
INTERPOLAÇÃO ESPACIAL DE PROBABILIDADES DE ESCOLHA DE … · A Krigagem é um método complexo de...
12
INTERPOLAÇÃO ESPACIAL DE PROBABILIDADES DE ESCOLHA DE MODO DE TRANSPORTE MOTORIZADO Anabele Lindner Cira Souza Pitombo Universidade de São Paulo (EESC)/Departamento de Engenharia de Transportes, São Carlos RESUMO A análise de demanda por transportes convencional é realizada pela utilização atributos socioeconômicos e de sistema de transportes e a estimação é dada apenas a domicílios anteriormente pesquisados. Este trabalho teve como objetivo a realização da interpolação espacial de probabilidades de escolha do modo de transporte motorizado em diversas coordenadas geográficas de valores não amostrados pela Pesquisa Origem/Destino da Região Metropolitana de São Paulo (2007). Neste trabalho foram usados apenas os dados domiciliares relativos ao município de São Paulo. Este artigo propôs um método sequencial que combina a abordagem tradicional de previsão de demanda (Regressão Logística Múltipla) a uma abordagem de estatística espacial (Modelagem Geoestatística). Concluiu-se que estudos de combinação de métodos tradicionais a métodos de estatística espacial são prósperos em tais estudos, obtendo-se, de forma confirmatória, uma superfície de escolha modal. ABSTRACT The conventional transportation demand analysis is carried out by using socioeconomic and transportation systems attributes and the estimate is given exclusively to households previously surveyed. This study aimed the spatial interpolation of motorized travel mode choice probabilities in several geographical coordinates of non-sampled values by an Origin-Destination Survey dataset, conducted in São Paulo Metropolitan Area in 2007. In this study it was used only the household data of São Paulo city. This paper purposes a sequential method, which associates the traditional approach of transportation demand forecasting (Multiple Logistic Regression) with a spatial statistical approach (Geostatistic Modeling). It was concluded that conjoint studies of spatial statistics and traditional methods are thriving in transportation issues, getting a mode choice surface through a confirmatory way. 1. INTRODUÇÃO Modelagem de demanda por transportes geralmente considera fatores explicativos, tais como características individuais, das viagens, do meio urbano e suas facilidades (Ortúzar e Willumsen, 2011). O modelo mais tradicional na previsão de demanda por transporte é o modelo sequencial ou Quatro Etapas. O Modelo Quatro Etapas é composto por: a) Geração de viagens, b) Distribuição de viagens, c) Divisão modal e d) Alocação de tráfego. A etapa de divisão modal, ou escolha modal, enfoque deste trabalho, é subdividida em modelos determinísticos e probabilísticos, fundamentados em econometria. Os dados de interesse nesta etapa podem ser a probabilidade de escolha do modo ou a escolha discreta. O modelo logístico (e suas variações) é um dos mais utilizado na etapa de divisão modal. A aplicação convencional de modelos logísticos se dá pela utilização de variáveis independentes, correlacionadas a atributos socioeconômicos, custo de uso e nível de serviço do modo de transporte. Contudo, as informações referentes à localização espacial das variáveis não são consideradas na modelagem tradicional de demanda. Ao longo dos anos, muitos estudos corroboraram com a afirmação de que comportamento relativo a viagens, sobretudo escolha modal, é fortemente relacionado também à distribuição espacial das atividades no meio urbano e à presença de zonas de tráfego de uso do solo misto (Cervero e Radisch, 1996; Kitamura et al., 1997). Levando-se em conta os avanços tecnológicos e disponibilidade de informações georreferenciadas, a análise espacial de demanda por transportes torna-se uma linha de pesquisa
Transcript of INTERPOLAÇÃO ESPACIAL DE PROBABILIDADES DE ESCOLHA DE … · A Krigagem é um método complexo de...

INTERPOLAÇÃO ESPACIAL DE PROBABILIDADES DE ESCOLHA DE MODO
DE TRANSPORTE MOTORIZADO
Anabele Lindner
Cira Souza Pitombo
Universidade de São Paulo (EESC)/Departamento de Engenharia de Transportes, São Carlos
RESUMO A análise de demanda por transportes convencional é realizada pela utilização atributos socioeconômicos e de
sistema de transportes e a estimação é dada apenas a domicílios anteriormente pesquisados. Este trabalho teve
como objetivo a realização da interpolação espacial de probabilidades de escolha do modo de transporte
motorizado em diversas coordenadas geográficas de valores não amostrados pela Pesquisa Origem/Destino da
Região Metropolitana de São Paulo (2007). Neste trabalho foram usados apenas os dados domiciliares relativos
ao município de São Paulo. Este artigo propôs um método sequencial que combina a abordagem tradicional de
previsão de demanda (Regressão Logística Múltipla) a uma abordagem de estatística espacial (Modelagem
Geoestatística). Concluiu-se que estudos de combinação de métodos tradicionais a métodos de estatística espacial
são prósperos em tais estudos, obtendo-se, de forma confirmatória, uma superfície de escolha modal.
ABSTRACT
The conventional transportation demand analysis is carried out by using socioeconomic and transportation systems
attributes and the estimate is given exclusively to households previously surveyed. This study aimed the spatial
interpolation of motorized travel mode choice probabilities in several geographical coordinates of non-sampled
values by an Origin-Destination Survey dataset, conducted in São Paulo Metropolitan Area in 2007. In this study
it was used only the household data of São Paulo city. This paper purposes a sequential method, which associates
the traditional approach of transportation demand forecasting (Multiple Logistic Regression) with a spatial
statistical approach (Geostatistic Modeling). It was concluded that conjoint studies of spatial statistics and
traditional methods are thriving in transportation issues, getting a mode choice surface through a confirmatory
way.
1. INTRODUÇÃO
Modelagem de demanda por transportes geralmente considera fatores explicativos, tais como
características individuais, das viagens, do meio urbano e suas facilidades (Ortúzar e
Willumsen, 2011). O modelo mais tradicional na previsão de demanda por transporte é o
modelo sequencial ou Quatro Etapas. O Modelo Quatro Etapas é composto por: a) Geração de
viagens, b) Distribuição de viagens, c) Divisão modal e d) Alocação de tráfego.
A etapa de divisão modal, ou escolha modal, enfoque deste trabalho, é subdividida em modelos
determinísticos e probabilísticos, fundamentados em econometria. Os dados de interesse nesta
etapa podem ser a probabilidade de escolha do modo ou a escolha discreta. O modelo logístico
(e suas variações) é um dos mais utilizado na etapa de divisão modal.
A aplicação convencional de modelos logísticos se dá pela utilização de variáveis
independentes, correlacionadas a atributos socioeconômicos, custo de uso e nível de serviço do
modo de transporte. Contudo, as informações referentes à localização espacial das variáveis
não são consideradas na modelagem tradicional de demanda. Ao longo dos anos, muitos estudos
corroboraram com a afirmação de que comportamento relativo a viagens, sobretudo escolha
modal, é fortemente relacionado também à distribuição espacial das atividades no meio urbano
e à presença de zonas de tráfego de uso do solo misto (Cervero e Radisch, 1996; Kitamura et
al., 1997).
Levando-se em conta os avanços tecnológicos e disponibilidade de informações
georreferenciadas, a análise espacial de demanda por transportes torna-se uma linha de pesquisa

potencial, sobretudo considerando a expectativa de inclusão de efeitos espaciais nos modelos
matemáticos (Páez et al., 2013).
Através de diferentes abordagens, alguns autores têm encontrado resultados promissores ao
considerar fatores espaciais em estudos de comportamento relativo a viagens. Bhat e Zhao
(2002) propuseram o modelo logit misto com múltiplos níveis a fim de incorporar fatores
espaciais no contexto de análise de demanda por viagens baseadas em atividades.
Recentemente, Páez et al. (2013) introduziram um indicador espacial que foi incorporado em
modelos de escolha discreta para estimativas de viagens com base domiciliar.
Dentre as técnicas de Estatística Espacial, destaca-se a geoestatística que torna possível realizar
a interpolação de valores de variáveis que possuam estrutura e continuidade espacial. Alguns
trabalhos recentes demonstram o potencial da geoestatística em termos de interpolação de
variáveis de demanda por transportes e entendimento do fenômeno no espaço, através de
elaboração de mapas krigados ou superfícies (Pitombo et al., 2015a; Lindner, 2015; Pitombo et
al., 2015b). Deve-se destacar, no entanto, a necessidade de adaptação de variáveis de
transportes, considerando que em geral são variáveis discretas e sem continuidade espacial.
Geralmente, a geoestatística é aplicada a casos cuja continuidade espacial é aparente, tais como
temperatura, precipitação ou composição e propriedade dos solos, por exemplo.
Apesar desta limitação, observa-se, ao longo de muitos anos, aplicação de modelagem
geoestatística a dados espacialmente discretos, sobretudo na área de saúde. Áreas de riscos de
contaminação ou mortalidade, antes detectadas por mapas temáticos ou mapas de Kernel,
podem ser observadas, em caráter confirmatório, com obtenção de valores estimados e
variâncias de estimação, através de técnicas de krigagem (Croner e De Cola, 2001; Boulos,
2004; Goovaerts, 2006).
O objetivo principal deste trabalho é realizar interpolação espacial de probabilidades de escolha
do modo de transporte motorizado (individual ou público). A ideia é estimar dados em diversas
coordenadas geográficas de valores não pesquisados. Através da superfície de divisão modal
obtida, é possível se obter “manchas” de preferência modal, associadas a valores estimados e
erros relativos a estimativas.
É proposto um método sequencial com o uso de regressão logística binomial, seguido da
Krigagem Ordinária. Neste artigo foi utilizada uma amostra desagregada por domicílios do
município de São Paulo, proveniente da Pesquisa Origem/Destino da Região Metropolitana de
São Paulo, realizada em 2007. Este artigo apresenta cinco seções, além desta introdutória. A
segunda e a terceira seções apresentam definições das técnicas abordadas. A quarta seção
descreve, essencialmente, o método utilizado. A quinta seção expõe os resultados e principais
discussões. Finalmente, a sexta seção apresenta as conclusões.
2. REGRESSÃO LOGÍSTICA MÚLTIPLA
A estimativa de escolha de uma variável discreta não pode ser obtida por meio de fundamentos
da Regressão Linear, pois sendo a variável dependente qualitativa, o método de mínimos
quadrados não oferece estimadores plausíveis. A solução para isso é o uso da Regressão
Logística, que permite o uso de um modelo (curva em S) para prever a probabilidade π de um
evento específico. A função logística g(x) é dada pela Equação 1.

(1)
Caso a variável discreta seja também binária (dicotômica), a representação do gráfico de
dispersão indicará apenas os valores de “0” e “1. A Regressão Logística pode ser subdividida
em: Regressão Logística Binomial Simples e Múltipla e Regressão Logística Multinomial
Simples e Múltipla. Neste artigo, foi utilizada a Regressão Logística Binomial Múltipla.
A Regressão Logística Binomial Múltipla (RLM) é indicada caso haja duas categorias para a
variável dependente e mais de uma variável independente. Para este caso, a equação de
calibração (Equação 2), derivada da Equação 1, é dada por:
(2)
Sendo x0=1, β0, β1,..., βn os coeficientes da equação de calibração e n o número de variáveis
independentes.
Em posse da equação de calibração e respectivos coeficientes, é simples calcular o valor de
probabilidade π (Equação 3).
(3)
A qualidade do ajuste pode ser mensurada por medidas estatísticas, como testes de regressão
de Cox & Snell e Nagelkerke e valores de máxima verossimilhança (Hair et al., 2010).
3. GEOESTATÍSTICA
A Geoestatística é uma técnica completa de análise espacial que tem caráter exploratório e
confirmatório, pois além de descrever e tornar possível a visualização de dados para a
verificação da existência de padrões de associação espacial, envolve também o conjunto de
modelos de estimação e procedimentos para sua validação. Na abordagem deste trabalho, esta
técnica se mostra como vantajosa devido ao fato de possibilitar a inferência sobre dados
desconhecidos.
A Geoestatística é melhor definida quando estabelecidas as seguintes etapas de sua aplicação:
1) Análise variográfica, 2) Krigagem e 3) Validação. Vale ressaltar que esta sequência pode
seguir a ordem inversa entre a Krigagem e a validação, caso esta seja cruzada.
3.1 Análise variográfica
A análise variográfica se dá, principalmente, pelo estudo da estrutura espacial. Esta análise é
realizada pela identificação da variável regionalizada, cálculo de semivariogramas
experimentais e posterior ajuste por curvas teóricas e verificação da direção principal.
Uma variável regionalizada é aquela que se distribui espacialmente e exibe certa estrutura e
distribuição espacial, sendo formada por uma componente espacialmente estruturada e uma
componente aleatória (Matheron, 1971). Quando a estrutura espacial apresenta mesmo
comportamento independente da direção de estudo, esta se denomina isotrópica. Caso contrário,
a variável possui comportamento anisotrópico e existe uma direção principal, em que a
variabilidade é maior que em outras direções.
1ln)(xg
nn xxxxg ...)( 22110
)(1
1xge
A análise e modelagem da estrutura espacial têm como ferramenta primária o semivariograma,
que representa o comportamento espacial da variável regionalizada. A função do
semivariograma é determinada pela média das variâncias entre os pontos:
(4)
Sendo N o número total de observações da amostra em cada distância h.
A partir dos conceitos matemáticos estabelecidos na Equação 4, torna-se necessária a definição
de parâmetros de cálculo, para representação gráfica do semivariograma. Estes parâmetros são:
a distância de corte, o lag, a tolerância de lag, a direção angular.
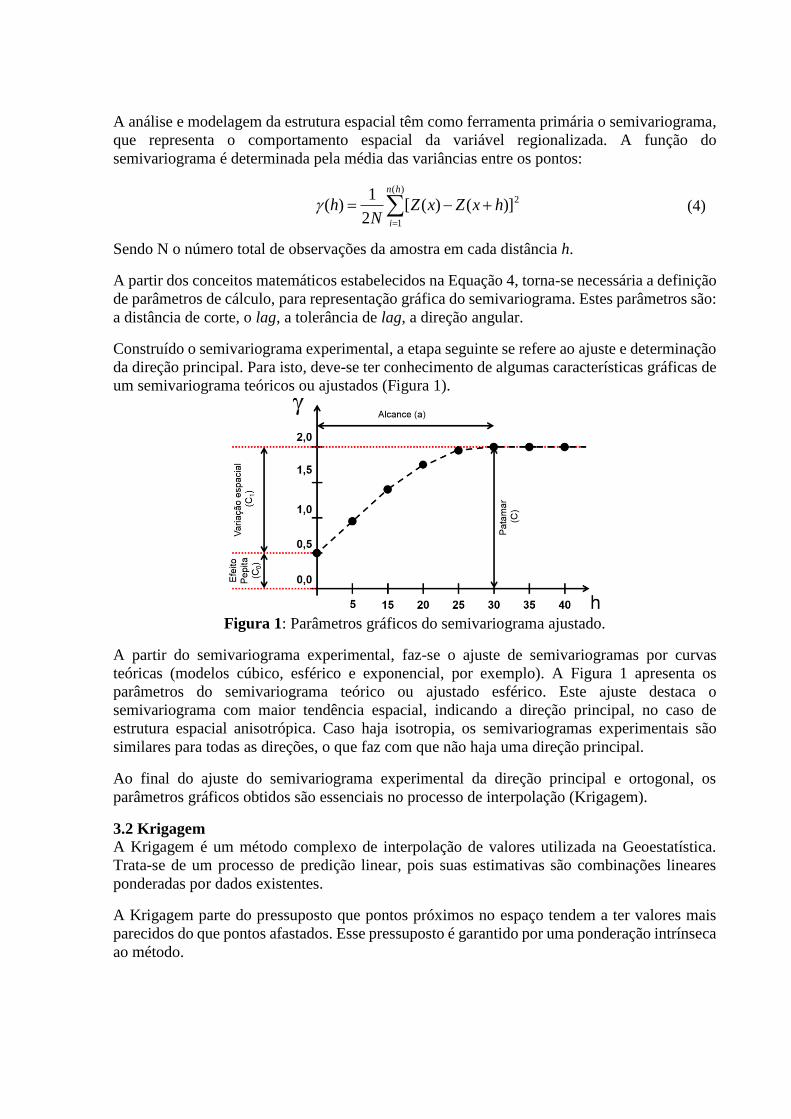
Construído o semivariograma experimental, a etapa seguinte se refere ao ajuste e determinação
da direção principal. Para isto, deve-se ter conhecimento de algumas características gráficas de
um semivariograma teóricos ou ajustados (Figura 1).
Figura 1: Parâmetros gráficos do semivariograma ajustado.
A partir do semivariograma experimental, faz-se o ajuste de semivariogramas por curvas
teóricas (modelos cúbico, esférico e exponencial, por exemplo). A Figura 1 apresenta os
parâmetros do semivariograma teórico ou ajustado esférico. Este ajuste destaca o
semivariograma com maior tendência espacial, indicando a direção principal, no caso de
estrutura espacial anisotrópica. Caso haja isotropia, os semivariogramas experimentais são
similares para todas as direções, o que faz com que não haja uma direção principal.
Ao final do ajuste do semivariograma experimental da direção principal e ortogonal, os
parâmetros gráficos obtidos são essenciais no processo de interpolação (Krigagem).
3.2 Krigagem
A Krigagem é um método complexo de interpolação de valores utilizada na Geoestatística.
Trata-se de um processo de predição linear, pois suas estimativas são combinações lineares
ponderadas por dados existentes.
A Krigagem parte do pressuposto que pontos próximos no espaço tendem a ter valores mais
parecidos do que pontos afastados. Esse pressuposto é garantido por uma ponderação intrínseca
ao método.
)(
1
2)]()([2
1)(
hn
i
hxZxZN
h

A partir das curvas ajustadas de semivariogramas do espaço amostral, valores de efeito pepita
(Co), variação espacial (C1) e amplitude (a), demonstrados na Figura 1, são utilizados para a
definição de ponderadores. Os ponderadores de Krigagem são considerados dentro de uma área
de atuação estabelecida por um elipsoide de raios determinados pelas amplitudes da direção
principal e ortogonal. Por consequência, a determinação dos parâmetros gráficos do
semivariograma, bem como da direção principal, deve ser feita de forma criteriosa.
As formas mais usuais de Krigagem são a Krigagem Simples (KS) e a Ordinária (KO). A KS é
utilizada quando a média é assumida como estatisticamente constante para toda área de
abrangência das amostras. Já a KO, por sua vez, considera a média flutuante ou móvel por toda
área. Para este trabalho, por se tratar de uma variável contínua, utilizou-se a Krigagem
Ordinária.
O resultado das estimativas pode ser representado por um mapa krigado com a superfície
espacial, que consiste de um novo conjunto de dados, obtido a partir de dados conhecidos. Este
mapa é representado por pontos espaçados a uma distância d e dotados de três informações:
latitude x, longitude y e valor da variável.
3.3 Validação
Um tipo de validação comum na Geoestatística é a validação cruzada (teste do ponto fictício).
Isto se deve ao fato de este método utilizar a amostra como um todo, sem separá-la em conjunto
de calibração e validação, reduzindo a susceptibilidade a erros. O teste do ponto fictício
considera um ponto do conjunto de validação como desconhecido e calcula seu valor através
dos outros pontos de valores conhecidos por meio de uma função advinda da Krigagem, que
leva em conta os ponderadores e a proximidade espacial. O processo de considerar um ponto
como desconhecido se repete para os demais, até que todos os pontos do conjunto de validação
sejam estimados. Para este trabalho, o processo de validação se deu pela leitura dos valores
estimados no mapa krigado e conferência com os valores observados da amostra de teste.
4. MATERIAIS E MÉTODO
4.1 Materiais: área de estudo, banco de dados e software Os dados desagregados utilizados neste trabalho são referentes à Pesquisa Origem/Destino
(O/D) realizada na Região Metropolitana de São Paulo (RMSP) em 2007, pela Companhia do
Metropolitano de São Paulo.
Este trabalho utilizou dados relacionados apenas ao município de São Paulo, onde estão
contidas 319 das 460 Zonas de Tráfego da RMSP. A Pesquisa O/D (2007) levantou informações
de 30.000 domicílios, sendo 23.101 destes relacionados à cidade de São Paulo.
As Zonas de Tráfego que não tiveram ou foram poucos os domicílios pesquisados são citadas
como: Cantareira, Estação de tratamento de água do Guaraú, Reserva do Cantareira, Vista
Alegre, Cidade Universitária, Marsilac, Parelheiros, Bororé. Estas Zonas de Tráfego podem ser
visualizadas pelas regiões em que não foram locados a maior parte dos domicílios, conforme a
Figura 2.
O trabalho teve como foco a escolha modal, mais especificamente, o transporte motorizado.
Dessa forma, as variáveis relativas ao modo de transporte público e individual motorizado por
domicílio, obtidas pela Pesquisa O/D, foram transformadas em uma variável binária. A variável
resultante desta discretização, utilizada neste estudo, foi a preferência por modo motorizado,

em que o valor “0” representa o uso predominante de modo individual motorizado e o valor “1”
o uso de transporte público por domicílio. Consequentemente, os domicílios em que não havia
viagens por transporte motorizado foram eliminados. Ao final, foram analisados 14.443
domicílios, para a cidade de São Paulo.
Figura 2: Domicílios entrevistados pela Pesquisa O/D (2007) nas zonas de tráfego da cidade
de São Paulo.
Com o intuito de prever de forma eficiente variáveis de demanda também em coordenadas onde
não foram amostrados domicílios, dois artifícios foram combinados. Utilizou-se, de forma
sequencial, a RLM, como método tradicional de estimação da variável dicotômica, e a
Geoestatística, para que fosse possível a previsão em outras localizações.
As variáveis independentes escolhidas para a estimação pela abordagem tradicional foram sete
variáveis socioeconômicas e de viagens.
O resultado primário da RLM produz uma probabilidade de ocorrência, que no caso é uma
variável de probabilidade de escolha do transporte público em relação ao transporte individual
motorizado. A partir desta proporção, foi realizada a estimação por método geoestatístico. A
Geoestatística, por definição, utiliza como dados de entrada a localização espacial e distância
entre os dados da amostra. Desta forma, foram utilizados dados originais da pesquisa Origem
Destino na etapa de aplicação da RLM e coordenadas geográficas e dados resultantes do modelo
de RLM (probabilidades de escolha do modo motorizado) na abordagem geoestatística.
Os aplicativos utilizados neste trabalho foram o IBM - Statistical Package for the Social
Sciences (SPSS) versão 22 para o cálculo de RLM e o Software GeoMS 1.0 para os processos
geoestatísticos de cálculo de semivariogramas experimentais, ajuste de curvas teóricas e
Krigagem. O software ArcGIS 10.1 foi manipulado a fim de se obter representações gráficas
dos resultados.
4.2 Método
O trabalho aqui apresentado seguiu os passos propostos pela Figura 3.

Figura 3: Representação do método proposto.
A Pesquisa O/D proveu de informações necessárias para a aplicação da Regressão Logística
Múltipla (RLM).
Deste ponto em diante, foram separados dois conjuntos de amostras. A amostra de 70% dos
dados foi reservada para a calibração de dois métodos: de Regressão Logística Múltipla (RLM)
e o método geoestatístico. A amostra de 30% foi delimitada com o propósito de prover a
validação dos métodos. Por conseguinte, pode-se resumir este trabalho em duas etapas: (1)
abordagem clássica: aplicação da RLM e (2) abordagem espacial: aplicação de Geoestatística.
4.2.1 Regressão Logística Múltipla
A partir da variável preferência por modo motorizado e do conjunto de calibração, foi feita a
RLM. O output trata de uma equação que estima valores de probabilidade de escolha do
transporte público em relação ao transporte individual motorizado.
Esta equação foi, então, utilizada ao conjunto de 30% para ser realizada a validação do método,
através da proporção de acertos obtida pela comparação com os valores binários observados. A
equação foi também aplicada ao conjunto de 70%, gerando resultados de probabilidade a serem
utilizados na etapa de Geoestatística.
4.2.2 Geoestatística
O produto da etapa anterior, aplicado ao conjunto de 70%, valeu-se como dado de entrada para
a modelagem geoestatística. A utilização deste método é interessante, pois permite que sejam
estimados valores da variável em domicílios com coordenadas diferentes das amostradas.
Desta forma, esta etapa gerou, ao invés de uma equação, um mapa de valores estimados em
área. Baseado neste mapa, permitiu-se extrair valores referentes ao conjunto de 30%, para que
houvesse a validação deste método.
A validação se deu pela análise de medidas de desempenho considerando valores observados
(probabilidades obtidas na abordagem clássica) e valores estimados pela krigagem em
coordenadas geográficas de valores conhecidos. As medidas adotadas foram: medidas sugeridas
no trabalho de Hollander e Liu (2008) sobre princípios de calibração de modelos de
microssimulação de tráfego (média do erro absoluto, erro quadrático médio, desvio do erro
quadrático médio) e desvio padrão, erro padrão e correlação, descritas na Tabela 1.

Tabela 1: Medidas estatísticas avaliadas nas modelagens.
Média do erro absoluto Erro quadrático médio Desvio do erro quadrático médio
1
N∑|xi − yi|
N
i=1
(5)
1
N∑(xi − yi)
2
N
i=1
(6)
√1
N∑(xi − yi)2
N
i=1
(7)
Desvio padrão Erro padrão Correlação de Pearson
√∑ (xi − yi)2𝑁
𝑖=1
𝑁 − 1 (8)
𝐷𝑒𝑠𝑣𝑖𝑜 𝑝𝑎𝑑𝑟ã𝑜
√𝑁 (9)
∑ (xi − �̅�) × (yi − �̅�)𝑁𝑖=1
√∑ (xi − �̅�)2𝑁𝑖=1 × ∑ (yi − �̅�)2𝑁
𝑖=1
(10)
Em que N: número de valores da amostra, x: valor calculado, y: valor observado, �̅�: média dos
valores calculados e �̅�: média dos valores observados.
5. RESULTADOS E DISCUSSÕES
5.1 Regressão Logística Múltipla
A equação de calibração da variável de probabilidade de escolha do transporte público em
relação ao transporte individual motorizado é apresentada pela Equação 11.
π =1
1 + e−(g(x))
g(x) = −0,547 + 0,271β1 + 0,318β2 − 0,878β3 − 1,180β4 − 0,172β5
+ 0,000193β6 − 0,000177β7 + 0,00003β8 (11)
Onde:
1-número de pessoas,
2-critério de renda,
3-quantidade de motocicletas,
4-quantidade de automóveis,
5-total de viagens,
6-distância de viagens transporte público,
7-distância de viagens por transporte individual motorizado,
8-distância de viagens por transporte não motorizado.
A qualidade do ajuste pode ser mensurada através de medidas estatísticas, como erro padrão e
significância; e também por medidas estatísticas apropriadas apenas para a análise de RLM, tais
como: valor Wald, valor da verossimilhança (-2LL), testes de regressão de Cox & Snell e
Nagelkerke, chi-quadrado avaliado pelo teste de Hosner e Lemeshow. Tais medidas encontram-
se na Tabela 2.
Tabela 2: Resultados para qualidade do ajuste da Regressão Logística Múltipla
Valor
Observado Valor Previsto Wald -2LL
Cox &
Snell Nagelkerke
Hosner &
Lemeshow
Erro
padrão Significância
0 1
130,9 4.214 0,652 0,873 7,25 0,018 0,000 0 5.662 294
1 264 6.947
% acertos 95,5 95,9

A análise da Tabela 2 indica que houve um ótimo ajuste pela RLM. Os valores de erro padrão
e significância foram extremamente baixos. Tais medidas estatísticas têm caráter genérico.
Entretanto, para as medidas de caráter específico, resultados igualmente satisfatórios foram
obtidos.
Similar ao coeficiente de determinação R2 utilizado para casos de Regressão Linear, por
exemplo, as medidas Cox & Snell e Nagelkerke têm valor ótimo quando tendem a “1”. No caso
da RLM atual, obtiveram-se valores próximos ao valor ótimo.
As estatísticas Wald, -2LL e Hosner e Lemeshow também atenderam às expectativas. Contudo,
a estatística que deixa mais evidente a qualidade do ajuste é a matriz de classificação, onde a
contagem de valores previstos e observados é comparada e a taxa de acertos é mensurada. A
taxa de acertos foi superior a 95%.
A Equação 11 foi, então, utilizada ao conjunto de 30% para ser realizada a validação do método.
Esta validação resultou em uma taxa de acertos alta, sendo esta, também, igual a 96%.
A Equação 11, aplicada ao conjunto de 70%, gerou resultados de probabilidade a serem
utilizados na etapa de Geoestatística.
5.2 Geoestatística
A etapa de geoestatística utilizou os valores estimados do conjunto de 70% pela Equação 8 para
um novo processo de estimação. A modelagem pelo método geoestatístico pode ser sumarizada
pela: 1) Análise variográfica e 2) Krigagem.
5.2.1 Análise variográfica
Em função da análise dos dados referentes à variável de preferência por transporte público em
relação ao transporte individual motorizado por domicílio, algumas características espaciais
puderam ser determinadas. Estas características são representadas pelos parâmetros de cálculo
do semivariograma, demonstrados na Tabela 3.
Tabela 3: Parâmetros para cálculo do semivariograma experimental.
Direção de teste Lag Tolerância Número de lags Distância de corte
90° 748 1° 13
10.000
0° 752 2° 13
75° 413 1° 24
-15° 329 1° 30
60° 398 1° 25
-30° 225 1° 44
45° 420 1° 23
-45° 125 1° 80
30° 608 1° 16
-60° 253 1° 39
15° 527 1° 18
-75° 264 1° 37
A partir dos semivariogramas experimentais calculados em função dos parâmetros da Tabela 3
no software Geoms, foi detectado o par de direção com maior amplitude de variância. Dessa
forma, pode-se concluir que a estrutura espacial da variável é anisotrópica. A direção principal
se deu para o ângulo de 60° e a consequente direção ortogonal foi de -30°.
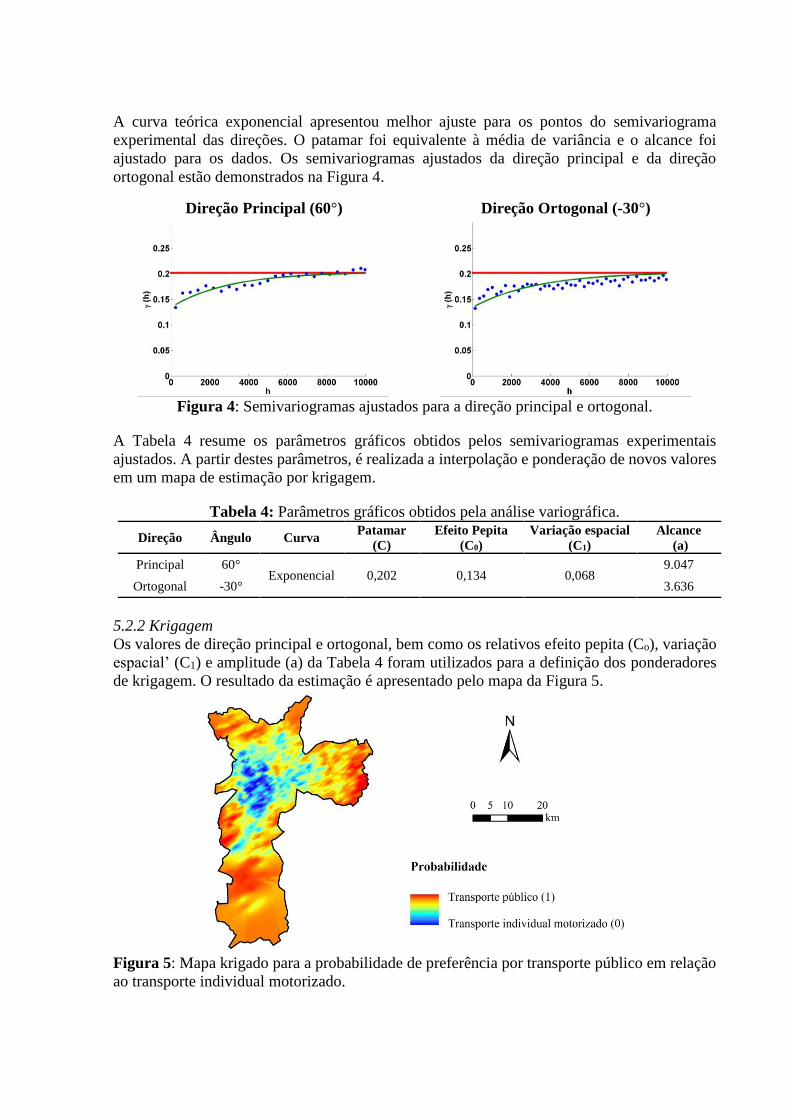
A curva teórica exponencial apresentou melhor ajuste para os pontos do semivariograma
experimental das direções. O patamar foi equivalente à média de variância e o alcance foi
ajustado para os dados. Os semivariogramas ajustados da direção principal e da direção
ortogonal estão demonstrados na Figura 4.
Direção Principal (60°) Direção Ortogonal (-30°)
Figura 4: Semivariogramas ajustados para a direção principal e ortogonal.
A Tabela 4 resume os parâmetros gráficos obtidos pelos semivariogramas experimentais
ajustados. A partir destes parâmetros, é realizada a interpolação e ponderação de novos valores
em um mapa de estimação por krigagem.
Tabela 4: Parâmetros gráficos obtidos pela análise variográfica.
Direção Ângulo Curva Patamar
(C)
Efeito Pepita
(C0)
Variação espacial
(C1)
Alcance
(a)
Principal 60° Exponencial 0,202 0,134 0,068
9.047
Ortogonal -30° 3.636
5.2.2 Krigagem
Os valores de direção principal e ortogonal, bem como os relativos efeito pepita (Co), variação
espacial’ (C1) e amplitude (a) da Tabela 4 foram utilizados para a definição dos ponderadores
de krigagem. O resultado da estimação é apresentado pelo mapa da Figura 5.
Figura 5: Mapa krigado para a probabilidade de preferência por transporte público em relação
ao transporte individual motorizado.

O mapa apresentado na Figura 5 representa a superfície de probabilidades de escolha do modo
de transporte motorizado. Interessante de observar uma tendência central ao uso do automóvel
e motocicleta e uma tendência periférica ao uso de transporte público. Pode-se pressupor,
possivelmente, maiores distâncias de viagens no entorno do município.
Verifica-se ainda que, através da superfície obtida, é possível estimar probabilidades de escolha
modal em diversos pontos, bem como associar erros de estimativa, sendo uma forma espacial
e confirmatória de observar tendências ou “manchas” urbanas de escolha modal.
5.2.3 Validação
Esta validação se deu pela extração de medidas de desempenho através da comparação de
valores observados e valores estimados a partir de modelagem geoestatística em coordenadas
geográficas de valores conhecidos. Vale ressaltar que os valores observados são provenientes
da abordagem tradicional, ou seja, são as probabilidades de escolha modal estimadas pela RLM.
Os resultados estão expressos na Tabela 5.
Tabela 5: Medidas de desempenho entre a RLM e os valores estimados por método
Geoestatístico.
Erro quadrático
médio
Desvio do erro
quadrático médio
Desvio
padrão
Erro
padrão
Média do erro
absoluto
Coeficiente de
correlação
0,16 0,40 0,23 0,00 0,01 0,46
Os resultados demonstram que os erros foram baixos, o que é atestado pelo valor aceitável de
desvio do erro quadrático médio. O coeficiente de correlação pode ser considerado razoável,
demonstrando correlação moderada entre valores observados e estimados pela interpolação
espacial. Pelos resultados de validação, pode-se afirmar que a técnica é adequada para as
finalidades propostas neste trabalho com um poder preditivo razoável.
6. CONCLUSÕES
Este trabalho teve como propósito o estudo e a aplicação da Geoestatística na área de demanda
por transportes em combinação a uma ferramenta tradicional de estimação. A variável objeto
de estudo qualitativa dicotômica utilizada foi a preferência por modo motorizado por domicílio,
em que o valor “1” é referente à preferência por transporte público e o valor “0” se refere à
preferência por transporte individual motorizado por domicílio.
O método sequencial proposto teve como primeira etapa a estimação da variável objeto de
estudo. Foram estimadas probabilidades de escolha do transporte público em relação ao
transporte individual motorizado, por meio da RLM. O modelo foi considerado bem ajustado
através de coeficientes de Cox & Snell e Nagelkerke satisfatórios. Este método foi validado por
meio de cálculo de taxas de acertos com a utilização da amostra de validação. A taxa de acertos
foi de 96%, demonstrando o bom poder preditivo da abordagem clássica não espacial.
Este trabalho utilizou como segunda etapa a interpolação espacial, com a finalidade de obter
uma superfície contínua de preferência modal no município de São Paulo.
A etapa de estimação geoestatística, baseada nos resultados da Regressão Logística, originou
um mapa estimado de probabilidades de escolha do modo de transporte motorizado (individual
ou público) condizente com a prática. Observou-se maior probabilidade de preferência por
transporte individual motorizado, realizado por automóveis e motocicletas, no centro da cidade

de São Paulo. À medida em que se afasta do centro, o domicílio tende a ter preferência pelo
transporte público. As Zonas de Tráfego mais periféricas, como Cantareira, Estação de
tratamento de água do Guaraú, Reserva do Cantareira, Vista Alegre, Cidade Universitária,
Marsilac, Parelheiros, Bororé, e consequentemente menos habitadas, demonstram essa
tendência.
Além da obtenção dos mapas krigados e valores observados, verificou-se baixos valores de
erros das medidas de desempenho utilizadas para validação da modelagem geoestatística. Além
disso, o coeficiente de correlação que mensura a proporcionalidade entre valores teve valor
razoável, assumindo associação entre valores observados e interpolados.
A partir do método sequencial proposto, demonstrou-se ser possível a obtenção de valores de
escolha modal interpolados espacialmente, com a utilização de ferramentas e variáveis
tradicionais (Regressão Logística) e posterior uso de interpolador espacial (Krigagem).
AGRADECIMENTOS O presente trabalho foi realizado com apoio da CAPES, CNPq e FAPESP. As autoras agradecem também à
Companhia do Metropolitano de São Paulo pela cessão dos dados da Pesquisa Origem/Destino de 2007.
REFERÊNCIAS BIBLIOGRÁFICAS Bhat, C.; H. Zhao (2002) The spatial analysis of activity stop generation. Transp. Res. B36, 557–575.
Boulos, M. N. K. (2004) Towards evidence-based, GIS-driven national spatial health information infrastructure
and surveillance services in the United Kingdom. International Journal of Health Geographics, v. 3, n. 1,
p. 1, 2004.
Cervero, R.; C. Radisch (1996) Pedestrian versus automobile oriented neighborhoods. Transport Policy 3, 127–
141.
Croner, C. M.; L. de Cola (2001) Visualization of disease surveillance data with geostatistics, Statistical Division
of the United Nations Economic Commission on Europe (UNECE), Tallinn, Estonia, 25 a 28 de Setembro
de 2001, p. 97-6.
Goovaerts, P. (2006) Geostatistical analysis of disease data: visualization and propagation of spatial uncertainty in
cancer mortality risk using Poisson kriging and p-field simulation. International Journal of Health
Geographics, v. 5, n. 1, p. 7, 2006.
Hair Jr., J. F.; W. C. Black; B. J. Babin; R. E. Anderson (2010) Multivariate Data Analysis. Prentice Hall. 7ed.
Hollander, Y.; Liu, R. (2008) The principles of calibrating traffic microsimulation models. Transportation, vol.
35, n° 3, p. 347-362.
Kitamura, R.; P. L. Mokhtarian; L. Laidet (1997) A micro-analysis of land use and travel in five neighborhoods in
the San Francisco Bay Area. Transportation 24, 125–158.
Lindner, A. (2015) Análise desagregada de dados de demanda por transportes através de modelagem
geoestatística e tradicional. Dissertação (Mestrado em Ciências) - Departamento de Engenharia de
Transportes, Escola de Engenharia de São Carlos, Universidade de São Paulo, São Carlos, 2015.
Matheron, G. (1971) The theory of regionalized variables and its applications. Les Cahiers du Centre de
Morphologie Mathématique de Fontainebleau. École Nationale Supérieure dês Mines de Paris nº 5. 211 p.
Metrô - Companhia do Metropolitano de São Paulo (2007) Pesquisa Origem-Destino 2007 - Região Metropolitana
de São Paulo: Síntese das informações.
Ortúzar, J. D.; L. G. Willumsen (2011) Modelling Transport. Londres: Wiley. 4ª ed. 586p.
Páez, A.; F. A. López; M. Ruiz; C. Morency (2013) Development of an indicator to assess the spatial fit of discrete
choice models. Transp. Res. B56, 217–233.
Pitombo, C. S.; A. S. G. Costa; A. R. Salgueiro (2015b) Proposal of a sequential method for spatial interpolation
of mode choice. Boletim de Ciências Geodésicas (Impresso) JCR v. 21, p. 3, 2015.
Pitombo, C. S.; A. R. Salgueiro; A. S. G. Costa; C. A. Isler (2015a) A Two-step method for mode choice estimation
with socioeconomic and spatial information. Spatial Statistics, v. 11, p. 45-64, 2015.


















