







Línguas
Páginas
Legal


Técnicas de Amostragem
É a parte da Teoria Estatística que define os procedimentos para os
planejamentos amostrais e as técnicas de estimação utilizadas.
As técnicas de amostragem, tal como o planejamento amostral, são
amplamente utilizados nas pesquisas científicas e de opinião para
se conhecer alguma característica da população.
Nos planejamentos amostrais, a coleta dos dados deve ser
realizada observando-se uma metodologia adequada para que os
resultados possam ser extrapolados para a população como um
todo.
Esse processo de extensão dos resultados para a população é o
que, na estatística, chamamos de INFERÊNCIA.

I- Conceitos Básicos
i) População objetivo e população amostral:
População objetivo: também chamada de população alvo, é
formada pelo conjunto de indivíduos (ou itens) que queremos
abranger em nosso estudo e para os quais desejamos que as
conclusões da pesquisa (inferências) sejam válidas.
Em alguns estudos a população não pode ser representada por um
“ente físico”. Nesses casos a estatística define a população pelo
conjunto de todos os valores possíveis de serem observados.
A definição da população depende dos objetivos da pesquisa.
População amostral: ocorre, entretanto, que nem todos os
indivíduos, ou elementos, da população podem ser observados.
Desta forma, define-se como população amostral ou acessível ao
conjunto de indivíduos que serão efetivamente observados.
“Os indivíduos que constituem a população têm, portanto, pelo menos uma característica em comum”.
Exemplos:
1) Um estudo foi realizado entre os professores da UFSCar para
saber as suas opiniões a respeito das decisões do Reitor.
População objetivo: a população objetivo é formada por todos os
professores da UFSCar.
População amostral: deve ser definida excluindo-se os professores
aposentados, afastados por doença ou capacitação, que ocupem
cargo junto a Reitoria, etc...

É importante destacar que nem sempre é fácil diferenciar as duas
populações, conforme vemos no exemplo a seguir:
2) Estudo realizado na cidade de São Carlos para avaliar como os
moradores avaliam o transporte público.
População objetivo: moradores da cidade de São Carlos (que
utilizam o transporte público).
População amostral: moradores da cidade de São Carlos que
utilizam o transporte público.
muitas vezes, especialmente em experimentos controlados, a
população objetivo população amostral.
ii) Amostra: é a parcela da população amostral efetivamente
selecionada para a realização do estudo, segundo um processo
de seleção adequado.
iii) Unidade amostral: é o indivíduo (ou elemento) da população
amostral que severa ser selecionado para participar da amostra.
As unidades amostrais podem ser os próprios elementos da
população amostral sobre os quais as medidas de interesse
serão observadas, ou, podem ser formadas por grupos de
elementos, compondo o que será chamado de conglomerado.
Conglomerados podem ser formados por:
quarteirões;
ruas (face dos quarteirões);
departamentos;

prateleiras;
lotes de produtos;
etc...
iv) Parâmetro: é uma característica fixa e desconhecida da
população a qual se tem interesse em estudar.
Os parâmetros representam quantidades numéricas que podem
ser interpretadas pelo pesquisador, como por exemplo: média;
proporção; variação; taxa de crescimento; etc...
Exemplos:
tempo até a cura de pacientes submetidos a um novo tratamento
ou a uma nova droga;
percentual de intenção de votos para um candidato numa
pesquisa eleitoral;
Proporção de crianças com a cobertura vacinal completa (estudo
PI);
número de latrocínios em Minas Gerais, por região
administrativa;
medida do desempenho escolar de crianças expostas à violência
doméstica do pai contra a mãe.
v) Estimativa: valor calculado a partir dos dados obtidos pela
amostra para se estimar o valor desconhecido do parâmetro.
Exemplos: média amostral, proporção amostral, variância amostral,
etc...
vi) Sistema de referência: é uma listagem completa de todas as
unidades da população amostral (aptas a serem selecionadas na
amostra);

vii) Amostragem probabilística: é a pesquisa por amostragem
realizada segundo critérios bem definidos da teoria estatística
das probabilidades.
Na amostragem probabilística todas as unidades da população
amostral devem ter a mesma probabilidade de serem
selecionadas.
Por que fazer amostragem ao invés de um censo?
Vantagens da pesquisa por amostragem em relação ao censo:
a) é mais barata;
b) é mais rápida;
c) é mais fácil de ser controlada por envolver operações menores.
Desvantagens da pesquisa por amostragem em relação ao censo:
a) o censo pode ser mais vantajoso quando a população é pequena
e/ou as informações são de fácil obtenção.
b) os resultados da pesquisa por amostragem carregam erro;
c) se a população for muito heterogênea o erro pode ser muito
grande (e a precisão muita baixa), sendo necessário uma
amostra muito grande.

viii) Dados
São os resultados observados para uma, ou mais, variáveis. Podem
ser secundários ou primários:
Dados secundários: podem ser obtidos de algum banco de dados
já existente, como por exemplo, IBGE, SEADE, fichas de cadastro
de clientes, em publicações (artigos, livros, revistas), etc...
Dados primários: necessitam ser coletados da população
amostral. São obtidos pela aplicação de um instrumento de coleta,
que será chamado de questionário.
Após serem coletados, os dados devem ser codificados e organizados para facilitar a tabulação e análise.
É importante, nesta fase, um sistema de processamento que
seja consistente.
a) Elaboração e aplicação do questionário
Na coleta efetuada com a aplicação de questionários, a elaboração
dos mesmos deve ser bastante criteriosa para evitar mal-entendidos
e ambiguidades.
Os objetivos da pesquisa devem estar bem definidos para que as
características de interesse (variáveis) sejam adequadamente
escolhidas.

Cuidados a serem seguidos na montagem do questionário
ter bem claro as variáveis a serem observadas;
estudar as formas de como essas variáveis devem ser medidas;
as formas e instrumentos de medição devem ser bem claros;
agrupar as perguntas por variáveis similares/complementares;
as perguntas devem ser simples e objetivas e devem estar numa
linguagem apropriada ao perfil dos respondentes;
os itens de resposta devem ser planejados de maneira a evitar
respostas conduzidas ou viciadas;
o questionário não deve ser longo e nem conter perguntas fora
do contexto.
b) Formas de aplicação do questionário
Entrevistas pessoais: aplicado por entrevistadores bem
treinados que tomam nota das respostas.
Prós: a taxa de “não resposta” é baixa.
Contras: requerem entrevistadores treinados, o que “eleva o
custo” da pesquisa.
Questionário auto-aplicativo: é respondido pelo próprio
entrevistado, que assinala as respostas.
Os questionários podem ser enviados pelo correio, em revistas
ou jornais, deixados para pegar depois, etc...
Nesses casos os questionários devem encorajar a participação,
podendo até oferecer prêmios.
Prós: não requerem entrevistadores, tornando a pesquisa mais
barata.
Contras: alta taxa de “não resposta”;
vícios em função de respostas por grupos de
interesse.

Entrevistas por telefone: o questionário é aplicado pelo
telefone.
Prós: requerem entrevistadores, mas é mais barata, pois não
incluí gastos com locomoção.
Contras: os entrevistadores devem ser bem treinados para
convencerem o indivíduo a participar;
a população alvo deve ser bem representada pelos
proprietários de telefone;
as entrevistas devem ser curtas e objetivas.
c) Alguns cuidados a serem tomados na aplicação do
questionário
i) Anonimato dos entrevistados em pesquisas que envolvam
aspectos íntimos ou temas polêmicos;
ii) Treinamento dos entrevistadores;
iii) Checagem de alguns questionários escolhidos aleatoriamente,
por parte de um supervisor;
iv) Os entrevistadores devem portar identificação (crachás),
estarem apresentáveis e serem amáveis. Se forem escalados em
duplas, devem formar um casal para passar mais confiança;
v) É aconselhável, alguns dias antes da pesquisa, fazer uma
divulgação através dos meios de comunicação.
vi) Antes de se aplicar o questionário é importante a realização de
uma pré-amostra, ou pré-teste, para se verificar se o
questionário está bom e corrigir possíveis falhas. A pré-
amostra deve ser aplicada num grupo reduzido de indivíduos
da população em estudo.

II- Planos de Amostragem
Para a definição do plano amostral devem-se ter bem definidos:
i) Unidade amostral: indivíduos ou grupos de indivíduos
(conglomerados);
ii) Sistema de referência: lista completa das unidades amostrais.
iii) N = tamanho da população, é definido pelo número de
indivíduos da população amostral;
iv) n = tamanho da amostra, definido pelo número de indivíduos
selecionados na amostra.
n < N
Fatores que interferem na escolha do Plano Amostral:
Tamanho da população N;
Custo;
Heterogeneidade da população;
Os elementos da amostra devem ser selecionados da população
amostral segundo alguma forma de sorteio.

Os Planos de Amostragem mais comuns são:
A) Amostragem Aleatória Simples (A.A.S.):
Na A.A.S., a amostra de tamanho n é selecionada ao acaso dentre
os N elementos da população amostral.
Procedimento de sorteio:
i) Na A.A.S. a probabilidade de qualquer indivíduo, ou elemento,
da população fazer parte da amostra é igual a N
n.
ii) Um indivíduo é selecionado ao acaso dentre os N possíveis;
iii) O segundo indivíduo é selecionado ao acaso dentre os (N – 1)
restantes...
iv) . . . e assim por diante, até que todos os n indivíduos sejam
sorteados.
Esse procedimento tem a característica de ser “sem reposição”,
significando que: cada indivíduo aparece uma única vez na
amostra.
Obs:
1) Procedimentos “com reposição” são definidos tais que o
indivíduo pode aparecer mais de uma vez na amostra, porém são
poucos comuns na prática;
2) Quando o tamanho da população for muito grande, os dois
procedimentos de sorteio (sem e com reposição) são
equivalentes.

Como realizar o sorteio:
i) geração de números aleatórios pelo computador;
ii) tabela de números aleatórios;
iii) globos com bolinhas numeradas;
iv) qualquer outra forma aleatória de escolha que preserve a
propriedade de que cada unidade amostral tenha a mesma
chance de ser selecionada.
B) Amostragem Aleatória Estratificada (A.A.E.):
Quando a população é muito heterogênea, ou seja, quando as
características observadas variam muito de um indivíduo para
outro, é aconselhável subdividir a população em estratos
homogêneos.
A população é, então, dividida em k estratos sendo que, uma A.A.S.
é aplicada em cada um deles.
Definições:
i) tamanhos dos estratos: N1, N2, N3, . . . , Nk.
N1 + N2 + N3 + . . . + Nk = N
ii) tamanhos das amostras em cada estrados: n1, n2, n3, . . . , nk.
n1 + n2 + n3 + . . . + nk = n
Obs:
1) A A.A.E. produz resultados mais precisos do que a A.A.S.
com o mesmo tamanho de amostra.
2) É mais cara, por segmentar a população.

Pergunta:
Sabendo que o tamanho da amostra é n, como alocar, ou,
determinar o número de indivíduos a serem selecionados em cada
um dos estratos?
i) Alocação por igual: utilizada quando se desconfia que os estratos
são de tamanhos parecidos, ou seja,
N1 ≈ N2 ≈ N3 ≈ . . . ≈ Nk
Neste caso pode-se utilizar: n1 = n2 = n3 = . . . = nk = k
n
Exemplo: Se, numa população com k = 4 estratos, de tamanhos
parecidos, for retirada uma amostra de tamanho n = 56, então, os
tamanhos das amostras em cada estrato deve ser:
n1 = n2 = n3 = n4 = 14.
ii) Alocação proporcional ao tamanho do estrato: na alocação
proporcional ao tamanho, os tamanhos das amostras devem
seguir a mesma relação de proporcionalidade dos tamanhos dos
estratos, ou seja,
N
N
n
n 11 , N
N
n
n 22 , . . . N
N
n
n kk
Desta forma, tem-se
N
nNn 1
1 , N
nNn 2
2 , . . . N
nNn k
k

Exemplo:
Considere uma amostra de tamanho n = 48 a ser selecionada de
uma população dividida em 3 estratos, tais que N1 = 40, N2 = 80
e N3 = 120, então:
N = 20 + 60 + 180 = 240
N
N1 = 240
40 =
6
1 n1 =
6
48 = 8
N
N2 = 240
80 =
3
1 n2 =
3
48 = 16
N
N3 = 240
120 =
2
1 n3 =
2
48 = 24
Portanto, n1 = 8, n2 = 16 e n3 = 24 é a alocação proporcional ao
tamanho dos estratos.
Esse resultado significa que se deve selecionar 8 indivíduos do
primeiro estrato, 16 do segundo estrato e 24 do terceiro.
iii) Alocação ótima: alocação que otimiza uma relação conhecida
(função), que normalmente envolve o tamanho dos estratos, as
medidas de suas heterogeneidades e o custo da amostragem.
Por otimizar entende-se escolher os tamanhos de amostras em
cada estratos que maximizam, ou minimizam, a função escolhida.

C) Amostragem Aleatória por Conglomerados (A.A.C.):
Na amostragem por conglomerados os elementos da população
são agrupados em conglomerados ou clusters (grupos), que serão
as unidades amostrais.
A divisão deve ser feita de forma que os conglomerados
tenham as mesmas características da população.
Na A.A.C. uma A.A.S. é aplicada para a seleção aleatória de k
conglomerados.
Uma vez selecionados os conglomerados, todos os seus
elementos devem são observados.
O procedimento descrito acima é uma A.A.C. em um estágio,
quando se realiza uma única seleção de conglomerados.
A A.A.C. pode, ainda, ser aplicada em dois ou mais estágios:
Na A.A.C. em dois estágios, após a escolha dos
conglomerados, aplica-se um segundo sorteio aleatório dentre os
seus elementos.
Exemplo: Estudo sobre a percepção social dos problemas de
quantidade, qualidade e custo dos recursos hídricos em São Carlos.
Definindo-se os quarteirões como sendo os conglomerados:
a) A.A.C. em 1 estágio:
Uma A.A.S. é aplicada para a seleção de uma amostra aleatória
de quarteirões, e o questionário é aplicado a todos os domicílios
dos quarteirões selecionados.

b) A.A.C. em 2 estágios:
no 1º. estágio: aplica-se uma A.A.S. para se selecionar uma
amostra de quarteirões;
no 2º. estágio: dentre os quarteirões selecionados no 1º.
estágio, sorteia-se uma amostra aleatória de domicílios que
efetivamente participarão da amostra.
Quadro comparativo entre os três métodos de amostragem:
A.A.E. Mais precisa do que a A.A.S., porém mais cara.
• considera a heterogeneidade da população
A.A.S.
Planejamento ideal.
• pode ser muito cara
• não considera a heterogeneidade da população
A.A.C.
Menos precisa do que a A.A.S. e A.A.E., porém mais
barata.
• resolve o problema do custo

Figura representativa dos três métodos de amostragem:

D) Amostragem Sistemática (A.S.):
A A.S. pode ser aplicada quando se tem em mãos um sistema de
referência de fácil acesso. Além disso, a informação a ser coletada
também é de fácil acesso.
Exemplos de sistemas de referências de fácil acesso:
Fichas de cadastro de assinantes (revistas, provedores de acesso
à internet, serviço telefônico, etc...);
Cadastro de funcionários;
Peças numa linha de produção;
Mudas num canteiro; etc...
Procedimento:
Com o sistema de referência em mãos
a) determina-se o intervalo de seleção, que é dado por: n
NR ;
b) sorteia-se um indivíduo, ou item, dentre os R primeiros da
relação;
c) a partir daí, seleciona-se os indivíduos sistematicamente a cada
intervalo de tamanho R.
Exemplo: se a população tem tamanho N = 84 e deve-se selecionar
uma amostra de tamanho n = 6, então, tendo-se em mão uma
relação com os 84 indivíduos da população:
i) divide-se população em 6 seções de tamanho R= 6
84 = 14;
ii) sorteia-se aleatoriamente o primeiro indivíduo da amostra
dentre os 14 primeiros da lista (por exemplo, o de número 5);

iii) o segundo indivíduo a ser selecionado é o 5 + 14 = 19, ou
seja, o 19o da relação;
iv) o terceiro é o 19 + 14 = 33, ou seja, o 33o da relação, e assim
por diante.
Indivíduos selecionados sistematicamente
pelo procedimento acima:
ordem indivíduo selecionado
1 5o
2 19o
3 33o
4 47o
5 61o
6 75o
Outro exemplo: N = 79 e n = 7 => 7
79 = 11.3 ≈ 11
* O primeiro selecionado é o 3o, e, dai por diante a seleção é feita
em intervalos de tamanho 11 (ver tabela).
Indivíduos selecionados sistematicamente
pelo procedimento acima:
ordem indivíduo selecionado
1 3o
2 14o
3 25o
4 36o
5 47o
6 58o
7 69o

Situações especiais: se, por acaso N = 68 e n = 7
=> R = 7
68 = 9.7 ≈ 10
* Supor que o primeiro selecionado é o 9o, logo,
Indivíduos selecionados sistematicamente
pelo procedimento acima:
ordem Indivíduo selecionado
1 9o
2 19o
3 29o
4 39o
5 49o
6 59o
7 69o !
Note que nesse caso, não há o 69o indivíduo, pois N = 68, logo, a
amostra fica com uma unidade a menos.
Ou ainda: N = 80 e n = 7 => R = 7
80 = 11.4 ≈ 11
* O primeiro selecionado é o 2o
Indivíduos selecionados sistematicamente
pelo procedimento acima:
ordem indivíduo selecionado
1 2o
2 13o
3 24o
4 35o
5 46o
6 57o
7 68o
8 79o

Já, nesse caso, o 79o indivíduo é o penúltimo da relação e deve ser
incluído, logo, a amostra fica com uma unidade a mais.
* A amostra pode ter uma unidade a mais ou a menos em função
do arredondamento.
E) Amostragens não aleatórias
Muitas vezes não se tem acesso a um sistema referência para a
realização do sorteio.
A A.A.C. pode resolver a maioria desses casos.
Outra saída, entretanto, é a utilização de métodos de amostragem
não aleatórios.
i) Amostragem por cotas: a população é dividida em grupos,
assemelhando-se à A.A.E., mas a seleção não é aleatória.
ii) Amostragem por julgamento e estudos comparativos:
selecionam-se as unidades da amostra segundo um
determinado perfil definido segundo os objetivos da pesquisa.
No estudo comparativo certas características são comparadas em
duas, ou mais, populações através de amostras escolhidas por
julgamento.

Exemplos:
1) Estudo sobre a produção científica dos departamentos de ensino
de uma universidade.
2) Estudo sobre a percepção do conceito de morte em crianças de
diferentes períodos de desenvolvimento cognitivo (subperíodo
pré-operacional, subperíodo das operações concretas, período
formal).
3) Estudo comparativo da incidência de câncer de pulmão em
grupos de fumantes e não fumantes.
Obs:
1) Nos estudos comparativos, normalmente não se busca a
generalidade, mas sim as diferenças entre os grupos em análise.
2) Nesse contexto, as amostras devem ser o mais similares
possíveis, diferindo apenas em relação ao fator de comparação.

III- O Erro Amostral
O erro amostral é definido como sendo a diferença entre a
estimativa obtida para um parâmetro (que será denotado por ) e
o seu verdadeiro valor.
É decorrente da variabilidade natural das unidades amostrais,
sendo assim, aleatório.
erro amostral = estimativa –
Como medir o erro?
A amostra é retirada sem erro?
O erro decorrente da coleta dos dados é chamado de erro não
amostral.
Os planejamentos e a execução da pesquisa devem ser feitos com
muita cautela para evitar os erros não amostrais.
Alguns erros em amostragem:
i) População acessível diferente da população alvo;
ii) Falta de resposta;
iii) Erros de mensuração.

A) Determinação do tamanho da amostra
A determinação do tamanho da amostra é, talvez, o grande dilema
dos pesquisadores, pois deve levar em conta um a precisão
desejada e, por consequência, um erro tolerável e a probabilidade
de se cometer tal erro.
O erro tolerável é uma margem de erro das estimativas em
relação ao parâmetro θ, para mais ou para menos, o qual o
pesquisador está disposto a aceitar.
O tamanho da amostra é determinado tal que a probabilidade de
que a estimativa do parâmetro esteja dentro da margem de erro
seja alta, como por exemplo, igual a 0.95.
P( estimativa de estar dentro da margem de erro ) = 0.95
Em linguagem estatística:
)( EestimativaP = 0.95
Obs:
Para o cálculo acima, deve-se associar uma distribuição de
probabilidades para a estimativa, normalmente a normal (ou
Gaussiana).

Procedimento simplificado para determinação do tamanho da
amostra:
Na prática, pode-se escolher um tamanho inicial n0 em função de
um erro relativo tal que:
20
1
RelativoErron
Conhecendo o tamanho da população, deve-se fazer a correção:
0
0
nN
nNn
Exemplo:
Considere N = 780 e um erro relativo de 5%, então
20
05.0
1n = 400
Fazendo a correção pelo tamanho da população, tem-se
1180
312000
780400
780400
n = 264,4 ≈ 265,
ou seja, a amostra deve ser de 265 unidades amostrais.

Obs:
10
0
0
0
N
n
n
nN
nNn
desta forma, se a população é muito grande, ou seja, N é
muito grande, então, 00 N
n, logo n = n0

IV- Exemplo de aplicação:
Estudar a influência do fato do chefe da família ser analfabeto e/ou mulher
no perfil sócio-econômico das famílias de UFSCarlândia.
Exemplo prático: Pesquisa em UFSCarlândia.
População amostral: Chefes de família de UFSCarlândia aptos a participar
da amostra.
Características a serem observadas:
i) número de moradores no domicílio;
ii) número de filhos estudando;
iii) chefe da família é analfabeto sim/não;
iv) chefe da família é mulher sim/não;
v) renda familiar, em salários mínimos (1s.m.= R$ 788,00).
Dados da População:
i) 250 domicílios;
ii) 1046 moradores (UFSCarlenses).
Amostra:
i) AAS: selecionar n = 30 domicílios;
ii) AAC: selecionar k = 5 quarteirões (conglomerados).

Figura 1: Mapa de UFSCarlândia com quarteirões
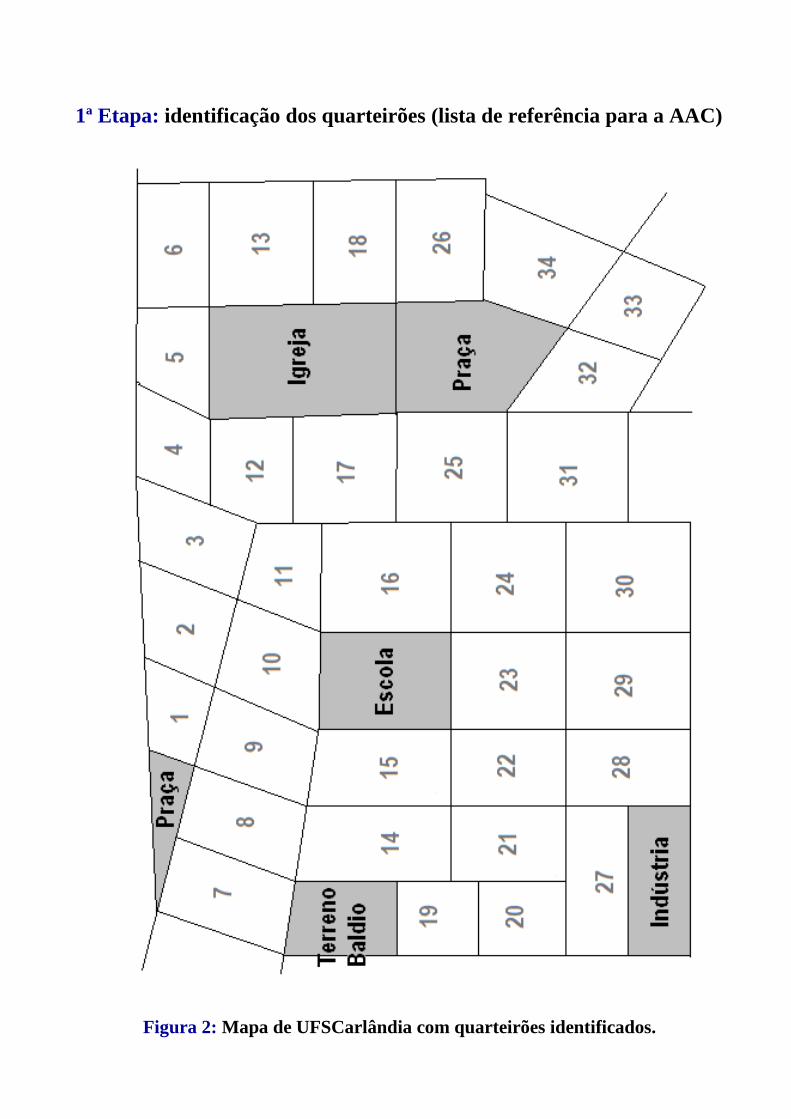
1ª Etapa: identificação dos quarteirões (lista de referência para a AAC)
Figura 2: Mapa de UFSCarlândia com quarteirões identificados.

2ª Etapa: identificação dos domicílios (lista de referência para a AAS)
Figura 3: Mapa de UFSCarlândia com domicílios.

Figura 4: Mapa de UFSCarlândia com domicílios numerados.

3ª Etapa: sorteio dos domicílios da amostra
Como realizar o sorteio?
v) geração números aleatórios, pelo computador;
vi) tabela de números aleatórios (em desuso, substituído pela geração via
computador);
vii) globo com bolinhas numeradas;
viii) qualquer outra forma aleatória de escolha que preserve a propriedade
de que cada unidade amostral tenha a mesma chance de ser
selecionada.
3.1. Sorteio da AAS no R:
## gerando a relação dos 250 domicílios:
> domicilios <- seq(1,250)
## sorteando a amostra de tamanho 30, dentre os 250 domicílios:
> aas <- sample(domicilios, 30, replace=FALSE)
## mostrando a amostra selecionada:
> aas
[1] 1 5 7 18 30 36 38 40 56 61 63 66 108 114 117
127 130 143 152 153 156 172 179 190 197 217 221 222
235 248
3.2. Sorteio da AAC no R:
## gerando a relação dos 34 quarteirões:
> quadras <- seq(1,34)
## sorteando a amostra de tamanho 5, dentre os 34 quarteirões:
> aac <- sample(quadras, 5, replace=FALSE)
## mostrando a amostra selecionada:
> aac
[1] 12 16 17 20 26

Domicílios sorteados na AAS: ( tamanho da amostra n = 30 domicílios )
Figura 5: AAS com os domicílios sorteados em destaque.

4ª Etapa: dados na AAS ( n = 30 domicílios sorteados )
# Domicílios
sorteados
Chefe
analf
Chefe
mulher
Num.
estud
Num.
morad
Renda
(sm)
1 1 N N 2 4 3.8
2 5 SIM N 0 4 3.8
3 7 N N 1 4 9.8
4 18 N N 2 4 9.1
5 30 N SIM 2 4 4.5
6 36 N N 2 6 6.9
7 38 N N 2 4 5.4
8 40 SIM N 1 3 2.6
9 56 SIM N 1 3 2.6
10 61 N N 1 3 4.6
11 63 N N 2 5 6.2
12 66 N N 2 5 5.6
13 108 N N 1 5 5.5
14 114 N N 1 5 7.5
15 117 N N 1 5 5.8
16 127 SIM N 2 4 3.5
17 130 N N 0 2 5.9
18 143 N N 0 1 4.6
19 152 N N 1 5 6.3
20 153 N N 1 5 5.5
21 156 N SIM 1 3 2.6
22 172 SIM SIM 1 5 3.1
23 179 N N 2 4 8.2
24 190 SIM SIM 1 5 3.4
25 197 N N 1 4 7.7
26 217 N N 1 5 7.9
27 221 N SIM 0 2 2.7
28 222 SIM SIM 1 5 2.1
29 235 N N 1 4 4.7
30 248 N N 1 5 8.4
Totais/somas 7 6 35 123 160.1
Médias/porcentagens 23.3 20.0 1.2 4.1 5.3

Quarteirões sorteados na AAC: ( tamanho da amostra k = 5 quarteirões )
Figura 6: AAC com os quarteirões sorteados em destaque.

4ª Etapa: dados na AAC ( k = 5 quarteirões e n = 37 domicílios )
# Quarteirões
sorteados
Chefe
analf
Chefe
mulher
Num.
estud
Num.
morad
renda
(sm)
1 12 N N 2 4 6.8
2 12 SIM N 0 2 2.1
3 12 N N 1 6 8.0
4 12 SIM N 2 5 2.6
5 12 N N 1 5 5.5
6 12 SIM N 1 4 2.1
7 12 N SIM 1 6 11.7
8 16 N N 0 5 8.0
9 16 N N 1 5 8.5
10 16 N N 1 4 4.7
11 16 N N 1 5 5.5
12 16 SIM SIM 2 4 3.1
13 16 N N 2 4 6.6
14 16 N SIM 1 5 5.7
15 16 N N 0 5 7.6
16 17 N N 1 4 5.4
17 17 N N 1 5 7.5
18 17 N N 2 4 5.0
19 17 N N 1 5 5.6
20 17 N N 1 5 5.8
21 17 N N 2 5 5.4
22 17 N N 0 1 3.3
23 17 SIM N 2 5 2.4
24 20 N N 2 5 5.8
25 20 N N 3 5 4.8
26 20 N N 1 4 6.3
27 20 N N 1 5 6.1
28 20 N N 1 4 4.6
29 20 N N 1 5 8.5
30 26 N N 0 3 6.4
31 26 N N 1 6 7.6
32 26 N N 0 4 5.4
33 26 N N 1 4 7.1
34 26 N N 1 4 7.2
35 26 SIM SIM 1 5 3.4
36 26 N N 2 4 3.7
37 26 N N 0 5 13.6
Totais/somas 6 4 41 134 219.3
Médias/porcentagens 16.2 10.8 1.1 3.6 5.9

5ª Etapa: análise estatística dos dados
Será realizada posteriormente na disciplina, durante os tópicos de análise
descritiva de dados.

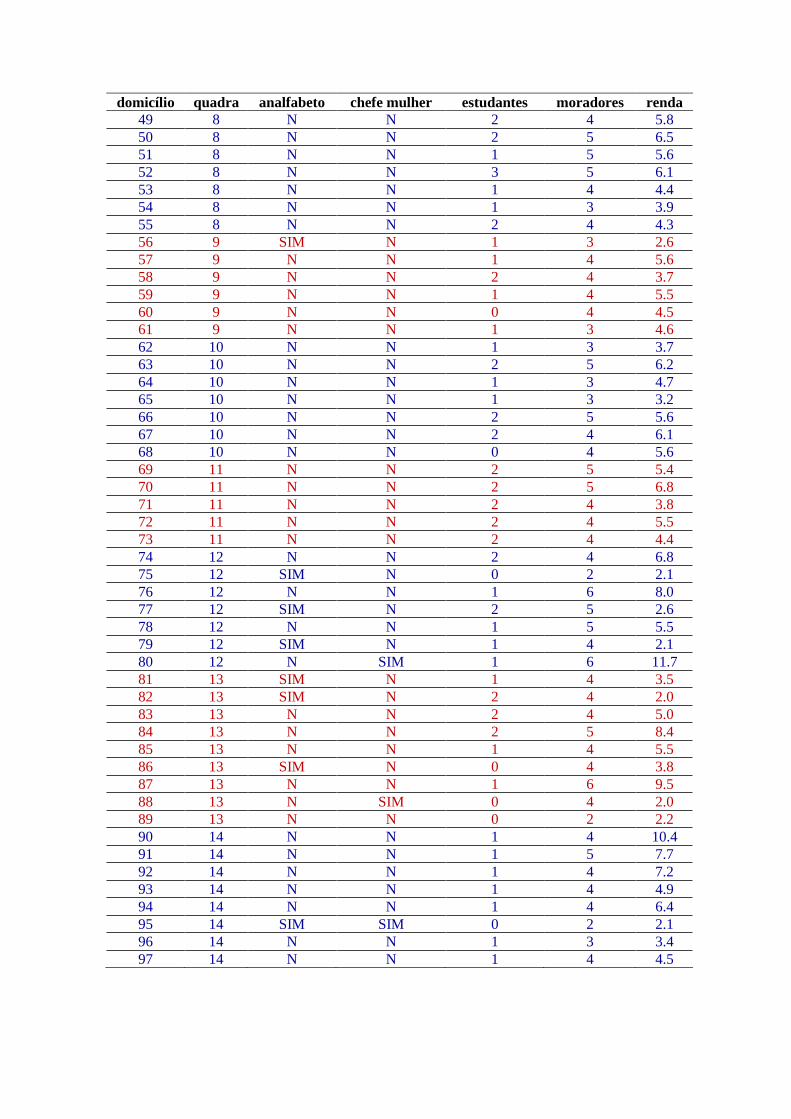
Anexo 1: Dados da população de UFSCarlândia:
domicílio quadra analfabeto chefe mulher estudantes moradores renda
1 1 N N 2 4 3.8
2 1 N N 2 4 4.0
3 1 N N 1 4 7.5
4 1 N N 1 6 7.2
5 2 SIM N 0 4 3.8
6 2 N N 1 5 6.2
7 2 N N 1 4 9.8
8 2 N N 0 5 6.6
9 2 N N 1 4 4.4
10 3 N N 2 4 6.1
11 3 N N 0 2 2.4
12 3 N N 1 3 3.9
13 3 N N 1 5 5.5
14 3 N N 2 4 4.3
15 3 N N 2 4 4.6
16 3 SIM N 3 5 2.7
17 3 N N 1 5 9.4
18 4 N N 2 4 9.1
19 4 N N 1 4 5.4
20 4 N SIM 1 5 5.8
21 4 N N 0 4 4.4
22 4 N N 2 4 4.9
23 4 N SIM 1 5 11.4
24 4 N SIM 2 5 8.0
25 5 SIM N 2 5 4.6
26 5 N N 1 5 5.9
27 5 SIM N 2 5 2.5
28 5 SIM SIM 2 4 2.1
29 5 N N 0 4 10.9
30 5 N SIM 2 4 4.5
31 5 SIM N 3 5 3.8
32 5 N SIM 1 5 5.6
33 6 N N 2 5 6.2
34 6 SIM N 2 4 3.5
35 6 N N 1 3 3.2
36 6 N N 2 6 6.9
37 6 N N 1 5 5.8
38 6 N N 2 4 5.4
39 6 N SIM 1 4 4.7
40 6 SIM N 1 3 2.6
41 7 N N 2 4 7.5
42 7 SIM N 2 4 2.5
43 7 N N 1 4 7.5
44 7 N N 2 4 4.6
45 7 N N 2 5 8.0
46 7 N N 2 4 3.7
47 7 SIM N 1 2 2.1
48 7 N N 1 3 3.4
domicílio quadra analfabeto chefe mulher estudantes moradores renda
49 8 N N 2 4 5.8
50 8 N N 2 5 6.5
51 8 N N 1 5 5.6
52 8 N N 3 5 6.1
53 8 N N 1 4 4.4
54 8 N N 1 3 3.9
55 8 N N 2 4 4.3
56 9 SIM N 1 3 2.6
57 9 N N 1 4 5.6
58 9 N N 2 4 3.7
59 9 N N 1 4 5.5
60 9 N N 0 4 4.5
61 9 N N 1 3 4.6
62 10 N N 1 3 3.7
63 10 N N 2 5 6.2
64 10 N N 1 3 4.7
65 10 N N 1 3 3.2
66 10 N N 2 5 5.6
67 10 N N 2 4 6.1
68 10 N N 0 4 5.6
69 11 N N 2 5 5.4
70 11 N N 2 5 6.8
71 11 N N 2 4 3.8
72 11 N N 2 4 5.5
73 11 N N 2 4 4.4
74 12 N N 2 4 6.8
75 12 SIM N 0 2 2.1
76 12 N N 1 6 8.0
77 12 SIM N 2 5 2.6
78 12 N N 1 5 5.5
79 12 SIM N 1 4 2.1
80 12 N SIM 1 6 11.7
81 13 SIM N 1 4 3.5
82 13 SIM N 2 4 2.0
83 13 N N 2 4 5.0
84 13 N N 2 5 8.4
85 13 N N 1 4 5.5
86 13 SIM N 0 4 3.8
87 13 N N 1 6 9.5
88 13 N SIM 0 4 2.0
89 13 N N 0 2 2.2
90 14 N N 1 4 10.4
91 14 N N 1 5 7.7
92 14 N N 1 4 7.2
93 14 N N 1 4 4.9
94 14 N N 1 4 6.4
95 14 SIM SIM 0 2 2.1
96 14 N N 1 3 3.4
97 14 N N 1 4 4.5

domicílio quadra analfabeto chefe mulher estudantes moradores renda
98 15 N N 1 2 3.1
99 15 N N 1 3 5.9
100 15 SIM N 0 1 2.2
101 15 SIM SIM 1 3 2.3
102 15 N N 1 3 3.1
103 15 N N 2 4 5.6
104 15 N N 1 5 6.1
105 16 N N 0 5 8.0
106 16 N N 1 5 8.5
107 16 N N 1 4 4.7
108 16 N N 1 5 5.5
109 16 SIM SIM 2 4 3.1
110 16 N N 2 4 6.6
111 16 N SIM 1 5 5.7
112 16 N N 0 5 7.6
113 17 N N 1 4 5.4
114 17 N N 1 5 7.5
115 17 N N 2 4 5.0
116 17 N N 1 5 5.6
117 17 N N 1 5 5.8
118 17 N N 2 5 5.4
119 17 N N 0 1 3.3
120 17 SIM N 2 5 2.4
121 18 SIM N 1 5 3.1
122 18 N N 1 5 6.7
123 18 N SIM 1 4 4.9
124 18 N N 1 4 9.5
125 18 N N 1 4 4.6
126 18 N N 2 4 6.5
127 18 SIM N 2 4 3.5
128 18 N N 1 3 2.9
129 19 N N 2 4 4.8
130 19 N N 0 2 5.9
131 19 N N 1 4 4.7
132 19 SIM N 3 6 3.1
133 19 N N 1 4 7.3
134 19 N N 1 4 6.4
135 19 N N 1 4 4.9
136 20 N N 2 5 5.8
137 20 N N 3 5 4.8
138 20 N N 1 4 6.3
139 20 N N 1 5 6.1
140 20 N N 1 4 4.6
141 20 N N 1 5 8.5
142 21 N N 2 3 3.2
143 21 N N 0 1 4.6
144 21 SIM N 0 5 4.7
145 21 N N 1 6 9.5
146 21 N N 0 3 7.8
147 21 N N 2 5 6.1
148 21 N N 1 4 4.6
149 21 N N 2 4 7.2
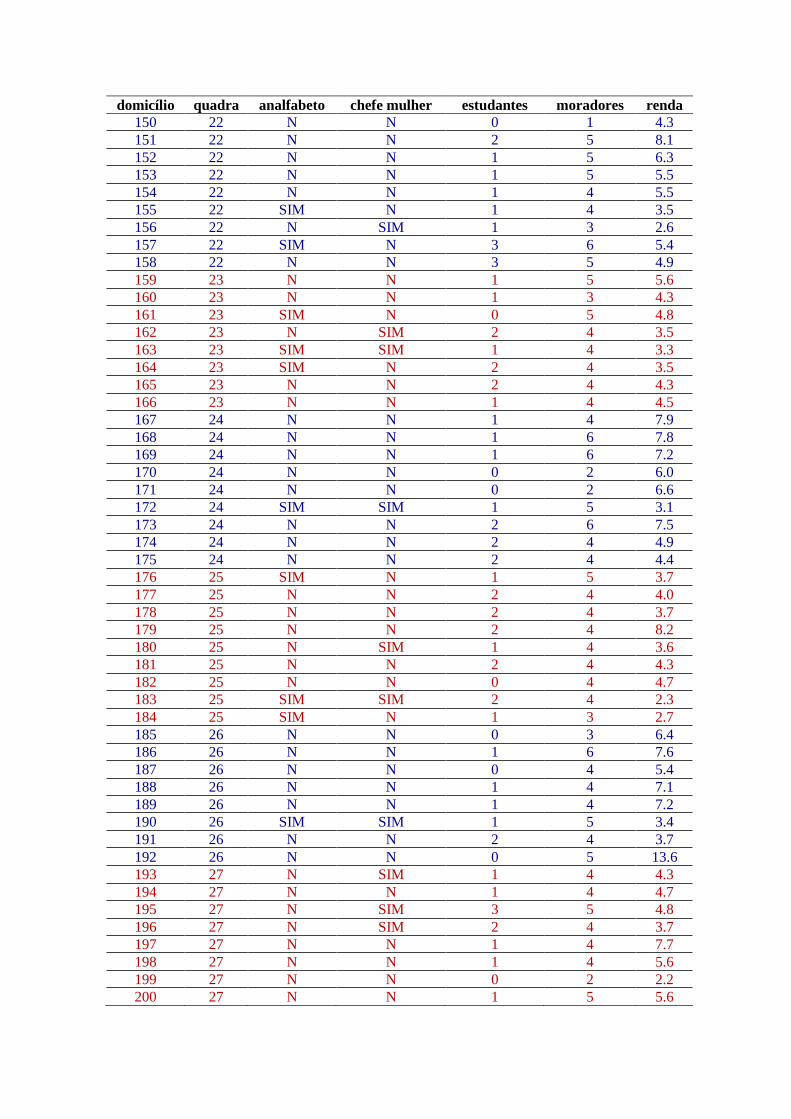
domicílio quadra analfabeto chefe mulher estudantes moradores renda
150 22 N N 0 1 4.3
151 22 N N 2 5 8.1
152 22 N N 1 5 6.3
153 22 N N 1 5 5.5
154 22 N N 1 4 5.5
155 22 SIM N 1 4 3.5
156 22 N SIM 1 3 2.6
157 22 SIM N 3 6 5.4
158 22 N N 3 5 4.9
159 23 N N 1 5 5.6
160 23 N N 1 3 4.3
161 23 SIM N 0 5 4.8
162 23 N SIM 2 4 3.5
163 23 SIM SIM 1 4 3.3
164 23 SIM N 2 4 3.5
165 23 N N 2 4 4.3
166 23 N N 1 4 4.5
167 24 N N 1 4 7.9
168 24 N N 1 6 7.8
169 24 N N 1 6 7.2
170 24 N N 0 2 6.0
171 24 N N 0 2 6.6
172 24 SIM SIM 1 5 3.1
173 24 N N 2 6 7.5
174 24 N N 2 4 4.9
175 24 N N 2 4 4.4
176 25 SIM N 1 5 3.7
177 25 N N 2 4 4.0
178 25 N N 2 4 3.7
179 25 N N 2 4 8.2
180 25 N SIM 1 4 3.6
181 25 N N 2 4 4.3
182 25 N N 0 4 4.7
183 25 SIM SIM 2 4 2.3
184 25 SIM N 1 3 2.7
185 26 N N 0 3 6.4
186 26 N N 1 6 7.6
187 26 N N 0 4 5.4
188 26 N N 1 4 7.1
189 26 N N 1 4 7.2
190 26 SIM SIM 1 5 3.4
191 26 N N 2 4 3.7
192 26 N N 0 5 13.6
193 27 N SIM 1 4 4.3
194 27 N N 1 4 4.7
195 27 N SIM 3 5 4.8
196 27 N SIM 2 4 3.7
197 27 N N 1 4 7.7
198 27 N N 1 4 5.6
199 27 N N 0 2 2.2
200 27 N N 1 5 5.6

domicílio quadra analfabeto chefe mulher estudantes moradores renda
201 28 SIM N 0 3 2.7
202 28 N N 2 4 3.9
203 28 N SIM 1 3 8.2
204 28 N N 2 4 4.9
205 28 N N 1 5 5.6
206 28 SIM N 2 5 4.3
207 28 N N 2 4 3.7
208 28 SIM N 1 4 3.6
209 29 N N 0 4 7.5
210 29 N N 1 4 5.8
211 29 SIM N 1 4 3.6
212 29 N SIM 1 4 4.6
213 29 N N 2 5 7.8
214 29 N N 1 5 5.5
215 29 N N 2 3 3.5
216 29 SIM N 2 4 3.2
217 30 N N 1 5 7.9
218 30 N N 0 4 4.6
219 30 N SIM 0 4 9.4
220 30 SIM N 3 5 4.0
221 30 N SIM 0 2 2.7
222 30 SIM SIM 1 5 2.1
223 30 N N 3 5 6.5
224 30 N N 1 4 4.9
225 31 SIM N 1 3 2.6
226 31 N N 2 4 6.4
227 31 N N 2 4 5.5
228 31 N N 0 4 4.4
229 31 N N 2 5 7.2
230 31 N N 1 5 6.3
231 31 N N 1 4 8.7
232 32 N N 1 5 7.5
233 32 N N 2 4 3.7
234 32 N N 2 5 5.5
235 32 N N 1 4 4.7
236 32 N SIM 1 5 5.5
237 32 N N 1 6 7.3
238 33 N N 1 5 6.3
239 33 N SIM 1 6 5.7
240 33 N N 1 5 5.6
241 33 SIM SIM 1 4 3.9
242 33 N SIM 1 3 2.1
243 33 N N 1 4 7.2
244 34 N N 1 6 7.1
245 34 SIM N 1 6 3.2
246 34 N N 1 3 3.7
247 34 SIM N 1 4 3.4
248 34 N N 1 5 8.4
249 34 N N 0 4 4.5
250 34 N N 2 5 11.2

Anexo 2: Parâmetros da população:
Chefe Mulher:
casos
33 => proporção = 0.132
13.2 %
Chefe Analfabeto:
casos
47 => proporção = 0.188
18.8 %
Chefe Mulher e Analfabeta:
casos
10 => proporção = 0.040
4.0 %
Crianças na escola:
num. freq. fi xi fi
0 36 0.144 0.000
1 126 0.504 0.504
2 78 0.312 0.624
3 10 0.040 0.120
total 250 1 1.248
Média de crianças estudando: 1.25/domicílio
Moradores por domicílio:
num. freq. fi xi fi
1 4 0.016 0.016
2 11 0.044 0.088
3 27 0.108 0.324
4 117 0.468 1.872
5 75 0.300 1.500
6 16 0.064 0.384
total 250 1 4.184
Média de moradores: 4.2 / domicílio
Top Related