
Classificação de Ocupação Florestal em Fotografias Aéreas ...afalcao/docs/DT3-pnn-class.pdf ·...
31
Instituto Superior de Agronomia - Departamento de Engenharia Florestal GEGREN Grupo de Economia e Gestão de Recursos Naturais Documento Técnico: 03/02 Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas André Falcão Outubro de 2002
Transcript of Classificação de Ocupação Florestal em Fotografias Aéreas ...afalcao/docs/DT3-pnn-class.pdf ·...

Instituto Super ior de Agronomia - Depar tamento de Engenhar ia Florestal
GEGREN Grupo de Economia e Gestão de Recursos Naturais Documento Técnico: 03/02
Classificação de Ocupação Florestal em Fotografias Aéreas
Orto-restituídas Com Redes Neuronais Probabilísticas
André Falcão
Outubro de 2002

Índice
Introdução 3
2. Pré-Processamento da Informação 6
2.1. Variáveis de classificação................................................................................................................... 6
2.2. Análise em componentes principais das variáveis que constituem o modelo de dados escolhido........... 7
2.3. Definição das classes.......................................................................................................................... 9
3. Métodos de Classificação 11
3.1. Classificação Bayesiana e classificador óptimo de Bayes.................................................................. 11
3.2. Redes Neuronais Probabilísticas....................................................................................................... 12 3.2.1. Funções de densidade de probabilidade e kernels de Parzen.............................................. 12 3.2.2. Redes neuronais probabilísticas........................................................................................ 13 3.2.3. A optimização dos sigmas................................................................................................ 15 3.2.4. Validação e avaliação de resultados de classificação......................................................... 16
3.3. Uso do Simulated Annealing para ajustamento dos sigmas da PNN................................................... 16
3.4. PNN versus outros classificadores.................................................................................................... 17
3.5. Comparação dos resultados com outros modelos............................................................................... 17
4. Implementação e Resultados 19
4.1. Eficiência do procedimento de avaliação de uma PNN...................................................................... 19
4.2. O programa implementado............................................................................................................... 20
4.3. Comparação de resultados................................................................................................................ 22
4.4. Processo de ajustamento dos sigmas................................................................................................. 25
5. Conclusões 26
Bibliografia Citada 28
Apêndice 29
Rotina de cálculo das estatísticas espaciais.............................................................................................. 29

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 1.Introdução •••• 3
1.Introdução
Pretende-se com este trabalho avaliar a qualidade de um classificador baseado em redes neuronais probabilísticas (PNN) para classificar diferentes tipos de ocupação florestal com base em informação textural retirada de fotografias aéreas orto-restituídas. Testa-se o método para uma área de 460 ha no Perímetro Florestal da Lousã, previamente fotointerpretada.
Para calibração do classificador e ajustamento dos sigmas das diferentes variáveis e classes util izar-se-á a heurística simulated annealing por se ter verificado ser extramamente robusta e rápida. Os resultados serão comparados com os obtidos por outros classificadores disponíveis no módulo de Redes Neuronais do package comercial STATISTICA.
A presente área de estudo compreende o Cantão das Hortas, incluído no Perímetro Florestal da Lousã. É uma área de 460 hectares sob gestão pública e a sua composição actual reflete o cuidado com que foi gerida no passado. Assim, 41.3% da sua área é constituída por povoamentos mistos de pinheiro bravo e castanheiro, este último aparecendo geralmente num andar mais baixo. Predominam ainda as áreas de pinheiro bravo puro (53.0 ha). Há ainda manchas com áreas significativas de várias outras espécies, por exemplo, pinheiro silvestre, Cupressus spp, Chamaecyparis, Pinheiro negro, Carvalhos alvarinho e americano, entre outras espécies.
A fotografia aérea orto-rectificada utilizada neste trabalho, provém do voo de 1995 da CELPA/CNIG realizado em falsa cor. Desta forma as 3 bandas que compõem as cores de cada imagem estão desviadas para o infra-vermelho. O canal vermelho corresponde ao infra-vermelho próximo, o verde ao vermelho e o azul, ao verde. A cor azul, por ser geralmente redundante relativamente ao verde, e relativamente pouco relevante para classificação não é captada por este tipo de filme. A resolução espacial deste voo é de um pixel por metro, contudo, por razões relativas ao peso de processamento das imagens e à própria capacidade classificatória dos fotointérpretes considerou-se suficiente usar pixeis de 2 metros.

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 1.Introdução •••• 4
Figura 1. Ocupação florestal do Cantão das hortas na Lousã sobreposto à Fotografia aérea ortorectificada de 1995
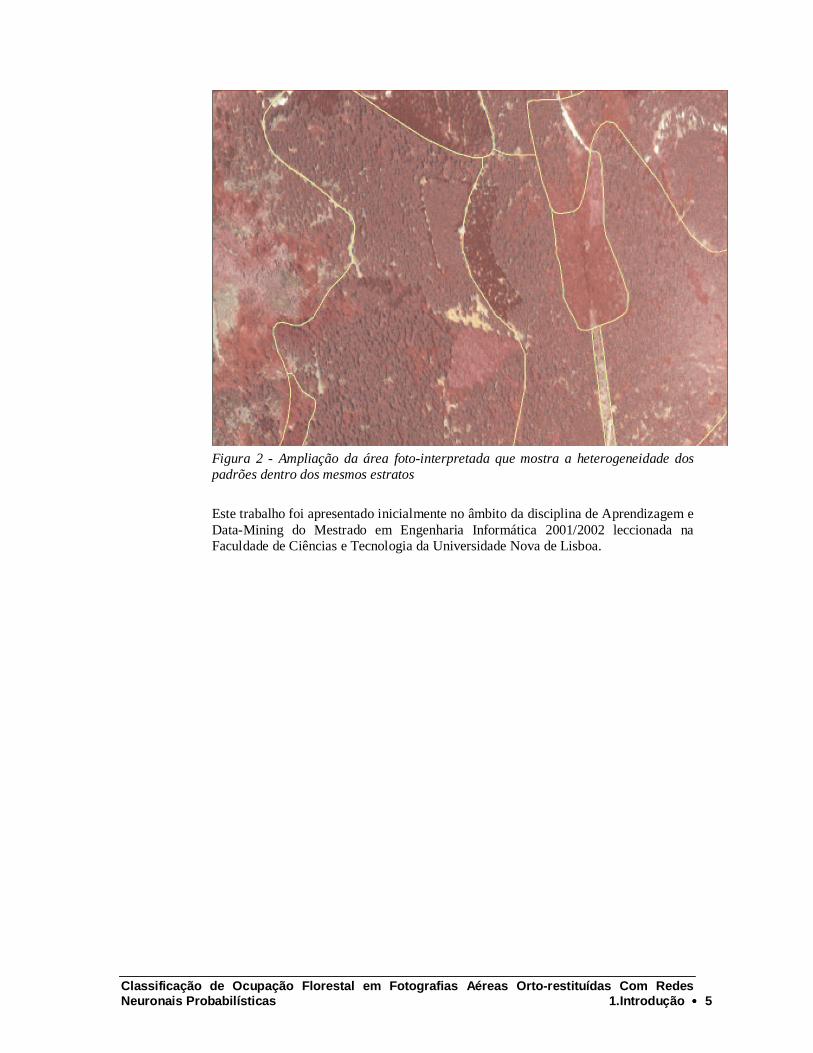
O trabalho de classificação inclui numerosas dificuldades previstas que foram sendo ultrapassadas ao longo do processo. Entre elas citam-se: a) dificuldade em escolher um conjunto relativamente reduzido de variáveis que significativamente caracterizasse cada área de análise; b) definição de critérios de agregação para as classes foto interpretadas; c) natural heterogeneidade dos dados, mesmo dentro do mesmo estrato foto-interpretado. Como exemplo (Figura 2) mostra-se uma ampliação do interior da área em análise sendo possível detectar visualmente vários padrões, que o foto-intérprete não discriminou em manchas diferentes.
Um outro problema com que seríamos confrontados seria a própria possibilidade de o método de classificação que iriamos testar não ser o mais adequado para análise de texturas. Com efeito, Dewdney (1993) apresentou resultados que mostram a incapacidade de classificadores neuronais do tipo MLP de detectarem certos tipos de padrões, como por examplo linhas conexas.
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 1.Introdução •••• 5
Figura 2 - Ampliação da área foto-interpretada que mostra a heterogeneidade dos padrões dentro dos mesmos estratos
Este trabalho foi apresentado inicialmente no âmbito da disciplina de Aprendizagem e Data-Mining do Mestrado em Engenharia Informática 2001/2002 leccionada na Faculdade de Ciências e Tecnologia da Universidade Nova de Lisboa.

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 2. Pré-Processamento da Informação •••• 6
2. Pré-Processamento da Informação
Para este trabalho usaram-se pequenas janelas da imagem, que se procurou que fossem representativas dos estratos em que estavam incluídas. Assim, e uma vez que, a estas resoluções o pixel por si não tem significado, considerou-se como unidade de classificação uma janela de dimensão previamente fixada. Testaram-se assim janelas de 10 x 10 m, 14 x 14 m e 22 x 22 m e 34x34m.
2.1. Variáveis de classificação
Várias tentativas prévias foram feitas com o intuito de representar a informação contida em cada janela de teste. A primeira abordagem testada era extremamamente simples, baseando-se essencialmente no uso do valor de cada pixel para cada banda para cada célula da janela. Assim para uma janela de 7 x 7 pixels (216 m2) usavam-se 147 (49 x 3) variáveis. Esta abordagem não se mostrou sequer capaz de diferenciar, usando redes neuronais MLP e PNN, as situações mais distintas entre as classes consideradas. Possuia ainda o sério inconveninete de, quanto maior a janela, maior o número de variáveis a incluir no modelo, que assim cresceriam em potência de 2.
Dada a dificuldade da informação "crua" em servir como parâmetro classificador pensou-se na utilização de informação textural característica de cada janela. Com efeito, além da cor, a textura é um dos pontos de referência mais importantes do foto-intérprete, servindo para distinguir diferentes tipos de ocupação do solo. Inicialmente os parâmetros texturais foram calculados de uma forma simplista, considerando o número de "montes" e "vales" em cada linha e coluna de cada janela, além de valores agregados relativos à intensidade cromática de cada banda (e.g. média, máximo e mínimo). Apesar de mais promissora, esta abordagem ainda era claramente deficiente

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 2. Pré-Processamento da Informação •••• 7
e só nos níveis mais grosseiros de classificação foi capaz de produzir alguns resultados.
Depois desta análise prévia foram definidas algumas estatísticas texturais simples retiradas das janelas que compôem cada amostra, calculadas, ao contrário da abordagem anterior, através da área total da janela. Assim, foram calculados os máximos e mínimos locais para a janela toda e avaliadas as distâncias entre eles para cada banda da imagem. O código util izado para este processamento está apresentado em anexo. Foram portanto calculadas para componente da imagem 9 estatísticas:
a) Média aritmética dos pixeis que compõem a janela
b) Máximo dos pixeis
c) Mínimo dos pixeis
d) Número de máximos locais presentes na janela
e) Distância mínima entre máximos locais
f) Distância média entre máximos locais
g) Número de mínimos locais presentes na janela
h) Distância mínima entre mínimos locais
i) Distância média entre mínimos locais
Desta forma, para cada janela, independentemente da sua dimensão, calcularam-se 27 estatísticas que se tornaram as variáveis do modelo.
2.2. Análise em componentes principais das variáveis que constituem o modelo de dados escolhido
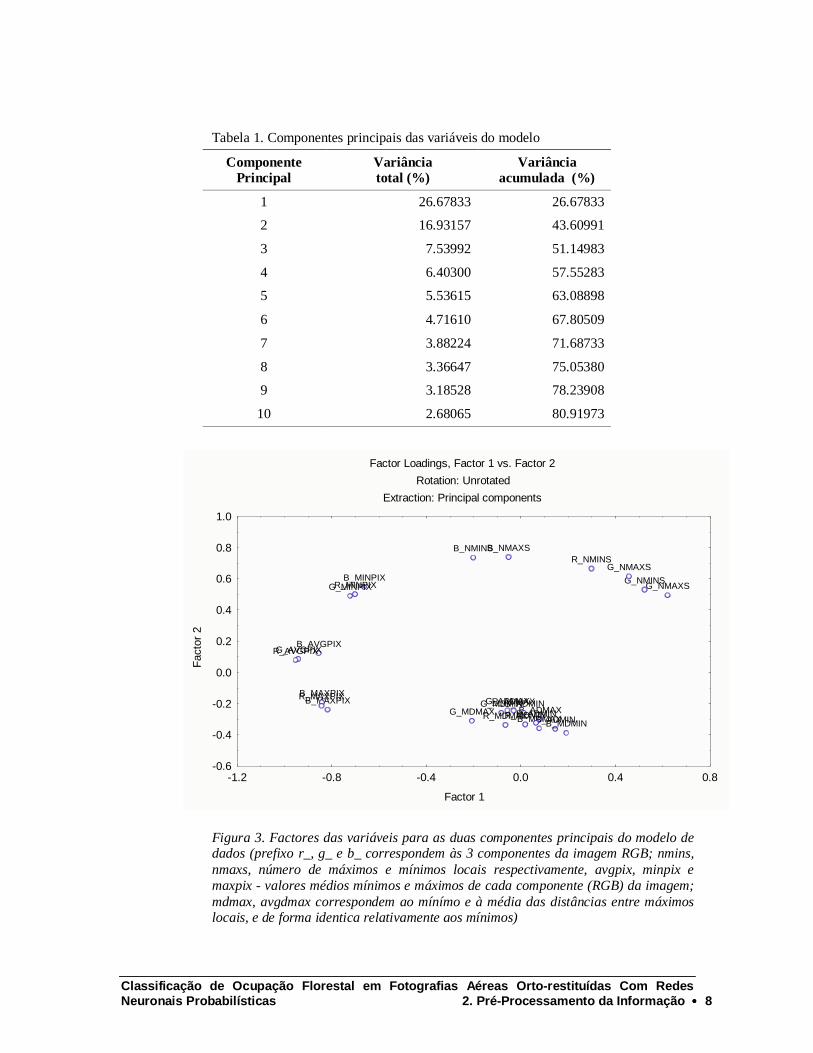
Para avaliar a dimensionalidade das variáveis realizou-se uma análise em componentes principais dos 2413 pontos usados para teste. Verificou-se que para representar 80 % da variância das variáveis de input necessitamos de 10 componentes principais. As 2 primeiras componentes representam cerca de 43.6 % da variabilidade total (Tabela 1).
Estes resultados permitem concluir que apesar de haver alguma correlação entre as variáveis, são necessárias pelo menos 10 componentes para representar 80% da variabilidade dos dados. Para analisar quais as variáveis mais correlacionadas, uma metodologia é a análise dos clusters de variáveis na representação bidimensional dos dois primeiros factores (figura 1). Podemos então verificar que as variáveis correspondentes às distâncias entre máximos e mínimos locais se agregam todas num bloco relativamente compacto e isolado dos demais. Interessante também verificar que os valores máximos e mínimos dos pixeis se separam nínidamente entre si e do valor da média, contribuindo decisivamente para a identidade dos dois factores. Um outro aspecto a realçar é relativamente à separação nítida da cor azul relativamente ao número de máximos e mínimos locais face ao vermelho e ao verde que se mostram relativamente próximos ums dos outros
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 2. Pré-Processamento da Informação •••• 8
Tabela 1. Componentes principais das variáveis do modelo
Componente Pr incipal
Var iância total (%)
Var iância acumulada (%)
1 26.67833 26.67833
2 16.93157 43.60991
3 7.53992 51.14983
4 6.40300 57.55283
5 5.53615 63.08898
6 4.71610 67.80509
7 3.88224 71.68733
8 3.36647 75.05380
9 3.18528 78.23908
10 2.68065 80.91973
Factor Loadings, Factor 1 vs. Factor 2
Rotation: Unrotated
Extraction: Principal components
Factor 1
Fac
tor
2
B_ADMAXB_ADMIN
B_AVGPIX
B_MAXPIX
B_MDMAXB_MDMIN
B_MINPIX
B_NMAXSB_NMINS
G_ADMAXG_ADMIN
G_AVGPIX
B_MAXPIX
G_MDMAXG_MDMIN
G_MINPIX G_NMAXSG_NMINS
R_ADMAXR_ADMIN
R_AVGPIX
R_MAXPIX
R_MDMAXR_MDMIN
R_MINPIX
G_NMAXSR_NMINS
-0.6
-0.4
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
-1.2 -0.8 -0.4 0.0 0.4 0.8
Figura 3. Factores das variáveis para as duas componentes principais do modelo de dados (prefixo r_, g_ e b_ correspondem às 3 componentes da imagem RGB; nmins, nmaxs, número de máximos e mínimos locais respectivamente, avgpix, minpix e maxpix - valores médios mínimos e máximos de cada componente (RGB) da imagem; mdmax, avgdmax correspondem ao mínímo e à média das distâncias entre máximos locais, e de forma identica relativamente aos mínimos)

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 2. Pré-Processamento da Informação •••• 9
2.3. Definição das classes
Além de uma correcta definição das variáveis de input era importante também definir qual o nível de detalhe a util izar na classificação. A informação fotointerpretada disponível identificava 41 estratos, que se diferenciavam não apenas pela composição em espécies mas também relativamente à densidade e idade. Além da grande diversidade de ocupações, a cobertura dos estratos estava longe de ser homogénea. Assim, dos 41 apenas 9 tinham mais de 10 hectares, havendo 24 estratos com menos de 5 hectares. Não seria então realista esperar que um classificador pudesse discriminar este número de classes correctamente, dada a heterogeneidade dos dados. Outra razão para não considerar um tão elevado número de classes é este facto poder aumentar grandemente a complexidade dos classificadores neuronais testados, potenciando fenómenos de sobre-aprendizagem.
Um dos estratos de foto-interpretação (áreas de povoamentos mistos de pinheiro bravo e castanheiro) foi considerado particularmente heterogéneo e de grande dominância na área de estudo. Mais de 40% da área estava por ele dominada (190.6 ha), o que condicionou, nos primeiros esforços, os resultados das classificações. Com efeito, nenhum dos métodos utilizados conseguiu ter resultados mínimamente relevantes. A grande dominância deste estrato relativamente aos outros fazia com que grande parte dos elementos testados fosse sistematicamente classificado nessa classe. Como se verá adiante, as probabilidades à priori desta classe eram muito superiores aos das outras todas, o que enviesava completamente os resultados da classificação. Para além do mais, a sua heterogeneidade espacial e textural dificultava grandemente os algoritmos de classificação testados, havendo casos muito semelhantes a praticamente todas as outras classes. Desta forma, e dada a natureza essencialmente académica do trabalho, optou-se por eliminar totalmente este estracto do conjunto dos dados e tentar apenas diferenciar as restantes ocupações que ficaram distribuídas de acordo com a Tabela 2. Depois de removidos os 190.6 ha correspondentes a área final para classificação totalizava 238.0 ha que, apesar de não estar dividida homogenenamente, se apresentava mais equilibrada para análise que a área inicial do Cantão.
Tabela 2 - Distribuição dos estratos fotointerpretados submetidos a classificação
Classes Área (ha)
Estratos correspondentes
A 23.9 Povoamentos puros de folhosas e manchas ripícolas
B 70.9 Povoamentos mistos de folhosas diversas (sobretudo castanheiro) e resinosas (essencialmente pinheiro bravo)
C 53.0 Povoamentos puros de pinheiro bravo
D 34.7
Outras resinosas (Cupressus spp, Pinheiro silvestre, Pseudotsuga, etc)
E 2.2 Povoamentos puros de eucalipto
F 53.3 Povoamentos jovens de pinheiro negro

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 2. Pré-Processamento da Informação •••• 10
Com esta informação, chama-se à atenção de dois aspectos a considerar na análise dos resultados: Em primeiro lugar, os resultados referentes à Classe E, correspondente à área de eucaliptal. Além de ser uma área algo pequena em comparação com as outras, era, na altura em que fotografia foi tirada, um povoamento muito jovem, em muitos aspectos semelhante à área de pinheiro negro (Classe F). Um outro ponto a considerar serão as estatísticas de classificação referentes à Classe A. Esta classe, apesar da sua expressividade tem, uma grande tendência para ser confundida com a classe B devido às caracteterísticas espectrais e texxturais das mesmas, que muitas vezes iludem os melhores fotointerpretes

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 11
3. Métodos de Classificação
3.1. Classificação Bayesiana e classificador óptimo de Bayes
Seja X um vector de m variáveis, e k classes distintas. O problema básico de classificação é conhecer a que classe pertence X, minimizando o erro de classificação em outras classes. Formalmente define-se um classificador óptimo de Bayes da seguinte forma: Um elemento X é classificado preferencialmente na classe i relativamente a j se:
)()( XfchXfch jjjiii > (1)
Em que:
hi - probabilidade a priori de um elemento pertencer à classe i
ci - custo de classificar mal um caso que na verdade pertence à classe i
f i - função de densidade de probabilidade para a classe i
Prova-se (Masters 1995) que este classificador dá os melhores resultados possíveis para qualquer problema genérico de classificação. Na generalidade dos casos hi e ci assumem-se iguais para todas as classes, sendo então o factor critíco a definição das funções de densidade de probabilidade (f.d.p) para cada classe.
Para resolver o problema da inexistência de f.d.ps para a maioria dos casos, várias abodagens foram tentadas. Entre outras, o método Naive-Bayes tem dado muito bons resultados (Mitchell, 1995). Este método assume que os diferentes atributos que constituem o vector de dados são independentes, determinando assim a probabilidade de um elemento pertencer a uma dada classe pelo produto das probabilidades

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 12
determinadas empíricamente dos diferentes atributos. Esta abordagem tem se revelado bastante robusta e aplicável numa grande generalidade de casos. Tem contudo dois problemas intrinsecos. Em primeiro lugar, e como foi referido, tem como pressuposto a independência dos diferentes atributos, que em muitos caso não se verifica na realidade. Em segundo lugar, há maior dificuldade na aplicação desta metodologia quando os atributos são contínuos, uma vez que é muito mais complicado determinar empirícamente as funções de densidade de probabilidade. Com efeito, ou as f.d.p são conhecidas à priori, ou é necessário um grande número de observações em cada classe para as poder determinar com algum rigor.
3.2. Redes Neuronais Probabilísticas
3.2.1. Funções de densidade de probabilidade e kernels de Parzen
Para resolver problemas relativos à inexistência de f.d.p. para amostras aleatórias, um método possível é o desenvolvido por Parzen em 1962. Este método, para amostras grandes, converge assimptoticamente para a verdadeira densidade de probabilidade. Tem como base a representação de cada ponto da amostra por uma função, designada de núcleo (kernel) de Parzen (Masters 1995). Para obter a f.d.p. de uma amostra estimada por este método é suficiente adicionar os valores de cada kernel, e escalar o valor para que o integral da função dê 1. Há dois factores críticos nesta abordagem, um a escolha da função kernel, o outro a parametrização desta que regula a sua forma. Masters (1995) discute as características necessárias para uma dada função servir como kernel, que são surpreendente poucas: a) deve ser positiva em todo o domínio; b) o seu valor máximo deve ser finito; c) deve decrescer rapidamente quando o seu argumento tende para (+/-) infinito; d) deve se tornar progressivamente mais estrita à medida que o número de pontos aumenta. Convém ainda que o seu integral seja 1 para poder funcionar, de facto, como f.d.p. Um kernel gaussiano (Equação 2) é a escolha óbvia para este problema, tendo numerosas propriedades estatísticas que a fazem ser uma função de eleição. Outras contudo podem ser usadas. A “amplitude” do kernel é quantificada por intermédio do factor σ (sigma). Este parâmetro tem o significado do desvio padrão na distribuição normal. Valores altos indicam uma função” larga” cobrindo com um leque de probabilidades uniformes, áreas relativamente grandes dentro do domínio dos dados; valores de sigma baixos são funções com expressividade muito localizada, tendo valores muito perto de 0 para a maior parte do domínio da variável.
��
�
�
��
�
�−
=22
2
1)( σ
πσ
x
exg (2)
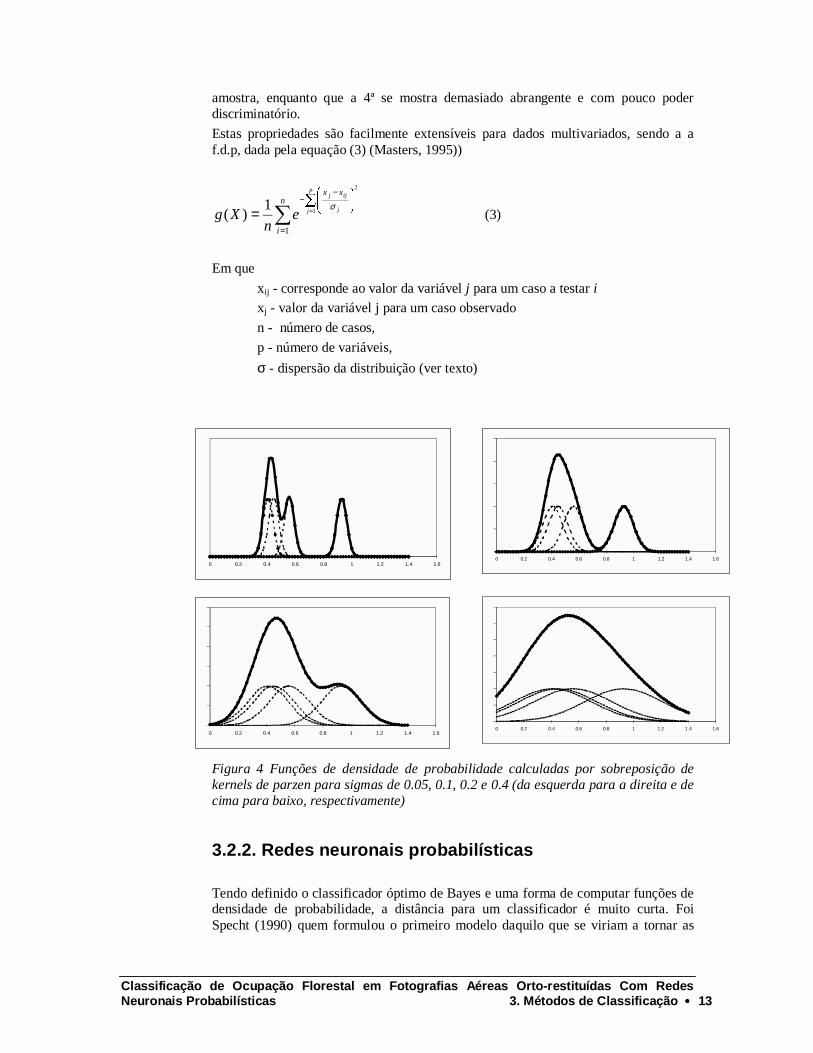
Como exemplo do exposto, a estimação da f.d.p. para uma amostra de 4 pontos com os seguintes valores: 0.41, 0.45, 0.56 e 0.93? A figura 4 mostra 4 possibilidades para sigmas de 0.05, 0.1, 0.2 e 0.4. Aparentemente, a melhor alternativa será a de sigma = 0.2, já que as 2 primeiras aparentemente mostram pouca capacidade de generalização para fora de uma vizinhança relativamente estreita à volta dos pontos que constituem a
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 13
amostra, enquanto que a 4ª se mostra demasiado abrangente e com pouco poder discriminatório.
Estas propriedades são facilmente extensíveis para dados multivariados, sendo a a f.d.p, dada pela equação (3) (Masters, 1995))
=
����
����
−− �
= =n
i
xxp
j j
i jj
en
Xg1
1
2
1)(
σ (3)
Em que
xi j - corresponde ao valor da variável j para um caso a testar i
xj - valor da variável j para um caso observado
n - número de casos,
p - número de variáveis,
σ - dispersão da distribuição (ver texto)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
Figura 4 Funções de densidade de probabilidade calculadas por sobreposição de kernels de parzen para sigmas de 0.05, 0.1, 0.2 e 0.4 (da esquerda para a direita e de cima para baixo, respectivamente)
3.2.2. Redes neuronais probabilísticas
Tendo definido o classificador óptimo de Bayes e uma forma de computar funções de densidade de probabilidade, a distância para um classificador é muito curta. Foi Specht (1990) quem formulou o primeiro modelo daquilo que se viriam a tornar as

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 14
redes neuronais probabilísticas (probabilistic neural networks - PNN). Como exemplo, para apoiar a discussão, a figura 5 mostra a arquitectura de uma PNN com 3 variáveis de input, 5 exemplos previamente classificados e duas classes. Cada neurónio da camada de padrão (pattern layer) contém a informação de um caso classificado. O processo de classificação é efectuado da seguinte forma:
1. É dado como input a cada neurónio da primeira camada um valor correspondente a cada um dos atributos do caso a classificar.
2. Avalia-se a distância de cada uma das variáveis, aos valores das variáveis correspondentes nos neurónios da pattern layer, que não são mais do que os casos previamente classificados.
3. Cada neurónio avalia a probabilidade conjunta correspondente à distância a que o caso a classificar se encontra atribuindo-lhe uma probabilidade de pertencer à sua própria classe.
4. Essas probabilidades são somadas na camada de soma, que contém um neurónio por cada classe considerada.
5. O resultado final no neurónio da última camada corresponde ao valor máximo dos neurónios da camada anterior
Figura 5 - Exemplo de uma rede neuronal probabiliística (PNN) com 4 variáveis de input, 5 exemplos de teste e 2 classes

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 15
3.2.3. A optimização dos sigmas
Como foi visto, o único parâmetro susceptível de afectar o comportamento de uma PNN é o sigma, que controla a dispersão das variáveis no seu domínio. Masters (1995) mostra que o processo de obter o sigma mais correcto para uma dada rede é um processo complexo, pois não é minimamente um processo linear. O processo de “aprendizagem” neste tipo de redes é apenas a determinação dos sigmas que minimizam o erro de classificação.
A - O modelo básico
A forma teórica mais corrente do modelo consiste no ajustamento de um sigma único para todas as variáveis e classes. É a abordagem mais fácil, pois o ajustamento incide apenas em um parâmetro. Contudo só se se assumir que as variáveis têm igual variância e essa variância é independente das diferentes classes, é que é lícito usar este modelo.
B - Sigmas diferentes para variáveis diferentes
Certas variáveis podem contudo ter escalas e dispersões diferentes entre si, o que pode tornar difícil que se encontre um sigma que correctamente permita classificar correctamente todas. Assim, uma modificação simples do modelo básico permite a inclusão de sigmas diferentes para diferentes variáveis (eq 3). Claro que o processo assim será mais complexo pois o espaço de procura aumenta exponencialmente com o número de variáveis do modelo bem como a possibilidade de ocorrência de óptimos locais sem interessse.
C - Sigmas diferentes para classes diferentes
Um outro problema que pode surgir, e de particular interesse para dados “ desequilibrados” , com variâncias diferentes para cada classe é a necessidade de por vezes ser mais conveniente, em vez de considerar sigmas diferentes para diferentes variáveis, coniserar o mesmo sigma para classe. Masters (1995) ilustra com clareza exemplos em que um item só é bem classificado caso haja diferenciação dos sigmas para cada classe. Esta modificação de conceito relativamente à anterior obriga contudo à modificação da f.d.p. (3), que tem que ser multiplicada pelos inverso do produto dos sigmas, obrigando a um procedimento de avaliação ligeiramente diferente
D - Sigmas diferentes para variáveis e classes diferentes
A junção das duas possibilidades anteriores, considerar um sigma para cada variável para cada elemento de cada classe, é a que teoricamente traz mais vantagens pois confere o maior grau de flexibil idade ao modelo. Pode também torná-lo mais dependente dos dados com que foi ajustado, pois o número de parâmetros é também muito maior (n_classes x n_variáveis), além de, pela mesma razão, ser o método que teoricamente necessitará de mais tempo para convergir.
O programa desenvolvido usa a mesma rotina para todos os casos, sendo o processamento divergente apenas nos dois últimos casos, em que a função para calcular a probabilidade é, como foi referido, l igeiramente diferente dos dois primeiros (Masters, 1995).

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 16
3.2.4. Validação e avaliação de resultados de classificação
As redes neuronais, mais do que qualquer outro classificador, depois de ajustadas necessitam de ser validadas com um conjunto de dados que nunca tenha sido utilizado durante a fase de treino. Contudo as PNN, devido à sua estrutura interna, podem, de certa forma, simplificar esse processo. diminuindo ao mínimo o conjunto de validação. Masters (1995) propõe uma metodologia semelhante à dos resíduos PRESS em análise da regressão: Uma vez que os neurónios da pattern layer são independentes e que não existem “ pesos” nas sua ligações com as outras camadas, é possível isolar um neurónio/caso e testá-lo contra todos os outros, verificando se a classificação conseguida com a restante rede coincide com o seu próprio valor. Esta forma de proceder tem como vantagerm imediata o facto de se poder utilizar a totalidade dos dados na aprendizagem e validação, o que pode garantir um melhor classificador. Por outro lado, o processo de ajustamento dos sigmas é muito mais demorado.
3.3. Uso do Simulated Annealing para ajustamento dos sigmas da PNN
Masters (1985) usa um método de gradientes semelhante ao utilizado por redes MLP. Determina empiricamente as derivadas parciais seguindo então pelo caminho do maior gradiente. Este método pode ter contudo problemas se o hiperplano constituído pelos parâmetros a ajustar não for convexo na sua totalidade, o que pode conduzir a máximos locais sub-óptimos. Testes prévios com esta metodologia de classificação mostraram que, mesmo em casos relativamente simples, com 2 variáveis e 3 classes, é frequente a ocorrência de máximos locais, o que, a não ser que haja uma boa sensibilidade prévia com consequente boa inicialização dos valores iniciais, pode não conduzir aos melhores resultados.
Uma possibilidade para lidar com sistemas multivariados complexos como este, é a heurística simulated annealing. Esta heurística efectua uma pesquisa local relativamente eficiente, tendo uma boa capacidade de evitar óptimos locais. É ainda uma das heurísticas com melhor “ perfomance” computacional devido ao reduzido número de avaliações que necessita no seu processo de convergência.
Foi assim implementado este algoritmo que contudo necessitou de algumas alterações específicas relativamente ao problema em estudo. Assim, uma vez que o problema consiste em descobrir um conjunto de variáveis contínuas (os sigmas) que minimizem o erro de classificação, e esta heurística funciona bem com variáveis discretas existima duas hipóteses: ou se trabalhava com os bits de cada elemento de vírgula flutuante (IEEE-754 de 32 bits), ou se discretizavam os sigmas dentro de um conjunto finito de hióteses. A opção tomada é um misto das duas. Assim, e uma vez que todas as variáveis estavam normalizadas (valores entre 0 e 1) e por verificação de vários conjuntos de dados com esta característica, verificou-se que os sigmas óptimos nunca ultrapassavam 1. Assim e para reduzir o número de valores possíveis, assumiu-se que cada sigma seria representado internamente por um byte, sendo o seu valor calculado dividindo-o por 255. A precisão entre valores consecutivos (0.004) foi julgada suficiente para efeitos de ajustamento. Um outro aspecto importante a considerar era a

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 17
modificação dos sigmas pelo SA. Uma possibilidade é a substituição total de um byte por outro escolhido aleatoriamente, outra consiste na escolha aleatoria de um bit de um, também aleatório, sigma. A primeira possibilidade provoca modificações mais “bruscas” o que pode dificultar o algoritmo de procura, a outra, pode por seu lado ter maior dificuldade em convergir dado que o número real de variáveis (8 x (sigmas) ) é muito superior.
Para o uso desta heurística usou-se como temperatura inicial um valor de 0.01; a taxa de arrefecimento (cooling schedule) tomou um valor de 0.98, considerando-se ainda 30 iterações para cada “ temperatura”, antes do arrefecimento. Uma vez que o tempo de processamento é uma questão crucial na utilização efectiva de um classificador, optou-se por não demorar tempo excessivo no processo de convergência. Assim e uma vez que cada avaliação de um conjunto de sigmas demora, na máquina de teste, cerca de 4 segundos, 30 avaliações por temperatura demoram cerca de 2 minutos. Estabeleceu-se assim um número fixo de 300 iterações (alterações de temperatura), o que corresponde a cerca de 10 horas de tempo de processamento.
3.4. PNN versus outros classificadores
Como já foi referido, a maior parte dos classificadores estatísticos tradicionais assume um determinado comportamento dos dados, nomeadamente assumem que as suas variáveis apresentam uma distribuição normal. A utilização das PNN como classificadores não assume nada, sendo inclusivamente um objectivo a definição das próprias funções de densidade de probabilidade das diferentes variáveis presentes nos dados. Desta forma, pode-se afirmar que, em teoria, as PNN aproximam o classificador Bayesiano óptimo
Uma outra vantagem é que devido à sua metodologia, os neurónios da camada intermédia correspondem aos dados usados no ajustamento e que, por definição, são independentes uns dos outros. Este facto simplifica o processo de aprendizagem, não sendo necessária uma divisão à priori do conjunto de dados em ajustamento, treino e teste.
As PNN geralmente são mais rápidas a aprender, mas a sua utilização é computacionalmente mais intensiva, o que pode por problemas à sua utilização em tempo real. As redes usadas são também geralmente muito maiores necessitando de mais memória que os outros sistemas. Por contra, dado os neurónios da pattern layer serem independentes, o algoritmo é altamente paralelizável, sendo relativamente fácil distribui-lo por diferentes computadores ou processadores dentro de uma mesma máquina.
3.5. Comparação dos resultados com outros modelos
Para comparação dos resultados das ferramentas implementadas, compararam-se os resultados com os obtidos pelo pacote estatístico STATISTICA 5.0. por intermédio do seu módulo de redes neuronais. O módulo de redes neuronais do Statistica 5.0 inclui as seguintes possibilidades de redes: Modelos lineares, Funções de base radial,

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 3. Métodos de Classificação •••• 18
PNNs, redes multicamadas de perceptrões (MLP) com 1 e 2 camadas de neurónios escondidos. O programa permite correr um lote de modelos pré-definidos, automaticamente seleccionar os melhores, ao mesmo tempo que escolhe a direcção de procura de outros modelos de rede. É possível escolher o número de redes que o programa salvará para posterior utilização como classificador.

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 19
4. Implementação e Resultados
4.1. Eficiência do procedimento de avaliação de uma PNN
Como foi dito, o processo de validação cruzada na convergência deste tipo de rede é feito retirando um elemento/neurónio da rede testando-o contra os restantes elementos, verificando então se ele está bem classificado. Desta forma, cada avaliação de um conjunto de sigmas tem a seguinte complexidade:
O(V.N2)
Em que V é o número de variáveis e N, o número de elementos no conjunto de treino. É então a avaliação de uma determinada rede o processo crítico no programa construído. Com efeito, de acordo com a metodologia usada, cada caso de teste é comparado com todos os outros, sendo avaliadas todas as variáveis que os constituem. Uma vez que temos 2413 casos com 27 variáveis, o número total de comparações de variáveis, e que envolvem pelo menos 3 operações de vírgula flutuante, é de 2413 x 2412 x 27 = 157 144 212. Tomou-se então particular cudado na codificação deste ciclo interno, por forma a reduzir o mais possível o tempo por ele tomado. Nas primeiras versões, esta parte do código necessitava de 52-54 ciclos de relógio por cada variável. A versão final optimizada necessita de 21 ciclos de relógio para completar (redução de cerca de 2.5x no tempo de processamento). Estes valores correspondem a código optimizado para um Pentium III com uma cache de nível 2 de 256 Kbytes, o que minimiza o acesso directo à memória com consequentes perdas de eficiência. O tipo de processamento e estrutura de dados usada contém a informação organizada de uma forma sequencial o que também possibilita optimização interna do processador e do controlador DMA, reduzindo mais uma vez as falhas de cache. Como comparação, para verificar a importância da cache de nível 2, o mesmo código a correr num
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 20
processador à mesma velocidade mas sem este tipo de cache (um Intel Celeron) demorou quatro vezes mais tempo de processamento. É contudo possível optimizar mais o código, nomeadamente, uma vez que o núcleo de processamento consiste numa avaliação de distâncias (multiplicações e somas de números de vírgula flutuante), seria possível tirar partido das extensões SIMD presentes no processador. Este tipo de optimização poderia reduzir para metade o tempo de processamento no ciclo interno e teria vantagens adicionais numa implementação num Pentium 4, que contém uma unidade FPU “ deficiente” . Por outro lado diminuiria a portabilidade do código, que foi inteiramente desenvolvido em ANSI C.
A máquina em que foi realizado todo o processo de cálculo e de ajustamento dos sigmas foi um computador PC compatível equipado com 256 Mbytes de RAM e um processador Intel Pentium III a 850 MHz a correr sobre o Sistema Operativo Windows 2000. O compilador util izado foi a versão 12.00.8804 do compilador de C/C++ da Microsoft para arquitectura IA32. A esta velocidade de processador, e para este conjunto de dados e variáveis, o tempo tomado por cada avaliação de um conjunto de sigmas é de cerca de 4 segundos. Como comparação compilou-se o mesmo código com o compilador gcc versão 2.95 a correr em Cygwin, tendo-se verificado uma melhor eficiência na compilação do código do ciclo interno, passando este a correr 20 ciclos (melhoria de 5%)
4.2. O programa implementado
O programa desenvolvido tem um interface muito simples, sendo totalmente parametrizado por um ficheiro que entra como argumento. Cada linha do ficheiro contém um parâmetro e um argumento, que pode ser texto ou numérico. Um parser extremamente básico interpreta os comandos do ficheiro e processa-os. O output é direccionado para stdout, contudo alguma informação relativa ao progresso do processo de ajustamento de parâmetros passa para stderr. Desta forma é possível redireccionar o output do programa para um ficheiro ao mesmo tempo que se acompanha em tempo real a evolução das estatísticas de classificação.
Para testar várias combinações de parâmetros, fez-se um programa de batch em que o mesmo executável testa vários scripts com parâmetros diversos.
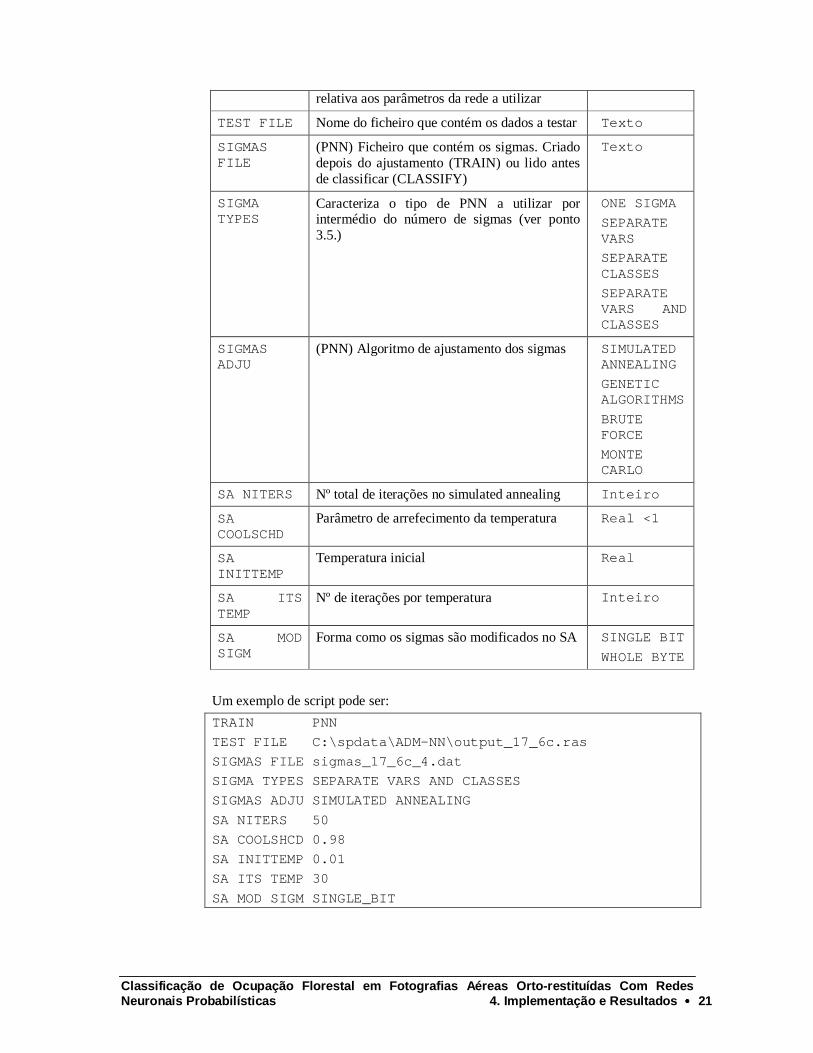
Tabela 3 - Descrição dos comandos do ficheiro de script para alimentar o programa de treinamento de redes neuronais
Comando Descr ição Parâmetros
TRAI N Informa o programa que o processamento que se segue é um “ treino” Ou seja, vai ser feito o ajustamento dos parâmetros do classificador, ou ajustando os pesos de um MLP ou os sigmas de uma PNN. O Parâmetro indica o método a usar: PNN ou MLP
PNN
MLP
CLASSI FY Comando usado em alternativa ao anterior. Pressupõe que existam os ficheiros com dados e com sigmas (ou pesos). O primeiro para ser classificado e o segundo com a informação
PNN
MLP
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 21
relativa aos parâmetros da rede a utilizar
TEST FI LE Nome do ficheiro que contém os dados a testar Text o
SI GMAS FI LE
(PNN) Ficheiro que contém os sigmas. Criado depois do ajustamento (TRAIN) ou lido antes de classificar (CLASSIFY)
Text o
SI GMA TYPES
Caracteriza o tipo de PNN a utilizar por intermédio do número de sigmas (ver ponto 3.5.)
ONE SI GMA
SEPARATE VARS
SEPARATE CLASSES
SEPARATE VARS AND CLASSES
SI GMAS ADJU
(PNN) Algoritmo de ajustamento dos sigmas SI MULATED ANNEALI NG
GENETI C ALGORI THMS
BRUTE FORCE
MONTE CARLO
SA NI TERS Nº total de iterações no simulated annealing I nt ei r o
SA COOLSCHD
Parâmetro de arrefecimento da temperatura Real <1
SA I NI TTEMP
Temperatura inicial Real
SA I TS TEMP
Nº de iterações por temperatura I nt ei r o
SA MOD SI GM
Forma como os sigmas são modificados no SA SI NGLE BI T
WHOLE BYTE
Um exemplo de script pode ser:
TRAI N PNN
TEST FI LE C: \ spdat a\ ADM- NN\ out put _17_6c. r as
SI GMAS FI LE si gmas_17_6c_4. dat
SI GMA TYPES SEPARATE VARS AND CLASSES
SI GMAS ADJU SI MULATED ANNEALI NG
SA NI TERS 50
SA COOLSHCD 0. 98
SA I NI TTEMP 0. 01
SA I TS TEMP 30
SA MOD SI GM SI NGLE_BI T

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 22
Neste exemplo, o processo de convergência da PNN é realizado com 50 iterações do simulated annealing, iniciando a uma temperatura de 0.01, decrescendo 0.98 a cada 30 modificações de sigmas. Os sigmas são modificados bit a bit e consideram-se sigmas separados por classe e variável
4.3. Comparação de resultados
Testaram-se duas PNNs, usando no primeiro caso, sigmas diferentes para cada variável, e no segundo sigmas diferentes para cada variável dentro de cada classe. Para a análise dos resultados do processo de classificação pelas diferentes metodologias, compararam-se os resultados com 3 outros modelos provindos do módulo de redes neuronais do STATISTICA. O primeiro, um modelo linear (rede com duas camadas, uma de input e outra de output), o segundo, um modelo PNN, e o terceiro, a melhor rede neuronal MLP que ele conseguiu obter dando-lhe um tempo de processamento semelhante ao necessário para calibrar os sigmas na nossa implementação de PNN. Os resultados brutos de classificação de cada um destes modelos podem ser analisados na tabela 4
Note-se contudo que os resultados não são directamente comparáveis. O módulo de redes neuronais do STATISTICA procura sempre fazer uma divisão dos dados em conjuntos de treino, de teste e verificação. Este último serve para testar os modelos desenvolvidos com dados que nunca foram apresentados ao sistema durante o período de avaliações de vários modelos de redes. Uma vez que neste package, a metodologia de validação cruzada é intrinseca ao sistema, todos os resultados se reportam a uma divisão feita à priori com 1600 elementos usados para ajustamento e 813 para teste (2/3 - 1/3).
Tabela 4 - Percentagem de classificações correctas obtidas com os diferentes classificadores
M etodologia de Classificação Classificações correctas (%)
Modelo Linear (STATISTICA) 68.63
Melhor PNN (STATISTICA) 62.85
Melhor MLP (STATISTICA) 75.52
PNN com sigmas separados por variáveis 77.95
PNN com sigmas separados por variáveis e classes 77.17
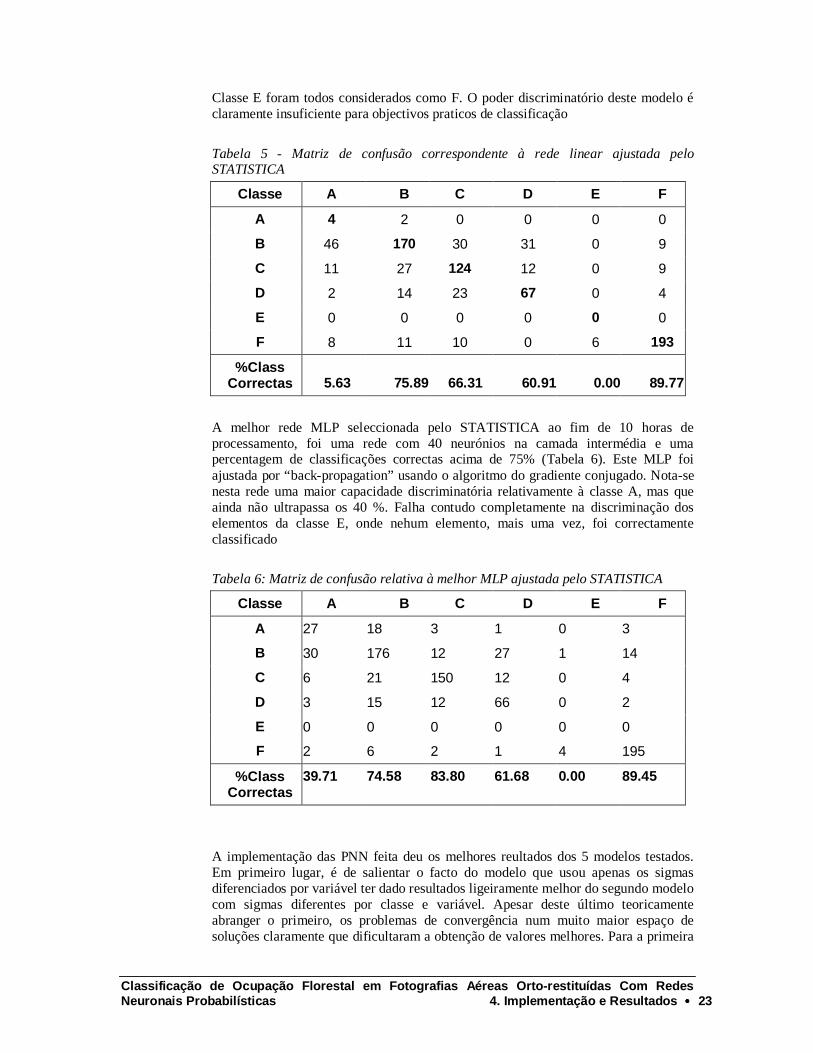
A melhor rede PNN obtida pelo STATISTICA tem uma percentagem de classificações correctas, para o conjunto de teste, de 62.85 %. Interessantemente, o modelo linear produziu muito melhores resultados. Com 68.63% de classificações correctas, este modelo, pela sua simplicidade, rapidez de convergência e facilidade de implementação é clararmente superior à PNN ajustada. A matriz de confusão (tabela 5) mostra contudo um aspecto importante. Pode-se notar a fraca capacidade do modelo linear para classificar elementos das classes A e E, centrando-se essencialmente nas classes com maior numero de elementos (B,C e F). Como seria de prever, grande parte dos elementos da classe A foram classificados como B e os da
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 23
Classe E foram todos considerados como F. O poder discriminatório deste modelo é claramente insuficiente para objectivos praticos de classificação
Tabela 5 - Matriz de confusão correspondente à rede linear ajustada pelo STATISTICA
Classe A B C D E F
A 4 2 0 0 0 0
B 46 170 30 31 0 9
C 11 27 124 12 0 9
D 2 14 23 67 0 4
E 0 0 0 0 0 0
F 8 11 10 0 6 193
%Class Correctas 5.63 75.89 66.31 60.91 0.00 89.77
A melhor rede MLP seleccionada pelo STATISTICA ao fim de 10 horas de processamento, foi uma rede com 40 neurónios na camada intermédia e uma percentagem de classificações correctas acima de 75% (Tabela 6). Este MLP foi ajustada por “ back-propagation” usando o algoritmo do gradiente conjugado. Nota-se nesta rede uma maior capacidade discriminatória relativamente à classe A, mas que ainda não ultrapassa os 40 %. Falha contudo completamente na discriminação dos elementos da classe E, onde nehum elemento, mais uma vez, foi correctamente classificado
Tabela 6: Matriz de confusão relativa à melhor MLP ajustada pelo STATISTICA
Classe A B C D E F
A 27 18 3 1 0 3
B 30 176 12 27 1 14
C 6 21 150 12 0 4
D 3 15 12 66 0 2
E 0 0 0 0 0 0
F 2 6 2 1 4 195
%Class Correctas
39.71 74.58 83.80 61.68 0.00 89.45
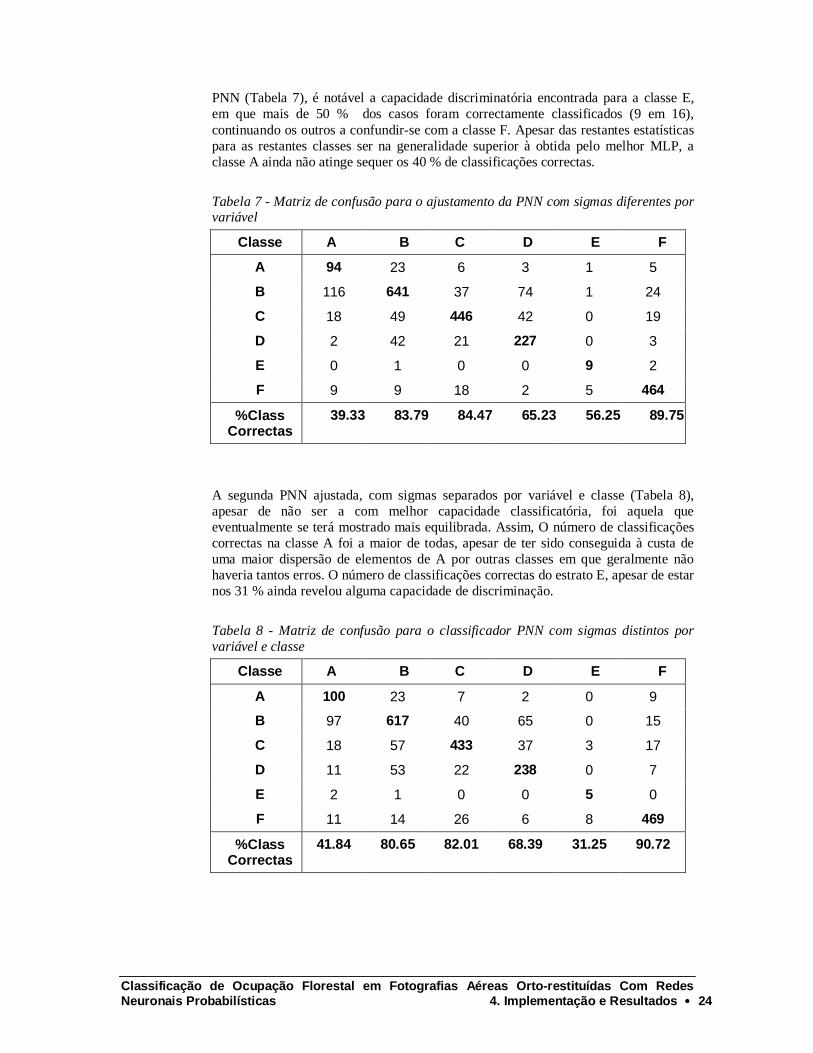
A implementação das PNN feita deu os melhores reultados dos 5 modelos testados. Em primeiro lugar, é de salientar o facto do modelo que usou apenas os sigmas diferenciados por variável ter dado resultados ligeiramente melhor do segundo modelo com sigmas diferentes por classe e variável. Apesar deste último teoricamente abranger o primeiro, os problemas de convergência num muito maior espaço de soluções claramente que dificultaram a obtenção de valores melhores. Para a primeira
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 24
PNN (Tabela 7), é notável a capacidade discriminatória encontrada para a classe E, em que mais de 50 % dos casos foram correctamente classificados (9 em 16), continuando os outros a confundir-se com a classe F. Apesar das restantes estatísticas para as restantes classes ser na generalidade superior à obtida pelo melhor MLP, a classe A ainda não atinge sequer os 40 % de classificações correctas.
Tabela 7 - Matriz de confusão para o ajustamento da PNN com sigmas diferentes por variável
Classe A B C D E F
A 94 23 6 3 1 5
B 116 641 37 74 1 24
C 18 49 446 42 0 19
D 2 42 21 227 0 3
E 0 1 0 0 9 2
F 9 9 18 2 5 464
%Class Correctas
39.33 83.79 84.47 65.23 56.25 89.75
A segunda PNN ajustada, com sigmas separados por variável e classe (Tabela 8), apesar de não ser a com melhor capacidade classificatória, foi aquela que eventualmente se terá mostrado mais equilibrada. Assim, O número de classificações correctas na classe A foi a maior de todas, apesar de ter sido conseguida à custa de uma maior dispersão de elementos de A por outras classes em que geralmente não haveria tantos erros. O número de classificações correctas do estrato E, apesar de estar nos 31 % ainda revelou alguma capacidade de discriminação.
Tabela 8 - Matriz de confusão para o classificador PNN com sigmas distintos por variável e classe
Classe A B C D E F
A 100 23 7 2 0 9
B 97 617 40 65 0 15
C 18 57 433 37 3 17
D 11 53 22 238 0 7
E 2 1 0 0 5 0
F 11 14 26 6 8 469
%Class Correctas
41.84 80.65 82.01 68.39 31.25 90.72
Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 4. Implementação e Resultados •••• 25
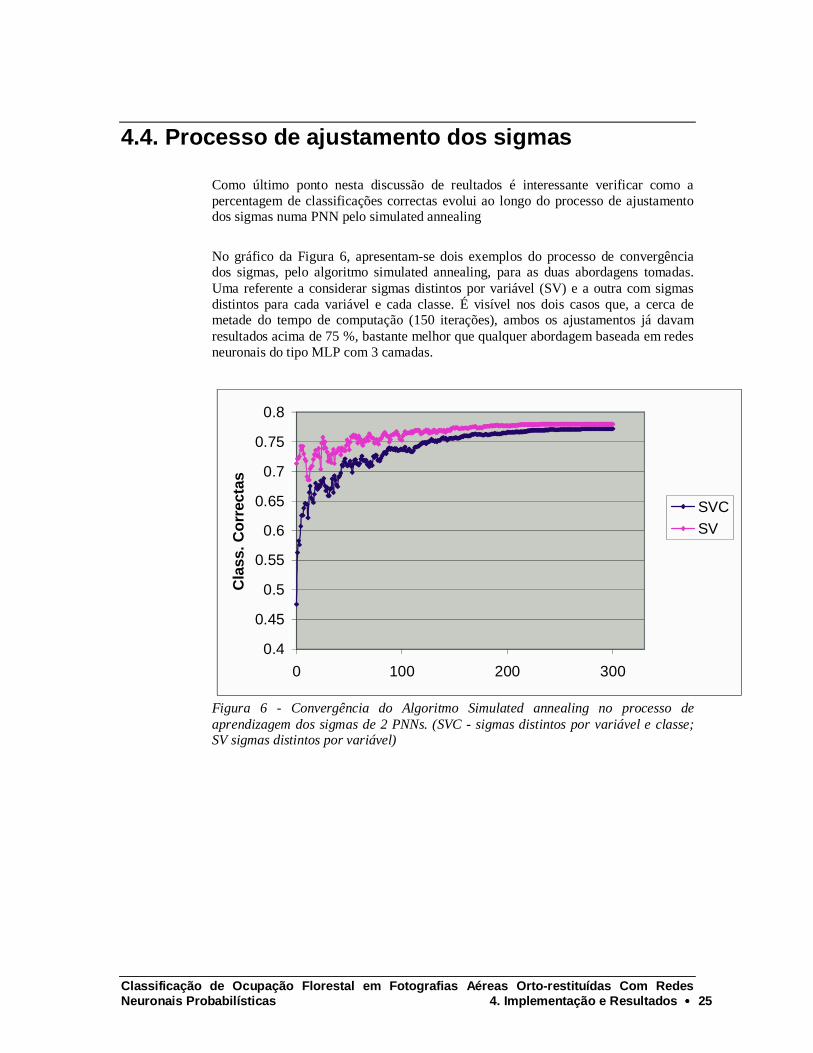
4.4. Processo de ajustamento dos sigmas
Como último ponto nesta discussão de reultados é interessante verificar como a percentagem de classificações correctas evolui ao longo do processo de ajustamento dos sigmas numa PNN pelo simulated annealing
No gráfico da Figura 6, apresentam-se dois exemplos do processo de convergência dos sigmas, pelo algoritmo simulated annealing, para as duas abordagens tomadas. Uma referente a considerar sigmas distintos por variável (SV) e a outra com sigmas distintos para cada variável e cada classe. É visível nos dois casos que, a cerca de metade do tempo de computação (150 iterações), ambos os ajustamentos já davam resultados acima de 75 %, bastante melhor que qualquer abordagem baseada em redes neuronais do tipo MLP com 3 camadas.
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0 100 200 300
Cla
ss. C
orr
ecta
s
SVCSV
Figura 6 - Convergência do Algoritmo Simulated annealing no processo de aprendizagem dos sigmas de 2 PNNs. (SVC - sigmas distintos por variável e classe; SV sigmas distintos por variável)

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 5. Conclusões •••• 26
5. Conclusões
Neste trabalho estudou-se a util ização de redes neuronais probabilísticas, na classificação de fotografias aéreas orto-rectificadas e compararam-se os seus resultados com outras metodologias de classificação implementadas num pacote estatístico. Concluiu-se que apesar de marginalmente superiores na precisão de classificação, o elevado tempo de processamento requerido no processo de parametrização e de classificação pode não conferir a este método a aplicabilidade desejada. Talvez mais importante foi a verificação do facto dos algoritmos implementados darem resultados muito melhores que um software comercial para o mesmo tipo de classificadores.
Mostrou-se ainda que um trabalho de classificação muitas vezes não se resume à escolha e parametrização de um classificador para uma dada tarefa. Outras componentes são extremamente importantes e condicionam todo o processo de classificação. Assim em primeiro lugar, verificámos que a forma como os dados são pré-processados para entrarem como variáveis no modelo é uma parte essencial no processo. Para conseguir estatísticas de classificação mínimamente credíveis foi necessário refazer muitas vezes o conjunto de dados de input, testando várias possibilidades até começar a obter resultados aceitáveis. Outro aspecto não menos importante é a definição da agregação dos estratos de foto interpretação. Um foto-intérprete experiente consegue retirar da fotografia aérea, além das espécies presentes em cada estrato, informação relativa à dimensão das árvores (relacionada estritamente com a idade) e à densidade do coberto. Como foi dito, testaram-se vários esquemas de agregações de estratos fotointerpretados, chegando a discriminar 19 classes. Não se obtiveram contudo resultados minimamente significativos. O método seguido iterativamente, de tentativa e erro, parou quando os classificadores começaram a responder minimamente bem, mas não se fez uma análise exaustiva para conhecer o detalhe máximo que é possível obter com os dados disponíveis.

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas 5. Conclusões •••• 27
Consideramos que será provavelmente possível exceder em muito os resultados obtidos se, além dos pontos enunciados, se passar por um pré-processamento das imagens (Oliveira, 1998), incidindo nos seguintes pontos:
1. Correcções referentes ao relevo (declives)
2. Correcções de exposição (posição do sol)
3. Correcção radiométrica do filme
Um outro factor que aumentará também a precisão de classificação é com certeza a util ização de índices de vegetação. Este tipo de índices podem ser obtidos por composição não linear das bandas de imagens através de funções simples. A literatura consultada mostra como este tipo de indíces (como o NDVI (Deering 1989) ou o SAVI (Huete 1988), por exemplo) é um factor fundamental em classificação por detecção remota.
Outros dois aspectos fundamentais nos resultados obtidos foi, em primeiro lugar a extraordinária importância que as probabilidades à priori de uma determinada classe podem exercer no processo classificativo. Em segundo lugar, e tomando como base a equação (1), a similaridade entre determinados tipos de estratos e total dissemelhança relativamente a outros necessariamente que corresponderá a cis diferentes entre classes. No nosso caso, e porque o resultado em si não era fundamental, optou-se por remover um estrato foto-interpretado do processo de classificação que reduziu a componente causada por estes dois factores. Outras abordagens seriam contudo possíveis. Na amostragem a realizar, e porque o conjunto de dados disponível é extenso, seria possível fazer uma amostragem selectiva para ter aproximadamente o mesmo número de pontos em cada classe. Tal método teria com certeza influência positiva nos resultados produzidos, seria no entanto problemática a extrapolação de reultados para a população, uma vez que os pressupostos básicos de amostragem de populações não estariam a ser cumpridos
Da mesma forma, outras variáveis de input poderiam ser estudadas, e outras estatísticas espaciais poderiam com certeza aumentar a precisão da classificação. Na análise em componentes principais foi detectada alguma correlação entre variáveis, nomeadamente ao nível das distâncias entre máximos e mínimos locais e provavelmente seria possível eliminar algumas das variáveis usadas e incluir outras com maior poder discriminante, sem aumentar demasiado o número de parâmetros dos modelos

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas Bibliografia Citada •••• 28
Bibliografia Citada
Deering, D. W. 1989, Field measurements of birerectional reflectance. Theory and allpications of Optical remote sensing. Ed. Ghassen Asrar. John Wiley and Sons. New York
Dewdney, A. K. 1993, The New Turing Omnibus. W H Freeman & Co. New York
Huete, A. R. 1988. A soil adjusted vegetation index (SAVI). Remote Sensing of Envirnoment 25: pp 295-309.
Masters, T, 1995, Advanced Neural Networks Recipes in C++. Academic Press
Mitchell, T, 1997. Machine Learning. McgrawHill.New York. 403pp
Oliveira, T, 1998 Cartografia quantitativa de formações arbustivas empregando dados de deteccção remota (Região florestal do Alto-Douro e Lafões). Tese de Mestrado em Gestão de Recursos Naturais. Instituto Superior de Agronomia. Lisboa. 127pp

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas Apêndice •••• 29
Apêndice
Rotina de cálculo das estatísticas espaciais
voi d Cal cSt at i s t i cs_Channel ( f l oat * buf , St at i s t i cs * st at ) { / / Cal cul ar est at í s t i cas par a cada cél ul a i ndependent ement e de l i nha e col una i nt wr , wc, wc1, wr 1, swc, swr ; f l oat sum_pi x=0; f l oat max_pi x=- 1e34f , mi n_pi x=1e34f ; f l oat pi xel ; i nt nmaxs=0, nmi ns=0; f l oat sum_maxs=0, sum_mi ns=0; bool maxi mum, mi ni mum; f l oat sqr t f 2=sqr t f ( 2. 0f ) ; f or ( wr = 0; wr < wi n_si ze; wr ++) { f or ( wc = 0; wc < wi n_si ze; wc++) { / / pr ocur ar maxs e mí ni mos l ocai s maxi mum = t r ue; mi ni mum = t r ue; pi xel =buf [ wr * wi n_si ze+wc] ; sum_pi x += pi xel ; i f ( pi xel > max_pi x) max_pi x=pi xel ; i f ( pi xel < mi n_pi x) mi n_pi x=pi xel ; f or ( swr = wr - 1; swr <= wr +1; swr ++) { f or ( swc = wc- 1; swc <= wc+1; swc++) { / / compar ar v i z i nhos com a cél ul a do cent r o wr 1 = swr ; wc1 = swc; i f ( swr < 0) wr 1 = wi n_si ze- 1; i f ( swc < 0) wc1 = wi n_si ze- 1; i f ( swr > wi n_si ze- 1) wr 1 = 0; i f ( swc > wi n_si ze- 1) wc1 = 0; i f ( ( wc1 ! = wc) | | ( wr 1 ! = wr ) ) { / / ver i f i car se é mai or ou menor que out r os i f ( pi xel < buf [ wr 1* wi n_si ze+wc1] ) maxi mum = f al se; i f ( pi xel > buf [ wr 1* wi n_si ze+wc1] ) mi ni mum = f al se; i f ( pi xel == buf [ wr 1* wi n_si ze+wc1] ) { mi ni mum = f al se; maxi mum = f al se; } } } }

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas Apêndice •••• 30
i f ( maxi mum && ! mi ni mum) { g_maxs[ nmaxs] . r ow=wr ; g_maxs[ nmaxs] . col =wc; nmaxs++; sum_maxs += pi xel ; } i f ( mi ni mum && ! maxi mum) { g_mi ns[ nmi ns] . r ow=wr ; g_mi ns[ nmi ns] . col =wc; nmi ns++; sum_mi ns += pi xel ; } } } s t at - >avg_pi x =sum_pi x/ ( wi n_si ze* wi n_si ze) ; s t at - >max_pi x = max_pi x; s t at - >mi n_pi x = mi n_pi x; / / Aval i ar as di s t ânci as ent r e máxi mos e mí ni mos i nt i , j , r i , r j , c i , c j ; f l oat di s t _r , di s t _c, di s t _p, di s t , max_di st =0, mi n_di st =1e34f , sum_di st s=0; f l oat ndi s t s=0; f or ( i =0; i <nmaxs- 1; i ++) { f or ( j =i +1; j <nmaxs; j ++) { r i =g_maxs[ i ] . r ow; r j =g_maxs[ j ] . r ow; c i =g_maxs[ i ] . col ; c j =g_maxs[ j ] . col ; di s t _r = ( f l oat ) ( r i - r j ) * ( r i - r j ) ; di s t _c = ( f l oat ) ( c i - c j ) * ( c i - c j ) ; di s t _p = ( f l oat ) ( buf [ r i * wi n_si ze+ci ] - buf [ r j * wi n_si ze+cj ] ) * ( buf [ r i * wi n_si ze+ci ] - buf [ r j * wi n_si ze+cj ] ) ; di s t =sqr t f ( di s t _r +di st _c+di st _p) ; i f ( di s t > max_di st ) max_di st =di st ; i f ( di s t < mi n_di st ) mi n_di st =di st ; sum_di st s += di s t ; ndi s t s++; } } i f ( ndi s t s>0) { s t at - >avg_di st _maxs =( sum_di st s/ ndi st s) / ( sqr t f 2* wi n_si ze) ; s t at - >mi n_di st _maxs=mi n_di st / ( sqr t f 2* wi n_si ze) ; s t at - >sum_maxs =nmaxs/ ( wi n_si ze* wi n_si ze/ 2. 0f ) ; } el se { s t at - >avg_di st _maxs=1. 0f ; s t at - >mi n_di st _maxs=1. 0f / ( sqr t f 2* wi n_si ze) ; s t at - >sum_maxs =nmaxs/ ( wi n_si ze* wi n_si ze/ 2. 0f ) ; } mi n_di st =1e34f ; max_di st =0; sum_di st s=0; ndi s t s=0; f or ( i =0; i <nmi ns- 1; i ++) { f or ( j =i +1; j <nmi ns; j ++) { / / par a var i ar f az- se a di s t ânci a em 3d! r i =g_mi ns[ i ] . r ow; r j =g_mi ns[ j ] . r ow; c i =g_mi ns[ i ] . col ; c j =g_mi ns[ j ] . col ; di s t _r = ( f l oat ) ( r i - r j ) * ( r i - r j ) ; di s t _c = ( f l oat ) ( c i - c j ) * ( c i - c j ) ; di s t _p = ( f l oat ) ( buf [ r i * wi n_si ze+ci ] - buf [ r j * wi n_si ze+cj ] ) * ( buf [ r i * wi n_si ze+ci ] -buf [ r j * wi n_si ze+cj ] ) ; di s t = sqr t f ( di s t _r +di st _c+di st _p) ; i f ( di s t > max_di st ) max_di st =di st ; i f ( di s t < mi n_di st ) mi n_di st =di st ; sum_di st s += di s t ; ndi s t s++; } } i f ( ndi s t s>0) { s t at - >avg_di st _mi ns =( sum_di st s/ ndi st s) / ( sqr t f 2* wi n_si ze) ; s t at - >mi n_di st _mi ns=mi n_di st / ( sqr t f 2* wi n_si ze) ; s t at - >sum_mi ns =nmi ns/ ( wi n_si ze* wi n_si ze/ 2. 0f ) ;

Classificação de Ocupação Florestal em Fotografias Aéreas Orto-restituídas Com Redes Neuronais Probabilísticas Apêndice •••• 31
} el se { s t at - >avg_di st _mi ns = 1. 0f ; s t at - >mi n_di st _mi ns = 1. 0f ; s t at - >sum_mi ns =nmi ns/ ( wi n_si ze* wi n_si ze/ 2. 0f ) ; } }


















