
O que é um corpus representativo.
26
1 O que é um corpus representativo? Tony Berber Sardinha LAEL, PUCSP (Programa de Estudos Pós-Graduados em Ling. Aplicada e Estudos da Linguagem) Pontifícia Universidade Católica de São Paulo Rua Monte Alegre 984 05014-001 São Paulo, SP, Brazil [email protected] DIRECT Papers 44 http://www.direct.f2s.com ISSN 1413-442x 2000 1. Introdução No ano de 1999 comemora-se o aniversário de 35 anos da criação do primeiro corpus lingüístico eletrônico, o corpus Brown. Lançado em 1964, o Brown University Standard Corpus of Present -Day American English, continha uma quantidade invejável de dados para a época: um milhão de palavras. Há 35 anos atrás as dificuldades de informatizar um conjunto de textos eram grandes. Vale lembrar, por exemplo, que os textos tiveram de ser transferidos para o computador por meio de cartões, perfurados um a um; tal era a tecnologia da época. Este feito por si só já traria respeito e admiração à empreitada. O corpus Brown marcou a Lingüística de Corpus por influenciar como seriam os corpora seguintes. Primeiramente, o seu formato foi reproduzido em vários outros corpora (LOB, FLOB, Wellington, etc.). Em segundo lugar, e isto é mais importante, definiu um padrão de tamanho para um corpus representativo. Ao se fixar como referência, o tamanho de 1 milhão de palavras passou a ser um tipo de ‘benchmark’ tácito de representatividade. Os padrões de tamanho de corpora mudaram neste 35 anos. Atualmente existem corpora de mais de 300 milhões de palavras (Bank of English), e um dos corpora mais influentes possui 100 milhões de palavras (BNC). Hoje em dia, um corpus de 1 milhão de palavras é, comparativamente aos demais em uso na pesquisa, apenas ‘médio -grande’ (Berber Sardinha, no prelo). Devido a esta mudança nos tamanhos de corpora disponíveis, a questão que se levanta é qual seria o tamanho que um corpus deveria ter para ser representativo. Seriam 1 milhão de palavras suficientes para constituírem uma amostra representativa? Ou seriam necessárias mais ou menos palavras? Enfim, qual seria o tamanho mínimo representativo de um corpus? Respostas a estas questões seriam de extrema utilidade para uma ampla gama de pesquisadores de corpora. Para compiladores, o conhecimento do tamanho mínimo
Transcript of O que é um corpus representativo.

1
O que é um corpus representativo?
Tony Berber Sardinha LAEL, PUCSP
(Programa de Estudos Pós-Graduados em Ling. Aplicada e Estudos da Linguagem) Pontifícia Universidade Católica de São Paulo
Rua Monte Alegre 984 05014-001 São Paulo, SP, Brazil
DIRECT Papers 44 http://www.direct.f2s.com
ISSN 1413-442x
2000
1. Introdução No ano de 1999 comemora-se o aniversário de 35 anos da criação do primeiro corpus lingüístico eletrônico, o corpus Brown. Lançado em 1964, o Brown University Standard Corpus of Present -Day American English, continha uma quantidade invejável de dados para a época: um milhão de palavras. Há 35 anos atrás as dificuldades de informatizar um conjunto de textos eram grandes. Vale lembrar, por exemplo, que os textos tiveram de ser transferidos para o computador por meio de cartões, perfurados um a um; tal era a tecnologia da época. Es te feito por si só já traria respeito e admiração à empreitada. O corpus Brown marcou a Lingüística de Corpus por influenciar como seriam os corpora seguintes. Primeiramente, o seu formato foi reproduzido em vários outros corpora (LOB, FLOB, Wellington, etc.). Em segundo lugar, e isto é mais importante, definiu um padrão de tamanho para um corpus representativo. Ao se fixar como referência, o tamanho de 1 milhão de palavras passou a ser um tipo de ‘benchmark’ tácito de representatividade. Os padrões de tamanho de corpora mudaram neste 35 anos. Atualmente existem corpora de mais de 300 milhões de palavras (Bank of English), e um dos corpora mais influentes possui 100 milhões de palavras (BNC). Hoje em dia, um corpus de 1 milhão de palavras é, comparativamente aos demais em uso na pesquisa, apenas ‘médio -grande’ (Berber Sardinha, no prelo). Devido a esta mudança nos tamanhos de corpora disponíveis, a questão que se levanta é qual seria o tamanho que um corpus deveria ter para ser representativo. Seriam 1 milhão de palavras suficientes para constituírem uma amostra representativa? Ou seriam necessárias mais ou menos palavras? Enfim, qual seria o tamanho mínimo representativo de um corpus? Respostas a estas questõ es seriam de extrema utilidade para uma ampla gama de pesquisadores de corpora. Para compiladores, o conhecimento do tamanho mínimo

2
representativo seria de extrema valia pois evitaria que se desperdiçassem recursos na coleta e preparação de quantidades de dados além do necessário. Para investigadores com recursos financeiros e de tempo reduzidos (a maioria, infelizmente), saber o tamanho mínimo representativo significaria também um trabalho mais eficiente e condizente com o contexto da pesquisa. Para todos, enfim, conhecer o tamanho mínimo representativo de corpus se traduziria num planejamento de pesquisa mais realista, e na consciência dos limites do corpus que se tem à disposição. Por falta de respostas à questão de o que seria uma amostra representativa de linguagem, a estratégia que se tem posto em prática é utilizar um corpus o maior possível. A noção do ‘quanto maior melhor’ é tida como uma ‘salvaguarda’ (Sinclair, 1991) para garantir que o corpus seja o mais representativo o possível, ao incluir o maior número possível de palavras raras. Esta estratégia pode ser válida para os grandes grupos de pesquisa, bem abastecidos de recursos materiais e de equipamento, mas para a maioria dos pesquisadores que se sentem compelidos a coletar um corpus o maior possível fica sempre a dúvida se não estão desperdiçando recursos já escassos em criar um corpus maior do que deveria. O presente trabalho se propõe justamente a sugerir respostas à questão do tamanho mínimo representativo de corpus. Para tanto, a investigação relatada aqui se utilizou do trabalho de Douglas Biber (1990, 1993) com corpora etiquetados. Antes, porém, de apresentar os fundamentos da pesquisa prévia de Biber, serão enfocadas as questões preliminares de fundo nas quais a presente investigação se insere. Primeiramente será apresentada uma pequena introdução à Lingüística de Corpus, o campo de pesquisa no qual as questões levantadas aqui são mais prementes. A seguir, passar-se-á a um relato dos tipos de abordagens à questão da representatividade exis tentes na literatura. Uma descrição do trabalho de Biber vem logo após. Passa-se a seguir à metodologia, resultados, e conclusões da investigação proposta aqui. 2. O que é a Lingüística de Corpus A Lingüística de Corpus se ocupa da coleta e exploração de corpora, ou conjuntos de dados lingüísticos textuais que foram coletados criteriosamente com o propósito de servirem para a pesquisa de uma língua ou variedade lingüística. Como tal, dedica-se à exploração da linguagem através de evidências empíricas, extraídas por meio de computador. Havia corpora antes do computador, já que o sentido original da palavra ‘corpus’ é ‘corpo’, ‘conjunto de documentos’ (conforme o dicionário Aurélio). Na Grécia Antiga, Alexandre o Grande definiu o Corpus Helenístico. Na Antiguidade e Idade Média, produzia-se corpora de citações da Bíblia. Durante boa parte do século XX houve muitos pesquisadores que se dedicaram à descrição da linguagem por meio de corpora, entre eles educadores como Thorndike e lingüistas de campo como Boas. Há duas diferenças fundamentais entre esta época e a atual. A primeira, obviamente, é que os corpora não eram eletrônicos, ou seja, eram coletados, mantidos, e analisados manualmente. A segunda é que a ênfase destes trabalhos era em geral o ensino de línguas. Atualmente o que prepondera na literatura é a descrição de linguagem, e não a pedagogia, embora recentemente tenha ressurgido um interesse no emprego de corpora na sala-de-aula e na investigação da linguagem de

3
alunos de língua (Granger, 1998). Foi um corpus não computadorizado que deu feição aos corpora atuais: o SEU (Survey of English Language), compilado por Randolf Quirk e sua equipe, em Londres, a partir de 1953. O SEU foi planejado para ter o tamanho de 1 milhão de palavras, depois tido como referência por outros corpora, inclusive o Brown. A composição do corpus também foi influente, ao definir um número fixo de textos (200) e uma quantidade de palavras igual para cada texto (5000). O Survey foi organizado em fichas de papel, cada um contendo uma palavra do corpus inserida em 17 linhas de texto. As palavras foram analisadas gramaticalmente, com cada ficha recebendo uma categoria gramatical. O conjunto de categorias resultante serviu de base para o desenvolvimento dos etiquetadores computadorizados contemporâneos, que fazem a identificação de traços gramaticais automaticamente. A famosa Comprehensive Grammar of the English Language de Quirk, Greenbaum, Leech e Svartvik foi baseada no SEU. A transformação completa do Survey em corpus eletrônico só foi atingida muitos anos depois, em 1989, mas a parte falada dele foi computadorizada antes e ficou conhecida como o London-Lund Corpus. Nos anos 60, os computadores mainframe passaram a equipar centros de pesquisa universitários e foram sendo aproveitados para a pesquisa em linguagem. Com a popularização dos computadores, possibilitou-se o acesso de mais pesquisadores ao processamento de linguagem natural, e concomitantemente, a sofisticação do equipamento permitiria a consecução de tarefas mais complexas, mais eficientemente, sem falar no aumento da capacidade de armazenamento e na introdução de novas mídias (fitas magnéticas, em vez de cartões hollorith perfurados, etc.), as quais facilitaram a criação e manutenção de corpora em maior número. Com a entrada em cena dos micro-computadores pessoais, nos anos 80, uma nova onda de mudanças viria a acontecer, com a popularização de corpora e de ferramentas de processamento, o que contribui decisivamente para o reaparecimento e fortalecimento da pesquisa lingüística baseada em corpus. 3. Histórico da Lingüística de Corpus A história da Lingüística de Corpus está intimamente ligada à disponibilidade de corpora eletrônicos. Os principais corpora compilados, ou em compilação, até hoje são: Corpus Lançamento /
Referência na literatura
Palavras Composição
Brown Corpus (Brown University Standard Corpus of Present-Day American English)
1964 1 milhão Inglês americano, escrito
AHI (American Heritage Intermediate Corpus)
1971 5 milhões Inglês americano, escrito
LOB (Lancaster-Oslo -Bergen) 1978 1 milhão Inglês britânico, escrito
LLC (London-Lund Corpus) 1980 500 mil Inglês britânico, falado
Birmingham Corpus 1987 20 milhões Inglês britânico
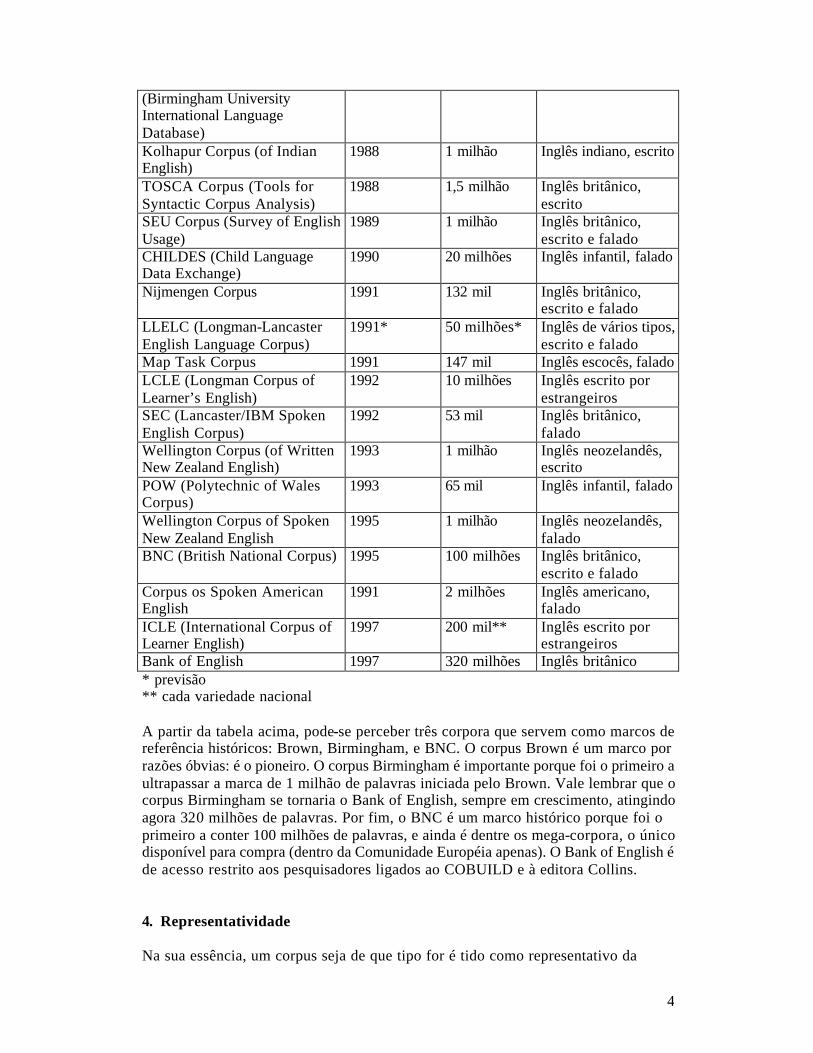
4
(Birmingham University International Language Database) Kolhapur Corpus (of Indian English)
1988 1 milhão Inglês indiano, escrito
TOSCA Corpus (Tools for Syntactic Corpus Analysis)
1988 1,5 milhão Inglês britânico, escrito
SEU Corpus (Survey of English Usage)
1989 1 milhão Inglês britânico, escrito e falado
CHILDES (Child Language Data Exchange)
1990 20 milhões Inglês infantil, falado
Nijmengen Corpus 1991 132 mil Inglês britânico, escrito e falado
LLELC (Longman-Lancaster English Language Corpus)
1991* 50 milhões* Inglês de vários tipos, escrito e falado
Map Task Corpus 1991 147 mil Inglês escocês, falado LCLE (Longman Corpus of Learner’s English)
1992 10 milhões Inglês escrito por estrangeiros
SEC (Lancaster/IBM Spoken English Corpus)
1992 53 mil Inglês britânico, falado
Wellington Corpus (of Written New Zealand English)
1993 1 milhão Inglês neozelandês, escrito
POW (Polytechnic of Wales Corpus)
1993 65 mil Inglês infantil, falado
Wellington Corpus of Spoken New Zealand English
1995 1 milhão Inglês neozelandês, falado
BNC (British National Corpus) 1995 100 milhões Inglês britânico, escrito e falado
Corpus os Spoken American English
1991 2 milhões Inglês americano, falado
ICLE (International Corpus of Learner English)
1997 200 mil** Inglês escrito por estrangeiros
Bank of English 1997 320 milhões Inglês britânico * previsão ** cada variedade nacional A partir da tabela acima, pode-se perceber três corpora que servem como marcos de referência históricos: Brown, Birmingham, e BNC. O corpus Brown é um marco por razões óbvias: é o pioneiro. O corpus Birmingham é importante porque foi o primeiro a ultrapassar a marca de 1 milhão de palavras iniciada pelo Brown. Vale lembrar que o corpus Birmingham se tornaria o Bank of English, sempre em crescimento, atingindo agora 320 milhões de palavras. Por fim, o BNC é um marco histórico porque foi o primeiro a conter 100 milhões de palavras, e ainda é dentre os mega-corpora, o único disponível para compra (dentro da Comunidade Européia apenas). O Bank of English é de acesso restrito aos pesquisadores ligados ao COBUILD e à editora Collins. 4. Representatividade Na sua essência, um corpus seja de que tipo for é tido como representativo da

5
linguagem, de um idioma, ou de uma variedade dele. Ou como diz Leech, o corpus possui uma função representativa . A característica mais facilmente associada à representatividade é justamente a extensão do corpus, o que significa em termos simples que para ter representatividade o corpus deve ser o maior possível (Sinclair, 1991). Isto se deve a dois fatores: (a) A linguagem é um sistema probabilístico (Halliday, 1991, 1992, 1993), no qual
certos traços são mais freqüentes que outros: (i) No caso do léxico, pode-se diferenciar as palavras entre aquelas de ‘maior
freqüência’ e as de ‘menor freqüência’, sendo que a diferença entre elas é relativa. Assim, algumas palavras têm freqüência de ocorrência muito rara, e para que haja probabilidade de elas ocorrerem no corpus é necessário incorporar-se uma quantidade grande de palavras ao corpus. Em outras palavras, quanto maior a quantidade de palavras, mais probabilidade há de palavras de baixa freqüência aparecerem.
(ii) No caso dos sentidos das palavras, também pode-se distinguir entre os sentidos mais freqüentes e os menos freqüentes dos itens lexicais. Assim, mesmo palavras de alta freqüência tem sentidos raros (por exemplo, ‘serviço’ entendido como ‘saque’ no jogo de tênis), e portanto estes sentidos terão maior probabilidade de ocorrerem quanto maior for o corpus.
(b) O corpus é uma amostra de uma população cuja dimensão não se conhece (a linguagem como um todo). Desse modo, não se pode estabelecer qual seria o tamanho ideal da amostra para que ela represente esta população. Uma salvaguarda neste caso é tornar a amostra o maior possível (Sinclair, 1991) a fim de que ela se aproxime o mais possível da população da qual deriva, sendo assim mais representativa.
Não há critérios objetivos para a determinação da representatividade. Por isso, uma amostra deve ter, além das características mencionadas, acima, uma dada extensão. Assim, quando se diz que um corpus deva ser representativo, entende-se representatividade em termos da extensão do corpus, isto é, um número determinado de palavras e de textos. Isto suscita de imediato duas questões: representativo do quê, e para quem? Para se responder à questão ‘representativo do quê?’, deve-se olhar para a questão de amostragem. Para que qualquer amostra seja representativa, é necessário se conhecer a população da qual ela provém. No caso da linguagem, a dimensão da população total é desconhecida. Por isso, não é possível estimar-se qual seria uma amostra representativa da linguagem, e portanto, estritamente falando, não se pode afirmar que um corpus qualquer seja representativo. Embora não se possa falar em representatividade em termos absolutos, pode-se tratar da questão em termos relativos. A principal maneira, ou ‘salvaguarda’ (Sinclair, 1991), pela qual se pode garantir maior representatividade é através do aumento da extensão do corpus. Um corpus maior é mais representativo do que um menor devido ao fato de que vai conter mais instâncias de traços lingüísticos raros, e conseqüentemente será uma amostra mais abrangente da totalidade de traços presentes na linguagem. A representatividade está ligada à questão da probabilidade. A linguagem é de caráter probabilístico (vide acima), isto é, alguns traços são mais comuns do que outros. O

6
conhecimento da probabilidade de ocorrência de traços lexicais, estruturais, pragmáticos, discursivos, etc. está no cerne da Lingüística de Corpus, e portanto o conhecimento acerca da probabilidade de ocorrência da maioria dos traços lingüísticos em vários contextos ainda está sendo adquirido. O campo do léxico, entretanto, é onde se possui a maior quantidade de conhecimento derivado do exame de corpora. Para esta discussão, é necessário distinguir-se entre a forma e o sentido lexical. Em qualquer corpus, as formas de freqüência 1 (também conhecidas como ‘hapax legomena’) são a maioria. Baseando-se neste fato, é possível afirmar que o léxico de freqüência baixa é o mais comum, isto é, a maioria das palavras de uma língua é composta de palavras que ocorrem poucas vezes. Em outras palavras, palavras de baixa freqüência tem uma probabilidade baixa de ocorrência (1 em 1 milhão, por exemplo), e já que elas formam a maior parte do vocabulário de uma língua, torna-se necessário amostras grandes para que elas possam ocorrer. O sentido das palavras também entra em jogo na discussão da representatividade. A freqüência das formas em si não é suficiente porque mesmo palavras de alta freqüência possuem vários sentidos. Assim, uma freqüência alta pode ‘esconder’ vários sentidos, os quais separados teriam baixa freqüência. Para que seja representativo, um corpus deve conter o maior número possível de sentidos de cada forma. Por exemplo, a forma ‘como’ pode significar a preposição ou a primeira pessoa do singular do verbo comer no presente do indicativo. Esta forma é comum na língua portuguesa, ocorrendo aproximadamente 531 vezes por milhão. Simplesmente olhando-se para a forma ‘como’ na listagem de freqüências do corpus não é possível se saber se ambos os sentidos estão representados. Um corpus geral que vise representar a língua portuguesa deve conter ambos os sentidos deste vocábulo, já que ambas existem na língua. A extensão do corpus comporta três dimensões. A primeira é o número de palavras. O número de palavras é uma medida da representatividade do corpus no sentido de que quanto maior o número de palavras maior será a chance do corpus conter palavras de baixa freqüência, as quais formam a maioria das palavras de uma língua. A segunda é o número de textos, a qual se aplica a corpora de textos específicos. Um número de textos maior garante que este tipo textual, gênero, ou registro, esteja mais adequadamente representado. A terceira é o número de gêneros, registros ou tipos textuais. Esta dimensão se aplica a corpora variados, desenhados para representar uma língua como um todo. Aqui, um número maior de textos de vários tipos permite uma maior abrangência do espectro genérico da língua. A outra perspectiva a partir da qual se pode enfocar a questão da representatividade é através da pergunta ‘representativo para quem?’. Esta pergunta tem validade porque, conforme discutido acima, não se pode demonstrar, neste estágio do nosso conhecimento dos fenômenos de larga escala da linguagem, qual seria uma amostra representativa. Devido a isso, tem-se falado em representatividade como um ‘ato de fé’ (Leech, 1991, p.27). Em outras palavras, os usuários de um corpus atribuem a ele a função de serem representativos de uma certa variedade. O ônus é dos usuários em demonstrar a representatividade da amostra, e de serem cuidadosos em relação à generalização dos seus achados para uma população inteira (um gênero ou a língua inteira, por exemplo). A caracterização da Lingüística de Corpus como uma área em desenvolvimento é

7
fundamental para se aceitar o critério de ‘representativo para quem?’. Não se trata de baixos padrões de qualidade dentro da comunidade de lingüistas do corpus, onde ‘tudo vale’. Ou mesmo de mal gerenciamento dos ‘gate-keepers’, os editores e pareceristas de periódicos e de conferências da área. Trata-se, na verdade, de uma característica fundamental da Lingüística de Corpus que é seu caráter orgânico. A Lingüística de Corpus está em constante desenvolvimento e assim seus parâmetros relativos ao que se considera adequado ou representativo muda, geralmente muito rápido. As mudanças na área seguem, de certo modo, as mudanças na tecnologia dos computadores, em especial aquela referente aos computadores pessoais. Estas mudanças afetam de modo especial a capacidade de armazenar e manipular corpora, e desse modo os corpora mudam pois se adaptam aos avanços tecnológicos. Isto, aliado ao fato de que a Lingüística de Corpus não parte de uma teoria, mas sim da exploração de corpora, faz com que os padrões de adequação de critérios da própria Lingüística de Corpus como um todo também mudem. O problema é que a quantidade mínima de dados necessário s para a formação de um corpus nunca foi estimada (Berber Sardinha, in press), e o critério de tamanho é empregado subjetivamente na definição de corpus. Este é o tema da próxima seção. 5. Tamanho do corpus Embora seja um critério fundamental na representatividade, pouco se tem pesquisado a questão da definição de critérios mínimos de extensão para a constituição de um corpus representativo. Pode-se definir três abordagens: • Impressionística: baseia-se em constatações derivadas da prática da criação e
exploração de corpora, em geral feitas por autoridades da área. Por exemplo, Aston (1997) menciona patamares que caracterizariam um corpus pequeno (20 a 200 mil palavras) e um grande (100 milhões ou mais). Leech (1991) fala de 1 milhão de palavras como a taxa usual (‘going rate’), sugerindo o que seja o patamar mínimo. Outros são mais vagos, como Sinclair (1996), o qual postula que o corpus deva ser tão grande quanto a tecnologia permitir para a época, deixando-se subentender que a extensão de um corpus deva variar de acordo com o padrão corrente nos grandes centros de pesquisa, os quais possuem equipamentos de última geração.
• Histórica: fundamenta-se na monitoração dos corpora efetivamente usados pela comunidade. Por exemplo, Berber Sardinha (in press) sugere uma classificação baseada na observação dos corpora utilizados segundo quatro anos de conferências de Lingüística de Corpus:
Tamanho em palavras Classificação Menos de 80 mil Pequeno 80 a 250 mil Pequeno-médio 250 mil a 1 milhão Médio 1 milhão a 10 milhões Médio-grande 10 milhões ou mais Grande

8
Graficamente, a escala seria esta:
Figura 1: Escala de tamanho relativo de corpora. Os números se referem a quantias em milhões, e as letras a ‘Pequeno’, ‘Médio’, e Grande’. O número sobre a linha tracejada superior indica a mediana, e sob a inferior a média aritmética.
• Estatística: fundamenta-se na aplicação de teorias estatísticas. Por exemplo, Biber
(1993) emprega fórmulas matemáticas para identificar quantidades mínimas de palavras, gêneros, e textos que se constituiriam em uma amostra representativa. Pode ser subdividida em três vertentes:
(1) Interna: Dado um corpus pré-existente que serve como amostra maior, qual o tamanho mínimo de uma amostra que mantém estáveis as características desta amostra maior? Esta é a perspectiva seguida por Biber (1990, 1993).
(2) Externa: Dada uma fonte externa de referência cuja dimensão é conhecid a, qual o tamanho do corpus necessário para representar majoritariamente esta fonte?
(3) Relativa: Quanto se perderia se o corpus fosse de um tamanho x? Dados meus recursos existentes, quais parâmetros posso utilizar para abalizar minha decisão relativa ao tamanho de corpus que posso compilar? Uma proposta segundo esta perspectiva ainda não foi formalizada, mas está presente, por exemplo, em Sanchez e Cantos (1997a, b), os quais estimam matematicamente a quantidade do vocabulário presente em corpora de diversos tamanhos hipotéticos, e em Yang e Song (1998), os quais fazem uma previsão da quantidade de dados necessários para incluir certas características gramaticais.
6. O trabalho de Biber Um dos poucos critérios para a montagem de corpus é sugerido por Biber (1990, 1993). Ele propõe, por meio de cálculos estatísticos, uma série de princípios de amostragem. Ele apresenta cálculos referentes a quantias mínimas estatisticamente válidas para: número de textos total, número de textos por variedade, e tamanho de texto. A metodologia empregada por ele para os cálculos se baseou na idéia de se comparar um conjunto de textos menor com um conjunto maior. O ponto central inicial é como ele define o que seria uma amostra representativa: seria aquela que ‘se parece’ com a
P M G
0,003 0,080 0,250 1 10 480
0,500
39,8

9
população, ou seja, está perto da média. A população, no caso, é a linguagem como um todo. Entretanto, como não se tem acesso à ela, não se pode a rigor estimar-se a média de qualquer traço lingüístico. Portanto, tem de se recorrer a um artifício, qual seja, usar-se um corpus existente como população, e daí tentar estabelecer qual o tamanho mínimo de uma amostra que seja representativa do corpus. Em termos simples, então, Biber faz uma comparação entre uma ‘amostrinha’ e uma ‘amostrona’ (de onde a pequena saiu). A questão que ele coloca é: qual o tamanho mínimo da ‘amostrinha’ para que ela seja parecida com a ‘amostrona’? Para serem parecidas elas devem ter uma média parecida, e para serem parecidas as médias diferir no máximo em 5% (isto é, o erro tolerável deve ser no máximo 5% da média). O valor de 5% foi fixado por ser intuitivamente aceitável e por ser usual nos cálculos estatísticos nas ciências humanas. O corpus utilizado como base por Biber é composto de 481 textos do inglês britânico escrito e falado. Os textos foram coletados em parte dos corpora Brown e London-Lund, e em parte de textos próprios. Para se saber o tamanho de uma amostra representativa em termos de número de textos, Biber (1990, 1993) conduziu duas investigações. Na primeira (Biber, 1990), foram comparadas as freqüências de vários traços lingüísticos em amostras de vários tamanhos, e computadas correlações entre as amostras pequenas e o corpus. As correlações indicaram que as amostras de 10 textos mantiveram as características dos traços em questão conforme eles aparecem no corpus. Portanto, uma amostra de 10 textos seria suficiente para representar o corpus. Contudo, os resultados destes cálculos se basearam em traços freqüentes, os quais estão presentes em muitos textos, e, portanto, podem ser adequadamente representados por amostras menores. Em um estudo posterior, Biber (1993) enfocou a questão da influência dos traços menos freqüentes na determinação do tamanho das amostras mínimas representativas. Os resultados indicaram que o número de textos mínimo varia de acordo com o traço que se toma como base. No caso de traços mais freqüentes, a quantidade mínima exigida é menor, e no caso de traços mais raros, a quantia é maior. Um traço freqüente no corpus são substantivos, que ocorrem em média 181 vezes por texto. Uma amostra representativa dos substantivos do corpus deveria ter, então, no mínimo, 60 textos. Isto porque uma amostra de 60 textos guardaria as características do corpus (a amostra maior). Como dada texto tinha 1000 palavras, isto significa que uma amostra mínima deva ter 60 mil palavras. Já uma característica infreqüente do corpus são orações condicionais, com média de apenas 2,5 por texto. Neste caso, a amostra representativa mínima teria de ser 1190 textos (ou 1.190.000 palavras), o que equivale a dizer que o corpus usado por Biber não seria representativo deste tipo de orações, pois contém apenas 481 textos. Estes resultados mostram uma grande discrepância em comparação aos números obtidos anteriormente (10 textos). Deste modo, ainda há disputa em relação à quantidade mínima de textos para se concretizar uma amostra representativa. 7. Cálculo das amostras Para estimar o tamanho das amostras, Biber (1993) emprega os seguintes conceitos: • Erro padrão: a distância da média da amostra (i.e. cada categoria gramatical) da
média real da população (i.e. a linguagem como um todo). O erro padrão diminui com o aumento do tamanho da amostra, mas é necessária um aumento de amostra

10
grande para uma diminuição pequena do erro padrão (nos exemplos oferecidos por Biber, um aumento de 4 vezes na amostra diminuiu o erro padrão pela metade, ou seja, uma relação de 4 para 1/2).
• Erro tolerável: quantidade de incerteza tolerável numa análise de corpus. Estes conceitos são operacionalizados com as fórmulas abaixo: • Erro padrão (s x): sx = s/n1/2
• ‘s’= desvio padrão • ‘n’ = tamanho dos textos no qual obteve-se o desvio padrão
• Erro tolerável (te): te = 1,96 * sx O tamanho da amostra para cada categoria é então obtido pela fórmula abaixo: • Tamanho da amostra (n): n = s2 /(te/1,96)2 Por exemplo, os dados referentes a substantivos no corpus usado por Biber (1993) são os seguintes:
s=35,6 n (tamanho do texto)= 1000
os quais resultam um erro padrão de 9.03, pois:
sx = 35,6/10001/2=9,03 Transpondo-se estes valores para a fórmula de tamanho de amostra, obtém-se:
n = 35,62 /(9,03/1.96)2
n = 59,8 ou seja, uma amostra significativa mínima de substantivos teria 59,8 textos de 1000 palavras, ou seja, 59.800 palavras Conforme Biber (1993, p.248) aponta, um defeito da fórmula é que funciona de modo circular. Ela exige um valor de desvio padrão que deve ser obtido em um corpus ‘confiável’, a fim de que o valor do desvio padrão também o seja. O tamanho deste corpus ‘confiável’ seria igual a 30, ou o tamanho mínimo necessário para a existência de distribuição normal. 8. Uma extensão do trabalho de Biber O trabalho de Biber mostrou que se dispõe de técnicas estatísticas para a determinação do tamanho de amostras representativas mínimas. Contudo, os seus resultados se referem a categorias gramaticais individuais: substantivos, orações condicionais, etc. Ou seja, para cada categoria gramatical é indicado uma quantidade mínima representativa de textos e palavras. Entretanto, o que se deseja é um número que seja relativo ao léxico, isto é, uma quantidade que indique quantas palavras são necessárias para se representar o vocabulário de uma língua. Por exemplo, usando-se a metodologia de Biber, poder-se-ia

11
estimar quantas palavras são necessárias para se representar estatisticamente os itens ‘the’, ‘it’, ‘of’, etc. O problema com esta técnica é que a totalidade do conjunto de palavras da língua, ao contrário das categorias gramaticais, não é conhecido. Em termos simples, este é um conjunto aberto. Desta forma, nunca se conseguiria estimar mais do que uma parcela apenas das palavras, e portanto não se poderia generalizar os números das amostras para o total do vocabulário, já que grande parte do léxico não estaria representada. Mesmo que se fizesse uma estimação de todas as palavras de um dado corpus, sempre haveria palavras novas que não estariam no corpus estudado. Em conclusão, não é possível obter-se um número relativo a toda a língua a partir do léxico. É possível, contudo, adaptar-se a metodologia. Isto poderia ser feito usando-se um sistema de classificação gramatical fechado que desse conta de todas as palavras da língua, isto é, que se mapeie em todos elementos do conjunto aberto. Ou seja, uma classificação gramatical na qual pudessem estar representadas todas as palavras. Para se obter tal número, e seguindo-se a abordagem de Biber, é necessário um sistema de categorias que seja:
(a) Abrangente: todas as palavras do texto devem ser categorizadas; (b) Discreto: nenhuma palavra pode ser categorizada de mais de uma maneira;
Aparentemente, poderia se chegar a um tamanho de amostra de todas as categorias gramaticais usadas por Biber simplesmente usando-se os dados apresentados por ele e tirando-se uma média dos tamanhos de amostra de todas as categorias empregadas por ele. Na verdade, entretanto, isto não é possível porque seu sistema de categorias não satisfaz a segunda condição acima, isto é, há casos em que uma mesma palavra possui mais de uma categoria gramatical. Um sistema classificatório que atende a ambas exigências é um sistema baseado em categorias morfossintáticas auto-excludentes. Ou seja, um sistema que atribua para cada palavra do corpus uma e apenas uma categoria morfossintática (substantivo, adjetivo, pronome, etc.) A aplicação de uma categorização morfossintático é vantajoso por dois motivos. Primeiramente, porque já existem tais sistemas, não havendo necessidade da criação de uma categorização nova. E em segundo lugar, a classificação morfossintática pode ser feita automaticamente, por computador, o que permite o uso de grandes quantidades de dados, emprestando mais credibilidade e robustez estatística aos resultados. 9. Metodologia No presente estudo objetiva-se aplicar a metodologia de estimação de amostras para traços lingüísticos individuais de Biber usando-se uma categorização morfossintática abrangente e discreta. Conforme dito acima, uma vantagem da morfossintaxe é que este nível de análise é automatizável. Mais especificamente, é possível usar-se etiquetadores morfossintáticos que atribuem categorias a cada palavra do corpus com até 97% de exatidão. Por isso, a etiquetagem empregada aqui foi feita automaticamente por etiquetadores computacionais. Os seguintes corpora foram utilizados:

12
Corpus Palavras Língua Brown 1 milhão Inglês americano LOB 1 milhão Inglês britânico BNC-S* 1 milhão Inglês britânico Cartas** 11.761 Inglês britânico Ensaios 23.653 Português brasileiro Total 3,034 milhões *Sigla usada aqui para designar o componente escrito do BNC Sampler **de pedido de emprego Os corpora LOB e BNC já estavam disponíveis etiquetados, mas o Brown1 não o estava, e teve de ser etiquetado especialmente para estudo. A etiquetagem foi feita localmente através do etiquetador Brill’s treinado anteriormente com o próprio corpus Brown. Assim, todas as palavras do corpus estavam presentes no léxico computacional do etiquetador com seus rótulos apropriados, não havendo necessidade de adivinhações (‘guessing’) por parte do etiquetador. Por isso, os resultados da etiquetagem são considerados confiáveis,. As classificações morfossintáticas empregadas para cada corpus são representadas pelos conjuntos de etiquetas (‘tagsets’) usados, que tinham o seguinte número de etiquetas (categorias): Corpus Etiquetas Brown & Cartas 36 LOB 122 BNC Sampler escrito 137* *135 de fato ocorreram Como se pode notar pelo número de etiquetas e pela composição dos conjuntos (vide apêndice), as categorizações de cada corpus eram diferentes, o que dificultaria a comparação dos resultados. Por isso, resolveu-se padronizar ao máximo os conjuntos de etiquetas, agrupando características de modo que o conjunto resultante fosse o menor possível. As categorias agrupadas aparecem elencadas no apêndice 2. Os conjuntos de etiquetas finais foram os seguintes:
Brown & Cartas LOB & BNC-S 1 Adjetivo Adjetivo 2 Advérbio Advérbio 3 Conjunção
coordenada Artigo
4 Determinante Conjunção 5 Substantivo Determinante 6 Numeral Substantivo 7 Outros Numeral 8 Preposição ou
conjunção subordinada
Outro
1 Existe uma versão previamente etiquetada do corpus Brown que não estava à nossa disposição.
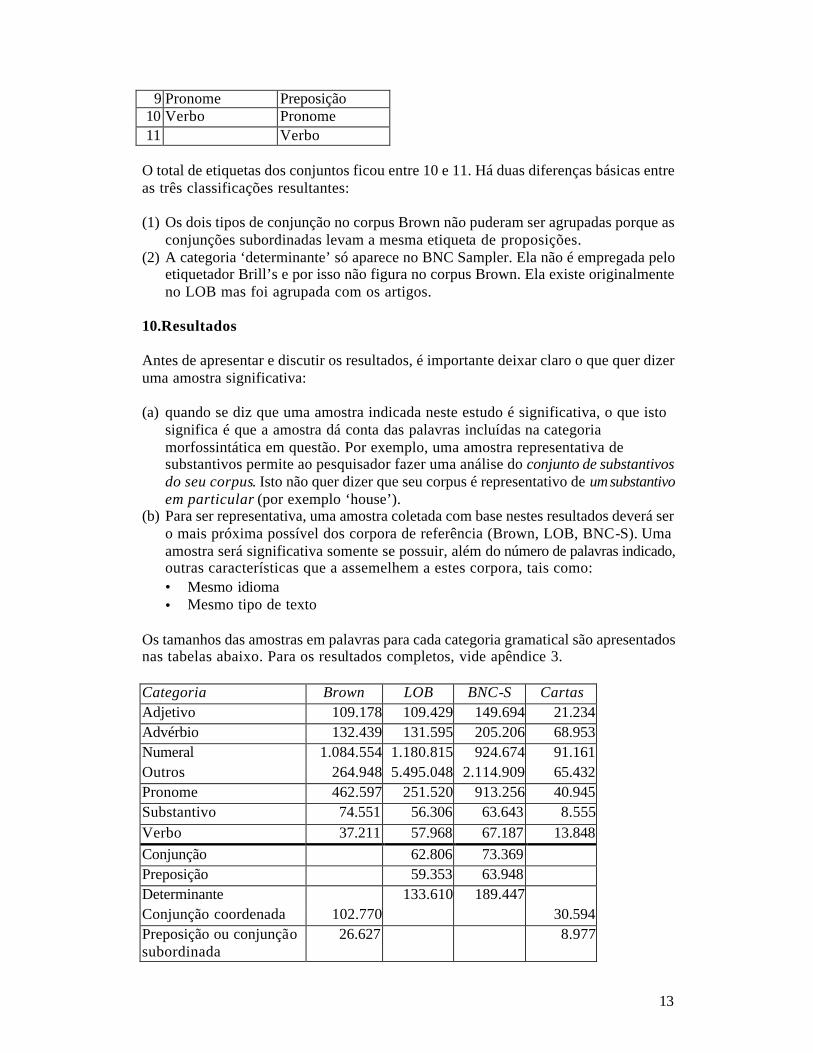
13
9 Pronome Preposição 10 Verbo Pronome 11 Verbo
O total de etiquetas dos conjuntos ficou entre 10 e 11. Há duas diferenças básicas entre as três classificações resultantes: (1) Os dois tipos de conjunção no corpus Brown não puderam ser agrupadas porque as
conjunções subordinadas levam a mesma etiqueta de proposições. (2) A categoria ‘determinante’ só aparece no BNC Sampler. Ela não é empregada pelo
etiquetador Brill’s e por isso não figura no corpus Brown. Ela existe originalmente no LOB mas foi agrupada com os artigos.
10.Resultados Antes de apresentar e discutir os resultados, é importante deixar claro o que quer dizer uma amostra significativa: (a) quando se diz que uma amostra indicada neste estudo é significativa, o que isto
significa é que a amostra dá conta das palavras incluídas na categoria morfossintática em questão. Por exemplo, uma amostra representativa de substantivos permite ao pesquisador fazer uma análise do conjunto de substantivos do seu corpus. Isto não quer dizer que seu corpus é representativo de um substantivo em particular (por exemplo ‘house’).
(b) Para ser representativa, uma amostra coletada com base nestes resultados deverá ser o mais próxima possível dos corpora de referência (Brown, LOB, BNC-S). Uma amostra será significativa somente se possuir, além do número de palavras indicado, outras características que a assemelhem a estes corpora, tais como: • Mesmo idioma • Mesmo tipo de texto
Os tamanhos das amostras em palavras para cada categoria gramatical são apresentados nas tabelas abaixo. Para os resultados completos, vide apêndice 3. Categoria Brown LOB BNC-S Cartas Adjetivo 109.178 109.429 149.694 21.234 Advérbio 132.439 131.595 205.206 68.953 Numeral 1.084.554 1.180.815 924.674 91.161 Outros 264.948 5.495.048 2.114.909 65.432 Pronome 462.597 251.520 913.256 40.945 Substantivo 74.551 56.306 63.643 8.555 Verbo 37.211 57.968 67.187 13.848
Conjunção 62.806 73.369 Preposição 59.353 63.948 Determinante 133.610 189.447 Conjunção coordenada 102.770 30.594 Preposição ou conjunção subordinada
26.627 8.977
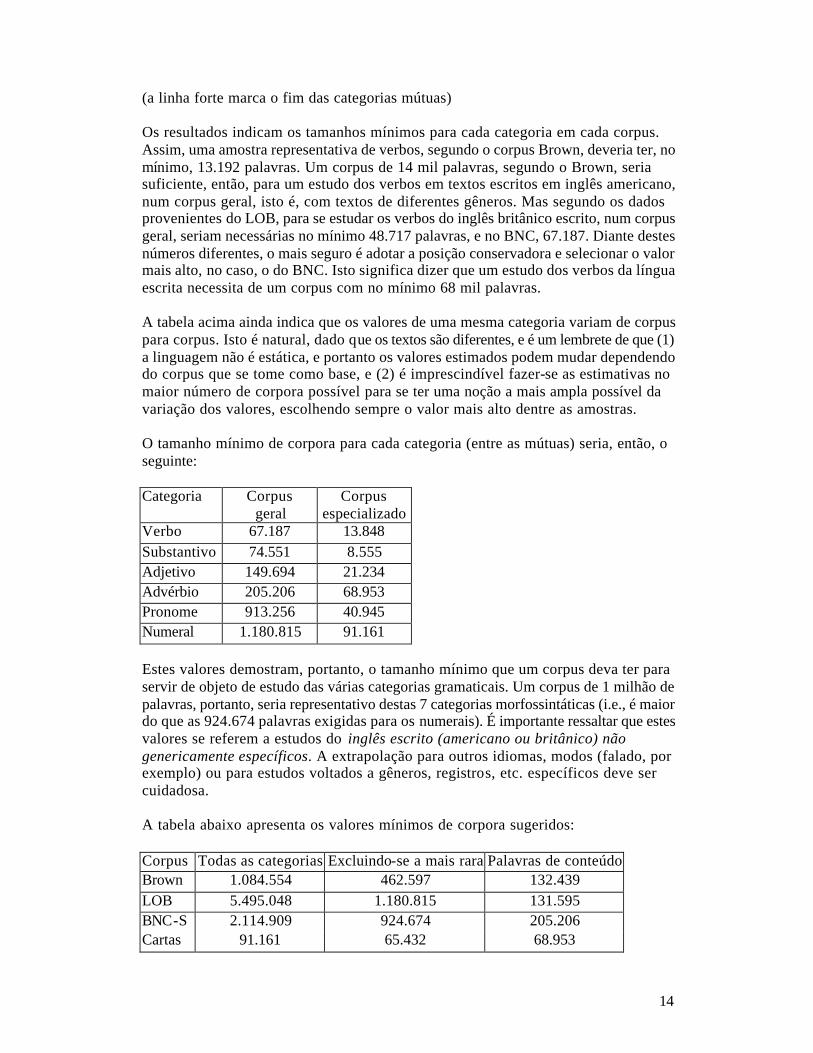
14
(a linha forte marca o fim das categorias mútuas) Os resultados indicam os tamanhos mínimos para cada categoria em cada corpus. Assim, uma amostra representativa de verbos, segundo o corpus Brown, deveria ter, no mínimo, 13.192 palavras. Um corpus de 14 mil palavras, segundo o Brown, seria suficiente, então, para um estudo dos verbos em textos escritos em inglês americano, num corpus geral, isto é, com textos de diferentes gêneros. Mas segundo os dados provenientes do LOB, para se estudar os verbos do inglês britânico escrito, num corpus geral, seriam necessárias no mínimo 48.717 palavras, e no BNC, 67.187. Diante destes números diferentes, o mais seguro é adotar a posição conservadora e selecionar o valor mais alto, no caso, o do BNC. Isto significa dizer que um estudo dos verbos da língua escrita necessita de um corpus com no mínimo 68 mil palavras. A tabela acima ainda indica que os valores de uma mesma categoria variam de corpus para corpus. Isto é natural, dado que os textos são diferentes, e é um lembrete de que (1) a linguagem não é estática, e portanto os valores estimados podem mudar dependendo do corpus que se tome como base, e (2) é imprescindível fazer-se as estimativas no maior número de corpora possível para se ter uma noção a mais ampla possível da variação dos valores, escolhendo sempre o valor mais alto dentre as amostras. O tamanho mínimo de corpora para cada categoria (entre as mútuas) seria, então, o seguinte: Categoria Corpus
geral Corpus
especializado Verbo 67.187 13.848 Substantivo 74.551 8.555 Adjetivo 149.694 21.234 Advérbio 205.206 68.953 Pronome 913.256 40.945 Numeral 1.180.815 91.161 Estes valores demostram, portanto, o tamanho mínimo que um corpus deva ter para servir de objeto de estudo das várias categorias gramaticais. Um corpus de 1 milhão de palavras, portanto, seria representativo destas 7 categorias morfossintáticas (i.e., é maior do que as 924.674 palavras exigidas para os numerais). É importante ressaltar que estes valores se referem a estudos do inglês escrito (americano ou britânico) não genericamente específicos. A extrapolação para outros idiomas, modos (falado, por exemplo) ou para estudos voltados a gêneros, registros, etc. específicos deve ser cuidadosa. A tabela abaixo apresenta os valores mínimos de corpora sugeridos: Corpus Todas as categorias Excluindo-se a mais rara Palavras de conteúdo Brown 1.084.554 462.597 132.439 LOB 5.495.048 1.180.815 131.595 BNC-S 2.114.909 924.674 205.206 Cartas 91.161 65.432 68.953
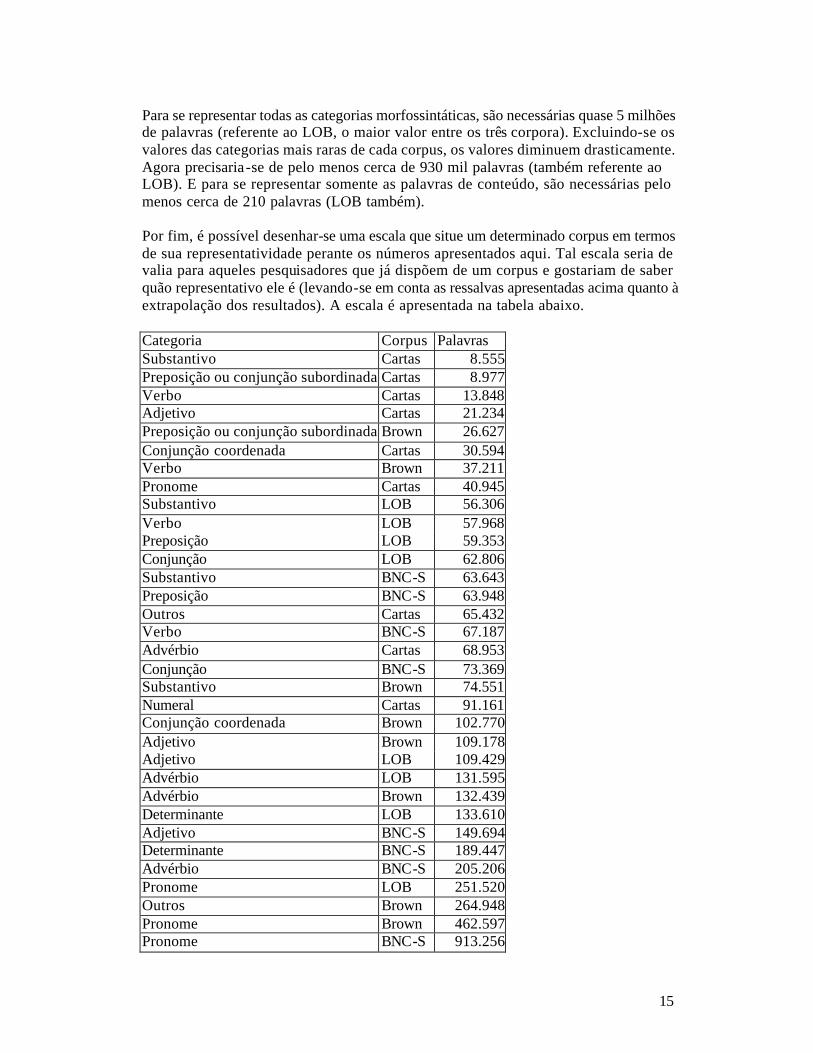
15
Para se representar todas as categorias morfossintáticas, são necessárias quase 5 milhões de palavras (referente ao LOB, o maior valor entre os três corpora). Excluindo-se os valores das categorias mais raras de cada corpus, os valores diminuem drasticamente. Agora precisaria -se de pelo menos cerca de 930 mil palavras (também referente ao LOB). E para se representar somente as palavras de conteúdo, são necessárias pelo menos cerca de 210 palavras (LOB também). Por fim, é possível desenhar-se uma escala que situe um determinado corpus em termos de sua representatividade perante os números apresentados aqui. Tal escala seria de valia para aqueles pesquisadores que já dispõem de um corpus e gostariam de saber quão representativo ele é (levando-se em conta as ressalvas apresentadas acima quanto à extrapolação dos resultados). A escala é apresentada na tabela abaixo. Categoria Corpus Palavras Substantivo Cartas 8.555 Preposição ou conjunção subordinada Cartas 8.977 Verbo Cartas 13.848 Adjetivo Cartas 21.234 Preposição ou conjunção subordinada Brown 26.627 Conjunção coordenada Cartas 30.594 Verbo Brown 37.211 Pronome Cartas 40.945 Substantivo LOB 56.306 Verbo LOB 57.968 Preposição LOB 59.353 Conjunção LOB 62.806 Substantivo BNC-S 63.643 Preposição BNC-S 63.948 Outros Cartas 65.432 Verbo BNC-S 67.187 Advérbio Cartas 68.953 Conjunção BNC-S 73.369 Substantivo Brown 74.551 Numeral Cartas 91.161 Conjunção coordenada Brown 102.770 Adjetivo Brown 109.178 Adjetivo LOB 109.429 Advérbio LOB 131.595 Advérbio Brown 132.439 Determinante LOB 133.610 Adjetivo BNC-S 149.694 Determinante BNC-S 189.447 Advérbio BNC-S 205.206 Pronome LOB 251.520 Outros Brown 264.948 Pronome Brown 462.597 Pronome BNC-S 913.256

16
Numeral BNC-S 924.674 Numeral Brown 1.084.554 Numeral LOB 1.180.815 Outros BNC-S 2.114.909 Outros LOB 5.495.048 Esta escala precisa ser interpretada conservadoramente, isto é, tomando-se como valor mínimo aquele que inclua os três corpora. Dessa forma, segundo a escala, um pesquisador que possua um corpus de 65 mil palavras poderia afirmar que este corpus é representativo dos substantivos da língua inglesa escrita. Por outro lado, um corpus de 50 mil palavras não poderia ser considerado representativo de nenhuma classe morfo-sintática da língua inglesa escrita, pois este tamanho de amostra não é o tamanho mínimo de amostra de nenhuma classe nos três corpora. Um corpus de 1 milhão de palavras é representativo de todas as categorias principais. 11.Comentários finais Em resumo, os resultados apresentados aqui permitem as seguintes conclusões: (1) Um corpus especializado demanda menos palavras para ser representativo (91 mil
palavras no máximo, contra 1,18 milhão dos gerais – LOB, excetuando-se ‘outros’) (2) Um corpus de 1 milhão de palavras é representativo da linguagem: é suficiente para
representar a vasta maioria das categorias (exceto ‘Outros’ de LOB e BNC-S, e Numeral de Brown e LOB);
(3) Um corpus de 190 mil palavras é o tamanho mínimo de um corpus representativo: com ele se representa a maioria (55% no mínimo, ie mais de 50%) das classes dos quatro corpora;
(4) Um corpus de 67 mil palavras representa verbos; (5) Um corpus de 75 mil palavras representa os substantivos; (6) Um corpus de 150 mil palavras representa adjetivos; (7) Um corpus de 206 mil palavras representa advérbios; (8) Um corpus de 206 mil palavras é o mínimo que se deve ter para se descrever as
palavras de conteúdo (ou melhor, o mínimo conservador, pois é o valor máximo, referente ao BNC-S; levando-se em conta apenas as cartas, o valor seria 69 mil).
12.Referências ASTON, G. (1997). Small and large corpora in language learning. Paper presented at the
PALC Conference, University of Lodz, Poland, April 1997. BERBER SARDINHA, A. P. (no prelo). O que é um corpus grande. The ESPecialist. BIBER, D. (1990) Methodological issues regarding corpus-based analyses of linguistic
variation. Literary and Linguistic Computing , 5: 257-269. ---. (1993) Representativeness in corpus design. Literary and Linguistic Computing, 8:
243-257. GRANGER, S. (Org.) (1998). Learner English on Computer. New York: Longman. HALLIDAY, M. A. K. (1991). Corpus studies and probabilistic grammar. IN: K. AIJMER &
B. ALTENBERG (org.). English corpus linguistics: Studies in honour of Jan Svartvik. London: Longman.
---. (1992). Language as system and language as instance: The corpus as a theoretical construct. IN: J. SVARTVIK (org.). Directions in Corpus Linguistics. Proceedings

17
of Nobel Symposium 82, Stockholm, 4-8 August 1991 . Berlin, New York: De Gruyter.
---. (1993). Quantitative studies and probabilities in grammar. IN: M. HOEY (org.). Data Description Discourse -- Papers on the English language in Honour of John McH Sinclair on his Sixtieth Birthday. London: HarperCollins.
LEECH, G. (1991). The state of the art in corpus linguis tics. IN: K. AIJMER & B. ALTENBERG (org.). English corpus linguistics - Studies in honour of Jan Svartvik. London: Longman.
SANCHEZ, A. & P. CANTOS. (1997a) El ritmo incremental de palabras nuevas en los repertorios de textos. Estudio experimental y comparativo basado en dos corpus linguisticos equivalentes de cuatro millones de palabras, de las lenguas inglesa y espanola y en cinco autores de ambas lenguas. Atlantis, 19 .2: 1-27.
---. (1997b) Predictability of word forms (types) and lemmas in linguistic corpora. A case study based on the analysis of the CUMBRE corpus: An 8-million word corpus of contemporary Spanish. International Journal of Corpus Linguistics, 2.2: 258-280.
SINCLAIR, J. (1991). Corpus, Concordance, Collocation . Oxford: Oxford University Press.
---. (1996). EAGLES Preliminary recommendations on Corpus Typology. EAGLES Document EAG TCWG CTYP/P. Pisa: Consiglio Nazionale delle Ricerche. Istituto di Linguistica Computazionale. Unpublished manuscript. Available at ftp://ftp.ilc.pi.cnr.it.
YANG, D.-H. & M. SONG. (1998). How much training data is required to remove data sparseness in statistical language learning? NLP Lab., Department of Computer Science, Yonsei University, Seoul, Korea, http:// december.yonsei.ac.kr/ ~dhyang.

18
Anexos (1) Conjunto de etiquetas Brown Etiqueta Explicação CC Coordinating conjunction CD Cardinal number DT Determiner EX Existential there FW Foreign word IN Preposition or subordinating conjunction JJ Adjective JJR Adjective, comparative JJS Adjective, superlative LS List item marker MD Modal NN Noun, singular or mass NNS Noun, plural NNP Proper noun, singular NNPS Proper noun, plural PDT Predeterminer POS Possessive ending PRP Personal pronoun PRP$ Possessive pronoun RB Adverb RBR Adverb, comparative RBS Adverb, superlative RP Particle SYM Symbol TO to UH Interjection VB Verb, base form VBD Verb, past tense VBG Verb, gerund or present participle VBN Verb, past participle VBP Verb, non-3rd person singular present VBZ Verb, 3rd person singular present WDT Wh-determiner WP Wh-pronoun WP$ Possessive wh-pronoun WRB Wh-adverb LOB Etiqueta Explicação &FO formula

19
&FW foreign word ABL pre-qualifier (QUITE, RATHER, SUCH) ABN pre-quantifier (ALL, HALF) ABX pre-quantifier/double conjunction (BOTH) AP post-determiner (FEW, FEWER, FEWEST, LAST, LATTER, LEAST,
LESS, LITTLE, MANY, MORE, MOST, MUCH, NEXT, ONLY, OTHER, OWN, SAME, SEVERAL, VERY)
AP$ OTHER'S APS OTHERS APS$ OTHERS' AT singular article (A, AN, EVERY) ATI singular or plural article (THE, NO) BE BE BED WERE BEDZ WAS BEG BEING BEM AM, 'M BEN BEEN BER ARE, 'RE BEZ IS, 'S CC coordinating conjunction (AND, AND/OR, BUT, NOR, ONLY, OR, YET) CD cardinal (2, 3, etc.; TWO, THREE, etc.; HUNDRED, THOUSAND, etc.;
DOZEN, ZERO) CD$ cardinal + genitive CD1 ONE, 1 CD1$ ONE'S CD1S ONES CD-CD hyphenated pair of cardinals CDS cardinal + plural (TENS, MILLIOBS, DOZENS, etc.) CS subordinating conjunction (AFTER, ALTHOUGH, etc.) DO DO DOD DID DOZ DOES DT singular determiner (ANOTHER, EACH, THAT, THIS) DT$ singular determiner + genitive (ANOTHER'S) DTI singular or plural determiner (ANY, ENOUGH, SOME) DTS plural determiner (THESE, THOSE) DTX determiner/double conjunction (EITHER, NEITHER) EX existential THERE HV HAVE, 'VE HVD HAD past tense, 'D HVG HAVING HVN HAD past participle HVZ HAS, 'S IN preposition (ABOUT, ABOVE, etc.) JJ adjective JJB attributive-only adjective (CHIEF, ENTIRE, MAIN, etc.) JJR comparative adjective JJT superlative adjective

20
JNP adjective with word-initial capital (ENGLISH, GERMAN, etc.) MD modal auxiliary NC cited word NN singular common noun NN$ singular common noun + genitive NNP singular common noun with word-initial capital (ENGLISHMAN,
GERMAN, etc.) NNP$ singular common noun with word-initial capital + genitive NNPS plural common noun with w.i.c. NNPS$ plural common noun with w.i.c. + genitive NNS plural common noun NNS$ plural common noun + genitive NNU abbreviated unit of measurement unmarked for number (\0HR, \0LB, etc.) NNUS abbreviated plural unit of measurement (\0GNS, \0YDS, etc.) NP singular proper noun NP$ proper noun + genitive NPL locative noun with w.i.c. (ABBEY, BRIDGE, etc.) NPL$ locative noun with w.i.c. + genitive NPLS plural locative noun with w.i.c. NPLS$ plural locative noun with w.i.c. + genitive NPS plural proper noun NPS$ plural proper noun + genitive NPT titular noun with w.i.c. (ARCHBISHOP, CAPTAIN, etc.) NPT$ titular noun with w.i.c. + genitive NPTS plural titular noun with w.i.c. NPTS$ plural titular noun with w.i.c. + genitive NR adverbial noun (JANUARY, FEBRUARY, ETC.; SUNDAY, MONDAY,
etc.; EAST, WEST, etc.; TODAY, TOMORROW, TONIGHT; DOWNTOWN, HOME)
NR$ adverbial noun + genitive NRS plural adverbial noun NRS$ plural adverbial noun + genitive OD ordinal (1st, 2nd, etc.; FIRST, SECOND, etc.) OD$ ordinal + genitive PN nominal pronoun (ANYBODY, ANYONE, ANYTHING; EVERYBODY,
EVERYONE, EVERYTHING; NOBODY, NONE, NOTHING; SOMEBODY, SOMEONE, SOMETHING; SO)
PN$ nominal pronoun + genitive PP$ possessive determiner (MY, YOUR, etc.) PP$$ possessive pronoun (MINE, YOURS, etc.) PP1A I PP1AS WE PP1O ME PP1OS US, 'S PP2 YOU PP3 IT PP3A HE, SHE PP3AS THEY PP3O HIM, HER

21
PP3OS THEM, 'EM PPL singular reflexive pronoun PPLS plural reflexive pronoun, reciprocal pronoun QL qualifier (AS, AWFULLY, LESS, MORE, SO, TOO, VERY, etc.) QLP post-qualifier (ENOUGH, INDEED) RB adverb RB$ adverb + genitive (ELSE'S) RBR comparative adverb RBT superlative adverb RI adverb (homograph of preposition: BELOW, NEAR, etc.) RN nominal adverb (HERE, NOW, THERE, THEN, etc.) RP adverbial particle (BACK, DOWN, OFF, etc.) TO infinitival TO UH interjection VB verb, base form VBD verb, past tense VBG present participle, gerund VBN past participle VBZ verb, 3rd person singular WDT WH-determiner (WHAT, WHATEVER, WHATSOEVER, interrogative
WHICH, WHICHEVER, WHICHSOEVER) WDTR WH-determiner, relative (WHICH) WP WH-pronoun, interrogative, nom+acc (WHO, WHOEVER) WP$ WH-pronoun, interrogative, gen (WHOSE) WP$R WH-pronoun, relative, gen (WHOSE) WPA WH-pronoun, nom (WHOSOEVER) WPO WH-pronoun, interrogative, acc (WHOM, WHOMSOEVER) WPOR WH-pronoun, relative, acc (WHOM) WPR WH-pronoun, relative, nom+acc (THAT, relative WHO) WRB WH-adverb (HOW, WHEN, etc.) XNOT NOT, N'T ZZ letter of the alphabet (E, PI, X, etc.) BNC Sampler Etiqueta Explicação APPGE possessive pronoun, pre-nominal (e.g. my, your, our) AT article (e.g. the, no) AT1 singular article (e.g. a, an, every) BCL before-clause marker (e.g. in order (that), in order (to)) CC coordinating conjunction (e.g. and, or) CCB adversative coordinating conjunction ( but) CS subordinating conjunction (e.g. if, because, unless, so, for) CSA as (as conjunction) CSN than (as conjunction) CST that (as conjunction) CSW whether (as conjunction) DA "after-determiner", or post-determiner capable of pronominal function

22
(e.g. such, former, same) DA1 singular post-determiner (e.g. little, much) DA2 plural post-determiner (e.g. few, several, many) DAR comparative post-determiner (e.g. more, less, fewer) DAT superlative post-determiner (e.g. most, least, fewest) DB "before-determiner", or pre-determiner capable of pronominal function
(all, half) DB2 plural before-determiner (both) DD central determiner (capable of pronominal function) (e.g any, some) DD1 singular determiner (e.g. this, that, another) DD2 plural determiner (these, those) DDQ wh-determiner (which, what) DDQGE wh-determiner, genitive (whose) DDQV wh-ever determiner, (whichever, whatever) EX existential there FO formula FU unclassified word FW foreign word GE germanic genitive marker - (' or 's) IF for (as preposition) II general preposition IO of (as preposition) IW with, without (as prepositions) JJ general adjective JJR general comparative adjective (e.g. older, better, stronger) JJT general superlative adjective (e.g. oldest, best, strongest) JK catenative adjective (able in be able to, willing in be willing to) MC cardinal number,neutral for number (two, three..) MC1 singular cardinal number (one) MC2 plural cardinal number (e.g. sixes, sevens) MCGE genitive cardinal number, neutral for number (two's, 100's) MCMC hyphenated number (40-50, 1770-1827) MD ordinal number (e.g. first, second, next, last) MF fraction,neutral for number (e.g. quarters, two-thirds) ND1 singular noun of direction (e.g. north, southeast) NN common noun, neutral for number (e.g. sheep, cod, headquarters) NN1 singular common noun (e.g. book, girl) NN2 plural common noun (e.g. books, girls) NNA following noun of title (e.g. M.A.) NNB preceding noun of title (e.g. Mr., Prof.) NNL1 singular locative noun (e.g. Island, Street) NNL2 plural locative noun (e.g. Islands, Streets) NNO numeral noun, neutral for number (e.g. dozen, hundred) NNO2 numeral noun, plural (e.g. hundreds, thousands) NNT1 temporal noun, singular (e.g. day, week, year) NNT2 temporal noun, plural (e.g. days, weeks, years) NNU unit of measurement, neutral for number (e.g. in, cc) NNU1 singular unit of measurement (e.g. inch, centimetre)

23
NNU2 plural unit of measurement (e.g. ins., feet) NP proper noun, neutral for number (e.g. IBM, Andes) NP1 singular proper noun (e.g. London, Jane, Frederick) NP2 plural proper noun (e.g. Browns, Reagans, Koreas) NPD1 singular weekday noun (e.g. Sunday) NPD2 plural weekday noun (e.g. Sundays) NPM1 singular month noun (e.g. October) NPM2 plural month noun (e.g. Octobers) PN indefinite pronoun, neutral for number (none) PN1 indefinite pronoun, singular (e.g. anyone, everything, nobody, one) PNQO objective wh-pronoun (whom) PNQS subjective wh-pronoun (who) PNQV wh-ever pronoun (whoever) PNX1 reflexive indefinite pronoun (oneself) PPGE nominal possessive personal pronoun (e.g. mine, yours) PPH1 3rd person sing. neuter personal pronoun (it) PPHO1 3rd person sing. objective personal pronoun (him, her) PPHO2 3rd person plural objective personal pronoun (them) PPHS1 3rd person sing. subjective personal pronoun (he, she) PPHS2 3rd person plural subjective personal pronoun (they) PPIO1 1st person sing. objective personal pronoun (me) PPIO2 1st person plural objective personal pronoun (us) PPIS1 1st person sing. subjective personal pronoun (I) PPIS2 1st person plural subjective personal pronoun (we) PPX1 singular reflexive personal pronoun (e.g. yourself, itself) PPX2 plural reflexive personal pronoun (e.g. yourselves, themselves) PPY 2nd person personal pronoun (you) RA adverb, after nominal head (e.g. else, galore) REX adverb introducing appositional constructions (namely, e.g.) RG degree adverb (very, so, too) RGQ wh- degree adverb (how) RGQV wh-ever degree adverb (however) RGR comparative degree adverb (more, less) RGT superlative degree adverb (most, least) RL locative adverb (e.g. alongside, forward) RP prep. adverb, particle (e.g about, in) RPK prep. adv., catenative (about in be about to) RR general adverb RRQ wh- general adverb (where, when, why, how) RRQV wh-ever general adverb (wherever, whenever) RRR comparative general adverb (e.g. better, longer) RRT superlative general adverb (e.g. best, longest) RT quasi-nominal adverb of time (e.g. now, tomorrow) TO infinitive marker (to) UH interjection (e.g. oh, yes, um) VB0 be, base form (finite i.e. imperative, subjunctive) VBDR were VBDZ was

24
VBG being VBI be, infinitive (To be or not..., It will be ..) VBM am VBN been VBR are VBZ is VD0 do, base form (finite) VDD did VDG doing VDI do, infinitive (I may do... To do...) VDN done VDZ does VH0 have, base form (finite) VHD had (past tense) VHG having VHI have, infinitive VHN had (past participle) VHZ has VM modal auxiliary (can, will, would, etc.) VMK modal catenative (ought, used) VV0 base form of lexical verb (e.g. give, work) VVD past tense of lexical verb (e.g. gave, worked) VVG -ing participle of lexical verb (e.g. giving, working) VVGK -ing participle catenative (going in be going to) VVI infinitive (e.g. to give... It will work...) VVN past participle of lexical verb (e.g. given, worked) VVNK past participle catenative (e.g. bound in be bound to) VVZ -s form of lexical verb (e.g. gives, works) XX not, n't ZZ1 singular letter of the alphabet (e.g. A, b) ZZ2 plural letter of the alphabet (e.g. A's, b's) Mais 11 categorias de pontuação (2) Agrupamentos das etiquetas originais Brown Categoria resultante Etiquetas originais Substantivo NN+NNS+NNP+NNPS Adjetivo JJ+JJR+JJS Verbo EX+MD+VB+VBD+VBG+VBN+VBP+VBZ Advérbio RB+RBR+RBS+WRB Pronome PRP+PRP$+WP+WP$ Conjunção coordenada CC Outros FW+LS+POS+RP+SYM+TO+UH Artigos DT+PDT+WDT Numeral CD Preposição ou conjunção subordinada IN
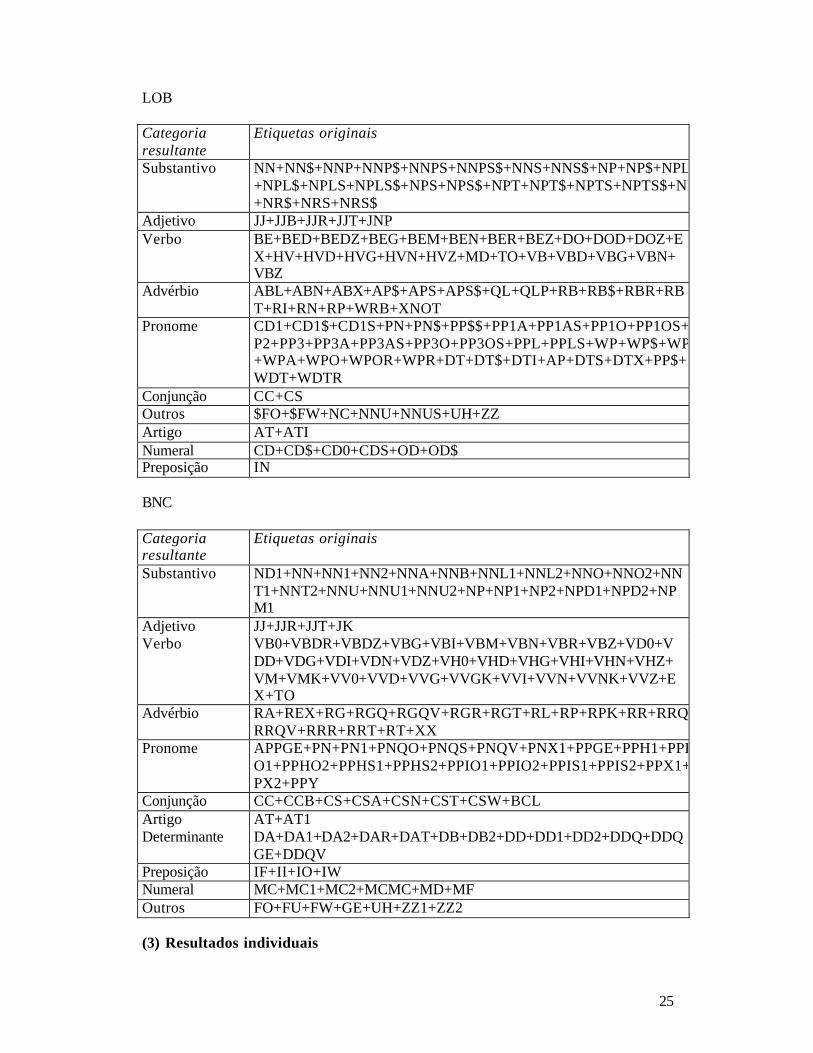
25
LOB Categoria resultante
Etiquetas originais
Substantivo NN+NN$+NNP+NNP$+NNPS+NNPS$+NNS+NNS$+NP+NP$+NPL+NPL$+NPLS+NPLS$+NPS+NPS$+NPT+NPT$+NPTS+NPTS$+NR+NR$+NRS+NRS$
Adjetivo JJ+JJB+JJR+JJT+JNP Verbo BE+BED+BEDZ+BEG+BEM+BEN+BER+BEZ+DO+DOD+DOZ+E
X+HV+HVD+HVG+HVN+HVZ+MD+TO+VB+VBD+VBG+VBN+VBZ
Advérbio ABL+ABN+ABX+AP$+APS+APS$+QL+QLP+RB+RB$+RBR+RBT+RI+RN+RP+WRB+XNOT
Pronome CD1+CD1$+CD1S+PN+PN$+PP$$+PP1A+PP1AS+PP1O+PP1OS+PP2+PP3+PP3A+PP3AS+PP3O+PP3OS+PPL+PPLS+WP+WP$+WP$+WPA+WPO+WPOR+WPR+DT+DT$+DTI+AP+DTS+DTX+PP$+WDT+WDTR
Conjunção CC+CS Outros $FO+$FW+NC+NNU+NNUS+UH+ZZ Artigo AT+ATI Numeral CD+CD$+CD0+CDS+OD+OD$ Preposição IN BNC Categoria resultante
Etiquetas originais
Substantivo ND1+NN+NN1+NN2+NNA+NNB+NNL1+NNL2+NNO+NNO2+NNT1+NNT2+NNU+NNU1+NNU2+NP+NP1+NP2+NPD1+NPD2+NPM1
Adjetivo JJ+JJR+JJT+JK Verbo VB0+VBDR+VBDZ+VBG+VBI+VBM+VBN+VBR+VBZ+VD0+V
DD+VDG+VDI+VDN+VDZ+VH0+VHD+VHG+VHI+VHN+VHZ+VM+VMK+VV0+VVD+VVG+VVGK+VVI+VVN+VVNK+VVZ+EX+TO
Advérbio RA+REX+RG+RGQ+RGQV+RGR+RGT+RL+RP+RPK+RR+RRQ+RRQV+RRR+RRT+RT+XX
Pronome APPGE+PN+PN1+PNQO+PNQS+PNQV+PNX1+PPGE+PPH1+PPHO1+PPHO2+PPHS1+PPHS2+PPIO1+PPIO2+PPIS1+PPIS2+PPX1+PPX2+PPY
Conjunção CC+CCB+CS+CSA+CSN+CST+CSW+BCL Artigo AT+AT1 Determinante DA+DA1+DA2+DAR+DAT+DB+DB2+DD+DD1+DD2+DDQ+DDQ
GE+DDQV Preposição IF+II+IO+IW Numeral MC+MC1+MC2+MCMC+MD+MF Outros FO+FU+FW+GE+UH+ZZ1+ZZ2 (3) Resultados individuais
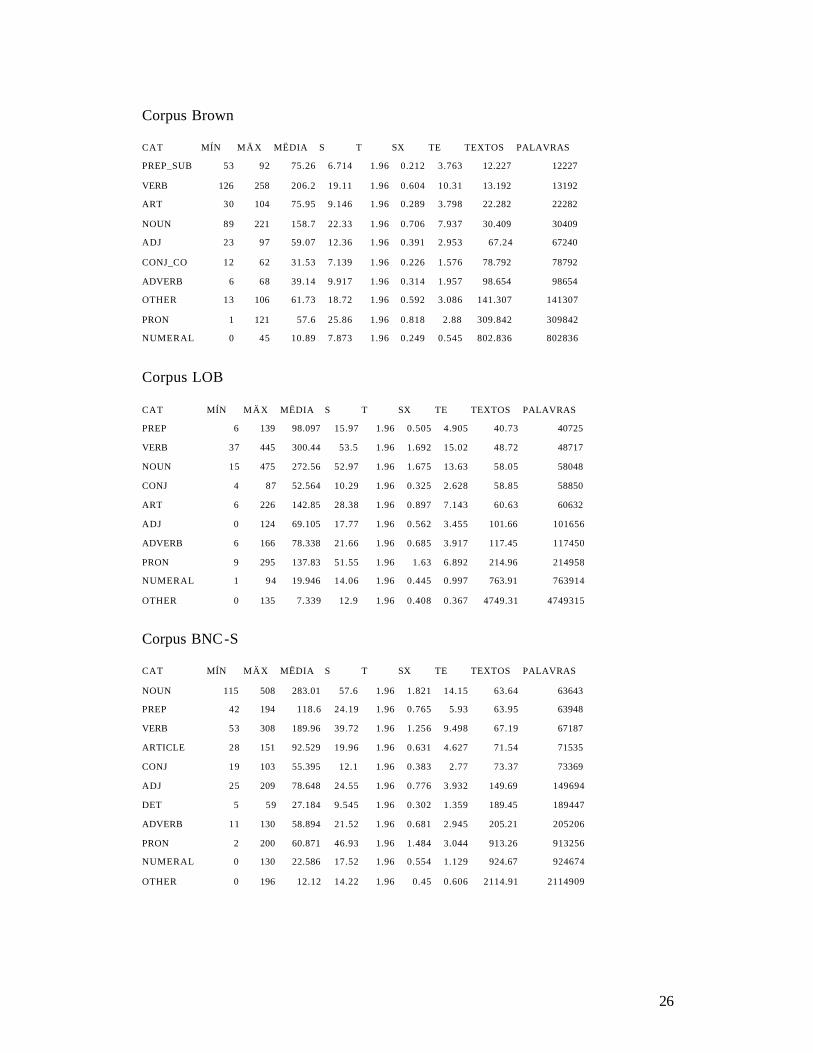
26
Corpus Brown CAT MÍN MÄX MËDIA S T SX TE TEXTOS PALAVRAS
PREP_SUB 53 92 75.26 6.714 1.96 0.212 3.763 12.227 12227
VERB 126 258 206.2 19.11 1.96 0.604 10.31 13.192 13192
ART 30 104 75.95 9.146 1.96 0.289 3.798 22.282 22282
NOUN 89 221 158.7 22.33 1.96 0.706 7.937 30.409 30409
ADJ 23 97 59.07 12.36 1.96 0.391 2.953 67.24 67240
CONJ_CO 12 62 31.53 7.139 1.96 0.226 1.576 78.792 78792
ADVERB 6 68 39.14 9.917 1.96 0.314 1.957 98.654 98654
OTHER 13 106 61.73 18.72 1.96 0.592 3.086 141.307 141307
PRON 1 121 57.6 25.86 1.96 0.818 2.88 309.842 309842
NUMERAL 0 45 10.89 7.873 1.96 0.249 0.545 802.836 802836
Corpus LOB CAT MÍN MÄX MËDIA S T SX TE TEXTOS PALAVRAS
PREP 6 139 98.097 15.97 1.96 0.505 4.905 40.73 40725
VERB 37 445 300.44 53.5 1.96 1.692 15.02 48.72 48717
NOUN 15 475 272.56 52.97 1.96 1.675 13.63 58.05 58048
CONJ 4 87 52.564 10.29 1.96 0.325 2.628 58.85 58850
ART 6 226 142.85 28.38 1.96 0.897 7.143 60.63 60632
ADJ 0 124 69.105 17.77 1.96 0.562 3.455 101.66 101656
ADVERB 6 166 78.338 21.66 1.96 0.685 3.917 117.45 117450
PRON 9 295 137.83 51.55 1.96 1.63 6.892 214.96 214958
NUMERAL 1 94 19.946 14.06 1.96 0.445 0.997 763.91 763914
OTHER 0 135 7.339 12.9 1.96 0.408 0.367 4749.31 4749315
Corpus BNC-S CAT MÍN MÄX MËDIA S T SX TE TEXTOS PALAVRAS
NOUN 115 508 283.01 57.6 1.96 1.821 14.15 63.64 63643
PREP 42 194 118.6 24.19 1.96 0.765 5.93 63.95 63948
VERB 53 308 189.96 39.72 1.96 1.256 9.498 67.19 67187
ARTICLE 28 151 92.529 19.96 1.96 0.631 4.627 71.54 71535
CONJ 19 103 55.395 12.1 1.96 0.383 2.77 73.37 73369
ADJ 25 209 78.648 24.55 1.96 0.776 3.932 149.69 149694
DET 5 59 27.184 9.545 1.96 0.302 1.359 189.45 189447
ADVERB 11 130 58.894 21.52 1.96 0.681 2.945 205.21 205206
PRON 2 200 60.871 46.93 1.96 1.484 3.044 913.26 913256
NUMERAL 0 130 22.586 17.52 1.96 0.554 1.129 924.67 924674
OTHER 0 196 12.12 14.22 1.96 0.45 0.606 2114.91 2114909


![Bernard Manin - As Metamorfoses Do Governo Representativo [COMPLETO]](https://static.fdocumentos.com/doc/165x107/54dcadb64a7959ef358b4a20/bernard-manin-as-metamorfoses-do-governo-representativo-completo.jpg)















