Cálculo das Probabilidades e Estatística I - DE/UFPBjuliana/Calculo das Probabilidades e...
91
Cálculo das Probabilidades e Estatística I Prof a . Juliana Freitas Pires Departamento de Estatística Universidade Federal da Paraíba - UFPB [email protected]
Transcript of Cálculo das Probabilidades e Estatística I - DE/UFPBjuliana/Calculo das Probabilidades e...

Cálculo das Probabilidadese Estatística I
Profa. Juliana Freitas PiresDepartamento de Estatística
Universidade Federal da Paraíba - [email protected]

Introdução
O curso foi dividido em três etapas:1 vimos como resumir descritivamente variáveisde um conjunto de dados.
2 conhecemos modelos probabilísticos, caracteri-zados por parâmetros, capazes de representaradequadamente o comportamento de algumasvariáveis.
3 esta etapa, apresentaremos métodos para fa-zer afirmações sobre as características de umapopulação (parâmetros), com base em informa-ções dadas por amostras.

Revisando alguns conceitos . . .
População: conjunto de todos os elementos ouindivíduos sob investigação.Amostra: qualquer subconjunto (não vazio) dapopulação.Variável Aleatória: característica da populaçãosujeita a variação.Parâmetro: Característica numérica observadana população.Estimador: Característica numérica estabelecidapor valores da amostra (uma função da amostra).Estimativa: um particular valor assumido porum estimador.

Introdução à Inferência Estatística
O uso de informações de uma amostra para con-cluir sobre o todo faz parte do dia a dia da maioriadas pessoas. Por exemplo:• Uma cozinheira ao verificar o sal de um pratoque está preparando;
• Um comprador, após experimentar uma pe-quena fatia de queijo, decide se vai ou não com-prar o queijo;
• A forma como as mães verificam a temperaturado mingau de seus bebês.

Inferência
• Inferência Estatística: conjunto de métodosde análise estatística que permitem tirar con-clusões sobre uma característica da populaçãocom base em somente uma parte dela (umaamostra).
• Em outras palavras, a inferência estatística tratade métodos que permitem a obtenção de con-clusões sobre um ou mais parâmetros de umaou mais populações através de quantidades (es-timadores) calculadas a partir da(s) amostra(s);

Inferência
• Fazer inferência (ou inferir) = tirar conclusõessobre as características de uma população (pa-râmetros), com base em informações dadas apartir da amostra (estimadores);
• Os métodos de inferência podem ser agrupadosem duas categorias:
1 Estimação: pontual ou intervalar2 Testes de Hipóteses

Com o que lida a Inferência?
Suponha que desejamos saber qual a altura médiados brasileiros adultos. Como podemos obter essainformação?• Medindo a altura de todos os brasileiros adul-tos. Nesse caso, não será necessário usar infe-rência estatística.
• Selecionar adequadamente uma amostra alea-tória (X1, X2, . . . , Xn) da população de brasi-leiros adultos e, através dessa amostra, inferirsobre a altura média (parâmetro).

Podemos inferir sobre a altura média dos brasileiros adultosde duas formas:
1 Estimação:• Estimativa Pontual: calculando a média das altu-ras dos brasileiros adultos selecionados na amostra;
• Estimativa Intervalar: através dos valores da amos-tra construir um intervalo de tal forma que a proba-bilidade de o verdadeiro valor da altura média dosbrasileiros pertencer a este intervalo seja alta.
2 Testes de Hipóteses:• Em uma outra situação, poderíamos estar interessa-dos em testar se a afirmação “os brasileiros têm, emmédia, 169 cm” é verdadeira. Com base na amostra,podemos realizar um Teste de Hipóteses.
Contudo, estes resultados dependerão da qualidade daamostra, que tem que ser representativa da população.


A forma como selecionamos uma amostrainterfere nos resultados?
Ex 1: Análise da quantidade de glóbulos bran-cos no sangue de certo indivíduo. Uma gotado dedo seguramente será representativa paraa análise. Caso Ideal!Ex 2: Opinião sobre um projeto governamen-tal. Se escolhermos uma cidade favorecida, oresultado certamente conterá erro (viés)
OBS: Observe que a forma como se obtém aamostra é determinante para a validade dapesquisa.

Como selecionar uma amostra?
• A maneira de selecionar a amostra é tão im-portante que existem diversos procedimentosde obtê-la.
• A teoria da amostragem é o ramo da estatísticaque fornece procedimentos adequados para aseleção de amostras.
• Aqui, trataremos do caso mais simples de amos-tragem probabilística, e que serve como basepara procedimentos mais elaborados: a amos-tragem aleatória simples, com reposição, a serdesignada por AAS.

Amostragem Aleatória Simples (AAS)
• Supomos que podemos listar todos os N ele-mentos de uma população homogênea e finita.
• Usando um procedimento aleatório, sorteia-seum elemento da população.
• Repete-se o procedimento até que sejam sorte-adas as “n” unidades da amostra.
• Temos AAS com reposição e sem reposição,contudo, com reposição implica independênciaentre as unidades selecionadas facilitando o es-tudo das propriedades dos estimadores.
• Neste curso, será considerada a amostragemaleatória simples, com reposição, a ser desig-nada por AAS.

Estimação
• Em qualquer área do conhecimento nos depara-mos com o problema de estimar alguma quan-tidade de interesse.
Exemplo: estimar a proporção de indivíduos quevotarão em determinado candidato.
• A estimação pode ser feita de duas formas:1 Estimação Pontual: um único valor e utilizadopara inferir sobre um parâmetro de interesse.
2 Estimação Intervalar: uma faixa de valores ouintervalo é utilizado para inferir sobre umparâmetro de interesse, com algum grau deconfiança.

Estimação Pontual
Na estimação pontual desejamos encontrar umúnico valor numérico que esteja bastante próximodo verdadeiro valor do parâmetro.
Parâmetro EstimadorMédia (µ)
X =
∑ni=1Xi
nVariância (σ2)
S2 =
∑ni=1(Xi −X)2
n− 1Desvio Padrão (σ)
S =√S2
Proporção (p)p̂ = X
nondeX é o número de indivíduos
que possuem a mesma característica deinteresse

Exemplo
Os preços de um determinado produto em 10 diferentesmercados em um determinado mês foram:
0.75 1.1 0.6 2 1.3 0.69 2.1 1.3 0.83 1
• A estimativa pontual da média do preço do produto édada por
X =0.75 + 1.1 + · · ·+ 0.83 + 1
10= 1.167
• A estimativa pontual da proporção de preços menoresque 1 real é dada por
p̂ =4
10= 0.4

Propriedades desejáveis de um estimador
Considere θ̂ um estimador pontual (função de umaamostra) para um parâmetro θ desconhecido.P1 Não-Viesado: diz-se que θ̂ é não-viesado (não-
tendencioso) se seu valor esperado é igual a θ.P2 Consistência: diz-se que θ̂ é consistente se
além de não-viesado, sua variância tende a zeroquando o tamanho de n é suficientemente grande.
P3 Eficiência: Se θ̂1 e θ̂2 são dois estimadoresnão-viesados de ummesmo parâmetro θ, e aindaV ar(θ̂1) < V ar(θ̂2), então, dizemos que θ̂1 émais eficiente do que θ̂2.

Suponha que alguém deseje comprar um rifle e,escolha quatro (A, B, C e D) para testá-los.foram dados 15 tiros com cada um deles. Arepresentação gráfica é dada abaixo.

Estimação Pontual × Estimação Intervalar
• Estimadores pontuais, especificam um único va-lor para o parâmetro.
• Mas, sabemos que diferentes amostras levam adiferentes estimativas, pois o estimador é umafunção de uma amostra aleatória.
• E, estimar um parâmetro através de um únicovalor não permite julgar a magnitude do erroque podemos estar cometendo.
• Daí, surge a ideia de contruir um intervalo devalores que tenha uma alta probabilidade deconter o verdadeiro valor do parâmetro (deno-minado intervalo de confiança).

Como construir um intervalo de confiança?
• Um intervalo de confiança (ou estimativa inter-valar) é construído de forma que a estimativapontual esteja acompanhada de uma medidade erro.
Intervalode Confiança =
[EstimativaPontual ± Erro de
Estimação
]
• Mas como obter o erro de estimação????

Distribuição Amostral dos Estimadores
• Como dissemos, um estimador é uma funçãode uma amostra. Uma amostra consiste de ob-servações de uma variável aleatória. Assim, es-timadores também são variáveis aleatórias.
• Por esta razão, cada estimador possui uma dis-tribuição de probabilidades e é importante conhecê-la, pois a partir dela conhecemos o comporta-mento do estimador e podemos determinar aprecisão das suas estimativas.
• A distribuição de probabilidades desses estima-dores é comumente denominada de distribuiçãoamostral do estimador.
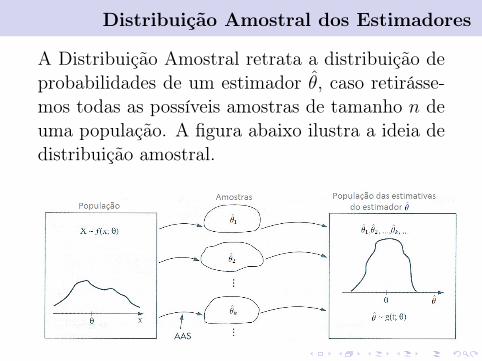
Distribuição Amostral dos Estimadores
A Distribuição Amostral retrata a distribuição deprobabilidades de um estimador θ̂, caso retirásse-mos todas as possíveis amostras de tamanho n deuma população. A figura abaixo ilustra a ideia dedistribuição amostral.

Distribuição Amostral de X
• Considere, como exemplo, uma população de 5elementos {2, 3, 6, 8, 11}.
• Nesta população temos que µ = E(X) = 6 eσ2 = Var(X) = 10, 8.
• Se agora retirarmos todas as possíveis amostrasde tamanho n = 2, com reposição, teremos:(2, 2); (2, 3); (2, 6); (2, 8); (2, 11); (3, 2) . . . (11, 11)
• Calculando a média para cada amostra, temos:
(X1, X2) (2, 2) (2, 3) (2, 6) (2, 8) (2, 11) (3, 2) · · · (11, 11)
X 2 2, 5 4 5 6, 5 2,5 · · · 11

Distribuição Amostral de X
Note que temos todos os possíveis resultados deX. Desta forma, podemos obter a distribuição deprobabilidade da variável aleatória X.
X 2 2, 5 3 4 4, 5 5 · · · 11
P(X = xi) 1/25 2/25 1/25 2/25 2/25 2/25 · · · 1/25
Baseando-se nestes dados, temos que:
E(X) =∑i
xi · p(xi) = 2 · 1
25+ . . .+ 11 · 1
25= 6
E(X2) =
∑i
x2i ·p(xi) = 22· 1
25+. . .+112· 1
25= 41, 4
Var(X) = E(X2)− [E(X)]2 = 41, 4− 62 = 5, 4

Distribuição Amostral de X
Com respeito a distribuição de X , podemos ob-servar que1) A sua média é igual à media da população,
E(X) = 6 = µ.
2) A sua variância é igual à variância da popula-ção dividida pelo tamanho da amostra
Var(X) = 5, 4 =10, 8
2=σ2
n.
Coincidência?

Distribuição Amostral de X
Não, estes dois fatos não são isolados. Na realidadetemos o seguinte resultado:
Teorema: Seja X uma v.a. com média µ e variân-cia σ2, e seja (X1, . . . , Xn) uma AAS de X. Então,µX = E(X) = µ e σX = Var(X) = σ2
n .
Prova:E(X) = E
(∑ni=1Xi
n
)= 1
n
∑ni=1 E(Xi) =
nµ
n= µ.
Var(X) = Var(∑n
i=1Xi
n
)= 1
n2
∑ni=1 Var(Xi) =
nσ2
n2=σ2
n.
Temos, então, informação sobre a média e avariância de X. Mas, o que dizer sobre suadistribuição de probabilidades?

Distribuição Amostral de X
A forma da distribuição amostral de X dependeráda distribuição da v.a. X. Duas situações sãoconsideradas:
1 Se X ∼ N(µ, σ2), então, X ∼ N(µ, σ2
n ).2 Se a v.a. X tem distribuição qualquer, a dis-tribuição da média amostral X aproxima-se dadistribuição normal quando o tamanho da amos-tra cresce. Esse resultado é garantido por umteorema chamado Teorema Central do Limite.(Tipicamente, se n > 30 então X ∼ N(µ, σ
2
n ).)

Distribuição Amostral de X

Exemplo
• Numa empresa A, os tempos de execução deuma certa tarefa pelos funcionários são distri-buídos conforme uma distribuição normal commédia µ = 22 minutos e variância σ2 = 9minutos2. Considere uma amostra de 25 fun-cionários selecionados para executar a tarefa.Qual a probabilidade de o tempo de execuçãomédio amostral ser menor que 20 minutos?

Exemplo
Resposta:Temos n = 25 < 30, mas como a população temdistribuição normal, então,X ∼ N
(22 min; 9
25 min2). Daí:
P (X < 20) = P
(X − 22√
9/25<
20− 22√9/25
)= P (Z < −3, 33)
= 0, 0004

Exemplo
• Considere que a distribuição das idades no mo-mento do aparecimento de problemas de audi-ção relacionados ao ruído no ambiente de tra-balho em funcionários de um determinado setorindustrial tenha média µ = 53, 9 anos e des-vio padrão σ = 18, 1 anos. Numa amostra de36 indivíduos qual a probabilidade de a médiaamostral das idades no momento do apareci-mento dos problemas ser inferior a 45 anos?

Exemplo
Resposta:Temos n = 36 > 30 podemos utilizar aaproximação normal. Nesse caso, temos queX ∼ N
(53, 9 anos; 18,12
36 anos2). Daí:
P (X < 45) = P
(X − 53, 9
18, 1/6<
45− 53, 9
18, 1/6
)= P (Z < −2, 95)
= 0, 0016

Distribuição Amostral de p̂
Vamos considerar uma população em que a pro-porção de indivíduos com uma certa característicaé p. Logo, podemos definir uma v.a. X como:
X =
{1, se o indivíduo possui a característica0, se o indivíduo não possui a característica ,
logo, µ = E(X) = p e σ2 = Var(X) = p(1− p).• Retirada uma AAS de tamanho n dessa po-pulação, seja Yn =
∑ni=1Xi, o número de in-
divíduos com a característica de interesse naamostra. Já vimos que Yn ∼ binomial(n, p).

Distribuição Amostral de p̂
• Observando que a proporção amostral é dadapor:
p̂ =Ynn
=
∑ni=1Xi
n= X.
• E, lembrando que X tem distribuição normal,para n suficientemente grande (n > 30), coma mesma média que X e com variância igual àvariância de X dividido por n.
• Neste caso, temos que se n é grande, então, adistribuição amostral de p̂ é:
p̂ ∼ N
(p;p(1− p)
n
)

Exemplo
• Um banco propõe a seus clientes inadimplentesum desconto para que quitem suas dívidas. Ogerente espera, com base em estratégias simi-lares realizadas anteriormente, que 50% dessesclientes procurem o banco para tentar uma ne-gociação. Num grupo de 200 clientes inadim-plentes, qual a probabilidade de a proporçãoamostral de clientes que tentam a negociaçãoestar entre 0, 48 e 0, 53?

Exemplo
Resposta:Temos que n = 200 e p = 0, 5, o que implica quep̂ ∼ N
(0, 5; 0,5(1−0,5)
200 anos2). Daí:
P (0, 48 < p̂ < 0, 53) =
= P
(0, 48− 0, 5√
0, 25/200<
p̂− 0, 5√0, 25/200
<0, 53− 0, 5√
0, 25/200
)= P (−0, 57 < Z < 0, 85)
= P (Z < 0, 85)− P (Z < −0, 57)
= 0, 8023− 0, 2843
= 0, 518

Estimação Intervalar
• Vimos que como os estimadores pontuais espe-cificam um único valor para o estimador, nãopodemos julgar qual a possível magnitude doerro que estamos comentendo.
• Daí, surge a idéia de construir os intervalos deconfiança, de forma que a estimativa pontualesteja acompanhada de uma medida de erro.
Intervalode Confiança =
[EstimativaPontual ± Erro de
Estimação
]• Mas como obter o erro de estimação??? Atra-vés da distribuição amostral do estimador pon-tual.

Estimação Intervalar
• Um intervalo de confiança (ou estimativaintervalar) representa uma amplitude de valo-res que tem alta probabilidade (grau de confi-ança) conter o verdadeiro valor do parâmetro.
• O grau de confiança (ou nível de confi-ança) é uma medida que representa a proba-bilidade do intervalo conter o parâmetro popu-lacional. Tal probabilidade é chamada de 1−α.Logo, α será a probabilidade de erro ao se afir-mar que o intervalo contém o verdadeiro valordo parâmetro.

Intervalo de confiança para a média populacional
• Duas situações são consideradas quando de-sejamos estabelecer um intervalo de confiançapara a média de uma população:
1 A variância σ2 é conhecida;
2 A variância σ2 é desconhecida;

Intervalo de confiança para a média populacional
• Adicionalmente, deve-se verificar se uma dasduas suposições seguintes é satisfeita:
1 A amostra é proviniente de uma populaçãonormal. Pois, sabemos que seX ∼ N(µ, σ2) então X ∼ N(µ, σ2/n).
2 A amostra tem tamanho maior do que 30,n > 30, o que nos permite aproximar a dis-tribuição da média amostral X pela distri-buição normal, como na suposição anterior.

Intervalo de confiança para a média populacional
De modo geral, estamos interessados em encontrar um inter-valo na forma:
IC = [X − ε0;X + ε0] = [X ± ε0]
onde ε0 representa a margem de erro ou erro de precisão emrelação à média µ.Portanto, o objetivo é encontrar ε0 tal que
P(|X − µ| < ε0) = 1− α,
que é equivalente a
P(−ε0 < X − µ < ε0) = 1− α.
A última expressão pode ser reescrita da forma
P(µ− ε0 < X < µ+ ε0) = 1− α.

Caso 1: A variância σ2 é conhecida
Sabemos que X é o estimador de µ. Supondo que pelo menosuma das suposições está satisfeita, temos queX ∼ N(µ, σ2/n)
e, então,X − µσ/√n
= Z ∼ N(0, 1).
P(µ− ε0 < X < µ+ ε0) = 1− α
P(µ− ε0 − µσ/√n
<X − µσ/√n<µ+ ε0 − µσ/√n
) = 1− α.
P(−ε0σ/√n< Z <
+ε0σ/√n
) = 1− α.
P(−zα/2 < Z < +zα/2) = 1− α.
Daí,−zα/2 =
−ε0σ/√n
e zα/2 =ε0
σ/√n

Caso 1: A variância σ2 é conhecida
Logo,ε0 = zα/2
σ√n

Caso 1: A variância σ2 é conhecida
Dessa forma, se X for a média de uma amostraaleatoria de tamanho n, proveniente de uma po-pulação com variância conhecida, um intervalo de100(1 − α)% de confiança para a média populaci-onal é dado por:
ICµ100(1−α)% =
(X − zα/2
σ√n,X + zα/2
σ√n
)em que zα/2 é o quantil da normal padrão de nívelα/2.

Exemplo
• Em uma industria de cerveja, a quantidade decerveja inserida em latas se comporta comouma distribuição normal com média 350 ml edesvio padrão 3 ml. Após alguns problemas nalinha de produção, suspeita-se que houve al-teração na média. Uma amostra de 20 latasacusou uma média de 346 ml. Obtenha umintervalo de 95% para a quantidade média decerveja inserida em latas, supondo que não te-nha ocorrido alteração na variabilidade.

Exemplo
Resposta: A variância σ2 é conhecida, então ointervalo é dado por
ICµ100(1−α)% =
(X − zα/2
σ√n,X + zα/2
σ√n
)Como 1− α = 0, 95, temos que α = 0, 05. Então,α/2 = 0, 025. Ou seja, devemos olhar na tabelada normal padrão qual o número z0,025.

Exemplo
Olhando na tabela, temos que zα/2 = 1, 96. Assim,o intervalo é obtido através de:
ICµ95% =
(346− 1, 96
3√20, 346 + 1, 96
3√20
)= (344.69, 347.31)
Isto é, o intervalo de valores [344, 69; 347, 31]contém a quantidade média de cerveja inseridanas latas está com 95% de confiança. Logo,conclui-se que realmente houve alteração, após osproblemas encontrados na linha de produção, naquantidade média de cerveja inserida em latas.

Calculando o tamanho da amostra
Note que, a partir da expressão obtida para a mar-gem de erro ε0, podemos estimar o tamanho daamostra, se α e ε0 estiverem especificados:
ε0 = zα/2σ√n⇒√n = zα/2
σ
ε0⇒ n =
(zα/2
σ
ε0
)2
Se a população for finita, com N elementos, deve-se utilizar o fator de correção para populações fi-nitas. Nesse caso, o tamanho da amostra será de-terminado por:
n∗ =n
1 + nN

Exemplo
• Uma construtora deseja estimar a resistênciamédia das barras de aço utilizadas na constru-ção de casas. Qual o tamanho amostral neces-sário para garantir que haja um risco de 0, 001de ultrapassar um erro de 5kg ou mais na es-timação? O desvio padrão da resistência paraeste tipo de barra é de 25kg.

Exemplo
Resposta: Do enunciado tem-se α = 0, 001, ε0 =5 e σ = 25. Da tabela da distribuição normalpadrão obtemos zα/2 = z0,0005 = 3, 29. Assim,
n =
(zα/2
σ
ε0
)2
=
(3, 29× 25
5
)2
= 270, 602 ∼= 271

Intervalo de confiança para a média populacionalCaso 2: A variância σ2 é desconhecida
O processo para se obter o intervalo de confiança ésemelhante ao anterior. Contudo, como σ2 é desco-nhecida, é preciso substitui-la pela variância amos-tral (S2):
S2 =
∑ni=1(Xi −X)2
n− 1
Nessa situação, a quantidade
T =X − µS/√n∼ t(n−1)
tem distribuição t-student com n− 1 graus deliberdade, e não mais distribuição normalpadrão.

Distribuição t-Student
• A distribuição t-student apresenta proprieda-des semelhantes as da distribuição normal pa-drão (como, por exemplo, simetria em torno de0), no entanto, é mais dispersa. Em outras pa-lavras, a distribuição t-student concentra maisprobabilidades nas caldas do que a distribuiçãonormal padrão.
• A medida que n cresce, a distribuição t-studentse aproxima mais da distribuição normal pa-drão, pois S se aproxima mais de σ.
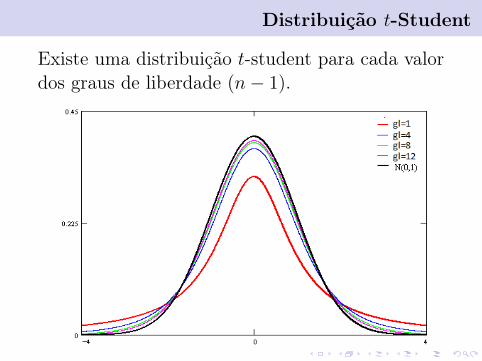
Distribuição t-Student
Existe uma distribuição t-student para cada valordos graus de liberdade (n− 1).

Intervalo de confiança para a média populacionalCaso 2: A variância σ2 é desconhecida
Dessa forma, se X for a média de uma amostraaleatória de tamanho n, proveniente de uma po-pulação com variância desconhecida, um intervalode 100(1 − α)% de confiança para a média popu-lacional é dado por:
ICµ100(1−α)% =
(X − t(n−1,α/2)
S√n,X + t(n−1,α/2)
S√n
),
onde t(n−1,α/2) é o quantil da t-student de nívelα/2.
Obs: Se σ2 for desconhecida, mas o tamanho da amostrafor grande (n > 30), pode-se utilizar zα/2 no lugar det(n−1;α/2)

Exemplo
Deseja-se avaliar a dureza média do aço produzidosob um novo processo de têmpera. Uma amostrade 10 corpos de prova de aço produziu os seguintesresultados, em HRc:
36, 4 35, 7 37, 2 36, 5 34, 9
35, 2 36, 3 35, 8 36, 6 36, 9.
Construir um intervalo de 95% de confiança paraa dureza média do aço.

Exemplo
Resposta:
• Temos a média amostral dada por:
X =
∑ni=1Xi
n= 36.15
• E a variância amostral:
S2 =
∑ni=1(Xi −X)2
n− 1=
4, 865
9= 0.5406
E, portanto, S = 0.7352.
• Além disso, n = 10 e 1− α = 0, 95, daí
t(n−1,α/2) = t(9,0.025) = 2.26

Exemplo
Assim,
ICµ95% =
(X − t(n−1,α/2)
S√n,X + t(n−1,α/2)
S√n
)=
(36.15− 2.26
0.7352√10
, 36.15 + 2.260.7352√
10
)= (35.625, 36.675) .
Ou seja, com 95% de confiança o intervalo [35, 625; 36, 675]
contém a dureza média do aço.

Intervalo de confiança para a proporçãopopulacional
Vimos que, para n suficientemente grande(n > 30),
p̂ ∼ N(p,p(1− p)
n
).
O intervalo que estamos procurando é da forma
IC = [p̂± ε0]
Assim, por um caminho semelhante ao adotadono caso da média, a margem de erro é dada por
ε0 = zα/2
√p(1− p)
n

Intervalo de confiança para a proporçãopopulacional
Dessa forma, se p̂ for a proporção de indivíduoscom uma característica de interesse em uma amos-tra aleatória, de tamanho n, proveniente de umapopulação onde a proporção verdadeira de indi-víduos com a característica é p, um intervalo de100(1−α)% de confiança para essa proporção po-pulacional p é dado por
ICp100(1−α)% =
(p̂− zα/2
√p(1− p)
n, p̂+ zα/2
√p(1− p)
n
)
em que zα/2 é o quantil da normal padrão comα/2 de nível de confiança.

Na prática, o valor de p é desconhecido (é justa-mente p que queremos estimar!). Nessa situação,duas abordagens são razoáveis:
1 Abordagem otimista: substituir o valor dep por sua estimativa p̂. Nesse caso,
ICp100(1−α)% =
(p̂− zα/2
√p̂(1− p̂)
n, p̂+ zα/2
√p̂(1− p̂)
n
)
2 Abordagem conservadora: substituirp(1− p) por seu valor máximo, 1/4, quandop = 1/2. Nesse caso,
ICp100(1−α)% =
(p̂− zα/2
1√4n, p̂+ zα/2
1√4n
)

Exemplo
• Um estudo foi feito para determinar a propor-ção de famílias que tem telefone em uma certacomunidade. Uma amostra de 200 famílias éselecionada ao acaso, e 160 afirmam ter tele-fone. Qual o intervalo para p com 95% de con-fiança?

Exemplo
Resposta:Temos que p̂ = 160/200 = 0, 8.Como 1− α = 0, 95 então zα/2 = z0,025 = 1, 96.Assim, adotando abordagem “otimista”, temos
ICµ95% =
(p̂− zα/2
√p̂(1− p̂)
n, p̂+ zα/2
√p̂(1− p̂)
n
)
=
(0, 8− 1, 96
√0, 8(1− 0, 8)
200, 0, 8 + 1, 96
√0, 8(1− 0, 8)
200
)= (0.7446, 0.8554).
Ou seja, com 95% de confiança o intervalo[74, 46%; 85, 54%] contém a porcentagem defamílias que tem telefone nessa comunidade.

Exemplo
Se calcularmos o intervalo adotando abordagem“conservadora”, temos
ICµ95% =
(p̂− zα/2
1√4n, p̂+ zα/2
1√4n
)=
(0, 8− 1, 96
1√4 · 200
, 0, 8 + 1, 961√
4 · 200
)= (0.7307, 0.8692).
Observe que, o intervalo com a abordagemconservadora fornece um intervalo maior.

Calculando o tamanho da amostra
Mais uma vez, podemos estimar o tamanho da amostra apartir da margem de erro ε0, basta especificar α e ε0:
ε0 = zα/2
√p(1− p)
n⇒√n = zα/2
√p(1− p)ε0
⇒ n = (zα/2)2 × p(1− p)
(ε0)2
Como p é desconhecido, para a substituição de p(1 − p) ouutiliza-se 1/4 ou adota-se um valor de p̂ obtida de um estudopiloto ou de um estudo similar. Se a população for finita,deve-se utilizar, de forma similar o fator de correção parapopulações finitas:
n∗ =n
1 + nN

Considerações: interpretação do intervalo deconfiança
• Um erro comum é dizer que a probabilidadedo parâmetro (µ ou p) estar no intervalo de100(1− α)%.
• O parâmetro (µ ou p) não é uma variável alea-tória, portanto não existe probabilidade sobreele.
• O parâmetro é uma constante desconhecida,sobre a qual desejamos inferir, através das quan-tidades amostrais (Xou p̂).
• Então, qual a interpretação do intervalo de con-fiança?????
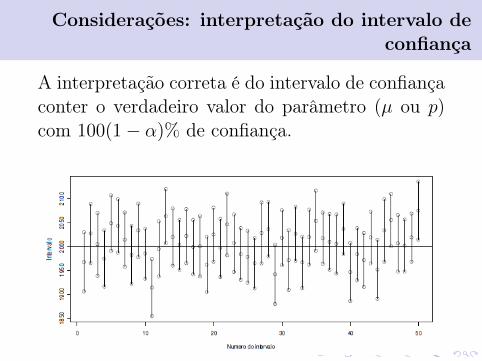
Considerações: interpretação do intervalo deconfiança
A interpretação correta é do intervalo de confiançaconter o verdadeiro valor do parâmetro (µ ou p)com 100(1− α)% de confiança.

Fatores determinantes do erro de estimação
O erro de estimação dependende do(a):• Tamanho da amostra (n): Quanto menoro tamanho da amostra, maior será o erro deestimação.
• Variabilidade da característica na popu-lação: Quanto maior for a variabilidade dacaracterística cuja média está sendo estimada,maior será o erro de estimação.
• Nível de confiança (1 − α): Se quisermosuma confiança maior no intervalo teremos umerro de estimação maior.

Teste de Hipóteses
O Teste de Hipóteses consiste em uma regra dedecisão elaborada para rejeitar (ou não) uma afir-mação (hipótese) feita a respeito de um parâmetropopulacional desconhecido, com base em informa-ções colhidas de uma amostra aleatória.
Exemplo:• Verificar se o salário médio de certa categoriaprofissional no Brasil é igual a R$1.500, 00.
• Testar se 40% dos eleitores votarão em certocandidato nas próximas eleições.
• Testar se um medicamento é mais eficaz queoutro.

Conceitos fundamentais
Hipótese Nula (H0): É a hipótese a ser testada.
Hipótese Alternativa (H1): É a hipótese a serconfrontada com H0.• O teste será feito de tal forma que deverá sem-pre concluir na rejeição (ou não) de H0.
• Como estamos tomando uma decisão com baseem informações de uma amostra, estaremos su-jeitos a cometer dois tipos de erros.

Conceitos fundamentais
Erro do tipo I: Rejeitarmos H0 quando H0 é ver-dadeira.
α = P(erro do tipo I) = P(rejeitar H0|H0 é verdadeira)
Erro do tipo II: Não rejeitarmos H0 quando H0
é falsa.
β = P(erro do tipo II) = P(não rejeitar H0|H0 é falsa)
Obs: α é denominado de nível de significânciado teste.

Conceitos fundamentais
Nossas decisões em um teste de hipóteses podemser resumidas na seguinte tabela:

Conceitos fundamentais
Estatística do teste: É a estatística utilizadapara julgar H0.
Região crítica do teste (RC): É formada peloconjunto de valores que levam a rejeição de H0.Ela depende do tipo de hipótese alternativa, donivel de significância (α) adotado, e dadistribuição de probabilidade da estatística doteste.

Etapas para a elaboração de um Teste deHipóteses
1 Definir as hipóteses nula (H0) e alternativa (H1);
2 Fixar o nível de significância (α);
3 Determinar a estatística do teste;
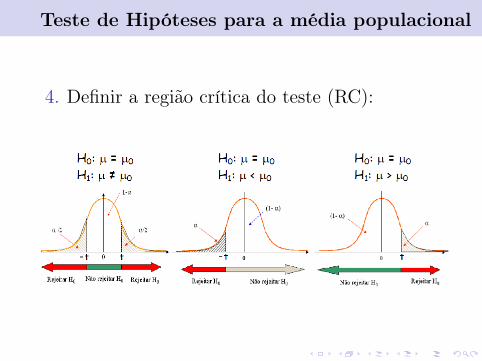
4 Determinar a região crítica do teste;
5 Calcular o valor da estatística do teste (combase numa amostra da população de interesse);
6 Se o valor calculado no passo 5 pertencer aRC, rejeitar H0, caso contrário, não rejeitar H0;
7 Conclusão do teste.

Teste de Hipóteses para a média populacional
Caso 1: σ2 conhecida.
1. Definição das hipóteses:
H0 : µ = µ0 H0 : µ = µ0 H0 : µ = µ0
H1 : µ 6= µ0 ou H1 : µ < µ0 ou H1 : µ > µ0
2. Fixar o nível de significância α;
3. Definir a estatística de teste:
Z =X − µσ/√n∼ N (0, 1)

Teste de Hipóteses para a média populacional
4. Definir a região crítica do teste (RC):

Teste de Hipóteses para a média populacional
5. Com base nos valores observados da amostra,calcular o valor da Estatística de teste Z :
Zc =X − µ0σ/√n
6. Se Zc ∈ RC ⇒ rejeitar H0 (aceitar H1).Se Zc /∈ RC⇒ não rejeitar H0 (não aceitar H1).
7. Concluir sobre a decisão tomada no passo 6.

Exemplo
Os sistemas de escapamento de uma aeronavefuncionam devido a propelente sólido. A taxa dequeima desse propelente é uma característicaimportante do produto. As especificaçõesrequerem que a taxa média de queima tem de ser50 centímetros por segundo. Sabemos que a taxade queima é normalmente distribuída com desviopadrão de σ = 2 centímetros por segundo. Oexperimentalista seleciona uma amostra aleatóriade tamanho 25 e obtém uma taxa média amostraligual a 51, 3 centímetros por segundo. Queconclusões poderiam ser tiradas ao nível designificância, de 0, 05?

Resolução: Teste para média com σ2 conhecida
1. As hipóteses que queremos testar são:
H0 : µ = 50 contra H1 : µ 6= 50
2. Fixamos α = 0, 05;3. A estatística de teste é: Z = X−µ
σ/√n∼ N (0, 1)
4. A região crítica é do tipo:
onde z = zα/2 = z0,025 = 1, 96 (tabela da dis-tribuição normal padrão).

Resolução: continuação
5. A partir dos dados amostrais temos que:
Zc =X − µ0σ/√n
=51, 3− 50
2/√
25
6. Temos que Zc ∈ RC pois 3, 25 > 1, 96, por-tanto, rejeitamos a hipótese nula.
7. Baseados nos dados amostrais, podemos con-cluir, ao nível de 5% de significância, que ataxa média de queima difere de 50 centímetrospor segundo.

Teste de Hipóteses para a média populacional
Caso 2: σ2 desconhecida.
1. Definição das hipóteses:
H0 : µ = µ0 H0 : µ = µ0 H0 : µ = µ0
H1 : µ 6= µ0 ou H1 : µ < µ0 ou H1 : µ > µ0
2. Fixar o nível de significância α;
3. Definir a estatística de teste:
T =X̄ − µS/√n∼ t(n−1)
Teste de Hipóteses para a média populacional
4. Definir a região crítica do teste (RC):

Teste de Hipóteses para a média populacional
5. Com base nos valores observados da amostra,calcular o valor da Estatística de teste Z :
Tc =X̄ − µ0S/√n
6. Se Tc ∈ RC ⇒ rejeitar H0 (aceitar H1).Se Tc /∈ RC⇒ não rejeitar H0 (não aceitar H1).
7. Concluir sobre a decisão tomada no passo 6.
Obs: se σ2 for desconhecida, mas o tamanho daamostra for grande (n > 30), pode-se definir aregião crítica através da distribuição Normalpadrão.

Exemplo
Suponha que, no exemplo anterior, o valor dodesvio padrão fosse desconhecido e oexperimentalista o tivesse estimado, a partir daamostra como S = 2, 5 centímetros por segundo.Ao nível de 5% de significância, que conclusãoobteríamos acerca da queima média dopropelente?

Resolução: Teste para média com σ2
desconhecida
1. As hipóteses que queremos testar são:
H0 : µ = 50 contra H1 : µ 6= 50
2. Fixamos α = 0, 05;3. A estatística de teste é: T = X−µ
S/√n∼ t(n−1)
4. A região crítica é do tipo:
onde t = tn−1;α/2 = t24;0,025 = 2, 064 (tabela dadistribuição t-student).

Resolução: continuação
5. A partir dos dados amostrais temos que:
Tc =X − µ0S/√n
=51, 3− 50
2, 3/√
25
6. Temos que Tc ∈ RC pois 2, 83 > 2, 064, por-tanto, rejeitamos a hipótese nula.
7. Baseados nos dados amostrais, podemos con-cluir, ao nível de 5% de significância, que ataxa média de queima difere de 50 centímetrospor segundo.

Teste de Hipóteses para a proporçãopopulacional
1. Definição das hipóteses:
H0 : p = p0 H0 : p = p0 H0 : p = p0
H1 : p 6= p0 ou H1 : p < p0 ou H1 : p > p0
2. Fixar o nível de significância α;
3. Definir a estatística de teste:
Z =p̂− p0√p0(1−p0)
n
∼ N (0, 1)

Teste de Hipóteses para a proporçãopopulacional
4. Definir a região crítica do teste (RC):

Teste de Hipóteses para a proporçãopopulacional
5. Com base nos valores observados da amostra,calcular o valor da Estatística de teste Z:
Zc =p̂− p0√p0(1−p0)
n
6. Se Zc ∈ RC ⇒ rejeitar H0 (aceitar H1).Se Zc /∈ RC⇒ não rejeitar H0 (não aceitar H1).
7. Concluir sobre a decisão tomada no passo 6.

Exemplo
Dentre 1655 pacientes tratados com ummedicamento A, 2, 1% tiveram reações adversas.A empresa que fabrica o medicamento afirma queapenas 1, 2% dos usuários têm algum tipo dereação adversa. Teste, ao nível de significância de1%, a afirmativa da empresa pode serconsiderada verdadeira.

Resolução: Teste para porporção
1. As hipóteses que queremos testar são:
H0 : p = 0, 012 contra H1 : p > 0, 012
2. Fixamos α = 0, 01;3. A estatística de teste é: Z = p̂−p0√
p0(1−p0)n
∼ N (0, 1)
4. A região crítica é do tipo:
onde z = zα = z0,01 = 2, 33 (tabela da distri-buição normal padrão).

Resolução: continuação
5. A partir dos dados amostrais temos que:
Zc =p̂− p0√p0(1−p0)
n
=0, 021− 0, 012√
0,012(1−0,012)1655
= 3, 36
6. Temos que Zc ∈ RC, pois 3, 36 > 2, 33 por-tanto, rejeitamos a hipótese nula.
7. Ao nível de significância de 1%, a amostra for-nece evidências estatísticas suficientes de queo percentual de usuários do medicamento quetêm alguma reação adversa é superior a 1, 2%

Valor p
• Valor p: é a probabilidade de se obter um va-lor da estatística de teste que seja, no mínimo,tão extremo quanto aquele que representa osdados amostrais, supondo que a hipótese nulaseja verdadeira.
• A hipótese nula deve ser rejeitada se o valor pfor muito pequeno. Na prática, adota-se quese o valor p for menor ou igual ao nível designificância do teste, então devemos rejeitara hipótese nula.