6. Medidas de associação entre variáveis categóricas em ... · 6. Medidas de associação entre...
15
6. Medidas de associação entre variáveis categóricas em tabelas de dupla entrada Quiquadrado de Pearson: mede a associação de tabelas de dupla entrada, sendo definida por: ij c 2 ij ij n X e ) e ( 2 , em que é o número de linhas e c o número de colunas da tabela. O termo ij n na expressão representa as frequências observadas da tabela e ij e as frequências esperadas na condição de independência entre as categorias. Exemplo 1: A tabela abaixo representa um levantamento a respeito do tipo de lesão sofrido na cabeça, por motociclistas, em relação do uso do capacete. a) Encontre as porcentagens do tipo de lesão em função do uso do capacete. b) Você diria que existe associação entre o uso do capacete e a gravidade da lesão na cabeça de motociclistas? Tabela 6.1: Uso do capacete x Tipo de lesão. Tipo de lesão Uso do capacete Marginal das linhas Sim Não Grave 15 22 37 Leve 45 18 63 Marginal das colunas 60 40 100
Transcript of 6. Medidas de associação entre variáveis categóricas em ... · 6. Medidas de associação entre...

6. Medidas de associação entre variáveis categóricas em
tabelas de dupla entrada
Quiquadrado de Pearson: mede a associação de tabelas de
dupla entrada, sendo definida por:
ij
c2
ijijn
Xe
)e(2
,
em que é o número de linhas e c o número de colunas da
tabela.
O termo ij
n na expressão representa as frequências
observadas da tabela e ij
e as frequências esperadas na condição
de independência entre as categorias.
Exemplo 1: A tabela abaixo representa um levantamento a
respeito do tipo de lesão sofrido na cabeça, por motociclistas, em
relação do uso do capacete.
a) Encontre as porcentagens do tipo de lesão em função do uso
do capacete.
b) Você diria que existe associação entre o uso do capacete e a
gravidade da lesão na cabeça de motociclistas?
Tabela 6.1: Uso do capacete x Tipo de lesão.
Tipo de lesão Uso do capacete Marginal das
linhas Sim Não
Grave 15 22 37
Leve 45 18 63
Marginal das
colunas 60 40 100
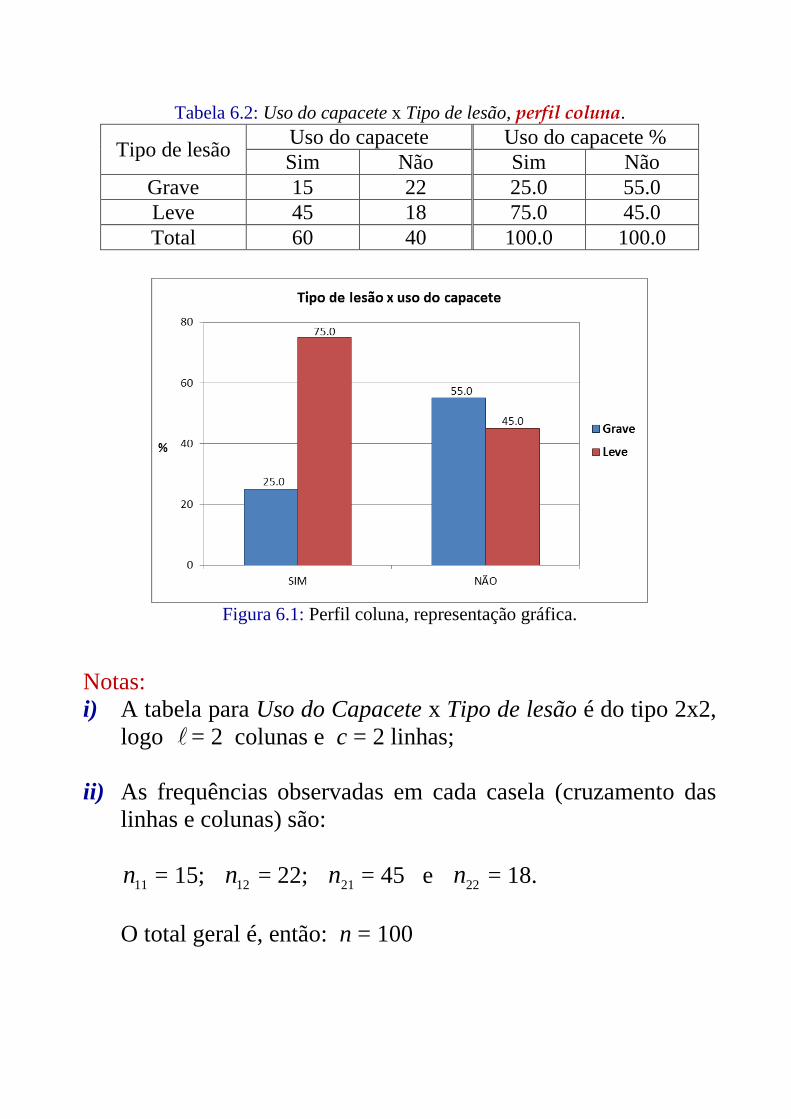
Tabela 6.2: Uso do capacete x Tipo de lesão, perfil coluna.
Tipo de lesão Uso do capacete Uso do capacete %
Sim Não Sim Não
Grave 15 22 25.0 55.0
Leve 45 18 75.0 45.0
Total 60 40 100.0 100.0
Figura 6.1: Perfil coluna, representação gráfica.
Notas:
i) A tabela para Uso do Capacete x Tipo de lesão é do tipo 2x2,
logo = 2 colunas e c = 2 linhas;
ii) As frequências observadas em cada casela (cruzamento das
linhas e colunas) são:
11
n = 15; 12
n = 22; 21
n = 45 e 22
n = 18.
O total geral é, então: n = 100
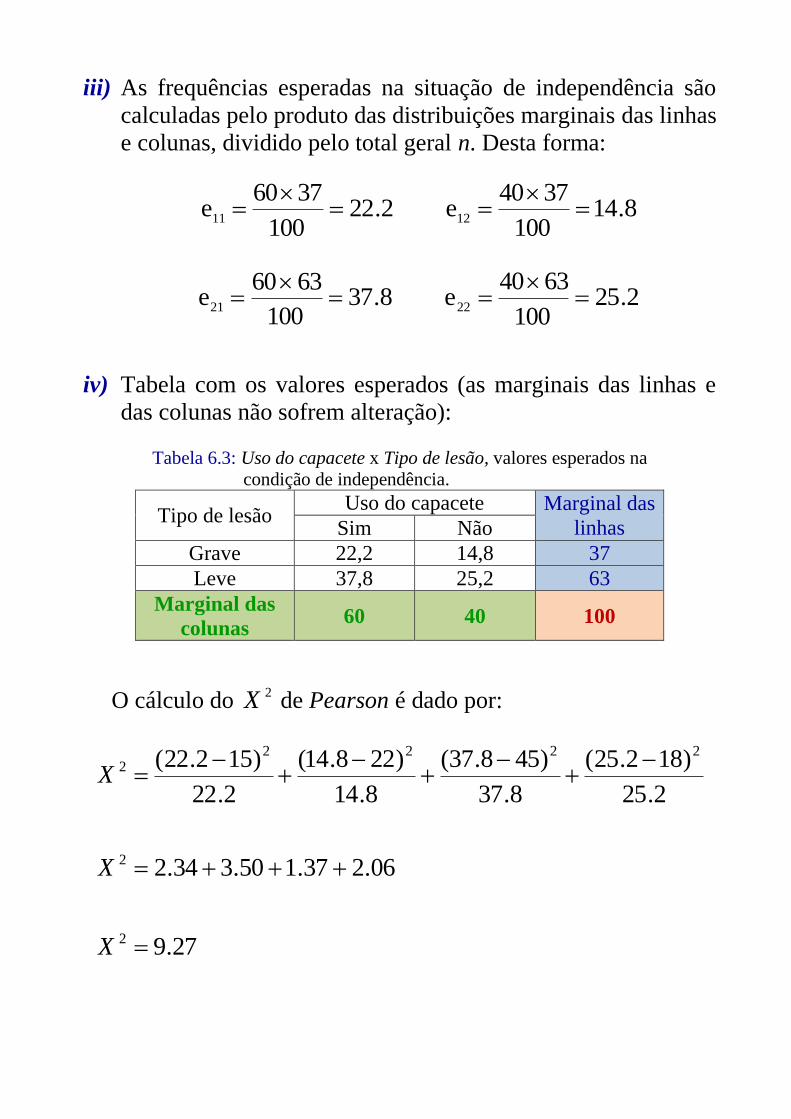
iii) As frequências esperadas na situação de independência são
calculadas pelo produto das distribuições marginais das linhas
e colunas, dividido pelo total geral n. Desta forma:
2.22100
3760e
11
8.14
100
3740e
12
8.37100
6360e
21
2.25
100
6340e
22
iv) Tabela com os valores esperados (as marginais das linhas e
das colunas não sofrem alteração):
Tabela 6.3: Uso do capacete x Tipo de lesão, valores esperados na
condição de independência.
Tipo de lesão Uso do capacete Marginal das
linhas Sim Não
Grave 22,2 14,8 37
Leve 37,8 25,2 63
Marginal das
colunas 60 40 100
O cálculo do 2X de Pearson é dado por:
27.9
06.237.150.334.2
2.25
)182.25(
8.37
)458.37(
8.14
)228.14(
2.22
)152.22(
2
2
22222
X
X
X

O 2X de Pearson deve ser comparado com um valor tabelado,
que depende do número de linhas e colunas da tabela (que é o
número de graus de liberdade).
O número de graus de liberdade se uma tabela é dado pelo
número de linhas menos um multiplicado pelo número de colunas
menos um, isto é: )1()1( cgl
Para uma tabela 2x2, o número de graus de liberdade é igual a
1)12()12( gl .
Para uma tabela 2x2, o número de graus de liberdade é 1 e o
valor de comparação* é igual a 3.84.
Portanto, o valor de 9.27, obtido pelo cálculo do 2X de
Pearson, é maior do que o valor de comparação 3.84, indicando
que há uma relação entre o uso do capacete e a gravidade da lesão
na cabeça.
O 2X de Pearson varia de 0 a n, sendo n o número total de
casos da tabela de contingência. O valor n indica a associação
perfeita e o valor 0 a falta total de associação, ou seja, de
independência.
Portanto, valores altos de 2X indicam associação entre as
categorias da tabela e, quanto maior o valor de 2X , mais forte
será essa associação.
Entretanto, como 2X depende do valor de n, e também do
número de linhas e colunas da tabela, essa dependência pode
afetar a interpretação. Nesse sentido outras medidas são propostas
na literatura.
* O valor de comparação para tabelas de dupla entrada depende de elementos da teoria das probabilidades e da inferência
estatística e não serão abordados aqui. O valor de comparação, quando necessário, será fornecido juntamente com o problema.

Assim sendo, serão introduzidas as medidas a seguir, que
quantificam do grau da associação.
9.1. Medidas do grau da associação baseadas no X 2
a) Coeficiente :
n
X 2
.
O coeficiente varia de 0 a 1, sendo que o valor 0
corresponde a ausência de associação e o valor 1 representa
associação completa.
Se todos os valores observados forem iguais a todos os
valores esperados o 2X será zero e, portanto, também será zero.
Já o limite superior 1 só é atingido para configurações†
específicas de tabelas 22.
Portanto, este coeficiente só será aplicado para tabelas 22.
b) Coeficiente V de Cramér : forma corrigida de , dividindo o
coeficiente por )1( t
)1(
2
tn
XV , t = min(l , c).
V também varia de 0 a 1, tendo a mesma interpretação de ;
O coeficiente V de Cramér tem a vantagem de poder ser
usado em tabelas de dimensão maior do que 22.
Para tabelas 22, e V são iguais.
† O único caso em que se pode dar uma interpretação para é para tabelas 2x2 o que faz com que, em geral, esta
medida só seja utilizada neste caso: http://www.ime.unicamp.br/~lramos/dachs/capitulo2-4.htm

c) Coeficiente de Contingência:
nX
XC
2
2
.
O coeficiente C não alcança o valor 1, sendo usualmente
apresentado na sua forma ajustada para que possa alcançar o
máximo 1.
))(1(1*
2
2
nXt
Xt
t
tCC
, t = min(l , c).
Critérios de classificação para os coeficientes e C (ou C*)
não são muito comuns de serem encontrados. As maiorias dos
autores citam apenas que valores próximos de 0 representam
associação fraca ou nenhuma e quanto mais próximo de 1, mais
forte é a associação, porém, a escala desses coeficientes não é
linear, interferindo na interpretação. A seguir são apresentadas
diversas classificações para os coeficientes acima:
i) Barbetta (2001), pag 261, apresenta a seguinte classificação
para o coeficiente de contingência ajustado.
C* 0 associação fraca
C* 0.5 associação moderada
C* 1 associação forte
ii) Witte & Witte, pag. 375, indicam uma classificação 2V .
2V 0.01 (V 0.1) associação fraca
2V 0.09 (V 0.3) associação moderada
2V 0.25 (V 0.5) associação forte

Na internet, diversos sites também indicam classificações
diferentes para tais o coeficiente de contingência.
a) De http://www.acastat.com/Statbook/chisqassoc.htm
0 a 0.1 associação fraca ou nenhuma
0.1 a 0.3 associação baixa
0.3 a 0.5 associação moderada
0.5 associação forte
b) De http://www.statisticssolutions.com/resources/directory-of-
statistical-analyses/nominal-variable-association ‡
0.1 associação fraca
0.1 a 0.3 associação moderada
0.3 associação forte
Apesar da dificuldade em se encontrar uma classificação mais
objetiva, podemos notar que praticamente todas as classificações
acima indicam o valor 0.3 para associação moderada.
Desta forma, tomando esse valor como referência, vamos
adotar a classificação do site:
www.acastat.com/Statbook/chisqassoc.htm
por ser o que mais discrimina.
‡ segundo o site, essa classificação é dada como regra geral para a interpretação de todas as medidas de associação.

Exemplo 1: Com os dados do uso do capacete, temos
t = min( 2 , 2 ) = 2, logo
2913.00848.0)10027.9(
27.9
C
412.022913.0)12(
2*
CC
O valor 412.0*C indica uma associação moderada.
Ainda:
Coeficiente : 304.0100
27.9 ,
Coeficiente V de Cramér:
304.0100)12(
27.9
V associação moderada.
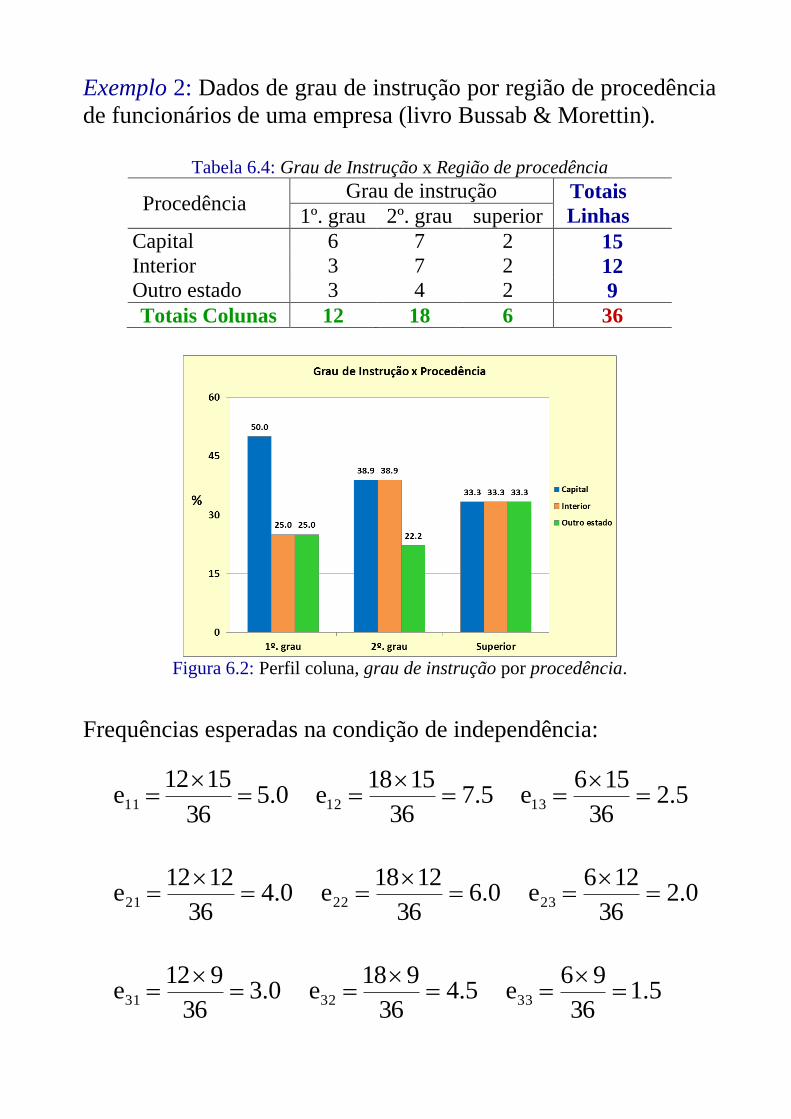
Exemplo 2: Dados de grau de instrução por região de procedência
de funcionários de uma empresa (livro Bussab & Morettin).
Tabela 6.4: Grau de Instrução x Região de procedência
Procedência Grau de instrução Totais
Linhas 1º. grau 2º. grau superior
Capital 6 7 2 15
Interior 3 7 2 12
Outro estado 3 4 2 9
Totais Colunas 12 18 6 36
Figura 6.2: Perfil coluna, grau de instrução por procedência.
Frequências esperadas na condição de independência:
0.536
1512e11
5.7
36
1518e12
5.2
36
156e13
0.436
1212e21
0.6
36
1218e22
0.2
36
126e23
0.336
912e31
5.4
36
918e32
5.1
36
96e33

Tabela 6.5: Grau de Instrução x Região de procedência, valores esperados
Procedência Grau de instrução Totais
Linhas 1º. grau 2º. grau superior
Capital 5.0 7.5 2.5 15
Interior 4.0 6.0 2.0 12
Outro estado 3.0 4.5 1.5 9
Totais Colunas 12 18 6 36
Cálculo do 2X de Pearson:
5.1
)25.1(
5.4
)45.4(
0.3
)30.3(
0.2
)20.2(
0.6
)70.6(
0.4
)30.4(
5.2
)25.2(
5.7
)75.7(
0.5
)60.5(
222
222
2222
X
0.1670.056000.167
0.2500.1000.033 0.2002
X
0.9722 X
Número de graus de liberdade para uma tabela 3x3:
4)13()13( gl .
Com 4 graus de liberdade o valor de comparação é 9.49.
Como o 2X de Pearson, igual a 0.972, é muito pequeno em
relação ao valor de comparação, não havendo evidência de
associação entre o grau de instrução e a região de procedência
dos empregados, isto é, o grau de instrução independe da região
de procedência (e vice-e-versa).

Neste caso, não é necessário calcular o coeficiente de
contingência, porém, vamos realizar os cálculos apenas como
curiosidade:
t = min( 3 , 3 ) = 3
162.00263.0)36972.0(
972.0
C
199.05.1162.0)13(
3*
CC
O valor 199.0*C indica uma associação fraca.
Ainda:
Coeficiente V de Cramér:
116.0362
972.0
V associação fraca.
No R:
# vcd: pacote para calcular as medidas de associação
require(vcd)
tab <- matrix(c(6,7,2,3,7,2,3,4,2),3,3, byrow=T)
dimnames(tab)[[2]] <- c("1º.grau","2º.grau","Superior")
dimnames(tab)[[1]] <- c("Capital","Interior","Outro Estado")
tab
1º.grau 2º.grau Superior
Capital 6 7 2
Interior 3 7 2
Outro Estado 3 4 2
assocstats(tab)
X^2 df P(> X^2)
Likelihood Ratio 0.96987 4 0.91433
Pearson 0.97222 4 0.91398
Phi-Coefficient : 0.164
Contingency Coeff.: 0.162
Cramer's V : 0.116
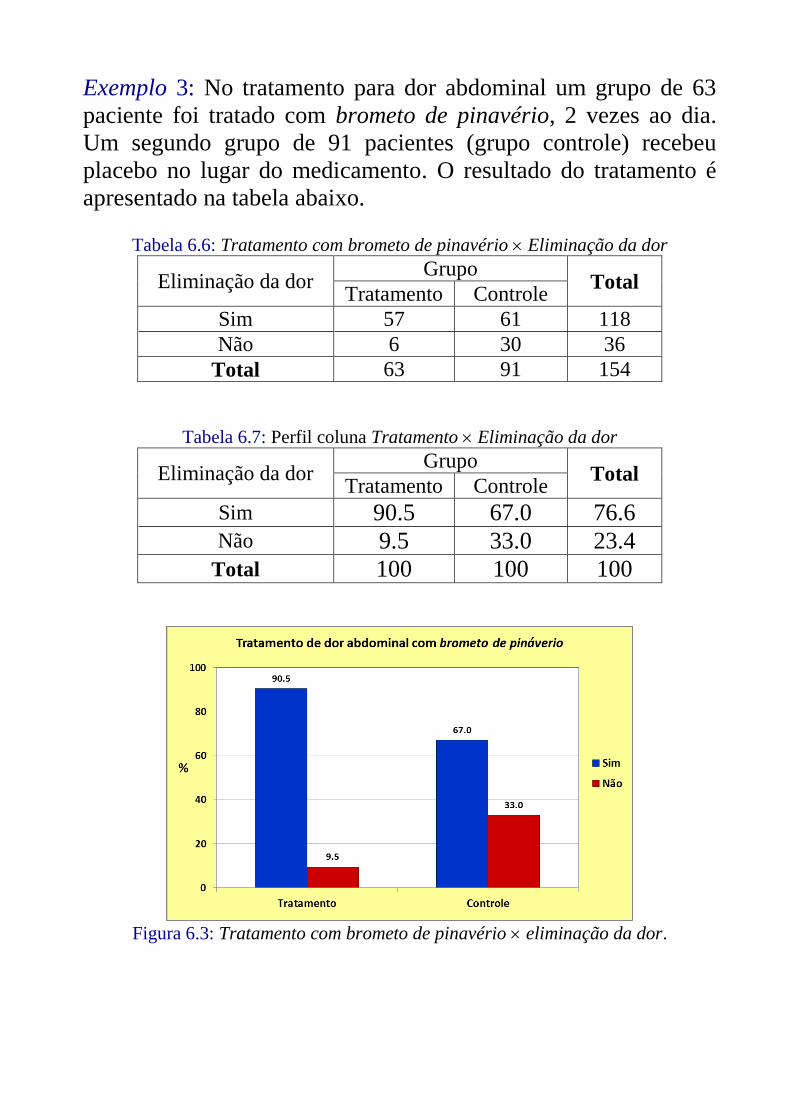
Exemplo 3: No tratamento para dor abdominal um grupo de 63
paciente foi tratado com brometo de pinavério, 2 vezes ao dia.
Um segundo grupo de 91 pacientes (grupo controle) recebeu
placebo no lugar do medicamento. O resultado do tratamento é
apresentado na tabela abaixo.
Tabela 6.6: Tratamento com brometo de pinavério Eliminação da dor
Eliminação da dor Grupo
Total Tratamento Controle
Sim 57 61 118
Não 6 30 36
Total 63 91 154
Tabela 6.7: Perfil coluna Tratamento Eliminação da dor
Eliminação da dor Grupo
Total Tratamento Controle
Sim 90.5 67.0 76.6
Não 9.5 33.0 23.4
Total 100 100 100
Figura 6.3: Tratamento com brometo de pinavério eliminação da dor.

Valores esperados na condição de independência:
3.48154
11863e11
7.69
154
11819e12
7.14154
3663e21
3.21
154
3691e22
Valor X 2 de Pearson:
21.3
30)-(21.3
14.7
6)-(14.7
69.7
61)-(69.7
48.3
57)-(48.3 22222 X
36.1155.315.509.157.12 X
O X 2 de Pearson é grande indicando que pode haver uma
associação entre as categorias.
Número de graus de liberdade: gl = (2 – 1)×(2 – 1) = 1
Com 1 grau de liberdade o valor de comparação é: 3.84.
11.36 > 3.84 há evidências de que existe associação
entre o uso do medicamento e a
eliminação da dor abdominal.

a) Coeficiente de contingência:
t = min( 2 , 2 ) = 2
262.00687.0)15436.11(
36.11
C
371.02262.0)12(
2*
CC
associação fraca a moderada.
b) Coeficiente : 272.0154
36.11
Coeficiente V de Cramér:
272.0)12(154
36.11
V
associação moderada.
No R:
# vcd: pacote para calcular as medidas de associação
####################################################
require(vcd)
tab <- matrix(c(57,61,6,30),2,2, byrow=T)
dimnames(tab)[[2]] <- c("Tratamento","Controle")
dimnames(tab)[[1]] <- c("Sim","Não")
tab
Tratamento Controle
Sim 57 61
Não 6 30
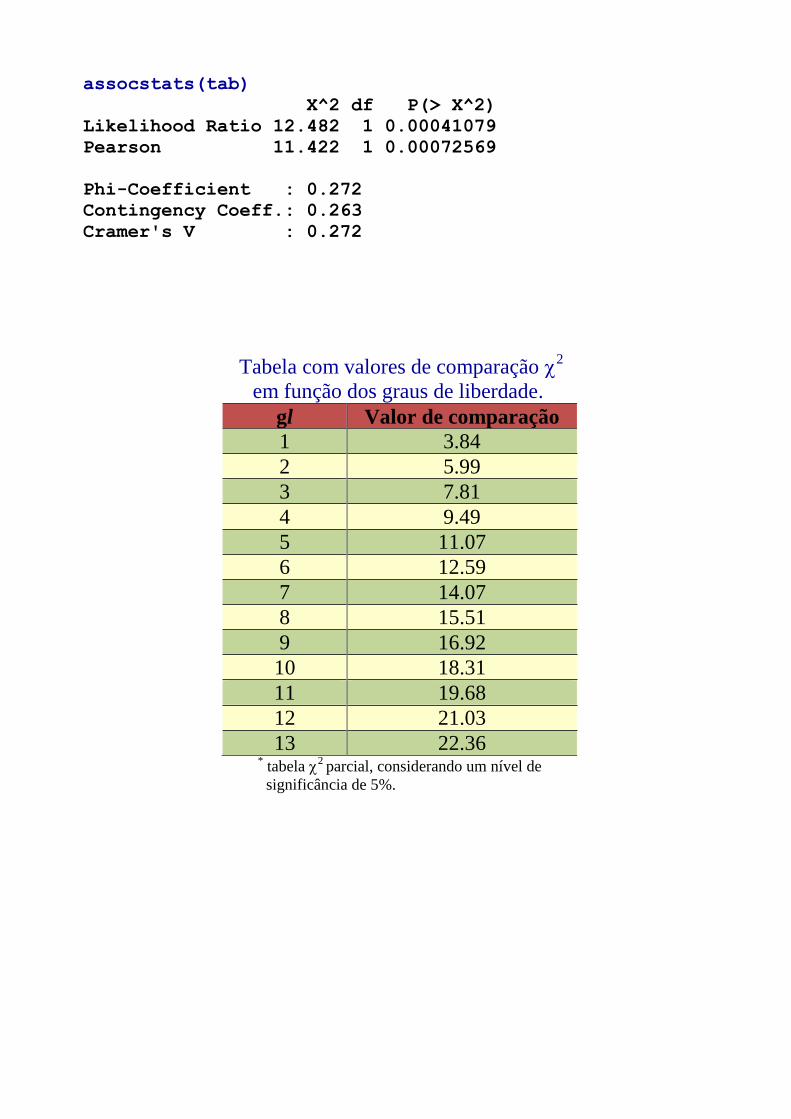
assocstats(tab)
X^2 df P(> X^2)
Likelihood Ratio 12.482 1 0.00041079
Pearson 11.422 1 0.00072569
Phi-Coefficient : 0.272
Contingency Coeff.: 0.263
Cramer's V : 0.272
Tabela com valores de comparação
2
em função dos graus de liberdade.
gl Valor de comparação
1 3.84
2 5.99
3 7.81
4 9.49
5 11.07
6 12.59
7 14.07
8 15.51
9 16.92
10 18.31
11 19.68
12 21.03
13 22.36 * tabela
2 parcial, considerando um nível de
significância de 5%.