
Proposta de um Modelo de Distribuição de Dados para o Sistema...
116
Diego Vinicius Lima Souza Proposta de um Modelo de Distribuição de Dados para o Sistema Acadêmico SigmaWeb Joinville - SC 2006
Transcript of Proposta de um Modelo de Distribuição de Dados para o Sistema...

Diego Vinicius Lima Souza
Proposta de um Modelo de Distribuição de Dados para o
Sistema Acadêmico SigmaWeb
Joinville - SC
2006

UNIVERSIDADE DO ESTADO DE SANTA CATARINA BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO
Diego Vinicius Lima Souza
PROPOSTA DE UM MODELO DE DISTRIBUIÇÃO DE DADOS PARA O SISTEMA ACADÊMICO SIGMAWEB
Trabalho de conclusão de curso submetido à Universidade do Estado de Santa Catarina como
parte dos requisitos para a obtenção do grau de Bacharel em Ciência da Computação
Luciana Rita Guedes
Joinville, Dezembro/2006

3
PROPOSTA DE UM MODELO DE DISTRIBUIÇÃO DE DADOS PARA O SISTEMA ACADÊMICO SIGMAWEB
Diego Vinicius Lima Souza
Este Trabalho de Conclusão de Curso foi julgado adequado para a obtenção do título de
Bacharel em Ciência da Computação e aprovado em sua forma final pelo Curso de Ciência da
Computação do CCT/UDESC.
__________________________________
Roberto Silvio Ubertino Rosso Jr.
Coordenador da Disciplina
Banca Examinadora
________________________________
Luciana Rita Guedes
Presidente da Banca (Orientadora)
________________________________
Éverlin Fighera Costa Marques
Membro da banca
________________________________
Rafael Stubs Parpinelli
Membro da Banca
________________________________
Rogério Eduardo da Silva
Membro da Banca

4
“Eu não pedi pra nascer
Eu não nasci pra perder
Nem vou sobrar de vítima
das circunstâncias...”
(Lulu Santos)

5
AGRADECIMENTOS
Agradeço a Deus, por ter chegado até aqui e concluído mais esta etapa da minha vida.
Agradeço aos meus pais, Paulo e Lígia, pelo incentivo e apoio para concluir o curso.
Agradeço a minha noiva Rose, que estando acordada ou não, sempre esteve ao meu
lado em todos os momentos difíceis que passei.
Agradeço a todos os meus amigos e familiares que em algum momento me deram uma
palavra de conforto e incentivo para concluir este trabalho.
Agradeço a professora Luciana Rita Guedes, que me orientou tanto na parte escrita
como na parte psicológica, com muito apoio moral.

6
SUMÁRIO
LISTA DE FIGURAS......................................................................................viii LISTA DE TABELAS ....................................................................................... x LISTA DE ALGORITMOS ............................................................................... xi LISTA DE SIGLAS ........................................................................................ xii RESUMO.....................................................................................................xiv ABSTRACT...................................................................................................xv 1. INTRODUÇÃO....................................................................................................................16
2. SISTEMAS DISTRIBUÍDOS E BANCOS DE DADOS DISTRIBUÍDOS........................18
2.1. Sistemas Distribuídos ........................................................................................................18
2.1.1. Características dos Sistemas Distribuídos .........................................................................18
2.1.2. Modelos de Sistemas Distribuídos....................................................................................19
2.1.3. Exemplos de Sistemas Distribuídos ..................................................................................20
2.2. Bancos de Dados................................................................................................................21
2.3. Bancos de Dados Distribuídos ..........................................................................................26
2.3.1. Arquitetura de Sistemas de Bancos de Dados Distribuídos ...............................................26
2.3.2. Processamento de Consultas.............................................................................................29
2.3.3. Gerenciamento de Transações ..........................................................................................30
2.3.4. Controle de Concorrência .................................................................................................33
2.3.5. Projeto de Distribuição de Dados......................................................................................36
2.3.6. Replicação em Bancos de Dados Distribuídos ..................................................................39
3. O SIGMAWEB E SEU MODELO DE DADOS .................................................................43
3.1. Organização do SigmaWeb – Menus e sub-menus ..........................................................46
3.2. Organização do SigmaWeb – Tabelas do banco de dados...............................................47
3.3. A Engenharia Reversa para os dados do SigmaWeb.......................................................49
3.3.1. Engenharia Reversa..........................................................................................................49
3.3.2. Modelo Entidade-Relacionamento do SigmaWeb.............................................................51
4. TECNOLOGIAS DE SGBD................................................................................................60
4.1. Oracle ................................................................................................................................60
4.2. SQL Server ........................................................................................................................61

7
4.3. My SQL .............................................................................................................................62
4.4. PostgreSQL .......................................................................................................................62
4.5. Firebird..............................................................................................................................63
4.6. Características dos SGBD’s ..............................................................................................63
4.6.1. Quanto a Distribuição.......................................................................................................64
5. PROPOSTA DE DISTRIBUIÇÃO DE DADOS DO SIGMAWEB ...................................66
5.1. Estratégias de Projeto .......................................................................................................67
5.2. Projeto de Distribuição SigmaWeb ..................................................................................69
5.2.1. Definição do Projeto de Distribuição ................................................................................70
5.2.2. Fragmentação...................................................................................................................71
5.2.3. Vantagens da Fragmentação .............................................................................................72
5.2.4. Grau de Fragmentação......................................................................................................72
5.2.5. Regras de fragmentação ...................................................................................................73
5.2.6. Fragmentação horizontal ..................................................................................................74
5.2.6.1. Requisitos de informações da fragmentação horizontal ..................................................74
5.2.6.2. Fragmentação horizontal primária .................................................................................76
5.2.6.3. Fragmentação horizontal derivada .................................................................................81
5.2.7. Alternativas de alocação...................................................................................................84
5.2.8. Alocação das tabelas do SigmaWeb..................................................................................84
6. CONCLUSÃO......................................................................................................................95
REFERÊNCIAS.......................................................................................................................98
ANEXOS ................................................................................................................................102
ANEXO 1 PLANO DE TRABALHO DE CONCLUSÃO DE CURSO ...............................103
ANEXO 2 MÓDULOS E ROTINAS DO SISTEMA SIGMAWEB.....................................109
ANEXO 3 TABELAS DO BANCO DE DADOS DO SIGMAWEB.....................................115
ANEXO 4 MODELO ENTIDADE-RELACIONAMENTO DO SIGMAWEB...................128

8
LISTA DE FIGURAS
Figura 2.1. Comunicação request-reply .....................................................................................19
Figura 2.2. Tabelas exemplo .....................................................................................................22
Figura 2.3. Tabela resultante de A U B .....................................................................................22
Figura 2.4. Tabela resultante de A ∩ B .....................................................................................23
Figura 2.5. Tabelas resultantes de A – B e B - A .......................................................................23
Figura 2.6. Tabela resultante de D x C ......................................................................................23
Figura 2.7. Tabela resultante da seleção COD >15 ....................................................................24
Figura 2.8. Tabela resultante da projeção ..................................................................................24
Figura 2.9. Tabela resultante da junção .....................................................................................24
Figura 2.10. Banco de Dados Distribuídos ................................................................................25
Figura 2.11. Arquitetura ANSI/SPARC.....................................................................................26
Figura 2.12. Arquitetura de banco de dados distribuído .............................................................27
Figura 2.13. Protocolo two-fase commit quando um participante consolida a transação .............31
Figura 2.14. Protocolo two-fase commit quando um participante aborta a transação ..................31
Figura 2.15. Exemplo de fragmentação horizontal.....................................................................36
Figura 2.16. Fragmentação horizontal derivada .........................................................................37
Figura 2.17. Exemplo de fragmentação vertical.........................................................................38
Figura 2.18. Modelo de propriedade de dados mestre/escravo ...................................................40
Figura 2.19. Modelo de propriedade de dados workflow............................................................40
Figura 2.20. Modelo de propriedade de dados ponto a ponto, onde os nós coloridos têm o
direito de atualização.............................................................................................41
Figura 3.21. Estrutura multi-campi da UDESC..........................................................................43
Figura 3.22. Evolução do sistema acadêmico da UDESC ..........................................................44
Figura 3.23. Grupos de tabelas do sistema SigmaWeb...............................................................47
Figura 3.24. Grupo Básicas e Estruturais...................................................................................51
Figura 3.25. Grupo Administrativo ...........................................................................................52
Figura 3.26. Grupo Disciplinas e Currículos..............................................................................52
Figura 3.27. Gurpo Acadêmicos................................................................................................53
Figura 3.28. Grupo Alunos Visitantes .......................................................................................54

9
Figura 3.29. Grupo Professores .................................................................................................54
Figura 3.30. Grupo Diários e Matrículas ...................................................................................55
Figura 3.31. Grupo Históricos Escolares ...................................................................................56
Figura 3.32. Grupo Requerimentos ...........................................................................................57
Figura 3.33. Grupo Estágio, Monografia e Outros .....................................................................57
Figura 5.34. Níveis dos elementos da organização de sistemas distribuídos...............................66
Figura 5.35. Estratégia Top-down (FONTE: [ÖZSU, 2001]) .....................................................68
Figura 5.36. Estratégia Top-down adaptada...............................................................................69
Figura 5.37. Exemplo de tabelas de um banco de dados ............................................................70
Figura 5.38. Exemplo de Completeza........................................................................................72
Figura 5.39. Exemplo de Disjunção na fragmentação vertical....................................................73
Figura 5.40. Relacionamentos entre tabelas utilizando vínculos ................................................74
Figura 5.41. Resultado de uma fragmentação horizontal primária da tabela ALUNO ................76
Figura 5.42. Fragmentação horizontal da tabela DISCIP ...........................................................80
Figura 5.43. Fragmentação horizontal derivada da tabela ALUNO............................................81
Figura 5.44. Fragmentação horizontal derivada da tabela AULA...............................................82
Figura 5.45. Divisão do grupo Básicas e Estruturais..................................................................85
Figura 5.46. Divisão do grupo Administrativo...........................................................................86
Figura 5.47. Divisão do grupo Disciplinas e Currículos.............................................................87
Figura 5.48. Divisão do grupo Acadêmicos...............................................................................88
Figura 5.49. Divisão do grupo Alunos Visitantes ......................................................................89
Figura 5.50. Divisão do grupo Professores ................................................................................90
Figura 5.51. Divisão do grupo Diários e Matrículas ..................................................................91
Figura 5.52. Divisão do grupo Históricos Escolares ..................................................................92
Figura 5.53. Divisão do grupo Requerimentos...........................................................................93
Figura 5.54. Divisão do grupo Estágios, Monografias e Outros .................................................93

10
LISTA DE TABELAS
Tabela 2.1. Comparação de métodos de controle de concorrência. FONTE: [CASANOVA &
MOURA, 1985].....................................................................................................33
Tabela 6.2. Comparação entre SGBD’s .....................................................................................63

11
LISTA DE ALGORITMOS
Algoritmo 5.1. Algoritmo COM_MIN. FONTE: (ÖZSU, 2001) ................................................77
Algoritmo 5.2. Algoritmo PHORIZONTAL. FONTE: (ÖZSU, 2001) .......................................79

12
LISTA DE SIGLAS
ACID – Atomicidade, Consistência, Isolamento e Durabilidade
ANSI – American National Standards Institute
ARO - Army Research Office
CAV – Centro de Ciências Agroveterinárias
CCT – Centro de Ciências Tecnológicas
CEAD – Centro de Educação à Distância
CEART – Centro de Artes
CEFID – Centro de Educação Física, Fisioterapia e Desportos
CEO – Centro Educacional do Oeste
CPU – Central Processor Unit
DARPA - Defense Advanced Research Projects Agency
DEC – Digital Equipament Corporation
DNS – Domain Name Service
DTS – Data Transformation Services
E/S – Entrada/Saída
ECG – Esquema conceitual Global
ECL – Esquema Conceitual Local
EE – Esquema Externo
EIL – Esquema Interno Local
ESAG – Centro de Ciências Administrativas
FK – Foreign Key
FAED – Centro de Ciências da Educação
IBM – International Business Machines
LAN – Local Area Network
MER – Modelo Entidade-Relacionamento
NSF – National Science Foundation
OLAP – Online Analytical Processing
PHP – Hypertext Preprocessor

13
RAM – Random Access Memory
SGBD – Sistema Gerenciador de Banco de Dados
SGBDD – Sistema Gerenciador de Banco de Dados Distribuídos
SO – Sistema Operacional
SPARC - Standards Planning and Requirements Committee
SQL – Structured Query Language
TCC – Trabalho de Conclusão de Curso
UDESC – Universidade do Estado de Santa Catarina
XML - Extensible Markup Language

14
RESUMO
Este trabalho apresenta uma proposta de um modelo de distribuição de dados para o
sistema acadêmico da UDESC, atualmente denominado SigmaWeb. Para realização deste
objetivo, primeiramente é feita uma revisão bibliográfica contendo conceitos relativos a
sistemas distribuídos e bancos de dados distribuídos. Após esta etapa, o sistema SigmaWeb é
descrito e, como não existe um modelo de dados do sistema, ele é construído utilizando-se o
método de engenharia reversa. Finalmente, com base neste modelo de dados, é proposto um
modelo de distribuição de dados. Como complemento do trabalho, é feita uma pesquisa das
tecnologias de SGBD’s existentes com o objetivo de analisar a viabilidade de aplicação da
proposta.
Palavras-Chave: Sistemas Distribuídos, Banco de Dados Distribuídos, SigmaWeb

15
ABSTRACT
This work presents a proposal of a distribution data model for the UDESC’s
academical system, actually called SigmaWeb. For the realization of this objective, first is
done a bibliographyc revision containing relative concepts about distributed systems and
distributed databases. After this stage, the SigmaWeb system is described and, as a database
model’s system does not exist, it is constructed using the reverse engineering method. Finally,
based in this data model, a distributing data model is proposed. As the work’s complement, a
research of existing SGBD’s technologies is done with the objective of analyze the viability
of application of the proposal.
Key-word: Distributed Systems, Distributed Databases, SigmaWeb

16
1. INTRODUÇÃO
A crescente utilização da Internet traz como conseqüência um número cada vez maior
de sistemas que a utilizam como o principal meio de tráfego de dados. Através da rede
mundial de computadores, certos sistemas possibilitam que usuários geograficamente
distantes possam acessá-los em busca de informações contidas em bancos de dados, que
segundo SILVA (2001), são conjuntos de informações manipuláveis de mesma natureza
inseridas em um mesmo local, obedecendo a um padrão de armazenamento.
A partir do desejo de compartilhamento de recursos, houve a motivação para a
construção de sistemas distribuídos, que têm na Web seu principal exemplo, garantindo
acesso aos recursos e serviços através da Internet (COULOURIS et. al, 2001).
Apesar disso, a disponibilidade dos sistemas e suas bases de dados na Internet não é
totalmente garantida. A queda de um link onde se encontra certa base de dados pode causar
um grande transtorno. Esta questão faz com que haja a busca por uma solução que transforme
bancos de dados centralizados em bancos de dados distribuídos, que segundo ÖZSU (2001),
são coleções de vários bancos de dados logicamente inter-relacionados, distribuídos por uma
rede de computadores.
A motivação para o desenvolvimento deste trabalho está na continuação do estudo
iniciado no trabalho de conclusão de curso da estudante Alessandra Maria Selhorst
(SELHORST, 2005) cujo objetivo era explorar as tecnologias de banco de dados utilizadas
naquela ocasião que permitiam o uso de bancos de dados distribuídos em aplicações Web.
Naquele trabalho, foi proposta uma pequena parte de modelo de distribuição de dados para o
sistema acadêmico da UDESC.
Conhecido como SigmaWeb, este sistema é responsável pelo armazenamento dos
registros da UDESC, como dados do alunos, professores, históricos dos alunos, notas e
informações sobre as matrículas.
Diferentemente da proposta de SELHORST (2005), que utilizou apenas algumas
tabelas do SigmaWeb para exemplificar a distribuição de dados, este trabalho visa aprofundar
a fundamentação teórica, com o objetivo de criar um modelo de distribuição que abrangerá a
base de dados completa do sistema acadêmico da UDESC. A utilização do banco de dados

17
completo, com todas as tabelas existentes, torna esta proposta única e poderia permitir que
fosse efetivamente utilizada pelo sistema SigmaWeb da UDESC.
Embora as estruturas das tabelas do SigmaWeb estejam solidamente definidas e o
banco de dados atual funcione adequadamente, o sistema não possui um modelo de dados
formalizado. Portanto, não há um diagrama que represente estas estruturas segundo os
padrões existentes, como é o caso do Diagrama Entidade-Relacionamento ou do Diagrama de
Classes (HEUSER, 2001). Por este motivo, será necessário um trabalho de engenharia reversa
para construir o modelo de dados deste sistema, já que suas tabelas apresentam-se apenas na
forma de planilhas.
Para atingir os objetivos deste trabalho, no segundo capítulo são apresentados
conceitos básicos sobre sistemas distribuídos, considerando que os bancos de dados
distribuídos são implantados em ambientes distribuídos. Além disso, são apresentadas as
características de bancos de dados distribuídos, que incluem sua definição, arquitetura, alguns
detalhes de implementação e a utilização de replicação em bancos de dados distribuídos. O
terceiro capítulo abordará a descrição do sistema acadêmico da UDESC (SigmaWeb),
enfatizando a estruturação dos dados e apresentará um modelo de dados construído com a
utilização de engenharia reversa. No quarto capítulo, será feita uma explanação sobre algumas
tecnologias de SGBD (Sistemas Gerenciadores de Bancos de Dados), com o objetivo de
encontrar algum SGBD livre que trabalhe com distribuição de dados. Por último, será
apresentado um projeto de distribuição de dados do SigmaWeb, ilustrando como será
fragmentada cada tabela do banco de dados do sistema. Este projeto será construído através de
algoritmos propostos por ÖSZU (2001) relativos a fragmentação.

18
2. SISTEMAS DISTRIBUÍDOS E BANCOS DE DADOS
DISTRIBUÍDOS
Este trabalho tem como proposta a criação de um modelo de distribuição de dados
para o sistema acadêmico SigmaWeb. Para a sua realização, é necessário o entendimento de
alguns conceitos relacionados a sistemas distribuídos e também a bancos de dados
distribuídos, os quais são descritos neste capítulo.
2.1. Sistemas Distribuídos
Segundo COULOURIS et. al (2001), sistemas distribuídos são aqueles nos quais
componentes de hardware ou software, localizados em computadores em rede, comunicam-se
e coordenam suas ações somente por meio de troca de mensagens. Estes componentes são
chamados de nós de processamento por VELOSO et. al (1989). Os computadores podem estar
separados por qualquer distância: na mesma sala ou em diferentes países. TANENBAUM
(1995) define sistema distribuído como uma coleção de computadores independentes que se
apresenta como um sistema único e consistente.
De acordo com CARVALHO (2005), o aparecimento desses sistemas ocorreu devido
ao surgimento de computadores mais rápidos e baratos, além de redes de computadores de
alta velocidade. Para entender melhor sistemas distribuídos, são listadas a seguir algumas
características do seu funcionamento.
2.1.1. Características dos Sistemas Distribuídos
De acordo com COULOURIS et. al (2001), os sistemas distribuídos apresentam
algumas características que ocorrem devido à coordenação de computadores em rede por

19
meio da troca de mensagens, e que devem ser relevadas na hora de projetar um sistema
distribuído, que são as seguintes:
• Concorrência: estando os sistemas localizados em rede, certamente programas
serão executados concorrentemente em algum momento, compartilhando recursos como
páginas Web ou arquivos. O controle deste compartilhamento é importante para que não
haja indisponibilidade de recursos.
• Inexistência de um relógio global: quando os programas precisam cooperar,
eles coordenam suas ações por troca de mensagens. Não é possível sincronizar
computadores em rede através do tempo, pois dificilmente o relógio de um computador
será exatamente igual ao de outro, devido às diferenças de hardware e software.
• Falhas independentes: a falha de um computador ou a finalização inesperada de
um programa em algum lugar no sistema não é imediatamente conhecida para outros
componentes com os quais estes se comunicam. Cada componente do sistema pode falhar,
deixando os outros ainda rodando.
Com o intuito de descrever melhor estas características dos sistemas distribuídos,
foram criados modelos, descritos na próxima seção.
2.1.2. Modelos de Sistemas Distribuídos
Segundo COULOURIS et. al, (2001), a descrição dos sistemas distribuídos ocorrem
através de dois conjuntos de modelos: os arquiteturais e os fundamentais, onde cada modelo
tem a intenção de disponibilizar uma descrição abstrata e simplificada, mas consistente dos
aspectos relevantes do projeto de sistemas distribuídos.
Os modelos arquiteturais preocupam-se com a disposição das partes do sistema
distribuído e da relação entre elas COULOURIS et. al, (2001), representando a estrutura de
um sistema através de seus componentes, especificando-os separadamente, com o objetivo de
fazer um sistema confiável, gerenciável, de custo razoável e fácil adaptação. Esses modelos
consideram a localização dos componentes na rede de computadores, definindo padrões de
distribuição de dados e carga de trabalho, e a inter-relação entre estes componentes,
analisando seus papéis funcionais e seus padrões de comunicação.
Um exemplo de modelo arquitetural é o modelo cliente/servidor, que é a arquitetura
mais freqüentemente citada quando se discute sistemas distribuídos (COULOURIS et. al

20
2001), por ser a mais utilizada. Este modelo utiliza a idéia de processo cliente e processo
servidor, onde o processo cliente interage com processos servidores com o intuito de acessar
os recursos compartilhados que o servidor gerencia. O servidor pode ser cliente de outro
servidor. Por exemplo, um servidor Web é freqüentemente cliente de um servidor de arquivos
onde as páginas estão armazenadas. Servidores Web e outros serviços na Internet são clientes
do serviço DNS que traduz os nomes de domínio Internet em endereços de rede.
A forma de comunicação desenvolvida para suportar as funções de troca de mensagens
em interações entre cliente e servidor é conhecida como request-reply (requisição-resposta),
ilustrada na Figura 2.1. Normalmente, esta comunicação é síncrona, pois o processo cliente é
bloqueado até que a resposta chegue do servidor. Isto pode ser confiável porque a resposta do
servidor é um reconhecimento para o cliente. A comunicação request-reply assíncrona pode
ser utilizada em situações onde clientes podem dispor de novas tentativas de resposta.
Figura 2.1. Comunicação request-reply
Os modelos fundamentais preocupam-se com as propriedades que são comuns a todos
os modelos arquiteturais (COULOURIS et. al, 2001). Neste modelo são vistos os aspectos que
ocorrem em sistemas distribuídos com relação à interação, falha e segurança.
2.1.3. Exemplos de Sistemas Distribuídos
Os sistemas distribuídos estão sendo muito utilizados atualmente, tendo como seus
exemplos mais conhecidos a Internet e as intranets.
A Internet é uma imensa coleção interconectada de redes de computador de tipos
diferentes. Os programas que rodam nos computadores conectados à rede interagem por meio
de troca de mensagens, em um meio de comunicação comum. Os protocolos da Internet
permitem que um programa rode em qualquer lugar para enviar mensagens para qualquer
outro programa em um lugar diferente.
Cliente Servidor requisição
resposta

21
A Internet possibilita aos usuários fazer uso de serviços como e-mail e transferência de
arquivos de onde quer que estejam. O conjunto de serviços na Internet está em aberto e pode
ser estendido para a adição de novos servidores e tipos de serviços.
A intranet é uma parte da Internet que pode ser administrada separadamente. Segundo
VIANI (2003), uma das diferenças entre a Internet e a intranet é que na primeira, o foco está
centrado na publicação de informações ao mundo externo à organização/empresa, e na
segunda, as informações têm como alvo o seu público interno. Outra diferença é que o
enfoque da intranet geralmente está baseado nas aplicações corporativas da
organização/empresa, como uma ferramenta para melhorar a sua produtividade.
Largamente utilizada em empresas privadas e instituições públicas, a intranet pode ser
configurada para utilizar políticas de seguranças locais. A configuração da rede de uma
intranet particular pode ter variações: desde uma LAN em um site único até a um conjunto de
LANs pertencendo a filiais de uma companhia ou unidades de uma universidade estadual. A
intranet tem como suas principais vantagens permitir que se faça uso de serviços que estão em
outros lugares, como a Web ou e-mail, e possibilita a restrição de acesso não autorizado
através de um firewall, que filtra as mensagens de entrada e saída.
A vantagem mais significativa do uso da Internet e das intranets é o compartilhamento
de dados e de componentes de hardware. Uma impressora conectada em rede pode ser
utilizada por todos os usuários desta rede, eliminando assim a necessidade de adquirir uma
impressora para cada usuário e, conseqüentemente, cortando custos.
Com relação ao compartilhamento de dados, a velocidade e a distância que os dados
podem alcançar, através da Internet principalmente, são os principais fatores que levam as
pessoas a utilizarem-na tanto no trabalho quanto no lazer. Mas a Internet por si só não tem
todos os requisitos para trabalhar com o compartilhamento de dados. Há a necessidade de algo
que trabalhe com a manipulação desses dados, e por isso há necessidade do conceito de banco
de dados.
2.2. Bancos de Dados
Segundo SILVA (2001), banco de dados é um conjunto de informações manipuláveis
de mesma natureza inseridas em um mesmo local, obedecendo a um padrão de

22
armazenamento. DATE (2002) completa esse conceito, dizendo que essas informações
(dados) são persistentes, ou seja, só podem ser removidas do banco de dados através de
alguma solicitação explícita feita ao Sistema Gerenciador de Banco de Dados (SGBD). De
acordo com SOARES (2005), um SGBD é um sistema constituído por um conjunto de dados
associados a um conjunto de programas para acesso a esses dados. Seu principal objetivo é
proporcionar um ambiente simples e eficiente para a recuperação e armazenamento das
informações do banco de dados.
De acordo com DATE (2002) e SILVA (2001), a utilização de bancos de dados traz
algumas vantagens como a eliminação de volumosos arquivos de papel, através da inserção
dos dados em meio digital, de uma forma compacta; o compartilhamento dos dados, onde
diversas aplicações podem operar sobre uma mesma base de dados; A rapidez de recuperação
e modificação dos dados, pela utilização dos SGBD’s; a redução de redundâncias, através da
integração de arquivos que possuem certos pontos em comum; uma maior segurança dos
dados através de restrições de segurança que podem ser verificadas toda vez que houver uma
tentativa de acesso; a padronização dos dados, evitando que haja a falta de informações ou
informações insatisfatórias no banco de dados; e o suporte a transações, permitindo a leitura e
a modificação dos dados.
As informações contidas em um banco de dados são requisitadas através de linguagens
de consulta, que segundo BIAJIZ (2001), geralmente são de mais alto nível que as linguagens
de programação comuns e são classificadas como procedurais e não-procedurais (ou
declarativas). Na primeira, o usuário dá instruções ao sistema, executando uma seqüência de
operações a ponto de atingir um resultado desejado. E na segunda, o usuário descreve a
informação que deseja, sem fornecer o caminho para obtê-lo.
De acordo com ÖZSU (2001), em questões de bancos de dados distribuídos, a álgebra
relacional (linguagem procedural) é mais utilizada que o cálculo relacional (linguagem não-
procedural), pois corresponde de forma mais direta aos programas trocados em uma rede,
além de seu nível ser mais baixo.
BIAJIZ (2001) diz que a álgebra relacional possui um conjunto de operações que são
usadas para manipular relações inteiras. E que o resultado de cada operação é uma nova
relação que também pode ser manipulada. As operações da álgebra relacional são divididas
em dois grupos (DATE, 2000):
- Operadores da Teoria de Conjuntos da matemática: união, interseção, diferença
e produto cartesiano.

23
- Operadores desenvolvidos para bancos de dados relacionais: seleção, projeção,
junção, entre outras.
Para exemplificar as operações citadas, serão utilizadas as tabelas A, B e C da Figura 2.2.
A B
COD NOME PROFISSAO EMPRESA COD NOME PROFISSAO EMPRESA
10 João Arquiteto X 10 João Arquiteto X
20 Pedro Contador Z 30 Paulo Engenheiro Y
C
PROFISSAO SALÁRIO
Arquiteto 4000
Contador 1500
Engenheiro 3000
Figura 2.2. Tabelas exemplo
Na operação de União, as linhas das tabelas manipuladas são agrupadas, formando
uma tabela contendo todas as linhas presentes em uma ou em ambas as tabelas. Na Figura 2.3,
temos o resultado da operação “A U B”.
A U B
COD NOME PROFISSAO EMPRESA
10 João Arquiteto X
20 Pedro Contador Z
30 Paulo Engenheiro Y
Figura 2.3. Tabela resultante de A U B
Na operação de Interseção, a tabela resultante é formada pelas linhas que estão
presentes em todas as tabelas, simultaneamente. Na Figura 2.4, a relação é composta pelas
linhas em comum das relações A e B.
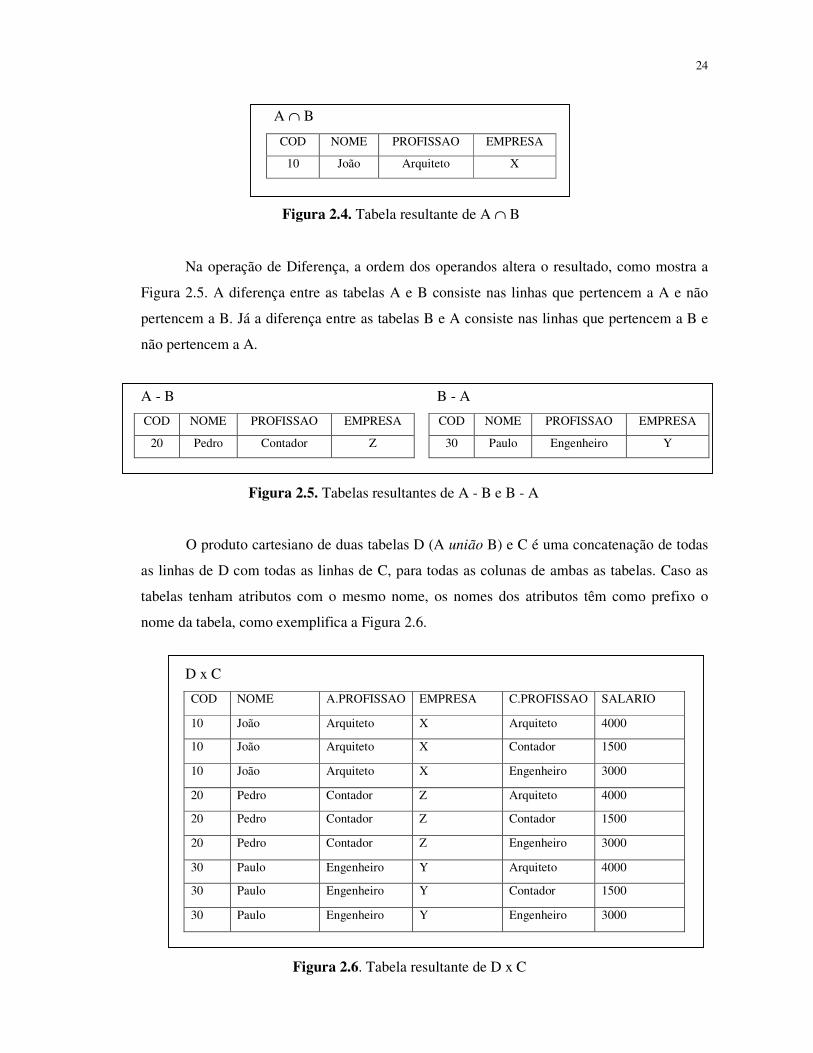
24
A ∩ B
COD NOME PROFISSAO EMPRESA
10 João Arquiteto X
Figura 2.4. Tabela resultante de A ∩ B
Na operação de Diferença, a ordem dos operandos altera o resultado, como mostra a
Figura 2.5. A diferença entre as tabelas A e B consiste nas linhas que pertencem a A e não
pertencem a B. Já a diferença entre as tabelas B e A consiste nas linhas que pertencem a B e
não pertencem a A.
A - B B - A
COD NOME PROFISSAO EMPRESA COD NOME PROFISSAO EMPRESA
20 Pedro Contador Z 30 Paulo Engenheiro Y
Figura 2.5. Tabelas resultantes de A - B e B - A
O produto cartesiano de duas tabelas D (A união B) e C é uma concatenação de todas
as linhas de D com todas as linhas de C, para todas as colunas de ambas as tabelas. Caso as
tabelas tenham atributos com o mesmo nome, os nomes dos atributos têm como prefixo o
nome da tabela, como exemplifica a Figura 2.6.
D x C
COD NOME A.PROFISSAO EMPRESA C.PROFISSAO SALARIO
10 João Arquiteto X Arquiteto 4000
10 João Arquiteto X Contador 1500
10 João Arquiteto X Engenheiro 3000
20 Pedro Contador Z Arquiteto 4000
20 Pedro Contador Z Contador 1500
20 Pedro Contador Z Engenheiro 3000
30 Paulo Engenheiro Y Arquiteto 4000
30 Paulo Engenheiro Y Contador 1500
30 Paulo Engenheiro Y Engenheiro 3000
Figura 2.6. Tabela resultante de D x C

25
A seleção é uma operação que apresenta como resultado todas as linhas de uma tabela
que satisfazem a uma dada condição. Como exemplo, a partir da tabela ilustrada na Figura
2.3, é feita uma seleção das pessoas cujo código é maior que 15 (COD > 15). O resultado é
mostrado na Figura 2.7.
COD > 15
COD NOME PROFISSAO EMPRESA
20 Pedro Contador Z
30 Paulo Engenheiro Y
Figura 2.7. Tabela resultante da seleção COD >15
A projeção produz uma tabela com um número menor ou igual de colunas do que a
tabela original, contendo apenas as colunas sobre as quais a projeção é executada. Na Figura
2.8, a projeção é executada sobre as colunas COD e PROFISSAO da tabela A.
COD PROFISSAO
10 Arquiteto
20 Contador
Figura 2.8. Tabela resultante da projeção
A junção de duas tabelas ocorre quando ambas possuem uma coluna em comum, com
valores em comum, como mostra a Figura 2.9, resultante da junção das tabelas A e C, que
possuem a coluna PROFISSAO em comum, ou seja, a junção é realizada através da condição
A.PROFISSAO = C.PROFISSAO.
COD NOME PROFISSAO EMPRESA SALARIO
10 João Arquiteto X 4000
20 Pedro Contador Z 1500
Figura 2.9. Tabela resultante da junção

26
2.3. Bancos de Dados Distribuídos
Banco de dados distribuído é uma coleção de diversos bancos de dados logicamente
inter-relacionados, e que são distribuídos por uma rede de computadores (ÖZSU, 2001). Ou
seja, bancos de dados distribuídos não são apenas arquivos armazenados em um computador
conectado em rede. Esses arquivos devem ter uma relação lógica entre si, e seu acesso deve
ser realizado através de uma interface comum.
Compartilhando a mesma idéia, mas em outras palavras, DATE (2002) diz que banco
de dados distribuídos é, na verdade, uma espécie de banco de dados virtual, cujas partes
componentes estão fisicamente armazenadas em diversos bancos de dados reais distintos,
como mostra a Figura 2.10. Para um melhor entendimento do funcionamento de bancos de
dados distribuídos, é necessário conhecer a sua arquitetura, bem como seus componentes e a
interação entre os mesmos.
Figura 2.10. Banco de Dados Distribuídos
2.3.1. Arquitetura de Sistemas de Bancos de Dados Distribuídos
No início da década de 70, o ANSI (American National Standards Institute) criou um
grupo de estudos sobre SGBD’s (Sistemas Gerenciadores de Bancos de Dados), com o
Joinville
Lages
Chapecó
Florianópolis
Rede de
Comunicações
BD
D
BD
D
BD
D
BD
D
HUB HUB
HUB HUB

27
objetivo de examinar a viabilidade de configurar padrões nessa área, e determinar quais
aspectos deveriam ser padronizados caso fosse viável. O grupo emitiu o relatório no qual foi
proposta uma estrutura arquitetônica que ficou conhecida como arquitetura ANSI/SPARC
(ÖZSU, 2001), representada na Figura 2.11.
Usuários
Esquema externo
Esquema conceitual
Esquema interno
Figura 2.11. Arquitetura ANSI/SPARC
Baseada na organização dos dados, a arquitetura ANSI/SPARC reconhece três visões
de dados: a visão externa (usuário), a visão interna (sistema ou máquina), e a visão conceitual
(empreendimento/organização). A visão interna lida com a definição física e a organização
dos dados, e encontra-se no nível inferior da arquitetura. Este nível trata da localização dos
dados nos diversos dispositivos de armazenamento, e dos mecanismos de acesso utilizados
para o alcance e a manipulação dos dados. Logo acima da visão interna, encontra-se a visão
conceitual, que é a definição abstrata do banco de dados. Ela representa os dados e
relacionamentos entre dados desconsiderando os requisitos de aplicativos ou as restrições do
local de armazenamento físico. Na parte superior da arquitetura está a visão externa,
relacionada com o modo como o banco de dados é visualizado pelos usuários. A visão de um
único usuário representa a porção do banco de dados que será acessada por esse usuário, e os
relacionamentos que o usuário gostaria de ver entre os dados.
Visão conceitual
Visão interna
Visão externa
Visão externa
Visão externa

28
De acordo com ÖZSU (2001), nos bancos de dados distribuídos, a organização dos
dados físicos em cada máquina, na maioria das vezes, é diferente. Logo, há a necessidade de
definir um esquema interno individual em cada local, chamado de esquema interno local
(EIL). O esquema conceitual divide-se em duas partes: global e local. O esquema conceitual
global (ECG) descreve a estrutura lógica dos dados em todos os locais onde se encontram.
Para lidar com os dados fragmentados e replicados, a organização lógica dos dados em cada
local é descrita através do esquema conceitual local (ECL). Seguindo estes conceitos, o
esquema conceitual global pode ser definido como a união dos esquemas conceituais locais.
Por último, os esquemas externos (EEs), responsáveis pelo acesso de aplicativos do usuário e
o acesso de usuários ao banco de dados, são definidos como se estivessem localizados acima
do esquema conceitual global.
A Figura 2.12 ilustra os esquemas apresentados anteriormente como parte do modelo
de arquitetura de banco de dados distribuídos. Este modelo, que é uma extensão do modelo
ANSI/SPARC, admite a independência dos dados, e também a transparência de localização e
replicação através da definição dos esquemas conceituais local e global. O usuário trabalha
com os dados independentemente de sua localização ou de qual componente local do sistema
de banco de dados distribuído o servirá.
Figura 2.12. Arquitetura de banco de dados distribuído
ECG
ECL 2 ECL 1 ECL n
EIL 1 EIL 2 EIL n
EE 1 EE 2 EE n

29
2.3.2. Processamento de Consultas
Segundo ÖSZÜ (2001), o sucesso da tecnologia de bancos de dados relacionais no
processamento de dados se deve à disponibilidade de linguagens não-procedurais, como o
SQL, que podem melhorar o desenvolvimento de aplicativos e a produtividade do usuário.
Essas linguagens de bancos de dados relacionais permitem a expressão de consultas
complexas de uma maneira mais simples, através da ocultação de detalhes da organização
física dos dados. Assim sendo, o usuário não necessita especificar o procedimento para
construir a resposta de uma consulta. Esse procedimento é projetado por um módulo do
SGBD, chamado processador de consultas, que libera o usuário da necessidade de realizar a
otimização da consulta. Em bancos de dados distribuídos, o problema do processamento de
consultas é mais difícil do que em bancos de dados centralizados, pois o desempenho de
consultas distribuídas é afetado por um número maior de parâmetros necessários para a
localização da informação desejada.
A principal função de um processador de consultas distribuídas é transformar uma
consulta de alto nível em bancos de dados distribuídos em uma consulta equivalente de nível
mais baixo em bancos de dados locais (ÖZSU, 2001). Esta transformação deve alcançar a
correção e a eficiência, considerando que ela será correta se a consulta de baixo nível tiver a
mesma semântica que a consulta de alto nível, ou seja, se ambas produzirem o mesmo
resultado.
Segundo CASANOVA (2005), o principal componente do processador de consultas é
um otimizador capaz de gerar planos alternativos para execução de consultas e escolher
aquele que minimiza o consumo de recursos. De acordo com ÖZSU (2001), uma boa solução
é o custo total, que é a soma de todos os tempos que incidem no processamento das operações
da consulta em diversos bancos de dados e na comunicação entre os mesmos. Em um sistema
de banco de dados distribuído, o custo total a ser minimizado inclui os custos de CPU
(relacionados com a execução de operações sobre dados na memória principal), de E/S
(relacionados com o tempo necessário para execução de operações de entrada e saída), e o
custo de comunicação (relacionado ao tempo necessário para a troca de dados entre os bancos
que participam da execução da consulta). O componente de custo de comunicação é o fator
mais importante considerado em bancos de dados distribuídos, pela razão de que estes
utilizam redes de computadores para transmitir os dados, podendo tornar a comunicação

30
muito lenta. Os custos de CPU e de operações de entrada e saída podem ser otimizados
localmente de forma independente, com a utilização eficiente da memória principal e a
redução do número de operações de entrada e saída.
2.3.3. Gerenciamento de Transações
Segundo ÖZSU (2001), quando a consulta é considerada a primitiva básica de acesso,
não existe nenhuma noção de “execução consistente” ou “computação confiável”. Assim
sendo, o conceito de transação é utilizado dentro do domínio de bancos de dados como uma
unidade básica de computação consistente e confiável, fazendo com que as consultas sejam
executadas como transações e convertidas em operações primitivas de bancos de dados.
Geralmente a transação é constituída por uma seqüência de operações de leitura e
gravação sobre banco de dados. Esta seqüência executa uma ação sobre um banco de dados e
gera uma nova versão do mesmo, provocando uma transição de estado. Se o banco de dados
era considerado consistente antes da execução da transação, ele deverá continuar consistente
ao final da mesma, independente de ter sido executada de forma concorrente com outras ou de
ter ocorrido falhas durante sua execução.
Os aspectos de consistência e confiabilidade das transações se devem a quatro
propriedades, conhecidas como ACID:
• (A) Atomicidade: trata a transação como um átomo, ou seja, uma unidade de
operação. Considera que se não houver a conclusão de todas as operações,
nenhuma delas se completa. Caso a execução de uma transação seja
interrompida por qualquer tipo de falha, o SGBD é responsável por determinar
se a transação será encerrada completando-se as ações restantes ou se ela será
encerrada desfazendo-se todas as ações que já foram executadas.
• (C) Consistência: responsável por mapear um estado consistente do banco de
dados em outro estado, também consistente. No início de uma transação, o
banco de dados se encontra em um estado consistente, que fica inconsistente
durante a execução da transação. Ao final da transação, o estado do banco de
dados deve voltar a ser consistente.
• (I) Isolamento: exige que uma transação veja um banco de dados consistente
em todos os momentos, não revelando seus resultados a outras transações

31
concorrentes antes de se consolidar. Com isso, o isolamento não permite que os
resultados incompletos sejam enviados por outras transações, resolvendo o
problema de atualizações perdidas. Além disso, caso uma transação resolva
abortar, qualquer transação que leia seus valores incompletos também terá de
abortar. Essa cadeia pode tornar-se crescente e impor uma sobrecarga ao
SGBD.
• (D) Durabilidade: assegura que uma vez que a transação se completa, seus
resultados se tornam permanentes e não podem ser apagados do banco de
dados. Com isso, o SGBD assegura que os resultados de uma transação
sobreviverão mesmo que ocorram falhas do sistema.
Em bancos de dados distribuídos é possível que ocorra execução de transações em
paralelo, podendo ocorrer falhas nos nós da rede, nos links de comunicação, além da
possibilidade de ocorrer acesso concorrente ao mesmo dado. Devido a esses fatos, são
necessários métodos que possibilitem a capacidade de recuperação e o controle de
concorrência.
Segundo SILVEIRA (2001), para lidar com tal situação, grande parte dos sistemas
distribuídos utilizam um protocolo denominado two-fase commit, que tem como princípio de
funcionamento o envio de mensagens por parte de cada nó para um nó chamado coordenador,
que grava um registro BEGIN_COMMIT em seu log, envia uma mensagem prepare a todos
os nós participantes e entra no estado de espera (WAIT). Quando um dos participantes recebe
essa mensagem, verifica se é possível completar a transação. Caso seja possível, ele grava um
registro no log avisando que está pronto (READY), envia uma mensagem VOTE COMMIT
ao coordenador e entra no estado READY. Caso não há a possibilidade de completar a
transação, o participante grava um registro ABORT e envia uma mensagem VOTE ABORT
ao coordenador. Após receber resposta de todos os participantes, o coordenador decide entre
completar ou abortar a transação, sendo que o voto negativo de um único participante faz com
que o coordenador aborte a transação de forma global. Caso aconteça, o coordenador grava
um registro ABORT, envia uma mensagem GLOBAL ABORT a todos os participantes e
entra em estado ABORT. No caso de uma transação ser completada, o coordenador grava um
registro COMMIT, envia uma mensagem GLOBAL COMMIT a todos os participantes e entra
no estado COMMIT. Deste modo, os participantes consolidam (Figura 2.13) ou abortam
(Figura 2.14) a transação de acordo com as decisões do coordenador, que após receber a
confirmação de todos os participantes, encerra a transação gravando no log um registro
END_OF_TRANSACTION.

32
BEGIN_COMMIT WAIT READY COMMIT END_OF_ TRANSACTION
Figura 2.13. Protocolo two-fase commit quando um participante consolida a transação
BEGIN_COMMIT WAIT ABORT END_OF_ TRANSACTION
Figura 2.14. Protocolo two-fase commit quando um participante aborta a transação
COORDENADOR PARTICIPANTE
prepare
VOTE COMMIT
GLOBAL COMMIT
confirmação
COORDENADOR PARTICIPANTE
prepare
VOTE ABORT
GLOBAL ABORT
confirmação

33
2.3.4. Controle de Concorrência
O controle de concorrência trata das propriedades de isolamento e consistência das
transações (ÖZSU, 2001), assegurando que a consistência de bancos de dados distribuídos
seja mantida. Este mecanismo procura equilibrar a manutenção da consistência do banco de
dados e a manutenção de um nível elevado de concorrência. De acordo com ÖZSU (2001), os
métodos baseados em bloqueios são aqueles em que a sincronização das transações é obtida
empregando-se bloqueios físicos ou lógicos em alguma parte do banco de dados. Estes
métodos são subdivididos de acordo com o local em que as atividades de gerenciamento de
bloqueios são executadas: bloqueio de cópia primária, bloqueio centralizado e bloqueio
descentralizado.
Os métodos baseados em pré-ordenação utilizam um protocolo onde inicialmente é
imposta uma ordem às transações que deve ser respeitada pela execução concorrente das
transações (CASANOVA & MOURA, 1985). Existem três algoritmos baseados em pré-
ordenação: básico, conservativo e de versões múltiplas. Genericamente, estes métodos operam
da seguinte forma:
1. Cada transação recebe uma senha ao ser iniciada, única na rede, de forma
transparente aos usuários;
2. Em cada nó há um mecanismo de controle de concorrência local que garante que
as ações geradas pelas transações são processadas em ordem de senha.
Vistos os diversos métodos de controle de concorrência, deve-se analisar qual o mais
apropriado para o projeto de distribuição de dados do SigmaWeb. A Tabela 2.1 resume as
principais características de cada método, facilitando a escolha da melhor opção.

34
Características Método
Estruturas de
Dados
Mensagens
Adicionais
Existência de
Cópias
Problemas
com
Terminações
Descentralizado Tabela de
bloqueios
distribuída
Não são
necessárias
Não
reconhece
Bloqueios
mútuos
difíceis de
detectar
Cópias Primárias Tabela de
bloqueios para
cópias primárias
Para
bloquear
cópias
primárias
Reconhece Bloqueios
mútuos
difíceis de
detectar
Bloqueio
Centralizado Tabela de
bloqueios
centralizada
Para
bloquear em
um nó
coordenador
Não
reconhece
Bloqueios
mútuos
fáceis de
detectar
Básico Listas de senhas Não são
necessárias
Não
reconhece
Reinício
cíclico e
mútuo, de
fácil solução
Conservativo Filas de
subcomandos
Para evitar
bloqueios
eternos
Não
reconhece
Bloqueios
eternos
Pré-Ordenação
Versões Múltiplas Listas de senhas
e versões
Não são
necessárias
Não
reconhece
Reinício
cíclico e
mútuo, de
fácil solução
Tabela 2.1. Comparação de métodos de controle de concorrência.
FONTE: (CASANOVA & MOURA, 1985)
A avaliação da performance de um método de controle de concorrência pode ocorrer
através de diversas variáveis. CASANOVA & MOURA (1985) utilizam o tempo de resposta
das transações para este fim, através de três parâmetros:
• Custo adicional de comunicação: medido pelo número médio de mensagens passadas
apenas para fins de controle de concorrência;
• Custo adicional de processamento local: medido pelo tempo médio de processamento
gasto apenas em controle de concorrência;

35
• Custo adicional de processamento das transações: medido pelo tempo médio que uma
transação passa bloqueada, ou pelo número médio de vezes que a transação é
reiniciada.
Além disso, a performance dos métodos é analisada dentro de dois cenários distintos,
pessimista e otimista. De acordo com ÖZSU (2001), em um cenário pessimista, os conflitos
entre as transações são freqüentes e não permitem que uma transação acesse um item de dados
se houver uma transação conflitante que tenha acesso ao mesmo item de dados. Nesse caso, a
seqüência de etapas de uma transação é Validação, Leitura, Computação e Gravação.
Já em um cenário otimista, a etapa de Validação é atrasada até um pouco antes da
etapa de Gravação, fazendo com que uma operação nunca seja atrasada. As operações de
Leitura, Computação e Gravação de cada transação são processadas livremente, atualizando
cópias locais dos itens de dados. A Validação verifica se essas atualizações manteriam a
consistência do banco de dados. Em caso positivo, as mudanças são gravadas no banco de
dados real. Caso contrário, a transação é abortada e reinicializada.
Em um cenário pessimista, o objetivo da escolha do melhor método de controle de
concorrência é diminuir o custo de resolver conflitos, ou seja, deve ser escolhido um método
que minimize o volume de transações reiniciadas. Analisando os métodos baseados em
bloqueios, somente o centralizado pode ser adequado, devido à facilidade que este método
proporciona em detectar e solucionar os bloqueios mútuos que surgem.
Quanto aos métodos baseados em pré-ordenação, as melhores opções são o
conservativo e o de versões múltiplas. O conservativo nunca reinicia transações, porém gera
muitas mensagens adicionais, bloqueando transações com freqüência. E o método de versões
múltiplas, por outro lado, gasta mais memória, devido ao armazenamento das diversas versões
dos objetos.
Em um cenário otimista, qualquer método é adequado, exceto o método de pré-
ordenação conservativo, pois este força o processamento das operações em ordem de senha,
independente de haver conflito ou não. Entre os métodos de pré-ordenação, o método básico é
o mais indicado neste cenário. Enquanto que nos métodos de bloqueio o método
descentralizado é o que tem melhor comportamento quanto às mensagens adicionais.

36
2.3.5. Projeto de Distribuição de Dados
A etapa de projeto de distribuição de dados tem como objetivo projetar os esquemas
conceituais locais (ECL) distribuindo as entidades pelos locais do sistema distribuído. Com a
possibilidade de tratar cada entidade como uma unidade de distribuição, e considerando o
modelo relacional como base deste estudo, afirma-se que as entidades correspondem a
relações. Estas relações comumente são divididas em sub-relações chamadas de fragmentos,
que são, então, distribuídas.
Quanto à fragmentação, a questão mais importante é a unidade apropriada de
distribuição. Segundo ÖZSU (2001), uma relação não é uma unidade adequada, por questões
como a utilização, eficiência, paralelismo e concorrência. Considerando a utilização,
geralmente as visões de aplicativos são subconjuntos de relações, logo o acesso local é
definido sobre esses subconjuntos. Desse modo, é natural considerar apenas subconjuntos de
relações como unidades de distribuição, sendo preferível utilizar fragmentos de relações no
lugar de relações inteiras.
Com relação à eficiência, se aplicativos que têm visões definidas sobre uma relação
encontram-se em locais diferentes, há dois caminhos a serem seguidos. A relação pode ser
armazenada em um único local, resultando em um volume alto de acessos remotos aos dados,
ou ela pode ser replicada em todos ou em alguns locais onde estão os aplicativos, tendo
replicações desnecessárias, gerando problemas na execução de atualizações e armazenamento
caso seu espaço seja limitado.
Quanto ao paralelismo e a concorrência, a decomposição de uma relação em
fragmentos, que são tratados como unidades, permite que várias transações sejam executadas
de forma concorrente. Outro fato é que a fragmentação de relações geralmente resulta na
execução paralela de uma única consulta, dividindo-a em um conjunto de subconsultas que
operam sobre fragmentos. Considerando que as relações são essencialmente tabelas, uma
questão importante da fragmentação é encontrar modos alternativos de dividir uma tabela em
tabelas menores. Segundo ÖZSU (2001), há duas alternativas para isso: dividir a tabela
horizontalmente (fragmentação horizontal), ou verticalmente (fragmentação vertical). A
fragmentação horizontal particiona uma relação em tuplas, com cada fragmento contendo um
subconjunto das tuplas desta relação, como mostra a Figura 2.15.

37
CONTA
NOME_AGENCIA NUMERO_CONTA SALDO
Floresta 2815-4 1200
Floresta 2832-5 100
Centro 1237-4 10000
Floresta 1523-8 5500
Centro 3645-0 15
CONTA1
NOME_AGENCIA NUMERO_CONTA SALDO
Floresta 2815-4 1200
Floresta 2832-5 100
Floresta 1523-8 5500
CONTA2
NOME_AGENCIA NUMERO_CONTA SALDO
Centro 1237-4 10000
Centro 3645-0 15
Figura 2.15. Exemplo de fragmentação horizontal
De acordo com ÖZSU (2001), a fragmentação horizontal pode ser de dois tipos:
primária e derivada. A primária é baseada em seleções, como o exemplo da Figura 2.15, onde
CONTA1 é o resultado da seleção onde o nome da agência é igual à Floresta e CONTA2 é o
resultado da seleção onde o nome da agência é igual à Centro. A fragmentação horizontal
derivada baseia-se no resultado de junções de seleções, sendo utilizada para facilitar essas
operações de junção e navegação entre fragmentos (MEYER & MATTOSO, 1997), como na
Figura 2.16, onde dois grupos podem ser unidos, as contas do cliente Pedro e as contas do
cliente Paulo.

38
CONTA
NOME_AGENCIA NUMERO_CONTA SALDO
Floresta 2815-4 1200
Floresta 2832-5 100
Centro 1237-4 10000
Floresta 1523-8 5500
Centro 3645-0 15
CLIENTE
NUMERO_CONTA CLIENTE
2815-4 Pedro
2832-5 Paulo
1237-4 Pedro
1523-8 Pedro
3645-0 Paulo
CONTA1
NOME_AGENCIA NUMERO_CONTA SALDO
Floresta 2815-4 1200
Centro 1237-4 10000
Floresta 1523-8 5500
CONTA2
NOME_AGENCIA NUMERO_CONTA SALDO
Floresta 2832-5 100
Centro 3645-0 15
Figura 2.16. Fragmentação horizontal derivada
A fragmentação vertical implica na definição de vários subconjuntos de atributos de
uma relação (SILBERSCHATZ, 1999), onde cada fragmento vertical é composto por um
subconjunto dos atributos mais utilizados pelas aplicações (CONNOLLY et. al, 1998). O seu
objetivo é identificar fragmentos de forma que várias aplicações possam ser executadas com
acesso à somente uma partição da relação global (MEYER & MATTOSO, 1997). Um
exemplo desta fragmentação está ilustrado na Figura 2.17, onde a tabela CONTA_CLIENTE
é fragmentada em CONTA_CLIENTE1 e CONTA_CLIENTE2. A tabela
CONTA_CLIENTE1 contém nomes de clientes e agências e CONTA_CLIENTE2 contém
informações sobre os saldos das contas.

39
CONTA_CLIENTE
NUMERO_CONTA CLIENTE NOME_AGENCIA SALDO
2815-4 Pedro Floresta 1200
2832-5 Paulo Floresta 100
1237-4 Pedro Centro 10000
1523-8 Pedro Floresta 5500
3645-0 Paulo Centro 15
CONTA_CLIENTE1
NUMERO_CONTA CLIENTE NOME_AGENCIA
2815-4 Pedro Floresta
2832-5 Paulo Floresta
1237-4 Pedro Centro
1523-8 Pedro Floresta
3645-0 Paulo Centro
CONTA_CLIENTE2
NUMERO_CONTA SALDO
2815-4 1200
2832-5 100
1237-4 10000
1523-8 5500
3645-0 15
Figura 2.17. Exemplo de fragmentação vertical
2.3.6. Replicação em Bancos de Dados Distribuídos
Segundo ÖZSU (2001), a distribuição dos dados de forma replicada é desejável em
alguns casos, principalmente por questões de desempenho, confiabilidade e disponibilidade.
Além disso, CONNOLLY et. al (1998) diz que atualmente os sistemas de bancos de dados
distribuídos não têm grande aceitação, e a replicação de dados é uma alternativa simplificada
de distribuição de dados. Deve-se lembrar que bancos de dados que utilizam apenas
replicação de dados não são considerados bancos de dados distribuídos.
Para CONNOLLY et. al (1998), replicação é o processo de reproduzir múltiplas cópias
de dados em um ou mais nós da rede. De acordo com DATE (2002), a replicação é desejável

40
por pelo menos duas razões: melhor desempenho, permitindo que aplicações operem sobre
cópias locais, sem precisar se comunicar com nós remotos, e melhor disponibilidade, pois um
objeto replicado permanece disponível para processamento enquanto houver pelo menos uma
cópia disponível. A maior desvantagem da replicação é que quando um determinado objeto
replicado é atualizado, todas as cópias devem ser atualizadas.
Segundo CONNOLLY et. al (1998), existem conceitos fundamentais relacionados à
replicação de dados, como atualização de dados, propriedade dos dados e funcionalidade
esperada, que por serem a base da replicação de dados, serão descritos a seguir.
Na atualização de dados existem dois tipos de replicação: síncrona e assíncrona. A
atualização síncrona ocorre quando a origem dos dados é atualizada e suas réplicas são
atualizadas de imediato (CONNOLLY et. al, 1998). Este tipo de replicação é interessante em
transações bancárias, que necessitam da completa sincronia de todas as suas réplicas. Porém,
apresenta desvantagens como não poder completar transações devido à indisponibilidade de
nós da rede que possuem as cópias, e o número significativo de mensagens requeridas para
coordenar a sincronização da atualização dos dados.
Na replicação assíncrona, segundo CONNOLLY et. al (1998), as réplicas são
atualizadas depois da origem dos dados ser atualizada. É mais apropriada para
organizações/empresas onde há uma tolerância de atraso da recuperação de consistência entre
a origem e as réplicas.
Na funcionalidade, um serviço de replicação de dados deve ser capaz de copiar dados
de um banco de dados para outro (CONNOLLY et. al, 1998). Para isso, levam-se em
consideração algumas questões como a escalabilidade, onde este serviço deve ser capaz de
controlar a replicação de pequenos ou grandes volumes de dados. O mapeamento e a
transformação também são considerados, pois este serviço deve ter a capacidade de replicar
dados através de SGBD’s e plataformas heterogêneas, envolvendo o mapeamento e a
transformação de dados de um determinado modelo de dados em um modelo de dados
diferentes ou o mapeamento e transformação de dados de um determinado tipo para o tipo
correspondente em outro SGBD. Ou seja, os dados que estão armazenados em um servidor
Windows que utiliza o SGBD Oracle deve ser capaz de replicar dados para um servidor Linux
que utiliza o SGBD MySQL.
E, finalizando, a propriedade dos dados, que tem como função decidir qual local
possui o privilégio de atualizar os dados é a preocupação deste conceito. De acordo com
CONNOLLY et. al (1998), há três modelos principais de propriedade dos dados:
mestre/escravo, workflow e ponto a ponto. No primeiro modelo, somente o nó que possui os

41
dados pode atualizá-los. Conhecido como nó mestre, este nó disponibiliza seus dados, e os
nós que solicitam os dados, chamados nós escravos, recebem cópias somente-leitura, como
mostra a Figura 2.18. Segundo CONNOLLY et. al (1998), qualquer nó pode se tornar um nó
mestre, desde que não sobreponha o conjunto de dados dos outros nós mestres, evitando
conflitos.
Figura 2.18. Modelo de propriedade de dados mestre/escravo
O modelo workflow (Figura 2.19) também não permite conflitos de atualização, com a
diferença de ser mais dinâmico que o modelo mestre/escravo, permitindo a passagem do
direito de atualizar os dados replicados de um nó para outro. Cabe ressaltar que num dado
momento somente um nó possui o direito de atualizar o conjunto de dados do qual é
responsável.
Figura 2.19. Modelo de propriedade de dados workflow
escravo
escravo
escravo
mestre
Atualiza
cópias somente-leitura
Nó 1 Nó 2
Nó 4 Nó 3
Direito de atualizar

42
Por último, o modelo ponto a ponto cria um ambiente em que diversos nós têm direitos
iguais na atualização dos dados replicados, como ilustrado na Figura 2.20. Isto permite que os
nós possam funcionar com autonomia.
Figura 2.20. Modelo de propriedade de dados ponto a ponto, onde os nós coloridos têm o
direito de atualização
Após descrever alguns conceitos importantes de bancos de dados distribuídos, como
fragmentação e replicação, o próximo passo é descrever o sistema SigmaWeb e analisar o seu
modelo de dados atual.
Nó 3
Nó 1 Nó 2
Nó 4
Nó 5

43
3. O SIGMAWEB E SEU MODELO DE DADOS
Antes de entender como o sistema acadêmico SigmaWeb funciona, é necessário um
entendimento da organização da UDESC no estado de Santa Catarina. Desde o início da sua
função acadêmica no estado, a UDESC adotou como formato uma estrutura multi-campi
(Figura 3.21), constituída por quatro Campi que atuam de acordo com o perfil sócio-
econômico e cultural da região onde estão inseridos (UDESC, 2003).
A criação e a implementação das Unidades de Ensino Superior do Estado, a partir de
1963, teve por objetivo inicial a formação e qualificação de recursos humanos, cuja carência
era um dos fatores limitantes à dinamização do processo de desenvolvimento do Estado de
Santa Catarina (UDESC, 1994). Desde então, a UDESC vem se consolidando como
Universidade, evoluindo do objetivo inicial para colocar em prática o princípio da
indissociabilidade entre ensino, pesquisa e extensão.
O Campus I, em Florianópolis, oferece cursos voltados à educação e ao setor terciário
da economia e de prestações de serviços, através de cinco centros: o Centro de Ciências
Administrativas (ESAG), o Centro de Artes (CEART), o Centro de Educação Física,
Fisioterapia e Desportos (CEFID), o Centro de Educação a Distância (CEAD) e o Centro de
Ciências da Educação (FAED). A reitoria também fica em Florianópolis. O Campus II, em
Joinville e São Bento do Sul, é voltado às áreas de conhecimento direcionadas ao setor
industrial, através do Centro de Ciências Tecnológicas (CCT). O Campus III, em Lages,
abriga o Centro de Ciências Agroveterinárias (CAV), direcionado às ciências agrárias. E o
Campus IV, em Chapecó, abriga o Centro Educacional do Oeste (CEO).

44
Figura 3.21. Estrutura multi-campi da UDESC
Atualmente, a UDESC utiliza um sistema acadêmico desenvolvido pelo professor
Lóris Luiz Daros, denominado SigmaWeb. O professor Lóris é formado em Engenharia
Florestal e tem mestrado em Engenharia Agrícola. Já lecionou as disciplinas de Estatística e
algumas eletivas de Computação, e atualmente leciona Topografia II no curso de Agronomia.
Na época da graduação, no fim dos anos oitenta, Lóris teve os primeiros contatos com a
informática, incluindo atividades de monitoria. Seu interesse pelos registros acadêmicos
iniciou assim que entrou no CAV, quando começaram a surgir as primeiras ferramentas
viáveis através da informatização.
Em 1988, foram criados os primeiros programas em BASIC para emissão dos diários
de classe (para DOS). No ano seguinte foi acrescentada a matrícula com registros em lotes,
sendo desenvolvido em Open Access (para DOS). No ano de 1992, foi desenvolvido o Sigma
com uma linguagem de programação conhecida como MUMPS, no sistema operacional
Xenix. Em 1993, o Sigma foi implementado no CEART e no CEFID. Após cinco anos, em
1998, o sistema operacional foi substituído pelo UNIX, instituiu-se a matrícula on-line através
da Internet, e foram desenvolvidas as primeiras páginas de Internet geradas a partir do Sigma.
O projeto do SigmaWeb foi desenvolvido no ano de 2001, e no ano seguinte o sistema
foi implementado. A partir do segundo semestre de 2002, o SigmaWeb foi implantado em
todos os centros da UDESC, sendo implementado no CCT no primeiro semestre de 2003. No
primeiro semestre de 2004, teve início o desenvolvimento da versão 2 do sistema, que foi
concluída em julho de 2005.

45
Figura 3.22. Evolução do sistema acadêmico da UDESC
Este sistema é composto por diversas páginas Web e tem como funções o registro e
controle acadêmico de todos os centro da UDESC. Segundo o professor Loris, o banco de
dados utilizado no desenvolvimento do sistema é o MySQL e linguagem de programação é o
PHP. O hardware utilizado não tem nenhuma configuração especial, sendo o sistema utilizado
um PC normal. Só são tomados alguns cuidados como a utilização de um bom nobreak, e
placa de rede e memória de qualidade.
Utilizando este sistema através do site http://sigmaweb.cav.udesc.br pode-se efetuar
operações de inclusão, exclusão, consulta e modificação de informações de alunos,
professores, cursos, notas, enfim, todos os dados referentes ao registro acadêmico da UDESC.
De acordo com DAROS (2003), o controle sobre estes registros é responsabilidade do
secretário acadêmico, que definirá quando e como ocorrerá o controle, quem são os usuários,
a que grupo pertencem e que privilégios de acesso cada grupo possui. Os alunos, por
exemplo, tem apenas a permissão de consultar e alterar suas informações, enquanto uma
secretária administrativa tem permissão total na manipulação dos dados (inserção, exclusão,
modificação e consulta).
O banco de dados do sistema acadêmico da UDESC encontra-se atualmente no
campus de Lages (CAV), onde são armazenadas as informações de todos os centros. Por isso,
o SigmaWeb utiliza um SGBD centralizado, onde a consulta e a atualização dos dados são
efetuadas remotamente.
O fato de o SigmaWeb utilizar SGBD centralizado traz algumas vantagens como a
diminuição da complexidade das configurações de bancos de dados, por serem efetuadas e
armazenadas em um único local. Sendo assim, o custo de comunicação para verificar a
integridade do banco de dados é minimizado. Outra vantagem é a redução do custo de
REGISTROS MANUAIS SIGMA SIGMAWEB

46
comunicação e o tempo de resposta, devido à manutenção e controle dos dados serem
realizados em um único local.
Por outro lado, a estrutura multi-campi da UDESC, dividida em centros fisicamente
afastados, favorece a implantação de um modelo descentralizado, onde cada centro armazena
seus dados. A utilização de SGBDD’s possibilita que os dados de todos os centros sejam
acessados e que estes dados estejam armazenados onde são mais utilizados, agilizando o
acesso aos dados. Outro problema enfrentado por um SGBD centralizado é a perda de
performance, já que é necessária a realização de consultas remotas para consultar as
informações de um centro que não seja o de Lages. Utilizando um SGBDD, cada centro
armazenaria seus dados, diminuindo o número de consultas remotas e reduzindo o tempo de
resposta destas consultas. E por último, há o maior problema, que é a possibilidade do link da
Internet falhar. Caso isso aconteça, a base de dados centralizada fica inacessível,
comprometendo todo o sistema. Com a utilização de SGBDD’s, os dados de cada centro
estariam sempre disponíveis, e o link da Internet seria utilizado para realizar atualizações e
consultas remotas quando necessário.
3.1. Organização do SigmaWeb – Menus e sub-menus
O SigmaWeb é um sistema dividido em módulos, que são os itens do menu, e esses
módulos são divididos em rotinas, que são os subitens do menu. Os módulos e rotinas
existentes no sistema são apresentados no ANEXO 2 deste trabalho. De acordo com DAROS
(2003), os módulos são os seguintes:
1. Sistema e Estrutural – Neste módulo estão os cadastros das tabelas superiores e da
estrutura do sistema. Ele permite a inserção, exclusão, atualização e consulta dos
registros, sendo liberado apenas ao secretário acadêmico e ao pessoal da manutenção e
desenvolvimento.
2. Usuários e Senhas – Aqui se encontram os recursos para administração dos usuários e
suas senhas de acesso.
3. Tabelas Básicas – Neste módulo é realizada a manutenção das tabelas básicas
inferiores àquelas cadastradas no módulo Sistema e Estrutural.

47
4. Disciplinas e Currículos – Aqui é onde fica o cadastro dos currículos e por isso grande
parte das rotinas fica sob responsabilidade do secretário acadêmico. Este cadastro deve
ser extremamente exato, e sugere-se que, quando houver alterações, cadastre-se um
novo currículo. O cadastro do currículo deve ser completo, pois cadastros incompletos
podem gerar problemas no sistema.
5. Acadêmicos – Neste módulo estão as informações sobre os alunos regulares do centro.
6. Alunos Visitantes – Módulo para o cadastro de alunos visitantes
7. Professores – Módulo para o cadastro dos professores do centro.
8. Matrículas – Este é o módulo mais pesado do sistema, contendo todas as etapas da
matrícula, desde oferecimento até efetivação e ajustes.
9. Matrículas Especiais – Aqui estão os tratamentos das exceções sobre a matrícula.
10. Diários de Classe – Este módulo serve para a emissão, preparação, recepção de notas e
freqüências, e divulgação dos resultados. É importante lembrar que as notas devem ser
lançadas sem o ponto decimal.
11. Estágio Monografia Outros – Aqui são registradas as disciplinas que exigem
tratamentos específicos, como o Estágio e o TCC.
12. Históricos Escolares – Neste módulo são realizados os lançamentos e as consultas nos
históricos.
13. Atestados e Requerimentos – Aqui são emitidos atestados e requerimentos. Também é
verificado quem pode solicitar que tipo de requerimento.
14. Ciclo Semestral – Este é um módulo exclusivo de controle acadêmico.
3.2. Organização do SigmaWeb – Tabelas do banco de dados
O banco de dados do SigmaWeb foi organizado em grupos de tabelas. Cada grupo
reúne tabelas que estão relacionadas a um mesmo objeto, ou seja, dizem respeito a dados que
se complementam. Esta divisão foi realizada pelo projetista do sistema e possui os seguintes
grupos, ilustrados na Figura 3.23: Básicas e Estruturais, Administrativo, Disciplinas e
Currículos, Acadêmicos, Alunos Visitantes, Professores, Diários e Matrículas, Históricos
Escolares, Requerimentos, e Estágio, Monografia e Outros.

48
Figura 3.23. Grupos de tabelas do sistema SigmaWeb
O grupo Básicas e Estruturais permite que sejam armazenadas as tabelas básicas do
sistema. Neste grupo também estão armazenados os cadastros da estrutura do sistema,
relativos à administração dos usuários do sistema e suas senha de acesso, por exemplo. O
grupo Administrativo possui duas tabelas: controle de logins e avisos seletivos na entrada,
contendo dados das mensagens visualizadas por cada usuário.
No grupo Disciplinas e Currículos, as tabelas armazenam dados relativos aos
currículos e disciplinas que o integram, como disciplinas antecipadas e eletivas, por exemplo.
As informações sobre os acadêmicos regulares do centro estão contidas no grupo
Acadêmicos. Entre as tabelas deste grupo estão o cadastro de acadêmicos, documentos e
dados do segundo grau. Informações de alunos não-regulares estão contidas no grupo Alunos
Visitantes, com informações sobre o aluno e seu histórico escolar.
O grupo Professores contém as informações sobre o corpo docente do centro, através
das tabelas cadastro de professores e endereço dos professores. O grupo Diários e Matrículas
inclui tabelas que armazenam dados das turmas e disciplinas oferecidas por semestre, bem
como solicitações de antecipações e troca de turma.
Para armazenar dados nos históricos utiliza-se o grupo Históricos Escolares, onde as
tabelas contêm dados como dispensas, validações e notas dos alunos. O grupo Requerimentos
SIGMAWEB

49
é utilizado para armazenar dados dos requerimentos solicitados pelos acadêmicos. E
finalizando, o grupo Estágio, Monografia e Outros serve para armazenar dados do projeto e da
defesa do Trabalho de Conclusão de Curso.
3.3. A Engenharia Reversa para os dados do SigmaWeb
O sistema acadêmico da UDESC não possui um modelo de dados documentado. O que
se tem de documentação é um arquivo do Excel contendo planilhas com as tabelas que
constituem o banco de dados, que são apresentadas no ANEXO 3. Esta é uma situação que
precisa ser mudada, pois somente com uma documentação bem feita é possível entender o
sistema e projetar futuras alterações sobre o mesmo. Apesar de existirem ferramentas que
fazem automaticamente o processo de engenharia reversa, como o DBDesigner, não foi
possível utiliza-la pela impossibilidade de acesso ao banco de dados do SigmaWeb, além de
outro problema que será descrito adiante. Porém, através da documentação em tabelas do
Excel, foi possível a criação de um modelo de dados manualmente utilizando o método de
engenharia reversa.
3.3.1. Engenharia Reversa
Para construir o modelo de dados do SigmaWeb, é necessário fazer uma engenharia
reversa do sistema, isto é, um processo de abstração partindo do modelo implementado
(SigmaWeb) e resultando em um modelo conceitual que descreve abstratamente a
implementação (HEUSER, 2001). Um caso específico de engenharia reversa de banco de
dados é o da engenharia reversa de modelos relacionais. Neste caso, o ponto de partida é um
modelo lógico de um banco de dados relacional e o resultado é um modelo conceitual. Como
o SigmaWeb não possui um modelo conceitual, a engenharia reversa de modelos relacionais
pode ser útil.
Segundo HEUSER (2001), o processo de engenharia reversa de um modelo relacional
é composto de quatro passos. A primeira etapa é a identificação da construção ER

50
(Entidade/Relacionamento) correspondente a cada tabela. Uma tabela pode corresponder a
uma entidade, um relacionamento n:n ou uma entidade especializada. Dependendo da
composição da sua chave primária, as tabelas podem ser classificadas em três tipos:
• Tipo 1: Quando a tabela possui uma chave primária composta por mais de uma
chave estrangeira, ela implementa um relacionamento n:n entre as entidades
correspondentes às tabelas referenciadas pelas chaves estrangeiras.
• Tipo 2: Quando a chave primária da tabela é uma chave estrangeira, a tabela
representa uma entidade que forma uma especialização da entidade
correspondente à tabela referenciada pela chave estrangeira.
• Tipo 3: Nos demais casos, a tabela representa uma entidade.
No caso do SigmaWeb, as tabelas contidas nas planilhas do Excel fazem parte do Tipo
3, ou seja, todas representam entidades, cujas chaves primárias estão identificadas com a
expressão primary key na coluna create table.
A segunda etapa é a identificação de relacionamentos 1:n ou 1:1, que são
representados por toda chave estrangeira que não corresponde a um relacionamento n:n, nem
a uma entidade especializada. Para definir qual dos dois tipos de relacionamento está sendo
representado pela chave estrangeira, é necessário verificar os possíveis conteúdos do banco de
dados. Nas tabelas do SigmaWeb, as entidades que possuem relação entre si estão marcadas
na coluna Tabela. Esta foi a etapa mais trabalhosa da construção do modelo de dados, pois o
conteúdo do banco de dados foi verificado diversas vezes, devido à dificuldade de identificar
relacionamentos 1:1.
A etapa seguinte é a definição de atributos, onde para cada coluna de uma tabela que
não seja chave estrangeira, é definido um atributo na ER correspondente à tabela. Nas tabelas
do SigmaWeb, as tabelas já contêm os atributos das entidades, apresentando o nome, o tipo, o
tamanho e a descrição de cada atributo.
Finalizando, a última etapa é a definição de identificadores de entidades. A regra para
definição de identificadores das entidades e dos relacionamentos é a seguinte: Toda coluna
que faz parte da chave primária e que não é chave estrangeira corresponde a um atributo
identificador da entidade ou relacionamento, e toda coluna que faz parte da chave primária e
que é chave estrangeira corresponde a um identificador externo da entidade. No caso das
tabelas do SigmaWeb, os atributos identificadores (com exceção da chave primária) são
aqueles que possuem a coluna Tabela preenchida.

51
Com base nas informações sobre engenharia reversa e sobre o SigmaWeb, foi criado
um modelo entidade-relacionamento (MER) do sistema acadêmico da UDESC, que será
apresentado a seguir.
3.3.2. Modelo Entidade-Relacionamento do SigmaWeb
Primeiramente, deve-se destacar a colaboração do professor Loris Luiz Daros, que
concedeu informações sobre o sistema SigmaWeb. O modelo que será aqui apresentado foi
construído a partir da documentação atual do sistema SigmaWeb e da técnica de engenharia
reversa de banco de dados. Além disso, foi utilizada a ferramenta DBDesigner 4 na
construção do modelo. Esta ferramenta é um sistema visual de projeto de banco de dados, que
integra além do projeto, a modelagem, criação e manutenção de banco de dados em um único
ambiente. Ela combina características profissionais e uma interface de usuário simples e clara,
oferecendo um meio eficiente de manipular bancos de dados (DBDESIGNER 4, 2006).
Sabe-se que existem ferramentas que fazem automaticamente o modelo de dados
através de um banco de dados existente. O próprio DBDesigner 4 possui essa funcionalidade,
mas no caso do SigmaWeb não foi possível, pois no seu banco de dados há diversos
relacionamentos um-para-um, que o DBDesigner não consegue resolver. E por isso a técnica
de engenharia reversa teve de ser utilizada, criando-se o MER (Modelo Entidade-
Relacionamento) manualmente.
O modelo será apresentado em partes, onde cada parte representa um grupo do banco
de dados. Os grupos serão apresentados somente com os relacionamentos internos, para evitar
a poluição visual. E por este motivo, os grupos Básicas e Estruturais, Administrativo,
Visitantes, Professores, Diários e Matrículas, Históricos Escolares, Requerimentos e Estágio
Monografia e Outros, apresentam tabelas sem relacionamentos, o que não significa que elas
estejam isoladas no banco de dados. A Figura 3.24 mostra o grupo Básicas e Estruturais, cujas
entidades armazenam informações relacionadas à estrutura do sistema, como informações
sobre os centros e departamentos. Os campos que apresentam uma chave do lado são as
chaves primárias das entidades e os que apresentam um losango laranja estão relacionados
com outras tabelas. Além disso, os campos que apresentam a sigla FK são as chaves
estrangeiras das entidades.

52
Figura 3.24. Grupo Básicas e Estruturais
Deve-se lembrar também que o modelo entidade-relacionamento apresentado possui
relacionamentos 1:1 e 1:n, onde as ligações sem bolinhas nas extremidades representam os
relacionamentos 1:1 e as ligações com bolinhas nas extremidades representam os
relacionamentos 1:n. O lado 1 é representado por uma bolinha branca e o lado n por uma
bolinha preta.
O segundo grupo de tabelas é o Administrativo, ilustrado na Figura 3.25, que possui
duas entidades que armazenam as mensagens visualizadas por cada usuário.
53
Figura 3.25. Grupo Administrativo
O grupo Disciplinas e Currículos, que armazena dados sobre os currículos dos
acadêmicos e as disciplinas contidas nestes currículos, possui nove entidades, como mostra a
Figura 3.26.
Figura 3.26. Grupo Disciplinas e Currículos

54
O grupo Acadêmicos (Figura 3.27) possui 13 entidades, que armazenam dados
relativos ao cadastro do acadêmico, como documentos, endereço e situação por semestre.
Figura 3.27. Grupo Acadêmicos

55
O quinto grupo é o de Alunos Visitantes, que contém informações sobre esses alunos e
seus históricos. Como mostra a Figura 3.28, o grupo possui duas entidades.
Figura 3.28. Grupo Alunos Visitantes
Assim como o grupo Alunos Visitantes, o grupo Professores (Figura 3.29) também
possui apenas duas entidades. Este grupo armazena dados dos professores como a data de
admissão, a titulação e o endereço.
Figura 3.29. Grupo Professores

56
O armazenamento dos dados das turmas e disciplinas oferecidas por semestre ocorre
no grupo Diários e Matrículas, que possui um total de 14 entidades, como mostra a Figura
3.30.
Figura 3.30. Grupo Diários e Matrículas

57
Os dados referentes aos históricos dos acadêmicos, como dados da formatura e
validações, ficam armazenados no grupo Históricos Escolares (Figura 3.31), que possui nove
entidades para este fim.
Figura 3.31. Grupo Históricos Escolares
Os dois grupos restantes do banco de dados do SigmaWeb são o grupo Requerimentos
e Estágio, Monografia e Outros. O primeiro é responsável pelo armazenamento dos dados dos
requerimentos solicitados pelos acadêmicos e possui três entidades, como ilustra a Figura

58
3.32. E o segundo grupo possui duas entidades representadas na Figura 3.33, que armazenam
dados sobre o projeto e a defesa dos trabalhos de conclusão de curso dos acadêmicos.
Figura 3.32. Grupo Requerimentos
Figura 3.33. Grupo Estágio, Monografia e Outros
Esses são os dez grupos de tabelas que compõem o sistema acadêmico SigmaWeb,
criados manualmente a partir de tabelas de dados armazenadas em um arquivo do Excel,
utilizando a técnica de engenharia reversa descrita neste capítulo. Visto como foi criado o

59
modelo e quais as dificuldades encontradas na criação, o próximo passo é fazer um
comparativo entre alguns Sistemas Gerenciadores de Banco de Dados afim de concluir qual o
melhor SGBD livre para utilizar na implementação de um modelo de distribuição de dados.

60
4. TECNOLOGIAS DE SGBD
Como já foi dito no segundo capítulo, um Sistema Gerenciador de Banco de Dados
(SGBD) é um sistema formado por um conjunto de dados associados a um conjunto de
programas que acessam esses dados. Esses sistemas têm o objetivo de proporcionar um
ambiente simples e eficiente para a recuperação e armazenamento das informações do banco
de dados.
Atualmente, existem dois tipos de SGBD’s: os proprietários e os livres. Os SGBD’s
proprietários são aqueles que pertencem a alguma empresa, como por exemplo, o SQL Server,
que é propriedade da Microsoft. E os SGBD’s livres não possuem vínculo com nenhuma
empresa. A seguir serão descritos os sistemas proprietários Oracle e SQL Server, por serem os
mais utilizados atualmente, e os sistemas livres MySQL, também por ser muito utilizado e
conhecido, PostgreSQL, pela indicação de professores devido a sua difusão cada vez maior, e
Firebird, que é lecionado no curso de Ciência da Computação da UDESC.
O objetivo é fazer uma análise comparativa entre estes SGBD´s e apresentar
alternativas para implementação do projeto de distribuição de dados que será proposto neste
trabalho.
4.1. Oracle
O Oracle foi desenvolvido nos Estados Unidos no ano de 1977 pela Oracle
Corporation, com o objetivo de atender a Nasa. Sua primeira instalação ocorreu em junho de
1979, tendo como principal propulsor o empresário Larry Ellison, que junto com os co-
fundadores da Oracle, Bob Miner e Ed Oates, perceberam o potencial de negócios do modelo
de bancos de dados relacional (NIEMIEC, 2003).
No início da década de 80, foi lançado o primeiro banco de dados Cliente/Servidor,
chamado de Oracle Client/Server, e no final desta década, foi lançada a versão 6, onde foi

61
introduzida a linguagem de programação PL/SQL. Na década de 90, novas versões são
lançadas, destacando-se a disponibilidade do Oracle8 no sistema operacional LINUX,
aplicações para Web e suporte a Java e XML.
No início da última década foram lançadas as versões Oracle9i Application Server, E-
Business Suíte, OracleMobile e Oracle9i Application Server Wireless. Em 2003 foi lançada a
versão Oracle10g (Enterprise Grid Computing) e em 2005 o Oracle Database 10g Express
Edition, gratuito para desenvolvedores e estudantes.
4.2. SQL Server
A primeira versão do SQL Server foi lançada no ano de 1988 pela Microsoft, em
parceria com a Sybase, sendo projetada para OS/2 (IBM) (COLLA, 2005). Em 1993, com o
objetivo de criar um gerenciador de banco de dados com uma interface intuitiva, foi lançada a
versão 4.2 do SQL Server. No ano seguinte, a Microsoft lançou a versão 6.0, melhorando a
performance e incluindo replicação de dados. Esta foi a última versão lançada em parceria
com a Sybase.
Em 1997, foi lançado o Microsoft SQL Server 6.5 Enterprise Edition, que acessava 4
Gb de RAM e suporte para até 4 processadores. No ano de 1998, a Microsoft lançou uma
versão praticamente reescrita. A versão 7.0 foi criada com características como a eliminação
de devices, crescimento automático de arquivos, paginação de 8k, autoconfiguração, looking
em nível de linha, Data Transformation Services e suporte a OLAP. Além disso, apresentou
melhorias nos procedimentos de segurança, replicação e backup.
No ano 2000, o SQL Server 2000 foi lançado especialmente para o SO Windows
2000, com melhorias no sistema de programação Query Analyzer, utilização de linguagem
XML, Views indexadas, Collations para tabelas, campos e servidor, Múltiplas instâncias.
Também apresentou melhorias em replicação, backup, DTS, e OLAP, que veio com recursos
de Datamining.
Atualmente o SQL Server se encontra na versão 2005.

62
4.3. My SQL
O MySQL é um SGBD multi-usuário e multi-threaded, sendo uma implementação
cliente-servidor que consiste de um servidor e diferentes programas clientes e bibliotecas
(TRIDAPALI & SANT’ANNA, 2005). É um sistema rápido e flexível, permitindo a
armazenagem de logs e figuras. Suas principais vantagens são a velocidade, robustez e
facilidade de uso. O MySQL foi desenvolvido pela equipe da TcX DataKonsultAB, que
precisava de um servidor SQL com a capacidade de manipular banco de dados grandes numa
ordem de magnitude mais rápida do que qualquer banco de dados comercial pudesse lhes
oferecer na época. Este SGBD tem sido utilizado por esta equipe desde 1996.
4.4. PostgreSQL
O PostgreSQL é um SGBD objeto-relacional de código aberto, extremamente robusto
e confiável, além de ser flexível e ter muitos recursos. É considerado objeto-relacional por
implementar algumas características de orientação a objetos, como herança e tipos
personalizados, além de características de um SGBD relacional (COUTINHO, 2003).
O PostgreSQL é uma derivação do projeto POSTGRES da universidade de Berkley,
que teve como última versão a 4.2. Este projeto foi patrocinado pelo DARPA (Agência de
Projetos de Pesquisa Avançada para Defesa), ARO (Departamento de Pesquisa Militar), NSF
(Fundação Científica Nacional) e ESL Inc. A sua implementação teve início em 1986,
tornando-se operacional no ano seguinte. Em 1989 foi lançada a primeira versão, que, devido
a uma crítica ao seu sistema de regras, teve essa parte reimplementada e lançada na segunda
versão no ano de 1990. A terceira versão foi lançada em 1991, com melhorias no executor de
consultas e revisão de algumas partes do código. As outras versões lançadas até o Postgres95
foram focadas em confiabilidade e portabilidade.
O Postgres95 teve grandes mudanças em relação ao projeto original, tendo seu código
totalmente revisado, 1/4 do tamanho dos códigos-fonte reduzido, e a linguagem SQL
implementada como interface padrão. Nesta versão a performance foi melhorada e vários

63
recursos foram adicionados. No ano de 1996 teve o nome alterado para PostgreSQL
referindo-se a relação do POSTGRES com a linguagem SQL. A versão 6.0 teve melhoria de
recursos e implementação de novos recursos, seguindo os padrões de SQL.
4.5. Firebird
O Firebird é um SGBD cliente/servidor relacional que foi desenvolvido para ser
independente de plataformas e de sistemas operacionais. Este SGBD utiliza pouco espaço em
disco para sua instalação e utiliza pouca memória em situações normais de uso
(RODRIGUES, 2005). O seu desenvolvimento teve início no ano de 1985, por uma equipe de
engenheiros da DEC (Digital Equipament Corporation). Sendo nomeado inicialmente como
Groton, esse SGBD sofreu várias alterações e em 1986 foi lançada uma nova versão, com o
nome de InterBase 2.0. O Firebird é baseado no código fonte do InterBase 6.0 que foi liberado
como Open Source pela Borland no ano de 2000.
4.6. Características dos SGBD’s
Para comparar os SGBD’s foram colhidas algumas características funcionais,
importantes para manter a consistência de um banco de dados, que são as seguintes:
- Constraints: capacidade de habilitar / desabilitar ou dropar / adicionar chave
primária e chave estrangeira;
- Fail Safe: Depois de excluir 100 de 10000 linhas, realizar o commit, desligar o
sistema sem shutdown e religar, haverá 9900 linhas corretas.
- Funções de Transação: realiza commit, rollback, níveis de isolamento;
- Hot Backup: verifica a possibilidade de realizar um backup consistente da base
de dados enquanto ela está no ar e transações estiverem sendo efetuadas;
- Lock de Linha: o select de atualização bloqueia apenas as linhas a serem
atualizadas, sem bloquear as leituras;
- Programável: permite a criação de triggers e extensões da linguagem SQL;

64
- Segurança: requer validação de usuário e senha.
- Replicação: permite reproduzir cópias de dados em um ou mais nós da rede;
- Transações Distribuídas: faz transações entre tabelas localizadas em diferentes
nós da rede.
A Tabela 6.2 ilustra o resultado da comparação dos SGBD’s de acordo com as
funcionalidades descritas.
ORACLE SQL SERVER MYSQL POSTGRESQL FIREBIRD
Constraints X X X Parcial X
Fail Safe X NE X NE
Funções de
Transação
X X X X X
Hot Backup X NE X X NE
Lock de
Linha
X X X X X
Programável X X Parcial X X
Segurança X X X X X
Replicação X X X X NE
Transações
Distribuídas
X X
Legenda: Em branco – não atende ao requisito X – atende ao requisito Parcial – atende ao requisito apenas parcialmente NE – Não encontrado
Tabela 6.2. Comparação entre SGBD’s
4.6.1. Quanto a Distribuição
Após pesquisas realizadas até o momento sobre a possibilidade de implementar os
conceitos de bancos de dados distribuídos com alguma das ferramentas SGBD’s descritas

65
anteriormente, chegou-se a conclusão de que atualmente, apenas as ferramentas proprietárias
têm suporte para esta tarefa. O Oracle, já estudado por SELHORST (2005), contém funções
de distribuição de dados em sua versão 9i. E o SQL Server 2005, de acordo com
MICROSOFT (2005), também possui funções que possibilitam a implementação de bancos
de dados distribuídos.
Em contrapartida, as ferramentas livres, que são o foco deste trabalho, não
apresentaram indícios de suporte à distribuição de dados durante a pesquisa realizada. Foram
consultados integrantes de fóruns como o Grupo de Usuários do PostgreSQL no Brasil (brasil-
[email protected]) e a Comunidade Firebird.br ([email protected]),
além de documentações e apostilas sobre os três SGBD’s livres escolhidos como as que estão
presentes em POSTGRESQL (2005), RODRIGUES (2005) e TRIDAPALI & SANT’ANNA
(2005).
Após consulta realizada na Internet, com professores, pessoas que trabalham com estas
ferramentas, fóruns, concluiu-se de que apesar de terem evoluído na questão de
gerenciamento de bancos de dados, as ferramentas livres ainda não são capazes de gerenciar
um banco de dados distribuído. Segundo LOZANO (2002), os SGBD’s livres fazem
replicação de dados, mas não têm suporte a transações distribuídas, característica fundamental
na distribuição de dados.

66
5. PROPOSTA DE DISTRIBUIÇÃO DE DADOS DO
SIGMAWEB
Depois de construir o modelo de dados do sistema SigmaWeb, o próximo passo é
fazer o projeto de distribuição de dados do mesmo. Segundo LEVIN e MORGAN (1975), a
organização de sistemas distribuídos pode ser analisada através de três tópicos: nível de
compartilhamento, comportamento dos padrões de acesso e nível de conhecimento sobre esse
comportamento (Figura 5.34).
Existem três níveis de compartilhamento. No primeiro nível, não há nenhum
compartilhamento, e sendo assim, cada programa e seus dados são executados em uma
estação, não havendo comunicação com outros programas ou acesso a dados de outras
estações. O segundo nível é o de compartilhamento de dados, onde todas as estações possuem
todos os programas, mas não possuem todos os dados. Ou seja, o usuário solicita os dados de
uma estação qualquer, e os dados são transportados pela rede. O último nível abrange o
compartilhamento de dados e também de programas. Assim, um programa em uma estação
pode solicitar serviços de outro programa que se encontra em uma estação diferente, e este
pode necessitar de dados que estão armazenados em uma terceira estação.
O comportamento de padrões de acesso pode ser estático, sem se alterar ao longo do
tempo, ou dinâmico. O fator primordial desse tópico é saber o quanto o sistema distribuído é
dinâmico.
Os níveis de conhecimento sobre o comportamento dos padrões de acesso também são
três. O nível mais baixo é onde os projetistas não possuem nenhuma informação sobre como
os usuários vão acessar o banco de dados. Os projetistas podem ter também informações
parciais, onde ocorrem desvios em relação às previsões dos padrões de acesso, ou
informações completas, onde os padrões de acesso são previstos com maior chance de acerto.

67
Figura 5.34. Níveis dos elementos da organização de sistemas ditribuídos
5.1. Estratégias de Projeto
De acordo com CERI et al., (1987), existem duas estratégias que podem ser adotadas
na realização de um projeto de bancos de dados distribuídos: top-down e bottom-up.
Na estratégia top-down (Figura 5.35), o projeto inicia com uma análise de requisitos,
definindo o ambiente do sistema e verificando as necessidades de dados e processamento de
todos os possíveis usuários do banco de dados. Os requisitos do sistema são a entrada para a
etapa de projeto conceitual, onde a organização é examinada visando determinar os tipos de
entidades e relacionamentos entre as mesmas, e para a etapa de projeto de visões, que define
as interfaces para os usuários finais.
Nível de compartilhamento
Comportamento de padrões de
acesso
Nível de conhecimento sobre comportamento dos padrões de acesso
Mínimo
Máximo dados
+ programas
nenhum Estático
Dinâmico
Nenhuma informação
Informações parciais
Informações completas
dados

68
O projeto conceitual pode ser interpretado como uma integração de visões do usuário
(ÖZSU, 2001), que é utilizada para garantir que o esquema conceitual tenha os requisitos de
entidades e relacionamentos para todas as visões. No projeto conceitual e no projeto de
visões, o usuário deve especificar as entidades de dados, escolher os aplicativos que serão
executados sobre o BD e informações estatísticas sobre os mesmos.
A etapa de projeto de distribuição recebe como entradas o esquema conceitual global e
as informações de padrões de acesso resultantes do projeto de visões. Esta etapa tem como
objetivo projetar os esquemas conceituais locais, distribuindo as entidades pelas estações do
sistema distribuído. Considerando que o SigmaWeb utiliza o modelo relacional, as entidades
correspondem a tabelas. Antes de distribuir as tabelas, é comum dividi-las em fragmentos
(tabelas menores). Logo, o projeto de distribuição é realizado em duas fases: fragmentação e
alocação, que serão descritas na próxima seção.
A última etapa do projeto de BD distribuídos é o projeto físico que, segundo ÖZSU
(2001), mapeia os esquemas conceituais locais nos dispositivos de armazenamento físico
disponíveis nas estações correspondentes. As entradas do projeto físico são o esquema
conceitual local e as informações de padrões de acesso sobre os fragmentos nessas estações.
A estratégia bottom-up é adequada quando o projeto envolve a integração de alguns
bancos de dados em um único. Por isso, o seu ponto de partida é o conjunto de esquemas
conceituais locais individuais. Essa estratégia busca integrar esquemas locais no esquema
conceitual global, e existe principalmente em conjunto com bancos de dados heterogêneos.

69
Figura 5.35. Estratégia Top-down. FONTE: (ÖZSU, 2001)
5.2. Projeto de Distribuição SigmaWeb
Com base na seção anterior, foi definido que a estratégia a ser utilizada no projeto de
distribuição do SigmaWeb será a Top-down, pois o projeto não envolve a integração de vários
bancos de dados em um único e não possui esquemas conceituais locais, por ser um banco de
dados centralizado. Como o SigmaWeb é um sistema já existente, a estratégia Top-down será
adaptada de acordo com a finalidade do projeto, como mostra a Figura 5.36. A primeira etapa,
já concluída, foi a criação do modelo de dados do SigmaWeb, através do processo de

70
engenharia reversa, resultando no Esquema Conceitual Global do banco de dados do sistema,
descrito no Capítulo 3. Este esquema apresenta as tabelas e seus atributos, além dos
relacionamentos existentes entre as mesmas.
O próximo passo será o projeto de distribuição em si, onde será descrito como as
tabelas serão distribuídas nos centros da UDESC, resultando nos esquemas conceituais locais.
Figura 5.36. Estratégia top-down adaptada da Figura 5.35
5.2.1. Definição do Projeto de Distribuição
De acordo com CANTO (2005), Para realizar a distribuição dos dados no banco de
dados é necessária a determinação da fragmentação e da alocação dos dados. Essas
características serão vistas nas próximas sessões. Além disso, existem fatores que influenciam
as decisões para a construção de um bom projeto, como a organização lógica do banco de
dados, as propriedades dos sistemas de computadores em cada estação, as características de
acesso dos aplicativos ao banco de dados e localização dos aplicativos. Estes fatores podem
Engenharia Reversa
Esquema Conceitual Global
Projeto de Distribuição
Esquemas Conceituais Locais

71
ser divididos em quatro categorias: informações de aplicativos, informações do banco de
dados, informações de sistemas de computadores e informações da rede de comunicações.
5.2.2. Fragmentação
Como já mencionado anteriormente e segundo CANTO (2005), existem duas
estratégias de fragmentação: horizontal e vertical. A Figura 5.37 apresenta as tabelas que
serão utilizadas nos exemplos desse capítulo.
ALUNO AULA
MAT NOME CURSO MAT COD PROFESSOR SALA
10 Almir Ciências Comp. 10 111 Jonas K-203
20 Ana Ed. Física 10 222 Ivan K-205
30 Jean Eng. Elét. 20 333 Beatriz A-108
40 José Ed. Física 30 111 Jonas K-203
50 Maria Veterinária 30 222 Ivan K-205
40 333 Beatriz A-108
50 333 Lucia E-301
50 444 Joana E-305
DISCIP LOC
COD DN-DISCIP CRED CURSO CENTRO
111 Cálculo 7 Ciências Comp. CCT
222 Física 4 Ed. Física CEFID
333 Anatomia 10 Eng. Elét. CCT
444 Zootecnia 2 Veterinária CAV
Figura 5.37. Exemplo de Tabelas de um Banco de Dados

72
5.2.3. Vantagens da Fragmentação
A questão mais importante na fragmentação é definir a unidade mais apropriada de
distribuição. Uma tabela não é uma unidade adequada, pois geralmente, as visões de
programas são subconjuntos de tabelas. Logo, o acesso local de programas não é sobre tabelas
e sim sobre seus subconjuntos. Além disso, caso os programas com visões definidas sobre
uma tabela estejam em estações diferentes, podem ser seguidos dois caminhos: ou a tabela é
armazenada em uma única estação, resultando em um número excessivo de acessos remotos
aos dados, ou ela é replicada em todos ou em parte das estações onde se encontram os
programas, gerando problemas na execução de atualizações.
A fragmentação de uma tabela também permite que várias transações sejam
executadas concorrentemente, além de resultar na execução paralela de uma consulta, criando
um conjunto de sub-consultas que operam sobre os fragmentos. Com isso, a fragmentação
aumenta o nível de concorrência e a vazão do sistema.
5.2.4. Grau de Fragmentação
O grau de fragmentação a que o banco de dados deve ser submetido representa uma
decisão importante que afeta o desempenho do processamento de consultas ÖZSU (2001).
Este grau de fragmentação vai do nível mais baixo (nenhuma fragmentação) até o nível mais
alto, tanto na fragmentação horizontal (linhas individuais) como na fragmentação vertical
(colunas individuais).
Para encontrar um nível adequado de fragmentação, deve-se levar em consideração os
programas que atuarão sobre o banco de dados. Geralmente, os programas precisam ser
caracterizados com relação a alguns parâmetros, diante dos quais podem ser identificados
fragmentos individuais.

73
5.2.5. Regras de fragmentação
Segundo ÖZSU (2001), existem três regras que garantem que o banco de dados não
sofrerá nenhuma mudança semântica durante a fragmentação: Completeza, Reconstrução e
Disjunção.
A Completeza diz que se uma tabela T é decomposta em fragmentos T1, T2,..., Tn, cada
linha ou cada coluna que pode ser encontrada em T também pode ser encontrada em um ou
mais dos fragmentos Ti (Figura 5.38).
T1
MAT NOME CURSO
T 10 Almir Ciências Comp.
MAT NOME CURSO
10 Almir Ciências Comp. T2
20 Ana Ed. Física MAT NOME CURSO
30 José Ed. Física 20 Ana Ed. Física
30 José Ed. Física
Figura 5.38. Exemplo de Completeza
Na Reconstrução, se uma tabela T é decomposta em fragmentos T1, T2,..., Tn, deve ser
possível definir um operador relacional de forma que:
T = Ti; Ti FT (Para todo Ti pertencente à FT)
Apesar do operador ser diferente para cada tipo de fragmentação, a identificação dele é
importante. A possível reconstrução da relação a partir de seus fragmentos garante que as
restrições de dependência definidas sobre os dados serão preservadas. Pegando como exemplo
os fragmentos da Figura 5.38, uma operação de união entre T1 e T2 é o suficiente para
reconstruir a tabela T.
E por último, a Disjunção diz que se uma tabela T é fragmentada horizontalmente em
T1, T2,..., Tn, o item de dados di está em apenas um fragmento, como demonstra a Figura 5.38.

74
Se a tabela T é fragmentada verticalmente, os atributos de sua chave primária geralmente se
repetem em todos os seus fragmentos (Figura 5.39). Então a disjunção só é definida sobre os
atributos que não fazem parte da chave primária de uma tabela.
T T3 T4
MAT NOME CURSO MAT NOME MAT CURSO
10 Almir Ciências Comp. 10 Almir 10 Ciências Comp.
20 Ana Ed. Física 20 Ana 20 Ed. Física
30 José Ed. Física 30 José 30 Ed. Física
Figura 5.39. Exemplo de Disjunção na fragmentação vertical
5.2.6. Fragmentação horizontal
A fragmentação horizontal divide uma tabela em suas linhas, onde cada fragmento tem
uma tabela menor com linhas da tabela de origem. O objetivo dessa fragmentação é produzir
fragmentos que fiquem localizados onde são mais utilizados (CANTO, 2005). Esse tipo de
fragmentação pode ser primária, sendo executada com a utilização de predicados definidos
sobre a tabela, ou derivada, que seria o particionamento de uma tabela que resulta da
definição de predicados sobre outra tabela.
5.2.6.1.Requisitos de informações da fragmentação horizontal
As informações do banco de dados correspondem ao esquema conceitual global deste
banco, e é importante observar como as tabelas do banco de dados estão relacionadas entre si.
No modelo relacional, esses relacionamentos também são representados como tabelas. Mas
em outros modelos de dados, como o modelo de entidades e relacionamentos, esses
relacionamentos entre tabelas do banco de dados são representados de forma explícita. Na
notação de CERI et al. (1983), são traçados vínculos orientados entre tabelas que estão

75
relacionadas entre si por uma operação de junção. A tabela de origem do vínculo é chamada
proprietária, e a tabela de destino do vínculo é chamada membro. A Figura 5.40 ilustra os
vínculos entre as tabelas da Figura 5.37.
Figura 5.40. Relacionamentos entre tabelas utilizando vínculos
As informações de aplicativos devem ser quantitativas e qualitativas. As quantitativas
são utilizadas pelos modelos de alocação e as qualitativas são utilizadas no processo de
fragmentação. Os predicados utilizados nas consultas dos usuários são informações básicas na
análise dos programas do usuário, sendo que deve-se analisar pelo menos os mais
importantes. Os predicados simples são condições utilizadas nas consultas do usuário à uma
tabela. Essas condições consistem em relacionar atributos da tabela com um valor referente
àqueles atributos utilizando os operadores relacionais (=, ≠, <, ≤, >, ≥). Como exemplo, os
seguintes predicados podem ser formados a partir da tabela ALUNO da Figura 5.37:
CURSO = “Ed. Física”
MAT > 20
Nem sempre as consultas são simples como no exemplo demonstrado. Algumas
utilizam operações booleanas em conjunto com os predicados simples. Um predicado muito
utilizado é o chamado predicado minterm, que é a conjunção de predicados simples. Na tabela
DISCIP da Figura 5.37 podem ser definidos alguns predicados simples:
CURSO, CENTRO
COD, DN-DISCIP, CRED MAT, NOME, CURSO
MAT, COD, PROFESSOR, SALA
LOC
DISCIP
AULA
ALUNO

76
DN-DISCIP = “Cálculo”
DN-DISCIP = “Anatomia”
DN-DISCIP = “Zootecnia”
CRED > 4
CRED < 4
Com esses predicados, podemos criar alguns predicados minterm, utilizando o
operador de conjunção:
DN-DISCIP = “Cálculo” CRED > 4
DN-DISCIP = “Zootecnia” CRED < 4
¬(DN-DISCIP = “Anatomia”) CRED > 4
Este último minterm pode ser escrito como:
DN-DISCIP ≠ “Anatomia” CRED > 4
5.2.6.2.Fragmentação horizontal primária
Como já foi dito anteriormente, a fragmentação horizontal primária é uma operação de
seleção sobre uma tabela, sendo que os atributos utilizados para fragmentar fazem parte da
mesma tabela (SIQUEIRA, 2006). Considerando a tabela ALUNO da Figura 5.37, pode-se
definir seus fragmentos horizontais do seguinte modo:
ALUNO1 = σCURSO = “Ciências Comp.” (ALUNO)
ALUNO2 = σCURSO = “Ed. Física” (ALUNO)
ALUNO3 = σCURSO = “Eng. Elét.” (ALUNO)
ALUNO4 = σCURSO = “Veterinária” (ALUNO)
O símbolo sigma (σ) representa a operação de seleção, e o resultado dessas
fragmentações são mostrados na Figura 5.41.

77
ALUNO1
MAT NOME CURSO
10 Almir Ciências Comp.
ALUNO2
MAT NOME CURSO
20 Ana Ed. Física
40 José Ed. Física
ALUNO3
MAT NOME CURSO
30 Jean Eng. Elét.
ALUNO4
MAT NOME CURSO
50 Maria Veterinária
Figura 5.41. Resultado de uma fragmentação horizontal primária da tabela ALUNO
O primeiro passo de um algoritmo de fragmentação é definir o conjunto de predicados
simples que formarão os predicados minterm. As duas características que devem ser
observadas nos predicados simples são a completeza e a minimalidade. Um conjunto de
predicados simples Ps só é completo quando há a probabilidade igual de acesso de cada
programa a qualquer linha pertencente a qualquer fragmento minterm definido de acordo com
Ps.
Para exemplificar a completeza, será utilizada a fragmentação da tabela ALUNO
mostrada na Figura 5.42. Caso o único programa que acessa ALUNO queira acessar as linhas
de acordo com o seu curso, o conjunto será completo, pois cada linha de cada fragmento tem a
mesma probabilidade de ser acessada. Mas se houver um segundo programa que acesse
somente as linhas de alunos em que a matrícula é maior que 30, Ps não será completo, pois
algumas linhas de cada fragmento terão uma maior probabilidade de serem acessadas. A
forma de garantir a completeza seria adicionar os predicados simples (MAT > 30, MAT ≤ 30)
a Ps:

78
Ps = {CURSO = “Ciências Comp.”, CURSO = “Ed. Física”, CURSO = “Eng. Elét.”,
CURSO = “Veterinária”, MAT > 30, MAT ≤ 30}
A minimalidade diz que o predicado simples deve ser relevante na determinação de
uma fragmentação. Caso todos os predicados de Ps sejam relevantes, então Ps é mínimo. Por
exemplo, o conjunto Ps descrito anteriormente é mínimo. Mas se inserirmos o predicado
NOME = “Ana” no conjunto Ps, este não seria mínimo, pois não haveria um programa que
acessasse os fragmentos de forma diferente, sendo que os dois programas exemplificados
acessam os dados através do CURSO e da MATRÍCULA, e não através do NOME. Ou seja,
este predicado não é relevante em Ps.
ÖZSU (2001) apresenta um algoritmo chamado COM_MIN, que gera um conjunto de
predicados completo e mínimo Ps’, a partir de um conjunto de predicados simples Ps.
Algoritmo COM_MIN
entrada: R: relação; Ps: conjunto de predicados simples
saída: Pr’: conjunto de predicados simples
declare
F: conjunto de fragmentos minterm
begin
encontrar um pi Pr tal que pi particione R de acordo com Regra 1
Pr’ ← pi
Pr ← Pr – pi
F ← fi {fi é o fragmento minterm de acordo com pi}
do
begin
encontrar um pj Pr tal que pj particione algum fk de Pr’ de
acordo com Regra 1
Pr’ ← Pr’ pj
Pr ← Pr – pj
F ← F fi
if pk Pr’ não relevante, then begin Pr’ ← Pr’ – pk F ← F – fk
end-if end-begin
until Pr’ se completar
end. {COM_MIN}
Algoritmo 5.1. Algoritmo COM_MIN. FONTE: (ÖZSU, 2001)

79
A Regra 1 citada no algoritmo é uma regra que estabelece que uma tabela ou
fragmento é particionado em duas ou mais partes que são acessadas de maneira diferente por
um ou mais programas. E a variável fi de Pr’ é um fragmento determinado de acordo com um
predicado minterm definido sobre os predicados simples de Pr’.
O algoritmo trabalha da seguinte maneira: primeiro ele encontra um predicado
relevante e que sirva para particionar a tabela de entrada. O laço do-until adiciona predicados
ao conjunto Pr’ interativamente, assegurando a minimalidade em cada etapa. Com isso, o
algoritmo garante que o conjunto Pr’ seja mínimo e completo.
Depois de efetuado o algoritmo, deve-se derivar o conjunto de predicados minterm
que podem ser definidos sobre os predicados simples do conjunto Pr’. Esses predicados
minterm determinam quais fragmentos serão utilizados na etapa de alocação. O problema é
que esse conjunto pode ser muito grande.
Esse problema pode ser resolvido com a eliminação de alguns fragmentos minterm
sem significado, através da identificação dos minterms que são contraditórios em relação a
um conjunto de implicações I. Em um conjunto Pr’ = {CURSO = “Ed. Física”, CURSO =
“Eng. Elét.”}, I contém duas implicações:
(CURSO = “Ed. Física”) ¬(CURSO = “Eng. Elét.”)
¬ (CURSO = “Ed. Física”) (CURSO = “Eng. Elét.”)
O predicados minterm que podem ser definidos através de Pr’ são os seguintes:
(CURSO = “Ed. Física”) (CURSO = “Eng. Elét.”)
(CURSO = “Ed. Física”) ¬(CURSO = “Eng. Elét.”)
¬ (CURSO = “Ed. Física”) (CURSO = “Eng. Elét.”)
¬ (CURSO = “Ed. Física”) ¬(CURSO = “Eng. Elét.”)
Verificando os predicados minterm acima, conclui-se que o primeiro e o quarto são
contraditórios em relação às implicações I, podendo ser eliminadas do conjunto de predicados
minterm M.
Após essas etapas, é utilizado um algoritmo de fragmentação primária, como o
descrito por ÖZSU (2001):

80
Algoritmo PHORIZONTAL
entrada: R: relação; Pr: conjunto de predicados simples
saída: M: conjunto de fragmentos minterm
begin
Pr’ ← COM_MIN (R, Pr)
determinar o conjunto M de predicados minterm
determinar o conjunto I de implicações entre pi Pr’
for each mi M do
if mi é contraditório de acordo com I then
M ← M – mi
end-if
end-for
end. {PHORIZONTAL}
Algoritmo 5.2. Algoritmo PHORIZONTAL. FONTE: (ÖZSU, 2001)
Pegando como exemplo o banco de dados da Figura 5.37, observa-se que existem duas
tabelas que podem ser particionadas através da fragmentação horizontal primária: LOC e
DISCIP. Considerando que há apenas um programa que acesse a tabela DISCIP, que verifica
o número de créditos que cada disciplina possui, e que os dados das disciplinas são
armazenados em dois locais, um de disciplinas com créditos menores que cinco e outro de
disciplinas com créditos iguais ou maiores que cinco, a consulta deve ser realizada nos dois
locais.
O conjunto inicial de predicados simples utilizados para fragmentar a tabela DISCIP
são os seguintes:
p1; CRED ≤ 5
p2: CRED > 5
Aplicando o algoritmo COM_MIN, o resultado obtido é Pr’ = {p1}, pois p2 não
particionaria o fragmento minterm formado com relação a p1 de acordo com a Regra 1. Os
predicados minterm definidos através de Pr’ são os seguintes:
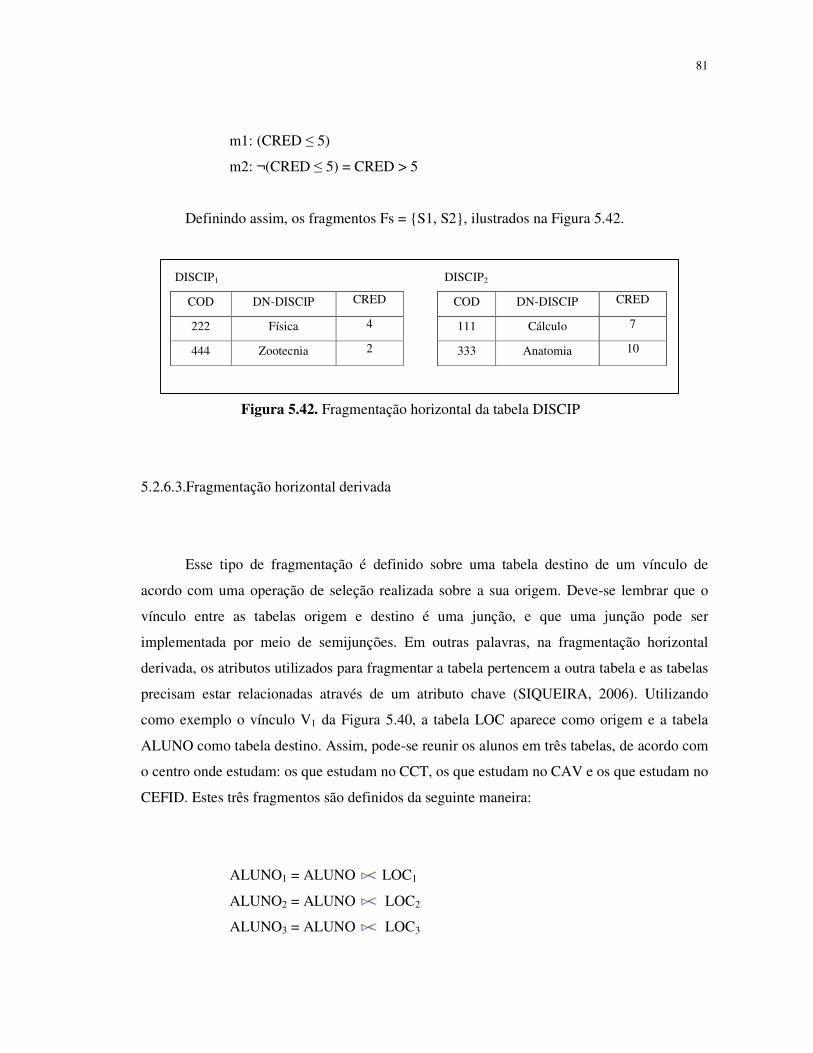
81
m1: (CRED ≤ 5)
m2: ¬(CRED ≤ 5) = CRED > 5
Definindo assim, os fragmentos Fs = {S1, S2}, ilustrados na Figura 5.42.
DISCIP1 DISCIP2
COD DN-DISCIP CRED COD DN-DISCIP CRED
222 Física 4 111 Cálculo 7
444 Zootecnia 2 333 Anatomia 10
Figura 5.42. Fragmentação horizontal da tabela DISCIP
5.2.6.3.Fragmentação horizontal derivada
Esse tipo de fragmentação é definido sobre uma tabela destino de um vínculo de
acordo com uma operação de seleção realizada sobre a sua origem. Deve-se lembrar que o
vínculo entre as tabelas origem e destino é uma junção, e que uma junção pode ser
implementada por meio de semijunções. Em outras palavras, na fragmentação horizontal
derivada, os atributos utilizados para fragmentar a tabela pertencem a outra tabela e as tabelas
precisam estar relacionadas através de um atributo chave (SIQUEIRA, 2006). Utilizando
como exemplo o vínculo V1 da Figura 5.40, a tabela LOC aparece como origem e a tabela
ALUNO como tabela destino. Assim, pode-se reunir os alunos em três tabelas, de acordo com
o centro onde estudam: os que estudam no CCT, os que estudam no CAV e os que estudam no
CEFID. Estes três fragmentos são definidos da seguinte maneira:
ALUNO1 = ALUNO LOC1
ALUNO2 = ALUNO LOC2
ALUNO3 = ALUNO LOC3
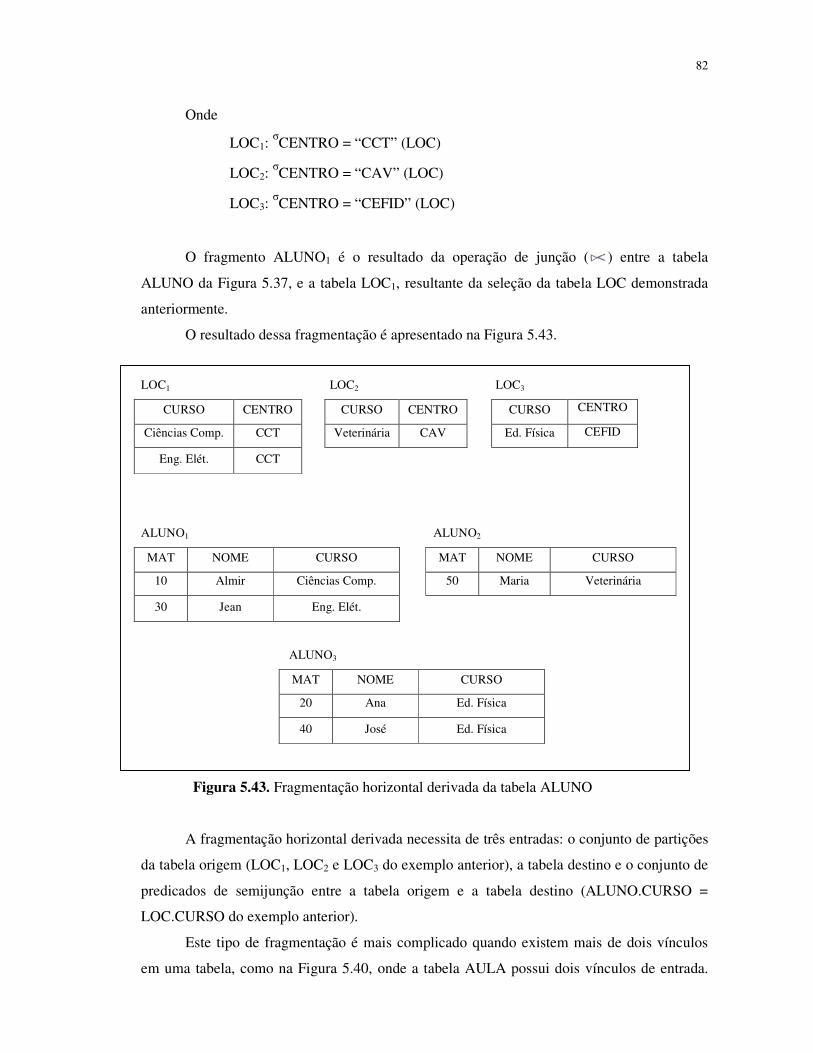
82
Onde
LOC1: σCENTRO = “CCT” (LOC)
LOC2: σCENTRO = “CAV” (LOC)
LOC3: σCENTRO = “CEFID” (LOC)
O fragmento ALUNO1 é o resultado da operação de junção ( ) entre a tabela
ALUNO da Figura 5.37, e a tabela LOC1, resultante da seleção da tabela LOC demonstrada
anteriormente.
O resultado dessa fragmentação é apresentado na Figura 5.43.
LOC1 LOC2 LOC3
CURSO CENTRO CURSO CENTRO CURSO CENTRO
Ciências Comp. CCT Veterinária CAV Ed. Física CEFID
Eng. Elét. CCT
ALUNO1 ALUNO2
MAT NOME CURSO MAT NOME CURSO
10 Almir Ciências Comp. 50 Maria Veterinária
30 Jean Eng. Elét.
ALUNO3
MAT NOME CURSO
20 Ana Ed. Física
40 José Ed. Física
Figura 5.43. Fragmentação horizontal derivada da tabela ALUNO
A fragmentação horizontal derivada necessita de três entradas: o conjunto de partições
da tabela origem (LOC1, LOC2 e LOC3 do exemplo anterior), a tabela destino e o conjunto de
predicados de semijunção entre a tabela origem e a tabela destino (ALUNO.CURSO =
LOC.CURSO do exemplo anterior).
Este tipo de fragmentação é mais complicado quando existem mais de dois vínculos
em uma tabela, como na Figura 5.40, onde a tabela AULA possui dois vínculos de entrada.

83
Quando isto ocorre, existe mais de uma fragmentação horizontal derivada possível de uma
tabela. Para escolher qual fragmentação será utilizada, existem dois critérios: a fragmentação
usada na maioria dos programas e a fragmentação com melhor característica de junção.
No primeiro critério, é importante tentar facilitar os acessos de usuários que exigem
maior processamento em suas consultas, para diminuir o impacto total sobre o desempenho do
sistema. O segundo critério é exemplificado através do seguinte exemplo: os usuários
desejariam consultar o professor da disciplina em que o aluno está matriculado e a sala onde
será ministrada a disciplina. Na linguagem SQL, esta consulta é descrita da seguinte maneira:
SELECT PROFESSOR, SALA
FROM AULA, ALUNOi
WHERE AULA.MAT = ALUNOi.MAT
onde i pode ser igual a 1 ou 2, dependendo do local em que a consulta é realizada. A
fragmentação derivada da tabela AULA de acordo com a fragmentação de ALUNO é
ilustrada na Figura 5.44 e definida como:
AULA1 = AULA ALUNO1
AULA2 = AULA ALUNO2
AULA3 = AULA ALUNO3
AULA1
MAT COD PROFESSOR SALA AULA2
10 111 Jonas K-203 MAT COD PROFESSOR SALA
10 222 Ivan K-205 50 333 Lucia E-301
30 111 Jonas K-203 50 444 Joana E-305
30 222 Ivan K-205
AULA3
MAT COD PROFESSOR SALA
20 333 Beatriz A-108
40 333 Beatriz A-108
Figura 5.44. Fragmentação horizontal derivada da tabela AULA

84
Geralmente, há mais de uma fragmentação candidata para uma tabela, e a escolha do
esquema de fragmentação pode ser solucionada durante a alocação.
5.2.7. Alternativas de alocação
Partindo-se do pré-suposto de que o banco de dados seja fragmentado de forma
apropriada, deve-se decidir sobre como os fragmentos serão alocados nas diversas estações da
rede. Na alocação, os dados podem ser replicados ou não. A replicação torna o banco de
dados mais confiável e as consultas somente leitura ficam mais eficientes. Com cópias em
diversas estações da rede, a chance dos dados estarem acessíveis em algum lugar do sistema é
maior, e as consultas de leitura que atuam sobre os mesmos dados poderão ser realizadas
paralelamente. Apesar disso, a atualização dos dados torna-se um problema, pois todas as
cópias devem ser atualizadas corretamente. Logo, a forma como será feita a replicação
depende da proporção entre consultas de leitura e de atualização.
Um banco de dados particionado (não replicado) contém fragmentos em várias
estações, sendo que existe apenas uma cópia de cada fragmento na rede. Com relação à
replicação, o banco de dados pode ser totalmente replicado, onde se encontra completo em
cada estação, ou parcialmente replicado, onde cópias de um fragmento podem se encontrar em
várias estações.
5.2.8. Alocação das tabelas do SigmaWeb
Analisando o modelo de dados do SigmaWeb e sua tabelas, chegou-se a conclusão de
que haverá cinco formas de distribuição destas tabelas:
R – Replicadas nos quatro Campi (Chapecó, Florianópolis, Joinville e Lages). São
tabelas utilizadas por todos os usuários, principalmente as relacionadas à estrutura do
sistema.
F – Fragmentadas diretamente através de um campo. No caso do SigmaWeb, a seleção
é feita através do campo relacionado ao código do centro.

85
FP – Fragmentadas parcialmente através de um campo, ou seja, algumas linhas são
comuns a todos os centros;
J – Fragmentadas através da junção com uma tabela que possui o campo relativo ao
código do centro;
CCT – Armazenadas integralmente no CCT (Centro de Ciências Tecnológicas).
Para facilitar a visualização da divisão das tabelas entre as cinco classes apresentadas,
foram designadas cinco cores de acordo com a classe em que se encaixam as tabelas. As
tabelas replicadas (R) são as vermelhas, as fragmentadas através da fragmentação horizontal
primária (F) são as azuis, as fragmentadas parcialmente (FP) são as roxas, as fragmentadas
através da fragmentação horizontal derivada (J) são as verdes e as tabelas armazenadas
integralmente no CCT são as laranjas.
Seguindo esta nomenclatura, a lista de tabelas e o modo como estão divididas são
apresentadas da seguinte forma:
GRUPO BÁSICAS E ESTRUTURAIS MODULO R ROTINA R STATUS R CATUSU R SITACA R RESFIN R CARDIS R REQTIP R TURNOS R REGACA R ESTADO R FORING R REGCON R TITULA R UNIVER R CAMPUS R CENTRO R CICLOS F (no campo csce (Código do Centro)) USUARI FP (no campo usce (Código do Centro)) USUESP J (do campo ueid com o campo usid da tabela USUARI) HORARI F (no campo hoce (Código do Centro)) ESPACO F (no campo efce (Código do Centro)) DEPART F (no campo dpce (Código do Centro)) MATTIP R CURSOS F (no campo crce (Código do Centro)) HABILI F (no campo hace (Código do Centro))

86
VESTIB F (no campo vece (Código do Centro))
Vermelho: Tabelas replicadas nos quatro campi Azul: Tabelas fragmentadas através da fragmentação horizontal primária Roxo: Tabelas fragmentadas parcialmente através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.45. Divisão do Grupo Básicas e Estruturais
Na divisão do grupo Básicas e Estruturais existe quatro das cinco classes de
particionamento em que as tabelas podem se encaixar, e por isso servirá como exemplo. As
tabelas que estão em vermelho na Figura 5.45 serão replicadas nos quatro campi, ou seja,
haverá uma cópia dessas tabelas em cada campi (Florianópolis, Joinville, Chapecó e Lages).
As tabelas que estão em azul serão fragmentadas utilizando a fragmentação horizontal
primária. O campo utilizado na fragmentação está na mesma cor da tabela, como na tabela
CURSOS, onde o campo crce (Sigla do Centro) está em azul. A fórmula utilizada para
fragmentar esta tabela seria a seguinte:
Dados do CCT
CCT = σcrce = “CCT” (CURSOS)
Dados da CAV
CAV = σcrce = “CAV” (CURSOS)

87
A tabela que está em roxo também será fragmentada utilizando a fragmentação
horizontal primária, porém haverá alguns dados que se encontrarão nos quatro campi. E por
último, as tabelas que estão em verde serão fragmentadas utilizando a fragmentação
horizontal derivada, onde antes de haver a fragmentação, estas tabelas são agrupadas com
outras tabelas através de um campo em comum. Na Figura 5.45 temos a tabela USUESP, que
por não ter um campo relacionado à Sigla do Centro, necessita ser agrupada aos fragmentos
da tabela USUARI através do campo ueid (Matrícula) da tabela USUESP, comparando-o com
o campo usid (Matrícula) da tabela USUARI. Exemplificando:
USUESP1 = USUESP USUARI1
USUESP2 = USUESP USUARI2
Onde
USUARI1 = σusid = CCT (USUARI)
USUARI2 = σusid = CAV (USUARI)
GRUPO ADMINISTRATIVO
LOGENT R AVISOS F (no campo aece (Código do Centro))
Vermelho: Tabelas replicadas nos quatro campi Azul: Tabelas fragmentadas através da fragmentação horizontal primária
Figura 5.46. Divisão do Grupo Administrativo

88
GRUPO DISCIPLINAS E CURRÍCULOS DISCIP F (no campo dice (Código do Centro)) CURRIC F (no campo rrce (Código do Centro)) CURDIS J (do campo cdcr com o campo rrid da tabela CURRIC) CUREQU J (do campo eqcr com o campo rrid da tabela CURRIC) CURPR1 J (do campo p1cr com o campo rrid da tabela CURRIC) CURPRM J (do campo pmcr com o campo rrid da tabela CURRIC) ANTECI J (do campo ancu com o campo rrid da tabela CURRIC) NROELE J (do campo necu com o campo rrid da tabela CURRIC) CURPR4 J (do campo p4cr com o campo rrid da tabela CURRIC)
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.47. Divisão do Grupo Disciplinas e Currículos

89
GRUPO ACADÊMICOS ACADEM F (no campo acce (Código do Centro)) ACASIG F (no campo msce (Código do Centro)) ACADOC J (do campo doid com o campo acid da tabela ACADEM) ACAMIL J (do campo doid com o campo acid da tabela ACADEM) ACASEG J (do campo sgid com o campo acid da tabela ACADEM) ACATRA J (do campo tfid com o campo acid da tabela ACADEM) ACAVES J (do campo dvid com o campo acid da tabela ACADEM) ACAEND J (do campo enid com o campo acid da tabela ACADEM) ACAENF J (do campo enid com o campo acid da tabela ACADEM) TRANCA J (do campo tmid com o campo acid da tabela ACADEM) SOLTRA J (do campo stid com o campo acid da tabela ACADEM) ACASIT J (do campo asid com o campo acid da tabela ACADEM) ACAOCP J (do campo ocid com o campo acid da tabela ACADEM)
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.48. Divisão do Grupo Acadêmicos

90
GRUPO ALUNOS VISITANTES ALUVIS F (no campo avce (Código do Centro)) HISVIS J (do campo hvid com o campo avid da tabela ALUVIS)
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.49. Divisão do Grupo Alunos Visitantes
GRUPOS PROFESSORES PROCAD F (no campo prce (Código do Centro)) PROEND J (do campo prid com o campo prid da tabela PROCAD)

91
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.50. Divisão do Grupo Professores
GRUPOS DIÁRIOS E MATRÍCULAS OFEDIS F (no campo doce (Código do Centro)) OFEDIA F (no campo doce (Código do Centro)) OFEHOR J (do campo doid com o campo doid da tabela OFEDIS) OFEHOA J (do campo doid com o campo doid da tabela OFEDIS) OFEPRO J (do campo doid com o campo doid da tabela OFEDIS) OFEPRA J (do campo doid com o campo doid da tabela OFEDIS) OFEBLO J (do campo doid com o campo doid da tabela OFEDIS) DIARIO J (do campo doid com o campo doid da tabela OFEDIS) DIARIA J (do campo doid com o campo doid da tabela OFEDIS) LIBCHO J (do campo lcid com o campo acid da tabela ACADEM) PREMAT F (no campo pmce (Código do Centro)) SOLANT J (do campo smma com o campo acid da tabela ACADEM) CCTVAG CCT CCTENQ CCT

92
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada Laranja: Tabelas armazenadas integralmente no CCT
Figura 5.51. Divisão do Grupo Diários e Matrículas
Na divisão do grupo Diários e Matrículas ilustrado na Figura 5.51 aparece a quinta
classe de tabelas que seria a classe CCT (laranja), que são as tabelas que não são

93
fragmentadas, mas simplesmente são armazenadas integralmente no campus de Joinville e
São Bento do Sul.
GRUPO HISTÓRICOS ESCOLARES HISTOR J (do campo heid com o campo acid da tabela ACADEM) HISDIS J (do campo hdid com o campo acid da tabela ACADEM) HISVAL J (do campo hvid com o campo acid da tabela ACADEM) HISNAO J (do campo hnid com o campo acid da tabela ACADEM) HISEST J (do campo hgid com o campo acid da tabela ACADEM) HISTCC J (do campo htid com o campo acid da tabela ACADEM) HISATP J (do campo hpid com o campo acid da tabela ACADEM) HISFOR J (do campo hfid com o campo acid da tabela ACADEM) HISCRE J (do campo cvid com o campo acid da tabela ACADEM)
Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.52. Divisão do Grupo Históricos Escolares

94
GRUPO REQUERIMENTOS REQNUM F (no campo rqce (Código do Centro)) REQUER F (no campo rqce (Código do Centro)) REQVAL J (do campo rvid com o campo acid da tabela ACADEM)
Azul: Tabelas fragmentadas através da fragmentação horizontal primária Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.53. Divisão do Grupo Requerimentos
GRUPO ESTÁGIOS, MONOGRAFIAS E OUTROS PROTCC J (do campo tcma com o campo acid da tabela ACADEM) DEFTCC J (do campo tcma com o campo acid da tabela ACADEM)
Verde: Tabelas fragmentadas através da fragmentação horizontal derivada
Figura 5.54. Divisão do Grupo Estágios, Monografias e Outros

95
Após efetuar a divisão das tabelas do sistema SigmaWeb de acordo com as cinco
regras estipuladas anteriormente, a última tarefa a ser efetuada é alocar as tabelas nos 4 Campi
da UDESC (Florianópolis, Joinville, Chapecó e Lages) de acordo com o Centro ao qual foram
designadas. Ou seja, as tabelas que foram divididas de acordo com os códigos do Centros
CEAD, CEART, CEFID, ESAG e FAED, ficarão alocadas em Florianópolis. As tabelas
divididas de acordo com o código do CCT ficarão armazenadas em Joinville, as divididas de
acordo com o código da CAV ficarão em Lajes e as divididas de acordo com o código do
CEO ficarão alocadas em Chapecó.

96
6. CONCLUSÃO
Com o intuito de atingir o objetivo deste trabalho, foram apresentados os conceitos
necessários para criar o modelo completo de distribuição de dados do SigmaWeb, sendo
realizado um levantamento bibliográfico sobre sistemas distribuídos, apresentando suas
características, modelos e exemplos. Também foram pesquisadas definições de bancos de
dados distribuídos, apresentando sua arquitetura e características, além de definições sobre
como projetá-los.
Dentro das definições de bancos de dados distribuídos, é importante salientar que a
distribuição de dados não é apenas a replicação destes em diversos computadores. A
fragmentação de dados nos diversos nós também deve ser utilizada, através de duas formas:
fragmentação horizontal e vertical. Quanto à fragmentação, foi interessante perceber que este
processo não se trata apenas de executar seleções em tabelas. Existem regras que devem ser
respeitadas, como a completeza, para que não ocorram mudanças na base de dados.
A primeira dificuldade encontrada foi a necessidade de realizar o processo de
engenharia reversa com o intuito de obter um modelo de dados para o sistema SigmaWeb, já
que sua documentação atual é apresentada através de tabelas construídas no Excel. Além
disso, não foi possível utilizar a funcionalidade de ferramentas CASE que são capazes de
construir o modelo de dados através do banco de dados já implementado. Por este motivo, foi
feita uma alteração no plano inicial deste trabalho.
A partir do modelo de dados resultante do processo de engenharia reversa, foi criado o
projeto de distribuição de dados do sistema SigmaWeb utilizando a base teórica adquirida
com a pesquisa inicial. Durante parte do projeto foram definidos alguns pontos relevantes,
como a estratégia do projeto, sendo utilizada uma adaptação da estratégia top-down, e o tipo
de fragmentação utilizada (fragmentação horizontal primária e derivada). A parte mais
trabalhosa desta tarefa foi determinar o tipo de alocação de cada tabela do Sigmaweb, sendo
que no projeto proposto, o banco de dados ficou parcialmente replicado.
A pesquisa sobre SGBD´s livres que oferecem suporte à distribuição de dados levou à
constatação de que nenhuma destas tecnologias atende a este requisito da forma abrangente
como acontece com os sistemas proprietários. Com isso, a proposta do projeto aqui

97
apresentado não poderia, neste momento, ser aplicada com estas ferramentas. Esta dificuldade
sugere um trabalho futuro que possa implementar características de distribuição de dados em
SGBD´s livres.
A proposta de distribuição de dados aqui apresentada foi construída formalmente com
base nos algoritmos de minimalidade e fragmentação horizontal propostos por Özsu. Esta
metodologia, por tratar-se de uma técnica formal, garante a validade do projeto apresentado.
No entanto, uma sugestão adicional de trabalho futuro seria a implementação do projeto em
pelo menos dois Centros da UDESC, de modo a avaliar, na prática, os resultados desta
proposta.
.

98
REFERÊNCIAS
CANTO, H. R. R. Um Estudo sobre Metodologias para o Projeto de Bancos de Dados
Distribuídos. Disponível em: <inf.univates.br/sicompi/wet2005:04-rohenkohl.pdf>. Acesso
em 25 set. 2006.
CARVALHO, B. M. Sistemas Distribuídos: Aula 1 – Introdução. Disponível em:
<www.dimap.ufrn.br/~motta/dim070/Aula01.pdf>. Acesso em 25 abr. 2006.
CASANOVA, M. A.; MOURA, A. V. Princípios de sistemas de gerência de bancos de
dados distribuídos. Rio de Janeiro: Campus, 1985.
CASANOVA, M. A. Processamento de consultas e gerência de transações. Disponível
em:<www.dpi.inpe.br/livros/bdados/cap7.pdf>. Acesso em 23 abr. 2006.
CERI, S.; PERNICI, B.; WIEDERHOLD, G. Distributed Database Design Methodologies.
Proc. IEEE (maio de 1987), pp 533-546.
CERI, S.; PERNICI, B.; WIEDERHOLD, G. Distribution Design of Logical Database
Schemes. IEEE Trans. Software Eng. (julho de 1983), pp 487-503.
COLLA, M. Histórico do SQL Server. Disponível em:
<http://www.freecode.com.br/drartigos/artigo.php?cdart=217&id=17381>. Acesso em: 2 set.
2006.
CONNOLLY, T.; BEGG, C.; STRACHAN, A. Database Systems: A Practical Approach
to Design, Implementation, and Management. 2.ª Edição. Addison-Wesley, 1998.
COULOURIS, G.; DOLLIMORE, J.; KINDBERG, T. Distributed Systems: Concepts and
Design. 3.ª Edição. Addison-Wesley, 2001.

99
COUTINHO, N. PostgreSQL. Disponível em:
<http://www.postgresql.org.br/wiki/Introdu%C3%A7%C3%A3o>. Acesso em: 1 set. 2006.
DAROS, L. L. Manual de operação – Sistema SigmaWeb. Mar. 2003.
DATE, C. J. Introdução a sistemas de bancos de dados. Rio de Janeiro: Campos, 2002.
DBDESIGNER 4. General Information – What is DBDesigner 4?. Disponível em:
<http://www.fabforce.net/dbdesigner4>. Acesso em 25 jun. 2006.
HEUSER, C. A. Projeto de banco de dados. Porto Alegre: Instituto de Informática da
UFRGS: Sagra Luzzatto, 2001.
LEVIN K. D.; MORGAN H. L. Optimizing Distributed Data Bases: A Framework for
Research. Proc. National Computer Conf., 1975, pp. 473-478.
LOZANO, F. MySQL x PostgreSQL: Quando Usar Cada Um. Disponível em:
<www.lozano.eti.br/palestras/pgsql-mysql.pdf>. Acesso em 15 out. 2006.
MEYER, L. A. V. C.; MATTOSO M. L. de Q. Paralelismo em banco de dados. XII
Simpósio Brasileiro de Banco de Dados. Fortaleza, Out. 1997.
MICROSOFT. O que é o SQL Server 2005? Disponível em:
<http://www.microsoft.com/portugal/sql/prodinfo/overview/what-is-sql-server.mspx>.
Acesso em 25 out. 2006.
NIEMIEC, R. J. Oracle 9i Performance Tuning: Dicas e Técnicas. Rio de Janeiro: Campus,
2003.
ÖZSU, M. T.; VALDURIEZ, P. Principios de Sistemas de Bancos de Dados Distribuídos.
Trad. Vandenberg D. de Souza. Rio de Janeiro: Campus, 2001.

100
POSTGRESQL. Documentação do PostgreSQL 8.0.0. Disponível em:
<http://sourceforge.net/projects/pgdocptbr>. Acesso em 23 out. 2006.
RODRIGUES, A. H. Apostila de Firebird 1.0. Disponível em:
<http://www.freecode.com.br/arquivos/apostilas/bancodados/firebird/ApostiladeFirebird.zip>.
Acesso em: 7 set. 2006.
SELHORST, A. M. Estudo de Soluções de Bancos de Dados Distribuídos em Aplicações
Web. 2005.
SILBERSCHATZ, A.; KORTH, H. F.; SUDARSHAN, S. Sistema de Banco de Dados. São
Paulo: MAKRON Books, 1999.
SILVA, L. C. da. Banco de Dados para Web: Do planejamento à implementação. São
Paulo: Érica, 2001.
SILVEIRA, F. F. Técnicas de Gerenciamento de Transações Distribuídas. Disponível em:
< http://www.urcamp.tche.br/site/ccei/revista/numero7.zip >. Acesso em 20 abr. 2006.
SIQUEIRA, F. Bancos de Dados Distribuídos. Disponível em:
<http://www.inf.ufsc.br/~frank/BDD/BDDIntro.pdf>. Acesso em 27 set. 2006.
SOARES, V. G. Aula 1 - Introdução a Banco de Dados. Disponível em:
<http://www.di.ufpb.br/valeria/BancoDados/Aula1-IntroducaoSlides.pdf>. Acesso em 22 abr.
2006.
TANENBAUM, A. S. Distributed Operating Systems. Ptice-Hall International, 1995.
TRIDAPALI, G. W.; SANT’SNNA, J. S. Apostila de MySQL. Disponível em:
<http://www.freecode.com.br/arquivos/apostilas/bancodados/mysql/mysql_.zip>. Acesso em:
4 set. 2006.
UDESC - UNIVERSIDADE DO ESTADO DE SANTA CATARINA. Conheça a UDESC:
para o aluno. Florianópolis, SC: UDESC. 3 v. 1994.

101
UDESC. UDESC: Ensino de Graduação Público, Gratuito, Vocacionado e de Qualidade.
Disponível em: < http://www.udesc.br/reitoria/proenAntiga/historiaensino.html>. Acesso em 15
mai. 2006.
VELOSO, S. R. M.; MENDES, S. B. T.; VELOSO, P. A. S. Um modelo abstrato para troca
de mensagens. Anais do seminário franco-brasileiro em sistemas informáticos distribuídos, p.
64-70, LCMI/UFSC, Florianópolis, Set. 1989.
VIANI, M. L. Nova Intranet da Celepar. Disponível em:
<http://www.pr.gov.br/batebyte/edicoes/1998/bb80/intra.htm>. Acesso em 22 abr. 2006.

102
ANEXOS

103
ANEXO 1 PLANO DE TRABALHO DE CONCLUSÃO DE
CURSO

104
Plano de Trabalho de Conclusão de Curso
Um estudo sobre a aplicação de bancos de dados distribuídos no
sistema acadêmico Sigmaweb
UDESC - Centro de Ciências Tecnológicas
Departamento de Ciência da Computação
Bacharelado em Ciência da Computação - Integral
Turma 2006/1 - Joinville – Santa Catarina
Diego Vinicius Lima Souza – [email protected]
Orientadora: Luciana Rita Guedes – [email protected]
Resumo – O trabalho aqui apresentado será voltado para o estudo do TCC de Alessandra Maria Selhorst sobre o estudo de bancos de dados distribuídos em aplicações Web, onde se pretende estudar e descrever novas tecnologias de bancos de dados distribuídos para propor uma nova distribuição de dados para o sistema acadêmico da Udesc, atualmente denominado Sigmaweb. Destaca-se que a proposta de Selhorst abrangeu apenas uma pequena amostra do modelo de dados do Sigmaweb, enquanto este trabalho pretende englobar o modelo completo, ou seja, todas as tabelas e seus respectivos campos. Neste plano serão apresentadas uma introdução e a justificativa do trabalho, seguidas pelos objetivos pretendidos. Também serão descritos a metodologia e o cronograma propostos para a realização do trabalho, bem como o grupo de pesquisa no qual está envolvido, a forma de orientação e as referências bibliográficas utilizadas neste plano. Palavras-chave: Sistemas Distribuídos, Banco de Dados Distribuídos, Aplicações
Web.
1. Introdução e Justificativa
A crescente utilização da Internet traz como conseqüência um número cada vez
maior de sistemas que a utilizam como o principal meio de tráfego de dados.
Através da rede mundial de computadores, certos sistemas possibilitam que
usuários geograficamente distantes possam acessá-los em busca de
informações contidas em bancos de dados, que segundo [SILVA, 2001], são
conjuntos de informações manipuláveis de mesma natureza inseridas em um
mesmo local, obedecendo a um padrão de armazenamento.

105
A partir do desejo de compartilhamento de recursos, houve a motivação para a
construção de sistemas distribuídos, que têm na Web seu principal exemplo,
garantindo acesso aos recursos e serviços através da Internet [COULOURIS,
2001].
Apesar disso, a disponibilidade dos sistemas e suas bases de dados na Internet
não é totalmente garantida. A queda de um link onde se encontra certa base de
dados pode causar um grande transtorno. Esta questão faz com que haja a
busca por uma solução que transforme bancos de dados centralizados em
bancos de dados distribuídos, que segundo [ÖZSU, 2001] são coleções de vários
bancos de dados logicamente inter-relacionados, distribuídos por uma rede de
computadores.
A motivação para o desenvolvimento deste trabalho está na continuação do
estudo iniciado no trabalho de conclusão de curso da estudante Alessandra
Maria Selhorst cujo objetivo era explorar as tecnologias de banco de dados
utilizadas naquela ocasião que permitiam o uso de bancos de dados distribuídos
em aplicações Web. Naquele trabalho, foram feitos estudos sobre uma única
tecnologia de banco de dados distribuído e foi proposto um único modelo de
distribuição de dados para o sistema acadêmico da Udesc. A proposta aqui
apresentada visa aprofundar estes estudos e buscar novas soluções, tanto para
a distribuição de dados quanto para a tecnologia proposta.
Dentre os tópicos abordados, estão: a descrição de sistemas distribuídos e
bancos de dados distribuídos, a descrição do sistema acadêmico da Udesc
(enfatizando o modelo de dados), a apresentação de uma nova proposta de
distribuição de dados para este sistema, o estudo e a descrição de novas
tecnologias de bancos de dados disponíveis atualmente que permitam a
aplicação no sistema acadêmico (buscando, se possível, soluções de software
livre), e a descrição da nova proposta de distribuição de dados utilizando uma
nova tecnologia de bancos de dados estudada.
2. Objetivos
Objetivo Geral:
Dar continuidade ao estudo de soluções de banco de dados distribuído para
aplicações Web e, a partir disso, propor uma nova solução para o sistema

106
acadêmico da Udesc, usando como base o modelo de dados completo deste
sistema.
Objetivos Específicos:
1. Estudar o trabalho de conclusão de curso da estudante Alessandra Maria
Selhorst;
2. Descrever sistemas distribuídos e bancos de dados distribuídos;
3. Descrever o sistema acadêmico da Udesc, enfatizando o modelo de
dados;
4. Propor uma nova solução de distribuição de dados para o sistema
acadêmico da Udesc;
5. Estudar e descrever nova(s) tecnologia(s) em banco de dados
disponível(is) atualmente que permita(m) a aplicação no sistema
acadêmico, buscando, se possível, solução(ões) de software livre;
6. Descrever a nova proposta de distribuição de dados utilizando uma nova
tecnologia de banco de dados estudada.
3. Metodologia
Primeiramente, será realizado um estudo do TCC (trabalho de conclusão de
curso) de Alessandra Maria Selhorst. Paralelamente, será feito um levantamento
bibliográfico sobre a definição e as características de sistemas distribuídos e de
bancos de dados distribuídos. Em seguida, será feita a descrição do sistema
acadêmico da Udesc, com ênfase no modelo de dados atualmente utilizado.
Após isso, uma nova proposta de distribuição de dados para este sistema será
descrita. Complementando o trabalho já realizado no TCC anteriormente
mencionado, será realizado um novo estudo dos bancos de dados disponíveis
que oferecem suporte à distribuição de dados para aplicações Web. Finalizando,
será apresentada uma nova proposta de solução de banco de dados distribuídos
para o sistema acadêmico da Udesc. Com relação às etapas de
desenvolvimento, elas são descritas abaixo de acordo com sua ordem de
execução:
1. Estudo do TCC de Alessandra Maria Selhorst [Selhorst, 2005];
2. Levantamento bibliográfico sobre sistemas distribuídos;

107
3. Levantamento bibliográfico sobre banco de dados distribuídos;
4. Desenvolvimento do Capítulo 1, descrevendo sistemas distribuídos e banco de
dados distribuídos;
5. Pesquisa e levantamento de dados sobre o sistema acadêmico da Udesc
(enfatizando o modelo de dados atualmente utilizado);
6. Desenvolvimento do Capítulo 2, sobre o Sigmaweb e seu modelo de dados, e do
Capítulo 3, sobre engenharia reversa para os dados do SigmaWeb;
7. Desenvolvimento do Capítulo 4, descrevendo uma nova proposta de distribuição
de dados para o sistema acadêmico;
8. Estudo das tecnologias de banco de dados disponíveis que oferecem suporte à
distribuição de dados para aplicações Web;
9. Escolha e descrição da tecnologia de banco de dados que será utilizada
(preferencialmente software livre);
10. Desenvolvimento do capítulo 5, descrevendo a tecnologia de banco de dados
escolhida;
11. Desenvolvimento do capítulo 6, descrevendo a nova proposta de solução de
banco de dados distribuídos para o sistema acadêmico da Udesc, utilizando a
tecnologia estudada.
4. Cronograma Proposto
2006
Etapas Março Abril Maio Junho Julho Agosto Setembro Outubro Novembro Dezembro
1
2
3
4
5
6
7
8
9
10
11
12
13

108
5. Linha e Grupo de pesquisa
Grupo de Pesquisa: BDES
6. Forma de Acompanhamento/Orientação
As reuniões serão realizadas uma vez por semana e as dúvidas mais urgentes
serão tiradas por e-mail ou por telefone.
7. Referências Bibliográficas
[SILVA, 2001] Silva, Luciano Carlos da. Banco de Dados para Web: Do
planejamento à implementação. São Paulo: Érica, 2001.
[SELHORST, 2005] Selhorst, Alessandra Maria. Estudo de Soluções de
Bancos de Dados Distribuídos em Aplicações Web. 2005.
[COULOURIS, 2001] Coulouris, G.; Dollimore, J.; Kindberg, Tim (2001).
Distributed Systems: Concepts and Design. 3.ª Edição. Addison-Wesley.
[ÖZSU, 2001] Özsu, M. Tamer; Valduriez, Patrick. Princípios de Sistemas de
Bancos de Dados Distribuídos. Trad. Vandenberg D. de Souza. Rio de Janeiro:
Campus, 2001.
___________________________ ____________________________
Luciana Rita Guedes Diego Vinicius Lima Souza

109
ANEXO 2 MÓDULOS E ROTINAS DO SISTEMA SIGMAWEB

110
MÓDULOS E ROTINAS DO SIGMAWEB 1. Sistema e Estrutural – Neste módulo estão os cadastros das tabelas superiores e da
estrutura do sistema. Ele permite a inserção, exclusão, atualização e consulta dos registros, sendo liberado apenas ao secretário acadêmico e ao pessoal da manutenção e desenvolvimento. 1.1. Cadastro de módulos 1.2. Cadastro de rotinas 1.3. Cadastro da Universidade 1.4. Cadastro de Unidades da Federação 1.5. Cadastro de Campi 1.6. Cadastro de Centros 1.7. Cadastro de Categoria de Usuários 1.8. Cadastro de Situação de Acadêmicos 1.9. Cadastro de Aproveitamentos 1.10. Cadastro de Caráter de Disciplina 1.11. Cadastro de Status 1.12. Cadastro de Tipos de Requerimentos 1.13. Verifica Consistência Arquivos
2. Usuários e Senhas – Aqui se encontram os recursos para administração dos usuários e
suas senhas de acesso. 2.1. Cadastro de Usuários Específicos 2.2. Troca Minha Senha 2.3. Troca Senha de Usuário 2.4. Libera Rotina para Usuário 2.5. Bloqueia/Libera Acesso a Usuário
3. Tabelas Básicas – Neste módulo é realizada a manutenção das tabelas básicas inferiores
àquelas cadastradas no módulo Sistema e Estrutural. 3.1. Cadastro de Horários 3.2. Cadastro de Espaços Físicos 3.3. Cadastro de Departamentos 3.4. Cadastro de Titulações 3.5. Cadastro de Cursos 3.6. Cadastro de Habilitações 3.7. Cadastro de Formas de Ingresso 3.8. Cadastro de Regimes Contratuais
4. Disciplinas e Currículos – Aqui é onde fica o cadastro dos currículos e por isso grande
parte das rotinas fica sob responsabilidade do secretário acadêmico. Este cadastro deve ser extremamente exato, e sugere-se que, quando houver alterações, cadastre-se um novo currículo. O cadastro do currículo deve ser completo, pois cadastros incompletos podem gerar problemas no sistema. 4.1. Cadastro de Disciplinas 4.2. Cadastro de Currículos 4.3. Define Disciplinas de um Currículo 4.4. Define Disciplina Estágio 4.5. Define Disciplina Atividades Programadas

111
4.6. Define Disciplina TCC 4.7. Define Disciplinas Orientadas 4.8. Cadastro de Equivalências 4.9. Define Disciplina de Módulo PR 4.10. Define Pré-Requisitos 4.11. Faz Cópia de um Currículo 4.12. Lista Disciplinas por Departamento 4.13. Lista Currículo 4.14. Número de Acadêmicos por Currículo 4.15. Relação de Acadêmicos por Currículo
5. Acadêmicos – Neste módulo estão as informações sobre os alunos regulares do centro.
5.1. Cadastro de Acadêmicos 5.2. Corrige Nome do Acadêmico 5.3. Consulta Cadastro de Acadêmicos 5.4. Atualiza Endereços 5.5. Registra Falecimento 5.6. Registra Reingresso Após Abandono 5.7. Registra Colação de Grau 5.8. Registra Expedição de Diploma 5.9. Registra Data de Provão 5.10. Prorroga Prazo para Conclusão de Curso 5.11. Acadêmicos por Semestre de Ingresso 5.12. Acadêmicos por Situação 5.13. Número de Acadêmicos por Curso 5.14. Número de Acadêmicos por Semestre 5.15. Acadêmicos com Choque de Horários Liberado 5.16. Prováveis Formandos 5.17. Prováveis Jubilandos 5.18. Situação do Acadêmico por Semestre 5.19. Formados Ordenados por Média 5.20. Base de Dados dos Acadêmicos 5.21. Acadêmicos com Documentos Incompletos 5.22. Relatório para INEP/MEC 5.23. Vagas Disponíveis para Transferências
6. Alunos Visitantes – Módulo para o cadastro de alunos visitantes
6.1. Cadastro de Alunos Visitantes 6.2. Consulta Cadastro de Visitantes 6.3. Efetua/Ajusta Matrículas 6.4. Lista Alunos Matriculados 6.5. Emite Certificado
7. Professores – Módulo para o cadastro dos professores do centro.
7.1. Cadastro de Professores 7.2. Consulta Cadastro de Professores 7.3. Atualiza Endereço 7.4. Lista Professores por Departamento 7.5. Grade de Horários de Professor 7.6. Horários Livres de Professores

112
7.7. Alocação Docente por Semestre 8. Matrículas – Este é o módulo mais pesado do sistema, contendo todas as etapas da
matrícula, desde oferecimento até efetivação e ajustes. 8.1. Oferece Turma/Disciplina 8.2. Aloca Professor de Outro Centro 8.3. Consulta Oferecimento de Disciplina 8.4. Lista Oferecimentos por Departamento 8.5. Lista Turmas/Disciplinas Oferecidas 8.6. Grade de Horários por Fase 8.7. Calcula Escores Ranking Matrícula 8.8. Estabelece Cronograma Matrículas 8.9. Consulta Cronograma de Matrículas 8.10. Consulta Ranking para Matrícula 8.11. Consulta Situação do Acadêmico para Matrícula 8.12. Boletim e Grade de Aptidão 8.13. Efetua/Ajusta Matrícula on-line (Só para acadêmicos) 8.14. Efetua/Ajusta Matrícula on-line 8.15. Tranca Matrícula 8.16. Cancela Trancamento 8.17. Registra Trancamento Antigo 8.18. Cancela Matrícula 8.19. Bloqueia/Libera Pendência Biblioteca 8.20. Bloqueia/Libera Pendência Quimono 8.21. Bloqueia/Libera Pendência Reprovação por Freqüência 8.22. Libera Choque de Horários 8.23. Pesquisa Possibilidade de Troca de Turma 8.24. Horários Livres de uma Turma 8.25. Consulta Demanda em Disciplina 8.26. Saldo de Vagas 8.27. Recalcula Vagas Remanescentes 8.28. Turmas Lotadas 8.29. Consulta Matrícula de Acadêmico 8.30. Relatório de Matrículas 8.31. Analisa Matrículas
9. Matrículas Especiais – Aqui estão os tratamentos das exceções sobre a matrícula.
9.1. Matrícula Disciplina não Curricular 9.2. Matrícula por Mandado Judicial 9.3. Matrícula em Turma de Outro Curso 9.4. Matrícula para Estudos em Outra IES 9.5. Efetua Pré-Matrícula 9.6. Relatório de Pré-Matrículas 9.7. Oferece Cursos de Férias 9.8. Matrícula em Cursos de Férias 9.9. Recebe Diários Cursos de Férias
10. Diários de Classe – Este módulo serve para a emissão, preparação, recepção de notas e
freqüências, e divulgação dos resultados. É importante lembrar que as notas devem ser lançadas sem o ponto decimal.

113
10.1. Consulta Diário 10.2. Diários Agrupados para Impressão 10.3. Emite Etiquetas 10.4. Faz Apontamentos de Aula no Diário 10.5. Lança Notas de Avaliações 10.6. Recebe Diários de Classe 10.7. Controle de Recepção dos Diários 10.8. Consulta Notas e Freqüências 10.9. Publicação de Aproveitamentos 10.10. Correção Posterior ao Fechamento 10.11. Relatório de Aproveitamentos 10.12. Turmas sem Alocação Docente 10.13. Monta Diários Semestre Implantação
11. Estágio, Monografia e Outros – Aqui são registradas as disciplinas que exigem
tratamentos específicos, como o Estágio e o TCC. 11.1. Registra Estágio de Acadêmico 11.2. Relatórios Acadêmicos em Estágio 11.3. Estabelece Bancas de Defesa de Estágio 11.4. Lista Bancas de Defesa de Estágio 11.5. Registra Resultados de Estágios 11.6. Participações em Bancas de Estágio 11.7. Registra Pré-projeto TCC 11.8. Relatórios Pré-projetos Entregues 11.9. Estabelece Bancas de Defesa de TCC 11.10. Lista Bancas de Defesa de TCC 11.11. Registra Resultados de TCC 11.12. Registra Atividades Programadas 11.13. Registra Disciplinas Orientadas
12. Históricos Escolares – Neste módulo são realizados os lançamentos e as consultas nos
históricos. 12.1. Registra/Corrige Dispensa em Disciplina 12.2. Lista Histórico Escolar 12.3. Lista Histórico Escolar Oficial 12.4. Registra Dispensa não Aproveitada 12.5. Lança Histórico Anterior à Implantação 12.6. Registra Dispensa Anterior à Implantação 12.7. Faz Equivalência Especial
13. Atestados e Requerimentos – Aqui são emitidos atestados e requerimentos. Também é verificado quem pode solicitar que tipo de requerimento. 13.1. Novo Requerimento ou Recuperação 13.2. Reimprime Requerimento 13.3. Requerimentos Emitidos por Semestre 13.4. Requerimentos Emitidos por Tipo 13.5. Requerimentos Emitidos por Acadêmico

114
14. Ciclo Semestral – Este é um módulo exclusivo de controle acadêmico. 14.1. Implanta Ciclo em Centro 14.2. Consulta Situação Atual 14.3. Troca Ciclo Semestral

115
ANEXO 3 TABELAS DO BANCO DE DADOS DO SIGMAWEB

116
ANEXO 4 MODELO ENTIDADE-RELACIONAMENTO DO
SIGMAWEB


















