
SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH CASSIANO … · 2 Campo Grande, 25 a 28 de julho de 2009,...
21
PREVISÃO DE PREÇOS FUTUROS DE CAFÉ UTILIZANDO MODELOS DE SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH [email protected] APRESENTACAO ORAL-Comercialização, Mercados e Preços CASSIANO BRAGAGNOLO; ALEXANDRE HATTNHER MENEGÁRIO; VITOR AUGUSTO OZAKI. ESALQ/USP, PIRACICABA - SP - BRASIL. PREVISÃO DE PREÇOS FUTUROS DE CAFÉ UTILIZANDO MODELOS DE SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH (PREDICTION OF COFFEE FUTURES PRICES USING TIME SERIES MODELS ARIMA AND ARFIMA–GARCH) Grupo de Pesquisa: Comercialização, mercados e preços Resumo Valendo-se dos dados da BM&F para contratos futuros de café para o período compreendido entre dezembro de 1999 e maio de 2004, utilizados anteriormente por Lima et al (2007), este artigo teve por objetivo estimar modelos de previsão de séries temporais ARIMA e ARFIMA– GARCH, com lambda determinado de forma conjunta e separada e buscando comparar os resultados obtidos com os alcançados pelos autores mencionados. Os resultados obtidos neste trabalho divergiram bastante dos encontrados por Lima et al. (2007), principalmente no que tange aos modelos estimados. O modelo mais bem ajustado, segundo o critério de menor Erro Quadrático Médio foi, também, bastante diferente do artigo original. A principal divergência entre as conclusões alcançadas neste trabalho e as de Lima et al. (2007) foi a de que neste não houve diferença entre os modelos ARIMA–GARCH e ARFIMA–GARCH, enquanto Lima et al. (2007) encontraram qualidade de previsão significativamente melhor para os modelos com diferenciação fracionária. Palavras-chaves: Modelos de previsão, Séries Temporais, Mercados Futuros, Café Abstract Making use of data from the BM&F futures contracts for coffee in the period between December 1999 and May 2004, used previously by Lima et al (2007), this paper aimed at estimating models for forecasting time series models ARIMA and ARFIMA–GARCH, with lambda determined jointly and separately. The results obtained in this study differed widely from those found in Lima et al. (2007), mainly regarding to the estimated models. The main difference between the conclusions reached in this work and those of Lima et al. (2007) was the fact that, in the first, there was no significant difference between the predictions made by
Transcript of SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH CASSIANO … · 2 Campo Grande, 25 a 28 de julho de 2009,...

PREVISÃO DE PREÇOS FUTUROS DE CAFÉ UTILIZANDO MODEL OS DE
SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH [email protected]
APRESENTACAO ORAL-Comercialização, Mercados e Preços
CASSIANO BRAGAGNOLO; ALEXANDRE HATTNHER MENEGÁRIO; VITOR AUGUSTO OZAKI.
ESALQ/USP, PIRACICABA - SP - BRASIL.
PREVISÃO DE PREÇOS FUTUROS DE CAFÉ UTILIZANDO MODEL OS DE SÉRIES TEMPORAIS ARIMA E ARFIMA–GARCH
(PREDICTION OF COFFEE FUTURES PRICES USING TIME SERIES MODELS
ARIMA AND ARFIMA–GARCH)
Grupo de Pesquisa: Comercialização, mercados e preços Resumo Valendo-se dos dados da BM&F para contratos futuros de café para o período compreendido entre dezembro de 1999 e maio de 2004, utilizados anteriormente por Lima et al (2007), este artigo teve por objetivo estimar modelos de previsão de séries temporais ARIMA e ARFIMA–GARCH, com lambda determinado de forma conjunta e separada e buscando comparar os resultados obtidos com os alcançados pelos autores mencionados. Os resultados obtidos neste trabalho divergiram bastante dos encontrados por Lima et al. (2007), principalmente no que tange aos modelos estimados. O modelo mais bem ajustado, segundo o critério de menor Erro Quadrático Médio foi, também, bastante diferente do artigo original. A principal divergência entre as conclusões alcançadas neste trabalho e as de Lima et al. (2007) foi a de que neste não houve diferença entre os modelos ARIMA–GARCH e ARFIMA–GARCH, enquanto Lima et al. (2007) encontraram qualidade de previsão significativamente melhor para os modelos com diferenciação fracionária. Palavras-chaves: Modelos de previsão, Séries Temporais, Mercados Futuros, Café Abstract Making use of data from the BM&F futures contracts for coffee in the period between December 1999 and May 2004, used previously by Lima et al (2007), this paper aimed at estimating models for forecasting time series models ARIMA and ARFIMA–GARCH, with lambda determined jointly and separately. The results obtained in this study differed widely from those found in Lima et al. (2007), mainly regarding to the estimated models. The main difference between the conclusions reached in this work and those of Lima et al. (2007) was the fact that, in the first, there was no significant difference between the predictions made by

2 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
ARIMA–GARCH and ARFIMA–GARCH, while Lima et al. (2007) found significantly better prediction for the models with fractional differentiation. Key-words: Prediction models, Time Series, Future markets, Coffee 1. Introdução
Uma série de trabalhos tem sido publicada envolvendo previsão de preços futuros
de commodities agrícolas com a utilização de modelos de séries temporais, como é o caso do artigo de Bressan (2004). Lima et al. (2007), no entanto, foram um dos poucos a comparar estimativas de previsão de preços futuros agrícolas, mediante a aplicação de modelos de séries temporais com diferenciações inteira e fracionária.
Para tanto, Lima et al. (2007) partiram das séries de dados originais de contratos futuros de açúcar, boi gordo, café, milho e soja, aplicando transformação logarítmica e, depois, uma diferença, para chegar às séries de retornos e, então, estimar modelos ARMA (auto-regressivos de médias móveis), como termo de comparação com os modelos ARFIMA (auto-regressivos fracionários integrados de médias móveis). Em ambos os casos, os erros foram modelados com uma estrutura GARCH (heteroscedasticidade condicional auto-regressiva generalizada). O poder de previsão de cada modelo foi comparado pelo critério do Erro Quadrático Médio (EQM). A estimação do termo de diferenciação fracionária (d) também foi utilizada para examinar as características de longa dependência das séries em questão.
Os resultados mostraram indícios de que a dependência temporal entre as observações das séries de retorno de preços futuros pode ser função do tipo de ativo examinado, no caso, commodities agrícolas. Isso significa que, para os ativos em que a resposta da oferta é mais rápida, as características de longa dependência tenderiam a ser de natureza antipersistente, do contrário, haveria uma maior dependência entre as observações não contemporâneas.
O modelo ARFIMA foi o que apresentou o melhor poder de previsão, segundo o critério do Erro Quadrático Médio, em comparação ao modelo ARMA, à exceção da série de soja. O valor do d fracionário da série de açúcar indicou um comportamento de antipersistência a choques, enquanto que esses valores para as demais commodities apresentaram comportamento persistente.
A quantidade de ordenadas harmônicas de baixa freqüência, representada pelo valor da estatística d, não mudou a classificação de dependência das séries, assim como não houve alteração significativa na eficiência do modelo ARFIMA no que se refere a seu poder de previsão, devido ao mesmo motivo.
Este artigo tem por objetivo estimar modelos de previsão de séries temporais ARIMA e ARFIMA–GARCH, com lambda determinado de forma conjunta e separada, utilizando-se as mesmas séries de dados da BM&F para café de Lima et al. (2007) e buscando comparar os resultados obtidos com os alcançados por aqueles autores. Além disso, ao invés de utilizar única e exclusivamente o critério de menor erro quadrado médio, optou-se por fazer uma análise conjunta do Critério de Informação de Akaike (AIC), Erro Quadrático Médio (EQM) e significância dos parâmetros estimados (estatística t dos parâmetros).
O presente trabalho está estruturado da seguinte forma: a seção 2 discutirá os modelos utilizados, com destaque para o ARFIMA e a modelagem de erros com estrutura GARCH; a seção 3 apresentará com mais detalhes os processos de identificação e estimação, além dos testes realizados; a seção 4 mostrará os resultados obtidos, sua interpretação,

3 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
discussão e, principalmente, a comparação com aqueles obtidos no artigo de Lima et al. (2007); por fim, a seção 5 apresentará as conclusões. 2. Modelos de Séries Temporais com Diferenciações Inteira e Fracionária 2.1. Os modelos ARIMA(p,d,q) e ARMA(p,q)
Os modelos de séries temporais do tipo ARIMA, auto-regressivos integrados de
médias móveis, são usados nos casos em que se supõem graus de diferenciação inteiros, baseado na formulação descrita a seguir, extraída de Morettin e Toloi (2006):
∅����1 − ����� − � = ���� , ~ �0, ���� (1) em que � é a série temporal, é a média da série, é o termo aleatório, com média zero e variância constante �����, �1 − �� é o operador de diferença, ∅��� = �1 − ∅��−. . . −∅���� e ���� = �1 − ���−. . . −�����. Escreve-se ARIMA(p,d,q), onde p e q são as ordens de ∅��� e ����, respectivamente. Nesse modelo, todas as raízes de ∅��� estão fora do círculo unitário.
O modelo acima também pode ser escrito da seguinte forma: ������ − � = ���� (2)
em que ���� é um operador auto-regressivo, não-estacionário, de ordem p + d, com d raízes iguais a um (sobre o círculo unitário) e as restantes p fora do círculo unitário.
Assim, o modelo descrito por meio da equação (1) supõe que a d-ésima diferença da série Zt pode ser representada por um modelo ARMA(p,q), estacionário e invertível. Morettin e Toloi (2006) afirmam que, usualmente, o grau de diferenciação d dos modelos ARIMA é um ou dois, fato esse corroborado por outros autores, como Pindyck e Rubinfeld (1991). 2.2. O modelo ARFIMA(p,d,q)
De acordo com Morettin e Toloi (2006), um processo de memória longa é um processo estacionário cuja função de autocorrelação decresce hiperbolicamente. As autocorrelações da série original indicam estacionariedade, enquanto a série diferençada pode parecer ser super-diferençada.
Procurando respeitar as características de uma série de memória longa, houve, no decorrer do tempo, a definição de dois modelos importantes: primeiro, foi introduzido o ruído gaussiano fracionário por Mandelbrot e Van Ness (1968); mais tarde, Granger e Joyeux (1980) e Hosking (1981) introduziram o modelo ARIMA fracionário (ou ARFIMA), que é uma generalização do modelo ARIMA.
Há estudos recentes incorporando memória longa a processos GARCH, nos processos denominados FIGARCH (heteroscedasticidade condicional auto-regressiva generalizada, integrada fracionariamente), introduzidos por Baillie at al. (1996).
Para qualquer número real d > –1, define-se o operador de diferença fracionária a partir da seguinte relação:
�1 − ��d= ∑ �� ! �−��" = 1 − �� + ��! ��� − 1��� − �
%! ��� − 1��� − 2��%+. . .∞k=0 (3)

4 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
Dizemos que uma série temporal Zt é um processo auto-regressivo fracionário
integrado de médias móveis, ou ARFIMA(p,d,q) com d ∈ (-½,½), se Zt for estacionário e satisfizer a relação abaixo, que é uma simplificação do modelo descrito na equação (1):
∅����1 − ����( = ���� (4) em que �( = �� − �, at é ruído branco e ∅��� e ���� são polinômios em B, de graus p e q, respectivamente.
A razão da escolha dessa família de processos, para fins de modelagem das séries com comportamento de memória longa, é que o efeito do parâmetro d em observações distantes decai hiperbolicamente conforme a distância aumenta, enquanto os efeitos dos parâmetros de B decaem exponencialmente. Então, d deve ser escolhido com o objetivo de explicar a estrutura de correlação de ordens altas da série enquanto os parâmetros ∅ e � explicariam a estrutura de correlação de ordens baixas.
Hosking (1981) demonstrou que o processo ARFIMA(p,d,q), dado por (4) é: i) estacionário se d < ½ e todas as raízes de ∅��� = 0 estiverem fora do círculo
unitário; ii) invertível se d > –½ e todas as raízes de θ�b� = 0 estiverem fora do círculo
unitário. A função de autocorrelação (fac) do processo decai mais lentamente do que
geometricamente para qualquer d diferente de zero. Ainda de acordo com Hosking (1981), quando –0,5 < d <0,5, a série é estacionária e invertível. Se d = 0, então o processo é um ruído branco estacionário com memória curta. Quando d = 1, o processo tem raiz unitária com variância infinita. Se d = 0,5, então a série é invertível, mas não-estacionária. Se d = –0,5, então a série é estacionária, mas não invertível. Se 0 < d < 0,5, então as autocorrelações são positivas e a função de autocorrelação (fac) diminui monotonicamente e hiperbolicamente em direção a zero. A correlação entre observações distantes pode ser relativamente alta, o que implica que existe memória de longo prazo. Se 0,5 ≤ d < 1, o processo ainda tem memória longa, mas com variância indefinida. Se –0,5 < d < 0, então o processo tem memória curta e é antipersistente. Por fim, processos com –1 < d ≤ –0,5 são atípicos em dados econômicos.
De acordo com Baillie et al(1996), existem dois métodos para estimar o parâmetro d: estimação por máxima verossimilhança e semi-paramétrica no domínio da freqüência ou estimação por métodos semi-paramétricos no domínio do tempo.
A função de verossimilhança de � = ���, … , �,� proveniente de um processo ARFIMA(p,d,q) pode ser expressa da seguinte forma:
��η, ���� = �2-����., �/ �01 … 0,.��.� �/ 23. ��456 ∑ 789.8:9;9<= >?9@= A
Os estimadores de máxima verossimilhança dos parâmetros são dados por: �BC� = D.�E�ηFBC�
em que E�GIJ� = ∑ ��K − �LK�� 0K.�/,KM� e ηFBC é o valor de η que minimiza ℓ�G� =ND�E�G�|D� + D.� ∑ ND 0K.�,KM�
Entretanto, o cálculo de ℓ�G� é bastante lento. Um procedimento alternativo seria considerar uma aproximação para ℓ�G� dada por:

5 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
ℓ�G� ≅ ℓ∗�G� R S,�TK�2-U�TK; G�,
KM�
em que:
S,�TK� = 1D WR �2.XY9,
M�W
�
é o periodograma dos dados, e:
U�TK; η� = ���2π Z1 − θ�2.XY9 − ⋯ − θ\2.�XY9Z�Z1 − ∅�2.XY9 − ⋯ − ∅]2.�XY9Z� Z1 − 2.XY9Z.�
é a função densidade espectral do processo � e K é a soma sobre todas as freqüências de Fourier, TK = 2-_ D⁄ ∈ �−-, -].
Hannan (1973) e Fox e Taqqu (1986) mostraram que: i) o estimador GIJ é consistente;
ii) se d > 0, GIJ b→ d�G, D.�e.��G�); em que e�G� é uma matriz de ordem (p+q+1) x (p+q+1) com o (j,k)-ésimo elemento dado por:
eK"�G� = 14- g hNDU�i; G�hGKhNDU�i; G�hG" �ij
.j
iii) a variância é estimada por:
�BC� = D.� R S,�TK�2πf�wm; η�m
Um método para estimação do parâmetro de memória longa foi proposto por
Geweke e Porter-Hudak (1983) e se baseia na equação que exibe a relação entre a função densidade espectral de um processo ARFIMA(p,d,q) e de um processo ARMA(p,q). Tal equação foi reescrita para que se assemelhasse a uma equação de regressão linear, onde o coeficiente de inclinação é dado por b = –d. De uma maneira simplificada, o processo de formação desse método é relatado a seguir:
Considera-se a função densidade espectral do processo �, que é um ARFIMA(p,d,q):
Un�i� = Z1 − 2.XoZ.��Up�i� (5)

6 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
em que Up�i� = 456�πZθ�q<rs�Z6Zϕ�q<rs�Z6 é a função densidade espectral do processo t = �1 − ����
que é um ARMA(p,q). Multiplicando ambos os lados de (5) por Up�0� e aplicando o logaritmo, obtém-se:
NDUn�i� = NDUp�0� − �NDZ1 − 2.XoZ� + ND �uv�o�uv�1�! (6)
Substituindo i por iK = 2-_ D⁄ e adicionando NDSn�iK�, em que Sn�iK� =
�2-D�.�Z∑ w2xy �−ziK{�,M� Z� , em ambos os lados de (6), tem-se:
NDSn�i� = NDUp�0� − �ND |4}2D� �o9� !~ + ND �uv�o9�uv�1� ! + ND |���o9�
u��o9�~ (7)
em que, novamente, Sn�i� é o periodograma dos dados e, além de ser um estimador de
Un�iK�. O termo ND �uv�o9�uv�1� ! pode ser desprezado quando se considerar apenas as freqüências iK
próximas de zero. Assim, pode-se reescrever (7) como um modelo de regressão linear, conforme abaixo: �K = − �wK + �K , _ = 1, … , � (8) em que: �K = NDSn�i� wK = ND |4}2D� �o9� !~
�K = ND |���o9�u��o9�~
= NDUp�0� m = n� , 0 < α < 1
A relação linear (8) sugere a utilização de um estimador de mínimos quadrados
para d, conforme a equação (9) a seguir:
�LI� = − ∑ ��r.�� ���r.�� ��r@=∑ ��r.�� �6�r@= (9)
A partir da estimação de d por meio de (9) pode-se, agora, identificar e estimar os
parâmetros do processo livre de componente de longa memória, t = �1 − ���� . Para isso utiliza-se o seguinte procedimento:
i) primeiro, calcula-se a transformada discreta de Fourier da série original �:
�8�iX� = R �2.or, iX = 2-XD , z = 0, … , D − 1,
M�
ii) segundo, calcula-se:
���iX� = �1 − 2.Xor�.�:���8�iX�, z = 0, … , D − 1

7 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
Brockwell e Davis (1991) demonstraram que ���iX� é, aproximadamente, a transformada de Fourier da série filtrada t = �1 − ���:��� .
iii) calcula-se, então, a transformada inversa de Fourier:
t� = 1D R 2XY9���iK�,.�
KM1
em que t� é uma estimativa da série livre da componente de longa memória, t
iv) utilizam-se as fac e facp de t� para identificar os parâmetros p e q; v) por fim, estimam-se os parâmetros ��, … , ��, ��, … , �� , ��� 2 �,
conjuntamente, utilizando o método de máxima verossimilhança. A vantagem da utilização desse procedimento é a possibilidade de se estimar d
sem conhecer os valores de p e q. À série t, pode-se aplicar as ferramentas de identificação adequadas aos processos ARMA(p,q) e, finalmente, utilizar o método de máxima verossimilhança para estimar todos os parâmetros do modelo ARFIMA(p,d,q). 2.3. Modelagem da volatilidade do erro – modelos ARCH(r) e GARCH(r,s)
De acordo com Lima et al. (2007), os modelos de séries temporais do tipo ARIMA ou ARMA assumem que a variância da série Zt é constante. Essa suposição, no entanto, pode ser restritiva, especialmente no caso de séries de preços do mercado financeiro
Corroborando essa idéia, Hamilton e Susmel (1994) afirmam que a volatilidade é uma característica dos mercados financeiros, ainda que não esteja presente o tempo todo. Descrever como essa volatilidade varia no tempo é importante por duas razões: i) primeiro, o risco de um ativo financeiro é um importante determinante de seu preço; ii) segundo, uma inferência econométrica eficiente sobre a média condicional de uma variável requer uma correta especificação de sua variância condicional.
Engle (1982) propôs considerar, no processo de estimação, uma modelagem do erro com estrutura denominada ARCH (heteroscedasticidade condicional auto-regressiva), para o caso de haver uma relação entre erro quadrado do modelo e seus valores defasados. Denomina-se ARCH(r) e sua especificação encontra-se descrita abaixo:
ℎ = �1 + ∑ �X;XM� .X� (10) em que: = ��ℎ em que �1 e �� são os parâmetros e εt é o termo aleatório.
Bollerslev (1986) foi o responsável por introduzir a especificação GARCH, uma generalização do modelo proposto por Engle (1982), e que permite uma estrutura de defasagem flexível, ao contrário do modelo ARCH. Um dos benefícios desse modelo GARCH é traduzir de forma mais parcimoniosa que no modelo ARCH a dependência temporal da variância condicional, já que esse último apresentava, em muitos casos, a necessidade de se introduzir grandes valores para r, a fim de evitar o aparecimento de variâncias negativas. Assim, a especificação do modelo GARCH ficaria conforme demonstrado a seguir:

8 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
ℎ = �1 + R �X;
XM� .X� + R �K
�
KM�ℎ.K
em que .X� é o termo ARCH (valores defasados do erro quadrado), já descrito em (10) e ℎ.K é o termo GARCH (valores defasados da variância) e cuja denominação seria apresentada como GARCH(r,s). 2.4. O Modelo ARFIMA(p,d,q)–GARCH(r,s)
Considerando os modelos ARFIMA e GARCH descritos nas seções anteriores, um modelo ARFIMA–GARCH utiliza modelagem GARCH para medir a volatilidade condicional e um modelo ARFIMA para a média condicional. Um processo ARFIMA (p,d,q)–GARCH (r,s) pode ser representado conforme abaixo:
∅����1 − ����( = ���� em que: = ��ℎ ℎ = �1 + ∑ �X;XM� .X� + ∑ �K�KM� ℎ.K ~���0, ����, �~z. z. �. �0,1�, �1 > 0, �X ≥ 0, �K ≥ 0, ∑ ��X +�XM��z<1, �=� x},0, �� 2 ���� são polinômios em B, de graus p e q, respectivamente, no qual B representa o operador de translação.
Nesta pesquisa estes parâmetros serão estimados de duas formas distintas. Inicialmente, modelar-se-á o valor d fracionário do processo ARFIMA, de acordo com a regressão espectral, para diferentes valores de α e, consequentemente, diferentes ordens harmônicas. Em seguida obter-se-á o processo ARMA–GARCH por meio da série diferenciada fracionariamente para cada um dos valores α. Esta análise tem como objetivo testar a sensibilidade de d com relação ao número de ordenadas harmônicas. Neste trabalho, a exemplo do contido em Lima et al. (2007), α assumirá os valores 0,500, 0,555 e 0,600.
A segunda forma de estimação utilizada ocorrerá por meio da obtenção conjunta dos parâmetros do modelo ARFIMA–GARCH, seguindo, de acordo com Bayer (2008), a tendência de estudos recentes que demonstram as vantagens desta estimação simultânea dos coeficientes do modelo. 3. Estratégia Empírica 3.1. Base de dados e aplicativo computacional utilizado
A fim de permitir a comparação com o artigo original de Lima et al., 2007, foram utilizados os mesmos dados de contratos futuros negociados na Bolsa de Mercadorias e Futuros (BM&F) para o café, considerando os mesmos períodos daquele trabalho, conforme descrito na tabela 1.
Tabela 1. Contratos futuros analisados.
Commodity Período considerado
Início Fim

9 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
Café 08/12/1999 24/05/2004
As previsões também foram realizadas para o mesmo período do artigo original, de 25/05/2004 a 07/06/2004.
Os dados foram analisados e os resultados estimados por meio do aplicativo computacional “R” (R FOUNDATION FOR STATISTICAL COMPUTING, 2009). 3.2. Processo de identificação/estimação dos modelos ARMA(p,q)–GARCH(r,s)
A partir das séries originais foram obtidas as séries de retorno. Segundo Enders (2003), as séries de retorno (r t) são construídas a partir da seguinte relação:
r t = ln[(Série original)t / (Série original)t-1]
Tal construção equivale também a transformar a série original, mediante aplicação
de logaritmo, tomando em seguida uma diferença, tendo, por objetivo, torná-la estacionária. Para comprovar referida estacionariedade, foi realizado, da mesma maneira que no artigo original – Lima et al., 2007, o teste estatístico Dickey-Fuller Aumentado (ADF), cuja regra de decisão é: H0 : estacionariedade; H1 : não-estacionariedade.
A finalidade do teste ADF é definir o nível de diferenciação inteira (d) do modelo ARIMA(p,d,q). No caso de d = 0, o modelo será estimado como um ARMA(p,q), como no presente estudo.
O passo seguinte é a identificação do modelo ARMA, definindo suas ordens, quanto à memória auto-regressiva (p) e de média móvel (q). Para tanto, selecionam-se os modelos de melhor ajuste usando-se estatísticas como o Critério de Informação de Akaike (AIC), Critério Bayesiano de Schwartz (SBC) e a estatísticas Q de Box-Pierce-Ljung. No presente estudo, decidiu-se pela utilização do Critério de Informação de Akaike (AIC), um dos mais utilizados em estudos empíricos que tratam do assunto e cujos resultados são fornecidos automaticamente pelo aplicativo computacional “R”, lembrando que quanto menor o valor de AIC, melhor o ajuste do modelo. Além do AIC, levou-se em consideração o Erro Quadrático Médio (EQM) e a significância dos parâmetros (estatística t dos parâmetros).
Identificado o modelo ARMA com o melhor ajuste, partiu-se para a identificação do modelo ARMA–GARCH, da mesma maneira descrita para o modelo ARMA, estimando-se os respectivos parâmetros e verificando sua significância.
Com relação aos testes estatísticos, foram realizados três deles, conforme descrito abaixo:
i) o primeiro, conhecido como teste de Shapiro e Wilk, citado em Shapiro et al. (1968), permite testar se os resíduos da série seguem uma distribuição normal;
ii) o segundo deles, o teste do Multiplicador de Lagrange (LM), descrito por Engle (1982), é utilizado para testar a hipótese nula de que a variância dos erros é constante, ��� = �1, contra a hipótese alternativa de que os erros seguem um processo ARCH:
H0 : �� = �� =. . . = �; = 0 H1 : �X ≠ 0, para pelo menos algum z = 1, … , 0;
iii) o terceiro é o Q-teste de Ljung-Box, descrito em Enders (1995), que tem por objetivo testar a hipótese nula de que os erros seguem uma estrutura ARCH, contra a hipótese alternativa de que os erros são do tipo GARCH:

10 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
H0 : �� = �� =. . . = �� = 0 H1 : �K ≠ 0, para pelo menos algum _ = 1, … , }.
3.3. Processo de identificação/estimação dos modelos ARFIMA(p,d,q)–GARCH(r,s)
No caso dos modelos ARFIMA, partiu-se das séries de retorno direto para a identificação do modelo, definindo o grau de diferenciação fracionária e suas ordens, quanto à memória auto-regressiva (p) e de média móvel (q). Da mesma maneira que nos modelos ARMA, selecionou-se os modelos de melhor ajuste usando-se o Critério de Informação de Akaike (AIC).
Identificado o modelo ARFIMA com o melhor ajuste, partiu-se para a identificação do modelo ARFIMA–GARCH, da mesma maneira descrita para o modelo ARMA–GARCH, estimando-se os respectivos parâmetros e verificando sua significância.
Com relação aos testes estatísticos, da mesma maneira que no modelo ARMA–GARCH, foram realizados três deles, conforme descrito abaixo:
i) o primeiro, conhecido como teste de Shapiro e Wilk, citado em Shapiro et al. (1968), permite testar se os resíduos da série seguem uma distribuição normal;
ii) o segundo deles, o teste do Multiplicador de Lagrange (LM), descrito por Engle (1982), é utilizado para testar a hipótese nula de que a variância dos erros é constante, ��� = �1, contra a hipótese alternativa de que os erros seguem um processo ARCH:
H0 : �� = �� =. . . = �; = 0 H1 : �X ≠ 0, para pelo menos algum z = 1, … , 0;
iii) o terceiro é o Q-teste de Ljung-Box, descrito em Enders (1995), tem por objetivo testar a hipótese nula de que os erros seguem uma estrutura ARCH, contra a hipótese alternativa de que os erros são do tipo GARCH:
H0 : �� = �� =. . . = �� = 0 H1 : �K ≠ 0, para pelo menos algum _ = 1, … , }.
3.4. Verificação do poder de previsão dos modelos ARMA(p,q)–GARCH(r,s) e ARFIMA(p,q)–GARCH(r,s)
Conforme já mencionado no item 3.1, as previsões foram realizadas para o período de 25/05/2004 a 07/06/2004.
Para se comparar os modelos ARMA(p,q)–GARCH(r,s) e ARFIMA(p,q)–GARCH(r,s) identificados, quanto a seu poder de previsão, utilizou-se o critério do Erro Quadrático Médio (EQM), calculado da seguinte forma:
�� = 1D R¡�¢£ − �L�ℎ�¤�,
£M�
em que h representa o período de previsão além do tempo t e n o número de observações da previsão. Em sendo uma previsão “out-of-sample”, �¢£ seria o conjunto de observações da série, além do tempo t, e �L�ℎ� os valores previstos do modelo referente a essa mesma série, calculado conforme abaixo, segundo Morettin e Toloi (2006): �L�ℎ� = ��¥�¢£.�]+. . . +��¢�¡�¢£.�.�¤ − ��¥ ¢£.�]−. . . −��¡ ¢£.�¤ + ¥ ¢£]
11 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
Assim, o melhor modelo, quanto ao poder de previsão, será aquele que apresentar
o menor EQM da previsão, o menor AIC e apresentar parâmetros significativos. 4. Resultados e discussão
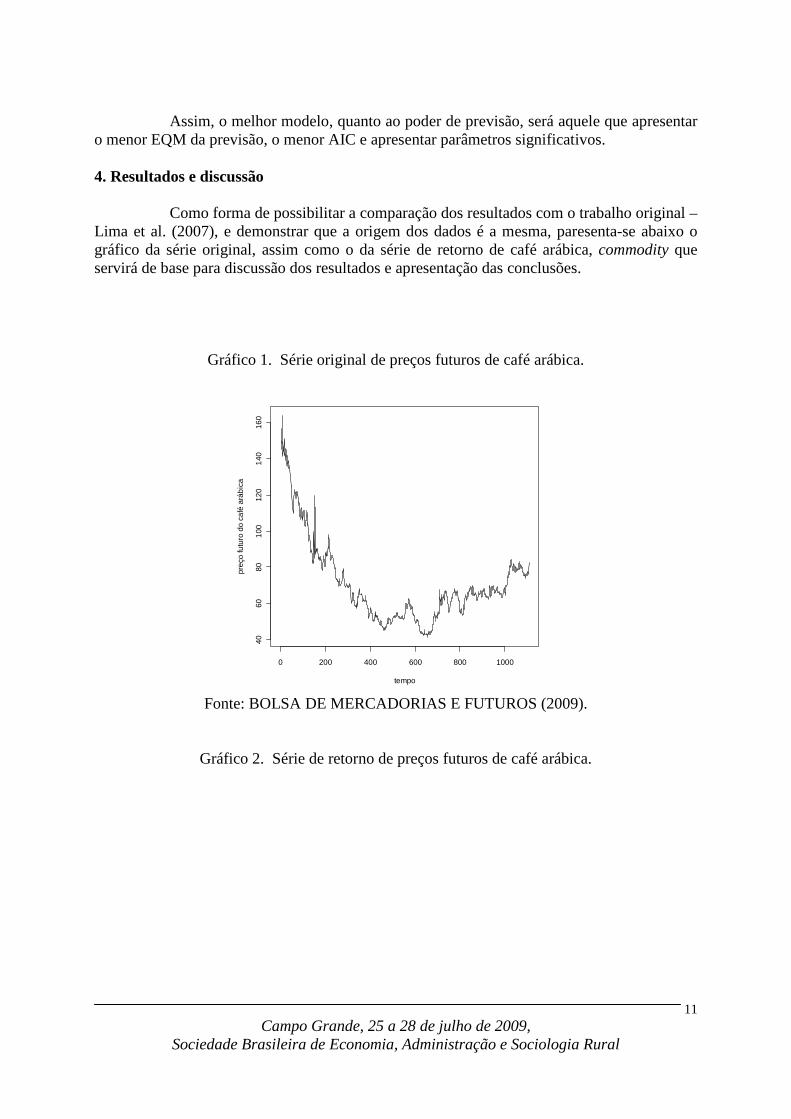
Como forma de possibilitar a comparação dos resultados com o trabalho original – Lima et al. (2007), e demonstrar que a origem dos dados é a mesma, paresenta-se abaixo o gráfico da série original, assim como o da série de retorno de café arábica, commodity que servirá de base para discussão dos resultados e apresentação das conclusões.
Gráfico 1. Série original de preços futuros de café arábica.
Fonte: BOLSA DE MERCADORIAS E FUTUROS (2009).
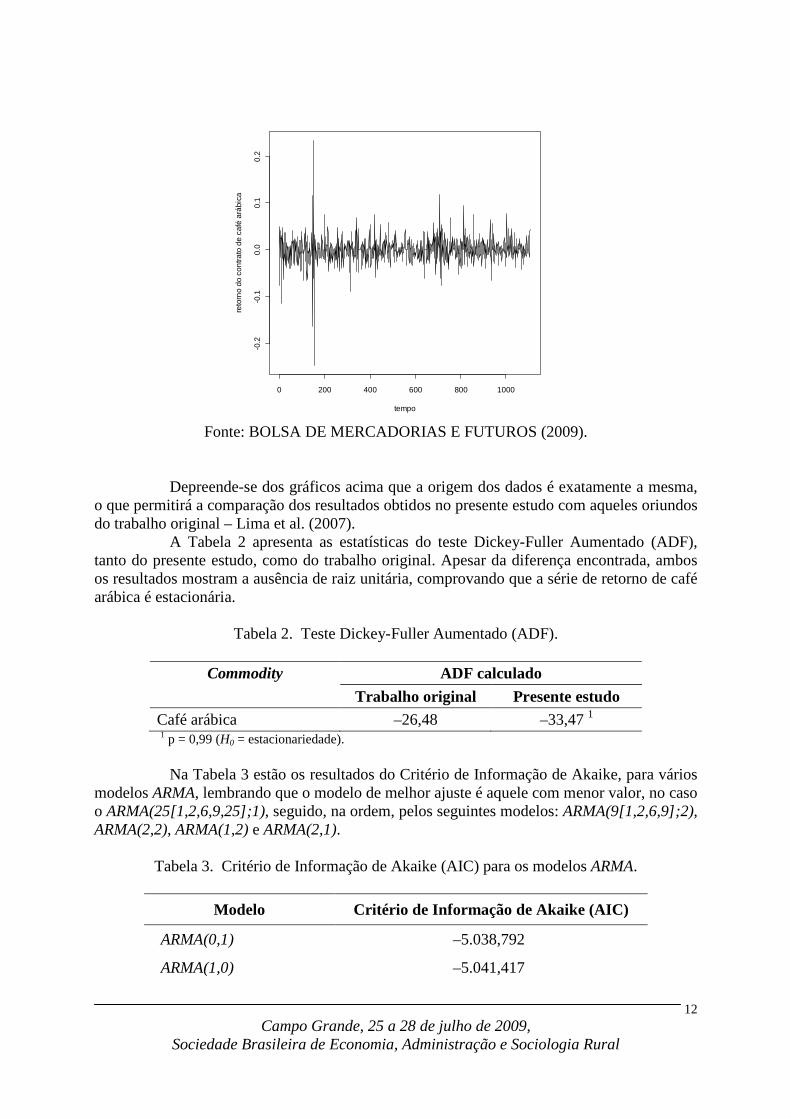
Gráfico 2. Série de retorno de preços futuros de café arábica.
tempo
preç
o fu
turo
do
café
ará
bica
0 200 400 600 800 1000
4060
8010
012
014
016
0
12 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
Fonte: BOLSA DE MERCADORIAS E FUTUROS (2009).
Depreende-se dos gráficos acima que a origem dos dados é exatamente a mesma, o que permitirá a comparação dos resultados obtidos no presente estudo com aqueles oriundos do trabalho original – Lima et al. (2007).
A Tabela 2 apresenta as estatísticas do teste Dickey-Fuller Aumentado (ADF), tanto do presente estudo, como do trabalho original. Apesar da diferença encontrada, ambos os resultados mostram a ausência de raiz unitária, comprovando que a série de retorno de café arábica é estacionária.
Tabela 2. Teste Dickey-Fuller Aumentado (ADF).
Commodity ADF calculado
Trabalho original Presente estudo Café arábica –26,48 –33,47 1
1 p = 0,99 (H0 = estacionariedade).
Na Tabela 3 estão os resultados do Critério de Informação de Akaike, para vários modelos ARMA, lembrando que o modelo de melhor ajuste é aquele com menor valor, no caso o ARMA(25[1,2,6,9,25];1), seguido, na ordem, pelos seguintes modelos: ARMA(9[1,2,6,9];2), ARMA(2,2), ARMA(1,2) e ARMA(2,1).
Tabela 3. Critério de Informação de Akaike (AIC) para os modelos ARMA.
Modelo Critério de Informação de Akaike (AIC)
ARMA(0,1) –5.038,792
ARMA(1,0) –5.041,417
tempo
reto
rno
do c
ontra
to d
e ca
fé a
rábi
ca
0 200 400 600 800 1000
-0.2
-0.1
0.0
0.1
0.2
13 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
ARMA(1,1) –5.043,867
ARMA(1,2) –5.056,907
ARMA(2,1) –5.056,667
ARMA(2,2) –5.059,560
ARIMA(1,1,2) –5.030,456
ARIMA(2,1,1) –5.044,634
ARIMA(2,1,2) –5.043,802
ARMA(9[1,2,6,9],2) –5.070,530
ARMA(25[1,2,6,9,25],1) –5.078,590 * * Menor valor.
A Tabela 4 mostra os valores do Critério de Informação de Akaike (AIC) e Erro Quadrático Médio (EQM) da previsão (“out-of-sample”), para vários modelos ARMA–GARCH, partindo dos modelos ARMA com o melhor ajuste, segundo o Critério de Informação de Akaike (AIC), conforme citado no parágrafo anterior. Cabe ressaltar que o Erro Quadrático Médio (EQM) também foi usado como critério para escolha dos modelos no trabalho original – Lima et al. (2007).
Tabela 4. AIC e EQM para os modelos ARMA–GARCH.
Modelo AIC EQM previsão
ARMA(1,2)–GARCH(1,1) –4,812999 4,133699x10-4
ARMA(2,1)–GARCH(1,0) –4,698720 4,318816x10-4
ARMA(2,1)–GARCH(1,1) –4.813301 4,110933x10-4
ARMA(2,1)–GARCH(1,2) –4,811957 4,113367x10-4
ARMA(2,1)–GARCH(2,0) –4,751753 4,834078x10-4
ARMA(2,1)–GARCH(2,1) –4,812382 3,891910x10-4 *
ARMA(2,1)–GARCH(2,2) –4,810573 4,112797x10-4
ARMA(2,2)–GARCH(1,0) –4,731385 4,372525x10-4
ARMA(2,2)–GARCH(1,1) –4,816909 3,901391x10-4
ARMA(2,2)–GARCH(1,2) –4,814415 3,900704x10-4
ARMA(2,2)–GARCH(2,0) –4,751492 4,318816x10-4
ARMA(2,2)–GARCH(2,1) –4,815424 3,891910x10-4 *

14 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
ARMA(2,2)–GARCH(2,2) –4,813616 4,110933x10-4
ARMA(9[1,2,6,9];2)–GARCH(1,1) –4,885362 4,278599x10-4
ARMA(25[1,2,6,9,25];1)–GARCH(1,1) –4,957614 * 4,439817x10-4 * Menor valor.
Em razão da diferença na escolha do modelo de melhor ajuste pelos critérios apresentados na Tabela 4, optou-se por escolher um modelo ARMA–GARCH que não apenas apresentasse resultados satisfatórios por ambos os critérios, mas que também tivesse, após a estimação, todos seus parâmetros significativos, pelo menos a 5%.
Assim, decidiu-se pelo modelo ARMA(2,2)–GARCH(1,1), que apresentou o terceiro menor valor do Critério de Informação de Akaike (AIC) e o quarto menor Erro Quadrático Médio (EQM), de um total de 15 modelos analisados. Apenas a título de informação, o modelo com menor valor de AIC (ARMA(25[1,2,6,7,9,25];1)–GARCH(1,1)) tem o segundo maior EQM, enquanto que os dois modelos com menor EQM (ARMA(2,1)–GARCH(2,1) e ARMA(2,2)–GARCH(2,1)) têm, respectivamente, o quarto e nono menor valor de AIC.
Na tabela 5, encontra-se o resultado da estimação para o modelo escolhido, ARMA(2,2)–GARCH(1,1). O modelo ARMA (2,2), ajustado inicialmente, possuía uma constante, que não apresentou significância, sendo então retirada do modelo. Conforme se pode observar, os demais parâmetros estimados apresentaram elevado grau de significância.
Diferentemente do presente trabalho, Lima et al. (2007) encontraram melhor ajuste para um modelo ARMA(2,1)–GARCH(1,1) incluindo uma constante na parte ARMA do modelo, que apresentou valor t não significativo. Os parâmetros ARMA estimados para o trabalho de Lima et al. (2007) são bastante diferentes dos encontrados na tabela 5. A parte GARCH do modelo é similar, porém havendo inversão entre os valores dos parâmetros ARCH (α) e GARCH (β).
O EQM do trabalho de Lima et al. (2007) foi consideravelmente inferior ao do encontrado na tabela 5, sendo estimado um valor de 3,274 x10-4 no primeiro e 3,901x10-4 no segundo. Cabe ressaltar que nenhum dos modelos ARMA–GARCH ajustados, conforme pode ser visto na tabela 4, apresentou EQM parecido com o apresentado por Lima et al. (2007).
Tabela 5. Resultados da estimação para o modelo ARMA(2,2)–GARCH(1,1).
Parâmetro Valor Estimado
Desvio padrão
Valor da estatística t
Probabilidade (>|t|)
ar1 –9,224e–01 3,075e–01 –2,999 0,00271 **
ar2 –6,329e–01 9,122e–02 –6,938 3,97e–12 ***
ma1 1,000e+00 3,062e–01 3,266 0,00109 **
ma2 6,480e–01 1,028e–01 6,301 2,96e–10 ***
alfa0 6,908e–05 1,632e–05 4,233 2,31e–05 ***
alfa1 1,099e–01 1,955e–02 5,620 1,91e–08 ***
beta1 7,528e–01 4,125e–02 18,251 < 2e–16 *** Códigos de significância: 0 = ‘***’; 0,001 = ‘**’; 0,01 = ‘*’; 0,05 = ‘.’; 0,1 = ‘ ’ 1. EQM (previsão) = 3,901391x10-4.
15 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
A tabela 6 mostra os resultados para os testes realizados, conforme citado no item
3.2.
Tabela 6. Testes realizados para o modelo ARMA(2,2)–GARCH(1,1).
Teste Estatística Valor de p
Shapiro-Wilk R W 0,95383 0
Ljung-Box R Q(10) 16,06281 0,0978484
Ljung-Box R Q(15) 18,92888 0,2169748
Ljung-Box R Q(20) 24,04457 0,2404508
Ljung-Box R^2 Q(10) 9,37363 0,4970491
Ljung-Box R^2 Q(15) 10,51174 0,7863763
Ljung-Box R^2 Q(20) 13,30889 0,8637408
LM R TR^2 10,61674 0,5620177
Conforme se pode observar na tabela 6, o teste de normalidade de Shapiro-Wilk demonstra que não existe normalidade nos erros do modelo ARMA(2,2)–GARCH(1,1), sendo então rejeitada a hipótese nula de distribuição normal dos erros. Embora tenha havido rejeição da normalidade dos erros, ajustou-se um modelo GARCH com distribuição normal, a fim de refazer o trabalho de Lima et al. (2007), embora fosse necessário testar outros tipos de distribuição para os erros.
O teste do multiplicador de Lagrange (LM) para o modelo ARMA(2,2)–GARCH(1,1) apresentou valores que levam à rejeição da hipótese nula de que a variância dos erros é constante. Portanto, o teste confirmou a necessidade do uso de um ARCH nos erros do modelo ARMA.
Tendo em vista a necessidade de ajustamento de um modelo ARCH nos erros, indicada pelo teste LM, cabe então avaliar a necessidade de ajuste de um modelo GARCH. Ressalta-se que os dois modelos se equivalem, porém os GARCH, em geral, representam os modelos ARCH de forma mais parcimoniosa. Os altos valores p encontrados nos testes Q e Q² de Ljung-Box demonstram que a opção de um modelo GARCH para os erros sobrepuja a do ajuste de um modelo ARCH, tendo sido escolhida, então, a primeira opção.
A identificação e estimação do modelo ARFIMA–GARCH seguiu o mesmo processo adotado para o modelo ARMA–GARCH, com uma diferença: a necessidade de estimação de três modelos, em vista da adoção de três alfas distintos (0,500, 0,555 e 0,600), tal qual no artigo original, para permitir a comparação dos resultados.
Dessa maneira, as tabelas de número 7 e 8 mostram os resultados para a estimação dos três modelos ARFIMA–GARCH melhor identificados, um para cada alfa.
Ao contrário do encontrado na tabela 6, Lima et al. (2007) encontraram melhor ajuste para um modelo ARFIMA(1,1)–GARCH(1,1) incluindo uma constante na parte ARMA do modelo, que à exemplo do ocorrido com o ARMA–GARCH, não apresentou valor t significativo. Novamente, os parâmetros ARMA do trabalho de Lima et al. (2007) são muito

16 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
diferentes dos encontrados na tabela 5. Igualmente ao caso do modelo ARMA–GARCH, houve inversão nos valores dos parâmetros ARCH (α) e GARCH (β).
Tabela 7. Resumo dos resultados dos modelos ARMA–GARCH e ARFIMA–GARCH.
Parâmetro ARFIMA(2,d,2)–GARCH(1,1)
ARFIMA(2,d,2)–GARCH(1,1)
ARFIMA(2,d,2)–GARCH(1,1)
α = 0,500 α = 0,555 α = 0,600
d valor –0,02102311 –0,03584390 –0,03994743
ar1 valor –9,102e–01 –9,006e–01 –8,977e–01
t –3,309 *** –3,359 *** 3,356 ***
ar2 valor –6,025e–01 –5,793e–01 –5,722e–01
t –5,850 *** –5,141 *** –4,949 ***
ma1 valor 1,000e+00 1,000e+00 1,000e+00
t 3,675 *** 3,794 *** 3,810 ***
ma2 valor 6,255e–01 6,092e–01 6,042e–01
t 5,458 *** 4,919 *** 4,771 ***
alfa0 valor 6,928e–05 6,904e–05 6,898e–05
t 4,245 *** 4,215 *** 4,205 ***
Parâmetro ARFIMA(2,d,2)–GARCH(1,1)
ARFIMA(2,d,2)–GARCH(1,1)
ARFIMA(2,d,2)–GARCH(1,1)
α = 0,500 α = 0,555 α = 0,600
alfa1 valor 1,084e–01 1,079e–01 1,077e–01
t 5,641 *** 5,640 *** 5,639 ***
beta1 valor 7,534e–01 7,544e–01 7,546e–01
t 18,231 *** 18,176 *** 18,157 ***
EQM (previsão)
2,921437x10-4 2,910776x10-4 2,910776x10-4
Códigos de significância: 0 = ‘***’; 0,001 = ‘**’; 0,01 = ‘*’; 0,05 = ‘.’; 0,1 = ‘ ’ 1.
Devido à inexistência de significância, a constante dos modelos ARFIMA–GARCH para os três valores de α foi retirada do modelo, à exemplo do que ocorreu no ajuste do modelo ARMA–GARCH. Cabe ressaltar que no cálculo destes modelos não foi possível calcular a significância dos parâmetros d fracionários. Conforme pode ser observado na tabela 7, os valores t apresentaram alta significância para todos os parâmetros dos três modelos.
Tabela 8. Resumo dos testes para os modelos ARMA–GARCH e ARFIMA–GARCH.
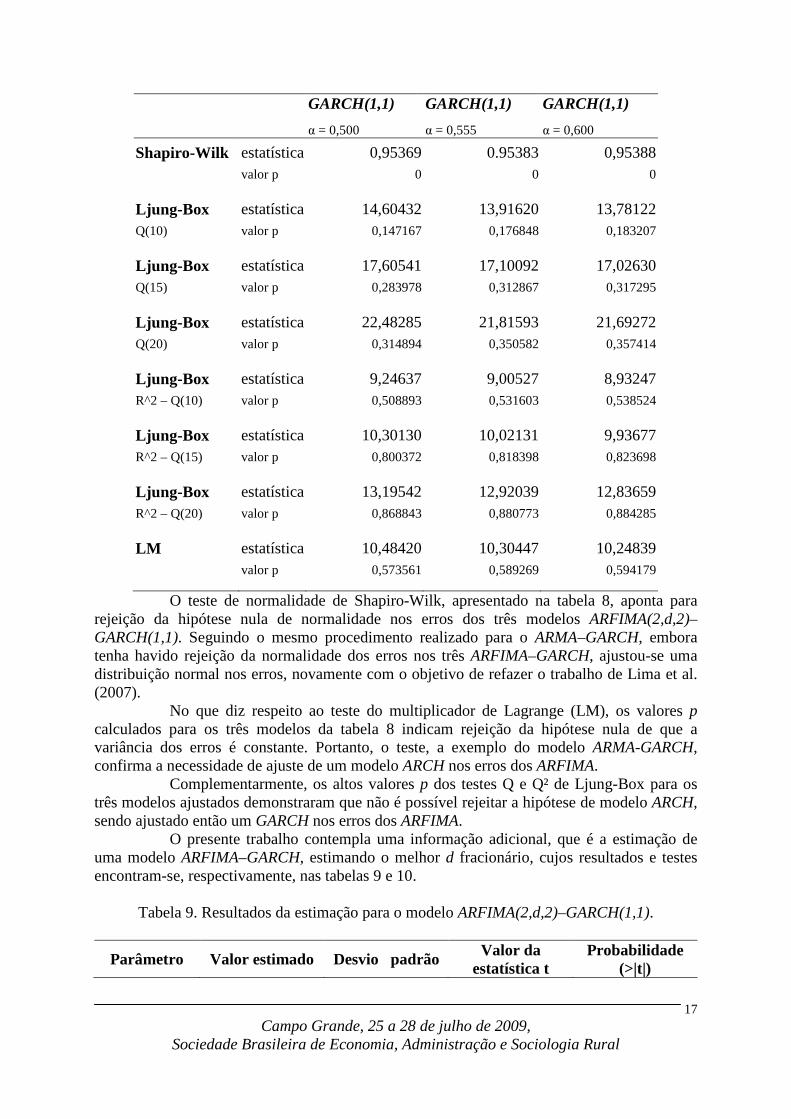
Teste ARFIMA(2,d,2)– ARFIMA(2,d,2)– ARFIMA(2,d,2)–
17 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
GARCH(1,1) GARCH(1,1) GARCH(1,1)
α = 0,500 α = 0,555 α = 0,600
Shapiro-Wilk estatística 0,95369 0.95383 0,95388 valor p 0 0 0
Ljung-Box estatística 14,60432 13,91620 13,78122 Q(10) valor p 0,147167 0,176848 0,183207
Ljung-Box estatística 17,60541 17,10092 17,02630 Q(15) valor p 0,283978 0,312867 0,317295
Ljung-Box estatística 22,48285 21,81593 21,69272 Q(20) valor p 0,314894 0,350582 0,357414
Ljung-Box estatística 9,24637 9,00527 8,93247 R^2 – Q(10) valor p 0,508893 0,531603 0,538524
Ljung-Box estatística 10,30130 10,02131 9,93677 R^2 – Q(15) valor p 0,800372 0,818398 0,823698
Ljung-Box estatística 13,19542 12,92039 12,83659 R^2 – Q(20) valor p 0,868843 0,880773 0,884285
LM estatística 10,48420 10,30447 10,24839 valor p 0,573561 0,589269 0,594179
O teste de normalidade de Shapiro-Wilk, apresentado na tabela 8, aponta para rejeição da hipótese nula de normalidade nos erros dos três modelos ARFIMA(2,d,2)–GARCH(1,1). Seguindo o mesmo procedimento realizado para o ARMA–GARCH, embora tenha havido rejeição da normalidade dos erros nos três ARFIMA–GARCH, ajustou-se uma distribuição normal nos erros, novamente com o objetivo de refazer o trabalho de Lima et al. (2007).
No que diz respeito ao teste do multiplicador de Lagrange (LM), os valores p calculados para os três modelos da tabela 8 indicam rejeição da hipótese nula de que a variância dos erros é constante. Portanto, o teste, a exemplo do modelo ARMA-GARCH, confirma a necessidade de ajuste de um modelo ARCH nos erros dos ARFIMA.
Complementarmente, os altos valores p dos testes Q e Q² de Ljung-Box para os três modelos ajustados demonstraram que não é possível rejeitar a hipótese de modelo ARCH, sendo ajustado então um GARCH nos erros dos ARFIMA.
O presente trabalho contempla uma informação adicional, que é a estimação de uma modelo ARFIMA–GARCH, estimando o melhor d fracionário, cujos resultados e testes encontram-se, respectivamente, nas tabelas 9 e 10.
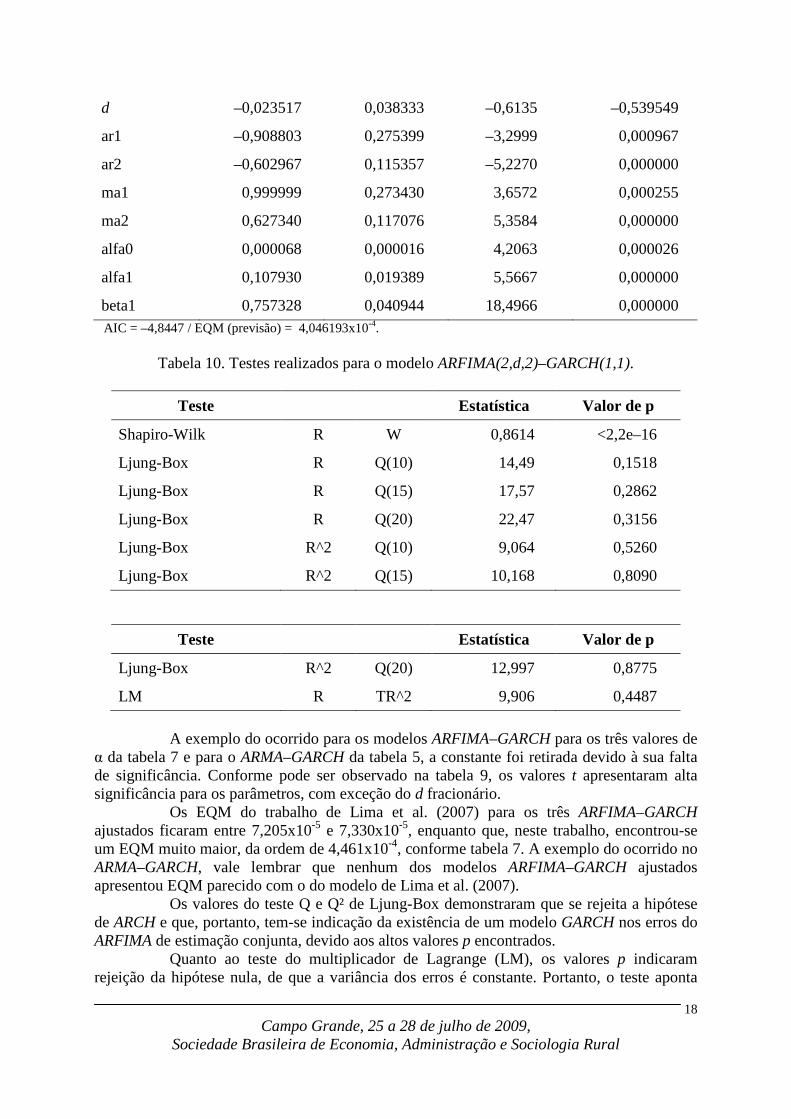
Tabela 9. Resultados da estimação para o modelo ARFIMA(2,d,2)–GARCH(1,1).
Parâmetro Valor estimado Desvio padrão Valor da estatística t
Probabilidade (>|t|)
18 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
d –0,023517 0,038333 –0,6135 –0,539549
ar1 –0,908803 0,275399 –3,2999 0,000967
ar2 –0,602967 0,115357 –5,2270 0,000000
ma1 0,999999 0,273430 3,6572 0,000255
ma2 0,627340 0,117076 5,3584 0,000000
alfa0 0,000068 0,000016 4,2063 0,000026
alfa1 0,107930 0,019389 5,5667 0,000000
beta1 0,757328 0,040944 18,4966 0,000000 AIC = –4,8447 / EQM (previsão) = 4,046193x10-4.
Tabela 10. Testes realizados para o modelo ARFIMA(2,d,2)–GARCH(1,1).
Teste Estatística Valor de p
Shapiro-Wilk R W 0,8614 <2,2e–16
Ljung-Box R Q(10) 14,49 0,1518
Ljung-Box R Q(15) 17,57 0,2862
Ljung-Box R Q(20) 22,47 0,3156
Ljung-Box R^2 Q(10) 9,064 0,5260
Ljung-Box R^2 Q(15) 10,168 0,8090
Teste Estatística Valor de p
Ljung-Box R^2 Q(20) 12,997 0,8775
LM R TR^2 9,906 0,4487
A exemplo do ocorrido para os modelos ARFIMA–GARCH para os três valores de
α da tabela 7 e para o ARMA–GARCH da tabela 5, a constante foi retirada devido à sua falta de significância. Conforme pode ser observado na tabela 9, os valores t apresentaram alta significância para os parâmetros, com exceção do d fracionário.
Os EQM do trabalho de Lima et al. (2007) para os três ARFIMA–GARCH ajustados ficaram entre 7,205x10-5 e 7,330x10-5, enquanto que, neste trabalho, encontrou-se um EQM muito maior, da ordem de 4,461x10-4, conforme tabela 7. A exemplo do ocorrido no ARMA–GARCH, vale lembrar que nenhum dos modelos ARFIMA–GARCH ajustados apresentou EQM parecido com o do modelo de Lima et al. (2007).
Os valores do teste Q e Q² de Ljung-Box demonstraram que se rejeita a hipótese de ARCH e que, portanto, tem-se indicação da existência de um modelo GARCH nos erros do ARFIMA de estimação conjunta, devido aos altos valores p encontrados.
Quanto ao teste do multiplicador de Lagrange (LM), os valores p indicaram rejeição da hipótese nula, de que a variância dos erros é constante. Portanto, o teste aponta

19 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
para a necessidade de um ARCH para modelar os erros do ARFIMA de estimação conjunta dos parâmetros.
Os resultados obtidos para o teste de normalidade de Shapiro-Wilk indicam que se rejeita a hipótese nula de normalidade nos erros do modelo de estimação conjunta dos parâmetros ARFIMA(2,d,2)–GARCH(1,1). Seguindo o mesmo critério dos modelos apresentados anteriormente, buscou-se refazer o trabalho de Lima et al. (2007), ajustando-se, portanto, um modelo GARCH com erros de distribuição normal. 5. Conclusões
Os resultados obtidos neste trabalho divergiram bastante dos encontrados por Lima et al. (2007), sendo que não foi possível obter as mesmas estimativas utilizando a base de dados que os autores declararam ter utilizado.
A escolha dos modelos de previsão mais bem ajustados foi bastante diferente do artigo original. Cabe lembrar, que no presente trabalho buscou-se o melhor modelo utilizando o critério de EQM, da mesma forma que em Lima et al. (2007). Porém, levou-se em consideração outros dois critérios relevantes: a significância dos parâmetros estimados e o Critério de Informação de Akaike (AIC). Os melhores modelos obtidos não coincidiram com os do artigo original. Enquanto em Lima et al. (2007) foram selecionados modelos ARMA(2,1)–GARCH(1,1) e ARFIMA(1,d,1)-GARCH(1,1) – para os três valores de α considerados no cálculo do número de ordenadas harmônicas, no presente trabalho os modelos escolhidos foram ARMA(2,2)-GARCH(1,1) e ARFIMA(2,d,2)-GARCH(1,1), também, considerando os mesmos três valores de α.
Faz-se necessário o comentário de que o trabalho de Lima et al. (2007) não revela qual o tipo de distribuição utilizada para os modelos ARCH e GARCH. Dessa forma, parte-se do princípio que o autor utilizou a distribuição normal, que é o padrão da maioria dos programas estatísticos. Os resultados encontrados para outros tipos de distribuição também não foram coerentes com os apresentados por Lima et al. (2007). Além disso, os autores não apresentaram testes para verificação de normalidade das séries de erro do modelo ARMA (teste de Shapiro-Wilk), nem qualquer outro teste equivalente, o que não permitiria o ajuste de modelos ARCH ou GARCH, com distribuição normal ou qualquer outro tipo de distribuição.
Os erros médios de previsão (EQM) do presente trabalho foram consideravelmente maiores que os encontrados pelos autores do artigo em questão. Porém, ao recalcular os EQM do trabalho de Lima et al. (2007), utilizando os dados apresentados nos gráficos 1 e 2, foram encontrados valores distintos dos daquele trabalho.
Quanto às propriedades de longa dependência das séries de retorno do café, os resultados para o melhor valor de α mostram indícios de que a dependência temporal entre as observações não é de longo prazo devido ao valor negativo para diferenciação fracionária encontrado. Além disso, o valor t para o parâmetro não foi significativo.
No que tange ao EQM da previsão, comparando os modelos ARMA–GARCH e ARFIMA–GARCH estimados, obteve-se uma diferença insignificante na qualidade de previsão, sendo que o modelo ARMA–GARCH apresentou melhor resultado. Enquanto que no modelo ARFIMA(2,d,2)–GARCH(1,1) obteve-se EQM de 4,046193 x10-4, para o ARMA(2,2)–GARCH(1,1) obteve-se 3,901391x10-4. Estes resultados também são divergentes dos obtidos por Lima et al. (2007), que encontraram qualidade de previsão substancialmente melhor para o modelo de diferenciação fracionária.
A principal diferença entre as conclusões obtidas neste trabalho e as de Lima et al. (2007) foi a de que neste não houve diferença entre os ajustes ARMA–GARCH e ARFIMA–

20 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
GARCH, enquanto Lima et al. encontraram qualidade de previsão significativamente melhor para os modelos de diferenciação fracionária. Referências Bibliográficas BAILLIE, R.T.; BOLLERSLEV, T.; MIKKELSEN, H.O. Fracionally integrated generalized autoregressive conditional heteroskedasticity. Journal of Econometrics. Amsterdam, v. 74, n. 1, p. 3-30, Sep. 1996. BAYER, F.M. Previsão do preço e da volatilidade de commodities agrícolas, por meio de modelos ARFIMA-GARCH. 2008. 83 p. Dissertação (Mestrado em Engenharia de Produção) – Universidade Federal de Santa Maria, Santa Maria, 2008. BOLLERSLEV, T. Generalized autoregressive conditional heteroscedasticity. Journal of Econometrics. Amsterdam, v. 31, n. 3, p. 307-327, Apr. 1986. BOLSA DE MERCADORIAS E FUTUROS – BM&F. Disponível em: <http://www.bmf.com.br>. Acesso em 16 novembro 2009. BRESSAN, A.A. Tomada de decisão em futuros agropecuários com modelos de previsão de séries temporais. RAE Eletrônica. São Paulo, v. 3, n. 1, artigo 9, Jan.-Jun. 2004. BROCKWELL, P.J.; DAVIS, R.A. Time series: Theory and Methods. New York: Springer, 2002. ENDERS, W. Applied Econometric Time Series. : Hoboken: John Wiley and Sons, 2003. ENGLE, R. F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica. New York, v. 50, n. 4, p. 987-1007, Jul. 1982. FOX, R.; TAQQU, M.S. Large-sample properties of parameter estimates for strongly dependent stationary Gaussian time series. The Annal of Statistics. Beachwood, vol. 14, n. 2, p. 517-532, Jun. 1986. GEWEKE, J.; PORTER-HUDACK, S. The estimation and application of long-memory time series models. Journal of Time Series Analysis. The Hague, v. 4, n. 4, p. 221-238, Jul. 1983. GRANGER, C.W.J.; JOYEUX, R. An introduction to long-memory time series models and fractional differencing. Journal of Time Series Analysis. The Hague, v. 1, n. 1, p. 15-29, Jan. 1980. HAMILTON, J.D.; SUSMEL, R. Autoregressive conditional heteroskedasticity and changes in regime. Journal of Econometrics. Amsterdam, v. 64, n. 1-2, p. 307-333, Sep.-Oct. 1994. HANNAN, E.J. The asymptotic theory of linear time-series models. Journal of Applied Probability . Sheffield, v. 10, n. 1, p. 130-145, Mar. 1973. HOSKING, J.R.M. Fractional differencing. Biometrika . Oxford, v. 68, n. 1, p. 165-176, 1981.

21 Campo Grande, 25 a 28 de julho de 2009,
Sociedade Brasileira de Economia, Administração e Sociologia Rural
LIMA, R.C.; OLIVEIRA, M.R.G. de; CARMONA, C.U.M. Previsão de preços futuros de commodities agrícolas com diferenciações inteira e fracionária, e erros heterocedásticos. Revista de Economia e Sociologia Rural. Brasília, v. 45, n. 3, p. 621-644, set. 2007. MANDELBROT, B.B.; VAN NESS, J.W. Fractional brownian, fractional noises and applications. SIAM Review. Philadelphia, v. 10, n. 4, p. 422-437, Oct. 1968. MORETTIN, P.A.; TOLOI, C.M.C. Análise de Séries Temporais. São Paulo: Edgard Blucher, 2006. PINDYCK, R.S.; RUBINFELD, D.L. Econometric Models and Economic Forecast. New York: McGraw-Hill, 1991. R FOUNDATION FOR STATISTICAL COMPUTING. R: A Language and Environment for Statistical Computing 2.10.0. Disponível em: <http://www.R-project.org>. Acesso em 16 novembro 2009. SHAPIRO, S.S.; WILK, M.B.; CHEN, H.J. A comparative study of various tests for normality. Journal of the American Statistical Association. Alexandria, v. 63, n. 324, p. 1343-1372, Dec. 1968.


















