e Statistic A
102
UNIVERSIDADE REGIONAL INTEGRADA DO ALTO URUGUAI E DAS MISSÕES DEPARTAMENTO DE CIÊNCIAS AGRÁRIAS APOSTILA DE AULA ESTATÍSTICA BÁSICA Professor Dr. Lauri Lourenço Radünz UFFS- Campus Erechim ERECHIM/RS 2009
-
Upload
herikaviana -
Category
Documents
-
view
33 -
download
1
description
estatistica
Transcript of e Statistic A

UNIVERSIDADE REGIONAL INTEGRADA DO ALTO URUGUAI E DAS MISSÕES
DEPARTAMENTO DE CIÊNCIAS AGRÁRIAS
APOSTILA DE AULA
ESTATÍSTICA BÁSICA
Professor Dr. Lauri Lourenço Radünz
UFFS- Campus Erechim
ERECHIM/RS
2009

SUMÁRIO
1 A NATUREZA DA ESTATÍSTICA ...................................................................................................... 2
1.1 CONSIDERAÇÕES GERAIS ........................................................................................................... 2
1.2 TIPOS DE CONHECIMENTO ......................................................................................................... 2
1.2.1 Conhecimento empírico ............................................................................................................. 2
1.2.2 Conhecimento filosófico ............................................................................................................ 2
1.2.3 Conhecimento teológico ............................................................................................................ 2
1.2.4 Conhecimento científico ............................................................................................................ 2
1.3 MÉTODO DE PESQUISA ................................................................................................................ 2
1.3.1 Pesquisa bibliográfica ................................................................................................................ 2
1.3.2 Pesquisa documental ................................................................................................................. 3
1.3.3 Levantamento ............................................................................................................................. 3
1.3.4 Estudo de caso ........................................................................................................................... 3
1.3.5 Estudo de protótipo .................................................................................................................... 3
1.3.6 Pesquisa não experimental ....................................................................................................... 3
1.3.7 Pesquisa ação ............................................................................................................................. 3
1.3.8 Pesquisa participante ................................................................................................................. 3
1.4 O MÉTODO CIENTÍFICO ................................................................................................................ 3
1.5 FASES DO MÉTODO ESTATÍSTICO ............................................................................................. 4
1.5.1 Planejamento .............................................................................................................................. 4
1.5.2 Coleta dos dados ........................................................................................................................ 4
1.5.3 Crítica dos dados ........................................................................................................................ 4
1.5.4 Apuração dos dados .................................................................................................................. 4
1.5.5 Exposição ou apresentação ...................................................................................................... 4
1.5.6 Análise dos resultados .............................................................................................................. 4
2 POPULAÇÃO E AMOSTRA .............................................................................................................. 5
2.1 CLASSIFICAÇÃO DAS VARIÁVEIS ................................................................................................ 5
2.2 POPULAÇÃO E AMOSTRA ............................................................................................................ 5
2.3 AMOSTRAGEM ............................................................................................................................... 5
2.3.1 Amostragem casual ou aleatória simples ................................................................................ 5
2.3.2 Amostragem proporcional estratificada ................................................................................... 6
2.3.3 Amostragem sistemática ........................................................................................................... 6
2.4 DETERMINAÇÃO DO TAMANHO DA AMOSTRA .......................................................................... 6
2.4.1 População conhecida e desvio padrão desconhecido ........................................................... 6
2.4.2 População desconhecida e desvio padrão conhecido ........................................................... 7
3.1 INTRODUÇÃO ................................................................................................................................. 8
3.2 SÉRIES ESTATÍSTICAS ................................................................................................................. 9

3.2.1 Séries históricas, cronológicas, temporais ............................................................................. 9
3.2.2 Séries geográficas, espaciais, territoriais ................................................................................ 9
3.2.3 Séries específicas ou categóricas ............................................................................................ 9
3.2.4 Séries conjugadas ou tabelas de dupla entrada ................................................................... 10
3.2.5 Séries de distribuição de freqüência ...................................................................................... 10
3.3 DADOS ABSOLUTOS E DADOS RELATIVOS ............................................................................. 10
3.3.1 Dados absolutos ....................................................................................................................... 10
3.3.2 Dados relativos ......................................................................................................................... 10
4 GRÁFICOS ESTATÍSTICOS ............................................................................................................ 12
4.1 INTRODUÇÃO ............................................................................................................................... 12
4.1.1 Gráfico em linha ........................................................................................................................ 12
4.1.2 Gráfico em colunas ou barras ................................................................................................. 12
4.1.3 Gráficos em colunas ou barras múltiplas .............................................................................. 13
4.1.4 Gráficos de setores ou pizza ................................................................................................... 13
4.1.5 Gráficos polares ou radar ........................................................................................................ 13
4.1.6 Cartograma ................................................................................................................................ 14
4.1.7 Pictograma ................................................................................................................................ 15
5 DISTRIBUIÇÃO DE FREQÜÊNCIA ................................................................................................. 16
5.1 TABELA PRIMITIVA E ROL .......................................................................................................... 16
5.2 FREQÜÊNCIA ............................................................................................................................... 16
5.3 ELEMENTOS DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIA ........................................................ 16
5.3.1 Classe de freqüência ou classe .............................................................................................. 16
5.3.2 Determinar o número de classes ............................................................................................ 16
5.3.3 Limites de classes .................................................................................................................... 17
5.3.4 Intervalos das classes ou amplitudes das classes (AC) ...................................................... 17
5.3.5 Amplitude total da distribuição (AT) ....................................................................................... 17
5.3.6 Amplitude amostral (AA) .......................................................................................................... 18
5.3.7 Ponto médio de uma classe ou centro de classe (CC) ......................................................... 18
5.3.8 Freqüência simples ou absoluta (Fi) ...................................................................................... 18
5.3.9 Freqüências relativas (fj) ......................................................................................................... 18
5.3.10 Freqüência absoluta acumulada (Fi‘) ................................................................................... 18
5.3.11 Freqüência relativa acumulada (fj`) ...................................................................................... 18
5.4 REPRESENTAÇÃO GRÁFICA ...................................................................................................... 19
5.4.1 Histograma (gráfico de coluna) ............................................................................................... 19
5.4.2 Polígono de freqüência ............................................................................................................ 19
5.4.3 Polígono de freqüência acumulada ........................................................................................ 19
5.4.4 Formas da curvas de freqüência ............................................................................................. 20
6 MEDIDAS DESCRITIVAS ................................................................................................................ 22
6.1 INTRODUÇÃO ............................................................................................................................... 22

6.2 MEDIDAS DE POSIÇÃO ............................................................................................................... 22
6.2.1 Média .......................................................................................................................................... 23
6.2.2 A moda (Mo) .............................................................................................................................. 26
6.2.3 A mediana (Md) ......................................................................................................................... 28
6.2.4 Separatrizes .............................................................................................................................. 30
7 MEDIDAS DE DISPERSÃO OU VARIAÇÃO OU DE VARIABILIDADE ......................................... 35
7.1 INTRODUÇÃO ............................................................................................................................... 35
7.2 AMPLITUDE TOTAL ...................................................................................................................... 35
7.2.1 Dados não agrupados .............................................................................................................. 35
7.2.2 Dados agrupados ..................................................................................................................... 36
7.3 AMPLITUDE INTERQUARTÍLICA ................................................................................................. 36
7.3.1 Dados não agrupados (pares ou impares) ............................................................................. 37
7.3.2 Dados agrupados (com ou sem intervalo de classe) ............................................................ 37
7.4 VARIÂNCIA E DESVIO PADRÃO ................................................................................................. 37
7.4.1 Para dados não agrupados ...................................................................................................... 37
7.4.2 Para dados agrupados ............................................................................................................. 40
7.5 COEFICIENTE DE VARIAÇÃO DE PEARSON (CV) .................................................................... 42
7.6 COEFICIENTE DE VARIAÇÃO DE THORNDIKE - CVT .............................................................. 43
8 MEDIDAS DE ASSIMETRIA E DE CURTOSE ................................................................................ 44
8.1 ASSIMETRIA ................................................................................................................................. 44
8.1.1 Relação de assimetria .............................................................................................................. 44
8.2 CURTOSE ..................................................................................................................................... 47
8.2.1 Coeficiente de curtose ............................................................................................................. 47
9 REGRESSÃO LINEAR SIMPLES .................................................................................................... 48
9.1 INTRODUÇÃO ............................................................................................................................... 48
9.2 GRÁFICO DA DISPERSÃO .......................................................................................................... 48
9.3 COEFICIENTE DE CORRELAÇÃO LINEAR (R) .......................................................................... 49
9.4 COEFICIENTE DE DETERMINAÇÃO (R2) ................................................................................... 50
9.5 EQUAÇÃO DA RETA E DETERMINAÇÃO DOS PARÂMETROS ................................................ 50
10 ANÁLISE COMBINATÓRIA ........................................................................................................... 52
10.1 INTRODUÇÃO ............................................................................................................................. 52
10.2 FATORIAL ................................................................................................................................... 52
10.3 PRINCÍPIO FUNDAMENTAL DA CONTAGEM - PFC ................................................................ 52
10.4 ARRANJOS SIMPLES ................................................................................................................. 53
10.5 PERMUTAÇÕES SIMPLES ........................................................................................................ 54
10.6 PERMUTAÇÕES COM ELEMENTOS REPETIDOS ................................................................... 55
10.7 COMBINAÇÕES SIMPLES ......................................................................................................... 55
11 INTRODUÇÃO A TEORIA DA PROBABILIDADE ........................................................................ 56
11.1 INTRODUÇÃO ............................................................................................................................. 56

11.2 CLASSIFICAÇÃO DOS MODELOS ............................................................................................ 56
11.3 ESPAÇO AMOSTRAL OU PONTOS AMOSTRAIS (S) .............................................................. 57
11.3.1 Tipos de espaço amostral ...................................................................................................... 57
11.4 EVENTO (E) ................................................................................................................................ 57
11.4.1 Possibilidades para a ocorrência de eventos aleatórios .................................................... 59
11.5 DEFINIÇÃO DE PROBABILIDADE ............................................................................................. 60
11.5.1 Clássica ................................................................................................................................... 60
11.5.2 Pela freqüência relativa .......................................................................................................... 60
11.5.3 Axiomática (kolmogorov) ....................................................................................................... 61
11.4.4 Regras básicas da probabilidade .......................................................................................... 61
11.4.5 Tipos de eventos .................................................................................................................... 62
11.4.6 Probabilidade subjetiva ......................................................................................................... 62
11.4.7 Probabilidade através da freqüência relativa ...................................................................... 63
11.4.8 Probabilidade condicional ..................................................................................................... 63
11.4.9 Teorema de Bayes .................................................................................................................. 64
12 VARIÁVEIS ALEATÓRIAS ............................................................................................................ 66
12.1 INTRODUÇÃO ............................................................................................................................. 66
12.2 ESPERANÇA MATEMÁTICA ...................................................................................................... 66
12.3 VARIÁVEL ALEATÓRIA DISCRETA ........................................................................................... 69
12.3.1 Distribuição conjunta de duas variáveis aleatórias ............................................................ 69
12.3.2 Distribuições marginais de probabilidade e esperança de X ............................................. 70
12.3.3 Probabilidade pela distribuição de Bernoulli ou binomial ................................................. 72
12.3.4 Probabilidade pela distribuição hipergeométrica ............................................................... 73
12.3.5 Probabilidade pela distribuição de Poisson ........................................................................ 75
12.3.6 Probabilidade geométrica ...................................................................................................... 76
12.4 VARIÁVEIS ALEATÓRIAS CONTÍNUAS .................................................................................... 77
12.4.1 Probabilidade pela distribuição normal ou de Gauss ......................................................... 77
13 INTERVALO DE CONFIANÇA ...................................................................................................... 81
13.1 PARA MÉDIA, QUANDO A VARIÂNCIA É CONHECIDA ........................................................... 81
13.2 PARA MÉDIA, QUANDO VARIÂNCIA POPULACIONAL NÃO É CONHECIDA ......................... 82
14 INFERÊNCIA ESTATÍSTICA E TESTE DE HIPÓTESES ................................................................ 2
14.1 INFERÊNCIA ESTATÍSTICA ......................................................................................................... 2
14.1.1 População e amostra ................................................................................................................ 4
14.1.2 Tipos de amostragem ............................................................................................................... 4
14.2 TESTE SIGNIFICÂNCIA OU DE HIPÓTESES .............................................................................. 4
14.2.1 Teste Z para avaliação de uma média populacional ............................................................. 6
14.2.2 Teste t para avaliação de uma ou duas médias ..................................................................... 7
14.2.3 Teste Qui-quadrado (2א) ......................................................................................................... 11
14.2.4 Teste F para comparação de duas variâncias ..................................................................... 12

14.2.5 Teste t para dados pareados ................................................................................................. 13
14.2.6 Teste de Hipótese – valor-P (p-value) ................................................................................... 14
REFERÊNCIAS ................................................................................................................................... 15

2
1 A NATUREZA DA ESTATÍSTICA
1.1 CONSIDERAÇÕES GERAIS - A estatística é um ramo da matemática que fornece métodos para a coleta, organização, descrição,
análise e interpretação de dados e para a utilização dos mesmos na tomada de decisões
- Desde a antiguidade vários povos já registravam os nascimentos, óbitos, etc
- A qualidade das decisões depende da verdadeira informação dos indicadores
- Os indicadores podem ser obtidos de levantamentos, que podem ser contínuos, regulares e
esporádicos
- Foi utilizada para acompanhar as coisas do estado (status)
- A partir do século XVII inicia-se a utilização da estatística
- Depois de 1960 a informática da um grande impulso a estatística
- Exemplo?????
1.2 TIPOS DE CONHECIMENTO
1.2.1 Conhecimento empírico
- Obtido ao acaso, após diversas tentativas
1.2.2 Conhecimento filosófico
- Através do raciocínio e da reflexão humana (razão)
1.2.3 Conhecimento teológico
- Gerado pela fé divina ou crença religiosa
1.2.4 Conhecimento científico
- É o conhecimento racional, sistemático e verificável
1.3 MÉTODO DE PESQUISA - Método é um conjunto de meios dispostos convenientemente para se chegar a um fim
1.3.1 Pesquisa bibliográfica
- Elaborada a partir de material já publicado

3
1.3.2 Pesquisa documental
- Materiais que não receberam tratamento analítico
1.3.3 Levantamento
- Questionário, formulário, entrevista
1.3.4 Estudo de caso
????
1.3.5 Estudo de protótipo
?????
1.3.6 Pesquisa não experimental
- Investigação sistemática e empírica
1.3.7 Pesquisa ação
- Resolução de um problema coletivo
O pesquisador fica envolvido de forma cooperativa
1.3.8 Pesquisa participante
- O pesquisador se inclui na pesquisa
1.4 O MÉTODO CIENTÍFICO
- Modelo padrão de pesquisa que permite que qualquer pessoa que realize determinada pesquisa
dentro da metodologia proposta possa encontrar resultados similares
a) Método experimental
Consiste em manter constante toda a causa (fatores), exceto uma, variando esta
convenientemente
Exemplo????
b) Método estatístico
Na impossibilidade de manter as causas constantes, admitem-se todas essas causas
presentes, registrando-se e procurando-se determinar o que a influência.
Ex: causas que definem o preço do produto

4
1.5 FASES DO MÉTODO ESTATÍSTICO
A coleta, a organização e a descrição dos dados estão a cargo da estatística descritiva
A análise e a interpretação ficam a cargo da estatística indutiva ou inferencial
1.5.1 Planejamento
Se refere a execução
1.5.2 Coleta dos dados
Pode ser direta ou indireta
a) Direta: é realizada com a própria tomada de dados. Ex.: nascimentos, importação, produção
A coleta de dados direta pode ser classificada relativamente ao fator tempo em:
a.1) Contínua: Ex.: freqüência as aulas
a.2) Periódica: Ex.: Censo
a.3) Ocasional: Ex.: doenças
b) Indireta: é inferida de outros dados. Ex.: peso médio ao abate, produtividade
1.5.3 Crítica dos dados
Pode ser externa ou interna
1.5.4 Apuração dos dados
Manual ou eletrônica
1.5.5 Exposição ou apresentação
Tabelas e gráficos
1.5.6 Análise dos resultados
Através da estatística indutiva e inferencial

5
2 POPULAÇÃO E AMOSTRA
2.1 CLASSIFICAÇÃO DAS VARIÁVEIS
Cada fenômeno corresponde a um número de resultados possíveis
Variável é o conjunto de resultados possíveis de um fenômeno
Exemplo:
# Sexo: são apenas dois
# Filhos: expresso pelos números naturais
# Estatura: assume diferentes valores dentro de determinado intervalo
A variável pode ser:
a) Qualitativa: são expressas por atributos (sexo, cor da pele, etc.).
b) Quantitativa: Expressa em números, sendo:
b.1) Variável contínua: pode assumir qualquer valor entre dois limites, teoricamente.
Ex: Produção de grãos
b.2) Variável discreta: só pode assumir valores pertencentes a um conjunto enumerável.
Ex: número de leitões por cria
2.2 POPULAÇÃO E AMOSTRA
# População: Conjunto de indivíduos de, pelo menos, uma característica comum
Ex: Grupo de estudantes, aves de um aviário
# Amostra: Subconjunto finito de uma população, o qual deve ser representativo
2.3 AMOSTRAGEM
Existem técnicas que garantem, tanto quanto possível, o acaso na escolha
Dessa forma, cada elemento deve ter a mesma chance de ser escolhido
Vantagens: Menor custo
Menor tempo
Material destrutivo
2.3.1 Amostragem casual ou aleatória simples
É equivalente ao sorteio
Ex: alunos numerados de 1 a 20

6
2.3.2 Amostragem proporcional estratificada
Quando a população se divide em extratos
Ex: alunos do sexo masculino e feminino
2.3.3 Amostragem sistemática
Quando os elementos da população já estão ordenados
Ex: Propriedades rurais em determinada estrada, prédios de certa rua, etc
Neste caso a amostra pode ser obtida por um sistema imposto pelo pesquisador
2.4 DETERMINAÇÃO DO TAMANHO DA AMOSTRA
2.4.1 População conhecida e desvio padrão desconhecido
1º) Aproximação do tamanho da amostra
2a
o E1n =
onde:
no= aproximação do tamanho da amostra 2aE = margem de erro amostral aceitável (decimal)
2º) Tamanho da amostra
onNonxNn
+=
onde:
n= tamanho da amostra
N= tamanho da população
Exemplos:
1) Considerando que se desejasse determinar o tamanho da amostra, num aviário com 15 mil
frangos de corte, para estimar o peso total de frangos vivos para comercialização. Considere um erro
de 2,5% para mais e para menos.
N= 15000
2o 0,0251n = = 1600
1600150001600x 15000n
+= = 1445,78 = 1446 frangos
2) Para população do RS, estimada em 10,6 milhões de habitantes?
3) De um povoado com 289 habitantes?

7
2.4.2 População desconhecida e desvio padrão conhecido
Tabela Z
2
Eσ zn ⎟⎠
⎞⎜⎝
⎛=
Onde: z= grau de confiança σ= desvio padrão E= erro máximo desejável
Exemplo:
Supondo-se que se deseje determinar o tamanho da amostra visando obter o preço médio da hora
máquina para a semeadura de milho em dada região. Conforme estudo prévio, o desvio-padrão para
o aluguel é de aproximadamente R$ 30,00. Use nível de confiança de 95%.
a) Qual o tamanho da amostra se a margem de erro para a média obtida esteja a menos de R$ 10,00
da verdadeira média? 2
1030 x 1,96n ⎟⎠
⎞⎜⎝
⎛= = 34,6 = 35 prestadores de serviço
b) Qual o tamanho da amostra se a margem de para a média obtida esteja a menos de R$ 5,00 da
verdadeira média?2
530 x 1,96n ⎟⎠
⎞⎜⎝
⎛= = 138,3 = 134 prestadores de serviço
Nível de confiança (1 - α) Zc 0,90 1,65 0,95 1,96 0,99 2,58

8
3 SÉRIES ESTATÍSTICAS
3.1 INTRODUÇÃO
São as tabelas (????) e os quadros (???)
Sintetizar os resultados
Devem ser de fácil interpretação
Reproduzir fielmente os resultados
A Tabela é o Quadro são compostos por:
Corpo: conjunto de linhas e colunas que contem informações sobre a variável em estudo.
Cabeçalho: parte superior da tabela que especifica o conteúdo das colunas.
Coluna indicadora: parte da tabela que especifica o conteúdo das linhas.
Linhas: retas imaginárias no sentido horizontal.
Casa ou célula: espaço destinado a um único número.
Título: conjunto de informações, mais completas possíveis, localizadas ?????.
Pode ter os elementos complementares como fonte, notas e chamadas, colocadas no rodapé.
Exemplo: Tabela 3.1 - Comparação entre a armazenagem no Brasil quanto à localização, em função da capacidade
Localização Capacidade (%)
Cidades 52
Zona rural (empresas e cooperativas) 32
Fazendas 11
Portos (terminal) 5
Fonte: CONAB, 2006.
A Tabela e o Quadro devem ser auto-explicativos.
Segundo a resolução 886 do IBGE, nas células devemos colocar:
# Um traço horizontal (-): valor zero
# Três pontos (...): quando não temos dados
# Um ponto de interrogação (?): quando temos dúvidas
# Zero (0): quando o valor é muito pequeno para ser expresso pela unidade empregada. Se tiver
decimais os mesmo deverão ser usados (0,0; 0,00; 0,000).

9
3.2 SÉRIES ESTATÍSTICAS
3.2.1 Séries históricas, cronológicas, temporais
Compara resultados ao longo de determinado período.
Tabela 3.2 - Evolução da produção de milho, no Brasil, durante o período de 2005 a 2009
Safra Produção (1000 t)
2005/06 41682,2
2006/07 42426,8
2007/08 58652,2
2008/09 50268,0
Fonte: Conab, agosto 2009.
3.2.2 Séries geográficas, espaciais, territoriais
Compara resultados para diferentes locais
Tabela 3.3 - Situação da armazenagem de grãos em diferentes do Brasil
Região Capacidade (milhões de t)
Centro-Oeste 43,95
Nordeste 7,24
Norte 2,46
Sudeste 20,52
Sul 51,33
Brasil 125,51 FONTE: CONAB, 2009.
3.2.3 Séries específicas ou categóricas
Descrevem os valores coletados segundo especificações ou categorias.
Tabela 3.4 – Rebanho efetivo para as principais categorias animais, em 2005
Rebanho Quantidade (1000 cabeças)
Bovinos 207.157
Suínos 34.064
Ovinos 15.558
Caprinos 10.307
Fonte: Mapa, 2009.

10
3.2.4 Séries conjugadas ou tabelas de dupla entrada
Apresentam mais de uma variável na mesma tabela.
Exemplo: Tabela 3.5 - Principais produtores mundiais de soja, durante as safras 2004 a 2009, expresso em milhões de
toneladas
Período Países
EUA Brasil Argentina China
2004/05 85,013 53,000 39,000 17,400
2005/06 83,368 55,000 40,500 16,350
2006/07 87,001 59,000 48,800 15,967
2007/08 72,859 61,000 46,200 14,000
2008/09 80,536 57,000 43,800 16,800
Fonte: USDA, 2009.
3.2.5 Séries de distribuição de freqüência
Será visto posteriormente devida sua grande importância.
Pode ser com intervalo de classe ou sem.
Exemplo peso suínos: 51, 57, 60, 62, 65, 67, 69, 70, 79, 85
Tabela 3.6 - Peso de um grupo de bovinos com determinada faixa de idade
Massa (kg) Número de suínos
50 l– 60 2
60 l– 70 5
70 l– 80 2
80 l– 90 1
Total 10
3.3 DADOS ABSOLUTOS E DADOS RELATIVOS
3.3.1 Dados absolutos
Resultantes da coleta direta, provenientes da contagem ou medida.
3.3.2 Dados relativos
São resultantes de comparações por quociente que se estabelece entre os dados absolutos,
realçando as possíveis diferenças.
São indicados por percentagens, índices, coeficientes e taxas.

11
a) Percentagens
Número de partes de um todo, o qual apresenta 100 partes, expresso em percentual
Exemplo: Tabela 3.7 - Resultados da avaliação final da disciplina X
Condição Número de alunos Percentual
Aprovado direto 220 57,89
Reprovado direto 18 4,74
Aprovado c/ recuperação 101 26,58
Reprovado na recuperação 41 10,79
Total 380 100,00
b) Coeficientes
São razões entre o número de ocorrências e o número total, não expressos em percentagem.
# Coeficiente de natalidade: número de nascimentos / população total
# Coeficiente de mortalidade: número de óbitos / população total
c) Taxas
São os coeficientes multiplicados por uma potência de 10 (10, 100, 1000) para tornar mais
inteligível o resultado.
# Taxa de mortalidade: coeficiente de mortalidade x 1000
# Taxa de nascimentos: coeficiente de nascimento x 1000
# Taxa de juros
d) Índices
São razões entre duas grandezas de modo que uma não inclui a outra.
Exemplo:
# Densidade demográfica: População / superfície
# Produção per capita: valor total da produção / população
# Consumo per capita: consumo total / população
# Renda per capita: renda total / população

12
4 GRÁFICOS ESTATÍSTICOS
4.1 INTRODUÇÃO
Deve produzir uma impressão rápida e fácil dos resultados.
- Portanto, deve ser:
# simplicidade
# claro
# verdadeiro
Os principais tipos de gráficos são os histogramas, cartogramas e pictogramas.
4.1.1 Gráfico em linha Exemplo: Dados da produção de milho, Tabela 2.
Fonte: Conab, 2009 Figura 1 - Evolução da produção de milho, no Brasil, durante o período de 2005 a 2009. Quando é usado?
4.1.2 Gráfico em colunas ou barras # Colunas: quando verticalmente
# Barras: quando horizontalmente
Fonte: Conab, 2009. Figura 2 - Situação da armazenagem de grãos em diferentes do Brasil.
# Dicas:

13
- Todas as colunas ou barras devem ter a mesma largura.
- Escrever de baixo para cima ou da direita para esquerda.
- Usar ordem cronológica ou decrescente.
- A distância entre colunas ou barras não deverá ser menor que a metade da largura e nem
maior que 2/3.
4.1.3 Gráficos em colunas ou barras múltiplas
Geralmente empregado quando queremos representar, simultaneamente, dois ou mais
fenômenos.
Fonte: USDA, 2009 Figura 3 - Principais produtores mundiais de soja, durante as safras 2004 a 2009, expresso em milhões de
toneladas.
4.1.4 Gráficos de setores ou pizza
Construído com base em um circulo. É empregado sempre que desejamos ressaltar a
participação do dado num todo.
Fonte: Conab, 2009 Figura 4 - Situação da armazenagem de grãos em diferentes do Brasil, expresso em milhões de t.
# Observação: - Não deve ser empregado quando houver muitos dados, normalmente até 7.
4.1.5 Gráficos polares ou radar
É ideal para representar séries temporais cíclicas.
Exemplo: Precipitação ao longo do ano, consumo de energia elétrica durante o mês.

14
Dados fictícios Figura 5 - Médias de precipitação pluviométrica durante determinado ano.
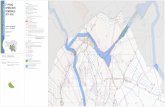
4.1.6 Cartograma
É a representação sobre uma carta geográfica.
Usado quando o objetivo é o de demonstrar dados estatísticos relacionados com áreas
geográficas.
Em geral usamos:
- Pontos: Para representar dados absolutos (população)
- Hachuras ou cores: representar dados relativos (densidade)
Exemplo: habitantes em determinado estado
Figura 6 – Predominância por setores no PIB brasileiro em 2009.

15
4.1.7 Pictograma
Método gráfico que melhor demonstra os resultados ao público geral, pois é atraente e
sugestivo.
A representação é feita por figuras.
Semelhante ao gráfico de barras.
Exemplo: População, exportação, doenças, etc.
Figura 7 – Evolução na matrícula no ensino superior no Brasil.

16
5 DISTRIBUIÇÃO DE FREQÜÊNCIA
5.1 TABELA PRIMITIVA E ROL
Exemplo: Dados de produtividade de plantas de figueira.
Tabela 5.1 – Quantidade de figo produzido por planta, expresso em kg
5,0 5,5 8,0 6,0 4,0 9,0 7,0 6,5 4,5 8,0 3,1 7,5 6,0 5,5 6,5
Acima é difícil de obter conclusões
Portanto, ordenar os dados, sendo a tabela então denominada de ROL.
Tabela 5.2 – Quantidade de figo produzido por planta, ordenados de forma crescente, expresso em kg 3,1 4,0 4,5 5,0 5,5 5,5 6,0 6,0 6,5 6,5 7,0 7,5 8,0 8,0 9,0
5.2 FREQÜÊNCIA
É o número de dados de observação que ficam relacionados com determinada variável.
# Freqüência de uma classe: número de valores da variável pertencente à classe.
Obs.: Simbologia empregada para determinar as classes:
–– = 3,1 < x < 4,3
l–– = 3,1 ≤ x < 4,3
––l = 3,1 < x ≤ 4,3
l––l = 3,1 ≤ x ≤ 4,3
5.3 ELEMENTOS DE UMA DISTRIBUIÇÃO DE FREQÜÊNCIA
5.3.1 Classe de freqüência ou classe
São os intervalos de variação de valores na classe.
São representados simbolicamente por “i“, sendo i= 1,2,3,...,k
k= número total de classes da distribuição.
5.3.2 Determinar o número de classes
Mais usual é a regra de Sturges.
k= 1 + 3,32 logn

17
n= número total de dados de observação.
Exemplo:
k= 1 + 3,32 log15 =k= 4,9
Logo serão k= 5
Também, pode ser empregada a seguinte regra:
k= n
Exemplo:
k= 15 k= 3,87 k= 4,0
5.3.3 Limites de classes
São os extremos de cada classe.
LI= limite inferior
LS= limite superior
Tabela 5.3 - Distribuição de freqüência da produtividade de figueiras, expresso em kg
I Peso kg (AC) CC Fi fj Fi` fj` 1 3,0 l– 4,2 3,6 2 0,13 2 0,13 2 4,2 l– 5,4 4,8 2 0,13 4 0,26 3 5,4 l– 6,6 6,0 6 0,41 10 0,67 4 6,6 l– 7,8 7,2 2 0,13 12 0,80 5 7,8 l–l 9,0 8,4 3 0,20 15 1,00
5.3.4 Intervalos das classes ou amplitudes das classes (AC)
É o tamanho da classe.
AC= k
variação Amplitude → 5,03,0-9,0AC = → AC= 1,20 kg
Exemplo:
1ª classe
LI= 3,0
LS= LI + AC → LS= 3,0 + 1,20 → LS= 4,20
2ª classe
LI= LI da 1ª classe
LS= 4,20 + 1,20 → LS= 5,40
5.3.5 Amplitude total da distribuição (AT)
É a diferença entre o valor superior da última classe e limite inferior da primeira classe.
Exemplo:
AT= 9,00 – 3,00 AT= 6,0 kg

18
5.3.6 Amplitude amostral (AA)
É a diferença entre o valor máximo e o mínimo observado.
AA= 9,0 – 3,1 AA= 5,9 kg
Obs.: Neste caso é igual à amplitude total da distribuição.
5.3.7 Ponto médio de uma classe ou centro de classe (CC)
Ponto que divide o intervalo de classe em duas partes iguais.
Conforme a tabela 5.3 temos para a classe 2:
CC= (4,2 + 5,4)/2 CC= 4,8 kg
5.3.8 Freqüência simples ou absoluta (Fi)
São os valores que realmente representam o número de dados de cada classe.
Exemplo:
F1= 2
∑Fi= n
5.3.9 Freqüências relativas (fj)
São os valores que de cada classe expresso em decimal.
fj= (Fi)/(∑Fi)
Exemplo:
f1= 2/15 f1= 0,13
5.3.10 Freqüência absoluta acumulada (Fi‘)
É igual a soma das freqüências simples, classe a classe.
Exemplo:
F1’= F1 F1`= 2
F2`= F1+F2 F2`= 2+2 F2`= 4
5.3.11 Freqüência relativa acumulada (fj`)
É igual a soma das freqüências relativas, classe a classe.
f1`= f1 f1`= 0,13
f2`= f1+f2 f2`= 0,13+0,27 f2`= 0,4

19
5.4 REPRESENTAÇÃO GRÁFICA
Pode ser representado por histograma e polígono de freqüência e polígono de freqüência
acumulada.
Histograma – Utiliza o centro de classe.
Polígono de freqüência – Utiliza o centro de classe.
Polígono de freqüência acumulada – Utiliza os limites superiores dos intervalos de classe.
5.4.1 Histograma (gráfico de coluna)
Exemplo: Freqüência absoluta
Utiliza o centro de classe.
Figura 5.1- Distribuição de freqüência absoluta, do peso de 15 suínos da raça landrace, na fase inicial,
expresso em kg.
5.4.2 Polígono de freqüência
Utiliza o centro de classe.
Figura 5.2 - Distribuição de freqüência absoluta, do peso de 15 suínos da raça landrace, na fase inicial,
expresso em kg.
5.4.3 Polígono de freqüência acumulada
Exemplo: Freqüência acumulada
Utiliza os limites superiores dos intervalos de classes.

20
Figura 5.2 - Distribuição de freqüência acumulada, do peso de 15 suínos da raça landrace, na fase inicial,
expresso em kg. 5.4.4 Formas da curvas de freqüência
a) Curvas em forma de sino: máximo no centro
Muitas curvas apresentam estas formas, como exemplo, altura, notas, peso, etc.
Esta curva assume a forma simétrica ou assimétrica, sendo esta última a mais comum.
a.1) Simétrica
Não ocorre com muita freqüência.
Figura 5.5 - Distribuição de freqüência simétrica.
a.2) Assimétrica
Na prática não encontramos curvas perfeitamente simétricas. Essas curvas apresentam cauda,
a qual é mais longa de um lado do que do outro.
Podem ser:
# Assimétrica positiva: Cauda para a direita
Figura 5.6 - Distribuição de freqüência simétrica positiva.
Mo

21
# Assimétrica negativa: Cauda para a esquerda
Figura 5.7 - Distribuição de freqüência assimétrica negativa.
a.3) Curvas em forma de jota
Máximo ocorre em uma das extremidades.
Exemplo: fenômenos econômicos e financeiros.
Jota Jota invertido Figura 5.8 - Distribuição de freqüência em forma jota.
a.3) Curvas em forma de U
Máximo em ambas as extremidades.
Exemplo: Mortalidade por faixa etária.
Figura 5.9 - Distribuição de freqüência em forma U.
a.4) Distribuição retangular ou linear
Rara, pois apresenta todas as classes com a mesma freqüência.
Figura 5.10 - Distribuição de freqüência linear.

22
6 MEDIDAS DESCRITIVAS
6.1 INTRODUÇÃO
Os elementos típicos da distribuição são:
# As medidas de posição
# As Medidas de variação ou dispersão
# As Medidas de assimetria
# As Medidas de curtose
Estas medidas são:
- de fácil interpretação
- apropriadas para processos mais elaborados
- representativas
Temos: Dados não agrupados
Dados agrupados (com e sem intervalo de classe)
6.2 MEDIDAS DE POSIÇÃO
Esta estatística representa uma série de dados, orientando-os quanto a posição da distribuição
em relação ao eixo horizontal.
Podem ser:
a) Tendência central: Os D.O. tendem a se agrupar em torno dos valores centrais.
- média
- mediana
- moda
b) Separatrizes: Separa a distribuição em partes iguais
- própria mediana
- quartis
- decis
- percentis

23
6.2.1 Média
a) Média aritmética simples
a.1) Para dados não agrupados
É a mais utilizada, sendo de fácil obtenção e de simples compreensão.
nXn)...X2(X1X +++
=−
=−X média aritmética
Xi= valores observados
n= número de observações.
Exemplo: peso médio, em kg, de 5 ovinos jovens.
8875
8896361839X ,,,,,,=
++++=
− kg
- Desvio ou erro em relação à média
É a diferença entre cada valor observado e a média aritmética. −
−= XXie
Exemplo:
e= (9,3-7,88) + (8,1-7,88) + (6,3-7,88) + (6,9-7,88) + (8,8-7,88)
e= 1,42 + 0,22 + (-1,58) + (-0,98) + (0,92)
- Propriedades da média
# Primeira propriedade
A soma dos desvios, obtidos a partir da média, é zero.
∑e= 0
Exemplo:
∑e= 1,42 + 0,22 + (-1,58) + (-0,98) + (0,92)
∑e= 0
# Segunda propriedade
Somando-se ou subtraindo-se de todas as observações uma constante, a média fica
aumentada ou diminuída desta constante.
kXnY ±=−
ou
nk)(Xn...k)(X2k)(X1Y ±++±+±=

24
Exemplo:
52,0)(8,82,0)(6,92,0)(6,32,0)(8,12,0)(9,3Y +++++++++
=
88,954,49==Y kg ou
Y= 7,88 +2,0
Y= 9,88 kg
# Terceira propriedade
Multiplicando-se ou dividindo-se de todas as observações uma constante, a média ficará
multiplicada ou dividida por esta constante.
kXnY÷
×−= ou
n
k)(Xnk)(X1k)(X1Y ÷
×+
÷
×+
÷
×
=
Exemplo:
52,0)(8,82,0)(6,92,0)(6,32,0)(8,12,0)(9,3Y ×+×+×+×+×
=
15,76578,8Y == kg ou
Y= 7,88*2
Y= 15,76 kg
# Quarta propriedade
A soma de quadrados dos desvios em relação à média é mínima, pois é menor que a soma
dos quadrados a partir de qualquer número.
Exemplo:
- Desvios reais:
Σe2= (1,42)2 + (0,22)2 + (-1,58)2 + (-0,98)2 + (0,92)2
Σe2= 6,368 kg
Se a média fosse 10:
Σe2= (9,3-10)2 + (8,1-10)2 + (6,3-10)2 + (6,9-10)2 + (8,8-10)2
Σe2= (-0,7)2 + (-1,9)2 + (-3,7)2 + (-3,1)2 + (-1,2)2
Σe2= 28,84 kg

25
b) Média ponderada
b.1) Dados não agrupados
Quando aos valores são atribuídos pesos diferenciados.
PesoXnX p ×∑=−
Exemplo: Considere que para uma turma serão feitas três avaliações, sendo a primeira valendo 30%
da nota final, a segunda 50% e a terceira o restante. Suponha que as notas obtidas de um aluno
foram, respectivamente, 6,5; 7,2 e 5,8. Qual será a média final do aluno?
71,6)2,08,55,02,73,05,6( =×+×+×=−
pX
b.2) Dados agrupados
b.2.1) Sem intervalos de classe
Avaliação da ocorrência da ferrugem da soja em determinada região.
FiXnFiX∑
∑=
−
Tabela 6.1 – Municípios com registros de ocorrência da ferrugem da soja, em determinada região Ocorrências Municípios (Fi) 0 15 1 10 2 8 3 5 4 2 Total 40
225140
245382101150 ,)()()()()(X =×+×+×+×+×
=−
ocorrências por município
b.2.2) Com intervalos de classes
FiCCnFiX∑
∑=
−
Exemplo: Produtividade de figueiras
Tabela 6.2 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
I Peso (kg) CC Fi fj Fi` fj` 1 3,0 l– 4,2 3,6 2 0,13 2 0,13 2 4,2 l– 5,4 4,8 2 0,13 4 0,26 3 5,4 l– 6,6 6,0 6 0,41 10 0,67 4 6,6 l– 7,8 7,2 2 0,13 12 0,80 5 7,8 l–l 9,0 8,4 3 0,20 15 1,00
Consideramos que todos os valores incluídos no intervalo de classe coincidem com CC.

26
Logo:
kg/planta6,1615
8,4)(37,2)(26,0)(64,8)(23,6)(2X =×+×+×+×+×
=−
Obs: se fosse utilizado todos os valores observados a média seria 6,14 kg/planta.
- Usos da média
# obter a medida de posição de maior estabilidade
# necessidade de tratamento algébrico posterior
c) Média geométrica
É usada para médias proporcionais de crescimento quando uma medida subseqüente depende
de medidas prévias.
nng nnX ×=
−
1
Exemplo:
- população em 1990= 2 milhões
- população em 2000= 8 milhões
- Qual é em 1995? Não é 5 milhões
milhõesX 4822 =×=−
6.2.2 A moda (Mo)
Observação que ocorre com maior freqüência.
a) Dados não agrupados
É o dado de observação que mais se repete.
Exemplo: Número de cachos por planta de mamona.
1, 3, 2, 5, 4, 3, 2, 3, 1, 2, 3, 3
Mo= 3 cachos planta
As distribuições podem ser:
a.1) amodal: Não existe um valor com maior freqüência
Exemplo: Peso ao nascer de terneiros
41, 34, 39, 43, 38, 45, 37, 31, 42, 47
a.2) unimodal ou modal: Apenas um conjunto com maior freqüência
Exemplo: Número de cachos por planta de mamona

27
a.3) multimodal: Apresentam mais de um conjunto com maior freqüência
Exemplo: Número de coelhos por cria
10, 12, 8, 10, 9, 12, 11, 13, 10, 11, 11
Logo temos 2 modas: 10 e 11 (bimodal)
b) Dados agrupados
b.1) Sem intervalo de classe
É só avaliar os valores na tabela 6.1 (apresentada anteriormente), e observar o valor com
maior freqüência.
Logo a maior freqüência é 15, então a moda é:
Mo= 0 ocorrências por município
b.2) Com intervalo de classe
A classe que apresenta maior freqüência é denominada classe modal.
A moda é o CC
Exemplo: Produtividade figueiras
Tabela 6.3 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
I Peso (kg) CC Fi 1 3,0 l– 4,2 3,6 2 2 4,2 l– 5,4 4,8 2 3 5,4 l– 6,6 6,0 6 4 6,6 l– 7,8 7,2 2 5 7,8 l–l 9,0 8,4 3
Então:
Classe modal é a 3
A moda é 6,0 kg/planta
- Expressões gráficas da moda
Na curva de freqüência a moda é o valor que corresponde, no eixo das abscissas, ao ponto de
ordenada máxima.
Curva modal Curva não modal Curva bimodal
Mo
ModaModa Moda
2Moda 2
Moda 1Moda 1

28
- Emprego da moda
- quando desejamos uma medida rápida e aproximada de posição
- quando a medida de posição deve ser o valor típico da distribuição
6.2.3 A mediana (Md)
É o número que se encontra no centro de uma série de dados de observação, dispostos
segundo uma ordem.
a) Dados não agrupados
a.1) Número impar de observações
21nMd +
=
Exemplo: Número de coelhos por cria
10, 12, 8, 10, 9, 12, 11, 13, 10, 11, 11
Primeiramente ordenamos a série:
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13
11Mdlogo posição 6Md2
111Md =→=→+
= coelhos/cria
a.2) Número par de observações
A mediana será o valor médio entre os 2 valores observados.
21nMd +
=
Exemplo: Número de coelhos por cria
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13, 13
2112Md +
= = 6,5 posição
Então:
11Md222Md
21111Md =→=→
+= leitões/porca
b) Dados agrupados
É semelhante àquele dos dados não agrupados, implicando, porém na determinação prévia
das freqüências acumuladas.

29
b.1) Sem intervalo de classe
Neste caso é suficiente identificar a freqüência acumulada imediatamente superior à metade
da soma das freqüências. A mediana é àquele valor da variável que corresponde a tal freqüência
acumulada.
Md= 2Fi∑
Tabela 6.4 - Municípios com registros de ocorrência da ferrugem da soja, em determinada região I Aplicações Fi (lavouras) Fi’ 1 0 15 15 2 1 10 25 3 2 8 33 4 3 5 38 5 4 2 40 Total 40
Então:
Md= 20240
2==
∑Fi posição
Assim, o valor mediano está na classe 2.
Md= 1 ocorrência por município
b.2) Com intervalo de classe
Md= 2Fi∑ , entretanto temos que determinar o valor dentro do intervalo de classe.
Exemplo: Tabela 6.4 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
i Peso (kg) CC Fi Fi’ 1 3,0 l– 4,2 3,6 2 2 2 4,2 l– 5,4 4,8 2 4 3 5,4 l– 6,6 6,0 6 10 4 6,6 l– 7,8 7,2 2 12 5 7,8 l–l 9,0 8,4 3 15
Md= 5,7215
2==
∑Fi posição
O valor está na 3ª classe, entre os valores 5,4 e 6,6.
Interpolação:
1,2 (6,6-5,4) –––– 6
x –––––– 3,5 (7,5-4)
x= 0,7 kg
Md= 5,4+0,7 = 6,1 kg

30
- Emprego da mediana
- obter o ponto que divide a distribuição em duas partes iguais
- há valores extremos que afetam de maneira acentuada a média
- a variável em estudo é o salário
6.2.4 Separatrizes
a) Os quartis
Valores de uma série que a dividem em quatro partes iguais.
Há, portanto 3 quartis, conforme segue:
# Primeiro quartil (Q1): primeiro 25% da série
# Segundo quartil (Q2): Coincide com a mediana (Q2=Md)
# Terceiro quartil (Q3): 75% da série
a.1) Dados não agrupados
a.1.1) Números pares de dados de observação
42nkQk +
=
Exemplo: Número de coelhos por cria
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13, 13
Obs.: Colocar os valores em ordem crescente.
Para o primeiro quartil
53,4
2121Q1logo =⎟⎠
⎞⎜⎝
⎛ +×= posição, logo Q1 = 10 coelhos/cria
Para o segundo quartil
6,54
212 x 2Q2 =+
= posição
1121111Q2logo =
+= coelhos/cria
Para o terceiro quartil
posição9,54
212 x 3Q3 =+
=
12=⎟⎠
⎞⎜⎝
⎛ +=
21212Q3logo coelho/cria

31
a.1.2) Números impares de dados de observação
41)nk(Qk +
=
Exemplo: Número de coelhos por cria
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13
Para o primeiro quartil
341)(111Q1 =
+×= posição
10Q1logo = coelhos/cria
Para o segundo quartil
Q2 641)2(11
=+
= posição
11Q2logo = coelhos/cria
Para o terceiro quartil
Q3 941)3(11
=+
= posição
12Q3logo = coelhos/cria
a.2) Dados agrupados
a.2.1) Sem intervalo de classe
Neste caso é suficiente identificar a freqüência acumulada imediatamente superior.
Qk=4Fik ∑ , onde k é o número de ordem do quartil.
Tabela 6.5 - Municípios com registros de ocorrência da ferrugem da soja, em determinada região
i Aplicações Fi (lavouras) Fi’ 1 0 15 15 2 1 10 25 3 2 8 33 4 3 5 38 5 4 2 40 Total 40
Para o primeiro quartil
Q1= 10440
440*1
== posição, está na classe 1
Logo: Q1= 0 ocorrências por município

32
Para o segundo quartil
Q2= igual a mediana
Q2= 20480
440*2
== posição, está na classe 2
Logo Q2= 1 ocorrência por município
Para o terceiro quartil
Q3= 304120
440*3
== posição, está na classe 3
Logo: Q1= 2 ocorrências por município
a.2.2) Com intervalo de classe
Igual a anterior.
Qk=4Fik ∑ , onde k é o número de ordem do quartil.
Entretanto, neste caso interpolar, pois existe um intervalo de valores em cada classe.
Exemplo:
Tabela 6.6 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta I Peso (kg) CC Fi Fi’ 1 3,0 l– 4,2 3,6 2 2 2 4,2 l– 5,4 4,8 2 4 3 5,4 l– 6,6 6,0 6 10 4 6,6 l– 7,8 7,2 2 12 5 7,8 l–l 9,0 8,4 3 15
Para o primeiro quartil
Q1= 75,34151
4=
×=
∑ Fik posição
Então o Q1 está na segunda classe, entre o intervalo de 4,2 l– 5,4
Interpolação:
(5,4-4,2) 1,2––— 2
X –––----– 1,75 (3,75-2)
x= 1,05 kg
Q1= 4,2 + 1,05 = 5,25 kg/planta
Para o terceiro quartil
Q3= 25,114153
4=
×=
∑Fik posição
Então o Q3 está situado na classe 4, entre o intervalo 6,6 l– 7,8

33
Interpolação
(7,8-6,6)1,2 –––– 2
X ––––------– 1,25 (11,25-10)
Q3= 0,75 kg
Q3= 6,6+0,75= 7,35 kg/planta
b) Os decis
Dividem a distribuição em 9 partes iguais
São indicados por D1, D2, ..., D9
Dk= 10Fik ∑ , sendo k o número de ordem do decil.
b.1) Dados agrupadas com intervalo de classe
Exemplo: Tabela 6.7 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
I Peso (kg) CC Fi Fi’ 1 3,0 l– 4,2 3,69 2 2 2 4,2 l– 5,4 4,87 2 4 3 5,4 l– 6,6 6,05 6 10 4 6,6 l– 7,8 7,23 2 12 5 7,8 l–l 9,0 8,41 3 15
Para o decil 4
D4= 610154
10Fik
=×
=∑ posição
Logo D4 está situado na classe 3, no intervalo de 5,4 a 6,6
Interpolação:
(6,6 – 5,4)1,2 –––– 6
X –––––------ 2(6-4)
X= 0,4 kg
D4= 5,4+0,4= 5,8 kg por planta
c) Os percentis ou centis
Dividem a distribuição em 99 partes iguais
São indicados por P1, P2, ..., P61, P99
Sendo assim sabe-se que P50= Md, P25= Q1 e P75= Q3.
Pk= 100Fik ∑ , sendo k o número de ordem do percentil.

34
Exemplo: Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
Para o percentil 90
P90= 13,51001590
100Fik
=×
=∑ posição
Logo P90 está situado na classe 5, no intervalo de 7,82 a 9,00
Interpolação:
(9,0-7,8)1,2 –––– 3
X ––––– 1,5 (13,5-12,0)
X= 0,6 kg
P90= 7,8+0,6= 8,4 kg por planta

35
7 MEDIDAS DE DISPERSÃO OU VARIAÇÃO OU DE VARIABILIDADE
7.1 INTRODUÇÃO
Indicam a variabilidade dos dados.
Ex: Precipitação mensal em três localidades, durante período de 1 ano.
Não podemos saber como é a distribuição desta chuva ao longo do ano
Tabela 1 – Precipitação média mensal em três localidades, durante o período de 1 ano
Local Período Jan Fev Mar Abr Mai Jun Jul Ago Set Out Nov Dez Média
A 0 12 25 80 121 150 210 250 230 105 50 15 104 B 239 220 200 100 46 2 0 0 55 88 140 158 104 C 99 105 110 109 100 112 104 98 101 100 105 105 104
# Qual cidade apresenta dados mais homogêneos?
# Qual a localidade com maior e menor dispersão?
# A média, por si só, é uma boa medida?
Logo temos como medidas de dispersão:
- Amplitude total
- Variância
- Desvio padrão
- Coeficiente de variação
7.2 AMPLITUDE TOTAL
É a diferença entre a maior e a menor medida.
Maior a amplitude total, maior a dispersão.
7.2.1 Dados não agrupados
AT= X(máximo) – X(mínimo)
Exemplo 1:
Para a cidade A, temos:
AT= 250 – 0 = 250 mm
# Para a cidade B
AT= 239 – 0 = 239 mm
# Para a cidade C

36
AT= 112 – 98 = 14 mm
7.2.2 Dados agrupados
a) Sem intervalos de classe
Também empregamos a fórmula que segue:
AT= LS última classe – LI primeira classe
Tabela 2 – Municípios com registros de ocorrência da ferrugem da soja, em determinada região
i Ocorrências Municípios Fi’ 1 0 15 15 2 1 10 25 3 2 8 33 4 3 5 38 5 4 2 40 Total 40
Logo:
AT= 4 – 0 = 4 ocorrências / município
b) Com intervalos de classe
Neste caso, a amplitude total é a diferença entre o limite superior da última classe e o limite
inferior da primeira classe.
AT= LS última classe – LI primeira classe
Exemplo:
Tabela 3 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta I Prod. (kg/planta) CC Plantas Fi’ 1 3,0 l– 4,2 3,69 2 2 2 4,2 l– 5,4 4,87 2 4 3 5,4 l– 6,6 6,05 6 10 4 6,6 l– 7,8 7,23 2 12 5 7,8 l–l 9,0 8,41 3 15
Logo:
AT= 9,0 – 3,0 = 6,0 kg / figueira
7.3 AMPLITUDE INTERQUARTÍLICA
É a diferença entre o terceiro e o primeiro quartil.
AIQ= Q3 – Q1

37
7.3.1 Dados não agrupados (pares ou impares)
Exemplo: Número de coelhos por cria
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13, 13
Q1= 10 coelhos/cria
Q3= 12 coelhos/cria
AIQ= 12 – 10 = 2 coelho/cria
7.3.2 Dados agrupados (com ou sem intervalo de classe)
Exemplo: Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
Q1= 5,25 kg/planta
Q3= 7,35 kg/planta
Logo:
AIQ= 7,35 – 5,25 = 2,1 kg/planta
7.4 VARIÂNCIA E DESVIO PADRÃO
# Tanto o desvio padrão como as variâncias são usadas como medidas de dispersão.
7.4.1 Para dados não agrupados
a) Variância
Baseia-se nos desvios em torno da média.
Σdi= Σ(Xi - −X ) = 0
É obtido a partir do somatório dos quadrados dos desvios em relação a média, dividido pelos
valores observados ou destes descontados de uma unidade.
Para cálculo usamos:
n= para população
n-1= para amostra
► Fórmula dedutiva
- Para população
n
XXi
nXXnXXXXS
n
i∑=
−−−− −
=−+−+−
= 1
2222
2)(
)...()2()1(

38
- Para amostra
1
)(1
2
2−
−
=
∑=
−
n
XXiS
n
i
►Fórmula de cálculo
- Para população
2
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛∑=−
∑==
n
n
1iXn
n
n
1i2Xn
2S
- Para amostra
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛∑=−
∑==
2
n
n
1iXn
n
n
1i2Xn
2S x 1n
n−
Isto por que:
1) como ∑=
−
−n
iXXi
1)( = 0, então somente n-1 desvios são independentes.
2) o divisor n-1 torna S2 uma medida “melhor” do que S2 divido por n.
►Interpretação dos valores da variância
Normalmente resulta num valor elevado, pois é um número em unidade quadrada em relação à
variável em questão, o que a torna de pouca aplicabilidade.
# Variância pequena= valores próximos a média
# Variância grande= valores distantes da média
# Na variância o ponto de referência é a média
b) Desvio padrão
É definido como a raiz quadrada da variância.
Tanto para população ou amostra
2SS =

39
- Propriedades do desvio:
1ª) Somando-se ou subtraindo-se uma constante a todos os valores observados, o desvio
padrão não se altera.
2ª) Multiplicando-se ou dividindo-se uma constante a todos os valores observados (diferente de
zero), o desvio padrão fica multiplicado ou dividido por essa constante.
# Observações:
- Tanto a variância como o desvio padrão não são adequados para comparar valores com
médias muito diferentes, mesmo que a unidade seja igual.
- Não é passível de comparação entre valores com distintas unidades.
Exemplo para dados não agrupados
Exemplo 2: Número de coelhos por cria, considerando uma amostragem.
8, 9, 10, 10, 10, 11, 11, 11, 12, 12, 13, 13
# Pela fórmula dedutiva, a variância e o desvio padrão são os seguintes:
- Média
−X = 130/12 = 10,83 coelhos/cria
- Variância
112
1122)83,1013(2)83,1013(2)83,1012(2)83,1012(2)83,1011(2)83,1011(2)83,1011(
2)83,1010(2)83,1010(2)83,1010(2)83,109(2)83,108(2
−
−
−+−+−+−+−+−+−
+−+−+−+−+−=S
11
2(2,17)2(2,17)2(1,17)2(1,17)2(0,17)2(0,17)2(0,17)20,83)(20,83)(2,830(21,83)(22,83)(2S +++++++−+−+−+−+−=
,341125,672S 2== coelhos/cria
- Desvio padrão
2,34S= = 1,53 coelhos/cria
# Pela fórmula de cálculo temos:
S2= 1nnx
n
Xn
n
Xn2n
1i
n
1i
2
−⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−∑∑==

40
Tabela 7.3- Número de coelhos por cria
Peso dos cordeiros (Xi) Xi2 8 64 9 81 10 100 10 100 10 100 11 121 11 121 11 121 12 144 12 144 13 169 13 169 130 1434
- Variância
1112
12130
121434 2
2 ×⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛−=S
S2= (119,5 - 117,36)x 12/11
S2= 2,34 coelhos/cria
- Desvio padrão
34,2=S
S= 1,53 coelhos/cria
7.4.2 Para dados agrupados
a) Sem intervalos de classe
Como temos intervalos de classes, fazemos uma modificação da fórmula:
►Variância
- Para população
S2=
2n
1i
n
1i
2
ΣFi
XnFi
ΣFi
XnFi
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛×
−× ∑∑
==
- Para amostra
Obs.: Para amostra se multiplica o resultado por 1Fi
Fi−

41
►Desvio padrão
2SS =
Exemplo
Consideraremos o exemplo da ferrugem como uma amostra.
Tabela 7.4 - Municípios com registros de ocorrência da ferrugem da soja, em determinada região
i Ocorrências Municípios FiXi FiXi2 1 0 15 0 0 2 1 10 10 10 3 2 8 16 32 4 3 5 15 45 5 4 2 8 32 soma 10 40 49 119
Então temos:
Variância
os/municípiocorrência 1,5139402
4049
401192S =×⎟
⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎠
⎞⎜⎝
⎛−=
Desvio padrão
51,1=S = 1,228 registros/município
b) Com intervalos de classe
►Variância
- Para população
S2=
2n
1i
n
1i
2
ΣFi
CCFi
ΣFi
CCiFi
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛×
−× ∑∑
==
- Para amostra
Obs.: Para amostra se multiplica o resultado por 1Fi
Fi−
Exemplo:
Consideraremos o exemplo do peso de suínos como uma amostra:

42
Tabela 7.5 - Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta
I Prod. (kg/planta) CC (Xi) Plantas FiCC FiCC2 1 3,0 l– 4,2 3,6 2 7,38 27,2322 2 4,2 l– 5,4 4,8 2 9,74 47,4338 3 5,4 l– 6,6 6,0 6 36,3 219,615 4 6,6 l– 7,8 7,2 2 14,46 104,5458 5 7,8 l–l 9,0 8,4 3 25,23 212,1843 30,25 15 93,11 611,0111
Variância
kg/planta1,131415
1593,11
15611,0111S
22 =×
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎠
⎞⎜⎝
⎛−=
Desvio padrão
13,1=S = 1,06 kg/planta
7.5 COEFICIENTE DE VARIAÇÃO DE PEARSON (CV)
É o desvio padrão expresso em percentagem da média.
O desvio padrão por si só não indica muita coisa por que:
- Difícil comparar grupos de valores quando as médias são bastante distintas, mesmo que
expressos na mesma unidade.
- Não é possível comparar grupos de valores expresso em unidades distintas.
Logo o Coeficiente de Variação é:
100X
SCV ×=−
Para os três exemplos temos:
a) Dados não agrupados
−X = 10,83 coelhos/cria
,142S 2= coelhos/cria
S= 1,46 coelhos/cria
=×= 01010,831,46CV 13,48%
b) Dados agrupados sem intervalo de classe
−X = 1,225 ocorrências de ferrugem município

43
1,512S = ocorrências de ferrugem município
=S 1,228 ocorrências de ferrugem município
%24,1000101,2251,228CV =×=
c) Dados agrupados com intervalo de classe
−X = 6,207 kg/planta
1,13S2 = kg/planta
=S 1,06 kg/planta
%08,170106,2071,06CV =×=
Interpretação do CV:
- Baixo (menor que 10): dados com pouca variação
- Médio (entre 10 e 20): dados com variação média
- Alto (maior que 20): dados com variações elevadas
7.6 COEFICIENTE DE VARIAÇÃO DE THORNDIKE - CVT É igual ao quociente entre o desvio padrão e a mediana.
100Md
SCVT ×=−
Exemplo: Distribuição de freqüência da produtividade de figueiras, expresso em kg/planta.
S= 1,06 kg/planta
Md= 6,1 kg/planta
1001,6
1,06CVT ×=
CVT= 17,38%

44
8 MEDIDAS DE ASSIMETRIA E DE CURTOSE
8.1 ASSIMETRIA
É o grau de afastamento de uma distribuição em relação a um determinado ponto referência
(pode ser a média) chamado de eixo de simetria.
a) Simétrica: média, moda e mediana coincidem.
b) Assimétrica positiva: apresenta mediana e média à direita da moda.
c) Assimétrica negativa: apresenta mediana e média à esquerda da moda.
8.1.1 Relação de assimetria
a) Média e moda
Baseando-se nas relações entre média e moda, podemos considerar:
0MoX =−−
→ distribuição simétrica
0MoX >−−
→ distribuição assimétrica positiva
0MoX <−−
→ distribuição assimétrica negativa
−X= Md = Mo −
X= Md = Mo
Mo < Md < −XMo < Md < −X
−X< Md < Mo −
X< Md < Mo

45
b) Coeficiente de assimetria
Entretanto, a mediada anterior é absoluta, apresentando a mesma deficiência do desvio
padrão, ou seja, não permite a comparação entre mediadas de duas distribuições.
Portanto, para comparação usaremos o coeficiente de assimetria de Pearson:
SMd)X3(As
−=
−
Interpretação:
- Simétrica: As = 0
- Assimetria fraca: IAsI < 0,15
- Assimetria moderada: 0,15 < IAsI < 1,0
- Assimetria forte: IAsI > 1
Obs.: conforme o sinal pode ser assimétrica positiva ou negativa
Exemplo 1: Tabela 8.1 - Consumo de óleo diesel (l h-1), por diferentes tratores agrícolas, durante a semeadura
I Consumo (l h-1) Trator Fi’ CC (Xn) FiXn FiXn2 1 4,0 I– 5,0 10 10 4,5 45 202,5 2 5,0 I– 6,0 23 33 5,5 126,5 695,75 3 6,0 I– 7,0 36 69 6,5 234 1521 4 7,0 I– 8,0 23 92 7,5 172,5 1293,75 5 8,0 I– 9,0 10 102 8,5 85 722,5 Σ 102 663 4435,5
Conforme a relação média e moda:
=−X (4,5 x 10) + (5,5 x 23) +...+(8,5 x 10) = 6,5 l h-1
Mo= 6,5 l h-1
Logo temos: 6,5-6,5= 0 l h-1 → distribuição simétrica
Conforme o coeficiente de assimetria:
Md= 102/2 = 51 posição
Logo está na classe 3, entre os valores 6 e 7:
36 –– 1,0
18 –– x x= 0,5
Md= 6,0 + 0,5 = 6,5 l h-1
S2=
2
11
2
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
=×
−=× ∑∑
n
n
iXiFi
n
n
iXiFi
24,12
102663
1025,44352 =⎟
⎠
⎞⎜⎝
⎛−=S l h-1

46
Logo: 024,1
)5,65,6(3=
−=sA simétrica
Exemplo 2: Tabela 8.2 - Consumo de óleo diesel (l h-1), por diferentes tratores agrícolas, durante a semeadura
I Consumo (l h-1) Trator Fi’ CC (Xn) FiXn FiXn2 1 4,0 I– 5,0 10 10 4,5 45 202,5 2 5,0 I– 6,0 20 30 5,5 110 605 3 6,0 I– 7,0 30 60 6,5 195 1267,5 4 7,0 I– 8,0 40 100 7,5 300 2250 5 8,0 I– 9,0 2 102 8,5 17 144,5 Σ 102 667 4469,5
Conforme a relação média e moda:
=−X (4,5 x 10) + (5,5 x 30) +...+(8,5 x 2) = 6,54 l h-1
Mo= 7,5 l h-1
Logo temos: 6,54-7,5= -0,96<0 → distribuição assimétrica negativa
Conforme o coeficiente de assimetria:
Md= 102/2 = 51 posição
Logo está na classe 3, entre os valores 6 e 7:
30 –– 1,0
21 –– x x= 0,7
Md= 6,0 + 0,7 = 6,7 l h-1
06,12
102667
1025,44692 =⎟
⎠
⎞⎜⎝
⎛−=S l h-1
Logo: 45,006,1
)7,654,6(3−=
−=sA assimétrica negativa moderada
Exemplo 3: Tabela 8.3 - Consumo de óleo diesel (l h-1), por diferentes tratores agrícolas, durante a semeadura
I Consumo (l h-1) Trator Fi’ CC (Xn) FiXn FiXn2 1 4,0 I– 5,0 2 2 4,5 9 40,5 2 5,0 I– 6,0 40 42 5,5 220 1210 3 6,0 I– 7,0 30 72 6,5 195 1267,5 4 7,0 I– 8,0 20 92 7,5 150 1125 5 8,0 I– 9,0 10 102 8,5 85 722,5 Σ 102 659 4365,5
Conforme a relação média e moda:
=−X (4,5 x 2) + (5,5 x 40) +...+(8,5 x 10) = 6,46 l h-1
Mo= 5,5 l h-1
Logo temos: 6,46-5,5= 0,96>0 → distribuição assimétrica positiva

47
Conforme o coeficiente de assimetria:
Md= 102/2 = 51 posição
Logo está na classe 3, entre os valores 6 e 7
30 –– 1,0
9 –– x x= 0,3
Md= 6,0 + 0,3 = 6,3 l h-1
06,12
102659
1025,43652 =⎟
⎠
⎞⎜⎝
⎛−=S l h-1
Logo: 45,006,1
)3,646,6(3=
−=sA assimétrica positiva moderada
8.2 CURTOSE
É o grau de achatamento de uma distribuição em relação a distribuição padrão, denominada
curva normal.
Temos 3 tipos:
- Leptocúrtica: mais fechada que a normal ou mais aguda.
- Platicúrtica: mais aberta que a normal ou achatada.
- Mesocúrtica: é a curva normal, sendo a referencial.
Exemplo: fazer no quadro.
8.2.1 Coeficiente de curtose
Para avaliar a curtose usa-se a seguinte fórmula:
)90(213
10PP
QQCC
−
−=
Interpretação:
- Leptocúrtica: CC<0,263
- Platicúrtica: CC>0,263
- Mesocúrtica: CC = 0,263
Exemplo: Distribuição de freqüência do peso de 15 suínos da raça landrace, nos primeiros 30
dias de idade.
Q1= 5,31 kg Q3= 7,38 kg P10= 3,985 kg P90= 8,41 kg
0,2343,985)2(8,415,317,38CC =
−
−= - logo, a distribuição é considerada leptocúrtica.

48
9 REGRESSÃO LINEAR SIMPLES
9.1 INTRODUÇÃO
É uma análise bivariada, pois tem o objetivo de estudar a relação entre duas variáveis.
Usados para fatores de tratamento quantitativos.
9.2 GRÁFICO DA DISPERSÃO
Pode indicar correlação linear positiva, negativa ou inexistência de correlação.
Também é útil para identificar existência de valores aberrantes.
A variável X é a independente e Y a dependente.
a) correlação positiva
Adubação Produtividade 100 2560 150 3000 200 3398 250 3378 300 4050 350 4298 400 4500
Gráfico 1 - Produtividade de determinada cultura em função da aplicação de adubo.
b) correlação negativa
Adubação Produtividade 400 4400 450 4000 500 3710 550 3480 600 3045 650 2871 700 2569
Gráfico 2 - Produtividade de determinada cultura em função da aplicação de adubo.
2000
2500
3000
3500
4000
4500
5000
50 150 250 350 450
Adubo (kg/ha)
Prod
utivi
dade
(kg/
ha)
2000
2500
3000
3500
4000
4500
5000
300 400 500 600 700 800
Adubação (kg/ha)
Prod
utiv
idad
e (k
g/ha
)

49
c) Sem correlação
Adubação Produtividade 100 2584 150 4012 200 3015 250 3958 300 2781 350 3451 400 2800
Gráfico 3 - Produtividade de determinada cultura em função da aplicação de adubo.
9.3 COEFICIENTE DE CORRELAÇÃO LINEAR (R)
Indica:
- o grau de intensidade da correlação entre as duas variáveis
- o sentido dessa correlação (positivo ou negativo).
Obtenção pelo coeficiente de Pearson:
[ ][ ]2i2i
2i
2i
iiii
)Y(Yn.)X(Xn
)Y.X(YXnr
∑−∑∑−∑
∑∑−∑=
onde n é o número de observações.
Os valores de r estão sempre entre -1 e 1, sendo adimensional.
Assim:
r= 1 → correlação entre as duas variáveis é perfeita e positiva;
r= -1 → correlação entre as duas variáveis é perfeita e negativa;
r= 0 → ausência de correlação entre as duas variáveis.
Exemplo 1 - Calcular o coeficiente de correlação para os dados a seguir:
2000
2500
3000
3500
4000
4500
0 100 200 300 400 500
Adubação (kg/ha)Pr
odut
ivid
ade
(kg/
ha)

50
Tabela 1 – Produtividade de leite em função da dose diária de ração
Ração (kg) Produtividade (l/dia) Xi.Yi Xi2 Yi2 5,0 15,1 75,50 25,00 228,01 5,3 15,3 81,09 28,09 234,09 5,6 15,7 87,92 31,36 246,49 5,9 16,0 94,40 34,81 256,00 6,2 16,2 100,44 38,44 262,44 6,5 15,9 103,35 42,25 252,81 6,8 16,4 111,52 46,24 268,96 7,1 17,0 120,70 50,41 289,00 7,4 16,7 123,58 54,76 278,89 55,80 144,30 898,50 351,36 2.316,69
Logo:
=−
=),,()55,80-(9x351,36
3055,80x144,-9x898,50r2 2301446923169xx
0,94158
Conclusão: Existe uma correlação positiva entre a dose de ração fornecida e a produtividade de leite
de 94,16%.
9.4 COEFICIENTE DE DETERMINAÇÃO (R2) Mede a proporção de variação de Y que é explicada linearmente pela variação de X.
Os valores de r2 ficam entre 0 e 1.
r2= (r)2
r2= (0,94158)^2
r2= 0,88658
Conclusão: Pode-se afirmar que 88,66% do aumento de produtividade de leite é explicada
linearmente pela dose de ração fornecida.
9.5 EQUAÇÃO DA RETA E DETERMINAÇÃO DOS PARÂMETROS Tem por objetivo descrever através de um modelo matemático a relação entre duas variáveis.
A modelo que descreve é:
Y=a + bX
Onde:
a= parâmetro
b= parâmetro da inclinação da reta.
Os parâmetros são obtidos pelas equações:

51
( )( )∑ ∑∑ ∑∑−×
−×= 22 XnXnn
YnXnnXnYnb
Cálculo dos parâmetros:
255,80-351,369144,3055,80-898,509b
×××
=
b= 0,7111
a= 11,6244
Logo o modelo fica descrito por:
Y= 11,6244 + 0,7111X
Obs: Para cada quilo de ração que for fornecido, teria um incremento de 0,7111 litros de leite.
Então o gráfico fica assim apresentado:
Gráfico 1 - Produtividade de leite em função da dose diária de ração.
Conclusão da regressão linear:
Espera-se que 88,66% das vezes a variação da produtividade de leite é explicada linearmente pela
dose de ração, sendo que o fornecimento de cada quilo de ração proporciona o incremento de 0,71
litro de leite.
Obs.: A regressão só pode estimar valores para o intervalo avaliado.
Exemplo: Estime a produtividade em função de alguma dose de ração
y = 0,7111x + 11,624R2 = 0,8866
15,0
15,5
16,0
16,5
17,0
17,5
4,5 5,5 6,5 7,5 8,5
Ração (kg)
Prod
utiv
idad
e (l/
ha)

52
10 ANÁLISE COMBINATÓRIA
10.1 INTRODUÇÃO
A necessidade de calcular o número de possibilidades existentes nos chamados jogos de
azar levou ao desenvolvimento da Análise Combinatória. Trata-se de uma parte da Matemática que
estuda os métodos de contagem. Esses estudos foram iniciados já no século XVI, pelo matemático
italiano Niccollo Fontana (1500-1557), conhecido como Tartaglia. Depois dele vieram os franceses
Pierre de Fermat (1601-1665) e Blaise Pascal (1623-1662).
10.2 FATORIAL
Para resolver problemas de Análise Combinatória precisamos utilizar uma ferramenta
matemática chamada Fatorial.
Seja n um número inteiro não negativo. Definimos o fatorial de n (indicado pelo símbolo n!) como
sendo:
n! = n .(n-1) . (n-2) . ... .4.3.2.1 para n ³ 2.
Exemplos:
a) 6! = 6.5.4.3.2.1 = 720
b) 4! = 4.3.2.1 = 24
c) 7! = 7.6.5.4.3.2.1 = 5040
d) 10! = 10.9.8.7.6.5.4.3.2.1
e) 3! = 3.2.1 = 6
Perceba que 7! = 7.6.5.4!, ou que
6! = 6.5.4.3!, e assim sucessivamente.
Casos especiais:
0! = 1
1! = 1
10.3 PRINCÍPIO FUNDAMENTAL DA CONTAGEM - PFC
Se determinado acontecimento ocorre em etapas independentes, e se a primeira etapa pode
ocorrer de k1 maneiras diferentes, a segunda de k2 maneiras diferentes, e assim sucessivamente,
então o número total “T” de maneiras de ocorrer o acontecimento, composto por “n” etapas, é dado
por:
T = k1. k2 . k3 . ... . kn

53
Exemplo 1:
No Brasil as placas dos veículos são confeccionadas usando-se 3 letras do alfabeto e 4
algarismos. Qual o número máximo de veículos que poderá ser licenciado?
Imaginemos a seguinte situação: Placa ACD – 2172.
Como o alfabeto possui 26 letras e nosso sistema numérico possui 10 algarismos (de 0 a 9),
podemos concluir que: para a 1ª posição, temos 26 alternativas, e como pode haver repetição, para a
2ª, e 3ª também teremos 26 alternativas. Com relação aos algarismos, concluímos facilmente que
temos 10 alternativas para cada um dos 4 lugares. Podemos então afirmar que o número total de
veículos que podem ser licenciados será igual a:
T= 26 x 26 x 26 xx10 x 10 x 10 x 10 = 175.760.000
No Brasil, antes da alteração do sistema de emplacamento de automóveis, as placas dos
veículos eram confeccionadas usando-se 2 letras do alfabeto e 4 algarismos. Qual o número máximo
de veículos que podia ser licenciado neste sistema?
Imaginemos a seguinte situação: Placa AC – 2172.
T= 26.26.10.10.10.10= 6.760.000
Percebe-se que a inclusão de apenas uma letra faz com que sejam licenciados,
aproximadamente, mais 170.000.000 de veículos.
10.4 ARRANJOS SIMPLES
Temos um Arranjo quando os agrupamentos conseguidos ficam diferentes ao se inverter a
posição dos seus elementos.
Perceba que, se quisermos formar centenas de algarismos distintos, utilizando apenas os 5
primeiros números ímpares (1; 3. 5; 7; 9) teremos as seguintes centenas:135; 137;139; 153, 157, e
assim sucessivamente.
Se invertermos a posição dos elementos de qualquer uma destas centenas conseguiremos
outra centena diferente: 135 ≠ 351. Temos então um ARRANJO de 5 números (1; 3; 5; 7; 9) em
grupos de três (centenas).
Representando o número total de arranjos de n elementos tomados k a k (taxa k) por An,k ,
teremos a seguinte fórmula:
!!,! =!!
! − ! !
Exemplo 1:
Considerando que desejamos formar arranjos de 3 números (centenas) a partir dos seguintes
números: 1, 2, 3, 4, 5, 6 e 7.
!!,! =!!
!!! != 210 arranjos de três a três

54
Exemplo 2:
Usando-se as 26 letras do alfabeto, quantos arranjos distintos com 4 letras podem ser
montados?
!!",! =!"!
!"!! != 358800 arranjos de quatro a quatro
10.5 PERMUTAÇÕES SIMPLES
Permutações simples de n elementos distintos são os agrupamentos formados com todos os
n elementos e que diferem uns dos outros pela ordem de seus elementos. De outro modo, podemos
entender permutação simples como um caso especial de arranjo, onde n = k, ou seja:
!!,! =!!
! − ! !
An, n = n!/(n-n)! = n!/0! = n!/1 = n!
Chega-se então à relação:
Pn = n!
Exemplo 1:
Quantas possibilidades de agrupamentos há com os elementos A, B, C?
São possíveis as seguintes permutações: ABC, ACB, BAC, BCA, CAB e CBA.
De forma matemática: P3 = 3! = 3.2.1 = 6
Exemplo 2:
Calcule o número de formas distintas de 5 pessoas ocuparem os lugares de um banco retangular de
cinco lugares.
P5 = 5! = 5.4.3.2.1 = 120
Exemplo 3
Denomina-se ANAGRAMA o agrupamento formado pelas letras de uma palavra, que podem ter ou
não significado na linguagem comum. Os possíveis anagramas da palavra REI são: REI, RIE, ERI,
EIR, IRE e IER. Calcule o número de anagramas da palavra MUNDIAL.
P7 = 7! = 7.6.5.4.3.2.1 = 5040

55
10.6 PERMUTAÇÕES COM ELEMENTOS REPETIDOS
Se entre os n elementos de um conjunto, existem a elementos repetidos, b elementos
repetidos, c elementos repetidos e assim sucessivamente, o número total de permutações que
podemos formar é dado por:
!!!,!,!,.. =
!!!! !! !!. .
Exemplo 1
Determine o número de anagramas da palavra MATEMÁTICA (não considere o acento).
Temos 10 elementos, com repetições M (repetida duas vezes), a letra A (três vezes) e a letra T (duas
vezes).
Na fórmula anterior, teremos: n=10, a=2, b=3 e c=2.
!!"!,!,! = !"!
!!!!!! =151200
10.7 COMBINAÇÕES SIMPLES
Temos uma combinação quando os agrupamentos conseguidos permanecem iguais ao se
inverter a posição dos seus elementos.
Perceba que se houverem cinco pessoas entre as quais desejamos formar grupos de três, o
grupo formado por João, Pedro e Luís é o mesmo grupo formado por Luís, Pedro e João. Temos,
então, uma combinação de cinco elementos em grupos de três.
Representando por Cn,k o número total de combinações de n elementos tomados k a k (taxa
k), temos a seguinte fórmula:
!!! =!!
!! (! − !)!
Exemplo 1:
Resolvendo o problema dos grupos de 3 pessoas, temos:
!!! =5!
3! (5− 3)! = 10 !"#$%&'çõ!" !" !"ê! ! !"ê!
Exemplo 2
Uma prova consta de 15 questões das quais o aluno deve resolver 10. De quantas formas ele poderá
escolher as 10 questões?
Observe que a ordem das questões não muda o teste. Logo, podemos concluir que se trata de um
problema de combinação de 15 elementos com taxa 10.
!!"!" =15!
10! (15− 10)! = 3003 !"#$%&'çõ!" !" !"ê! ! !"ê!

56
11 INTRODUÇÃO A TEORIA DA PROBABILIDADE
11.1 INTRODUÇÃO
Os cálculos de probabilidade pertencem ao campo da matemática
A maioria dos fenômenos de que trata à estatística é de natureza aleatória ou probabilística.
As raízes da Teoria de Probabilidade encontram-se nos jogos de azar, cuja origem remonta ao
século XVII (Chevalier de Meré, Fermat e Pascal).
Bernoulli (1713) introduziu a base matemática da teoria fazendo relação entre probabilidade e
freqüência relativa.
O conhecimento dos aspectos fundamentais do cálculo da probabilidade é fundamental para o
estudo da estatística Inferencial.
Por exemplo:
# Acerto em jogo
# Defeito em algum produto (máquina, peça)
# Seguros sobre bens duráveis
# Números de animais em determinado intervalo de peso
# Seca
11.2 CLASSIFICAÇÃO DOS MODELOS a) Determinísticos
É aquele cujo resultado é conhecido a priori. Todos os experimentos determinísticos podem
ser representados por um modelo determinístico.
Ex.: área de um círculo
Pode ser facilmente determinada, basta conhecer seu raio.
a= πr2
b) Probabilísticos ou aleatórios
É o experimento cujo resultado final não pode ser determinado com certeza.
É o experimento cujos resultados não são previsíveis, mesmo que ele seja repetido inúmeras
vezes em condições idênticas.
Exemplo: Jogar um dado e verificar o resultado
Encontrar uma peça com defeito.
Características
- Todo experimento aleatório pode ser repetido sob condições essencialmente idênticas.

57
- Todo experimento aleatório pode ter resultados estáveis se for repetido um número
suficientemente grande.
11.3 ESPAÇO AMOSTRAL OU PONTOS AMOSTRAIS (S)
É o conjunto de todos os possíveis resultados de um experimento aleatório.
Cada experimento, em geral, pode ter vários resultados possíveis.
No lançamento de uma moeda, os resultados possíveis são cara (K) e coroa (C). O espaço
amostral é:
S = {K, C}
No lançamento de um dado, o espaço amostral é:
S = {1, 2, 3, 4, 5, 6}
No lançamento de duas moedas, uma após a outra.
S = {(K, K), (K, C), (C, K), (C, C)}
Ao extrairmos uma bola de uma urna contendo bolas brancas, vermelhas e pretas.
S = {B, V, P}
No lançamento de dois dados, um após o outro.
S = {(1, 1), (1, 2), (1, 3) ... (6, 5), (6, 6)}
11.3.1 Tipos de espaço amostral
# Enumerável: é o espaço amostral que se consegue enumerar todos os elementos do
conjunto.
Ex.: jogo do dado
# Não enumerável: é aquele conjunto cujos elementos não podem ser numerados.
Exemplo: lâmpada - acender e anotar o tempo.
11.4 EVENTO (E)
Também, pode ser representado por qualquer letra.
É um subconjunto do espaço amostral.
O evento pode ser:
# certo: próprio espaço amostral
# Impossível: aquele evento que não tem possibilidade de aparecer. Ex: dado 1 a 6, evento
impossível aparecer 1>x>6.
# Elementar: quando o conjunto é unitário.
Os eventos de um só elemento são chamados eventos elementares.
O espaço S é o evento certo e Ø é o evento impossível.

58
Exemplos:
1) No lançamento de uma moeda, já vimos que S = {K, C}. Temos os eventos:
A = {K}: ocorrência de cara (evento elementar)
B = {C}: ocorrência de coroa (evento elementar)
S = {K, C}: ocorrência de cara ou coroa (evento certo)
Ø: ocorrência de nem cara nem coroa (evento impossível)
2) No lançamento de dois dados, alguns dos eventos são:
A = {(1, 3), (2, 2), (3, 1)}: Ocorrência de soma 4.
B = {(1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6)}: ocorrência de resultados iguais nos dois
lançamentos.
Logo Quando:
- E = S, E é chamado evento certo
- E ⊂ S e E é um conjunto unitário, E é um evento elementar (⊂ está contido)
- E = Ø, E é chamado evento impossível
Exemplo: Lançar um dado
A= {1, 2, 3} ⊂ S → A evento de S
B= {1, 2, 3, 4, 5, 6} ⊂ S → B evento certo
C= {4} ⊂ S → evento elementar
D= Ø ⊂ S → evento impossível
Ø= conjunto vazio
{Ø}= conjunto cujo componente é vazio
Por exemplo:
1) Ao lançarmos uma moeda há dois resultados possíveis: Logo temos S1= {K, C}
2) Ao lançarmos um dado há seis resultados possíveis: Logo temos: S2= {1, 2, 3, 4, 5, 6}
3) Ligar uma lâmpada e medir o tempo que ele fica ligada.
Logo temos S3= {t ≥ 0}
Assim teremos:
S1 e S2 são enumeráveis e denominados discretos.
S3 é não enumerável e denominado contínuo.

59
Exemplo 4
Situação 1
A= {1, 2, 3}
B= {3, 4}
A e B são eventos de S.
A U B= {1, 2, 3, 4}
A ∩ B= {3}
Situação 2:
A= {2, 4, 6}
B= {1, 3, 5}
A U B= {1, 2, 3, 4, 5, 6}
A ∩ B= { }
11.4.1 Possibilidades para a ocorrência de eventos aleatórios
a) União (A U B)
É formado pelos pontos amostrais que pertencem a, pelo menos, um dos eventos.
A= {1, 2, 3}
B= {3, 4}
A U B= {1, 2, 3, 4}
b) Intersecção (A ∩ B)
É formado pelos pontos que pertencem simultaneamente aos eventos A e B.
A= {1, 2, 3}
B= {3, 4}
A ∩ B= {3}
c) Complementação (S – A = Ā)
Lançam-se 2 moedas, seja A: saída de faces iguais e B: saída de cara na primeira moeda.
Logo:
S= {(C, C), (C, K), (K, C), (K, K)}
A= {(C, C), (K, K)}
B= {(C, C), (C, K)}
AA BB
SS

60
A U B= {(C, C), (C, K), (K, K)}
A ∩ B= {(C, C)}
Ā= {(C, K), (K, C)} __B = {(K, C), (K, K)}
d) Exclusão
Quando os dois eventos não têm nenhum elemento comum.
A= {2, 4, 6}
B= {1, 3, 5}
A ∩ B= { }
11.5 DEFINIÇÃO DE PROBABILIDADE
11.5.1 Clássica
Num experimento aleatório, sendo S o seu espaço amostral, admitindo que todos os elementos
de S tenham a mesma chance de acontecer, ou seja, que S é um subconjunto equiprovável.
Exemplos: Dado, baralho, bolas pretas e brancas
Denominamos de probabilidade de um evento A (A ⊂ S) o número real P(A), tal que:
P(A)= (S) possíveis casos de número
(A) evento ao favoráveis casos de número
Exemplo 1:
Qual é a probabilidade, entre 6 alternativas, do aluno errar a questão. As chances são
equiprováveis.
P(A)= 1/6 ou 16,67%
11.5.2 Pela freqüência relativa
Realizando-se um experimento um grande número de vezes, pode-se determinar qual a
chance de determinado evento ocorrer. A freqüência de ocorrência desse evento é a estimativa da
probabilidade.
P(A)= (S) sobservaçõe de total número
(A) desejada situação da observadas vezes de número
# Onde:
1º) 0 ≤ P(A) ≤1
2º) P(A)= 1, se, e somente se, A ocorrer em todas as n situações
3º) P(A)= 0, se, e somente se, A nunca ocorrer nas n situações

61
Exemplo 1:
Qual a probabilidade de uma pessoa ser atingida por um raio num período de um ano. O
espaço amostral consiste de 2 eventos, não equiprováveis. Digamos que numa determinada região
caia 122110 raios em um ano e, em média, 199 atinjam pessoas, segundo registros locais.
Qual é a probabilidade de uma pessoa ser atingida, sabendo-se que a população total é de
80.000.000 de pessoas.
P(A)= hab010.4021
80.000.000199
=
Exemplo 2: Uma companhia de seguros automotivos tem na sua base de registros as seguintes
informações sobre acidentes de trânsito durante um período X:
- 3.102 por falhas mecânicas;
- 8.080 por defeitos na pista;
- 32.581 por imprudência, sendo destes, 21.022 por excesso de velocidade e 11.559 por
ultrapassagem em local proibido.
Qual a probabilidade de ocorrência de acidente por defeitos na pista e por excesso de
velocidade?
# defeitos – P(A)= 8.080/43.763 = 18,46%
# velocidade – P(B)= 21.022/43.763 = 48,04%
11.5.3 Axiomática (kolmogorov)
Axioma - é uma afirmação que não é possível de demonstração.
Probabilidade ou medida de probabilidade é a função P definida em S que se associa a cada
evento a um número real, que satisfaz os axiomas seguintes:
1º) 0 ≤ P(A) ≤1
2º) P(S)=1
3º) Se A e B são mutuamente exclusivos P(A U B) = P(A) + P(B)
11.4.4 Regras básicas da probabilidade
a) Adição
Usa-se essa regra para calcular a probabilidade da ocorrência de eventos mutuamente
exclusivos
P(A U B)= P(A) + P(B) – P( A ∩ B)
Onde P(A ∩/ou B)= denota a interseção de A e B
b) Multiplicação
Usa-se essa regra para calcular a probabilidade da ocorrência de eventos independentes

62
P(A ∩/e B)= P(A) x P(B)
11.4.5 Tipos de eventos a) Evento complementar
Sabe-se que um evento pode ocorrer ou não. Sendo a probabilidade de que ele ocorra é
denotada por A e que não ocorra por Ā, temos a relação:
P(A ou Ā)= P(A) + P(Ā) = 1
P(Ā)= 1- P(A)
Eventualmente, devemos determinar a probabilidade de um evento A não ocorrer.
O complemento de um evento A, denotado por Ā, consiste em todos os resultados em que o
evento A não ocorre.
Ex.: tirar 4 num dado é 1/6, logo a probabilidade de não tirar 4 é 5/6.
b) Eventos independentes
Quando a realização de um evento não afeta a probabilidade da realização do outro.
Por exemplo, quando lançamos dois dados, o resulto obtido em um é independente do outro.
Se dois eventos são independentes a probabilidade que eles ocorram simultaneamente é igual
ao produto das probabilidades dos dois.
Para serem independentes P(A ∩ B)= P(A) x P(B), ou seja, se P(A)= 0,8, P(B)=0,35 e P(A ∩
B)= 0,28, logo A e B são independentes.
Exemplo: qual a probabilidade de obtermos 2 no lançamento do primeiro dado e 6 no segundo.
P= 361
61
61
=×
c) Eventos mutuamente exclusivos
Quando a realização de um exclui a realização do outro.
Assim, ao lançar uma moeda o “evento tirar cara” e o “evento tirar coroa” são mutuamente
exclusivos.
Então a probabilidade de que um ou outro ocorra é igual a soma das probabilidades.
Exemplo: ao lançar um dado a probabilidade de tirar 1 ou 4 é.
P= 31
62
61
61
==+
11.4.6 Probabilidade subjetiva
Consiste no palpite. Baseia-se no conhecimento de fatores relevantes.
Exemplo: alunos quando não estudaram para uma prova
Para seguro de um animal de alta genética para uma exposição.
É baseada em conhecimentos relevantes.

63
11.4.7 Probabilidade através da freqüência relativa
Realizando-se um experimento um grande número de vezes, pode-se determinar qual a
chance de determinado evento ocorrer. A freqüência de ocorrência desse evento é a estimativa da
probabilidade.
P(S)P(x)x)(XP ==
Exemplo 1:
Digamos que numa determinada região sejam roubados em um mês, em média, 9 veículos da
marca X, segundo registros locais.
Qual é a probabilidade de um veículo da marca X ser roubado no período de um ano, sabendo-
se que o número total de carros emplacados é de 833524, sendo 8,3% da marca X.
P(X= 9)= %156,05,69183
1080,083 x 833524
129==
×
11.4.8 Probabilidade condicional
Sejam os eventos A, B, denota-se P(A/B) a probabilidade condicionada do evento A, quando B
tiver ocorrido ou a probabilidade condicional do evento A dado B é definida por:
( )P(B)
BAPP(A/B) ∩= ou ( )
P(A)ABPP(B/A) ∩
=
Podemos dizer que:
P(A ∩ B): número de casos favoráveis a (A∩B) e
P(B): número de casos favoráveis a B.
Exemplo:
Considerando criador de gado tem 500 cabeças no seu campo, sabendo-se que destas 300
são fêmeas (F) e 200 machos (M). Destes, 200 são da raça charolês (A), 100 da raça braford (B),
150 da raça devon (C) e 50 da raça nelore (D). Considerar que a distribuição de animais para sexo
conforme a tabela abaixo.
Sendo escolhido ao acaso um animal, qual a probabilidade de ser braford, dado ser macho.
A B C D Total
M 91 25 64 20 200
F 109 75 86 30 300
Total 200 100 150 50 500
Logo temos: ( )P(M)
MBPP(B/M) ∩=

64
P(B ∩ M)= 25/500 e P(M)= 200/500
%5,121250,0
50020050025
P(B/M) ou== de ser braford dado ser macho
11.4.9 Teorema de Bayes
Tem-se uma partição do espaço amostral S em um número finito de eventos Si (i= 1, 2,3,...,
n) se:
a) Os Si são mutuamente excludentes dois a dois, isto é, Si ∩ Sj = Ø para i ≠ j.
b) Sn
iSi =
=1
isto é, os eventos S são exaustivos, pois sua união esgota ou exaure todo o espaço
amostral S.
Partição de S subdividido, sendo A é um evento arbitrário de S, com P(A) > 0.
P(Si / A)= P(A)
) A ( ∩SiP
O teorema de Bayes é uma generalização da probabilidade condicional para mais de dois
eventos.
P(A)= P(S1 ∩ A) + P(S2 ∩ A) +...+ P(Sn ∩ A) = A) (Sin
ni P ∩
=∑
Pela probabilidade condicional:
P(Si / A)= Si)\ P(A *(Si) P
)Si\ A(*)(n
ni∑=
PSiP
Exemplo: Numa fábrica três máquinas denominadas A, B e C, que correspondem, respectivamente,
por 40, 35 e 25% da produção, sendo de 2, 1, 3% as peças defeituosas produzidas pelas máquinas
na mesma ordem. Sabe-se que a peça é defeituosa, qual a probabilidade, tomada ao acaso, de ter
sido produzida pela máquina B?
Denominaremos B o evento fabricado pela máquina “B” e “d” o evento defeito.
Queremos a P(B / d).
P(B / d)= )(
)/(*)(P(d)
)d B(dP
BdPBPP=
∩
S1
S2S2
S5S5
S3S3
S4S4 S6
S6
SS
AA

65
Mas a peça defeituosa pode provir de qualquer uma das máquinas, logo:
P(d)= P(A)*P(d / A) + P(B)*P(d / B) + P(C)*P(d / C)
P(d)= (0,40 x 0,02) + (0,35 x 0,01) + (0,25 x 0,03) = 0,019 ou 1,9%
Então:
P(B / d)= %4,18184,00,019
01,0*35,0==
Qual a probabilidade de ter sido fabricada por C e ter defeito?
P(C / d)= 39,5%0,3950,0190,03*0,25
P(d)P(C/d)P(C)
===×

66
12 VARIÁVEIS ALEATÓRIAS
12.1 INTRODUÇÃO
Muitos experimentos produzem resultados não numéricos, sendo conveniente transformar
seus resultados em números. Isto é feito através da variável aleatória, que é uma regra que associa
um valor numérico a cada ponto do espaço amostral.
Então, uma variável aleatória (geralmente representada por x) que tem um valor numérico
único (determinado aleatoriamente) para cada resultado de um experimento.
Exemplo:
Lançam-se duas moedas e observa-se o resultado.
O espaço amostral pode ser S={KK, KC, CK, CC}
Uma variável aleatória de interesse é X= {número de coroas}. A cada evento simples,
associamos um número, que é o valor assumido pela variável aleatória X:
Evento KK KC CK CC
X 2 1 1 0
Outro passo fundamental é associar cada valor a sua probabilidade, obtendo o que
denominamos de uma distribuição de probabilidade.
Esta fica caracterizada pelos valores da v.a. X e pela regra, ou função, que associa a cada
valor uma probabilidade, denominada função de probabilidade, representada por f(x).
Valores de X 2 1 0
Probabilidade f(x) 1/4 1/2 1/4
Obs.: A variável aleatória pode ser denominada:
a) Discreta: se seu espaço amostral é enumerável. Ex.: número de expectadores
b) Contínua: se seu espaço amostral não é enumerável. Ex.: carga de uma pilha
12.2 ESPERANÇA MATEMÁTICA
Podemos definir, para as distribuições de probabilidade, as mesmas medidas de tendência
central e de dispersão utilizadas nas distribuições de freqüências.
A média de uma v.a. X é também chamado valor esperado, ou esperança matemática ou
esperança de X. É representada por E(X) e se define como:
E(X) = Σxi f(xi),

67
estendendo-se o somatório a todos os valores possíveis de X.
É uma média ponderada dos xi,em que os pesos são as probabilidades associadas.
A esperança matemática é uma medida de centro, ou de tendência central de uma distribuição.
Portanto, E(X) é também chamada média populacional, denotada por µ.
Exemplo 1: consideremos a soma dos pontos que aparecem na jogada de dois dados. Os
valores possíveis da soma de X, com suas probabilidades associadas f(x) = P(X = x) são:
x 2 3 4 5 6 7 8 9 10 11 12
f(x) 1/36 2/36 3/36 4/36 5/36 6/36 5/36 4/36 3/36 2/36 1/36
X . f(x)
E(X) = 2*(1/36)+3*(2/36)+4*(3/36)+...+12*(1/36) = 7
Neste caso a esperança matemática é a média populacional ponderada, conforme pode ser
observado no gráfico abaixo:
Exemplo 2: Um produtor rural, com 40 anos, obtém um empréstimo agrícola para implantação
de lavouras anuais no valor de R$ 30.000, para pagar no prazo de um ano. Sabe-se que a
probabilidade de um homem com esta idade falecer antes de completar 41 anos é de 3,53 em 1.000.
Entretanto, ele deseja fazer um seguro de vida por esse prazo, pois caso morra antes deste período
a divida fique remida (a companhia seguradora ficará responsável pelo pagamento). Qual o prêmio
que ele deve pagar a seguradora para cobrir o risco de morte, sem contabilizar os seus encargos e
lucro?
O prêmio que deve ser pago é a esperança de perda da companhia.
Sendo X a perda da companhia, a distribuição de probabilidade X é dada por:
X 0 30.000
f(x) = P(X = x) 1-(3,53/1.000) 3,53/1.000
X * f(x) 0 105,90
2 3 4 5 6 7 8 9 10 11 12 X
f(x)

68
E(X) = 30.000 * 0,00353 + 0 * (1-0,00353) = R$ 105,90
Então este é o prêmio que deve ser pago a seguradora para cobrir o risco de morte, mas no
valor total serão acrescidos o encargo e lucro.
Claro que este valor só é válido para um grande número de segurados e não apenas poucos.
a) Propriedades
Se a e b são constantes e X é uma v.a., então:
1ª) E(a) = a
2ª) E(bX) = bE(X)
3ª) E(X ± Y) = E(X) ± E(Y)
4ª) E(aX ± b) = aE(X) ± b
5ª) E(X – µx) = 0
b) Variância e desvio padrão
# Variância: mediada que avalia a dispersão (ou concentração) de probabilidade em torno da
média.
σ2 = Var(X) = E[(X – µ)2] = E(X2) – µ2
# Desvio padrão:
σ = dp(X) = Var(X)
Exemplo:
X P(X) X * P(X) X2 * P(X)
-2 1/5 -2/5 4/5
-1 1/5 -1/5 1/5
0 1/5 0 0
3 1/5 3/5 9/5
5 1/5 5/5 25/5
µx= 1 E(X2)= 39/5
Var(X)= E(X2) – µ2
Var(X)= 39/5 -12
Var(X)= 6,8
dp(X)= 2,61
b.1) Propriedades da variância
Para a e b constantes, temos:
1. Var(a)> 0
2. Var(X + a) = Var(X)

69
3. Var(b*X)= b2 Var(X)
4. Var(a ± bX) = b2 Var(X)
5. Var(X ± Y) = Var(X) + Var(Y) ± 2 Cov(X, Y)
12.3 VARIÁVEL ALEATÓRIA DISCRETA
12.3.1 Distribuição conjunta de duas variáveis aleatórias
Quando objetivamos estudar mais de um resultado de um experimento aleatório.
Exemplo:
Considerando o salário e o tempo de serviço de dez funcionários de determinada empresa,
determine a distribuição conjunta de probabilidade da variável X: salário (reais) e da variável Y:
tempo serviço (anos).
Funcionário A B C D E F G H I J
X 500 600 600 800 800 800 700 700 700 600
Y 6 5 6 4 6 6 5 6 6 5
Construiremos uma tabela de dupla entrada, onde colocaremos as probabilidades conjuntas
de X e Y.
X Y
4 5 6 Totais
500 0 0 1/10 1/10
600 0 2/10 1/10 3/10
700 0 1/10 2/10 3/10
800 1/10 0 2/10 3/10
Totais 1/10 3/10 6/10 10/10
Assim a probabilidade de P(X=600, Y=5) = 2/10 e P(X=800, Y=5) = 0

70
12.3.2 Distribuições marginais de probabilidade e esperança de X
Distribuição marginal de X (salário), dos dados anteriores temos:
X P(X) X . P(X)
500 1/10 500/10
600 3/10 1800/10
700 3/10 2100/10
800 3/10 2400/10
1 E(X)= 680
Logo a média salarial é de R$ 680,00
Distribuição marginal de Y (tempo trabalho), dos dados anteriores temos:
X P(X) Y . P(X)
4 1/10 4/10
5 3/10 15/10
6 6/10 36/10
1 E(X)= 5,5
Logo o tempo médio de serviço é de 5 anos e 6 meses.
Consideremos a distribuição de freqüência em relação ao número de multas em
determinada rodovia.
Tabela 2 – Freqüência de multas de transito
Multas Freqüências (dias) Probabilidades para 1 dia
0 3 0,10
1 6 0,20
2 12 0,40
3 6 0,20
4 3 0,10
Σ 30 1,00
A esta tabela denominamos distribuição de probabilidade.
Seja X uma variável aleatória que pode assumir valores x1, x2, x3, ... , xn. A cada valor xi
correspondem pontos do espaço amostral. Associamos, então, a cada valor xi a probabilidade pi de
ocorrência de tais pontos no espaço amostral.
Então para que uma função f(x) seja uma distribuição de probabilidade é necessário que:
1. Σp(x) = 1, onde x toma todos os valores possíveis
2. 0 ≤ P(x) ≤ 1, para todo x

71
Os valores de x1, x2, x3, ... , xn e seus correspondentes p1, p2, p3, ..., pn definem uma
distribuição de probabilidade.
Ao definir distribuição de probabilidade estabelecemos uma relação entre a variável aleatória
X e os valores da variável P. Esta relação define uma função.
Os valores de xi (i= 1, 2, 3, ..., n) formam o domínio da função e os valores pi (i= 1, 2, 3, ...,
n) o seu conjunto imagem.
É denominada função de probabilidade, sendo:
f(x)= P(X = xi)
A função de P(X = xi) determina a distribuição de probabilidade da variável aleatória X.
Lançamento de 2 moedas, sendo cara o objetivo.
Número de caras (X) P(X = x)
0 1/4
1 2/4
2 1/4
Σ= 1
a) Representação gráfica de uma distribuição de probabilidade
Há várias representações gráficas para uma distribuição de probabilidade, como histograma,
o polígono de freqüência, etc.
Para a tabela das multas de carro já que os valores possíveis da soma de X, com suas
probabilidades associadas f(x) = P(X = x) são:
x 0 1 2 3 4
f(x) 0,10 0,20 0,40 0,20 0,10
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0 1 2 3 4 X
f(x)

72
Exemplo 1: P(x) = x/5 (onde x toma os valores 0, 1, 2, 3) define uma função de
probabilidade?
Para que seja definida uma distribuição de probabilidade deve satisfazer as condições
anteriores.
ΣP(x) = P(0) + P(1) + P(2) + P(3)
= 0/5 + 1/5 + 2/5 + 3/5 = 6/5, logo ΣP(x) ≠ 1
Como não satisfaz a primeira condição não é uma distribuição de probabilidade.
Exemplo 2: P(x) = x/3 (onde x pode ser 0, 1 ou 2) define uma função de probabilidade?
ΣP(x) = 0/3 + 1/3 + 2/3 = 3/3 = 1
As duas condições são satisfeitas, pois ΣP(x) = 1 e os valores de P(x) estão entre 0 e 1.
12.3.3 Probabilidade pela distribuição de Bernoulli ou binomial
Existem apenas duas situações: “A” ocorre ou “A” não ocorre, pode-se determinar a
probabilidade de A não ocorrer como sendo q = 1 - p. Em certas situações a probabilidade “p” é
denominada de probabilidade de “sucesso” e a probabilidade “q” de probabilidade de fracasso.
Observação:
a) As probabilidades permanecem constantes durante todo experimento
b) As provas são independente uma das outras, ou seja, a ocorrência de sucesso ou falha
não modifica a probabilidade futura.
A probabilidade é dada por:
P(X= x)= ⎟⎠
⎞⎜⎝
⎛xn px . qn-x
na qual:
P(X= x)= é a probabilidades que evento se realize x vezes em n provas
p= probabilidade que o evento obtenha sucesso
q= probabilidade de insucesso
n= número de opções
x= número desejado de ocorrências
⎟⎠
⎞⎜⎝
⎛xn é o coeficiente binomial de n sobre x, igual a
)!(!!xnx
n−
. (é uma combinação)
Exemplo 1: Determinar a probabilidade de se obter um único “2” em três jogadas um dado.
P(X= 1)= ⎟⎠
⎞⎜⎝
⎛13 (1/6)1 . (5/6)3-1

73
P(X= 1)= ⎟⎟⎠
⎞⎜⎜⎝
⎛
1)!-(31!3! (1/6)1 . (5/6)3-1
P(X= 1)= 0,3472 ou 34,72%
Exemplo 2:
Considerando X como sendo a VAD igual a “número de vezes que ocorre face cara em 5
lançamentos de uma moeda equilibrada”, determinar a probabilidade de ocorrer:
(a) Duas caras
(b) Quatro caras
(c) No máximo duas caras
a)
252
21
21
25 =2) =P(X
−
⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛
%25,313125,021
21
2)!-(52!5! =2) =P(X
252
ou=⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎟⎠
⎞⎜⎜⎝
⎛−
b)
454
21
21
45 =4) =P(X
−
⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛
%63,151563,021
21
4)!-(54!5! =4) =P(X
454
ou=⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎟⎠
⎞⎜⎜⎝
⎛−
c)
50,00%2)P(X1)P(X0)P(X =2)P(X31,25% =2) =P(X
%63,151563,021
21
1)!-(51!5! =
21
21
15 =1) =P(X
%13,30313,021
21
0)!-(50!5! =
21
21
05 =0) =P(X
151151
050050
==+=+=≤
=⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛
=⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛×⎟⎠
⎞⎜⎝
⎛
−−
−−
ou
ou
12.3.4 Probabilidade pela distribuição hipergeométrica
O modelo hipergeométrico trata da retirada sem reposição, enquanto que a distribuição de
Bernoulli (binomial) as retiradas são com reposição.
Considere-se um conjunto de N elementos, r dos quais tem uma determinada característica (r
≤ N) e N -r não tenham esta característica. Extraí-se n elementos (n ≤ N) sem reposição. Seja X a
variável aleatória igual ao número de elementos que possuem a característica entre os n retirados. X
é denominada de variável aleatória hipergeométrica.
P(X = x)= ⎟⎠
⎞⎜⎝
⎛
⎟⎠
⎞⎜⎝
⎛−
−⎟⎠
⎞⎜⎝
⎛
nN
xnkN.
xk
Onde:
x: número desejado
n: tamanho amostra

74
N: população
k: considerado sucesso
N-k: insucesso
Onde é resolvido através da combinação simples:
C n, x= )!(!
!xnx
n− ou
⎟⎠
⎞⎜⎝
⎛xn é igual a
)!(!!xnx
n−
Exemplo1: Lotes com 40 peças são considerados aceitáveis se contém, no máximo, três peças
defeituosas. O processo de amostragem consiste em extrair aleatoriamente 5 peças de cada lote e
rejeitá-lo se for obtida pelo menos uma peça defeituosa das cinco extraídas. Qual a probabilidade de
se encontrar uma peça defeituosa, sabendo-se que há três peças defeituosas em todo lote?
Solução: N= 40 n= 5 k= 3 x=1
P(X = 1)= =
⎟⎠
⎞⎜⎝
⎛
⎟⎠
⎞⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛
=
⎟⎠
⎞⎜⎝
⎛
⎟⎠
⎞⎜⎝
⎛−
−⎟⎠
⎞⎜⎝
⎛
540437.
13
540
15340.
13
P(X = 1)= ( )( )( )
30,11%ou0,301165800866045.3
5!.35!40!4!.33!37!.
1!.2!3!
==
⎟⎠
⎞⎜⎝
⎛
⎟⎠
⎞⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛
Exemplo 2: Uma caixa contém 12 lâmpadas das quais 5 estão queimadas. São escolhidas 6
lâmpadas ao acaso. Qual a probabilidade de que:
(a) Exatamente duas estejam queimadas?
(b) Pelo menos uma esteja boa?
(c) Pelo menos duas estejam queimadas?
(d) O número esperado de lâmpadas queimadas?
a) N= 12 n= 6 k=5 x=2
P(X = 2)= %88,373788,09243510
)!612(!6!12
)!47(!4!7
)!25(!2!5
612
2-6512.
25
ou=×
=
−
⎟⎟⎠
⎞⎜⎜⎝
⎛
−×⎟⎟⎠
⎞⎜⎜⎝
⎛
−=
⎟⎠
⎞⎜⎝
⎛
⎟⎠
⎞⎜⎝
⎛ −⎟⎠
⎞⎜⎝
⎛
b) N= 12 n= 6 k=5 x=1
Se forem retiradas 6 lâmpadas e somente 5 estão queimadas, então necessariamente uma
será boa, portanto:
P(pelo menos uma boa)= 100%, ou seja:
P(X≥5)= P(X=0) + P(X=1) + P(X=2) + P(X=3) + P(X=4) + (P(X=5)

75
P(X≥5)= 0,76% + 11,36% +37,88% + 37,88% 11,36%+ 0,76= 100%
c) P(X≤2)= P(X=0) + P(X=1) + P(X=2)
P(X≤2)= 0,76% + 11,36% +37,88%= 50%
d) E(X) = (rn) / N = 5.6 / 12 = 30/12 = 5/2 = 2,50
12.3.5 Probabilidade pela distribuição de Poisson
Em estudos de fenômenos de ocorrências raras.
A distribuição de Poisson é adequada para descrever situações onde existe uma probabilidade
de ocorrência em um campo ou intervalo contínuo, geralmente tempo ou área
Por exemplo, o número acidentes por mês, número defeitos por metro quadrado, número
clientes atendidos por hora.
Nota-se que a variável aleatória é discreta (número de ocorrência), no entanto a unidade de
medida é contínua (tempo, área).
# Condições de aplicação:
(i) Eventos definidos em intervalos não sobrepostos são independentes;
(ii) Em intervalos de mesmo comprimento, são iguais as probabilidades de ocorrência de um
mesmo número de sucessos;
(iii) Em intervalos muito pequenos, a probabilidade de mais de um sucesso é desprezível;
(iv) Em intervalos muito pequenos, a probabilidade de um sucesso é proporcional ao
comprimento do intervalo.
# A função de probabilidade é dada por:
x!
x.λ-λex)P(X == , x= 0, 1, 2, ...
em que λ é a taxa de ocorrência, que é np.
Exemplo:

76
Em certo tipo de fabricação de fita magnética, ocorrem defeitos a uma taxa de 1 a cada 2000
metros. Qual a probabilidade de que um rolo com 2000 metros de fita magnética:
(a) Não tenha defeitos?
(b) Tenha no máximo dois defeitos?
(c) Tenha pelo menos dois defeitos?
Solução:
Neste caso, tem-se:
λ= Taxa de defeitos a cada 2000 metros
X= número de defeitos a cada dois mil metros
x= 0, 1,2, 3, ...
a) 36,79%ou0,36790!
0.11-e0)P(X ===
b) 91,97%ou0,91970,18390,36790,36792!
2.11-e1!
1.11-e0!
0.11-e2)P(X =++=++=≤
c) %42,262642,0)23679,0(11!
1.11-e0!
0.11-e1)1P(X12)P(X ou=×−=⎟⎟
⎠
⎞
⎜⎜
⎝
⎛+−=≤−=≥
12.3.6 Probabilidade geométrica
A distribuição geométrica é a menos usada dentre as distribuições. Ela está relacionada ao
número de tentativas de um processo de Bernoulli, antes do primeiro sucesso ser obtido. Em
problemas de confiabilidade, este fato passa a ser algo importante, que deve ser considerado. Por
exemplo: a célula de potência de um satélite pode durar indefinidamente até que haja uma colisão
com um micro meteoro. Cada dia é considerado como uma tentativa no processo de Bernoulli.
A expressão matemática para esta distribuição é dada abaixo:
para x=1,2,3,...
pxx)P(X q 1x−==
Sendo X o número de tentativas no processo de Bernoulli até que o primeiro sucesso seja
atingido e p a probabilidade de sucesso.
Exemplo 1: Cada dia há uma probabilidade de p=0,01 que um satélite seja danificado em
uma colisão. A probabilidade de sobrevivência diária é conseqüentemente igual a 1-p=0,99. Calcule
a probabilidade de que o satélite seja danificado exatamente no vigésimo e centésimo dias de
operação.

77
Exemplo: Numa seqüência de lançamentos de uma moeda honesta ao ar, em que cada
lançamento pode dar Cara ou Coroa, pretende-se estimar a probabilidade que a primeira cara se
obtenha no 5º lançamento.
12.4 VARIÁVEIS ALEATÓRIAS CONTÍNUAS
12.4.1 Probabilidade pela distribuição normal ou de Gauss
É a mais importante das distribuições contínuas de probabilidade.
A curva obtida é praticamente simétrica, denominada curva normal, pois primeiramente se
suspeitava que todos os fenômenos “normais” apresentavam distribuição deste tipo.
Todas as curvas normais representativas de distribuições de freqüências podem ser
transformadas em uma curva normal padrão.
A distribuição normal tem sua função de probabilidade dada por:
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡⎟⎠
⎞⎜⎝
⎛ −−=
2
σµx
21exp
2πσ1f(x) , onde x ∈ IR
Em que:
µ= média aritmética da população
σ= desvio padrão populacional
exp= constante 2,718
Figura 10.1- Curva normal.
a) Variável normal padronizada (distribuição Z)
Para facilitar a determinação da probabilidade foram criados valores em tabelas para as
probabilidades da variável aleatória normal.
µµ
xx
σσ
µ+σµ+σ
µ-σµ-σ
f=(x)f=(x)

78
Mas, é necessária a transformação da v.a. X na v.a. Z.
Os valores de z permitem delimitar a área sob a curva.
Logo para transformar X e Z temos:
σµx −
=Z , variável normal padronizada.
Onde a sua média é 0 (zero), e seu desvio padrão é 1.
Exemplo do uso da tabela Z:
Qual é a área sob a curva normal contida entre z = 0 e z = 1?
Procura-se o valor 1 na primeira coluna da tabela e o valor da coluna 0,00. O valor da
intersecção é de 0,3413, ou seja 34,13%.
Entretanto, lembrando que a curva normal é simétrica, sabe-se que a área sob a curva
normal contida entre z = 0 e z = -1 também é 34,13%.
Portanto, a área referente a -1 < z < 1 vale 68,26%.
Figura 10.2- Demonstração da probabilidade sob a área da curva.
b) Características da distribuição normal
1- A média da distribuição normal é µ.
2- O desvio padrão é σ.
3- A moda ocorre em x= µ.
4- A curva normal é simétrica em relação a µ, com probabilidade igual de ocorrer valores
maiores e menores que as médias.
5- A curva tem inflexões nos pontos x= µ±σ.
6- A curva normal é assíntota (aproxima-se do eixo sem alcançá-lo).
7- A área total sob a curva normal e acima do eixo horizontal é igual a 1.
8- A área sob a curva normal contida entre .......... é igual a:
P(x)= µ ± 1 σ ►68,26%
P(x)= µ ± 2 σ ► 95,44%
P(x)= µ ± 3 σ
►99,74%
Logo a probabilidade de X é:
P(x)= µ ± z σ

79
Exemplos do uso de z:
1. Uma fábrica de tratores tem em seus dados estatísticos que a vida média útil de sua máquina é de
15 anos, apresentado distribuição normal, com desvio padrão de 2,8 anos, qual é o intervalo de vida
útil de 95% dos tratores?
P (95%) → P (0,95/2) → P (0,475)
Logo P (0,95)= µ ± z σ
Então valor Z= 1,96
P(0,95)= µ ± 1,96 σ
P(0,95)= 15 ± 1,96 x 2,8
P(0,95)= 15 ± 5,488
Portanto:
P(maior durabilidade)= 20,488 anos
P(menor durabilidade)= 9,512
Conclusão: Espera-se que 95% dos tratores terão sua vida útil entre 9,512 e 20,488 anos. Será
pouco provável encontrar um trator que dure menos (P = 2,5%) ou que dure mais (P = 2,5%).
2. Qual a probabilidade de se encontrar trator com vida útil entre 13 e 16 anos?
Calculam-se dois valores de z:
Agora quero a Probabilidade, logo preciso determinar o valor de Z para os 2 valores.
σµX −
=Z
Assim temos:
zmenor= 8,21513 − = -0,71
zmaior= 8,21516 − = 0,36
Na tabela temos:
A área entre z = 0 e z = -0,71 é 0,26115 ou 26,115%
A área entre z = 0 e z = 0,36 = 0,14058 ou 14,058%
Portanto, a probabilidade de se encontrar trator com vida útil entre 13 e 16 anos é:
P(13<x<16)= 26,115 + 14,058 = 40,17%
3. Qual a probabilidade de se encontrar um trator que tenha vida útil superior a 25 anos?
Novamente a probabilidade.
zmaior = 8,21525 − = 3,57
Na tabela temos:

80
A área entre z = 0 e z = 3,57 é 0,49992 ou 49,992%.
Portanto, a probabilidade do trator durar mais de 25 anos é:
P(x>25)= 50 - 49,992 = 0,008%

81
13 INTERVALO DE CONFIANÇA
13.1 PARA MÉDIA, QUANDO A VARIÂNCIA É CONHECIDA
Definimos como Nível de confiança (1 - α) a probabilidade de que o intervalo construído contenha o
verdadeiro valor da média populacional que está sendo estimada.
Pode ser utilizada, nesse caso, a tabela Z sempre que tivermos uma das seguintes situações:
1ª - se n ≥ 30, considerada suficientemente grande, pode-se adotar o desvio padrão S
2ª - se n < 30, sendo a população estudada normalmente distribuída e o desvio padrão
populacional σ conhecido.
Então:
Se “x” for a média observada duma amostra aleatória de dimensão “n” duma população normal (ou
duma população qualquer desde que “n” suficientemente grande, mas nesse caso o intervalo é
apenas aproximado) com variância conhecida S2, um intervalo de confiança a 100 x (1-α)% para µ é
dado por:
nσZE =
Onde: E é o erro, conforme o α estabelecido.
Logo:
E X)(ICinferior__−=α
EX)(ICinferior__+=α
Temos o IC inferior e o IC superior
Quadro 1- Valores de Z para diferentes intervalos confiança.

82
Exemplo:
Determinada empresa que trabalha com erva mate têm em seus registros as seguintes informações
estatísticas sobre o empacotamento, que após pesar 100 pacotes, obtiveram como média de peso
de cada pacote 1005 g com desvio padrão amostral de 45 g. Considerando que a distribuição dos
pesos seja considerada normal, determine qual é o Erro e os IC inferior e superior para 95% dos
pacotes produzidos pela ervateira.
g82,8100451,96E ==
g 996,28,82 1005)95(ICinferior =−= g 1013,88,82 1005)95(ICsuperior =+=
Conclusão: Espera-se que 95% dos pacotes de erva mate apresentem peso entre 996,2 e 1013, 8 g
13.2 PARA MÉDIA, QUANDO VARIÂNCIA POPULACIONAL NÃO É CONHECIDA
Quando o desvio padrão da população não for conhecido, a estimativa da média da população
deverá ser realizada com a distribuição t (student), pois com a distribuição Z se obtém um resultado
aproximado para n>30.
nStE =
Onde: E é o erro, conforme o α estabelecido.
S é desvio padrão da amostra
Logo:
E X)(ICinferior__−=α
EX)(ICinferior__+=α
Pode-se usar o valor exato da Tabela t (usar GL), ou conforme Quadro abaixo:
Exemplo:
Determinada empresa que trabalha com erva mate têm em seus registros as seguintes informações
estatísticas sobre o empacotamento, que após pesar 10 amostras, obtiveram como média de peso
de cada pacote 1015 g com desvio padrão 65 g. Considerando que a distribuição dos pesos seja

83
considerada normal, determine qual é o Erro e os IC inferior e superior para 99% dos pacotes
produzidos pela ervateira.
g5,56106575,2E ==
g 958,5 56,5 1015)95(ICinferior =−= g 1071,556,5 1015)95(ICsuperior =+=
Conclusão: Espera-se que 99% dos pacotes de erva mate apresentem peso entre 958,5g e 1071,5g.

2
14 INFERÊNCIA ESTATÍSTICA E TESTE DE HIPÓTESES
14.1 INFERÊNCIA ESTATÍSTICA
Latim: Inferentia - Ato de inferir (tirar por conclusão).
Casos especiais:
Inferência Dedutiva (certa).
Inferência Indutiva (incerta, há um nível de probabilidade envolvido).
Exemplos:
Dedutiva: Premissa principal - um dos ângulos de um triângulo retângulo tem sempre 90º.
Premissa secundária - T é um triângulo retângulo.
Conclusão: T tem um ângulo de 90º (particular para o geral).
Indutiva: 107 sementes são plantadas, deseja-se saber quantas darão flores brancas e quantas
vermelhas. Há um nível de probabilidade envolvido para cada flor (cor) (geral para o particular).
Usualmente, é impraticável observar toda uma população, seja pelo custo alto seja por
dificuldades operacionais. Examina-se então uma amostra, de preferência bastante representativa,
para que os resultados obtidos possam ser generalizados para toda a população.
O que desejamos é saber se os resultados obtidos podem ser extrapolados para toda a
população, pois se a informação só serve para o grupo amostrado, qual o significado da pesquisa.
Mas, podemos considerar este resultado para toda a população?
É preciso beber todo o vinho de uma garrafa para se saber se o mesmo é bom?
O que desejamos é poder inferir os resultados.
Logo, inferência é estender a informação obtida da parte estudada para toda a população.
Entretanto, a inferência deve ser feita com certa confiabilidade, utilizando-se para tal um teste
estatístico.
Até agora preparamos o caminho para poder entrar nos problemas da inferência estatística.
Vimos as diversas técnicas da análise exploratória de dados, as técnicas de amostragem e a teoria
de probabilidades, cada uma dessas áreas constitui o tripé da inferência estatística (Figuras 1 e 2).

3
Figura 1- Esquema geral do processo estatístico.
Figura 2- Esquema do processo de inferência estatística.
A inferência estatística se divide em duas grandes áreas:
Pontual Estimação Inferência Por intervalo Estatística Teste de Hipóteses
Pegamos por exemplo a nota dos alunos de uma Universidade. O mais provável de
acontecer, dado que a maioria dos alunos está perto da média, é que a média amostral, também,
fique próxima da verdadeira média. Podemos calcular todas essas probabilidades, uma vez que
podemos aproximar a distribuição da média amostral para a distribuição normal.

4
14.1.1 População e amostra
a) População objetivo ou alvo: é a totalidade de elementos que estão sob discussão e das quais se
deseja informação.
b) Amostra: conjunto representativo da população.
14.1.2 Tipos de amostragem
Existem técnicas que garantem, tanto quanto possível, o acaso na escolha
Dessa forma, cada elemento deve ter a mesma chance de ser escolhido
Vantagens: Menor custo
Menor tempo
Material destrutivo
a) Amostragem casual ou aleatória simples
É equivalente ao sorteio
Ex: alunos numerados de 1 a 20
b) Amostragem proporcional estratificada
Quando a população se divide em extratos
Ex: alunos do sexo masculino e feminino
c) Amostragem sistemática
Quando os elementos da população já estão ordenados
Ex: Propriedades rurais em determinada estrada, prédios de certa rua, etc
Neste caso a amostra pode ser obtida por um sistema imposto pelo pesquisador
14.2 TESTE SIGNIFICÂNCIA OU DE HIPÓTESES
Os testes de significância (também conhecidos como testes de hipóteses) correspondem a
uma regra decisória que nos permite rejeitar ou não rejeitar uma hipótese estatística com base nos
resultados de uma amostra.
Hipótese é uma suposição quanto ao valor de um parâmetro populacional, ou uma afirmação
quanto à natureza da população.
Não basta saber que a média dos alunos amostrados do diurno apresenta valores superiores
aos do noturno, é necessário saber que todos os alunos (população), sob iguais condições, terão
esta diferença de desempenho.

5
Os testes estatísticos fornecem condições para o pesquisador fazer a inferência com
determinada confiabilidade.
Com os testes estatísticos é possível estabelecer o nível de significância, que fornece a idéia
de que é muito provável que um resultado, similar ao obtido na amostra, ocorra com toda a
população.
Logo teremos duas hipóteses:
H0: Hipótese de nulidade, onde se considera que as médias são iguais
HA ou H1: Hipótese alternativa, onde considera que as médias são diferentes
Assim teremos dois tipos de erros:
Erro tipo I – rejeitar H0 quando ela é verdadeira
Erro tipo II – aceitar H0 quando há diferenças entre tratamentos (falsa)
A probabilidade do erro tipo I é denotada por α e do erro tipo II por β.
Então se estabelece o nível de significância para α, normalmente menor e igual a 5%
(P≤0,05).
Decisão sobre o nível de significância:
valor cal ≥ valor tab = rejeita-se H0
valor cal < valor tab = aceita-se H0
ou
teste cal < teste tab 0,05 = NS
teste 0,05 < teste cal < teste 0,01 = significativo
teste 0,01 < teste cal < teste 0,001 = muito significativo
teste cal > teste 0,001 = altamente significativo
- Etapas para os testes de hipóteses:
a) Enunciar as hipóteses (H0 e HA);
b) Fixar o nível de significância á e identificar a estatística do teste;
c) Determinar a região crítica (faixa de valores que nos levam à rejeição da hipótese H0) e a região
de aceitação em função do nível α pelas tabelas estatísticas apropriadas;
d) Baseado na amostra, calcular o valor da estatística do teste
e) Concluir: Se estatística do teste pertence à região crítica rejeita-se H0, caso contrário aceita-se.
Veremos os seguintes testes:
a) Teste z
b) Teste t
c) Teste de Qui-quadrado (teste 2א)

6
d) Teste F
14.2.1 Teste Z para avaliação de uma média populacional
Para tal procedimento é utilizado o teste Z. Para este teste de hipóteses devemos conhecer a
variância populacional. Esta tabela pode ser unilateral ou bilateral.
A estatística do teste é baseada na média amostral (_x ). Pode ser demonstrado que a média
amostral tem distribuição aproximadamente normal com média µ e variância σ2/2, onde n é o
tamanho da amostra.
A estatística do teste z para 1 média é:
n
xZcal σµ−
=
_
Decisão sobre o nível de significância de Z:
│Z cal│≥ Z tab = rejeita-se H0
│Z cal│ < Z tab = aceita-se H0
Exemplo:
Uma máquina automática de encher pacotes de café enche-os segundo uma distribuição normal,
com média µ e variância 400 g. O valor de µ pode ser fixado num mostrador situado numa posição
um pouco inacessível dessa máquina. A máquina foi regulada para µ = 500 g. Desejamos, de meia
em meia hora, colher uma amostra de 16 pacotes e verificar se a produção está sob controle, isto é,
se µ = 500 g ou não. Se uma dessas amostras apresentasse uma média _x = 492 g, você pararia ou
não a produção para verificar se o mostrador está na posição correta? Usar α = 1%.
60,1
1620500492
−=−
=Zcal
Z (0,01)= -2,33
Conclusão: Aceito a hipótese H0, portanto não pararia a produção para verificar a posição do
mostrador, com P≤0,01.

7
14.2.2 Teste t para avaliação de uma ou duas médias
É utilizado quando a variância populacional é desconhecida, devendo-se calcular a variância
da amostra. Pode ser empregado para amostras pequenas.
a) Para avaliação de uma média
A estatística do teste t para uma média é:
nsxtcal
µ−=
_
Decisão sobre o nível de significância de Z:
│t cal│≥ t tab = rejeita-se H0
│t cal│ < t tab = aceita-se H0
Determinada firma desejava comprar cabos tendo recebido do fabricante a informação de que a
tensão média de ruptura é 8000 kgf. Para analisar se a afirmação do fabricante é verdadeira,
efetuou-se um teste de hipótese unilateral. Se um ensaio com 6 cabos forneceu uma tensão média
de ruptura de 7750 kgf, com desvio padrão de 145 kgf, a qual conclusão chegar, usando um nível de
significância de 5%?
22,4
614580007750
−=−
=tcal
Agora precisamos obter o valor tabelado (t), para α= 0,05 e GL 5, onde encontramos:
t tab (5; 0,05)= 2,571
Conclusão: Aceita-se H0, os cabos apresentam tensão média de 8000 kgf, P≤0,05.
b) Para comparação de duas médias
Primeiramente devemos realizar a análise descritiva para comparar as duas médias.
b.1) Análise descritiva
Considere que se deseje comparar o desempenho de 2 turmas de alunos, uma diurna e outra
noturna, avaliando 11 alunos ao acaso em cada turma. Sabe-se que ambas as aulas são ministradas
pelo mesmo educador, sendo a mesma disciplina e utilizando o mesmo método de ensino. As notas
obtidas estão na Tabela 1.

8
Tabela 1- Notas obtidas por duas turmas de alunos, uma noturna e outra diurna, submetidas à aulas com o mesmo educador e utilizando o mesmo método
Turma diurna (TD) Turma noturna (TN)
9,5 5,4 8,1 8,7 4,8 6,6 7,4 8,0 6,4 5,4 7,0 3,7 6,1 6,2 8,4 7,5 6,8 6,7 9,3 5,7 7,5 7,0
Observando os valores, pode-se verificar que as notas obtidas pela turma diurna são
superiores as obtidas pela turma noturna.
Para facilitar a observação, podemos calcular a média, onde temos:
- Média turma diurna:
nXn
X(TD)
__ ∑=
39,711
5,7...1,85,9X(TD)
__=
+++=
- Média turma noturna:
nXn
X(TN)
__ ∑=
=+++
=11
0,7...7,84,5X(TN)
__6,45
Com as médias calculadas pode-se supor que o desempenho de notas da turma diurna foi
superior.
Mas, apenas com a média não temos uma resposta confiável, pois depende da variabilidade
da amostra coletada.
Logo podemos determinar a variância, o desvio e a variância da média.
a) Variância da amostra:
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛∑=−
∑==
2
n
n
1iXi
n
n
1i2Xi
2Sx
1nn−

9
# Para turma diurna
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎠
⎞⎜⎝
⎛−=2
113,81
1137,6202S )(TD x
1011
=)(2S TD 1,95
# Para turma diurna
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎟⎠
⎞⎜⎝
⎛−=2
119,70
1133,4762S )(TN x
1011
=)(2S TN 1,93
b) Desvio padrão ou erro padrão da amostra:
2SS =
# Para turma diurna
95,1)( =TDS
S (TD)= 1,40
# Para turma noturna
93,1)( =TNS
S (TN)= 1,39
c) Variância da média:
n
2S2S Y =−
# Para turma diurna
111,952S (TD)Y =−
=−(TD)Y
2S 0,1773
# Para turma noturna
1193,12S (TN)Y =−
1755,02S (TN)Y =−

10
d) Desvio padrão ou erro padrão da média:
n
2SSY=−
# Para turma diurna
111,95S
Y=−
4210,0S
Y=−
# Para turma noturna
111,93S
Y=−
4189,0S
Y=−
Logo podemos construir uma tabela para facilitar a compreensão dos resultados:
Tabela 2- Médias e erros padrões das médias das notas obtidas pelos alunos diurnos e noturnos
Estatística Período
Diurno Noturno
Média 7,39 6,45
Erro padrão da média 0,4210 0,4189
A média e o erro padrão da média são estatísticas descritivas, pois descrevem a amostra.
Observando-se os valores, pode-se verificar que a nota obtida pelos alunos diurnos foi melhor
que a obtida pelo noturno.
Entretanto, será que esta resposta pode ser inferida para toda a população de alunos, que
estão sobre as mesmas condições.
b.2) Teste t propriamente dito
É o teste mais usado para comparação de duas médias.
Para calcular o valor de t precisamos:
a) Estipular o valor de α
b) Obter a média de cada grupo
c) Determinar a variância de cada grupo
d) Calcular a variância ponderada, dada pela fórmula:
( ) ( )( ) ( )1n21n1
S221n2S211n1pond2S
−+−
−+−=
e) Assim, obtemos o valor de t calculado:

11
S2Pondn2
1n1
12X
1X t
⎟⎟⎠
⎞⎜⎜⎝
⎛+
−−
−
=
Dando continuidade ao exemplo da Tabela 1, das notas obtidas por duas turmas de alunos, teremos:
a) α = 5% ou 0,05
b) 39,7X(TD)
__=
45,6X(TN)
__=
c) =)(2S TD 1,95 =)(
2S TN 1,93
d)
( ) ( )( ) ( )
94,111111193,111195,1111
pond2S =−+−
−+−=
e) 583,194,1
111
111
45,639,7t =
⎟⎠
⎞⎜⎝
⎛ +
−=
Agora precisamos obter o valor tabelado (t), para α= 0,05 e GL 20, onde encontramos o valor
de t= 2,086
t cal= 1,583
t (0,05; 20)= 2,086
Conclusão: Conforme resultado do teste t (P≤0,05), deve-se aceitar a hipótese H0. Logo pode
concluir que a diferença das notas obtidas entre os dois grupos de alunos não pode ser atribuída ao
período que estudam.
Observação: Pode-se estar incorrendo para o erro tipo II, ou seja, aceitar a hipótese H0
apesar de haver diferenças reais entre os dois grupos de notas.
14.2.3 Teste Qui-quadrado (2א)
O teste de Qui-quadrado faz parte dos chamados “testes não paramétricos”, ou seja, que não
dependem dos parâmetros populacionais, nem de suas respectivas estimativas.
O teste de Qui-quadrado pode ser usado principalmente como:
i) Teste de aderência
ii) Teste de independência
iii) Teste de homogeneidade
Veremos, a princípio, apenas o teste de aderência, sendo os demais testes filosoficamente (e
até mesmo “mecanicamente”) similares, mas aplicáveis quando queremos estudar a relação entre
duas ou mais variáveis de classificação.
Teste de Aderência

12
Existe apenas uma variável e o que se testa é o padrão hipotético de freqüências ou a
distribuição da variável.
A estatística do teste é dada por:
!!"#! =(!" − !")!
!"
Onde:
Oi freqüência observada da categoria (evento) i Ei freqüência esperada da categoria (evento) i
A expressão acima nos dá um valor sempre positivo e tanto menor quanto maior for o
acordo entre as freqüências observadas e as freqüências esperadas, calculadas com base em
H0.
A hipótese H0 afirmará não haver discrepâncias entre as freqüências observadas e o as
freqüências esperadas, ou H0 será colocada em termos de distribuição de probabilidade que vamos
por à prova.
O valor de !!"#! é comparado com !!"#! , sendo se !!"#! ≥ !!"!! , rejeita-se H0.
Também, precisamos obter !!"#! a partir da significância e dos graus de liberdade v (v= k - 1 -
r, onde k é o número de categorias em que foi dividida a amostra; e r é o número de parâmetros
estimados para o cálculo das Ei.
Exemplo:
Suponhamos que um pesquisador, desejando colocar à prova a hipótese de que a idade da
mãe tem certa influência sobre o nascimento de criança prematura, verificou que, dentre 90 casos de
prematuridade, 40 envolviam mães com idade inferior a 18 anos; 15 envolviam mães de 18 a 35
anos e 35 mães com idade acima de 35 anos. Isto leva o pesquisador a manter sua hipótese? Use
nível de significância de 0,01.
Espera-se 30 casos para cada 1 das três situações
!!"#! =40 − 30 !
30+
15 − 30 !
30+(35 − 30)!
30= 11,66
!!"#! 0,01 (0,99); 2 = 9,210
Conclusão: Rejeita-se H0, logo pode dizer que a idade da mãe tem influência sobre o
nascimento de crianças pré-maturas.
14.2.4 Teste F para comparação de duas variâncias
Mesma idéia dos testes para médias, teste z e t, porém usa-se a razão das variâncias, e não
a sua diferença, como no caso dos testes para médias.
A estatística do teste é dada por:
!!"# =!!!
!!!
Onde: !!!= Variância da amostra A

13
!!!= Variância da amostra B
Fcal(gl1; gl2; ), sendo gl1 do numerador e gl2 do denominador
A distribuição F não é simétrica e, portanto, não possui a área da cauda superior, FS, igual a
área da cauda inferior, FI. Neste caso, a regra de decisão é:
Se Fcal > FSc ou Fcal < FIc , para gl1 e gl2, então rejeita-se H0. Caso contrário, aceita-se H0.
Na prática colocamos no numerador a variância de maior valor e concentramos a decisão na
cauda superior.
Exemplo: Deseja-se comparar a variância do desempenho de duas equipes de atletismo.
Particularmente, testar se elas são estatisticamente diferentes, assumindo-se α de 5%. As variâncias
observadas são apresentadas na tabela abaixo:
!!"# =!!!
!!!=1,5200,784
= 1,94
Ftab (6; 5; 0,05)= 4,95
Conclusão: Aceita-se a hipótese H0, com P≤0,05, portanto as variâncias são consideradas iguais.
14.2.5 Teste t para dados pareados
Dados pareados são aqueles registrados em pares (o indivíduo é controle de si mesmo).
Por exemplo, um estudo compara o efeito de um colírio oftálmico com o de simplesmente higienizar o
olho. Um grupo de pacientes usa, durante um período, a colírio no direito, enquanto o olho esquerdo
recebe apenas o anti-séptico.
a) Hipóteses
H0: µD = 0
HA: µD ≠ 0
Onde µD é a média populacional, sobre a qual desejamos inferir.
b) Estatística do teste
Como as observações estão relacionadas, construímos o teste sobre as diferenças observadas
em cada par.
DEPMDDt_
= EPMDD= nSD
Variâncian
Equipe A Equipe B0,784 1,520
6 7

14
Seja Di a diferença (no mesmo indivíduo) entre as observações registradas, para n pares. A média
das diferenças de todos os indivíduos chamamos _D , e o desvio-padrão das diferenças de SD.
Exemplo: Um hipnótico foi aplicado em um grupo de pacientes que tinham se submetido
anteriormente a um tratamento padrão. Foi observado o número de horas de sono de cada paciente
nos dois momentos. Deseja-se testar se a diferença média observada é não nula, considerando-se
um nível de significância de 5%.
_D = 0,433
SD= 0,27
EPMDD= 09,0927,0
=
81,409,0433,0
==t
t(8; 0,05)= 2,306
Conclusão: Como fcal > ftab, rejeita-se a hipótese H0, logo há diferenças entre os períodos de sono.
14.2.6 Teste de Hipótese – valor-P (p-value)
O p-value é definido como a probabilidade de qualquer média da amostra ser mais extrema
que a média da amostra _
x extraída para o teste, sem rejeitar a hipótese nula.
A partir do exposto e da definição de p-value, temos:
ü O p-value é o nível de significância observado.
ü Se o p-value for maior ou igual a α então a hipótese nula será aceita.
ü Se o p-value for menor ou igual a α então a hipótese nula será rejeitada. Quanto menor for o
p-value, mais forte será a evidência para rejeitar a hipótese nula.
ü A decisão do teste de hipóteses será resultado da comparação do p-value com o nível de
significância α que o analista julgar mais adequado.
Paciente Droga Trat. Padrão Di1 8,6 8,2 0,42 8,8 8,3 0,53 8,1 7,6 0,54 9,8 9,4 0,45 9,7 8,9 0,86 8,0 7,2 0,87 8,4 8,5 -0,18 9,5 9,3 0,29 9,5 9,1 0,4
Horas de sono

15
REFERÊNCIAS BUNCHAFT, Guenia; KELLNER, Sheilah Rubino de Oliveira. Estatística sem mistérios. 4. ed. Petrópolis: Vozes, 2002. 227 p. BUSSAB, Wilton de Oliveira; MORETTIN, Pedro A. Estatística básica. 4. ed. São Paulo: Atual, 1999. 321 p. CALEGARE, Álvaro J. A. Introdução ao delineamento de experimentos. São Paulo: Edgard Blücher, 2001. 130p. CRESPO, Antônio Arnot. Estatística fácil. 18. ed. São Paulo: Saraiva, 2004. 224 p. FARIAS, Alfredo Alves de; CÉSAR, Cibele Comini; SOARES, José Francisco. Introdução à estatística. 2. ed. Rio de Janeiro: LTC, 2003. xiii, 340p. FONSECA, Jairo Simon da; MARTINS, Gilberto de Andrade. Curso de estatística. 6. ed. São Paulo: Atlas, 2006. 320 p. FREIRE, Clarice Azevedo De Luna. Análise de modelos de regressão linear com aplicações. Campinas, SP: Unicamp, 1999. 356 p. HINES, William; MONTGOMERY, Douglas C; GOLDSMAN, David M.; BORROR, Connie M.; FLORES, Vera Regina Lima de Farias e (Trad.). Probabilidade e estatística na engenharia. Rio de Janeiro: LTC, 2006. x, 588 p. LAPPONI, Juan Carlos. Estatística usando Excel. São Paulo: Lapponi Treinamento e Editora, 2000. 450 p. MAGALHÃES, Marcos Nascimento; LIMA, Antonio Carlos de. Noções de probabilidade e estatística. 6. ed. São Paulo: EDUSP, 2005. xiv, 392 p. MOORE, David S; FLORES, Vera Regina Lima de Farias e (Colab.). A estatística básica e sua prática. Rio de Janeiro: LTC, 2000. xv, 482p. MORETTIN, Luiz Gonzaga. Estatística básica. São Paulo: Makron Books do Brasil, 2000. xi, 182 p. GOMES, Frederico Pimentel. Curso de estatística experimental. 14. ed. Piracicaba, SP: F. Pimentel Gomes, EDUSP, 2000. 477 p. STORCK, Lindolfo (Org.). Experimentação vegetal. 2. ed. Santa Maria: Universidade Federal de Santa Maria, 2006. 198 p. TRIOLA, Mario F. Introdução à estatística. 7. ed. Rio de Janeiro: Livros Técnicos e Científicos, 1999. xviii, 410p. VIEIRA, Sonia. Estatística experimental. 2. ed. São Paulo: Atlas, 1999. 185 p.
![Poesia de António Gedeão e a Formação de Professores de ... · Gede o oco e a ela o q e e tabelece e t e [...] a ciência e a poesia, a vida e o sonho, a lucidez e a esperança,](https://static.fdocumentos.com/doc/165x107/5c03be6b09d3f21e408caaca/poesia-de-antonio-gedeao-e-a-formacao-de-professores-de-gede-o-oco-e.jpg)