigschmid (2018) apresentou
acurácia de 0,583, segundo a métrica definida pela Kaggle e apresentada na seção 4.1.2. O resultado pode ser considerado insatisfatório, partindo de que os líderes da competição obtiveram pontuações próximas de 0,90. Entretanto, a utilização deste modelo como base inicial auxiliou no desenvolvimento de outros.
O modelo primário foi treinado durante sessenta épocas, até que o Early Stoping efetuasse a parada do treinamento, seguindo os critérios estabelecidos nos parâmetros previamente definidos por Hönigschmid (2018). A Tabela 4 apresenta os valores finais da acurácia8 e do erro alcançados pelo modelo primário, ao passo que a Figura 29 e a Figura 30 ilustram as curvas de erro e acurácia, respectivamente. Notou-se que a acurácia obtida no treinamento pode ser considerada satisfatória (90,55% para dados de training e 89,54% para os dados de test). No entanto, os erros apresentados pelos dados de test foram maiores do que pelos dados de training, indicando o overfitting no modelo. Essas diferenças entre os erros, aliado ao resultado obtido na Kaggle, indicam que o modelo apresenta deficiência para generalizar suas predições em dados que não foram implementados no treinamento. Nesse sentido, buscou-se construir modelos secundários que aprimorassem estes resultados.
6 Percentual do conjunto de dados de treino separado para teste. 7 Stochastic gradient descent (SGD) 8 A acurácia do treinamento deste modelo é verificada considerando a
predição correta de cada um dos pixels das imagens de treino, estabelecendo um percentual da precisão dos acertos.

83
Tabela 4 – Acurácia e erro final do treinamento do modelo primário Acurácia Erro train 0,9055 0,2289 test 0,8954 0,2519
Fonte: elaborado pelo autor (2018) Figura 29 – Curva de erros do modelo primário
Fonte: elaborado pelo autor (2018) Figura 30 – Curva de acurácia do modelo primário
Fonte: elaborado pelo autor (2018) 4.2.2 Descrição de modelos secundários promissores
Seguindo o Epiciclo da Análise de Dados definido no Capítulo 3,
foi necessário identificar potenciais melhorias no modelo de

84
Hönigschmid (2018), o que conduziu ao desenvolvimento de modelos secundários para este trabalho. Segundo Peng e Matsui (2016), o modelo primário tende a ser um resultado da análise exploratória de dados. Trata-se de um modelo no qual serão feitas comparações com outros modelos secundários. Os modelos secundários podem ser desenvolvidos com o objetivo de testar a legitimidade e robustez do modelo primário e gerar evidências contra o modelo primário (PENG e MATSUI, 2016).
Neste contexto, Deep Learning Book (2018) aponta que o processo de refinamento de um modelo de rede neural convolucional consiste em “tentativas e erros”, alterando parâmetros da rede e observando os resultados alcançados. Faz-se isto enquanto os resultados de predição não forem considerados satisfatórios. Segundo Gu et al. (2018), a arquitetura e os hiperparâmetros das CNN’s são fatores que podem ser modificados visando o progresso de um modelo.
Nesse sentido, buscou-se identificar possíveis ajustes que pudessem ser aplicados ao modelo primário com o intuito de aprimorá-lo. Inicialmente, percebeu-se que os hiperparâmetros poderiam ser ajustados pouco a pouco, avaliando para cada ajuste, como as curvas de erro e acurácia respondiam a estes ajustes. À medida que os resultados apresentados no treinamento mostrassem evolução, novas submissões9 eram realizadas a Kaggle para a validação final dos modelos secundários propostos. Dentre os parâmetros que foram alterados, destaca-se: otimizador, função de perdas, learning rate e quantidade de épocas de treinamento.
Posteriormente, buscou-se alterar a arquitetura da CNN proposta por Hönigschmid (2018). As modificações consistiram na quantidade de camadas utilizadas, nos parâmetros de cada uma das camadas, bem como no design da arquitetura utilizada. Procurou-se, na literatura e nos kernels
da Kaggle, potenciais melhorias que pudessem ser aplicadas ao modelo a fim de maximizar os resultados de predição de segmentos de sal em imagens sísmicas. Dessa forma, foi possível adaptar o modelo primário e aplicar uma série de modelos secundários. 4.3 APLICAÇÃO DOS MODELOS
Os modelos primário e secundários foram desenvolvidos e
aplicados em linguagem de programação Python 3.6. Por meio de bibliotecas e API’s (Application Programming Interface) internas desta
9 Ressalta-se que havia o limite diário de cinco submissões na
plataforma.

85
linguagem é possível desenvolver modelos de Deep Learning com maior facilidade, haja vista que diversas das funções inerentes a estes problemas estão disponíveis nessas bibliotecas e aplicativos. Destaca-se o API Keras, biblioteca própria de Redes Neurais, que foi utilizado no modelo de Hönigschmid (2018) para construção de camadas de convolução, pooling, dropout, treinamento da rede neural e predição dos segmentos de sal nas imagens de teste.
A aplicação dos modelos só foi possível com a utilização de máquinas com GPU (Graphics Processing Unit), isto porque o mesmo pode ser considerado “pesado” para máquinas que não possuem este equipamento. Em um computador com 8GB de Memória RAM, processador I7, 3,4 GHz de clock e sem GPU, o tempo total estimado para o treinamento do modelo seria de alguns dias. Nesse sentido, inicialmente, trabalhou-se com o notebook virtual do Google, denominado Google Colab, cujo serviço disponibiliza de algumas unidades de GPUs em seu servidor. Por meio do Google Colab, foi possível reduzir o tempo de treinamento para cerca de algumas horas e aplicar o modelo primário proposto na seção 4.2.1.
Posteriormente, foram criados servidores no portal AWS (Amazon
Web Services) como medida para minimizar o tempo de treinamento e desta maneira avaliar com maior frequência os ajustes realizados nos modelos secundários. Por meio desses servidores, que podem contar com até dezenas de GPUs, o tempo de treinamento pôde ser reduzido a minutos. Portanto, após a utilização dos servidores da AWS, mais ajustes puderam ser realizados e a verificação dos resultados obtidos se tornou mais ágil. A próxima seção detalha o refinamento e os ajustes propostos no desenvolvimento dos modelos secundários. 4.4 REFINAMENTO E AJUSTE DOS MODELOS
Consoante ao que foi descrito na seção 4.2.2, buscou-se realizar
uma série de ajustes no modelo primário. Com o propósito de aprimorar os resultados obtidos, procurou-se alterar diversos parâmetros e até mesmo o design da arquitetura utilizada. As modificações foram efetuadas com base em tentativas e erros, avaliando em cada alteração o comportamento das curvas de erro e acurácia dos modelos. A maior parte dos ajustes propostos não resultou em melhorias efetivas ao modelo primário, contudo, adaptações pontuais resultaram em avanços significativos. Dentre as modificações estabelecidas, registrou-se três modelos que se destacaram, os quais foram denominados de modelo secundário 1, modelo secundário 2 e modelo secundário 3.

86
O modelo secundário 1 sucedeu da alteração do otimizador utilizado no modelo primário, cuja modificação resultou em predições significativamente melhores. O otimizador utilizado neste modelo secundário foi o Adam. Segundo Facure (2017), o Adam é uma versão melhorada do otimizador que utiliza a descida do gradiente. O Adam incorpora uma taxa de aprendizado adaptativa, isto é, além de adaptar os pesos e bias do modelo, também ajusta o learning rate do treinamento, de modo que o erro final seja minimizado. A Tabela 5 contempla os melhores valores de acurácia e erro que este modelo alcançou em seu treinamento, à medida que a Figura 31 e Figura 32 ilustram as curvas de erro e acurácia, respectivamente. Notou-se que após as melhorias, o modelo ainda continuou com problema de overfitting. No entanto, segundo a métrica da Kaggle, o modelo teve precisão média de 0,7160, resultado consideravelmente superior ao obtido no modelo primário (0,583). Tabela 5 – Acurácia e erro final do treinamento do modelo secundário 1
Acurácia Erro train 0,9064 0,2171 test 0,8983 0,2423
Fonte: elaborado pelo autor (2018)
87
Figura 31 – Curva de erros do modelo secundário 1
Fonte: elaborado pelo autor (2018) Figura 32 – Curva de acurácia do modelo secundário 1
Fonte: elaborado pelo autor (2018)
Posteriormente, o modelo secundário 2 obteve melhorias importantes nos resultados do seu treinamento. Segundo a Tabela 6, os índices de acurácia e erro deste modelo apresentaram valores superiores aos alcançados nos modelos primário (Tabela 4) e secundário 1 (Tabela 5). Nesse sentido, a Figura 33 e a Figura 34 apresentam as curvas de erro e acurácia deste modelo, respectivamente. Segundo a métrica da Kaggle, a precisão média do modelo secundário 2 foi de 0,7240, mostrando evolução em relação ao modelo anterior. A principal modificação deste modelo secundário foi estabelecida com variações nos valores das
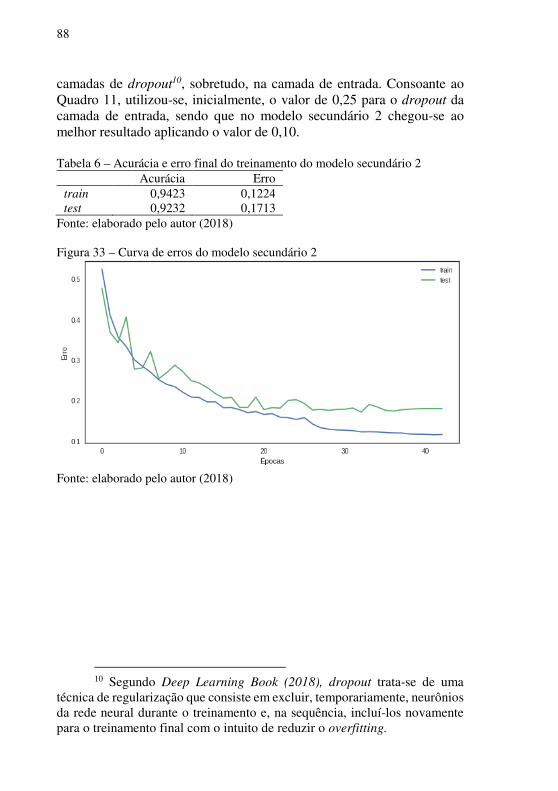
88
camadas de dropout10, sobretudo, na camada de entrada. Consoante ao Quadro 11, utilizou-se, inicialmente, o valor de 0,25 para o dropout da camada de entrada, sendo que no modelo secundário 2 chegou-se ao melhor resultado aplicando o valor de 0,10.
Tabela 6 – Acurácia e erro final do treinamento do modelo secundário 2
Acurácia Erro train 0,9423 0,1224 test 0,9232 0,1713
Fonte: elaborado pelo autor (2018) Figura 33 – Curva de erros do modelo secundário 2
Fonte: elaborado pelo autor (2018)
10 Segundo Deep Learning Book (2018), dropout trata-se de uma
técnica de regularização que consiste em excluir, temporariamente, neurônios da rede neural durante o treinamento e, na sequência, incluí-los novamente para o treinamento final com o intuito de reduzir o overfitting.
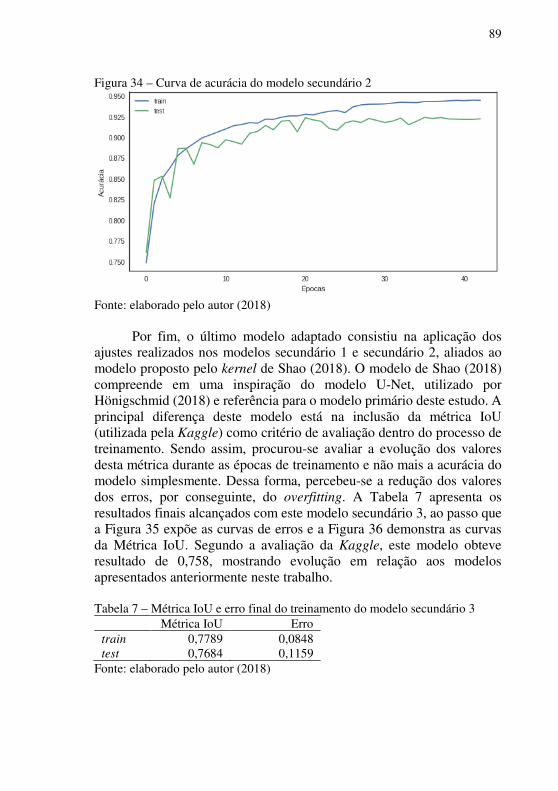
89
Figura 34 – Curva de acurácia do modelo secundário 2
Fonte: elaborado pelo autor (2018)
Por fim, o último modelo adaptado consistiu na aplicação dos ajustes realizados nos modelos secundário 1 e secundário 2, aliados ao modelo proposto pelo kernel de Shao (2018). O modelo de Shao (2018) compreende em uma inspiração do modelo U-Net, utilizado por Hönigschmid (2018) e referência para o modelo primário deste estudo. A principal diferença deste modelo está na inclusão da métrica IoU (utilizada pela Kaggle) como critério de avaliação dentro do processo de treinamento. Sendo assim, procurou-se avaliar a evolução dos valores desta métrica durante as épocas de treinamento e não mais a acurácia do modelo simplesmente. Dessa forma, percebeu-se a redução dos valores dos erros, por conseguinte, do overfitting. A Tabela 7 apresenta os resultados finais alcançados com este modelo secundário 3, ao passo que a Figura 35 expõe as curvas de erros e a Figura 36 demonstra as curvas da Métrica IoU. Segundo a avaliação da Kaggle, este modelo obteve resultado de 0,758, mostrando evolução em relação aos modelos apresentados anteriormente neste trabalho. Tabela 7 – Métrica IoU e erro final do treinamento do modelo secundário 3
Métrica IoU Erro train 0,7789 0,0848 test 0,7684 0,1159
Fonte: elaborado pelo autor (2018)

90
Figura 35 - Curva de erros do modelo secundário 3
Fonte: elaborado pelo autor (2018) Figura 36 – Curva da métrica de avaliação IoU do modelo secundário 3
Fonte: elaborado pelo autor (2018) 4.5 ANÁLISE DOS RESULTADOS
Os resultados obtidos foram considerados satisfatórios. O modelo
secundário 3, o qual apresentou o melhor resultado deste trabalho, foi capaz de predizer cerca de 75,80% dos segmentos de sal corretamente, considerando a métrica da Kaggle. Entretanto, ressalta-se que os vencedores da competição obtiveram índice de precisão média (segundo a Kaggle) próximos de 0,90, isto é, significativamente superior ao modelo proposto neste trabalho.
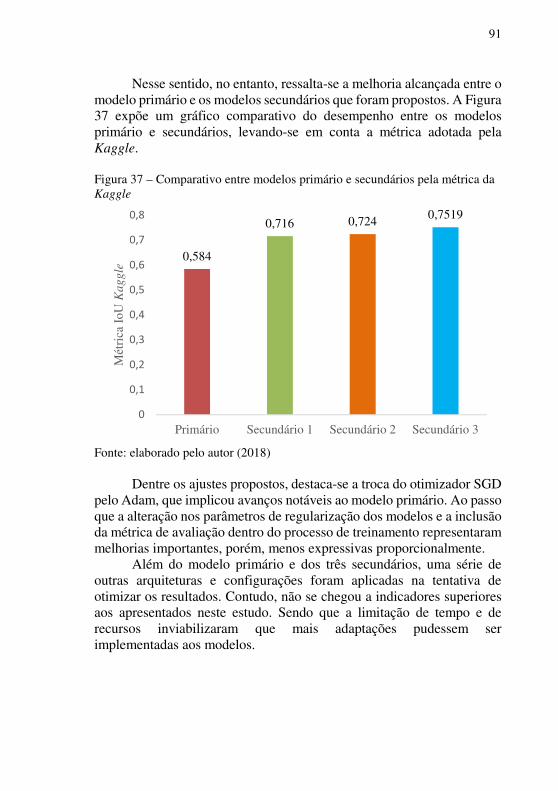
91
Nesse sentido, no entanto, ressalta-se a melhoria alcançada entre o modelo primário e os modelos secundários que foram propostos. A Figura 37 expõe um gráfico comparativo do desempenho entre os modelos primário e secundários, levando-se em conta a métrica adotada pela Kaggle.
Figura 37 – Comparativo entre modelos primário e secundários pela métrica da Kaggle
Fonte: elaborado pelo autor (2018)
Dentre os ajustes propostos, destaca-se a troca do otimizador SGD
pelo Adam, que implicou avanços notáveis ao modelo primário. Ao passo que a alteração nos parâmetros de regularização dos modelos e a inclusão da métrica de avaliação dentro do processo de treinamento representaram melhorias importantes, porém, menos expressivas proporcionalmente.
Além do modelo primário e dos três secundários, uma série de outras arquiteturas e configurações foram aplicadas na tentativa de otimizar os resultados. Contudo, não se chegou a indicadores superiores aos apresentados neste estudo. Sendo que a limitação de tempo e de recursos inviabilizaram que mais adaptações pudessem ser implementadas aos modelos.
0,584
0,716 0,724 0,7519
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
Primário Secundário 1 Secundário 2 Secundário 3
Mét
rica
IoU
Ka
gg
le


93
5 CONCLUSÕES E RECOMENDAÇÕES O notável avanço da Inteligência Artificial nos últimos anos vem
trazendo benefícios para as mais diversas áreas de estudo, inclusive para a indústria dos hidrocarbonetos. Com o crescimento da demanda de energia no planeta, a busca por novos depósitos de petróleo e gás se intensifica; por conseguinte, aumenta a procura por regiões que contenham depósitos de sal. Neste contexto, este estudo selecionou e aplicou modelos que utilizam redes neurais convolucionais com capacidade de processar imagens sísmicas, reconhecer padrões nas mesmas e identificar pixels que possam representar segmentos de sal. Dessa forma, os objetivos geral e específicos deste estudo puderam ser atendidos.
Os modelos propostos puderam ser aplicados em um cenário de estudo, de modo que a validação desses pôde ser realizada por meio da plataforma de dados Kaggle. Esta plataforma promoveu, em conjunto com a empresa TGS, uma competição de análise de dados que visava identificar segmentos de sal em camadas subterrâneas profundas, por meio do processamento de milhares de imagens sísmicas profissionais fornecidas pela TGS. Desse modo, os modelos foram aplicados em um cenário real; contudo, as predições estabelecidas não foram utilizadas de forma prática, isto é, não foram empregadas por empresas de exploração de sal ou petróleo.
Os resultados obtidos com os modelos propostos foram considerados medianos. Comparando-se com os líderes da competição promovida pela Kaggle, as soluções dos modelos aplicados neste trabalho obtiveram resultados significativamente inferiores. Todavia, confrontando com o tempo que se levaria utilizando interpretação humana para este problema, os modelos propostos puderam ser uma boa alternativa, haja vista que em questão de minutos, o modelo foi capaz de processar milhares de imagens sísmicas e fazer predições com acurácia aceitável. Ressalta-se que a Universidade Federal de Santa Catarina (UFSC) não dispõe de máquinas virtuais de porte apropriado para a utilização no treinamento das redes neurais convolucionais, para tanto, fez-se necessário utilizar outros servidores virtuais como o gratuito, mas limitado, Google Colab. Além deste, foi crucial a utilização do servidor da AWS, o qual dispõe de mais recursos, mas que não é gratuito.
Considerando os resultados obtidos e seu impacto promissor na detecção de depósitos ainda ocultos de petróleo sugere-se desenvolver estudos detalhados sobre outras perspectivas que possam ser abordadas para a predição de segmentos de sal em imagens sísmicas. Em especial,

94
julga-se relevante identificar e compreender os modelos que foram utilizados pelos líderes da competição promovida pela Kaggle, os quais obtiveram resultados superiores aos modelos propostos neste trabalho. Dessa forma, propõe-se como um possível trabalho futuro, o estudo ainda aprofundado sobre as técnicas de processamento de imagens, buscando o desenvolvimento de modelos que possam melhorar os resultados obtidos neste estudo, na tentativa de igualar ou mesmo superar a acurácia dos modelos propostos pelos vencedores da competição. Não obstante, ressalta-se que, em geral, os líderes das competições promovidas pela Kaggle são profissionais com vasta experiência em machine learning e análise de dados, sendo um desafio tentar superá-los com os recursos limitados de equipamentos e de tempo disponível para execução deste trabalho de conclusão de curso.
Por fim, destaca-se que este trabalho identificou uma série de modelos de redes neurais convolucionais com capacidade de reconhecer padrões em imagens. Além da arquitetura U-Net, utilizada neste estudo, percebeu-se outros modelos que podem ser promissores para este fim, como: Waldeland CNN, ResNet50, VGG16 CNN, AlexNet, ZFNet, VGGNet e GoogleNet. Nesse sentido, recomenda-se a aplicação desses modelos em possíveis trabalhos futuros.

95
REFERÊNCIAS ABDULLAHIL, H.S.; SHERIFF, R.E.; MAHIEDDINE, F. Convolution neural network in precision agriculture for plant image recognition and classification. In: INTERNATIONAL CONFERENCE ON INNOVATIVE COMPUTING TECHNOLOGY, 7, 2017, Luton. IEEE. ABEPRO. Áreas e Sub-áreas de Engenharia de Produção. 2018. ABEPRO. Disponível em: <http://www.abepro.org.br/interna.asp?p=399&m=424&ss=1&c=362> Acesso em: 15 de agosto de 2018. ALAUDAH, Y. et al. Learning to label seismic structures with deconvolution networks and weak labels. SEG Technical Program Expanded Abstracts. 2018: pp. 2121-2125. AMARAL, B.G. UNet with depth. Kaggle. 2018. Disponível em: <https://www.kaggle.com/bguberfain/unet-with-depth/versions> Acesso em: 16 de agosto de 2018. ARAÚJO, A.A.P. Uma arquitetura utilizando algoritmo genético interativo e aprendizado de máquina aplicado ao problema do próximo release. 2015. 97p. Dissertação (Mestrado em Ciências da Computação) – Universidade Estadual do Ceará, Fortaleza, 2015. BITTAR, R.B.; ALVES, S.M.F.; MELO, F.R. Estimation of physical and chemical soil properties by artificial neural networks. Rev. Caatinga, Mossoró , v. 31, n. 3, p. 704-712, Jul. 2018 .Disponível em: <http://www.scielo.br/scielo.php?script=sci_arttext&pid=S1983-21252018000300704&lng=en&nrm=iso>. Acesso em: 02 de agosto de 2018. BITTENCOURT, G. Inteligência Artificial – Ferramentas e Teorias. 3ª ed., Florianópolis: Editora da UFSC, 2006. COUPER, H.; HENBEST, N. A História da Astronomia. 1ª ed., São Paulo: Larousse, 2009, 288p. COSTA, A.M. et al. Triaxial Creep Tests in Salt Applied in Drilling Through Thick Salt Layers in Campos Basin – Brazil. SPE/IADC

96
Drilling Conference. 2005. Amsterdam: Society of Petroleum Engineers Inc. (SPE). DEEP LEARNING BOOK. Capítulos. 2018. Deep Learning Book. Disponível em: <http://deeplearningbook.com.br/capitulos/> Acesso em: 25 de setembro de 2018. DI, H. et al. Why using CNN for seismic interpretation? An investigation. SEG Technical Program Expanded Abstracts. 2018: pp. 2216-2220. DRAMSCH, J. Intro to seismic, salt, and how to geophysics. Kaggle. 2018. Disponível em: <https://www.kaggle.com/jesperdramsch/intro-to-seismic-salt-and-how-to-geophysics> Acesso em: 14 de agosto de 2018. DRAMSCH, J.S., LÜTHJE, M. Deep-learning seismic facies on state-of-the-art CNN architectures. SEG Technical Program Expanded Abstracts. 2018: pp. 2036-2040. FACURE, M. Tensor Flow essencial. GITHUB. 2018. Disponível em: <https://matheusfacure.github.io/2017/05/12/tensorflow-essencial/> Acesso em: 21 de outubro de 2018. FALCÃO, J.L. Perfuração de formações salíferas. In: W. Mohriak, P. Szatmari, & S.M. Couto Anjos. Sal – Geologia e Tectônica – Exemplos nas Bacias Brasileiras. 2009. p. 386—405. São Paulo. Editora Beca. FERREIRA, A.S. Redes Neurais Convolucionais Profundas na Detecção de Plantas Daninhas em Lavroura de Soja. 2017. 80f.. Dissertação (Mestrado em Ciências da Computação) – Universidade Federal do Mato Grosso do Sul, Campo Grande, 2017. FIRME, P.A.L.P. Modelagem Constitutiva e Análise Probabilística Aplicadas a Poços em Zonas de Sal. 2013. 232f. Dissertação (Mestrado em Engenharia Civil) – Pontifícia Universidade Católica do Rio de Janeiro, Rio de Janeiro, 2013. FLORENCIO, C.P. A mineração de evaporitos. In: W. Mohriak, P. Szatmari, & S.M. Couto Anjos. Sal – Geologia e Tectônica –

97
Exemplos nas Bacias Brasileiras. 2009. p. 406—415. São Paulo. Editora Beca. GRAMSTAD, O., NICKEL,M. Automated interpretation of top and base salt using deep-convolutional networks. SEG Technical Program Expanded Abstracts. 2018: pp. 1956-1960. GU, J. et al. Recent advances in convolutional neural networks. Pattern Recognition. V 77. p.354-377. Maio - 2018 HAGAN, M.T. et al. Neural Network Design. 2ª ed., Frisco: eBook, 2014. HAYKIN, S. Redes Neurais – Princípios e Prática. 2ª ed. – Porto Alegre: Bookman, 2001. HÖNIGSCHMID, P. U-net, dropout, augmentation, stratification. Kaggle. 2018. Disponível em: <https://www.kaggle.com/phoenigs/u-net-dropout-augmentation-stratification> Acesso em: 14 de agosto de 2018. KAGGLE – TGS Salt identification Challenge - Segment salt deposits beneath the Earth’s surface. 2018. Disponível em: <https://www.kaggle.com/c/tgs-salt-identification-challenge> Acesso em: 25 de Agosto de 2018. KONING, T. Industry eager for repeat of Brazil pre-salt boom offshore Angola. Drilling Contractor. 2014. Disponível em: <http://www.drillingcontractor.org/industry-eager-for-repeat-of-brazil-pre-salt-boom-offshore-angola-30574> Acesso em: 19 de outubro de 2018. LARDINOIS, F. et al. Google is acquiring data science community Kaggle. TechCrunch. 2018. Disponível em: <https://techcrunch.com/2017/03/07/google-is-acquiring-data-science-community-kaggle/>. Acesso em: 12 de outubro de 2018. LE CUN, Y. et al. Handwritten Digit Recognition with a Back-Propagation Network. Proceedings of the Advances in Neural Information Processing Systems (NIPS). 1990. p.396-404.

98
LE CUN, Y. et al. Gradient-based learning applied to document recognition. IEEE. 1998. LIAO, A. U-Net-BN-Aug-Strat-Focal_Loss(fixed). Kaggle. 2018. Disponível em: <https://www.kaggle.com/alexanderliao/u-net-bn-aug-strat-focal-loss-fixed> Acesso em: 20 de agosto de 2018. LEEK, J. The Elements of Data Analytic Style: A guide for people who want to analyze data. 1ª ed. Baltimore: Leanpub, 2015. LINDEN, R. Algoritmos Genéticos. – 3ª ed. Rio de Janeiro : Editora Ciência Moderna Ltda., 2012. MCCULLOCH, W.S.; PITTS, W.H. A Logical Calculus of the ideas imanente in nervous activity. Bulletin of Mathematical Biophysics, v.5, p. 115-133, 1943. Disponível em: <http://www.cse.chalmers.se/~coquand/AUTOMATA/mcp.pdf> Acesso em: 11 de agosto de 2018. MELLO, U. Inteligência Artificial e o futuro do Petróleo. 2018. IBM. Disponível em: <https://www.ibm.com/blogs/ibm-comunica/inteligencia-artificial-e-o-futuro-do-petroleo/> Acesso em: 28 de setembro de 2018. MENDES, D. Detecção de Emoções em Imagens com Inteligência Artificial. GITHUB. 2018. Disponível em: <https://github.com/dsacademybr/PythonFundamentos/blob/master/Cap12/DSA-Python-Cap12-01-Deep-Learning-Treinamento.ipynb> Acesso em: 20 de outubro de 2018. MOYER, E. Google buys Kaggle and its gaggle of AI geeks. 2017. CNET. Disponível em: <https://www.cnet.com/news/google-buys-kaggle-and-its-gaggle-of-ai-geeks/> Acesso em: 12 de outubro de 2018. PENG, R.D; MATSUI, E. The Art of Data Sciente: A guide for anyone who works with Data. 1ª ed. Baltimore: Leanpub, 2016. ROCHA, J.C. Bias e variância, Underfitting e overfitting. WORDPRESS. 2017. Disponível em: <https://juliocprocha.wordpress.com/2017/04/01/bias-e-varianciaunderfitting-e-overfitting/> Acesso em: 20 de outubro de 2018.

99
RONNEBERGER, O. et al. U-Net: Convolutional Networks for Biomedical Image Segmentation. Computer Science Department and BIOSS Centre For Biological Signalling Studies. Freiburg, 2015. ROSEBROCK, A. Intersection over Union (IoU) for object detection. 2016. Pyimage search. Disponível em: <https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/> Acesso em 20 de outubro de 2018. SANTOS, V.S. "O que é neurônio?". 2018. BRASIL ESCOLA. Disponível em: <https://brasilescola.uol.com.br/o-que-e/biologia/o-que-e-neuronio.htm>. Acesso em: 12 de agosto de 2018. SHAO, J. U-net with simple ResNet Blocks v2 (New loss). Kaggle. 2018. Disponível em: <https://www.kaggle.com/shaojiaxin/u-net-with-simple-resnet-blocks-v2-new-loss> Acesso em: 15 de agosto de 2018. SHI, Y. et al. Automatic salt-body classification using deep-convolutional neural network. SEG Technical Program Expanded Abstracts. 2018: pp. 1971-1975. SILVA, Edna Lúcia da; MENEZES, Estera Muszkat. Metodologia da Pesquisa e Elaboração de Dissertação. 4.ed. Florianópolis. UFSC, 2005. 139p. TGS. About TGS. 2018. Disponível em: <http://www.tgs.com/about-tgs/>. Acesso em: 12 de outubro de 2018. TUPINAMBÁ, R., TABOAS, S. Áreas da sociedade em que a inteligência artificial já é realidade. 2018. CRYPTOID. Disponível em: <https://cryptoid.com.br/banco-de-noticias/areas-da-sociedade-em-que-inteligencia-artificial-ja-e-realidade/> Acesso em: 29 de setembro de 2018. TURING, G. Uma simples introdução às Redes Neurais Artificiais. Medium. 2017. Disponível em: <https://medium.com/grupo-turing/uma-simples-introdu%C3%A7%C3%A3o-a-redes-neurais-artificiais-fd5c486fc0c4> Acesso em: 19 de setembro de 2018.

100
VEEN, F.J. Neural Network Zoo Prequel: Cell and Layers. 2018. ASIMOV INSTITUTE. Disponível em: <http://www.asimovinstitute.org/author/fjodorvanveen/> Acesso em: 29 de setembro de 2018. VIEIRA, C.L.S. Proposta de um modelo de implantação de tecnologias de informação e comunicação para prestadores de serviços logísticos. 2012. 181p. Dissertação (Mestrado em Engenharia de Produção) – Universidade Federal de Santa Catarina, Florianópolis, 2012. WALDERLAND, A.U. et al. Convolutional neural networks for automated seismic interpretation. The Leading Edge. 2018. 37(7), p.529–537. WIKIPEDIA. Jaccard index. 2018. Disponível em: <https://en.wikipedia.org/wiki/Jaccard_index> Acesso em: 13 de outubro de 2018. WIKIPEDIA. Kaggle. 2018. Disponível em: <https://en.wikipedia.org/wiki/Kaggle>. Acesso em: 12 de outubro de 2018. YUAN, S. et al. Seismic Waveform Classification and First-Break Picking Using Convolution Neural Networks in IEEE Geoscience and Remote Sensing Letters, vol. 15, no. 2, pp. 272-276, Feb. 2018. ZHAO, T. Seismic facies classification using different deep convolutional neural networks. SEG Technical Program Expanded Abstracts. 2018: pp. 2046-2050.


















