
UNIVERSIDADE FEDERAL DE SERGIPE PROGRAMA DE PÓS … · implementação de métodos matemáticos...
136
i UNIVERSIDADE FEDERAL DE SERGIPE PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA DETECÇÃO DE ERROS PLANTA-MODELO EM SISTEMAS DE CONTROLE PREDITIVO (MPC) UTILIZANDO TÉCNICAS DE INFORMAÇÃO MÚTUA Diego Déda Gonçalves Brito Cruz São Cristóvão – SE, Brasil Março de 2017
Transcript of UNIVERSIDADE FEDERAL DE SERGIPE PROGRAMA DE PÓS … · implementação de métodos matemáticos...

i
UNIVERSIDADE FEDERAL DE SERGIPE
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA
DETECÇÃO DE ERROS PLANTA-MODELO EM SISTEMAS DE
CONTROLE PREDITIVO (MPC) UTILIZANDO TÉCNICAS DE
INFORMAÇÃO MÚTUA
Diego Déda Gonçalves Brito Cruz
São Cristóvão – SE, Brasil
Março de 2017

ii
DETECÇÃO DE ERROS PLANTA-MODELO EM SISTEMAS DE
CONTROLE PREDITIVO (MPC) UTILIZANDO TÉCNICAS DE
INFORMAÇÃO MÚTUA
Diego Déda Gonçalves Brito Cruz
São Cristóvão – SE, Brasil
Março de 2017
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Engenharia
Elétrica – PROEE, da Universidade Federal de
Sergipe, como parte dos requisitos necessários à
obtenção do título de Mestre em Engenharia
Elétrica.
Orientador: Prof. Dr. Oscar A. Z. Sotomayor


FICHA CATALOGRÁFICA ELABORADA PELA BIBLIOTECA CENTRAL UNIVERSIDADE FEDERAL DE SERGIPE
C957d
Cruz, Diego Déda Gonçalves Brito Detecção de erros planta-modelo em sistemas de controle
preditivo (MPC) utilizando técnicas de informação mútua / Diego Déda Gonçalves Brito Cruz ; orientador Oscar A. Z. Sotomayor. – São Cristóvão, 2017.
135 f. ; il. Dissertação (mestrado em Engenharia Elétrica) – Universidade
Federal de Sergipe, 2017.
1. Engenharia elétrica. 2. Controle preditivo. 3. Modelos lineares (Estatística). 4. Correlação (Estatística). I. Sotomayor, Oscar A. Z., orient. II. Título.
CDU: 621.3

iv
Aos meus pais, Manoel e Lindenil,
aos meus irmãos, Victor e Mirelle,
à minha noiva, Isla e à família da
minha noiva, Ivan, Cássia e Ian.

v
Agradecimentos
Primeiramente a Deus por me abençoar nesta caminhada acadêmica, me dando
forças para que eu pudesse alcançar os meus objetivos. Sou grato também ao Senhor por
me manter firme na conclusão deste trabalho.
Aos meus pais Manoel e Lindenil, pessoas admiráveis e exemplos de vida, que
sempre me ensinaram que o caráter, a honestidade e a humildade são virtudes essenciais
para lograr êxito na vida.
A minha noiva Isla um agradecimento especial, pelo amor, dedicação, carinho,
compreensão e apoio. Muito obrigado pelo incentivo incondicional e por ter acreditado
sempre em mim.
Aos meus irmãos Mirelle, Victor, pelo incentivo, carinho e compreensão,
presentes durante todo o tempo.
A família da minha noiva, Ivan, Cássia e Ian, por todo carinho, apoio
incondicional e incentivo dados.
Ao professor Dr. Oscar por toda contribuição e orientação deste trabalho.
Aos professores Jugurta e Jânio pelas sugestões e contribuições no
desenvolvimento do trabalho.
A todos os meus amigos, em especial Stephanie e Lívia pelas contribuições ao
trabalho.
Ao PRH/ANPUFS-45 e a CAPES pelo auxílio financeiro.

vi
Resumo da Dissertação apresentada ao PROEE/UFS como parte dos requisitos
necessários para a obtenção do grau de Mestre (Me.)
DETECÇÃO DE ERROS PLANTA-MODELO EM SISTEMAS DE CONTROLE
PREDITIVO (MPC) UTILIZANDO TÉCNICAS DE INFORMAÇÃO MÚTUA
Diego Déda Gonçalves Brito Cruz
Março/2017
Orientador: Prof. Dr. Oscar A. Z. Sotomayor
Programa: Engenharia Elétrica
Estratégias de controle preditivo (MPC) têm-se tornado o padrão para aplicações de
controle avançado na indústria de processos. Os benefícios significativos são gerados a
partir da habilidade do controlador MPC de assegurar que a planta opere dentro das
restrições de forma mais lucrativa. Porém, como todo controlador, depois de algum tempo
em operação, os MPCs raramente funcionam como quando foram inicialmente
projetados. Uma grande porcentagem da degradação do desempenho dos controladores
MPC está associada à deterioração do modelo que o controlador usa para fazer a predição
das saídas do processo e calcular as entradas. O objetivo do presente trabalho é a
implementação de métodos matemáticos que possam ser utilizados para a detecção de
erros planta-modelo em sistemas de controle MPC lineares e não lineares. Neste trabalho,
técnicas baseadas em correlação cruzada, correlação parcial e informação mútua são
implementadas e testadas por simulação numérica em estudos de caso característicos da
indústria petroquímica, representados por modelos lineares e não lineares, operando sob
controle MPC. Os resultados obtidos através da aplicação das técnicas são analisados e
comparados quanto à sua eficiência no objetivo proposto avaliando seu potencial para
aplicações industriais reais.
Palavras chaves: Detecção de erro planta-modelo, controle preditivo, correlação
cruzada, correlação parcial e informação mútua.

vii
Abstract of Dissertation presented to PROEE/UFS as a partial fulfillment of the
requirements for the degree of Master
DETECTING PLANT-MODEL MISMATCH IN PREDICTIVE CONTROL
SYSTEMS (MPC) USING MUTUAL INFORMATION TECHNIQUES
Diego Déda Gonçalves Brito Cruz
March/2017
Advisors: Prof. Dr. Oscar A. Z. Sotomayor
Department: Electrical Engineering
Model predictive control (MPC) strategies have become the standard for advanced
control applications in the process industry. Significant benefits are generated from the
MPC's capacity to ensure that the plant operates within its constraints more profitably.
However, like any controller, after some time under operation, MPCs rarely function as
when they were initially designed. A large percentage of performance degradation of
MPC is associated with the deterioration of model that controller uses to predict process
outputs and calculate inputs. The objective of the present work is implementation of
mathematical methods that can be used to detect model-plant mismatch in linear and non-
linear MPC systems. In this work, techniques based on cross correlation, partial
correlation and mutual information are implemented and tested by numerical simulation
in case studies characteristic of the petrochemical industry, represented by linear and
nonlinear models, operating under MPC control. The results obtained through the
applying the techniques are analyzed and compared as to their efficiency is not intended
to offer their potential for real industrial applications.
Keywords: Plant-model mismatch, predictive control, cross-correlation, partial
correlation and mutual information.

viii
Sumário
Lista de Figuras .............................................................................................................. xi
Lista de Abreviaturas ................................................................................................. xvii
Lista de Símbolos ......................................................................................................... xix
Capítulo 1 ......................................................................................................................... 1
Introdução ..................................................................................................................... 1
1.1 Motivação ........................................................................................................... 1
1.2 Objetivos ............................................................................................................. 3
1.3 Revisão bibliográfica .......................................................................................... 3
1.4. Estrutura do trabalho .......................................................................................... 8
1.5. Publicações ........................................................................................................ 9
Capítulo 2 ....................................................................................................................... 10
Controladores Preditivos (MPC) ................................................................................ 10
2.1 Controle de Processos Industriais ..................................................................... 10
2.2 O MPC .............................................................................................................. 11
2.2.1 Sistema MIMO .......................................................................................... 14
2.2.2 O Controlador QDMC ............................................................................... 14
2.2.3 Representação do MPC utilizando IMC .................................................... 16
2.2.4 O Modelo do MPM .................................................................................... 17
2.2.5 Importância do Set-Point ........................................................................... 18
Capítulo 3 ....................................................................................................................... 20
Métodos de Detecção Linear e Não Linear de MPM ................................................. 20
3.1 Correlação Cruzada ........................................................................................... 20
3.2 Correlação Parcial ............................................................................................. 29
3.2.1 Correlação Parcial por Badwe ................................................................... 31
3.3 Informação Mútua ............................................................................................. 33

ix
3.3.1 Estimação da MI – K Vizinhos Mais Próximos (KNN) ............................ 35
3.3.2 Aplicação Teste do Método da Informação Mútua por KNN ................... 39
3.3.3 Estimação da MI – Histograma ................................................................. 41
3.3.4 Aplicação Teste do Método da Informação Mútua por Histograma ......... 42
Capítulo 4 ....................................................................................................................... 51
Processo da Coluna de Destilação Binária e Detecção de MPM Linear .................... 51
4.1 Introdução ......................................................................................................... 51
4.2 Descrição do Processo ...................................................................................... 52
4.4 Sinais de Excitação Aplicados .......................................................................... 55
4.5 Caso 1 ............................................................................................................... 56
4.6 Caso 2 ............................................................................................................... 62
4.7 Caso 3 ............................................................................................................... 68
Capítulo 5 ....................................................................................................................... 74
Estudo de Caso da Unidade de FCC e Detecção de MPM Não Linear ...................... 74
5.1 Introdução ......................................................................................................... 74
5.2 Descrição do Processo ...................................................................................... 75
5.3 Controle da Unidade FCC ................................................................................. 76
5.4 MPC em Duas Camadas ................................................................................... 77
5.5 Estratégia de Controle por Faixas ..................................................................... 79
5.6 Controle MPC da Unidade FCC ....................................................................... 80
5.6 Caso 1 ............................................................................................................... 83
5.7 Caso 2 ............................................................................................................... 89
5.8 Caso 3 ............................................................................................................... 95
Capítulo 6 ..................................................................................................................... 101
Conclusões e Recomendações de Trabalhos Futuros ............................................... 101
Referências Bibliográficas .......................................................................................... 103
Apêndice A ................................................................................................................... 109

x
Identificação por Subespaços .................................................................................... 109
A.1 Introdução ...................................................................................................... 109
A.2 Os métodos de identificação por subespaços ................................................. 110
A.3 Exemplo Prático ............................................................................................. 112

xi
Lista de Figuras
Figura 1.1: Diagrama de fluxo de causas de degradação do desempenho do controlador
MPC (adaptação de Naidoo, 2010) ................................................................................... 1
Figura 2.1: Visão geral do sistema de controle de processos industriais (adaptação de
Carlsson, 2010) ............................................................................................................... 10
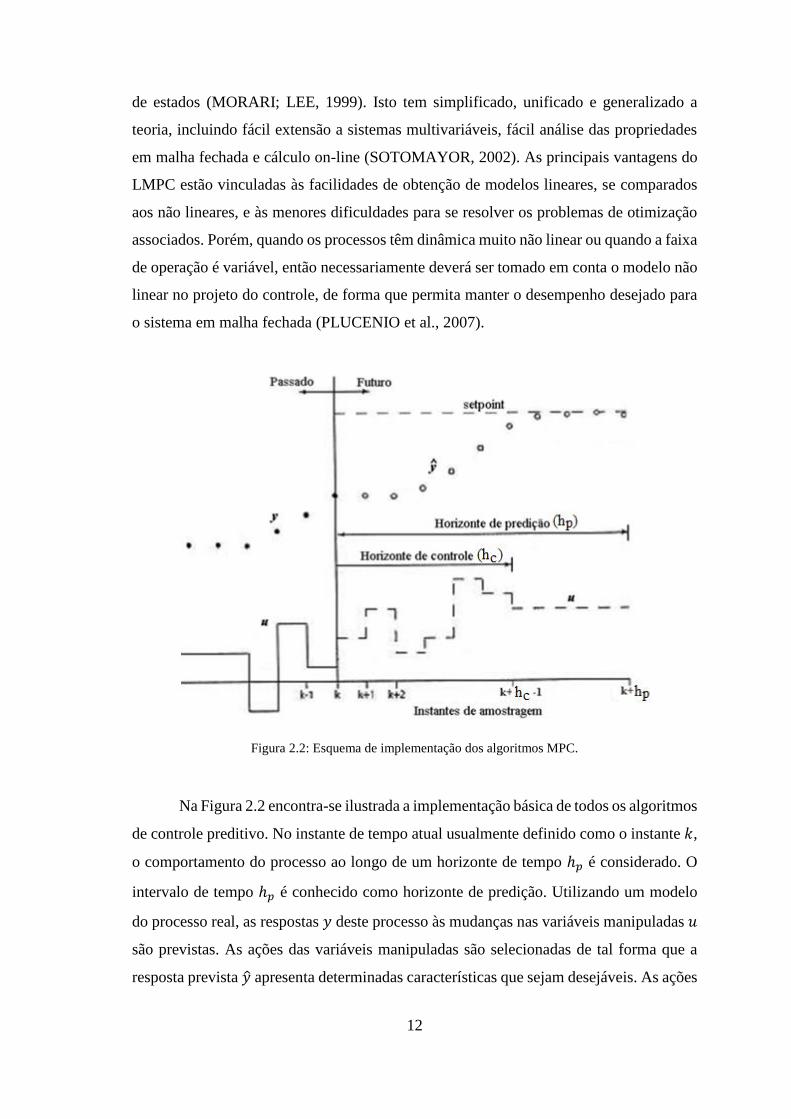
Figura 2.2: Esquema de implementação dos algoritmos MPC. ...................................... 12
Figura 2.3: Estrutura do controlador MPC. .................................................................... 13
Figura 2.4: Estrutura de controle por modelo interno (IMC) em malha fechada (Badwe et
al., 2009). ........................................................................................................................ 17
Figura 3.1: Ilustração de forte relação linear através de instâncias das variáveis 𝒙 e 𝒚.
Cada ponto é uma instância observada do par (𝒙,𝒚)....................................................... 25
Figura 3.2: Ilustração de ausência de relação linear através de instâncias das variáveis 𝒙
e 𝒚. Cada ponto é uma instância observada do par (𝒙,𝒚). .............................................. 25
Figura 3.3: Variáveis x com aplicação de um atraso. ..................................................... 26
Figura 3.4: Correlação cruzada entre variáveis linearmente dependentes. ..................... 26
Figura 3.5: Correlação cruzada entre variáveis sem relação linear. ............................... 27
Figura 3.6: Correlação cruzada de uma variável aleatória com ela mesma
(autocorrelação). ............................................................................................................. 27
Figura 3.7: Variáveis com dependência não linear. ........................................................ 28
Figura 3.8: Correlação cruzada entre variáveis com relações não lineares. ................... 29
Figura 3.9: Interpretação gráfica da correlação parcial (adaptação de Carlsson, 2010). 30
Figura 3.10: Relação entre entropia e informação mútua (adaptação de Cover e Thomas,
2005) ............................................................................................................................... 34
Figura 3.11: Gráfico da função digama. ......................................................................... 37
Figura 3.12: Determinação de 𝜖𝑖, 𝑛𝑥𝑖 e 𝑛𝑦𝑖 no primeiro algoritmo, para 𝑘 = 1 (𝑛𝑥𝑖 = 2
e 𝑛𝑦𝑖 = 6) ....................................................................................................................... 37
Figura 3.13: Determinação de 𝜖𝑥𝑖, 𝜖𝑦𝑖, 𝑛𝑥𝑖 e 𝑛𝑦𝑖 no segundo algoritmo para um mesmo
ponto, com 𝑘 = 2 (𝑛𝑥𝑖 = 6 e 𝑛𝑦𝑖 = 5) .......................................................................... 38
Figura 3.14: Determinação de 𝜖𝑥𝑖, 𝜖𝑦𝑖, 𝑛𝑥𝑖 e 𝑛𝑦𝑖 no segundo algoritmo para pontos
diferentes, com 𝑘 = 2 (𝑛𝑥𝑖 = 5 e 𝑛𝑦𝑖 = 2) ................................................................... 39
Figura 3.15: Estimação da MI através do método por KNN entre variáveis linearmente
dependentes. .................................................................................................................... 40

xii
Figura 3.16: Estimação da MI através do método por KNN entre variáveis aleatórias
descorrelacionadas. ......................................................................................................... 40
Figura 3.17: Estimação da MI através do método por KNN entre variáveis com relação
não linear. ........................................................................................................................ 41
Figura 3.18: Estimativa da PDF de 𝑥 no caso de sinais linearmente dependentes. ........ 43
Figura 3.19: Estimativa da PDF de 𝑦 no caso de sinais linearmente dependentes. ........ 44
Figura 3.20: Estimativa da PDF conjunta formada por x e y no caso de sinais linearmente
dependentes. .................................................................................................................... 44
Figura 3.21: Estimação da MI através do método por histograma entre variáveis
linearmente dependentes. ................................................................................................ 45
Figura 3.22: Semelhança entre a estimação da MI através dos métodos por histograma e
KNN entre duas variáveis linearmente dependentes. ..................................................... 45
Figura 3.23: Estimativa da PDF de x no caso de sinais sem dependência linear. .......... 45
Figura 3.24: Estimativa da PDF de y no caso de sinais sem dependência linear. .......... 46
Figura 3.25: Estimativa da PDF conjunta formada por x e y no caso de sinais sem
dependência linear. ......................................................................................................... 46
Figura 3.26: Estimação da MI através do método por histograma entre variáveis aleatórias
descorrelacionadas. ......................................................................................................... 47
Figura 3.27: Semelhança entre a estimação da MI através dos métodos por histograma e
KNN entre duas variáveis aleatórias descorrelacionadas. .............................................. 47
Figura 3.28: Estimativa da PDF de x no caso de sinais com dependência não linear. ... 48
Figura 3.29: Estimativa da PDF de y no caso de sinais com dependência não linear. ... 48
Figura 3.30: Estimativa da PDF conjunta formada por x e y no caso de sinais com
dependência não linear. ................................................................................................... 49
Figura 3.31: Estimação da MI através do método por histograma entre variáveis com
relação não linear. ........................................................................................................... 49
Figura 3.32: Semelhança entre a estimação da MI através dos métodos por histograma e
KNN entre duas variáveis com relação não linear. ......................................................... 50
Figura 4.1: Representação de uma coluna de destilação. ............................................... 52
Figura 4.2: Simulador da coluna de destilação binária de Wood e Berry (1973). .......... 55
Figura 4.3: Modelos de sinais PRBS. ............................................................................. 56
Figura 4.4: Sinais PRBS de excitação e variáveis controladas do processo da coluna de
destilação binária de Wood-Berry – Caso 1. .................................................................. 56

xiii
Figura 4.5: Sinais das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 1. ............................................................................................... 57
Figura 4.6: Sinais dos erros do modelo do processo da coluna de destilação binária de
Wood-Berry – Caso 1. .................................................................................................... 58
Figura 4.7: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo da coluna de destilação binária de Wood-Berry – Caso 1. ............ 58
Figura 4.8: Correlações cruzadas do processo da coluna de destilação binária de Wood-
Berry – Caso 1. ............................................................................................................... 59
Figura 4.9: Correlações parciais do processo da coluna de destilação binária de Wood-
Berry – Caso 1. ............................................................................................................... 59
Figura 4.10: Estimativas das PDFs das variáveis manipuladas do processo da coluna de
destilação binária de Wood-Berry – Caso 1. .................................................................. 60
Figura 4.11: Estimativas das PDFs dos erros do modelo processo da coluna de destilação
binária de Wood-Berry – Caso 1. ................................................................................... 60
Figura 4.12: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo da coluna de destilação binária de Wood-Berry - Caso 1.61
Figura 4.13: Informações mútuas através do KNN do processo da coluna de destilação
binária de Wood-Berry – Caso 1. ................................................................................... 61
Figura 4.14: Informações mútuas através de histograma do processo da coluna de
destilação binária de Wood-Berry – Caso 1. .................................................................. 62
Figura 4.15: Sinais PRBS de excitação e variáveis controladas do processo da coluna de
destilação binária de Wood-Berry – Caso 2. .................................................................. 63
Figura 4.16: Sinais das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 2. ............................................................................................... 63
Figura 4.17: Sinais dos erros do modelo do processo da coluna de destilação binária de
Wood-Berry – Caso 2. .................................................................................................... 64
Figura 4.18: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo da coluna de destilação binária de Wood-Berry – Caso 2. ............ 64
Figura 4.19: Correlações cruzadas do processo da coluna de destilação binária de Wood-
Berry – Caso 2. ............................................................................................................... 65
Figura 4.20: Correlações parciais do processo da coluna de destilação binária de Wood-
Berry – Caso 2. ............................................................................................................... 65

xiv
Figura 4.21: Estimativas das PDFs das variáveis manipuladas do processo da coluna de
destilação binária de Wood-Berry – Caso 2. .................................................................. 66
Figura 4.22: Estimativas das PDFs dos erros do modelo processo da coluna de destilação
binária de Wood-Berry – Caso 2. ................................................................................... 66
Figura 4.23: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo da coluna de destilação binária de Wood-Berry - Caso 2.67
Figura 4.24: Informações mútuas através do KNN do processo da coluna de destilação
binária de Wood-Berry – Caso 2. ................................................................................... 67
Figura 4.25: Informações mútuas através de histograma do processo da coluna de
destilação binária de Wood-Berry – Caso 2. .................................................................. 68
Figura 4.26: Sinais PRBS de excitação e variáveis controladas do processo da coluna de
destilação binária de Wood-Berry – Caso 3. .................................................................. 68
Figura 4.27: Sinais das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 3. ............................................................................................... 69
Figura 4.28: Sinais dos erros do modelo do processo da coluna de destilação binária de
Wood-Berry – Caso 3. .................................................................................................... 69
Figura 4.29: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo da coluna de destilação binária de Wood-Berry – Caso 3. ............ 70
Figura 4.30: Correlações cruzadas do processo da coluna de destilação binária de Wood-
Berry – Caso 3. ............................................................................................................... 70
Figura 4.31: Correlações parciais do processo da coluna de destilação binária de Wood-
Berry – Caso 3. ............................................................................................................... 71
Figura 4.32: Estimativas das PDFs das variáveis manipuladas do processo da coluna de
destilação binária de Wood-Berry – Caso 3. .................................................................. 71
Figura 4.33: Estimativas das PDFs dos erros do modelo processo da coluna de destilação
binária de Wood-Berry – Caso 3. ................................................................................... 72
Figura 4.34: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo da coluna de destilação binária de Wood-Berry - Caso 3.72
Figura 4.35: Informações mútuas através do KNN do processo da coluna de destilação
binária de Wood-Berry – Caso 3. ................................................................................... 73
Figura 4.36: Informações mútuas através de histograma do processo da coluna de
destilação binária de Wood-Berry – Caso 3. .................................................................. 73
Figura 5.1: Esquema simplificado da unidade de FCC da REVAP. ............................... 76

xv
Figura 5.2: Controle MPC em duas camadas. ................................................................ 77
Figura 5.3: Implementação do simulador do sistema FCC. ............................................ 82
Figura 5.4: Sinal de excitação introduzido nos coeficientes econômicos 𝑊1. ............... 83
Figura 5.5: Sinais variáveis controladas do processo FCC - Caso 1. ............................. 84
Figura 5.6: Sinais variáveis manipuladas do processo FCC - Caso 1. ............................ 84
Figura 5.7: Sinais dos erros do modelo do processo FCC - Caso 1. ............................... 85
Figura 5.8: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo FCC do - Caso 1. ............................................................................ 85
Figura 5.9: Correlações cruzadas do processo FCC - Caso 1. ........................................ 86
Figura 5.10: Correlações parciais do processo FCC do caso 1. ...................................... 86
Figura 5.11: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 1.
........................................................................................................................................ 87
Figura 5.12: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 1. ... 87
Figura 5.13: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo FCC – Caso 1. .................................................................. 88
Figura 5.14: Informações mútuas através de KNN do processo FCC – Caso 1. ............ 88
Figura 5.15: Informações mútuas através de histograma do processo FCC – Caso 1. ... 89
Figura 5.16: Sinais das variáveis controladas do processo FCC - Caso 2. ..................... 90
Figura 5.17: Sinais das variáveis manipuladas do processo FCC - Caso 2. ................... 90
Figura 5.18: Sinais dos erros do modelo do processo FCC - Caso 2. ............................. 91
Figura 5.19: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo FCC do - Caso 2. ............................................................................ 91
Figura 5.20: Correlações cruzadas do processo FCC - Caso 2. ...................................... 92
Figura 5.21: Correlações parciais do processo FCC - Caso 2. ....................................... 92
Figura 5.22: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 2.
........................................................................................................................................ 93
Figura 5.23: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 2. ... 93
Figura 5.24: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo FCC – Caso 2. .................................................................. 94
Figura 5.25: Informações mútuas através de KNN do processo FCC – Caso 2. ............ 94
Figura 5.26: Informações mútuas através de histograma do processo FCC – Caso 2. ... 95
Figura 5.27: Sinais das variáveis controladas do processo FCC - Caso 3. ..................... 96
Figura 5.28: Sinais das variáveis manipuladas do processo FCC - Caso 3. ................... 96

xvi
Figura 5.29: Sinais dos erros do modelo do processo FCC - Caso 3. ............................. 97
Figura 5.30: Distribuições de pontos formadas pelas variáveis manipuladas e erros do
modelo do processo FCC do - Caso 3. ............................................................................ 97
Figura 5.31: Correlações cruzadas do processo FCC - Caso 3. ...................................... 97
Figura 5.32: Correlações parciais do processo FCC - Caso 3. ....................................... 98
Figura 5.33: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 3.
........................................................................................................................................ 98
Figura 5.34: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 3. ... 99
Figura 5.35: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e
erros do modelo do processo FCC – Caso 3. .................................................................. 99
Figura 5.36: Informações mútuas através de KNN do processo FCC – Caso 3. .......... 100
Figura 5.37: Informações mútuas através de histograma do processo FCC – Caso 3. . 100
Figura A.1: Valores singulares para a escolha do modelo do processo da coluna de
destilação de Wood e Berry – Caso 3. .......................................................................... 113
Figura A.2: Identificação de modelo por DSR e otimização por PEM. ....................... 114
Figura A.3: Localização dos polos do modelo reidentificado. ..................................... 115

xvii
Lista de Abreviaturas
ARMAX: Modelo auto regressivo, de média móvel com entradas exógenas
(auto-regressive moving average with exogenous input)
ARX: Modelo auto regressivo com entradas exógenas (auto regressive
with exogenous inputs)
CCA: Canonical correlation analysis
CONSTSID: Continuous-time system identification
CVA: Análises de variáveis canônicas (canonical variate analysis)
DSR: Deterministic and stochastic subspace system identification and
realization
FCC: Unidade industrial de craqueamento catalítico (fluid catalytic
cracking)
FIR: Resposta ao impulso finita (finite impulse response)
IMC: Controle por modelo interno (internal model control)
ITL: Aprendizado de máquina baseado na teoria da informação
(information theory learning)
IV-4SID: Instrumental variable subspace-based state-space system
identification
KNN: K vizinho maior próximo (K-nearest neighbor)
LMPC: Controle preditivo linear (linear model predictive control)
LP: Programação linear (linear programming)
LQ: Linear quadrático (linear quadratic)
LTI: Linear invariante no tempo (linear time-invariant)
MI: Informação mútua (mutual information)
MIMO: Múltiplas entradas e múltiplas saídas (multiple input - multiple
output)
MOESP: Multivariable output-error state-space model identification
MPC: Controle preditivo (model predictive control)
MPM: Erro entre o modelo e a planta (model-plant mismatch)
N4SID: Numerical algorithms for subspace state space system
identification
NMPC: Controle preditivo não linear (nonlinear MPC)

xviii
PCA: Análise de componentes principais (principal component analysis)
PDF: Função de densidade de probabilidade (probability density
function)
PID: Controlador proporcional-integral-derivativo (proporcional-
integral-derivativo)
PMR: Relação planta-modelo (plant-model ratio)
PRBS: Sinais binários pseudoaleatórios (pseudo-random binary signal)
RHC: Controle de horizonte móvel (receding horizon control)
RTO: Real time optimization
SISO: Uma entrada e uma saída (single input - single output)
SVD: Decomposição em Valores Singulares (singular value
decomposition)

xix
Lista de Símbolos
𝑨: Matriz dinâmica.
𝑑(. ): Operador distância
Δ: Modelo do MPM.
𝜹𝒖: Vetor de incremento das entradas
𝜹𝒖𝑚á𝑥: Limite máximo de incremento nas entradas
𝛿𝑦: Vetor de variáveis de folga
𝑐𝑜𝑣(. ): Operador covariância.
𝐸[. ]: Operador esperança.
𝒆: Vetor de erros do modelo.
𝒆′: Vetor de erros do modelo não houver nenhuma ação de controle
futura (sistema malha aberta).
휀: Resíduos.
𝐺: Processo.
�̂�: Modelo do processo.
𝐻(. ): Operador entropia
ℎ𝑐: Horizonte de controle.
ℎ𝑝: Horizonte de predição.
𝑰: Matriz identidade
𝐼(. ): Operador informação mútua
𝑘: Instante de amostragem.
𝜇: Média.
𝜎: Desvio padrão.
𝑚: Número de entradas.
𝑛: Número de saídas.
𝑄: Controlador.
𝑇𝑠: Tempo de amostragem.
𝑹: Matriz de fatores de supressão das variáveis manipuladas
𝒓: Set-point.
𝑐𝑜𝑟𝑟(. ): Coeficiente de correlação.
𝑝𝑐𝑜𝑟𝑟(. ): Coeficiente de correlação parcial.

xx
𝑥𝑐𝑜𝑟𝑟(. ): Coeficiente de correlação cruzada.
𝑢𝑚: Entrada do processo (variável manipulada)
𝒖: Vetor de entradas do processo (variáveis manipuladas).
𝒖𝒎á𝒙: Limite máximo das entradas
𝒖𝒎í𝒏: Limite mínimo das entradas
𝑢𝑠𝑠: Vetor de targets para as variáveis manipuladas.
𝒗: Distúrbios não medidos.
𝑣𝑎𝑟(. ): Operador variância.
𝑾: Fator de supressão das controladas.
𝜙: Função objetivo.
𝑋: Variável aleatória.
𝑿: Conjunto de dados.
𝑌: Variável aleatória.
𝒀: Conjunto de dados.
𝑦𝑛 Saída do processo (variável controlada)
𝒚: Vetor de saídas do processo (variáveis controladas).
�̂�: Saída do modelo.
𝑦𝑚á𝑥: Limite máximo das saídas
𝑦𝑚í𝑛: Limite mínimo das saídas
𝑦𝑠𝑠: Vetor de saídas preditas no estado estacionário
𝒁: Conjunto de variáveis

1
Capítulo 1
Introdução
1.1 Motivação
Com o aumento das exigências em termos de eficiência de produção, a indústria
necessita cada vez mais da utilização de controle de processos mais avançados. Uma
classe de controladores avançados é a dos controladores preditivos ou MPC (Model
Predictive Control) (BADWE et al., 2009). De acordo com Desborough e Miller (2002)
66% dos controladores têm algum tipo de degradação no desempenho. As principais
causas desta degradação podem ser vistas na Figura 1.1 (NAIDOO, 2010):
Diagnóstico de
Mau
Desempenho
PerturbaçõesProblemas de
Equipamento
Sintonização do
Controlador
Deficiente
Modelo
Impreciso
(MPM)
Figura 1.1: Diagrama de fluxo de causas de degradação do desempenho do controlador MPC (adaptação
de Naidoo, 2010)
O controlador MPC utiliza o modelo da planta e o estado atual para estimar o ideal
de controle (levando em consideração alguns critérios) para uma série de entradas futuras
(CARLSSON, 2010). Nos controladores preditivos o modelo do processo realiza uma
função essencial, de maneira que o desempenho do controlador depende diretamente da
qualidade do modelo e, consequentemente, do erro entre o modelo e a planta ou MPM
(Model-Plant Mismatch) (BADWE et al., 2009).
Com o tempo é natural que os processos sofram modificações e os modelos
precisam acompanhá-los para manter o comportamento adequado do controlador. Para

2
que isso ocorra muitas vezes há a necessidade de atualização e reajuste do modelo
(WANG; XIE; SONG, 2012).
Quando um canal de entrada e saída de um controlador preditivo de múltiplas
entradas e múltiplas saídas ou MIMO (Multiple Input – Multiple Output) apresenta erro
de modelagem, várias saídas são afetadas. A identificação do MPM torna-se, então, um
fator importante no auxílio da reidentificação e sintonia do controlador, bem como na
manutenção contínua, com a finalidade de se obter o máximo ganho de produtividade do
controlador preditivo (BADWE et al., 2009; CARLSSON, 2010).
Embora o MPM seja inevitável, devido a simplificações e dinâmicas
desconhecidas, é de grande importância que seja o menor possível (SEBORG; THOMAS;
MELLICHAMP, 2004; WANG; XIE; SONG, 2012). Em processos com grande número
de entradas e saídas a reidentificação do modelo depende de métodos que comprometem
a produção, como aqueles que mantêm um grande número de entradas em um estado
perturbado por um longo período de tempo, causando custos elevados à produção normal.
Portanto seria desejável a detecção da localização exata do erro do modelo, necessitando
perturbar um menor número de entradas e atualizar apenas a parte degradada (BADWE
et al., 2009).
Recentemente muitas pesquisas sobre a detecção do MPM foram realizadas com
sucesso utilizando métodos matemáticos como as correlações cruzada e parcial, mas em
grande parte direcionadas para sistemas lineares (BADWE et al., 2009; WEBBER;
GUPTA, 2008). Porém, em muitos casos, os modelos não lineares são normalmente
utilizados para melhorar o desempenho dos sistemas de controle MPC, e as ferramentas
desenvolvidas para detecção de erro em sistemas lineares podem apresentar resultados
insatisfatórios ou são demasiadamente restritas a determinados tipos de sinais não lineares
(CHEN et al., 2013).
A presença do MPM causa a degradação no desempenho do controlador e suas
predições ficam imprecisas. Desta forma é necessário detectar o erro e efetuar a
reindentificação do modelo periodicamente. Contudo, este tipo de operação envolve altos
custos, principalmente em casos onde tem-se um número grande de canais de entrada e
saída, pois muitas vezes são necessários testes invasivos (YERRAMILLI; TANGIRALA,
2016). Por conseguinte, a detecção do MPM motiva grande interesse tanto no meio
acadêmico quanto no ambiente industrial, já que uma detecção mais precisa de qual
relação de entrada e saída do erro significa uma reidentificação mais rápida dos modelos

3
afetados e, consequentemente, maior rentabilidade na operação e manutenção do
controlador MPC.
1.2 Objetivos
O objetivo principal deste trabalho é utilizar a informação mútua para a detecção
de erros entre a planta e o modelo em sistemas de controle MPC que utilizem modelos
não lineares. De forma paralela são utilizadas correlações cruzada e parcial para comparar
os resultados obtidos com a aplicação da informação mútua.
A metodologia desenvolvida consiste primeiramente na realização de testes
aplicando as técnicas da informação mútua e as correlações cruzada e parcial, utilizando
o processo da Coluna de Destilação Binária (WOOD; BERRY, 1973), que é um
simulador de um sistema de controle MPC baseado em modelos lineares. Posteriormente
as mesmas técnicas são aplicadas para o processo de uma Unidade Industrial de
Craqueamento Catalítico ou FCC (Fluid Catalytic Cracking) (LAUTENSCHLAGER
MORO; ODLOAK, 1995), neste caso o controlador MPC utilizado no simulador é
baseado em modelos não lineares.
1.3 Revisão bibliográfica
Na literatura técnico-científica foram propostos vários métodos de detecção do
MPM em sistemas de controle MPC, entretanto a maioria das técnicas desenvolvidas são
direcionadas a sistemas de controle que utilizam modelos lineares. No campo de pesquisa
de sistemas de controle MPC com modelos não lineares as pesquisas mais recentes devem
receber maiores destaques. Algumas pesquisas relacionadas à detecção do MPM e
metodologias aplicadas no ambiente acadêmico são brevemente descritas seguir:
Stanfelj, Marlin e Macgregor (1993) apresentaram um método para monitorar e
diagnosticar o desempenho em sistemas de controle SISO (Single Input – Single Output),
baseado em dados típicos da planta operacional. O método realiza uma análise estatística
simples, porém, rigorosa dos dados de séries temporais da planta utilizando as funções de
auto correlação e correlação cruzada.

4
Huang e Tamayo (2000) utilizaram métodos de validação de modelos para
sistemas de controle MPC. A validação é feita através de um algoritmo de divergências
entre dois modelos, independentemente de perturbações dinâmicas.
Huang, Malhotra e Tamayo (2003) estudaram a função da pré-filtragem de dados
na identificação e validação de modelos. É apresentado um pré-filtro de dados relevantes
em sistemas controle MPC, chamado de filtro preditor de múltiplos passos à frente, para
previsões ótimas, durante cada passo com um horizonte finito. Também foi demonstrado
que os modelos que minimizam os erros de predição de múltiplos passos podem ser
identificados ou verificados por meio da filtragem dos dados utilizando os pré-filtros, em
seguida, aplica-se o método da predição do erro aos dados filtrados.
Kraskov, Stögbauer e Grassberger (2004) apresentaram duas classes de
estimadores aperfeiçoados de informação mútua, a partir de pontos amostrais
aleatoriamente distribuídos de acordo com alguma densidade de probabilidade conjunta.
As duas classes contrastam com os estimadores convencionais, baseados em bins, devido
à utilização da teoria do k-ésimo vizinho mais próximo ou KNN (K-Nearest Neighbor)
para o cálculo de entropias.
Conner e Seborg (2005) utilizaram medidas baseadas na análise de componentes
principais ou PCA (Principal Component Analysis) e no critério de informação de Akaike
para decidir a importante questão de determinar quando é necessário reidentificar o
modelo do processo. Através do procedimento desenvolvido pelos autores é possível
também determinar se é há a necessidade de uma reidentificação em grande escala dos
modelos ou isolar apenas um submodelo do processo.
Jiang; Li e Shah (2006) propuseram uma nova metodologia de detecção e
isolamento do MPM para sistemas dinâmicos com múltiplas variáveis. O MPM é
formulado em termos de modelos de espaço de estados em tempo discreto, tal abordagem
é amplamente utilizada em controladores MPC. Foram propostos três índices de detecção
de erro. Além desta técnica, um enquadramento lógico foi proposto para isolar as matrizes
do sistema que contém erros.
Liang et al. (2008) propuseram um método para analisar e invalidar modelos caso
exista MPM. Através de uma inferência estatística o MPM do controlador MPC é
analisado por meio de uma estrutura de controle por modelo interno ou IMC (Internal
Model Control) e com base em um limiar, os modelos são invalidados caso o limite
estatístico seja ultrapassado significativamente.

5
Webber e Gupta (2008) utilizaram a correlação entre sinais de excitação (dithering
signals) e o erro de predição para detecção de erros em sistemas de controle com múltiplas
e múltiplas saídas (MIMO), estendendo o método utilizado por Stanfelj, Marlin e
Macgregor (1993). O método consiste em utilizar correlação cruzada em malha fechada
para detectar qual dos pares de entrada-saída, do controlador MPC, contêm erros.
Podendo ainda ser utilizado para pesquisa de um conjunto de modelos que possam ser
escolhidos para uma reindentificação.
Badwe et al. (2009) realizaram a detecção do MPM, em sistemas de controle em
malha fechada, baseada em análises de correlações parciais entre o erro de predição e as
variáveis manipuladas. Devido aos bons resultados de detecção a metodologia pode ser
considerada como parte de um procedimento de avaliação e diagnóstico do desempenho
do controlador preditivo. A vantagem da abordagem utilizada por Badwe et al. (2009) é
que ela requer uma operação em rotina para ser realizada a análise.
Harrison e Qin (2009) propuseram um novo método para discriminação de falhas
para controladores MPC. O método consiste no monitoramento das inovações,
diferentemente dos resíduos (AGUIRRE, 2007), do filtro de Kalman para detectar a
presença de autocorrelações, que seriam uma indicação de estimação subótima de estado.
A causa da estimação subótima de estado é diagnosticada pela observabilidade do
processo de inovações. A tarefa de discriminação envolve a determinação do fim da
correlação presente nas inovações.
Badwe et al. (2010) apresentaram uma análise sobre o impacto da existência do
MPM no desempenho do controlador em malha fechada. Também foi mostrado que o
impacto do MPM na qualidade do controlador depende da natureza do sinal do set-point
utilizado.
Carlsson (2010) utilizou métodos de correlação, incluindo uma simplificação da
correlação parcial utilizada por Badwe et al. (2009), para mostrar que a detecção do MPM
é possível nos canais de entrada e saída que contiverem modelos ruins. Foi também
proposto o método correlação parcial não linear utilizando o coeficiente de Spearman
para a detecção do MPM para controladores MPC que utilizem modelos não lineares, em
vez do coeficiente de Pearson, que é normalmente utilizado em sinais com relações
lineares. Contudo os resultados para a detecção do MPM não linear mostraram-se
insatisfatórios além de necessário um esforço computacional excessivo.

6
Naidoo (2010) apresentou métodos de detecção do MPM utilizando correlações
cruzadas e parciais, filtro de Kalman e janela móvel de regressão. Além dos métodos de
detecção o autor discutiu sobre conceitos base como identificação de sistemas, validação
de modelos e a teoria de regressão linear.
Nafsun e Yusoff (2011) apresentaram os efeitos do MPM no desempenho dos
controladores MPC. Foram investigados quatro tipos de erros presentes em uma função
de transferência: erro no ganho, erro no ganho inverso, erro na constante de tempo e erro
no tempo de atraso. Os autores classificaram o erro no ganho da função de transferência
do modelo do processo como o pior caso.
Ji, Zhang e Zhu (2012) apresentaram um novo método de detecção do MPM em
sistemas de controle MPC em malha fechada e on-line. Os autores utilizaram sinais testes
senoidais de baixa amplitude e sem perturbações, no intuito de obter estimativas precisas
de respostas em frequência do processo. Em seguida, as diferenças entre as respostas em
frequência estimadas e as respostas do modelo utilizado pelo controlador MPC foram
utilizadas para gerar uma matriz de índices do MPM que indica a localização precisa do
MPM.
Wang, Xie e Song (2012) apresentaram vários tipos de medições do MPM,
classificando-os em vários grupos, com base em diferentes descrições de modelos
lineares. O potencial destes tipos de MPM foram analisados e avaliados separadamente.
Os autores concluíram que a detecção em malha fechada tem maior vantagem prática e
que o tema diagnóstico de MPM é ainda de ampla discussão principalmente em casos nos
quais são utilizados modelos não lineares.
Chen et al. (2013) consideraram não linearidades generalizadas e utilizaram a
informação mútua ou MI (Mutual Information) como uma medida de dependência geral
para a detecção do MPM. Os autores utilizaram a estimação da MI utilizando o método
do KNN com base no trabalho de Kraskov, Stögbauer e Grassberger (2004). São
utilizados sinais de excitação e os resíduos do modelo para formar uma matriz
correspondente aos índices da MI estimada pelo KNN que indica a localização do MPM
entre os submodelos do controlador MPC.
Iqbal, Yusoff e Tufa (2014) utilizaram a correlação parcial para a detecção do
MPM aplicando as estruturas de modelos ARX (Auto Regressive with Exogenous Inputs)
e FIR (Finite Impulse Response) com o objetivo de testar a eficácia destas diferentes
estruturas para a utilização em controladores MPC.

7
Loeff (2014) demonstrou que o método de Carlsson (2010) é uma solução
particular do método de Badwe et al. (2009), quando os modelos utilizados no processo
de identificação são estruturas FIR (Finite Impulse Response). O autor também realizou
estudos de outros tipos de estruturas, verificando se elas são adequadas para análise da
correlação parcial, com o objetivo de detectar o MPM.
Botelho et al. (2015) apresentaram um método para avaliação da qualidade do
modelo baseado na investigação de dados do controlador em malha fechada e em uma
função de sensibilidade complementar nominal. Tal abordagem considera dados relativos
a um modelo nominal da planta sem a presença do MPM.
Forbes et al. (2015) examinaram as tendências atuais de pesquisas e práticas na
indústria no sentido da manutenção do desempenho dos controladores MPC.
Silva et al. (2015) apresentaram os três pilares teóricos do Aprendizado de
Máquina Baseado na Teoria da Informação ou ITL (Auto-Regressive Moving Average
with Exogenous Input): a teoria da informação, as formulações de Rényi e estimadores
estatísticos. Os autores discutiram conceitos essenciais de entropia, entropia conjunta,
entropia condicional e informação mutua. Também são abordados problemas e técnicas
de resolução da estimação de entropia.
Tsai et al. (2015) propuseram um algoritmo que estabelece uma métrica
quantitativa para a detecção da existência do MPM, com a planta em operação, e a
identificação de qual canal de entrada e saída do modelo está causando o MPM. Os
autores fizeram uma adaptação do método utilizado por Badwe et al. (2010), que indica
a presença do MPM baseado nos valores singulares máximos da matriz de transferência
entre as entradas e as trajetórias dos set-points.
Yousefi et al. (2015) propuseram uma nova técnica de detecção do MPM com
base na correlação cruzada entre o erro de predição e a entrada do processo, sem a
necessidade de introduzir sinais de excitação externos.
Tufa e Ka (2016) apresentaram os efeitos do MPM sobre o desempenho do
controlador MPC e uma abordagem sistemática para determinar o limite do MPM, acima
do qual a deterioração do desempenho pode ser considerada significativa.
Uddin et al. (2016) estenderam a técnica de detecção do MPM desenvolvida por
Badwe et al.(2009), que utiliza modelos dinâmicos para a descorrelação de variáveis,
aplicando os modelos ARX e ARMAX (Auto-Regressive Moving Average with

8
Exogenous Input) com o objetivo de testar a eficácia destas diferentes estruturas para a
utilização em controladores MPC.
Yerramilli e Tangirala (2016) estenderam o conceito de relação planta-modelo ou
PMR (Plant-Model Ratio), inicialmente utilizado em sistemas SISO, para sistemas
MIMO. O método proposto tanto detecta MPM significativo quanto identifica a fonte do
MPM dentro dos respectivos canais de entrada e saída.
Apesar de vários trabalhos descritos na revisão acima serem direcionados à
detecção de MPM em sistemas de controle MPC de processos lineares, a exemplo de
Badwe et al. (2009), Carlsson (2010), Loeff (2014), Webber e Gupta (2008), apenas o
trabalho de Chen et al. (2013) é direcionado a sistemas de controle MPC de processos
não lineares. Tais processos não lineares são muito comuns em ambientes industriais e
faz-se necessário o desenvolvimento ou melhoria de métodos de detecção que facilitem a
manutenção dos controladores MPC destes tipos de processo. Outra consideração
importante é que os métodos propostos por Badwe et al. (2009), Carlsson (2010), Loeff
(2014), Webber e Gupta (2008) são baseados em correlações, que são métodos práticos
para a implementação. No trabalho de Chen et al. (2013) a utilização do KNN mostrou-
se computacionalmente custosa. Tendo em vista estas informações, o presente trabalho
visa contribuir com o conhecimento sobre a detecção de MPM em controladores MPC de
processos em sistemas não lineares, com grande foco no desenvolvimento de métodos de
fácil implementação.
1.4. Estrutura do trabalho
No primeiro capítulo foram apresentados a motivação, os objetivos do trabalho,
uma ampla revisão bibliográfica sobre métodos de detecção de MPM em sistemas de
controle preditivos MPC e os trabalhos publicados em congressos de áreas relacionadas
ao tema desta dissertação.
No segundo capítulo são apresentados alguns conceitos base sobre controladores
MPC e o equacionamento explícito do MPM.
O terceiro capítulo descreve de forma detalhada os métodos de detecção de MPM
utilizados neste trabalho.

9
No quarto capítulo é descrito o estudo de caso para a detecção de MPM linear e
são apresentados os resultados de detecção de MPM descritos no presente trabalho.
No quinto capítulo está presente o estudo de caso para detecção de MPM não
linear e são apresentados os resultados de detecção de MPM descritos no presente
trabalho.
O sexto capítulo apresenta as principais conclusões sobre os resultados obtidos
assim como as perspectivas futuras de continuação deste trabalho.
1.5. Publicações
Com os resultados obtidos na realização deste trabalho foram publicados dois
artigos em dois congressos de importante relevância para a área:
“Detecção de Erro em Planta-Modelo em Sistemas de Controle Preditivo”,
dos autores Diego D. G. B. Cruz e Oscar A. Z. Sotomayor. Este artigo foi publicado no
Congresso Rio Automação 2015, realizado no Rio de Janeiro - RJ nos 25 e 26 de maio de
2015.
“Técnicas de Correlação para Detecção de Erro Planta-Modelo em
Aplicações MPC”, dos autores Diego D. G. B. Cruz, Danilo D. Tannus e Oscar A. Z.
Sotomayor. Este artigo foi publicado do 8º Congresso Brasileiro de P&D em Petróleo e
Gás – (PDPETRO), realizado em Curitiba - PR entre os dias 20 a 22 de outubro de 2015.

10
Capítulo 2
Controladores Preditivos (MPC)
2.1 Controle de Processos Industriais
O sistema de controle completo em um processo industrial de larga escala é uma
combinação de várias camadas, cada uma com diferentes prioridades. Uma estrutura
típica para o controle de um processo industrial é ilustrada na Figura 2.1 (CARLSSON,
2010).
Figura 2.1: Visão geral do sistema de controle de processos industriais (adaptação de Carlsson, 2010)
As definições de cada uma das camadas são descritas a seguir:
RTO (Real Time Optimization): Determina os ajustes econômicos ideias do
estado estacionário para as unidades de processo da planta química (TORO, 2012).
Controlador MPC: Com os set-points da camada LP o controlador MPC tenta
otimizar a produção de uma única unidade de processamento. Ele mantém o processo
dentro dos limites seguros de operação especificados e otimiza a produção com base nas
regras decididas pela camada acima.

11
Controle PID (Controle de Baixo Nível): Mantém os parâmetros em seus
devidos set-points dados pelo controlador MPC como por exemplo fluxos e temperaturas.
Processo Industrial: O processo real que deve ser controlado.
2.2 O MPC
O controle preditivo ou MPC, do inglês Model Predictive Control, se refere a uma
classe de algoritmos de controle automático que controla a resposta futura da planta
através do uso de um modelo explícito do processo. Em cada instante de amostragem, o
MPC soluciona on-line um problema linear quadrático (LQ), usando o estado atual da
planta como estado inicial. O resultado da otimização gera uma sequência de controle
ótimo em malha aberta que é aplicada de acordo com a filosofia de controle de horizonte
móvel ou RHC (Receding Horizon Control), onde só a primeira ação de controle desta
sequência é usada, fornecendo um controlador com as características de realimentação
desejadas.
Atualmente, MPC pode ser considerado como a mais importante inovação em
controle avançado de processos dos últimos 40 anos e a ferramenta padrão para aplicações
industriais (QIN; BADGWELL, 2003). Relatórios industriais recentes apontam em
aproximadamente 6000 o número de aplicações bem-sucedidas de MPC em todo o
mundo, revelando um mercado em crescimento contínuo nos últimos anos (BAUER;
CRAIG, 2008). Benefícios significativos são gerados diretamente a partir da habilidade
do MPC de assegurar que a planta opere dentro das suas restrições de forma mais
lucrativas. MPC é também uma das áreas de pesquisa mais ativas da teoria de controle.
Desde o trabalho pioneiro de Richalet et al. (1978), a teoria do MPC tem evoluído de
forma substancial. Atualmente, questões teóricas tais como otimalidade, estabilidade,
desempenho e robustez são bem conhecidas, principalmente para sistemas descritos por
modelos lineares, fato que pode ser comprovado pelos inúmeros artigos disponíveis na
literatura.
Apesar do aparecimento de algoritmos MPC não-lineares (NMPC) (HENSON,
1998; QIN; BADGWELL, 2000), a geração corrente de algoritmos MPC comercialmente
disponíveis são baseados em modelos lineares (LMPC, ou simplesmente MPC). Mais
ainda, atualmente, na literatura de pesquisa, o MPC é quase sempre formulado em espaço
12
de estados (MORARI; LEE, 1999). Isto tem simplificado, unificado e generalizado a
teoria, incluindo fácil extensão a sistemas multivariáveis, fácil análise das propriedades
em malha fechada e cálculo on-line (SOTOMAYOR, 2002). As principais vantagens do
LMPC estão vinculadas às facilidades de obtenção de modelos lineares, se comparados
aos não lineares, e às menores dificuldades para se resolver os problemas de otimização
associados. Porém, quando os processos têm dinâmica muito não linear ou quando a faixa
de operação é variável, então necessariamente deverá ser tomado em conta o modelo não
linear no projeto do controle, de forma que permita manter o desempenho desejado para
o sistema em malha fechada (PLUCENIO et al., 2007).
Figura 2.2: Esquema de implementação dos algoritmos MPC.
Na Figura 2.2 encontra-se ilustrada a implementação básica de todos os algoritmos
de controle preditivo. No instante de tempo atual usualmente definido como o instante 𝑘,
o comportamento do processo ao longo de um horizonte de tempo ℎ𝑝 é considerado. O
intervalo de tempo ℎ𝑝 é conhecido como horizonte de predição. Utilizando um modelo
do processo real, as respostas 𝑦 deste processo às mudanças nas variáveis manipuladas 𝑢
são previstas. As ações das variáveis manipuladas são selecionadas de tal forma que a
resposta prevista �̂� apresenta determinadas características que sejam desejáveis. As ações

13
de controle podem variar apenas dentro de um horizonte ℎ𝑐 ≤ ℎ𝑝 conhecido como
horizonte de controle. De forma geral, minimiza-se um critério de desempenho desejado
sujeito à dinâmica do modelo e às possíveis restrições nas variáveis de entrada/saída.
Apenas a primeira ação de controle calculada é de fato implementada no processo real.
As variáveis controladas da planta são então medidas. No próximo instante de
amostragem, isto é, em k+1, o mesmo problema de otimização é resolvido com a nova
condição inicial obtida mediante informação tirada das medidas da planta em k+1 (é desta
maneira que se introduz retro-alimentação ou “feedback” no controlador) e com o
horizonte movido adiante por um intervalo de amostragem (QIN; BADGWELL, 2003).
A estrutura inerente a todos os algoritmos MPC é ilustrada na Figura 2.3, onde o
controlador é também chamado de otimizador.
Figura 2.3: Estrutura do controlador MPC.

14
2.2.1 Sistema MIMO
Em um sistema MIMO temos 𝑚 entradas 𝑢 e 𝑛 saídas 𝑦 conforme Equação (2.1)
𝒖(𝑘) = [
𝑢1(𝑘)
𝑢2(𝑘)⋮
𝑢𝑚(𝑘)
] , 𝒚(𝑘) = [
𝑦1(𝑘)
𝑦2(𝑘)⋮
𝑦𝑛(𝑘)
] (2.1)
Diferentes tipos de modelos podem ser utilizados para representar as relações
entre 𝒖(𝑘) e 𝒚(𝑘), sendo a mais comum à de sistemas lineares invariantes no tempo ou
LTI (Linear Time-Invariant). Neste caso as saídas de 𝒚 do sistema é um mapeamento
linear produzido por cada entrada de 𝒖, considerando que os princípios da superposição
e da invariância do tempo podem ser aplicados. Diferentes tipos de formulações de
sistemas LTI podem ser utilizadas. Como exemplo temos as funções de transferência ou
TF (Transfer Function) e equações de estados ou SS (State Space) (AGUIRRE, 2007;
CARLSSON, 2010).
2.2.2 O Controlador QDMC
Os primeiros controladores aplicados na indústria no final dos anos 70 utilizavam
a estratégia MPC sem restrições também conhecido como DMC, que usavam um modelo
de convolução linear de resposta ao degrau e geração da sequência de controle por
otimização analítica. Porém, com o aparecimento de restrições presentes nos processos
que necessitavam a sua inclusão no desenvolvimento do controlador, foi necessária uma
evolução do algoritmo de controle. A otimização neste caso passou a ser numérica e a
solução do problema convexo DMC por meio de programação quadrática (QP) deu
origem ao QDMC, proposto por (GARCIA; MORSHEDI, 1986).
O QDMC usa as mesmas equações de predição do DMC, ou seja:
𝒆 = −𝑨𝛅𝒖 + 𝒆′ (2.2)
Em que:
𝒆 – é o vetor de erros entre os valores previstos e o valor desejado.

15
𝒆′ – é o vetor de erros entre o valor desejado e os valores previstos, se não
houver nenhuma ação de controle futura (sistema em malha aberta).
𝑨 – é matriz dinâmica.
𝛅𝒖 – é o vetor das ações de controle
Considerando a seguinte função objetivo:
𝜙 =
1
2𝒆𝑇𝑾𝑇𝑾𝒆 +
1
2𝛅𝑢
𝑇𝑹𝑇𝑹𝚫𝒖 (2.3)
Sendo que:
𝑹 – é a matriz de fatores de supressão que pondera (atenua) as variações
das ações de controle, é normalmente uma matriz diagonal com todos os valores
constantes e iguais. Quanto maior o valor de 𝑹 mais suave a ação de controle
resultante, caracterizada por ser um parâmetro de sintonia do controlador.
𝑾 – é a matriz diagonal de ponderação onde os valores da diagonal
principal são proporcionais à importância da variável controlada.
Substituindo a Equação (2.2) na Equação (2.3), temos:
𝜙 =
1
2[(−𝑨𝛅𝒖 + 𝒆′)𝑇𝑾𝑇𝑾(−𝑨𝛅𝒖 + 𝒆′)] +
1
2𝛅𝒖
𝑇𝑹𝑇𝑹𝛅𝒖 (2.4)
𝜙 =
1
2[𝛅𝒖
𝑇(𝑨𝑇𝑾𝑇𝑾𝑨 + 𝑹𝑇𝑹)𝛅𝒖] − 𝒆′𝑇𝑾𝑇𝑾𝑨𝛅𝒖 +1
2𝒆′𝑇𝑾𝑇𝑾𝒆′ (2.5)
Como o último termo do segundo membro, não depende da variável de interesse
𝛅𝒖, a função objetivo do controlador pode ser escrita como:
min𝛅𝒖
𝜙 =1
2𝜹𝒖
𝑇𝑯𝛅𝒖 + 𝒄𝑇𝜹𝒖 (2.6)
Em que:
𝑯 = 𝑨𝑇𝑾𝑇𝑾𝑨 + 𝑹𝑇𝑹 (2.7)

16
𝒄𝑇 = −𝜺𝑇𝑾𝑇𝑾𝑨 (2.8)
Ao problema definido na Equação (2.6) podemos incluir as restrições nas
variáveis manipuladas e controladas:
1. Inclusão de restrições nos incrementos das manipuladas: −𝛅𝒖𝑚𝑎𝑥≤ 𝛅𝒖 ≤ 𝛅𝒖𝑚𝑎𝑥
.
2. Inclusão de restrições nos valores das manipuladas: 𝒖𝑚𝑖𝑛 ≤ 𝒖 ≤ 𝒖𝑚𝑎𝑥.
Resumindo, o problema de otimização que o QDMC resolve tem a função objetivo
definida na Equação (2.6) e as restrições. É fácil observar que a função objetivo é quadrática
e as restrições são todas lineares. Esse tipo de problema é clássico dentro da área de
otimização e é conhecido como o problema de programação quadrática (PQ). Do resultado
da otimização, só a primeira ação de controle do vetor é usada na planta.
2.2.3 Representação do MPC utilizando IMC
Em muitas bibliografias o controlador MPC é elucidado através da representação
de uma estrutura de controle por modelo interno ou IMC (Internal Model Control), devido
à existência de uma modelo explícito em uma estrutura LTI capaz de descrever
corretamente o MPC (BADWE et al., 2009; CARLSSON, 2010; CHEN et al., 2013;
NAFSUN; YUSOFF, 2011; UDDIN et al., 2016; WEBBER; GUPTA, 2008).
O IMC, visualizado na Figura 2.4, utiliza um modelo �̂� do processo 𝐺 para
subtrair os efeitos das variáveis manipuladas 𝒖(𝑘) da saída 𝒚(𝑘). Se assumirmos por um
momento que o modelo é uma representação perfeita do processo, então o sinal
realimentado é equivalente à influência das perturbações 𝒗(𝑘) e não é afetado pela ação
das variáveis manipuladas. Desta forma o sistema encontra-se efetivamente em malha
aberta e os problemas de estabilidade habituais associados à realimentação desaparecem,
considerando que todo o sistema é estável se e somente se o processo e o controlador são
estáveis (MORARI; ZAFIRIOU, 1989).

17
.
Figura 2.4: Estrutura de controle por modelo interno (IMC) em malha fechada (Badwe et al., 2009).
Caso o modelo não represente o processo perfeitamente, o sinal realimentado será
composto tanto pelos distúrbios (não medidos) quanto o efeito do erro entre a planta e o
modelo ou MPM. Neste caso o MPM passa a fazer parte da realimentação e poderá causar
problemas de estabilidade (MORARI; ZAFIRIOU, 1989).
2.2.4 O Modelo do MPM
O erro do modelo, que é a diferença entre saída do processo 𝒚 e o a saída do
modelo �̂�, representado por 𝒆 na Figura 2.4, pode ser expressa pela seguinte relação:
𝒆(𝑘) = 𝒚(𝑘) − �̂�(𝑘) = Δ𝒖(𝑘) + 𝒗(𝑘) (2.9)
Δ ≜ 𝐺 − �̂� (2.10)
Em que o Δ𝒖(𝑘) representa a componente determinística e 𝒗(𝑘) a componente
determinada pelo ruído.
Supõe-se que 𝐺 e �̂� sejam LTI, então Δ também será. Considerando então Δ uma
matriz com 𝑛 linhas e 𝑚 colunas, conforme a Equação (2.11), de forma que 𝑛 seja o
número de saídas da planta e 𝑚 o número de entradas.
Δ = [
Δ11 ⋯ Δ1𝑚
⋮ ⋱ ⋮Δ𝑛1 ⋯ Δ𝑛𝑚
] (2.11)
Para Δ𝑖𝑗 ≠ 0 será acusada a presença de erro entre a variável de predição �̂�𝑖 e a
variável de saída do controlador 𝒚𝑖, para 𝑖 = 0,1,2,… 𝑛 e 𝑗 = 0,1,2, …𝑚. Contudo,
mesmo que Δ𝑖𝑗 seja diferente de zero ele pode não ser significativa.

18
Pode-se notar através da Equação (2.9) que 𝒆(𝑘) tem uma correlação com o sinal
de 𝒖(𝑘) através do modelo do MPM definido por Δ, na Equação (2.10). Isto significa que
quanto mais expressivo o Δ, mais expressiva também será a correlação entre 𝒆(𝑘) e 𝒖(𝑘)
(BADWE et al., 2009).
Considerando que o controlador é multivariável, operando em malha
fechada, 𝒆(𝑘) e 𝒖(𝑘) podem ser determinados a partir de Δ, 𝑄, 𝒓(𝑘) e 𝒗(𝑘), conforme as
Equações (2.17) e (2.21):
𝒖(𝑘) = 𝑄[𝒓(𝑘) − 𝒆(𝑘)] (2.12)
𝒆(𝑘) = Δ𝑄[𝒓(𝑘) − 𝒆(𝑘)] + 𝒗(𝑘) (2.13)
𝒆(𝑘) = Δ𝑄𝒓(𝑘) − Δ𝑄𝒆(𝑘) + 𝒗(𝑘) (2.14)
𝒆(𝑘) + Δ𝑄𝒆(𝑘) = Δ𝑄𝒓(𝑘) + 𝒗(𝑘) (2.15)
𝒆(𝑘)[𝐼 + Δ𝑄] = Δ𝑄𝒓(𝑘) + 𝒗(𝑘) (2.16)
𝒆(𝑘) = [𝐼 + Δ𝑄]−1Δ𝑄𝒓(𝑘) + [𝐼 + Δ𝑄]−1𝒗(𝑘) (2.17)
Aplicando-se 2.17 em 2.12 obtém-se:
𝒖(𝑘) = 𝑄𝒓(𝑘) − 𝑄{[𝑰 + Δ𝑄]−1Δ𝑄𝒓(𝑘) + [𝐼 + Δ𝑄]−1𝒗(𝑘)} (2.18)
𝒖(𝑘) = 𝑄𝒓(𝑘) − 𝑄[𝐼 + Δ𝑄]−1Δ𝑄𝒓(𝑘) − 𝑄[𝐼 + Δ𝑄]−1𝒗(𝑘) (2.19)
𝒖(𝑘) = 𝑄{[𝑰 + Δ𝑄]−1Δ𝑄}𝒓(𝑘) − 𝑄[𝑰 + Δ𝑄]−1𝒗(𝑘) (2.20)
Utilizando a relação algébrica [𝐼 − (𝐼 + 𝐴)−1𝐴] = (𝐼 + 𝐴)−1
𝒖(𝑘) = 𝑄[𝑰 + Δ𝑄]−1𝒓(𝑘) − 𝑄[𝑰 + Δ𝑄]−1𝒗(𝑘) (2.21)
Já nas Equações (2.17) e (2.21) nota-se que 𝒓(𝑘) será de grande importância na
detecção do MPM, tal fato será discutido na seção a seguir.
2.2.5 Importância do Set-Point
A importância do set-point na detecção do MPM pode ser verificada através das
Equações (2.22) e (2.23). Quando 𝒓(𝑘) = 0, a relações transformam-se em (BADWE et
al., 2009; CARLSSON, 2010):

19
𝒆(𝑘) = [𝐼 + Δ𝑄]−1𝒗(𝑘) (2.22)
𝒖(𝑘) = −𝑄[𝐼 + Δ𝑄]−1𝒗(𝑘) (2.23)
Simplificando as duas equações, tornam-se:
𝒆(𝑘) = −𝑄−1𝒖(𝑘) (2.24)
Deste modo, na ausência de alterações no set-point, não será possível determinar
a extensão do MPM, já que o termo Δ desaparece da equação do erro em (2.24). Para que
não ocorra este problema faz-se necessária a variação do set-point por um tempo
suficiente.

20
Capítulo 3
Métodos de Detecção Linear e Não
Linear de MPM
3.1 Correlação Cruzada
A correlação é uma medida de similaridade entre duas ou mais variáveis.
Exemplos de aplicações do conceito de correlação podem ser encontrados em diversos
campos, como por exemplo no de comunicações digitais, em que um conjunto de
símbolos de dados é representado por sequências em tempo discreto. Caso uma destas
sequências seja transmitida, o receptor tem de determinar qual sequência específica foi
recebida por meio da comparação do sinal recebido com cada elemento do grupo de
sequências já existentes; a comparação então é realizada utilizando correlação. Da mesma
maneira, em aplicações de sonar e de radar, o sinal refletido recebido a partir do alvo é a
versão atrasada do sinal transmitido e, através da medição do atraso, é possível determinar
a localização do alvo (MITRA, 2001).
A forma adimensional da correlação é mais usual e conveniente, denominada de
coeficiente de correlação de Pearson ela introduz um conceito cujo valor é independente
de unidades de medida. O coeficiente de correlação pode ser dado como se segue.
Sejam 𝑿 e 𝒀 duas variáveis aleatórias, cujas amostras são dadas por
{𝑥(1), 𝑥(2),… , 𝑥(𝑡)} e {𝑦(1), 𝑦(2), … , 𝑦(𝑡)}. O coeficiente de correlação entre elas é
definido por (GUBNER, 2006):
𝑐𝑜𝑟𝑟(𝑿, 𝒀) = 𝐸 [(𝑿 − 𝜇𝑿
𝜎𝑿) (
𝒀 − 𝜇𝒀
𝜎𝒀)] (3.1)
Em que 𝜇 e 𝜎 são a média e desvio padrão de 𝑿 e 𝒀, e 𝐸 o operador esperança.
Neste trabalho, por simplicidade de apresentação, usaremos indistintamente o operador
esperança tanto para a esperança exata (definido em termos das distribuições de

21
probabilidade associadas aos conjuntos X e Y), quanto para o estimador empírico de
esperança, como nas definições da equação 3.7, em que o desconhecimento dessas
probabilidades leva ao uso de frequências de ocorrências dos elementos em 𝑿 e 𝒀. De
formas equivalentes:
𝑐𝑜𝑟𝑟(𝑿, 𝒀) =𝐸[𝑿𝒀] − 𝑚𝑿𝑚𝒀
𝜎𝑿𝜎𝒀 (3.2)
𝑐𝑜𝑟𝑟(𝑿, 𝒀) =𝑐𝑜𝑣(𝑿, 𝒀)
√𝑣𝑎𝑟𝑿𝑣𝑎𝑟𝒀 (3.3)
Tal coeficiente pode assumir valores entre -1 e 1 (LOEFF, 2014):
• 𝑐𝑜𝑟𝑟 = 1: Significa uma correlação perfeita positiva entre 𝑿 e 𝒀;
• 𝑐𝑜𝑟𝑟 = −1: Significa uma negativa perfeita entre 𝑿 e 𝒀, isto é, se um aumenta
o outro diminui;
• 𝑐𝑜𝑟𝑟 = 0: Significa que 𝑿 e 𝒀 não dependem linearmente um do outro.
Considerando agora a aplicação dos conceitos da correlação entre os vetores de 𝑛
variáveis manipuladas 𝒖 e 𝑚 erros dos modelos 𝒆 é formada a seguinte matriz de
coeficientes de correlação.
𝑐𝑜𝑟𝑟(𝒖, 𝒆) = [𝑐𝑜𝑟𝑟(𝒖1, 𝒆1) ⋯ 𝑐𝑜𝑟𝑟(𝒖1, 𝒆𝑚)
⋮ ⋱ ⋮𝑐𝑜𝑟𝑟(𝒖𝑛, 𝒆1) ⋯ 𝑐𝑜𝑟𝑟(𝒖𝑛, 𝒆𝑚)
] (3.4)
Um resultado igual a zero para os coeficientes na Equação (3.4) indica que 𝒖𝑛 e
𝒆𝑚 não são correlacionados, contanto que 𝒓 e 𝒗 da Equação (2.13) não sejam
correlacionados e que |𝒓| ≫ |𝒗| (CARLSSON, 2010; LOEFF, 2014; WEBBER;
GUPTA, 2008). Esta condição pode ser verificada supondo que o modelo está em sintonia
com o processo, ou seja, Δ = 0. Desta forma as Equações (2.9) e (2.12) tornam-se:
𝒆 = 𝒗 (3.5)
𝒖 = 𝑄(𝒓 − 𝒆) = 𝑄(𝒓 − 𝒗) (3.6)

22
Multiplicando os dois termos da Equação (3.5) por 𝒖:
𝐸(𝒖𝒆) = 𝐸(𝒖𝒗) (3.7)
A partir da Equação (3.7) conclui-se que 𝐸(𝒖𝒆) será zero caso 𝒖 seja
independente de 𝒗. No entanto a Equação (3.6) demonstra que 𝒖 e 𝒗 ainda serão
correlacionados, exceto quando a relação sinal/ruído for muito alta, de maneira que a
Equação (3.6) se torna:
𝒖 = 𝑄𝒓 (3.8)
Portanto deve-se manter a relação sinal-ruído elevada com o objetivo de obter
resultados mais precisos na utilização da correlação. No presente trabalho as perturbações
são desprezadas já que não é objetivo deste trabalho avaliar a influência das perturbações
na detecção de MPM.
Através da correlação será possível analisar apenas a relação atual entre as
variáveis, por exemplo, entre 𝒖1(𝑘) e 𝒆1(𝑘), desconsiderando o passado delas. Tal fato
torna a correlação inconveniente, já que não são analisadas as influências passadas de
uma variável sobre outra, podendo mascarar uma correlação existente entre 𝒖 e 𝒆.
Uma solução para o inconveniente é utilizar a correlação cruzada, que é uma
medida de similaridade aplicando-se 𝑙 atrasos em um dos pares de 𝒖 e 𝒆. Desta maneira
o passado de 𝒖 e 𝒆 será considerado.
Aplicando 𝑙 atrasos na equação da covariância, de forma análoga para os pares 𝒖1
e 𝒆1, encontra-se o seguinte equacionamento:
𝑥𝑐𝑜𝑣𝒖1,𝒆1
(𝑙) =1
𝑁∑ (𝒖1(𝑘 + 𝑙) − 𝜇𝒖1
)(𝒆1(𝑘) − 𝜇𝒆1)
𝑁−𝑙
𝑡=1−𝑙
, para 𝑙
= 0,1, … ,𝑁 − 1
(3.9)
De maneira que o coeficiente de correlação cruzada entre 𝒖1 e 𝒆1, aplicando 𝑙
atrasos será (WEBBER; GUPTA, 2008):

23
𝑥𝑐𝑜𝑟𝑟(𝒖𝟏, 𝒆𝟏) =𝑥𝑐𝑜𝑣𝒖𝟏,𝒆𝟏
(𝑙)
√𝑣𝑎𝑟𝒖𝟏𝑣𝑎𝑟𝒆𝟏
(3.10)
O mesmo raciocínio vale para os outros pare de 𝒖 e 𝒆 presentes na Equação (3.4).
Embora o inconveniente de utilizar a correlação convencional seja solucionado
com a aplicação da correlação cruzada, outro problema presente é a correlação entre as
variáveis manipuladas que pode influenciar nos resultados de detecção de MPM a
depender da estrutura do controlador 𝑄. Este problema é evidenciado em Carlsson (2010)
e Loeff (2014) através do seguinte exemplo:
Supondo a presença de MPM apenas em Δ11 em um sistema MIMO 2×2 em que
a variância da perturbação 𝒗(𝑘) seja pequena a ponto de ser desprezada, a Equação (2.9)
será apresentada seguinte maneira.
𝒆1(𝑘) = Δ11𝒖1(𝑘) (3.11)
Deste modo, com a presença de em Δ11 apenas, espera-se a seguinte matriz de
correlação:
𝑥𝑐𝑜𝑟𝑟(𝒖, 𝒆) = [𝑥𝑐𝑜𝑟𝑟(𝒖1, 𝒆1) 0
0 0] (3.12)
Considerando a Equação 2.12 em que:
𝒖(𝑘) = 𝑄 (𝒓(𝑘) − (𝒚(𝑘) − �̂�(𝒌))) = 𝑄(𝒓(𝑘) − Δ𝒖(𝑘)) (3.13)
Então para um sistema 2×2,
[𝒖1(𝑘 + 1)
𝒖2(𝑘 + 1)] = [
𝑄11(𝑞) 𝑄12(𝑞)
𝑄21(𝑞) 𝑄22(𝑞)] [
𝒓1(𝑘)
𝒓2(𝑘)]
− [𝑄11(𝑞) 𝑄12(𝑞)
𝑄21(𝑞) 𝑄22(𝑞)] [
Δ11(𝑞) Δ12(𝑞)
Δ21(𝑞) Δ22(𝑞)] [
𝒖1(𝑘)
𝒖2(𝑘)]
(3.14)
Como definido anteriormente, há a presença de MPM apenas em Δ11,

24
[𝒖1(𝑘 + 1)
𝒖2(𝑘 + 1)] = [
𝑄11(𝑞) 𝑄12(𝑞)
𝑄21(𝑞) 𝑄22(𝑞)] [
𝒓1(𝑘)
𝒓2(𝑘)]
− [𝑄11(𝑞) 𝑄12(𝑞)
𝑄21(𝑞) 𝑄22(𝑞)] [
Δ11(𝑞)𝒖1(𝑘)0
]
(3.15)
[𝒖1(𝑘 + 1)
𝒖2(𝑘 + 1)] = [
𝑄11(𝑞) 𝑄12(𝑞)
𝑄21(𝑞) 𝑄22(𝑞)] [
𝒓1(𝑘)
𝒓2(𝑘)] − [
𝑄11(𝑞)Δ11(𝑞)𝒖1(𝑘)
𝑄21(𝑞)Δ11(𝑞)𝒖1(𝑘)] (3.16)
Desta maneira nota-se que 𝑥𝑐𝑜𝑟𝑟(𝒖2, 𝒆1) não será igual a zero, evidenciada pela
correlação entre as variáveis manipuladas 𝒖1 e 𝒖2, mesmo que não se tenha presença de
MPM no canal de entrada e saída 𝒚1 − 𝒖2. A alternativa proposta para este problema é a
medida de correlação parcial de Badwe et al. (2009), apresentada da seção seguinte. Nas
subseções adiante são demonstrados alguns exemplos práticos da utilização da correlação
cruzada.
Aplicações da Correlação Cruzada
Como exemplo ilustrativo da correlação cruzada são considerados três níveis
correlação entre duas variáveis discretas, conforme o seguinte modelo.
𝒚 = 𝒙 + 𝒆1 𝒙 = 0.01𝑡 + 𝒆2
(3.17)
Considerando 𝑡 = 1,… ,500 e 𝒆1 e 𝒆2 sinais de ruído independentes com
distribuição normal de média zero e desvio padrão igual a 0.5. A Figura 3.2 demonstra
uma forte relação linear entre a variável independente 𝒙 e a variável dependente 𝒚.
No segundo caso são utilizadas apenas os mesmos sinais de ruído 𝒆1 e 𝒆2
conforme o gráfico da Figura 3.3.
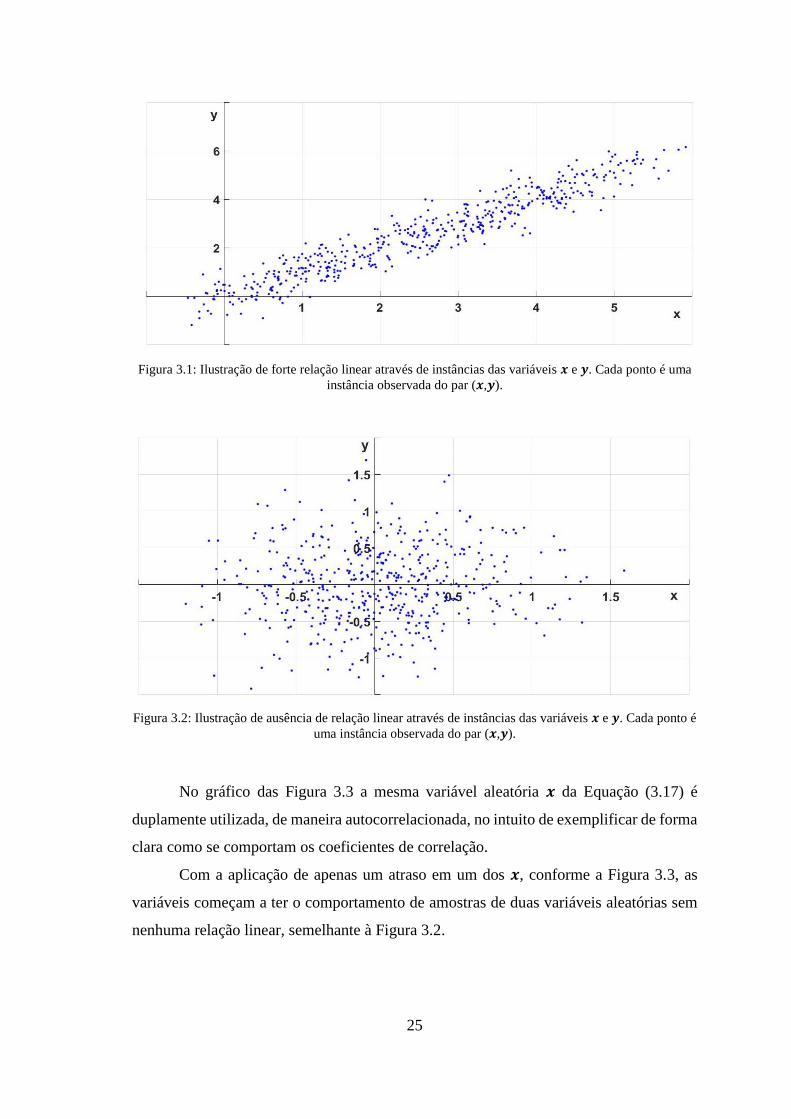
25
Figura 3.1: Ilustração de forte relação linear através de instâncias das variáveis 𝒙 e 𝒚. Cada ponto é uma
instância observada do par (𝒙,𝒚).
Figura 3.2: Ilustração de ausência de relação linear através de instâncias das variáveis 𝒙 e 𝒚. Cada ponto é
uma instância observada do par (𝒙,𝒚).
No gráfico das Figura 3.3 a mesma variável aleatória 𝒙 da Equação (3.17) é
duplamente utilizada, de maneira autocorrelacionada, no intuito de exemplificar de forma
clara como se comportam os coeficientes de correlação.
Com a aplicação de apenas um atraso em um dos 𝒙, conforme a Figura 3.3, as
variáveis começam a ter o comportamento de amostras de duas variáveis aleatórias sem
nenhuma relação linear, semelhante à Figura 3.2.
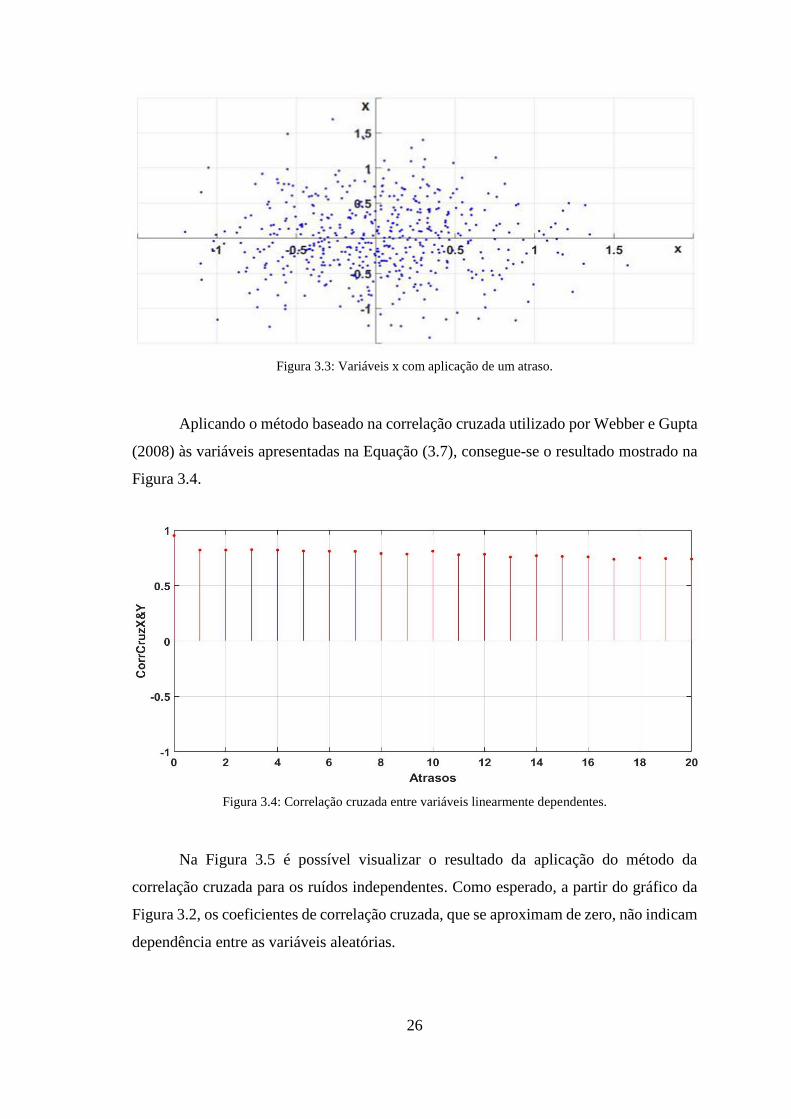
26
Figura 3.3: Variáveis x com aplicação de um atraso.
Aplicando o método baseado na correlação cruzada utilizado por Webber e Gupta
(2008) às variáveis apresentadas na Equação (3.7), consegue-se o resultado mostrado na
Figura 3.4.
Figura 3.4: Correlação cruzada entre variáveis linearmente dependentes.
Na Figura 3.5 é possível visualizar o resultado da aplicação do método da
correlação cruzada para os ruídos independentes. Como esperado, a partir do gráfico da
Figura 3.2, os coeficientes de correlação cruzada, que se aproximam de zero, não indicam
dependência entre as variáveis aleatórias.
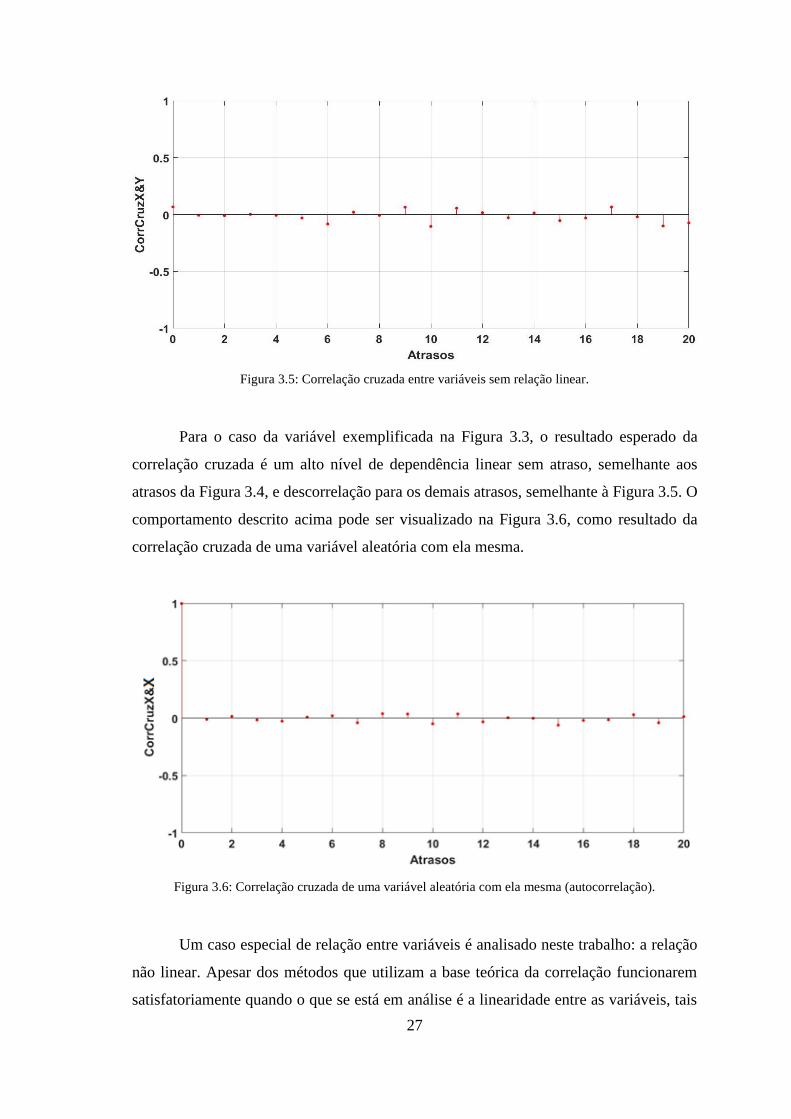
27
Figura 3.5: Correlação cruzada entre variáveis sem relação linear.
Para o caso da variável exemplificada na Figura 3.3, o resultado esperado da
correlação cruzada é um alto nível de dependência linear sem atraso, semelhante aos
atrasos da Figura 3.4, e descorrelação para os demais atrasos, semelhante à Figura 3.5. O
comportamento descrito acima pode ser visualizado na Figura 3.6, como resultado da
correlação cruzada de uma variável aleatória com ela mesma.
Figura 3.6: Correlação cruzada de uma variável aleatória com ela mesma (autocorrelação).
Um caso especial de relação entre variáveis é analisado neste trabalho: a relação
não linear. Apesar dos métodos que utilizam a base teórica da correlação funcionarem
satisfatoriamente quando o que se está em análise é a linearidade entre as variáveis, tais

28
métodos deixam a desejar caso as variáveis sejam compostas por transformações não
lineares das demais (CHEN et al., 2013; LOEFF, 2014; WEBBER; GUPTA, 2008).
Como forma de ilustrar a eficácia da detecção pela correlação cruzada de relações
não lineares entre variáveis é proposto um modelo, conforme a Equação (3.18) e Figura
3.7, considerando os mesmos parâmetros utilizados para as variáveis dos ruídos na
Equação (3.17) (LUNA; BALLINI; SOARES, 2006). Em seguida é mostrado o resultado
da aplicação do método na Figura 3.10.
𝒚 = 𝒙4 + 𝒆1 𝒙 = 𝑠𝑒𝑛 (2𝜋
𝑇𝑡) + 𝑒2
(3.18)
Figura 3.7: Variáveis com dependência não linear.
A desvantagem de utilizar o método da correlação cruzada para a detecção de
relações não lineares fica em evidenciada na Figura 3.8. É visto que na figura os
coeficientes de correlação cruzada estão muito próximo de zero, em todos os atrasos,
demonstrando não há correlação entre as variáveis. Contudo na Figura 3.8 é perceptível
a relação não linear entre as variáveis.

29
Figura 3.8: Correlação cruzada entre variáveis com relações não lineares.
3.2 Correlação Parcial
A abordagem através de correlação parcial é utilizada para encontrar correlações
entre duas variáveis após a remoção dos efeitos de uma terceira variável. Tal análise vem
sendo extensivamente utilizada em diversos campos de estudo como ciências sociais,
econometria, astronomia, bioinformática e engenharia. Em 2006 Gudi e Rawlings
utilizaram correlação parcial para isolar as interações entre os canais de entrada e saída
na identificação de sistemas de controle MPC descentralizados (BADWE et al., 2009;
CARLSSON, 2010; GUDI; RAWLINGS, 2006).
Em Loeff (2014) define-se a correlação parcial entre 𝑿 e 𝒀, controladas por um
conjunto de variáveis 𝒁 = {𝒁1, 𝒁2, … , 𝒁𝑛}, como a correlação convencional entre os
resíduos da regressão linear de 𝑿 e 𝒁 e de 𝒀 e 𝒁.
Portanto a aplicação da correlação parcial consiste primeiramente na obtenção dos
resíduos, referentes à 𝑿 e 𝒀 (휀𝑿 e 휀𝒀), através da determinação de um problema de
regressão linear entre 𝑿 e 𝒁 e 𝒀 e 𝒁. Em seguida é calculada a correlação regular entre os
resíduos obtidos.
Assumindo uma relação linear entre 𝑿 e 𝒁, a regressão poder ser escrita como:
𝑿 = 𝒁𝜃𝑿 + 휀𝑿 (3.19)

30
𝒁𝑇𝑿 = 𝒁𝑇𝒁𝜃𝑿 + 𝒁𝑇휀𝑿 (3.20)
Assumindo que 𝒁𝑇 e 𝜖𝑿 sejam perpendiculares:
𝜃𝑿 = (𝒁𝑇𝒁)−𝟏𝒁𝑇𝑿 (3.21)
Aplicando a Equação (3.21) a Equação (3.19) encontra-se o resíduo 휀𝑿:
휀𝑿 = 𝑿 − 𝒁(𝒁𝑇𝒁)−𝟏𝒁𝑇𝑿 (3.22)
De forma semelhante é possível encontrar também o resíduo 휀𝒀:
휀𝒀 = 𝒀 − 𝒁(𝒁𝑇𝒁)−𝟏𝒁𝑇𝒀 (3.23)
Após encontrar os resíduos 휀𝑿 e 휀𝒀 a operação final será dada através da aplicação
de 휀𝑿 e 휀𝒀 na correlação convencional, encontrando o coeficiente de correlação parcial
𝑝𝑐𝑜𝑟𝑟(𝑿, 𝒀|𝒁) livre dos efeitos de 𝒁.
Uma interpretação gráfica pode ser visualizada na Figura 3.9. Na figura é visto
que a correlação entre 𝑿 e 𝒀 é realizada em um plano ortogonal ao subespaço de 𝒁.
Figura 3.9: Interpretação gráfica da correlação parcial (adaptação de Carlsson, 2010).

31
3.2.1 Correlação Parcial por Badwe
Apesar do método da correlação parcial em sua forma usual ter diversas aplicações,
como mostrado na seção anterior, o mesmo precisa ser adaptado neste trabalho por dois
motivos:
• Os modelos utilizados são modelos dinâmicos, significando que as variáveis
consideradas são séries temporais;
• A presença de perturbações não medidas no processo, que podem sujeitar a análise
a falsos resultados quanto à existência do MPM.
O emprego de modelos dinâmicos na etapa de regressão baseados no método de erros
de predição ou PEM (Prediction Error Method) foi utilizado por Badwe et al. (2009) para
a resolução do primeiro problema. Neste trabalho foi utilizado o algoritmo do DSR
(Deterministic and Stochastic Subspace System Identification and Realization), por ser
um método mais rápido e robusto (SOTOMAYOR; PARK; GARCIA, 2003), para que
em seguida seja aplicado o PEM com a finalidade de otimizar o modelo, uma
demonstração do emprego de modelos dinâmicos está presente no Apêndice A. O
segundo problema é resolvido encontrando a componente de cada variável manipulada
que contém somente os efeitos dos set-points.
A seguir são apresentados vários passos propostos pela metodologia de Badwe et al.
(2009):
1. Selecionar os dados (erros do modelo e das variáveis manipuladas) de um
determinado período em que se possua excitação ou variação suficiente do set-
point no processo.
2. Encontrar as componentes das variáveis manipuladas livre de perturbações a parti
da Equação (2.20):
𝒖(𝑘) = 𝑄[𝑰 + Δ𝑄]−1𝒓(𝑘) − 𝑄[𝑰 + Δ𝑄]−1𝒗(𝑘) (3.24)
𝒖(𝑘) = 𝑺𝒓𝒖𝒓(𝑘) + 𝑺𝒗𝒖𝒗(𝑘) = 𝒖𝒓(𝑘) + 𝒖𝒗(𝑘) (3.25)

32
Em que 𝒖𝒓 e 𝒖𝒗 são as componentes de 𝒖 que contém os efeitos dos set-points e
perturbações, respectivamente. A componente 𝒖𝒓 é livre das perturbações devido
a 𝒓 e 𝒗 serem descorrelacionadas. Primeiramente, 𝑺𝒓𝒖 identificado como,
𝒖(𝑘) = �̂�𝒓𝒖𝒓(𝑘) + �̂�𝒗𝒖𝒗(𝑘) (3.26)
E 𝒖𝒓 reconstruído da seguinte forma,
�̂�(𝑘) = �̂�𝒓𝒖𝒓(𝑘) (3.27)
3. Encontrar a componente 휀�̂�𝑖 das variáveis manipuladas, que é descorrelacionada
com as demais variáveis manipuladas presentes em �̃�𝒊𝒓, com exceção de �̂�𝑖
𝑟.
�̂�𝑖𝑟(𝑘) = 𝑮𝑢𝑖
�̃�𝒊𝒓(𝑘) + 휀𝑢𝑖
(𝑘) (3.28)
휀�̂�𝑖(𝑘) = �̂�𝑖
𝑟(𝑘) − 𝑮𝑢𝑖�̃�𝒊
𝒓(𝑘) (3.29)
4. De forma análoga encontra-se 휀�̂�𝑗, que é a componente descorrelacionada dos
erros dos modelos com as variáveis manipuladas presentes em �̃�𝒊𝒓
𝑒𝑗(𝑘) = 𝑮𝑒𝑗�̃�𝒊
𝒓(𝑘) + 휀𝑒𝑗(𝑘) (3.30)
휀�̂�𝑗(𝑘) = 𝑒𝑗(𝑘) − 𝑮𝑒𝑗
�̃�𝒊𝒓(𝑘) (3.31)
5. Calcular a correlação cruzada entre 휀�̂�𝑖 e 휀�̂�𝑗
. Os coeficientes de correlação
encontrados têm a mesma interpretação da correlação cruzada convencional,
quanto mais significativo o coeficiente, maior é o nível de correlação entre as
variáveis em análise.
Na metodologia acima, proposta por Badwe et al. (2009), podem ser incluídas
variáveis de perturbações medidas. Tais variáveis também podem ser utilizadas para ser
descorrelacionadas tanto das variáveis manipuladas quanto dos erros do modelo.
A análise pelo método descrito, considera a utilização de conjuntos de dados de
comprimento finitos com variações aleatórias devido a perturbações. Esta característica

33
afeta ligeiramente os resultados de forma a apresentar uma correlação parcial diferente
de zero onde não existe correlação. A significância dos coeficientes de correlação pode
ser dada utilizando o teste t de Student, que dará a probabilidade de obter uma correlação
tão grande quanto o valor observado devido a erros ou perturbações aleatórias quando a
correlação real é zero.
3.3 Informação Mútua
Apesar do coeficiente de correlação cruzada ser bastante utilizado, devido à
importância de atuar como a medida de similaridade entre variáveis, seu emprego é
restrito a relações lineares (CHEN et al., 2013). Para relações não lineares, o coeficiente
não funciona de maneira satisfatória, como demonstrado na seção 3.1.
Em algumas pesquisas houve tentativas de adaptação das ferramentas direcionadas à
natureza linear entre as variáveis, contudo os resultados ou se mostraram insatisfatórios
ou tiveram sua aplicação restrita a determinados tipos de problemas (CARLSSON, 2010;
LOEFF, 2014; YOUSEFI et al., 2015). Em muitos casos, em que ocorre a relação não
linear entre as variáveis, restringir a detecção do tipo de não linearidade é tão arriscado
quanto encontrar um falso resultado a partir do método da correlação cruzada. Devido a
estes fatores será apresentada neste trabalho uma medida de relação não linear entre
variáveis mais geral, que é a informação mútua ou simplesmente MI (Mutual
Information), estimada de duas maneiras diferentes (CHEN et al., 2013).
Conforme Cover e Thomas, (2005) a MI é uma medida da quantidade de informação
que uma variável aleatória contém sobre outra variável aleatória. Em outras palavras é a
redução na incerteza de uma variável aleatória devido ao conhecimento de outra variável.
Considerando as variáveis aleatórias 𝐗 e 𝐘, a MI entre as varáveis 𝑿 e 𝒀 é definida
como (CHEN et al., 2013; COVER; THOMAS, 2005):
𝐼(𝐗; 𝐘) = 𝐻(𝐗) + 𝐻(𝐘) − 𝐻(𝐗, 𝐘) (3.32)
Em que 𝐻(𝐗) e 𝐻(𝐘) representam as entropias de 𝑿 e 𝒀 e 𝐻(𝐗, 𝐘) a entropia conjunta
das variáveis aleatórias 𝑿 e 𝒀. Denotando suas funções de densidade de probabilidade ou

34
PDF (Probability Density Function) respectivamente como 𝑝X(𝑥), 𝑝X(𝑦) e 𝑝X,Y(𝑥, 𝑦),
cada componente a direita da Equação (3.32) é definida da seguinte maneira:
𝐻(𝐗) = −∫𝑝X(𝑥) log2(𝑝X(𝑥))𝑑𝑥 (3.33)
𝐻(𝐘) = −∫𝑝Y(𝑦) log2(𝑝Y(𝑦)) 𝑑𝑦 (3.34)
𝐻(𝐗, 𝐘) = −∫𝑝X,Y(𝑥, 𝑦) log2 (𝑝X,Y(𝑥, 𝑦)) 𝑑𝑥 𝑑𝑦 (3.35)
A MI definida na Equação (3.32) é a informação média de 𝑿 que pode ser predita
por 𝒀. Com 𝑙𝑜𝑔 na base 2 essa medida expressa em unidades de bits. As relações entre
𝐻(𝐗), 𝐻(𝐘) e 𝐻(𝐗, 𝐘) podem ser expressas através de um diagrama de Venn, conforma
a Figura 3.10. É possível notar que a MI corresponde à intersecção das informações em
X com a informações em Y.
Figura 3.10: Relação entre entropia e informação mútua (adaptação de Cover e Thomas, 2005)
A MI descrita medirá a dependência entre duas variáveis aleatórias de maneira
que 𝐼(𝑿; 𝒀) ≥ 0, com a igualdade se e somente se 𝑿 for independente de 𝒀. Caso as
variáveis aleatórias sejam gaussianas, a informação irá se reduzir a
𝐼(𝑿; 𝒀) = −1
2log2(1 − 𝑐𝑜𝑟𝑟(𝑿, 𝒀)2) (3.36)

35
Em que 𝑐𝑜𝑟𝑟(𝑿, 𝒀) corresponde a coeficiente de correlação entre 𝑿 e 𝒀. Se
𝑐𝑜𝑟𝑟(𝑿, 𝒀) = 0, 𝑿 é independente de 𝒀, e MI será igual a 0. Se 𝑐𝑜𝑟𝑟(𝑿, 𝒀) = ±1, 𝑿 e 𝒀
são perfeitamente correlacionadas e a MI é infinita. A formulação da Equação (3.36)
deduzida por Cover e Thomas (2005, p. 252) faz-se de grande importância como um teste
prático para o desenvolvimento dos algoritmos de estimadores de MI, que serão
apresentados a seguir.
3.3.1 Estimação da MI – K Vizinhos Mais Próximos (KNN)
A forma como é encontrada a MI, de acordo a Equação (3.32), torna-se
inconveniente quando não é conhecida de forma explícita a PDF das variáveis aleatórias
analisadas. A alternativa para este tipo de análise é utilizar estimadores de MI
(KRASKOV; STÖGBAUER; GRASSBERGER, 2004; SILVA et al., 2015).
A estimação da MI pode ser realizada de diversas maneiras, Chen et al. (2013)
adotaram para o trabalho deles o método do k vizinho mais próximo ou KNN (K-Nearest
Neighbor), por ser um método mais adequado para dados de pequena extensão com níveis
de ruído relativamente baixos e por ser também mais estável, comparado aos métodos de
estimação de densidade de kernel ou KDE (Kernel Density Estimation) e do
particionamento adaptativo do plano XY (Adaptive Partitioning of XY Plane). Estas
conclusões foram feitas com base nas pesquisas de Khan et al. (2007) e Papana e
Kugiumtzis (2009).
Estimação da MI através do KNN
A ideia básica do emprego do KNN para encontrar MI consiste em estimar o valor
da entropia a partir da distância média do k vizinho mais próximo com todos os pontos
de dados. Kraskov, Stögbauer e Grassberger (2004) utilizaram a métrica compreendida
pelos espaços de 𝑿, 𝒀 e 𝒁 = (𝑿, 𝒀), em que cada ponto é classificado de acordo com as
distâncias de seus k vizinhos mais próximos. Desta maneira são determinadas para cada
𝑧𝑖 = (𝑥𝑖, 𝑦𝑖) as distâncias para todos os seus pontos vizinhos 𝑧𝑗 = (𝑥𝑗 , 𝑦𝑗). Formando
assim uma matriz de distâncias, 𝑑𝑖𝑗 = ‖𝑧𝑖 − 𝑧𝑗‖. O mesmo procedimento pode ser
utilizado para os subespaços de 𝑿 e 𝒀.

36
Kraskov, Stögbauer e Grassberger (2004) propuseram dois algoritmos, ambos
utilizando para o espaço 𝒁 = (𝑿,𝒀), a norma máxima dada por:
‖𝑧𝑖 − 𝑧𝑗‖ = max{‖𝑥𝑖 − 𝑥𝑗‖, ‖𝑦 − 𝑦𝑗‖} (3.37)
Para ‖𝑥𝑖 − 𝑥𝑗‖ e ‖𝑦 − 𝑦𝑗‖ podem ser utilizadas quaisquer normas, sem a
necessidade de ser a mesma norma em ambas, devido aos espaços serem completamente
diferentes (neste trabalho foi utilizada a norma Euclidiana para a determinação das duas
distâncias). Por simplificação considera-se que a distância de 𝑧𝑖 para o seu k-ésimo
vizinho, ordenado de forma crescente, é denotada por 𝜖(𝑖)/2, assim como as distâncias
desses mesmos pontos projetadas nos subespaços 𝑿 e 𝒀 são 𝜖𝑥(𝑖)/2 e 𝜖𝑦(𝑖)/2,
respectivivamente. Então,
𝜖(𝑖) = max{𝜖𝑥(𝑖), 𝜖𝑦(𝑖)} (3.38)
Seguindo a metodologia de Kraskov, Stögbauer e Grassberger (2004) e com base
nas discussões de Khan et al. (2007), para o primeiro algoritmo, considera-se as duas
variáveis aleatórias 𝑿 e 𝒀, em que cada 𝑥 e 𝑦 estão dentro do espaço unidimensional, sua
informação mutua pode ser estimada por:
𝐼(𝑿, 𝒀) = 𝜓(𝑘) −1
𝑛∑[𝜓(𝑛𝑥(𝑖) + 1) + 𝜓(𝑛𝑦(𝑖) + 1)]
𝑛
𝑖=1
+ 𝜓(𝑛) (3.39)
Onde 𝑛𝑥(𝑖) e 𝑛𝑦(𝑖) são as quantidades de pontos 𝑥𝑗 e 𝑦𝑗 cujas distâncias de 𝑥𝑖 e
𝑦𝑖, respectivamente, são estritamente menores que 𝜖(𝑖)/2 e 𝜓(. ) é o operador da função
digama representada na Figura 3.11. Um exemplo do funcionamento da contagem de
pontos deste primeiro algoritmo pode ser visto na Figura 3.12, onde 𝑛𝑥(𝑖) = 2 e 𝑛𝑦(𝑖) =
6, para 𝑘 = 1.
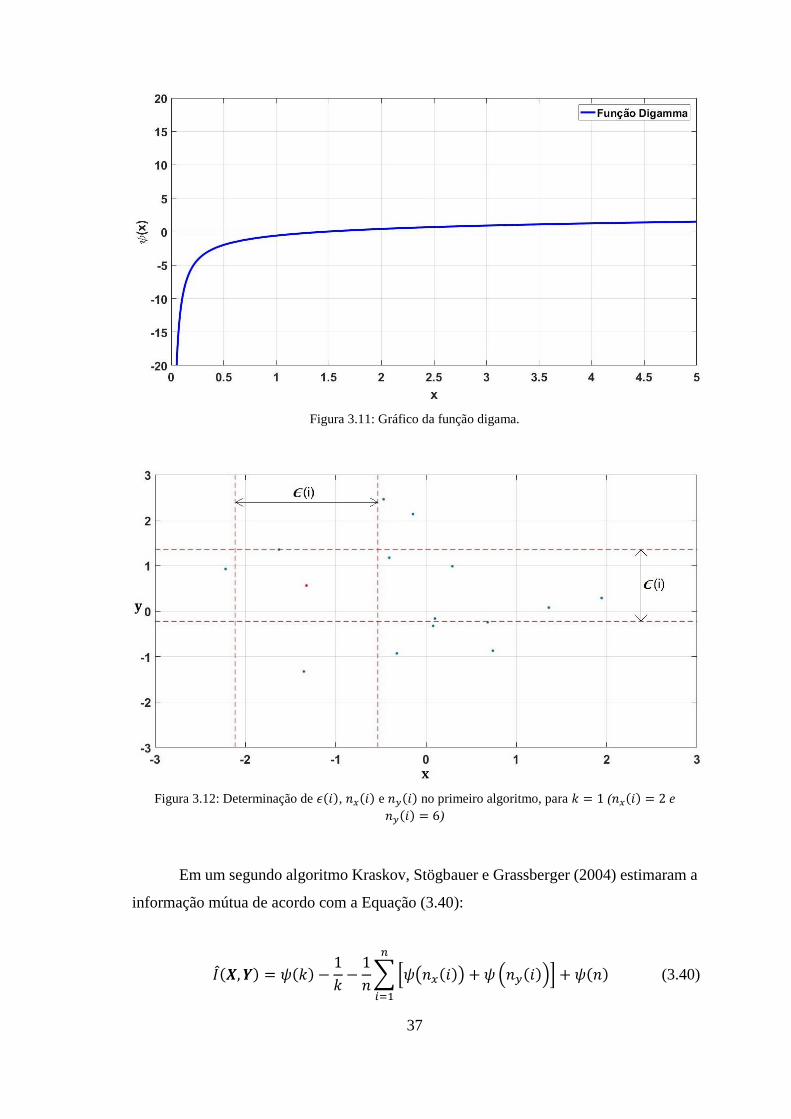
37
Figura 3.11: Gráfico da função digama.
Figura 3.12: Determinação de 𝜖(𝑖), 𝑛𝑥(𝑖) e 𝑛𝑦(𝑖) no primeiro algoritmo, para 𝑘 = 1 (𝑛𝑥(𝑖) = 2 e
𝑛𝑦(𝑖) = 6)
Em um segundo algoritmo Kraskov, Stögbauer e Grassberger (2004) estimaram a
informação mútua de acordo com a Equação (3.40):
𝐼(𝑿, 𝒀) = 𝜓(𝑘) −1
𝑘−
1
𝑛∑[𝜓(𝑛𝑥(𝑖)) + 𝜓 (𝑛𝑦(𝑖))]
𝑛
𝑖=1
+ 𝜓(𝑛) (3.40)
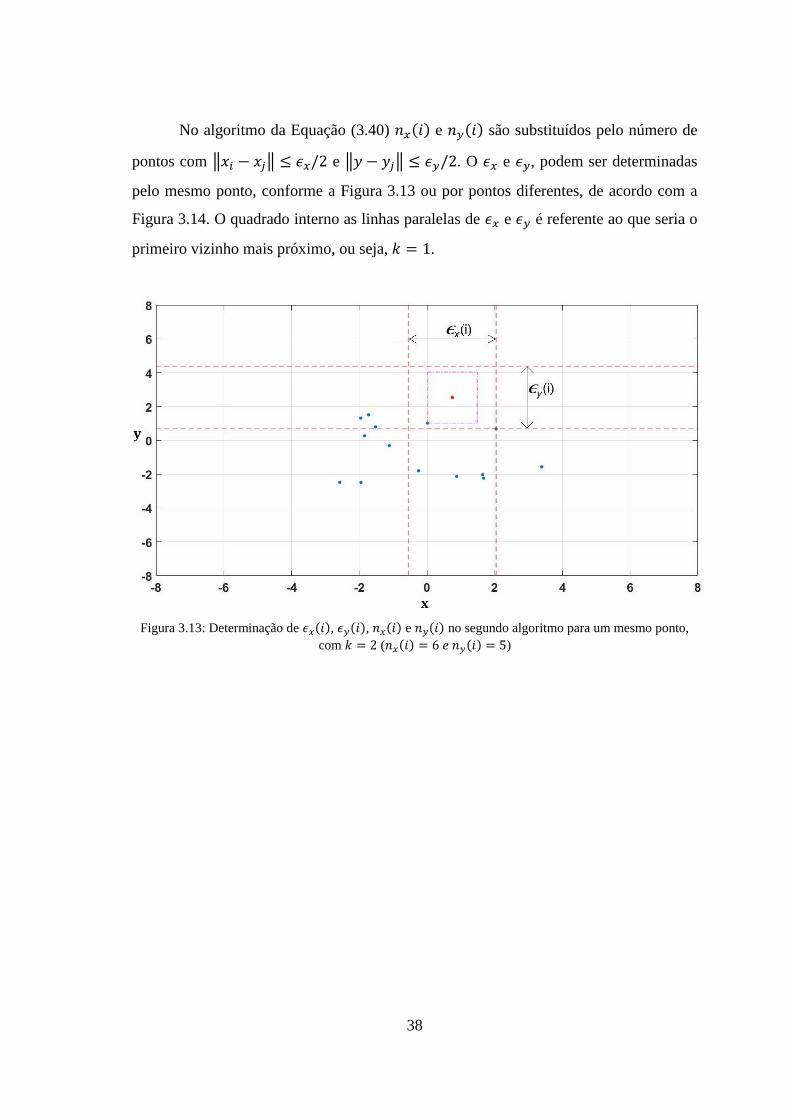
38
No algoritmo da Equação (3.40) 𝑛𝑥(𝑖) e 𝑛𝑦(𝑖) são substituídos pelo número de
pontos com ‖𝑥𝑖 − 𝑥𝑗‖ ≤ 𝜖𝑥/2 e ‖𝑦 − 𝑦𝑗‖ ≤ 𝜖𝑦/2. O 𝜖𝑥 e 𝜖𝑦, podem ser determinadas
pelo mesmo ponto, conforme a Figura 3.13 ou por pontos diferentes, de acordo com a
Figura 3.14. O quadrado interno as linhas paralelas de 𝜖𝑥 e 𝜖𝑦 é referente ao que seria o
primeiro vizinho mais próximo, ou seja, 𝑘 = 1.
Figura 3.13: Determinação de 𝜖𝑥(𝑖), 𝜖𝑦(𝑖), 𝑛𝑥(𝑖) e 𝑛𝑦(𝑖) no segundo algoritmo para um mesmo ponto,
com 𝑘 = 2 (𝑛𝑥(𝑖) = 6 e 𝑛𝑦(𝑖) = 5)
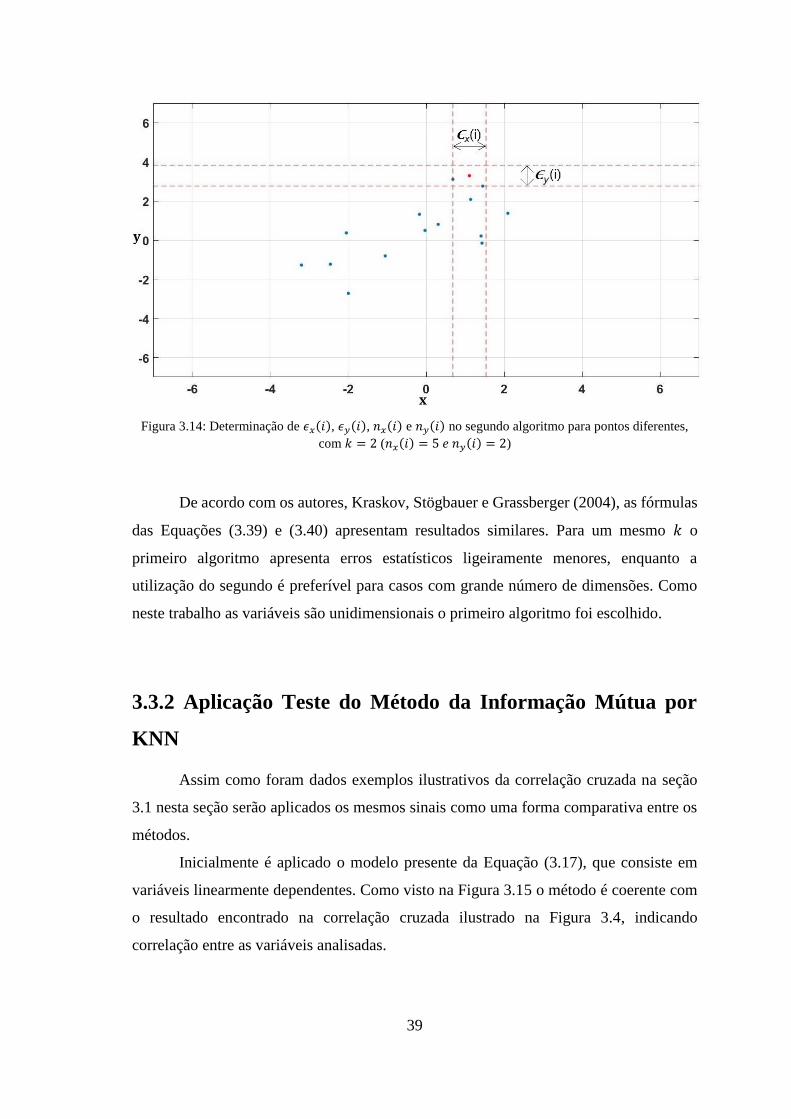
39
Figura 3.14: Determinação de 𝜖𝑥(𝑖), 𝜖𝑦(𝑖), 𝑛𝑥(𝑖) e 𝑛𝑦(𝑖) no segundo algoritmo para pontos diferentes,
com 𝑘 = 2 (𝑛𝑥(𝑖) = 5 e 𝑛𝑦(𝑖) = 2)
De acordo com os autores, Kraskov, Stögbauer e Grassberger (2004), as fórmulas
das Equações (3.39) e (3.40) apresentam resultados similares. Para um mesmo 𝑘 o
primeiro algoritmo apresenta erros estatísticos ligeiramente menores, enquanto a
utilização do segundo é preferível para casos com grande número de dimensões. Como
neste trabalho as variáveis são unidimensionais o primeiro algoritmo foi escolhido.
3.3.2 Aplicação Teste do Método da Informação Mútua por
KNN
Assim como foram dados exemplos ilustrativos da correlação cruzada na seção
3.1 nesta seção serão aplicados os mesmos sinais como uma forma comparativa entre os
métodos.
Inicialmente é aplicado o modelo presente da Equação (3.17), que consiste em
variáveis linearmente dependentes. Como visto na Figura 3.15 o método é coerente com
o resultado encontrado na correlação cruzada ilustrado na Figura 3.4, indicando
correlação entre as variáveis analisadas.

40
Figura 3.15: Estimação da MI através do método por KNN entre variáveis linearmente dependentes.
Um segundo teste é realizado entre duas variáveis aleatórias totalmente
descorrelacionadas, de acordo com o modelo apresentando os ruídos apenas O resultado
da aplicação do método pode ser visualizado na Figura 3.16, que demonstra uma relação
extremamente fraca entre as variáveis, podendo ser desconsiderada. Os índices abaixo de
zero são devidos a pequenos desvios de cálculo relacionados ao algoritmo no momento
da soma e subtração entre as entropias marginais e conjunta.
Figura 3.16: Estimação da MI através do método por KNN entre variáveis aleatórias descorrelacionadas.
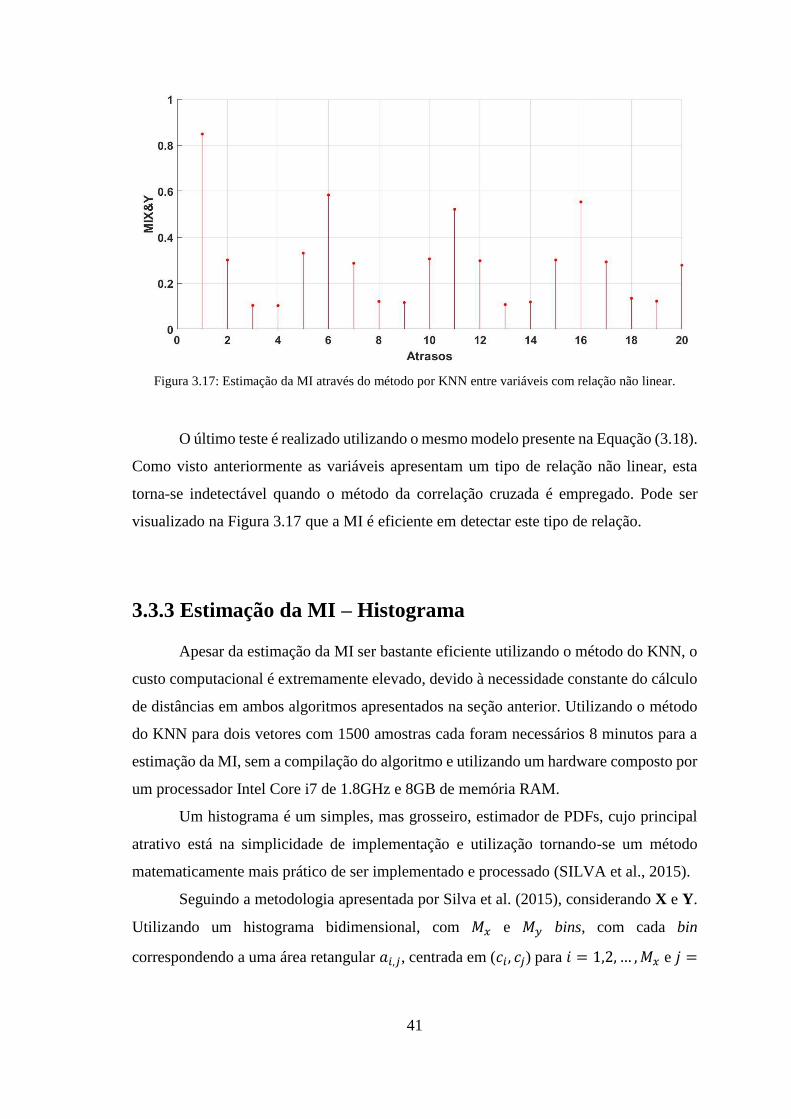
41
Figura 3.17: Estimação da MI através do método por KNN entre variáveis com relação não linear.
O último teste é realizado utilizando o mesmo modelo presente na Equação (3.18).
Como visto anteriormente as variáveis apresentam um tipo de relação não linear, esta
torna-se indetectável quando o método da correlação cruzada é empregado. Pode ser
visualizado na Figura 3.17 que a MI é eficiente em detectar este tipo de relação.
3.3.3 Estimação da MI – Histograma
Apesar da estimação da MI ser bastante eficiente utilizando o método do KNN, o
custo computacional é extremamente elevado, devido à necessidade constante do cálculo
de distâncias em ambos algoritmos apresentados na seção anterior. Utilizando o método
do KNN para dois vetores com 1500 amostras cada foram necessários 8 minutos para a
estimação da MI, sem a compilação do algoritmo e utilizando um hardware composto por
um processador Intel Core i7 de 1.8GHz e 8GB de memória RAM.
Um histograma é um simples, mas grosseiro, estimador de PDFs, cujo principal
atrativo está na simplicidade de implementação e utilização tornando-se um método
matematicamente mais prático de ser implementado e processado (SILVA et al., 2015).
Seguindo a metodologia apresentada por Silva et al. (2015), considerando X e Y.
Utilizando um histograma bidimensional, com 𝑀𝑥 e 𝑀𝑦 bins, com cada bin
correspondendo a uma área retangular 𝑎𝑖,𝑗, centrada em (𝑐𝑖, 𝑐𝑗) para 𝑖 = 1,2, … ,𝑀𝑥 e 𝑗 =

42
1,2, … ,𝑀𝑦. Sendo 𝑘𝑖,𝑗 o número de medidas que estão dentro de 𝑎𝑖,𝑗, a probabilidade de
uma medida aleatória (𝑿, 𝒀) estar em 𝑎𝑖,𝑗 é estimada como:
𝑃[(𝑿, 𝒀) ∈ 𝑎𝑖,𝑗] ≈ 𝑓𝑖,𝑗 =𝑘𝑖,𝑗
𝑁 (3.41)
Baseado na teoria proposta o estimador de MI ficará da seguinte maneira:
Î𝑁(𝑿; 𝒀) = −∑𝑓𝑖 log 𝑓𝑖
𝑀𝑥
𝑖=1
− ∑𝑓𝑗 log 𝑓𝑗
𝑀𝑦
𝑗=1
+ ∑∑𝑓𝑖,𝑗 log 𝑓𝑖,𝑗
𝑀𝑦
𝑗=1
𝑀𝑥
𝑖=1
(3.42)
Em que 𝑓𝑖 = ∑ 𝑓𝑖,𝑗𝑀𝑦
𝑗=1 e 𝑓𝑗 = ∑ 𝑓𝑖,𝑗
𝑀𝑥𝑗=1 .
Um problema de viés é apresentado no resultado da informação mútua da forma
como é proposta na Equação 3.42. Mesmo que a frequência relativa seja um estimador de
probabilidade de verossimilhança sem nenhuma tendência, o viés é originado pela
transformação logarítmica (não-linear) presente no algoritmo. Silva et al. (2015)
utilizaram um fator compensação criado por (MILLER, 1955):
𝐸[�̂�(𝑿)] ≈ 𝐻(𝑿) −𝑀𝑥 − 1
2𝑁 (3.43)
De forma análoga a Equação (3.42) pode ser utilizada para encontrar 𝐸[�̂�(𝒀)] e
𝐸[�̂�(𝑿, 𝒀)]
3.3.4 Aplicação Teste do Método da Informação Mútua por
Histograma
Os mesmos exemplos ilustrativos da seção 3.1 serão utilizados também como teste
para a o método da estimação da MI por histograma. O número de bins para as estimações
é igual 5, assim como o fator de correção da Equação (3.40) é utilizado para estimar a MI
nos três casos.
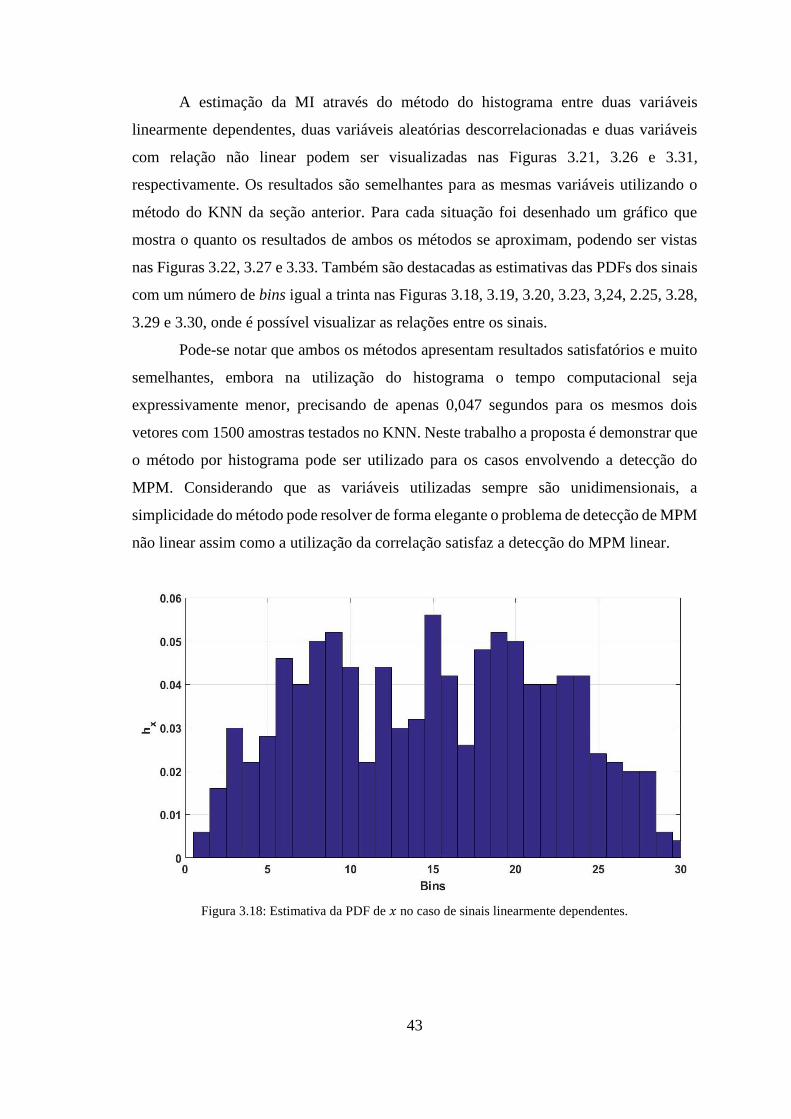
43
A estimação da MI através do método do histograma entre duas variáveis
linearmente dependentes, duas variáveis aleatórias descorrelacionadas e duas variáveis
com relação não linear podem ser visualizadas nas Figuras 3.21, 3.26 e 3.31,
respectivamente. Os resultados são semelhantes para as mesmas variáveis utilizando o
método do KNN da seção anterior. Para cada situação foi desenhado um gráfico que
mostra o quanto os resultados de ambos os métodos se aproximam, podendo ser vistas
nas Figuras 3.22, 3.27 e 3.33. Também são destacadas as estimativas das PDFs dos sinais
com um número de bins igual a trinta nas Figuras 3.18, 3.19, 3.20, 3.23, 3,24, 2.25, 3.28,
3.29 e 3.30, onde é possível visualizar as relações entre os sinais.
Pode-se notar que ambos os métodos apresentam resultados satisfatórios e muito
semelhantes, embora na utilização do histograma o tempo computacional seja
expressivamente menor, precisando de apenas 0,047 segundos para os mesmos dois
vetores com 1500 amostras testados no KNN. Neste trabalho a proposta é demonstrar que
o método por histograma pode ser utilizado para os casos envolvendo a detecção do
MPM. Considerando que as variáveis utilizadas sempre são unidimensionais, a
simplicidade do método pode resolver de forma elegante o problema de detecção de MPM
não linear assim como a utilização da correlação satisfaz a detecção do MPM linear.
Figura 3.18: Estimativa da PDF de 𝑥 no caso de sinais linearmente dependentes.
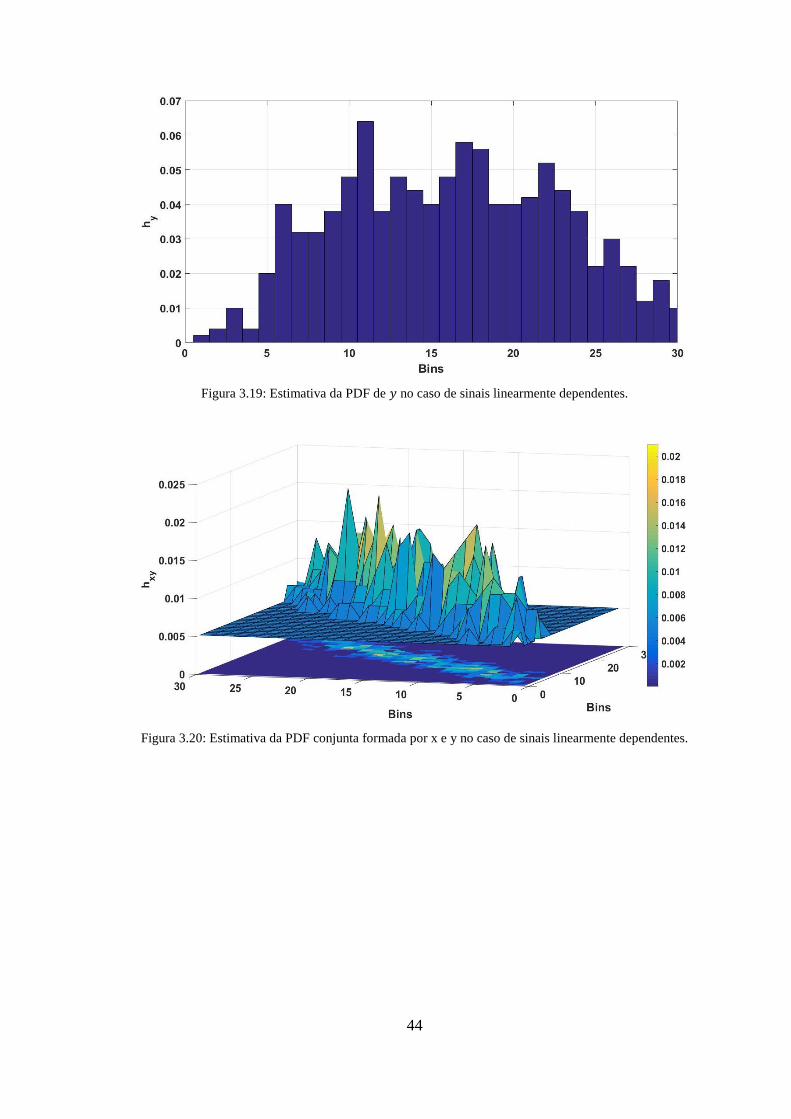
44
Figura 3.19: Estimativa da PDF de 𝑦 no caso de sinais linearmente dependentes.
Figura 3.20: Estimativa da PDF conjunta formada por x e y no caso de sinais linearmente dependentes.
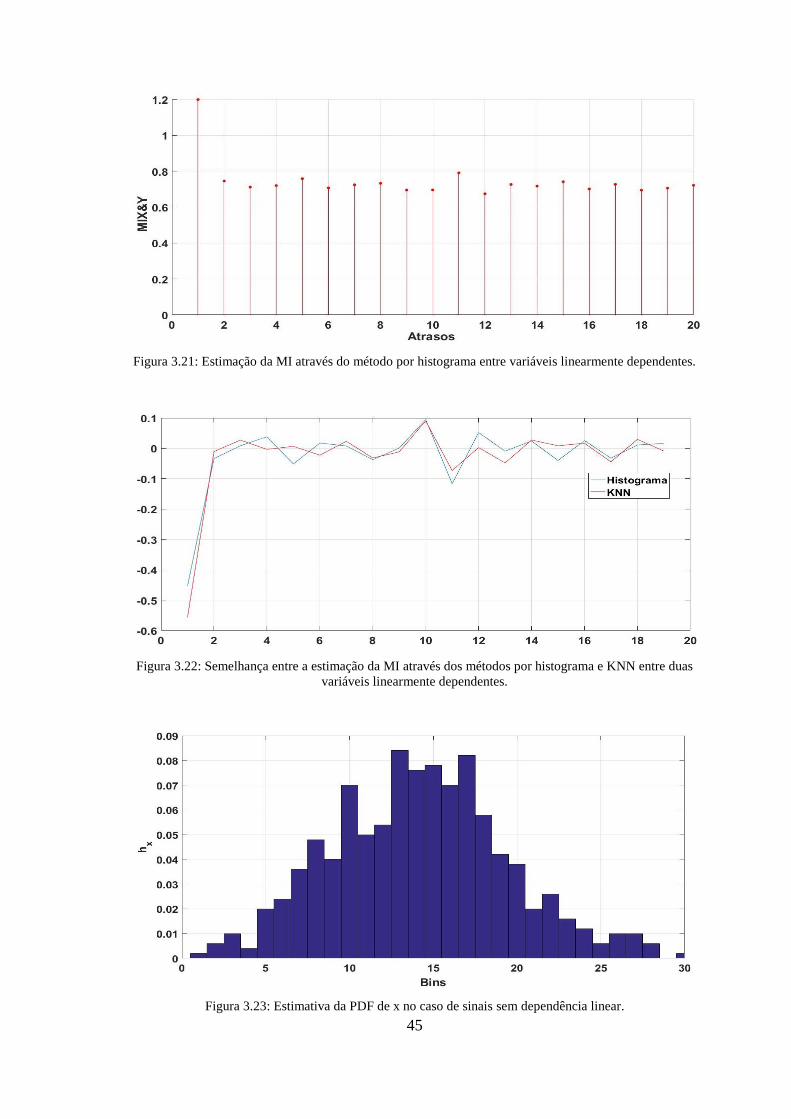
45
Figura 3.21: Estimação da MI através do método por histograma entre variáveis linearmente dependentes.
Figura 3.22: Semelhança entre a estimação da MI através dos métodos por histograma e KNN entre duas
variáveis linearmente dependentes.
Figura 3.23: Estimativa da PDF de x no caso de sinais sem dependência linear.
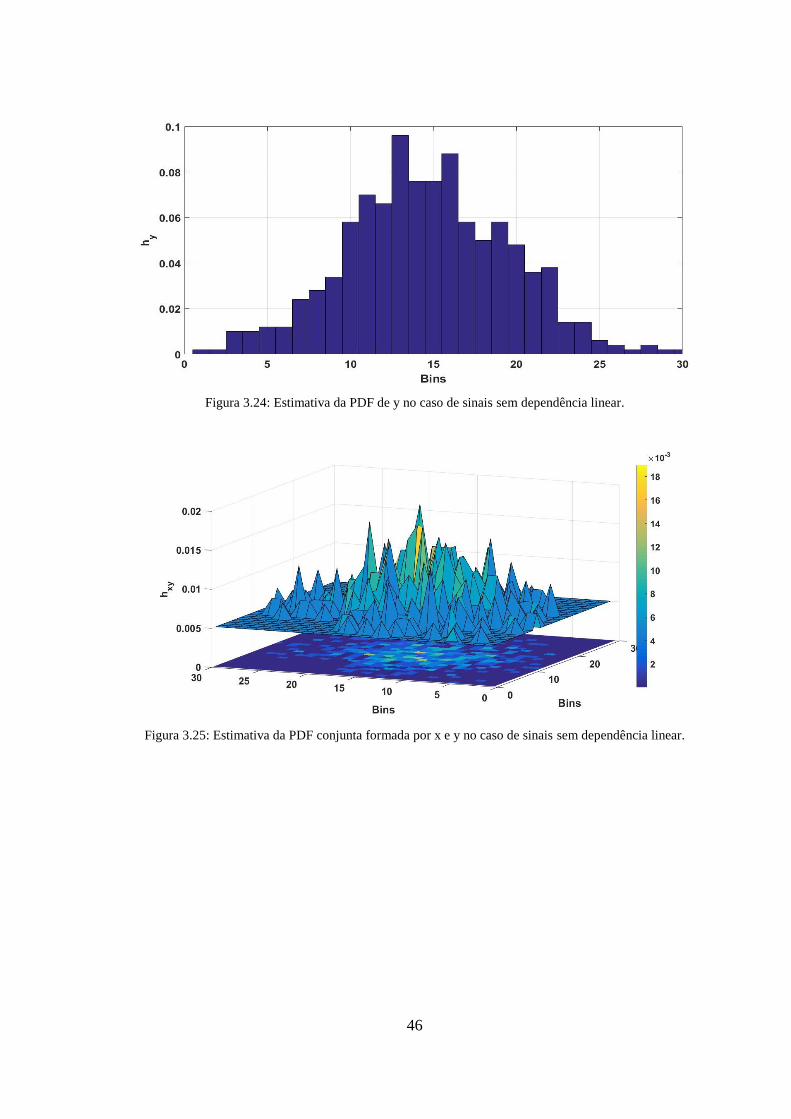
46
Figura 3.24: Estimativa da PDF de y no caso de sinais sem dependência linear.
Figura 3.25: Estimativa da PDF conjunta formada por x e y no caso de sinais sem dependência linear.
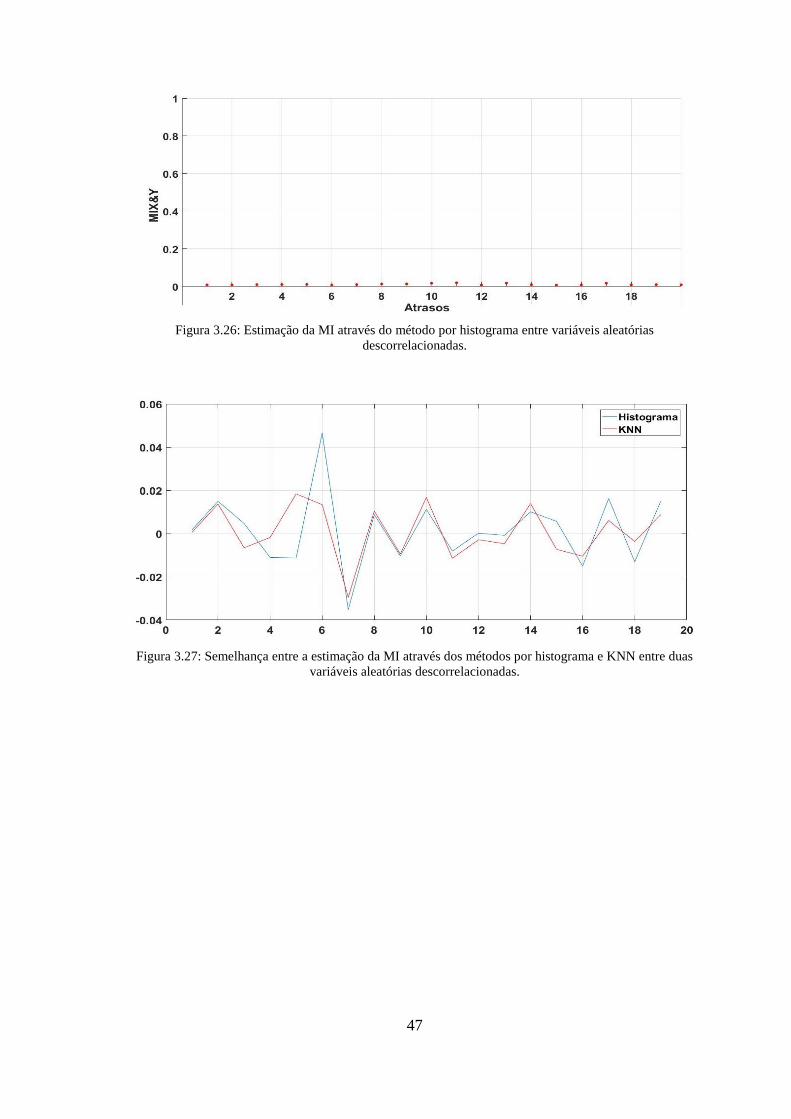
47
Figura 3.26: Estimação da MI através do método por histograma entre variáveis aleatórias
descorrelacionadas.
Figura 3.27: Semelhança entre a estimação da MI através dos métodos por histograma e KNN entre duas
variáveis aleatórias descorrelacionadas.
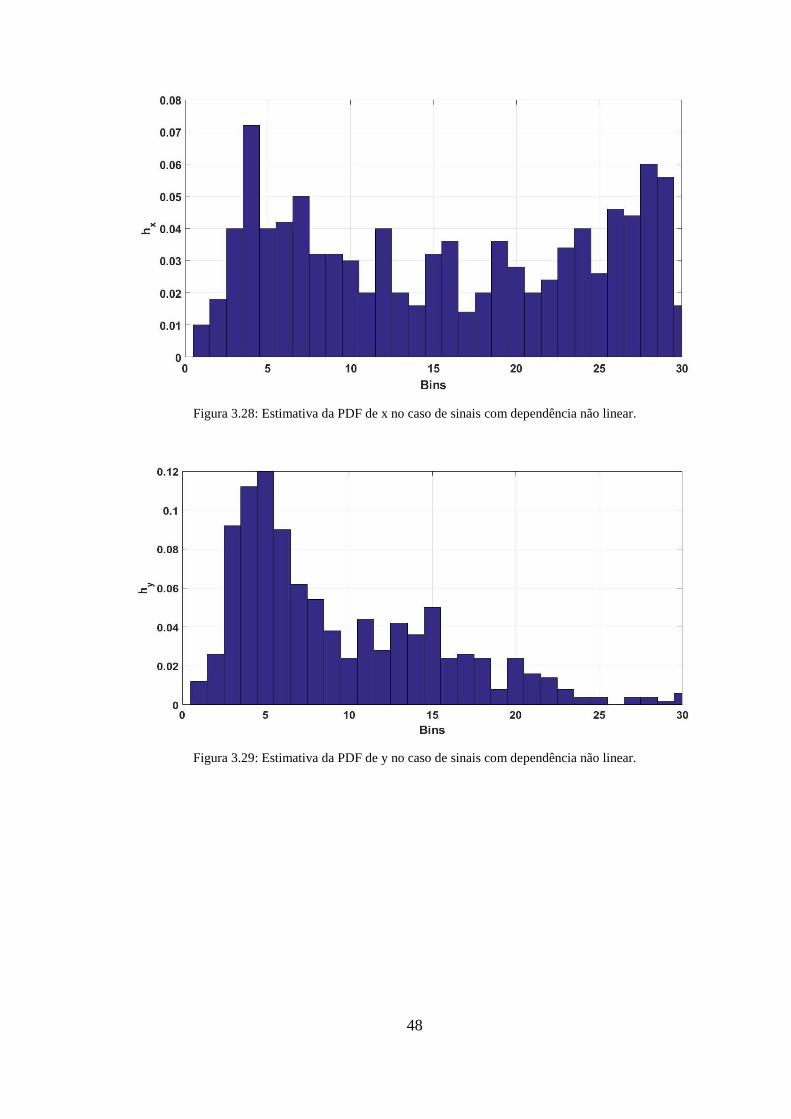
48
Figura 3.28: Estimativa da PDF de x no caso de sinais com dependência não linear.
Figura 3.29: Estimativa da PDF de y no caso de sinais com dependência não linear.
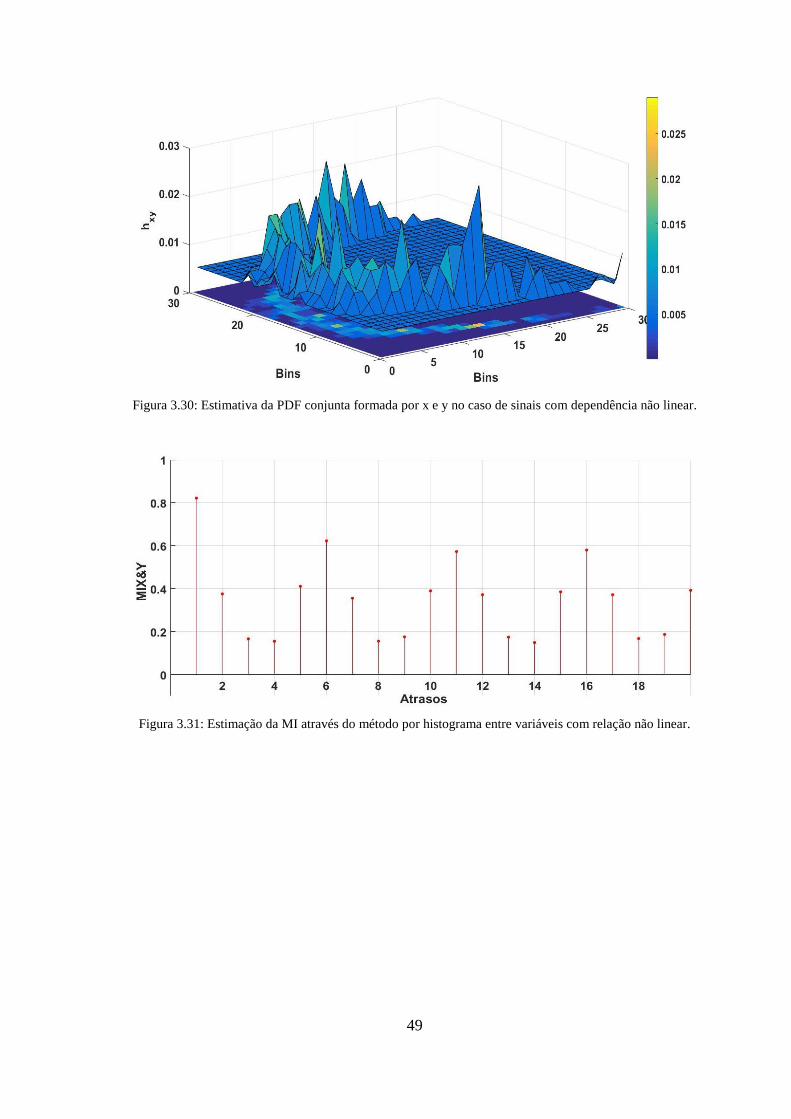
49
Figura 3.30: Estimativa da PDF conjunta formada por x e y no caso de sinais com dependência não linear.
Figura 3.31: Estimação da MI através do método por histograma entre variáveis com relação não linear.
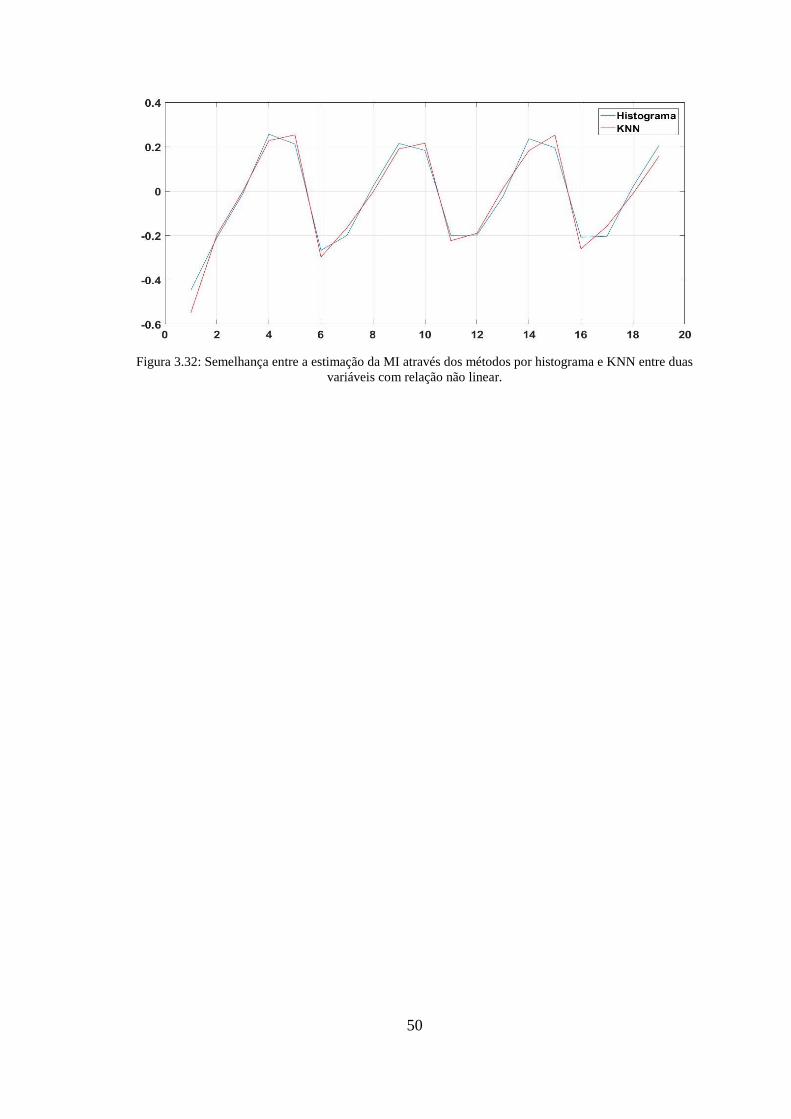
50
Figura 3.32: Semelhança entre a estimação da MI através dos métodos por histograma e KNN entre duas
variáveis com relação não linear.

51
Capítulo 4
Processo da Coluna de Destilação
Binária e Detecção de MPM Linear
4.1 Introdução
Neste capítulo serão apresentados o processo da coluna de destilação binária de
Wood e Berry (1973), como um estudo de caso linear, e a aplicação dos métodos
propostos divididos em casos. Os casos são baseados no modo como a planta está
operando, com a ausência ou presença de MPM. Com base nisto são feitas sete
ponderações:
• Como é um estudo de caso simulado, as modificações realizadas para os casos
são aplicadas diretamente ao processo, com o objetivo de simular eventuais
mudanças que podem ocorrer na planta.
• Em todos os casos o modelo presente no controlador é mantido com seus
parâmetros de funcionamento nominais, no intuito de dispor de condições
suficientes para detectar ou não o MPM.
• Os métodos são aplicados entre o erro do modelo e as variáveis manipuladas,
conforme as teorias apresentadas no capítulo anterior.
• No método correlações cruzadas e parciais é utilizado um intervalo de
confiança de 95% com base na equação 𝑙𝑖𝑚𝑖𝑡𝑒𝑠 = ±2√𝑉𝑎𝑟[𝑟𝑢,𝑒(𝑘)], como
base de medida da significância do MPM. (STANFELJ; MARLIN;
MACGREGOR, 1993; WEBBER; GUPTA, 2008).

52
• No método da MI é utilizado o mesmo intervalo de confiança aplicado nas
metodologias das correlações cruzadas e parciais.
• Em todos os casos foram utilizadas 1500 amostras, referentes à parte em
estado estacionário da dinâmica do processo.
• Nos casos em que há a presença do erro, o mesmo é assumido como 20% do
valor acima do valor nominal do ganho da função de transferência avaliada.
Tal abordagem segue o estudo de Nafsun e Yusoff (2011), em que é
demonstrado ser o pior caso ao desempenho do processo o erro presente no
ganho da função de transferência.
4.2 Descrição do Processo
A coluna de destilação binária (Figura 4.1) de Wood e Berry (1973) é um estudo
de caso clássico bastante utilizado na literatura em simulações de processos, por retratar
bem situações reais (NAFSUN; YUSOFF, 2011). O objetivo da planta é controlar a
composição de metanol no destilado (𝑦1) e na corrente inferior (𝑦2) (medidos em
porcentagem de mol) através da manipulação de vazão de refluxo (𝑢1) e vazão de vapor
(𝑢2) (medidos em 𝑙𝑏.𝑚𝑖𝑛−1). Portando o processo MIMO é caracterizado por duas
variáveis controladas e duas variáveis manipuladas (2×2).
Figura 4.1: Representação de uma coluna de destilação.

53
Apesar do processo incluir perturbações do sistema (𝑣), as mesmas foram
retiradas, pois não apresentariam nenhum diferencial à análise dos resultados. Desta
maneira não há o termo referente às perturbações do sistema conforme as Equações (4.1)
e (4.2):
𝑦(𝑘) = 𝑮𝑢(𝑘) (4.1)
𝑒(𝑘) = 𝚫𝑢(𝑘) (4.2)
A expressão do modelo dinâmico do processo é referente ao proposto por
(WOOD; BERRY, 1973)
[𝑋𝐷(𝑠)
𝑋𝐵(𝑠)] = [
𝐺11(𝑠) 𝐺12(𝑠)
𝐺21(𝑠) 𝐺22(𝑠)] [
𝑅(𝑠)
𝑆(𝑠)] (4.3)
Em que:
𝐺11(𝑠) =
12.8
16.7𝑠 + 1𝑒−𝑠 (4.4)
𝐺12(𝑠) =
−18.9
21𝑠 + 1𝑒−3𝑠 (4.5)
𝐺21(𝑠) =
6.6
10.9𝑠 + 1𝑒−7𝑠 (4.6)
𝐺22(𝑠) =
−19.4
14.4𝑠 + 1𝑒−3𝑠 (4.7)
As variáveis controladas e manipuladas do sistema (Figura 4.1) são detalhadas a
seguir:
• Variáveis manipuladas:
Vazão de refluxo (𝑢1)
Vazão de vapor (𝑢2)
• Variáveis controladas:
Composição do destilado (𝑦1)
Composição inferior (𝑦2)

54
A relação entre estas variáveis pode ser vista na Tabela 4.1.
Tabela 1: Relação entre variáveis manipuladas e controladas do processo da coluna de destilação binária
de Wood e Berry (1973).
Canal Descrição
𝑮𝟏𝟏 Função de transferência relacionada a composição do destilado e vazão
de refluxo.
𝑮𝟏𝟐 Função de transferência relacionada a composição do destilado e vazão
de vapor.
𝑮𝟐𝟏 Função de transferência relacionada a composição inferior e vazão de
refluxo.
𝑮𝟐𝟐 Função de transferência relacionada a composição inferior e vazão de
vapor.
Os parâmetros de sintonia do controlador MPC para a coluna de destilação binária
de Wood e Berry (1973) que foram utilizados nas simulações estão listados na Tabela
4.2.
Tabela 2: parâmetros de sintonia do controlador MPC utilizados na coluna de destilação binária de Wood
e Berry (1973).
Parâmetros Descrição Valor
𝑻𝒔 Tempo de amostragem 1 min
𝑵 Horizonte do modelo 80
𝒉𝒑 Horizonte de predição 30
𝒉𝒄 Horizonte de controle 5
𝛅𝒖𝒎á𝒙 Limite máximo de incremento nas entradas [0.1,0; 0.1]
𝒖𝒎á𝒙 Limite máximo das entradas [1; 1]
𝒖𝒎𝒊𝒏 Limite mínimo das entradas [-0.15; -0.15]
𝒚𝒎á𝒙 Limite máximo das saídas [1.8; 1.8]
𝒚𝒎𝒊𝒏 Limite mínimo das saídas [-1.8; -1.8]
𝑹 Fator de supressão das manipuladas [5 5]
W Fator de supressão das controladas [1 1]

55
Na Figura 4.2 é possível visualizar a implementação do simulador com a presença
do controlador e os distúrbios desacoplados. Nas Figuras 4.4 e 4.5 vê-se os gráficos
contendo as variáveis controladas, variáveis manipuladas e set-point, para uma operação
nominal da planta.
Figura 4.2: Simulador da coluna de destilação binária de Wood e Berry (1973).
4.4 Sinais de Excitação Aplicados
Como foi dito na seção 2.2.5 é necessário ser aplicado um set-point que excite o
processo por tempo suficiente para a obtenção do comportamento dinâmico do sistema.
No caso do processo da coluna de destilação binária de Wood e Berry (1973), os sinais
utilizados para os casos foram do tipo PRBS, conforme mostrado na Figura 4.3.

56
Figura 4.3: Modelos de sinais PRBS.
4.5 Caso 1
O primeiro caso tem como objetivo testar um falso resultado para a detecção de
MPM. Nesta circunstância é utilizado o processo em sua forma inicialmente
comissionada, ou seja, sem a presença de MPM. O comportamento das variáveis
controladas para um tempo de simulação de 200 a 2000 minutos pode ser visualizado na
Figura 4.4.
Figura 4.4: Sinais PRBS de excitação e variáveis controladas do processo da coluna de destilação binária
de Wood-Berry – Caso 1.
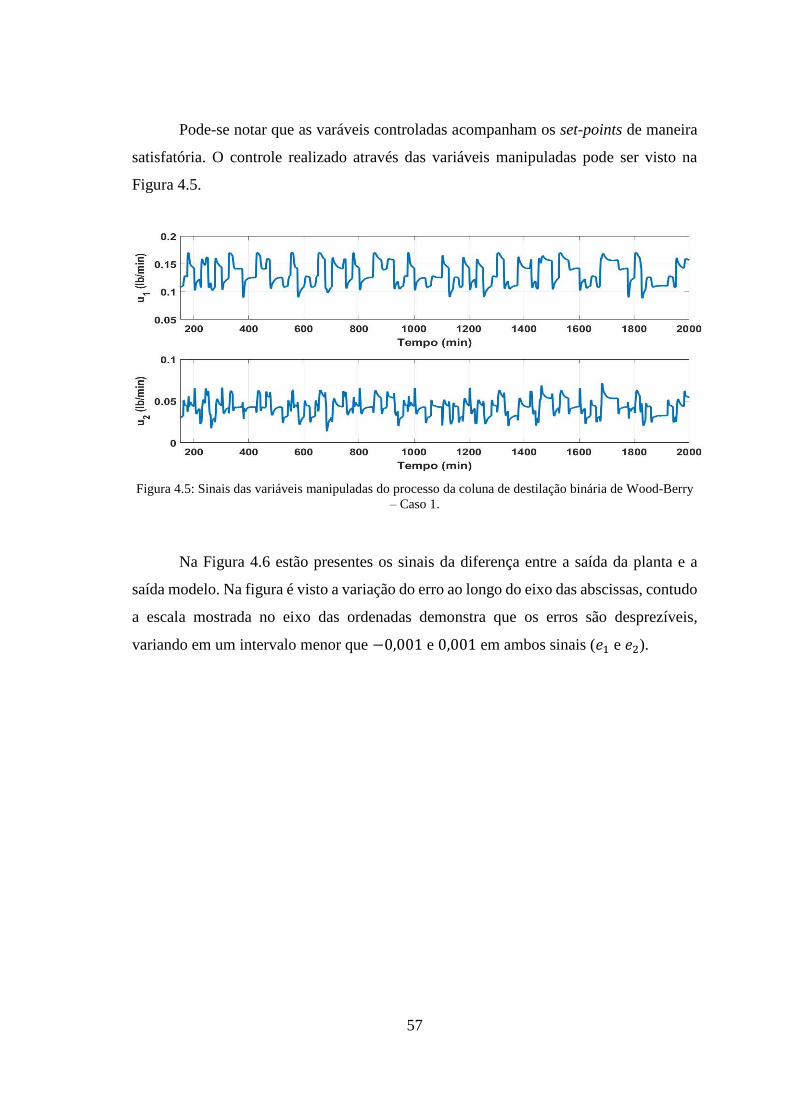
57
Pode-se notar que as varáveis controladas acompanham os set-points de maneira
satisfatória. O controle realizado através das variáveis manipuladas pode ser visto na
Figura 4.5.
Figura 4.5: Sinais das variáveis manipuladas do processo da coluna de destilação binária de Wood-Berry
– Caso 1.
Na Figura 4.6 estão presentes os sinais da diferença entre a saída da planta e a
saída modelo. Na figura é visto a variação do erro ao longo do eixo das abscissas, contudo
a escala mostrada no eixo das ordenadas demonstra que os erros são desprezíveis,
variando em um intervalo menor que −0,001 e 0,001 em ambos sinais (𝑒1 e 𝑒2).
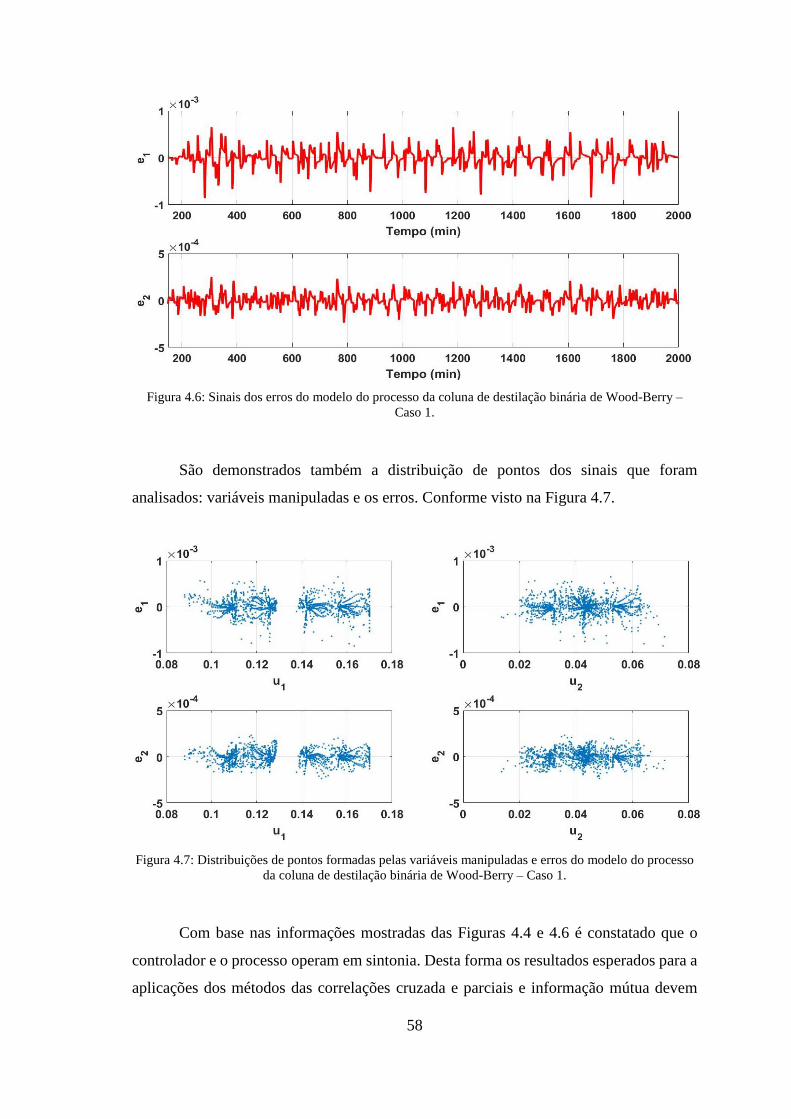
58
Figura 4.6: Sinais dos erros do modelo do processo da coluna de destilação binária de Wood-Berry –
Caso 1.
São demonstrados também a distribuição de pontos dos sinais que foram
analisados: variáveis manipuladas e os erros. Conforme visto na Figura 4.7.
Figura 4.7: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
da coluna de destilação binária de Wood-Berry – Caso 1.
Com base nas informações mostradas das Figuras 4.4 e 4.6 é constatado que o
controlador e o processo operam em sintonia. Desta forma os resultados esperados para a
aplicações dos métodos das correlações cruzada e parciais e informação mútua devem

59
demonstrar a ausência de MPM. Conforme pode ser visto nas Figuras 4.8 e 4.9 os
coeficientes de correlação cruzada e parcial não demonstram a presença de MPM.
Figura 4.8: Correlações cruzadas do processo da coluna de destilação binária de Wood-Berry – Caso 1.
Figura 4.9: Correlações parciais do processo da coluna de destilação binária de Wood-Berry – Caso 1.
Para as aplicações dos métodos MI são demonstradas as estimativas das PDFs
marginais (ℎ𝑢1, ℎ𝑢2
, ℎ𝑒1 e ℎ𝑒2
) e conjuntas (ℎ𝑢1𝑒1, ℎ𝑢2𝑒1
, ℎ𝑢1𝑒2 e ℎ𝑢2𝑒2
) das variáveis

60
manipuladas e os erros do processo para a utilização no cálculo da MI utilizando um
número de 30 bins, presentes nas Figuras 4.10, 4.11 e 4.12.
Figura 4.10: Estimativas das PDFs das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 1.
Figura 4.11: Estimativas das PDFs dos erros do modelo processo da coluna de destilação binária de
Wood-Berry – Caso 1.

61
Figura 4.12: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo da coluna de destilação binária de Wood-Berry - Caso 1.
Figura 4.13: Informações mútuas através do KNN do processo da coluna de destilação binária de Wood-
Berry – Caso 1.

62
Figura 4.14: Informações mútuas através de histograma do processo da coluna de destilação binária de
Wood-Berry – Caso 1.
Pode-se notar que os resultados das Figuras 4.8, 4.9, 4.13 e 4.14 estão conforme
o esperado. Como não há MPM, todos os coeficientes de todos os métodos estão dentro
ou próximos dos intervalos de confiança.
4.6 Caso 2
Para este caso é incluído ao ganho da função de transferência 𝐺11 da planta 20%
a mais do seu valor nominal. Assim como no Caso 1, é demonstrado na Figura 4.15 o
comportamento das variáveis controladas de acordo com os set-points utilizados, e as
variáveis controladas na Figura 4.16.
Nota-se que apesar da presença de MPM o controlador e o processo aparentam
estar em sintonia, contudo na Figura 4.17 é visível o aumento da magnitude do erro 𝑒1
em comparação com a Figura 4.6.
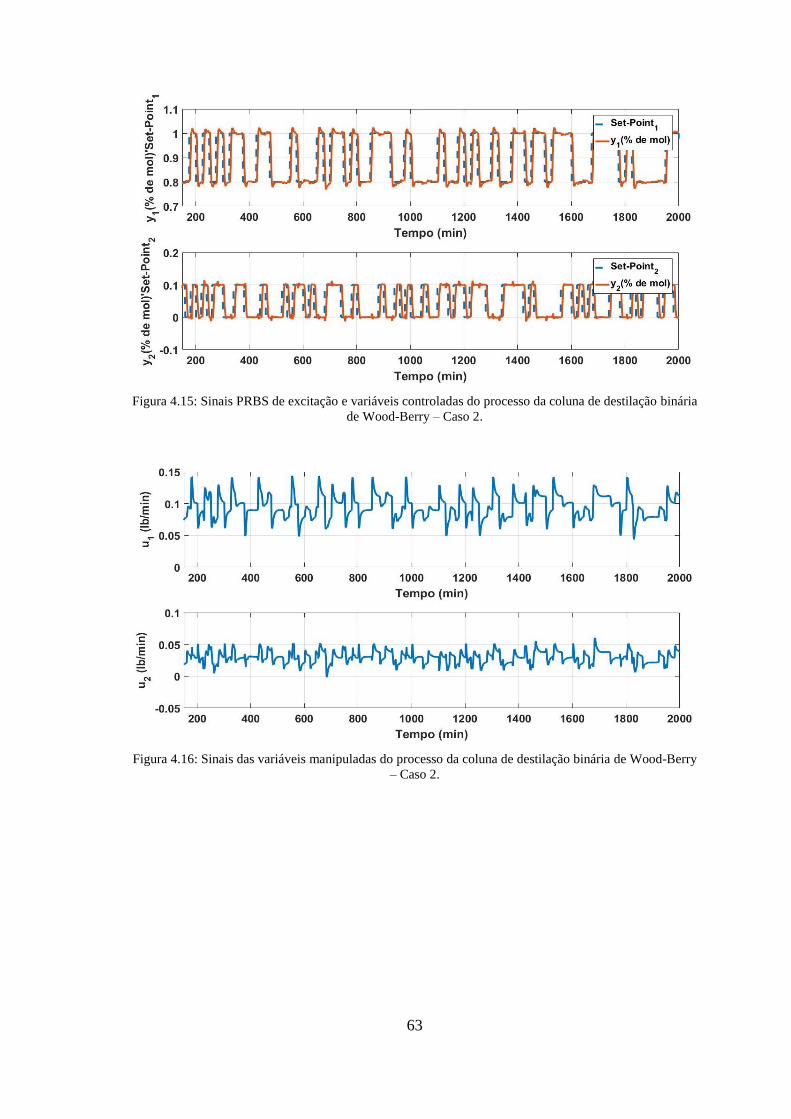
63
Figura 4.15: Sinais PRBS de excitação e variáveis controladas do processo da coluna de destilação binária
de Wood-Berry – Caso 2.
Figura 4.16: Sinais das variáveis manipuladas do processo da coluna de destilação binária de Wood-Berry
– Caso 2.
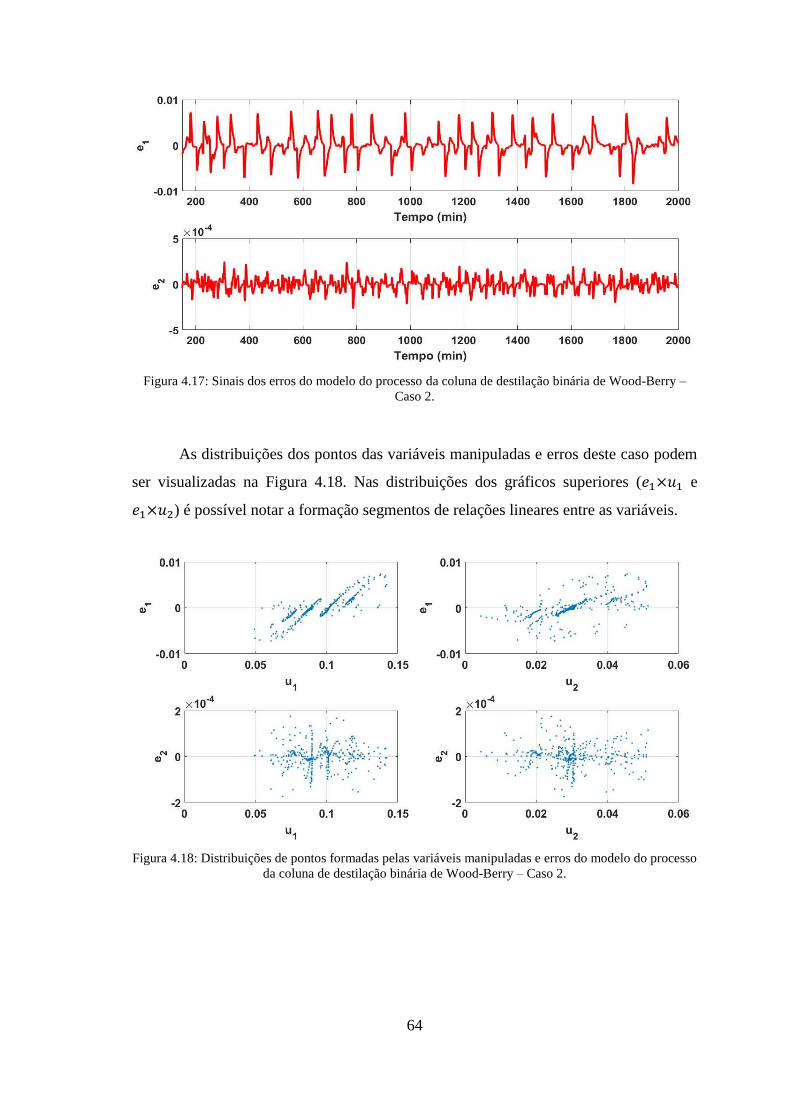
64
Figura 4.17: Sinais dos erros do modelo do processo da coluna de destilação binária de Wood-Berry –
Caso 2.
As distribuições dos pontos das variáveis manipuladas e erros deste caso podem
ser visualizadas na Figura 4.18. Nas distribuições dos gráficos superiores (𝑒1×𝑢1 e
𝑒1×𝑢2) é possível notar a formação segmentos de relações lineares entre as variáveis.
Figura 4.18: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
da coluna de destilação binária de Wood-Berry – Caso 2.
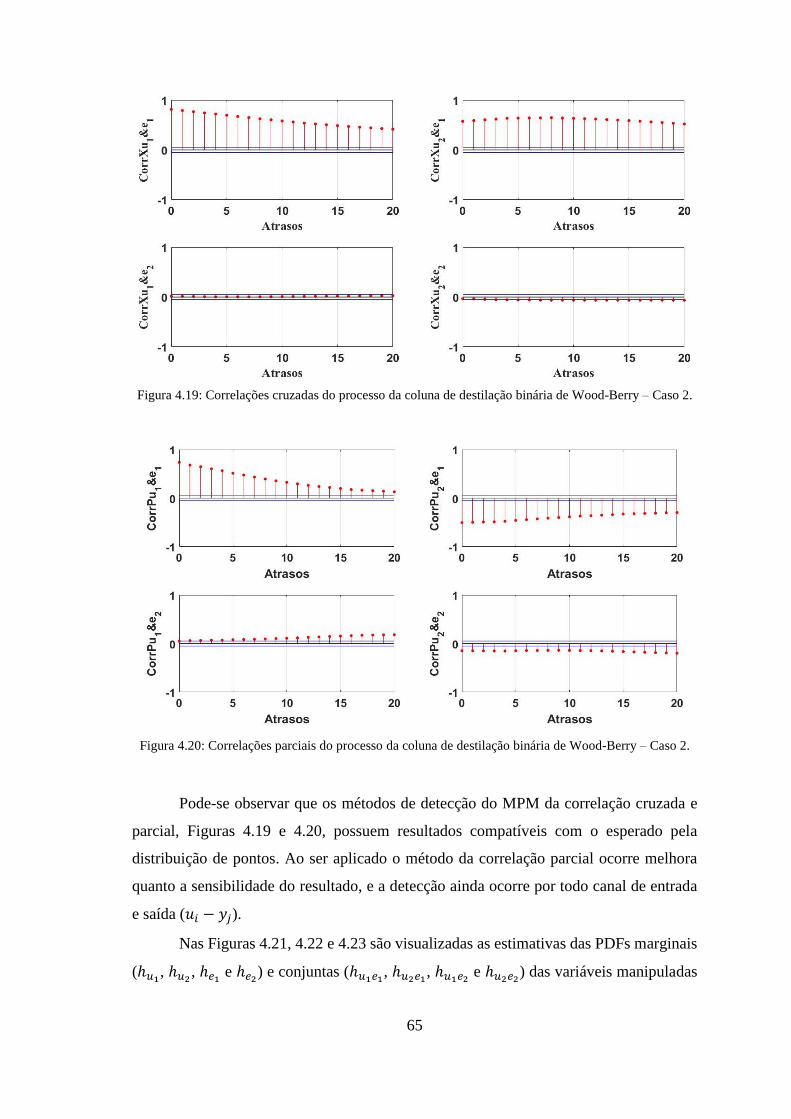
65
Figura 4.19: Correlações cruzadas do processo da coluna de destilação binária de Wood-Berry – Caso 2.
Figura 4.20: Correlações parciais do processo da coluna de destilação binária de Wood-Berry – Caso 2.
Pode-se observar que os métodos de detecção do MPM da correlação cruzada e
parcial, Figuras 4.19 e 4.20, possuem resultados compatíveis com o esperado pela
distribuição de pontos. Ao ser aplicado o método da correlação parcial ocorre melhora
quanto a sensibilidade do resultado, e a detecção ainda ocorre por todo canal de entrada
e saída (𝑢𝑖 − 𝑦𝑗).
Nas Figuras 4.21, 4.22 e 4.23 são visualizadas as estimativas das PDFs marginais
(ℎ𝑢1, ℎ𝑢2
, ℎ𝑒1 e ℎ𝑒2
) e conjuntas (ℎ𝑢1𝑒1, ℎ𝑢2𝑒1
, ℎ𝑢1𝑒2 e ℎ𝑢2𝑒2
) das variáveis manipuladas

66
e os erros do processo para a utilização no cálculo da MI com um número de 30 bins. As
figuras mostram sinais com várias similaridades para os canais 𝑢1 − 𝑦1 e 𝑢2 − 𝑦1.
Figura 4.21: Estimativas das PDFs das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 2.
Figura 4.22: Estimativas das PDFs dos erros do modelo processo da coluna de destilação binária de
Wood-Berry – Caso 2.
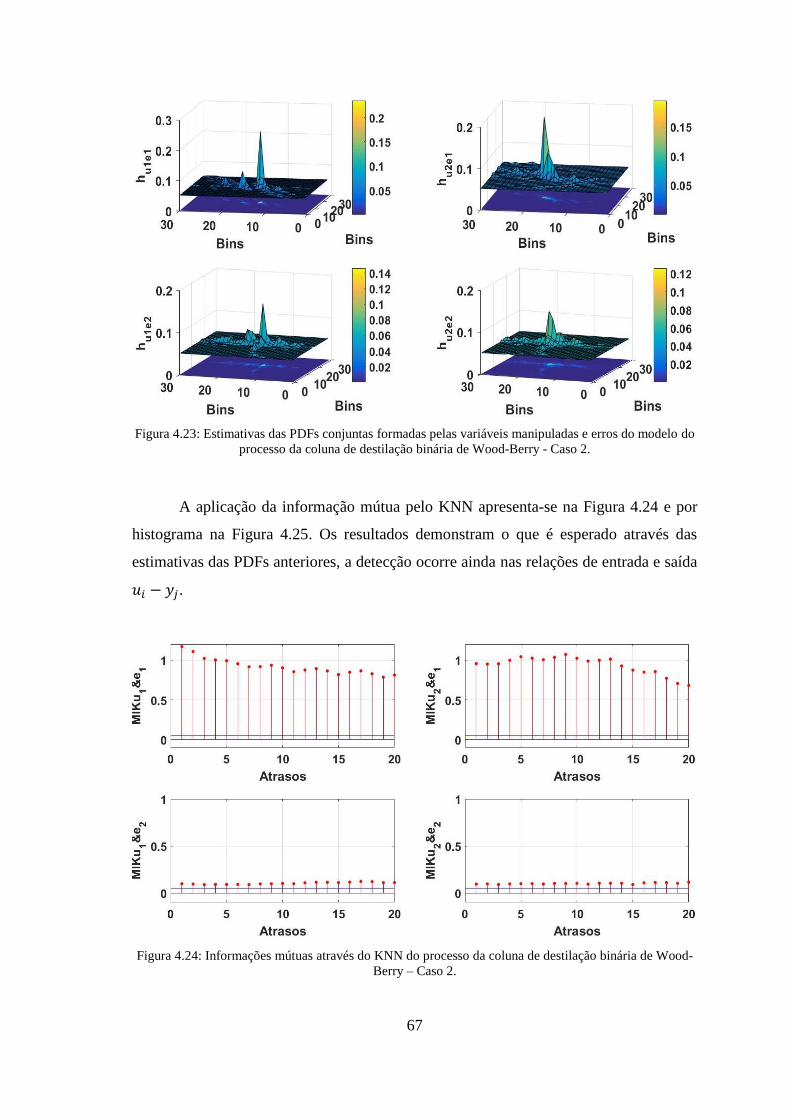
67
Figura 4.23: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo da coluna de destilação binária de Wood-Berry - Caso 2.
A aplicação da informação mútua pelo KNN apresenta-se na Figura 4.24 e por
histograma na Figura 4.25. Os resultados demonstram o que é esperado através das
estimativas das PDFs anteriores, a detecção ocorre ainda nas relações de entrada e saída
𝑢𝑖 − 𝑦𝑗.
Figura 4.24: Informações mútuas através do KNN do processo da coluna de destilação binária de Wood-
Berry – Caso 2.

68
Figura 4.25: Informações mútuas através de histograma do processo da coluna de destilação binária de
Wood-Berry – Caso 2.
4.7 Caso 3
Neste caso um erro de 20% foi incluído no ganho da função de transferência 𝐺22.
Diferentemente do Caso 2, a variável controlada 𝑦2 não consegue acompanhar o segundo
Set-Point, como pode ser visto na Figura 4.26. As variáveis manipuladas podem ser
visualizadas na Figura 4.27.
Figura 4.26: Sinais PRBS de excitação e variáveis controladas do processo da coluna de destilação binária
de Wood-Berry – Caso 3.
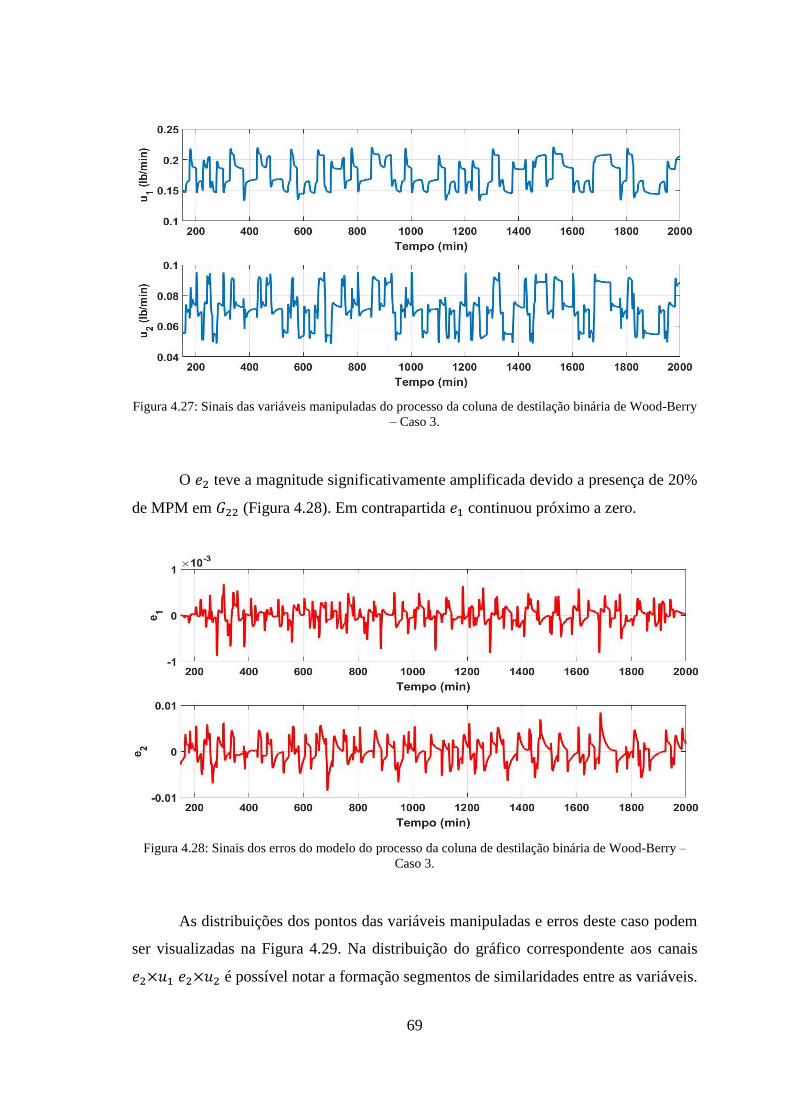
69
Figura 4.27: Sinais das variáveis manipuladas do processo da coluna de destilação binária de Wood-Berry
– Caso 3.
O 𝑒2 teve a magnitude significativamente amplificada devido a presença de 20%
de MPM em 𝐺22 (Figura 4.28). Em contrapartida 𝑒1 continuou próximo a zero.
Figura 4.28: Sinais dos erros do modelo do processo da coluna de destilação binária de Wood-Berry –
Caso 3.
As distribuições dos pontos das variáveis manipuladas e erros deste caso podem
ser visualizadas na Figura 4.29. Na distribuição do gráfico correspondente aos canais
𝑒2×𝑢1 𝑒2×𝑢2 é possível notar a formação segmentos de similaridades entre as variáveis.

70
Figura 4.29: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
da coluna de destilação binária de Wood-Berry – Caso 3.
As similaridades na Figura 4.29 são evidenciadas nas Figuras 4.30 e 4.31, as quais
são encontradas as correlações cruzadas e parciais. Embora a inclusão do erro tenha sido
apenas em 𝐺22 a correlação cruzada (Figura 4.30) mostra detecção no modelo 𝐺21 devido
à presença de dependência linear entre as variáveis manipuladas.
A utilização da correlação parcial (Figura 4.31) reduz a dependência entre estas
variáveis, de maneira que a detecção de MPM aparece de forma mais significativa em
𝐺22.
Figura 4.30: Correlações cruzadas do processo da coluna de destilação binária de Wood-Berry – Caso 3.
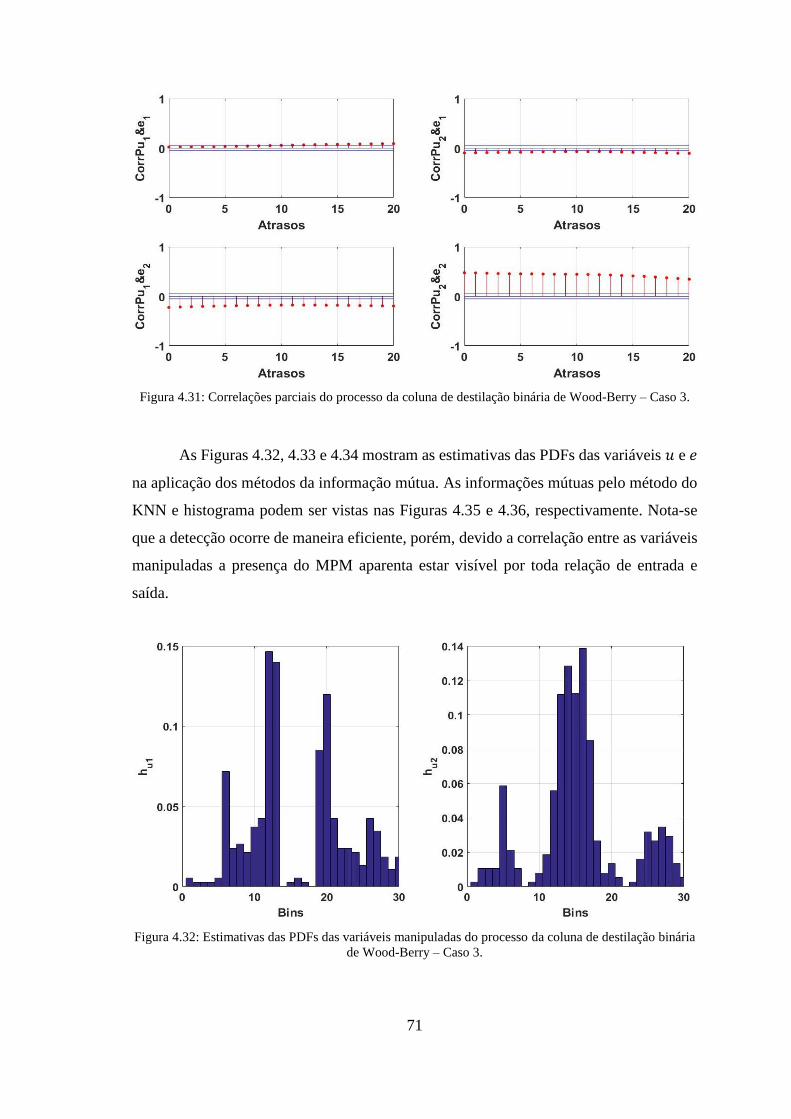
71
Figura 4.31: Correlações parciais do processo da coluna de destilação binária de Wood-Berry – Caso 3.
As Figuras 4.32, 4.33 e 4.34 mostram as estimativas das PDFs das variáveis 𝑢 e 𝑒
na aplicação dos métodos da informação mútua. As informações mútuas pelo método do
KNN e histograma podem ser vistas nas Figuras 4.35 e 4.36, respectivamente. Nota-se
que a detecção ocorre de maneira eficiente, porém, devido a correlação entre as variáveis
manipuladas a presença do MPM aparenta estar visível por toda relação de entrada e
saída.
Figura 4.32: Estimativas das PDFs das variáveis manipuladas do processo da coluna de destilação binária
de Wood-Berry – Caso 3.
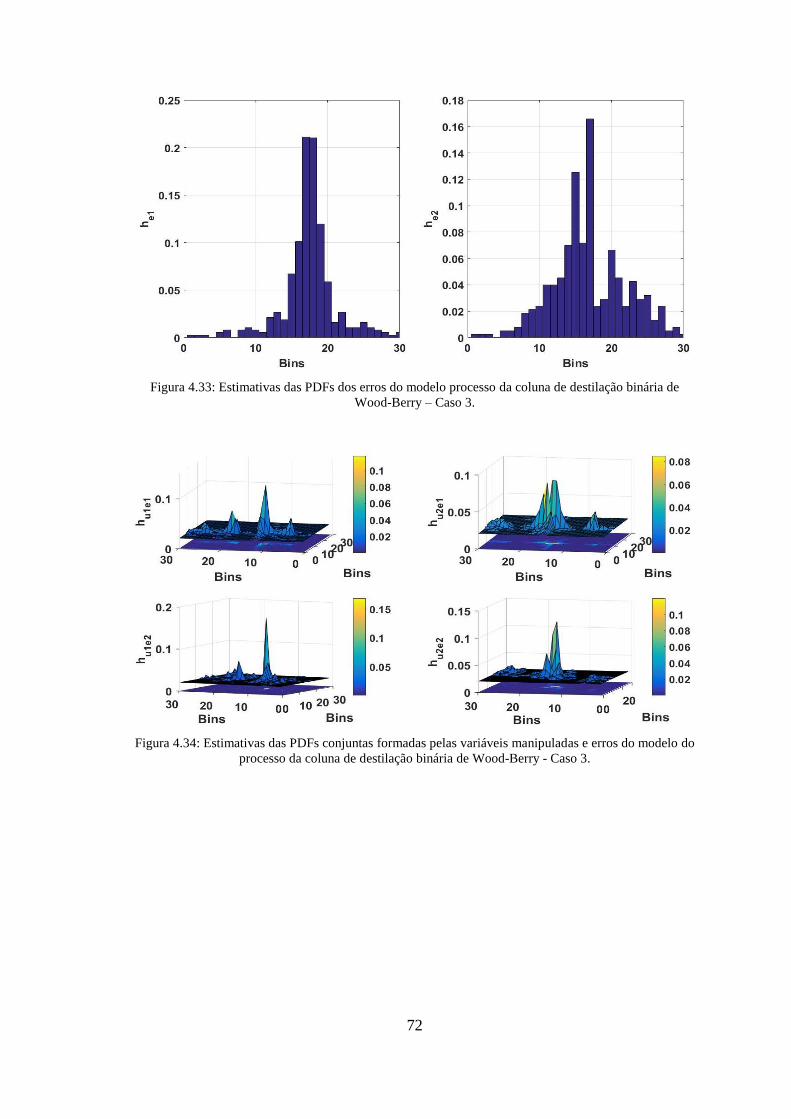
72
Figura 4.33: Estimativas das PDFs dos erros do modelo processo da coluna de destilação binária de
Wood-Berry – Caso 3.
Figura 4.34: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo da coluna de destilação binária de Wood-Berry - Caso 3.
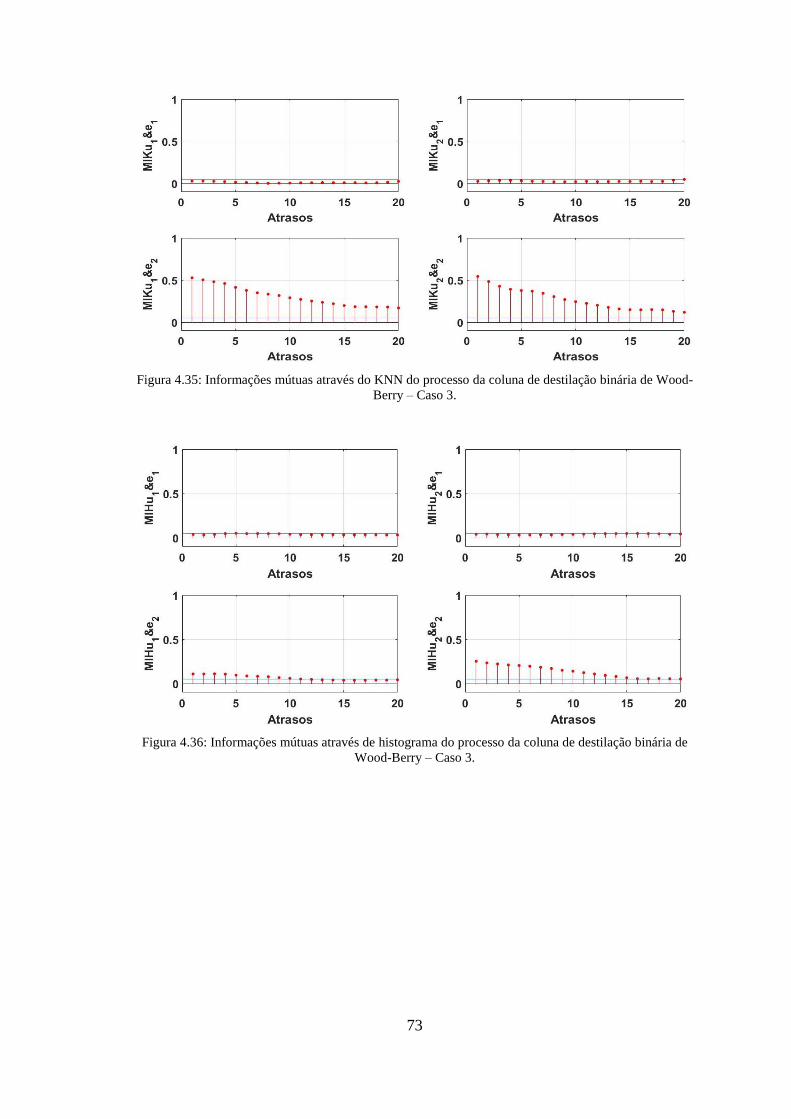
73
Figura 4.35: Informações mútuas através do KNN do processo da coluna de destilação binária de Wood-
Berry – Caso 3.
Figura 4.36: Informações mútuas através de histograma do processo da coluna de destilação binária de
Wood-Berry – Caso 3.

74
Capítulo 5
Estudo de Caso da Unidade de FCC e
Detecção de MPM Não Linear
5.1 Introdução
Neste capítulo são apresentados o processo da unidade de FCC como um estudo
de caso não linear e a aplicação dos métodos propostos divididos em casos.
Diferentemente do processo anterior, os casos seguirão um roteiro que simulam a
necessidade de reidentificação do modelo do processo, seguindo as seguintes
ponderações:
• O roteiro será dividido em 3 casos. No primeiro, os testes dos métodos serão
realizados com o controlador em sintonia com o processo, ou seja, em sua
forma nominal. No segundo caso serão incluídos erros que farão com que o
processo e controlador passem a trabalhar com a presença de MPM. No
terceiro caso será aplicada a reidentificação do modelo, para que o controlador
volte a trabalhar em sintonia com o processo. Em todos os casos serão
aplicados os métodos utilizados neste trabalho;
• São analisadas 1800 amostras do conjunto de variáveis manipuladas e dos
erros dos modelos, referentes a parte em estado estacionário da dinâmica do
processo.
• Como o processo não é baseado em funções de transferência, não há como
modifica-las para incluir o MPM. A inclusão se dará através da modificação
de um dos parâmetros do processo que será apresentado a seguir.

75
5.2 Descrição do Processo
Um diagrama simplificado da unidade de craqueamento catalítico (FCC) Kellog
modelo F, similar à usada atualmente na Refinaria Vale do Paraíba (REVAP) de São José
dos Campos-SP, é apresentado na Figura 5.1. A unidade é alimentada por duas correntes:
gasóleo, proveniente de tanque, e óleo desasfaltado, o qual vem diretamente da unidade
de desasfaltação a propano e contém um alto teor de hidrocarbonentos pesados. Estas
correntes se juntam e a mistura após aquecimento no forno é enviada para o riser junto
com o catalisador proveniente do regenerador, provocando as reações endotérmicas de
craqueamento catalítico. Os produtos da reação e o catalisador deixam o riser e entram
no reator. Nesta secção o catalisador é separado da fase gasosa que contém os
hidrocarbonetos, os quais são conduzidos à etapa de recuperação na fracionadora
principal. Durante as reações de craqueamento ocorre a deposição de coque na superfície
do catalisador, a qual afeta o rendimento da reação. Assim, o catalisador precisa ser
reativado fato que ocorre no regenerador através da combustão de coque com ar
proveniente do soprador. O regenerador é dividido em duas partes principais
denominadas 1o e 2o estágios de regeneração. Cada um dos estágios é composto por uma
fase densa formada por um leito fluidizado de catalisador e, sobre a mesma, uma fase
diluída formada pelos gases de combustão proveniente da queima do coque e catalisador
arrastado da fase densa. O catalisador que vem do reator é depositado na fase densa do 1o
estágio o qual transborda sobre um vertedouro para o 2o estágio onde é concluído o
processo de reativação. Acima das fases diluídas do 1o e 2o estágios forma-se uma região
denominada fase diluída geral, da qual os gases de combustão são usados na geração de
vapor na caldeira de CO.
O processo pode ser simulado com o modelo fenomenológico provido por Moro
e Odloak (1995), o qual foi validado com dados industriais provenientes da REVAP. Este
modelo, constituído por 26 ODEs e 74 equações algébricas lineares e não-lineares, vem
sendo usado para avaliação de novas estruturas de controle de FCC na PETROBRAS
(ZANIN; TVRZSKA DE GOUVEA; ODLOAK, 2002). No presente trabalho, as
equações do modelo e os parâmetros do processo serão omitidos, porém, podem ser
encontrados na referência acima mencionada.
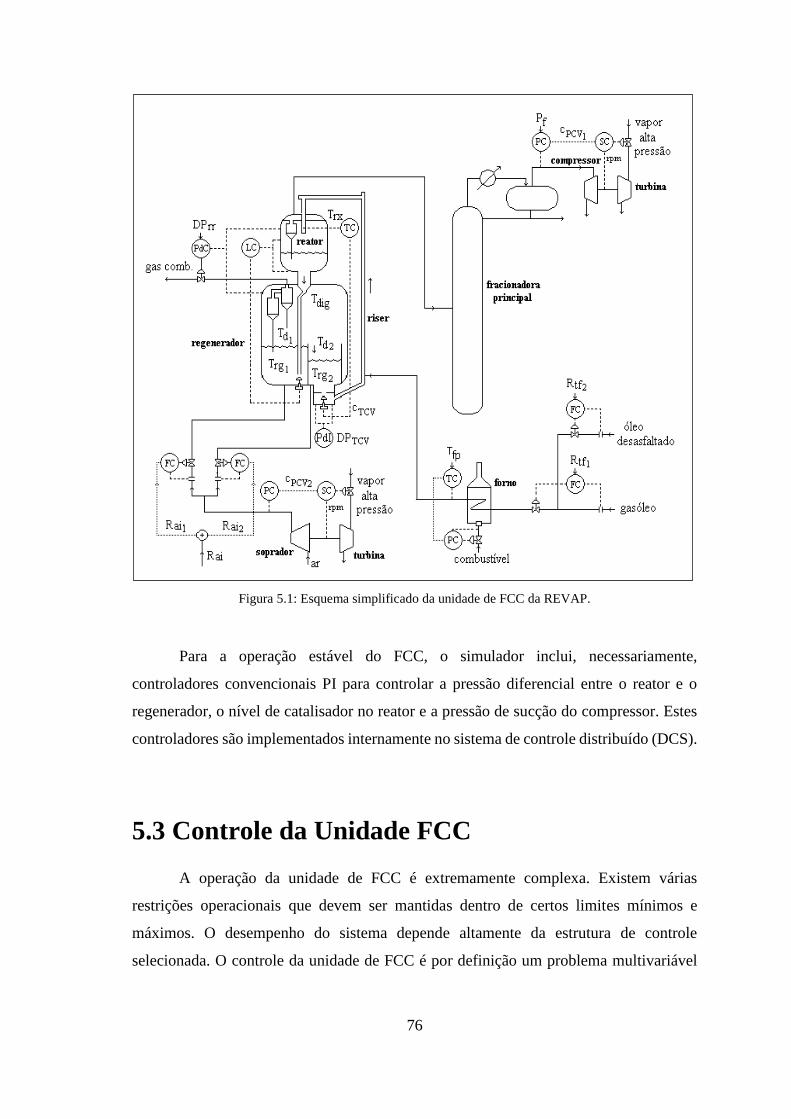
76
Figura 5.1: Esquema simplificado da unidade de FCC da REVAP.
Para a operação estável do FCC, o simulador inclui, necessariamente,
controladores convencionais PI para controlar a pressão diferencial entre o reator e o
regenerador, o nível de catalisador no reator e a pressão de sucção do compressor. Estes
controladores são implementados internamente no sistema de controle distribuído (DCS).
5.3 Controle da Unidade FCC
A operação da unidade de FCC é extremamente complexa. Existem várias
restrições operacionais que devem ser mantidas dentro de certos limites mínimos e
máximos. O desempenho do sistema depende altamente da estrutura de controle
selecionada. O controle da unidade de FCC é por definição um problema multivariável

77
ao invés de um problema multi-malha e, portanto, MPC tende a ser a melhor escolha para
este propósito.
No presente caso, a unidade FCC opera sob um esquema MPC em duas camadas,
com estratégia de controle por zonas, como mostrado na Figura 5.2. Neste esquema, o
nível superior corresponde a um algoritmo de otimização econômica o qual computa um
ótimo estado estacionário (i.e., set-points para as variáveis controladas e/ou targets para
as variáveis manipuladas) o qual é passado ao controlador MPC para sua implementação.
5.4 MPC em Duas Camadas
Esquemas de controle MPC em duas camadas são comumente encontrados na
industria de petróleo e petroquímica (ROTAVA; ZANIN, 2005; YING;
VOORAKARANAM; JOSEPH, 1998). No controlador usado neste trabalho, a camada
superior corresponde a um algoritmo de otimização econômica simplificada definida da
seguinte forma (SOTOMAYOR; ODLOAK; MORO, 2009):
Figura 5.2: Controle MPC em duas camadas.

78
minΔ𝑢𝑠𝑠,𝛿𝑦
−𝑊1Δ𝑢𝑠𝑠 +‖𝑊2Δ𝑢𝑠𝑠‖22 + ‖𝑊3𝛿𝑦‖
2
2 (5.1)
Sujeito a:
𝑢𝑚𝑖𝑛 ≤ 𝑢𝑠𝑠 ≤ 𝑢𝑚𝑎𝑥
𝑦𝑚𝑖𝑛 ≤ 𝑦𝑠𝑠 + δy ≤ 𝑦𝑚𝑎𝑥
Onde:
Δ𝑢𝑠𝑠 = 𝑢𝑠𝑠 − 𝑢(𝑘 − 1)
𝑦𝑠𝑠 = 𝐺0Δ𝑢𝑠𝑠 + �̂�(𝑘 + 𝑛/𝑘)
(5.2)
𝑢𝑠𝑠 é o vetor de targets para as variáveis manipuladas, 𝑦𝑠𝑠 é o vetor de saídas
preditas no estado estacionário, �̂�(𝑘 + 𝑛/𝑘) é a predição da saída controlada no instante
𝑘 + 𝑛 calculado no tempo 𝑘 (𝑛 é o horizonte do modelo ou o tempo de acomodação do
modelo), 𝐺0 é a matriz de ganhos estacionários do processo e 𝛿𝑦 é o vetor de variáveis de
folga para as variáveis controladas, 𝑢𝑚𝑎𝑥 e 𝑢𝑚𝑖𝑛 são os limites máximos e mínimos das
variáveis manipuladas, 𝑦𝑚𝑎𝑥 e 𝑦𝑚𝑖𝑛 são os limites máximos e mínimos das variáveis
controladas, e 𝑊1, 𝑊2 e 𝑊3 são vetores de ponderação de dimensões adequadas. Neste
ponto, é necessário notar que o vetor de ponderação 𝑊1 é usualmente disponível para ser
ajustado on-line pelo operador do sistema.
Como resultado da solução do problema das Equações (5.1) e (5.2), obtemos os
“targets” das entradas (𝑢𝑠𝑠) que são passados ao controlador MPC, neste caso um QDMC,
o qual soluciona o seguinte problema de otimização (SOTOMAYOR; ODLOAK;
MORO, 2009):
minΔ𝑢
∑(�̂�(𝑘 + 𝑖) − 𝑦𝑠𝑝)𝑇𝑄(�̂�(𝑘 + 𝑖) − 𝑦𝑠𝑝)
𝑝
𝑖=1
+ ∑Δ𝑢(𝑘 + 𝑗 − 1)𝑇𝑅Δ𝑢(𝑘 + 𝑗 − 1)
𝑚
𝑗=1
+ ∑[𝑢(𝑘 + 𝑗 − 1) − 𝑢𝑠𝑠]𝑇𝑅u[𝑢(𝑘 + 𝑗 − 1) − 𝑢𝑠𝑠]
𝑚
𝑗=1
(5.3)

79
Sujeito a:
−Δ𝑢𝑚𝑎𝑥 ≤ Δ𝑢(𝑘 + 𝑗 − 1) ≤ Δ𝑢𝑚𝑎𝑥, 𝑗 = 1, … ,𝑚
−𝑢𝑚𝑖𝑛 ≤ 𝑢(𝑘 + 𝑗 − 1) ≤ 𝑢𝑚𝑎𝑥, 𝑗 = 1,… ,𝑚 (5.4)
Onde �̂�(𝑘 + 1) é a predição da saída no instante 𝑘 + 1, 𝑦𝑠𝑝 é o set-point,
Δ𝑢(𝑘 + 𝑖 − 1) = 𝑢(𝑘 + 𝑖 − 1) − 𝑢(𝑘 + 𝑖 − 1) é o incremento nas entradas, 𝑘 é o
instante atual de amostragem, 𝑝 é o horizonte de otimização ou de predição do
controlador, 𝑚 é o horizonte de controle, 𝑢𝑚𝑎𝑥 e 𝑢𝑚𝑖𝑛 são os limites máximos e mínimos
das entradas, Δ𝑢𝑚𝑎𝑥 é o limite máximo de incremento nas entradas, 𝑄, 𝑅 e 𝑅𝑢 são
matrizes diagonais de ponderação de dimensões apropriadas.
O problema de otimização da Equação (5.3) sujeito às restrições da Equação (5.4)
é resolvido usando programação QP. Note-se que só a primeira ação de controle do vetor
Δ𝑢 é aplicado na planta.
5.5 Estratégia de Controle por Faixas
Em grande parte de aplicações industriais, as saídas são controladas por zonas ou
faixas de operação ao invés de set-points fixos. Esta estratégia é usualmente adotada nos
casos em que o número de saídas controladas é maior que o número de entradas
manipuladas, com a intenção de obter alguns graus de liberdade que permitam levar o
processo a seu target ótimo, e suavizar a resposta do sistema perante perturbações.
Para levar em conta o controle por zonas das saídas, a Equação (5.5) é modificada
da seguinte forma (SOTOMAYOR; ODLOAK; MORO, 2009):
minΔ𝑢
∑(�̂�(𝑘 + 𝑖) − 𝑦𝑏)𝑇𝑄(�̂�(𝑘 + 𝑖) − 𝑦𝑏)
𝑝
𝑖=1
+ ∑Δ𝑢(𝑘 + 𝑗 − 1)𝑇𝑅Δ𝑢(𝑘 + 𝑗 − 1)
𝑚
𝑗=1
+ ∑[𝑢(𝑘 + 𝑗 − 1) − 𝑢𝑠𝑠]𝑇𝑅u[𝑢(𝑘 + 𝑗 − 1) − 𝑢𝑠𝑠]
𝑚
𝑗=1
(5.5)

80
A estratégia de controle por zonas das saídas é implementada da seguinte forma.
Para cada saída 𝑗 observamos sua predição no instante 𝑘 + 𝑖:
• Se 𝑦𝑗,𝑚𝑖𝑛 ≤ �̂�𝑗(𝑘 + 𝑖) ≤ 𝑦𝑗,𝑚𝑎𝑥, a saída 𝑦𝑗 deve ser ignorada (liberada ou
removida dos cálculos de controle) no instante 𝑘 + 𝑖. Portanto, o parâmetro da
matriz 𝑄 correspondente a essa saída deve ser zero. 𝑦𝑗𝑏(𝑘 + 𝑖) pode ser qualquer
valor.
• Se �̂�𝑗(𝑘 + 𝑖) > 𝑦𝑗,𝑚𝑎𝑥, a saída 𝑦𝑗 deve ser trazida para seu limite superior.
Portanto, fazemos 𝑦𝑗𝑏(𝑘 + 𝑖) = 𝑦𝑗,𝑚𝑎𝑥. O parâmetro da matriz 𝑄 correspondente
a essa saída é um parâmetro de sintonia do controlador.
• �̂�𝑗(𝑘 + 𝑖) < 𝑦𝑗,𝑚𝑖𝑛, a saída 𝑦𝑗 deve ser trazida para seu limite inferior. Portanto,
fazemos 𝑦𝑗𝑏(𝑘 + 𝑖) = 𝑦𝑗,𝑚𝑎𝑥. O parâmetro da matriz 𝑄 correspondente a essa
saída é o mesmo do caso anterior.
5.6 Controle MPC da Unidade FCC
No presente caso, a estrutura de controle do FCC é baseada na versão original do
controlador usado na REVAP. Deste esquema, e para efeitos do nosso estudo, só
consideraremos um subsistema 2×2 onde as entradas manipuladas 𝑢1 e 𝑢2 são a vazão
total de ar introduzida no regenerador (ton/h) e abertura da válvula de catalisador
regenerado (%), respectivamente, e as saídas controladas 𝑦1 e 𝑦2 são a temperatura da
fase densa do 1o estágio do regenerador (°C) e a temperatura na saída do riser (°C),
respectivamente. Além disso, as saídas 3y e 4y , i.e., a temperatura da fase densa do 2o
estágio do regenerador (°C) e a severidade da reação de craqueamento (%),
respectivamente, não estão sob controle, mas podem ser monitoradas a partir do sistema.
O modelo linear do processo usado no controlador, obtido através da resposta ao
degrau, é representado pela seguinte matriz de funções de transferência:

81
𝐺(𝑠)
=
[ 0,04088𝑠 + 0,0004847
𝑠2 + 0,0253𝑠 + 0,0017
−3,17𝑠 + 0,04581
𝑠2 + 0,0293𝑠 + 0,0008547
0,0226𝑠 + 0,0008945
𝑠2 + 0,0567𝑠 + 0,00234
3,77𝑠2 + 0,091𝑠 + 0,003
𝑠3 + 0,0738𝑠2 + 0,002𝑠 + 4,82×10−5]
(5.6)
A implementação do controlador MPC considera os parâmetros de sintonia
conforme listados na Tabela 1.
Tabela 3: Parâmetros de sintonia do controlador MPC.
Parâmetro Descrição Valor
𝑻𝒔 Tempo de amostragem 1 min
𝑵 Horizonte do modelo 300
𝒉𝒑 Horizonte de predição 10
𝒉𝒄 Horizonte de controle 2
𝛅𝐮𝐦𝐚𝐱 Limite máx. de incremento nas entradas [1 0,015]𝑇
𝐮𝐦𝐚𝐱 Limite máximo das entradas [240 0,95]𝑇
𝐮𝐦𝐢𝐧 Limite mínimo das entradas [210 0,45]𝑇
𝐲𝐦𝐚𝐱 Limite máximo das saídas [675 545]𝑇
𝐲𝐦𝐚𝐱 Limite mínimo das saídas [665 538]𝑇
𝑸 Matriz de ponderação de predições das saídas 𝑑𝑖𝑎𝑔([1 1]) 𝑹 Matriz de fatores de supressão de
incrementos nas entradas 𝑑𝑖𝑎𝑔([0,2 2])
𝑹𝒖 Matriz de ponderação da distância entre a
entrada calculada e o target ótimo 𝑑𝑖𝑎𝑔([0,111 0,525])
𝑾𝟏 Vetor de coeficientes econômicos das
variáveis manipuladas
[30 30]𝑇
𝑾𝟐 Matriz de ponderação de incrementos nas
entradas 𝑑𝑖𝑎𝑔([200 1000])
𝑾𝟑 Matriz de ponderação das variáveis de folga
das saídas 𝑑𝑖𝑎𝑔([1000 1000])
Os valores no estado estacionário das entradas manipuladas e saídas controladas
são 𝑢0 = [221 0,82]𝑇 e 𝑦0 = [670,14 542,2]𝑇, respectivamente. A Figura 5.3
mostra a implementação do simulador do sistema controlado em uma ambiente de
simulação computacional.

82
Figura 5.3: Implementação do simulador do sistema FCC.
Neste processo não há aplicação de perturbação através dos set-points do sistema,
no entanto a premissa de que o sistema deve ser perturbado para capturar a dinâmica do
processo deve ser seguida, uma metodologia similar é então realizada. Nesta metodologia,
o conhecimento a priori do processo (Equação (5.6)) é usado para projetar de forma off-
line sinais de excitação persistentes entre 1 e -1 (Figura 5.4), os quais são introduzidos
nos coeficientes econômicos 𝑊1 da função custo da otimização econômica em estado
estacionário. Como resultado desta perturbação, nas Figuras 5.5 e 5.6 são mostradas as
respostas das variáveis manipuladas e controladas, respectivamente, coletados com uma
taxa de amostragem de 1 min. Como pode ser visualizado nestas respostas, as variáveis
manipuladas e controladas são mantidas dentro de seus limites operacionais, oferecendo
segurança ao sistema e mantendo as especificações da qualidade do produto.
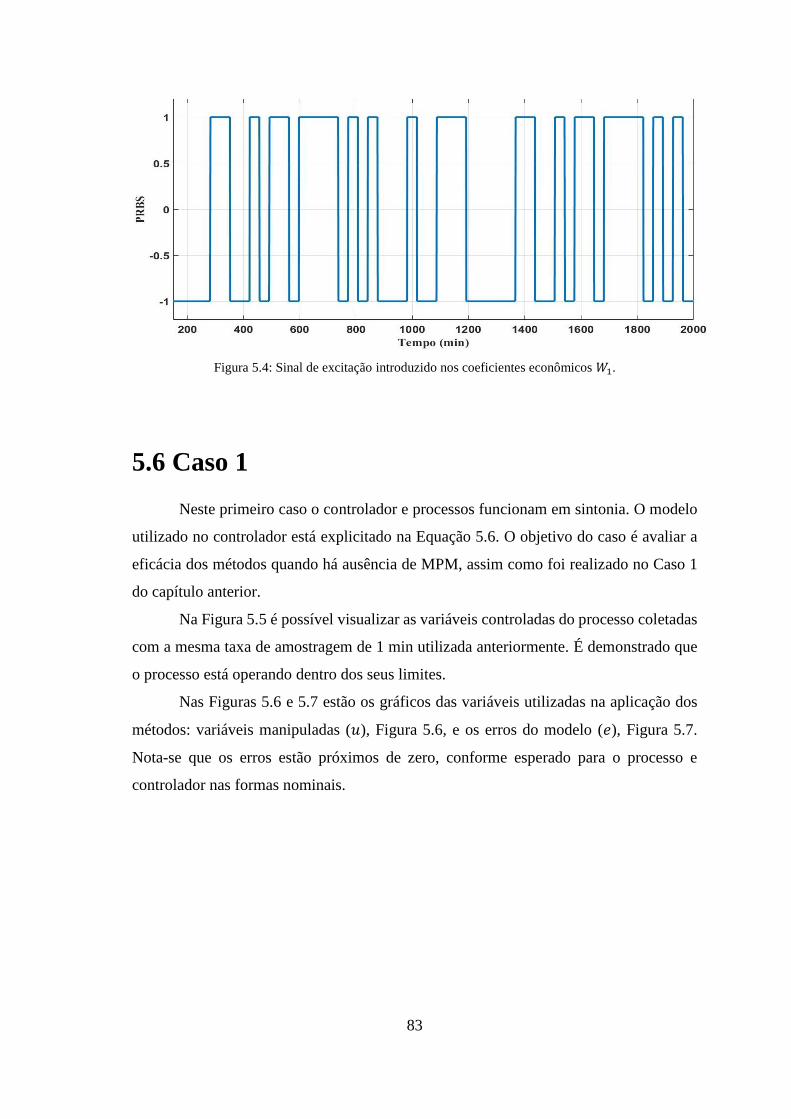
83
Figura 5.4: Sinal de excitação introduzido nos coeficientes econômicos 𝑊1.
5.6 Caso 1
Neste primeiro caso o controlador e processos funcionam em sintonia. O modelo
utilizado no controlador está explicitado na Equação 5.6. O objetivo do caso é avaliar a
eficácia dos métodos quando há ausência de MPM, assim como foi realizado no Caso 1
do capítulo anterior.
Na Figura 5.5 é possível visualizar as variáveis controladas do processo coletadas
com a mesma taxa de amostragem de 1 min utilizada anteriormente. É demonstrado que
o processo está operando dentro dos seus limites.
Nas Figuras 5.6 e 5.7 estão os gráficos das variáveis utilizadas na aplicação dos
métodos: variáveis manipuladas (𝑢), Figura 5.6, e os erros do modelo (𝑒), Figura 5.7.
Nota-se que os erros estão próximos de zero, conforme esperado para o processo e
controlador nas formas nominais.
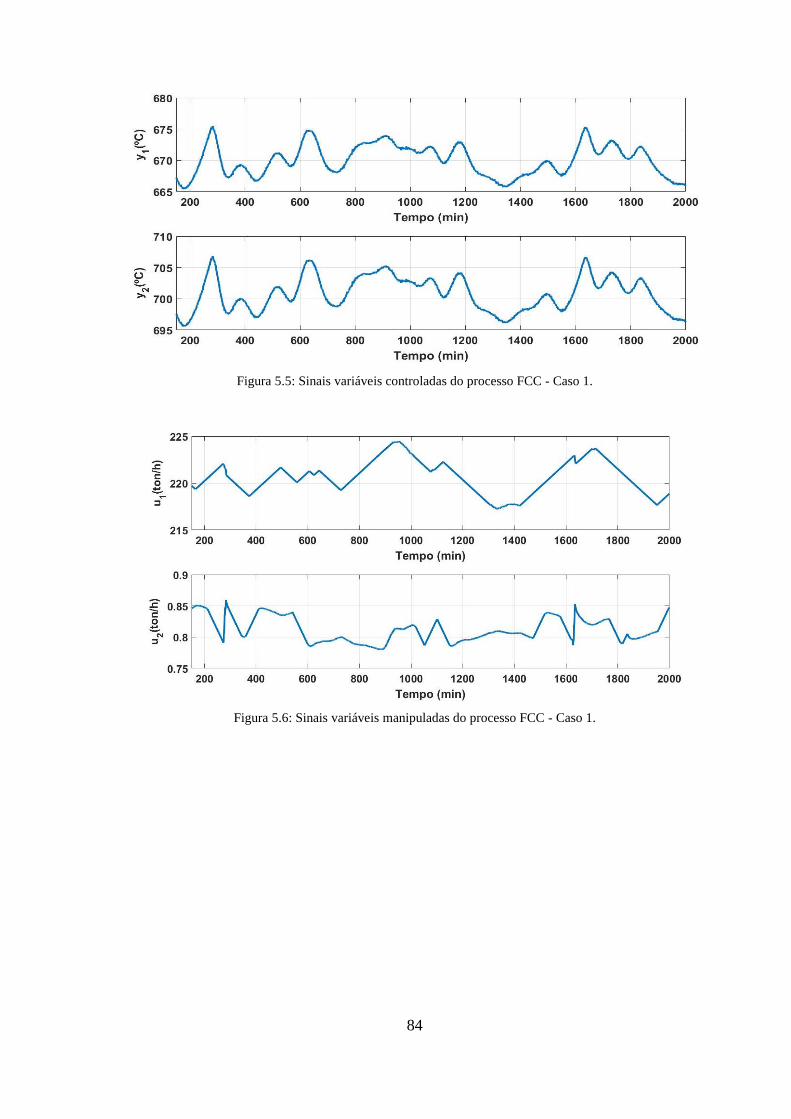
84
Figura 5.5: Sinais variáveis controladas do processo FCC - Caso 1.
Figura 5.6: Sinais variáveis manipuladas do processo FCC - Caso 1.
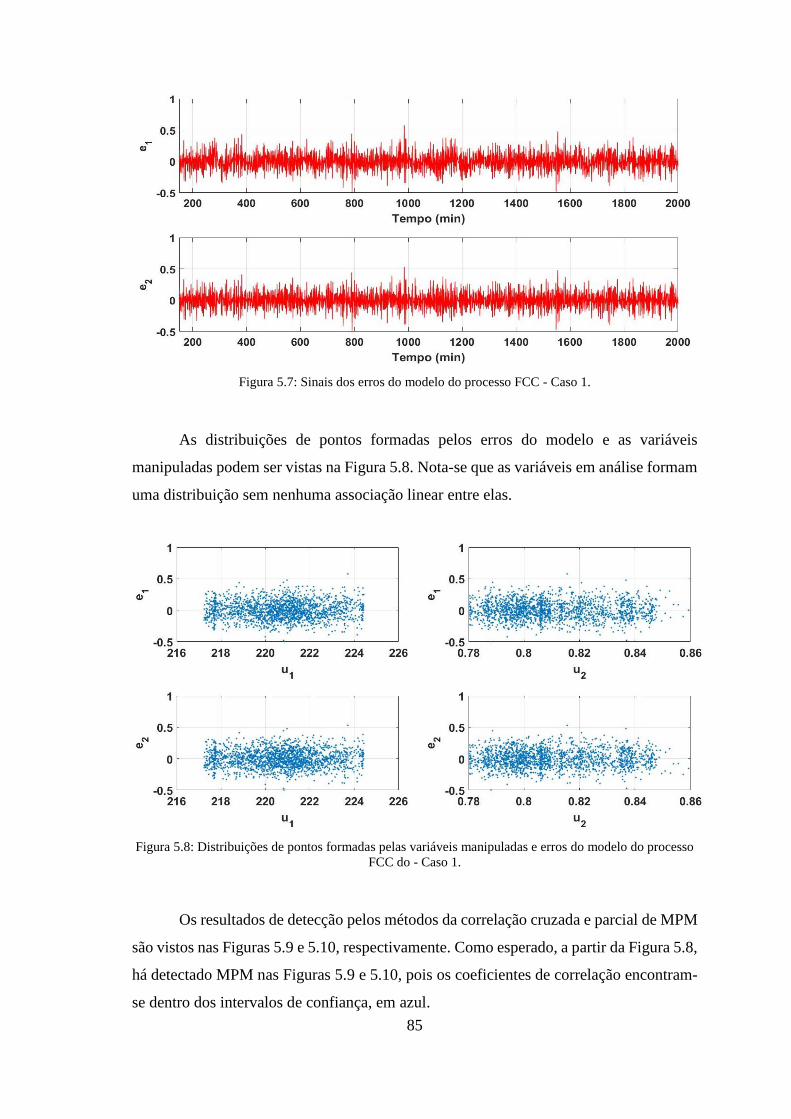
85
Figura 5.7: Sinais dos erros do modelo do processo FCC - Caso 1.
As distribuições de pontos formadas pelos erros do modelo e as variáveis
manipuladas podem ser vistas na Figura 5.8. Nota-se que as variáveis em análise formam
uma distribuição sem nenhuma associação linear entre elas.
Figura 5.8: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
FCC do - Caso 1.
Os resultados de detecção pelos métodos da correlação cruzada e parcial de MPM
são vistos nas Figuras 5.9 e 5.10, respectivamente. Como esperado, a partir da Figura 5.8,
há detectado MPM nas Figuras 5.9 e 5.10, pois os coeficientes de correlação encontram-
se dentro dos intervalos de confiança, em azul.

86
Figura 5.9: Correlações cruzadas do processo FCC - Caso 1.
Figura 5.10: Correlações parciais do processo FCC do caso 1.
Para a demonstração do desenvolvimento dos métodos utilizando informação
mútua são geradas as estimativas das PDFs de 𝑢 e 𝑒 , presentes nas Figuras 5.11 e 5.12.
Na Figura 5.13 encontram-se as PDFs conjuntas formadas por 𝑢 e 𝑒.
Nota-se através das Figuras 5.11, 5.12 e 5.13 que 𝑢 e 𝑒 não formam qualquer tipo
de associação linear ou não linear entre elas. Desta maneira os métodos da informação
mútua não detectam presença de MPM, como pode ser visto nas Figuras 5.14 e 5.15, em
que os coeficientes se apresentam também dentro dos intervalos de confiança em azul.
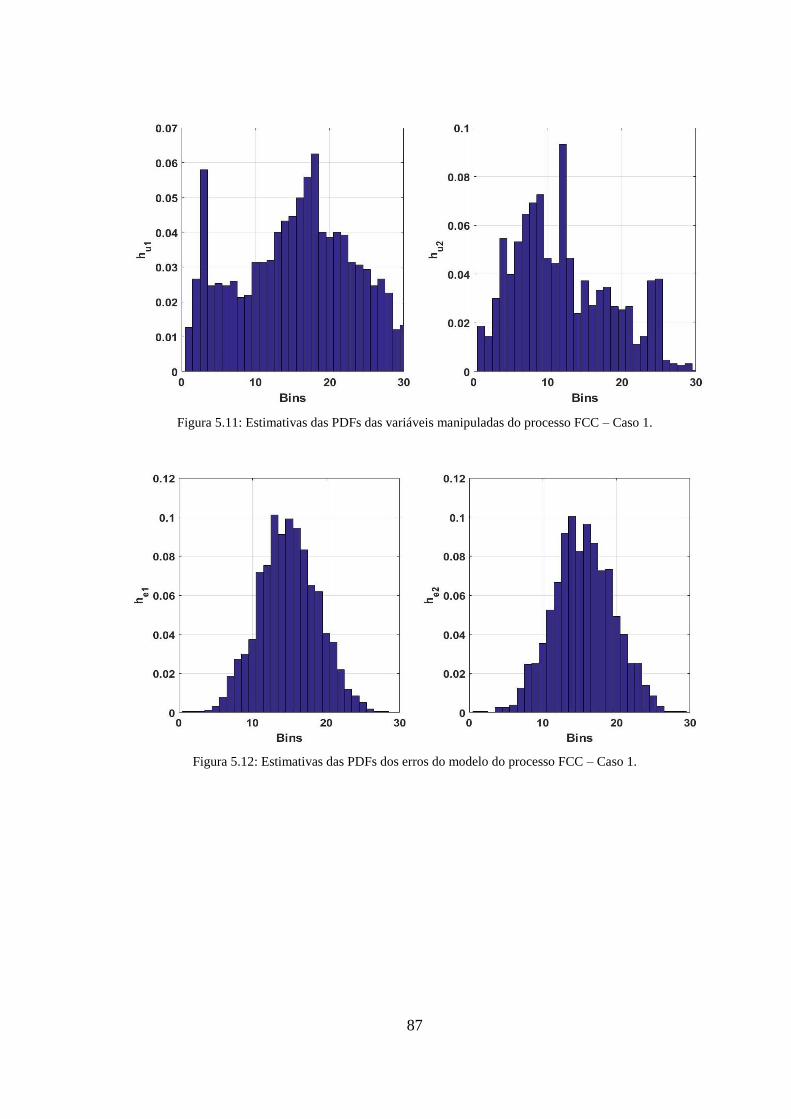
87
Figura 5.11: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 1.
Figura 5.12: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 1.

88
Figura 5.13: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo FCC – Caso 1.
Figura 5.14: Informações mútuas através de KNN do processo FCC – Caso 1.

89
Figura 5.15: Informações mútuas através de histograma do processo FCC – Caso 1.
5.7 Caso 2
Neste segundo caso é incluído MPM através do acréscimo de 25% do valor do
parâmetro 𝐾𝑐𝑐 no processo, tal parâmetro corresponde a constante cinética da reação de
formação do coque. O valor que antes era 4,2 passa a ser igual a 5,25. Esta perturbação
afeta a operação da unidade FCC, e resulta em mais deposição de coque no riser e na
concentração de coque do catalisador usado. Após a ocorrência da mudança de condição,
verifica-se que há uma diminuição na taxa de fluxo total do ar e na quantidade de
catalisador regenerado. Estas consequências, evidentemente, representam a diminuição
do valor médio das variáveis manipuladas
Os efeitos da presença de MPM podem ser notados de forma aparente nas
variáveis controladas, manipuladas e erros do modelo, vistas na Figura 5.16, 5,17 e 5.18,
respectivamente. Os sinais das variáveis 𝑦 demonstram o funcionamento incorreto do
controlador, devido ao formato senoidal dos sinais caracterizando uma resposta não
amortecida.
Assim como nas variáveis 𝑦, os sinais das variáveis manipuladas e os erros do
modelo demonstram o mau desempenho do controlador. Analisando estas variáveis pode
ser esperado que a detecção deva ocorrer principalmente nos canais de entrada e saída
formados por 𝑢1 − 𝑦1 e 𝑢2 − 𝑦1.

90
Tal análise pode ser baseada nos níveis de similaridade entre as variáveis das
Figuras 5.17 e 5.18, que aparentam ser maiores entre as variáveis de 𝑢 e 𝑒1 do que 𝑢 e 𝑒2,
de maneira que a detecção de MPM esperada ocorre em 𝐺11 e 𝐺12.
Figura 5.16: Sinais das variáveis controladas do processo FCC - Caso 2.
Figura 5.17: Sinais das variáveis manipuladas do processo FCC - Caso 2.
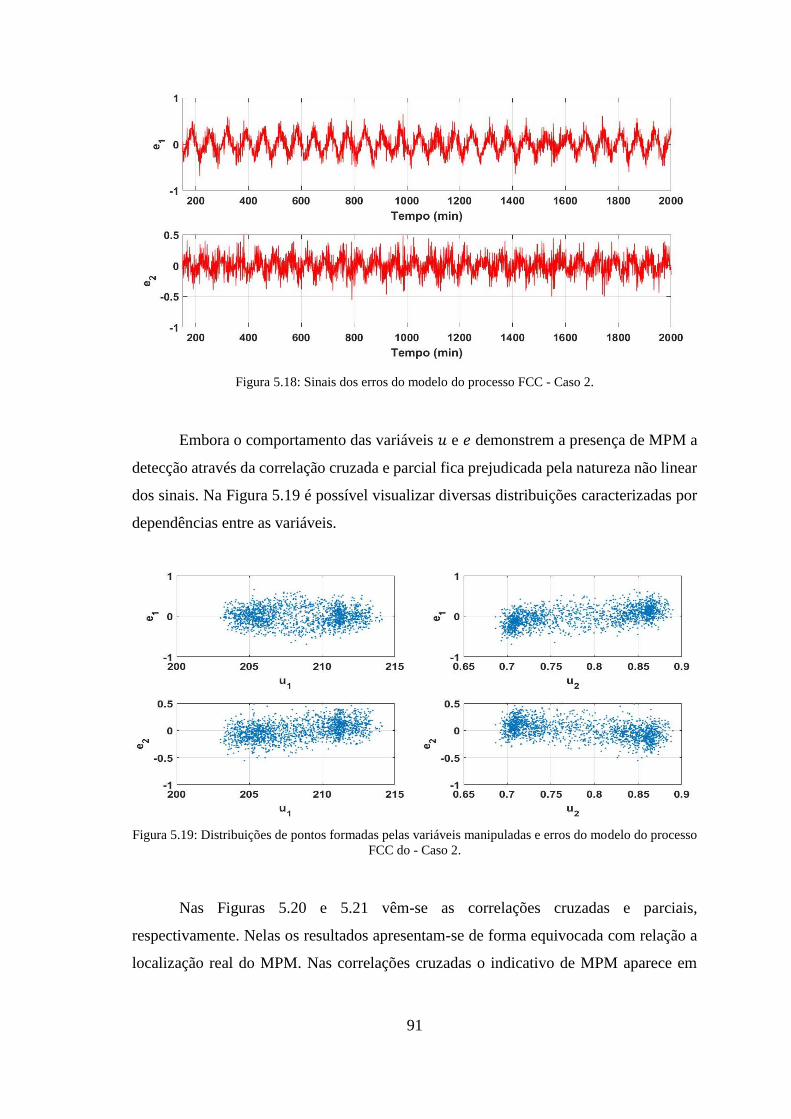
91
Figura 5.18: Sinais dos erros do modelo do processo FCC - Caso 2.
Embora o comportamento das variáveis 𝑢 e 𝑒 demonstrem a presença de MPM a
detecção através da correlação cruzada e parcial fica prejudicada pela natureza não linear
dos sinais. Na Figura 5.19 é possível visualizar diversas distribuições caracterizadas por
dependências entre as variáveis.
Figura 5.19: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
FCC do - Caso 2.
Nas Figuras 5.20 e 5.21 vêm-se as correlações cruzadas e parciais,
respectivamente. Nelas os resultados apresentam-se de forma equivocada com relação a
localização real do MPM. Nas correlações cruzadas o indicativo de MPM aparece em

92
todos os canais de entrada e saída, enquanto nas parciais não há indicação da presença de
MPM
Figura 5.20: Correlações cruzadas do processo FCC - Caso 2.
Figura 5.21: Correlações parciais do processo FCC - Caso 2.
Nas Figuras 5.22 e 5.23 estão presentes as estimativas das PDFs das variáveis 𝑢 e
𝑒 deste caso. Na Figura 5.24 encontra-se as estimativas das PDFs conjuntas destas
variáveis. É importante ressaltar as distribuições encontradas, diferente dos outros casos
presentes neste trabalho com bastante característica não linear.
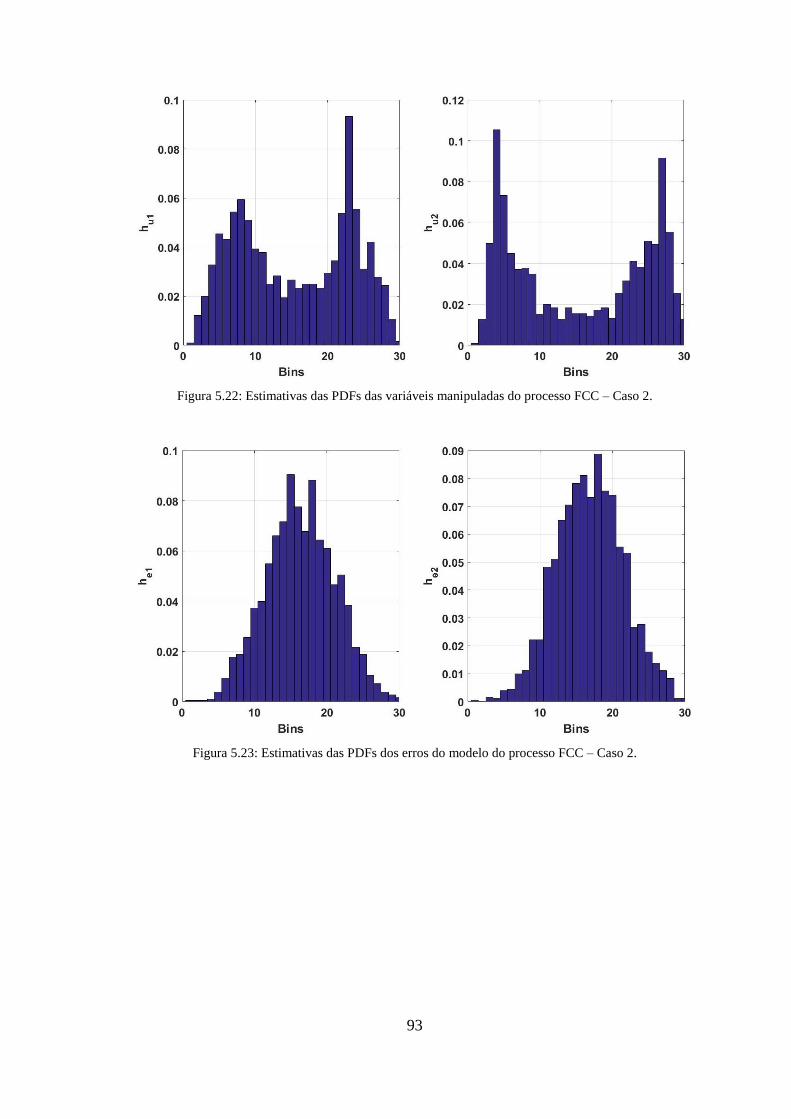
93
Figura 5.22: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 2.
Figura 5.23: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 2.
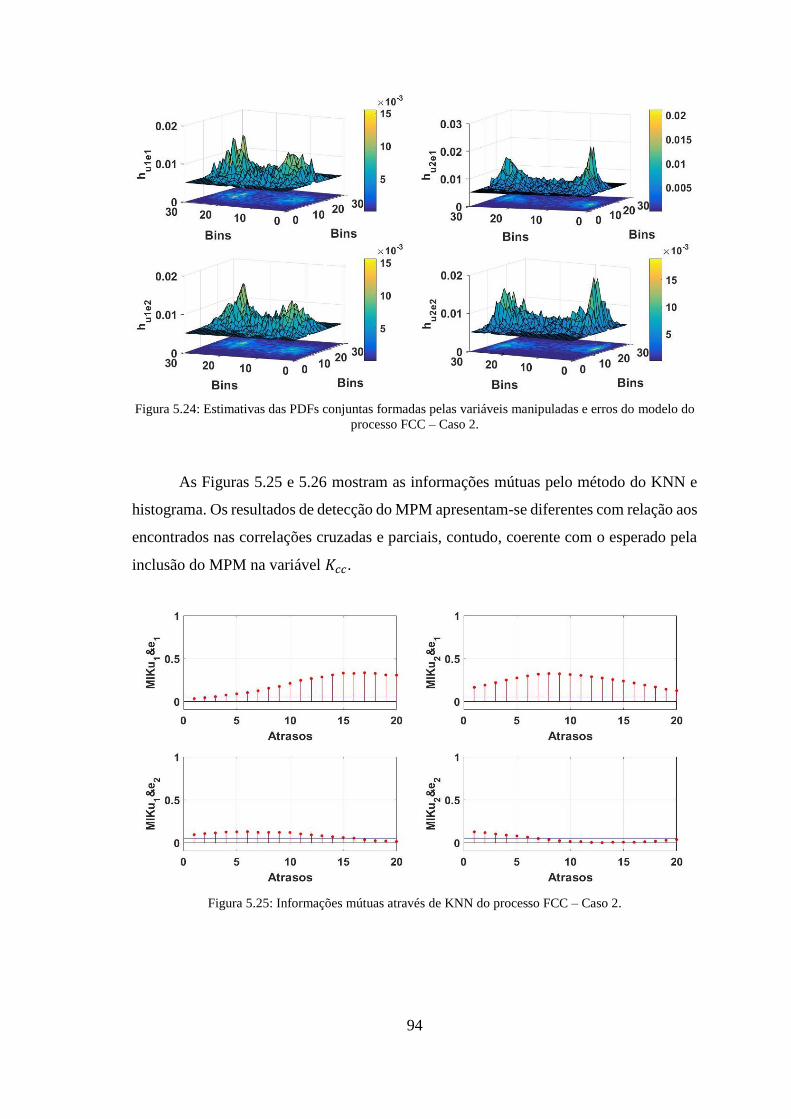
94
Figura 5.24: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo FCC – Caso 2.
As Figuras 5.25 e 5.26 mostram as informações mútuas pelo método do KNN e
histograma. Os resultados de detecção do MPM apresentam-se diferentes com relação aos
encontrados nas correlações cruzadas e parciais, contudo, coerente com o esperado pela
inclusão do MPM na variável 𝐾𝑐𝑐.
Figura 5.25: Informações mútuas através de KNN do processo FCC – Caso 2.
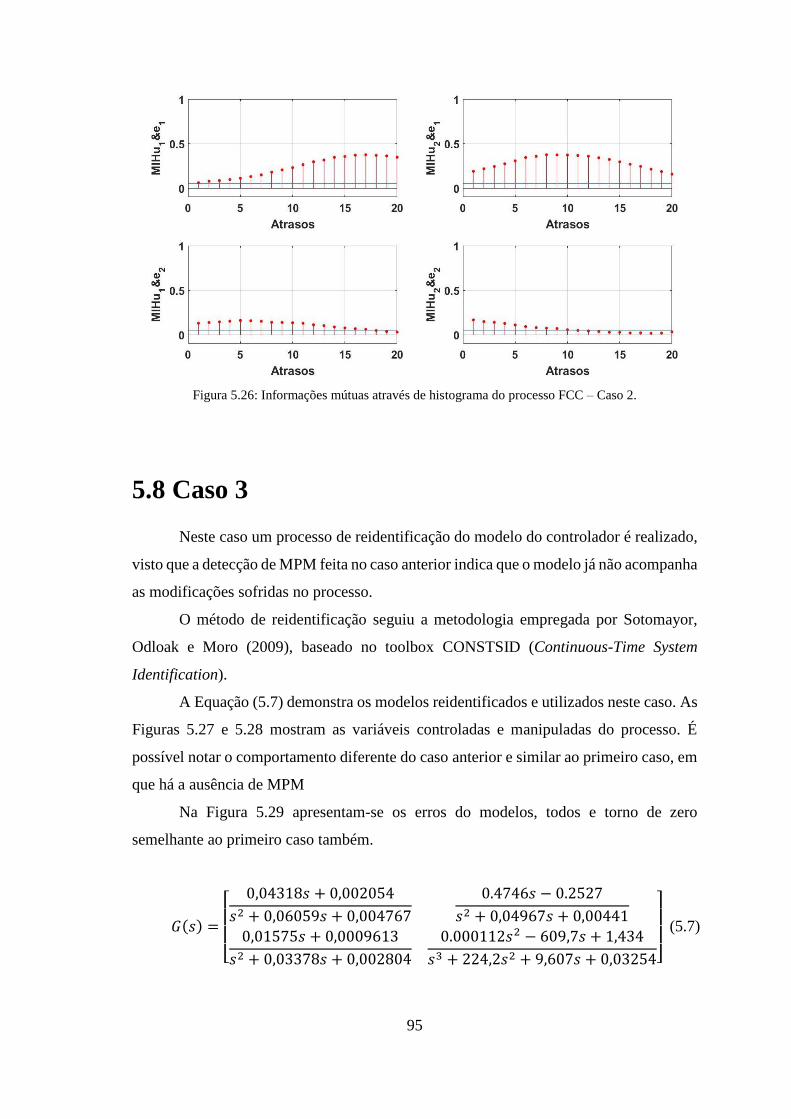
95
Figura 5.26: Informações mútuas através de histograma do processo FCC – Caso 2.
5.8 Caso 3
Neste caso um processo de reidentificação do modelo do controlador é realizado,
visto que a detecção de MPM feita no caso anterior indica que o modelo já não acompanha
as modificações sofridas no processo.
O método de reidentificação seguiu a metodologia empregada por Sotomayor,
Odloak e Moro (2009), baseado no toolbox CONSTSID (Continuous-Time System
Identification).
A Equação (5.7) demonstra os modelos reidentificados e utilizados neste caso. As
Figuras 5.27 e 5.28 mostram as variáveis controladas e manipuladas do processo. É
possível notar o comportamento diferente do caso anterior e similar ao primeiro caso, em
que há a ausência de MPM
Na Figura 5.29 apresentam-se os erros do modelos, todos e torno de zero
semelhante ao primeiro caso também.
𝐺(𝑠) =
[
0,04318𝑠 + 0,002054
𝑠2 + 0,06059𝑠 + 0,004767
0.4746𝑠 − 0.2527
𝑠2 + 0,04967𝑠 + 0,00441
0,01575𝑠 + 0,0009613
𝑠2 + 0,03378𝑠 + 0,002804
0.000112𝑠2 − 609,7𝑠 + 1,434
𝑠3 + 224,2𝑠2 + 9,607𝑠 + 0,03254]
(5.7)
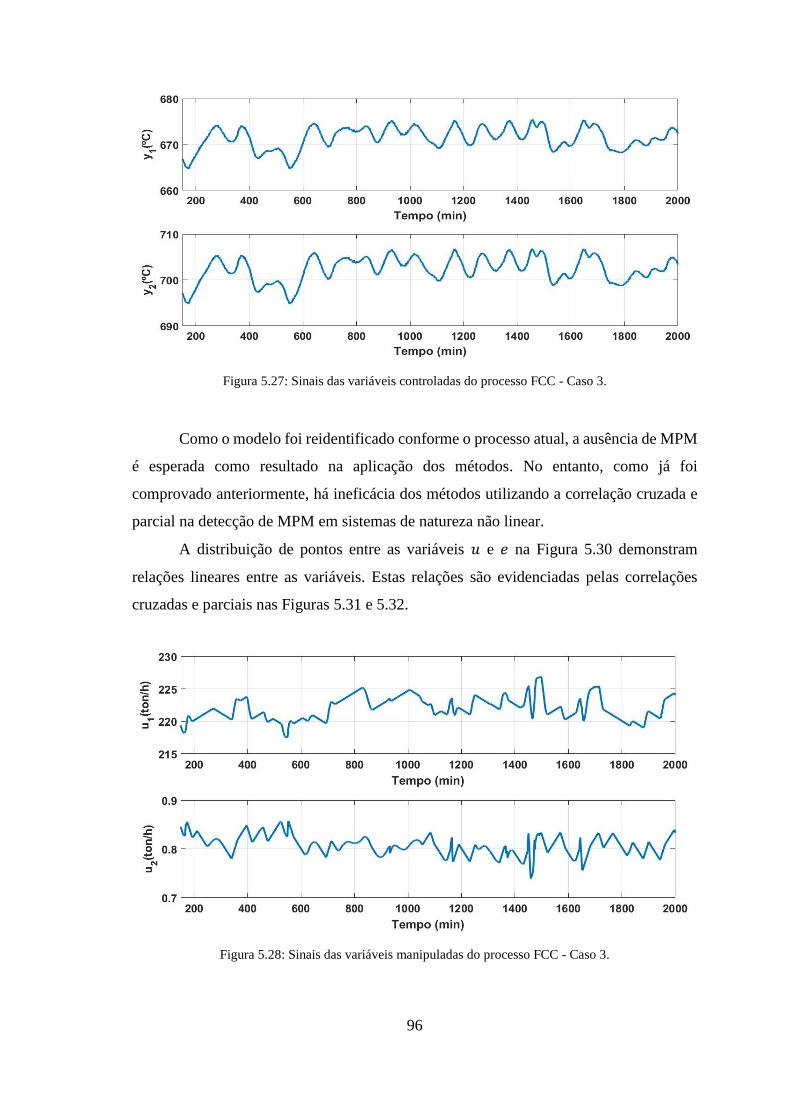
96
Figura 5.27: Sinais das variáveis controladas do processo FCC - Caso 3.
Como o modelo foi reidentificado conforme o processo atual, a ausência de MPM
é esperada como resultado na aplicação dos métodos. No entanto, como já foi
comprovado anteriormente, há ineficácia dos métodos utilizando a correlação cruzada e
parcial na detecção de MPM em sistemas de natureza não linear.
A distribuição de pontos entre as variáveis 𝑢 e 𝑒 na Figura 5.30 demonstram
relações lineares entre as variáveis. Estas relações são evidenciadas pelas correlações
cruzadas e parciais nas Figuras 5.31 e 5.32.
Figura 5.28: Sinais das variáveis manipuladas do processo FCC - Caso 3.
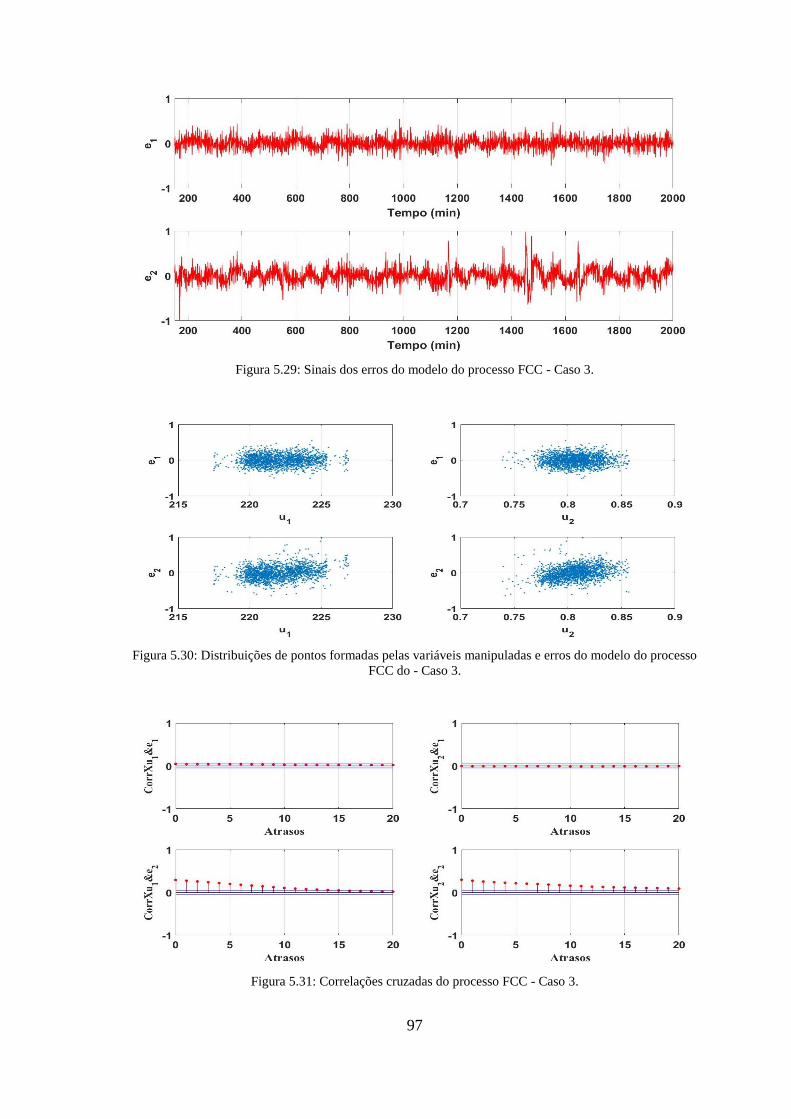
97
Figura 5.29: Sinais dos erros do modelo do processo FCC - Caso 3.
Figura 5.30: Distribuições de pontos formadas pelas variáveis manipuladas e erros do modelo do processo
FCC do - Caso 3.
Figura 5.31: Correlações cruzadas do processo FCC - Caso 3.

98
Figura 5.32: Correlações parciais do processo FCC - Caso 3.
As estimativas das PDFs são apresentadas nas Figuras 5.33, 5.34 e 5.35. Através
delas pode ser deduzido que os resultados para a detecção de MPM não indicaram MPM,
pois não ocorre a formação de relações lineares ou não lineares entre as varáveis,
semelhante ao primeiro caso deste capítulo.
As Figuras 5.36 e 5.37 mostram as informações mútuas através do KNN e do
histograma, respectivamente. Os coeficientes para os dois métodos encontram-se dentro
dos intervalos de confiança, significando a ausência de MPM.
Figura 5.33: Estimativas das PDFs das variáveis manipuladas do processo FCC – Caso 3.
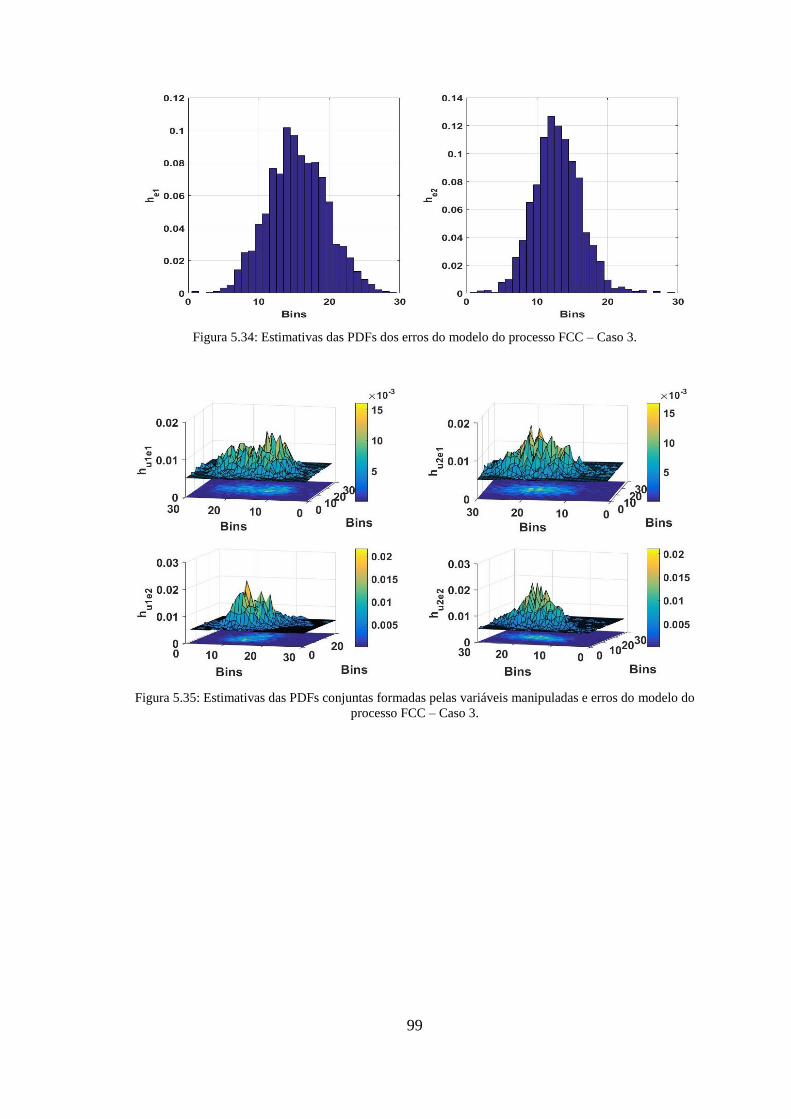
99
Figura 5.34: Estimativas das PDFs dos erros do modelo do processo FCC – Caso 3.
Figura 5.35: Estimativas das PDFs conjuntas formadas pelas variáveis manipuladas e erros do modelo do
processo FCC – Caso 3.
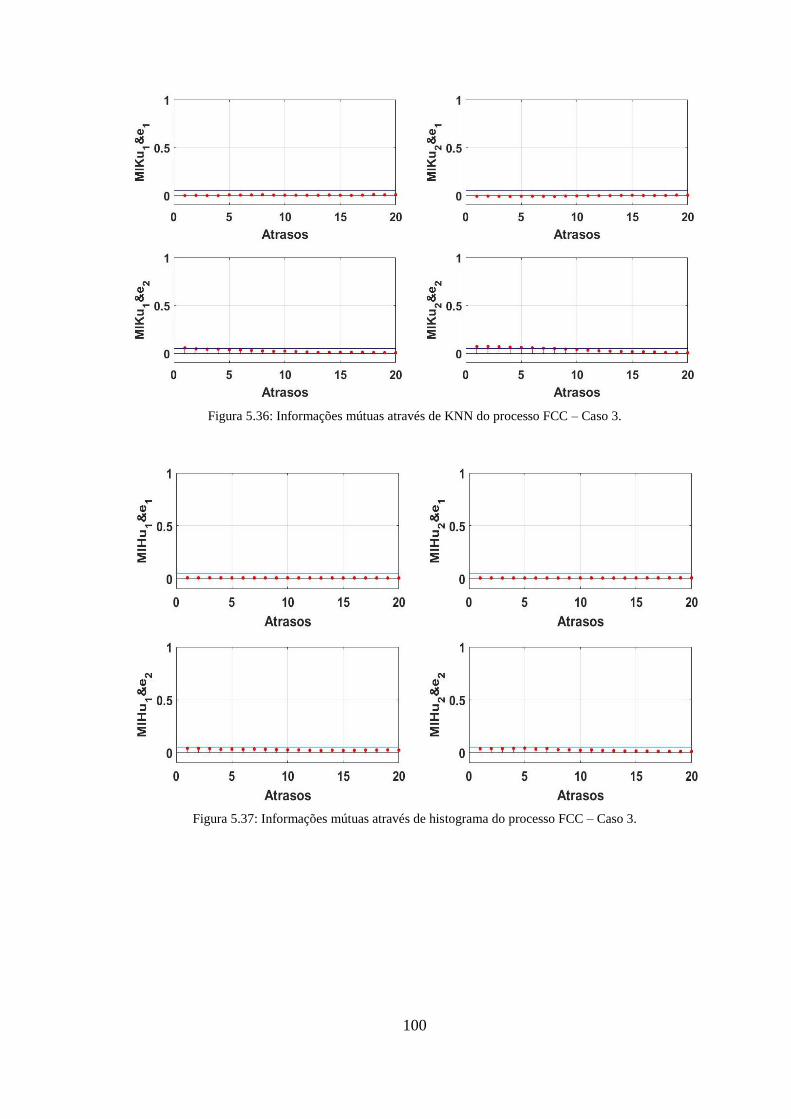
100
Figura 5.36: Informações mútuas através de KNN do processo FCC – Caso 3.
Figura 5.37: Informações mútuas através de histograma do processo FCC – Caso 3.

101
Capítulo 6
Conclusões e Recomendações de
Trabalhos Futuros
Neste trabalho quatro técnicas foram aplicadas na detecção de MPM em sistemas
de controle MPC de processos lineares e não lineares. Três destas técnicas são baseadas
em metodologias já difundidas para detecção de MPM, que são a Correlação Cruzada, a
Correlação Parcial e a Informação Mútua estimada por KNN, sendo a quarta técnica
baseada na estimação de Informação Mútua por histogramas. Estas técnicas usam níveis
e tipos de similaridades entre as variáveis manipuladas e os erros do modelo para a
realização da detecção de MPM.
Os resultados obtidos com as aplicações das técnicas foram satisfatórios e
coerentes com a literatura técnica direcionada a detecção de MPM. Nas aplicações
envolvendo as correlações cruzada e parcial em sistemas de controle MPC linear, a
detecção de MPM ocorreu de acordo com as previsões nas análises das distribuições
produzidas pelos sinais das variáveis manipuladas e erros do modelo. Ressaltando que a
correlação cruzada, uma ferramenta de aplicação simples, não atuou de forma correta com
relação a dependência entre variáveis manipuladas, detectando MPM em toda realação
de entrada e saída dos modelos.
Na utilização da correlação parcial, que mede a correlação entre duas variáveis
excluindo o efeito de uma terceira, foi possível obter resultados de detecção de MPM
mais precisos, sem que a dependência entre variáveis manipuladas interferisse de forma
acentuada na detecção do MPM. Contudo o processo de implementação da correlação
parcial mostrou-se demasiadamente oneroso, devido à necessidade da obtenção de
modelos dinâmicos com altos níveis de precisão.
Verificou-se também que as ferramentas utilizando correlação cruzada e parcial
não obtiveram resultados satisfatórios em sistemas de controle MPC não linear, pois os
resultados são dependentes dos coeficientes que são gerados através do ajuste linear.
Portanto são técnicas matemáticas voltadas a sistemas lineares.

102
Com as técnicas de detecção utilizando a MI pelo KNN e Histograma foram
obtidos resultados satisfatórios e semelhantes, tanto em sistemas de controle MPC linear
quanto não-linear. Ao serem aplicadas em sistemas lineares ficou evidenciado a mesma
característica de detecção de toda relação de entrada e saída dos modelos. A ferramenta
utilizando Histograma também se mostrou matematicamente mais simples e
computacionalmente mais rápida.
Pode ser ressaltado que os resultados obtidos neste trabalho não invalidam a
utilização das técnicas já conhecidas. É necessário então que se tenha conhecimento da
dinâmica do processo na escolha da técnica a ser utilizada de detecção do MPM.
Portanto, a partir dos resultados obtidos neste trabalho conclui-se que as técnicas
desenvolvidas para detecção de MPM em sistemas de controle MPC lineares e não
lineares obtiveram êxito dentro dos objetivos desejados, contudo, apesar de não serem
produtos prontos para aplicações em sistemas reais, oferecem soluções apropriadas e
fornecem subsídios para o desenvolvimento de implementações posteriores.
A seguir são listadas algumas perspectivas futuras deste trabalho:
• Aplicar os métodos em estruturas de controle mais complexas, envolvendo
maior número de entradas e saídas;
• Uso de técnicas de identificação não linear para obter modelos dinâmicos mais
precisos que relacionam os resíduos dos erros e as variáveis manipuladas, para
ser utilizado na correlação parcial;
• Implementação das técnicas desenvolvidas em sistemas reais.

103
Referências Bibliográficas
AGUIRRE, L. A. Introdução à identificação de sistemas - técnicas lineares e não-
lineares aplicadas a sistemas reais. 3. ed. Belo Horizonte: Editora UFMG, 2007.
BADWE, A. S. et al. Detection of model-plant mismatch in MPC applications. Journal
of Process Control, v. 19, n. 8, p. 1305–1313, 2009.
BADWE, A. S. et al. Quantifying the impact of model-plant mismatch on controller
performance. Journal of Process Control, v. 20, n. 4, p. 408–425, 2010.
BAUER, M.; CRAIG, I. K. Economic assessment of advanced process control - A survey
and framework. Journal of Process Control, v. 18, n. 1, p. 2–18, 2008.
BOTELHO, V. R. et al. Assessment of model-plant mismatch by the nominal sensitivity
function for unconstrained MPC. IFAC Proceedings Volumes (IFAC-PapersOnline),
v. 48, n. 8, p. 753–758, 2015.
CARLSSON, R. A practical approach to detection of plant model mismatch for
MPC. [s.l.] Linköpings universitet, 2010.
CHEN, G. et al. Detecting model−plant mismatch of nonlinear multivariate systems using
mutual information. Industrial and Engineering Chemistry Research, v. 52, n. 5, p.
1927–1938, 2013.
CONNER, J. S.; SEBORG, D. E. Assessing the need for process re-identification.
Industrial and Engineering Chemistry Research, v. 44, n. 8, p. 2767–2775, 2005.
COVER, T. M.; THOMAS, J. A. Elements of information theory. 2nd. ed. New Jersey,
United States: Wiley-Interscience, 2005.
DE MOOR, B.; VAN OVERSCHEE, P. Numerical algorithms for subspace state space
system identification. Trends in control: An european perspective, p. 385–422, 1995.
DE MOOR, B.; VAN OVERSCHEE, P.; FAVOREEL, W. Algorithms for subspace state
space system identification - An overview. Applied and computational control, signal
and circuits, v. 1, p. 247–311, 1999.
DESBOROUGH, L.; MILLER, R. Increasing customer value of industrial control
performance monitoring-Honeywell’s experience. AIChE symposium series, p. 169–
189, 2002.
DI RUSCIO, D. A method for identification of combined deterministic and stochastic
systems. Applications of computer aided time series modeling, p. 181–235, 1997.
FORBES, M. G. et al. Model predictive control in industry: challenges and opportunities.

104
IFAC-PapersOnLine, v. 48, n. 8, p. 531–538, 2015.
GARCIA, C. E.; MORSHEDI, A. M. Quadratic Programming Solution of Dynamic
Matrix Control (QDMC). Chemical Engineering Communications, v. 46, n. 1–3, p. 73–
87, 1986.
GOLUB, G. H.; VAN LOAN, C. F. Matrix Computations. 3. ed. Baltimore: MD: Johns
Hopkins University Press, 1996.
GUBNER, J. A. Probability and Random Processes for Electrical and Computer
Engineers. 1. ed. New York: Cambridge University Press, 2006.
GUDI, R. D.; RAWLINGS, J. B. Identification for Decentralized Model Predictive
Control. AIChE Journal, v. 52, n. 6, p. 2198–2210, 2006.
GUSTAFSSON, T. System identification using subspace-based instrumental variable
methods. IFAC SYMPOSIUM ON SYSTEM IDENTIFICATION, SYSID’97, 11th,
p. 1119–1124, 1997.
HARRISON, C. A.; QIN, S. J. Discriminating between disturbance and process model
mismatch in model predictive control. Journal of Process Control, v. 19, n. 10, p. 1610–
1616, 2009.
HENSON, M. A. Nonlinear model predictive control: current status and future directions.
Computers & Chemical Engineering, v. 23, n. 2, p. 187–202, 1998.
HO, B. L.; KALMAN, R. E. Effective construction of linear state-variable models from
input/output functions. Regelungstechnik, v. 14, n. 12, p. 545–548, 1966.
HUANG, B.; MALHOTRA, A.; TAMAYO, E. C. Model predictive control relevant
identification and validation. Chemical Engineering Science, v. 58, n. 11, p. 2389–2401,
2003.
HUANG, B.; TAMAYO, E. C. Model validation for industrial model predictive control
systems. Chemical Engineering Science, v. 55, n. 12, p. 2315–2327, 2000.
IQBAL, N. H. I.; YUSOFF, N.; TUFA, L. D. Comparison betweeen ARX and FIR
decorrelation models in detecting model-plant mismatch.pdf. Journal of Applied
Sciences, 2014.
JI, G.; ZHANG, K.; ZHU, Y. A method of MPC model error detection. Journal of
Process Control, v. 22, n. 3, p. 635–642, 2012.
JIANG, H.; LI, W.; SHAH, S. L. Detection and isolation of model-plant mismatch for
multivariate dynamic systems. IFAC Proceedings Volumes, v. 39, n. 13, p. 1396–1401,
2006.
KHAN, S. et al. Relative performance of mutual information estimation methods for
quantifying the dependence among short and noisy data. Physical Review E - Statistical,
Nonlinear, and Soft Matter Physics, v. 76, n. 2, p. 1–15, 2007.

105
KRASKOV, A.; STÖGBAUER, H.; GRASSBERGER, P. Estimating mutual
information. Physical Review E - Statistical, Nonlinear, and Soft Matter Physics, v.
69, n. 6 2, p. 1–16, 2004.
LARIMORE, W. E. System Identification, Reduced-Order Filtering and Modeling via
Canonical Variate Analysis. American Control Conference, 1983.
LARIMORE, W. E. Canonical variate analysis in identification, filtering, and adaptive
control. Proceedings of the IEEE Conference on Decision and Control, v. 2, p. 596–
604, 1990.
LAUTENSCHLAGER MORO, L. F.; ODLOAK, D. Constrained multivariable control
of fluid catalytic cracking converters. Journal of Process Control, v. 5, n. 1, p. 29–39,
1995.
LIANG, T. et al. A scheme of model invalidation assessment for multivariable dynamic
matrix controllers. 2008 Fifth International Conference on Fuzzy Systems and
Knowledge Discovery, v. 2, p. 230–234, 2008.
LOEFF, M. V. Deteção de divergências entre o processo e o modelo utilizado no
controlador preditivo. [s.l.] Unversidade de São Paulo, 2014.
LUNA, I.; BALLINI, R.; SOARES, S. Técnica de identificação de modelos lineares e
não lineares de séries temporais. Revista Controle & Automação, v. 17, n. 3, p. 245–
256, 2006.
MILLER, G. A. Note on the bias of information estimates. Information Theory in
Psychology: Problems and Methods, v. 2, p. 95–100, 1955.
MITRA, S. K. Digital Signal Processing - Computer Based Approach. 2. ed. Santa
Barbara: McGraw-Hill, 2001. v. 128
MOONEN, M. et al. On- and off-line identification of linear state-space models.
International Journal of Control, v. 49, n. 1, p. 219–232, 1989.
MORARI, M.; LEE, J. H. Model predictive control: past, present and future. Computers
& Chemical Engineering, v. 23, n. 4, p. 667–682, 1999.
MORARI, M.; ZAFIRIOU, E. Robust Process Control.pdf. Englewood Cliffs: Prentice-
Hall, 1989.
NAFSUN, A. I.; YUSOFF, N. Effect of model-plant mismatch on MPC controller
performance. Journal of Applied Sciences, v. 21, n. 11, p. 3579–3585, 2011.
NAIDOO, Y. T. Practical on-line model validation for model predictive controllers
(MPC). [s.l.] University of KwaZulu-Natal, 2010.
OTTERSTEN, B.; VIBERG, M. A subspace based instrumental variable method for
state-space system identification. IFAC SYMPOSIUM ON SYSTEM

106
IDENTIFICATION, SYSID’94, 10th, v. 2, p. 139–144, 1994.
OVERSCHEE, V.; MOOR, B. DE. N4SID: Subspace algorithm for the identification of
combined deterministic-stochastic systems. Automatica (Special Issue on Statistical
Signal Processing and Control), v. 30, n. 1, p. 75–93, 1994.
PAPANA, A.; KUGIUMTZIS, D. Evaluation of Mutual Information Estimators for Time
Series. International Journal of Bifurcation and Chaos, v. 19, n. 12, p. 4197–4215,
2009.
PETERNELL, K.; SCHERRER, W.; DEISTLER, M. Statistical analysis of novel
subspace identification methods. Signal Processing, v. 52, n. 2, p. 161–177, 1996.
PLUCENIO, A. et al. Controle Preditivo Não Linear na indústria do petróleo e gás. IV
PDPETRO Congresso Brasileiro de P&D em PETROLEO e GAS, p. 11, 2007.
QIN, J.; BADGWELL, T. A survey of industrial model predictive control technology.
Control Engineering Practice, v. 11, n. 7, p. 733–764, 2003.
QIN, S. J.; BADGWELL, T. A. An Overview of Nonlinear Model Predictive Control
Applications. Progress in Systems and Control Theory, v. 26, p. 24, 2000.
RICHALET, J. et al. Model predictive heuristic control. Automatica, v. 14, n. 5, p. 413–
428, 1978.
ROTAVA, O.; ZANIN, A. C. Multivariable control and real-time optimization – an
industrial practical view. Hydrocarbon Processing, v. 84, n. 6, p. 61–71, 2005.
SEBORG, D. E.; THOMAS, F. E.; MELLICHAMP, D. A. Process Dynamics and
Control.pdf. 2. ed. Hoboken: John Wiley & Sons, Inc., 2004.
SILVA, D. G. et al. An Introduction to Information Theoretic Learning, Part I:
Foundations. Journal of Communication and Information Systems, v. 31, n. April, p.
68–79, 2015.
SOTOMAYOR, O. A. Z. Modelagem, identificação e controle de sistemas de
tratamento de lodo ativado com remoção de nitrogênio. [s.l.] Universidade de São
Paulo, 2002.
SOTOMAYOR, O. A. Z.; ODLOAK, D.; MORO, L. F. L. Closed-loop model re-
identification of processes under MPC with zone control. Control Engineering Practice,
v. 17, n. 5, p. 551–563, 2009.
SOTOMAYOR, O. A. Z.; PARK, S. W.; GARCIA, C. Multivariable identification of an
activated sludge process with subspace-based algorithms. Control Engineering
Practice, v. 11, n. 8, p. 961–969, 2003.
STANFELJ, N.; MARLIN, T. E.; MACGREGOR, J. F. Monitoring and diagnosing
process control performance: the single-loop case. Industrial & Engineering Chemistry
Research, v. 32, n. 2, p. 301–314, 1993.

107
TORO, L. A. A. Strategies with guarantee of stability for the integration of Model
Predictive Control and Real Time Optimization. [s.l.] Universidade de São Paulo,
2012.
TSAI, Y. et al. A novel slgorithm for model-plant mismatch detection for model
predictive controllers. IFAC-PapersOnLine, v. 48, n. 8, p. 746–752, 2015.
TUFA, L. D.; KA, C. Z. Effect of model plant mismatch on MPC performance and
mismatch Threshold determination. Procedia Engineering, v. 148, p. 1008–1014, 2016.
UDDIN, F. et al. Comparison of ARX and ARMAX Decorrelation Models for Detecting
Model-Plant Mismatch. Procedia Engineering, v. 148, p. 985–991, 2016.
VAN OVERSCHEE, P.; DE MOOR, B. Subspace Identification for Linear System:
Theory - Implementation - Applications. Leuven, Belgium: Dordrecht: Kluwer
Academic Publishers, 1996. v. 2008
VERHAEGEN, M.; DEPRETTERE, E. Subspace model identification. Algorithms and
parallel VLSI architectures, v. II, 1991.
VERHAEGEN, M.; DEWILDE, P. Subspace model identification Part 1. The output-
error state-space model identification class of algorithms. International Journal of
Control, v. 56, n. March 2015, p. 1187–1210, 1992.
VIBERG, M. Subspace methods in system identification. IFAC SYMPOSIUM ON
SYSTEM IDENTIFICATION, SYSID’94, 10th., v. 1, p. 1–12, 1994.
VIBERG, M. Subspace-based methods for the identification of linear time-invariant
systems. Automatica, v. 31, n. 12, p. 1835–1851, 1995.
VIBERG, M. Subspace-based state-space system identification. Circuits, Systems, and
Signal Processing, v. 21, n. 1, p. 23–37, 2002.
WANG, H.; XIE, L.; SONG, Z. A review for model plant mismatch measures in process
monitoring. Chinese Journal of Chemical Engineering, v. 20, n. 6, p. 1039–1046, 2012.
WEBBER, J. R.; GUPTA, Y. P. A closed-loop cross-correlation method for detecting
model mismatch in MIMO model-based controllers. ISA Transactions, v. 47, n. 4, p.
395–400, 2008.
WOOD, R. K.; BERRY, M. W. Terminal composition control of a binary distillation
column. Chemical Engineering Science, v. 28, n. 9, p. 1707–1717, 1973.
YERRAMILLI, S.; TANGIRALA, A. K. Detection and diagnosis of model-plant
mismatch in MIMO systems using plant-model ratio. IFAC-PapersOnLine, v. 49, n. 1,
p. 266–271, 2016.
YING, C. M.; VOORAKARANAM, S.; JOSEPH, B. Analysis and performance of the
LP-MPC and QP-MPC cascade control system. Proceedings of the American Control
Conference, v. 2, n. 7, p. 806–810, 1998.

108
YOUSEFI, M. et al. Detecting model-plant mismatch without external excitation.
Proceedings of the American Control Conference, p. 4976–4981, 2015.
ZANIN, A. C.; TVRZSKA DE GOUVEA, M.; ODLOAK, D. Integrating real-time
optimization into the model predictive controller of the FCC system. Control
Engineering Practice, v. 10, n. 8, p. 819–831, 2002.

109
Apêndice A
Identificação por Subespaços
A.1 Introdução
Os métodos de identificação por subespaços estão intimamente relacionados com
a teoria de realização. Uma vez que se busca, a partir de um banco de dados de variáveis
de entrada 𝑈 e um banco de dados de variáveis de resposta 𝑌 estabelecer um modelo,
ainda hoje linear, pode ser considerado de fato, uma implementação computacional da
teoria de realização, e, portanto, muito ligado a balanceamento de realizações.
Tremenda quantidade de trabalhos foram realizados em identificação caixa-preta
de entrada-saída, baseados em métodos de predição de erros (PEM). Pode ser tentado
fazer uma identificação PEM e posteriormente aplicar a teoria de realização no modelo
obtido, mas é instintivo que uma identificação direta do modelo de espaço de estado é
superior.
PEM geralmente resulta essencialmente em um problema de otimização não-
linear de estimação de parâmetros, mesmo o modelo sendo linear. O método de
subespaços utiliza diretamente os métodos robustos de álgebra linear.
PEM trata a determinação da ordem do modelo como um problema preliminar a
ser resolvido, e geralmente se trata de um desafio para os praticantes. O método de
subespaço trata conjuntamente o problema adicional de identificação de estrutura. O
modelo resultante será necessariamente observável e controlável. Mas em termos teóricos
de ordem mínima, e em termos práticos com uma flexibilidade para determinar a ordem
da variável de estados. Porém nota-se que a determinação de estrutura é de um modo geral
melhor tratável do que em métodos de predição de erros.
Em se tratando de método computacional, está muito ligado com a teoria de
fatoração de matrizes, decomposição em valores singulares, projeções ortogonais e
oblíquos, e as matrizes de Hankel e de Toeplitz.

110
Em termos de resultados e de aplicabilidade, este método se aproxima muito de
técnicas de PLS – modelos de estruturas latentes parciais, desenvolvidos no ramo de
química instrumental, quando este é aplicado para modelos dinâmicos.
Pela sua natureza de ferramentas de álgebra linear, existe uma convergência de
foco muito grande entre as técnicas de SID – identificação por subespaços e TLS –
mínimos quadrados totais.
Finalmente, é suficientemente curioso descobrir que na intersecção de planos
entre o banco de dados de entrada 𝑈 e o banco de dados de saída 𝑌 está o banco de estado
𝑋, demonstrado matematicamente!
Todos estes aspectos não serão apontados detalhadamente. No presente texto será
apresentado a visão da teoria de identificação por subespaços. Mas quem tiver
familiaridade com algum destes aspectos citados acima: teoria de realização, método de
predição de erros, estrutura e homeomorfismo de sistemas lineares, álgebra linear,
fatoração QR, LQ, SVD, projeções de mapas lineares, técnicas PLS e TLS, e outros,
reconhecerá em cada um deles estas ligações.
A.2 Os métodos de identificação por subespaços
Os métodos de identificação por subespaços são uma classe de algoritmos cuja
principal característica é a aproximação de subespaços gerados pelos espaços linha das
matrizes de Hankel em blocos, de dados de entrada/saída, para calcular um modelo
confiável em espaço de estado discreto da seguinte forma:
𝑥(𝑘 + 1) = 𝐴𝑥(𝑘) + 𝐵𝑢(𝑘) + 𝑤(𝑘)
𝑦(𝑘) = 𝐶𝑥(𝑘) + 𝐷𝑢(𝑘) + 𝑣(𝑘) (A.1)
com
𝐸 [(𝑤𝑝
𝑣𝑝) (𝑤𝑝
𝑇 𝑣𝑝𝑇)] = (
𝑄 𝑆
𝑆𝑇 𝑅) 𝛿𝑝𝑞 ≥ 0 (A.2)
Onde 𝑥 ∈ ℜ𝑛×𝑚, 𝑢 ∈ ℜ𝑚×1 e 𝑦 ∈ ℜ𝑙×1 são o vetor de estados, o vetor de entradas e o
vetor de saídas do processo, respectivamente. 𝐴 ∈ ℜ𝑛×𝑛 é a matriz (de transição de

111
estados) do sistema, 𝐵 ∈ ℜ𝑛×𝑚 é a matriz de entrada, 𝐶 ∈ ℜ𝑙×𝑛 é a matriz de saída e 𝐷 ∈
ℜ𝑙×𝑚 é a matriz de entrada e saída direta. 𝑤 ∈ ℜ𝑙×𝑛 é o ruído do processo e 𝑣 ∈ ℜ𝑙×1 é
o ruído de medição. Estes sinais são assumidos como vetores de sequencias não
mensuráveis de ruído branco estacionário com média zero e não correlacionados com as
entradas 𝑢. 𝑄 ∈ ℜ𝑛×𝑛, 𝑆 ∈ ℜ𝑛×1 e 𝑅 ∈ ℜ𝑙×1 são matrizes de covariância das sequencias
de ruído 𝑤 e 𝑣. 𝐸 denota o operador esperança, 𝛿𝑝𝑞 o delta de Kronecker e 𝑘 p tempo
discreto. Na Equação (A.1) assume-se que o sistema seja assintoticamente estável, o par
(𝐴,𝐵) é controlável e o par (𝐴,𝐶) é observável.
É comum, na prática, distinguir três situações possíveis, dependendo das entradas
atuando no sistema da Equação (5.1):
1. O caso puramente determinístico (𝑤 = 𝑣 = 0);
2. O caso puramente estocástico (𝑢 = 0);
3. O caso combinado determinístico-estocástico.
Os métodos baseados em subespaços para identificação de modelos em espaço de
estados têm suas origens na realização em espaço de estados, conforme desenvolvido por
Ho e Kalman (1966). Estas técnicas determinam um modelo em espaço de estados a partir
de uma resposta ao impulso, o que recebeu uma enorme atenção na área de processamento
de sinais nos anos setenta. Na área de identificação de sistemas, onde usualmente tem-se
dados de entrada/saída ao invés de uma resposta ao impulso, os métodos se subespaços
foram desenvolvidos no final dos anos oitenta.
O termo “identificação por subespaços” foi incialmente introduzido por
Verhaegen e Deprettere (1991) .Estes incluem uma versão anterior de algoritmos por
subespaços apresentado por Moonen et al. (1989). Atualmente, existem métodos de
identificação por subespaços e todos têm alcançado um alto nível de desenvolvimento.
Entre eles tem-se: CVA (Canonical Variate Analysis) por Larimore (1983, 1990),
MOESP (Multivariable Output-Error State-Space Model Indentification) por Verhaegen
e Dewilde (1992), basic-4SID e IV-4SID (Instrumental Variable Subspace-Based State-
Space System Identification) por Ottersten e Viberg (1994), Gustafsson (1997) e Viberg
(2002), N4SID (Numerical Algorithms for Subspace State Space System Identification)
por Overschee e Moor (1994,1996), CCA (Canonical Correlation Analysis) por Peternell,
Scherrer e Deistler (1996) e DSR (Deterministic and Stochastic Subspace System

112
Identification and Realization) por Di Ruscio (1997). A análise de consistência dos
métodos de identificação por subespaços tem sido mostrada em vários trabalhos. Uma
visão geral do estado da arte é apresentada em Viberg (1994, 1995), De Moor e Van
Overschee (1995) e De Moor e Van Overschee e Favoreel (1999).
A maior vantagem destes métodos é que somente precisam de dados de
entrada/saída e muito pouco conhecimento sobre o sistema a ser identificado. Além disso,
estes métodos estão baseados na teoria de sistemas, geometria e operações
numericamente robustas e não-iterativas da álgebra linear, tais como fatoração QR e LQ
e decomposição em valores singulares (SVD) e suas generalizações, para as quais boas
ferramentas numéricas são bem conhecidas (GOLUB; VAN LOAN, 1996). Uma
desvantagem destes algoritmos é que a percepção física do processo, no modelo obtido,
é perdida, o que é uma característica dos modelos caixa-preta. Por exemplo, os estados
são “artificiais” e não é possível entender como uma variável do processo, que não está
diretamente incluída no modelo, afeta o processo. Além disto, uma grande quantidade de
dados é necessária para obter modelos precisos. De fato, gerar e coletar dados de alguns
processos pode ser demasiado caro.
A.3 Exemplo Prático
Como forma de demonstrar de que modo foi utilizada a teoria de identificação por
subespaços, previamente introduzida acima, é utilizado o mesmo processo da coluna de
destilação binária (Figura 4.1) de Wood e Berry (1973), mais especificamente o Caso 3,
em que é incluído MPM através da alteração de 20% no valor do ganho da função de
transferência 𝐺22.
Com base neste Caso 3 são coletadas as variáveis manipuladas e os erros do
modelo, livres dos distúrbios, conforme a metodologia proposta por Badwe et al. (2009)
apresentada na seção 3.2.1, para a detecção de MPM através da correlação parcial. Neste
caso as variáveis de entrada e saída para a identificação dos modelos 𝑮𝑢𝑖 e 𝑮𝑒𝑗
são
mostradas na Tabela A.1. A identificação destes modelos dinâmicos faz-se necessário
como parte do processo para encontrar os resíduos 휀�̂�𝑖 e 휀�̂�𝑗
. Os resíduos são responsáveis
pela análise de dependência entre as variáveis em análise e encontrados pela máxima
aproximação entre �̂�𝑖𝑟 ou 𝑒𝑗 e �̃�𝒊
𝒓, dado pelo modelo 𝑮𝑢𝑖 ou 𝑮𝑒𝑗
.

113
Tabela A.1: Variáveis de entrada e saída utilizadas para a identificação dos modelos explícitos.
Entradas Modelos Saídas
𝑢2 𝑮𝑢1 𝑢1
𝑢1 𝑮𝑢2 𝑢2
𝑢2 𝑮𝑒1 𝑒1
𝑢1 𝑮𝑒2 𝑒2
Considerando que o objetivo principal é demonstrar a identificação de modelos
dinâmicos encontrados através de subespaços para a correlação parcial, e não a detecção
de MPM, será identificado apenas o modelo 𝐺𝑢2, o mesmo procedimento é válido para a
identificação de outros modelos e processos.
Desta maneira é necessário escolher uma ordem (Figura A.1) para o modelo de
maneira que possa aproximar o máximo as variáveis �̂�𝑖𝑟 ou 𝑒𝑗 e �̃�𝒊
𝒓.
Figura A.1: Valores singulares para a escolha do modelo do processo da coluna de destilação de Wood e
Berry – Caso 3.
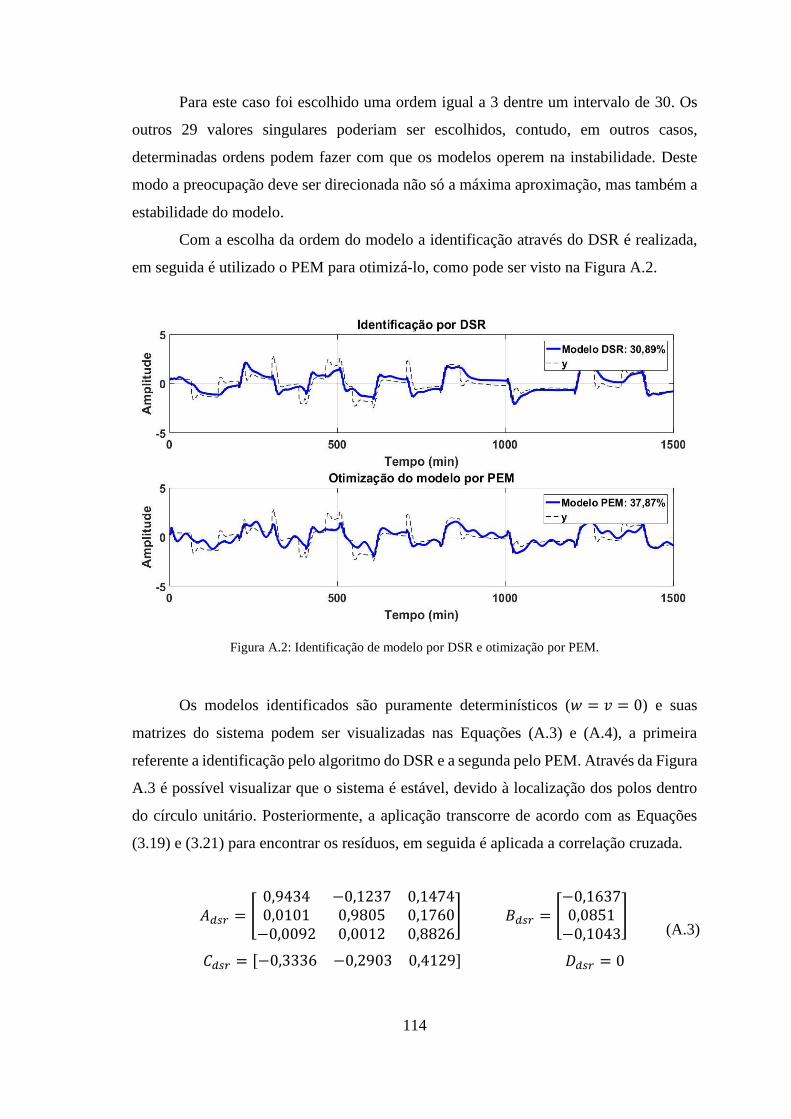
114
Para este caso foi escolhido uma ordem igual a 3 dentre um intervalo de 30. Os
outros 29 valores singulares poderiam ser escolhidos, contudo, em outros casos,
determinadas ordens podem fazer com que os modelos operem na instabilidade. Deste
modo a preocupação deve ser direcionada não só a máxima aproximação, mas também a
estabilidade do modelo.
Com a escolha da ordem do modelo a identificação através do DSR é realizada,
em seguida é utilizado o PEM para otimizá-lo, como pode ser visto na Figura A.2.
Figura A.2: Identificação de modelo por DSR e otimização por PEM.
Os modelos identificados são puramente determinísticos (𝑤 = 𝑣 = 0) e suas
matrizes do sistema podem ser visualizadas nas Equações (A.3) e (A.4), a primeira
referente a identificação pelo algoritmo do DSR e a segunda pelo PEM. Através da Figura
A.3 é possível visualizar que o sistema é estável, devido à localização dos polos dentro
do círculo unitário. Posteriormente, a aplicação transcorre de acordo com as Equações
(3.19) e (3.21) para encontrar os resíduos, em seguida é aplicada a correlação cruzada.
𝐴𝑑𝑠𝑟 = [
0,9434 −0,1237 0,14740,0101 0,9805 0,1760
−0,0092 0,0012 0,8826] 𝐵𝑑𝑠𝑟 = [
−0,16370,0851
−0,1043]
𝐶𝑑𝑠𝑟 = [−0,3336 −0,2903 0,4129] 𝐷𝑑𝑠𝑟 = 0
(A.3)

115
𝐴𝑃𝐸𝑀 = [
0,8881 −0,1974 0,2462−0,0453 0,7956 0,33590,0563 0,2723 0,5067
] 𝐵𝑃𝐸𝑀 = [−0,10470,2474
−0.4475]
𝐶𝑃𝐸𝑀 = [−0,3882 −0,3730 0,5023] 𝐷𝑃𝐸𝑀 = 0
(A.4)
Figura A.3: Localização dos polos do modelo reidentificado.


















