Convergencia de matrizes estocˆ asticas regulares´ · 1 Introduc¸ao˜ O interesse em...
11
ISSN 2316-9664 Volume 8, dez. 2016 Edic ¸˜ ao Iniciac ¸˜ ao Cient´ ıfica Fabiano Borges da Silva Faculdade de Ciˆ encias, UNESP, Bauru/SP. [email protected] Isabela Silva Rota Faculdade de Engenharia, UNESP, Bauru/SP. [email protected] Iniciac ¸˜ ao Cient´ ıfica FAPESP Processo n. 2015/21044-1 Convergˆ encia de matrizes estoc´ asticas regulares Convergence of regular stochastic matrices Resumo Seja T uma matriz estoc´ astica associada a uma Cadeia de Markov finita, isto ´ e, as entradas da matriz representam as probabilidades de transic ¸˜ ao entre os estados do processo. O presente artigo mos- tra que se T ´ e regular, ent˜ ao T n converge para M, quando n tende ao infinito, onde M ´ e uma matriz em que todas as colunas s˜ ao iguais ao ´ unico vetor de probabilidade w que satisfaz a equac ¸˜ ao Tw = w. Al´ em disso, dado um vetor de probabilidade v qual- quer, temos que T n v converge para o vetor w. Geralmente, este resultado ´ e conhecido como uma consequˆ encia do Teorema de Perron-Frobenius para operadores positivos. Por´ em, neste traba- lho apresentamos uma demonstrac ¸˜ ao utilizando conceitos b´ asicos de matrizes e sequˆ encias de n ´ umeros reais. Palavras-chave: Matrizes estoc´ asticas. Cadeias de Markov. Convergˆ encia. Probabilidade de transic ¸˜ ao. Abstract Let T be a stochastic matrix associated with a finite Markov Chain, i.e. the matrix wich entries represent the probabilities tran- sition for the states of the process. This article shows that if T is regular, then T n converges to M when n tends to infinity, where M is the matrix which all columns are the same as unique proba- bility vector w satisfying the equation Tw = w. In addition, given any probability vector v, we have T n v converges to the vector w. Generally, this result is known as a result of the Perron-Frobenius theorem for positive operators. However, in this paper we present a demonstration using basic concepts of matrices and sequences of real numbers. Keywords: Stochastic matrices. Markov Chains. Convergence. Transition probability.
Transcript of Convergencia de matrizes estocˆ asticas regulares´ · 1 Introduc¸ao˜ O interesse em...

ISSN 2316-9664Volume 8, dez. 2016
Edicao IniciacaoCientıfica
Fabiano Borges da SilvaFaculdade de Ciencias,UNESP, Bauru/[email protected]
Isabela Silva RotaFaculdade de Engenharia,UNESP, Bauru/[email protected] Cientıfica FAPESPProcesso n. 2015/21044-1
Convergencia de matrizes estocasticas regularesConvergence of regular stochastic matrices
ResumoSeja T uma matriz estocastica associada a uma Cadeia de Markovfinita, isto e, as entradas da matriz representam as probabilidadesde transicao entre os estados do processo. O presente artigo mos-tra que se T e regular, entao T n converge para M, quando n tendeao infinito, onde M e uma matriz em que todas as colunas saoiguais ao unico vetor de probabilidade w que satisfaz a equacaoTw = w. Alem disso, dado um vetor de probabilidade v qual-quer, temos que T nv converge para o vetor w. Geralmente, esteresultado e conhecido como uma consequencia do Teorema dePerron-Frobenius para operadores positivos. Porem, neste traba-lho apresentamos uma demonstracao utilizando conceitos basicosde matrizes e sequencias de numeros reais.Palavras-chave: Matrizes estocasticas. Cadeias de Markov.Convergencia. Probabilidade de transicao.
AbstractLet T be a stochastic matrix associated with a finite MarkovChain, i.e. the matrix wich entries represent the probabilities tran-sition for the states of the process. This article shows that if T isregular, then T n converges to M when n tends to infinity, whereM is the matrix which all columns are the same as unique proba-bility vector w satisfying the equation Tw = w. In addition, givenany probability vector v, we have T nv converges to the vector w.Generally, this result is known as a result of the Perron-Frobeniustheorem for positive operators. However, in this paper we presenta demonstration using basic concepts of matrices and sequencesof real numbers.Keywords: Stochastic matrices. Markov Chains. Convergence.Transition probability.

1 IntroducaoO interesse em convergencia de matrizes estocasticas, aparece entre outros, no contexto de
Cadeias de Markov finita, o qual e um caso especial de processo estocastico. Mais precisamente,considere um espaco de estados com um numero finito de elementos E = e1, ...,er. Um pro-cesso estocastico discreto (Xn)n∈N, definido em um espaco de probabilidade (Ω,F ,P), e umaCadeia de Markov se a probabilidade condicional satisfizer
P(Xn+1 = xn+1|Xn = xn...,X0 = x0) = P(Xn+1 = xn+1|Xn = xn), (1)
para todo n≥ 1 e para toda sequencia x0,x1, ...,xn+1 de elementos do espaco de estados E. Essacondicao (1) significa, em linguagem natural, que o futuro do processo, uma vez conhecido oestado presente, e independente do passado. Esta definicao tambem pode ser estendida para umconjunto enumeravel E.
As probabilidades condicionais
P(Xn+1 = ei|Xn = e j)
sao chamadas probabilidades de transicao. E se para cada i, j
P(Xn+1 = ei|Xn = e j) = P(X1 = ei|X0 = e j),
para todo natural n, a Cadeia de Markov e dita homogenea e as probabilidades de transicao saodenotadas por pi j.
Intuitivamente, pensando em um modelo de uma partıcula que salta em tempos discretos entreos estados, atribui-se a cada estado e j uma probabilidade da partıcula, estando em e j, de saltarpara o ei. E no caso homogeneo, essa probabilidade nao se altera com o tempo.
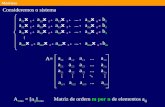
Um processo de Markov esta completamente definido a partir do momento em que se espe-cifica as probabilidades de transicao e a distribuicao inicial dos estados (ver por exemplo [2, 3]).Ao processo associa-se uma matriz de probabilidades de transicao T , chamada em geral pormatriz estocastica ou simplesmente de transicao, em que as entradas da matriz sao dadas pelasprobabilidades de transicao pi j. Ou seja,
T = [pi j]r×r,
onde pi j ≥ 0 e a soma das entradas de cada coluna e igual a 1.As entradas da matriz T n correspondem a probabilidade de, saindo do estado e j, chegar-se ao
estado ei depois de n passos, como pode ser visto, entre outros, em [2, 3]. Desta maneira, dadauma distribuicao inicial, representada matricialmente pelo vetor de probabilidade
v =
v1...
vr
,a distribuicao do processo no tempo n≥ 1 e dada por
T n · v.
5
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Uma questao interessante nas aplicacoes modeladas por Cadeias de Markov, e saber o queacontece com o vetor T n(v) quando n tende ao infinito. Mostraremos que, se T e regular, istoe, em alguma potencia N ≥ 1, todas as entradas de (T N) sao elementos nao-nulos, entao T n
aproxima-se de uma matriz M quando n tende ao infinito, onde a matriz estocastica M e talque todas as suas colunas sao iguais w, sendo w o unico vetor que satisfaz Tw = w. O objetivoprincipal deste artigo e demonstrar este resultado (Teorema 5), que e enunciado em [1], livrobastante utilizado em cursos de Algebra Linear, mas que nao apresenta uma demonstracao pornao ser um dos objetivos do livro, conforme menciona os autores do mesmo.
Na literatura, a demonstracao do Teorema 5 aparece, em geral, como consequencia do Teo-rema de Perron-Frobenius, onde resultados de teoria espectral sao utilizados para sua demonstracao.Neste artigo, nao seguimos essa direcao. Fizemos uma demonstracao baseada em tecnicas apre-sentadas por [3], porem com algumas modificacoes necessarias, uma vez que trabalhamos nestetexto com a matriz estocastica agindo a esquerda (T · v) (como em [1]), enquanto que em [3] aacao e a direita (v ·T ). Tambem serviu de apoio para este trabalho algumas ideias apresentadas nademonstracao para o caso particular de matrizes estocasticas 2×2 apresentada em [4]. Por fim,e importante ressaltar que a demonstracao do Teorema 5, apresentada neste artigo, mesmo sendogeral para matrizes r× r, utiliza resultados basicos de matrizes e convergencia de sequenciasde numeros reais, tornando um texto bastante acessıvel para leitores iniciantes em estudos deCadeias de Markov Finitas ou Algebra Linear.
2 Matrizes estocasticas regularesNesta secao daremos definicao de matrizes regulares e um resultado sobre matrizes estocasticas
que serao utilizados no Teorema 5.
Definicao 1 Dizemos que uma matriz estocastica T e regular se existe natural n tal que T n temtodas as entradas nao nulas.
Por exemplo, vamos verificar se a matriz
A =
0 1 0,20,3 0 0,30,7 0 0,5
, (2)
e uma matriz estocastica regular. Fazendo A2, obtemos:
A2 =
0,44 0 0,400,21 0,30 0,210,35 0,70 0,39
,logo, em um primeiro momento nao podemos afirmar que a matriz A e regular. Continuando oprocesso, temos que
A3 =
0,280 0,440 0,2880,237 0,210 0,2370,483 0,350 0,475
,e, portanto, A e uma matriz estocastica regular.
6
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Contudo, nem toda matriz estocastica e regular. Tomando por exemplo,
B =
[0 11 0
],
temos que e estocastica, mas nao e regular, pois T 2n = I e T 2n+1 = T , para todo n = 0,1,2, ... .
Notemos que no nosso exemplo acima, para a matriz estocastica A obtivemos matrizes A2 eA3 tambem estocasticas. E isto nao e um caso particular para a matriz A. Em geral, se T e umamatriz estocastica, entao T n tambem e estocastica, para todo n≥ 1. Isso pode ser verificado coma seguinte proposicao.
Proposicao 2 Produto de matrizes estocasticas e estocastica.
Demonstracao. Basta mostrar que se A = (ai j)r×r e B = (bi j)r×r sao matrizes estocasticas, entaoa matriz AB tambem e estocastica.
Cada entrada i j da matriz AB e dada por
(AB)i j =r
∑k=1
aikbk j.
E somando os elementos da j-esima coluna, temos que:
r
∑i=1
(AB)i j =r
∑i=1
(r
∑k=1
aikbk j)
=r
∑k=1
(r
∑i=1
aik︸ ︷︷ ︸1
)bk j
=r
∑k=1
bk j
= 1.
2
3 Convergencia para matrizes estocasticas regularesNesta secao mostraremos que matrizes estocasticas regulares convergem. Para isso, faremos
dois lemas que serao uteis na demonstracao desta convergencia.
Lema 3 Seja T uma matriz r× r tal que todas as entradas sao iguais a ε = 1r . Temos entao que
T n = T , para todo n≥ 1.
7
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Demonstracao.Considere B a matriz com todas as entradas iguais a 1, desta forma temos que Tr×r = εBNote que B2 = rB. Logo,
B3 = B.B2 = B(rB)= rB2
= r.rB= r2B.
E fazendo isso sucessivamente, concluımos que
Bn = rn−1B.
Portanto, para qualquer n≥ 1, temos que:
T n = εn.rn−1B
=1rn .r
n−1B
=1r
B
= εB= T.
2
Para simplificar, denotaremos de agora em diante por max(x) a maxima componente do vetorx e min(x) a menor componente do vetor x. Por exemplo, sendo x = (3
7 ,17 ,
17 ,
27), temos que
max(x) = 37 e min(x) = 1
7 .
Lema 4 Seja T uma matriz estocastica r× r com todas as entradas nao-nulas e seja ε o menorvalor entre todas as entradas. Seja tambem x um vetor linha tal que M0 = max(x) e m0 = min(x).E seja M1 = max(xT ) e m1 = min(xT ). Entao,
M1−m1 ≤ (1−2ε)(M0−m0).
Demonstracao.Seja x′ o vetor linha obtido de x em que todas as entradas foram substituıdas por M0 com
excecao da unica entrada m0. Ao fazer x′T , observa-se que uma entrada α qualquer de T emultiplicada pela mınima componente m0 do vetor x′ e todas as outras entradas sao multiplicadaspor M0. Como as colunas de T somam 1, nos permite representar cada entrada da nova matrizx′T da forma
αm0 +(1−α)M0 = M0−α(M0−m0).
Para cada coluna de T temos um valor de α diferente, porem em todos os casos α ≥ ε , e sendoassim
M0−α(M0−m0)≤M0− ε(M0−m0).
8
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Como max(xT )≤ max(x′T ), temos
M1 ≤M0− ε(M0−m0).
Seja agora x′ o vetor linha obtido de x em que todas as entradas foram substituıdas por m0com excecao da unica entrada M0.
Novamente, ao fazer x′T , observa-se que uma entrada α qualquer de T e multiplicada pelamaxima componente M0 do vetor x′ e todas as outras entradas sao multiplicadas por m0 e, por-tanto, cada entrada da nova matriz x′T e da forma
αM0 +(1−α)m0 = m0 +α(M0−m0).
Para o α de cada coluna, temos α ≥ ε , e assim
m0 +α(M0−m0)≥ m0 + ε(M0−m0).
E como min(xT )≥ min(x′T ), concluımos que
m1 ≥ m0 + ε(M0−m0),
ou ainda,−m1 ≤−m0− ε(M0−m0).
Logo,
M1−m1 ≤ M0−m0−2ε(M0−m0)
= (1−2ε)(M0−m0).
2
Teorema 5 Se T e uma matriz estocastica regular r× r entao:
(i) T n se aproxima de uma matriz M, no sentido de que cada entrada da matriz T n aproxima-seda entrada correspondente em M;
(ii) Todas as colunas de M sao iguais, sendo dadas por um vetor coluna
w =
w1...
wr
,com wi > 0, para i = 1, . . . ,r ;
9
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

(iii) Para qualquer vetor de probabilidades inicial
v =
v1...
vr
,o vetor de probabilidades T nv converge para w, quando n→ ∞ ;
(iv) O vetor w e o unico que satisfaz Tw = w.
Demonstracao.Prova dos itens (i) e (ii). Dividiremos em duas partes:Parte A. Vamos supor inicialmente que T e uma matriz com entradas todas nao nulas e que
ε > 0 seja uma entrada da matriz, cujo valor e menor ou igual que as outras entradas. Particular-mente, para a coluna na qual ε pertence, que escrito como vetor linha [δ1,δ2, ...,ε, ...,δr−1] (comε podendo ocupar qualquer posicao e δi ≥ ε), temos que
0 < rε ≤ δ1 +δ2 + ...+ ε + ...δr−1 = 1.
Logo
0 < ε ≤ 1r.
O caso em que ε = 1r temos pelo pela Lema 3 que T n→ T , e neste caso, M = T . Vamos supor
daqui em diante que 0 < ε < 1r .
Tomemos o vetor e j = (0, ...,0,1,0, ...,0), ou seja, um vetor com o numero 1 na j-esimaposicao, e sejam Mn = max(e jT n) e mn = min(e jT n), para n = 0,1,2, ... . Vamos considerar aquiT 0 = I e, portanto, M0 = max(e jT 0) = max(e j) = 1 e m0 = min(e jT 0) = min(e j) = 0. ComoM1 = max(e jT ) e m1 = min(e jT ), pelo Lema 4 temos que
M1−m1 ≤ (1−2ε)(M0−m0).
Analogamente, podemos escrever M2 = max((e jT )T ) e m2 = min((e jT )T ), e aplicando no-vamente o Lema 4, chegamos a
M2−m2 ≤ (1−2ε)(M1−m1)
= (1−2ε)(1−2ε)(M0−m0),
ou seja,M2−m2 ≤ (1−2ε)2(M0−m0).
Para um n qualquer podemos escrever Mn = max((e jT n−1)T ) e mn = min((e jT n−1)T ), apli-car o procedimento anteriormente descrito sucessivas vezes e assim obter que
Mn−mn ≤ (1−2ε)n(M0−m0).
10
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Como 0 < ε < 1r , segue que 0 < (1− 2ε) < 1 e, portanto, (1− 2ε)n→ 0 quando n→ ∞. E
ainda, como M0−m0 = 1, segue na desigualdade acima que Mn e mn se aproximam para umlimite comum quando n→ ∞, digamos w j. E claro que mn ≤ w j ≤Mn. Note ainda que m1 > 0,pois m1 e por definicao a menor entrada da j-esima linha de T , a qual possui entradas nao nulas,e M1 < 1, pois se alguma linha de T tiver 1 numa das entradas, terıamos 0 nas demais entradasda coluna, o que nao e o caso. E sendo assim, temos que 0 < w j < 1.
Portanto, em resumo temos que e jT n tende a um vetor em que a maior e a menor componentese aproximam, ou seja, um vetor onde todas as componentes tendem a w j > 0. Logo, a j-esimalinha de M e dada por um vetor de entradas w j. Assim, as colunas de M sao iguais a um vetor
w =
w1...
wr
.Como T e uma matriz estocastica, segue pela Proposicao 2 que T n tambem e estocastica. E,
desta forma, a matriz limite M tambem e estocastica. De fato, em termos das entradas da j-esimacoluna de T n, obtemos uma sequencia em n, digamos γn
1 j...
γnr j
tal que γn
1 j + ...+ γnr j = 1, para todo n≥ 1. E tomando o limite na sequencia dada pela soma das
entradas da j-esima coluna temos que
1 = limn→∞
(γn1 j + ...+ γ
nr j)
= limn→∞
γn1 j + ...+ lim
n→∞γ
nr j
= w1 + ...+wr.
Ou seja, M tambem e uma matriz estocastica.Parte B. Vamos supor que T e regular e que alguma entrada de T seja zero. Nas mesmas
condicoes do Lema 4, porem para ε = 0, e usando as notacoes como na Parte A para Mn e mn,obtemos que
M0−m0 ≥M1−m1 ≥M2−m2 ≥ ... .
Agora, usando o fato que T e regular, temos que existe N tal que T N e uma matriz estocasticacujas entradas sao nao nulas. Denotando por ε ′ o menor valor das entradas de T N e tomando asmesmas ideias utilizadas na Parte A, temos que 0 < ε ′ ≤ 1
r . O caso em que ε ′ = 1r e resolvido
como no Lema 3. Vamos de agora em diante analisar o caso em que 0 < ε ′ < 1r .
Idem a Parte A, tambem usaremos o vetor e j = (0, ...0,1,0, ...0) com 1 na j-esima posicao.Temos assim que
MNk = max(e j(T N)k) = max((e jT Nk−1)T )
emNk = min(e j(T N)k) = min((e jT Nk−1)T )
11
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

para k≥ 1. Quando k= 0, obtemos MN0 =max(e j(T N)0)=max(e j)=M0 e mN0 =min(e j(T N)0)=min(e j) = m0. Portanto, analogamente ao que fizemos na Parte A, obtemos que
MNk−mNk ≤ (1−2ε′)k(M0−m0),
para k≥ 0. Como 0 < ε ′ < 1r segue que (1−2ε ′)k→ 0 quando k→∞ e, portanto, a subsequencia
(MNk−mNk) da sequencia nao crescente (Mn−mn) tende a 0. Logo a sequencia (Mn−mn) tendea 0 tambem. E o restante da prova segue como na Parte A.
Prova do item (iii).Temos que T nv tende Mv quando n→ ∞. Alem disso, uma vez que v1 + · · ·+ vr = 1, segue
que
Mv =
w1 w1 · · · w1w2 w2 · · · w2...
... . . . ...wr wr · · · wr
v1v2...
vr
=
w1(v1 + · · ·+ vr)w2(v1 + · · ·+ vr)
...wr(v1 + · · ·+ vr)
=
w1w2...
wr
.Portanto,
T nv→ w.
Prova do item (iv).Temos que T nT →MT . Por outro lado, T n+1→M. Logo, pela unicidade do limite, MT =M.
Analogamente, T M = M. E assim temos: p11 · · · p1r... . . . ...
pr1 · · · prr
w1 · · · w1
... . . . ...wr · · · wr
=
w1 · · · w1... . . . ...
wr · · · wr
.E desta equacao matricial extraımos p11 · · · p1r
... . . . ...pr1 · · · prr
w1
...wr
=
w1...
wr
.Ou seja,
Tw = w.
Vamos agora mostrar a unicidade de w. Suponha que w seja outro vetor de probabilidadecom T w = w. Logo T nw = w, para todo n ≥ 1. E assim, T nw→ w. Mas por (iii) sabemos queT nw→ w. Logo, pela unicidade do limite, segue que w = w.
2
Este resultado acima, no contexto de Cadeias de Markov, diz que se a matriz de transicao T eregular, entao e possıvel fazer previsoes a longo prazo e elas nao dependem da distribuicao inicialv. O item (iv) nos fornece uma maneira facil de encontrar o vetor de probabilidades w, que doponto de vista dinamico, e um ponto fixo atrator para a aplicacao T .
12
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

Apenas para ilustrar como este teorema e usado no contexto de Cadeias de Markov, dare-mos a seguir um exemplo omitindo alguns detalhes formais de processos estocasticos, que saoabordados, por exemplo, em [2, 3, 5].
Exemplo 1 Vamos supor que uma empreza XZ pertencente ao mercado de alimentos industria-lizados esta interessada em fazer um estudo das preferencias de seus consumidores. Para isso,notou que quando tres produtos A, B e C sao ofertados no mercado, inicialmente, 10% dos con-sumidores compram o produto A, 20% o produto B e 70% preferem o C. No entanto, passado umano, em 30% das vezes, o consumidor que sempre compra A, opta por comprar B e o restantedos consumidores compram C. Uma vez tendo comprado B, o cliente sempre volta a comprarA. E quando compra C, metade dos clientes permanecem comprando C e 20% deles voltam acomprar A. E este processo se repete a cada ano que passa.
A longo prazo, como estara a distribuicao de preferencia do consumidor?
Na questao acima, podemos tomar A,B,C como sendo os estados 1, 2 e 3, ou seja, E =1,2,3. Sendo assim, a matriz de probabilidades de transicao e dada pelas porcentagens de trocade preferencias entre os produtos A, B e C. Portanto, a matriz de transicao T para este exemploacima e a matriz dada em (2), a qual ja verificamos ser regular. E o vetor de probabilidades iniciale dado por:
v =
0,10,20,7
.A fim de descobrirmos qual sera o vetor de preferencias a longo prazo w, podemos usar o
item (iv) do Teorema 5, ou seja, resolver a equacao matricial 0 1 0,20,3 0 0,30,7 0 0,5
wAwBwC
=
wAwBwC
.Resolvendo o sistema obtemos que
w =
25783133578
=
0.32051280.2307690.4487179
.Isto quer dizer que a longo prazo, teremos aproximadamente 32,1% dos consumidores preferindoo produto A, 23,1% o B e 44,9% preferindo o produto C.
Agora, apenas para ilustrar a convergencia T n · v→ w no exemplo acima, explicitaremos aseguir alguns resultados para potencias da matriz T aplicadas ao vetor de probabilidade inicial v.Em termos da primeira potencia temos 0 1 0,2
0,3 0 0,30,7 0 0,5
0,10,20,7
=
0,340,240,42
.Para a potencia 2 por exemplo, obtemos o vetor de probabilidade
13
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/

0 1 0,20,3 0 0,30,7 0 0,5
2 0,10,20,7
=
0,3240,2280,448
.Significando que 32,4%, 22,8% e 44,8% dos consumidores preferem os produtos A, B e C, res-pectivamente, no segundo ano de vendas. E por exemplo, para as potencias 5 e 10, obtemosrespectivamente que: 0 1 0,2
0,3 0 0,30,7 0 0,5
5 0,10,20,7
=
0.3200640.2308440.449092
, 0 1 0,2
0,3 0 0,30,7 0 0,5
10 0,10,20,7
=
0,320514226240,230769049080,44871672468
.Alem disso, podemos tambem notar que as colunas da matriz T 10, 0 1 0,2
0,3 0 0,30,7 0 0,5
10
=
0,3205236024 0,3204770800 0,32052350000,2307678681 0,2307737730 0,23076786810,4487085295 0,4487491470 0,4487086319
,possui valores que se aproximam do vetor de probabilidade w como garante o Teorema 5.
Referencias[1] BOLDRINI, J. L. et al. Algebra linear. 3. ed. Sao Paulo: Harper e Row do Brasil, 1980.
[2] BRZEZNIAK, Z.; ZASTAWNIAK, T. Basic stochastic processes: a course through exer-cises. London: Springer, 1999.
[3] KEMENY, J. G.; SNELL, J. L. Finite Markov chains. New York: Springer-Verlag, 1960.
[4] MANOEL, M. R. Cadeias de Markov: uma abordagem voltada para o ensino medio.2016. 69 f. Dissertacao (Mestrado Profissional) - Instituto de Matematica, Estatıstica eComputacao Cientıfica, Universidade Estadual de Campinas, Campinas, 2016.
[5] RUFFINO, P. R. C. Uma iniciacao aos sistemas dinamicos estocasticos. 2. ed. Rio deJaneiro: IMPA, 2009.
14
SILVA, F. B.; ROTA, I. S. Convergência de matrizes estocásticas regulares. C.Q.D.– Revista Eletrônica Paulista de Matemática, Bauru, v. 8, p. 4-14, dez.
2016. Edição Iniciação Científica.
DOI: 10.21167/cqdvol8201623169664fbsisr0414 - Disponível em: http://www.fc.unesp.br/#!/departamentos/matematica/revista-cqd/